一种抗菌肽及其原核表达方法和应用与流程
本发明属于基因工程技术领域,特别是涉及一种抗菌肽及其原核表达方法和应用。
背景技术:
抗菌肽(antimicrobialpeptide)是一种天然存在于几乎所有生物体中的小分子多肽,是生物体天然免疫的重要组成部分,不仅具有广谱抗菌作用,对一些真菌、寄生虫和部分有被膜的病毒也具有杀灭作用。与常规抗生素不同,抗菌肽不易引起细菌产生耐药性,且对抗生素耐菌株也具有杀灭作用,在新型抗菌药物开发领域显示出巨大的潜力。但是,天然抗生素也存在来源受限、效价较低、较长的多肽序列导致人工合成成本较高等不足。因此,开发和制备能够克服上述缺点的新一代抗菌肽具有重要意义。
天然抗菌肽大多为阳离子抗菌肽(电荷数在+2~+9之间),并可形成稳定的α‐螺旋结构。α‐螺旋可位于肽链的n-端或c-端,具有水脂两亲性,是抗菌肽发挥抗菌活性的构象基础。一般认为,带正电荷的抗菌肽通过静电引力作用被吸附到带负电荷的细菌质膜表面,进而形成两亲性螺旋构象,这种构象有助于抗菌肽的疏水面插入细胞膜磷脂双分子层,从而破坏细菌质膜,起到杀菌作用。已有研究显示,在一定范围内提高抗菌肽的疏水性和净正电荷数可增强其杀菌活性,这是因为疏水性升高可增强抗菌肽的疏水基团插入细菌质膜的能力,而增加净电荷数可增强抗菌肽与细菌质膜的结合能力。此外,增强疏水性和净电荷数也更有利于提高α‐螺旋的稳定性。
天蚕素a(cecropina)是最早从昆虫中发现的一类阳离子抗菌肽,前体肽由61个氨基酸构成。cathelicidins抗菌肽是哺乳动物内源性抗菌肽中最主要的一类阳离子抗菌肽,bmap-27是cathelicidins家族的代表,成熟肽由129个氨基酸残基构成。为获得抗菌活性强、肽链较短的新型抗菌肽,本发明以天然天蚕素a和bmap-27为蓝本,在分析这两种肽的α‐螺旋、净正电荷数、疏水性和两亲性等理化性质的基础上,设计了一条由32个氨基酸残基构成的阳离子抗菌肽,并建立了该新型抗菌肽的原核表达方法。抑菌试验结果表明该抗菌肽具有良好的抗菌活性。
技术实现要素:
本发明的目的在于提供一种抗菌肽及其原核表达方法和应用。本发明的抗菌肽是一种新型的阳离子抗菌肽,由32个氨基酸残基构成,且本发明的原核表达方法获得的重组抗菌肽在纯化后不经任何处理即具有明显的体外抑菌效果。
为了达到上述的目的,本发明采取以下技术方案:
一种抗菌肽cecropin-bm的编码基因,其核苷酸序列如seqidno.1所示。
优选地,对所述表达载体进行pcr扩增的引物序列为8条:
p1:cgcggatccatgagctatggccagggccagttttttcgtgaaattgaaaatctgaaagaatatttca;
p2:ccgcctttcgccacatccgggctgctcgcgttgaaatattctttcagattttcaatttca;
p3:gatgtggcgaaaggcggtcctctgtttagcgaaattctgaaaaattggaaagatgaaagc;
p4:aagctcacaactggctctgaataatctttttatcgctttcatctttccaatttttcaga;
p5:cagagccagattgtgagcttttacttcaaactgtttgagaacttgaaagatgaggagtaa;
p6:cgcaaacacaaagctcagaatacgcacaaatgtcattactcctcatctttcaagttctca;
p7:attctgagctttgtgtttggctggtgctggcgctgcgttttaagcgttttcgtaaaaag;
p8:cggaattcgctcagcttcttaaacagttttttgaactttttacgaaaacgcttaaaacg。
本发明还提供一种抗菌肽cecropin-bm的重组载体,该重组载体包含如seqidno.1所示的cecropin-bm的编码基因。
本发明还提供一种抗菌肽cecropin-bm,其由如seqidno.10所示的核苷酸序列编码。
本发明还提供一种抗菌肽cecropin-bm原核表达的方法,该方法包括以下步骤:
获取抗菌肽cecropin-bm的编码基因;
构建重组载体:将抗菌肽cecropin-bm的编码基因的pcr扩增产物连接到pmd19-t克隆载体中,构建得到重组质粒pmd19-inf-cecropin-bm;分别酶切重组质粒pmd19-inf-cecropin-bm和原核表达载体pet-28a(+),构建得到包含cecropin-bm的编码基因的重组载体pet28-inf-cecropin-bm;
表达抗菌肽cecropin-bm:将重组载体pet28-inf-cecropin-bm转化至bl21菌株中,利用iptg诱导后收集包含抗菌肽cecropin-bm的细菌。
优选地,所述方法还包括:采用含脲和咪唑的pbs重悬液处理离心破碎后的细胞菌液,随后离心并收集沉淀,获得上清液;
采用ni柱亲和层析法纯化所述上清液,获得纯化后的抗菌肽cecropin-bm。
本发明还提供抗菌肽cecropin-bm在抑制大肠杆菌和金黄葡萄球菌生长中的应用。
本发明具有以下技术特点:
本发明采用原核表达载体构建包含抗菌肽cecropin-bm的编码基因的重组载体,实现了抗菌肽cecropin-bm的原核表达,方法简单易行,获得的重组抗菌肽在纯化后不经任何处理即具有明显的体外抑菌效果。
附图说明
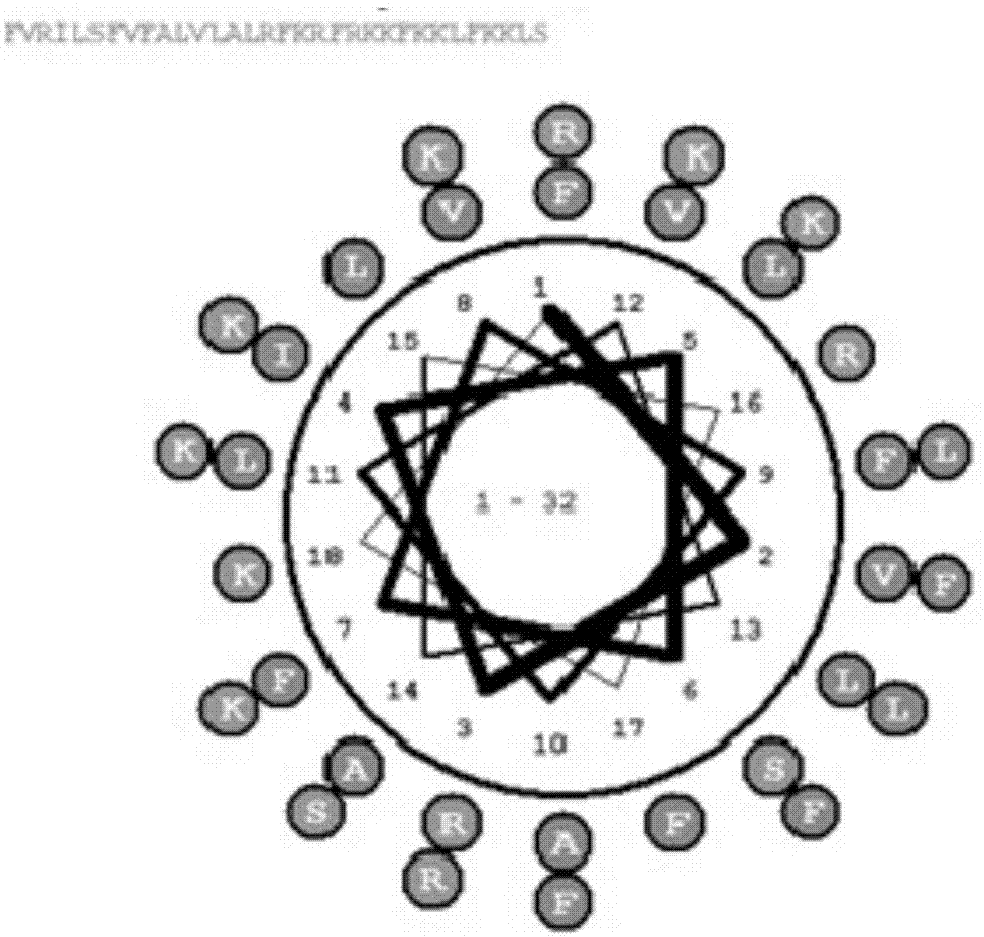
图1cecropin-bm两亲性预测。
图2soe-pcr凝胶电泳结果。
图3tricine-sds-page凝胶电泳结果(1:pet-cecropin-bm质粒表达全蛋白;2:pet-28a(+)质粒表达全蛋白;3:纯化后的pet-cecropin-bm质粒表达蛋白;4:纯化后的pet-28a(+)空质粒表达蛋白)。
图4重组蛋白抑菌试验(a:e.coli、b:金葡菌;1:卡那霉素(100μg);2:cecropin-bm(100μg);3:cecropin-bm(50μg);4::cecropin-bm(25μg);5:pet-28a(+)空载体质粒对照)
具体实施方式
以下具体实施例是对本发明提供的方法与技术方案的进一步说明,但不应理解成对本发明的限制。
一、本发明具体实施方式中采用的材料和来源如下:
1菌种与质粒
dh5αchemicallycompetentcell(北京擎科新业生物技术有限公司);bl21(de3)chemicallycompetentcell(上海唯地生物技术有限公司);pmd19-tvector(takara公司);pet-28a(+)载体、e.coli、金黄色葡萄球菌均来自本实验室保存。
2试剂
高保真酶primestarhsdnapolymerase、taq酶、琼脂糖凝胶电泳10×loadingbuffer、dl1000dnamarker、限制性核酸内切酶ecorⅰ和bamhⅰ、质粒连接dnaligationkit、纯化蛋白所用镍柱his60nigravitycolumns均为takara公司产品;axyprep质粒dna小量试剂盒为axygen公司产品;pcr产物纯化试剂盒、bca蛋白定量试剂盒均购自美仑生物公司;tricine-sds-page所用proteinmarker为弗德生物产品;tricine-sds-page蛋白上样缓冲液(5×)为beyotime产品。
二、本发明具体实施方式中抗菌肽cecropin-bm的原核表达方法如下:
1新型抗菌肽cecropin-bm的设计及理化性质预测
采用在线工具sopma(https://npsa-prabi.ibcp.fr/)分析天蚕素a(登录号:np_001037462)和bmap-27(登录号:np_001037462)的二级结构,获得两种肽链中α-螺旋氨基酸序列。选取来自上述两种肽的α-螺旋片段进行组合,采用在线工具expasy(https://web.expasy.org/protparam/)分析组合后的肽段的电荷数和亲疏水性,采用antheprot6.9.3软件进行两亲性预测。综合α-螺旋、电荷、疏水性和两亲性等参数,确定新抗菌肽的氨基酸序列,将该新抗菌肽命名为cecropin-bm。
2cecropin-bm的原核表达
2.1核苷酸序列设计
利用双顺反子表达载体表达cecropin-bm,以inf-γ(np_776511)的第21-85位氨基酸序列作为第一顺反子,以cecropin-bm的核苷酸序列作为第二顺反子。根据大肠杆菌密码子偏嗜性进行基因改造后,两条基因序列以5’-gaggagtaatgaca-3’相连,合并所得inf-cecropin-bm基因序列如下:
2.2pcr扩增
设计8条引物,在首尾两条引物的5’-端分别引入bamhⅰ和ecorⅰ酶切位点,通过重叠延伸pcr法合成inf-cecropin-bm基因。引物由杭州擎科梓熙生物技术有限公司合成(表1)。
pcr扩增分2步进行:第一步,在20μlpcr体系中分别加入引物p1~p4、引物p5~p8,扩增获得两种pcr产物,分别命名为p14和p58;第二步,在20μlpcr体系中加入pcr产物p14和p58,以p1和p8为上下游引物,扩增inf-cecropin-bm全长基因。反应体系见表2。pcr反应条件为:94℃5min、(98℃30s、57℃5s、72℃15s~1min)×25个循环,72℃延伸10min。pcr产物用1.5%琼脂糖凝胶电泳进行检测。
表1.pcr引物
注:下划线为酶切位点
表2.pcr反应体系
2.3pmd19-inf-cecropin-bm质粒的构建
采用pcr产物纯化试剂盒纯化cecropin-bm产物,利用taq酶进行加a尾反应,反应条件为72℃、30min,反应体系见表3。将带有a尾的cecropin-bm亚克隆到pmd19-t载体,转化dh5α感受态细胞,挑取阳性菌落扩大培养,菌液送至杭州擎科梓熙生物技术有限公司测序。
表3.cecropin-bm产物加a尾反应体系
在lb液体培养基中扩大培养测序正确的dh5α,使用axyprep质粒dna小量试剂盒提取质粒dna。提取方法按说明书进行。
2.4表达载体pet28-inf-cecropin-bm的构建
2.4.1质粒和载体双酶切
将pmd19-inf-cecropin-bm质粒和pet-28a(+)载体分别使用限制酶bamhⅰ和ecorⅰ在10×k缓冲液中进行双酶切,37℃酶切过夜。将pmd19-inf-cecropin-bm质粒和pet-28a(+)载体的双酶切产物按摩尔比10:1混合(总体积为5μl),置65℃水浴中反应2min,取出后立即冰浴2min,加入solutionⅰ5μl,16℃连接过夜。
2.4.2质粒转化
将pet28-inf-cecropin-bm质粒加入bl21感受态中,冰浴静置25min后,置42℃水浴锅中热激45s,并立即插入冰浴中静置2min。加入700μl不含抗生素的无菌lb培养基,37℃、200rpm振摇培养60min。吸取100μl菌液均匀涂布到含卡那霉素的固体lb培养基表面,置37℃培养箱中培养10~14h。挑取单菌落,接种于3ml含卡那霉素的液体lb培养基中,37℃、200rpm振摇培养至菌液浑浊,送擎科公司测序。
2.4.3目的蛋白诱导表达
挑取阳性转化子接种于lb培养基,37℃、200rpm振摇培养过夜,取50μl菌液接种于500ml液体lb培养基中,37℃、230rpm振摇培养至od570达0.6,加入iptg至终浓度为0.75mm,37℃诱导表达4h。将转化有pet28a(+)空载体质粒的bl21(de3)为对照。
诱导表达结束后,离心收集菌体(4℃、10000g离心30min),用含8m脲、20mm咪唑的pbs液重悬菌体,超声破碎菌体(4℃,功率40%,超声开2s、关4s,共30min),10000g离心30min,收集上清。
2.4.4ni柱亲和层析
取上述上清液,采用ni柱亲和层析法纯化目的蛋白,具体步骤如下:(1)使用5ml结合缓冲液(含8m脲、20mm咪唑)润洗ni柱;(2)加入5ml重组蛋白上清,颠倒混匀,使得蛋白与ni柱充分结合;(3)将ni柱竖直放置,待填料沉降在底部后,流净柱子内的液体,收集过柱后的液体;(4)重复步骤2和3,直至过滤完所有的上清液;(5)向柱子内加入5ml漂洗液(含8m脲、40mm咪唑),颠倒混匀,静置,待填料沉降后,再流净柱内液体,使得杂蛋白被充分洗脱;(6)向柱子内加入1ml洗脱液(含8m脲、300mm咪唑),上下颠倒混匀,静置,待填料沉降后,充分收集柱内液体,获得目的蛋白。重复步骤1~6以充分收集目的蛋白。
2.4.5tricine-sds-page凝胶电泳
纯化的目的蛋白经bca试剂盒进行蛋白定量后,在tricine-sds-page凝胶(4%浓缩胶、10%间隔胶、20%分离胶)上进行电泳,考马斯亮染色,拍照记录结果。
3重组蛋白抗菌活性鉴定
使用琼脂糖平板扩散法进行抗菌活性鉴定,所用e.coli和金葡菌均为本实验室保存的临床分离株。具体步骤如下:(1)将e.coli和金葡菌分别在液体lb培养基中培养至对数生长期(od570为0.4-0.6);(2)将菌液进行10倍倍比稀释,并取50μl菌液分别涂布在固体lb平板上,37℃培养16h后进行菌落计数;(3)将e.coli和金葡菌的菌液稀释至0.5麦氏标准单位(1.5×108cfu/ml),取50μl菌液分别均匀涂布在lb平板上;(4)使用无菌打孔器在上述平皿上打孔,每孔分别加入25μg、50μg和100μg经ni柱纯化的cecropin-bm。设置卡那霉素阳性对照孔(100μg/孔)、阴性对照孔(每孔加入pet-28a(+)空质粒表达产物,100μg/孔),37℃培养14h后观察抑菌效果。
三、抗菌肽cecropin-bm的理化性质及抗菌活性
1重组蛋白cecropin-bm理化性质预测
生物信息学分析结果表明,本发明所设计的cecropin-bm具有较高的α-螺旋度,净电荷数为+11,为疏水性蛋白,性质稳定(表4)。两亲性分析结果表明,cecropin-bm肽链具有良好的两亲性(图1)。
表4.cecropin-bm二级机构及理化性质预测
2pcr产物凝胶电泳结果
如图2所示,采用重叠延伸pcr法合成的cecropin-bm基因片段大小为320bp,与预期大小相符。测序结果表明序列完全正确。
3tricine-sds-page电泳结果
纯化后的目的蛋白在tricine-sds-page凝胶上形成2条条带,分子量大小分别为8.23kda和4.8kda,与预期的ifn-his和cecropin-bm-his分子量大小相符(图3),表明cecropin-bm成功表达。
4重组蛋白cecropin-bm抑菌活性试验结果
如图4所示,加入25~100μg重组cecropin-bm至e.coli和金葡菌培养平板的加样孔后均能形成明显的抑菌圈,加入量越高,抑菌圈越大,而pet-28a(+)空质粒表达产物无抑菌效果。100μgcecropin-bm在e.coli和金葡菌琼脂糖平板上形成的抑菌圈直径分别为2.9cm和2.8cm,而100μg在e.coli和金葡菌琼脂糖平板上形成的抑菌圈直径分别为3.2cm和3.1cm(表5)。上述结果表明本发明cecropin-bm具有较好的体外抑菌作用。
表5.cecropin-bm抑菌试验结果
以上实施例的说明只是用于帮助理解本发明方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求保护范围内。
序列表
<110>浙江大学
<120>一种抗菌肽及其原核表达方法和应用
<160>10
<170>siposequencelisting1.0
<210>1
<211>308
<212>dna
<213>人工序列(artificialsequence)
<400>1
atgagctatggccagggccagttttttcgtgaaattgaaaatctgaaagaatatttcaac60
gcgagcagcccggatgtggcgaaaggcggtcctctgtttagcgaaattctgaaaaattgg120
aaagatgaaagcgataaaaagattattcagagccagattgtgagcttttacttcaaactg180
tttgagaacttgaaagatgaggagtaatgacatttgtgcgtattctgagctttgtgtttg240
cgctggtgctggcgctgcgttttaagcgttttcgtaaaaagttcaaaaaactgtttaaga300
agctgagc308
<210>2
<211>67
<212>dna
<213>人工序列(artificialsequence)
<400>2
cgcggatccatgagctatggccagggccagttttttcgtgaaattgaaaatctgaaagaa60
tatttca67
<210>3
<211>60
<212>dna
<213>人工序列(artificialsequence)
<400>3
ccgcctttcgccacatccgggctgctcgcgttgaaatattctttcagattttcaatttca60
<210>4
<211>60
<212>dna
<213>人工序列(artificialsequence)
<400>4
gatgtggcgaaaggcggtcctctgtttagcgaaattctgaaaaattggaaagatgaaagc60
<210>5
<211>59
<212>dna
<213>人工序列(artificialsequence)
<400>5
aagctcacaactggctctgaataatctttttatcgctttcatctttccaatttttcaga59
<210>6
<211>60
<212>dna
<213>人工序列(artificialsequence)
<400>6
cagagccagattgtgagcttttacttcaaactgtttgagaacttgaaagatgaggagtaa60
<210>7
<211>60
<212>dna
<213>人工序列(artificialsequence)
<400>7
cgcaaacacaaagctcagaatacgcacaaatgtcattactcctcatctttcaagttctca60
<210>8
<211>59
<212>dna
<213>人工序列(artificialsequence)
<400>8
attctgagctttgtgtttggctggtgctggcgctgcgttttaagcgttttcgtaaaaag59
<210>9
<211>59
<212>dna
<213>人工序列(artificialsequence)
<400>9
cggaattcgctcagcttcttaaacagttttttgaactttttacgaaaacgcttaaaacg59
<210>10
<211>97
<212>dna
<213>人工序列(artificialsequence)
<400>10
tttgtgcgtatttctgagctttgtgtttgcgctggtgctggcgctgcgttttaagcgttt60
tcgtaaaaagttcaaaaaactgtttaagaagctgagc97
- 还没有人留言评论。精彩留言会获得点赞!