组蛋白赖氨酸N-甲基转移酶KMT5B突变蛋白及应用的制作方法
本发明涉及一种基因工程领域,尤其涉及组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白及应用。
背景技术:
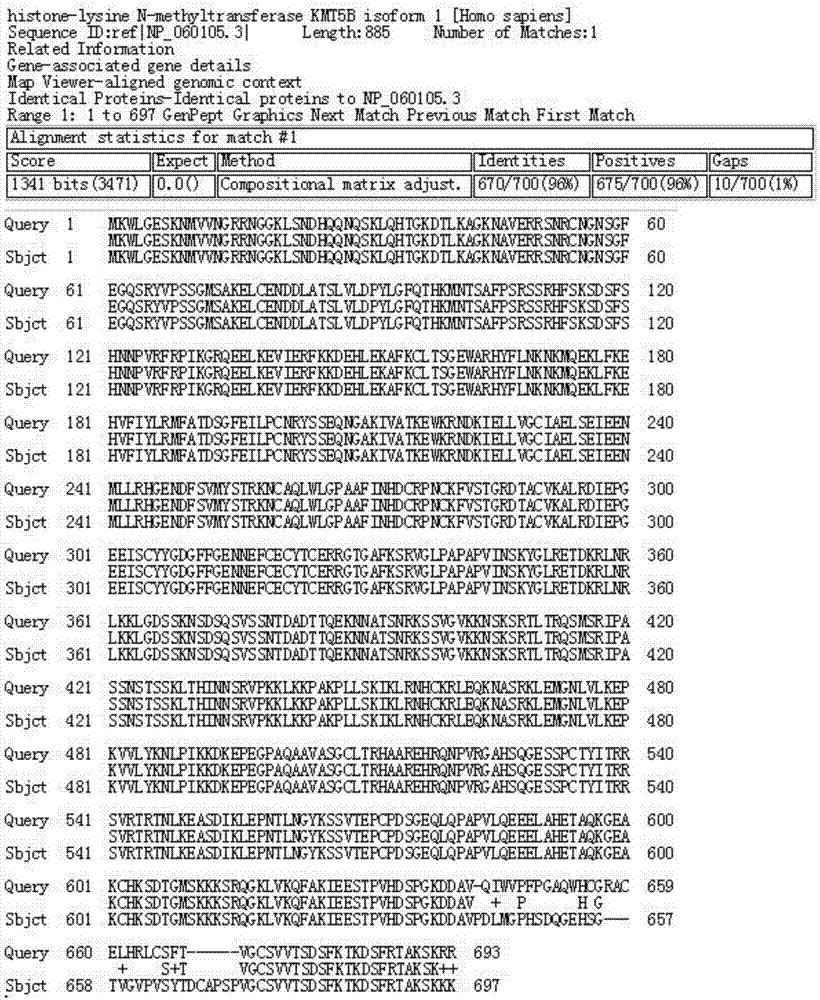
:组蛋白赖氨酸甲基化是生物体中一种普遍而重要的表遗传修饰方式,常发生在h3和h4号组蛋白赖氨酸残基上,由组蛋白赖氨酸甲基转移酶(histonelysinemethyltransfereses,hkmt)完成。组蛋白赖氨酸甲基化在表观遗传调控中起着关键作用。组蛋白赖氨酸甲基转移酶kmt5b通过和rb1家族蛋白相互作用,作用于组蛋白h3,在肌细胞生成中通过调节靶基因的表达发挥作用。组蛋白甲基化是一种重要的组蛋白共价修饰,在染色质结构和基因表达的调控过程中起着重要的、多样化的作用。因此,组蛋白赖氨酸n-甲基转移酶kmt5b的基因发生突变与多数疾病的发生相关。在对大量白血病患者的外周血进行基因测序的过程中,发现患者的组蛋白赖氨酸n-甲基转移酶kmt5b发生了突变,因此,对人的组蛋白赖氨酸n-甲基转移酶kmt5b突变的检测对判断人体是否患有相关疾病具有一定的指引作用。技术实现要素:本发明目的在于提供组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白及应用。本发明技术方案包括:第一方面,提供一种人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白,其氨基酸序列如seqidno:1所示。第二方面,提供一种人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的编码基因,其核苷酸序列如seqidno:2所示。第三方面,提供一种基因芯片,包括:固相载体和固定在该载体上的核苷酸探针;所述核苷酸探针根据上述所述人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的核苷酸序列,与人的组蛋白赖氨酸n-甲基转移酶kmt5b正常蛋白的核苷酸序列的比对结果确定。优选地,所述核苷酸探针为seqidno:3所示的碱基序列;或,所述核苷酸探针为seqidno:4所示的碱基序列;或,所述核苷酸探针为seqidno:5所示的碱基序列。第四方面,提供一种试剂,所述试剂中含有用于检测上述人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的引物对。优选地,其所述引物对包括下述任一上游引物与下述任一下游引物的组合:上游引物为如seqidno:8~no:23中任一所示的碱基序列;下游引物为如seqidno:24~no:40中任一所示的碱基序列。第五方面,提供一种特异性识别人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的单克隆抗体,由上述试剂制备而成,其可与seqidno:1所示的氨基酸序列特异性结合。第六方面,提供一种用于检测人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的elisa试剂盒,所述elisa试剂盒包括:包被有上述单克隆抗体的elisa酶标板、酶标二抗、样品稀释液、包被缓冲液、elisa酶标板洗涤液、显色液和终止液。优选地,所述酶标二抗为稀释的hrp辣根过氧化物酶标记的山羊抗人igg。本发明提供了组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白及应用,将大量白血病患者作为研究病例,对病例进行基因检测并分析,确定出人的组蛋白赖氨酸n-甲基转移酶kmt5b的突变蛋白,根据该人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白制备基因芯片、单克隆抗体和elisa试剂盒,为白血病的基因诊断提供指引作用,为疾病的诊断和治疗提供一定的理论基础。上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。附图说明图1是本发明实施例一提供的一种比对结果示意图;图2是本发明实施例一提供的一种基因芯片布局图;图3是本发明实施例二提供的一种显色结果示意图;图4是本发明实施例二提供的另一种显色结果示意图;图5是本发明实施例五提供的为蛋白含量的标准曲线;图6是本发明实施例五提供的westernblot检测结果示意图。具体实施方式下述实施例中所使用的实验方法如无特殊说明,均为常规方法。下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。实施例一、基因芯片的制备首先,可以根据申请号为“201710429915.8”、
专利名称:为“一种突变蛋白的检测方法及装置”的中国发明专利中描述的检测方法,确定出人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的编码基因,其核苷酸序列如seqidno:2所示;相应地,根据该编码基因确定出人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白,其氨基酸序列如seqidno:1所示。其次,根据人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白及其编码基因,按照如下方式实现基因芯片的制备。1、核苷酸探针的设计(1)核苷酸探针的设计:核苷酸探针根据人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的核苷酸序列,与人的组蛋白赖氨酸n-甲基转移酶kmt5b正常蛋白的核苷酸序列的比对结果来确定,并根据如下探针的设计原则,设计出针对人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的特异性的核苷酸探针。其中,核苷酸探针设计的原则如下:①核苷酸探针tm值应接近整个基因组的平均tm值,上下波动5℃;②核苷酸探针分子内重复的单一碱基连续不超过4个;③g+c含量为40%-60%,减少非特异性杂交保证杂交的特异性;④核苷酸探针序列中与探针分子内部稳定二级结构配对的碱基长度应少于4bp,这样可以保证不会因核苷酸探针内部稳定的二级结构而影响杂交效率;⑤经同源比较与其他序列的相似性小于40%;⑥经对比与非探针备选序列的同源片段连续不超过20个碱基。其中,人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白对应的氨基酸序列与人的组蛋白赖氨酸n-甲基转移酶kmt5b正常蛋白对应的氨基酸序列的比对结果请参考图1,其中,图1中的query序列是人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白对应的氨基酸序列,sbjct序列是人的组蛋白赖氨酸n-甲基转移酶kmt5b正常蛋白对应的氨基酸序列,query序列与sbjct序列之间的序列为比对结果,根据图1可知,人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白相对于人的组蛋白赖氨酸n-甲基转移酶kmt5b正常蛋白,有多处氨基酸序列发生了突变,并存在部分插入和缺失。根据seqidno:2所示的核苷酸序列,以及图1的比对结果,为了能够特异性识别待检测对象的组蛋白赖氨酸n-甲基转移酶kmt5b是否发生了突变,那么在选取核苷酸探针时,可以按照如下几种方式中的任一种方式设计核苷酸探针:①选取插入位置的插入核苷酸序列生成核苷酸探针;②在插入位置之前,和/或,在插入位置之后,各选择若干个核苷酸序列,将选择的若干个序列核苷酸与插入位置的插入核苷酸序列共同生成核苷酸探针,其中,生成的核苷酸探针中相邻核苷酸的先后顺序与其在突变蛋白对应的核苷酸序列中的顺序一致;③在插入位置之前选择若干个核苷酸序列,与在插入位置的开始位置处选择若干个核苷酸序列,生成核苷酸探针;④在插入位置之后选择若干个核苷酸序列,与在插入位置的结束位置处选择若干个核苷酸序列,生成核苷酸探针;⑤将包含有突变位置核苷酸的一条核苷酸序列作为核苷酸探针。⑥在缺失位置之前与在缺失位置之后各选择若干个核苷酸序列(碱基序列的顺序不变),生成核苷酸探针。在本实施例中,根据seqidno:2所示的核苷酸序列以及根据上述核苷酸探针设计原则,按照上述方式至少可以设计出如下几种优选地核苷酸探针:如seqidno:3所示的核苷酸探针为:gcggtacagatttgatgggt;如seqidno:4所示的核苷酸探针为:ttctgaccagggtgagcaca;如seqidno:5所示的核苷酸探针为:tccttcaccgtcggt。(2)核苷酸探针的合成:通过核苷酸序列合成上述设计好的核苷酸探针。2、检测人的组蛋白赖氨酸n-甲基转移酶kmt5b是否发生突变的基因芯片的制备为了保证检测对象样品的质量,还需在基因芯片上设计空白对照、阳性对照和阴性对照。其中,该基因芯片的布局至少可以为如图2所示的一种布局。在图2中,□为空白对照,○为阴性对照,为阳性对照,☆为实验组。其中,实验组的位置即为核苷酸探针的点样位置。对于空白对照、阴性对照所需点样的阴性内参质控探针、以及阳性对照所需点样的阳性内参质控探针设计如下:空白对照:是不含任何基因片段的空白点样液作为芯片制备过程中的污染监控指标。阴性内参质控探针:是一段与检测基因没有同源性的其他基因片段,作为杂交过程中非特异性杂交的监控指标,阴性内参质控探针包括的核苷酸个数可以与核苷酸探针的碱基个数相同,也可以不同。本发明实施例中,基因芯片所需的阴性内参探针序列可以为:tgatgctgataattgcat。阳性内参质控探针:是一段与检测基因有同源性的其他基因片段,在人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白中,选择与核苷酸探针对应的序列不同,且可以与核苷酸探针碱基的个数相同,也可以与核苷酸探针碱基的个数不同的一段核苷酸序列作为阳性内参质控探针。优选地,选取核苷酸个数与核苷酸探针碱基的个数相同的阳性内参质控探针。本发明实施例中,基因芯片所需的阳性内参探针序列可以为:caaccagtttggttc。需要说明的是,在基因芯片的点样过程中,按照基因芯片的布局点入阴性内参探针和阳性内参探针溶液;空白对照所用的试剂为1倍的点样缓冲液(10%海藻糖溶液)。实施例二、基因芯片的应用1、样品处理(1)采集检测对象的血液1-3ml。(2)取depc处理的1.5mlep管,将其作为被检测样品处理管,在被检测样品处理管中加入检测对象的血液300μl,再加入trizol700μl,充分混匀,室温放置10min。(3)加入140μl的氯仿,盖紧管盖,用力震荡,室温放置3-5min,置于离心机中,12000r/min,4℃离心15min,小心吸取离心管中上清,将吸取的上清转移到干净的离心管中。(4)在储存有步骤(3)中上清的离心管中加入等体积异丙醇,轻轻颠倒离心管充分混匀液体,室温放置10min,12000r/min,4℃离心15min,小心吸去所有上清。(5)用1ml75%的乙醇清洗一次,7500r/min,4℃离心15min,小心吸去所有上清,在超净台中干燥15min,加入10μldepc处理水溶解。(6)所得产物为rna,如果总rna的纯度不高,会影响探针的标记效率和芯片杂交结果。所以使用qiagenkit纯化总rna。2、cdna第一链和第二链一步法合成(1)取2μgrna于1.5ml的离心管中配置如下反应溶液:总rna2μg最多6.5μlt7promotorprimer5μlrnase-freewaterxμl总体积11.5μl其中,rnase-freewater的加入量xμl,是根据总体积11.5μl减去t7promotorprimer的加入量5μl,再减去总rna的加入量计算得来的。(2)在65℃下保温10min,并冰浴5min,将5×firststrandbμffer在65℃下预热5min。(3)配置如下cdna合成体系:5×firststrandbuffer4μl0.1mdtt2μl10mmdntpmix1μlmmlvrt1μlrnaseout0.5μl总体积8.5μl(4)将上述8.5μl混合均匀后加入变性后冰浴的rna中。(5)用枪头混匀之后离心。(6)40℃反应2h。3、aautp标记crna合成ntp的配置:100mmatp250μl100mmgtp250μl100mmctp250μl100mmutp187.5μlrnasefreeh2o62.5μl总体积1000μl分装成10管备用,注:50%peg(聚乙二醇)使用之前40℃保温1min。同时按如下操作配置transcriptionmix;(1)配置transcriptionmix(2)加入60μltranscriptionmix并混匀。(3)pcr仪中热盖60℃,40℃反应2h。4、crna纯化qiagenrneasyminikit纯化crna,具体方法可参见qiagen公司随试剂盒提供的操作手册。(1)加入20μlrnasefree水,加入350μlbufferrlt并充分混匀。(2)加入250μl无水乙醇,tip头充分混匀。(3)将共计700μl含总rna的溶液转入套在2ml离心管内的rneasy柱子内≥8000g离心15-30s,弃去滤过液。(4)吸取500μlbufferrpe到rneasymini柱子内≥8000g离心洗涤15-30s弃去滤过液再用500μlbufferrpe在≥8000g离心洗涤2min弃去滤过液和2ml的套管将rneasymini柱子转入一新的1.5mleppendorf管中。(5)吸取30μlrnasefree的水静置1min,≥8000g离心洗脱1min。(6)重复步骤(5)一次。5、crna浓度测定用分光光度计分析crna浓度。需要测定260nm和280nm处的吸光值来确定样品的浓度和纯度,a260/a280应接近2.0为较纯的crna(比值在1.9-2.1也可)。6、crna样品荧光标记;(1)取上述crna4μg并浓缩至6.6μl。(2)加10μldmso混匀。(3)加3.4μl的0.3mph为9.0的碳酸氢钠(nahco3)并混匀。(4)将上述20μlcrna混合物加入到荧光染料cy3中并混匀。25℃保温1h。(5)加9μl的4mhydroxylamine混匀后25℃保温15min。7、荧光标记crna样品纯化具体步骤同本实施例的步骤4中crna纯化的过程,本步骤不在赘述。8、crna样品片段化和芯片杂交4×44kmicroarrays(1)按下表配制片段化混合液然后在60℃温浴30min进行片段化。cy3crna绿色荧光875ng10×blockingagent11μl25×fragmentationbuffer2.2μlnuclease-freewaterxμl总体积55μl(2)加入55μl2×gexhybridizationbuffer。(3)取100μl杂交液滴加到芯片皿上,同时按芯片布局如图2所示分别滴加在空白、阴性、阳性、实验组位置上。盖上芯片并密封于杂交盒中,60℃滚动杂交16h。9、芯片洗涤洗液1(1l)配置:depc-h2o700ml20×sspe300ml20%n-lauroylsarcosine0.25ml洗液2(1l)配置:depc-h2o997ml20×sspe3.0ml20%n-lauroylsarcosine0.25ml洗液3:stabilizationanddryingsolution(1)取出芯片于洗液1中洗涤1min;(2)再将芯片放入洗液2中洗涤1min(37℃);(3)最后将芯片于洗液3中洗涤30s。10、芯片扫描将芯片在扫描仪中进行扫描,根据扫描结果确定检测对象的组蛋白赖氨酸n-甲基转移酶kmt5b蛋白是否发生了突变。请参考图3和图4,图3所示的结果中,阴性对照无绿色荧光,阳性对照为绿色荧光,表明采集检测对象的样品质量是没有问题的,而实验组为绿色荧光,那么表明检测对象的组蛋白赖氨酸n-甲基转移酶kmt5b蛋白发生了突变。图4所示的结果中,阴性对照为无色荧光,阳性对照为绿色荧光,表明采集检测对象的样品质量是没有问题的,而实验组无绿色荧光,那么表明检测对象的组蛋白赖氨酸n-甲基转移酶kmt5b蛋白未发生突变。实施例三、特异性识别人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的单克隆抗体的制备1、试剂的确定该试剂中含有用于检测上述人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的引物对。其中,根据人的组蛋白赖氨酸n-甲基转移酶kmt5b正常蛋白的orf(如seqidno:6所示),可以确定出人的组蛋白赖氨酸n-甲基转移酶kmt5b正常蛋白的orf对应的碱基序列(如seqidno:7所示)。进一步地,可以根据人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的碱基序列(如seqidno:2所示),以及根据人的人的组蛋白赖氨酸n-甲基转移酶kmt5b正常蛋白的orf对应的碱基序列(如seqidno:7所示),设计出如下上游引物和下游引物:上游引物(f):如seqidno:8所示:gttctgtataaaaatttgcccattaaaaaa如seqidno:9所示:gataaggagccagagggaccagcccaagcc如seqidno:10所示:gcagttgccagcgggtgcttgactagacac如seqidno:11所示:gcggcgagagaacacagacagaatcctgtg如seqidno:12所示:agaggtgctcattcgcagggggagagctcg如seqidno:13所示:ccctgcacctacataactcggcggtcagtg如seqidno:14所示:aggacaagaacaaatctgaaggaggcctct如seqidno:15所示:gacatcaagcttgaaccaaatacgttgaat如seqidno:16所示:ggctataaaagcagtgtgacggaaccttgc如seqidno:17所示:cccgacagtggtgaacagctgcagccagct如seqidno:18所示:cctgtgctgcaggaggaagaactggctcat如seqidno:19所示:gagactgcacaaaaaggggaggcaaagtgt如seqidno:20所示:cataagagtgacacaggcatgtccaaaaag如seqidno:21所示:aagtcacgacaaggaaaacttgtgaaacag如seqidno:22所示:tttgcaaaaatagaggaatctactccagtg如seqidno:23所示:cacgattctcctggaaaagacgacgcggta下游引物(r):如seqidno:24所示:atcatagtcatcctcctcttcatcgccctc如seqidno:25所示:agaagaggaggaatcatctgtactttcttc如seqidno:26所示:ctcatactgactatagtcatccacctccat如seqidno:27所示:tcgagactccaagagagaaagaggatcact如seqidno:28所示:gcagcacaccccattttcatgaagcccctc如seqidno:29所示:tgtataagaccccctattttcctcatctcg如seqidno:30所示:ttttagctggatttttaattttgtagaact如seqidno:31所示:actgcctgatcctgagttaaatccattatt如seqidno:32所示:aagctttgctacatagagattgttatcgtt如seqidno:33所示:gtcatggtctttgcttaacttgatgcttat如seqidno:34所示:tttggaagagttcattccatcattctcttg如seqidno:35所示:gtcatttgttttgctgctgctatcatgacg如seqidno:36所示:cctacgaagagtcaatttgggaatcccaga如seqidno:37所示:gttattttctaggattaactgtgcatcata如seqidno:38所示:ccttgtgattcgcctcttctttttactttt如seqidno:39所示:tgcagttctaaagctgtcttttgttttgaa如seqidno:40所示:gctatctgatgtcacaactgaacaaccgac在本实施例中,试剂中含有的用于检测上述人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的引物对包括:上述任一上游引物与上述任一下游引物的组合。针对每一种组合生成的引物对(引物(f)和引物(r)),执行下述pcr扩增步骤。2、检测对象的dna为模板进行pcr扩增10×buffer5uldntp2ulextaq1ulddh2o5ul模板dna1ul引物(f)3ul引物(r)3ul总体系20ul以检测对象的dna为模板进行pcr扩增,获得人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白基因完整片段,并连接pmd19-tvector(takara公司),进行测序。然后由专门的生物公司制备抗体,是一种人源化或嵌合型抗体。其中,制备出的单克隆抗体可与seqidno:1所示的氨基酸序列特异性结合。将制备的抗体采用elisa法测定含量。实施例四、用于检测人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白的抗体的elisa试剂盒本实施例中,elisa试剂盒的组成为:包被有实施例三所述单克隆抗体的elisa酶标板、酶标二抗、检测对象的组蛋白赖氨酸n-甲基转移酶kmt5b蛋白、样品稀释液、包被缓冲液、elisa酶标板洗涤液、显色液和终止液。其中,上述各个组成的参数至少可以为如下一种参数:elisa酶标板可以为96孔的elisa酶标;酶标二抗可以是稀释的hrp(辣根过氧化物酶)标记的山羊抗人igg;其中,稀释倍数可以是8000倍。包被缓冲液可以是1×pbs,ph:7.4;elisa酶标板洗涤液可以是含0.05%tween-20的1×pbs溶液;显色液可以是3,3’,5,5’-四甲基联苯胺;终止液可以是2mol/l的硫酸溶液。实施例五在本发明实施例中,将白血病患者作为检测对象,并利用elisa试剂盒检测该白血病患者的组蛋白赖氨酸n-甲基转移酶kmt5b蛋白是否发生了突变,该方法至少可以包括如下一种:a、使用所述包被缓冲液将实施例三制备的单克隆抗体进行稀释,例如,稀释成2.0ug/ml,并将稀释后的单克隆抗体加样至elisa酶标板的孔中,室温孵育1-2h。b、使用样品稀释液将白血病患者的组蛋白赖氨酸n-甲基转移酶kmt5b蛋白稀释成不同浓度梯度,并将不同浓度梯度的组蛋白赖氨酸n-甲基转移酶kmt5b蛋白分别加样至elisa酶标板的孔中,并室温孵育1-2h;c、甩去各孔中的液体,加入所述elisa酶标板洗涤液,洗涤并甩干;d、加入所述酶标二抗,并室温孵育1-2h;e、甩去各孔中的液体,加入elisa酶标板洗涤液,洗涤并甩干;f、加入所述显色液,室温避光孵育10-20min,加入所述终止液终止反应;g、在酶标仪上测定波长为450nm处的吸光值。h、制作标准曲线:以标准品浓度为横坐标,标准品测定的吸光值为纵坐标,作出标准曲线;计算标准曲线回归系数r2,当r2>0.99时本次测定有效;其中,可以使用elisacalc软件绘制该标准曲线,根据该elisacalc软件可以获知回归系数r2=0.99925,因此,本次测定有效。将检测得到的波长为450nm处的吸光值代入标准曲线即可求得白血病患者的组蛋白赖氨酸n-甲基转移酶kmt5b蛋白的浓度。利用建立的elisa方法检测白血病患者血清样品中组蛋白赖氨酸n-甲基转移酶kmt5b蛋白的含量。并用westernblot进行鉴定。请参考图5,为吸光值的标准曲线。其中,x轴为吸光值,y轴为对应的浓度。i、westernblot鉴定1、制胶(1)清洗玻璃板并擦干;(2)参考分子克隆方法配制sds-page胶:a.下层分离胶配制体系(totalvolum:15ml)ddh2o5.9ml30%丙烯酰胺混合液5.9ml1.5mol/ltris(ph8.8)3.8ml10%sds0.15ml10%过硫酸铵0.15mltemed0.006mlb.上层积层胶浓缩配制体系(totalvolum:8ml)ddh2o5.5ml30%丙烯酰胺混合液1.3ml1.0mol/ltris(ph6.8)1.0ml10%sds0.08ml10%过硫酸铵0.08mltemed0.008ml(3)在每个胶板中加入相应体积的下层分离胶,再加入1ml的无菌ddh2o,压平分离胶,待分离胶凝固后,用滤纸吸干制胶板中剩余的水分,而后加入上层浓缩胶,插入梳子后等待上层浓缩胶凝固。2、蛋白上样电泳:(1)拔下梳子,做好孔道标记,加入5×sds电泳缓冲液,随后给蛋白样品中加入sds-page蛋白上样缓冲液(5×),沸水浴加热3-5min,上样;(2)先用80v电压进行电泳,待条带跑过浓缩胶之后,换用100v电压跑大约100min。3、转膜及孵育:(1)先把pvdf膜在甲醇中活化约30s。分别将凝胶、海绵垫和pvdf膜预先在电转移缓冲液中平衡30min。按滤纸-胶-膜-滤纸的顺序夹好,按照黑面对黑面的原则放入转膜器中,加入制冷器(冰袋),在冰中以150ma的电流跑约120min;(2)完成后将膜取出,立刻放入5%的脱脂牛奶中,摇床上轻轻室温封闭1h;(3)pbst清洗已封闭的膜,清洗3次,每次10min;(4)加入稀释到相应倍数的一抗,4℃摇床过夜孵育;(5)回收一抗,pbst清洗膜3次,每次10min;(6)二抗(用3%的牛奶以1:5000-1:10000稀释)室温孵育膜2h;(7)用pbst清洗膜3次,每次10min;(8)pierceeclwesternblottingsubstrate试剂盒a、b液等体积混匀后,逐滴滴加在pvdf膜上;(9)fluorchemefe0511中曝光成像,实验用imagej分析。其中,一抗是公司制备的人的组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白单克隆抗体,二抗是辣根过氧化物酶标记的山羊抗人igg。j、westernblot检测结果分析:按照westernblot实验步骤显示结果,如图6所示,其中,图6中的marker用于表征标记蛋白的大小。与空白对照相比,仅在实验组168kd附近出现明显条带,其中,组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白分子量大约为168kd,表明该白血病患者的组蛋白赖氨酸n-甲基转移酶kmt5b蛋白确实存在突变。以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。序列表<110>天津市湖滨盘古基因科学发展有限公司<120>组蛋白赖氨酸n-甲基转移酶kmt5b突变蛋白及应用<160>40<170>siposequencelisting1.0<210>1<211>693<212>prt<213>智人种(homosapiens)<400>1metlystrpleuglygluserlysasnmetvalvalasnglyargarg151015asnglyglylysleuserasnasphisglnglnasnglnserlysleu202530glnhisthrglylysaspthrleulysalaglylysasnalavalglu354045argargserasnargcysasnglyasnserglyphegluglyglnser505560argtyrvalproserserglymetseralalysgluleucysgluasn65707580aspaspleualathrserleuvalleuaspprotyrleuglyphegln859095thrhislysmetasnthrseralapheproserargserserarghis100105110pheserlysseraspserpheserhisasnasnprovalargphearg115120125proilelysglyargglnglugluleulysgluvalilegluargphe130135140lyslysaspgluhisleuglulysalaphelyscysleuthrsergly145150155160glutrpalaarghistyrpheleuasnlysasnlysmetglnglulys165170175leuphelysgluhisvalpheiletyrleuargmetphealathrasp180185190serglyphegluileleuprocysasnargtyrsersergluglnasn195200205glyalalysilevalalathrlysglutrplysargasnasplysile210215220gluleuleuvalglycysilealagluleusergluileglugluasn225230235240metleuleuarghisglygluasnasppheservalmettyrserthr245250255arglysasncysalaglnleutrpleuglyproalaalapheileasn260265270hisaspcysargproasncyslysphevalserthrglyargaspthr275280285alacysvallysalaleuargaspilegluproglyglugluileser290295300cystyrtyrglyaspglyphepheglygluasnasngluphecysglu305310315320cystyrthrcysgluargargglythrglyalaphelysserargval325330335glyleuproalaproalaprovalileasnserlystyrglyleuarg340345350gluthrasplysargleuasnargleulyslysleuglyaspserser355360365lysasnseraspserglnservalserserasnthraspalaaspthr370375380thrglnglulysasnasnalathrserasnarglysserservalgly385390395400vallyslysasnserlysserargthrleuthrargglnsermetser405410415argileproalaserserasnserthrserserlysleuthrhisile420425430asnasnserargvalprolyslysleulyslysproalalysproleu435440445leuserlysilelysleuargasnhiscyslysargleugluglnlys450455460asnalaserarglysleuglumetglyasnleuvalleulysglupro465470475480lysvalvalleutyrlysasnleuproilelyslysasplysglupro485490495gluglyproalaglnalaalavalalaserglycysleuthrarghis500505510alaalaarggluhisargglnasnprovalargglyalahissergln515520525glygluserserprocysthrtyrilethrargargservalargthr530535540argthrasnleulysglualaseraspilelysleugluproasnthr545550555560leuasnglytyrlysserservalthrgluprocysproaspsergly565570575gluglnleuglnproalaprovalleuglngluglugluleualahis580585590gluthralaglnlysglyglualalyscyshislysseraspthrgly595600605metserlyslyslysserargglnglylysleuvallysglnpheala610615620lysileglugluserthrprovalhisaspserproglylysaspasp625630635640alavalglniletrpvalpropheproglyalaglntrphiscysgly645650655argalacysgluleuhisargleucysserphethrvalglycysser660665670valvalthrseraspserphelysthrlysaspserpheargthrala675680685lysserlysargarg690<210>2<211>2088<212>dna<213>智人种(homosapiens)<400>2atgaagtggttgggagaatccaagaacatggtggtgaatggcaggagaaatggaggcaag60ttgtctaatgaccatcagcagaatcaatcaaaattacagcacacggggaaggacaccctg120aaggctggcaaaaatgcagtcgagaggaggtcgaacagatgtaatggtaactcgggattt180gaaggacagagtcgctatgtaccatcctctggaatgtccgccaaggaactctgtgaaaat240gatgacctagcaaccagtttggttcttgatccctatttaggttttcaaacacacaaaatg300aatactagcgcctttccttcgaggagctcaaggcatttttcaaaatctgacagtttttct360cacaacaaccctgtgagatttaggcctattaaaggaaggcaggaagaactaaaggaagta420attgaacgttttaagaaagatgaacacttggagaaagccttcaaatgtttgacttcaggc480gaatgggcacggcactattttctcaacaagaataaaatgcaggagaaattattcaaagaa540catgtatttatttatttgcgaatgtttgcaactgacagtggatttgaaatattgccatgt600aatagatactcatcagaacaaaatggagccaaaatagttgcaacaaaagagtggaaacga660aatgacaaaatagaattactggtgggttgtattgccgaactttcagaaattgaggagaac720atgctacttagacatggagaaaacgacttcagtgtcatgtactccacaaggaaaaactgt780gctcaactctggctgggtcctgctgcgtttataaaccatgattgcagacctaattgtaag840tttgtgtcaactggtcgagatacagcatgtgtgaaggctctaagagacattgaacctgga900gaagaaatttcttgttattatggagatgggttctttggagaaaataatgagttctgcgag960tgttacacttgcgaaagacggggcactggtgcttttaaatccagagtgggactgcctgcg1020cctgctcctgttatcaatagcaaatatggactcagagaaacagataaacgtttaaatagg1080cttaaaaagttaggtgacagcagcaaaaattcagacagtcaatctgtcagctctaacact1140gatgcagataccactcaggaaaaaaacaatgcaacttctaaccgaaaatcttcagttggc1200gtaaaaaagaatagcaagagcagaacgttaacgaggcaatctatgtcaagaattccagct1260tcttccaactctacctcatctaagctaactcatataaataattccagggtaccaaagaaa1320ctgaagaagcctgcaaagcctttactttcaaagataaaattgagaaatcattgcaagcgg1380ctggagcaaaagaatgcttcaagaaaactcgaaatgggaaacttagtactgaaagagcct1440aaagtagttctgtataaaaatttgcccattaaaaaagataaggagccagagggaccagcc1500caagccgcagttgccagcgggtgcttgactagacacgcggcgagagaacacagacagaat1560cctgtgagaggtgctcattcgcagggggagagctcgccctgcacctacataactcggcgg1620tcagtgaggacaagaacaaatctgaaggaggcctctgacatcaagcttgaaccaaatacg1680ttgaatggctataaaagcagtgtgacggaaccttgccccgacagtggtgaacagctgcag1740ccagctcctgtgctgcaggaggaagaactggctcatgagactgcacaaaaaggggaggca1800aagtgtcataagagtgacacaggcatgtccaaaaagaagtcacgacaaggaaaacttgtg1860aaacagtttgcaaaaatagaggaatctactccagtgcacgattctcctggaaaagacgac1920gcggtacagatttgatgggtcccattctgaccagggtgagcacagtggcactgtgggcgt1980gcctgtgagctacacagactgtgctccttcaccgtcggttgttcagttgtgacatcagat2040agcttcaaaacaaaagacagctttagaactgcaaaaagtaaaagaaga2088<210>3<211>20<212>dna<213>人工序列(artificialsequence)<400>3gcggtacagatttgatgggt20<210>4<211>20<212>dna<213>人工序列(artificialsequence)<400>4ttctgaccagggtgagcaca20<210>5<211>15<212>dna<213>人工序列(artificialsequence)<400>5tccttcaccgtcggt15<210>6<211>885<212>prt<213>智人种(homosapiens)<400>6metlystrpleuglygluserlysasnmetvalvalasnglyargarg151015asnglyglylysleuserasnasphisglnglnasnglnserlysleu202530glnhisthrglylysaspthrleulysalaglylysasnalavalglu354045argargserasnargcysasnglyasnserglyphegluglyglnser505560argtyrvalproserserglymetseralalysgluleucysgluasn65707580aspaspleualathrserleuvalleuaspprotyrleuglyphegln859095thrhislysmetasnthrseralapheproserargserserarghis100105110pheserlysseraspserpheserhisasnasnprovalargphearg115120125proilelysglyargglnglugluleulysgluvalilegluargphe130135140lyslysaspgluhisleuglulysalaphelyscysleuthrsergly145150155160glutrpalaarghistyrpheleuasnlysasnlysmetglnglulys165170175leuphelysgluhisvalpheiletyrleuargmetphealathrasp180185190serglyphegluileleuprocysasnargtyrsersergluglnasn195200205glyalalysilevalalathrlysglutrplysargasnasplysile210215220gluleuleuvalglycysilealagluleusergluileglugluasn225230235240metleuleuarghisglygluasnasppheservalmettyrserthr245250255arglysasncysalaglnleutrpleuglyproalaalapheileasn260265270hisaspcysargproasncyslysphevalserthrglyargaspthr275280285alacysvallysalaleuargaspilegluproglyglugluileser290295300cystyrtyrglyaspglyphepheglygluasnasngluphecysglu305310315320cystyrthrcysgluargargglythrglyalaphelysserargval325330335glyleuproalaproalaprovalileasnserlystyrglyleuarg340345350gluthrasplysargleuasnargleulyslysleuglyaspserser355360365lysasnseraspserglnservalserserasnthraspalaaspthr370375380thrglnglulysasnasnalathrserasnarglysserservalgly385390395400vallyslysasnserlysserargthrleuthrargglnsermetser405410415argileproalaserserasnserthrserserlysleuthrhisile420425430asnasnserargvalprolyslysleulyslysproalalysproleu435440445leuserlysilelysleuargasnhiscyslysargleugluglnlys450455460asnalaserarglysleuglumetglyasnleuvalleulysglupro465470475480lysvalvalleutyrlysasnleuproilelyslysasplysglupro485490495gluglyproalaglnalaalavalalaserglycysleuthrarghis500505510alaalaarggluhisargglnasnprovalargglyalahissergln515520525glygluserserprocysthrtyrilethrargargservalargthr530535540argthrasnleulysglualaseraspilelysleugluproasnthr545550555560leuasnglytyrlysserservalthrgluprocysproaspsergly565570575gluglnleuglnproalaprovalleuglngluglugluleualahis580585590gluthralaglnlysglyglualalyscyshislysseraspthrgly595600605metserlyslyslysserargglnglylysleuvallysglnpheala610615620lysileglugluserthrprovalhisaspserproglylysaspasp625630635640alavalproaspleumetglyprohisseraspglnglygluhisser645650655glythrvalglyvalprovalsertyrthraspcysalaproserpro660665670valglycysservalvalthrseraspserphelysthrlysaspser675680685pheargthralalysserlyslyslysargargilethrargtyrasp690695700alaglnleuileleugluasnasnserglyileprolysleuthrleu705710715720argargarghisaspserserserlysthrasnaspglngluasnasp725730735glymetasnserserlysileserilelysleuserlysasphisasp740745750asnaspasnasnleutyrvalalalysleuasnasnglypheasnser755760765glyserglyserserserthrlysleulysileglnleulysargasp770775780glugluasnargglysertyrthrgluglyleuhisgluasnglyval785790795800cyscysseraspproleuserleuleugluserargmetgluvalasp805810815asptyrserglntyrgluglugluserthraspaspserserserser820825830gluglyaspgluglugluaspasptyraspaspaspphegluaspasp835840845pheileproleuproproalalysargleuargleuilevalglylys850855860aspserileaspileaspileserserargargarggluaspglnser865870875880leuargleuasnala885<210>7<211>2658<212>dna<213>智人种(homosapiens)<400>7atgaagtggttgggagaatccaagaacatggtggtgaatggcaggagaaatggaggcaag60ttgtctaatgaccatcagcagaatcaatcaaaattacagcacacggggaaggacaccctg120aaggctggcaaaaatgcagtcgagaggaggtcgaacagatgtaatggtaactcgggattt180gaaggacagagtcgctatgtaccatcctctggaatgtccgccaaggaactctgtgaaaat240gatgacctagcaaccagtttggttcttgatccctatttaggttttcaaacacacaaaatg300aatactagcgcctttccttcgaggagctcaaggcatttttcaaaatctgacagtttttct360cacaacaaccctgtgagatttaggcctattaaaggaaggcaggaagaactaaaggaagta420attgaacgttttaagaaagatgaacacttggagaaagccttcaaatgtttgacttcaggc480gaatgggcacggcactattttctcaacaagaataaaatgcaggagaaattattcaaagaa540catgtatttatttatttgcgaatgtttgcaactgacagtggatttgaaatattgccatgt600aatagatactcatcagaacaaaatggagccaaaatagttgcaacaaaagagtggaaacga660aatgacaaaatagaattactggtgggttgtattgccgaactttcagaaattgaggagaac720atgctacttagacatggagaaaacgacttcagtgtcatgtactccacaaggaaaaactgt780gctcaactctggctgggtcctgctgcgtttataaaccatgattgcagacctaattgtaag840tttgtgtcaactggtcgagatacagcatgtgtgaaggctctaagagacattgaacctgga900gaagaaatttcttgttattatggagatgggttctttggagaaaataatgagttctgcgag960tgttacacttgcgaaagacggggcactggtgcttttaaatccagagtgggactgcctgcg1020cctgctcctgttatcaatagcaaatatggactcagagaaacagataaacgtttaaatagg1080cttaaaaagttaggtgacagcagcaaaaattcagacagtcaatctgtcagctctaacact1140gatgcagataccactcaggaaaaaaacaatgcaacttctaaccgaaaatcttcagttggc1200gtaaaaaagaatagcaagagcagaacgttaacgaggcaatctatgtcaagaattccagct1260tcttccaactctacctcatctaagctaactcatataaataattccagggtaccaaagaaa1320ctgaagaagcctgcaaagcctttactttcaaagataaaattgagaaatcattgcaagcgg1380ctggagcaaaagaatgcttcaagaaaactcgaaatgggaaacttagtactgaaagagcct1440aaagtagttctgtataaaaatttgcccattaaaaaagataaggagccagagggaccagcc1500caagccgcagttgccagcgggtgcttgactagacacgcggcgagagaacacagacagaat1560cctgtgagaggtgctcattcgcagggggagagctcgccctgcacctacataactcggcgg1620tcagtgaggacaagaacaaatctgaaggaggcctctgacatcaagcttgaaccaaatacg1680ttgaatggctataaaagcagtgtgacggaaccttgccccgacagtggtgaacagctgcag1740ccagctcctgtgctgcaggaggaagaactggctcatgagactgcacaaaaaggggaggca1800aagtgtcataagagtgacacaggcatgtccaaaaagaagtcacgacaaggaaaacttgtg1860aaacagtttgcaaaaatagaggaatctactccagtgcacgattctcctggaaaagacgac1920gcggtaccagatttgatgggtccccattctgaccagggtgagcacagtggcactgtgggc1980gtgcctgtgagctacacagactgtgctccttcacccgtcggttgttcagttgtgacatca2040gatagcttcaaaacaaaagacagctttagaactgcaaaaagtaaaaagaagaggcgaatc2100acaaggtatgatgcacagttaatcctagaaaataactctgggattcccaaattgactctt2160cgtaggcgtcatgatagcagcagcaaaacaaatgaccaagagaatgatggaatgaactct2220tccaaaataagcatcaagttaagcaaagaccatgacaacgataacaatctctatgtagca2280aagcttaataatggatttaactcaggatcaggcagtagttctacaaaattaaaaatccag2340ctaaaacgagatgaggaaaatagggggtcttatacagaggggcttcatgaaaatggggtg2400tgctgcagtgatcctctttctctcttggagtctcgaatggaggtggatgactatagtcag2460tatgaggaagaaagtacagatgattcctcctcttctgagggcgatgaagaggaggatgac2520tatgatgatgactttgaagacgattttattcctcttcctccagctaagcgcttgaggtta2580atagttggaaaagactctatagatattgacatttcttcaaggagaagagaagatcagtct2640ttaaggcttaatgcctaa2658<210>8<211>30<212>dna<213>人工序列(artificialsequence)<400>8gttctgtataaaaatttgcccattaaaaaa30<210>9<211>30<212>dna<213>人工序列(artificialsequence)<400>9gataaggagccagagggaccagcccaagcc30<210>10<211>30<212>dna<213>人工序列(artificialsequence)<400>10gcagttgccagcgggtgcttgactagacac30<210>11<211>30<212>dna<213>人工序列(artificialsequence)<400>11gcggcgagagaacacagacagaatcctgtg30<210>12<211>30<212>dna<213>人工序列(artificialsequence)<400>12agaggtgctcattcgcagggggagagctcg30<210>13<211>30<212>dna<213>人工序列(artificialsequence)<400>13ccctgcacctacataactcggcggtcagtg30<210>14<211>30<212>dna<213>人工序列(artificialsequence)<400>14aggacaagaacaaatctgaaggaggcctct30<210>15<211>30<212>dna<213>人工序列(artificialsequence)<400>15gacatcaagcttgaaccaaatacgttgaat30<210>16<211>30<212>dna<213>人工序列(artificialsequence)<400>16ggctataaaagcagtgtgacggaaccttgc30<210>17<211>30<212>dna<213>人工序列(artificialsequence)<400>17cccgacagtggtgaacagctgcagccagct30<210>18<211>30<212>dna<213>人工序列(artificialsequence)<400>18cctgtgctgcaggaggaagaactggctcat30<210>19<211>30<212>dna<213>人工序列(artificialsequence)<400>19gagactgcacaaaaaggggaggcaaagtgt30<210>20<211>30<212>dna<213>人工序列(artificialsequence)<400>20cataagagtgacacaggcatgtccaaaaag30<210>21<211>30<212>dna<213>人工序列(artificialsequence)<400>21aagtcacgacaaggaaaacttgtgaaacag30<210>22<211>30<212>dna<213>人工序列(artificialsequence)<400>22tttgcaaaaatagaggaatctactccagtg30<210>23<211>30<212>dna<213>人工序列(artificialsequence)<400>23cacgattctcctggaaaagacgacgcggta30<210>24<211>30<212>dna<213>人工序列(artificialsequence)<400>24atcatagtcatcctcctcttcatcgccctc30<210>25<211>30<212>dna<213>人工序列(artificialsequence)<400>25agaagaggaggaatcatctgtactttcttc30<210>26<211>30<212>dna<213>人工序列(artificialsequence)<400>26ctcatactgactatagtcatccacctccat30<210>27<211>30<212>dna<213>人工序列(artificialsequence)<400>27tcgagactccaagagagaaagaggatcact30<210>28<211>30<212>dna<213>人工序列(artificialsequence)<400>28gcagcacaccccattttcatgaagcccctc30<210>29<211>30<212>dna<213>人工序列(artificialsequence)<400>29tgtataagaccccctattttcctcatctcg30<210>30<211>30<212>dna<213>人工序列(artificialsequence)<400>30ttttagctggatttttaattttgtagaact30<210>31<211>30<212>dna<213>人工序列(artificialsequence)<400>31actgcctgatcctgagttaaatccattatt30<210>32<211>30<212>dna<213>人工序列(artificialsequence)<400>32aagctttgctacatagagattgttatcgtt30<210>33<211>30<212>dna<213>人工序列(artificialsequence)<400>33gtcatggtctttgcttaacttgatgcttat30<210>34<211>30<212>dna<213>人工序列(artificialsequence)<400>34tttggaagagttcattccatcattctcttg30<210>35<211>30<212>dna<213>人工序列(artificialsequence)<400>35gtcatttgttttgctgctgctatcatgacg30<210>36<211>30<212>dna<213>人工序列(artificialsequence)<400>36cctacgaagagtcaatttgggaatcccaga30<210>37<211>30<212>dna<213>人工序列(artificialsequence)<400>37gttattttctaggattaactgtgcatcata30<210>38<211>30<212>dna<213>人工序列(artificialsequence)<400>38ccttgtgattcgcctcttctttttactttt30<210>39<211>30<212>dna<213>人工序列(artificialsequence)<400>39tgcagttctaaagctgtcttttgttttgaa30<210>40<211>30<212>dna<213>人工序列(artificialsequence)<400>40gctatctgatgtcacaactgaacaaccgac30当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1