与小麦种子休眠/穗发芽抗性相关的CAPS标记及其检测方法与流程
本发明涉及的是小麦分子育种的技术领域,尤其涉及的是一种与小麦种子休眠期或穗发芽抗性相关的基因及其检测方法。
背景技术
小麦是全球最重要的粮食作物之一,为人类提供约21%食物热量和20%蛋白质。中国是全球最大的小麦生产国和消费国,因此,高产、稳产和优质一直是小麦育种的重要目标。然而,小麦收获期若遭遇阴雨天气,容易穗上发芽(简称穗发芽),如果阴雨天气持续时间较长,则加剧穗发芽,严重影响产量和品质。因此,培育穗发芽抗性持续期长的小麦品种尤为必要,是减轻其危害的根本途径;克隆抗穗发芽持续期长的基因,开发功能标记,将有助于加快这类品种的培育进程。
种子休眠性是穗发芽抗性的主要遗传因素,包括休眠深度(水平)和持续期两个方面,种子休眠程度深(或水平高)且持续期长的穗发芽抗性持续性就强。但是,以往的研究多关注于收获后某一时期的种子休眠深度对穗发芽抗性的影响,忽略了在麦收季节阴雨持续时间较长的环境下,较长的种子休眠期对抗穗发芽持续性的作用。因此,有关种子休眠深度(或水平)的基因报道较多,如已克隆的tasdr(2as/2bs,zhang等2014,2017)、tavp-1(3al/3bl,yang等2007;chang等2011)、tamft和taphs1(3as,nakamura等2011;liu等2013)以及pm19-a1(4al,barrero等2015)和tamkk3-a(4al,torada等2016);而调控种子休眠持续期(简称休眠期)的基因报道较少,一定程度上阻碍了穗发芽抗性持续期较长的品种的培育。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种与小麦种子休眠/穗发芽抗性相关的基因及其检测方法。
本发明提供一种与小麦种子休眠/穗发芽抗性持续期长短相关的caps标记,所述caps标记命名为qsd1-5bl,qsd1-5bl的核苷酸序列为seqidno.1。
本发明还提供一种用于扩增上述caps标记的引物对,该引物对的核苷酸序列如下:f:gtttgaccgtacaagtttccseqidno.2
r:agacagcaatgcctcccseqidno.3。
本发明还提供一种利用上述caps标记鉴定小麦种子休眠/穗发芽抗性持续期长短的方法,该方法包括以下步骤:
步骤1、提取待测小麦基因组dna
步骤2、利用seqidno.2和seqidno.3所述的序列对步骤1获得的待测小麦基因组dna进行pcr扩增,获得扩增产物;
步骤3、利用hhai限制性内切酶对步骤2获得的扩增产物进行酶切,获得酶切产物;
步骤4、当酶切产物为一条主带时,其对应的最终扩增产物的基因序列命名为qsd1-5bl-a,对应的小麦种子具有较长的种子休眠期或较长的穗发芽抗性持续期;当酶切产物为两条主带时,其对应的最终扩增产物的基因序列命名为qsd1-5bl-b,对应的小麦种子具有较短的种子休眠期或较短的穗发芽抗性持续期。
进一步,步骤2中pcr扩增体系为20μl,包括10buffer(含有2.0mmoll-1mg2+)2.0μl,2.5mmoll-1dntps1.6μl,5uμl-1taqdnapolymerase0.2μl,10μmoll-1引物各0.8μl,2.0μl模板dna(50~60ngμl-1),ddh2o13.8μl,反应程序为94℃预变性5min;35个循环(94℃变性30s,55℃退火30s,72℃延伸30s);72℃延伸8min;12℃保存。
本发明具有如下有益效果:
本发明提供的caps标记能有效区分种子休眠/穗发芽抗性持续期不同的品种,可以为培育具有较强的抗穗发芽持续性的小麦品种提供基因资源和功能标记,拓宽其抗性遗传基础。
附图说明
图1为功能标记qsd1-5bl在不同小麦品种中的扩增电泳图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
1、小麦种子休眠期表型的测定
于小麦蜡熟期分别收获主茎穗,室内风干2天,立即存放于-20℃冰箱以维持种子的休眠性,待全部试验材料收获完毕,手工脱粒,一并进行种子发芽率(germinationpercentage,gp)测定。记录每个品种的发芽率超过50%的天数,即为该品种种子的休眠期(periodofdormancy,pd)。具体为:每个材料取50粒种子进行发芽试验,2次重复。籽粒腹沟朝下摆放在培养皿内,加9ml无菌水,置于人工气候培养箱(20℃,光照14h,黑暗10h,湿度90%),24小时后开始统计每个培养皿中萌芽的种子数,于每天同一时间统计萌芽数并剔除萌芽种子(以胚部露白为萌芽鉴定标准),3天后统计种子发芽率,计算两次平均值。
种子发芽率(gp)计算公式:gp=萌芽种子数/供检种子总数(50粒)×100%
注:对于363份小麦品种组成的自然群体,2015,2016和2017年测定的pd分别命名为15pd-363,16pd-363和17pd-363。
2、sds-tris饱和酚法抽提小麦基因组dna
(1)取2-3粒小麦种子置于2ml灭菌离心管,利用mp高通量组织研磨仪研磨成粉末。
(2)加入1.2mldna提取缓冲液(200mmtris-cl,250mmnacl,25mmedta,0.5%sds,2%β-me)。
(3)60℃水浴45min,期间间歇振荡以充分提取。
(4)室温下12000rpm离心10min。
(5)转移上清液至新的2ml灭菌离心管中,加入预冷的等体积tris饱和酚/氯仿异/戊醇(体积比为25:24:1),于冰上颠倒混匀15min,期间间歇振荡。
(6)室温下12000rpm离心10min。
(7)转移上清液至新的2ml灭菌离心管中,重复步骤(5)、(6),以充分去除蛋白。
(8)转移上清液至新的1.5ml灭菌离心管中,加入0.6倍异丙醇(300μl)和1/10倍体积(50μl)naac(ph5.2),充分混合混匀后冰上静置17min,使dna白色沉淀充分析出。
(9)4℃10000rpm离心10min。
(10)弃上清,加入预冷的70%乙醇漂洗2遍,然后用无水乙醇漂洗1遍,室温晾干,加入100μl其中含2μl10mg/mlrnase酶的1×te缓冲液(或双蒸水)过夜溶解。
(11)在nanovueplus微量分光光度计上检测dna浓度,并统一稀释成50ng/ul工作液,备用。
3、功能标记在自然群体中的验证
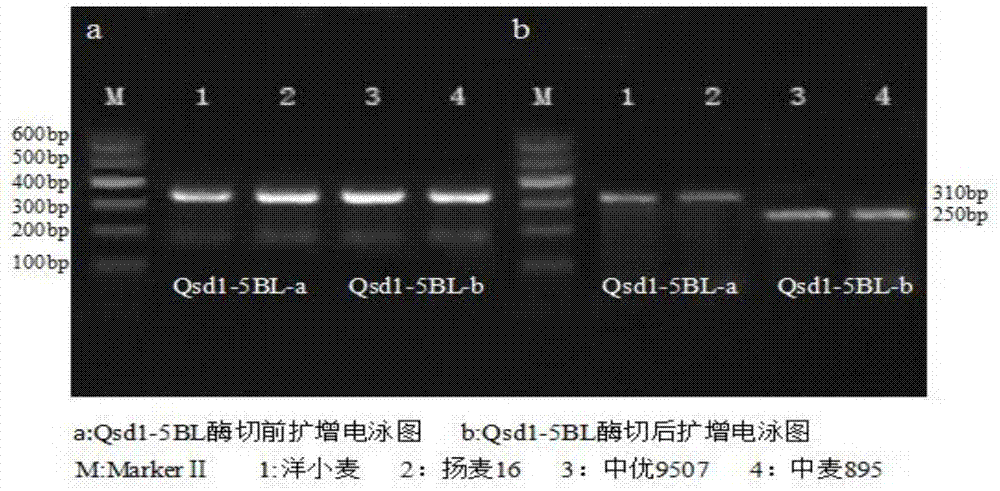
选取种子休眠期差异显著的4个小麦品种(洋小麦、扬麦16、中优9507及中麦895)利用引物对seqidno.2、seqidno.3对步骤1获取的小麦dna进行pcr扩增:f:gtttgaccgtacaagtttccseqidno.2
r:agacagcaatgcctcccseqidno.3
pcr扩增体系为20μl,包括10×buffer(含有2.0mmoll-1mg2+)2.0μl,2.5mmoll-1dntps1.6μl,5uμl-1taqdnapolymerase0.2μl,10μmoll-1引物各0.8μl,2.0μl模板dna(50~60ngμl-1),ddh2o13.8μl。反应程序为94℃预变性5min;35个循环(94℃变性30s,55℃退火30s,72℃延伸30s);72℃延伸8min;12℃保存。扩增产物经hhai限制性内切酶(gcg/c)于37℃酶切过夜后直接在1.5%琼脂糖凝胶电泳中进行检测。gelstain荧光染料染色,bio-rad凝胶成像系统扫描拍照(图1)。
当酶切产物为一条主带时,其对应的最终扩增产物的基因序列命名为qsd1-5bl-a,对应的小麦种子具有较长的种子休眠期或较长的穗发芽抗性持续期;当酶切产物为两条主带时,其对应的最终扩增产物的基因序列命名为qsd1-5bl-b。
其中qsd1-5bl-b为携带g碱基的等位变异,是可被酶切类型,酶切产物长度分别为250bp和59bp(图1)。
在363份小麦品种中,qsd1-5bl存在两种等位类型,与不同环境下的种子休眠期pd均呈显著或极显著相关(p<0.05或0.01),且携带qsd1-5bl-a等位类型的材料具有较长的种子休眠期或较长的穗发芽抗性持续期(表1,图1)。
表1利用363份小麦品种验证taqsd1-5b基因与种子休眠期的关系
由表1可以看出,qsd1-5bl-a,对应的小麦种子具有较长的种子休眠期或较长的穗发芽抗性持续期;qsd1-5bl-b,对应的小麦种子具有较短的种子休眠期或较短的穗发芽抗性持续期。
序列表
<110>安徽农业大学
<120>与小麦种子休眠/穗发芽抗性相关的caps标记及其检测方法
<160>3
<170>siposequencelisting1.0
<210>1
<211>309
<212>dna
<213>小麦(triticumaestivuml)
<220>
<221>mutation
<222>(250)
<223>nisaorg
<220>
<221>misc_feature
<222>(250)..(250)
<223>nisa,c,g,toru
<400>1
agacagcaatgcctcccagattaagtttttttttggagagtgtgattaagggttataacc60
tcacggaagaaggttatgggtcgctggccgagagcctgggggttcccaaggttgcagtat120
gttatctgcaaggaagcaactcatcatcatcgattagtgaatttggccaggattgaacat180
aagtatatatgtaaacaaagacgcacctctggaaaagggcgagaacctgggctcttctcc240
atctcctgcnccaaccgctggataacacgaaaaccggcatatgccgataggaaacttgta300
cggtcaaac309
<210>2
<211>20
<212>dna
<213>人工序列(syntheticsequence)
<400>2
gtttgaccgtacaagtttcc20
<210>3
<211>17
<212>dna
<213>人工序列(syntheticsequence)
<400>3
agacagcaatgcctccc17
- 还没有人留言评论。精彩留言会获得点赞!