经人工操纵的免疫细胞的制作方法
本发明涉及免疫调节基因的人工操纵或修饰。更特别是,本发明涉及用于对免疫调节基因进行人工操纵的基因操纵组合物以及包含所述经人工操纵的免疫调节基因的免疫细胞。
背景技术:
细胞治疗剂是使用活细胞诱导再生以修复受损或患病的细胞/组织/实体的药物,其为通过物理、化学或生物操纵(例如对自体细胞、同种异体细胞或异种细胞进行离体培养、增殖、选择等)产生的药物。
其中,免疫调节细胞治疗剂是通过使用免疫细胞(例如树突细胞、自然杀伤细胞、t细胞等)调节体内的免疫应答来实现疾病治疗目的的药物。
目前,正在开发的免疫调节细胞治疗剂主要靶向癌症治疗作为适应证。与传统用于癌症治疗的手术疗法、抗癌剂和放射疗法不同的是,免疫调节细胞治疗剂具有的治疗机制和效力在于通过将免疫细胞直接给予患者来活化免疫功能,从而获得疗效;免疫调节细胞治疗剂有望在未来的新兴生物学中扮演重要角色。
导入细胞的抗原的物理和化学特性根据免疫调节细胞治疗剂的类型而彼此不同。当以病毒载体等形式将外源基因导入免疫细胞时,这些细胞将能够同时具有细胞治疗剂和基因治疗剂的特征。
可采用如下方式来实施免疫调节细胞治疗剂的给予:通过利用多种抗体和细胞因子活化多种免疫细胞(例如通过单采(apheresis)从患者分离的外周血单核细胞(pbmc)、t细胞、nk细胞等),随后离体增殖并再次注射至患者中;或者将其中导入有基因(例如t细胞受体(tcr)或嵌合抗原受体(car))的免疫细胞再次注射至患者中。
过继性免疫疗法涉及离体(exvivo)产生的自体抗原特异性免疫细胞(例如t细胞)的递送,其可能成为治疗多种免疫疾病以及癌症的有希望的策略。
最近报道了免疫细胞治疗剂可以以多种方式使用,例如作为自体免疫抑制剂等以及表现出抗癌功能。因此,免疫细胞治疗剂可以通过调控免疫应答而用于多种适应证中。因此,在对用于过继性免疫疗法的经操纵的免疫细胞的治疗效力进行开发和改善方面具有巨大需求。
技术实现要素:
技术问题
作为示例性实施方式,本发明提供了用于对免疫细胞进行操纵的组合物,所述组合物用于对免疫细胞进行人工操纵。
作为示例性实施方式,本发明提供了经操纵的免疫细胞,所述经操纵的免疫细胞包含至少一种经人工修饰的免疫调节基因以及至少一种人工受体。
作为示例性实施方式,本发明提供了用于生产人工免疫细胞的方法,所述人工免疫细胞包含至少一种经人工修饰的免疫调节基因以及至少一种人工受体。
作为示例性实施方式,本发明提供了用于治疗免疫疾病的方法,所述方法包括人工免疫细胞,所述人工免疫细胞包含至少一种经人工修饰的免疫调节基因以及至少一种人工受体作为活性成分。
技术方案
为解决这些问题,本发明涉及用于对免疫细胞进行操纵的组合物。更具体地,本发明涉及用于对免疫细胞进行操纵的组合物,所述组合物用于人工操纵免疫细胞;以及使用所述组合物产生的包含经人工修饰的免疫调节基因和人工受体的经操纵的免疫细胞,以及它们的用途。
本发明提供了用于特定目的对免疫细胞进行操纵的组合物。
术语“用于对免疫细胞进行操纵的组合物”是指选自dna、rna、核酸、蛋白、病毒、化学化合物等的一种或多种物质,所述物质用于对免疫细胞进行人工操纵或修饰。
在某些实施方式中,用于对免疫细胞进行操纵的组合物可包含:
引导核酸,所述引导核酸能够与选自于由以下基因所组成的组中的至少一种免疫调节基因的核酸序列中的靶序列形成互补结合:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和kdm6a基因;以及
人工受体,所述人工受体为人工制备的受体,并且不为野生型受体。
术语“免疫调节基因”旨在包括直接预期或间接影响免疫功能或应答的形成和性能的任何基因。在本发明中,免疫调节基因包括直接预期或间接影响免疫细胞的功能性调节,还直接预期或间接影响与免疫细胞相互作用的细胞(例如吞噬细胞)的功能性调节的任何基因。此处,免疫调节基因能够以免疫调节基因本身或由免疫调节基因表达的蛋白的形式实施与免疫功能或应答的形成和性能有关的功能。
术语“人工受体”是指人工制备的不是野生型受体的功能性实体,其具有识别抗原并执行特定功能的特定能力。
用于对免疫细胞进行操纵的组合物可选择性地进一步包含至少一种编辑蛋白,所述编辑蛋白选自于由以下蛋白所组成的组:酿脓链球菌(streptococcuspyogenes)衍生而来的cas9蛋白、空肠弯曲杆菌(campylobacterjejuni)衍生而来的cas9蛋白、嗜热链球菌(streptococcusthermophilus)衍生而来的cas9蛋白、金黄色葡萄球菌(streptocuccusaureus)衍生而来的cas9蛋白、脑膜炎奈瑟菌(neisseriameningitidis)衍生而来的cas9蛋白以及cpf1蛋白。
靶序列可为位于免疫调节基因的启动子区域的连续的10bp-25bp核苷酸序列。
靶序列可为位于免疫调节基因的内含子区域的连续的10bp-25bp核苷酸序列。
靶序列可为位于免疫调节基因的外显子区域的连续的10bp-25bp核苷酸序列。
靶序列可为位于免疫调节基因的增强子区域的连续的10bp-25bp核苷酸序列。
靶序列可为位于免疫调节基因的3'-utr(非翻译区)或5'-utr的连续的10bp-25bp核苷酸序列。
靶序列可为临近免疫调节基因的核酸序列中的pam(前间区序列邻近基序)序列的5'端和/或3'端的连续的10bp-25bp核苷酸序列。
此处,pam序列可为选自以下序列中的至少一种序列:
5'-ngg-3'(n为a、t、c或g);
5'-nnnnryac-3'(n各自独立地为a、t、c或g;r为a或g;y为c或t);
5'-nnagaaw-3'(n各自独立地为a、t、c或g;w为a或t);
5'-nnnngatt-3'(n各自独立地为a、t、c或g);
5'-nngrr(t)-3'(n各自独立地为a、t、c或g;r为a或g;y为c或t);以及
5'-ttn-3'(n为a、t、c或g)。
在某些实施方式中,靶序列可为选自seqidno:1-seqidno:289的一个或多个。
引导核酸可包含能够与免疫调节基因上的靶序列形成互补结合的引导结构域,其中,互补结合可包含0-5个错配。
此处,引导结构域可包含与免疫调节基因上的靶序列互补的核苷酸序列,其中,互补核苷酸序列可包含0-5个错配。
引导核酸可包含选自于由以下所组成的组的至少一个结构域:第一互补结构域、接头结构域、第二互补结构域、近端结构域和尾部结构域。
人工受体可具有针对至少一种抗原的结合特异性。
此处,至少一种抗原可为癌细胞和/或病毒特异性表达的抗原。
此处,至少一种抗原可为肿瘤相关抗原。
此处,至少一种抗原可为选自于由以下所组成的组中的一种或多种:a33、alk、甲胎蛋白(afp)、肾上腺素受体β3(adrb3)、α-叶酸受体、ad034、akt1、bcma、β-人绒毛膜促性腺激素、b7h3(cd276)、bst2、brap、cd5、cd13、cd19、cd20、cd22、cd24、cd30、cd33、cd38、cd40、cd44v6、cd52、cd72、cd79a、cd79b、cd89、cd97、cd123、cd138、cd160、cd171、cd179a、碳酸酐酶ix(caix)、ca-125、癌胚抗原(cea)、ccr4、c型凝集素样分子(cll-1或clecl1)、claudin6(cldn6)、cxorf61、cage、cdx2、clp、ct-7、ct8/hom-tes-85、ctage-1、erbb2、表皮生长因子受体(egfr)、egfriii型变异体(egfrviii)、上皮细胞黏附分子(epcam)、e74样因子2突变体(elf2m)、肝配蛋白a型受体2(epha2)、emr2、fms样酪氨酸激酶3(flt3)、fcrl5、fibulin-1、g250、gd2、糖蛋白36(gp36)、糖蛋白100(gp100)、糖皮质激素诱导的肿瘤坏死因子受体(gitr)、gprc5d、globoh、g蛋白偶联受体20(gpr20)、gpc3、hsp70-2、人高分子量黑色素瘤相关抗原(hmwmaa)、甲型肝炎病毒细胞受体1(havcr1)、人乳头瘤病毒e6(hpve6)、人乳头瘤病毒e7(hpve7)、hage、hca587/mage-c2、hcap-g、hce661、her2/neu、hla-cw、hom-hd-21/半乳凝素9、hom-meel-40/ssx2、hom-rcc-3.1.3/caxii、hoxa7、hoxb6、hu、hub1、胰岛素生长因子(igf1)-i、igf-ii、igfi受体、白介素-13受体亚基α-2(il-13ra2或cd213a2)、白介素11受体α(il-11ra)、igll1、kit(cd117)、km-hn-3、km-kn-1、koc1、koc2、koc3、koc3、laga-1a、lage-1、lair1、lilra2、ly75、lewisy抗原、muc1、mn-caix、m-csf、mage-1、mage-4a、间皮素、mage-a1、mad-ct-1、mad-ct-2、mart1、mppl1、msln、神经细胞黏附分子(ncam)、ny-eso-1、ny-eso-5、nkp30、nkg2d、ny-br-1、ny-br-62、ny-br-85、ny-co-37、ny-co-38、nnp-1、ny-lu-12、ny-ren-10、ny-ren-19/lkb/stk11、ny-ren-21、ny-ren-26/bcr、ny-ren-3/ny-co-38、ny-ren-33/snc6、ny-ren-43、ny-ren-65、ny-ren-9、ny-sar-35、o-乙酰-gd2神经节苷脂(oacgd2)、ogfr、psma、前列腺酸性磷酸酶(pap)、p53、前列腺癌肿瘤抗原1(pcta-1)、前列腺干细胞抗原(psca)、丝氨酸蛋白酶21(testisin或prss21)、血小板源性生长因子受体β(pdgfr-β)、plac1、泛连接蛋白3(panx3)、plu-1、ror-1、rage-1、ru1、ru2、rab38、rbpjκ、rhamm、阶段特异性胚胎抗原4(ssea-4)、scp1、ssx3、ssx4、ssx5、tyrp-1、tag72、甲状腺球蛋白、人端粒酶逆转录酶(htert)、5t4、肿瘤相关糖蛋白(tag72)、酪氨酸酶、转谷氨酰胺酶5(tgs5)、tem1、tem7r、促甲状腺激素受体(tshr)、tie2、trp-2、top2a、top2b、uroplakin2(upk2)、波形蛋白、血管内皮生长因子受体2(vegfr2)、wilms肿瘤蛋白1(wt1)和lewis(y)抗原。
人工受体可为嵌合抗原受体(car)。
人工受体可为经人工操纵或修饰的t细胞受体(tcr)。
引导核酸、人工受体和编辑蛋白可处于编码它们各自的核酸序列的形式。
核酸序列可包含在质粒或病毒载体中。
此处,病毒载体可为选自于由以下所组成的组中的一种或多种:逆转录病毒、慢病毒、腺病毒、腺相关病毒(aav)、痘苗病毒、痘病毒或单纯疱疹病毒。
人工受体和编辑蛋白可处于编码它们各自的mrna的形式。
人工受体和编辑蛋白可处于多肽或蛋白的形式。
当用于对免疫细胞进行操纵的组合物选择性地进一步包含编辑蛋白时,该组合物可处于引导核酸-编辑蛋白复合体的形式。
本发明提供了用于特定目的的经操纵的免疫细胞。
“经操纵的免疫细胞”是指经人工操纵的而非野生型的免疫细胞。
在某些实施方式中,经操纵的免疫细胞可包含至少一种人工工程化免疫调节基因和/或由所述人工工程化免疫调节基因表达的产物,所述免疫调节基因选自于由以下基因所组成的组:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和kdm6a基因;以及至少一种人工受体蛋白和/或编码所述人工受体蛋白的核酸。
至少一种人工工程化免疫调节基因可在免疫调节基因的核苷酸序列内包含人工修饰。
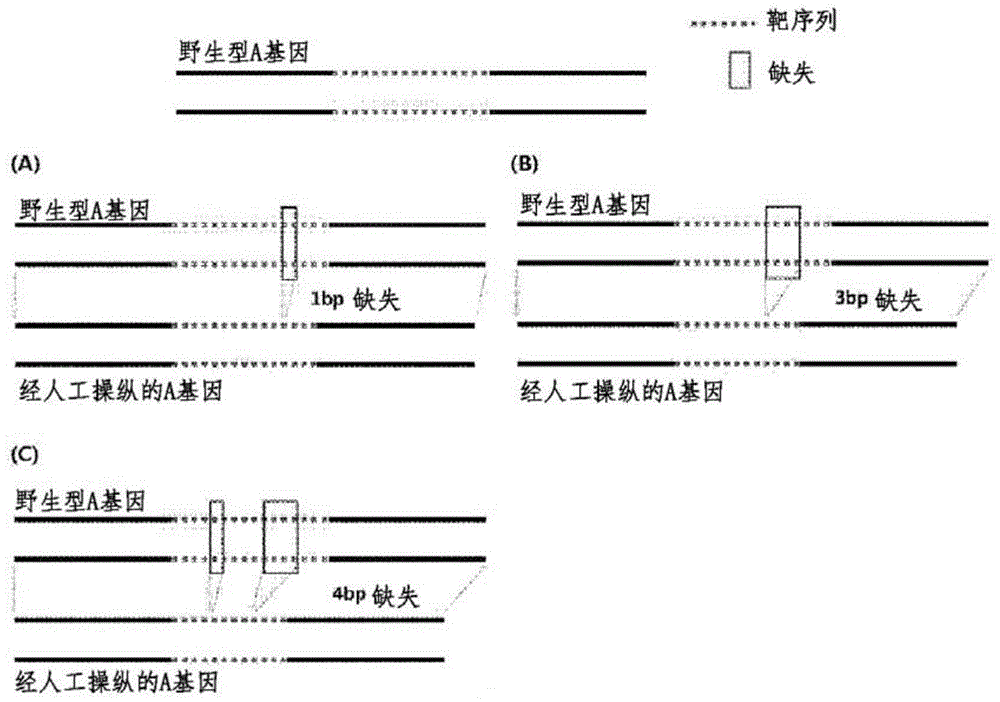
至少一种人工工程化免疫调节基因可包含免疫调节基因中的靶序列内或临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中的至少一个核苷酸的缺失和/或插入。
至少一种人工工程化免疫调节基因可包含临近免疫调节基因的核酸序列中的pam序列的5'端和/或3'端的连续的1bp-50bp核苷酸序列区域中至少一个核苷酸的缺失和/或插入。
此处,至少一个核苷酸的缺失可为连续的1bp-50bp的缺失、不连续的1bp-50bp的缺失或其中连续形式和不连续形式混合的1bp-50bp的缺失。
此处,至少一个核苷酸的缺失可为连续的2bp-50bp的缺失。
此处,至少一个核苷酸的插入可为连续的1bp-50bp的插入、不连续的1bp-50bp的插入或其中连续形式和不连续形式混合的1bp-50bp的插入。
此处,至少一个核苷酸的插入可为连续的5bp-1000bp核苷酸片段的插入。
此处,至少一个核苷酸的插入可为特定基因的部分或全部核苷酸序列的插入。
特定基因可为从外部区域导入的外源性基因,其不包含在含有免疫调节基因的免疫细胞中。
特定基因可为存在于包含免疫调节基因的免疫细胞的基因组中的内源性基因。
此处,至少一个核苷酸的缺失和插入可在同一核苷酸序列区域中发生。
此处,至少一个核苷酸的缺失和插入可在不同的核苷酸序列区域中发生。
由人工工程化免疫调节基因表达的至少一种产物可处于mrna和/或蛋白的形式。
与由未经人工操纵的野生型免疫细胞的免疫调节基因表达的产物的量相比,由人工工程化免疫调节基因表达的产物可具有减少的或被抑制的表达量。
此处,未经人工操纵的野生型免疫细胞可为分离自人的免疫细胞。
此处,未经人工操纵的野生型免疫细胞可为人工操纵前的免疫细胞。
编码人工受体蛋白的核酸存在于细胞中,但可不插入至经操纵的免疫细胞的基因组中。
编码人工受体蛋白的核酸可插入到经操纵的免疫细胞的基因组中的免疫调节基因的3'-utr、5'-utr、内含子、外显子、启动子和/或增强子区域中。
编码人工受体蛋白的核酸可插入到选自经操纵的免疫细胞的基因组中存在的内含子中的至少一个内含子中。
编码人工受体蛋白的核酸可插入到选自经操纵的免疫细胞的基因组中存在的外显子中的至少一个外显子中。
编码人工受体蛋白的核酸可插入到选自经操纵的免疫细胞的基因组中存在的启动子中的至少一个启动子中。
编码人工受体蛋白的核酸可插入到选自经操纵的免疫细胞的基因组中存在的增强子中的至少一个增强子中。
编码人工受体蛋白的核酸可插入到除经操纵的免疫细胞的基因组中存在的内含子、外显子、启动子和增强子外的一个或多个区域中。
经操纵的免疫细胞可为选自于由以下细胞所组成的组并经人工操纵的免疫细胞:树突细胞、t细胞、nk细胞、nkt细胞和cik细胞。
本发明提供了用于特定目的的经操纵的免疫细胞,所述免疫细胞显示至少一种特征。
在某些实施方式中,所述至少一种特征可为选自于由以下所组成的组中的一种或多种:
细胞因子的产生和/或分泌增加;
细胞增殖,以及
细胞毒性增加。
此处,细胞因子可为选自于由il-2、tnfα和ifn-γ所组成的组中的一种或多种。
与经操纵的免疫细胞有关的解释如上所述。
本发明提供了生产用于特定目的的经操纵的免疫细胞的方法。
在某些实施方式中,用于生产经操纵的免疫细胞的方法可包括将以下进行接触:
(a)免疫细胞;
(b)人工受体蛋白或用于表达人工受体蛋白的组合物;以及
(c)用于基因操纵的组合物,所述组合物能够对选自于由以下基因所组成的组中的至少一种免疫调节基因进行人工操纵:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d、tet2基因、psgl-1基因、a20基因和kdm6a基因。
(a)免疫细胞可为从人体分离的免疫细胞或从干细胞分化的免疫细胞。
(b)用于表达人工受体蛋白的组合物可包含编码该人工受体蛋白的核酸序列。
(c)用于基因操纵的组合物可包含:
引导核酸或编码该引导核酸的核酸,所述引导核酸与选自于由以下基因所组成的组中的至少一种免疫调节基因的核酸序列中的靶序列seqidno:1-seqidno:289具有同源性或能够与其形成互补结合:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和kdm6a基因;以及
至少一种编辑蛋白或编码该编辑蛋白的核酸,所述至少一种编辑蛋白选自于由以下编辑蛋白所组成的组中:酿脓链球菌衍生而来的cas9蛋白、空肠弯曲杆菌衍生而来的cas9蛋白、嗜热链球菌衍生而来的cas9蛋白、金黄色葡萄球菌衍生而来的cas9蛋白、脑膜炎奈瑟菌衍生而来的cas9蛋白以及cpf1蛋白。
此处,引导核酸和编辑蛋白可以各自以核酸序列的形式处于至少一个载体中,或者可处于其中引导核酸和编辑蛋白结合的引导核酸-编辑蛋白复合体的形式。
所述接触可离体进行。
接触可为依次或同时使(a)免疫细胞与(b)用于表达人工受体蛋白的组合物以及(c)用于基因操纵的组合物进行接触。
接触可通过选自于如下方法中的至少一种方法进行:电穿孔、脂质体、质粒、病毒载体、纳米粒子和蛋白易位结构域(ptd)融合蛋白法。
本发明提供了使用用于特定目的的经操纵的免疫细胞对免疫疾病进行治疗的方法。
在某些实施方式中,用于治疗免疫疾病的方法包括向受试者给予药物组合物,所述药物组合物包含经操纵的免疫细胞作为活性成分。
与经操纵的免疫细胞有关的解释如上所述。
所述药物组合物可进一步包含额外的组分。
此处,额外的组分可为免疫检查点抑制剂。
免疫检查点抑制剂可为pd-1、pd-l1、lag-3、tim-3、ctla-4、tigit、btla、ido、vista、icos、kir、cd160、cd244或cd39的抑制剂。
此处,额外的组分可为抗原结合剂、细胞因子、细胞因子的促分泌素、或细胞因子的抑制剂。
此处,额外的组分可为用于将经操纵的免疫细胞递送至体内的合适的运载体。
所述药物组合物中包含的经操纵的免疫细胞可为受试者的自体细胞、或同种异体细胞。
免疫疾病可为自身免疫疾病。
此处,自身免疫疾病可为移植物抗宿主病(gvhd)、系统性红斑狼疮、乳糜泻、1型糖尿病、graves病、炎症性肠病、银屑病、类风湿性关节炎、或多发性硬化症。
疾病可为其中病原体已知但治疗未知的难治性疾病。
此处,难治性疾病可为病毒感染疾病、朊毒体病原体引起的疾病或癌症。
向患有免疫疾病的受试者给予药物组合物可通过选自注射、输液、植入或移植的方法来进行。
受试者为哺乳动物,包括人、猴、小鼠和大鼠。
附图说明
图1至图27说明了经人工修饰或操纵的靶基因的示例。
图28为示出了用crispr/cas9处理的139car-t细胞中car表达水平的图表。
图29为示出了电穿孔crispr/cas9复合体后的t细胞生长的图表。
图30示出了在t细胞中通过crispr/cas9进行的dgk选择性敲除,其中图表确认了dgk的插入缺失(%)(a)和dgk的蛋白表达(b)。
图31为说明了使用digenome-seq所鉴定的关于各dgk的grna的脱靶位点的图表。
图32为示出了139car-t细胞的细胞毒性作用的图表,其中通过crispr/cas9敲除aavs1。
图33为对139car-t细胞的细胞毒性作用(a)和细胞因子分泌水平(b)进行比较的图表,所述139car-t细胞为通过crispr/cas9而来的敲除aavs1的139car-t细胞或敲除dgk的139car-t细胞。
图34为对u87细胞或u87viii细胞与139car-t细胞共培养后u87viii的pdl-1表达水平(a)和t细胞的pd-1表达水平(b)进行比较的图表。
图35为示出了在敲除dgk的139car-t细胞中钙内流的变化(a)和perk蛋白的表达(b)的图表。
图36为对在免疫抑制因子存在下敲除aavs1的139car-t细胞或敲除dgk的139car-t细胞的细胞毒性作用和细胞因子分泌水平进行比较的图表,分别示出了tgf-β存在的情况(a)以及peg2存在的情况(b)。
图37为示出了在免疫抑制因子存在的情况下,敲除aavs1的139car-t细胞或敲除dgk的139car-t细胞的效应物功能的图表。
图38为示出了在免疫抑制因子存在的情况下,敲除aavs1的c259tcrt细胞或敲除dgk的c259tcrt细胞的效应物功能的图表。
图39说明了用于鉴别在重复的抗原暴露下的敲除dgk的t细胞的效应物活性的实验设计。
图40说明了在重复抗原暴露下敲除dgk的t细胞的细胞增殖,其中图表比较了(a)存活细胞数和(b)增殖细胞数(%)。
图41说明了敲除dgk的t细胞中诱导细胞死亡的fas介导活性,其中图表示出了(a)激活诱导细胞死亡(aicd,%)和(b)fas的表达水平(%)。
图42为示出了敲除aavs1的139car-t细胞或敲除dgk的139car-t细胞的细胞因子分泌水平,随后进行重复的肿瘤接种的图表。
图43为示出了敲除aavs1的139car-t细胞或敲除dgk的139car-t细胞的(a)初始t细胞的集合量和(b)效应记忆t细胞的集合量的图表。
图44为示出了敲除aavs1的139car-t细胞或敲除dgk的139car-t细胞的(a)效应记忆调节因子的表达水平、(b)1型细胞因子的表达水平以及(c)2型细胞因子的表达水平的图表。
图45为示出了敲除aavs1的139car-t细胞或敲除dgk的139car-t细胞中与t细胞耗竭有关的标志物的表达水平的图表。
图46说明了敲除aavs1的139car-t细胞或敲除dgk的139car-t细胞的抗肿瘤作用,其中图表示出了静脉内注射时的抗肿瘤作用(a)以及瘤内注射时的抗肿瘤作用(b),以及图像比较了每种情况下的肿瘤尺寸(c)。
图47示出了对体内注射的aavs1139car-t细胞、αko139car-t细胞、ζko139car-t细胞和dko139car-t细胞的保持状况(a,b)以及每种情况下的肿瘤尺寸(c)进行比较的图;以及说明了每种情况下肿瘤浸润性t细胞数(d)的图表。
图48为对体内注射的aavs1139car-t细胞、αko139car-t细胞、ζko139car-t细胞和dko139car-t细胞的ifn-γ、tnfα阳性细胞(%)(a)、ki-67阳性细胞(%)(b)和t-bet阳性细胞(%)(c)进行比较的图表。
具体实施方式
除非另有定义,本文使用的全部技术术语和科学术语具有与本发明所属领域的普通技术人员通常理解的含义相同的含义。尽管与本文所述的方法和材料类似或相同的方法和材料可用于本发明的实践或测试中,适合的方法和材料在下文中描述。本文提及的所有出版物、专利申请、专利和其它参考文献都以引用的方式将它们整体并入。此外,材料、方法和实例仅为说明性的,而不旨在进行限制。
本发明中公开的一个方面涉及引导核酸。
术语“引导核酸”是指可识别靶核酸、靶基因或靶染色体并与编辑蛋白相互作用的核苷酸序列。引导核酸可与靶核酸、靶基因或靶染色体中的核苷酸序列的一部分互补结合。并且,引导核酸中的部分核苷酸序列可与编辑蛋白中的部分氨基酸相互作用,并形成引导核酸-编辑蛋白复合体。
引导核酸可起到诱导引导核酸-编辑蛋白复合体定位于靶核酸、靶基因或靶染色体的靶区域的作用。
引导核酸可以以dna、rna或dna/rna混合物的形式存在,并具有5-150个核酸的序列。
引导核酸可为一条连续的核酸序列。
例如,所述一条连续的核酸序列可为(n)m,其中n为a、t、c或g,或为a、u、c或g;m为1-150的整数。
引导核酸可为两条以上连续的核酸序列。
例如,所述两条以上连续的核酸序列可为(n)m以及(n)o,其中n代表a、t、c或g,或代表a、u、c或g;m和o为1-150的整数,并且可彼此相同或彼此不同。
引导核酸包含一个或多个结构域。
所述结构域可为功能性结构域,例如引导结构域、第一互补结构域、接头结构域、第二互补结构域、近端(proximal)结构域或者尾部结构域,但不限于此。
此处,一个引导核酸可具有两个以上功能性结构域。此外,两个以上功能性结构域可彼此不同。或者,引导核酸中包含的两个以上功能性结构域可彼此相同。例如,一个引导核酸可具有两个以上近端结构域,并且在另一实例中,一个引导核酸可具有两个以上尾部结构域。然而,引导核酸中包含的功能性结构域是两个相同的结构域并不表示两个功能性结构域具有相同的序列;尽管结构域的序列不同,只要它们执行相同的功能,就可认为它们是相同的。
关于功能性结构域的细节在下面进行详述。
i)引导结构域
术语“引导结构域”是具有能够与靶基因或核酸中的部分序列形成互补结合的互补引导序列的结构域,功能在于与靶基因或核酸特异性相互作用。例如,引导结构域可用于将引导核酸-编辑蛋白复合体诱导至具有靶基因或核酸的特定核苷酸序列的位置。
引导结构域可为10bp-35bp的核苷酸序列。
在一个实例中,引导结构域可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp的核苷酸序列。
在另一实例中,引导结构域可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp的核苷酸序列。
引导结构域可包含引导序列。
术语“引导序列”为与靶基因或核酸的双链的一条链中的部分序列互补的核苷酸序列,其中,引导序列可为具有至少50%、55%、60%、65%、70%、75%、80%、85%、90%或95%或更高的互补性或完全互补性的核苷酸序列。
引导序列可为10bp-25bp的核苷酸序列。
在一个实例中,引导序列可为10bp-25bp、15bp-25bp或20bp-25bp的核苷酸序列。
在另一实例中,引导序列可为10bp-15bp、15bp-20bp或20bp-25bp的核苷酸序列。
此外,引导结构域可具有额外的核苷酸序列。
额外的核苷酸序列可为促进或抑制引导结构域的功能的序列。
额外的核苷酸序列可为促进或抑制引导序列的功能的序列。
额外的核苷酸序列可为1bp-10bp的核苷酸序列。
在一个实例中,额外的核苷酸序列可为2bp-10bp、4bp-10bp、6bp-10bp或8bp-10bp的核苷酸序列。
在另一实例中,额外的核苷酸序列可为1bp-3bp、3bp-6bp或7bp-10bp的核苷酸序列。
在实施方式中,额外的核苷酸序列可为1bp、2bp、3bp、4bp、5bp、6bp、7bp、8bp、9bp或10bp的核苷酸序列。
例如,额外的核苷酸序列可为1个碱基的核苷酸序列g(鸟嘌呤)或2个碱基的核苷酸序列gg。
额外的核苷酸序列可位于引导序列的5’端。
额外的核苷酸序列可位于引导序列的3’端。
ii)第一互补结构域
术语“第一互补结构域”是包含与下文阐释的第二互补结构域互补的核苷酸序列的结构域,其具有足够的互补性以便与第二互补结构域形成双链。例如,第一互补结构域可为与第二互补结构域具有至少50%、55%、60%、65%、70%、75%、80%、85%、90%或95%或更高的互补性或完全互补性的核苷酸序列。
第一互补结构域可通过互补结合与第二互补结构域形成双链。双链可用于与编辑蛋白中的部分氨基酸相互作用,从而形成引导核酸-编辑蛋白复合体。
第一互补结构域可为5-35个核苷酸的序列。
在一个实例中,第一互补结构域可为5-35个核苷酸、10-35个核苷酸、15-35个核苷酸、20-35个核苷酸、25-35个核苷酸或30-35个核苷酸的序列。
在另一实例中,第一互补结构域可为1-5个核苷酸、5-10个核苷酸、10-15个核苷酸、15-20个核苷酸、20-25个核苷酸、25-30个核苷酸或30-35个核苷酸的序列。
iii)接头结构域
术语“接头结构域”是连接两个以上结构域(两个以上相同或不同的结构域)的核酸序列。接头结构域可借助共价键或非共价键与两个以上结构域连接,或可借助共价键或非共价键连接两个以上结构域。
接头结构域可为1-30个核苷酸的序列。
在一个实例中,接头结构域可为1-5个核苷酸、5-10个核苷酸、10-15个核苷酸、15-20个核苷酸、20-25个核苷酸或25-30个核苷酸的序列。
在另一实例中,接头结构域可为1-30个核苷酸、5-30个核苷酸、10-30个核苷酸、15-30个核苷酸、20-30个核苷酸或25-30个核苷酸的序列。
iv)第二互补结构域
术语“第二互补结构域”是包含核苷酸序列的结构域,所述结构域包含与上述所述第一互补结构域互补的核酸序列,其具有足够的互补性以与第一互补结构域形成双链。例如,第二互补结构域可为与第一互补结构域具有至少50%、55%、60%、65%、70%、75%、80%、85%、90%或95%或更高的互补性或完全互补性的核苷酸序列。
第二互补结构域可通过互补结合与第一互补结构域形成双链。所形成的双链可用于与编辑蛋白中的部分氨基酸相互作用,从而形成引导核酸-编辑蛋白复合体。
第二互补结构域可具有与第一互补结构域互补的核苷酸序列以及与第一互补结构域没有互补性的核苷酸序列(例如不与第一互补结构域形成双链的核苷酸序列),并可具有比第一互补结构域更长的核苷酸序列。
第二互补结构域可具有5-35个核苷酸的序列。
在实例中,第二互补结构域可为1-35个核苷酸、5-35个核苷酸、10-35个核苷酸、15-35个核苷酸、20-35个核苷酸、25-35个核苷酸或30-35个核苷酸的序列。
在另一实例中,第二互补结构域可为1-5个核苷酸、5-10个核苷酸、10-15个核苷酸、15-20个核苷酸、20-25个核苷酸、25-30个核苷酸或30-35个核苷酸的序列。
v)近端结构域
术语“近端结构域”是其位置靠近第二互补结构域的核苷酸序列。
近端结构域中可具有互补核苷酸序列,可基于互补核苷酸序列形成双链。
近端结构域可为1-20个核苷酸的序列。
在一个实例中,近端结构域可为1-20个核苷酸、5-20个核苷酸、10-20个核苷酸或15-20个核苷酸的序列。
在另一实例中,近端结构域可为1-20个碱基、5-20个碱基、10-20个碱基或15-20个碱基的序列。近端结构域可为1-5个核苷酸、5-10个核苷酸、10-15个核苷酸或15-20个核苷酸的序列。
vi)尾部结构域
术语“尾部结构域”为位于引导核酸两个末端中的一个或多个末端处的核苷酸序列。
尾部结构域中可具有互补核苷酸序列,并可基于互补核苷酸序列形成双链。
尾部结构域可为1-50个核苷酸的序列。
在实例中,尾部结构域可为5-50个核苷酸、10-50个核苷酸、15-50个核苷酸、20-50个核苷酸、25-50个核苷酸、30-50个核苷酸、35-50个核苷酸、40-50个核苷酸或45-50个核苷酸的序列。
在另一实例中,尾部结构域可为1-5个核苷酸、5-10个核苷酸、10-15个核苷酸、15-20个核苷酸、20-25个核苷酸、25-30个核苷酸、30-35个核苷酸、35-40个核苷酸、40-45个核苷酸或45-50个核苷酸的序列。
同时,所述结构域(即引导结构域、第一互补结构域、接头结构域、第二互补结构域、近端结构域和尾部结构域)中包含的部分或全部核酸序列可任选地或额外地包含化学修饰。
化学修饰可为但不限于甲基化、乙酰化、磷酸化、硫代磷酸酯连接、锁核酸(lna)、2'-o-甲基3'硫代磷酸酯(ms)或2'-o-甲基3'硫代pace(msp)。
引导核酸包含一个或多个结构域。
引导核酸可包含引导结构域。
引导核酸可包含第一互补结构域。
引导核酸可包含接头结构域。
引导核酸可包含第二互补结构域。
引导核酸可包含近端结构域。
引导核酸可包含尾部结构域。
此处,可以存在1、2、3、4、5、6个以上结构域。
引导核酸可包含1、2、3、4、5、6个以上引导结构域。
引导核酸可包含1、2、3、4、5、6个以上第一互补结构域。
引导核酸可包含1、2、3、4、5、6个以上接头结构域。
引导核酸可包含1、2、3、4、5、6个以上第二互补结构域。
引导核酸可包含1、2、3、4、5、6个以上近端结构域。
引导核酸可包含1、2、3、4、5、6个以上尾部结构域。
此处,在引导核酸中,一种类型的结构域可以是重复的。
引导核酸可包含具有或不具有重复的数个结构域。
引导核酸可包含相同类型的结构域。此处,相同类型的结构域可具有相同的核酸序列或不同的核酸序列。
引导核酸可包含两种类型的结构域。此处,两种不同类型的结构域可具有不同的核酸序列或相同的核酸序列。
引导核酸可包含三种类型的结构域。此处,三种不同类型的结构域可具有不同的核酸序列或相同的核酸序列。
引导核酸可包含四种类型的结构域。此处,四种不同类型的结构域可具有不同的核酸序列或相同的核酸序列。
引导核酸可包含五种类型的结构域。此处,五种不同类型的结构域可具有不同的核酸序列或相同的核酸序列。
引导核酸可包含六种类型的结构域。此处,六种不同类型的结构域可具有不同的核酸序列或相同的核酸序列。
例如,引导核酸可由[引导结构域]-[第一互补结构域]-[接头结构域]-[第二互补结构域]-[接头结构域]-[引导结构域]-[第一互补结构域]-[接头结构域]-[第二互补结构域]组成。此处,两个引导结构域可包含针对不同或相同靶标的引导序列;两个第一互补结构域和两个第二互补结构域可具有相同或不同的核酸序列。当引导结构域包含针对不同靶标的引导序列时,引导核酸可与两种不同靶标特异性结合;此处,该特异性结合可以同时进行或顺序进行。此外,接头结构域可被特定的酶切割,在特定的酶的存在下,引导核酸可被分为两个或三个部分。
作为本说明书公开的内容的实施方式,引导核酸可为grna。
grna
术语“grna”是指能够将grna-crispr酶复合体(即,crispr复合体)特异性导向至靶基因或核酸的核酸。此外,grna是可结合至crispr酶并将crispr酶引导至靶基因或核酸的核酸特异性rna。
grna可包含多个结构域。基于各结构域,相互作用可出现在三维结构或者grna的活性形式的链中或者这些链之间。
grna可指单链grna(单个rna分子)或者双链grna(包含多于一个rna分子,通常为两个独立的rna分子)。
在一个示例性实施方式中,单链grna从5'至3'方向可包含引导结构域(即,包含能够与靶基因或核酸形成互补结合的引导序列的结构域)、第一互补结构域、接头结构域、第二互补结构域(该结构域具有与第一互补结构域序列互补的序列,因此与第一互补结构域形成双链核酸)、近端结构域以及任选的尾部结构域。
在另一实施方式中,双链grna可包含第一链和第二链,所述第一链包含引导结构域(即,包含能够与靶基因或核酸形成互补结合的引导序列的结构域)以及第一互补结构域;所述第二链从5'至3'方向包含第二互补结构域(该结构域具有与第一互补结构域序列互补的序列,因此与第一互补结构域形成双链核酸)、近端结构域以及任选的尾部结构域。
此处,第一链可称为crrna,第二链可称为tracrrna。crrna可包含引导结构域和第一互补结构域;tracrrna可包含第二互补结构域、近端结构域和任选的尾部结构域。
在又一实施方式中,单链grna从3'至5'方向可包含引导结构域(即,包含能够与靶基因或核酸形成互补结合的引导序列的结构域)、第一互补结构域,第二互补结构域(该结构域具有与第一互补结构域序列互补的序列,因此与第一互补结构域形成双链核酸)。
第一互补结构域可与天然第一互补结构域具有同源性,或可由天然第一互补结构域衍生而来。此外,第一互补结构域可取决于天然存在的物种而在第一互补结构域的碱基序列中存在差异、可由天然存在的物种中含有的第一互补结构域衍生而来、或可与天然存在的物种中含有的第一互补结构域具有部分或完全同源性。
在一个示例性实施方式中,第一互补结构域可与酿脓链球菌、空肠弯曲杆菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟菌的第一互补结构域或由它们衍生而来的第一互补结构域具有部分(即至少50%以上)或完全同源性。
例如,当第一互补结构域是酿脓链球菌的第一互补结构域或由其衍生而来的第一互补结构域时,第一互补结构域可为5'-guuuuagagcua-3'或与5'-guuuuagagcua-3'具有部分(即至少50%以上)或完全同源性的碱基序列。此处,第一互补结构域可进一步包含(x)n,使得其为5'-guuuuagagcua(x)n-3'。x可选自于由碱基a、t、u和g所组成的组;n可表示碱基数,其为5-15的整数。此处,(x)n可为相同碱基的n个重复,或者为n个碱基a、t、u和g的混合。
在另一实施方式中,当第一互补结构域为空肠弯曲杆菌的第一互补结构域或由其衍生而来的第一互补结构域时,第一互补结构域可为5'-guuuuagucccuuuuuaaauuucuu-3'或5'-guuuuagucccuu-3',或者与5'-guuuuagucccuuuuuaaauuucuu-3'或5'-guuuuagucccuu-3'具有部分(即至少50%以上)或完全同源性的碱基序列。此处,第一互补结构域可进一步包含(x)n,使得其为5'-guuuuagucccuuuuuaaauuucuu(x)n-3'或5'-guuuuagucccuu(x)n-3'。x可选自于由碱基a、t、u和g所组成的组;n可表示碱基数,其为5-15的整数。此处,(x)n可表示相同碱基的n个重复,或者表示n个碱基a、t、u和g的混合。
在另一实施方式中,第一互补结构域可与如下菌的第一互补结构域或由其衍生而来的第一互补结构域具有部分(即至少50%以上)或完全同源性:俭菌(parcubacteriabacterium)(gwc2011_gwc2_44_17)、毛螺菌(lachnospiraceaebacterium)(mc2017)、butyrivibrioproteoclasiicus、peregrinibacteriabacterium(gw2011_gwa_33_10)、氨基酸球菌属(acidaminococcussp.)(bv3l6)、猕猴卟啉单胞菌(porphyromonasmacacae)、毛螺菌(nd2006)、porphyromonascrevioricanis、解糖胨普雷沃菌(prevotelladisiens)、moraxellabovoculi(237)、smiihellasp.(sc_ko8d17)、稻田钩端螺旋体(leptospirainadai)、毛螺菌(ma2020)、新凶手弗朗西斯菌(francisellanovicida)(u112)、candidatusmethanoplasmatermitum或挑剔真杆菌(eubacteriumeligens)。
例如,当第一互补结构域是俭菌的第一互补结构域或由其衍生而来的第一互补结构域时,第一互补结构域可为5'-uuuguagau-3'或与5'-uuuguagau-3'具有部分(即至少50%以上)同源性的碱基序列。此处,第一互补结构域可进一步包含(x)n,使得其为5'-(x)nuuuguagau-3'。x可选自于由碱基a、t、u和g所组成的组;n可表示碱基数,其为1-5的整数。此处,(x)n可表示相同碱基的n个重复,或者表示n个碱基a、t、u和g的混合。
此处,接头结构域可为使得第一互补结构域与第二互补结构域连接的核苷酸序列。
接头结构域可通过共价或非共价键分别与第一互补结构域和第二互补结构域连接。
接头结构域可通过共价或非共价键连接第一互补结构域和第二互补结构域。
接头结构域适合用于单链grna分子中,并可用于借助共价或非共价键与双链grna的第一链和第二链连接或者连接第一链和第二链来产生单链grna。
接头结构域可用于借助共价或非共价键与双链grna的crrna和tracrrna连接或者连接crrna和tracrrna来产生单链grna。
此处,第二互补结构域可与天然第二互补结构域具有同源性,或可由天然第二互补结构域衍生而来。此外,第二互补结构域可取决于天然存在的物种而在第二互补结构域的碱基序列中存在差异、可由天然存在的物种中含有的第二互补结构域衍生而来、或可与天然存在的物种中含有的第二互补结构域具有部分或完全同源性。
在示例性实施方式中,第二互补结构域可与酿脓链球菌、空肠弯曲杆菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟菌的第二互补结构域或由它们衍生而来的第二互补结构域具有部分(即至少50%以上)或完全同源性。
例如,当第二互补结构域是酿脓链球菌的第二互补结构域或由其衍生而来的第二互补结构域时,第二互补结构域可为5'-uagcaaguuaaaau-3'或与5'-uagcaaguuaaaau-3'具有部分(即至少50%以上)同源性的碱基序列(下划线标出与第一互补结构域形成双链的碱基序列)。此处,第二互补结构域可进一步包含(x)n和/或(x)m,使得其为5'-(x)nuagcaaguuaaaau(x)m-3'。x可选自于由碱基a、t、u和g所组成的组;n和m各自可表示碱基数,其中n可为1-15的整数,m可为1-6的整数。此处,(x)n可表示相同碱基的n个重复,或者表示n个碱基a、t、u和g的混合。此外,(x)m可表示相同碱基的m个重复,或者表示m个碱基a、t、u和g的混合。
在另一实例中,当第二互补结构域是空肠弯曲杆菌的第二互补结构域或由其衍生而来的第二互补结构域时,第二互补结构域可为5'-aagaaauuuaaaaagggacuaaaau-3'或5'-aagggacuaaaau-3,或者与5'-aagaaauuuaaaaagggacuaaaau-3'或5'-aagggacuaaaau-3'具有部分(即至少50%以上)同源性的碱基序列(下划线标出与第一互补结构域形成双链的碱基序列)。此处,第二互补结构域可进一步包含(x)n和/或(x)m,使得其为5'-(x)naagaaauuuaaaaagggacuaaaau(x)m-3'或5'-(x)naagaaauuuaaaaau(x)m-3’。x可选自于由碱基a、t、u和g所组成的组;n和m各自可表示碱基数,其中n可为1-15的整数,m可为1-6的整数。此处,(x)n可表示相同碱基的n个重复,或者表示n个碱基a、t、u和g的混合。此外,(x)m可表示相同碱基的m个重复,或者表示m个碱基a、t、u和g的混合。
在另一实施方式中,第二互补结构域可与如下菌的第一互补结构域或由其衍生而来的第二互补结构域具有部分(即至少50%以上)或完全同源性:俭菌(parcubacteriabacterium)(gwc2011_gwc2_44_17)、毛螺菌(lachnospiraceaebacterium)(mc2017)、butyrivibrioproteoclasiicus、peregrinibacteriabacterium(gw2011_gwa_33_10)、氨基酸球菌属(acidaminococcussp.)(bv3l6)、猕猴卟啉单胞菌(porphyromonasmacacae)、毛螺菌(nd2006)、porphyromonascrevioricanis、解糖胨普雷沃菌(prevotelladisiens)、moraxellabovoculi(237)、smiihellasp.(sc_ko8d17)、稻田钩端螺旋体(leptospirainadai)、毛螺菌(ma2020)、新凶手弗朗西斯菌(francisellanovicida)(u112)、candidatusmethanoplasmatermitum或挑剔真杆菌(eubacteriumeligens)。
例如,当第二互补结构域是俭菌的第二互补结构域或由其衍生而来的第二互补结构域时,第二互补结构域可为5'-aaauuucuacu-3'或与5'-aaauuucuacu-3'具有部分(即至少50%以上)同源性的碱基序列(下划线标出与第一互补结构域形成双链的碱基序列)。此处,第二互补结构域可进一步包含(x)n和/或(x)m,使得其为5'-(x)naaauuucuacu(x)m-3'。x可选自于由碱基a、t、u和g所组成的组,n和m各自可表示碱基数,其中n可为1-10的整数,m可为1-6的整数。此处,(x)n可表示相同碱基的n个重复,或者表示n个碱基a、t、u和g的混合。此外,(x)m可表示相同碱基的m个重复,或者表示m个碱基a、t、u和g的混合。
此处,第一互补结构域和第二互补结构域可形成互补结合。
第一互补结构域和第二互补结构域可通过互补结合形成双链。
形成的双链可与crispr酶相互作用。
任选地,第一互补结构域可包含不与第二链的第二互补结构域形成互补结合的额外核苷酸序列。
此处,额外核苷酸序列可为1bp-15bp的核苷酸序列。例如,额外核苷酸序列可为1bp-5bp、5bp-10bp或10bp-15bp的核苷酸序列。
此处,近端结构域可为第二互补结构域在5'至3'方向上的结构域。
近端结构域可与天然近端结构域具有同源性,或可由天然近端结构域衍生而来。此外,近端结构域可取决于天然存在的物种而在碱基序列中存在差异、可由天然存在的物种中含有的近端结构域衍生而来、或可与天然存在的物种中含有的近端结构域具有部分或完全同源性。
在示例性实施方式中,近端结构域可与酿脓链球菌、空肠弯曲杆菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟菌的近端结构域或由它们衍生而来的近端结构域具有部分(即至少50%以上)或完全同源性。
例如,当近端结构域是酿脓链球菌的近端结构域或由其衍生而来的近端结构域时,近端结构域可为5'-aaggcuaguccg-3'或与5'-aaggcuaguccg-3'具有部分(即至少50%以上)同源性的碱基序列。此处,近端结构域可进一步包含(x)n,使其为5'-aaggcuaguccg(x)n-3'。x可选自于由碱基a、t、u和g所组成的组;n可表示碱基数,其可为1-15的整数。此处,(x)n可表示相同碱基的n个重复,或者表示n个碱基a、t、u和g的混合。
在又一实施方式中,当近端结构域是空肠弯曲杆菌的近端结构域或由其衍生而来的近端结构域时,近端结构域可为5'-aaagaguuugc-3'或与5'-aaagaguuugc-3'具有至少50%或更高同源性的碱基序列。此处,近端结构域可进一步包含(x)n,使其为5'-aaagaguuugc(x)n-3'。x可选自于由碱基a、t、u和g所组成的组;n可表示碱基数,其可为1-40的整数。此处,(x)n可表示相同碱基的n个重复,或者表示n个碱基a、t、u和g的混合。
此处,可将尾部结构域任选地添加至单链grna或双链grna的第一链的3'端或第二链的3'端。
此外,尾部结构域可与天然尾部结构域具有同源性,或可由天然尾部结构域衍生而来。此外,尾部结构域可取决于天然存在的物种而在碱基序列中存在差异、可由天然存在的物种中含有的尾部结构域衍生而来、或可与天然存在的物种中含有的尾部结构域具有部分或完全同源性。
在一个示例性实施方式中,尾部结构域可与酿脓链球菌、空肠弯曲杆菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟菌的尾部结构域或由它们衍生而来的尾部结构域具有部分(即至少50%以上)或完全同源性。
例如,当尾部结构域是酿脓链球菌的尾部结构域或由其衍生而来的尾部结构域时,尾部结构域可为5'-uuaucaacuugaaaaaguggcaccgagucggugc-3'或与5'-uuaucaacuugaaaaaguggcaccgagucggugc-3'具有部分(即至少50%以上)同源性的碱基序列。此处,尾部结构域可进一步包含(x)n,使其为5'-uuaucaacuugaaaaaguggcaccgagucggugc(x)n-3'。x可选自于由碱基a、t、u和g所组成的组;n可表示碱基数,其可为1-15的整数。此处,(x)n可表示相同碱基的n个重复,或者表示n个碱基(如a、t、u和g)的混合。
在另一实例中,当尾部结构域是空肠弯曲杆菌的尾部结构域或由其衍生而来的尾部结构域时,尾部结构域可为5'-gggacucugcgggguuacaauccccuaaaaccgcuuuu-3'或与5'-gggacucugcgggguuacaauccccuaaaaccgcuuuu-3'具有部分(即至少50%以上)同源性的碱基序列。此处,尾部结构域可进一步包含(x)n,使其为5'-gggacucugcgggguuacaauccccuaaaaccgcuuuu(x)n-3'。x可选自于由碱基a、t、u和g所组成的组;n可表示碱基数,其可为1-15的整数。此处,(x)n可表示相同碱基的n个重复,或者表示n个碱基a、t、u和g的混合。
在另一实施方式中,尾部结构域可在3'端包含参与体外或体内转录方法的1-10个碱基的序列。
例如,当将t7启动子用于grna的体外转录时,尾部结构域可为存在于dna模板3'端的任意碱基序列。此外,当将u6启动子用于体内转录时,尾部结构域可为uuuuuu;当将h1启动子用于转录时,尾部结构域可为uuuu;并且当使用pol-iii启动子时,尾部结构域可包含数个尿嘧啶碱基或可替代的碱基。
grna可包含上文所述的多个结构域,因此可根据grna中含有的结构域来调整核酸序列的长度;基于各结构域,相互作用可出现在三维结构或者grna的活性形式的链中或者这些链之间。
grna可指单链grna(单个rna分子)或者双链grna(包含多于一个rna分子,通常为两个独立的rna分子)。
双链grna
双链grna由第一链和第二链组成。
此处,第一链可由
5'-[引导结构域]-[第一互补结构域]-3'组成;以及
第二链可由
5'-[第二互补结构域]-[近端结构域]-3'或者
5'-[第二互补结构域]-[近端结构域]-[尾部结构域]-3'组成。
此处,第一链可以指crrna,第二链可以指tracrrna。
此处,第一链和第二链可任选地包含额外的核苷酸序列。
在一个实例中,第一链可为
5'-(n靶标)-(q)m-3';或者
5'-(x)a-(n靶标)-(x)b-(q)m-(x)c-3'。
此处,n靶标是与靶基因或核酸的双链的一条链中的部分序列互补的核苷酸序列,是可根据靶基因或核酸上的靶序列进行改变的核苷酸序列区域。
此处,(q)m是包含第一互补结构域的碱基序列,其能够与第二链的第二互补结构域形成互补结合。(q)m可为与天然存在的物种的第一互补结构域具有部分或完全同源性的序列;根据来源的物种,可对第一互补结构域的碱基序列进行改变。q可各自独立地选自于由a、u、c和g所组成的组;m可为碱基数,其为5-35的整数。
例如,当第一互补结构域与酿脓链球菌的第一互补结构域或由酿脓链球菌衍生而来的第一互补结构域具有部分或完全同源性时,(q)m可为5'-guuuuagagcua-3'或与5'-guuuuagagcua-3'具有至少50%或更高同源性的碱基序列。
在另一实例中,当第一互补结构域与空肠弯曲杆菌的第一互补结构域或由空肠弯曲杆菌衍生而来的第一互补结构域具有部分或完全同源性时,(q)m可为5'-guuuuagucccuuuuuaaauuucuu-3'或5'-guuuuagucccuu-3',或者与5'-guuuuagucccuuuuuaaauuucuu-3'或5'-guuuuagucccuu-3'具有至少50%或更高同源性的碱基序列。
在又一实例中,当第一互补结构域与嗜热链球菌的第一互补结构域或由嗜热链球菌衍生而来的第一互补结构域具有部分或完全同源性时,(q)m可为5'-guuuuagagcuguguuguuucg-3'或与5'-guuuuagagcuguguuguuucg-3'具有至少50%或更高同源性的碱基序列。
此外,(x)a、(x)b、(x)c各自为任选的额外碱基序列,其中x可各自独立地选自于由a、u、c和g所组成的组;a、b、c各自可为碱基数,其为0或1-20的整数。
在一个示例性实施方式中,第二链可为5'-(z)h-(p)k-3';或者5'-(x)d-(z)h-(x)e-(p)k-(x)f-3'。
在另一实施方式中,第二链可为5'-(z)h-(p)k-(f)i-3';或者5'-(x)d-(z)h-(x)e-(p)k-(x)f-(f)i-3'。
此处,(z)h是包含第二互补结构域的碱基序列,其能够与第一链的第一互补结构域形成互补结合。(z)h可为与天然存在的物种的第二互补结构域具有部分或完全同源性的序列;根据来源的物种,可对第二互补结构域的碱基序列进行修饰。z可各自独立地选自于由a、u、c和g所所组成的组;h可为碱基数,其可为5-50的整数。
例如,当第二互补结构域与酿脓链球菌的第二互补结构域或由酿脓链球菌衍生而来的第二互补结构域具有部分或完全同源性时,(z)h可为5'-uagcaaguuaaaau-3'或与5'-uagcaaguuaaaau-3'具有至少50%或更高同源性的碱基序列。
在另一实例中,当第二互补结构域与空肠弯曲杆菌的第二互补结构域或由空肠弯曲杆菌衍生而来的第二互补结构域具有部分或完全同源性时,(z)h可为5'-aagaaauuuaaaaagggacuaaaau-3'或5'-aagggacuaaaau-3',或者与5'-aagaaauuuaaaaagggacuaaaau-3'或5'-aagggacuaaaau-3'具有至少50%或更高同源性的碱基序列。
在又一实例中,当第二互补结构域与嗜热链球菌的第二互补结构域或由嗜热链球菌衍生而来的第二互补结构域具有部分或完全同源性时,(z)h可为5'-cgaaacaacacagcgaguuaaaau-3'或与5'-cgaaacaacacagcgaguuaaaau-3'具有至少50%或更高同源性的碱基序列。
(p)k是包含近端结构域的碱基序列,其可与天然存在的物种的近端结构域具有部分或完全同源性;根据来源的物种,可对近端结构域的碱基序列进行修饰。p可各自独立地选自于由a、u、c和g所组成的组;k可为碱基数,其为1-20的整数。
例如,当近端结构域与酿脓链球菌的近端结构域或由酿脓链球菌衍生而来的近端结构域具有部分或完全同源性时,(p)k可为5'-aaggcuaguccg-3'或与5'-aaggcuaguccg-3'具有至少50%或更高同源性的碱基序列。
在另一实例中,当近端结构域与空肠弯曲杆菌的近端结构域或由空肠弯曲杆菌衍生而来的近端结构域具有部分或完全同源性时,(p)k可为5'-aaagaguuugc-3'或与5'-aaagaguuugc-3'具有至少50%或更高同源性的碱基序列。
在又一实例中,当近端结构域与嗜热链球菌的近端结构域或由嗜热链球菌衍生而来的近端结构域具有部分或完全同源性时,(p)k可为5'-aaggcuuaguccg-3'或与5'-aaggcuuaguccg-3'具有至少50%或更高同源性的碱基序列。
(f)i可为包含尾部结构域的碱基序列,其可与天然存在的物种的尾部结构域具有部分或完全同源性;根据来源的物种,可对尾部结构域的碱基序列进行修饰。f可各自独立地选自于由a、u、c和g所组成的组;i可为碱基数,其为1-50的整数。
例如,当尾部结构域与酿脓链球菌的尾部结构域或由酿脓链球菌衍生而来的尾部结构域具有部分或完全同源性时,(f)i可为5'-uuaucaacuugaaaaaguggcaccgagucggugc-3'或与5'-uuaucaacuugaaaaaguggcaccgagucggugc-3'具有至少50%或更高同源性的碱基序列。
在另一实例中,当尾部结构域与空肠弯曲杆菌的尾部结构域或由肠弯曲杆菌衍生而来的尾部结构域具有部分或完全同源性时,(f)i可为5'-gggacucugcgggguuacaauccccuaaaaccgcuuuu-3'或与5'-gggacucugcgggguuacaauccccuaaaaccgcuuuu-3'具有至少50%或更高同源性的碱基序列。
在又一实例中,当尾部结构域与嗜热链球菌的尾部结构域或由嗜热链球菌衍生而来的尾部结构域具有部分或完全同源性时,(f)i可为5'-uacucaacuugaaaagguggcaccgauucgguguuuuu-3'或与5'-uacucaacuugaaaagguggcaccgauucgguguuuuu-3'具有至少50%或更高同源性的碱基序列。
此外,(f)i可在3'端包含参与体外或体内转录方法的1-10个碱基的序列。
例如,当将t7启动子用于grna的体外转录时,尾部结构域可为存在于dna模板3'端的任意碱基序列。此外,当将u6启动子用于体内转录时,尾部结构域可为uuuuuu;当将h1启动子用于体内转录时,尾部结构域可为uuuu;并且当使用pol-iii启动子时,尾部结构域可包含数个尿嘧啶碱基或可替代的碱基。
此外,(x)d、(x)e和(x)f可为任选添加的碱基序列,其中x可各自独立地选自于由a、u、c和g所组成的组;d、e、f各自可为碱基数,其为0或1-20的整数。
单链grna
单链grna可分为第一单链grna和第二单链grna。
第一单链grna
第一单链grna为其中借助接头结构域使得双链grna的第一链和第二链连接的单链grna。
具体而言,单链grna可由
5'-[引导结构域]-[第一互补结构域]-[接头结构域]-[第二互补结构域]-3',
5'-[引导结构域]-[第一互补结构域]-[接头结构域]-[第二互补结构域]-[近端结构域]-3';或者
5'-[引导结构域]-[第一互补结构域]-[接头结构域]-[第二互补结构域]-[近端结构域]-[尾部结构域]-3'组成。
第一单链grna可任选地包含额外的核苷酸序列。
在一个示例性实施方式中,第一单链grna可为
5'-(n靶标)-(q)m-(l)j-(z)h-3';
5'-(n靶标)-(q)m-(l)j-(z)h-(p)k-3';或者
5'-(n靶标)-(q)m-(l)j-(z)h-(p)k-(f)i-3'。
在另一示例性实施方式中,单链grna可为
5'-(x)a-(n靶标)-(x)b-(q)m-(x)c-(l)j-(x)d-(z)h-(x)e-3';
5'-(x)a-(n靶标)-(x)b-(q)m-(x)c-(l)j-(x)d-(z)h-(x)e-(p)k-(x)f-3';或者
5'-(x)a-(n靶标)-(x)b-(q)m-(x)c-(l)j-(x)d-(z)h-(x)e-(p)k-(x)f-(f)i-3'。
此处,n靶标是能够与靶基因或核酸上的靶序列形成互补结合的碱基序列,是可根据靶基因或核酸上的靶序列进行改变的碱基序列区域。
(q)m含有包含第一互补结构域的碱基序列,其能够与第二互补结构域形成互补结合。(q)m可为与天然存在的物种的第一互补结构域具有部分或完全同源性的序列;根据来源的物种,可对第一互补结构域的碱基序列进行改变。q可各自独立地选自于由a、u、c和g所组成的组;m可为碱基数,其可为5-35的整数。
例如,当第一互补结构域与酿脓链球菌的第一互补结构域或由酿脓链球菌衍生而来的第一互补结构域具有部分或完全同源性时,(q)m可为5'-guuuuagagcua-3'或与5'-guuuuagagcua-3'具有至少50%或更高同源性的碱基序列。
在另一实例中,当第一互补结构域与空肠弯曲杆菌的第一互补结构域或由空肠弯曲杆菌衍生而来的第一互补结构域具有部分或完全同源性时,(q)m可为5'-guuuuagucccuuuuuaaauuucuu-3'或5'-guuuuagucccuu-3',或者与5'-guuuuagucccuuuuuaaauuucuu-3'或5'-guuuuagucccuu-3'具有至少50%或更高同源性的碱基序列。
在又一实例中,当第一互补结构域与嗜热链球菌的第一互补结构域或由嗜热链球菌衍生而来的第一互补结构域具有部分或完全同源性时,(q)m可为5'-guuuuagagcuguguuguuucg-3'或与5'-guuuuagagcuguguuguuucg-3'具有至少50%或更高同源性的碱基序列。
此外,(l)j是包含接头结构域的碱基序列,它连接第一互补结构域和第二互补结构域,由此产生单链grna。此处,l可各自独立地选自于由a、u、c和g所组成的组;j可为碱基数,其为1-30的整数。
(z)h是包含第二互补结构域的碱基序列,其能够与第一互补结构域形成互补结合。(z)h可为与天然存在的物种的第二互补结构域具有部分或完全同源性的序列;根据来源的物种,可对第二互补结构域的碱基序列进行改变。z可各自独立地选自于由a、u、c和g所组成的组;h为碱基数,其可为5-50的整数。
例如,当第二互补结构域与酿脓链球菌的第二互补结构域或由酿脓链球菌衍生而来的第二互补结构域具有部分或完全同源性时,(z)h可为5'-uagcaaguuaaaau-3'或与5'-uagcaaguuaaaau-3'具有至少50%或更高同源性的碱基序列。
在另一实例中,当第二互补结构域与空肠弯曲杆菌的第二互补结构域或由空肠弯曲杆菌衍生而来的第二互补结构域具有部分或完全同源性时,(z)h可为5'-aagaaauuuaaaaagggacuaaaau-3'或5'-aagggacuaaaau-3',或者与5'-aagaaauuuaaaaagggacuaaaau-3'或5'-aagggacuaaaau-3'具有至少50%或更高同源性的碱基序列。
在又一实例中,当第二互补结构域与嗜热链球菌的第二互补结构域或由嗜热链球菌衍生而来的第二互补结构域具有部分或完全同源性时,(z)h可为5'-cgaaacaacacagcgaguuaaaau-3'或与5'-cgaaacaacacagcgaguuaaaau-3'具有至少50%或更高同源性的碱基序列。
(p)k是包含近端结构域的碱基序列,其可与天然存在的物种的近端结构域具有部分或完全同源性;根据来源的物种,可对近端结构域的碱基序列进行修饰。p可各自独立地选自于由a、u、c和g所组成的组;k可为碱基数,其为1-20的整数。
例如,当近端结构域与酿脓链球菌的近端结构域或由酿脓链球菌衍生而来的近端结构域具有部分或完全同源性时,(p)k可为5'-aaggcuaguccg-3'或与5'-aaggcuaguccg-3'具有至少50%或更高同源性的碱基序列。
在另一实例中,当近端结构域与空肠弯曲杆菌的近端结构域或由空肠弯曲杆菌衍生而来的近端结构域具有部分或完全同源性时,(p)k可为5'-aaagaguuugc-3'或与5'-aaagaguuugc-3'具有至少50%或更高同源性的碱基序列。
在又一实例中,当近端结构域与嗜热链球菌的近端结构域或由嗜热链球菌衍生而来的近端结构域具有部分或完全同源性时,(p)k可为5'-aaggcuuaguccg-3'或与5'-aaggcuuaguccg-3'具有至少50%或更高同源性的碱基序列。
(f)i可以是包含尾部结构域的碱基序列,其可与天然存在的物种的尾部结构域具有部分或完全同源性;根据来源的物种,可对尾部结构域的碱基序列进行修饰。f可各自独立地选自于由a、u、c和g所组成的组;i可为碱基数,其为1-50的整数。
例如,当尾部结构域与酿脓链球菌的尾部结构域或由酿脓链球菌衍生而来的尾部结构域具有部分或完全同源性时,(f)i可为5'-uuaucaacuugaaaaaguggcaccgagucggugc-3'或与5'-uuaucaacuugaaaaaguggcaccgagucggugc-3'具有至少50%或更高同源性的碱基序列。
在另一实例中,当尾部结构域与空肠弯曲杆菌的尾部结构域或由空肠弯曲杆菌衍生而来的尾部结构域具有部分或完全同源性时,(f)i可为5'-gggacucugcgggguuacaauccccuaaaaccgcuuuu-3'或与5'-gggacucugcgggguuacaauccccuaaaaccgcuuuu-3'具有至少50%或更高同源性的碱基序列。
在又一实例中,当尾部结构域与嗜热链球菌的尾部结构域或由嗜热链球菌衍生而来的尾部结构域具有部分或完全同源性时,(f)i可为5'-uacucaacuugaaaagguggcaccgauucgguguuuuu-3'或与5'-uacucaacuugaaaagguggcaccgauucgguguuuuu-3'具有至少50%或更高同源性的碱基序列。
此外,(f)i可在3'端包含参与体外或体内转录方法的1-10个碱基的序列。
例如,当将t7启动子用于grna的体外转录时,尾部结构域可为存在于dna模板3'端的任意碱基序列。此外,当将u6启动子用于体内转录时,尾部结构域可为uuuuuu;当将h1启动子用于转录时,尾部结构域可为uuuu;并且当使用pol-iii启动子时,尾部结构域可包含数个尿嘧啶碱基或可替代的碱基。
此外,(x)a、(x)b、(x)c、(x)d、(x)e和(x)f可为任选添加的碱基序列,其中x可各自独立地选自于由a、u、c和g所组成的组;a、b、c、d、e和f各自可为碱基数,其为0或1-20的整数。
第二单链grna
第二单链grna可为由引导结构域,第一互补结构域和第二互补结构域组成的单链grna。
此处,第二单链grna可由
5'-[第二互补结构域]-[第一互补结构域]-[引导结构域]-3';或者
5'-[第二互补结构域]-[接头结构域]-[第一互补结构域]-[引导结构域]-3'组成。
第二单链grna可任选地包含额外的核苷酸序列。
在一个示例性实施方式中,第二单链grna可为
5'-(z)h-(q)m-(n靶标)-3';或者
5'-(x)a-(z)h-(x)b-(q)m-(x)c-(n靶标)-3'。
在另一实施方式中,单链grna可为
5'-(z)h-(l)j-(q)m-(n靶标)-3';或者
5'-(x)a-(z)h-(l)j-(q)m-(x)c-(n靶标)-3'。
此处,n靶标是能够与靶基因或核酸上的靶序列形成互补结合的碱基序列,是可根据靶基因或核酸上的靶序列进行改变的碱基序列区域。
(q)m是包含第一互补结构域的碱基序列,其能够与第二链的第二互补结构域形成互补结合。(q)m可为与天然存在的物种的第一互补结构域具有部分或完全同源性的序列;根据来源的物种,可对第一互补结构域的碱基序列进行改变。q可各自独立地选自于由a、u、c和g所组成的组;m可为碱基数,其可为5-35的整数。
例如,当第一互补结构域与俭菌的第一互补结构域或由其衍生而来的第一互补结构域具有部分或完全同源性时,(q)m可为5'-uuuguagau-3'或与5'-uuuguagau-3'具有至少50%或更高同源性的碱基序列。
(z)h是包含第二互补结构域的碱基序列,其能够与第一链的第一互补结构域形成互补结合。(z)h可为与天然存在的物种的第二互补结构域具有部分或完全同源性的序列;根据来源的物种,可对第二互补结构域的碱基序列进行修饰。z可各自独立地选自于由a、u、c和g所组成的组;h可为碱基数,其为5-50的整数。
例如,当第二互补结构域与俭菌的第二互补结构域或由俭菌衍生而来的第二互补结构域具有部分或完全同源性时,(z)h可为5'-aaauuucuacu-3'或与5'-aaauuucuacu-3'具有至少50%或更高同源性的碱基序列。
此外,(l)j是包含接头结构域的碱基序列,它连接第一互补结构域和第二互补结构域。此处,l可各自独立地选自于由a、u、c和g所组成的组;j可为碱基数,其为1-30的整数。
此外,(x)a、(x)b和(x)c各自为任选的额外碱基序列,其中x可各自独立地选自于由a、u、c和g所组成的组;a、b和c可为碱基数,其为0或1-20的整数。
作为本发明公开的方面,引导核酸可为能够与免疫调节基因的靶序列形成互补结合的grna。
术语“免疫调节基因”是指直接参与或间接影响免疫功能的调节或与免疫应答的形成和性能相关的功能的调节的所有基因。在本发明中,免疫调节基因包括直接参与或间接影响免疫细胞以及能够与免疫细胞相互作用的吞噬细胞等的功能的调节的所有基因。特别是,由于免疫调节基因本身或由免疫调节基因表达的蛋白,免疫调节基因可执行免疫功能或与免疫应答的形成和性能相关的功能。
可根据免疫调节基因表达的蛋白的功能对免疫调节基因进行分类。以下列出的免疫调节基因仅为基于功能的免疫调节基因的实例,因此并不是对本发明涵盖的免疫调节基因的类型进行限制。下面列出的基因可能不仅具有一种类型的免疫调节功能,而可能具有多种类型的功能。此外,可提供两个以上免疫调节基因(如果需要)。
在一个实例中,免疫调节基因可为免疫细胞活性调节基因。
术语“免疫细胞活性调节基因”是发挥对免疫应答的程度或活性进行调节的功能的基因,例如,它可为刺激或抑制免疫应答的程度或活性的基因。此处,免疫细胞活性调节基因可执行以下功能:通过免疫细胞活性调节基因或通过免疫细胞活性调节基因表达的蛋白来控制免疫应答的程度或活性。
免疫细胞活性调节基因可执行与免疫细胞的活化或失活相关的功能。
免疫细胞活性调节基因可执行与免疫细胞的活化或失活相关的功能。
免疫细胞活性调节基因可发挥抑制免疫应答的功能。
免疫细胞活性调节基因可与细胞膜的通道蛋白和受体结合,从而执行与调节免疫应答的蛋白合成相关的功能。
例如,免疫细胞活性调节基因可为程序性细胞死亡蛋白(pd-1)
pd-1基因(也称为pdcd1基因;下文中使用pd-1基因和pdcd1基因来表示相同的基因)是指编码pd-1蛋白(也称为分化簇279(cd279))的基因(全长dna、cdna或mrna)。在实施方式中,pd-1基因可为选自于由如下基因所组成的组中的一种或多种,但不限于此:编码人pd-1的基因(例如ncbi登记号np_005009.2等),例如以ncbi登记号nm_005018.2、ng_012110.1等表示的pd-1基因。
免疫细胞活性调节基因可为细胞毒t淋巴细胞相关蛋白4(ctla-4)。
ctla-4基因是指编码ctla-4蛋白(也称为分化簇152(cd152))的基因(全长dna、cdna或mrna)。在实施方式中,ctla-4基因可为选自于由如下基因所组成的组中的一种或多种,但不限于此:编码人ctla-4的基因(例如ncbi登记号np_001032720.1、np_005205.2等),例如以ncbi登记号nm_001037631.2、nm_005214.4、ng_011502.1等表示的ctla-4基因。
免疫细胞活性调节基因可为cblb。
免疫细胞活性调节基因可为psgl-1。
免疫细胞活性调节基因可为ilt2。
免疫细胞活性调节基因可为kir2dl4。
免疫细胞活性调节基因可为shp-1。
上述基因可来自于包括灵长类动物(例如人、猴等)、啮齿类动物(例如小鼠、大鼠等)在内的哺乳动物。
可从已知数据库(例如美国国立生物技术信息中心(ncbi)的genbank)获得遗传信息。
在一个实施方式中,免疫细胞活性调节基因可发挥刺激免疫应答的作用。
免疫细胞活性调节基因可为免疫细胞生长调节基因。
术语“免疫细胞生长调节基因”是指通过调节免疫细胞中蛋白的合成等来调节免疫细胞生长的基因,例如,刺激或抑制免疫细胞生长的基因。在此情况下,免疫细胞生长调节基因可通过控制具有免疫细胞生长调节基因本身或由免疫细胞生长调节基因表达的蛋白的免疫细胞中的蛋白合成来执行控制免疫细胞生长的功能。
免疫细胞生长调节基因可在dna转录、rna翻译和细胞分化中发挥功能。
免疫细胞生长调节基因的实例可为涉及nfat、iκb/nf-κb、ap-1、4e-bp1、eif4e以及s6的表达通路的基因。
例如,免疫细胞生长调节基因可为dgk-α。
dgka(dgk-alpha,dgkα)基因是指编码二酰甘油(diacylglycerol)激酶α蛋白(dgka)的基因(全长dna、cdna或mrna)。在实施方式中,dgka基因可为选自于由如下基因所组成的组中的一种或多种,但不限于此:编码人dgka的基因(例如ncbi登记号np_001336.2、np_958852.1、np_958853.1、np_963848.1等),例如以ncbi登记号nm_001345.4、nm_201444.2、nm_201445.1、nm_201554.1、nc_000012.12等表示的dgka基因。
免疫细胞生长调节基因可为dgk-ζ。
dgkz(dgk-zeta,dgkζ)基因是指编码二酰甘油激酶ζ蛋白(dgkz)的基因(全长dna、cdna或mrna)。在实施方式中,dgkz基因可为选自于由如下基因所组成的组中的一种或多种,但不限于此:编码人dgkz的基因(例如ncbi登记号np_001099010.1、np_001186195.1、np_001186196.1、np_001186197.1、np_003637.2、np_963290.1、np_963291.2等),例如以ncbi登记号nm_001105540.1、nm_001199266.1、nm_001199267.1、nm_001199268.1、nm_003646.3、nm_201532.2、nm_201533.3、ng_047092.1等表示的dgkz基因。
免疫细胞生长调节基因可为egr2。
egr2基因是指编码早期生长应答蛋白2(egr2)的基因(全长dna、cdna或mrna)。在实施方式中,egr2基因可为选自于由如下基因所组成的组中的一种或多种,但不限于此:编码人egr2的基因(例如ncbi登记号np_000390、np_001129649、np_001129650、np_001129651、np_001307966等)。例如以ncbi登记号nm_000399、nm_001136177、nm_001136178、nm_001136179、nm_001321037等表示的egr2基因。
免疫细胞生长调节基因可为egr3。
免疫细胞生长调节基因可为ppp2r2d。
免疫细胞生长调节基因可为a20(tnfaip3)。
上述基因可衍生自包括灵长类动物(例如人、猴等)、啮齿类动物(例如小鼠、大鼠等)在内的哺乳动物。
可从已知数据库(例如美国国立生物技术信息中心(ncbi)的genbank)获得遗传信息。
在实施方式中,免疫细胞活性调节基因可为免疫细胞死亡调节基因。
术语“免疫细胞死亡调节基因”是指其功能涉及免疫细胞死亡的基因,例如,刺激或抑制免疫细胞的死亡。此处,免疫细胞死亡调节基因可通过免疫细胞死亡调节基因本身或由免疫细胞死亡调节基因表达的蛋白来执行控制免疫细胞死亡的功能。
免疫细胞死亡调节基因可执行与免疫细胞凋亡或坏死相关的功能。
例如,免疫细胞死亡调节基因可为胱天蛋白酶级联相关基因(caspasecascade-associatedgene)。
在此情况下,免疫细胞死亡调节元件可为fas。下文当提及基因时,对本领域普通技术人员而言显而易见的是,可对受体或结合区(所述基因作用于所述受体或结合区)进行操纵。
免疫细胞死亡调节基因可为死亡结构域(deathdomain)相关基因。
此处,免疫细胞死亡调节基因可为daxx。
免疫细胞死亡调节基因可为bcl-2家族基因。
免疫细胞死亡调节基因可为bh3-only家族基因。
免疫细胞死亡调节基因可为bim。
免疫细胞死亡调节基因可为bid。
免疫细胞死亡调节基因可为bad。
免疫细胞死亡调节基因可为编码位于免疫细胞外膜的配体或受体的基因。
此处,免疫细胞死亡调节基因可为pd-1。
此外,免疫细胞死亡调节基因可为ctla-4。
上述基因可衍生自包括灵长类动物(例如人、猴等)、啮齿类动物(例如小鼠、大鼠等)在内的哺乳动物。
可从已知数据库(例如美国国立生物技术信息中心(ncbi)的genbank)获得遗传信息。
在实施方式中,免疫细胞活性调节基因可为免疫细胞耗竭调节基因。
术语“免疫细胞耗竭调节基因”是执行与免疫细胞功能逐渐丧失相关的功能的基因,并且此处,免疫细胞耗竭调节基因可通过免疫细胞耗竭调节基因本身或由免疫细胞耗竭调节基因表达的蛋白执行控制免疫细胞功能逐渐丧失的功能。
免疫细胞耗竭调节基因可发挥辅助参与免疫细胞失活的基因的转录或翻译的功能。
此处,辅助转录的功能可为将相应基因去甲基化的功能。
此外,参与免疫细胞失活的基因包括免疫细胞活性调节基因。
例如,免疫细胞耗竭调节基因可为tet2。
tet2基因是指编码tet2(tet甲基胞嘧啶加双氧酶2)的基因(全长dna、cdna或mrna)。在实施方式中,tet2基因可为一个或多个选自于由以下所组成的组的编码人tet2的基因(例如ncbi登记号np_001120680.1、np_060098.3等)(例如以ncbi登记号nm_001127208.2、nm_017628.4、ng_028191.1等表示的tet2基因),但不限于此。
免疫细胞耗竭调节元件可发挥参与免疫细胞过度生长的功能。此处,经历过度生长并且未再生的免疫细胞将丧失其功能。
此处,免疫细胞耗竭调节基因可为wnt。
此外,免疫细胞耗竭调节基因可为akt。
上述基因可衍生自包括灵长类动物(例如人、猴等)、啮齿类动物(例如小鼠、大鼠等)在内的哺乳动物。
可从已知数据库(例如美国国立生物技术信息中心(ncbi)的genbank)获得遗传信息。
在另一实施方式中,免疫细胞活性调节元件可为细胞因子产生调节基因。
术语“细胞因子产生调节基因”是参与免疫细胞的细胞因子分泌的元件,其由执行此类功能的免疫细胞表达,并且此处,细胞因子产生调节基因可通过细胞因子产生调节基因本身或由细胞因子产生调节基因表达的蛋白发挥控制免疫细胞的细胞因子产生的功能。
细胞因子是由免疫细胞分泌的蛋白的统称,是在体内发挥重要作用的信号蛋白。细胞因子涉及感染、免疫力、炎症、创伤、溃烂、癌症等。细胞因子可由细胞分泌并随后影响其它细胞,或者影响分泌其自身的细胞。例如,细胞因子可诱导巨噬细胞增殖或促进分泌细胞自身的分化。然而,当细胞因子分泌过量时,可造成诸如攻击正常细胞等问题,因此在免疫应答中细胞因子的适当分泌也是重要的。
细胞因子产生调节基因优选可为例如tnfα、ifn-γ、tgf-β、il-2、il-4、il-10、il-13、il-1、il-6、il-12和ifn-α分泌通路中的基因。
或者,细胞因子可发挥将信号递送至其它免疫细胞以诱导免疫细胞杀死所识别的抗原携带细胞或帮助分化的功能。在此情况下,细胞因子产生调节基因优选可为涉及il-2分泌的基因通路中的基因。
上述基因可衍生自包括灵长类动物(例如人、猴等)、啮齿类动物(例如小鼠、大鼠等)在内的哺乳动物。
可从已知数据库(例如美国国立生物技术信息中心(ncbi)的genbank)获得遗传信息。
在实施方式中,本说明书公开的免疫调节基因可为免疫细胞活性调节基因。
免疫调节基因可为pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
在本说明书公开的内容的一个实施方式中,引导核酸可为与pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因的靶序列互补结合的grna。
术语“靶序列”是指靶基因或核酸中的核苷酸序列,特别是靶基因或核酸中靶区域的部分核苷酸序列,其中,“靶区域”是靶基因或核酸中可被引导核酸-编辑蛋白修饰的区域。
本说明书公开的靶基因可为免疫调节基因。
本说明书公开的靶基因可为pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
在下文中,术语“靶序列”可指两种核苷酸序列信息。例如,对于靶基因,靶序列可指靶基因dna的转录链序列信息,或非转录链的核苷酸序列信息。
例如,靶序列可指靶基因a的靶区域中的部分核苷酸序列(转录链)5'-atcattggcagactagttcg-3'或与其互补的核苷酸序列(非转录链)5'-cgaactagtctgccaatgat-3'。
靶序列可为5-50个核苷酸的序列。
在实施方式中,靶序列可为16bp、17bp、18bp、19bp、20bp、21bp、22bp、23bp、24bp或25bp的核苷酸序列。
靶序列包含引导核酸结合序列或引导核酸非结合序列。
术语“引导核酸结合序列”是指与包含在引导核酸的引导结构域中的引导序列具有部分或完全互补性的核苷酸序列,其可与包含在引导核酸的引导结构域中的引导序列形成互补结合。靶序列和引导核酸结合序列是可根据靶基因或核酸(即基因操纵或修正的对象物)而改变的核苷酸序列,可根据靶基因或核酸将其设计为多种形式。
术语“引导核酸非结合序列”是指与包含在引导核酸的引导结构域中的引导序列具有部分或完全同源性的核苷酸序列,其不能与包含在引导核酸的引导结构域中的引导序列形成互补结合。此外,引导核酸非结合序列是与引导核酸结合序列互补的核苷酸序列,可与引导核酸结合序列形成互补结合。
引导核酸结合序列为靶序列中的部分核苷酸序列,可为具有靶序列的顺序不同的序列的两个核苷酸序列的任一个,即可形成互补结合的两个核苷酸序列。此处,引导核酸非结合序列可为除引导核酸结合序列外的靶序列的核苷酸序列。
例如,当靶基因a的靶区域中的部分核苷酸序列5'-atcattggcagactagttcg-3'和与其互补的核苷酸序列5'-cgaactagtctgccaatgat-3'为靶序列时,引导核酸结合序列可为两个靶序列的任一个,即5'-atcattggcagactagttcg-3'或5'-cgaactagtctgccaatgat-3'。此处,当引导核酸结合序列为5'-atcattggcagactagttcg-3'时,引导核酸非结合序列可为5'-cgaactagtctgccaatgat-3';或当引导核酸结合序列为5'-cgaactagtctgccaatgat-3'时,引导核酸非结合序列可为5'-atcattggcagactagttcg-3'。
引导核酸结合序列可为选自于与靶序列(即,转录链)同源的核苷酸序列和与非转录链同源的核苷酸序列的核苷酸序列。此处,引导核酸非结合序列可为选自于与靶序列中的引导核酸结合序列(即转录链)同源的核苷酸序列以及与非转录链同源的核苷酸序列以外的核苷酸序列。
引导核酸结合序列可具有与靶序列相同的长度。
引导核酸非结合序列可具有与靶序列或引导核酸结合序列相同的长度。
引导核酸结合序列可为5-50个核苷酸的序列。
在实施方式中,引导核酸结合序列可为16bp、17bp、18bp、19bp、20bp、21bp、22bp、23bp、24bp或25bp的核苷酸序列。
引导核酸非结合序列可为5bp-50bp的核苷酸序列。
在实施方式中,引导核酸非结合序列可为16bp、17bp、18bp、19bp、20bp、21bp、22bp、23bp、24bp或25bp的核苷酸序列。
引导核酸结合序列可与引导核酸的引导结构域中含有的引导序列形成部分或完全互补结合,并且引导核酸结合序列的长度可与引导序列的长度相同。
引导核酸结合序列可为与引导核酸的引导结构域中含有的引导序列互补的核苷酸序列,其具有例如至少70%、75%、80%、85%、90%或95%或更高的互补性或完全互补性。
在一个实例中,引导核酸结合序列可具有或包含不与引导核酸的引导结构域中包含的引导序列互补的1bp-8bp的核苷酸序列。
引导核酸非结合序列可与引导核酸的引导结构域中包含的引导序列具有部分或完全同源性,并且引导核酸非结合序列的长度可与引导顺序的长度相同。
引导核酸非结合序列可为与引导核酸的引导结构域中包含的引导序列具有同源性的核苷酸序列,其具有例如至少70%、75%、80%、85%、90%或95%或更高的同源性或完全同源性。
在一个实例中,引导核酸非结合序列可具有或包含不与引导核酸的引导结构域中包含的引导序列互补的1bp-8bp核苷酸序列。
引导核酸非结合序列可与引导核酸结合序列形成互补结合,并且引导核酸非结合序列的长度可与引导核酸结合序列的长度相同。
引导核酸非结合序列可为与引导核酸结合序列互补的核苷酸序列,其具有例如至少90%或95%或更高的互补性或完全互补性。
在一个实例中,引导核酸非结合序列可具有或包含不与引导核酸结合序列互补的1bp-2bp核苷酸序列。
此外,引导核酸结合序列可为位于能够被编辑蛋白识别的核苷酸序列附近的核苷酸序列。
在一个实例中,引导核酸结合序列可为临近能够被编辑蛋白识别的核苷酸序列的5'端和/或3'端的连续的5bp-50bp核苷酸序列。
在实施方式中,本说明书公开的靶序列可为位于免疫调节基因的启动子区域中的连续的10bp-35bp核苷酸序列。
此处,靶序列可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp核苷酸序列。
或者,靶序列可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp核苷酸序列。
在一个实例中,靶序列可为位于pd-1基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ctla-4基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于a20基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于dgka基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于dgkz基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于fas基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于egr2基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ppp2r2d基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于tet2基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于psgl-1基因的启动子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于kdm6a基因的启动子区域中的连续的10bp-25bp核苷酸序列。
本说明书公开的靶序列可为位于免疫调节基因的内含子区域中的连续的10bp-35bp核苷酸序列。
此处,靶序列可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp核苷酸序列。
或者,靶序列可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp核苷酸序列。
在一个实例中,靶序列可为位于pd-1基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ctla-4基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于a20基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于dgka基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于dgkz基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于fas基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于egr2基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ppp2r2d基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于tet2基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于psgl-1基因的内含子区域中的连续的10bp-25bp核苷酸序列。
在又一实例中,靶序列可为位于kdm6a基因的内含子区域中的连续的10bp-25bp核苷酸序列。
本说明书公开的靶序列可为位于免疫调节基因的外显子区域中的连续的10bp-35bp核苷酸序列。
此处,靶序列可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp核苷酸序列。
或者,靶序列可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp核苷酸序列。
在一个实例中,靶序列可为位于pd-1基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ctla-4基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于a20基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于dgka基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于dgkz基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于fas基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于egr2基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ppp2r2d基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于tet2基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于psgl-1基因的外显子区域中的连续的10bp-25bp核苷酸序列。
在又一实例中,靶序列可为位于kdm6a基因的外显子区域中的连续的10bp-25bp核苷酸序列。
本说明书公开的靶序列可为位于免疫调节基因的增强子区域中的连续的10bp-35bp核苷酸序列。
此处,靶序列可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp核苷酸序列。
或者,靶序列可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp核苷酸序列。
在一个实例中,靶序列可为位于pd-1基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ctla-4基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于a20基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于dgka基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于dgkz基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于fas基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于egr2基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ppp2r2d基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于tet2基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于psgl-1基因的增强子区域中的连续的10bp-25bp核苷酸序列。
在又一实例中,靶序列可为位于kdm6a基因的增强子区域中的连续的10bp-25bp核苷酸序列。
本说明书公开的靶序列可为位于免疫调节基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-35bp核苷酸序列。
此处,靶序列可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp核苷酸序列。
或者,靶序列可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp核苷酸序列。
在一个实例中,靶序列可为位于pd-1基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ctla-4基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于a20基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于dgka基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于dgkz基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于fas基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于egr2基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ppp2r2d基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于tet2基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于psgl-1基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在又一实例中,靶序列可为位于kdm6a基因的编码区域、非编码区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
本说明书公开的靶序列可为位于免疫调节基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-35bp核苷酸序列。
此处,靶序列可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp核苷酸序列。
或者,靶序列可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp核苷酸序列。
在一个实例中,靶序列可为位于pd-1基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ctla-4基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于a20基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于dgka基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于dgkz基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于fas基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于egr2基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ppp2r2d基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于tet2基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于psgl-1基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在又一实例中,靶序列可为位于kdm6a基因的启动子区域、增强子区域、3'-utr区域、5'-utr区域、polya区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
本说明书公开的靶序列可为位于免疫调节基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-35bp核苷酸序列。
此处,靶序列可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp核苷酸序列。
或者,靶序列可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp核苷酸序列。
在一个实例中,靶序列可为位于pd-1基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ctla-4基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于a20基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于dgka基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于dgkz基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于fas基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于egr2基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于ppp2r2d基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为位于tet2基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为位于psgl-1基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
在又一实例中,靶序列可为位于kdm6a基因的外显子区域、内含子区域或它们的组合区域中的连续的10bp-25bp核苷酸序列。
本说明书公开的靶序列可为包含或临近免疫调节基因的突变区(例如与野生型基因不同的区域)的连续的10bp-35bp核苷酸序列。
此处,靶序列可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp核苷酸序列。
或者,靶序列可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp核苷酸序列。
在一个实例中,靶序列可为包含pd-1基因或临近pd-1基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为包含或临近ctla-4基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为包含或临近a20基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为包含或临近dgka基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为包含或临近dgkz基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为包含或临近fas基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为包含或临近egr2基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为包含或临近ppp2r2d基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为包含或临近tet2基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为包含或临近psgl-1基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
在又一实例中,靶序列可为包含或临近kdm6a基因的突变区(例如与野生型基因不同的区域)的连续的10bp-25bp核苷酸序列。
本说明书公开的靶序列可为临近免疫调节基因的核酸序列中的前间区序列邻近基序(pam)序列的5'端和/或3'端的连续的10bp-35bp核苷酸序列。
术语“前间区序列邻近基序(pam)序列”是可被编辑蛋白识别的核苷酸序列。此处,pam序列可具有根据编辑蛋白的类型和来源物种而改变的核苷酸序列。
此处,pam序列可为例如如下序列中的一种或多种(以5'至3'方向来描述):
ngg(n为a、t、c或g);
nnnnryac(n各自独立地为a、t、c或g;r为a或g;y为c或t);
nnagaaw(n各自独立地为a、t、c或g;w为a或t);
nnnngatt(n各自独立地为a、t、c或g);
nngrr(t)(n各自独立地为a、t、c或g;r为a或g;y为c或t);以及
ttn(n为a、t、c或g)。
此处,靶序列可为10bp-35bp、15bp-35bp、20bp-35bp、25bp-35bp或30bp-35bp核苷酸序列。
或者,靶序列可为10bp-15bp、15bp-20bp、20bp-25bp、25bp-30bp或30bp-35bp核苷酸序列。
在一个实例中,靶序列可为临近pd-1基因的核酸序列中的pam序列的5'端和/或3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近pd-1基因的核酸序列中的5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近pd-1基因的核酸序列中的5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近pd-1基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近pd-1基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近pd-1基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近pd-1基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近pd-1基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10-25个核苷酸序列。
在另一实例中,靶序列可为临近ctla-4基因的核酸序列中的pam序列的5'端和/或3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近ctla-4基因的核酸序列中的5'-ngg-3'、5'-nag-3′或/和5′-nga-3′(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近ctla-4基因的核酸序列中的5'-nggng-3'或/和5′-nnagaaw-3′(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近ctla-4基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近ctla-4基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近ctla-4基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近ctla-4基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近ctla-4基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为临近a20基因的核酸序列中的pam序列的5'端和/或3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近a20基因的核酸序列中的5'-ngg-3'、5'-nag-3′或/和5′-nga-3′(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近a20基因的核酸序列中的5'-nggng-3'或/和5′-nnagaaw-3′(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近a20基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近a20基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近a20基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近a20基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近a20基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为临近dgka基因的核酸序列中的pam序列的5'端和/或3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近dgka基因的核酸序列中的5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近dgka基因的核酸序列中的5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a,u、g或c)时,靶序列可为临近dgka基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近dgka基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近dgka基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近dgka基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在一个实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近dgka基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为临近dgkz基因的核酸序列中的pam序列的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近dgkz基因的核酸序列中的5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近dgkz基因的核酸序列中的5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a,u、g或c)时,靶序列可为临近dgkz基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近dgkz基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近dgkz基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近dgkz基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近dgkz基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为临近fas基因的核苷酸序列中的pam序列的5'端和/或3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近fas基因的核酸序列中的5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近fas基因的核酸序列中的5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近fas基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近fas基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近fas基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近fas基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近fas基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为临近egr2基因的核酸序列中的前间区序列邻近基序(pam)的5'端和/或3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近egr2基因的核酸序列中的5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a,t,g或c,或a、u、g或c)时,靶序列可为临近egr2基因的核酸序列中的5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近egr2基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近egr2基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近egr2基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近egr2基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近egr2基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为临近ppp2r2d基因的核苷酸序列中的pam序列的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近ppp2r2d基因的核酸序列中的5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近ppp2r2d基因的核酸序列中的5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列,。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近ppp2r2d基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近ppp2r2d基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近ppp2r2d基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近ppp2r2d基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近ppp2r2d基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在一个实例中,靶序列可为临近tet2基因的核酸序列中的pam序列的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近tet2基因的核酸序列中的5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近tet2基因的核酸序列中的5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近tet2基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近tet2基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近tet2基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近tet2基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近tet2基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实例中,靶序列可为临近psgl-1基因的核酸序列中的pam序列的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近psgl-1基因的核酸序列中的5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'、5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近psgl-1基因的核酸序列中的5'-nggng-3'、5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近psgl-1基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近psgl-1基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近psgl-1基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近psgl-1基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近psgl-1基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实例中,靶序列可为临近kdm6a基因的核酸序列中的前间区序列邻近基序(pam)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ngg-3'、5'-nag-3'或/和5'-nga-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近kdm6a基因的核酸序列中的5'-ngg-3'、5'-nag-3′或/和5′-nga-3′(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近kdm6a基因的核酸序列中的5'-nggng-3'或/和5'-nnagaaw-3'(w=a或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近kdm6a基因的核酸序列中的5'-nnnngatt-3'或/和5'-nnngctt-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近kdm6a基因的核酸序列中的5'-nnnvryac-3'(v=g、c或a;r=a或g;y=c或t;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在另一实施方式中,当编辑蛋白识别的pam序列为5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近kdm6a基因的核酸序列中的5'-naar-3'(r=a或g;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在又一实施方式中,当编辑蛋白识别的pam序列为5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)时,靶序列可为临近kdm6a基因的核酸序列中的5'-nngrr-3'、5'-nngrrt-3'或/和5'-nngrrv-3'(r=a或g;v=g、c或a;n=a、t、g或c,或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
在实施方式中,当编辑蛋白识别的pam序列为5'-ttn-3'(n=a、t、g或c;或a、u、g或c)时,靶序列可为临近kdm6a基因的核酸序列中的5'-ttn-3'(n=a、t、g或c;或a、u、g或c)的5'端或/和3'端的连续的10bp-25bp核苷酸序列。
下文将可在本发明的一个实施方式中使用的靶序列的实例制成表,表中描述的靶序列为引导核酸非结合序列;互补序列,即可通过所述的序列来预测引导核酸结合序列。
[表1]免疫调节基因的靶序列
本说明书公开的内容的方面涉及用于对免疫调节基因进行人工操纵的基因操纵组合物。
用于基因操纵的组合物可用于生产人工修饰的免疫调节基因。此外,通过基因操纵的组合物人工修饰的免疫调节基因可调节免疫系统。
术语“人工修饰或工程化的或人工工程化的”是指其中施加人工修饰的状态,而非自然状态下存在的原状态。下文的人工修饰或工程化的非天然免疫调节基因可与人工免疫调节基因互换使用。
本发明的“免疫系统”为包括通过经操纵的免疫调节因子的功能改变来影响体内免疫应答(即,参与表现出新的免疫效力的机制)的全部现象在内的术语,其包括直接或间接参与此类免疫系统的全部物质、组合物、方法和用途。例如,免疫系统包括参与先天免疫、适应性免疫、细胞免疫、体液免疫、主动免疫和被动免疫应答的全部基因、免疫细胞和免疫器官/组织。
本说明书公开的用于基因操纵的组合物可包含引导核酸和编辑蛋白。
用于基因操纵的组合物可包含:
(a)引导核酸,所述引导核酸可与免疫调节基因的靶序列或编码其的核酸序列形成互补结合;以及
(b)一种或多种编辑蛋白或编码其的核酸序列。
关于上述免疫调节基因的解释如上所述。
关于上述靶序列的解释如上所述。
用于基因操纵的组合物可包含引导核酸-编辑蛋白复合体。
术语“引导核酸-编辑蛋白复合体”是指由引导核酸与编辑蛋白之间的相互作用形成的复合体。
关于上述引导核酸的解释如上所述。
“编辑蛋白”是指能够与核酸直接结合或无需直接结合而与核酸相互作用的肽、多肽或蛋白。
在此情况下,核酸可为靶核酸、基因或染色体中含有的核酸。此处,核酸可为引导核酸。
编辑蛋白可为酶。
此处,术语“酶”是指含有能够切割核酸、基因或染色体的结构域的多肽或蛋白。
酶可为核酸酶或限制性酶。
编辑蛋白可包括具有完全活性的酶。
此处,“具有完全活性的酶”是指具有与切割核酸、基因或染色体的野生型酶的原始功能相同的功能的酶。例如,切割双链dna的野生型酶可为切割所有双链dna的具有完全活性的酶。在另一实例中,当通过人工修饰对切割双链dna的野生型酶的部分氨基酸序列进行删除或置换时,如果人工修饰的酶突变体与野生型酶同等地切割双链dna,则该人工修饰的酶突变体可为具有完全活性的酶。
此外,具有完全活性的酶可包括与野生型酶的功能相比具有改善的功能的酶。例如,切割双链dna的野生型酶的特定修饰或工程化的形式可具有与野生型酶相比改善的完全酶活性,即切割双链dna的活性改善。
编辑蛋白可包括具有不完全或部分活性的酶。
此处,术语“具有不完全或部分活性的酶”是指仅具有切割核酸、基因或染色体的野生型酶的部分原始功能的酶。例如,切割双链dna的野生型酶的特定修饰或工程化的形式可为具有第一功能的形式或具有第二功能的形式。此处,第一功能可为切割双链dna的第一链的功能,第二功能可为切割双链dna的第二链的功能。此处,具有第一功能的酶或具有第二功能的酶可为具有不完全或部分活性的酶。
编辑蛋白可包括失活的酶。
此处,术语“失活的酶”是指切割核酸、基因或染色体的野生型酶的原始功能完全失活的酶。例如,野生型酶的特定修饰或工程化的形式可为既丧失第一功能又丧失第二功能的形式,即切割双链dna的第一链的第一功能和切割双链dna的第二链的第二功能均丧失。此处,丧失第一功能和第二功能的酶可为失活的酶。
编辑蛋白可为融合蛋白。
此处,融合蛋白是指通过将酶与额外的结构域、肽、多肽或蛋白融合而产生的蛋白。
所述额外的结构域、肽、多肽或蛋白可以是具有与所述酶中包含的功能性结构域、肽、多肽或蛋白相同或不同的功能的功能结构域、肽、多肽或蛋白。
融合蛋白可以在酶的氨基末端或其附近、酶的羧基末端或其附近、酶的中间部分及它们的组合中的一个或多个区域处包含额外的功能结构域、肽、多肽或蛋白。
此处,功能结构域、肽、多肽或蛋白可为具有甲基化酶活性、去甲基化酶活性、转录激活活性、转录阻遏活性、转录释放因子活性、组蛋白修饰活性、rna切割活性或核酸结合活性的结构域、肽、多肽或蛋白,或者为用于纯化和分离蛋白(包括肽)的标签或报告基因,但本发明不限于此。
功能结构域、肽、多肽或蛋白可为脱氨酶。
标签包括组氨酸(his)标签、v5标签、flag标签、流感血凝素(ha)标签、myc标签、vsv-g标签和硫氧还蛋白(trx)标签;报告基因包括谷胱甘肽硫转移酶(gst)、辣根过氧化物酶(hrp)、氯霉素乙酰转移酶(cat)、β-半乳糖苷酶、β-葡萄糖醛酸酶、萤光素酶、自发荧光蛋白(包括绿色荧光蛋白(gfp)、hcred、dsred、青色荧光蛋白(cfp)、黄色荧光蛋白(yfp)和蓝色荧光蛋白(bfp)),但本发明不限于此。
此外,功能结构域、肽、多肽或蛋白可为核定位序列或信号(nls)或者核输出序列或信号(nuclearexportsequenceorsignal,nes)。
nls可为:具有氨基酸序列pkkkrkv的sv40病毒大t抗原的nls;由核质蛋白衍生而来的nls(例如具有序列krpaatkkagqakkkk的双分型核质蛋白(nucleoplasminbipartite)nls);具有氨基酸序列paakrvkld或rqrrnelkrsp的c-mycnls;具有序列nqssnfgpmkggnfggrssgpyggggqyfakprnqggy的hrnpa1m9nls;由输入蛋白α(importin-α)衍生而来的ibb结构域序列rmrizfknkgkdtaelrrrrvevsvelrkakkdeqilkrrnv;肌瘤t蛋白序列vsrkrprp和ppkkared;人p53序列popkkkpl;小鼠c-abliv序列salikkkkkmap;流感病毒ns1序列drlrr和pkqkkrk;肝炎病毒δ抗原序列rklkkkikkl;小鼠mx1蛋白序列rekkkflkrr;人多聚(adp-核糖)聚合酶序列krkgdevdgvdevakkkskk;或者类固醇激素受体(人)糖皮质激素序列rkclqagmnlearktkk,但本发明不限于此。
额外的结构域、肽、多肽或蛋白可为不执行特定功能的功能失调性结构域、肽、多肽或蛋白。此处,功能失调性结构域、肽、多肽或蛋白可为不影响酶功能的结构域、肽、多肽或蛋白。
融合蛋白可在酶的氨基末端或其附近、酶的羧基末端或其附近、酶的中间部分以及它们的组合中的一个或多个区域处包含额外的功能失调性结构域、肽、多肽或蛋白。
编辑蛋白可为天然的酶或融合蛋白。
编辑蛋白可以以部分修饰的天然酶或融合蛋白的形式存在。
编辑蛋白可为在天然状态下不存在的人工产生的酶或融合蛋白。
编辑蛋白可以以在天然状态下不存在的部分修饰的人工酶或融合蛋白的形式存在。
此处,修饰可为对编辑蛋白中含有的氨基酸进行置换、删除、添加或上述修饰的组合。
此外,修饰可为对编码编辑蛋白的碱基序列中的部分碱基进行置换、删除、添加或上述修饰的组合。
此外,用于基因操纵的组合物可任选地进一步包含供体或编码所述供体的核酸序列,所述供体包含期望被插入的特定核苷酸序列。
此处,期望被插入的核苷酸序列可为涉及免疫的基因中的部分核苷酸序列。
此处,期望被插入的核苷酸序列可为对经受操纵的免疫调节基因的突变进行修正或导入的核苷酸序列。
术语“供体”是指通过hdr帮助修复损伤的基因或核酸的核酸序列。
供体可为双链核酸或单链核酸。
供体可为线性或环状。
供体可包含与靶基因或核酸具有同源性的核酸序列。
例如,供体可包含与待插入特定核酸的位置(例如损伤核酸的上游和下游)处的核苷酸序列分别具有同源性的核苷酸序列。具体而言,待插入的特定核酸可位于与损伤核酸的下游核苷酸序列具有同源性的核苷酸序列和与损伤核酸的上游核苷酸序列具有同源性的核苷酸序列之间。具体而言,具有上述同源性的核苷酸序列可具有至少50%、55%、60%、65%、70%、75%、80%、85%、90%或95%或更高的同源性或完全同源性。
供体可任选包含额外的核苷酸序列。具体而言,额外的核苷酸序列可在增强供体的hdr效率、稳定性或敲入效率方面发挥作用。
例如,额外的核苷酸序列可为富含a和t碱基的核苷酸序列(即富a-t结构域)。或者,额外的核苷酸序列可为支架/基质附着区(s/mar)。
可以各种形式将本说明书公开的引导核酸、编辑蛋白或引导核酸-编辑蛋白复合体递送或导入受试者。
术语“受试者”是指导入引导核酸、编辑蛋白或引导核酸-编辑蛋白复合体的有机体;其中运行(operates)引导核酸、编辑蛋白或引导核酸-编辑蛋白复合体的有机体;或获取自所述有机体的试样或样本。
受试者可为包含引导核酸-编辑蛋白复合体的靶基因或染色体的有机体。
有机体可为动物、动物组织或动物细胞。
有机体可为人、人组织或人细胞。
组织可为眼、皮肤、肝、肾、心脏、肺、脑、肌肉或血液。
细胞可为免疫细胞,例如自然杀伤细胞(nk细胞)、t细胞、b细胞、树突细胞、以及巨噬细胞或干细胞。
可由包含靶基因或染色体的有机体(例如唾液、血液、肝组织、脑组织、肝细胞、神经元、吞噬细胞、t细胞、b细胞、星形胶质细胞、癌细胞或干细胞)获得试样或样本。
优选地,受试者可为包含免疫调节基因的有机体。
可以以dna、rna或混合形式的形式将引导核酸、编辑蛋白或引导核酸-编辑蛋白复合体递送入或导入受试者。
此处,可借助本领域已知的方法将编码引导核酸和/或编辑蛋白的dna、rna或其混合物的形式递送入或导入受试者。
或者,可借助载体、非载体或其组合将编码引导核酸和/或编辑蛋白的dna、rna或其混合物的形式递送入或导入受试者。
载体可为病毒载体或非病毒载体(例如质粒)。
非载体可为裸dna、dna复合体或mrna。
可借助载体将编码引导核酸和/或编辑蛋白的核酸序列递送入或导入受试者。
载体可包含编码引导核酸和/或编辑蛋白的核酸序列。
例如,载体可同时包含分别编码引导核酸和编辑蛋白的核酸序列。
例如,载体可包含编码引导核酸的核酸序列。
作为实例,引导核酸中包含的结构域可全部包含于一个载体中,或可将其分割并随后包含于不同载体中。
例如,载体可包含编码编辑蛋白的核酸序列。
在一个实例中,在编辑蛋白的情况下,编码编辑蛋白的核酸序列可包含于一个载体中,或可将其分割并随后包含于数个载体中。
载体可含有一种或多种调节/控制组分。
此处,调节/控制组分可以包括:启动子、增强子、内含子、多聚腺苷酸信号、kozak共有序列、内部核糖体进入位点(ires)、剪接受体和/或2a序列。
启动子可为由rna聚合酶ii识别的启动子。
启动子可为由rna聚合酶iii识别的启动子。
启动子可为诱导型启动子。
启动子可为受试者特异性启动子。
启动子可为病毒或非病毒启动子。
就启动子而言,可根据控制区(即,编码引导核酸或编辑蛋白的核酸序列)而使用适当的启动子。
例如,可用于引导核酸的启动子可为h1、ef-1a、trna或u6启动子。例如,可用于编辑蛋白的启动子可为cmv、ef-1a、efs、mscv、pgk或cag启动子。
载体可为病毒载体或重组病毒载体。
病毒可为dna病毒或rna病毒。
此处,dna病毒可为双链dna(dsdna)病毒或单链dna(ssdna)病毒。
此处,rna病毒可为单链rna(ssrna)病毒。
病毒可为逆转录病毒、慢病毒、腺病毒、腺相关病毒(aav)、痘苗病毒、痘病毒或单纯疱疹病毒,但本发明不限于此。
一般说来,病毒可感染宿主(例如细胞),由此将编码病毒遗传信息的核酸导入宿主或将编码遗传信息的核酸插入宿主基因组。可使用具有此类特征的病毒将引导核酸和/或编辑蛋白导入受试者。使用病毒导入的引导核酸和/或编辑蛋白可在受试者(例如细胞)中瞬时表达。或者,使用病毒导入的引导核酸和/或编辑蛋白可在受试者(例如细胞)中长时间持续表达(例如1、2或3周,1、2、3、6或9个月,1或2年,或永久)。
根据病毒的类型,病毒的包装能力可在至少2kb至50kb间变化。取决于此类包装能力,可设计包含引导核酸或编辑蛋白的病毒载体或者包含引导核酸和编辑蛋白二者的病毒载体。或者,可设计包含引导核酸、编辑蛋白和额外组分的病毒载体。
在一个实例中,可使用重组慢病毒递送或导入编码引导核酸和/或编辑蛋白的核酸序列、。
在另一实例中,可使用重组腺病毒递送或导入编码引导核酸和/或编辑蛋白的核酸序列。
在又一实施方式中,可使用重组aav递送或导入编码引导核酸和/或编辑蛋白的核酸序列。
在又一实例中,可使用混合病毒(例如本文列出的病毒中的一种或多种的混合)递送或导入编码引导核酸和/或编辑蛋白的核酸序列。
可使用非载体将编码引导核酸和/或编辑蛋白的核酸序列递送入或导入受试者。
非载体可包含编码引导核酸和/或编辑蛋白的核酸序列。
非载体可为裸dna、dna复合体、mrna或它们的混合物。
可借助电穿孔、粒子轰击、声致穿孔(sonoporation)、磁性转染、瞬时细胞压缩或挤压(transientcellcompressionorsqueezing)(例如在文献“lee等(2012)nanolett.,12,6322-6327”中所描述的)、脂质介导的转染、树枝状大分子、纳米粒子、磷酸钙、二氧化硅、硅酸盐(ormosil)或它们的组合将非载体递送入或导入受试者。
作为实例,可通过将细胞与编码引导核酸和/或编辑蛋白的核酸序列在卡盒(cartridge)、腔室(chamber)或比色皿(cuvette)中混合并以预定的持续时间和振幅将电刺激施加至细胞来实施借助电穿孔的递送。
在另一实例中,可使用纳米粒子递送非载体。纳米粒子可为无机纳米粒子(例如磁性纳米粒子、二氧化硅等)或有机纳米粒子(例如聚乙二醇(peg)包覆的脂质等)。纳米粒子的外表面可缀合有能够进行附着的带正电的聚合物(例如聚乙烯亚胺、聚赖氨酸、聚丝氨酸等)。
在某些实施方式中,可使用脂质壳递送非载体。
在某些实施方式中,可使用外泌体(exosome)递送非载体。外泌体是对蛋白和rna进行转移并可将rna递送至脑和另一靶器官的内源性纳米囊泡。
在某些实施方式中,可使用脂质体递送非载体。脂质体为由围绕内部水性室的单个或多个层状脂质双层以及相对不可渗透的外部亲脂性磷脂双层组成的球形囊泡结构。尽管脂质体可由数种不同类型的脂质制成,但最常使用磷脂来生产作为药物运载体的脂质体。
此外,用于非载体递送的组合物可包含其它添加剂。
可将编辑蛋白以肽、多肽或蛋白的形式递送入或导入受试者。
可借助本领域已知的方法以肽、多肽或蛋白的形式将编辑蛋白递送入或导入受试者。
可借助电穿孔、显微注射、瞬时细胞压缩或挤压(例如在文献“lee等(2012)nanolett.,12,6322-6327”中所描述的)、脂质介导的转染、纳米粒子、脂质体、肽介导的递送或它们的组合将肽、多肽或蛋白形式递送入或导入受试者。
肽、多肽或蛋白可与编码引导核酸的核酸序列一起递送。
在一个实例中,可通过将待导入编辑蛋白的细胞与引导核酸一起(或不与引导核酸一起)在卡盒、腔室或比色皿中混合并以预定的持续时间和振幅将电刺激施加至细胞来实施借助电穿孔的递送。
可将引导核酸和编辑蛋白以核酸-蛋白混合物的形式递送入或导入受试者。
可以以引导核酸-编辑蛋白复合体的形式将引导核酸和编辑蛋白递送入或导入受试者。
例如,引导核酸可为dna、rna或其混合物。编辑蛋白可为肽、多肽或蛋白。
在一个实例中,可以以包含rna型引导核酸和蛋白型编辑蛋白的引导核酸-编辑蛋白复合体(即核糖核蛋白(rnp))的形式将引导核酸和编辑蛋白递送入或导入受试者。
本说明书公开的引导核酸-编辑蛋白复合体可对靶核酸、基因或染色体进行修饰。
例如,引导核酸-编辑蛋白复合体诱导对靶核酸、基因或染色体的序列的修饰。因此,由靶核酸、基因或染色体表达的蛋白可具有它们的经修饰的结构和/或功能、它们的受控的表达或它们的删除的表达。
引导核酸-编辑蛋白复合体可在dna、rna、基因或染色体水平发挥作用。
在一个实例中,引导核酸-编辑蛋白复合体可用于对由靶基因编码的蛋白的表达进行调节(例如抑制、阻遏、降低、升高或促进),或对蛋白活性进行调节(例如抑制、阻遏、降低、升高或促进),或通过对靶基因进行工程化或修饰来表达修饰的蛋白。
引导核酸-编辑蛋白复合体可在基因转录和翻译阶段发挥作用。
在一个实例中,引导核酸-编辑蛋白复合体可促进或阻遏靶基因的转录,从而对靶基因编码的蛋白的表达进行调节(例如抑制、阻遏、降低、升高或促进)。
在另一实例中,引导核酸-编辑蛋白复合体可促进或阻遏靶基因的翻译,从而对靶基因编码的蛋白的表达进行调节(例如抑制、阻遏、降低、升高或促进)。
在本说明书公开的实施方式中,用于基因操纵的组合物可包含grna和crispr酶。
用于基因操纵的组合物可包含:
(a)grna,所述grna能够与免疫调节基因的靶序列或编码所述免疫调节基因的靶序列的核酸序列形成互补结合;以及
(b)一种或多种crispr酶或编码所述crispr酶的核酸序列。
关于上述免疫调节基因的解释如上所述。
关于上述靶序列的解释如上所述。
基因操纵的组合物可包含grna-crispr酶复合体。
术语“grna-crispr酶复合体”是指由grna和crispr酶之间的相互作用形成的复合体。
关于上述grna的解释如上所述。
“crispr酶”是crispr-cas系统的主要蛋白组分,其通过与grna形成复合体而形成crispr-cas系统。
crispr酶可为具有编码crispr酶的序列的核酸或多肽(或蛋白)。
crispr酶可为ii型crispr酶。
根据对两种以上类型的天然微生物ii型crispr酶分子的研究(jinek等,science,343(6176):1247997,2014)以及对酿脓链球菌cas9(spcas9)与grna复合的研究(nishimasu等,cell,156:935-949,2014;和anders等,nature,2014,doi:10.1038/nature13579)确定了ii型crispr酶的晶体结构。
ii型crispr酶包含两个叶(lobes),即识别(rec)叶和核酸酶(nuc)叶,各叶包含数个结构域。
rec叶包含富含精氨酸的螺旋桥(bh)结构域、rec1结构域和rec2结构域。
此处,bh结构域为长的α螺旋并且为富含精氨酸区域,而rec1结构域和rec2结构域在识别grna(例如单链grna、双链grna或tracrrna)中形成的双链中起重要作用。
nuc叶包含ruvc结构域、hnh结构域和pam相互作用(pi)结构域。此处,ruvc结构域包括ruvc样结构域,或者hnh结构域用于包括hnh样结构域。
此处,ruvc结构域与具有ii型crispr酶的天然存在的微生物家族的成员共享结构相似性,并切割单链(例如靶基因或核酸的非互补链,即不与grna形成互补结合的链)。在本领域中,ruvc结构域有时指ruvci结构域、ruvcii结构域或ruvciii结构域,一般称为ruvci、ruvcii或ruvciii。
hnh结构域与hnh核酸内切酶共享结构相似性,并切割单链(例如靶核酸分子的互补链,即与grna形成互补结合的链)。hnh结构域位于ruvcii和iii基序之间。
pi结构域识别靶基因或核酸中的特定核苷酸序列(即前间区序列邻近基序(pam))或与pam相互作用。此处,pam可根据ii型crispr酶的来源而变化。例如,当crispr酶是spcas9,pam可为5'-ngg-3';当crispr酶是嗜热链球菌cas9(stcas9)时,pam可为5'-nnagaaw-3'(w=a或t);当crispr酶是脑膜炎奈瑟菌cas9(nmcas9)时,pam可为5'-nnnngatt-3';当crispr酶是空肠弯曲杆菌cas9(cjcas9)时,pam可为5'-nnnvryac-3'(v=g或c或a;r=a或g;y=c或t),其中,n可为a、t、g或c,或a、u、g或c。然而,尽管通常理解根据如上所述的酶的来源来确定pam,pam可随着关于所述来源的酶的突变体的研究进展而变化。
ii型crispr酶可为cas9。
cas9可由以下各种微生物衍生而来:例如,酿脓链球菌(streptococcuspyogenes)、嗜热链球菌(streptococcusthermophilus)、链球菌属(streptococcussp.)、金黄色葡萄球菌(staphylococcusaureus)、达松维尔拟诺卡式菌(nocardiopsisdassonvillei)、始旋链霉菌(streptomycespristinaespiralis)、产绿色链霉菌(streptomycesviridochromogenes)、粉红链孢囊菌(streptosporangiumroseum)、酸热脂环酸芽孢杆菌(alicyclobachlusacidocaldarius)、假真菌样芽孢杆菌(bacilluspseudomycoides)、bacillusselenitireducens、exiguobacteriumsibiricum、德氏乳杆菌(lactobacillusdelbrueckii)、唾液乳杆菌(lactobacillussalivarius)、microscillamarina、burkholderialesbacterium、polaromonasnaphthalenivorans、极单孢菌属(polaromonassp.)、crocosphaerawatsonii、蓝杆藻属(cyanothecesp.)、铜绿微囊藻(microcystisaeruginosa)、聚球藻属(synechococcussp.)、阿拉伯糖醋杆菌(acetohalobiumarabaticum)、ammonifexdegensii、caldicelulosiruptorbescii、candidatusdesulforudis、肉毒梭状芽胞杆菌(clostridiumbotulinum)、艰难梭状芽胞杆菌(clostridiumdifficile)、微小微单胞菌(finegoldiamagna)、natranaerobiusthermophilus、pelotomaculumthermopropionicu、喜温嗜酸硫杆菌(acidithiobacilluscaldus)、嗜酸氧化亚铁硫杆菌(acidithiobacillusferrooxidans)、allochromatiumvinosum、海杆菌属(marinobactersp.)、nitrosococcushalophilus、nitrosococcuswatsonii、pseudoalteromonashaloplanktis、ktedonobacterracemifer、methanohalobiumevestigatum、多变鱼腥藻(anabaenavariabilis)、泡沫节球藻(nodulariaspumigena)、念珠藻属(nostocsp.)、极大节旋藻(arthrospiramaxima)、钝顶节旋藻(arthrospiraplatensis)、节旋藻属(arthrospirasp.)、鞘丝藻属(lyngbyasp.)、原型微鞘藻(microcoleuschthonoplastes)、颤藻属(oscillatoriasp.)、运动石袍菌(petrotogamobilis)、非洲栖热腔菌(thermosiphoafricanus)以及acaryochlorismarina。
cas9为与grna结合以便切割或修饰靶基因或核酸上的靶序列或位置的酶,可由hnh结构域(能够切割与grna形成互补结合的核酸链)、ruvc结构域(能够切割与grna形成非互补结合的核酸链)、rec结构域(识别靶标)以及pi结构域(识别pam)组成。对于cas9的具体结构特征,可参见hiroshinishimasu等,(2014)cell156:935-949。
可从天然存在的微生物中分离或者通过重组或合成方法非天然地产生cas9。
此外,crispr酶可为v型crispr酶。
v型crispr酶包含类似的ruvc结构域(对应于ii型crispr酶的ruvc结构域),并且可由nuc结构域(而不是ii型crispr酶的hnh结构域)、rec结构域和wed结构域(与靶标相互作用)以及pi结构域(识别pam)组成。对于v型crispr酶的具体结构特征,可参见takashiyamano等(2016)cell165:949-962。
v型crispr酶可与grna相互作用,从而形成grna-crispr酶复合体,即crispr复合体,并且可在grna的协作下允许引导序列接近包含pam序列的靶序列。此处,v型crispr酶与靶基因或核酸相互作用的能力依赖于pam序列。
pam序列是存在于靶基因或核酸中的序列,其可被v型crispr酶的pi结构域识别。pam序列可根据v型crispr酶的来源改变。即,取决于物种,存在能够被特异性识别的不同pam序列。例如,由cpf1识别的pam序列可为5'-ttn-3'(n为a、t、c或g)。然而,尽管通常理解根据如上所述的酶的来源来确定pam,pam可随着关于所述来源的酶的突变体的研究进展而改变。
v型crispr酶可为cpf1。
cpf1可为由以下衍生而来的cpf1:链球菌(streptococcus)、弯曲杆菌(campylobacter)、nitratifractor、葡萄球菌(staphylococcus)、parvibaculum、罗斯氏菌(roseburia)、奈瑟菌(neisseria)、葡糖醋杆菌(gluconacetobacter)、固氮螺菌(azospirillum)、sphaerochaeta、乳杆菌(lactobacillus)、真杆菌(eubacterium)、棒状杆菌(corynebacter)、肉食杆菌(carnobacterium)、红细菌(rhodobacter)、李斯特菌(listeria)、paludibacter、梭菌(clostridium)、毛螺菌(lachnospiraceae)、clostridiaridium、纤毛菌(leptotrichia)、弗朗西斯氏菌属(francisella)、军团杆菌(legionella)、脂环酸芽孢杆菌(alicyclobacillus)、methanomethyophilus、卟啉单胞菌(porphyromonas)、普雷沃菌(prevotella)、拟杆菌(bacteroidetes)、创伤球菌(helcococcus)、钩端螺旋体(letospira)、脱硫弧菌(desulfovibrio)、desulfonatronum、丰佑菌(opitutaceae)、肿块芽孢杆菌(tuberibacillus)、芽孢杆菌(bacillus)、短芽孢杆菌(brevibacilus)、甲基杆菌(methylobacterium)或氨基酸球菌(acidaminococcus)。
cpf1包含ruvc结构域(类似于并对应于ii型crispr酶的ruvc结构域),并且可由nuc结构域(而不是cas9的hnh结构域)、rec结构域和wed结构域(与靶标相互作用)以及pi结构域(识别pam)组成。对于cpf1的具体结构特征,可参见takashiyamano等(2016)cell165:949-962。
可从天然存在的微生物分离或者通过重组或合成方法非天然地产生cpf1。
crispr酶可为具有切割靶基因或核酸的双链功能的核酸酶或限制性酶。
crispr酶可为具有完全活性的crispr酶。
此处,“具有完全活性”是指具有与野生型crispr酶相同的功能的状态,此状态下的crispr酶被称为“具有完全活性的crispr酶”。此处,“野生型crispr酶的功能”是指具有切割双链dna的功能的状态,即具有切割双链dna的第一链的第一功能和切割双链dna的第二链的第二功能的状态。
具有完全活性的crispr酶可为切割双链dna的野生型crispr酶。
具有完全活性的crispr酶可为其中对切割双链dna的野生型crispr酶进行修饰或操纵的crispr酶突变体。
crispr酶突变体可为将野生型crispr酶的氨基酸序列中的一个或多个氨基酸置换为另一氨基酸置换或将一个或多个氨基酸删除的酶。
crispr酶突变体可为在野生型crispr酶的氨基酸序列中添加一个或多个氨基酸的酶。此处,添加的氨基酸的位置可为n端、c端或在野生型酶的氨基酸序列内。
crispr酶突变体可为与野生型crispr酶相比具有改善的功能的具有完全活性的酶。
例如,野生型crispr酶的特定修饰或经操纵的形式(即crispr酶突变体)可切割双链dna而不结合至待切割的双链dna或保持一定距离。在此情况下,修饰或经操纵的形式可为与野生型crispr酶相比具有改善的功能的具有完全活性的crispr酶。
crispr酶突变体可为与野生型crispr酶相比具有降低的功能的具有完全活性的酶。
例如,野生型crispr酶的特定修饰或经操纵的形式(即crispr酶突变体)可在与待切割双链dna的特定距离处或更接近待切割双链dna处,或在某些结合存在的情况下对双链dna进行切割。此处,某些结合可为例如酶的特定位置的氨基酸与切割位置中的dna核苷酸序列之间的结合。在此情况下,修饰或经操纵的形式可为与野生型crispr酶相比功能降低的具有完全活性的crispr酶。
crispr酶可为具有不完全或部分活性的crispr酶。
术语“具有不完全或部分活性的”是指具有选自野生型crispr酶的功能(即,切割双链dna的第一链的第一功能,以及切割双链dna的第二链的第二功能)的功能的状态。此外,具有不完全或部分活性的crispr酶可称为切口酶。
术语“切口酶”是指经操纵或修饰而仅切割靶基因或核酸双链中的一条链的crispr酶,切口酶具有切割单链(例如不与靶基因或核酸的grna互补的链或与其互补的链)的核酸酶活性。因此,为了切割双链需要两种切口酶的核酸酶活性。
切口酶可具有crispr酶的ruvc结构域的核酸酶活性。即,切口酶可不包含crispr酶的hnh结构域的核酸酶活性,为此可对hnh结构域进行操纵或修饰。
在一个实例中,当crispr酶是ii型crispr酶时,切口酶可为包含修饰的hnh结构域的ii型crispr酶。
例如,当ii型crispr酶为野生型spcas9时,切口酶可为其中野生型spcas9的氨基酸序列中的第840位残基由组氨酸突变为丙氨酸并且hnh结构域的核酸酶活性失活的spcas9突变体。此处,所产生的切口酶(即spcas9突变体)具有ruvc结构域的核酸酶活性,因此能够切割靶基因或核酸的非互补链,即不与grna形成互补结合的链。
在另一实例中,当ii型crispr酶为野生型cjcas9时,切口酶可为其中野生型cjcas9氨基酸序列中的第559位残基由组氨酸突变为丙氨酸并且hnh结构域的核酸酶活性失活的cjcas9突变体。此处,所产生的切口酶(即cjcas9突变体)具有ruvc结构域的核酸酶活性,因此能够切割靶基因或核酸的非互补链,即不与grna形成互补结合的链。
此外,切口酶可具有crispr酶的hnh结构域的核酸酶活性。即,切口酶可不包含crispr酶的ruvc结构域的核酸酶活性,为此可对ruvc结构域进行操纵或修饰。
在一个实例中,当crispr酶为ii型crispr酶时,切口酶可为包含修饰的ruvc结构域的ii型crispr酶。
例如,当ii型crispr酶为野生型spcas9时,切口酶可为其中野生型spcas9的氨基酸序列中的第10位残基由天冬氨酸突变为丙氨酸并且ruvc结构域的核酸酶活性失活的spcas9突变体。此处,所产生的切口酶(即spcas9突变体)具有hnh结构域的核酸酶活性,因此能够切割靶基因或核酸的互补链,即与grna形成互补结合的链。
在另一实例中,当ii型crispr酶是野生型cjcas9时,切口酶可为其中野生型cjcas9的氨基酸序列中的第8位残基由天冬氨酸突变为丙氨酸并且ruvc结构域的核酸酶活性失活的cjcas9突变体。此处,所产生的切口酶(即cjcas9突变体)具有hnh结构域的核酸酶活性,因此能够切割靶基因或核酸的互补链,即与grna形成互补结合的链。
crispr酶可为失活的crispr酶。
术语“失活”是指完全丧失野生型crispr酶功能(即,切割双链dna的第一链的第一功能,以及切割双链dna的第二链的第二功能)的状态。此状态下的crispr酶称为失活的crispr酶。
通过具有核酸酶活性的野生型crispr酶的结构域中的突变,可使失活的crispr酶具有失活的核酸酶。
失活的crispr酶可为其中ruvc结构域和hnh结构域的核酸酶活性由于突变而失活的失活的crispr酶。即,失活的crispr酶可不包含crispr酶的ruvc结构域和hnh结构域的核酸酶活性,为此可对ruvc结构域和hnh结构域进行操纵或修饰。
在一个实例中,当crispr酶为ii型crispr酶时,失活的crispr酶可为包含修饰的ruvc结构域和hnh结构域的ii型crispr酶。
例如,当ii型crispr酶为野生型spcas9时,失活的crispr酶可为其中通过分别将野生型spcas9的氨基酸序列中的第10位残基和第840位残基由天冬氨酸和组氨酸突变为丙氨酸,ruvc结构域和hnh结构域的核酸酶活性失活的spcas9突变体。此处,所产生的失活的crispr酶(即spcas9突变体)具有失活的ruvc结构域和hnh结构域的核酸酶活性,因此可完全不切割靶基因或核酸的双链。
在另一实例中,当ii型crispr酶为野生型cjcas9时,失活的crispr酶可为其中通过分别将野生型cjcas9的氨基酸序列中的第8位残基和第559位残基由天冬氨酸和组氨酸突变为丙氨酸,ruvc结构域和hnh结构域的核酸酶活性失活的cjcas9突变体。此处,所产生的失活的crispr酶(即spcas9突变体)具有失活的ruvc结构域和hnh结构域的核酸酶活性,因此可完全不切割靶基因或核酸的双链。
除上述所述的核酸酶活性外,crispr酶可具有解旋酶活性,即使双链核酸的螺旋结构解旋的能力。
此外,可对crispr酶进行修饰以使crispr酶具有解旋酶活性的完全活性、不完全活性或部分活性。
crispr酶可为野生型crispr酶经过人工操纵或修饰的crispr酶突变体。
crispr酶突变体可为经人工操纵或修饰的crispr酶突变体以修饰野生型crispr酶的功能(即,切割双链dna的第一链的第一功能,和/或切割双链dna的第二链的第二功能)。
例如,crispr酶突变体可为丧失野生型crispr酶功能的第一功能的形式。
或者,crispr酶突变体可为丧失野生型crispr酶功能的第二功能的形式。
例如,crispr酶突变体可为丧失野生型crispr酶的功能(即第一功能和第二功能)的形式。
crispr酶突变体可通过与grna相互作用而形成grna-crispr酶复合体。
crispr酶突变体可为经人工操纵或修饰的crispr酶突变体,以对野生型crispr酶与grna相互作用的功能进行修饰。
例如,crispr酶突变体可为相比野生型crispr酶与grna的相互作用减小的形式。
或者,crispr酶突变体可为相比野生型crispr酶与grna的相互作用增加的形式。
例如,crispr酶突变体可为具有野生型crispr酶的第一功能并且与grna的相互作用减小的形式。
或者,crispr酶突变体可为具有野生型crispr酶的第一功能并且与grna的相互作用增加的形式。
例如,crispr酶突变体可为具有野生型crispr酶的第二功能并且与grna的相互作用减小的形式。
或者,crispr酶突变体可为具有野生型crispr酶的第二功能并且与grna的相互作用增加的形式。
例如,crispr酶突变体可为不具有野生型crispr酶的第一功能和第二功能但与grna的相互作用减小的形式。
或者,crispr酶突变体可为不具有野生型crispr酶的第一功能和第二功能但与grna的相互作用增加的形式。
此处,取决于grna与crispr酶突变体之间的相互作用的强度,可形成多种grna-crispr酶复合体,并且接近或切割靶序列的功能可取决于crispr酶突变体而改变。
例如,由与grna的相互作用降低的crispr酶突变体形成的grna-crispr酶复合体仅当接近或定位于与grna形成完全互补结合的靶序列时才能够切割靶序列的双链或单链。
crispr酶突变体可为对野生型crispr酶的氨基酸中的至少一个进行修饰。
在一个实例中,crispr酶突变体可为对野生型crispr酶的氨基酸中的至少一个进行置换。
在另一实例中,crispr酶突变体可为对野生型crispr酶的氨基酸中的至少一个进行删除。
在又一实例中,crispr酶突变体可对野生型crispr酶的氨基酸中的至少一个进行添加。
在一个实例中,crispr酶突变体可为对野生型crispr酶的氨基酸中的至少一个进行置换、删除和/或添加。
此外,除野生型crispr酶的原始功能(即,切割双链dna的第一链的第一功能以及切割双链dna的第二链的第二功能)外,crispr酶突变体可进一步包含任选的功能结构域。此处,crispr酶突变体可具有除野生型crispr酶的原始功能以外的额外功能。
功能结构域可为具有甲基化酶活性、去甲基化酶活性、转录激活活性、转录阻遏活性、转录释放因子活性、组蛋白修饰活性、rna切割活性或核酸结合活性的结构域,或者为用于分离和纯化蛋白(包括肽)的标签或报告基因,但本发明不限于此。
标签包括组氨酸(his)标签、v5标签、flag标签、流感血凝素(ha)标签、myc标签、vsv-g标签和硫氧还蛋白(trx)标签;报告基因包括谷胱甘肽-s-转移酶(gst)、辣根过氧化物酶(hrp)、氯霉素乙酰转移酶(cat)、β-半乳糖苷酶、β-葡萄糖醛酸酶、萤光素酶、自发荧光蛋白(包括绿色荧光蛋白(gfp)、hcred、dsred、青色荧光蛋白(cfp)、黄色荧光蛋白(yfp)和蓝色荧光蛋白(bfp)),但本发明不限于此。
功能结构域可为脱氨酶。
例如,不完整或部分的crispr酶可额外包含胞苷脱氨酶作为功能结构域。在一个示例性实施方式中,可将胞苷脱氨酶(例如载脂蛋白b编辑复合体1(apobec1))添加至spcas9切口酶,从而生成融合蛋白。由此形成的[spcas9切口酶]-[apobec1]可用于由核苷酸c到t或u、或者由核苷酸g到a的编辑或者核苷酸修复中。
在另一实例中,不完整或部分的crispr酶可进一步包含胞苷脱氨酶作为功能结构域。在一个实施方式中,可将腺嘌呤脱氨酶(例如tada变体、adar2变体、adat2变体等)添加至spcas9切口酶,从而产生融合蛋白。由此形成的[spcas9切口酶]-[tada变体]、[spcas9切口酶]-[adar2变体]或[spcas9切口酶]-[adat2变体]将核苷酸a修饰为肌苷,修饰的肌苷被聚合酶识别为核苷酸g,并本质上表现出由核苷酸a到g的修复或编辑作用,因此可用于由核苷酸a到g、或者由核苷酸t到c的编辑或者核苷酸修复中。
功能结构域可为核定位序列或信号(nls)或者核输出序列或信号(nes)。
在一个实例中,crispr酶可包含一个或多个nls。此处,一个或多个nls可包含于cripsr酶的n端或其附近、酶的c端或其附近或者它们的组合。nls可为由如下nls衍生而来的nls序列,但本发明不限于此:具有氨基酸序列pkkkrkv的sv40病毒大t抗原的nls;来自核质蛋白的nls(例如具有序列krpaatkkagqakkkk的双分型核质蛋白nls);具有氨基酸序列paakrvkld或rqrrnelkrsp的c-mycnls;具有序列nqssnfgpmkggnfggrssgpyggggqyfakprnqggy的hrnpa1m9nls;来自输入蛋白α的ibb结构域的序列rmrizfknkgkdtaelrrrrvevsvelrkakkdeqilkrrnv;肌瘤t蛋白的序列vsrkrprp和ppkkared;人p53的序列popkkkpl;小鼠c-abliv的序列salikkkkkmap;流感病毒ns1的序列drlrr和pkqkkrk;肝炎病毒δ抗原的序列rklkkkikkl;小鼠mx1蛋白的序列rekkkflkrr;人多聚(adp-核糖)聚合酶的序列krkgdevdgvdevakkkskk;或者由类固醇激素受体(人)糖皮质激素的序列衍生而来的nls序列rkclqagmnlearktkk。
此外,crispr酶突变体可包括通过将crispr酶分为两个以上部分而制备的拆分型(split-type)crispr酶。术语“拆分”是指对蛋白进行功能或结构性划分,或者将蛋白随机划分为两个以上部分。
拆分型crispr酶可为具有完全活性的酶、具有不完全或部分活性的酶或失活的酶。
例如,当crispr酶为spcas9时,可在第656位残基(酪氨酸)和第657位残基(苏氨酸)之间将spcas9分为两部分来产生拆分型spcas9。
拆分型crispr酶可任选包含用于重构(reconstitution)的额外的结构域、肽、多肽或蛋白。
可对用于重构的额外的结构域、肽、多肽或蛋白进行组装,使得拆分型crispr酶在结构方面与野生型crispr酶相同或类似。
用于重构的额外的结构域、肽、多肽或蛋白可为frb和fkbp二聚化结构域;内含肽(intein);ert和vpr结构域;或者在特定条件下形成异二聚体的结构域。
例如,可在第713位残基(丝氨酸)和第714位残基(甘氨酸)之间将spcas9分为两部分,从而生成拆分型spcas9。可将frb结构域连接至两部分中的一个部分,并将fkbp结构域连接至另一部分。在由此产生的拆分型spcas9中,frb结构域和fkbp结构域可以在存在雷帕霉素的环境中形成二聚体,从而生成重构的crispr酶。
本发明所述的crispr酶或crispr酶突变体可为多肽、蛋白或者具有编码所述多肽、蛋白的序列的核酸,并可针对待导入所述crispr酶或crispr酶突变体的受试者实施密码子优化。
术语“密码子优化”是指对核酸序列的修饰过程,该修饰过程通过在保持天然氨基酸序列的同时将天然序列中的至少一个密码子替换为在宿主细胞中更常或最常使用的密码子来改善在宿主细胞中的表达。多种物种对特定氨基酸的特定密码子具有特定偏好,该密码子偏好(不同生物体间密码子使用的差别)通常与mrna的翻译效率相关,认为这取决于所翻译的密码子的特征和特定trna分子的可获得性。细胞中选择的优势trna通常反映了肽合成中最常使用的密码子。因此,可基于密码子优化在给定生物体中通过优化基因表达来对基因进行定制化。
可以以各种形式将本说明书公开的grna、crispr酶或grna-crispr酶复合体递送入或导入受试者。
关于上述受试者的解释如上所述。
在实施方式中,可通过包含分别编码grna和/或crispr酶的核酸序列的载体将所述grna和/或crispr酶递送入或导入受试者。
载体可包含编码grna和/或crispr酶的核酸序列。
在一个实例中,载体可同时包含编码grna和crispr酶的核酸序列。
在另一实例中,载体可包含编码grna的核酸序列。
例如,grna中含有的结构域可全部包含在载体中,或者可将所述结构域分开并单独包含在载体中。
在另一实例中,载体可包含编码crispr酶的核酸序列。
例如,对于crispr酶,编码crispr酶的核酸序列可全部包含在载体中,或者可将其拆开并单独包含在载体中。
载体可包含一种或多种调节/控制组分。
此处,调节/控制组分可包括:启动子、增强子、内含子、多聚腺苷酸信号、kozak共有序列、内部核糖体进入位点(ires)、剪接受体和/或2a序列。
启动子可为由rna聚合酶ii识别的启动子。
启动子可为由rna聚合酶iii识别的启动子。
启动子可为诱导型启动子。
启动子可为受试者特异性启动子。
启动子可为病毒启动子或非病毒启动子。
就启动子而言,可根据控制区(即,编码grna和/或crispr酶的核酸序列)而使用合适的启动子。
例如,可用于grna的启动子可为h1、ef-1a、trna或u6启动子。例如,可用于crispr酶的启动子可为cmv、ef-1a、efs、mscv、pgk或cag启动子。
载体可为病毒载体或重组病毒载体。
病毒可为dna病毒或rna病毒。
此处,dna病毒可为双链dna(dsdna)病毒或单链dna(ssdna)病毒。
此处,rna病毒可为单链rna(ssrna)病毒。
病毒可为但不限于逆转录病毒、慢病毒、腺病毒、腺相关病毒(aav)、痘苗病毒、痘病毒或单纯疱疹病毒。
在一个实例中,可通过重组慢病毒对编码grna和/或crispr酶的核酸序列进行递送或导入。
在另一实例中,可通过重组腺病毒对编码grna和/或crispr酶的核酸序列进行递送或导入。
在又一实例中,可通过重组aav对编码grna和/或crispr酶的核酸序列进行递送或导入。
在又一实例中,可通过混合病毒(例如本文列出的病毒中的一种或多种的混合)对编码grna和/或crispr酶的核酸序列进行递送或导入。
在实施方式中,可将grna-crispr酶复合体的形式递送入或导入受试者。
例如,grna可为dna、rna或其混合物。crispr酶可为肽、多肽或蛋白。
在一个实例中,可以以包含rna型grna和蛋白型crispr的grna-crispr酶复合体(即核糖核蛋白(rnp))的形式将grna和crispr酶递送入或导入受试者。
可借助电穿孔、显微注射、瞬时细胞压缩或挤压(例如在文献[lee等(2012)nanolett.,12,6322-6327]中所描述的)、脂质介导的转染、纳米粒子、脂质体、肽介导的递送或它们的组合将grna-crispr酶复合体递送入或导入受试者。
本说明书中公开的grna-crispr酶复合体可用于对靶基因(即免疫调节基因)进行人工操纵或修饰。
可使用上述所述grna-crispr酶复合体(即crispr复合体),对靶基因进行操纵或修饰。此处,靶基因的操纵或修饰包括以下所有阶段:i)对靶基因进行切割或损伤;以及ii)对所损伤的靶基因进行修复或恢复。
i)对靶基因进行切割或损伤可使用crispr复合体对靶基因进行切割或损伤,特别是对靶基因中的靶序列进行切割或损伤。
靶序列可为grna-crispr酶复合体的靶标,靶序列可包含由crispr酶识别的pam序列或者可不包含由crispr酶识别的pam序列。此类靶序列可为实施者提供用于设计grna的重要标准。
靶序列可由grna-crispr酶复合体的grna特异性识别,从而可将grna-crispr酶复合体放置在靠近所识别的靶序列的位置。
靶位点处的“切割”是指多聚核苷酸共价骨架的断裂。切割可包括但不限于磷酸二酯键的酶促水解或化学水解,并可通过多种其它方法进行。单链切割和双链切割都是可能的,双链切割可以作为两条不同的单链切割的结果而发生。双链切割可产生平末端或交错(staggered)末端。
在一个实例中,使用crispr复合体对靶基因进行切割或损伤可为将靶序列的双链完全切割或损伤。
在实施方式中,当crispr酶为野生型spcas9时,crispr复合体可完全切割与grna形成互补结合的靶序列的双链。
在另一实施方式中,当crispr酶为spcas9切口酶(d10a)和spcas9切口酶(h840a)时,各crispr复合体可单独切割与grna形成互补结合的靶序列的两条单链。即,spcas9切口酶(d10a)可切割与grna形成互补结合的靶序列的互补单链,而spcas9切口酶(h840a)可切割与grna形成互补结合的靶序列的非互补单链,可顺序或同时实施切割。
在另一实例中,使用crispr复合体对靶基因或核酸进行切割或损伤可为仅对靶序列的双链中的单链进行切割或损伤。此处,单链可为靶序列中与grna形成互补结合的引导核酸结合序列(即互补单链),或不与grna形成互补结合的引导核酸非结合序列(即与grna非互补的单链)。
在一个实施方式中,当crispr酶为spcas9切口酶(d10a)时,crispr复合体可切割靶序列中与grna形成互补结合的引导核酸结合序列,即spcas9切口酶(d10a)可切割互补单链,而不与grna形成互补结合的引导核酸非结合序列(即与grna非互补的单链)可不被切割。
在另一实施方式中,当crispr酶为spcas9切口酶(h840a)时,crispr复合体可切割靶序列中不与grna形成互补结合的引导核酸非结合序列,即spcas9切口酶(h840a)可切割与grna非互补的单链,而靶序列中与grna形成互补结合的引导核酸结合序列(即互补单链)可不被切割。
在又一实例中,使用crispr复合体对靶基因或核酸的切割或损伤可为部分去除核酸片段。
在实施方式中,当由两个与各自不同的靶序列形成互补结合的grna以及野生型spcas9形成crispr复合体时,可对与第一grna形成互补结合的靶序列的双链进行切割,并可对与第二grna形成互补结合的靶序列的双链进行切割,从而借助第一grna和第二grna以及spcas9删除核酸片段。
ii)关于损伤的靶基因的修复或恢复,可借助非同源末端接合(nhej)或同源介导的修复(hdr)来进行修复或恢复。
非同源末端接合(nhej)是通过将被切割的双链或单链的两端进行连接对dna中的双链断裂进行恢复或修复的方法,一般而言,当将通过双链断裂(例如切割)形成的两个相容末端持续彼此接触使得两个末端完全相接,受损的双链得以修复。nhej是能够用于整个细胞周期的恢复方法,通常在细胞中无同源基因组作为模板时(例如g1期)发生。
在利用nhej对损伤的基因或核酸进行修复的过程中,nhej修复区中的核酸序列出现一些插入和/或缺失(插入缺失,indel),此类插入和/或缺失导致读码框位移,产生移码的转录组mrna。其结果是,由于无义介导的衰变(nonsense-mediateddecay)或正常蛋白无法合成,造成固有功能丧失。此外,即使读码框保持不变,序列中相当数量的插入或缺失造成的突变也可导致蛋白功能破坏。由于相比蛋白中非重要区域的突变,对重要功能结构域中的突变可能耐受性更低,突变为基因座依赖型的。
由于不能预测在天然状态下由nhej产生的插入缺失突变,特定的插入缺失序列优选位于指定的受损区中,并可来自于微同源的小区域。常规地,缺失的长度范围为1bp-50bp,插入趋向于更短,并通常包含直接包围受损区域的短重复序列。
此外,nhej是造成突变的过程,当不必须生成特定的最终序列时,可将nhej用于对短序列基序进行删除。
可使用该nhej进行crispr复合体所靶向的基因的特异性敲除。可使用crispr酶(例如cas9或cpf1)切割靶基因或核酸的双链或两条单链,并可借助nhej使得靶基因或核酸中的受损的双链或两条单链具有插入缺失,从而诱导靶基因或核酸的特异性敲除。此处,crispr酶所切割的靶基因或核酸的位点可在非编码区或编码区;此外,由nhej所恢复的靶基因或核酸的位点可在非编码区或编码区。
在一个实例中,由于通过使用crispr复合体对靶基因的双链进行切割并通过nhej进行恢复的过程,可在恢复区中发生各种插入和缺失(插入缺失)。
术语“插入缺失”统称此类突变:其中,在dna的核苷酸序列中插入或删除了一些核苷酸。如上所述,当引导核酸-编辑蛋白复合体切割免疫调节基因的核酸(dna、rna)时,插入缺失可为在通过同源重组(hdr)或非同源末端接合(nhej)机制进行修复的过程中引入靶序列的插入缺失。
同源定向修复(hdr)是无错修正方法,其使用同源序列作为模板对损伤的基因或核酸进行修复或恢复,一般而言,为修复或恢复受损dna(即,恢复细胞的固有信息),利用未被修饰的互补核苷酸序列的信息或者姐妹染色单体的信息对受损dna进行修复或恢复。hdr最常见的类型为同源重组(hr)。hdr是通常出现在活跃分裂的细胞的s期或g2/m期的修复或恢复方法。
为借助hdr而不使用细胞的姐妹染色单体或互补核苷酸序列对损伤的dna进行修复或恢复,可将使用互补核苷酸序列或同源核苷酸序列的信息人工合成的dna模板(即,包含互补核苷酸序列或同源核苷酸序列的核酸模板)提供至细胞来修复或恢复受损dna。此处,当进一步将核酸序列或核酸片段添加至核酸模板来修复受损dna时,可将进一步添加至受损dna的核酸序列或核酸片段敲入。进一步添加的核酸序列或核酸片段可为对由正常基因或核酸的突变修饰的靶基因或核酸进行修正的核酸序列或核酸片段,或者为期望在细胞中表达的基因或核酸,但不限于此。
在一个实例中,可使用crispr复合体切割靶基因或核酸的双链或单链,可将核酸模板(该核酸模板包含与临近切割位点的核苷酸序列互补的核苷酸序列)提供至细胞以通过hdr方法修复或恢复靶基因或核酸中被切割的核苷酸序列。
此处,包含互补核苷酸序列的核酸模板可具有受损dna(即,互补核苷酸序列中被切割的双链或单链),并进一步包含期望被插入至受损dna的核酸序列或核酸片段。可使用包含互补碱基序列和待插入的核酸序列或核酸片段的核酸模板将额外核酸序列或核酸片段插入至受损dna(即,靶基因或核酸的切割位点)。此处,待插入的核酸序列或核酸片段以及额外核酸序列或核酸片段可为对由正常基因或核酸的突变造成的修饰的靶基因或核酸进行修正的核酸序列或核酸片段,或者为待在细胞中表达的基因或核酸。互补核苷酸序列可为与受损dna形成互补结合的核苷酸序列(即,靶基因或核酸被切割的双链或单链的左侧或右侧的核苷酸序列)。或者,互补核苷酸序列可为与受损dna形成互补结合的核苷酸序列(即,靶基因或核酸被切割的双链或单链的3'和5'端)。互补核苷酸序列可为15bp-3000bp核苷酸序列,可根据核酸模板或靶基因或核酸的大小对互补核苷酸序列的长度或大小进行适当设计。此处,作为核酸模板,可使用双链或单链的核酸,或者其可为线性或环状,但本发明不限于此。
在另一实例中,可使用crispr复合体切割双链或单链靶基因或核酸,可将核酸模板(该核酸模板包含临近切割位点的核苷酸序列的同源核苷酸序列)提供至细胞,并可通过hdr方法修复或恢复靶基因或核酸中被切割的核苷酸序列。
此处,包含同源核苷酸序列的核酸模板可具有受损dna(即,被切割的双链或单链同源核苷酸序列),并进一步包含期望被插入至受损dna的核酸序列或核酸片段。可使用包含同源碱基序列和待插入的核酸序列或核酸片段的核酸模板将额外核酸序列或核酸片段插入至受损dna(即,靶基因或核酸的切割位点)。此处,待插入的核酸序列或核酸片段以及额外核酸序列或核酸片段可为对由正常基因或核酸的突变造成的修饰的靶基因或核酸进行修正的核酸序列或核酸片段,或者为待在细胞中表达的基因或核酸。同源核苷酸序列可为与受损dna具有同源性的核苷酸序列,即,与靶基因或核酸中被切割的双链或单链的左侧和右侧的核苷酸序列具有同源性的核苷酸序列。或者,同源核苷酸序列可为与受损dna具有同源性的核苷酸序列,即,与靶基因或核酸中被切割的双链或单链的3'和5'端具有同源性的碱基序列。同源核苷酸序列可为15bp-3000bp核苷酸序列,可根据核酸模板或者靶基因或核酸的大小对同源核苷酸序列的长度或大小进行适当设计。此处,作为核酸模板,可使用双链或单链的核酸,或者其可为线性或环状,但本发明不限于此。
除了nhej和hdr,存在对受损的靶基因进行修复或恢复的方法。例如,对受损的靶基因进行修复或恢复的方法可为单链退火、单链断裂修复、错配修复、或核苷酸受损修复或使用核苷酸受损修复的方法。
单链退火(ssa)是对靶核酸中存在的两个重复序列间的双链断裂进行修复的方法,一般使用多于30bp核苷酸序列的重复序列。可对重复序列进行切割(以产生粘性末端),从而在靶核酸双链的各断裂端产生单链;并且,在切割后利用rpa蛋白对含有重复序列的单链垂悬部分(overhang)进行包覆,来防止重复序列彼此的不适当退火。rad52结合至垂悬部分上的各重复序列,并排列能够对互补重复序列进行退火的序列。退火后,垂悬部分的单链悬垂(flap)被切割,合成新dna来填充特定缺口,从而恢复dna双链。该修复的结果是两个重复间的dna序列被删除,删除长度可取决于多种因素(包括此处使用的两个重复的位置和切割的路径或进行度)。
就对靶核酸序列进行修饰或修正而言,与hdr类似,ssa使用互补序列(即互补重复序列);与hdr不同,ssa不需要核酸模板。
单链断裂修复(ssbr)可借助与上述修复机制不同的机制对基因组中的单链断裂进行修复。在单链dna断裂的情况下,parp1和/或parp2识别断裂并动员修复机制。parp1对dna断裂的结合和活性是暂时的,通过促进损伤区域中ssbr蛋白复合体的稳定性来促进ssbr。ssbr复合体中最重要的蛋白是xrcc1,它与促进dna的3'和5'端加工的蛋白相互作用来稳定dna。末端加工通常涉及将损伤的3'端修复为羟基化状态和/或将损伤的5'端修复为具有磷酸部分,并在末端加工后发生dna缺口填充。存在两种dna缺口填充方法,即短补丁(patch)修复和长补丁修复,短补丁修复涉及易位的单核苷酸的插入。在dna缺口填充后,dna连接酶促进末端连接。
错配修复(mmr)可作用于错配的dna核苷酸。msh2/6或msh2/3复合体各自具有atpase活性,并因此在识别错配和引发修复中起到重要作用,以及msh2/6主要识别核苷酸-核苷酸错配并识别一个或两个核苷酸的错配,而msh2/3主要识别更长的错配。
碱基切除修复(ber)是在整个细胞周期中均活跃的修复方法,其用于从基因组中去除较小的非螺旋扭曲核苷酸损伤区。在损伤的dna中,通过切割连接碱基与脱氧核糖-磷酸骨架的n-糖苷键去除损伤的核苷酸,随后切割磷酸二酯键骨架,从而生成单链dna断裂。去除由此形成的受损单链末端,并利用新的互补碱基填充由于单链去除而造成的缺口,随后利用dna连接酶将新填充的互补碱基的末端连接至骨架,实现对损伤dna的修复或恢复。
ner(核苷酸切除修复)是对于从dna中去除较大的螺旋扭曲损伤而言重要的切除机制,当识别到损伤时,去除含有损伤区域的短单链dna片段,产生22bp-30bp核苷酸序列的单链缺口。利用新的互补碱基填充产生的缺口,并利用dna连接酶将新填充的互补碱基的末端连接至骨架,实现对损伤dna的修复或恢复。
用grna-crispr复合体对靶基因(即免疫调节基因)进行人工操纵的效果很大程度上可为敲除、敲减和敲入。
术语“敲除”是指靶基因或核酸的失活,而“靶基因或核酸的失活”是指不发生靶基因或核酸的转录和/或翻译的状态。通过敲除可对造成疾病的基因或具有异常功能的基因的转录和翻译进行抑制,阻止蛋白表达。
例如,当使用grna-crispr酶复合体(即crispr复合体)对靶基因或染色体进行编辑或修正时,可使用crispr复合体对靶基因或染色体进行切割。可利用crispr复合体通过nhej对损伤的靶基因或染色体进行修复。由于nhej,损伤的靶基因或染色体可具有插入缺失,从而可诱导针对靶基因或染色体的特异性敲除。
在另一实例中,当使用grna-crispr酶复合体(即crispr复合体)和供体对靶基因或染色体进行编辑或修正时,可使用crispr复合体对靶基因或核酸进行切割。由crispr复合体损伤的靶基因或核酸可使用供体借助hdr进行恢复。此处,供体包含互补核苷酸序列和期望被插入的核苷酸序列。此处,可根据插入的位置或目的来对期望插入的核苷酸序列的数目进行调节。当通过使用供体对损伤的基因或染色体进行修复时,将期望插入的核苷酸序列插入到损伤的核苷酸序列区域,从而可诱导靶基因或染色体的特异性敲除。
术语“敲减”是指靶基因或核酸的转录和/或翻译或靶蛋白的表达降低。用敲减对基因或蛋白的过表达进行调节,可预防发病或可治疗疾病。
例如,当利用grna-crispr失活酶-转录抑制活性结构域复合体(即,包含转录抑制活性结构域的crispr失活复合体)对靶基因或染色体进行编辑或修正时,crispr失活复合体可特异性地结合至靶基因或染色体,通过crispr失活复合体中包含的转录抑制活性结构域可对靶基因或染色体的转录进行抑制,从而诱导敲减(其中相应基因或染色体的表达被抑制)。
在另一实例中,当使用grna-crispr酶复合体(即crispr复合体)对靶基因或染色体进行编辑或修正时,crispr复合体可切割靶基因或染色体的启动子和/或增强子区域。此处,grna可识别靶基因或染色体的启动子和/或增强子区域中作为靶序列的部分核苷酸序列。可通过nhej对由crispr复合体损伤的靶基因或染色体进行恢复。由于nhej,损伤的靶基因或染色体可具有插入缺失,从而可诱导针对靶基因或染色体的特异性敲除。或者,当选择性地使用供体时,可通过hdr对由crispr复合体损伤的靶基因或染色体进行恢复。当使用供体对损伤的基因或染色体进行恢复时,将期望插入的核苷酸序列插入至损伤的核苷酸序列区域,从而可诱导针对靶基因或染色体的特异性敲减。
术语“敲入”是指将特定核酸或基因插入至靶基因或核酸,特别是,术语“特定核酸或基因”是指意图被插入或期望被表达的核酸或基因。通过对造成疾病的突变基因进行精确修正或通过插入正常基因来诱导正常基因表达,可将敲入用于疾病的治疗。
此外,敲入可需要额外供体。
例如,当使用grna-crispr酶复合体(即crispr复合体)和供体对靶基因或核酸进行编辑或修正时,可使用crispr复合体对靶基因或核酸进行切割。可使用crispr复合体通过hdr对损伤的靶基因或核酸进行恢复。此处,供体包含特定核酸或基因,并可使用供体将特定核酸或基因插入至损伤的基因或染色体。此处,插入的特定核酸或基因可诱导蛋白表达。
作为本说明书公开的实施方式,grna-crispr酶复合体可对以下基因进行人工操纵或修饰:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
grna-crispr酶复合体可特异性识别以下基因的靶序列:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
grna-crispr酶复合体的grna可特异性识别靶序列,从而将grna-crispr酶复合体定位于靠近所识别的靶序列的位置。
靶序列可为对pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因进行人工修饰的区域或范围。
靶序列可为位于以下基因的启动子区域中的连续的10bp-25bp核苷酸序列:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
靶序列可为位于以下基因的内含子区域中的连续的10bp-25bp核苷酸序列:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
靶序列可为位于以下基因的外显子区域中的连续的10bp-25bp核苷酸序列:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
靶序列可为位于以下基因的增强子区域中的连续的10bp-25bp核苷酸序列:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
靶序列可为位于以下基因的3'-utr区域中的连续的10bp-25bp核苷酸序列:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
靶序列可为位于以下基因的5'-utr区域中的连续的10bp-25bp核苷酸序列:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
靶序列可为临近以下基因的核苷酸序列中的前间区序列邻近基序(pam)序列的5'端和/或3'端区域的连续的10bp-25bp核苷酸序列:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
此处,pam序列可为例如以下序列的一种或多种(以5'至3'方向描述)
ngg(n为a、t、c或g);
nnnnryac(n各自独立地为a、t、c或g;r为a或g;y为c或t);
nnagaaw(n各自独立地为a、t、c或g;w为a或t);
nnnngatt(n各自独立地为a、t、c或g);
nngrr(t)(n各自独立地为a、t、c或g;r为a或g;y为c或t);以及
ttn(n为a、t、c或g)。
在实施方式中,靶序列可为选自表1中所述的核苷酸序列中的一个或多个核苷酸序列。
可由grna和crispr酶形成grna-crispr酶复合体。
grna可包含能够与以下基因的靶序列中的引导核酸结合序列形成部分或完全互补结合的引导结构域:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
引导结构域可为与引导核酸结合序列互补的核苷酸序列,例如具有至少70%、75%、80%、85%、90%或95%或更高的互补性或完全互补性。
引导结构域可包含与pd-1基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与ctla-4基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与a20基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与dgka基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与dgkz基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与fas基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与egr2基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与ppp2r2d基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与tet2基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与psgl-1基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
引导结构域可包含与kdm6a基因的靶序列中的引导核酸结合序列互补的核苷酸序列。此处,互补核苷酸序列可包含0-5个、0-4个、0-3个或0-2个错配。
grna可包含选自于由第一互补结构域、连接结构域、第二互补结构域、近端结构域和尾部结构域所组成的组中的一个或多个结构域。
crispr酶可为选自于由如下蛋白所组成的组中的一种或多种蛋白:酿脓链球菌衍生而来的cas9蛋白、空肠弯曲杆菌衍生而来的cas9蛋白、嗜热链球菌衍生而来的cas9蛋白、金黄色葡萄球菌衍生而来的cas9蛋白、由脑膜炎奈瑟菌衍生而来的cas9蛋白以及cpf1蛋白。在一实例中,编辑蛋白可为空肠弯曲杆菌衍生而来的cas9蛋白或金黄色葡萄球菌衍生而来的cas9蛋白。
根据grna和crispr酶的类型,grna-crispr酶复合体可对以下基因进行人工操纵或修饰:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
在一个实例中,当crispr酶为spcas9蛋白时,处于临近经人工操纵或修饰的基因的靶区域中存在的5'-ngg-3'(n为a、t、g或c)pam序列的5’端和/或3’端的位置中的连续的1bp-50bp、1bp-40bp、1bp-30bp、优选1bp-25bp核苷酸序列区域中可包含以下一种或多种修饰,所述经人工操纵或修饰的基因为经人工操纵或修饰的pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在另一实例中,当crispr酶为cjcas9蛋白时,处于临近经人工操纵或修饰的基因的靶区域中存在的5'-nnnnryac-3'(n各自独立地为a、t、g或c;r为a或g;y为c或t)pam序列的5’端和/或3’端的位置中的连续的1bp-50bp、1bp-40bp、1bp-30bp、优选1bp-25bp核苷酸序列区域中可包含以下一种或多种修饰,所述经人工操纵或修饰的基因为经人工操纵或修饰的pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在又一实例中,当crispr酶为stcas9蛋白时,处于临近经人工操纵或修饰的基因的靶区域中存在的5'-nnagaaw-3'(n各自独立地为a、t、g或c;w为a或t)pam序列的5’端和/或3’端的位置中的连续的1bp-50bp、1bp-40bp、1bp-30bp、优选1bp-25bp核苷酸序列区域中可包含以下一种或多种修饰,所述经人工操纵或修饰的基因为经人工操纵或修饰的pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在一个实例中,当crispr酶为nmcas9蛋白时,处于临近经人工操纵或修饰的基因的靶区域中存在的5'-nnnngatt-3'(n各自独立地为a、t、g或c)pam序列的5’端和/或3’端的位置中的连续的1bp-50bp、1bp-40bp、1bp-30bp、优选1bp-25bp核苷酸序列区域中可包含以下一种或多种修饰,所述经人工操纵或修饰的基因为经人工操纵或修饰的pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在另一实例中,当crispr酶为sacas9蛋白时,处于临近经人工操纵或修饰的基因的靶区域中存在的5'-nngrr(t)-3'(n各自独立地为a、t、g或c;r为a或g;以及(t)为可任选包含的任意序列)pam序列的5’端和/或3’端的位置中的连续的1bp-50bp、1bp-40bp、1bp-30bp、优选1bp-25bp核苷酸序列区域中可包含以下一种或多种修饰,所述经人工操纵或修饰的基因为经人工操纵或修饰的pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在另一实例中,当crispr酶为cpf1蛋白时,处于临近经人工操纵或修饰的基因的靶区域中存在的5'-ttn-3'(n各自独立地为a、t、g或c)pam序列的5’端和/或3’端的位置中的连续的1bp-50bp、1bp-40bp、1bp-30bp、优选1bp-25bp核苷酸序列区域中可包含以下一种或多种修饰,所述经人工操纵或修饰的基因为经人工操纵或修饰的pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
借助grna-crispr酶复合体对pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因进行人工操纵的效果可为敲除。
借助grna-crispr酶复合体对pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因进行人工操纵的作用可抑制由pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因编码的蛋白的表达。
借助grna-crispr酶复合体对pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因进行人工操纵的效果可为敲减。
借助grna-crispr酶复合体对pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因进行人工操纵的作用可降低分别由pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因编码的蛋白的表达。
借助grna-crispr酶复合体对pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因进行人工操纵的效果可为敲入。
此处,可通过grna-crispr酶复合体(以及额外地通过包含外来核苷酸序列或基因的供体)来诱导敲入效果。
借助grna-crispr酶复合体对pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因进行人工操纵的作用可使由外来核苷酸序列或基因编码的肽或蛋白得以表达。
本说明书公开的一方面涉及经操纵的免疫细胞。
“免疫细胞”为参与免疫应答的细胞,其包括直接或间接参与免疫应答的所有细胞以及它们的预分化细胞。
免疫细胞可具有细胞因子分泌、分化成其它免疫细胞和细胞毒性的功能。免疫细胞还包括从其自然状态下经历突变的细胞。
免疫细胞由骨髓中的造血干细胞分化出来,其主要包括淋巴样祖细胞和髓样祖细胞;还包括如下全部细胞:由淋巴样祖细胞分化而来并负责获得性免疫的t细胞和b细胞;以及由髓样祖细胞分化而来的巨噬细胞、嗜酸性粒细胞、中性粒细胞、嗜碱性粒细胞、巨核细胞、红细胞等。
具体地,所述细胞可为选自于由如下细胞所组成的组中的至少一种:t细胞,例如cd8+t细胞(例如cd8+初始t细胞、cd8+效应t细胞、中心记忆t细胞或效应记忆t细胞)、cd4+t细胞、自然杀伤t细胞(nkt细胞)、调节t细胞(treg)、干细胞记忆t细胞;淋巴样祖细胞;造血干细胞;自然杀伤细胞(nk细胞);树突细胞;细胞因子诱导的杀伤细胞(cik);外周血单核细胞(pbmc);单核细胞;巨噬细胞;自然杀伤t(nkt)细胞等。
“经操纵的免疫细胞”是指经历了人工操纵而不处于自然状态的免疫细胞。最近,积极研究了通过从体内提取免疫细胞以及实施人工操纵来增强免疫力的技术。由于针对某些疾病具有优异的免疫效力,此类经操纵的免疫细胞已被证明是一种新治疗方法。特别地,对经操纵的免疫细胞的研究已与癌症治疗相关联地积极进行。
经操纵的免疫细胞可为由用于免疫细胞操纵的组合物进行人工操纵或修饰的免疫细胞。此处,术语“用于免疫细胞操纵的组合物”是指用于对免疫细胞进行人工修饰或操纵的一种或多种物质(例如dna、rna、核酸、蛋白、病毒、组合物),例如用于免疫细胞操纵的组合物可包含用于基因操纵的组合物的部分或全部组合物,还可包含编码外源蛋白的核酸用于表达所述外源蛋白。
经操纵的免疫细胞可为通过基因操纵产生的免疫细胞。
此处,可考虑基因表达的调节过程来实施基因操纵。
在一个实例中,可通过选择适合于各步骤的操纵方法,在如下步骤中实施基因操纵:转录调节、rna加工调节、rna转运调节、rna降解调节、翻译调节或蛋白修饰调节。
例如,基因操纵可使用rna干扰(rnai)或rna沉默通过阻止mrna,来控制基因信息的表达;并且,在某些情况下,可通过破坏来阻止中间步骤期间蛋白合成信息的递送,从而控制遗传信息的表达。
在另一实例中,基因操纵可使用能够催化dna或rna分子水解(切割)、优选能够催化dna分子中的核酸之间的键水解(切割)的野生型酶或变体酶。可使用引导核酸-编辑蛋白复合体。
例如,基因操纵可通过使用选自于由如下核酸酶所组成的组中的一种或多种对基因进行操纵来控制遗传信息的表达:大范围核酸酶、锌指核酸酶、crispr/cas9(cas9蛋白)、crispr-cpf1(cpf1蛋白)以及tale核酸酶。
在优选的实例中,不受限地,可通过引导核酸-编辑蛋白复合体实施基因操纵,关于上述引导核酸-编辑蛋白的解释如上所述。
此外,经操纵的免疫细胞可为由于特定蛋白功能的丧失或损伤而具有修饰的功能的免疫细胞。
此处,特定蛋白的功能可因化合物而丧失或损伤。
化合物可与特定蛋白结合并阻碍免疫调节因子的功能。
此外,该化合物可与特定蛋白结合并对免疫调节因子的结构进行修饰,从而阻碍其正常功能。
或者,可通过蛋白与特定蛋白结合的修饰使特定蛋白的功能丧失或损伤。
经操纵的免疫细胞可为经功能性操纵的免疫细胞或者经混合型操纵的免疫细胞。
作为本发明公开的实施方式,经操纵的免疫细胞可为经功能性操纵的免疫细胞。
术语“经功能性操纵的免疫细胞”是指其中的野生型免疫调节因子的天然表达已被修饰或人工操纵至损伤该免疫调节因子的功能的免疫细胞。
术语“免疫调节因子”是指由免疫调节基因编码的多肽或蛋白,也可称为由免疫调节基因转录、翻译和表达的免疫调节蛋白。
经功能性操纵的免疫细胞可为经操纵以阻遏或抑制免疫调节因子表达的免疫细胞。
此处,经功能性操纵的免疫细胞可为其中的免疫调节基因被操纵以阻遏或抑制免疫调节因子表达的免疫细胞。
经功能性操纵的免疫细胞可为其中的免疫细胞活性调节基因被操纵的免疫细胞。
此处,经功能性操纵的免疫细胞可为其中选自shp-1、pd-1、ctla-4、cblb、ilt-2、kir2dl4和psgl-1中的一种或多种基因失活的免疫细胞。
经功能性操纵的免疫细胞可为其中的免疫细胞生长调节基因被操纵的免疫细胞。
此处,经功能性操纵的免疫细胞可为其中选自dgk-α、dgk-ζ、fas、egr2、egr3、ppp2r2d和a20中的一个或多个基因失活的免疫细胞。在优选的实施方式中,选自dgk-α、dgk-ζ、egr2、ppp2r2d和a20中的一个或多个基因失活。
经功能性操纵的免疫细胞可为其中的免疫细胞死亡调节基因被操纵的免疫细胞。
此处,经功能性操纵的免疫细胞可为其中选自daxx、bim、bid、bad、pd-1和ctla-4中的一个或多个基因失活的免疫细胞。
此外,经功能性操纵的免疫细胞可为其中插入有诱导自身死亡的元件的免疫细胞。
经功能性操纵的免疫细胞可为其中的免疫细胞耗竭调节元件被操纵的免疫细胞。
此处,经功能性操纵的免疫细胞可为其中选自tet2、wnt和akt中的一个或多个基因失活的免疫细胞。
经功能性操纵的免疫细胞可为其中的细胞因子分泌元件被操纵的免疫细胞。
经功能性操纵的免疫细胞可为其中的抗原结合调节元件被操纵的免疫细胞。
此处,经功能性操纵的免疫细胞可为其中选自dck、cd52、b2m和mhc中的一个或多个基因失活的免疫细胞。
经功能性操纵的免疫细胞可为其中的不同于前述基因的免疫调节基因被操纵的免疫细胞。
经功能性操纵的免疫细胞可为其中的一种或多种免疫调节基因被同时操纵的免疫细胞。此处,一种或多种免疫调节基因可被操纵。
此处,当操纵一种免疫调节基因时,并不一定表现出新免疫效力。对一种免疫调节基因的操纵可造成多种新免疫效力或抑制多种新免疫效力。
经功能性操纵的免疫细胞可为其中除免疫调节基因之外的编码野生型受体的基因被操纵的免疫细胞。
此处,野生型受体可为t细胞受体(tcr)。
经功能性操纵的免疫细胞可为其中的野生型受体缺失或以较低比率存在于表面上的免疫细胞。
经功能性操纵的免疫细胞可为其中的野生型受体以大比例存在于表面上的免疫细胞。
经功能性操纵的免疫细胞可为其中的野生型受体对特定抗原具有增强的识别能力的免疫细胞。
通过对野生型受体和免疫调节基因进行操纵,经功能性操纵的免疫细胞可具有新免疫学效力。
新免疫效力可为其中调节了识别特定抗原的能力的免疫效力。
新免疫效力可为其中改善了识别特定抗原的能力的免疫效力。
特别是,特异性抗原可为疾病抗原,例如癌细胞抗原。
新免疫效力可为其中识别特定抗原的能力恶化的免疫效力。
新免疫效力可为其中改善了新免疫效力的免疫效力。
新免疫效力可为其中调控了免疫细胞生长的免疫效力。特别地,免疫效力可为其中促进或延迟了生长和分化的免疫效力。
新的免疫效力可为调控了免疫细胞死亡的免疫效力。特别地,免疫效力可为防止免疫细胞的死亡。此外,免疫效力可为在经过合适的时间后引起免疫细胞自杀。
新免疫效力可为其中减轻了免疫细胞的功能丧失的免疫效力。
新免疫效力可为其中调控了免疫细胞的细胞因子分泌的免疫效力。特别地,免疫效力可为促进或抑制细胞因子分泌。
新免疫效力可为调控免疫细胞中野生型受体的抗原结合能力。特别地,免疫效力可为改善野生型受体针对特定抗原的特异性。
此外,经功能性操纵的免疫细胞可为经操纵使得免疫调节因子的功能损伤的免疫细胞。
此处,可通过化合物使免疫调节因子的功能丧失或损伤。
化合物可与免疫调节因子或与免疫调节因子相互作用的特异性蛋白结合,并阻碍免疫调节因子的功能。
此外,化合物可与免疫调节因子结合并对免疫调节因子的三维结构进行人工修饰,从而阻碍其正常功能。
或者,可通过与免疫调节因子相互作用的蛋白的修饰而使免疫调节因子的功能丧失或损伤。
作为本说明书公开的实施方式,经操纵的免疫细胞可为其中免疫调节基因被人工操纵的经功能性操纵的免疫细胞。
此处,免疫调节基因可为pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因。
可通过用于基因操纵的组合物对经功能性操纵的免疫细胞进行操纵。
关于上述用于基因操纵的组合物的解释如上所述。
经功能性操纵的免疫细胞可包含一种或多种经人工操纵或修饰的免疫调节基因。
此处,人工修饰的免疫调节基因可在靶序列中或在临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中包含以下一种或多种修饰:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在一个实例中,经功能性操纵的免疫细胞可包含一种或多种经人工操纵或修饰的免疫调节基因。
此处,经人工操纵或修饰的免疫调节基因可在靶序列中或在临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中包含一个或多个核苷酸的缺失。
例如,经人工操纵或修饰的免疫调节基因可在位于靶序列中的核苷酸序列区域中包含一个或多个核苷酸的缺失。
此处,缺失的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸。例如,缺失的核苷酸可为位于靶序列中的1bp核苷酸。或者,缺失的核苷酸可为位于靶序列中的1bp核苷酸。或者,缺失的核苷酸可为连续的3bp核苷酸。或者,缺失的核苷酸可为位于靶序列中的不连续的4bp核苷酸,其中不连续的4bp核苷酸可为1bp核苷酸和连续的3bp核苷酸,或者连续的2bp核苷酸和另一连续的2bp核苷酸(图1)。例如,缺失的核苷酸可为位于靶序列中的不连续的30bp核苷酸,其中不连续的30bp核苷酸可为连续的25bp核苷酸、连续的4bp核苷酸和不连续的1bp核苷酸。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。核苷酸片段可为2bp-5bp、6bp-10bp、11bp-15bp、16bp-20bp、21bp-25bp、26bp-30bp、31bp-35bp、36bp-40bp、41bp-45bp或46bp-50bp。例如,缺失的核苷酸可为位于靶序列中的2bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的10bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的16bp核苷酸片段(图2)。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。此处,包含2bp以上核苷酸的核苷酸片段可为具有不连续的核苷酸序列的单个核苷酸片段(即具有一个或多个核苷酸序列缺口),可由两个以上的缺失的核苷酸片段来产生两个以上的缺失区域。例如,缺失的核苷酸可为位于靶序列中的2bp核苷酸片段和6bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的12bp核苷酸片段和6bp核苷酸片段(图3)。
在另一实例中,经人工操纵或修饰的免疫调节基因可在临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中包含一个或多个核苷酸的缺失。
此处,缺失的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸。例如,缺失的核苷酸可为位于靶序列中的1bp核苷酸。或者,缺失的核苷酸可为位于临近靶序列的3′端的连续的4bp核苷酸。或者,缺失的核苷酸可为位于临近靶序列的5'端和/或3'端的不连续的4bp核苷酸,其中不连续的4bp核苷酸可为位于临近靶序列的5'端的连续的3bp核苷酸,以及位于临近靶序列的3'端的1bp核苷酸(图4)。例如,缺失的核苷酸可为位于靶序列中的不连续的25bp核苷酸,其中不连续的25bp核苷酸可为连续的15bp核苷酸、连续的8bp核苷酸、不连续的1bp核苷酸和不连续的1bp核苷酸。
或者此处,缺失的核苷酸可为包含连续的2bp以上核苷酸的核苷酸片段。核苷酸片段可为2bp-5bp、6bp-10bp、11bp-15bp、16bp-20bp、21bp-25bp、26bp-30bp、31bp-35bp、36bp-40bp、41bp-45bp或46bp-50bp。例如,缺失的核苷酸可为位于临近靶序列的3'端的2bp核苷酸片段。或者,缺失的核苷酸可为位于临近靶序列的5’端的10bp核苷酸片段。或者,缺失的核苷酸可为位于临近靶序列的3’端的20bp核苷酸片段(图5)。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。此处,包含2bp以上核苷酸的核苷酸片段可为具有不连续的核苷酸序列的单个核苷酸片段(即具有一个或多个核苷酸序列缺口),并且可用两个以上缺失的核苷酸片段来产生两个以上缺失区域。例如,缺失的核苷酸可为位于临近靶序列的5’端的3bp核苷酸片段和位于临近靶序列的3’端的6bp核苷酸片段。或者,缺失的核苷酸可为位于临近靶序列的3′端的12bp核苷酸片段和6bp核苷酸片段(图6)。
在又一实例中,经人工操纵或修饰的免疫调节基因可在靶序列中以及在位于临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中包含一个或多个核苷酸的缺失。
此处,缺失的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸。例如,缺失的核苷酸可为位于靶序列中以及临近于靶序列的3’端的连续的4bp核苷酸。或者,缺失的核苷酸可为位于靶序列中以及临近靶序列的3’端的位置中的不连续的3bp核苷酸,并且不连续的3bp核苷酸可为位于靶序列中的连续的2bp核苷酸以及位于临近于靶序列的3’端的1bp核苷酸(图7)。例如,缺失的核苷酸可为位于靶序列中的不连续的40bp核苷酸,并且不连续的25bp核苷酸可为连续的10bp核苷酸、连续的8bp核苷酸和不连续的5bp(不连续的1bp、1bp、1bp、1bp和1bp)核苷酸。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。核苷酸片段可为2bp-5bp、6bp-10bp、11bp-15bp、16bp-20bp、21bp-25bp、26bp-30bp、31bp-35bp、36bp-40bp、41bp-45bp或46bp-50bp。例如,缺失的核苷酸可为位于靶序列中以及临近靶序列的3’端的位置中的25bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中以及临近靶序列的5'端和3'端的位置中的35bp核苷酸片段(图8)。
或者此处,缺失的核苷酸可为两个以上核苷酸片段。此处,两个以上核苷酸片段可为具有不连续的核苷酸序列的单个核苷酸片段(即具有一个或多个核苷酸序列缺口),并且可用两个以上缺失的核苷酸片段来产生两个以上缺失区域。例如,缺失的核苷酸可为位于靶序列中以及临近于靶序列的5’端的位置中的6bp核苷酸片段,以及位于靶序列中以及临近于靶序列的3'端的位置中的13bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中以及临近于靶序列的3'端的位置中的17bp核苷酸片段,和位于临近靶序列的3'端的4bp核苷酸片段(图9)。
在另一实例中,经功能性操纵的免疫细胞可包含一种或多种经人工操纵或修饰的免疫调节基因。
此处,经人工操纵或修饰的免疫调节基因可在靶序列中或在位于临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中包含插入的一个或多个核苷酸。
例如,经人工操纵或修饰的免疫调节基因可在位于靶序列中的核苷酸序列区域中包含插入的一个或多个核苷酸。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸。例如,插入的核苷酸可为在靶序列的核苷酸序列区域中插入的连续的2bp核苷酸。或者,插入的核苷酸可为在靶序列中的核苷酸序列区域中插入的不连续的3bp核苷酸,并且不连续的3bp核苷酸可为1bp核苷酸和连续的2bp核苷酸。或者,插入的核苷酸可为在靶序列中的核苷酸序列区域中插入的不连续的4bp核苷酸,并且不连续的4bp核苷酸可为1bp核苷酸、连续的2bp核苷酸和另一1bp核苷酸(图10)。例如,插入的核苷酸可为在靶序列中的核苷酸序列区域中插入的不连续的30bp核苷酸,并且不连续的30bp核苷酸可为连续的15bp核苷酸、连续的12bp核苷酸和不连续的3bp(不连续的1bp、1bp和1bp)核苷酸。
或者此处,插入的核苷酸可为包含连续的5bp以上核苷酸的核苷酸片段。核苷酸片段可为5bp-10bp、11bp-50bp、50bp-100bp、100bp-200bp、200bp-300bp、300bp-400bp、400bp-500bp、500bp-750bp、或750bp-1000bp。例如,插入的核苷酸可为在靶序列中的核苷酸序列区域中插入的10bp核苷酸片段。或者,插入的核苷酸可为在靶序列中的核苷酸序列区域中插入的28bp核苷酸片段(图11)。
或者此处,插入的核苷酸可为特定基因的部分或全部核苷酸序列。特定基因可为由包含免疫调节基因的受试者(例如人细胞)不含有的外部区域的导入而来的基因。或者,特定基因可为包含免疫调节基因的受试者(例如人细胞)中存在的基因,例如人细胞基因组中存在的基因。例如,插入的核苷酸可为在靶序列中的核苷酸序列区域中插入的外源性基因的部分核苷酸序列。或者,插入的核苷酸可为在靶序列中的核苷酸序列区域中插入的外源性基因的全部核苷酸序列。或者,插入的核苷酸可为在靶序列中的核苷酸序列区域中插入的内源性基因的部分核苷酸序列,所述内源性基因可为靶基因(即免疫调节基因)的等位基因,或靶基因之外的其它基因。或者,插入的核苷酸可为在靶序列中的核苷酸序列区域中插入的内源性基因的全部核苷酸序列,所述内源性基因可为靶基因(即免疫调节基因)的等位基因、或靶基因之外的其它基因(图12)。
在另一实例中,经人工操纵或修饰的免疫调节基因可在靶序列中或在位于临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中包含插入的一个或多个核苷酸。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸。例如,插入的核苷酸可为在位于临近靶序列的5'端的核苷酸序列区域中插入的连续的2bp核苷酸。或者,插入的核苷酸可为在位于临近靶序列的3'端的核苷酸序列区域中插入的不连续的3bp核苷酸,并且所述不连续的3bp核苷酸可为1bp核苷酸和连续的2bp核苷酸(图13)。例如,插入的核苷酸可为在靶序列的核苷酸区域中插入的不连续的40bp核苷酸,并且所述不连续的40bp核苷酸可为连续的15bp核苷酸、连续的20bp核苷酸和连续的5bp核苷酸。
或者此处,插入的核苷酸可为包含连续的5bp以上核苷酸的核苷酸片段。核苷酸片段可为5bp-10bp、11bp-50bp、50bp-100bp、100bp-200bp、200bp-300bp、300bp-400bp、400bp-500bp、500bp-750bp或750bp-1000bp。例如,插入的核苷酸可为在位于临近靶序列的5'端的核苷酸序列区域中插入的22bp核苷酸片段。或者,插入的核苷酸可为在位于临近靶序列的3'端的核苷酸序列区域中插入的37bp核苷酸片段(图14)。
或者此处,插入的核苷酸可为特定基因的部分或全部核苷酸序列。特定基因可为由包含免疫调节基因的受试者(例如人细胞)不含有的外部区域的导入而来的基因。或者,特定基因可为包含免疫调节基因的受试者(例如人细胞)中含有的基因,例如人细胞基因组中存在的基因。例如,插入的核苷酸可为位于在临近靶序列的5'端的核苷酸序列区域中插入的外源性基因的部分核苷酸序列。或者,插入的核苷酸可为在位于临近靶序列的3'端的核苷酸序列区域中插入的外源性基因的全部核苷酸序列。或者,插入的核苷酸可为在位于临近靶序列的5'端的核苷酸序列区域中插入的内源性基因的部分核苷酸序列,并且所述内源性基因可为靶基因(即免疫调节基因)的等位基因,或靶基因之外的其它基因。或者,插入的核苷酸可为在位于临近靶序列的3'端的核苷酸序列区域中插入的内源性基因中的全部核苷酸序列,并且所述内源性基因可为靶基因(即免疫调节基因)的等位基因、或靶基因之外的其它基因(图15)。
在又一实例中,经功能性操纵的免疫细胞可包含一种或多种经人工操纵或修饰的免疫调节基因。
此处,经人工操纵或修饰的免疫调节基因可在靶序列中或在位于临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中包含一个或多个核苷酸的缺失和插入。
例如,经人工操纵或修饰的免疫调节基因可在位于靶序列中的核苷酸序列区域中包含一个或多个核苷酸的缺失和插入。
此处,缺失的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸;核苷酸片段;或特定基因的部分或全部核苷酸序列,并且所述缺失和插入可顺序进行或同时进行。
插入的核苷酸片段可为5bp-10bp、11bp-50bp、50bp-100bp、100bp-200bp、200bp-300bp、300bp-400bp、400bp-500bp、500bp-750bp或750bp-1000bp。
特定基因可为由包含免疫调节基因的受试者(例如人细胞)不含有的外部区域的导入而来的基因。或者,特定基因可为包含免疫调节基因的受试者(例如人细胞)中含有的基因,例如人细胞基因组中存在的基因。
例如,核苷酸的缺失和插入可发生在靶序列中的相似位置,并且缺失的核苷酸可为位于靶序列中的1bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的连续的2bp核苷酸。或者,缺失的核苷酸可为位于靶序列中的连续的3bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的连续的20bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的连续的2bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的外源性基因的部分核苷酸序列。或者,缺失的核苷酸可为位于靶序列中的连续的3bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的内源性基因的全部核苷酸序列,所述内源性基因可为靶基因(即免疫调节基因)的等位基因、或靶基因之外的其它基因(图16)。
例如,核苷酸的缺失和插入可发生在靶序列中的不同位置,并且缺失的核苷酸可为位于靶序列中的连续的4bp核苷酸,在此情况下,插入的核苷酸可为在靶序列中未缺失的不同位置中插入的连续的12bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的连续的5bp核苷酸;在此情况下,插入的核苷酸可为在靶序列中未缺失的不同位置中插入的内源性基因的部分核苷酸序列,所述内源性基因可为靶基因(即免疫调节基因)的等位基因、或靶基因之外的其它基因(图17)。
例如,核苷酸的缺失和插入可发生在靶序列的相似或不同位置,缺失的核苷酸可为位于靶序列中的1bp核苷酸和连续的4bp核苷酸;在此情况下,插入的核苷酸可为在靶序列的两个缺失位置之一(即1bp核苷酸缺失的位置)中插入的连续的10bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的连续的5bp核苷酸和1bp核苷酸;在此情况下,插入的核苷酸可为在两个缺失位置之一(即连续的5bp核苷酸缺失的位置)中插入的内源性基因的全部核苷酸序列,所述内源性基因可为靶基因(即免疫调节基因)的等位基因、或靶基因之外的其它基因(图18)。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。
缺失的核苷酸片段可为2bp-5bp、6bp-10bp、11bp-15bp、16bp-20bp、21bp-25bp、26bp-30bp、31bp-35bp、36bp-40bp、41bp-45bp或46bp-50bp。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸;核苷酸片段;或特定基因的部分或全部核苷酸序列,缺失和插入可顺序进行或同时进行。
例如,核苷酸的缺失和插入可发生在靶序列中的相似位置,并且缺失的核苷酸可为位于靶序列中的10bp核苷酸片段;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的连续的2bp核苷酸。或者,缺失的核苷酸可为位于靶序列中的连续的17bp核苷酸片段;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的连续的20bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的15bp核苷酸片段;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的内源性基因的部分核苷酸序列,所述内源性基因可为靶基因(即免疫调节基因)的等位基因、或靶基因之外的其它基因。或者,缺失的核苷酸可为位于靶序列中的7bp核苷酸片段;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的外源性基因的全部核苷酸序列(图19)。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸;核苷酸片段;或特定基因的部分或全部核苷酸序列,并且缺失和插入可顺序进行或同时进行。此外,插入可发生在两个以上缺失区域的部分或全部区域中。
例如,核苷酸的缺失和插入可发生在靶序列的相似和/或不同位置,并且缺失的核苷酸可为位于靶序列中的6bp核苷酸片段和12bp核苷酸片段;在此情况下,插入的核苷酸可为在靶序列的两个缺失位置之一(即6bp核苷酸缺失的位置)中的15bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的12bp核苷酸片段和8bp核苷酸片段;在此情况下,插入的核苷酸可为分别在两个缺失的核苷酸序列中插入的13bp核苷酸片段,即,在缺失的12bp核苷酸片段的位置中插入的13bp核苷酸片段,以及在缺失的8bp核苷酸的位置中插入的13bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的7bp核苷酸片段和8bp核苷酸片段;在此情况下,插入的核苷酸可为分别在两个缺失的核苷酸序列中插入的内源性基因的部分或全部核苷酸序列,即在缺失的7bp核苷酸片段的位置中插入的内源性基因的全部核苷酸序列以及在缺失的8bp核苷酸片段的位置中插入的内源性基因的部分核苷酸序列。或者,缺失的核苷酸可为位于靶序列中的9bp核苷酸片段和8bp核苷酸片段;在此情况下,插入的核苷酸可为分别在两个缺失的核苷酸序列中插入的8bp核苷酸片段以及外源性基因的全部或部分核苷酸序列,即在缺失的9bp核苷酸片段的位置中插入的8bp核苷酸片段,以及在缺失的8bp核苷酸片段的位置中插入的外源型基因的部分核苷酸序列(图20)。
在另一实例中,经人工操纵或修饰的免疫调节基因可在位于临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中包含一个或多个核苷酸的缺失和插入。
此处,缺失的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸;核苷酸片段;或特定基因的部分或全部核苷酸序列,并且缺失和插入可顺序进行或同时进行。
插入的核苷酸片段可为5bp-10bp、11bp-50bp、50bp-100bp、100bp-200bp、200bp-300bp、300bp-400bp、400bp-500bp、500bp-750bp或750bp-1000bp。
特定基因可为由包含免疫调节基因的受试者(例如人细胞)不含有的外部区域的导入而来的基因。或者,特定基因可为包含免疫调节基因的受试者(例如人细胞)中含有的基因,例如人细胞基因组中存在的基因。
例如,核苷酸的缺失和插入可在临近靶序列的5'端和/或3'端的相似位置发生,缺失的核苷酸可为位于临近靶序列的3'端的1bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的连续的2bp核苷酸。或者,缺失的核苷酸可为位于临近靶序列的5'端的连续的3bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的20bp核苷酸。或者,缺失的核苷酸可为位于临近靶序列的3'端的连续的3bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的内源性基因的部分核苷酸序列。或者,缺失的核苷酸可为位于临近靶序列的5'端的连续的2bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的外源性基因的全部核苷酸序列。或者,缺失的核苷酸可为位于临近靶序列的3'端的1bp核苷酸和连续的4bp核苷酸;在此情况下,插入的核苷酸可为分别在两个缺失的核苷酸序列中插入的内源性基因的全部核苷酸序列和连续的4bp核苷酸序列,即在缺失的1bp核苷酸序列的位置中插入的内源性基因的全部核苷酸序列,以及在缺失的连续的4bp核苷酸的位置中插入的连续的4bp核苷酸序列(图21)。
例如,核苷酸的缺失和插入可发生在位于临近靶序列的5'端和/或3'端的核苷酸序列的相似或不同位置,缺失的核苷酸可为位于临近靶序列5'端的1bp核苷酸和位于临近靶序列3'端的连续的3bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置之一(即缺失的连续的3bp核苷酸的位置)中插入的8bp核苷酸片段。或者,缺失的核苷酸可为位于临近靶序列的5'端的连续的4bp核苷酸;在此情况下,插入的核苷酸可为在临近靶序列的3'端的非缺失的不同位置中插入的内源性基因的部分核苷酸序列(图22)。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。
缺失的核苷酸片段可为2bp-5bp、6bp-10bp、11bp-15bp、16bp-20bp、21bp-25bp、26bp-30bp、31bp-35bp、36bp-40bp、41bp-45bp或46bp-50bp。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸;核苷酸片段;或特定基因的部分或全部核苷酸序列,并且缺失和插入可顺序进行或同时进行。
例如,核苷酸的缺失和插入可发生在临近靶序列的5'端和/或3'端的相似位置,缺失的核苷酸可为位于临近靶序列的3'端的17bp核苷酸片段;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的连续的2bp核苷酸。或者,缺失的核苷酸可为位于临近靶序列的5'端的15bp核苷酸片段;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的30bp核苷酸片段。或者,缺失的核苷酸可为位于临近靶序列的5'端的15bp核苷酸片段;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的内源性基因的部分核苷酸序列。或者,缺失的核苷酸可为位于临近靶序列的3'端的25bp核苷酸片段;在此情况下,插入的核苷酸可为在缺失的核苷酸序列位置中插入的内源性基因的全部核苷酸序列(图23)。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。
此处,插入的核苷酸可为1bp、2bp、3bp、4bp或5bp;核苷酸片段;或特定基因的部分或全部核苷酸序列,缺失和插入可顺序进行或同时进行。或者,插入可发生在两个以上删除区域的部分或全部区域中。
例如,核苷酸的缺失和插入可发生在临近靶序列的5'端和/或3'端的相似位置,缺失的核苷酸可为位于临近靶序列的5'端的7bp核苷酸片段以及位于临近靶序列的3'端的18bp核苷酸片段;在此情况下,插入的核苷酸可为分别在两个缺失的核苷酸序列中插入的外源性基因的部分核苷酸序列和12bp核苷酸片段,即,在缺失的7bp核苷酸片段的位置中插入的外源性基因的部分核苷酸序列,以及在缺失的18bp核苷酸片段的位置中插入的12bp核苷酸片段。或者,缺失的核苷酸可为位于临近靶序列的3'端的10bp核苷酸片段以及位于临近靶序列的5'端的6bp核苷酸片段;在此情况下,插入的核苷酸可为分别在两个缺失的核苷酸序列中插入的内源性基因的全部核苷酸序列和连续的4bp核苷酸,即,在缺失的10bp核苷酸片段的位置中插入的内源性基因的完整核苷酸序列以及在缺失的6bp核苷酸片段的位置中插入的连续的4bp核苷酸(图24)。
在又一实例中,经人工操纵或修饰的免疫调节基因可靶序列中以及在位于临近靶序列的5'端和/或3'端的1bp-50bp核苷酸序列区域中包含一个或多个核苷酸的缺失和插入。
此处,缺失的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸;核苷酸片段;或特定基因的部分或全部核苷酸序列,并且缺失和插入可顺序进行或同时进行。
插入的核苷酸片段可为5bp-10bp、11bp-50bp、50bp-100bp、100bp-200bp、200bp-300bp、300bp-400bp、400bp-500bp、500bp-750bp或750bp-1000bp。
特定基因可为由包含免疫调节基因的受试者(例如人细胞)不含有的外部区域的导入而来的基因。或者,特定基因可为包含免疫调节基因的受试者(例如人细胞)中含有的基因,例如人细胞基因组中存在的基因。
例如,核苷酸的缺失和插入可发生在位于靶序列中以及临近靶序列的5'端和/或3'端的核苷酸序列的相似位置,缺失的核苷酸可为位于靶序列中以及临近靶序列的3'端的连续的4bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的5bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中的连续的2bp核苷酸以及位于临近靶序列的3'端的连续的2bp核苷酸;在此情况下,插入的核苷酸可为分别在两个缺失的核苷酸序列中插入的10bp核苷酸片段和外源性基因的部分核苷酸序列,即,在位于靶序列中的缺失的连续的2bp核苷酸序列的位置中插入的10bp核苷酸片段,以及在位于临近靶序列的3'端的缺失的连续的2bp核苷酸序列的位置中插入的外源性基因的部分核苷酸序列(图25)。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。
缺失的核苷酸片段可为2bp-5bp、6bp-10bp、11bp-15bp、16bp-20bp、21bp-25bp、26bp-30bp、31bp-35bp、36bp-40bp、41bp-45bp或46bp-50bp。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸;核苷酸片段;或特定基因的部分或全部核苷酸序列,并且缺失和插入可顺序进行或同时进行。
例如,核苷酸的缺失和插入可发生在位于靶序列中以及临近靶序列的5'端和/或3'端的核苷酸序列的相似位置,缺失的核苷酸可为位于靶序列中以及临近靶序列的3'端的连续的25bp核苷酸;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的外源性基因的全部核苷酸序列。或者,缺失的核苷酸可为位于靶序列中以及临近靶序列的5'端或3'端的30bp核苷酸片段;在此情况下,插入的核苷酸可为在缺失的核苷酸序列的位置中插入的45bp核苷酸片段。(图26)。
或者此处,缺失的核苷酸可为包含2bp以上核苷酸的核苷酸片段。
此处,插入的核苷酸可为其中连续、不连续或两种形式(即连续和不连续)混合的1bp-50bp核苷酸;核苷酸片段;或特定基因的部分或全部核苷酸序列,并且缺失和插入可顺序进行或同时进行。此外,插入可发生在两个以上缺失区域的部分或全部区域中。
例如,核苷酸的缺失和插入可发生在位于靶序列中以及临近靶序列的5'端和/或3'端的核苷酸序列的相似位置,缺失的核苷酸可为位于靶序列中以及临近靶序列的3'端的25bp核苷酸片段,位于临近靶序列的3'端的6bp核苷酸片段;在此情况下,插入的核苷酸可为分别在两个缺失的核苷酸序列中插入的内源性基因的全部核苷酸序列和20bp核苷酸片段,即,在缺失的25bp核苷酸片段的位置中插入的内源性基因的全部核苷酸序列以及在缺失的6bp核苷酸片段的位置中插入的20bp核苷酸片段。或者,缺失的核苷酸可为位于靶序列中以及临近靶序列的5'端的10bp核苷酸片段,以及位于靶序列中以及临近靶序列的3'端的22bp核苷酸片段;在此情况下,插入的核苷酸可为分别在两个缺失的核苷酸序列中插入的内源性基因的部分核苷酸序列和外源性基因的全部核苷酸序列,即,在缺失的10bp核苷酸片段的位置中插入的内源性基因的部分核苷酸序列以及在缺失的22bp核苷酸片段的位置中插入的外源性基因的全部核苷酸序列(图27)。
经功能性操纵的免疫细胞可包含一种或多种经人工操纵或修饰的免疫调节基因。
经人工操纵或修饰的免疫调节基因可在位于临近免疫调节基因的核苷酸序列中存在的pam序列的5'端和/或3'端的连续的1bp-50bp核苷酸序列区域中包含以下一种或多种修饰:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在一个实例中,当crispr酶为spcas9蛋白时,经人工操纵或修饰的免疫调节基因可在位于临近免疫调节基因的核苷酸序列中存在的5'-ngg-3'(n为a、t、g或c)pam序列的5'端和/或3'端的连续的1bp-50bp、1bp-40bp、1bp-30bp或1bp-25bp核苷酸序列区域中包含以下一种或多种修饰:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在另一实例中,当crispr酶为cjcas9蛋白时,经人工操纵或修饰的免疫调节基因可在位于临近免疫调节基因的核苷酸序列中存在的5'-nnnnryac-3'(n各自独立地为a、t、c或g;r为a或g;y为c或t)pam序列的5'端和/或3'端的连续的1bp-50bp、1bp-40bp、1bp-30bp或1bp-25bp核苷酸序列区域中包含以下一种或多种修饰:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在又一实例中,当crispr酶为stcas9蛋白时,经人工操纵或修饰的免疫调节基因可在位于临近免疫调节基因的核苷酸序列中存在的5'-nnagaaw-3'(n各自独立地为a、t、c或g;w为a或t)pam序列的5'端和/或3'端的连续的1bp-50bp、1bp-40bp、1bp-30bp或1bp-25bp核苷酸序列区域中包含以下一种或多种修饰:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在一个实例中,当crispr酶为nmcas9蛋白时,经人工操纵或修饰的免疫调节基因可在位于临近免疫调节基因的核苷酸序列中存在的5'-nnnngatt-3'(n各自独立地为a、t、c或g)pam序列的5'端和/或3'端的连续的1bp-50bp、1bp-40bp、1bp-30bp或1bp-25bp核苷酸序列区域中包含以下一种或多种修饰:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在另一实例中,当crispr酶为sacas9蛋白时,经人工操纵或修饰的免疫调节基因可在位于临近免疫调节基因的核苷酸序列中存在的5'-nngrr(t)-3'(n各自独立地为a、t、g或c;r为a或g;并且(t)为可任选包含的任意序列)pam序列的5'端和/或3'端的连续的1bp-50bp、1bp-40bp、1bp-30bp和1bp-25bp核苷酸序列区域中包含以下一种或多种修饰:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
在又一实例中,当crispr酶为cpf1蛋白时,经人工操纵或修饰的免疫调节基因可在位于临近免疫调节基因的核苷酸序列中存在的5'-ttn-3'(n为a、t、c或g)pam序列的5'端和/或3'端的连续的1bp-50bp、1bp-40bp、1bp-30bp和1bp-25bp核苷酸序列区域中包含以下一种或多种修饰:
i)一个或多个核苷酸的缺失;
ii)将一个或多个核苷酸置换为不同于野生型基因的核苷酸;
iii)一个或多个核苷酸的插入;或
iv)选自于以上i)-iii)中的两种以上的组合。
经功能性操纵的免疫细胞可包含一种或多种经敲除人工操纵或修饰的免疫调节基因。
此处,敲除可为由免疫调节基因的人工操纵或修饰引起的效果。
此处,敲除可为通过人工操纵或修饰抑制由免疫调节基因编码的蛋白的表达。
经功能性操纵的免疫细胞可包含一种或多种经敲减人工操纵或修饰的免疫调节基因。
此处,敲减可为由免疫调节基因的人工操纵或修饰引起的效果。
此处,敲减可为通过人工操纵或修饰抑制由免疫调节基因编码的蛋白的表达。
经功能性操纵的免疫细胞可包含一种或多种敲入的外来核酸或外来基因。
此处,可通过免疫调节基因的人工操纵或修饰导入一种或多种敲入的外来核酸或外来基因。
此处,一种或多种敲入的外来核酸或外来基因可表达编码外来肽或外来蛋白。
此外,经功能性操纵的免疫细胞可为具有被阻遏或抑制的免疫调节因子表达的免疫细胞。
此处,免疫调节因子可为由免疫调节基因(即pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和/或kdm6a基因)表达的多肽或蛋白。
此处,与野生型免疫细胞(即天然存在的免疫细胞)表达的免疫调节因子的量相比时,经功能性修饰的免疫细胞表达的修饰的免疫调节因子的量降低了至少30%。此处,作为比较标准的由野生型免疫细胞表达的免疫调节因子的量可为由从无免疫学疾病(例如癌症和获得性免疫缺陷综合征(aids))的健康人中收集的天然存在的免疫细胞表达的免疫调节因子的平均量,在此情况下,所述群(即可从中获得野生型免疫细胞的健康人的数量)可为至少50。
此处,当与野生型免疫细胞(即人工操纵前的免疫细胞)表达的免疫调节因子的量相比时,经功能性修饰的免疫细胞表达的修饰的免疫调节因子的量降低了至少30%。此处,作为比较标准的由野生型免疫细胞表达的免疫调节因子的量可为野生型免疫细胞(即人工操纵前的免疫细胞,例如在用于免疫细胞操纵的组合物或用于基因操纵的免疫调节基因靶向组合物治疗前,从人分离的免疫细胞)表达的免疫调节因子的平均量。
作为本说明书公开的实施方式,经操纵的免疫细胞可为经混合型操纵的免疫细胞。
术语“经混合型操纵的免疫细胞”为免疫细胞,是指其中有通过人工操纵增补的一种或多种人工结构的经功能性操纵的免疫细胞,或其中进行了人工操纵以修饰天然免疫调节因子的表达或损伤免疫调节因子的功能的增补人工结构的免疫细胞。
术语“增补人工结构的免疫细胞”是指具有增补的一种或多种人工结构的免疫细胞。
例如,人工结构可为人工受体。
术语“人工受体”是指人工制备的不是野生型受体的功能性实体,其具有抗原识别和执行特定功能的能力。
此类人工受体可以以改善的特定抗原识别能力或通过产生加强的免疫应答信号,来有助于免疫应答的增强。
作为实例,人工受体可具有以下构成:
(i)抗原识别部分
人工受体包含抗原识别部分。
术语“抗原识别部分”是人工受体的一部分,是指识别抗原的区域。
抗原识别部分可为相比野生型受体而言对特定抗原具有改善的识别的抗原识别部分。特别是,特定抗原可为癌细胞的抗原。此外,特定抗原可为机体中正常细胞的抗原。
抗原识别部分可具有抗原结合亲和力。
在结合抗原的同时,抗原识别部分可产生信号。信号可为电信号。信号可为化学信号。
抗原识别部分可包含信号序列。
信号序列是指在蛋白合成过程中允许将蛋白递送至特定位点的肽序列。
信号序列可位于靠近抗原识别部分的n末端处。特别是,其与n末端的距离可为约100个氨基酸。信号序列可位于靠近抗原识别部分的c末端处。特别是,其与c末端的距离可为约100个氨基酸。
抗原识别部分可与第一信号发生部分具有有机功能性关系。
抗原识别部分可与抗体的抗原结合片段(fab)结构域具有同源性。
抗原识别部分可为单链可变片段(scfv)。
抗原识别部分可通过其自身抗原识别,或者通过形成抗原识别结构来识别抗原。
抗原识别结构可通过建立特定结构来识别抗原,本领域普通技术人员可容易地理解构成该特定结构的单体单元(monomericunits)和单体单元的结合。此外,抗原识别结构可由一个或两个以上的单体单元组成。
抗原识别结构可为其中的单体单元串联连接的结构,或者可为其中的单体单元并联连接的结构。
串联连接的结构是指其中的两个以上单体单元在一个方向上连续连接的结构,而并联连接的结构是指其中的两个以上单体单元各自同时例如在不同方向上连接在一个单体单元的末端处的结构。
例如,单体单元可为无机物。
单体单元可为生化配体。
单体单元可与野生型受体的抗原识别部分具有同源性。
单体单元可与抗体蛋白具有同源性。
单体单元可为免疫球蛋白重链或可与其具有同源性。
单体单元可为免疫球蛋白轻链或可与其具有同源性。
单体单元可包含信号序列。
同时,单体单元可通过化学键连接,或者可通过特定组合部分结合。
术语“抗原识别单元组合部分(antigenrecognitionunitcombiningpart)”是抗原识别单元彼此连接的区域,当存在由两个以上抗原识别单元组成的抗原识别结构时,抗原识别单元组合部分可以以任选组成存在。
抗原识别单元组合部分可为肽。特别是,所述组合部分可具有高丝氨酸和苏氨酸比例。
抗原识别单元组合部分可为化学结合。
抗原识别单元组合部分可通过具有特定长度来辅助抗原识别单元三维结构的表达。
抗原识别单元组合部分可通过在抗原识别单元之间具有特定位置关系来辅助抗原识别结构的功能。
(ii)受体主体(receptorbody)
人工受体包含受体主体。
术语“受体主体”是介导抗原识别部分和信号发生部分之间的连接的区域,抗原识别部分和信号发生部分可物理连接。
受体主体的功能可为对抗原识别部分或信号发生部分中产生的信号进行递送。
根据情况,受体主体的结构可同时具有信号发生部分的功能。
受体主体的功能可为允许人工受体固定在免疫细胞上。
受体主体可包含氨基酸螺旋结构。
受体主体的结构可包含与体内存在的正常受体蛋白的一部分具有同源性的部分。同源性可在50%-100%的范围内。
受体主体的结构可包含与免疫细胞上的蛋白具有同源性的部分。同源性可在50%-100%的范围内。
例如,受体主体可为cd8跨膜结构域。
受体主体可为cd28跨膜结构域。特别是,当第二信号发生部分是cd28时,cd28可执行第二信号发生部分和受体主体的功能。
(iii)信号发生部分
人工受体可包含信号发生部分。
术语“第一信号发生部分”是人工受体的一部分,是指产生免疫应答信号的部分。
术语“第二信号发生部分”是人工受体的一部分,是指通过与第一信号发生部分相互作用产生免疫应答信号或者独立产生免疫应答信号的部分。
人工受体可包含第一信号发生部分和/或第二信号发生部分。
人工受体可分别包含两个以上的第一信号发生部分和/或第二信号发生部分。
第一信号发生部分和/或第二信号发生部分可包含特定序列基序。
所述序列基序可与指定簇(clusterofdesignation,cd)蛋白的基序具有同源性。
特别是,cd蛋白可为cd3、cd247和cd79。
所述序列基序可为氨基酸序列yxxl/i。
所述序列基序在第一信号发生部分和/或第二信号发生部分内可为多个。
特别是,第一序列基序可位于距离第一信号发生部分的起始位置1-200个氨基酸处。第二序列基序可位于距离第二信号发生部分的起始位置1-200个氨基酸处。
此外,各序列基序之间的距离可为1-15个氨基酸。
特别是,各序列基序之间的优选距离为6-8个氨基酸。
例如,第一信号发生部分和/或第二信号发生部分可为cd3ζ。
第一信号发生部分和/或第二信号发生部分可为fcεriγ。
第一信号发生部分和/或第二信号发生部分可为仅当满足特定条件时才产生免疫应答的信号发生部分。
特定条件可为抗原识别部分识别抗原。
特定条件可为抗原识别部分与抗原形成结合。
特定条件可为当抗原识别部分与抗原形成结合时产生的信号被递送。
特定条件可为抗原识别部分识别抗原或者在与抗原结合的情况下抗原识别部分与抗原分离。
免疫应答信号可为与免疫细胞的生长和分化相关的信号。
免疫应答信号可为与免疫细胞的死亡相关的信号。
免疫应答信号可为与免疫细胞的活性相关的信号。
免疫应答信号可为与免疫细胞的辅助相关的信号。
免疫应答信号可由抗原识别部分产生的信号特异性活化。
免疫应答信号可为调节感兴趣的基因的表达的信号。
免疫应答信号可为阻遏免疫应答的信号。
在实施方式中,信号发生部分可包含额外信号发生部分。
术语“额外信号发生部分”是人工受体的一部分,是指相对于由第一信号发生部分和/或第二信号发生部分产生的免疫应答信号而言产生额外免疫应答信号的区域。
下文中,将额外信号发生部分按顺序称为第n信号发生部分(n≠1)。
除第一信号发生部分外,人工受体还可包含额外信号发生部分。
人工受体可包含两个以上额外信号发生部分。
额外信号发生部分可为其中可产生4-1bb、cd27、cd28、icos和ox40的免疫应答信号或其它信号的结构。
额外信号发生部分产生免疫应答信号的条件及其所产生的免疫应答信号的特征包括与第一信号发生部分和/或第二信号发生部分的免疫应答信号相对应的详细情况。
免疫应答信号可为促进细胞因子合成的信号。免疫应答信号可为促进或抑制细胞因子分泌的信号。特别是,细胞因子优选可为il-2、tnfα或ifn-γ。
免疫应答信号可为辅助其它免疫细胞生长或分化的信号。
免疫应答信号可为将其它免疫细胞吸引至信号出现的位置的信号。
本发明包括人工受体全部可能的结合关系。因此,本发明的人工受体的方面不限于本文所述的这些。
人工受体可由抗原识别部分-受体主体-第一信号发生部分组成。受体主体可为任选包含的。
人工受体可由抗原识别部分-受体主体-第二信号发生部分-第一信号发生部分组成。受体主体可为任选包含的。特别是,可对第一信号发生部分和第二信号发生部分的位置进行改变。
人工受体可由抗原识别部分-受体主体-第二信号发生部分-第三信号发生部分-第一信号发生部分组成。受体主体可为任选包含的。特别是,可对第一信号发生部分至第三信号发生部分的位置进行改变。
在人工受体中,信号发生部分的数量不限于1-3个,可包含多于3个。
除上述实施方式外,人工受体还可具有抗原识别部分-信号发生部分-受体主体的结构。当需要产生在具有该人工受体的细胞外发挥作用的免疫应答信号时,该结构可以是有利的。
人工受体可以通过相当于野生型受体的方式发挥功能。
人工受体可通过与特定抗原形成结合而发挥形成特定位置关系的功能。
人工受体可发挥识别抗原并产生免疫应答信号(该免疫应答信号促进针对该特定抗原的免疫应答)的功能。
人工受体可发挥识别体内一般细胞的抗原并在体内抑制针对该细胞的免疫应答的功能。
(iv)信号序列
在实施方式中,人工受体可任选包含信号序列。
当人工受体包含特定蛋白的信号序列时,这可帮助人工受体容易地定位在免疫细胞的膜上。优选地,当人工受体包含跨膜蛋白的信号序列时,这可帮助人工受体穿过免疫细胞膜而定位在免疫细胞的外膜上。
人工受体可包含一个或多个信号序列。
信号序列可包含多个带正电荷的氨基酸。
信号序列可在靠近n末端或c末端的位置处包含带正电荷的氨基酸。
信号序列可为跨膜蛋白的信号序列。
信号序列可为位于免疫细胞的外膜上的蛋白的信号序列。
信号序列可优选为scfv的信号序列。
可将信号序列包含于人工受体所具有的结构中,即,抗原识别部分、受体主体、第一信号发生部分以及额外信号发生部分。
特别是,信号序列可位于靠近各结构的n末端或c末端的位置处。
特别是,信号序列距n末端或c末端的距离可为约100个氨基酸。
在实施方式中,人工受体可为嵌合抗原受体(car)。
嵌合抗原受体可为对一种或多种抗原具有结合特异性的受体。
一种或多种抗原可为癌细胞和/或病毒特异性表达的抗原。
一种或多种抗原可为肿瘤相关抗原。
一种或多种抗原可为,但不限于:a33、alk、甲胎蛋白(afp)、肾上腺素受体β3(adrb3)、α-叶酸受体、ad034、akt1、bcma、β-人绒毛膜促性腺激素、b7h3(cd276)、bst2、brap、cd5、cd13、cd19、cd20、cd22、cd24、cd30、cd33、cd38、cd40、cd44v6、cd52、cd72、cd79a、cd79b、cd89、cd97、cd123、cd138、cd160、cd171、cd179a、碳酸酐酶ix(caix)、ca-125、癌胚抗原(cea)、ccr4、c型凝集素样分子(cll-1或clecl1)、claudin6(cldn6)、cxorf61、cage、cdx2、clp、ct-7、ct8/hom-tes-85、ctage-1、erbb2、表皮生长因子受体(egfr)、egfriii型变异体(egfrviii)、上皮细胞黏附分子(epcam)、e74样因子2突变体(elf2m)、肝配蛋白a型受体2(epha2)、emr2、fms样酪氨酸激酶3(flt3)、fcrl5、fibulin-1、g250、gd2、糖蛋白36(gp36)、糖蛋白100(gp100)、糖皮质激素诱导的肿瘤坏死因子受体(gitr)、gprc5d、globoh、g蛋白偶联受体20(gpr20)、gpc3、hsp70-2、人高分子量黑色素瘤相关抗原(hmwmaa)、甲型肝炎病毒细胞受体1(havcr1)、人乳头瘤病毒e6(hpve6)、人乳头瘤病毒e7(hpve7)、hage、hca587/mage-c2、hcap-g、hce661、her2/neu、hla-cw、hom-hd-21/半乳凝素9、hom-meel-40/ssx2、hom-rcc-3.1.3/caxii、hoxa7、hoxb6、hu、hub1、胰岛素生长因子(igf1)-i、igf-ii、igfi受体、白介素-13受体亚基α-2(il-13ra2或cd213a2)、白介素11受体α(il-11ra)、igll1、kit(cd117)、km-hn-3、km-kn-1、koc1、koc2、koc3、koc3、laga-1a、lage-1、lair1、lilra2、ly75、lewisy抗原、muc1、mn-caix、m-csf、mage-1、mage-4a、间皮素、mage-a1、mad-ct-1、mad-ct-2、mart1、mppl1、msln、神经细胞黏附分子(ncam)、ny-eso-1、ny-eso-5、nkp30、nkg2d、ny-br-1、ny-br-62、ny-br-85、ny-co-37、ny-co-38、nnp-1、ny-lu-12、ny-ren-10、ny-ren-19/lkb/stk11、ny-ren-21、ny-ren-26/bcr、ny-ren-3/ny-co-38、ny-ren-33/snc6、ny-ren-43、ny-ren-65、ny-ren-9、ny-sar-35、o-乙酰-gd2神经节苷脂(oacgd2)、ogfr、psma、前列腺酸性磷酸酶(pap)、p53、前列腺癌肿瘤抗原1(pcta-1)、前列腺干细胞抗原(psca)、丝氨酸蛋白酶21(testisin或prss21)、血小板源性生长因子受体β(pdgfr-β)、plac1、泛连接蛋白3(panx3)、plu-1、ror-1、rage-1、ru1、ru2、rab38、rbpjκ、rhamm、阶段特异性胚胎抗原4(ssea-4)、scp1、ssx3、ssx4、ssx5、tyrp-1、tag72、甲状腺球蛋白、人端粒酶逆转录酶(htert)、5t4、肿瘤相关糖蛋白(tag72)、酪氨酸酶、转谷氨酰胺酶5(tgs5)、tem1、tem7r、促甲状腺激素受体(tshr)、tie2、trp-2、top2a、top2b、uroplakin2(upk2)、波形蛋白、血管内皮生长因子受体2(vegfr2)、wilms肿瘤蛋白1(wt1)和lewis(y)抗原。
作为本说明书公开的实施方式,经混合型操纵的免疫细胞可为经人工操纵的免疫细胞,所述经人工操纵的免疫细胞包含以下所有:
(i)一种或多种经人工操纵或修饰的免疫调节基因和/或其的表达产物;以及
(ii)人工受体蛋白和/或编码其的核酸
关于上述一种或多种经人工操纵或修饰的免疫调节基因的解释如上所述。
(i)的表达产物可为由一种或多种经人工操纵或修饰的免疫调节基因表达的mrna或蛋白。
此外,关于上述人工受体的解释如上所述。
例如,经混合型操纵的免疫细胞可为包含人工受体的经功能性操纵的免疫细胞。
此处,人工受体可为嵌合抗原受体,与其相关的解释如上所述。
经混合型操纵的免疫细胞可为具有一种或多种经人工操纵或修饰的免疫调节基因的免疫细胞,包括一种或多种嵌合抗原受体。此处,具有一种或多种经人工操纵或修饰的免疫调节基因的免疫细胞可为经功能性操纵的免疫细胞,与其相关的解释如上所述。
经混合型操纵的免疫细胞可为其中的一种或多种的免疫调节基因的表达(包括一种或多种嵌合抗原受体)被阻遏或抑制的免疫细胞。此处,其中的一种或多种免疫调节基因的表达被阻遏或抑制的免疫细胞可为经功能性操纵的免疫细胞,与其相关的解释如上所述。
作为实例,经混合型操纵的免疫细胞可为通过将编码嵌合抗原受体的一种或多种核酸或基因人工导入经功能性操纵的免疫细胞中而产生的免疫细胞。
此处,编码嵌合抗原受体的核酸或基因可以以未插入至经功能性操纵的免疫细胞的基因组中的形式存在于细胞中。
此处,可将编码嵌合抗原受体的核酸或基因插入至经功能性操纵的免疫细胞的基因组的特定基因座中。特定基因座可为免疫调节基因的内含子、外显子、启动子或增强子基因座。
此处,可将编码嵌合抗原受体的核酸或基因随意插入至经功能性操纵的免疫细胞的基因组中存在的一个或多个内含子中。
此处,可将编码嵌合抗原受体的核酸或基因随意插入至经功能性操纵的免疫细胞的基因组中存在的一个或多个外显子中。
此处,可将编码嵌合抗原受体的核酸或基因随意插入至经功能性操纵的免疫细胞的基因组中存在的一个或多个启动子中。
此处,可将编码嵌合抗原受体的核酸或基因随意插入至经功能性操纵的免疫细胞的基因组中存在的一个或多个增强子中。
此处,可将编码嵌合抗原受体的核酸或基因随意插入至经功能性操纵的免疫细胞的基因组中存在的内含子、外显子、启动子和增强子以外的一个或多个区域。
人工导入至经功能性操纵的免疫细胞中的嵌合抗原受体在经混合型操纵的免疫细胞中可以以蛋白的形式表达,以蛋白表达的嵌合抗原受体可位于经混合型操纵的免疫细胞的表面上。此处,人工导入有编码嵌合抗原受体的核酸或基因的经功能性操纵的免疫细胞可为经混合型操纵的免疫细胞的形式。
在另一实例中,经混合型操纵的免疫细胞可为通过将一种或多种嵌合抗原受体蛋白人工导入经功能性操纵的免疫细胞中而产生的免疫细胞。
人工导入至经功能性操纵的免疫细胞中的嵌合抗原受体蛋白可位于经混合型操纵的免疫细胞的表面上。此处,人工导入有嵌合抗原受体蛋白的经功能性操纵的免疫细胞可为经混合型操纵的免疫细胞的形式。
在另一实例中,经混合型操纵的免疫细胞可为增补人工结构的免疫细胞,所述增补人工结构的免疫细胞包含一种或多种经人工操纵或修饰的免疫调节基因。
此处,增补人工结构的免疫细胞可为包含人工受体的免疫细胞。人工受体可为嵌合抗原受体。
包含一种或多种经人工操纵或修饰的免疫调节基因的增补人工结构的免疫细胞可具有被阻遏或抑制的免疫调节因子表达。此处,其中的一种或多种免疫调节基因被人工修饰的增补人工结构的免疫细胞可为经混合型操纵的免疫细胞的形式。
在又一实例中,经混合型操纵的免疫细胞可为其中的一种或多种免疫调节因子的表达被阻遏或抑制的增补人工结构的免疫细胞。
本说明书公开的方面涉及生产经操纵的免疫细胞的方法。
关于与人工修饰的免疫调节基因有关的解释可参考上述解释。下文将集中于经操纵的免疫细胞的代表性实施方式来解释该方法。
作为实例,用于生产经操纵的免疫细胞的方法可为生产经功能性操纵的免疫细胞的方法。该方法可在体内、离体或体外进行。
在一些实施方式中,所述方法包括:从人或非人动物中对细胞或细胞群组进行样本提取,以及对所述细胞或细胞群组进行修饰。培养可在离体的任何步骤进行。甚至可将所述细胞再导入至非人类动物或植物中。
在实施方式中,所述方法可为用于产生经功能性操纵的免疫细胞的方法,所述经功能性操纵的免疫细胞包含一种或多种经人工操纵的免疫调节基因,所述方法包括将以下进行接触:
(a)免疫细胞;
(b)用于基因操纵的组合物,所述组合物能够对选自于由以下基因所组成的组中的至少一种免疫调节基因进行人工操纵:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d、tet2基因、psgl-1基因、a20基因和kdm6a基因。
此处,(a)免疫细胞可从人体分离,或者可为由干细胞分化的免疫细胞。
(b)用于基因操纵的组合物包含以下:
(b')引导核酸,所述引导核酸与选自于由以下基因所组成的组的一种或多种基因的核酸序列中的靶序列seqidno:1-seqidno:289具有同源性或者能够与其形成互补结合:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和kdm6a基因;以及
(b”)编辑蛋白,所述编辑蛋白为选自于由如下蛋白所组成的组中的一种或多种蛋白:酿脓链球菌衍生而来的cas9蛋白、空肠弯曲杆菌衍生而来的cas9蛋白、嗜热链球菌衍生而来的cas9蛋白、金黄色葡萄球菌衍生而来的cas9蛋白、脑膜炎奈瑟菌衍生而来的cas9蛋白以及cpf1蛋白。
关于上述用于基因操纵的组合物的解释如上所述。
所述接触可离体进行。
所述接触可包括将(b)用于基因操纵的组合物导入(a)免疫细胞中。
所述方法可在体内或体外(例如离体)进行。
例如,所述接触可在体外进行,并且可在接触后将经接触的细胞返回受试者体内。
所述方法可使用活体内的免疫细胞或从活体(例如人体)分离的免疫细胞、或人工生产的免疫细胞。作为实例,可包括接触来自患有癌症的受试者的细胞。
用于方法中的免疫细胞可为由包括灵长类动物(例如人、猴等)和啮齿类动物(例如小鼠、大鼠等)在内的哺乳动物衍生而来的免疫细胞。例如,免疫细胞可为nkt细胞、nk细胞、t细胞等。此处,免疫细胞可为增补了免疫受体的经操纵的免疫细胞(例如增补了嵌合抗体受体(car)或经操纵的t细胞受体(tcr))。
可在适合免疫细胞的培养基中实施所述方法,所述培养基可含有血清(例如胎牛血清或人血清)、白介素-2(il-2)、胰岛素、ifn-γ、il-4、il-7、gm-csf、il-10、il-15、tgf-β以及tnf-α;或者合适的培养基可含有对于增殖和存活而言必要的因子,包括本领域技术人员已知的其它细胞生长添加剂(例如最小必需培养基、rpmi1640培养基或x-vivo-10、x-vivo-15、x-vivo-20(lonza)),但所述培养基不限于此。
在另一实例中,生产经操纵的免疫细胞的方法可为生产经混合型操纵的免疫细胞的方法。所述方法可在体内、离体或体外进行。
在一些实施方式中,所述方法包括:从人或非人动物中对细胞或细胞群组进行样本提取,以及对所述细胞或细胞群组进行修饰。培养可在离体的任何步骤进行。甚至可将所述细胞再导入至非人类动物或植物中。
在实施方式中,所述方法可为用于产生经混合型操纵的免疫细胞的方法,所述经混合型操纵的免疫细胞包含一种或多种经人工操纵的免疫调节基因以及一种或多种人工受体,所述方法包括将以下进行接触:
(a)免疫细胞;
(b)用于人工受体表达的组合物或人工受体蛋白;以及
(c)用于基因操纵的组合物,所述组合物能够对选自于由以下基因所组成的组中的一种或多种免疫调节基因进行人工操纵:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d、tet2基因、psgl-1基因、a20基因和kdm6a基因。
(a)免疫细胞可从人体分离,或可为从干细胞分化的免疫细胞。
(b)用于人工受体表达的组合物可为包含具有编码嵌合抗原受体的核苷酸序列的载体的组合物。
可使用选自电穿孔、脂质体、质粒、病毒载体、纳米粒子和蛋白易位结构域ptd)融合蛋白法中的一种或多种方法将(b)用于人工受体表达的组合物导入免疫细胞中。
例如,病毒载体可为选自于由逆转录病毒、慢病毒、腺病毒、腺相关病毒(aav)、痘苗病毒、痘病毒或单纯疱疹病毒所组成的组中的一种或多种。
(c)用于基因操纵的组合物可包含以下:
(c')引导核酸,所述引导核酸与选自于由以下基因所组成的组的一种或多种免疫调节基因的核酸序列中的靶序列seqidno:1-seqidno:289具有同源性或者能够与其形成互补结合:pd-1基因、ctla-4基因、dgka基因、dgkz基因、fas基因、egr2基因、ppp2r2d基因、tet2基因、psgl-1基因、a20基因和kdm6a基因;以及
(c”)编辑蛋白,所述编辑蛋白为选自于由如下蛋白所组成的组中的一种或多种蛋白:酿脓链球菌衍生而来的cas9蛋白、空肠弯曲杆菌衍生而来的cas9蛋白、嗜热链球菌衍生而来的cas9蛋白、金黄色葡萄球菌衍生而来的cas9蛋白、脑膜炎奈瑟菌衍生而来的cas9蛋白以及cpf1蛋白。
关于上述用于基因操纵的组合物的解释如上所述。
所述接触可离体执行。
所述接触可使(a)免疫细胞与(b)用于人工受体表达的组合物以及(c)用于基因操纵的组合物顺序接触或同时接触。
所述接触可使(a)免疫细胞与(c)用于基因操纵的组合物以及(b)用于人工受体表达的组合物顺序接触或同时接触。
所述接触可包括将(b)用于人工受体表达的组合物和(c)用于基因操纵的组合物导入(a)免疫细胞。
所述方法可在体内或离体(例如在人体外)进行。
例如,所述接触可离体进行,并可在接触后将经接触的细胞返回受试者体内。
所述方法可采用有机体中的免疫细胞或有机体,例如从人体分离的免疫细胞或人工产生的免疫细胞。在一个实例中,可包括接触来自患有癌症的受试者的细胞。
用于上述方法中的免疫细胞可为由包括灵长类动物(例如人、猴等)和啮齿类动物(例如小鼠、大鼠等)在内的哺乳动物衍生而来的免疫细胞。例如,免疫细胞可为nkt细胞、nk细胞、t细胞等。特别是,免疫细胞可为增补了免疫受体的经操纵的免疫细胞(例如增补了嵌合抗体受体(car)或经操纵的t细胞受体(tcr))。
可在适合免疫细胞的培养基中实施所述方法,所述培养基可含有血清(例如胎牛血清或人血清)、白介素-2(il-2)、胰岛素、ifn-γ、il-4、il-7、gm-csf、il-10、il-15、tgf-β以及tnf-α;或者合适的培养基可含有对于增殖和存活而言必要的因子,包括本领域技术人员已知的其它细胞生长添加剂(例如最小必需培养基、rpmi1640培养基或x-vivo-10、x-vivo-15、x-vivo-20(lonza)),但所述培养基不限于此。
本说明书公开的方面涉及使用经操纵的免疫细胞的疾病治疗方法。
本说明书公开的实施方式为使用免疫疗法方法用于疾病治疗的用途,所述免疫疗法方法包括给予受试者人工修饰的细胞(例如含有嵌合抗原受体的基因修饰的免疫细胞)。
待治疗的受试者可为包括灵长类动物(例如人、猴等)和啮齿类动物(例如小鼠、大鼠等)在内的哺乳动物。
本说明书公开的实施方式为使用人工修饰的免疫细胞用于疾病治疗的药物组合物。
所述药物组合物可用于使用免疫应答的疾病治疗中。例如,所述药物组合物为含有经修饰的免疫细胞的组合物。所述药物组合物可称为用于治疗的组合物或细胞疗法产品。
在一个实例中,所述药物组合物可包含经功能性修饰的免疫细胞。
此处,所述药物组合物中包含的经功能性修饰的免疫细胞群可占所述药物组合物中包含的总免疫细胞群的50%-60%、60%-70%、70%-80%、80%-90%或90%-100%。
在另一实例中,所述药物组合物可包含经混合型操纵的免疫细胞。
此处,所述药物组合物中包含的经功能性修饰的免疫细胞群可占所述药物组合物中包含的总免疫细胞群的50%-60%、60%-70%、70%-80%、80%-90%或90%-100%。
在又一实例中,所述药物组合物可包含经功能性操纵的免疫细胞和经混合型操纵的免疫细胞。
此处,所述药物组合物中包含的经功能性修饰的免疫细胞群可占所述药物组合物中包含的总免疫细胞群的1%-20%、20%-60%、60%-80%或80%-99%;在此情况下,所述药物组合物中包含的经混合型修饰的免疫细胞群可占所述药物组合物中包含的总免疫细胞群的80%-99%、60%-80%、40%-60%、20%-40%或1%-20%。
此处,所述药物组合物可进一步包含额外组分。
例如,所述药物组合物可包含免疫检查点抑制剂。
此处,免疫检查点抑制剂可为pd-1、pd-l1、lag-3、tim-3、ctla-4、tigit、btla、ido、vista、icos、kir、cd160、cd244或cd39的抑制剂。此处,所述抑制剂可为,但不限于:抗体;化合物;能够与免疫检查点结合或相互作用的核酸、肽、多肽或蛋白;用于rna干扰(rnai)的microrna(mirna)、小干扰rna(sirna)或短发夹rna(shrna);用于免疫检查点基因的敲除或敲减的核酸酶,例如锌指核酸酶(zfn)、转录激活因子样效应物核酸酶(talen)或crispr/cas。
所述药物组合物可包含抗原结合介质。
所述药物组合物可包含细胞因子。
所述药物组合物可包含细胞因子分泌刺激物或遏抑物。
所述药物组合物可包含用于将经操纵的免疫细胞递送入体内的合适的运载体。
此处,所述药物组合物中包含的免疫细胞可为患者的自体细胞或患者的同种异体细胞。
本说明书公开的另一实施方式为对患者中的疾病进行治疗的方法,所述方法包括生产上阐释的药物组合物,并将所述药物组合物给予有需要的患者。
-待治疗的疾病
所述疾病可为免疫疾病。
特别是,免疫疾病可为其中免疫能力(immunecompetence)恶化的疾病。
免疫疾病可为自身免疫疾病。
例如,自身免疫疾病可包括移植物抗宿主病(gvhd)、系统性红斑狼疮、乳糜泻、i型糖尿病、graves病、炎症性肠病、银屑病、类风湿性关节炎、多发性硬化症等。
此外,疾病可为其病原体已知但治疗未知的难治性疾病。
难治性疾病可为病毒感染疾病。
难治性疾病可为由朊病毒病原体引起的疾病。
难治性疾病可为癌症。
-增强免疫力的治疗
对于免疫力显著降低的患者而言,即便轻微感染也可导致致命后果。免疫力降低由免疫细胞功能下降、免疫细胞产量减少等造成。作为用于增强免疫力来治疗免疫功能恶化的方法,其可为活化正常免疫细胞产生的永久性治疗方法,也可为对免疫细胞进行瞬时注入的暂时治疗方法。
增强免疫力的治疗可意在将治疗组合物注入患者体内来永久增强免疫力。
增强免疫力的治疗可为将治疗组合物注入患者的特定身体部分的方法。具体而言,特定的身体部分可为具有供应免疫细胞源的组织的部分。
增强免疫力的治疗可为在患者体内制造新免疫细胞源。具体而言,在一个实例中,治疗组合物可包含干细胞。具体而言,干细胞可为造血干细胞。
增强免疫力的治疗可意在将治疗组合物注入患者体内来暂时增强免疫力。
增强免疫力的治疗可为将治疗组合物注入患者体内。
具体而言,优选的治疗组合物可含有分化的免疫细胞。
用于增强免疫力的治疗的治疗组合物可含有特定数量的免疫细胞。
可根据免疫力的恶化程度来改变所述特定数量。
可根据身体体积来改变所述特定数量。
可根据患者释放的细胞因子量来调整所述特定数量。
-顽固性疾病的治疗
免疫细胞操纵技术可提供针对例如hiv、朊病毒以及癌症等的病原体(其完全治疗尚且未知)的疾病治疗方法。虽然这些疾病的病原体已知,但在很多情况下由于存在抗体难以形成、疾病迅速发展且患者免疫系统失活以及病原体在体内具有潜伏期等问题,难以对这些疾病进行治疗。经操纵的免疫细胞可为解决这些问题的强有力手段。
可通过将治疗组合物注入体内来实施顽固性疾病的治疗。具体而言,优选的治疗组合物可含有经操纵的免疫细胞。此外,可将治疗组合物注入特定的身体部分。
经操纵的免疫细胞可为对目标疾病的病原体具有改善的识别能力的免疫细胞。
经操纵的免疫细胞可为免疫应答强度或活性增强的免疫细胞。
-基因修正治疗
除借助外源提取的免疫细胞的治疗方法外,还存在通过操纵活体基因直接影响免疫细胞表达的治疗方法。可通过将用于基因操纵的基因修正组合物直接注入体内来实施该治疗方法。
基因修正组合物可含有引导核酸-编辑蛋白复合体。
可将基因修正组合物注入特定的身体部分。
特定的身体部分可为免疫细胞源,例如骨髓。
待给药的受试者可为包括灵长类动物(例如人、猴等)和啮齿类动物(例如小鼠、大鼠等)在内的哺乳动物。
可以通过任何方便的方式(例如注射、输液、植入、移植等)实施组合物给药。给药途径可选自于皮下、皮内、瘤内、结内(intranodal)、髓内、肌内、静脉内、淋巴管内和腹膜内给药等。
组合物的单次剂量(用于实现期望效果的药物有效量)可选自于约104-109个细胞/kg待给药的受试者的体重的范围内的全部整数数值(例如约105-106个细胞/kg体重),但所述剂量不限于此;可考虑待给药的受试者的年龄、健康状况和体重;同时进行的治疗的种类,(如果有的话)治疗频率和期望效果的性质,来适当规定组合物的单次剂量。
例如,当通过本说明书公开的用于基因操纵的组合物对免疫调节基因进行人工操纵和控制时,涉及免疫细胞的存活、增殖、持久性、细胞毒性、细胞因子释放和/或浸润等方面的免疫效力可得到改善。此外,免疫疾病和顽固性疾病可通过药物组合物和使用该药物组合物的治疗方法得到减轻或治愈,所述药物组合物包含本说明书公开的经操纵的免疫细胞。
实施例
1.sgrna的设计
使用crisprrgen工具(instituteforbasicscience,韩国)选择如下基因的crispr/cas9靶区域并通过脱靶测试进行评估:人pd-1基因(pdcd1;ncbi登记号nm_005018.2)、ctla-4基因(ncbi登记号nm_001037631.2)、a20基因(tnfaip3;ncbi登记号nm_001270507.1)、dgkα基因(ncbi登记号nm_001345.4)、dgkζ基因(ncbi登记号nm_001105540.1)、egr2基因(ncbi登记号nm_000399.4)、ppp2r2d基因(ncbi登记号nm_001291310.1)、psgl-1基因(ncbi登记号nm_001193538.1)、和tet2基因(ncbi登记号nm_017628.4)。对于crispr/cas9靶区域,在人基因组(grch38/hg38)内选择除中靶序列区之外的不具有0bp、1bp或2bp错配位点的dna序列作为sgrna的靶区域。
2.sgrna的合成
通过对两条互补寡核苷酸进行退火和延伸来对sgrna合成模板进行pcr扩增。
此时使用的靶区域序列、用于对其进行扩增的引物序列和由此获得的sgrna所靶向的dna靶序列在下表2中描述。
使用t7rna聚合酶(newenglandbiolabs)对模板dna(去除靶序列3'端的'ngg')实施体外转录,根据制造商的说明合成rna,随后使用dnaase(ambion)去除模板dna。利用expincombo试剂盒(geneall)和异丙醇沉淀纯化转录的rna。
在使用t细胞的实验中,为将sgrna的免疫原性和降解最小化,使用碱性磷酸酶(newenglandbiolabs)从利用上述方法合成的sgrna去除5'端磷酸残基,随后利用expincombo试剂盒(geneall)和异丙醇沉淀再次纯化rna。此外,在一些t细胞实验中使用了化学合成的sgrna(trilink)。
在某些实施例中使用的化学合成的sgrna为具有2'ome和硫代磷酸酯修饰的sgrna。
例如,该实施例中使用的dgkαsgrna#11具有
在另一实例中,该实施例中使用的a20sgrna#1为
[表2]
同时,关于表1中描述的dna靶序列seqidno:1-seqidno:84的,以与上述用于psgl-1基因的相同方法产生sgrna。
实施例3.在jurkat细胞中筛选sgrna
在jurkat细胞中测试靶向a20、dgkα、egr2、ppp2r2d、pd-1、ctla-4、dgkζ、psgl-1、kdm6a和tet2的外显子的上述合成sgrna的活性。
在补充有10%(v/v)胎牛血清(geneall)的rpmi1640培养基中对jurkat细胞(atcctib-152;人t细胞的永生细胞系)进行培养。并在37℃和5%co2的条件下在培养箱中对细胞进行培养。
为活化细胞,将培养基中的细胞浓度分别保持为1×106个细胞/ml。
以3:1的比例(珠:细胞;基于珠和细胞的数目)添加cd2/cd3/cd28珠(抗cd2/3/cd28dynabeads;miltenyibiotec),并在37℃和5%co2的条件下在培养箱中对细胞进行培养。在进行细胞活化72小时后,用磁铁去除cd2/cd3/cd28珠,并在无珠条件下进一步对细胞培养12-24小时。
通过电穿孔将1μg体外转录的sgrna和4μgcas9蛋白(toolgen)导入1×106个培养的jurkat细胞(体外)。使用neon转染系统(thermofisherscientific,grandisland,ny)的10μl枪头在如下条件下导入基因:
jurkat(缓冲液r):1,400v,20ms,2个脉冲。
将细胞涂板于500μl无抗生素培养基上,并在37℃和5%co2下在培养箱中进行培养。
与未转染的jurkat细胞(表示为“-argen”)相比,对转染的jurkat细胞(表示为“+argen”)的插入缺失比例进行测试。表3中总结了测试的crispr/cas9靶序列,表4中总结了各种sgrna的插入缺失比例。
[表3]
[表4]各sgrna在jurkat细胞上对靶序列的活性
4.肿瘤细胞系培养
egfrviii阳性u87mg成胶质细胞瘤细胞系(u87viii)购自celtherpolska。a375p黑色素瘤细胞系购自koreancelllinebank。在含有10%胎牛血清白蛋白(fbs)的dmem培养基中对细胞系进行培养。
5.慢病毒制备
从sampson,choi等的研究中(sampson等,2014,rapoport,stadtmauer等,2015)参考了与含有cd8铰链、4-1bb和cd3ζ结构域的融合蛋白139car融合的抗egfrviiiscfv以及靶向ny-eso-1的c259tcr构建体。用plvx载体对经密码子优化的cdnacar和tcr构建体进行亚克隆。使用lipofectamine2000(thermofisherscientific)将慢病毒载体和辅助质粒转染到至293t细胞中,并通过培养转染的293t细胞获得所产生慢病毒的培养上清液。获得培养上清液后,将含有慢病毒的培养上清液以4:1的比例覆盖至含蔗糖的缓冲液(100mmnacl,0.5mm乙二胺四乙酸[edta],50mmtri-hcl,ph7.4),并在4℃下以10,000g离心4小时。离心后,去除上清液,并在加入磷酸盐缓冲生理盐水(pbs)后重悬。
6.dgkko139car-t细胞的构建
人外周血t细胞(pan-t细胞)购自stemcelltechnologies。在活化前,将解冻的t细胞在添加有fbs、50u/ml的hil-2和5ng/ml的hil-7的rpmi培养基中培养过夜。将抗cd3/cd28dynabeads(thermofisherscientific)用于活化细胞,在添加有10%fbs的rpmi培养基中以3:1的比例(珠:细胞)使用。活化24小时后,在100μg/mlretronectin包被的板中将t细胞与139-car慢病毒混合48小时。刺激3天后去除珠。使用amaxap3原代细胞试剂盒和4d-nucleofecter(lonza)实施电穿孔。为了形成cas9核糖核蛋白(rnp)复合体,将40μg重组酿脓链球菌cas9(toolgen)与10μg化学合成的tracr/crrna(integrateddnatechnologies)孵育20分钟。将预孵育的cas9rnp复合体添加至在p3缓冲液中重悬的3×106个经刺激的t细胞中。使用程序eo-115将cas9rnp复合体导入细胞核中。电穿孔后,将细胞以5×105个细胞/ml的浓度接种在添加有50u/ml的hil-2、5ng/ml的hil-7和10%fbs的rpmi培养基中。测试中使用的crrna的靶序列如下:dgkα:ctctcaagctgagtgggtcc;dgkζ:acgagcactcaccagcatcc。
7.流式细胞术染色和抗体
除非另有指明,在4℃下在添加有1%fbs的pbs中进行细胞染色。用于流式细胞术和功能研究的抗体和试剂列表如下:celltracecfse/farred(thermofisher);7-aad(sigma);抗cd3:ucht1(bd);抗cd4:rpa-t4(bd);抗cd8:hit8a(bd);抗cd56:b159(bd);抗nkg2d:1d11(biolegend);抗cd45ro:uchl1(bd);抗ccr7:150513(bd);抗pd-1:eh12.2h7(biolegend);抗cd25:m-a251(bd);抗fas:dx2(bd);抗cd107a:h4a3(molecularprobes);抗egfrviii:(biorbyt);山羊抗人igg:(biorad)。数据在attunenxt声波聚焦细胞仪中收集,并使用flowjo.进行分析。
8.体外杀伤测定、细胞因子释放和增殖测定
将u87viii和a375p用celltracefarred(invitrogen)进行染色。将肿瘤细胞系与t细胞按指定比例进行共培养,并在u型底96孔板中每孔分配2×104至5×104个肿瘤细胞系。将静息的139car-t细胞和c259t细胞以指定的效应物:靶标(e:t)的比例添加至各靶细胞。共培养18小时后收集细胞,并用7-氨基放线菌素进行染色以鉴别活细胞/死细胞。用attunenxt声波聚焦细胞仪对样本进行测量,并用flowjo进行分析。使用方程式[(裂解样品值%-裂解最小值%)/(裂解最大值%[100%]-裂解最小值%)]×100%)来计算细胞毒性。测试重复3次。将共培养后收集的培养上清液用于使用elisa试剂盒(biolegend)测量il-2和ifn-γ的分泌量。将celltrace标记的139car-t细胞与u87viii细胞共培养4天用于增殖分析,并使用流式细胞术对139car-t细胞中celltrace的分布进行评价。
9.重复性肿瘤激发实验
对于连续肿瘤测试,将139car-t与u87viii以3:1(e:t)的比例在il-7培养基中共培养(第0天)。在第4天,收集139car-t细胞,并以相同的e:t比例与u87viii在il-7培养基中再次共培养。在第一和第二肿瘤接种后24小时分别收集培养上清液以评价ifn-γ和il-2的释放。
10.蛋白印迹分析
为了评价t细胞的tcr远端信号,通过使用抗cd3活化珠(miltenyibiotec)以1:2(珠:细胞)的比例将1×106个细胞活化15分钟和60分钟。为了测量erk、perk和gapdh,使用ripa裂解和提取缓冲液制备细胞裂解物。测试中使用的每种抗体购自cellsignaling。
11.钙内流
根据钙分析试剂盒(bd)手册进行t细胞钙内流的测量。简言之,将t细胞用rpmi培养基洗涤,重悬于相同的培养基中,并与色剂在37℃下孵育1小时。从非处理的细胞获得fitc信号的基本标准后,以5:1的珠:细胞比例添加抗cd3活化珠(miltenyibiotec),并用流式细胞术进行测量。用flowjo软件使用动力学模式分析从流式细胞术收集的数据。
12.实时pcr
对于rna测序,使用人t激活剂抗cd3/cd28dynabeads(thermofisher)以1:1(珠:细胞)的比例将1×106个细胞活化48小时。使用rneasymini试剂盒(qiagen)提取rna,并根据制造商的说明(abi)生产cdna。使用taqman基因表达分析试剂盒/探针套装(thermofisher)进行实时pcr。用gapdh表达对每个基因的表达进行归一化。此处,用于测试的引物如下:hdgkαf:5'-aatacctggattgggatgtgtct-3';hdgkαr:5'-gtccgtcgtccttcagagtc;hdgkζf:5'-gtactggcaacgacttggc-3';hdgkζr:5'-gcccaggctgaagtagttgtt;hβf:5′-ggcactcttccagccttc-3′;hβr:5'-tacaggtctttgcggatgtc-3′;id2:hs00747379_m1;prdm1:hs00153357_m1;il10:00174086_m1;ifng:hs00174143_m1;il2:hs00174114。
13.双基因组测序
使用dneasytissue试剂盒(qiagen)分离人t细胞的基因组dna。在1000μl反应溶液(neb3.1缓冲液)中将基因组dna(20μg)用cas9蛋白(10μg)、crrna(3.8μg)和tracrrna(3.8μg)处理,并在37℃下培养4小时。在37℃下将消化的dna与rnasea(50μg/ml)一起培养30分钟,并用dneasytissue试剂盒纯化。使用covaris系统将消化的dna片段化,并与接头连接以形成文库。使用theragenetex的illuminahiseq×tensequencer将dna文库应用至全基因组序列。为了形成bam文件,使用isaacaligner,使用以下参数:版本01.14.03.12;人基因组参比,来自ucsc的hg19(来自ncbi的原始grch37,2009年2月);小鼠基因组参比,来自ucsc的mm10;碱基量截取,15;保持重复读取,是;可变的读取长度支持,是;realigngaps,否;以及接头剪切,是(接头:5'-agatcggaagagc-3'、5'-gctcttccgatct-3')
14.小鼠异种移植研究
对于u87viii肿瘤模型,以100μlpbs体积将1×106个u87viii细胞皮下注射至6-8周的雌性nsc小鼠的右胁腹(第0天)。移植后第28天,肿瘤大小达到150±50mm2,并将小鼠随机分组。每组由6-8只小鼠组成,并且肿瘤大小类似。在第28天和第32天分别向各组静脉内(iv)或瘤内(it)注射5×106个t细胞、139aavs1car-t细胞和139dgkαζcar-t细胞。对139aavs1car-t细胞和139dgkαζcar-t细胞的car的表面表达进行鉴别(表面car表达范围:25%-70%)。从第32天至第35天,每天向每只小鼠腹膜内给予替莫唑胺(tmz)(sigma)(0.33mg/小鼠/天)。用卡尺每周两次监测肿瘤大小。当肿瘤大小达到2000mm3时处死小鼠。为了进一步研究体内递送后的car-t细胞,从每只小鼠中分离外周血、脾和肿瘤组织。为了分离肿瘤组织,将肿瘤样品用剪刀修剪并在37℃水浴中用100u/ml胶原酶iv和20u/mldnase处理1小时。之后使细胞通过无菌细胞过滤器以进行进一步研究。为了从脾分离细胞,将组织用无菌柱塞压碎并通过无菌细胞过滤器。关于溶血,将ack缓冲液(150mmnh4cl,10mmkhco3、1mmedta,ph7.2)额外处理5分钟至细胞悬浮液。为了分析肿瘤浸润t细胞的效应物功能,在co2培养箱中用50ng/mlpma和1μg/ml离子霉素将从肿瘤组织中离解的细胞重新活化5小时,然后实施细胞内ifn-γ和tnfα染色。
实施例1.通过优化的crispr/cas9rnp递送有效抑制人原代t细胞中的dgk
为了鉴别dgk在人原代t细胞的抗肿瘤活性中的作用,分别筛选了靶向dgkα基因的外显子5-外显子7和dgkζ基因的外显子3-外显子12的grna。在优化的crispr/cas9rnp电穿孔和慢病毒转染后,用crispr/cas9处理的t细胞显示出活跃的car表达(图28)。即使观测到存活力和细胞生长略有降低,电穿孔后2天存活力和细胞生长迅速恢复(图29)。在实例中,139car(具有高特异性的抗egfrviiicar)用于靶向成胶质细胞瘤细胞(sampson等,2014)。egfrviii的表达严格限于恶性组织,因此,有关通过使用139-car的经操纵car-t细胞的潜在安全性(例如靶向效应)的担忧有望得到改善。基于深度测序测得单基因敲除实验中的插入缺失比为大约80%-90%(图30)。通过对切割位点进行详细的序列分析,发现在dgkα和dgkζ139car-t细胞中由nhkj恢复诱导的框外(out-of-frame)突变分别为66.7%和59.6%,与dgk蛋白表达的降低显著一致(图30)。由于先前研究报道了dgkα和dgkζ的非重叠功能,通过产生显示出与单个dgk敲除139t细胞相当的敲除效率的dgkαζ双敲除t细胞来鉴别协同作用(图30)。为了研究靶向dgk的crispr/cas9的脱靶,在dgkα139car-t和dgkζ139car-t中进行了基于错配的计算机分析和digenome-seq(全基因组脱靶鉴别方法)(图31)。总的来说,结果说明了crispr/cas9介导的基因操纵有效且特异性地抑制了dgk,而未严重减慢人原代t细胞的细胞生长和car表达。
实施例2.通过经人工操纵的dgk扩增的cd3末端信号呈现的增强的效应物功能
由于先前由不同组报道了dgkζ-缺陷t细胞中细胞因子分泌增加,在实施例中对dgk139car-t细胞的抗肿瘤功能进行评价(shin等,2012;riese等,2013)。在体外特性分析中,将aavs1139car-t(其维持139car-t的细胞毒性,并且与139car-t相比具有与dgk139car-t更相似的生理状态)用作阴性对照(图32)。当与u87viii共培养时,与aavs1car-t相比,dgk139car-t表现出优异的效应物功能,例如细胞因子的显著增加和细胞毒性(图33)。有趣的是,相比dgkα或dgkζ139car-t,dgkαζ139car-t产生更多的ifn-γ和il-2,有力地表明了dgk双敲除在抗肿瘤活性中存在协同作用。此外,当将car-t细胞和靶肿瘤细胞系共培养时,pd-1的表达增加,并且还鉴别到在u87viii成胶质细胞瘤细胞系中pd-l1强表达。这意味着当与pd-1阻断(例如pd-1抗体或pd-1敲除)结合时,可显示出协同效应(图34)。
接下来,研究了signal1(cd3信号)通路是否受dgk破坏的影响。用抗cd3珠以指定的时间段刺激aavs1t细胞和dgkt细胞,并测量钙内流和erk(signal1的周围信号)。钙流入不受tcr活化的影响,但磷酸化的erk信号得到扩增,并且在dgk敲除突变体中持续更长的时间(图35)。dgkαζt细胞中磷酸化的erk信号的显著增加与图33中dgk双敲除的协同作用一致。此结果说明了dgk的去除增加了tcr周围信号,从而增加了t细胞的细胞毒性以及细胞因子的释放。
实施例3.通过经dgk人工操纵的t细胞对tgf-β和pge2的免疫抑制作用的逃避。
在从先前实施例中发现去除dgk有效地活化了tcr信号传导后,对经人工操纵的dgk是否能够降低t细胞对signal1抑制剂的敏感性进行测试。由于car-t治疗方法的治疗结果因肿瘤微环境(tme)中tgf-β和pge2的高水平而受到限制,tgf-β和pge2在抑制因子中受到重点关注(arumugam,bluemn等,2015;perng和lim(2015);o'rourke,nasrallah等,2017)。首先,关于u87viii对tgf-β对car-t活性的抑制效力进行研究。由于dgk双敲除的139car-t在pge2和tgf-β介导的免疫抑制中显示出协同抗性,将dgkαζ139car-t用于测试(图36)。当暴露于高生理浓度的tgf-β(10ng/ml)时,肿瘤死亡活性以及诸如aavs1139car-t的ifn-γ和il-2产生的活性急剧降低(图36)(xu,ahmad等,2000)(ivanovic,todorovic-rakovic等,2003)。同时,即使用tgf-β治疗时,dgkαζ139car-t也保持了效应物功能。同样,与其中由pge2处理而来的细胞毒性能力严重受损的aavs1139car-t相反,dgkαζ139car-t对抑制因子相对不敏感(图36)。总之,aavs1car-t的肿瘤响应性显著丧失,而dgkcar-t细胞即使暴露至tgf-β和pge2时仍保持49%-99%的活性并显示出不变的抗肿瘤功能(图37)。此外,鉴别出dgk敲除在c259tcr-t中的有利作用。当与表达ny-eso的a375p细胞一起培养时,dgkc259tcr-t对tgf-β和pge2的敏感性较低,证实了dgk敲除平台在过继细胞转移中的适应性(图38)。tgk-β和pge2抑制实验期间dgkαζ139car-t抗肿瘤活性的轻微降低被认为是由于dgk的不完全破坏,因为dgkα和dgkζ的框外敲除率分别为66.7%和59.6%(图30)。数据表明,通过dgk敲除引起的细胞内dag可用性的提高使得t细胞能够克服singal1遏抑物的免疫抑制,并表明当与signal2遏抑物联合给予时,可表现出有效的协同作用。
实施例4.在重复抗原刺激中维持经dgk人工操纵的t细胞的效应物功能
当重复识别抗原时,t细胞经常处于抑制状态,其中的il-2分泌和细胞毒性丧失。dag代谢为调节t细胞活化和无能的重要决定因素(olenchock,guo等,2006;zha,marks等,2006)。大量研究报道了dgkα的药理学抑制能够逆转小鼠t细胞的无能状态,从而对经dgk人工操纵的人t细胞是否克服了t细胞无能进行鉴别(olenchock,guo等,2006;moon,wang等,2014)。首先,对重复抗原攻击期间dgkαζ139car-t的增殖能力进行评价。将139car-t细胞与u87viii一起培养96小时,然后再次接种u87viii,并且通过使用celltrace分布和细胞计数来测量car-t的细胞增殖能力(图39)。与显示出不显著的增殖的aavs1139car-t不同,dgkαζ139car-t在重复活化下成功增殖(图40)。为了鉴别dgkαζ139car-t的优异扩增是否是增殖能力增强或激活诱导细胞死亡(aicd)减少的结果,进行了凋亡分析。与aavs1139car-t相比,当将与u87viii遇到的139cart细胞用7-aad染色时,dgkαζ139car-t显示出更大的7-aad阳性t细胞群(图41)。由于dgkα的抑制能够诱导fas依赖性凋亡,对139car-t中的fas表达进行了鉴别,结果鉴别出139car-t表面上的fas表达显著增加(图41)(alonso,rodriguez等,2005)。此类数据说明了肿瘤识别增加的dgkαζ139car-t细胞主要由细胞增殖能力引起,并且该增加补偿了肿瘤识别诱导的t细胞凋亡。对在多次肿瘤接种中dgkαζ139car-t的细胞因子分泌进行了分析(图42)。在首次暴露于u87viii后,aavs1139car-t细胞强烈产生ifn-γ和il-2,但收集aavs1139car-t细胞后,将其再次暴露于新的u87viii,并使用elisa鉴定细胞因子的产生,鉴定出明显降低的细胞因子产生能力。相反,即使在二次暴露后,dgkαζ139car-t也通过对u87viii活化进行反应而保持细胞因子的分泌,证实了dgk敲除使得能够避免t细胞无能。
实施例5.将经dgk人工操纵的t细胞重编程为效应记忆t细胞的作用
据报道,dgkα和dgkζ均丧失使cd8t细胞分化为短寿命效应细胞和效应记忆组(yang,zhang等,2016)。为了研究dgk缺乏是否改变t细胞分化,对经dgk操纵的139car-t细胞与u87viii共培养4天时,经dgk操纵的car-t细胞的记忆亚群的特征进行了说明。在接种至肿瘤前,dgkαζ139car-t细胞显示出小于aavs1139car-t细胞的初始t细胞群(图43)。肿瘤接种4天后,dgkαζ139car-t细胞的初始t细胞群优先分化为效应记忆细胞,结果形成了较小的初始t细胞和中心记忆t细胞群(图43)。接下来,对dgk的人工操纵是否对t细胞在转录层面重新程序化进行了研究。作为使用cd3/28dynabead活化t细胞48小时后对相关转录因子进行鉴别的结果,鉴别出id2和prdm1(dgkαζt细胞的效应记忆控制因子)的大量增加(图44)。此外,在经dgk人工操纵的t细胞中,i型细胞因子的表达增加,但ii型细胞因子il-10的转录显著降低(图44)。最后,为了鉴别由dgk敲除产生的效应t细胞不具有功能障碍,对dgkαζ139car-t中的耗竭标志物pd-1和tim-3进行研究。当使用u87viii活化139car-t细胞7天时,与aavs1139car-t相比,dgk139car-t表现出pd-1和tim-3表达的相似水平(图45)。将经dgk人工操纵的t细胞重新程序化为效应记忆t细胞而无t细胞耗竭,因此说明了强的离体抗肿瘤作用。
实施例6.经dgk人工操纵的t细胞的肿瘤浸润能力和肿瘤清除效果
为了研究dgkαζ139car-t的增强的效应物功能的体内功能相关性,将aavs1139car-t或dgkαζ139car-t静脉内(iv)或肿瘤内(it)注射至经u87viii移植的nsg小鼠中。根据存在的肿瘤的数量和免疫细胞数,过继细胞转移的效果可能会明显不同。levij,rupp等在具有低肿瘤量的小鼠的实验中证明了在对照组cd19car-t细胞和pd1敲除cd19car-t细胞中,高t细胞注射均能够完全清除肿瘤(rupp,schumann等,2017)。因此,本研究在高肿瘤量模型中使用了低t细胞量以研究dgk敲除t细胞的体内效力。当肿瘤体积达到150±50mm3时第一次注射t细胞;当肿瘤体积达到400±50mm3时4天后进行第二次t细胞注射。此处,第一和第二次注射分别以大约1:10和1:20的e:t比进行。大量研究报道在抗egfrviii成胶质细胞瘤靶向t细胞治疗期间无替莫唑胺(tmz)的治疗通常显示无效的结果(ohno,ohkuri等,2013;johnson,scholler等,2015),因此在第二次t细胞注射期间腹膜内注射替莫唑胺佐剂以刺激肿瘤消退。在tmz处理32天后每个iv注射组显示出肿瘤生长的延迟,但与对照组t细胞小鼠组相比,注射有aavs1139car-t的小鼠未表显出抗肿瘤作用(图46)。相反,第56天在dgkαζ139car-t小鼠组中发现了肿瘤完全消退。同样地,尽管aavs1139car-t的瘤内注射不能消除u87viii肿瘤,但dgkαζ139car-t的过继细胞转移在第52天显示出肿瘤消退的有意义的结果。为了表征dgkαζ139car-t的体内功能,在第49天提取了肿瘤,并对肿瘤浸润t细胞数进行计数。
为了额外表征dgk敲除的139car-t细胞的体内功能,对注射的aavs1139car-t细胞、αko139car-t细胞、ζko139car-t细胞和dko139car-t细胞的存活力进行了分析。结果,鉴别出ζko139car-t细胞和dko139car-t细胞在肿瘤中维持了显著大的数量(图47)。这是因为,分裂的t细胞(以ki-67染色的细胞为代表)以较大的数量存在,被鉴定为功能上占优势的效应t细胞,其具有增加的t-bet表达以及增强的细胞因子(如ifn-γ和tnf-α)的分泌能力(图48)。
总之,数据结果说明了通过cripsr/cas9进行的dgk的人工操纵能够增强人car-t细胞的体内抗肿瘤效力。
工业实用性
用经修饰的免疫细胞(含有人工修饰的免疫调节基因和人工受体)可获得有效的免疫细胞治疗剂。例如,当使用通过本发明的用于免疫细胞操纵的组合物免疫操纵的免疫细胞时,由于其可以改善涉及免疫细胞(所述免疫细胞能够特异性结合特定抗原)的存活、增殖、持久性、细胞毒性、细胞因子释放和/或浸润等方面的免疫效力,可将它们用作有效的免疫细胞治疗剂。
【序列表文字】
免疫调节基因的靶序列
序列表
<110>株式会社图尔金(toolgenincorporation)
<120>经人工操纵的免疫细胞
<130>opp17-041-np-pct-pct
<150>us62/502,822
<151>2017-05-08
<150>pct/kr2017/008835
<151>2017-08-14
<150>us62/595159
<151>2017-12-06
<160>289
<170>siposequencelisting1.0
<210>1
<211>23
<212>dna
<213>智人(homosapiens)
<400>1
cttgtggcgctgaaaacgaacgg23
<210>2
<211>23
<212>dna
<213>智人(homosapiens)
<400>2
atgccacttctcagtacatgtgg23
<210>3
<211>23
<212>dna
<213>智人(homosapiens)
<400>3
gccacttctcagtacatgtgggg23
<210>4
<211>23
<212>dna
<213>智人(homosapiens)
<400>4
gccccacatgtactgagaagtgg23
<210>5
<211>23
<212>dna
<213>智人(homosapiens)
<400>5
tcagtacatgtggggcgttcagg23
<210>6
<211>23
<212>dna
<213>智人(homosapiens)
<400>6
gggcgttcaggacacagacttgg23
<210>7
<211>23
<212>dna
<213>智人(homosapiens)
<400>7
cacagacttggtactgaggaagg23
<210>8
<211>23
<212>dna
<213>智人(homosapiens)
<400>8
ggcgctgttcagcacgctcaagg23
<210>9
<211>23
<212>dna
<213>智人(homosapiens)
<400>9
cacgcaactttaaattccgctgg23
<210>10
<211>23
<212>dna
<213>智人(homosapiens)
<400>10
cggggctttgctatgatactcgg23
<210>11
<211>23
<212>dna
<213>智人(homosapiens)
<400>11
ggcttccacagacacacccatgg23
<210>12
<211>23
<212>dna
<213>智人(homosapiens)
<400>12
tgaagtccacttcgggccatggg23
<210>13
<211>23
<212>dna
<213>智人(homosapiens)
<400>13
ctgtacgacacggacagaaatgg23
<210>14
<211>23
<212>dna
<213>智人(homosapiens)
<400>14
tgtacgacacggacagaaatggg23
<210>15
<211>23
<212>dna
<213>智人(homosapiens)
<400>15
cacggacagaaatgggatcctgg23
<210>16
<211>23
<212>dna
<213>智人(homosapiens)
<400>16
gatgcgagtggctgaatacctgg23
<210>17
<211>23
<212>dna
<213>智人(homosapiens)
<400>17
gagtggctgaatacctggattgg23
<210>18
<211>23
<212>dna
<213>智人(homosapiens)
<400>18
agtggctgaatacctggattggg23
<210>19
<211>23
<212>dna
<213>智人(homosapiens)
<400>19
attgggatgtgtctgagctgagg23
<210>20
<211>23
<212>dna
<213>智人(homosapiens)
<400>20
atgaaagagattgactatgatgg23
<210>21
<211>23
<212>dna
<213>智人(homosapiens)
<400>21
ctctgtctctcaagctgagtggg23
<210>22
<211>23
<212>dna
<213>智人(homosapiens)
<400>22
tctctcaagctgagtgggtccgg23
<210>23
<211>23
<212>dna
<213>智人(homosapiens)
<400>23
ctctcaagctgagtgggtccggg23
<210>24
<211>23
<212>dna
<213>智人(homosapiens)
<400>24
caagctgagtgggtccgggctgg23
<210>25
<211>23
<212>dna
<213>智人(homosapiens)
<400>25
ttgacatgactggagagaagagg23
<210>26
<211>23
<212>dna
<213>智人(homosapiens)
<400>26
gactggagagaagaggtcgttgg23
<210>27
<211>23
<212>dna
<213>智人(homosapiens)
<400>27
gagacgggagcaaagctgctggg23
<210>28
<211>23
<212>dna
<213>智人(homosapiens)
<400>28
agagacgggagcaaagctgctgg23
<210>29
<211>23
<212>dna
<213>智人(homosapiens)
<400>29
tggtttctaggtgcagagacggg23
<210>30
<211>23
<212>dna
<213>智人(homosapiens)
<400>30
taagtgaaggtctggtttctagg23
<210>31
<211>23
<212>dna
<213>智人(homosapiens)
<400>31
tgcccatgtaagtgaaggtctgg23
<210>32
<211>23
<212>dna
<213>智人(homosapiens)
<400>32
gaacttgcccatgtaagtgaagg23
<210>33
<211>23
<212>dna
<213>智人(homosapiens)
<400>33
tccattgaccctcagtaccctgg23
<210>34
<211>23
<212>dna
<213>智人(homosapiens)
<400>34
tatgccttctgggtagcagctgg23
<210>35
<211>23
<212>dna
<213>智人(homosapiens)
<400>35
tgagtgcaggcatcttgcaaggg23
<210>36
<211>23
<212>dna
<213>智人(homosapiens)
<400>36
gagtgcaggcatcttgcaagggg23
<210>37
<211>23
<212>dna
<213>智人(homosapiens)
<400>37
gatgaggctgtggttgaagctgg23
<210>38
<211>23
<212>dna
<213>智人(homosapiens)
<400>38
ccactggccacaggacccctggg23
<210>39
<211>23
<212>dna
<213>智人(homosapiens)
<400>39
gggacatggtgcacacacccagg23
<210>40
<211>23
<212>dna
<213>智人(homosapiens)
<400>40
gagtacaggtggtccaggtcagg23
<210>41
<211>23
<212>dna
<213>智人(homosapiens)
<400>41
gcggagagtacaggtggtccagg23
<210>42
<211>23
<212>dna
<213>智人(homosapiens)
<400>42
gcggtggcggagagtacaggtgg23
<210>43
<211>23
<212>dna
<213>智人(homosapiens)
<400>43
tctcctgcacagccagaataagg23
<210>44
<211>23
<212>dna
<213>智人(homosapiens)
<400>44
acgcagaagggtcctggtagagg23
<210>45
<211>23
<212>dna
<213>智人(homosapiens)
<400>45
aggtggtgggtaggccagagagg23
<210>46
<211>23
<212>dna
<213>智人(homosapiens)
<400>46
cccaagccagccacggacccagg23
<210>47
<211>23
<212>dna
<213>智人(homosapiens)
<400>47
acctgggtccgtggctggcttgg23
<210>48
<211>23
<212>dna
<213>智人(homosapiens)
<400>48
aagagacctgggtccgtggctgg23
<210>49
<211>23
<212>dna
<213>智人(homosapiens)
<400>49
ggatcattgggaagagacctggg23
<210>50
<211>23
<212>dna
<213>智人(homosapiens)
<400>50
gggatcattgggaagagacctgg23
<210>51
<211>23
<212>dna
<213>智人(homosapiens)
<400>51
caggatagtctgggatcattggg23
<210>52
<211>23
<212>dna
<213>智人(homosapiens)
<400>52
ggaaagaatccaggatagtctgg23
<210>53
<211>23
<212>dna
<213>智人(homosapiens)
<400>53
cagtgccagagagacctacatgg23
<210>54
<211>23
<212>dna
<213>智人(homosapiens)
<400>54
ctgtaccatgtaggtctctctgg23
<210>55
<211>23
<212>dna
<213>智人(homosapiens)
<400>55
agagacctacatggtacagctgg23
<210>56
<211>23
<212>dna
<213>智人(homosapiens)
<400>56
ctgggccagctgtaccatgtagg23
<210>57
<211>23
<212>dna
<213>智人(homosapiens)
<400>57
agggaaagggcttacggtctggg23
<210>58
<211>23
<212>dna
<213>智人(homosapiens)
<400>58
cagggaaagggcttacggtctgg23
<210>59
<211>23
<212>dna
<213>智人(homosapiens)
<400>59
tctggagatcttcttgcaacagg23
<210>60
<211>23
<212>dna
<213>智人(homosapiens)
<400>60
ctccggttcatgactttgaaagg23
<210>61
<211>23
<212>dna
<213>智人(homosapiens)
<400>61
gtcttccatcttcgtctttcagg23
<210>62
<211>23
<212>dna
<213>智人(homosapiens)
<400>62
gaagacttcgagacccatttagg23
<210>63
<211>23
<212>dna
<213>智人(homosapiens)
<400>63
tcgagacccatttaggatcacgg23
<210>64
<211>23
<212>dna
<213>智人(homosapiens)
<400>64
gtagcgccgtgatcctaaatggg23
<210>65
<211>23
<212>dna
<213>智人(homosapiens)
<400>65
cgtagcgccgtgatcctaaatgg23
<210>66
<211>23
<212>dna
<213>智人(homosapiens)
<400>66
catttaggatcacggcgctacgg23
<210>67
<211>23
<212>dna
<213>智人(homosapiens)
<400>67
ggtcccaatattgaagcccatgg23
<210>68
<211>23
<212>dna
<213>智人(homosapiens)
<400>68
gatccatgggcttcaatattggg23
<210>69
<211>23
<212>dna
<213>智人(homosapiens)
<400>69
agatccatgggcttcaatattgg23
<210>70
<211>23
<212>dna
<213>智人(homosapiens)
<400>70
gcttctaccataagatccatggg23
<210>71
<211>23
<212>dna
<213>智人(homosapiens)
<400>71
cgcttctaccataagatccatgg23
<210>72
<211>23
<212>dna
<213>智人(homosapiens)
<400>72
gcatttgcaaaaattcgccgtgg23
<210>73
<211>23
<212>dna
<213>智人(homosapiens)
<400>73
atgacctgagaattaatttatgg23
<210>74
<211>23
<212>dna
<213>智人(homosapiens)
<400>74
ccatgcactcccagacatcgtgg23
<210>75
<211>23
<212>dna
<213>智人(homosapiens)
<400>75
gcactggtgcgggtggaactcgg23
<210>76
<211>23
<212>dna
<213>智人(homosapiens)
<400>76
acacgttgcactggtgcgggtgg23
<210>77
<211>23
<212>dna
<213>智人(homosapiens)
<400>77
cgaacacgttgcactggtgcggg23
<210>78
<211>23
<212>dna
<213>智人(homosapiens)
<400>78
acgaacacgttgcactggtgcgg23
<210>79
<211>23
<212>dna
<213>智人(homosapiens)
<400>79
tgtagacgaacacgttgcactgg23
<210>80
<211>23
<212>dna
<213>智人(homosapiens)
<400>80
gcgcatgtcacacaggcggatgg23
<210>81
<211>23
<212>dna
<213>智人(homosapiens)
<400>81
aggagcgcatgtcacacaggcgg23
<210>82
<211>23
<212>dna
<213>智人(homosapiens)
<400>82
ccgaggagcgcatgtcacacagg23
<210>83
<211>23
<212>dna
<213>智人(homosapiens)
<400>83
cctgtgtgacatgcgctcctcgg23
<210>84
<211>23
<212>dna
<213>智人(homosapiens)
<400>84
cgactggccagggcgcctgtggg23
<210>85
<211>23
<212>dna
<213>智人(homosapiens)
<400>85
accgcccagacgactggccaggg23
<210>86
<211>23
<212>dna
<213>智人(homosapiens)
<400>86
caccgcccagacgactggccagg23
<210>87
<211>23
<212>dna
<213>智人(homosapiens)
<400>87
gtctgggcggtgctacaactggg23
<210>88
<211>23
<212>dna
<213>智人(homosapiens)
<400>88
ctacaactgggctggcggccagg23
<210>89
<211>23
<212>dna
<213>智人(homosapiens)
<400>89
cacctacctaagaaccatcctgg23
<210>90
<211>23
<212>dna
<213>智人(homosapiens)
<400>90
cggtcaccacgagcagggctggg23
<210>91
<211>23
<212>dna
<213>智人(homosapiens)
<400>91
gccctgctcgtggtgaccgaagg23
<210>92
<211>23
<212>dna
<213>智人(homosapiens)
<400>92
cggagagcttcgtgctaaactgg23
<210>93
<211>23
<212>dna
<213>智人(homosapiens)
<400>93
cagcttgtccgtctggttgctgg23
<210>94
<211>23
<212>dna
<213>智人(homosapiens)
<400>94
aggcggccagcttgtccgtctgg23
<210>95
<211>23
<212>dna
<213>智人(homosapiens)
<400>95
ccgggctggctgcggtcctcggg23
<210>96
<211>23
<212>dna
<213>智人(homosapiens)
<400>96
cgttgggcagttgtgtgacacgg23
<210>97
<211>23
<212>dna
<213>智人(homosapiens)
<400>97
cataaagccatggcttgccttgg23
<210>98
<211>23
<212>dna
<213>智人(homosapiens)
<400>98
ccttggatttcagcggcacaagg23
<210>99
<211>23
<212>dna
<213>智人(homosapiens)
<400>99
ccttgtgccgctgaaatccaagg23
<210>100
<211>23
<212>dna
<213>智人(homosapiens)
<400>100
cactcacctttgcagaagacagg23
<210>101
<211>23
<212>dna
<213>智人(homosapiens)
<400>101
ttccatgctagcaatgcacgtgg23
<210>102
<211>23
<212>dna
<213>智人(homosapiens)
<400>102
ggccacgtgcattgctagcatgg23
<210>103
<211>23
<212>dna
<213>智人(homosapiens)
<400>103
ggcccagcctgctgtggtactgg23
<210>104
<211>23
<212>dna
<213>智人(homosapiens)
<400>104
aggtccgggtgacagtgcttcgg23
<210>105
<211>23
<212>dna
<213>智人(homosapiens)
<400>105
ccgggtgacagtgcttcggcagg23
<210>106
<211>23
<212>dna
<213>智人(homosapiens)
<400>106
ctgtgcggcaacctacatgatgg23
<210>107
<211>23
<212>dna
<213>智人(homosapiens)
<400>107
caactcattccccatcatgtagg23
<210>108
<211>23
<212>dna
<213>智人(homosapiens)
<400>108
ctagatgattccatctgcacggg23
<210>109
<211>23
<212>dna
<213>智人(homosapiens)
<400>109
ggctaggagtcagcgacatatgg23
<210>110
<211>23
<212>dna
<213>智人(homosapiens)
<400>110
gctaggagtcagcgacatatggg23
<210>111
<211>23
<212>dna
<213>智人(homosapiens)
<400>111
ctaggagtcagcgacatatgggg23
<210>112
<211>23
<212>dna
<213>智人(homosapiens)
<400>112
gtactgtgtagccaggatgctgg23
<210>113
<211>23
<212>dna
<213>智人(homosapiens)
<400>113
acgagcactcaccagcatcctgg23
<210>114
<211>23
<212>dna
<213>智人(homosapiens)
<400>114
aggctccaggaatgtccgcgagg23
<210>115
<211>23
<212>dna
<213>智人(homosapiens)
<400>115
acttacctcgcggacattcctgg23
<210>116
<211>23
<212>dna
<213>智人(homosapiens)
<400>116
caccctgggcacttacctcgcgg23
<210>117
<211>23
<212>dna
<213>智人(homosapiens)
<400>117
gtgccgtacaaaggttggctggg23
<210>118
<211>23
<212>dna
<213>智人(homosapiens)
<400>118
ggtgccgtacaaaggttggctgg23
<210>119
<211>23
<212>dna
<213>智人(homosapiens)
<400>119
ctctcctcagtaccacagcaagg23
<210>120
<211>23
<212>dna
<213>智人(homosapiens)
<400>120
cctggggcctccgggcgcggagg23
<210>121
<211>23
<212>dna
<213>智人(homosapiens)
<400>121
agtactcacctggggcctccggg23
<210>122
<211>23
<212>dna
<213>智人(homosapiens)
<400>122
agggtctccagcggccctcctgg23
<210>123
<211>23
<212>dna
<213>智人(homosapiens)
<400>123
gcaagtacttacgcctccttggg23
<210>124
<211>23
<212>dna
<213>智人(homosapiens)
<400>124
ttgcggtacatctccagcctggg23
<210>125
<211>23
<212>dna
<213>智人(homosapiens)
<400>125
tttgcggtacatctccagcctgg23
<210>126
<211>23
<212>dna
<213>智人(homosapiens)
<400>126
gcaaaacctgtccactcttatgg23
<210>127
<211>23
<212>dna
<213>智人(homosapiens)
<400>127
ttggtgccataagagtggacagg23
<210>128
<211>23
<212>dna
<213>智人(homosapiens)
<400>128
ggtgcaagtttcttatatgttgg23
<210>129
<211>23
<212>dna
<213>智人(homosapiens)
<400>129
acctgatgcatataataatcagg23
<210>130
<211>23
<212>dna
<213>智人(homosapiens)
<400>130
acctgattattatatgcatcagg23
<210>131
<211>23
<212>dna
<213>智人(homosapiens)
<400>131
cagagcaccagagtgccgtctgg23
<210>132
<211>23
<212>dna
<213>智人(homosapiens)
<400>132
agagcaccagagtgccgtctggg23
<210>133
<211>23
<212>dna
<213>智人(homosapiens)
<400>133
agagtgccgtctgggtctgaagg23
<210>134
<211>23
<212>dna
<213>智人(homosapiens)
<400>134
aggaaggccgtccattctcaggg23
<210>135
<211>23
<212>dna
<213>智人(homosapiens)
<400>135
ggatagaaccaaccatgttgagg23
<210>136
<211>23
<212>dna
<213>智人(homosapiens)
<400>136
tctgttgccctcaacatggttgg23
<210>137
<211>23
<212>dna
<213>智人(homosapiens)
<400>137
ttagtctgttgccctcaacatgg23
<210>138
<211>23
<212>dna
<213>智人(homosapiens)
<400>138
gtctggcaaatgggaggtgatgg23
<210>139
<211>23
<212>dna
<213>智人(homosapiens)
<400>139
cagaggttctgtctggcaaatgg23
<210>140
<211>23
<212>dna
<213>智人(homosapiens)
<400>140
ttgtagccagaggttctgtctgg23
<210>141
<211>23
<212>dna
<213>智人(homosapiens)
<400>141
acttctggatgagctctctcagg23
<210>142
<211>23
<212>dna
<213>智人(homosapiens)
<400>142
agagctcatccagaagtaaatgg23
<210>143
<211>23
<212>dna
<213>智人(homosapiens)
<400>143
ttggtgtctccatttacttctgg23
<210>144
<211>23
<212>dna
<213>智人(homosapiens)
<400>144
ttctggcttcccttcatacaggg23
<210>145
<211>23
<212>dna
<213>智人(homosapiens)
<400>145
caggactcacacgactattctgg23
<210>146
<211>23
<212>dna
<213>智人(homosapiens)
<400>146
ctactttcttgtgtaaagtcagg23
<210>147
<211>23
<212>dna
<213>智人(homosapiens)
<400>147
gactttacacaagaaagtagagg23
<210>148
<211>23
<212>dna
<213>智人(homosapiens)
<400>148
gtctttctccattagccttttgg23
<210>149
<211>23
<212>dna
<213>智人(homosapiens)
<400>149
aatggagaaagacgtaacttcgg23
<210>150
<211>23
<212>dna
<213>智人(homosapiens)
<400>150
atggagaaagacgtaacttcggg23
<210>151
<211>23
<212>dna
<213>智人(homosapiens)
<400>151
tggagaaagacgtaacttcgggg23
<210>152
<211>23
<212>dna
<213>智人(homosapiens)
<400>152
tttggttgactgctttcacctgg23
<210>153
<211>23
<212>dna
<213>智人(homosapiens)
<400>153
tcactcaaatcggagacatttgg23
<210>154
<211>23
<212>dna
<213>智人(homosapiens)
<400>154
atctgaagctctggattttcagg23
<210>155
<211>23
<212>dna
<213>智人(homosapiens)
<400>155
gcttcagattctgaatgagcagg23
<210>156
<211>23
<212>dna
<213>智人(homosapiens)
<400>156
cagattctgaatgagcaggaggg23
<210>157
<211>23
<212>dna
<213>智人(homosapiens)
<400>157
aaggcagtgctaatgcctaatgg23
<210>158
<211>23
<212>dna
<213>智人(homosapiens)
<400>158
gcagaaactgtagcaccattagg23
<210>159
<211>23
<212>dna
<213>智人(homosapiens)
<400>159
accgcaatggaaacacaatctgg23
<210>160
<211>23
<212>dna
<213>智人(homosapiens)
<400>160
tgtggttttctgcaccgcaatgg23
<210>161
<211>23
<212>dna
<213>智人(homosapiens)
<400>161
cataaatgccattaacagtcagg23
<210>162
<211>23
<212>dna
<213>智人(homosapiens)
<400>162
attagtagcctgactgttaatgg23
<210>163
<211>23
<212>dna
<213>智人(homosapiens)
<400>163
cgatgggtgagtgatctcacagg23
<210>164
<211>23
<212>dna
<213>智人(homosapiens)
<400>164
actcacccatcgcatacctcagg23
<210>165
<211>23
<212>dna
<213>智人(homosapiens)
<400>165
ctcacccatcgcatacctcaggg23
<210>166
<211>23
<212>dna
<213>智人(homosapiens)
<400>166
agcaacaggaggagttgcagagg23
<210>167
<211>23
<212>dna
<213>智人(homosapiens)
<400>167
ccagtaggatcagcaacaggagg23
<210>168
<211>23
<212>dna
<213>智人(homosapiens)
<400>168
ctcctgttgctgatcctactggg23
<210>169
<211>23
<212>dna
<213>智人(homosapiens)
<400>169
ggcccagtaggatcagcaacagg23
<210>170
<211>23
<212>dna
<213>智人(homosapiens)
<400>170
ttgctgatcctactgggccctgg23
<210>171
<211>23
<212>dna
<213>智人(homosapiens)
<400>171
tggcaacagcttgcagctgtggg23
<210>172
<211>23
<212>dna
<213>智人(homosapiens)
<400>172
cttgggtcccctgcttgcccggg23
<210>173
<211>23
<212>dna
<213>智人(homosapiens)
<400>173
gtcccctgcttgcccgggaccgg23
<210>174
<211>23
<212>dna
<213>智人(homosapiens)
<400>174
ctccggtcccgggcaagcagggg23
<210>175
<211>23
<212>dna
<213>智人(homosapiens)
<400>175
tctccggtcccgggcaagcaggg23
<210>176
<211>23
<212>dna
<213>智人(homosapiens)
<400>176
gtctccggtcccgggcaagcagg23
<210>177
<211>23
<212>dna
<213>智人(homosapiens)
<400>177
gcttgcccgggaccggagacagg23
<210>178
<211>23
<212>dna
<213>智人(homosapiens)
<400>178
ggtggcctgtctccggtcccggg23
<210>179
<211>23
<212>dna
<213>智人(homosapiens)
<400>179
cggtggcctgtctccggtcccgg23
<210>180
<211>23
<212>dna
<213>智人(homosapiens)
<400>180
catattcggtggcctgtctccgg23
<210>181
<211>23
<212>dna
<213>智人(homosapiens)
<400>181
atctaggtactcatattcggtgg23
<210>182
<211>23
<212>dna
<213>智人(homosapiens)
<400>182
ataatctaggtactcatattcgg23
<210>183
<211>23
<212>dna
<213>智人(homosapiens)
<400>183
ttatgatttcctgccagaaacgg23
<210>184
<211>23
<212>dna
<213>智人(homosapiens)
<400>184
atttctggaggctccgtttctgg23
<210>185
<211>23
<212>dna
<213>智人(homosapiens)
<400>185
actgacaccactcctctgactgg23
<210>186
<211>23
<212>dna
<213>智人(homosapiens)
<400>186
ctgacaccactcctctgactggg23
<210>187
<211>23
<212>dna
<213>智人(homosapiens)
<400>187
accactcctctgactgggcctgg23
<210>188
<211>23
<212>dna
<213>智人(homosapiens)
<400>188
aacccctgagtctaccactgtgg23
<210>189
<211>23
<212>dna
<213>智人(homosapiens)
<400>189
ctccacagtggtagactcagggg23
<210>190
<211>23
<212>dna
<213>智人(homosapiens)
<400>190
gctccacagtggtagactcaggg23
<210>191
<211>23
<212>dna
<213>智人(homosapiens)
<400>191
ggctccacagtggtagactcagg23
<210>192
<211>23
<212>dna
<213>智人(homosapiens)
<400>192
cctgctgcaaggcgttctactgg23
<210>193
<211>23
<212>dna
<213>智人(homosapiens)
<400>193
ccagtagaacgccttgcagcagg23
<210>194
<211>23
<212>dna
<213>智人(homosapiens)
<400>194
cgttctactggcctggatgcagg23
<210>195
<211>23
<212>dna
<213>智人(homosapiens)
<400>195
tctactggcctggatgcaggagg23
<210>196
<211>23
<212>dna
<213>智人(homosapiens)
<400>196
ccacggagctggccaacatgggg23
<210>197
<211>23
<212>dna
<213>智人(homosapiens)
<400>197
cgtggacaggttccccatgttgg23
<210>198
<211>23
<212>dna
<213>智人(homosapiens)
<400>198
gtccacggattcagcagctatgg23
<210>199
<211>23
<212>dna
<213>智人(homosapiens)
<400>199
gaccactcaaccagtgcccacgg23
<210>200
<211>23
<212>dna
<213>智人(homosapiens)
<400>200
ggagtggtctgtgcctccgtggg23
<210>201
<211>23
<212>dna
<213>智人(homosapiens)
<400>201
ggcacagacaactcgactgacgg23
<210>202
<211>23
<212>dna
<213>智人(homosapiens)
<400>202
gacaactcgactgacggccacgg23
<210>203
<211>23
<212>dna
<213>智人(homosapiens)
<400>203
aactcgactgacggccacggagg23
<210>204
<211>23
<212>dna
<213>智人(homosapiens)
<400>204
cacagaacccagtgccacagagg23
<210>205
<211>23
<212>dna
<213>智人(homosapiens)
<400>205
ggtagtaggttccatggacaggg23
<210>206
<211>23
<212>dna
<213>智人(homosapiens)
<400>206
tggtagtaggttccatggacagg23
<210>207
<211>23
<212>dna
<213>智人(homosapiens)
<400>207
tcttttggtagtaggttccatgg23
<210>208
<211>23
<212>dna
<213>智人(homosapiens)
<400>208
atggaacctactaccaaaagagg23
<210>209
<211>23
<212>dna
<213>智人(homosapiens)
<400>209
aacagacctcttttggtagtagg23
<210>210
<211>23
<212>dna
<213>智人(homosapiens)
<400>210
gggtatgaacagacctcttttgg23
<210>211
<211>23
<212>dna
<213>智人(homosapiens)
<400>211
tgtgtcctctgttactcacaagg23
<210>212
<211>23
<212>dna
<213>智人(homosapiens)
<400>212
gtgtcctctgttactcacaaggg23
<210>213
<211>23
<212>dna
<213>智人(homosapiens)
<400>213
gtagttgacggacaaattgctgg23
<210>214
<211>23
<212>dna
<213>智人(homosapiens)
<400>214
tttgtccgtcaactacccagtgg23
<210>215
<211>23
<212>dna
<213>智人(homosapiens)
<400>215
ttgtccgtcaactacccagtggg23
<210>216
<211>23
<212>dna
<213>智人(homosapiens)
<400>216
tgtccgtcaactacccagtgggg23
<210>217
<211>23
<212>dna
<213>智人(homosapiens)
<400>217
gtccgtcaactacccagtggggg23
<210>218
<211>23
<212>dna
<213>智人(homosapiens)
<400>218
ctctgtgaagcagtgcctgctgg23
<210>219
<211>23
<212>dna
<213>智人(homosapiens)
<400>219
cctgctggccatcctaatcttgg23
<210>220
<211>23
<212>dna
<213>智人(homosapiens)
<400>220
ccaagattaggatggccagcagg23
<210>221
<211>23
<212>dna
<213>智人(homosapiens)
<400>221
ggccatcctaatcttggcgctgg23
<210>222
<211>23
<212>dna
<213>智人(homosapiens)
<400>222
caccagcgccaagattaggatgg23
<210>223
<211>23
<212>dna
<213>智人(homosapiens)
<400>223
agtgcacacgaagaagatagtgg23
<210>224
<211>23
<212>dna
<213>智人(homosapiens)
<400>224
tatcttcttcgtgtgcactgtgg23
<210>225
<211>23
<212>dna
<213>智人(homosapiens)
<400>225
cttcgtgtgcactgtggtgctgg23
<210>226
<211>23
<212>dna
<213>智人(homosapiens)
<400>226
ggcggtccgcctctcccgcaagg23
<210>227
<211>23
<212>dna
<213>智人(homosapiens)
<400>227
gcggtccgcctctcccgcaaggg23
<210>228
<211>23
<212>dna
<213>智人(homosapiens)
<400>228
aattacgcacggggtacatgtgg23
<210>229
<211>23
<212>dna
<213>智人(homosapiens)
<400>229
tgggggagtaattacgcacgggg23
<210>230
<211>23
<212>dna
<213>智人(homosapiens)
<400>230
gtgggggagtaattacgcacggg23
<210>231
<211>23
<212>dna
<213>智人(homosapiens)
<400>231
ggtgggggagtaattacgcacgg23
<210>232
<211>23
<212>dna
<213>智人(homosapiens)
<400>232
taattactcccccaccgagatgg23
<210>233
<211>23
<212>dna
<213>智人(homosapiens)
<400>233
agatgcagaccatctcggtgggg23
<210>234
<211>23
<212>dna
<213>智人(homosapiens)
<400>234
gagatgcagaccatctcggtggg23
<210>235
<211>23
<212>dna
<213>智人(homosapiens)
<400>235
tgagatgcagaccatctcggtgg23
<210>236
<211>23
<212>dna
<213>智人(homosapiens)
<400>236
ggatgagatgcagaccatctcgg23
<210>237
<211>23
<212>dna
<213>智人(homosapiens)
<400>237
atctcatccctgttgcctgatgg23
<210>238
<211>23
<212>dna
<213>智人(homosapiens)
<400>238
tcatccctgttgcctgatggggg23
<210>239
<211>23
<212>dna
<213>智人(homosapiens)
<400>239
ctcacccccatcaggcaacaggg23
<210>240
<211>23
<212>dna
<213>智人(homosapiens)
<400>240
gagggcccctcacccccatcagg23
<210>241
<211>23
<212>dna
<213>智人(homosapiens)
<400>241
gggccctctgccacagccaatgg23
<210>242
<211>23
<212>dna
<213>智人(homosapiens)
<400>242
ccctctgccacagccaatggggg23
<210>243
<211>23
<212>dna
<213>智人(homosapiens)
<400>243
cccccattggctgtggcagaggg23
<210>244
<211>23
<212>dna
<213>智人(homosapiens)
<400>244
gcccccattggctgtggcagagg23
<210>245
<211>23
<212>dna
<213>智人(homosapiens)
<400>245
ggacaggcccccattggctgtgg23
<210>246
<211>23
<212>dna
<213>智人(homosapiens)
<400>246
ccgggctcttggccttggacagg23
<210>247
<211>23
<212>dna
<213>智人(homosapiens)
<400>247
ctgtccaaggccaagagcccggg23
<210>248
<211>23
<212>dna
<213>智人(homosapiens)
<400>248
tggcgtcaggcccgggctcttgg23
<210>249
<211>23
<212>dna
<213>智人(homosapiens)
<400>249
cgggcctgacgccagagcccagg23
<210>250
<211>23
<212>dna
<213>智人(homosapiens)
<400>250
caacaaccatgctgggcatctgg23
<210>251
<211>23
<212>dna
<213>智人(homosapiens)
<400>251
gagggtccagatgcccagcatgg23
<210>252
<211>23
<212>dna
<213>智人(homosapiens)
<400>252
catctggaccctcctacctctgg23
<210>253
<211>23
<212>dna
<213>智人(homosapiens)
<400>253
agggctcaccagaggtaggaggg23
<210>254
<211>23
<212>dna
<213>智人(homosapiens)
<400>254
ggagttgatgtcagtcacttggg23
<210>255
<211>23
<212>dna
<213>智人(homosapiens)
<400>255
tggagttgatgtcagtcacttgg23
<210>256
<211>23
<212>dna
<213>智人(homosapiens)
<400>256
agtgactgacatcaactccaagg23
<210>257
<211>23
<212>dna
<213>智人(homosapiens)
<400>257
gtgactgacatcaactccaaggg23
<210>258
<211>23
<212>dna
<213>智人(homosapiens)
<400>258
actccaagggattggaattgagg23
<210>259
<211>23
<212>dna
<213>智人(homosapiens)
<400>259
cttcctcaattccaatcccttgg23
<210>260
<211>23
<212>dna
<213>智人(homosapiens)
<400>260
tacagttgagactcagaacttgg23
<210>261
<211>23
<212>dna
<213>智人(homosapiens)
<400>261
ttggaaggcctgcatcatgatgg23
<210>262
<211>23
<212>dna
<213>智人(homosapiens)
<400>262
agaattggccatcatgatgcagg23
<210>263
<211>23
<212>dna
<213>智人(homosapiens)
<400>263
gacagggcttatggcagaattgg23
<210>264
<211>23
<212>dna
<213>智人(homosapiens)
<400>264
tgtaacatacctggaggacaggg23
<210>265
<211>23
<212>dna
<213>智人(homosapiens)
<400>265
gtgtaacatacctggaggacagg23
<210>266
<211>23
<212>dna
<213>智人(homosapiens)
<400>266
cgtacctgtgcaactcctgttgg23
<210>267
<211>23
<212>dna
<213>智人(homosapiens)
<400>267
gatctactggaattcctaatggg23
<210>268
<211>23
<212>dna
<213>智人(homosapiens)
<400>268
gagtcagctgttggcccattagg23
<210>269
<211>23
<212>dna
<213>智人(homosapiens)
<400>269
ctgcctacaaactcagtctctgg23
<210>270
<211>23
<212>dna
<213>智人(homosapiens)
<400>270
gggcaggcaggacggactccagg23
<210>271
<211>23
<212>dna
<213>智人(homosapiens)
<400>271
ggagtccgtcctgcctgccctgg23
<210>272
<211>23
<212>dna
<213>智人(homosapiens)
<400>272
gagtccgtcctgcctgccctggg23
<210>273
<211>23
<212>dna
<213>智人(homosapiens)
<400>273
gaaaagggtccattggccaaagg23
<210>274
<211>23
<212>dna
<213>智人(homosapiens)
<400>274
gcctgcagaaaagggtccattgg23
<210>275
<211>23
<212>dna
<213>智人(homosapiens)
<400>275
ttgatgtgctacagggaacatgg23
<210>276
<211>23
<212>dna
<213>智人(homosapiens)
<400>276
agcgttcttgatgtgctacaggg23
<210>277
<211>23
<212>dna
<213>智人(homosapiens)
<400>277
cagcgttcttgatgtgctacagg23
<210>278
<211>23
<212>dna
<213>智人(homosapiens)
<400>278
ctgtagcacatcaagaacgctgg23
<210>279
<211>23
<212>dna
<213>智人(homosapiens)
<400>279
tgtagcacatcaagaacgctggg23
<210>280
<211>23
<212>dna
<213>智人(homosapiens)
<400>280
ataggcaataatcatataacagg23
<210>281
<211>23
<212>dna
<213>智人(homosapiens)
<400>281
agtgcgtttcgctgcaggtaagg23
<210>282
<211>23
<212>dna
<213>智人(homosapiens)
<400>282
gagtgagtgcgtttcgctgcagg23
<210>283
<211>23
<212>dna
<213>智人(homosapiens)
<400>283
gtcaggtttgtgcggttatgagg23
<210>284
<211>23
<212>dna
<213>智人(homosapiens)
<400>284
cgctgctggtcaggtttgtgcgg23
<210>285
<211>23
<212>dna
<213>智人(homosapiens)
<400>285
aaacctgaccagcagcgcagagg23
<210>286
<211>23
<212>dna
<213>智人(homosapiens)
<400>286
ccagcagcgcagaggagccgtgg23
<210>287
<211>23
<212>dna
<213>智人(homosapiens)
<400>287
ccacggctcctctgcgctgctgg23
<210>288
<211>23
<212>dna
<213>智人(homosapiens)
<400>288
ccaactatctaactccactcagg23
<210>289
<211>23
<212>dna
<213>智人(homosapiens)
<400>289
cctgagtggagttagatagttgg23
- 还没有人留言评论。精彩留言会获得点赞!