具有D-阿洛酮糖3-差向异构酶活性的多肽和编码其的多核苷酸的制作方法
序列表的引用本申请含有处于计算机可读形式的序列表,将其通过引用并入本文。发明背景本发明涉及具有d-阿洛酮糖3-差向异构酶活性的多肽和编码这些多肽的多核苷酸。本发明还涉及包含这些多核苷酸的核酸构建体、载体和宿主细胞,以及产生和使用这些多肽的方法。
背景技术:
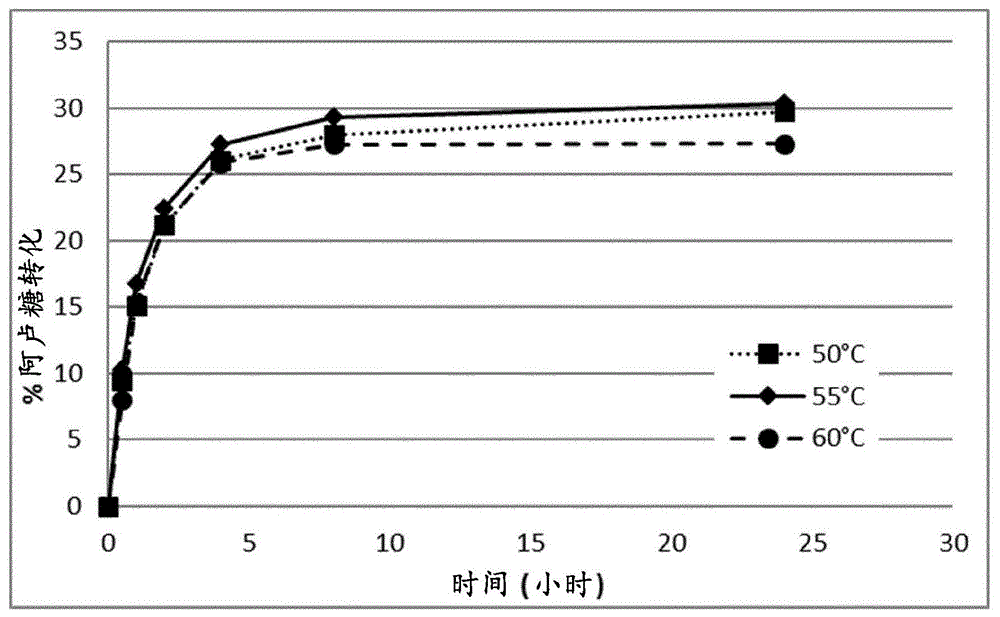
:单糖d-阿洛酮糖,也称为阿卢糖,是果糖的异构体。就甜度而言,d-阿洛酮糖与d-果糖类似。然而,与d-果糖不同,d-阿洛酮糖在人体中几乎是不可代谢的,并且因此其卡路里值几乎为零。因此,d-阿洛酮糖作为饮食甜味剂是有吸引力的。d-阿洛酮糖以非常少的量天然存在于,例如,食用蘑菇、菠萝蜜、小麦和鼠刺(itea)植物中,并且难以化学合成。本领域需要开发用于高效产生d-阿洛酮糖的方法。通过由阿洛酮糖3-差向异构酶催化的酶的差向异构化作用而进行的d-果糖和d-阿洛酮糖之间的相互转化是用于产生d-阿洛酮糖的有吸引力的方式。本发明提供了具有d-阿洛酮糖3-差向异构酶活性的多肽和编码这些多肽的多核苷酸。技术实现要素:本发明涉及具有d-阿洛酮糖3-差向异构酶活性的分离的多肽,这些分离的多肽选自下组,该组由以下组成:(a)与seqidno:2或seqidno:4的多肽具有至少70%序列同一性的多肽;(b)由多核苷酸编码的多肽,该多核苷酸在非常高严格条件下与以下杂交:(i)seqidno:1或seqidno:3的多肽编码序列、(ii)其cdna序列、或(iii)(i)或(ii)的全长互补体;(c)由多核苷酸编码的多肽,该多核苷酸与seqidno:1或seqidno:3的多肽编码序列具有至少70%序列同一性;(d)seqidno:2或seqidno:4的多肽的变体,该变体在一个或多个(例如,若干个)位置处包含取代、缺失和/或插入;以及(e)(a)、(b)、(c)或(d)的多肽的片段,该片段具有d-阿洛酮糖3-差向异构酶活性。本发明还涉及编码本发明的多肽的分离的多核苷酸;包含这些多核苷酸的核酸构建体、重组表达载体、和重组宿主细胞;以及产生这些多肽的方法。本发明还涉及用于产生d-阿洛酮糖的方法,该方法包括:(a)在适于多肽将d-果糖转化成d-阿洛酮糖的条件下,使包含本发明的具有d-阿洛酮糖3-差向异构酶的多肽的组合物与d-果糖接触;和任选地(b)回收所产生的d-阿洛酮糖。附图说明图1显示了温度对通过象粪宏基因组d-阿洛酮糖3-差向异构酶将果糖转化为d-阿洛酮糖的影响。图2显示了温度对通过厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶将果糖转化为d-阿洛酮糖的影响。定义等位基因变体:术语“等位基因变体”意指占据同一染色体基因座的基因的两种或更多种替代形式中的任一种。等位基因变异通过突变而自然产生,并且可以导致群体内部的多态性。基因突变可以是沉默的(所编码的多肽无变化)或可以编码具有改变的氨基酸序列的多肽。多肽的等位基因变体是由基因的等位基因变体编码的多肽。cdna:术语“cdna”意指可以通过从获得自真核或原核细胞的成熟的、剪接的mrna分子进行反转录而制备的dna分子。cdna缺乏可以存在于对应基因组dna中的内含子序列。初始的初级rna转录物是mrna的前体,其要通过一系列的步骤(包括剪接)进行加工,然后呈现为成熟的剪接的mrna。编码序列:术语“编码序列”意指直接指定多肽的氨基酸序列的多核苷酸。编码序列的边界通常由可读框确定,该可读框以起始密码子(例如atg、gtg或ttg)开始并且以终止密码子(例如taa、tag或tga)结束。编码序列可为基因组dna、cdna、合成dna或其组合。控制序列:术语“控制序列”意指对于表达编码本发明的多肽的多核苷酸所必需的核酸序列。每个控制序列对于编码该多肽的多核苷酸来说可以是天然的(即,来自相同基因)或外源的(即,来自不同基因),或相对于彼此是天然的或外源的。此类控制序列包括但不限于前导序列、多腺苷酸化序列、前肽序列、启动子、信号肽序列、以及转录终止子。最少,控制序列包括启动子、以及转录和翻译终止信号。这些控制序列可以提供有接头用于引入有利于将这些控制序列与编码多肽的多核苷酸的编码区连接的特异性限制位点。d-阿洛酮糖:术语“d-阿洛酮糖”意指单糖(3r,4r,5r)-1,3,4,5,6-五羟基己-2-酮。d-阿洛酮糖也称为d-阿卢糖、阿卢糖、阿洛酮糖、或d-核-2-己酮糖。d-阿洛酮糖3-差向异构酶:术语“d-阿洛酮糖3-差向异构酶”意指具有d-阿洛酮糖3-差向异构酶活性的酶(ec5.1.3.30),该酶催化d-阿洛酮糖到d-果糖的差向异构化作用。d-阿洛酮糖3-差向异构酶活性可以根据mu等人,2011,j.agric.foodchem.[农业与食品化学杂志]59:7785-7792所描述的程序来确定。在一方面,本发明的多肽具有seqidno:2或seqidno:4的多肽的至少20%,例如至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、或至少100%的d-阿洛酮糖3-差向异构酶活性。表达:术语“表达”包括涉及多肽产生的任何步骤,包括但不限于:转录、转录后修饰、翻译、翻译后修饰、以及分泌。表达载体:术语“表达载体”意指直链或环状dna分子,其包含编码多肽的多核苷酸并且可操作地连接至提供用于其表达的控制序列。片段:术语“片段”意指具有从多肽的氨基和/或羧基末端缺失的一个或多个(例如,若干个)氨基酸的多肽,其中该片段具有d-阿洛酮糖3-差向异构酶活性。在一方面,片段含有具有d-阿洛酮糖3-差向异构酶活性的多肽的至少85%、至少90%、或至少95%的氨基酸残基。果糖:术语“果糖”意指单糖1,3,4,5,6-五羟基-2-己酮。果糖也称为水果糖、左旋糖、d-呋喃果糖、d-果糖或d-阿拉伯-己酮糖。宿主细胞:术语“宿主细胞”意指易于用包含本发明的多核苷酸的核酸构建体或表达载体进行转化、转染、转导等的任何细胞类型。术语“宿主细胞”涵盖由于复制期间出现的突变而与亲本细胞不完全相同的任何亲本细胞后代。分离的:术语“分离的”意指处于自然界中不存在的形式或环境中的物质。分离的物质的非限制性实例包括(1)任何非天然存在的物质,(2)包括但不限于任何酶、变体、核酸、蛋白质、肽或辅因子的任何物质,该物质至少部分地从与其性质相关的一种或多种或所有天然存在的成分中去除;(3)相对于自然界中发现的物质通过人工修饰的任何物质;或(4)通过相对于与其天然相关的其他组分,增加物质的量而修饰的任何物质(例如,宿主细胞中的重组产生;编码该物质的基因的多个拷贝;以及使用比与编码该物质的基因天然相关的启动子更强的启动子)。成熟多肽:术语“成熟多肽”意指在翻译和任何翻译后修饰例如n-末端加工、c-末端截短、糖基化作用、磷酸化作用等之后处于其最终形式的多肽。本领域内公知,宿主细胞可以产生由相同多核苷酸表达的两种或更多种不同的多肽(即,具有不同的c-末端和/或n-末端氨基酸)的混合物。在本领域中还已知的是,不同的宿主细胞以不同的方式加工多肽,并且因此表达多核苷酸的一种宿主细胞当与表达相同多核苷酸的另一种宿主细胞相比时可以产生不同的多肽(例如,具有不同的c-末端和/或n-末端氨基酸)。成熟多肽编码序列:术语“成熟多肽编码序列”意指编码成熟多肽的多核苷酸。核酸构建体:术语“核酸构建体”意指单-链或双链的核酸分子,该核酸分子是从天然存在的基因中分离的,或以本来不存在于自然界中的方式被修饰成含有核酸的区段,或是合成的,该核酸分子包含一个或多个控制序列。可操作地连接:术语“可操作地连接”意指如下构型,在该构型中,控制序列被放置在相对于多核苷酸的编码序列适当的位置处,使得该控制序列指导该编码序列的表达。序列同一性:两个氨基酸序列之间或两个核苷酸序列之间的关联度通过参数“序列同一性”来描述。出于本发明的目的,使用如在emboss软件包(emboss:欧洲分子生物学开放软件包(emboss:theeuropeanmolecularbiologyopensoftwaresuite),rice等人,2000,trendsgenet.[遗传学趋势]16:276-277)(优选5.0.0版或更新版)的尼德尔程序中所实施的尼德曼-翁施算法(needleman-wunschalgorithm)(needleman和wunsch,1970,j.mol.biol.[分子生物学杂志]48:443-453)来确定两个氨基酸序列之间的序列同一性。使用的参数是空位开放罚分10、空位延伸罚分0.5以及eblosum62(blosum62的emboss版本)取代矩阵。使用尼德尔标记的“最长同一性”的输出(使用非简化(-nobrief)选项获得)作为同一性百分比并且如下计算:(相同的残基x100)/(比对长度-比对中的空位总数)出于本发明的目的,使用如在emboss软件包(emboss:欧洲分子生物学开放软件包(emboss:theeuropeanmolecularbiologyopensoftwaresuite),rice等人,2000,同上)(优选5.0.0版或更新版)的尼德尔程序中所实施的尼德曼-翁施算法(needleman和wunsch,1970,同上)来确定两个脱氧核糖核苷酸序列之间的序列同一性。使用的参数是空位开放罚分10、空位延伸罚分0.5以及ednafull(ncbinuc4.4的emboss版本)取代矩阵。使用尼德尔标记的“最长同一性”的输出(使用非简化(-nobrief)选项获得)作为同一性百分比并且如下计算:(相同的脱氧核糖核苷酸x100)/(比对长度-比对中的空位总数)。严格条件:术语“非常低严格条件”意指对于长度为至少100个核苷酸的探针而言,遵循标准dna印迹程序,在42℃、于5xsspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和25%甲酰胺中预杂交和杂交12至24小时。运载体材料最终使用0.2xssc、0.2%sds,在45℃下洗涤三次,每次15分钟。术语“低严格条件”意指对于长度为至少100个核苷酸的探针而言,遵循标准dna印迹程序,在42℃、于5xsspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和25%甲酰胺中预杂交和杂交12至24小时。运载体材料最终使用0.2xssc、0.2%sds,在50℃下洗涤三次,每次15分钟。术语“中严格条件”意指对于长度为至少100个核苷酸的探针而言,遵循标准dna印迹程序,在42℃、于5xsspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和35%甲酰胺中预杂交和杂交12至24小时。运载体材料最终使用0.2xssc、0.2%sds,在55℃下洗涤三次,每次15分钟。术语“中-高严格条件”意指对于长度为至少100个核苷酸的探针而言,遵循标准dna印迹程序,在42℃、于5xsspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和35%甲酰胺中预杂交和杂交12至24小时。运载体材料最终使用0.2xssc、0.2%sds,在60℃下洗涤三次,每次15分钟。术语“高严格条件”意指对于长度为至少100个核苷酸的探针而言,遵循标准dna印迹程序,在42℃、于5xsspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和50%甲酰胺中预杂交和杂交12至24小时。运载体材料最终使用0.2xssc、0.2%sds,在65℃下洗涤三次,每次15分钟。术语“非常高严格条件”意指对于长度为至少100个核苷酸的探针而言,遵循标准dna印迹程序,在42℃、于5xsspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和50%甲酰胺中预杂交和杂交12至24小时。运载体材料最终使用0.2xssc、0.2%sds,在70℃下洗涤三次,每次15分钟。子序列:术语“子序列”意指具有从多肽编码序列的5'端和/或3'端缺失的一个或多个(例如,若干个)核苷酸的多核苷酸;其中子序列编码具有d-阿洛酮糖3-差向异构酶活性的片段。在一方面,子序列含有编码具有d-阿洛酮糖3-差向异构酶活性的多肽的多核苷酸的至少85%、至少90%、或至少95%的核苷酸。变体:术语“变体”意指在一个或多个(例如,若干个)位置处包含改变(即,取代、插入和/或缺失)的、具有d-阿洛酮糖3-差向异构酶活性的多肽。取代意指用不同的氨基酸替代占据某一位置的氨基酸;缺失意指去除占据某一位置的氨基酸;而插入意指在邻接并且紧随占据某一位置的氨基酸之后添加氨基酸。具体实施方式具有d-阿洛酮糖3-差向异构酶活性的多肽在实施例中,本发明涉及与seqidno:2或seqidno:4的多肽具有至少70%、至少75%、至少80%、至少81%、至少82%、至少83%、至少84%、至少85%、至少86%、至少87%、至少88%、至少89%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的分离的多肽,这些分离的多肽具有d-阿洛酮糖3-差向异构酶活性。在一方面,这些多肽与seqidno:2或seqidno:4的多肽相差多达10个(例如1个、2个、3个、4个、5个、6个、7个、8个、9个、或10个)氨基酸。在一方面,该多肽包含seqidno:2的氨基酸序列或其等位基因变体或由其组成;或者是其具有d-阿洛酮糖3-差向异构酶活性的片段。在另一方面,该多肽包含seqidno:2的氨基酸序列或由其组成。在另一方面,该多肽包含seqidno:4的氨基酸序列或其等位基因变体或由其组成;或者是其具有d-阿洛酮糖3-差向异构酶活性的片段。在另一方面,该多肽包含seqidno:4的氨基酸序列或由其组成。在另一个实施例中,本发明涉及由多核苷酸编码的具有d-阿洛酮糖3-差向异构酶活性的分离的多肽,这些多核苷酸在非常低严格条件、低严格条件、中严格条件、中-高严格条件、高严格条件、或非常高严格条件下与以下杂交:(i)seqidno:1或seqidno:3的多肽编码序列、或(ii)其全长互补体(sambrook等人,1989,molecularcloning,alaboratorymanual[分子克隆实验指南],第二版,冷泉港(coldspringharbor),纽约)。可以使用seqidno:1的多核苷酸或其子序列,以及seqidno:2或seqidno:4的多肽或其片段来设计核酸探针,以根据本领域熟知的方法来鉴定并克隆对来自不同属或物种的菌株的、具有d-阿洛酮糖3-差向异构酶活性的多肽进行编码的dna。可以遵循标准dna印迹程序,使用探针来与目的细胞的基因组dna或cdna杂交,以便鉴定和分离其中的对应基因。这些探针可明显短于完整序列,但是长度应为至少15,例如至少25、至少35、或至少70个核苷酸。优选地,该核酸探针长度为至少100个核苷酸,例如长度为至少200个核苷酸、至少300个核苷酸、至少400个核苷酸、至少500个核苷酸、至少600个核苷酸、至少700个核苷酸、至少800个核苷酸、或至少900个核苷酸。dna和rna探针两者都可使用。典型地将探针进行标记(例如,用32p、3h、35s、生物素、或抗生物素蛋白),用于检测对应基因。此类探针涵盖于本发明中。可以筛选由此类其他菌株制备的基因组dna或cdna文库的与上述探针杂交并编码具有d-阿洛酮糖3-差向异构酶活性的多肽的dna。来自此类其他菌株的基因组dna或其他dna可通过琼脂糖或聚丙烯酰胺凝胶电泳或其他分离技术来分离。可将来自文库的dna或分离的dna转移到并固定在硝化纤维素或其他适合的运载体材料上。为了鉴定与seqidno:1或seqidno:3或其子序列杂交的克隆或dna,将该运载体材料用于dna印迹中。出于本发明的目的,杂交表示多核苷酸在非常低至非常高严格条件下与对应于以下的标记的核酸探针杂交:(i)seqidno:1或seqidno:3;(ii)其全长互补体;或(iii)其子序列。可以使用例如x-射线胶片或本领域中已知的任何其他检测手段来检测在这些条件下与该核酸探针杂交的分子。在一方面,该核酸探针是编码seqidno:2的多肽或其片段的多核苷酸。在另一方面,该核酸探针是seqidno:1。在另一方面,该核酸探针是编码seqidno:4的多肽或其片段的多核苷酸。在另一方面,该核酸探针是seqidno:3。在另一个实施例中,本发明涉及由多核苷酸编码的具有d-阿洛酮糖3-差向异构酶活性的分离的多肽,这些多核苷酸与seqidno:1或seqidno:3的多肽编码序列具有至少70%,例如至少75%、至少80%、至少81%、至少82%、至少83%、至少84%、至少85%、至少86%、至少87%、至少88%、至少89%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性。在另一个实施例中,本发明涉及seqidno:2或seqidno:4的多肽的变体,这些变体在一个或多个(例如,若干个)位置处包含取代、缺失和/或插入。在一方面,引入到seqidno:2或seqidno:4的多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1个、2个、3个、4个、5个、6个、7个、8个、9个、或10个。这些氨基酸改变可以具有微小性质,即,不会显著地影响蛋白质的折叠和/或活性的保守氨基酸取代或插入;典型地为1-30个氨基酸的小缺失;小的氨基-末端或羧基末端延伸,例如氨基末端的甲硫氨酸残基;多达20-25个残基的小接头肽;或小的延伸,其通过改变净电荷或另一官能(例如聚组氨酸段、抗原表位或结合结构域)来促进纯化。保守取代的实例是在下组之内:碱性氨基酸(精氨酸、赖氨酸及组氨酸)、酸性氨基酸(谷氨酸和天冬氨酸)、极性氨基酸(谷氨酰胺和天冬酰胺)、疏水性氨基酸(亮氨酸、异亮氨酸及缬氨酸)、芳香族氨基酸(苯丙氨酸、色氨酸及酪氨酸)及小氨基酸(甘氨酸、丙氨酸、丝氨酸、苏氨酸及甲硫氨酸)。一般不会改变比活性的氨基酸取代是本领域已知的并且例如由h.neurath和r.l.hill,1979,于theproteins[蛋白质],academicpress[学术出版社],纽约中描述。常见取代为ala/ser、val/ile、asp/glu、thr/ser、ala/gly、ala/thr、ser/asn、ala/val、ser/gly、tyr/phe、ala/pro、lys/arg、asp/asn、leu/ile、leu/val、ala/glu和asp/gly。可替代地,这些氨基酸改变具有这样一种性质:改变多肽的物理化学性质。例如,这些氨基酸改变可以改善多肽的热稳定性、改变底物特异性、改变最适ph等。可以根据本领域中已知的程序,例如定点诱变或丙氨酸扫描诱变(cunningham和wells,1989,science[科学]244:1081-1085)来鉴定多肽中的必需氨基酸。在后一项技术中,在该分子中的每个残基处引入单个丙氨酸突变,并且测试所得分子的d-阿洛酮糖3-差向异构酶活性以鉴定对于该分子的活性关键的氨基酸残基。还参见,hilton等人,1996,j.biol.chem.[生物化学杂志]271:4699-4708。酶或其他生物学相互作用的活性部位还可通过对结构的物理分析来确定,如由下述技术确定:核磁共振、晶体学(crystallography)、电子衍射、或光亲和标记,连同对推定的接触位点(contactsite)氨基酸进行突变。参见例如,devos等人,1992,science[科学]255:306-312;smith等人,1992,j.mol.biol.[分子生物学杂志]224:899-904;wlodaver等人,1992,febslett.[欧洲生化学会联合会快报]309:59-64。还可以从与相关多肽的比对来推断必需氨基酸的身份。使用已知的诱变、重组和/或改组方法,随后进行相关的筛选程序可以做出单或多氨基酸取代、缺失和/或插入并对其进行测试,该相关的筛选程序例如由reidhaar-olson和sauer,1988,science[科学]241:53-57;bowie和sauer,1989,proc.natl.acad.sci.usa[美国国家科学院院刊]86:2152-2156;wo95/17413;或wo95/22625披露的那些。其他可以使用的方法包括易错pcr、噬菌体展示(例如lowman等人,1991,biochemistry[生物化学]30:10832-10837;美国专利号5,223,409;wo92/06204)以及区域定向诱变(derbyshire等人,1986,gene[基因]46:145;ner等人,1988,dna7:127)。诱变/改组方法可以与高通量、自动化的筛选方法组合以检测由宿主细胞表达的克隆的、诱变的多肽的活性(ness等人,1999,naturebiotechnology[自然生物技术]17:893-896)。可从宿主细胞回收编码活性多肽的诱变的dna分子,并使用本领域的标准方法快速测序。这些方法允许快速确定多肽中各个氨基酸残基的重要性。该多肽可以是杂合多肽,其中一种多肽的区域在另一种多肽的区域的n-末端或c-末端处融合。该多肽可以是融合多肽或可切割的融合多肽,其中另一种多肽在本发明的多肽的n-末端或c-末端处融合。通过将编码另一种多肽的多核苷酸与本发明的多核苷酸融合来产生融合多肽。用于产生融合多肽的技术是本领域已知的,且包括连接编码多肽的编码序列使得它们在框内,而且融合多肽的表达处于一个或多个相同的启动子和终止子的控制之下。还可以使用内含肽技术构建融合多肽,其中在翻译后产生融合多肽(cooper等人,1993,emboj.[欧洲分子生物学学会杂志]12:2575-2583;dawson等人,1994,science[科学]266:776-779)。融合多肽可进一步包含两个多肽之间的切割位点。在融合蛋白分泌之时,该位点被切割,从而释放出这两种多肽。切割位点的实例包括但不限于在以下文献中披露的位点:martin等人,2003,j.ind.microbiol.biotechnol.[工业微生物生物技术杂志]3:568-576;svetina等人,2000,j.biotechnol.[生物技术杂志]76:245-251;rasmussen-wilson等人,1997,appl.environ.microbiol.[应用与环境微生物学]63:3488-3493;ward等人,1995,biotechnology[生物技术]13:498-503;和contreras等人,1991,biotechnology[生物技术]9:378-381;eaton等人,1986,biochemistry[生物化学]25:505-512;collins-racie等人,1995,biotechnology[生物技术]13:982-987;carter等人,1989,proteins:structure,function,andgenetics[蛋白质:结构、功能以及遗传学]6:240-248;以及stevens,2003,drugdiscoveryworld[世界药物发现]4:35-48。具有d-阿洛酮糖3-差向异构酶活性的多肽的来源本发明的具有d-阿洛酮糖3-差向异构酶活性的多肽可从任何属的微生物获得。出于本发明的目的,如本文结合给定来源使用的术语“获得自”应当意指由多核苷酸编码的多肽是由该来源或由已经插入了来自该来源的多核苷酸的菌株产生的。在一方面,获得自给定来源的多肽被分泌到细胞外。在一方面,该多肽是土壤杆菌属(agrobacterium)、节杆菌属(arthrobacter)、芽孢杆菌属(bacillus)、棒杆菌属(corynebacterium)、梭菌属(clostridium)、链孢子菌属(desmospora)、埃希氏杆菌属(escherichia)、假单胞菌属(pseudomonas)、红杆菌属(rhodobacter)、或瘤胃球菌属(ruminococcus)多肽。在另一方面,该土壤杆菌属多肽是根癌土壤杆菌(agrobacteriumtumefaciens)多肽。在另一方面,该节杆菌属多肽是运动节杆菌(arthrobacteragilis)、金黄节杆菌(arthrobacteraurescens)、氯酚节杆菌(arthrobacterchlorophenolicus)、柠檬色节杆菌(arthrobactercitreus)、成晶节杆菌(arthrobactercrystallopoietes)、卡明斯节杆菌(arthrobactercumminsii)、球形节杆菌(arthrobacterglobiformis)、藤黄节杆菌(arthrobacterluteolus)、嗜烟碱节杆菌(arthrobacternicotinovorans)、硝基愈疮木胶节杆菌(arthrobacternitroguajacolicus)、耐盐节杆菌(arthrobacterpascens)、或沃氏节杆菌(arthrobacterwoluwensis)多肽。在另一方面,该芽孢杆菌属多肽是嗜碱芽孢杆菌(bacillusalkalophilus)、解淀粉芽孢杆菌(bacillusamyloliquefaciens)、短芽孢杆菌(bacillusbrevis)、环状芽孢杆菌(bacilluscirculans)、克劳氏芽孢杆菌(bacillusclausii)、凝结芽孢杆菌(bacilluscoagulans)、坚硬芽孢杆菌(bacillusfirmus)、灿烂芽孢杆菌(bacilluslautus)、迟缓芽孢杆菌(bacilluslentus)、地衣芽孢杆菌(bacilluslicheniformis)、巨大芽孢杆菌(bacillusmegaterium)、短小芽孢杆菌(bacilluspumilus)、嗜热脂肪芽孢杆菌(bacillusstearothermophilus)、枯草芽孢杆菌(bacillussubtilis)、或苏云金芽孢杆菌(bacillusthuringiensis)多肽。在另一方面,该棒杆菌属多肽是谷氨酸棒杆菌(corynebacteriumglutamicum)多肽。在另一方面,该梭菌属多肽是鲍氏梭菌(clostridiumbolteae)、解纤维梭菌(clostridiumcellulolyticum)、海利氏梭菌(clostridiumhylemonae)、闪烁梭菌(clostridiumscindens)多肽。在另一方面,该链孢子菌属多肽是活跃链孢子菌(desmosporaactiva)多肽。在另一方面,该埃希氏杆菌属多肽是大肠杆菌(escherichiacoli)多肽。在另一方面,该假单胞菌属多肽是菊苣假单胞菌(pseudomonascichorii)或恶臭假单胞菌(pseudomonasputida)多肽。在另一方面,该红杆菌属多肽是类球红杆菌(rhodobactersphaeroides)多肽。在另一方面,该瘤胃球菌属多肽是白色瘤胃球菌(ruminococcusalbus)、布氏瘤胃球菌(ruminococcusbromii)、伶俐瘤胃球菌(ruminococcuscallidus)、黄化瘤胃球菌(ruminococcusflavefaciens)、或活泼瘤胃球菌(ruminococcusgnavus)多肽。应理解的是,对于前述物种,本发明涵盖完全和不完全阶段(perfectandimperfectstates),和其他分类学等同物(equivalent),例如无性型,而与它们已知的种名无关。本领域的技术人员会容易地识别适当等同物的身份。这些物种的菌株可容易地在若干培养物保藏中心为公众所获得,例如美国典型培养物保藏中心(americantypeculturecollection,atcc)、德国微生物和细胞培养物保藏中心(deutschesammlungvonmikroorganismenundzellkulturengmbh,dsmz)、荷兰菌种保藏中心(centraalbureauvoorschimmelcultures,cbs)以及美国农业研究服务专利培养物保藏中心北方地区研究中心(agriculturalresearchservicepatentculturecollection,northernregionalresearchcenter,nrrl)。可以使用以上提到的探针从其他来源,包括从自然界(例如,土壤、堆肥、水等)分离的微生物或直接从天然材料(例如,土壤、堆肥、水等)获得的dna样品鉴定和获得该多肽。用于从天然生境中直接分离微生物和dna的技术是本领域熟知的。然后可以通过类似地筛选另一微生物的基因组dna或cdna文库或混合的dna样品来获得编码该多肽的多核苷酸。一旦已经用一种或多种探针检测到编码多肽的多核苷酸,则可以通过利用本领域普通技术人员已知的技术(参见例如,sambrook等人,1989,同上)分离或克隆多核苷酸。多核苷酸本发明还涉及编码本发明的多肽的分离的多核苷酸,如本文所述。用于分离或克隆多核苷酸的技术是本领域已知的且包括从基因组dna或cdna或其组合进行分离。可以例如通过使用熟知的聚合酶链式反应(pcr)或表达文库的抗体筛选来检测具有共有结构特征的克隆dna片段,实现从基因组dna克隆多核苷酸。参见例如,innis等人,1990,pcr:aguidetomethodsandapplication[pcr:方法和应用指南],academicpress[学术出版社],纽约。可以使用其他核酸扩增程序例如连接酶链式反应(lcr)、连接激活转录(lat)和基于多核苷酸的扩增(nasba)。该多核苷酸可以是多核苷酸的多肽编码区的等位基因或种类变体。编码本发明的多肽的多核苷酸的修饰对于合成基本上类似于该多肽的多肽可以是必需的。术语“基本上类似”于该多肽是指多肽的非天然存在的形式。这些多肽可以因某种工程化方式而与从其天然来源分离的多肽不同,例如在比活性、热稳定性、最适ph等方面不同的变体。可以如下构建这些变体:基于以seqidno:1或seqidno:3的多肽编码序列(例如其子序列)呈现的多核苷酸,和/或通过引入核苷酸取代,这些核苷酸取代不会导致该多肽的氨基酸序列变化,但对应于旨在用于产生该酶的宿主生物体的密码子使用,或通过引入可产生不同氨基酸序列的核苷酸取代。对于核苷酸取代的一般描述,参见例如ford等人,1991,proteinexpressionandpurification[蛋白质表达与纯化]2:95-107。核酸构建体本发明还涉及核酸构建体,这些核酸构建体包含可操作地连接至一个或多个控制序列的本发明的多核苷酸,在与控制序列相容的条件下,该一个或多个控制序列指导该编码序列在适合的宿主细胞中的表达。可用许多方式操作该多核苷酸以提供多肽的表达。取决于表达载体,在多核苷酸插入载体之前对其进行操作可以是理想的或必需的。用于利用重组dna方法修饰多核苷酸的技术是本领域熟知的。该控制序列可为启动子,即,被宿主细胞识别用于表达编码本发明的多肽的多核苷酸的多核苷酸。该启动子含有介导该多肽的表达的转录控制序列。该启动子可以是在宿主细胞中显示转录活性的任何多核苷酸,包括突变型、截短型和杂合型启动子,并且可以获得自编码与宿主细胞同源或异源的细胞外或细胞内多肽的基因。用于在细菌宿主细胞中指导本发明核酸构建体的转录的适合启动子的实例是从以下基因中获得的启动子:解淀粉芽孢杆菌α-淀粉酶基因(amyq)、地衣芽孢杆菌α-淀粉酶基因(amyl)、地衣芽孢杆菌青霉素酶基因(penp)、嗜热脂肪芽孢杆菌产麦芽糖淀粉酶基因(amym)、枯草芽孢杆菌果聚糖蔗糖酶基因(sacb)、枯草芽孢杆菌xyla和xylb基因、苏云金芽孢杆菌cryiiia基因(agaisse和lereclus,1994,molecularmicrobiology[分子微生物学]13:97-107)、大肠杆菌lac操纵子、大肠杆菌trc启动子(egon等人,1988,gene[基因]69:301-315)、天蓝链霉菌(streptomycescoelicolor)琼脂水解酶基因(daga)和原核β-内酰胺酶基因(villa-kamaroff等人,1978,proc.natl.acad.sci.usa[美国国家科学院院刊]75:3727-3731)以及tac启动子(deboer等人,1983,proc.natl.acad.sci.usa[美国国家科学院院刊]80:21-25)。其他启动子描述于gilbert等人,1980,scientificamerican[科学美国人]242:74-94的“usefulproteinsfromrecombinantbacteria[来自重组细菌的有用蛋白质]”;和在sambrook等人,1989,同上。串联启动子的实例披露于wo99/43835中。该控制序列也可为由宿主细胞识别以终止转录的转录终止子。该终止子可操作地连接至编码该多肽的多核苷酸的3’-末端。在宿主细胞中有功能的任何终止子可用于本发明中。细菌宿主细胞的优选终止子从以下的基因获得:克劳氏芽孢杆菌碱性蛋白酶(aprh)、地衣芽孢杆菌α-淀粉酶(amyl)、和大肠杆菌核糖体rna(rrnb)。该控制序列也可以是启动子下游和基因的编码序列上游的mrna稳定子区域,其增加该基因的表达。适合的mrna稳定子区域的实例是从以下获得的:苏云金芽孢杆菌cryiiia基因(wo94/25612)和枯草芽孢杆菌sp82基因(hue等人,1995,journalofbacteriology[细菌学杂志]177:3465-3471)。该控制序列也可为编码与多肽的n-末端连接的信号肽并指导多肽进入细胞的分泌途径的信号肽编码区。该多核苷酸的编码序列的5’-端可以固有地含有在翻译阅读框中与编码多肽的编码序列的区段天然地连接的信号肽编码序列。可替代地,该编码序列的5’-端可以含有对于该编码序列是外源的信号肽编码序列。在编码序列天然地不含有信号肽编码序列的情况下,可能需要外源信号肽编码序列。可替代地,外源信号肽编码序列可以简单地替换天然信号肽编码序列以增强多肽的分泌。然而,可以使用指导已表达多肽进入宿主细胞的分泌途径的任何信号肽编码序列。用于细菌宿主细胞的有效信号肽编码序列是从芽孢杆菌ncib11837产麦芽糖淀粉酶、地衣芽孢杆菌枯草杆菌蛋白酶、地衣芽孢杆菌β-内酰胺酶、嗜热脂肪芽孢杆菌α-淀粉酶、嗜热脂肪芽孢杆菌中性蛋白酶(nprt、nprs、nprm)和枯草芽孢杆菌prsa的基因获得的信号肽编码序列。另外的信号肽由simonen和palva,1993,microbiologicalreviews[微生物评论]57:109-137描述。该控制序列还可以是编码位于多肽的n-末端处的前肽的前肽编码序列。所得的多肽被称为前体酶(proenzyme)或多肽原(或在一些情况下被称为酶原(zymogen))。多肽原通常是无活性的并且可通过催化切割或自身催化切割来自多肽原的前肽而转化为活性多肽。该前肽编码序列可以从以下的基因获得:枯草芽孢杆菌碱性蛋白酶(apre)和枯草芽孢杆菌中性蛋白酶(nprt)。在信号肽序列和前肽序列二者都存在的情况下,该前肽序列位于紧邻多肽的n-末端且该信号肽序列位于紧邻该前肽序列的n-末端。还可以希望添加调节序列,这些调节序列相对于宿主细胞的生长来调控多肽的表达。调节序列的实例是引起基因表达以响应于化学或物理刺激(包括调节化合物的存在)而开启或关闭的那些。原核系统中的调节序列包括lac、tac、和trp操纵子系统。调节序列的其他实例是允许基因扩增的那些序列。在真核系统中,这些调节序列包括在甲氨蝶呤存在下扩增的二氢叶酸还原酶基因以及用重金属扩增的金属硫蛋白基因。在这些情况中,编码多肽的多核苷酸将与调节序列可操作地连接。表达载体本发明还涉及包含本发明的多核苷酸、启动子、以及转录和翻译终止信号的重组表达载体。多个核苷酸和控制序列可连接在一起以产生重组表达载体,该重组表达载体可包括一个或多个便利的限制位点以允许编码该多肽的多核苷酸在此类位点处的插入或取代。可替代地,该多核苷酸可以通过将该多核苷酸或包含该多核苷酸的核酸构建体插入用于表达的适当载体中来表达。在产生该表达载体时,该编码序列位于该载体中,这样使得该编码序列与这些用于表达的适当控制序列可操作地连接。该重组表达载体可以是可以方便地经受重组dna程序并且可以引起该多核苷酸表达的任何载体(例如,质粒或病毒)。载体的选择将典型地取决于载体与待引入载体的宿主细胞的相容性。载体可以是直链或闭合环状质粒。载体可以是自主复制载体,即作为染色体外实体存在的载体,其复制独立于染色体复制,例如质粒、染色体外元件、微染色体或人工染色体。载体可以含有用于确保自我复制的任何手段。可替代地,载体可以是这样的载体,当它引入宿主细胞中时整合入基因组中并与其中已整合了它的一个或多个染色体一起复制。此外,可以使用单独的载体或质粒或两个或更多个载体或质粒,其共同含有待引入宿主细胞基因组的总dna,或可以使用转座子。载体优选地含有允许方便地选择转化细胞、转染细胞、转导细胞等细胞的一个或多个选择性标记。选择性标记是基因,其产物提供了杀生物剂抗性或病毒抗性、对重金属抗性、对营养缺陷型的原养型等。细菌选择性标记的实例是地衣芽孢杆菌或枯草芽孢杆菌dal基因、或赋予抗生素抗性(例如氨苄青霉素、氯霉素、卡那霉素、新霉素、大观霉素、或四环素抗性)的标记。载体优选地含有允许载体整合到宿主细胞的基因组中或载体在细胞中独立于基因组自主复制的一个或多个元件。对于整合到该宿主细胞基因组中,该载体可以依靠编码该多肽的多核苷酸序列或用于通过同源或非同源重组整合到该基因组中的该载体的任何其他元件。可替代地,该载体可含有用于指导通过同源重组而整合入宿主细胞基因组中的一个或多个染色体中的一个或多个精确位置处的另外的多核苷酸。为了增加在精确位置处整合的可能性,整合元件应当含有足够的核酸,例如100至10,000个碱基对、400至10,000个碱基对和800至10,000个碱基对,这些核酸与对应的靶序列具有高度序列同一性以增强同源重组的概率。整合元件可以是与宿主细胞基因组内的靶序列同源的任何序列。此外,整合元件可以是非编码多核苷酸或编码多核苷酸。另一方面,载体可以通过非同源重组整合入宿主细胞的基因组中。对于自主复制,载体可以进一步包含使该载体能够在所讨论的宿主细胞中自主复制的复制起点。复制起点可以是在细胞中发挥作用的介导自主复制的任何质粒复制子。术语“复制起点”或“质粒复制子”意指使质粒或载体能够在体内复制的多核苷酸。细菌复制起点的实例是允许在大肠杆菌中复制的质粒pbr322、puc19、pacyc177、和pacyc184的复制起点,以及允许在芽孢杆菌属中复制的质粒pub110、pe194、pta1060、和pamβ1的复制起点。可将本发明多核苷酸的多于一个拷贝插入宿主细胞以增加多肽的产生。通过将序列的至少一个另外的拷贝整合到宿主细胞基因组中或者通过包括与该多核苷酸一起的可扩增的选择性标记基因可以获得多核苷酸的增加的拷贝数目,其中通过在适当的选择性试剂的存在下培养细胞可以选择含有选择性标记基因的经扩增的拷贝以及由此该多核苷酸的另外的拷贝的细胞。用于连接以上所述的元件以构建本发明的重组表达载体的程序是本领域技术人员熟知的(参见例如,sambrook等人,1989,同上)。宿主细胞本发明还涉及重组宿主细胞,这些宿主细胞包含可操作地连接至一个或多个控制序列的本发明的多核苷酸,该一个或多个控制序列指导本发明的多肽的产生。将包含多核苷酸的构建体或载体引入到宿主细胞中,这样使得该构建体或载体被维持作为染色体整合体或作为自主复制的染色体外载体,如早前所描述。术语“宿主细胞”涵盖由于复制期间出现的突变而与亲本细胞不完全相同的任何亲本细胞后代。宿主细胞的选择将取决于编码该多肽的基因及其来源。该宿主细胞可以是在本发明的多肽重组生产中有用的任何细胞。在一个实施例中,该宿主细胞是原核细胞。原核宿主细胞可以是任何革兰氏阳性或革兰氏阴性细菌。革兰氏阳性细菌包括但不限于:芽孢杆菌属、梭菌属、肠球菌属(enterococcus)、土芽孢杆菌属(geobacillus)、乳杆菌属(lactobacillus)、乳球菌属(lactococcus)、大洋芽孢杆菌属(oceanobacillus)、葡萄球菌属(staphylococcus)、链球菌属(streptococcus)和链霉菌属(streptomyces)。革兰氏阴性细菌包括但不限于弯曲杆菌属(campylobacter)、大肠杆菌、黄杆菌属(flavobacterium)、梭杆菌属(fusobacterium)、螺杆菌属(helicobacter)、泥杆菌属(ilyobacter)、奈瑟氏菌属(neisseria)、假单胞菌属、沙门氏菌属(salmonella)、以及脲原体属(ureaplasma)。细菌宿主细胞可以是任何芽孢杆菌属细胞,包括但不限于嗜碱芽孢杆菌、解淀粉芽孢杆菌、短芽孢杆菌、环状芽孢杆菌、克劳氏芽孢杆菌、凝结芽孢杆菌、坚硬芽孢杆菌、灿烂芽孢杆菌、迟缓芽孢杆菌、地衣芽孢杆菌、巨大芽孢杆菌、短小芽孢杆菌、嗜热脂肪芽孢杆菌、枯草芽孢杆菌以及苏云金芽孢杆菌细胞。细菌宿主细胞还可以是任何链球菌属细胞,包括但不限于似马链球菌(streptococcusequisimilis)、酿脓链球菌(streptococcuspyogenes)、乳房链球菌(streptococcusuberis)和马链球菌兽疫亚种(streptococcusequisubsp.zooepidemicus)细胞。细菌宿主细胞还可以是任何链霉菌属细胞,包括但不限于:不产色链霉菌(streptomycesachromogenes)、除虫链霉菌(streptomycesavermitilis)、天蓝链霉菌、灰色链霉菌(streptomycesgriseus)、以及浅青紫链霉菌(streptomyceslividans)细胞。将dna引入芽孢杆菌属细胞中可以通过以下方式来实现:原生质体转化(参见例如,chang和cohen,1979,mol.gen.genet.[分子遗传学与基因组学]168:111-115)、感受态细胞转化(参见例如,young和spizizen,1961,j.bacteriol.[细菌学杂志]81:823-829;或dubnau和davidoff-abelson,1971,j.mol.biol.[分子生物学杂志]56:209-221)、电穿孔(参见例如,shigekawa和dower,1988,biotechniques[生物技术]6:742-751)或接合(参见例如,koehler和thorne,1987,j.bacteriol.[细菌学杂志]169:5271-5278)。将dna引入大肠杆菌细胞中可以通过以下方式来实现:原生质体转化(参见例如,hanahan,1983,j.mol.biol.[分子生物学杂志]166:557-580)或电穿孔(参见例如,dower等人,1988,nucleicacidsres.[核酸研究]16:6127-6145)。将dna引入链霉菌属细胞中可以通过以下方式来实现:原生质体转化、电穿孔(参见例如,gong等人,2004,foliamicrobiol.(praha)[叶线形微生物学(布拉格)]49:399-405)、接合(参见例如,mazodier等人,1989,j.bacteriol.[细菌学杂志]171:3583-3585)、或转导(参见例如,burke等人,2001,proc.natl.acad.sci.usa[美国国家科学院院刊]98:6289-6294)。将dna引入假单胞菌属细胞中可以通过以下方式来实现:电穿孔(参见例如,choi等人,2006,j.microbiol.methods[微生物学方法杂志]64:391-397)或接合(参见例如,pinedo和smets,2005,appl.environ.microbiol.[应用与环境微生物学]71:51-57)。将dna引入链球菌属细胞中可以通过以下方式来实现:天然感受态(naturalcompetence)(参见例如,perry和kuramitsu,1981,infect.immun.[感染与免疫]32:1295-1297)、原生质体转化(参见例如,catt和jollick,1991,microbios[微生物学]68:189-207)、电穿孔(参见例如,buckley等人,1999,appl.environ.microbiol.[应用与环境微生物学]65:3800-3804)、或接合(参见例如,clewell,1981,microbiol.rev.[微生物学评论]45:409-436)。然而,可以使用本领域已知的将dna引入宿主细胞中的任何方法。产生方法本发明还涉及产生本发明的多肽的方法,这些方法包括(a)在有益于产生该多肽的条件下培养细胞,该细胞以其野生型形式产生该多肽;和任选地(b)回收该多肽。本发明还涉及产生本发明的多肽的方法,这些方法包括(a)在有益于产生该多肽的条件下培养本发明的重组宿主细胞;和任选地(b)回收该多肽。宿主细胞是在适合使用本领域已知的方法产生多肽的营养培养基中培养的。例如,可以通过摇瓶培养、或在实验室或工业发酵罐中小规模或大规模发酵(包括连续、分批、补料分批或固态发酵)培养细胞,该培养在合适的培养基中并且在允许表达和/或分离多肽的条件下进行。使用本领域中已知的程序,培养发生在包含碳和氮来源及无机盐的适合的营养培养基中。适合的培养基可从商业供应商获得或可以根据所公开的组成(例如,在美国典型培养物保藏中心的目录中)制备。如果多肽被分泌到该营养培养基中,那么可以直接从该培养基中回收该多肽。如果多肽不进行分泌,那么其可以从细胞裂解液中进行回收。可以使用本领域已知的对于多肽是特异性的方法来检测多肽。这些检测方法包括但不限于:特异性抗体的使用、酶产物的形成或酶底物的消失。例如,可以使用酶测定来确定多肽的活性。可以使用本领域已知的方法来回收多肽。例如,可通过常规程序,包括但不限于,收集、离心、过滤、提取、喷雾干燥、蒸发或沉淀,从该营养培养基中回收该多肽。在一方面,回收包含多肽的全发酵液。可以通过本领域已知的多种程序纯化多肽以获得基本上纯的多肽,这些程序包括但不限于:色谱法(例如,离子交换、亲和、疏水、色谱聚焦和尺寸排阻)、电泳程序(例如,制备型等电聚焦)、差示溶解度(例如,硫酸铵沉淀)、sds-page、或提取(参见例如,proteinpurification[蛋白质纯化],janson和ryden编辑,vchpublishers[vch出版公司],纽约,1989)。在一替代性方面,不回收多肽,而是将表达该多肽的本发明的宿主细胞用作多肽的来源。植物本发明还涉及分离的植物,例如转基因植物、植物部分或植物细胞,这些植物包含本发明的多核苷酸以按可回收的量表达和产生多肽。该多肽可以从植物或植物部分回收。可替代地,可以按原样将含有该多肽的植物或植物部分用于改善食品或饲料的质量,例如,改善营养价值、适口性、以及流变性质,或用以破坏抗营养因子。转基因植物可以是双子叶的(双子叶植物)或单子叶的(单子叶植物)。单子叶植物的实例是草,例如草地早熟禾(蓝草,早熟禾属);饲用草,例如羊茅属(festuca)、黑麦草属(lolium);温带草,例如翦股颖属(agrostis);以及谷物,例如小麦、燕麦、黑麦、大麦、稻、高粱和玉蜀黍(玉米)。双子叶植物的实例是烟草、豆科植物(例如羽扇豆、马铃薯、糖甜菜、豌豆、菜豆和大豆)以及十字花科植物(十字花科)(例如花椰菜、油菜籽和紧密相关的模式生物体拟南芥)。植物部分的实例是茎、愈伤组织、叶、根、果实、种子和块茎以及包含这些部分的独立组织,例如表皮、叶肉、薄壁组织、维管组织、分生组织。特定植物细胞区室,例如叶绿体、质外体(apoplast)、线粒体、液泡、过氧化物酶体以及细胞质也被认为是植物部分。此外,任何植物细胞,无论是何种组织来源,都被认为是植物部分。同样地,植物部分,例如分离以有助于本发明的利用的特定组织和细胞也被认为是植物部分,例如胚、胚乳、糊粉和种皮。同样包含于本发明范围内的是此类植物、植物部分以及植物细胞的后代。表达多肽的转基因植物或植物细胞可以根据本领域已知的方法构建。简而言之,通过将编码该多肽的一个或多个表达构建体结合到植物宿主基因组或叶绿体基因组中并且将所得经修饰的植物或植物细胞繁殖成转基因的植物或植物细胞来构建植物或植物细胞。表达构建体宜为包含编码多肽的多核苷酸的核酸构建体,该多核苷酸与在选择的植物或植物部分中表达该多核苷酸所需的适当的调节序列可操作地连接。此外,表达构建体可以包含用于鉴定整合了此表达构建体的植物细胞的选择性标记,和将此构建体引入所讨论的植物所必需的dna序列(后者取决于所用的引入dna的方法)。例如,基于希望在何时、何处、以及如何表达该多肽来确定对调节序列例如启动子和终止子序列和任选的信号或转运序列的选择(sticklen,2008,naturereviews[自然综述]9:433-443)。例如,编码多肽的基因的表达可以是组成性的或可诱导的,或可以为发育、阶段或组织特异性的,并且可以使基因产物靶向特定组织或植物部分,例如种子或叶。调节序列由例如tague等人,1988,plantphysiology[植物生理学]86:506描述。对于组成性表达,可以使用35s-camv、玉蜀黍泛素1、或稻肌动蛋白1启动子(franck等人,1980,cell[细胞]21:285-294;christensen等人,1992,plantmol.biol.[植物分子生物学]18:675-689;zhang等人,1991,plantcell[植物细胞]3:1155-1165)。器官特异性启动子可以是以下的启动子,例如来自贮藏库组织(例如种子、马铃薯块茎、和果实)(edwards和coruzzi,1990,ann.rev.genet.[遗传学年鉴]24:275-303),或来自代谢库组织(例如分生组织)(ito等人,1994,plantmol.biol.[植物分子生物学]24:863-878)的启动子,种子特异性启动子,例如来自稻的谷蛋白、醇溶谷蛋白、球蛋白或白蛋白启动子(wu等人,1998,plantcellphysiol.[植物与细胞生理学]39:885-889),来自豆球蛋白b4的蚕豆启动子和来自蚕豆的未知种子蛋白基因(conrad等人,1998,j.plantphysiol.[植物生理学杂志]152:708-711),来自种子油体蛋白的启动子(chen等人,1998,plantcellphysiol.[植物与细胞生理学]39:935-941),来自欧洲油菜的贮藏蛋白napa启动子,或本领域已知的任何其他种子特异性启动子,例如,如在wo91/14772中所描述的。此外,启动子可以是叶特异性启动子,例如来自稻或番茄的rbcs启动子(kyozuka等人,1993,plantphysiol.[植物生理学]102:991-1000)、小球藻病毒腺嘌呤甲基转移酶基因启动子(mitra和higgins,1994,plantmol.biol.[植物分子生物学]26:85-93)、来自稻的aldp基因启动子(kagaya等人,1995,mol.gen.genet.[分子遗传学与基因组学]248:668-674)、或伤口诱导型启动子(例如马铃薯pin2启动子)(xu等人,1993,plantmol.biol.[植物分子生物学]22:573-588)。同样地,该启动子可以通过例如温度、干旱或盐度变化等非生物处理来诱导,或通过外源地应用使该启动子活化的物质(例如,乙醇;雌激素;植物激素,例如乙烯、脱落酸及赤霉酸;及重金属)来诱导。启动子增强子元件也可以用于实现多肽在植物中的更高表达。例如,启动子增强子元件可以是置于启动子与编码多肽的多核苷酸之间的内含子。例如,xu等人,1993,同上,披露了使用稻肌动蛋白1基因的第一内含子以增强表达。该选择性标记基因及该表达构建体的任何其他部分可以选自本领域中可用的那些。可以根据本领域中已知的常规技术将核酸构建体结合到植物基因组中,这些常规技术包括土壤杆菌介导的转化、病毒介导的转化、微注射、粒子轰击、生物射弹转化、以及电穿孔(gasser等人,1990,science[科学]244:1293;potrykus,1990,bio/technology[生物/技术]8:535;shimamoto等人,1989,nature[自然]338:274)。根癌土壤杆菌介导的基因转移是用于产生转基因双子叶植物(关于综述,请参见hooykas和schilperoort,1992,plantmol.biol.[植物分子生物学]19:15-38)并且用于转化单子叶植物的方法,尽管对于这些植物可以使用其他转化方法。用于产生转基因单子叶植物的方法是粒子(涂覆有转化dna的微观金或钨粒子)轰击胚愈伤组织或发育中的胚(christou,1992,plantj.[植物杂志]2:275-281;shimamoto,1994,curr.opin.biotechnol.[生物技术当前述评]5:158-162;vasil等人,1992,bio/technology[生物/技术]10:667-674)。用于转化单子叶植物的替代方法是基于原生质体转化,如由omirulleh等人,1993,plantmol.biol.[植物分子生物学]21:415-428所描述。另外的转化方法包括美国专利号6,395,966和7,151,204(两者都通过引用以其全文并入本文)中所描述的那些。在转化后,根据本领域熟知的方法选出已结合了表达构建体的转化体,并使其再生成为完整植物。通常设计转化程序用于通过如下方法在再生期间或在后续世代中选择性消除选择基因:例如,使用带有两个独立的t-dna构建体的共转化或利用特异性重组酶位点特异性地切除选择基因。除用本发明的构建体直接转化具体植物基因型之外,还可以通过使具有构建体的植物与缺乏该构建体的第二植物杂交来产生转基因植物。例如,可以将编码多肽的构建体通过杂交引入具体植物品种,而根本无需直接转化那个给定品种的植物。因此,本发明不仅涵盖了从根据本发明已经转化的细胞直接再生的植物,而且还涵盖了此类植物的后代。如本文使用的,后代可以是指根据本发明制备的亲本植物的任何世代的后代。此类后代可以包括根据本发明制备的dna构建体。杂交导致通过将起始系用供体植物系交叉授粉,将转基因引入植物系。此类步骤的非限制性实例描述于美国专利号7,151,204中。植物可以通过回交转化工艺生成。例如,植物包括被称为回交转化的基因型、种系、近交体、或杂交体的植物。可以使用遗传标记以协助本发明的一种或多种转基因从一个遗传背景渗入到另一个。标记协助的选择提供了相对于常规育种的优势,在于其可以用于避免由表型变异引起的错误。另外,遗传标记可以在具体杂交的个别后代中提供有关良种种质相对程度的数据。例如,当具有所希望性状并且另外具有非农艺学所希望的遗传背景的植物与良种亲本杂交时,可以使用遗传标记来选择不仅具有目的性状,还具有相对较大比例所希望种质的后代。以此方式,使一种或多种性状渗入特定遗传背景所需的世代数得以最小化。本发明还涉及产生本发明的多肽的方法,这些方法包括(a)在有益于产生该多肽的条件下培养转基因植物或植物细胞,该转基因植物或植物细胞包含编码该多肽的多核苷酸;和(b)回收该多肽。发酵液配制品或细胞组合物本发明还涉及包含本发明的多肽的发酵液配制品或细胞组合物。该发酵液产物进一步包含在发酵过程中使用的另外的成分,例如像细胞(包括含有编码本发明的多肽的基因的宿主细胞,这些宿主细胞用于产生目的多肽)、细胞碎片、生物质、发酵培养基和/或发酵产物。在一些实施例中,组合物是含有一种或多种有机酸、杀灭的细胞和/或细胞碎片以及培养基的细胞杀灭的全培养液。如本文使用的术语“发酵液”是指由细胞发酵产生的、不经历或经历最少的回收和/或纯化的制剂。例如,当微生物培养物在允许蛋白质合成(例如,由宿主细胞表达酶)并且将蛋白质分泌到细胞培养基中的碳限制条件下孵育生长到饱和时,产生发酵液。该发酵液可以含有在发酵结束时得到的发酵材料的未分级的或分级的内容物。典型地,该发酵液是未分级的并且包含用过的培养基以及例如通过离心去除微生物细胞(例如,细菌细胞)之后存在的细胞碎片。在一些实施例中,发酵液含有用过的细胞培养基、胞外酶以及有活力的和/或无活力的微生物细胞。在实施例中,发酵液配制品和细胞组合物包含第一有机酸组分(包含至少一种1-5个碳的有机酸和/或其盐)和第二有机酸组分(包含至少一种6个或更多个碳的有机酸和/或其盐)。在一个特定的实施例中,第一有机酸组分是乙酸、甲酸、丙酸、其盐或前述两种或更多种的混合物;并且该第二有机酸组分是苯甲酸、环己烷羧酸、4-甲基戊酸、苯乙酸、其盐或前述两种或更多种的混合物。在一方面,组合物含有一种或多种有机酸,并且任选地进一步含有杀灭的细胞和/或细胞碎片。在一个实施例中,从细胞杀灭的全培养液中去除这些杀灭的细胞和/或细胞碎片,以提供不含这些组分的组合物。这些发酵液配制品或细胞组合物可以进一步包含防腐剂和/或抗微生物(例如,抑菌)剂,包括但不限于山梨醇、氯化钠、山梨酸钾、以及本领域已知的其他试剂。这些发酵液配制品或细胞组合物可以进一步包含多种酶活性,例如一种或多种(例如,若干种)选自下组的酶,该组由以下组成:水解酶、异构酶、连接酶、裂解酶、氧化还原酶、或转移酶,例如,α-半乳糖苷酶、α-葡糖苷酶、氨肽酶、α-淀粉酶、β-半乳糖苷酶、β-葡糖苷酶、β-木糖苷酶、糖酶、羧肽酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、壳多糖酶、角质酶、环糊精葡萄糖基转移酶、脱氧核糖核酸酶、内切葡聚糖酶、酯酶、葡糖淀粉酶、葡萄糖异构酶、转化酶、漆酶、脂肪酶、甘露糖苷酶、变聚糖酶、氧化酶、果胶分解酶、过氧化物酶、植酸酶、多酚氧化酶、蛋白水解酶、核糖核酸酶、转谷氨酰胺酶、或木聚糖酶。该细胞杀灭的全培养液或组合物可以含有在发酵结束时得到的发酵材料的未分级的内容物。典型地,该细胞杀灭的全培养液或组合物含有用过的培养基以及在微生物细胞(例如,细菌细胞)生长至饱和、在碳限制条件下孵育以允许蛋白合成之后存在的细胞碎片。在一些实施例中,该细胞杀灭的全培养液或组合物含有用过的细胞培养基、胞外酶和杀灭的细胞。在一些实施例中,可以使用本领域已知的方法来使细胞杀灭的全培养液或组合物中存在的微生物细胞透性化和/或裂解。如本文所述的全培养液或细胞组合物典型地是液体,但是可以含有不溶性组分,例如杀灭的细胞、细胞碎片、培养基组分和/或一种或多种不溶性酶。在一些实施例中,可以去除不溶性组分以提供澄清的液体组合物。本发明的全培养液配制品和细胞组合物可以通过wo90/15861或wo2010/096673中所述的方法来产生。酶组合物本发明还涉及包含本发明的多肽的组合物。优选地,这些组合物富含这种多肽。术语“富含”指示具有d-阿洛酮糖3-差向异构酶活性的多肽的量已经增加,例如,富集因子为至少1.1。这些组合物可以包含本发明的多肽作为主要酶组分,例如单组分组合物。可替代地,这些组合物可以包含多种酶活性,例如一种或多种(例如,若干种)选自下组的酶,该组由以下组成:水解酶、异构酶、连接酶、裂解酶、氧化还原酶、或转移酶,例如,α-半乳糖苷酶、α-葡糖苷酶、氨肽酶、α-淀粉酶、β-半乳糖苷酶、β-葡糖苷酶、β-木糖苷酶、糖酶、羧肽酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、壳多糖酶、角质酶、环糊精葡萄糖基转移酶、脱氧核糖核酸酶、内切葡聚糖酶、酯酶、葡糖淀粉酶、葡萄糖异构酶、转化酶、漆酶、脂肪酶、甘露糖苷酶、变聚糖酶、氧化酶、果胶分解酶、过氧化物酶、植酸酶、多酚氧化酶、蛋白水解酶、核糖核酸酶、转谷氨酰胺酶、或木聚糖酶。可以根据本领域已知的方法来制备组合物,并且这些组合物可以处于液体或干组合物的形式。可以根据本领域已知的方法将组合物稳定化。下面给出了本发明的组合物的优选的用途的实例。该组合物的剂量以及使用该组合物的其他条件可以基于本领域已知的方法来确定。用途本发明还涉及用于产生d-阿洛酮糖的方法,该方法包括:(a)在适于具有d-阿洛酮糖3-差向异构酶活性的多肽将d-果糖转化成d-阿洛酮糖的条件下,使包含本发明的具有d-阿洛酮糖3-差向异构酶活性的多肽的组合物与d-果糖接触;和任选地(b)回收所产生的d-阿洛酮糖。在该方法的一方面,该d-果糖先前是通过葡萄糖异构酶由d-葡萄糖产生的。在该方法的另一方面,该d-果糖同时是通过葡萄糖异构酶由d-葡萄糖产生的。该葡萄糖异构酶也称为木糖异构酶(ec.5.3.1.5)。先前产生的d-果糖可以处于高果糖糖浆的形式,并且,具体是高果糖玉米糖浆的形式。这种高果糖玉米糖浆是可以商购的。同时产生的d-果糖优选使用处于葡萄糖糖浆形式,具体是葡萄糖玉米糖浆形式的d-葡萄糖。在另一方面,通过如下产生d-果糖:使淀粉与α-淀粉酶和葡糖淀粉酶接触以释放d-葡萄糖,然后将其通过葡萄糖异构酶异构化为d-果糖。可以固定该葡萄糖异构酶(参见例如,美国专利号3,868,304、3,982,997、4,208,482、4,687,742、以及5,177,005)。葡萄糖异构酶的实例包括但不限于:鼠灰链霉菌(streptomycesmurinus)(例如itextra,诺维信公司(novozymes))和锈赤链霉菌(streptomycesrubiginosus)(gensweettmigi,杜邦公司(dupont))。具有阿洛酮糖3-差向异构酶活性的多肽与d-果糖之间的反应可使用d-果糖在以下条件下进行:浓度为5%至95%(w/w),ph为约5.5至约9.0,优选约6至约7,更优选约6.5,并且温度为约50℃和约60℃,优选约55℃,持续合适的时间。合适的时间是约8至约24小时,优选约10至约12小时。在另一方面,具有阿洛酮糖3-差向异构酶活性的多肽与d-果糖之间的反应在二价金属离子作为辅因子存在下进行。该二价金属离子选自下组,该组由以下组成:co2+、mg2+、mn2+、和ni2+。在一优选的方面,该二价金属离子是co2+。在另一优选的方面,该二价金属离子是mg2+。在另一优选的方面,该二价金属离子是mn2+。在另一优选的方面,该二价金属离子是ni2+。该金属阳离子辅因子的浓度可以为约0.1至约5mm,例如1mm,以提高d-阿洛酮糖的产量。本发明的方法可以分批进行或使用固定的差向异构酶进行。d-阿洛酮糖3-差向异构酶与d-果糖之间的反应以产生d-阿洛酮糖可以在分批反应器中进行。d-阿洛酮糖3-差向异构酶与d-果糖之间的反应以产生d-阿洛酮糖也可以通过将阿洛酮糖3-差向异构酶固定在运载体上来进行。任选地,葡萄糖异构酶和d-阿洛酮糖3-差向异构酶两者均可被固定。在替代方案中,固定产生酶的微生物而不是固定酶。用于固定的运载体可以是已知用于其在酶固定中使用的任何运载体。该一种或多种酶或微生物可以固定在,例如,任何合适的支持体上,例如海藻酸钠、amberlite树脂、sephadex树脂、或duolite树脂。可以将固定的一种或多种酶或微生物填充到合适的柱中,并将葡萄糖或果糖液体或糖浆连续引入该柱中。用于将d-阿洛酮糖3-差向异构酶固定在支持体上以产生d-阿洛酮糖的方法是本领域技术人员熟知的(参见例如,wo2011/040708)。由此产生的d-阿洛酮糖可以用作饮食或药物添加剂。所得产物可以是d-果糖和d-阿洛酮糖的混合物,且甚至是d-葡萄糖、d-果糖和d-阿洛酮糖的混合物。通过以下实例进一步描述本发明,这些实例不应理解为对本发明的范围进行限制。实例培养基lb培养基由以下构成:10g的胰蛋白胨、5g的酵母提取物、5g的nacl、以及加至1升的去离子水。lb板由以下构成:10g的胰蛋白胨、5g的酵母提取物、5g的nacl、15g的细菌用琼脂(bactoagar),以及加至1升的去离子水。基于酵母提取物的培养基由以下构成:40g的酵母提取物、1.3g的mgso4·7h2o、50g的麦芽糊精、20g的nah2po4·h2o、0.1ml的消泡剂,以及加至1升的去离子水。实例1:来自象粪宏基因组和厌氧海泥宏基因组的d-阿洛酮糖3-差向异构酶基因的鉴定和表征象粪样品收集自德国汉堡动物园中的亚洲象。海泥样品收集自丹麦中的海洋沉积物。如制造商的方案所描述,用qiaampdna粪便试剂盒(qiaampdnastoolkit)(凯杰公司(qiagen))从象粪样品中进行dna分离,并且用qiaampdna血液迷你试剂盒(qiaampdnabloodminikit)(凯杰公司)从海泥样品中进行dna分离。将2μg的每个染色体dna提交到瑞士fasterissa进行基因组测序。通过illumina测序对基因组进行测序。基于它们与来自解纤维梭菌的已知的差向异构酶(geneseqp:azw24274)的序列同一性来鉴定差向异构酶dna序列。从象粪样品的宏基因组中鉴定出的d-阿洛酮糖3-差向异构酶的基因组dna序列和推导的氨基酸序列分别示于seqidno:1(d448hc)和seqidno:2(p44dja)。该编码序列是873bp,包括终止密码子,其未被任何内含子打断。编码的预测蛋白质是290个氨基酸。使用signalp4.0程序(petersen等人,2011,naturemethods[自然方法]8:785-786),未预测到信号肽。所预测的分子量为32.57kda,并且所预测的等电点为6.68。从厌氧海泥样品的宏基因组中鉴定出的d-阿洛酮糖3-差向异构酶的基因组dna序列和推导的氨基酸序列分别示于seqidno:3(d343vr)和seqidno:4(p43mzv)。该编码序列是870bp,包括终止密码子,其未被任何内含子打断。编码的预测蛋白质是289个氨基酸。使用signalp4.0程序(petersen等人,2011,同上),未预测到信号肽。所预测的分子量为32.85kda,并且所预测的等电点为4.94。使用尼德曼和翁施算法(needleman和wunsch,1970,j.mol.biol.[分子生物学杂志]48:443-453)确定氨基酸序列的比较性成对地总体比对,使用空位开放罚分10、空位延伸罚分0.5以及eblosum62矩阵。比对显示,从象粪样品的宏基因组中鉴定出的d-阿洛酮糖3-差向异构酶的推导的氨基酸序列与解纤维梭菌d-阿洛酮糖3-差向异构酶(geneseqpbbv23667)的推导的氨基酸序列共享67.6%序列同一性(排除空位),并且从厌氧海泥样品的宏基因组中鉴定出的d-阿洛酮糖3-差向异构酶的推导的氨基酸序列与链孢子菌属物种8437d-阿洛酮糖3-差向异构酶(geneseqpbbe80336)的推导的氨基酸序列共享67.1%序列同一性(排除空位)。实例2:象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶基因的表达使用软件(分别是seqidno:5和seqidno:6)对象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶dna基因(分别是seqidno:1和seqidno:3)进行密码子优化用于在枯草芽孢杆菌中表达,并通过基因技术公司(geneartag)合成。将6xhis-标签直接与密码子优化的基因中的每个经c-末端融合。使用saci和mlui限制位点,通过基因技术公司将密码子优化的基因亚克隆到wo2012/025577中描述的载体c6221中。将以下序列添加到编码序列中的每个的两端以使克隆成为可能:n-末端:gagctctataaaaatgaggagggaaccga(包括saci限制位点;seqidno:7)以及c-末端:catcatcaccatcaccactaaacgcgt(包括6xhis-标签和mlui限制位点;seqidno:8)。对于含有来自象粪宏基因组的d-阿洛酮糖3-差向异构酶的质粒,将表达质粒表示为1196,并且对于含有来自海泥宏基因组的d-阿洛酮糖3-差向异构酶的质粒,将表达质粒表示为1204。使用标准程序将两个表达质粒转化到感受态枯草芽孢杆菌中。在补充有6μg氯霉素/ml的、在37℃下孵育18小时的lb板上选择转化体。将表达盒通过同源重组整合到果胶裂解酶基因座中。对两个基因构建体中的每个的若干重组克隆进行测序。针对两个差向异构酶基因中的每个选择具有正确序列的重组克隆。将每个重组克隆于30℃、在含有100ml基于酵母提取物的培养基的500ml带挡板的锥形瓶(bafflederlenmeyerflask)中以225rpm振荡培养6天。将培养液中的每个以20,000xg离心20分钟,并且将上清液小心地与丸粒化材料倾析分开。使用配备有0.2μm过滤器的过滤装置(乐基因公司(nalgene))过滤每种上清液以去除任何细胞碎片。实例3:象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的纯化使用如下所述的相同方案,从如实例2中所述制备的培养上清液中纯化该象粪宏基因组d-阿洛酮糖3-差向异构酶和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶。将上清液的ph用3mtris调节至ph8,静置1小时,并且然后使用配备有0.2μm过滤器的过滤装置(乐基因公司)过滤。将过滤的上清液应用到5mlhistraptmexcel柱(ge医疗集团生命科学部(gehealthcarelifesciences))上,将该柱用5个柱体积(cv)的50mmtris/hclph8预平衡。通过用8cv的50mmtris/hclph8洗涤该柱来洗脱未结合的蛋白质。用50mmhepesph7-10mm咪唑洗脱差向异构酶,并通过在280nm处的吸光度监测洗脱。将洗脱的差向异构酶在hipreptm26/10脱盐柱(ge医疗集团生命科学部)上脱盐,将该柱用3cv的50mmhepesph7-100mmnacl预平衡。使用相同的缓冲液,以10ml/分钟的流速从该柱洗脱差向异构酶。选择相关级分,并且使用4%-12%bis-tris凝胶(英杰公司(invitrogen))和2-(n-吗啉代)乙磺酸(mes)sds-page运行缓冲液(英杰公司),基于色谱图和sds-page分析进行合并。将凝胶用instantblue(诺韦新公司(novexin))染色,并使用miliq水脱色。分别使用1.560和1.451作为针对象粪宏基因组d-阿洛酮糖3-差向异构酶和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的消光系数,通过在280nm处的吸光度确定两种纯化酶的浓度。通过sds-page分析估计d-阿洛酮糖3-差向异构酶中的每种的纯度水平为大于95%。实例4:海泥宏基因组d-阿洛酮糖3-差向异构酶对金属离子辅因子的依赖性mu等人,2013,biotechnol.lett.[生物技术通讯]35:1481-1486披露了一些d-阿洛酮糖3-差向异构酶需要金属离子作为辅因子用于差向异构酶活性,而其他差向异构酶则不需要金属离子辅因子用于差向异构酶活性或可以通过金属离子增强的其他差向异构酶的活性。进行测定以确定不同金属离子辅因子对厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的酶活性的依赖性。将该海泥宏基因组d-阿洛酮糖3-差向异构酶(3.83mg/ml)用100mmedta处理1小时以从溶液中去除任何金属离子,随后使用zebatm旋转脱盐柱(赛默飞世尔科技公司(thermofisherscientific))进行脱盐,并将这些酶稀释至该测定的储备液浓度。以200μl规模进行每种测定,其中将50克/升果糖作为底物。将在ph8的50mmtris缓冲液中的总共0.3mg经edta处理的差向异构酶蛋白/克果糖添加到反应中。针对四水合氯化锰、六水合硝酸钴(ii)、氯化镁、氯化镍(ii)、四水合氯化亚铁、氯化锌(ii)或硫酸铜(ii),制备了金属离子储备溶液。将这些辅因子以0.2和0.1mm的终浓度添加到反应中。在96孔板中一式两份地进行每种测定。将这些板用硅树脂板密封机密封,并置于热循环仪中于55℃持续24小时。通过将这些板在热循环仪中于100℃加热10分钟来终止测定。终止测定后,将这些板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。将样品转移至hplc可读的96孔板中,并使用300x7.8mmaminexhpx-87c(ca2+)柱(伯乐实验室有限公司(bio-radlaboratories,inc.)),在65℃下,流速为0.7ml/分钟,持续30分钟,以milliq水作为流动相对d-阿洛酮糖的产生进行分析。分别运行果糖、d-阿洛酮糖和葡萄糖的标准曲线。hplc分析后,基于相对于标准曲线的峰面积,计算了由果糖产生的d-阿洛酮糖的百分比。以下结果是两份的平均值。表1中所示的结果表明,相对于具有没添加任何金属离子辅因子的经edta处理的差向异构酶的对照(“无”),具有co2+、mg2+、mn2+、和ni2+的经edta处理的厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶在将果糖转化为d-阿洛酮糖中的活性增加,即24.65%和25.12%。在0.2或1.0mm金属离子的存在下产生了类似的结果。表1.在55℃下,具有不同的金属离子作为辅因子的d-阿洛酮糖%辅因子0.2mm1.0mmmn2+28.5028.40co2+28.7928.70mg2+28.5728.71ni2+26.8819.84fe2+16.5923.13zn2+1.790.00cu2+1.850.74无24.6525.12实例5:象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶在将果糖转化为d-阿洛酮糖方面的剂量应答在不同剂量的差向异构酶下,测定了象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶将果糖转化为d-阿洛酮糖的能力。以200μl规模进行每种测定,其中作为底物,果糖/葡萄糖比率为42%或95%,总干固体为35%。添加氯化镁(0.2mm)作为金属离子辅因子。使用50mmtris缓冲液在ph8下进行反应。将在96孔板中的差向异构酶以0.004、0.011、0.033、0.1、0.3和0.9μg的差向异构酶蛋白/g果糖一式四份地添加到测定中。然后将这些板用硅树脂板密封机密封,并在热循环仪中于50℃孵育24小时。通过将这些板在热循环仪中于100℃加热10分钟来终止测定。终止测定后,将这些板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。将样品转移至hplc可读的96孔板中,并根据实例4通过hplc进行分析,以确定由果糖产生的d-阿洛酮糖的百分比。以下结果是四份的平均值。表2中所示的结果表明,42%和95%果糖/葡萄糖底物两者在50℃下24小时后,象粪宏基因组d-阿洛酮糖3-差向异构酶在0.3mg酶蛋白/g果糖的剂量下产生了最大d-阿洛酮糖%。表2.来自35%ds的42%和95%果糖/葡萄糖底物的、不同剂量的象粪宏基因组d-阿洛酮糖3-差向异构酶的d-阿洛酮糖%表3中所示的结果表明,42%和95%果糖/葡萄糖底物两者在50℃下24小时后,厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶在0.1mg酶蛋白/g果糖的剂量下产生了最大d-阿洛酮糖%。表3.来自35%ds的42%和95%果糖/葡萄糖底物的、不同剂量的厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的d-阿洛酮糖%实例6:干固体(ds)对通过象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶产生d-阿洛酮糖的影响象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的性能被评估为35%、50%和70%干固体(果糖:葡萄糖的比率为42%)的函数。每种测定均由35%、50%和70%干固体(果糖:葡萄糖的比率为42%),0.2mm氯化镁作为金属离子辅因子,以及0.1mg海泥差向异构酶蛋白/克果糖或0.3mg象粪差向异构酶蛋白/克果糖构成。使用50mmtris缓冲液在ph8下以200μl规模进行测定。使用96孔板一式四份地进行每种测定。将这些板用硅树脂板密封机密封,并置于热循环仪中于55℃持续24小时。通过将这些板在热循环仪中于100℃加热10分钟来终止测定。终止测定后,将这些板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。将样品转移至hplc可读的96孔板中,并根据实例4通过hplc进行分析,以确定由果糖产生的d-阿洛酮糖的百分比。以下结果是四份的平均值。表4中所示的结果表明,当%ds(果糖:葡萄糖的比率为42%)从35%变为50%至70%时,用象粪宏基因组d-阿洛酮糖3-差向异构酶获得了类似的d-阿洛酮糖产量。表4.d-阿洛酮糖%作为干固体百分比的函数表5中所示的结果表明,当%ds(果糖:葡萄糖的比率为42%)从35%变为50%至70%时,用海泥宏基因组d-阿洛酮糖3-差向异构酶获得了类似的d-阿洛酮糖产量。表5.d-阿洛酮糖%作为干固体百分比的函数实例7:温度对通过象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶将果糖转化为d-阿洛酮糖的影响进行了时程研究以检验温度对通过象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶将果糖转化为d-阿洛酮糖的影响。以200μl规模进行该测定,其中将50克/升果糖作为底物。将氯化锰用作金属辅因子,终浓度为0.2mm。将差向异构酶以0.5μm的浓度添加到反应中。将ph用50mmtris缓冲液调节至ph8。在96孔板中一式两份地进行每种处理。在0、0.5、1、2、4、8和24小时时取样。将这些板用硅树脂板密封机密封,并置于热循环仪中于50℃、55℃和60℃持续24小时。通过将这些板在热循环仪中于100℃加热10分钟来终止测定。终止测定后,将这些板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。将样品转移至hplc可读的96孔板中,并根据实例4通过hplc进行分析,以确定由果糖产生的d-阿洛酮糖的百分比。以下结果是两份的平均值。表6和图1中所示的结果表明,在50℃、55℃和60℃温度中的每个下10-12小时后,象粪宏基因组d-阿洛酮糖3-差向异构酶达到了转化平衡。表6.在不同温度下24小时内的d-阿洛酮糖%时间,hr50℃55℃60℃00.000.000.000.59.4210.257.96115.1116.7215.30221.1922.4421.25426.0427.2425.87827.9929.2927.232429.7130.3227.32表7和图2中所示的结果表明,在50℃、55℃和60℃温度中的每个下10-12小时后,厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶达到了转化平衡。表7.在不同温度下24小时内的d-阿洛酮糖%时间,hr50℃55℃60℃00.800.000.000.59.1610.227.93116.7518.8218.82224.3826.3227.18428.4228.6229.08828.6829.6229.262427.7430.3228.91实例8:ph和温度对象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的活性的影响在ph7.0、7.5、8、8.5、和9.0以及温度50℃、55℃、和60℃下确定ph和温度对象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的活性的影响。以200μl规模进行该测定,其中将50克/升果糖作为底物。将氯化锰用作金属辅因子,终浓度为0.2mm。将差向异构酶以0.5μm添加到反应中。将ph用50mmtris缓冲液调节至ph7、7.5、8、8.5和9.0,该tris缓冲液用hcl调节。在96孔板中一式两份地进行每种处理。使用了三个不同的96孔板,一个板针对各个温度(45℃、55℃或65℃)。通过移液管抽吸将溶液混合。将三个温度板用硅树脂板密封机密封,并置于热循环仪中于45℃、55℃或65℃持续24小时。通过将这些板在热循环仪中于100℃加热10分钟来终止测定。将这些板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。将样品转移至hplc可读的96孔板中,并根据实例4通过hplc进行分析,以确定由果糖产生的d-阿洛酮糖的百分比。以下结果是两份的平均值。表8中所示的结果表明,象粪宏基因组d-阿洛酮糖3-差向异构酶在ph为7-9的范围内在45℃和55℃下是稳定的,均达到最大d-阿洛酮糖产量。在65℃下,该差向异构酶在ph7.0下是稳定的。表8.表9中所示的结果表明,厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶在ph为7-9的范围内在45℃、55℃和65℃下是稳定的,均达到最大d-阿洛酮糖产量。表9.实例9:ph和温度对象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的活性的影响在ph5.5、6.0、和6.5以及温度50℃、53.8℃、57.5℃、62℃、65.9℃、和70℃下确定ph和温度对象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的活性的影响。以200μl规模进行该测定,其中42%果糖:葡萄糖作为底物,总固体为50%。将厌氧海泥宏基因组差向异构酶以0.1mg蛋白质/克果糖添加,并且将象粪宏基因组差向异构酶以0.3mg差向异构酶蛋白/克果糖添加。将硫酸镁(0.2mm)用作金属辅因子。使用50mm乙酸钠缓冲液将ph调节至5.5、6和6.5。将该板用硅树脂板密封机密封,并置于热循环仪中,其程序为整个板上从50℃到70℃的温度梯度持续24小时。通过将这些板在热循环仪中于100℃加热10分钟来终止测定。终止测定后,将这些板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。将样品转移至hplc可读的96孔板中,并根据实例4通过hplc进行分析,以确定由果糖产生的d-阿洛酮糖的百分比。这些结果是四份的平均值。表10中所示的结果表明,象粪宏基因组d-阿洛酮糖3-差向异构酶在50℃至62℃下在ph5.5、6.0和6.5下是稳定的,均达到最大d-阿洛酮糖转化,其中转化随着温度的升高而略有增加。表10.表11中所示的结果表明,厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶在50℃至62℃下在ph5.5、6.0和6.5下达到了最大d-阿洛酮糖转化,其中转化随着温度的升高而略有增加。表11实例10:象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶作为不同果糖浓度的函数的动力学通过监测不同果糖浓度对酶活性的影响,测定了象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶在将果糖转化为d-阿洛酮糖中的动力学。以200μl规模进行该测定,其中将50、420和950克/升果糖作为底物。将氯化锰用作金属辅因子,终浓度为0.2mm。将差向异构酶以0.33mg差向异构酶蛋白/克果糖的浓度添加到该测定中。将ph用50mmtris缓冲液调节至8。在96孔板中一式两份地进行每种测定。将三个板用硅树脂板密封机密封,并置于在40℃、55℃、或65℃下的三个不同的热循环仪中。在1、2、4、24、48和72小时时收集样品。在取样时间点之前,将这些板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。在给定时间点从板中收集200μl体积的各个样品,并将其转移到新的pcr96孔板中。将原始板放回热循环仪中以继续测定直到下一个取样时间点。然后在特定时间点将包含样品的pcr板置于不同的热循环仪中于98℃持续10分钟以灭活酶。然后将含有灭活样品的板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。将420和950g/l果糖样品用去离子水分别稀释10倍和20倍,并将其转移到hplc可读的96孔板中。将未稀释的50g/l果糖样品转移到hplc板中。将这些板加热密封,并根据实例4通过hplc进行分析,以确定由果糖产生的d-阿洛酮糖的百分比。以下结果是两份的平均值表12中所示的结果表明,相对于起始果糖浓度,针对象粪宏基因组d-阿洛酮糖3-差向异构酶,在40℃下,果糖向d-阿洛酮糖的转化百分比。在40℃以50和420g/l果糖作为底物的情况下,差向异构酶在4小时内达到了果糖向d-阿洛酮糖的最大转化,并且即使在以950g/l果糖作为底物的情况下,到24小时达到了约66%的最大转化。表12.表13中所示的结果表明,相对于起始果糖浓度,针对象粪宏基因组d-阿洛酮糖3-差向异构酶,在55℃下,果糖向d-阿洛酮糖的转化百分比。在55℃以50和420g/l果糖作为底物的情况下,差向异构酶在24小时达到了果糖向d-阿洛酮糖的最大转化,并且即使在以950g/l果糖作为底物的情况下,到24小时达到了约70%的最大转化。表13.表14中所示的结果表明,相对于起始果糖浓度,针对象粪宏基因组d-阿洛酮糖3-差向异构酶,在65℃下,果糖向d-阿洛酮糖的转化百分比。底物浓度的增加提高了差向异构酶的热稳定性,参见在65℃用420g/l果糖的情况下,仅4小时后就达到了30%的转化。表14.表15中所示的结果表明,相对于起始果糖浓度,针对厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶,在40℃下,果糖向d-阿洛酮糖的转化百分比。在40℃下、在50和420g/l果糖下,4小时后达到最大d-阿洛酮糖。表15.表16中所示的结果表明,相对于起始果糖浓度,针对厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶,在55℃下,果糖向d-阿洛酮糖的转化百分比。在55℃下、在50和420g/l果糖下,24小时后达到最大d-阿洛酮糖。表16.表17中所示的结果表明,相对于起始果糖浓度,针对厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶,在55℃下,果糖向d-阿洛酮糖的转化百分比。在65℃下、在50和420g/l果糖下4小时后以及在950g/l果糖24小时后达到最大d-阿洛酮糖。表17.实例11:象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的温度灭活使差向异构酶经受一定范围的温度后,确定象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的残留活性。将每种差向异构酶暴露在60℃-85℃的温度范围持续30和60分钟,并将其暴露在100℃持续10分钟作为阴性对照。还包括未经温度处理的阳性对照。在该测定中使用热循环仪,其程序温度梯度为从60℃-85℃。在热循环仪中,针对30和60分钟的灭活孵育期中的每个都有一个板。分别地,将稀释的酶添加到另一个pcr96孔板中,并在热循环仪中于100℃孵育10分钟。在所有的差向异构酶样品已经受适当的灭活时间和温度后,将它们全部合并在96孔板中。该板中还包括未经处理的差向异构酶样品作为阳性对照。然后如下所述测定样品的差向异构酶活性,以确定残留差向异构酶活性。以200μl规模进行该测定,其中将50克/升果糖作为底物。将氯化锰用作金属辅因子,终浓度为0.2mm。将差向异构酶以0.5μm添加到测定中。将ph用50mmtris缓冲液调节至8。在96孔板中一式两份地进行每种测定。将硅树脂盖应用到pcr板上,并将这些板置于热循环仪中于55℃持续24小时。反应结束后,将这些板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。将样品转移至hplc可读的96孔板中,并根据实例4通过hplc进行分析,以确定由果糖产生的d-阿洛酮糖的百分比。以下结果是两份的平均值。表18中所示的结果表明,相对于起始果糖浓度,针对象粪宏基因组d-阿洛酮糖3-差向异构酶,在灭活后产生的d-阿洛酮糖的百分比。在80.4℃下孵育30分钟后,该差向异构酶被完全灭活。表18.表19中所示的结果表明,相对于起始果糖浓度,针对厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶,在灭活后产生的d-阿洛酮糖的百分比。在80.4℃下孵育30分钟后,该差向异构酶被完全灭活。表19.实例12:象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的ph灭活在范围为从1.5至8.0的ph下孵育后,确定象粪宏基因组和厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶的残留活性。将正确量的hcl添加到pcr板中的酶中,并允许静置10分钟,同时轻轻振荡。然后,添加25μl正确浓度的naoh以中和溶液。然后使含有ph灭活酶的pcr板经受差向异构酶反应方案。将100μl体积的100g/l果糖的反应缓冲液添加到pcr板中的100μl先前已灭活的差向异构酶溶液中。通过移液管抽吸将该含有50g/l果糖和0.5μm差向异构酶的合并溶液进行混合。储备反应缓冲液的终浓度为100g/l果糖、50mmtris、和0.2mmmncl2。将硅树脂盖应用到pcr板上,并将这些板置于热循环仪中于55℃持续24小时。通过在热循环仪中于100℃加热10分钟来终止测定。测定结束后,将这些板在3,000rpm下离心1分钟以去除任何冷凝物,然后去除板密封。将样品转移至hplc可读的96孔板中,并根据实例4通过hplc进行分析,以确定由果糖产生的d-阿洛酮糖的百分比。以下结果是两份的平均值。表20中所示的结果表明,象粪宏基因组d-阿洛酮糖3-差向异构酶在表20中所示的ph下孵育10分钟后,果糖向d-阿洛酮糖的转化%。通过在ph2.5下孵育10分钟来灭活差向异构酶。表20表20中所示的结果表明,厌氧海泥宏基因组d-阿洛酮糖3-差向异构酶在表21中所示的ph下孵育10分钟后,果糖向d-阿洛酮糖的转化%。在孵育10分钟后,该差向异构酶在低至至少ph1.5时是稳定的。表21本文描述和要求保护的本发明不限于本文披露的特定方面的范围,因为这些方面旨在作为本发明若干方面的说明。任何等同方面旨在处于本发明的范围之内。实际上,除了本文所示和描述的那些之外,本发明的各种修改对于本领域的技术人员会从前述说明变得清楚。此类修改也旨在落入所附权利要求书的范围内。在冲突的情况下,以包括定义的本披露为准。序列表<110>诺维信公司shen,xinyudeinhammer,randallshuffman,jamesr.stallings,kendrahoff,tinesalomon,jesperolsen,anneg.<120>具有d-阿洛酮糖3-差向异构酶活性的多肽和编码其的多核苷酸<130>14207-wo-pct<160>8<170>patentin3.5版<210>1<211>873<212>dna<213>未知<220><223>未鉴定的微生物<400>1atgaaatacggaatctactacgcctattgggaagacaagtgggaagcggactacttcaag60tacatcgagaaggtcgccaagctcggcttcgacttcctggagatcgcctgcacgccgatc120aacggctattccaagcagacgctgaaggacctgcgccaggcggcgaaggacaacggcatc180ttcctgacggccggtcacggaccgaacgccgaccagaaccttgcctcgccggacgcggct240gtccgcaagaacgcgaagaagttcttcacgacgcttctcaagaacctcgagatcctcgac300atccactcgatcggcggcggcatctacagctactggccggtggactactcgaagccgatc360gacaagaagggcgactgggcgcgctccgtgaagggcgtgcgcgagatgggcaaggtggct420caggactgcggcgtcgactactgcctggaggtcctgaaccgcttcgagggttatctgctc480aacacggccgccgaaggcgtgaagttcgtgaaagaggtggacgtgccgtccgtcaaggtc540atgctcgatacgttccacatgaacatcgaggaggactcgatcggcggagcgattcgctcg600accaaggggctgctcggccacttccacacgggcgagtgcaaccgtcgcgtgccgggccgc660ggccgcacgccgtggcacgagatcgcctgcgcgctcaaggacatcggctacaagggcaac720gtctgcatggagccgttcgttcggatgggcggcaaggtcggcgaggacatcaaggtctgg780cgcgaactcgaacccggcatttccgaggcgaagatggatgcggacgcgaaggcggcgctc840gacttcgagaggatcgtgatggagaaggtttga873<210>2<211>290<212>prt<213>未知<220><223>未鉴定的微生物<400>2metlystyrglyiletyrtyralatyrtrpgluasplystrpgluala151015asptyrphelystyrileglulysvalalalysleuglypheaspphe202530leugluilealacysthrproileasnglytyrserlysglnthrleu354045lysaspleuargglnalaalalysaspasnglyilepheleuthrala505560glyhisglyproasnalaaspglnasnleualaserproaspalaala65707580valarglysasnalalyslysphephethrthrleuleulysasnleu859095gluileleuaspilehisserileglyglyglyiletyrsertyrtrp100105110provalasptyrserlysproileasplyslysglyasptrpalaarg115120125servallysglyvalargglumetglylysvalalaglnaspcysgly130135140valasptyrcysleugluvalleuasnargphegluglytyrleuleu145150155160asnthralaalagluglyvallysphevallysgluvalaspvalpro165170175servallysvalmetleuaspthrphehismetasnileglugluasp180185190serileglyglyalaileargserthrlysglyleuleuglyhisphe195200205histhrglyglucysasnargargvalproglyargglyargthrpro210215220trphisgluilealacysalaleulysaspileglytyrlysglyasn225230235240valcysmetgluprophevalargmetglyglylysvalglygluasp245250255ilelysvaltrparggluleugluproglyileserglualalysmet260265270aspalaaspalalysalaalaleuaspphegluargilevalmetglu275280285lysval290<210>3<211>870<212>dna<213>未知<220><223>未鉴定的微生物<400>3atgaagtttggaacctattttgcctattgggaaaaagactgggatacggattatattaag60tatgtaaaaaaagttgccgacctgggctttgatgttttagaagtaggagctgcagggatt120gttaatatgtctgatgaacaattatttgctttaaagtctgaagcggagaaattcaatatt180actttaacagccgggattggtcttccgaaggaatatgatgtttcttctctagatgaagat240gtccgacagaatggaattgcttttatgaaaagaattttagacgcattatataaagccggc300atacatgcaatcggcggaacaatctattcttattggcctgccgattatacttctcctata360aacaaaccagaagttcgaaaacaaagcattaaaagtatgaaagaattggctgattatgca420gctcagtataatatcactttgctggtggaaacactaaaccgatttgagcagtttttaatt480aatgatgcaaaagaagctgtcgcctttgtaaaagatattaataaagagaatgttaaggtc540atgttagatagttttcatatgaacattgaggaagattatattggggatgcgatccgctat600acaggtgaatatttagggcatttccatatcggagaatgcaatcgcaaagtgcctggcaaa660ggtcatatgccttgggcagaaattggacaggctcttcgggatattaattacaatggatgc720gtcgtcatggaaccatttgttcgtacaggtggggttgtaggatcagatataagagtctgg780agagatctttccgaaaatgcagatgatgctaaattagatgcagatattaaagaatctctt840gaatttattaaaaacgagtttttaaaatag870<210>4<211>289<212>prt<213>未知<220><223>未鉴定的微生物<400>4metlyspheglythrtyrphealatyrtrpglulysasptrpaspthr151015asptyrilelystyrvallyslysvalalaaspleuglypheaspval202530leugluvalglyalaalaglyilevalasnmetseraspgluglnleu354045phealaleulysserglualaglulyspheasnilethrleuthrala505560glyileglyleuprolysglutyraspvalserserleuaspgluasp65707580valargglnasnglyilealaphemetlysargileleuaspalaleu859095tyrlysalaglyilehisalaileglyglythriletyrsertyrtrp100105110proalaasptyrthrserproileasnlysprogluvalarglysgln115120125serilelyssermetlysgluleualaasptyralaalaglntyrasn130135140ilethrleuleuvalgluthrleuasnargphegluglnpheleuile145150155160asnaspalalysglualavalalaphevallysaspileasnlysglu165170175asnvallysvalmetleuaspserphehismetasnileglugluasp180185190tyrileglyaspalaileargtyrthrglyglutyrleuglyhisphe195200205hisileglyglucysasnarglysvalproglylysglyhismetpro210215220trpalagluileglyglnalaleuargaspileasntyrasnglycys225230235240valvalmetgluprophevalargthrglyglyvalvalglyserasp245250255ileargvaltrpargaspleusergluasnalaaspaspalalysleu260265270aspalaaspilelysgluserleuglupheilelysasnglupheleu275280285lys<210>5<211>870<212>dna<213>人工序列<220><223>人工dna序列<400>5atgaagtatggcatctactatgcatactgggaggacaaatgggaggctgactatttcaaa60tacatcgagaaagttgcaaaacttggtttcgacttccttgagatcgcgtgcacaccaatc120aacggatattctaaacaaactcttaaggaccttcgccaagctgcgaaagacaacggcatc180tttcttactgctggccatggtccgaacgctgaccaaaaccttgcttctccggacgcagct240gttcgcaaaaacgcgaagaaattcttcacgacacttcttaagaaccttgagatcttagac300atccactctatcggtggcggaatctattcatactggcctgttgactactctaaacctatc360gacaaaaagggcgactgggctcgctctgttaaaggcgtacgcgagatgggcaaagtagct420caagactgtggcgttgactattgccttgaggtacttaaccgcttcgagggctaccttctt480aacactgcagctgagggcgttaagtttgttaaagaggttgacgtaccatctgttaaagtt540atgttagacacattccacatgaacatcgaggaggactctattggtggcgcaatccgctca600actaagggccttcttggccattttcatactggcgagtgtaatcgtcgcgttcctggtcgt660ggtcgcactccatggcatgagatcgcttgcgctcttaaagacatcggctacaaaggcaac720gtttgtatggagccttttgtacgcatgggtggcaaagttggcgaggacatcaaagtttgg780cgtgagcttgagcctggcatctctgaggccaaaatggacgcagacgcaaaagcagctctt840gacttcgagcgcatcgttatggagaaggta870<210>6<211>867<212>dna<213>人工序列<220><223>人工dna序列<400>6atgaaattcggcacttacttcgcttactgggagaaggactgggacacggactacatcaag60tacgtaaagaaggttgctgaccttggcttcgacgttcttgaggtaggcgctgcaggcatc120gttaacatgagcgacgagcaacttttcgcacttaagtctgaggctgagaagttcaacatc180acacttacagctggcatcggccttcctaaggagtatgacgttagcagccttgacgaggac240gtacgccagaacggcatcgctttcatgaagcgcatccttgacgcactttacaaggctggc300atccacgcgattggtggcactatctactcttattggcctgcagactacacatctcctatc360aacaaacctgaggtacgcaaacaatcaatcaagtctatgaaggagcttgctgactatgct420gctcaatacaacatcactcttcttgttgagactcttaaccgctttgagcagtttcttatc480aacgacgcaaaggaggctgttgcgttcgtaaaggacatcaacaaggagaacgttaaggtt540atgcttgactctttccacatgaacatcgaggaggactacatcggcgacgcaatccgctac600actggcgagtaccttggccacttccatatcggcgagtgtaaccgcaaagttccaggcaag660ggccatatgccttgggcagagatcggccaagcgcttcgcgacatcaactataacggctgc720gttgttatggagccatttgttcgcactggtggcgtagtaggcagcgacatccgcgtatgg780cgtgaccttagcgagaacgcggacgacgctaagcttgacgctgacatcaaggagtcactt840gagttcatcaagaacgagttccttaag867<210>7<211>29<212>dna<213>人工序列<220><223>人工引物<400>7gagctctataaaaatgaggagggaaccga29<210>8<211>27<212>dna<213>人工序列<220><223>人工引物<400>8catcatcaccatcaccactaaacgcgt27当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1