基于转录组测序开发的云锦杜鹃SSR引物对及筛选方法与应用与流程
本发明属于生物技术领域,具体涉及基于转录组测序开发的云锦杜鹃ssr引物对及筛选方法与应用。
背景技术:
云锦杜鹃(rhododendronfortuneilindl.)是一种主要生长在海拔600-2000m的常绿灌木或小乔木,中国特有的杜鹃属物种,云锦杜鹃是常绿杜鹃亚属的代表种和杜鹃属植物种间杂种的重要祖先亲本,山顶生态功能重要的维持者,在我国陕西、湖南、浙江、湖北、江西、广西、贵州、云南、福建等省份均有分布,花朵有香味,且抗性较强,具有较高的观赏价值和经济价值。关于云锦杜鹃的研究报道主要集中于区域性云锦杜鹃植物形态学特征、资源分布、资源评价、扦插繁殖技术、离体快繁技术、引种栽培等。云锦杜鹃ssr分子标记的开发可为云锦杜鹃种质资源评价、杂交育种、杜鹃花属植物亲缘关系、群体结构等分析提供参考。
简单重复序列(simplesequencerepeats,ssr)是指2-6个核苷酸基本单位重复多次的dna序列,广泛分布在真核生物基因组、多态信息量高,共显性遗传、重复性好、特异性强,广泛应用于植物品种纯度鉴定、分子标记辅助育种、遗传图谱构建、功能基因定位、遗传多样性分析等研究中。ssr分子标记可分为基因组ssr(genomic-ssr)和转录组ssr(est-ssr),genomic-ssr的开发需要经过基因组文库构建、探针杂交、测序等步骤,成本高且效率低,在非模式植物中难以大规模开展。目前,基于转录组数据开发的est-ssr标记在豇豆、芝麻等多个植物内报道。此外,由于杜鹃花的基因组尚未测序或者测序数据尚未公布,而其同源物种基因组开发的ssr尚无确定是否能与其通用,所以从转录组上获取ssr分子标记更加经济、可靠,且常与功能基因连锁,在分子标记辅助育种中具有较高的应用价值。
第二代高通量测序技术的发展与成熟使得通过转录组测序高通量获取est-ssr标记成为了可能。目前,云锦杜鹃多态性ssr标记的报道比较少,极大地限制了其在遗传学研究中的应用。
技术实现要素:
本发明针对现有技术的不足,提供基于转录组测序开发的云锦杜鹃ssr引物对及筛选方法与应用。本发明利用rna-seq技术对云锦杜鹃新鲜花瓣材料进行转录组测序,将数据组装拼接后挖掘含有ssr标记的序列,并将符合ssr引物设计要求的unigenes进行ssr标记的开发,并随机合成部分ssr引物,进行适用性验证。该引物的开发为云锦杜鹃的遗传多样性和遗传结构研究、遗传图谱构建、分子标记辅助育种、重要性状基因定位和克隆等研究奠定基础。
为了实现上述目的,本发明采用以下技术方案:
第一方面,提供一种基于转录组测序开发的云锦杜鹃est-ssr引物对,在检测过程中使用25对引物,所述引物分别为:
表1多态性ssr引物信息
第二方面,提供上述云锦杜鹃est-ssr引物对的下述a1-a6中的任一种用途:
a1、所述est-ssr引物对在构建云锦杜鹃遗传图谱中的应用;
a2、所述est-ssr引物对在云锦杜鹃种质鉴定中的应用;
a3、所述est-ssr引物对在云锦杜鹃育种中的应用;
a4、所述est-ssr引物对在云锦杜鹃遗传多样性分析中的应用;
a5、所述est-ssr引物对在云锦杜鹃亲缘关系分析中的应用;
a6、所述est-ssr引物对在云锦杜鹃分子标记辅助育种中的应用。
第三方面,提供一种鉴定云锦杜鹃亲缘关系和遗传特性的试剂盒,包括上述的25对est-ssr引物。
第四方面,提供基于转录组测序开发云锦杜鹃est-ssr引物的方法,包括
(1)选取云锦杜鹃盛花期新鲜花瓣材料,获取后用锡箔纸包裹置于液氮中速冻并迅速转移至-70度冰箱保存;采用高盐trizol试剂和rna结合柱的方法提取总rna;
(2)利用链特异性转录组文库构建试剂盒对总rna先进行mrna磁珠富集;将富集到的mrna进行双链cdna合成、末端修复和接头连接;再用user酶降解cdna第二链,保留真实转录的mrna第一链信息;经pcr扩增和3%的琼脂糖凝胶电泳,回收300-500bp范围的片段,即得到测序文库;再利用illuminahiseq2500pe125进行高通量rna-seq测序;
(3)采用fastx和cutadapt软件过滤数据,并采用cufflinks软件进行数据组装得到unigene,将其作为后续ssr引物开发的背景数据;
(4)使用misa软件对unigene进行ssr位点搜索,搜索标准为:二核苷酸、三核苷酸、四核苷酸、五核苷酸、六核苷酸最少重复次数分别为10次、7次、6次、5次、5次,筛选出符合ssr引物设计的序列;
(5)利用primer3.0软件对含有est-ssr位点且侧翼序列大于50bp的unigene序列进行引物设计,引物退火温度54-65℃之间,pcr产物大小100-300bp,引物长度18-25nt之间,cg含量40%-60%,避免引物产生二聚体结构、发夹结构和引物错配;
(6)挑选合成步骤(5)设计的est-ssr引物对,对云锦杜鹃种群进行pcr扩增和6%page凝胶电泳检测,验证est-ssr引物对的有效性和通用性。
第五方面,提供获取云锦杜鹃est-ssr分子标记的方法,包括:
(1)以云锦杜鹃的基因组dna为模板,用上述云锦杜鹃的est-ssr引物进行pcr扩增,得到pcr扩增产物;
(2)将(1)中得到的所述pcr扩增产物进行电泳,得到云锦杜鹃est-ssr分子标记。
上述方法中,所述pcr扩增采用的引物退火条件可为55-60℃,30s。
上述方法中,所述pcr扩增中采用的pcr反应温度程序可为:94℃预变性5min;然后进入30个循环:94℃变性40s,55-60℃下退火30s,72℃延伸30s,最后72℃延伸7min。
第六方面,提供由表1所述的引物对以云锦杜鹃的基因组为模板扩增得到的分离的est-ssr标记。
实验证明,本发明基于转录组测序开发云锦杜鹃est-ssr引物的方法拼接得到的59,887个unigene,含ssr序列的unigene有9,108个,从中统计出10,224个ssr,见表2。挑选合成的25对ssr引物对云锦杜鹃群体(35个个体)进行pcr扩增验证其有效性,引物序列见表1。采用popgene32.0软件计算大别山云锦杜鹃群体遗传结构,各项遗传多样性结果见表3,大别山云锦杜鹃种群遗传多样性处于较高的水平。
本发明的有益效果在于:
1、本发明通过花转录组数据获取云锦杜鹃est-ssr标记开发的背景数据,方法快捷、准确,比基因组数据获取的gssr具有更高的通用性和实用性。
2、本发明的25个est-ssr标记能够很好地用于云锦杜鹃种群的多样性研究,可将本发明提供的est-ssr标记应用于云锦杜鹃近缘属种种质资源遗传多样性研究、遗传图谱构建、目标性状基因定位、分子标记辅助育种等研究。
附图说明
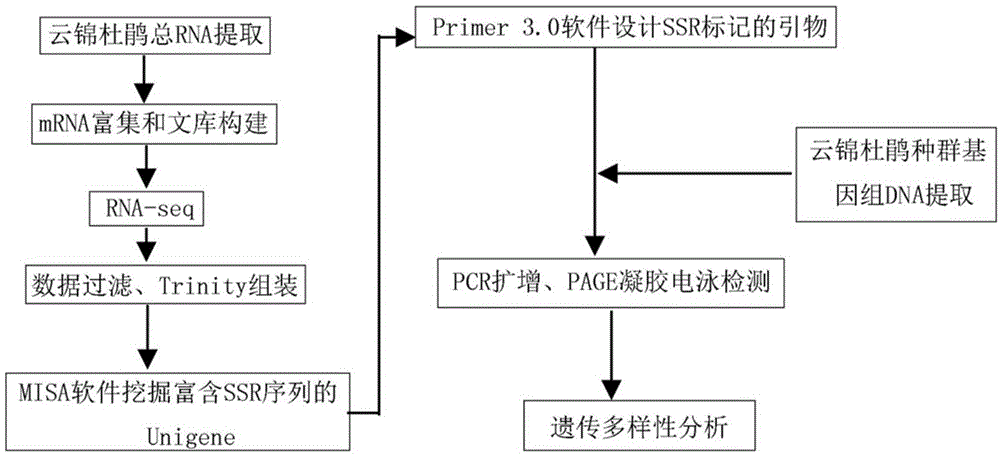
图1基于云锦杜鹃转录组数据的ssr引物开发和遗传多样性研究应用的流程示意图。
图2是实施例中rfe-1引物在云锦杜鹃种群(35个个体)的扩增和page电泳检测结果。
具体实施方式
通过以下详细说明结合附图可以进一步理解本发明的特点和优点。所提供的实施例仅是对本发明方法的说明,而不以任何方式限制本发明揭示的其余内容。下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
【实施例1】多态性高的云锦杜鹃的est-ssr引物的开发
本发明提供的基于转录组高通量测序,并结合生物信息学方法进行ssr序列查找和ssr标记引物设计和验证,其具体实施方式如下:
(1)富含ssr位点的unigene序列筛选:选取云锦杜鹃花材料提取总rna,构建转录组测序文库,采用illumina二代测序仪进行高通量测序。测序数据进过严格的过滤后进行组装,得到unigene,将其作为后续ssr引物开发的背景数据。采用misa软件对unigene进行ssr位点搜索,搜索标准为:二核苷酸、三核苷酸、四核苷酸、五核苷酸、六核苷酸最少重复次数分别为10、7、6、5、5次。
其中,拼接得到的59,887个unigene,含ssr序列的unigene有9,108个,从中统计出10,224个ssr,见表2。
表2unigene中ssr重复序列和重复次数统计
(2)采用primer3.0软件批量设计含有ssr位点的unigene序列引物,并且ssr位点离侧翼序列长度大于50bp,引物退火温度54-65℃之间,pcr产物大小100-300bp,引物长度18-25nt之间,cg含量40%-60%,避免引物产生二聚体结构、发夹结构和错配情况,筛选出符合ssr引物设计要求的序列。
(3)采用8个云锦杜鹃个体,pcr扩增后3%琼脂糖凝胶电泳筛选多态性的ssr引物对。ssr引物序列见表1。引物合成由南京金斯瑞生物科技有限公司合成并采用rpc的方式进行纯化。
【实施例2】25对est-ssr引物在云锦杜鹃种群遗传多样性研究中的应用
检测est-ssr标记检测云锦杜鹃遗传多样性包括以下步骤:
(1)dna提取:在湖北大别山区采集云锦杜鹃种群,共35个个体(采集地分布于东经114.56°-115.043°e、北纬31.03°-31.68°n、海拔420-1430m),编号为编号为yjdj1-yjhd35。利用3×ctab法提取35个云锦杜鹃叶片组织的基因组dna,并经1%琼脂糖凝胶电泳检测质量和紫外分光光度测定浓度,保证dna的纯度od260/od280大于1.8。叶片经液氮研磨、酚/氯仿(体积比1:1)抽提、无水乙醇沉淀、75%乙醇洗涤、rna酶消化等步骤后,将dna溶于50μlte溶液中,稀释至100ng/μl后置于-20℃冰箱保存备用。
(2)pcr扩增:20μl反应体系包含:ddh2o15.7μl,10×buffer(含mg2+)1.5μl,dntps(10mm)0.2μl,10μm正反引物各0.2μl,taqdna聚合酶0.2μl,dna模板(50ng/μl)1μl。反应程序为:94℃5min;94℃40sec,退火温度(见表1)30sec,72℃30sec,30cycles;72℃7min。所选引物序列见表1。
(3)6%的page胶检测。将pcr扩增产物取3μl,加0.5μl6×dnaloadingbuffer,进行6%page胶电泳,page胶经硝酸银染色和氢氧化钠溶液进行染色和显色。结果代表图见图2。
(4)根据引物扩增条带的有无和大小,统计开发的est-ssr标记在35个云锦杜鹃个体内的基因型,采用popgene32.0软件统计大别山云锦杜鹃种群的遗传结构,结果表明开发的est-ssr引物能够较好地解析云锦杜鹃种群遗传结构。结果见表3。
表3基于est-ssr标记的云锦杜鹃种群的遗传结构解析
na:等位基因;i:shannon信息指数;nei's:nei's遗传距离;ho:观察杂合度;he:期望杂合度;fis:种群内近交系数;fit:总近交系数;fst:遗传分化系数
申请人开发的est-ssr引物检测结果表明本发明利用转录组数据开发了大量的云锦杜鹃多态性est-ssr引物,并用这些引物对云锦杜鹃遗传结构进行解析。据此,本发明专利适用于云锦杜鹃est-ssr引物的开发,可将本发明提供的est-ssr分子标记应用于更多的杜鹃花植物中,为后续的云锦杜鹃的种质资源遗传多样性检测、品种鉴定、纯度鉴定、遗传图谱构建、重要性状定位和分子标记辅助育种等方面提供支撑。
序列表
<110>黄冈师范学院
<120>基于转录组测序开发的云锦杜鹃ssr引物对及筛选方法与应用
<160>50
<170>siposequencelisting1.0
<210>1
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>1
tcatataaggtgagctgca19
<210>2
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>2
caaagtgggagctcgtatta20
<210>3
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>3
gcaaacacacacatacagac20
<210>4
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>4
acggtgcttgagaaactatt20
<210>5
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>5
gatttgccaattccattcgt20
<210>6
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>6
gaaccgggtcaattcgtata20
<210>7
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>7
cacggcgatcaactctttt19
<210>8
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>8
ggtcagatacagaagcac18
<210>9
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>9
cactcgatacacatacacga20
<210>10
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>10
gcttgaaagttcgatcgatc20
<210>11
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>11
aaacagtgcctcataccac19
<210>12
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>12
agcgtctatggatcttgatg20
<210>13
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>13
tagtttcgtgcaagttctga20
<210>14
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>14
ctgttcataaagggccatct20
<210>15
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>15
gttgtatcactgggcatctt20
<210>16
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>16
ctgtgattgttgctgttgtt20
<210>17
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>17
agagcattgacacattcgat20
<210>18
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>18
tgtgacctgaacctcatttt20
<210>19
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>19
acactgctacatacagtcac20
<210>20
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>20
agcttcgttaaacccttgat20
<210>21
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>21
gtatgccagtgattcagaga20
<210>22
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>22
cagagcttgtatgtataggac21
<210>23
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>23
ttacagtctagtcacagtgt20
<210>24
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>24
gatttgtgaccgttgtatcg20
<210>25
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>25
atctcatcactccacagtct20
<210>26
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>26
ccgacttgataggagaaag19
<210>27
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>27
ggccttgaatccttcttctt20
<210>28
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>28
cagctttatggcccttacg19
<210>29
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>29
cggccttaaccattatcgt19
<210>30
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>30
tggcacatctgtatatgct19
<210>31
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>31
tcttccgattccatcattcc20
<210>32
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>32
tgggcgtgatttggttataa20
<210>33
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>33
aacgtcatctctctccttct20
<210>34
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>34
acaccgactttatcacaaca20
<210>35
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>35
ctaaaaccccacaaaagcaa20
<210>36
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>36
ctttccttctcctttgctct20
<210>37
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>37
gtccgcattctcttctacaa20
<210>38
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>38
caggcttctctgtcatcttc20
<210>39
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>39
actctctcctcataagtccc20
<210>40
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>40
caggcttctctgtcatcttc20
<210>41
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>41
tcatgtgcttgatggtctg19
<210>42
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>42
tcctctccctcaatatatcc20
<210>43
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>43
actcgtctctatagtcttgc20
<210>44
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>44
catccaaccagtacgactac20
<210>45
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>45
ttccagttccaattcatcgg20
<210>46
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>46
cccaacaacaattccatcac20
<210>47
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>47
catatagctcaccgactgtt20
<210>48
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>48
aacaatgctcgtaaccagat20
<210>49
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>49
catagcttctctccgatct19
<210>50
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>50
gtggaatggctcggtaga18
- 还没有人留言评论。精彩留言会获得点赞!