一组判别尼群洛尔个体化用药型的引物组合物的制作方法
本发明属于分子生物学检测领域,涉及一种利用质谱特征峰图检测多重pcr单碱基延伸产物的方法及其产品,该方法可以在3个多重pcr反应中同时检测多个pcr单碱基延伸扩增的寡核苷酸产物。更具体的说,该方法利用不同目的寡核苷酸片段在质谱分型过程中生成的不同的时间飞行质谱特征峰图,针对多个目的snp位点同时进行检测,指导降高血压药物尼群洛尔的用药。
背景技术:
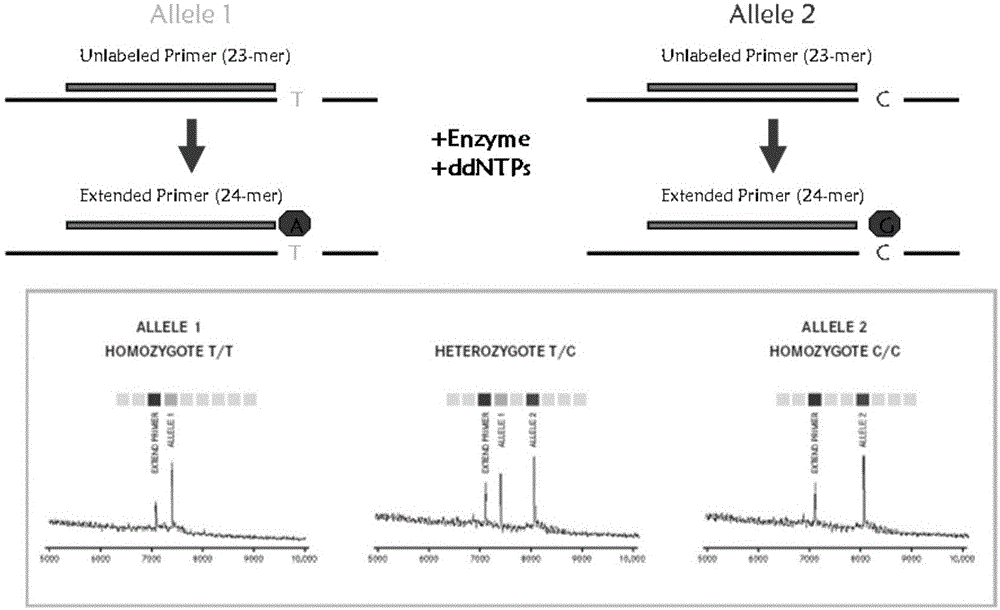
:人类的遗传信息储存在基因组中,2002年国际合作项目人类基因组计划的最终完成,绘制出了人类基因组结构的精细图,为相关研究提供了参考序列。人类基因组序列共由30亿个碱基组成,大量研究表明,人群中>1%的遗传差异大约占基因组序列的0.1%左右,即大约300万个碱基的差异,在人群中超过1%的变异频率。这些差异极有可能是造成两个人之间个体差异的遗传因素。发现这些位点,可广泛地应用于遗传标记的研究、评估个体遗传关系、评估物种进化等研究领域。在人类基因组中,约90%的差异是以单个核苷酸的形式体现出来的,这样的差异位点被称作单核苷酸多态性(singlenucleotidepolymorphism,snp)。snp具有两个显著的特点:一是数目众多,据估计人类基因组中的snp数目约在1100万左右,目前ncbidbsnp数据库中已收录来源于人类基因组的snp达1083万,其中经过确认的为644万(截至2007年8月22日),如此大量的snp方便了选择合适的位点进行疾病研究,也使得绝大多数基因组区域在snp覆盖范围内;另外一个特点是snp位点大多数为双态,即在一个位点上仅有两种表现形式(基因型),这样很容易就能设计出高通量自动化的检测方法。正因为这两个特点,使得snp位点越来越受到研究者的青睐,被誉为是继限制性片段长度多态性(restrictionfragmentlengthpolymorphism,rflp)和短串联重复序列(shorttandemrepeat,str)之后的第三代分子标记物。人类基因组计划完成前后,基因组学研究的重点逐渐转向snp领域,因此,snp在遗传标记学、生物群体遗传学、生物分类学、遗传育种学、物种或人类进化学、法科学、药物基因组学等领域都有重要的应用。心血管疾病是全球人类健康的首要疾病负担。我国心血管病患病率处于持续上升阶段。高血压是最常见的心血管疾病之一,也是心血管病的主要危险因素。推算我国心血管病现患人数2.9亿,其中高血压占2.7亿。约70%的脑卒中和50%的心肌梗死的发生与血压升高有关,至少一半的心血管病死亡与高血压有关。根据历次全国性大规模高血压患病率调查,从1959年到2012年,大于等于18岁居民高血压患病率已由5.1%上升到25.2%,上升趋势明显,已成为我国重要疾病负担。因此,高血压的防治已经成为预防心血管疾病、保障国民健康的重要需求。临床上用于预测降压药物疗效的方法主要有两种,一种是医生经验性预测,医生首先会根据患者的一般性临床检查,经验性的选择一种降压药,当一段时期之后,发现疗效不好或副作用大,才会考虑加量或换药或合并用药;另一种预测方法是血压监测,而且已由静态发展为动态血压监测,可以实时有效监测血压,但目前动态血压监测技术本身存在不少局限性,动态血压值尚无统一标准,检查费价格较贵,并且不能真正预测某一药物的降压作用,更不能给医生选择药物提供准确的个体化信息。综上,现有的两种方法都存在一定的滞后性和盲目性,表现在医生在用药时不能根据个体差异进行选择药物、配伍和确定剂量,相对降低了临床用药、治疗的效率和安全性,增加了发生毒副作用和经济负担的风险。如今药物基因组学已成为指导临床个体化用药、评估严重药物不良反应发生风险的重要工具。通过检测药物代谢酶和药物靶点基因,可指导临床医生针对特定患者选择合适的降压药物和给药剂量,提高降压药物治疗的有效性和安全性。药物发挥作用的各个环节都可能因基因变异而表现出明显的差异性反应。降高血压药物尼群洛尔是一种钙离子拮抗剂,其机制为抑制钙离子移动到血管平滑肌细胞和心肌细胞。钙通道是细胞膜上对钙离子具有高度选择性通透能力的亲水性孔道。钙离子通过钙通道进入细胞内,参与细胞跨膜信号传导过程,介导兴奋-收缩偶联和兴奋-分泌偶联、维持细胞正常形态和功能完整性、调节血管平滑肌的舒缩活动等。钙拮抗剂在临床应用上存在一些争议。furberg等人(“nifedipine.dose-relatedincreaseinmortalityinpatientswithcoronaryheartdisease”,circulation,1995)认为钙离子拮抗剂尤其是短效的钙拮抗剂可增加冠心病发病甚至死亡的危险,也可增加癌症和消化道出血的危险。pahor等人(“healthoutcomesassociatedwithcalciumantagonistscomparedwithotherfirst-lineantihypertensivetherapies:ameta-analysisofrandomisedcontrolledtrials”,lancet,2000)报道使用钙拮抗剂造成的急性心肌梗死、心力衰竭及主要心血管事件风险,明显高于利尿剂、β-受体阻滞剂、acei或可乐定。个体之间的遗传背景的差异是解释该现象的重要原因之一。由美国国立卫生研究院(nih)创建的药物基因组学知识库(pharmgkb,thepharmacogenetics&pharmacogenomicsknowledgebase),收集了史上最完整的与药物基因组相关的基因型和表型信息,并将这些信息系统地归类,是目前全球最重要的药物基因组学知识库,依据其制定的临床药物基因组实施协作组(cpic,clinicalpharmacogeneticsimplementationconsortium)是药物基因组学临床部署遵循的主要规范。研究表明,降高血压药物尼群洛尔存在多个代谢相关的基因位点。例如,国家卫生计生委合理用药专家委员会和中国医师协会高血压专业委员会共同编写的《高血压合理用药指南(第2版)》筛选出了pharmgkb和cpic收录的与尼群洛尔的吸收、转运、代谢、效应相关的8个基因座位(agtr1、kcnh2、prox1、galnt2、abcb1、9p23、cacna1c、ldlr)的10个多态性位点信息。进行降压药物选择指导的基因检测。根据检测的基因型结果所指向的用药建议,进行更适于个体遗传背景的降压药物种类及剂量选择,从而提高降压药物治疗的有效性和安全性。为了能更加全面的指导用药,需要同时对这些snp位点进行分析,综合考虑才能给予更加可靠有效的用药指导。因此,以高灵敏、高通量为特点的snp检验方法成为实现基因个体化用药的最优之选。与传统的snp检验方法(荧光定量pcr,基因芯片,sanger法)不同,近年发展起来的新型软电离生物质谱——基质辅助激光解吸电离飞行时间质谱,即matrix-assistedlaserdesorptionionisationtime-of-flightmassspectrometry(maldi-tofms)[1,2]同时具备灵敏度高,通量高,特异性好,成本低廉,操作简单,环境友好等优点。maldi-tofms仪器主要由两部分组成:基质辅助激光解吸电离离子源(maldi)和飞行时间质量分析器(tof)。maldi的原理是用激光照射样品与基质形成的共结晶薄膜,基质从激光中吸收能量传递给生物分子,而电离过程中将质子转移到生物分子或从生物分子得到质子,而使生物分子电离的过程。因此它是一种软电离技术,适用于混合物及生物大分子的测定。tof的原理是离子在电场作用下加速飞过飞行管道,根据到达检测器的飞行时间不同而被检测即测定离子的质荷比(m/z)与离子的飞行时间成正比,检测离子。maldi-tof这种软电离技术,不产生或产生较少的碎片离子。由于分子量是有机化合物最基本的理化性质参数,分子量正确与否往往代表着所测定的有机化合物及生物大分子的结构正确与否。maldi-tofms基因分型技术基于“引物延伸法”,即延伸引物在待检测snp位点上延伸一个或若干个碱基,然后根据延伸产物所带荧光的不同或其分子质量的不同而确定其基因型(图1)。美国sequenom公司的hme和iplex方法,德国bruker公司的goodassay方法,韩国genematrix公司的rfmp方法是基于maldi-tofms开发的一些具体的snp检测方法。这些方法的原理是设计一条与待检测snp位点上游的基因组序列匹配的寡核苷酸探针,根据snp位点的基因型差异,探针将在待检测snp位点处连接上不同的脱氧核苷酸。其中,组成dna片段的四种脱氧核苷酸的分子量分别是:damp313.21da,dcmp289.19da,dgmp329.21da,dtmp304.20da。不同脱氧核苷酸之间是存在分子量差异的,其中差异最小的是damp与dtmp之间的9.01da,差异最大的是dcmp与dgmp之间的40.02da,通过质谱仪能检测到这种差异,从而将分子量不同的探针区分开来。质谱仪的检测效果与探针的分子量相关,探针片段越短,分子量越小,区分效果越明显:例如,在图2中,图2-a标示的两个峰,对应的两个寡核苷酸片段为5'-acgt-3'和5'-acga-3',分子量分别为1174.699和1183.770da,相差9.071da,b图标示的两个峰,对应的两个寡核苷酸片段为5'-acgtacgt-3’和5'-acgtacga-3',分子量分别为2410.628和2419.821da,相差9.193da,图2-c标示的两个峰,对应的两个寡核苷酸片段为5'-acgtacgtacgt-3'和5'-acgtacgtacga-3',分子量分别为3645.917和3654.736da,相差8.819da,同样相差9da左右,因此,maldi-tofms能够灵敏且准确地测量出单个snp差异。但如图所示,图2-a中两个峰之间的差异最明显,图2-b次之,图2-c中两个峰之间的差异相对不明显,也就是说,分子量越小,质谱仪的区分效果越明显,即分辨率越高。为了提高质谱仪的分辨率,对snp位点进行检测倾向于检测分子量较小的寡核苷酸片段,如rfmp方法通过对含snp位点的pcr产物进行限制性酶切,产生2000~4000da左右的寡核苷酸片段进行检测,而goodassay方法通过磷酸二酯酶(phosphodiesterase,pde)将含snp位点的寡核苷酸片段切割成1000~2000da左右的小片段进行检测。中国专利申请cn101748196a、“cyp1a2基因的snprs762551及其在相关药物代谢活性检测中的应用”,公开了一种通过检测cyp1a2基因的snprs762551预先判断药物代谢活性的方法,其包括检测人个体的细胞色素氧化酶p4501a2基因(cyp1a2)、转录本与正常相比是否存在变异,存在变异就表明对该个体而言,其药物代谢活性不同于普通人群或正常人群。该发明还公开了相应的用于预先判断个体的药物代谢活性的检测试剂盒。但是,上述发明专利并特异性针对降高血压药物尼群洛尔,尼群洛尔部分由cyp1a2进行代谢,而cyp1a2对于尼群洛尔的药效临床意义尚不明朗或者影响较弱。并且该发明仅能针对单一基因(cyp1a2)的多态性位点(rs762551)进行snp检测与用药效果的预测,在临床应用中的检测成本较高,检测效果具有一定的局限性。作为最接近的现有技术,中国专利申请cn1810986a、“一种预测降血压药物钙拮抗剂药效的方法及其应用”,公开了一种通过测定受试者的肾上腺素受体基因多态性位点的基因型,预测钙拮抗剂类降压药药效的方法,其中从全血或者唾液中提取基因组dna,然后使用pcr或者荧光定量pcr的方法分别检测arg347cys、arg389gly、gln27glu三个多态性位点,根据结果给予相应的用药意见。但是该发明专利所提供的检测方法和试剂盒仅针对肾上腺素受体基因的多态性位点,检测对象具有局限性。并且,该方法主要采用了荧光定量pcr的检测方法,由于荧光定量pcr需要针对snp位点变异设计特异性的探针,导致该方法通量低,一次实验只能测定一个多态位点,不适宜多snp的检测。另外若需获得所有相关snp的信息,需要进行多个检测试验,会造成成本的上升。因此,需要一种试剂盒及其配套的检测方法,能够针对与目标药物代谢相关的所有基因的多态性位点进行检测,提高药物使用的有效率,降低不良反应的发生率,有利于临床制定更加合理有效的个体化用药方案。技术实现要素:由于药物反应的个体差异是一个复杂表型特征,是由多种遗传因素和多种环境因素交互作用的结果。今后根据个体患者的遗传环境特征设计的个体化的用药方案,能够根据患者多种遗传特征综合地预期患者对特定的药物产生的反应,选出对于相应患者个体最适的治疗方案,指导医生为患者提供个体化的医药服务。因此,基于maldi-tofms的snp基因分型检测,具有灵敏、准确、高通量的特点,适于个体遗传背景的尼群洛尔剂量选择,提高尼群洛尔治疗的有效性和安全性。本发明原理在于:根据现代人类遗传学和药物基因组学研究成果,在特定基因区域选择能够代表中国人群遗传特征体现药物吸收、代谢效率改变,并且在中国人群中高频变异的snp位点,组成一套10位点的snp组合,使用这个snp组合可有效地在中国人群中进行降高血压药物尼群洛尔的用药型判别工作。基于以上基础,本发明通过大量实验摸索,创造性发现选择由10个snp位点组成的检测系统,来用于判别降高血压药物尼群洛尔的个体化用药型。因此,本发明的第一个目的是提供一种用于检测人snp标记进行判别降高血压药物尼群洛尔的用药型的引物组合物,其特征在于,该引物组合包括针对能判别尼群洛尔的用药型的10个snp标记的pcr引物对和延伸引物,其中,pcr引物序列对选自如seqidno:1a-10a所示的序列,延伸引物序列选自如seqidno:1b-10b所示的序列。其中,所述snp选自rs5186、rs1137617、rs340874、rs2144297、rs2144300、rs3213619、rs12346562、rs1104514、rs1051375、rs688。在一个实施方案中,该引物组合物分为3个独立进行的多重pcr反应引物组合物,并且所述序列如表1所示。表1其中,seq1-3序列代表的位点组成第一个独立进行的完整反应体系,这个反应体系包括两个步骤:多重pcr反应和单碱基延伸反应,seq1a-seq3a引物对参与多重pcr反应,seq1b-seq3b引物参与单碱基延伸反应。seq4-6序列代表的位点组成第二个独立进行的完整反应体系,这个反应体系也包括多重pcr反应和单碱基延伸反应两个步骤:seq4a-seq6a引物对参与多重pcr反应,seq4b-seq6b引物参与单碱基延伸反应。seq7-10序列代表的位点组成第三个独立进行的完整反应体系,这个反应体系也包括多重pcr反应和单碱基延伸反应两个步骤:seq7a-seq10a引物对参与多重pcr反应,seq7b-seq10b引物参与单碱基延伸反应。所述的snp位点rs5186、rs1137617、rs340874、rs2144297、rs2144300、rs3213619、rs12346562、rs1104514、rs1051375、rs688,其序列可从已知公开的人基因组序列库中获得。在另一实施方案中,各位点对应的延伸引物及延伸产物分子量如表2所示。表2在一个实施方案中,上述pcr引物序列为核心序列,其在5'端可包括保护碱基序列,优选5-15个碱基。在一个具体实施方案中,保护碱基序列选自在5'段加入10bp的tag(acgttggatg)。在另一个具体实施方案中,延伸引物的5'端也可以增加作为接头的碱基序列。本发明第二个目的是提供了由上述引物组合物所制备的用于判别降高血压药物尼群洛尔的用药型相关多态位点的产品。在一个实施方案中,该产品为检测试剂盒,包括:(1)用于pcr的反应试剂,包括:上述扩增引物对,耐高温的dna聚合酶,dntps,pcr反应缓冲液;(2)用于pcr产物纯化的试剂;(3)用于单碱基延伸反应的试剂,包括:上述延伸引物,耐高温的单碱基延伸酶(sap酶),ddntps,延伸反应缓冲液。在一个实施方案中,上述产品还包括用于质谱检测且保护上述snp组合的载体,该载体包括但不限于:芯片和靶板。在一个具体实施方案中,该试剂盒还可包括:阴性质控品,阳性质控品,纯化用树脂,点样及质谱检测用靶片,外切酶,人基因组dna提取试剂等试剂。在另一个具体实施方案中,用于pcr产物纯化的试剂:碱性磷酸酶,或碱性磷酸酶和外切酶exoi,或电泳凝胶回收试剂,或pcr产物纯化柱。其中当包括碱性磷酸酶和外切酶exoi的纯化试剂时,所使用的pcr引物无需包括保护碱基。本发明的第三个目的是提供一种利用上述引物组合物或产品,通过不同snp位点的不同质谱峰图判别尼群洛尔用药型的方法,包括:(1)多重pcr:使用上述pcr引物对,在两个反应体系中,对上述10个snp位点所在dna区域同时进行扩增,得到含10处多态位点所在dna区域的pcr产物;(2)pcr产物纯化:对步骤(1)得到的pcr产物进行纯化,以减少对后续反应的干扰;(3)单碱基延伸:使用上述10条特异性的延伸引物,对步骤(2)得到的纯化后pcr产物进行多重单碱基延伸,延伸引物在对应的snp位点处延伸一个核苷酸,该核苷酸与snp位点处的基因型互补配对;(4)延伸产物纯化:对步骤(3)得到的延伸产物进行纯化,以获得高纯的延伸产物,避免盐离子等杂质对后续检测的影响;(5)质谱仪检测:将步骤(4)得到的纯化产物点在含有基质的靶片上,放入质谱仪进行检测。在一个实施方案中,步骤2的纯化过程可以选自碱性磷酸酶消化、碱性磷酸酶和外切酶exoi消化、切胶纯化、pcr纯化柱过柱等。在一个具体实施方案中,当使用碱性磷酸酶消化、或碱性磷酸酶和外切酶exoi消化进行纯化后,进行高温酶失活处理。本发明的第四个目的是提供一种利用上述引物组合物或产品,用于进行判别降高血压药物尼群洛尔的用药型的用途。在一个实施方案中,所述用途包括:指导尼群洛尔的个体化用药和人类药物基因组学遗传易感研究等。技术效果通过对抗高血压药物相关基因的检测,可以根据患者基因型制定出更加合理有效的个性化给药方案。避免由于用药剂量不足而达不到治疗效果,或者用药过量又容易发生不良反应,用药种类不合适又会加重患者的经济负担。在医疗模式由“大众医疗”转向以人为本的“个体医疗”的趋势下,进行药物相关基因的检测为患者提供了更优质的医疗服务,同时大大推进了合理用药的进程。本发明具有如下技术效果:1.质谱技术和多重pcr技术结合,可以实现snp的高通量自动化检测,输出结果由电脑进行直接判读,增加检测的速度,避免人为的主观错误;2.在实验周期上,本方法检测snp主要包括多重pcr反应、sap酶消化反应、单碱基延伸反应、纯化、点样和质谱仪分型。其中多重pcr反应、sap酶消化反应、单碱基延伸反应和纯化,理论最少耗时分别为68min、25min、53.5min和30min;3.相比于传统的方法,本发明具有成本低(无需合成探针)、耗时短(可在一次反应中检测36个目的snp位点,最多一次可检测380个样品)、结果分析简单便捷(每个snp位点只有两个等位基因,组合成三种基因型)、应用领域极其广泛的优点;4、敏感:本发明综合了多重pcr、单碱基延伸、质谱检测等技术为一体,既可通过pcr技术放大检测模板,又可通过质谱技术检测微量样本,综合了两种技术的优点,远远优于单独使用pcr检测多态性snp,因此它的检测灵敏度很高;5、特异:单碱基延伸又称为“微测序”,使用特异性探针对dna分子进行识别,具有测序技术的高准确性,特异性好、假阳性低等特点,该技术仅延伸单个碱基,出错概率更低;6、操作简单、安全、自动化程度高、防污染;7、高通量,可在5-6小时内完成数百个样本的检测;8、本发明可对多个待检个体进行检测,分别得到具有不同snp位点的检测结果,其中受检者可以是单个snp位点发生突变变异,也可以是多个snp位点发生突变变异,这表示受检者可以携带一个或多个snp突变变异。原理与定义本发明提供了一种联合多重pcr、单碱基延伸和质谱检测等技术,检测与判别用药型相关多态位点(snp)的检测方案。其原理在于:在多重pcr步骤中,通过设计并使用合适的引物,从而能同时扩增10个snp位点所在dna片段。在单碱基延伸步骤中,对上一步多重pcr的产物依次进行纯化和多重单碱基延伸。其中,延伸引物共10条,分别与10个snp位点对应,并在对应的snp位点处延伸一个核苷酸,该核苷酸与snp位点处的基因型互补配对(如某snp位点处是a基因型,将在对应的延伸引物上延伸t核苷酸)。在单碱基延伸步骤中,采用ddntp代替dntp,因此,在延伸一个碱基后,延伸引物将终止延伸。在质谱检测过程中,单碱基延伸产物在纯化后,点至含基质的靶片,并在真空环境中被激光激发,通过飞行管至检测器。不同物质通过飞行管的时间与它们的分子量呈负相关,即分子量越大,飞行速度越慢,到达检测器的时间越晚。术语“rs5186、rs1137617、rs340874、rs2144297、rs2144300、rs3213619、rs12346562、rs1104514、rs1051375、rs688”,均是人snp位点在ncbidb_snp数据库的统一编号。术语“引物组合物”,指本发明中由10对pcr扩增引物对和10条延伸引物组成的系统或组合物。该引物是依据各个位点前后各200bp序列设计出来的。术语“碱性磷酸酶消化”,其作用是降解pcr反应后体系中残余dntp,其原理是使dntp的5'-p末端转换成5'-oh末端,从而失去与引物结合使引物延伸的能力,避免了对下一步单碱基延伸的影响。术语“外切酶exoi消化”,其作用是从单链dna的一端开始按序催化水解组成dna的dntp之间3,5-磷酸二酯键,使单链dna最终水解为dntp。在本技术方案中用于降解pcr反应后残余的pcr引物。由于外切酶可以将单链的pcr引物切除,并不会在检测窗口中出现,因此使用该外切酶时,所使用的pcr引物无需包括保护碱基。术语“单碱基延伸”,又被称之为微测序(minisequence),指在体系中加入延伸引物和ddntp,ddntp与延伸引物的3'端连接形成延伸产物(即引物延伸了一个碱基),根据碱基互补配对原则,由snp位点处基因型决定具体连接何种ddntp,这个过程类似于pcr过程中dntp根据互补链的碱基组成,逐个添加到pcr引物上。由于“ddntp”与普通dntp不同的是,在脱氧核糖的3'位置缺少一个羟基,不能同后续的ddntp形成磷酸二酯键,因而,延伸引物仅在snp位点处连接一个ddntp,而不能像pcr那样,不断的往下延伸,因此称之为单碱基延伸。单碱基延伸与测序过程非常相似,测序体系中加入的是dntp和ddntp的混合物,测序引物连接dntp后将继续延伸,只有连接ddntp后,方终止延伸,因此测序产生的是长短不一的核苷酸片段的混合物;单碱基延伸体系中加入只有ddntp,延伸引物只能连接一个ddntp,并终止延伸,因此单碱基延伸产生的是延伸引物仅延伸一个碱基的核苷酸片段。术语“检测产品”,指用于检测snp位点基因型的任何常规产品,包括:检测试剂、检测芯片(如基因芯片、液体芯片等)、检测载体,以及检测试剂盒等。术语“ddntp”是一种特殊的核苷酸,它们之间存在分子量差异,如ddatp、ddctp、ddgtp、ddttp的分子量分别是271.2da、247.2da、287.2da、327.1da(其中ddttp是修饰后的分子量)。当延伸引物根据snp位点的基因型而延伸不同的核苷酸,将形成分子量差异。通过质谱检测,可分辨出这种差异。例如,某snp位点若是g/a多态,对应的延伸引物长度为20个碱基(分子量6153da),当该snp位点处是g基因型,延伸引物将延伸一个c核苷酸并终止延伸,形成23个碱基长、分子量6400.2da的延伸产物,当该snp位点处是a基因型,延伸引物将延伸一个t核苷酸并终止延伸,形成23个碱基长、分子量6480.1da的延伸产物,两种产物之间存在80.1da的分子量差异。即对该snp位点而言,若使用此6153da的延伸引物,g基因型将对应6400.2da的质谱峰,a基因型将对应6480.1da的质谱峰。在实际检测过程中,使用者可通过软件对6153da、6400.2da、6480.1da三处进行观察:若6153da处出现质谱峰,则是有部分或全部延伸引物没有与ddntp结合;不论6153da处是否出现质谱峰,若6400.2da与6480.1da处仅出现一处质谱峰,则该snp位点的基因型为纯合型,并与质谱峰的位置对应,如前所述,6400.2da的质谱峰对应g基因型,6480.1da的质谱峰对应a基因型;若6400.2da与6480.1da两处质谱峰均出现,则该snp位点的基因型为杂合型;若6400.2da与6480.1da两处质谱峰均未出现,则实验失败。术语“纯化”,指用于减少待检体系内其他物质对后续反应的影响的处理步骤。本发明的pcr产物纯化有两种方式:一是分离杂质并丢弃,二是使杂质失去活性。其中,切胶纯化、过纯化柱等都是通过电泳、纯化柱等分离杂质,并回收相对较纯的pcr产物,可以认为是第一种纯化方式,该方式一般耗时,操作复杂,特别是样本量大时;碱性磷酸酶的作用是降解(亦称“消化”)dntp,使之不能继续作为dna聚合酶或单碱基延伸酶的底物参与pcr或单碱基延伸反应,从而不干扰后续反应,可以认为是第二种纯化方式。应当指出的是,单独的外切酶exoi不起纯化作用,当它与碱性磷酸酶混合使用时,其作用是预先将单链dna(在反应完成后的pcr产物体系中,主要是剩余的pcr引物)降解成dntp,再由碱性磷酸酶使dntp继续降解。由于pcr引物被降解,不会进入最后的质谱检测步骤,因此,如果计划纯化步骤中增加exoi外切酶处理,那么无需使用具有保护碱基的pcr引物。此外,在单碱基延伸步骤之前,由于外切酶和碱性磷酸酶都通过高温失活,其不会降解在单碱基延伸步骤中加入的单链的延伸引物、ddntp等,因此避免对后续实验产生影响。术语“检测窗口”,指可用于质谱检测核苷酸分子量的范围,通常涉及引物的设计参考范围。其中,在设计延伸引物时,对于不同的snp位点,根据这些位点所在dna区域的序列特点,以及snp位点的基因型,可以设计出分子量不同的延伸引物和延伸产物,避免不同延伸引物及产物之间由于分子量接近而存在干扰,从而可在一个相对宽阔的检测窗口,如4000-9000da,实现对多个snp位点的检测。术语“snp”基因型,指表示人基因组中单核苷酸多态性的类型。其中,在实际检查中,作为对照的用于检测的基因型既可来自于对照人基因组中,也可来自已克隆入质粒的载体工具,而后者具有可复制和保存便捷、来源稳定而受到实际使用者的欢迎。术语“snp突变变异频率”,指snp位点发生突变变异的概率。理论上,本发明能同时检测单个个体中同时存在10个snp突变变异。但实践中研究者发现,不同snp突变变异在个体中存在一定的突变变异频率。10个snp位点的中国人群(hcb,hanchinesebeijing)中的变异频率参见:https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=5186https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=1137617https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=340874https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=2144297https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=2144300https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=3213619https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=12346562https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=1104514https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=1051375https://www.ncbi.nlm.nih.gov/projects/snp/snp_ref.cgi?rs=688术语“seqidno:1-10”指10个位点的前后各200bp序列,其序列参见序列表。附图说明图1:maldi-tof-ms分型snp原理图示;图2:分别是具有相同snp(t/a)的不同长度的序列分子量与质谱仪分辨率关系的示意图。其中,图例a是5bp长度(5’-acgt-3’和5’-acga-3’)的分子量质谱检测差异,图例b是8bp长度(5’-acgtacgt-3’和5’-acgtacga-3’)的分子量质谱检测差异,图例c是12bp长度(5’-acgtacgtacgt-3’和5’-acgtacgtacga-3’)的分子量质谱检测差异;图3(a-d):尼群洛尔的多个位点同时检测时的质谱峰图结果,其中横坐标单位是分子量,每个位点的延伸引物都有可能在两个位置出现质谱峰,每个位点的质谱峰都没有重叠;图4:野生型质粒(图4-a、图4-b、图4-c和图4-d)和突变型质粒(图4-e、图4-f、图4-g和图4-h)质谱峰图。参考文献1.eleutherobin:definingastructure-activityprofileandpatternsofcross-resistanceintaxol-resistantcelllines.proceedingsoftheamericanassociationforcancerresearchannualmeeting,1999.40:p.623.2.themultidrugtransporter,adouble-edgedsword.journalofbiologicalchemistry,1988.263(25):p.12163-12166.具体实施方式实施例一:引物设计及合成本试剂盒的目的snp周边序列是在db_snp(build132)和hapmap(rel28,phaseⅱ+ⅲ,aug10)数据库查询,并使用这些序列设计多重pcr引物和单碱基延伸引物。针对rs5186、rs1137617、rs340874、rs2144297等10个与判别用药型相关的多态位点设计对应特异性pcr引物核心序列(seq1a至seq10a)和特异性延伸引物核心序列(seq1b至seq10b)。10对pcr引物和10条延伸引物(seq1a/b至seq10a/b)组成3个独立进行的反应体系。seq1a/b至seq3a/b组成第一个反应体系,seq4a/b至seq7a/b组成第二个反应体系,seq8a/b至seq10a/b组成第三个反应体系。在这3个独立进行的反应体系中,seq1a至seq3a,seq4a至seq6a,seq7a至seq10a参与3个独立的多重pcr反应,seq1b至seq3b,seq4b至seq6b,seq7b至seq10b分别参与后续的3个独立的单碱基延伸反应。相关引物在生工生物工程(上海)有限公司进行合成。实施例二:样本dna提取收集普通中国人dna样本共10例,分别标记为a1-a10。其中,样本采集、dna提取等按照说明书要求,采集人静脉血,并以edta抗凝管收集。按照说明书要求,采集的血液在2-8℃保存不应超过一周,-20℃保存不应超过一个月,并可采用冰壶加冰或泡沫箱加冰密封进行运输,建议尽量采用新鲜血液进行基因组dna提取。由于本试剂盒不提供人基因组dna提取试剂,因此采用商业化的核酸提取试剂盒(如qiagen公司的dneasybloodandtissuekit),从每位患者的200μl全血中提取人基因组dna,以nanodrop2000(thermo公司)定量,并标化至30ng/μl(分别为a1-a10)。其中,该试剂盒推荐对浓度为30ng/μl的人基因组dna进行检测,但对比实验表明,本试剂盒对浓度低至10ng/μl的人基因组dna也能检测出阳性结果。按照说明书要求,提取后的人基因组dna,在2-8℃保存不应超过一周,-20℃保存不应超过两年,-80℃可长期保存,应避免反复冻融,并置于冰盒中进行运输。实施例三:生物学实验使用abi9700型pcr仪,按说明书对10个与判别用药型的多态位点进行检验。试剂盒中用于pcr、pcr产物纯化和单碱基延伸的组分为:序号组分名称主要成分规格1pcr引物混合液pcr引物24μl/管x1管2pcr反应液taq酶、dntp72μl/管x1管3酶切反应液sap酶48μl/管x1管4延伸引物混合液延伸引物24μl/管x1管5延伸反应液单碱基延伸酶、ddntp24μl/管x1管6阳性质控品人基因组dna(30ng/μl)10μl/管x1管其中各引物对浓度均为500nmol/l。按说明书,具体操作方法如下:1.pcr扩增1.1在pcr配液区,按照待检样品数(含阳性质控品、阴性对照、空白对照)准备200ulpcr反应管,并在管上标记样本编号;1.2从试剂盒中取出pcr引物混合液、pcr反应液,使其自然解冻,涡旋振荡使其充分混匀,瞬时离心至管底;1.3根据样本数目,按下表的比例取出pcr引物混合液和pcr反应液,置于一个离心管中混匀,按每pcr反应管加入4ul混合物进行分装。由于分装过程中,移液器吸头残留等因素可能造成不足以分装出所需的份数,建议适当放大混合物的配制体积。例如有10份待测样品时,可按10.5-11份样品配制混合物。组分名称单反应体积pcr引物混合液1μlpcr反应液3μl合计4μlpcr反应的总反应体系为:1.4在pcr扩增区内向每管混合物中加入1μl待测样品,使每份pcr反应体系总体积为5μl。其中,阴性对照为纯化水,空白对照为不加模板。1.5将pcr反应管置于pcr扩增仪中,按下表的程序进行pcr扩增反应。反应步骤为:于94℃120s活化dna聚合酶后,于94℃变性10s,56℃退火10s和72℃延伸60s,循环45次。2.sap酶消化sap酶反应体系为:在pcr反应管中加入2μl酶切反应液,然后将pcr反应管置于pcr扩增仪中,执行下表程序。温度时间(分)循环数855137201反应步骤为:在反应体系中加入2μl0.3usap酶,于85℃放置5min进行活化,再置于37℃下恒温20min进行多余碱基消减反应。3.延伸3.1在pcr配液区,根据样本数目,按下表的比例取出延伸引物混合液和延伸反应液,置于一个离心管中混匀。由于分装过程中,移液器吸头残留等因素可能造成不足以分装出所需的份数,建议适当放大混合物的配制体积。例如有10份酶切产物时,可按10.5-11份样品配制混合物。组分名称单反应体积延伸引物混合液1μl延伸反应液1μl合计2μl单碱基延伸反应的总反应体系为:3.2在pcr扩增区,按每管酶切产物加入2μl混合物进行分装。3.3将pcr反应管置于pcr扩增仪中,按下表的程序进行延伸反应。反应步骤为:于94℃30s活化dna聚合酶后,于94℃变性5s,52℃退火5s和80℃延伸5s,循环200次。最后一步72℃延伸180s。4.纯化在pcr扩增区向每管延伸产物中加入16μl纯化水,6mg树脂,颠倒混匀30分钟。5.点样使用微量移液器,吸取1μl纯化产物,点样至靶片。实施例四:上机检测及结果判读使用毅新兴业(北京)科技有限公司生产的clin-tof型飞行时间质谱仪对点样后的靶片进行检测和结果判断。所述的质谱峰图是单碱基延伸反应完成后,将反应产物点样到质谱芯片上,再用质谱仪进行分析得到的图谱。各个位点的延伸引物分子量各不相同,各个位点的两种等位基因进行单碱基延伸后,也会产生两条不同分子量的延伸产物,这样在不同的分子量横坐标上,不同样品和不同位点产生不同的质谱峰。。另外,分别设置以上位点的野生型对照b1-b10、突变变异型对照c1-c10。其中,野生型对照b1-b10、突变变异型对照c1-c10分别来自市售或实验室保藏的人工质粒。本发明中所用的野生型对照质粒b1-b10和突变变异型对照质粒c1-c10,为在商品化质粒pmd18-tvector(takara公司)的基础上,根据《分子克隆》记载的常规方法,用引物和正常人dna进行pcr后,将pcr产物插入pmd18-tvector,即构建野生型质粒b1-b10,再分别定点突变变异,即构建10个突变变异型质粒c1-c10。所述质粒b1-b10和c1-c10可长期保存于-20℃甘油中,用时活化并提取质粒dna。如前述表2所示,10条延伸引物及它们在10个多态位点上根据各自基因型产生的延伸产物具有不同的分子量,这些分子量对应各自的质谱峰,若在某分子量处出现质谱峰,则判断为存在与该分子量对应的物质(延伸引物或产物):判断标准:(1)若野生型和突变变异型对应的质谱峰均未出现,无论延伸引物对应的质谱峰是否存在,均判断为实验失败;(2)若野生型或突变变异型对应的质谱峰仅出现一个,则判断为所出现质谱峰对应的基因型的纯合型;(3)若野生型或突变变异型对应的质谱峰均出现,则判断为杂合型。质谱结果如图4所示,其中图4-a~图4-d为10个snp位点均为野生型质粒的质谱图,图4-e~图4-h为10个snp位点均为变异型质粒的质谱图。以前述表2所示各位点延伸引物及延伸产物的分子量检查样本a1-a10的质谱结果,确定各snp位点的基因型,结果如表3所示:表3对照实施例一一、根据实施例1所公开的snp位点,使用以下如表4所示引物,通过常规pcr检测法对各位点进行测序:表4二、样本dna来源为使不同实验之间产生的数据具有可比性,测序验证采用实施例二中从10例待检者体内采集的静脉血中提取的人基因组dna(a1-a10)。三、测序鉴定1、pcr反应体系为25μl用ddho补齐。2、反应条件:反应在abi公司9700热循环仪上进行,反应条件为94℃预变性5分钟,94℃变性30秒,55℃退火30秒,72℃延伸40秒,35个循环,反应结束后再72℃延伸7分钟,4℃保存。3、pcr产物纯化和测序(1)向装有pcr产物的96孔板中加入50微升洗涤缓冲液,混匀。(2)将其转移到millipore纯化板中,放到真空泵上抽滤约3分钟,看到纯化板中没有水即可。(3)向纯化板中再次加入50微升的洗涤缓冲液,继续抽滤,直到纯化板中没有水为止。(4)将纯化板从真空泵上取下,向板中加入20微升的去离子水,静置15分钟。(5)再震荡15分钟,然后吸到一新96孔板内。测序反应所需试剂应为新鲜配制,需要经高压灭菌的试剂必须灭菌后方可使用。测序反应所需的器材(如384孔板、tip头等)同样应为洁净无菌的。(6)为了保证测序样本及反应试剂的新鲜,加样时应在冰上操作。(7)测序反应体系为5μl,各种试剂加入量如下:pcr产物3-10ng,bigdyev3.10.25μl,5*bigdyebuffer0.875μl,引物1.6pmol;(8)样品放于pcr仪上做如下反应:步骤:95℃,5分;95℃,10秒;60℃,4分;重复30个循环;4℃保持直到准备纯化。(9)在每个孔中加入20μl80%乙醇,4,000rpm离心30min;(10)将样品板放在折好的纸巾上,在离心机中倒甩,倒甩时速率1000rpm;(11)在每孔中加入30μl70%乙醇,4000rpm离心10min,倒甩;(12)重复第11步的操作2次;(13)将样品板放于干净的抽屉中,避光干燥30min;(14)加人5μl甲酰胺,封膜,离心后置于-20℃冰箱中;(15)测序仪前95℃变性5分钟,放置冰上2分钟,离心后上样。(16)使用abi3730xl型遗传分析仪进行序列测定四、结果对a1-a10样本,使用上表所述的引物,分别对上述10个snp位点rs5186、rs1137617、rs340874、rs2144297、rs2144300、rs3213619、rs12346562、rs1104514、rs1051375、rs688(分别编号no:1-10)测序,最终测序结果如表5所示:表5经过比较,表3的结果与表5完全一致,说明本发明检测方法的准确性。序列表<110>北京毅新博创生物科技有限公司<120>一组判别尼群洛尔个体化用药型的引物组合物<160>30<170>siposequencelisting1.0<210>1<211>30<212>dna<213>人工序列(artificialsequence)<400>1acgttggatgtcagagctttagaaaagtcg30<210>2<211>30<212>dna<213>人工序列(artificialsequence)<400>2acgttggatgagaacattcctctgcagcac30<210>3<211>21<212>dna<213>人工序列(artificialsequence)<400>3tcaattctgaaaagtagctaa21<210>4<211>30<212>dna<213>人工序列(artificialsequence)<400>4acgttggatggagactgagacactgacctg30<210>5<211>29<212>dna<213>人工序列(artificialsequence)<400>5acgttggatgatgatggccgacacgttgc29<210>6<211>16<212>dna<213>人工序列(artificialsequence)<400>6ccccagccctcatgta16<210>7<211>30<212>dna<213>人工序列(artificialsequence)<400>7acgttggatggctctccgcccttttaaatg30<210>8<211>30<212>dna<213>人工序列(artificialsequence)<400>8acgttggatgcatataagttagcgccagcc30<210>9<211>24<212>dna<213>人工序列(artificialsequence)<400>9cgttgtaaggtgtggaaaggtata24<210>10<211>30<212>dna<213>人工序列(artificialsequence)<400>10acgttggatgggcctcatgggtattggtaa30<210>11<211>30<212>dna<213>人工序列(artificialsequence)<400>11acgttggatgggatgatttgtcccaaatgc30<210>12<211>19<212>dna<213>人工序列(artificialsequence)<400>12tgggtattggtaaggattc19<210>13<211>30<212>dna<213>人工序列(artificialsequence)<400>13acgttggatgtttgagtttacccagccgtg30<210>14<211>30<212>dna<213>人工序列(artificialsequence)<400>14acgttggatgccaaaaccctgtcaattccc30<210>15<211>21<212>dna<213>人工序列(artificialsequence)<400>15cgttggaaaggacgctgtacc21<210>16<211>30<212>dna<213>人工序列(artificialsequence)<400>16acgttggatggctctctttgccacaggaag30<210>17<211>30<212>dna<213>人工序列(artificialsequence)<400>17acgttggatgccgactttagtggaaagacc30<210>18<211>17<212>dna<213>人工序列(artificialsequence)<400>18gcctgagctcattcgag17<210>19<211>30<212>dna<213>人工序列(artificialsequence)<400>19acgttggatgattgtgtgtgggtcatctgg30<210>20<211>29<212>dna<213>人工序列(artificialsequence)<400>20acgttggatgctcaatagtaaagtgttgg29<210>21<211>21<212>dna<213>人工序列(artificialsequence)<400>21catctcttcacatgttttttt21<210>22<211>30<212>dna<213>人工序列(artificialsequence)<400>22acgttggatgatagcaatgccccaccaatc30<210>23<211>30<212>dna<213>人工序列(artificialsequence)<400>23acgttggatgggacgatgagcccattaaac30<210>24<211>22<212>dna<213>人工序列(artificialsequence)<400>24ccccgcattaggctattcttgc22<210>25<211>29<212>dna<213>人工序列(artificialsequence)<400>25acgttggatgttggagctgagcttccacg29<210>26<211>30<212>dna<213>人工序列(artificialsequence)<400>26acgttggatgtcaacaacgccaacaacacc30<210>27<211>15<212>dna<213>人工序列(artificialsequence)<400>27ctccacagtgctgac15<210>28<211>30<212>dna<213>人工序列(artificialsequence)<400>28acgttggatgtcactccatctcaagcatcg30<210>29<211>30<212>dna<213>人工序列(artificialsequence)<400>29acgttggatgatctcgtacgtaagccacac30<210>30<211>19<212>dna<213>人工序列(artificialsequence)<400>30tctcaagcatcgatgtcaa19当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1