检测样本中PRCC-TFE3融合基因的寡核苷酸、方法和试剂盒与流程
本发明属于生物科学和生物技术领域,特别涉及一种检测样本中prcc-tfe3融合基因的方法、寡核苷酸和试剂盒,采用荧光pcr技术,检测人类xp11.2易位/tfe3融合基因相关性肾癌患者体内prcc-tfe3融合基因的表达水平。
背景技术:
xp11.2易位/tfe3基因融合相关性肾癌(简称xp11.2易位性肾癌)是2004年who新分类出的一种肾癌独立亚型,其特征为xp11.2位点上tfe3基因发生断裂,并与prcc、aspl、psf、cltc、nono等相关基因发生平衡易位形成新的融合基因。据统计,xp11.2易位性肾癌的发病率在儿童肾癌患者中约占1/3,占45岁以下肾癌的15%,对儿童及青少年患者有极大影响。
tfe3基因的断裂主要发生在启动子与主要功能域之间,发生易位的是包含了tfe3功能域的断裂点端粒侧的全部基因,而新的融合基因的启动子来源于与tfe3基因发生融合的启动子。在基因组内,与tfe3形成融合的aspl、prcc等均属于管家基因,由于其启动子的转录活性明显高于原tfe3基因启动子,使得融合后的tfe3基因表达量升高,因而肿瘤组织高表达tfe3蛋白,这种高表达的tfe3蛋白影响细胞对转录调节的干扰作用,促进肿瘤形成。研究发现prcc-tfe3融合蛋白的转录活性大约是野生型tfe3蛋白的3倍,有可能改变转录因子的转录能力。此外,在与有丝分裂调控点蛋白mad2b相互作用时,prcc-tfe3融合蛋白可能还干扰黏合与有丝分裂调控点的功能,导致基因的异常调控,最终形成肿瘤。
xp11.2易位性肾癌具有特征性的基因改变,其诊断、治疗以及预后亦有特殊之处,而其组织形态与肾透明细胞癌、乳头状肾细胞癌较为相似,常规诊断极易误诊和漏诊。因此,检测prcc-tfe3融合基因对xp11.2易位性肾癌的分类诊断及个体化治疗均有重要意义。
prcc-tfe3融合基因检测的常用技术有荧光原位杂交技术(fish)、实时定量pcr技术(rq-pcr)等方法。fish检测结果较为直观,但是试验过程繁琐,涉及试剂种类繁多,费时费力,且结果需经验丰富的专业人士来判读,结果判读存在较大的主观性。实时荧光定量pcr中常见的方法有sybrgreeni染料法,双探针杂交法以及taqman技术等。其中sybrgreeni由于是非饱和染料,特异性不如双探针杂交法以及taqman法,必须通过观察溶解曲线来判断其特异性;而双探针法杂交法成本又较为昂贵。在taqman技术中,rq-pcr采用taqman探针荧光定量技术,综合生物学、酶学和荧光化学于一体,从扩增到结果分析均在pcr反应管封闭状态下进行,解决了pcr产物污染而导致假阳性的问题,同时也提高了敏感度,其结果用拷贝数表示,实现了对pcr产物的准确定量,易于统一标准,与定性pcr技术相比,具有特异度好,灵敏度高,线性关系好,操作简单,自动化程度高、防污染,有较大的线性范围等优点。
技术实现要素:
本发明设计了检测内参/目的基因用引物、探针序列,采用荧光定量pcr技术,利用双标准曲线的方法,分别构建内参基因β-actin和目的基因prcc-tfe3的定量标准曲线,检测目的基因prcc-tfe3相对于内参基因β-actin的表达水平。通过调整目的基因和内参基因的引物探针比例,以及pcr反应条件,使扩增效率和速率均达到最佳,从而能够满足prcc-tfe3融合基因的检测,用于评价治疗效果、预测预后。
本发明中的“prcc-tfe3cdna序列”指的是prcc-tfe3融合基因经转录后产生的mrna经逆转录后产生的cdna序列,或者根据这种cdna序列通过化学合成手段直接合成出。将不论是经过逆转录还是通过化学合成手段直接产生的prcc-tfe3cdna序列插入到合适的质粒后,可作为阳性对照品进行使用。
本发明提供用于检测样本中prcc-tfe3融合基因的寡核苷酸,所述寡核苷酸包括(1)~(4)中的至少一种:(1)针对1型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、2和4;(2)针对2型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、3和4;(3)针对3型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:5、6和7;(4)针对4型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:8、9和10。
进一步地,所述寡核苷酸还包括针对β-actin内参基因的上下游引物和探针,其碱基序列分别为seqidno:11、12和13。
本发明还提供一种检测样本中prcc-tfe3融合基因的方法,所述方法包括以下步骤:
(1)提取样本中的rna;
(2)将(1)提取出的rna逆转录为cdna;
(3)加入(2)中所述的cdna到反应管中,利用针对1型prcc-tfe3的上下游引物和探针检测样本中的1型prcc-tfe3的荧光信号,其碱基序列分别为seqidno:1、2和4;利用针对2型prcc-tfe3的上下游引物和探针检测样本中的2型prcc-tfe3的荧光信号,其碱基序列分别为seqidno:1、3和4;利用针对3型prcc-tfe3的上下游引物和探针检测样本中的3型prcc-tfe3的荧光信号,其碱基序列分别为seqidno:5、6和7;利用针对4型prcc-tfe3的上下游引物和探针检测样本中的4型prcc-tfe3的荧光信号,其碱基序列分别为seqidno:8、9和10;利用针对β-actin内参基因的上下游引物和探针检测样本中的β-actin内参基因的荧光信号,其碱基序列分别为seqidno:11、12和13;
(4)根据(3)中的1型prcc-tfe3、2型prcc-tfe3、3型prcc-tfe3或4型prcc-tfe3的荧光信号和β-actin内参基因的荧光信号,确定样本中的1型prcc-tfe3、2型prcc-tfe3、3型prcc-tfe3或4型prcc-tfe3的相对表达量。
本发明还提供一种检测样本中prcc-tfe3融合基因的试剂盒,所述试剂盒包括检测体系pcr反应液,所述检测体系pcr反应液包括(1)~(4)中的至少一种:(1)针对1型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、2和4;(2)针对2型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、3和4;(3)针对3型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:5、6和7;(4)针对4型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:8、9和10。
进一步地,所述引物和探针还包括针对β-actin内参基因的上下游引物和探针,其碱基序列分别为seqidno:11、12和13。
进一步地,所述试剂盒还包括阳性对照品、阴性对照品和空白对照品,所述阳性对照品为含有prcc-tfe3cdna序列的阳性质粒溶液,所述阴性对照品为不含有prcc-tfe3cdna序列的质粒溶液,所述空白对照品为生理盐水或不加任何物质。
进一步地,所述阳性质粒包括含有1型prcc-tfe3cdna序列的阳性质粒、含有2型prcc-tfe3cdna序列的阳性质粒、含有3型prcc-tfe3cdna序列的阳性质粒和含有4型prcc-tfe3cdna序列的阳性质粒。
进一步地,所述试剂盒还包括样本rna提取试剂,所述样本rna提取试剂包括trizol、氯仿、异丙醇、75%乙醇和rnase-free水。
进一步地,所述样本rna提取试剂还包括红细胞裂解液,所述红细胞裂解液包括16μmol/l氯化铵、1mmol/l碳酸氢钠和12.5μmol/ledta-na2。
本发明的有益效果:将实时荧光pcr技术结合采用taqman探针,利用双标准曲线的方法,分别构建内参基因β-actin和aspl-tfe3目的基因的定量标准曲线,检测受测者体内aspl-tfe3的表达。相比于以往的fish和△△ct法等检测手段,该方法具有精确度高,结果便于判读等优点。加之该方法将反应体系所需的引物、探针进行合理配比和优化,使实验条件达到最佳,从而省去了繁琐的条件摸索环节,大大提升了实验效率。该方法经测试特异性好,灵敏度高,操作简便,可为人类xp11.2易位/tfe3融合基因相关性肾癌患者的治疗提供参考和依据,有助于个体化医疗方案的制定。此外,根据tfe3基因的断裂位点的不同,prcc-tfe3融合基因可分为4种不同的类型:1型prcc-tfe3、2型prcc-tfe3、3型prcc-tfe3和4型prcc-tfe3,本发明根据不同类型的prcc-tfe3融合基因的序列特征,让1型prcc-tfe3和2型prcc-tfe3共用上游引物和探针,这样就可减少引物和探针的使用数量,从而降低检测成本。
附图说明
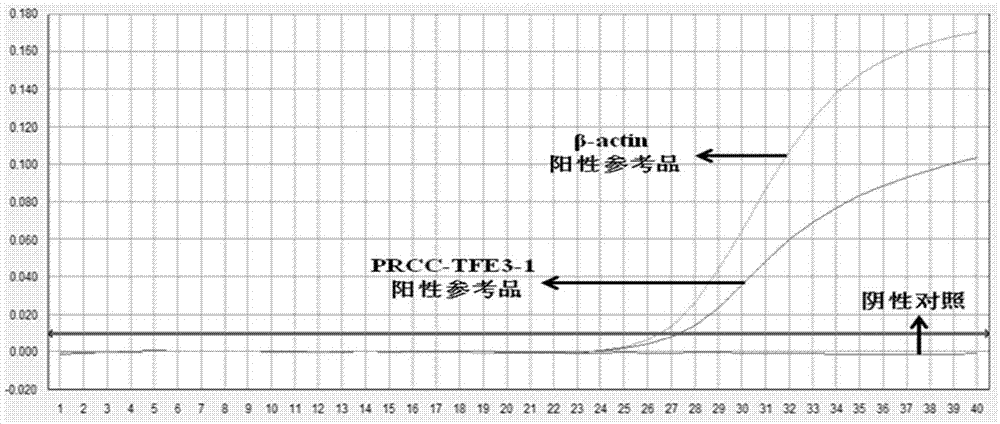
图1为阳性质粒扩增曲线图:(a)pmd18-t/prcc-tfe3-1阳性质粒扩增曲线图;(b)pmd18-t/prcc-tfe3-2阳性质粒扩增曲线图;(c)pmd18-t/prcc-tfe3-3阳性质粒扩增曲线图;(d)pmd18-t/prcc-tfe3-4阳性质粒扩增曲线图。
图2为灵敏度检测结果图:(a)100copies/μlpmd18-t/prcc-tfe3-1阳性质粒扩增曲线图;(b)100copies/μlpmd18-t/prcc-tfe3-2阳性质粒扩增曲线图;(c)100copies/μlpmd18-t/prcc-tfe3-3阳性质粒扩增曲线图;(d)100copies/μlpmd18-t/prcc-tfe3-4阳性质粒扩增曲线图。
图3为外周血样本(样本3)的荧光pcr检测结果图:(a)3号血液样本的prcc-tfe3-1扩增曲线图;(b)3号血液样本的prcc-tfe3-2扩增曲线图;(c)3号血液样本的prcc-tfe3-3扩增曲线图;(d)3号血液样本的prcc-tfe3-4扩增曲线图。
图4为肾组织样本(样本2)的荧光pcr检测结果图:(a)2号肾组织样本的prcc-tfe3-1扩增曲线图;(b)2号肾组织样本的prcc-tfe3-2扩增曲线图;(c)2号肾组织样本的prcc-tfe3-3扩增曲线图;(d)2号肾组织样本的prcc-tfe3-4扩增曲线图。
具体实施方式
下面结合具体实施例和附图,进一步阐述本发明。应当注意的是,实施例中未说明的常规条件和方法,通常按照所属领域实验人员常规采用方法:譬如,奥斯柏和金斯顿主编的《精编分子生物学实验指南》第四版,或者按照制造厂商所建议的步骤和条件。
实施例1
用于检测样本中prcc-tfe3融合基因的寡核苷酸,所述寡核苷酸包括(1)~(4)中的至少一种:(1)针对1型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、2和4;(2)针对2型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、3和4;(3)针对3型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:5、6和7;(4)针对4型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:8、9和10。
进一步地,所述寡核苷酸还包括针对β-actin内参基因的上下游引物和探针,其碱基序列分别为seqidno:11、12和13。
用于检测样本中prcc-tfe3融合基因的寡核苷酸,所述寡核苷酸包括(1)~(4):(1)针对1型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、2和4;(2)针对2型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、3和4;(3)针对3型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:5、6和7;(4)针对4型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:8、9和10。
进一步地,所述寡核苷酸还包括针对β-actin内参基因的上下游引物和探针,其碱基序列分别为seqidno:11、12和13。
一种检测样本中prcc-tfe3融合基因的方法,所述方法包括以下步骤:
(1)提取样本中的rna;
(2)将(1)提取出的rna逆转录为cdna;
(3)加入(2)中所述的cdna到反应管中,利用针对1型prcc-tfe3的上下游引物和探针检测样本中的1型prcc-tfe3的荧光信号,其碱基序列分别为seqidno:1、2和4;利用针对2型prcc-tfe3的上下游引物和探针检测样本中的2型prcc-tfe3的荧光信号,其碱基序列分别为seqidno:1、3和4;利用针对3型prcc-tfe3的上下游引物和探针检测样本中的3型prcc-tfe3的荧光信号,其碱基序列分别为seqidno:5、6和7;利用针对4型prcc-tfe3的上下游引物和探针检测样本中的4型prcc-tfe3的荧光信号,其碱基序列分别为seqidno:8、9和10;利用针对β-actin内参基因的上下游引物和探针检测样本中的β-actin内参基因的荧光信号,其碱基序列分别为seqidno:11、12和13;
(4)根据(3)中的1型prcc-tfe3、2型prcc-tfe3、3型prcc-tfe3或4型prcc-tfe3的荧光信号和β-actin内参基因的荧光信号,确定样本中的1型prcc-tfe3、2型prcc-tfe3、3型prcc-tfe3或4型prcc-tfe3的相对表达量。
一种检测样本中prcc-tfe3融合基因的试剂盒,所述试剂盒包括检测体系pcr反应液,所述检测体系pcr反应液包括(1)~(4)中的至少一种:(1)针对1型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、2和4;(2)针对2型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、3和4;(3)针对3型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:5、6和7;(4)针对4型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:8、9和10。
一种检测样本中prcc-tfe3融合基因的试剂盒,所述试剂盒包括检测体系pcr反应液,所述检测体系pcr反应液包括(1)~(4):(1)针对1型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、2和4;(2)针对2型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:1、3和4;(3)针对3型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:5、6和7;(4)针对4型prcc-tfe3的上下游引物和探针,其碱基序列分别为seqidno:8、9和10。
进一步地,所述寡核苷酸还包括针对β-actin内参基因的上下游引物和探针,其碱基序列分别为seqidno:11、12和13。
进一步地,所述试剂盒还包括阳性对照品、阴性对照品和空白对照品,其特征在于,所述阳性对照品为含有prcc-tfe3cdna序列的阳性质粒溶液,所述阴性对照品为不含有prcc-tfe3cdna序列的质粒溶液,所述空白对照品为生理盐水或不加任何物质。
进一步地,所述阳性质粒包括含有1型prcc-tfe3cdna序列的阳性质粒、含有2型prcc-tfe3cdna序列的阳性质粒、含有3型prcc-tfe3cdna序列的阳性质粒和含有4型prcc-tfe3cdna序列的阳性质粒。
所述试剂盒的检测体系pcr反应液还包括thnderbirdprobeqpcrmix(2×)(toyobo公司)。
所述试剂盒还包括样本提取试剂,所述样本提取试剂可选自组织rna抽提试剂或血液rna抽提试剂。组织rna抽提试剂可购买自toyobo和qiagen等公司的商业化试剂盒,当然也可自行配制;血液rna抽提试剂包括红细胞裂解液、trizol、氯仿、异丙醇、75%乙醇和rnase-free水,其中红细胞裂解液包括16μmol/l氯化铵、1mmol/l碳酸氢钠和12.5μmol/ledta-na2。当然,血液rna抽提试剂也购买自toyobo和qiagen等公司的商业化试剂盒。
所述试剂盒还包括rna逆转录试剂,所述rna逆转录试剂可自行配制,也可购买自toyobo等公司的商业化试剂盒,如toyobo公司的revertraaceqpcrrtkit试剂盒。
最后本发明所使用的引物和探针seqidno:1~13的碱基序列如表1所示。
表1.引物和探针的序列
实施例2
本发明方法的操作流程:
(1)抽提血液样本中的组织rna:在洁净的1.5ml的离心管中加入1ml实施例1中的红细胞裂解液,取抗凝血0.5ml混匀,室温静置10min;5000rpm离心5min,弃上清,收集底部的细胞;再次加入0.5ml实施例1中的红细胞裂解液,5000rpm离心5min,弃上清,收集底部的细胞;向细胞中加入1mltrizol,反复吹打直至沉淀完全溶解,室温静止5min;加入0.2ml氯仿,震荡均匀;14000rpm4℃离心10min,吸取上清层转移至另一新的离心管中(不要吸取白色中间层);加入等体积的异丙醇,上下充分混匀,室温静置10min;14000rpm4℃离心10min,弃上清,加入75%乙醇1ml,轻轻上下颠倒洗涤管壁;14000rpm4℃离心5min,弃乙醇;室温干燥10~15min,加入20ulrnase-free水溶解沉淀。采用nanodrop2000(购自thermoscientific公司)检测制备出的rna浓度及纯度,-30℃保存备用。
此外,也可提取肾组织样本的rna,其制备方法为:切取组织或者刮取石蜡玻片样本于1.5ml离心管中,加入1ml组织透明液(杭州西奈山生物科技有限公司),振荡混匀后13000rpm离心1min。去除上清,加入500ml组织透明液(杭州西奈山生物科技有限公司),振荡混匀后13000rpm离心1min。去除上清,加入1ml无水乙醇,振荡混匀后13000rpm离心1min。去除上清,置于37℃金属浴至干燥(开盖)。加入150ulpkdbuffer(来自rneasyffpekit,qiagen公司),振荡混匀。加入10ulpk(来自rneasyffpekit,qiagen公司),上下颠倒混匀。在56℃金属浴15min,后80℃金属浴15min。冰上放置3min后,13200rpm离心15min,吸取上清至新的1.5mlep管,加入dnaseboosterbuffer(来自rneasyffpekit,qiagen公司)16ul和dnase1(来自rneasyffpekit,qiagen)10ul振荡混匀后低速离心,室温静置15min。加入320ulrbcbuffer(来自rneasyffpekit,qiagen公司)混匀后加入720ul无水乙醇混匀。向层析柱(来自rneasyffpekit,qiagen公司)内加入700ul前一步液体,10000rpm15s,弃去管中液体,向层析柱内加入剩下液体,10000rpm15s,弃去管中液体。向层析柱内加入500ulrpebuffer(来自rneasyffpekit,qiagen公司),10000rpm15s,弃去废液。向层析柱内加入500ulrpebuffer,10000rpm2min,弃去废液,打开盖子,全速离心5min。将层析柱置于新的1.5mlep管,向层析柱中加入30uldepc水,静置2min后,全速离心1min。采用nanodrop2000(购自thermoscientific公司)检测rna浓度及纯度,-30℃保存备用。
(2)cdna制备:参考toyobo公司的revertraaceqpcrrtkit试剂盒说明书,将(1)中制备出的rna反转为cdna。
(3)试剂配制:按检测人份数配制检测体系pcr反应液各xμl,每人份23μl分装,如表2所示:
x=23μl反应液×(8份内参(标准曲线)+8份目的基因(标准曲线)+n份样本+1份阳性对照+1份阴性对照+1份空白对照);
表2prcc-tfe3反应体系
其中forwardprimer、reverseprimer和taqmanprobe分别选自prcc-tfe3-1/2-f、prcc-tfe3-1-r和prcc-tfe3-1/2-probe,或者prcc-tfe3-1/2-f、prcc-tfe3-2-r和prcc-tfe3-1/2-probe,或者prcc-tfe3-3-f、prcc-tfe3-3-r和prcc-tfe3-3-probe,或者prcc-tfe3-4-f、prcc-tfe3-4-r和prcc-tfe3-4-probe,或者β-actin-f、β-actin-r和β-actinprobe。
(4)加样:将(3)中配制的检测体系pcr反应液和步骤(2)中制备出的cdna2μl加入到96孔板的孔或者反应管中;阳性对照和阴性对照直接加2μl阳性对照品和阴性对照品;空白对照加2μl生理盐水或不加任何物质。
(5)检测:检测在实时荧光pcr仪上进行,可用仪器包括abi7300,7500(美国appliedbiosystems公司)等。反应条件:95℃预变性1min;95℃15s,58℃35sec40个循环,荧光信号于58℃35sec时采集。
(6)结果判断:将阈值线调整至背景信号及阴性扩增线以上,系统根据标准曲线和ct值自动计算出拷贝数。
1)内参阳性时,检测结果才认为有效;
2)阳性判断标准:ct<36,为阳性;35≤ct≤38,为疑似阳性,需要再次
验证;ct>38,为阴性。
实施例3阳性质粒检测和灵敏度检测
在制备阳性质粒时,可先直接合成出1型prcc-tfe3cdna、2型prcc-tfe3cdna、3型prcc-tfe3cdna和4型prcc-tfe3cdna,再分别插入到事先选择的质粒(这里以pmd18-t质粒为例进行说明)中,这样就可制备出pmd18-t/prcc-tfe3-1阳性质粒、pmd18-t/prcc-tfe3-2阳性质粒、pmd18-t/prcc-tfe3-3阳性质粒和pmd18-t/prcc-tfe3-4阳性质粒。
分别以106copies/μl浓度的阳性质粒pmd18-t/prcc-tfe3-1、pmd18-t/prcc-tfe3-2、pmd18-t/prcc-tfe3-3和pmd18-t/prcc-tfe3-4作为模板,结果如图1所示,prcc-tfe3(1型prcc-tfe3、2型prcc-tfe3、3型prcc-tfe3和4型prcc-tfe3)和β-actin均起线,本发明的引物和探针可用来检测阳性质粒,说明本发明可以检测这4种类型的阳性质粒。以质粒浓度为103、102、10copies/μl作为模板进行实验,每个浓度重复10次,结果如图2所示。由图2可知,100copies/μl的质粒都能全部出现扩增,而10copies/μl的质粒未能全部出现扩增,因此本发明对这4种类型的阳性质粒的检测下限均为100copies。
实施例4检测健康体检人群外周血样本
取待检的健康体检外周血样本10例,按实施例2所述方提取rna、法制备cdna、配制试剂并检测。
每份样本加入检测体系pcr反应液中2μl。同时做阳性,阴性及空白对照,内参基因/目的基因的标准曲线各一份。一台96孔的荧光pcr仪可同时检测10份样本,每个样本2次重复,一份阳性对照,一份阴性对照,检测时间仅为100分钟。10例筛查样本中所有样本的β-actin均起线,但所有类型的prcc-tfe3(1型prcc-tfe3、2型prcc-tfe3、3型prcc-tfe3和4型prcc-tfe3)未有样本出现起线。结果如表3所示。3号样本的检测结果如图3所示。
表310例外周血样本prcc-tfe3mrna表达水平
实施例5检测肾组织临床样本
取待检的临床样本10例,按实施例2所述方法提取rna并制备cdna、配制试剂并检测。
每份样本加入检测体系pcr反应液中2μl。同时做阳性,阴性及空白对照,内参基因/目的基因的标准曲线各一份。一台96孔的荧光pcr仪可同时检测10份样本,每个样本2次重复,一份阳性对照,一份阴性对照,检测时间仅为100分钟。10例筛查样本中所有样本的β-actin均起线,但prcc-tfe3未有样本出现起线。实验结果如下表4所示。2号样本的检测结果图4所示。
表410例临床样本prcc-tfe3mrna表达水平
序列表
<110>福州艾迪康医学检验所有限公司
<120>检测样本中prcc-tfe3融合基因的寡核苷酸、方法和试剂盒
<160>13
<170>siposequencelisting1.0
<210>1
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>1
ccgagtgtggtggacaggta20
<210>2
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>2
gccccagatgcctccttc18
<210>3
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>3
caggattattacagtggtggctac24
<210>4
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>4
cgttgggttctccagatgggtct23
<210>5
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>5
agtcctgtggtgcctccg18
<210>6
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>6
aggaaagagcccgtgaagat20
<210>7
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>7
agctgagcatttcatcattgtaactggac29
<210>8
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>8
tgccacgccttgactactgt20
<210>9
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>9
tgaggaagatgaacccacaaag22
<210>10
<211>26
<212>dna
<213>人工序列(artificialsequence)
<400>10
acacatcaagcagattccctgacaca26
<210>11
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>11
tgagcgaggctacagctt18
<210>12
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>12
tccttgatgtcgcgcacgattt22
<210>13
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>13
accaccacggccgagcgg18
- 还没有人留言评论。精彩留言会获得点赞!