用于将体细胞重编程的RNA复制子的制作方法
本发明包括可通过甲病毒(alphavirus)来源的复制酶(repliase)进行复制并且包含编码重编程因子(reprogrammingfactor)的开放阅读框(openreadingframe)的rna复制子(rnareplicon)。这样的rna复制子可用于从体细胞产生具有干细胞特征的细胞,并且特别是在通过将一个或更多个rna复制子引入到体细胞中并且培养所述体细胞以允许细胞去分化来使体细胞去分化为具有干细胞特征(特别是多能性)的细胞(例如干细胞样细胞)而不产生胚胎或胎儿的方法中。去分化之后,可诱导细胞再分化为相同或不同的体细胞类型,例如神经元、造血、肌肉、上皮和其他细胞类型。由本发明来源的干细胞样细胞具有通过“细胞治疗(celltherapy)”来治疗退行性疾病(degenerativedisease)的医学应用,并且可用于治疗心脏、神经、内分泌、血管、视网膜、皮肤、肌肉骨骼疾病和其他疾病。
背景技术:
干细胞也被称为祖细胞,是具有自我更新、保持未分化、以及开始分化为具有成熟表型的一种或更多种特化(specialized)细胞类型的能力的细胞。干细胞不终末分化,并且它们不在分化途径的末端。
全能细胞(totipotentcell)包含产生身体所有细胞(包括胎盘细胞)所需的所有遗传信息。人细胞仅在受精卵的前几次分裂期间才具有这种全能能力。在全能细胞的三至四次分裂之后,接下来是一系列阶段,在这些阶段中,细胞变得越来越特化。分裂的下一阶段产生了多能细胞(pluripotentcell),所述细胞是高度通用的,并且可产生除了胎盘细胞或子宫的其他支持组织以外的任何细胞类型。在下一阶段,细胞变得多潜能(multipotent),意味着它们可产生多种其他细胞类型,但是这些类型的数量有限。在构成胚胎的细胞分裂的长链末端,是“终末分化(terminallydifferentiated)”细胞,其被认为永久地定向(committed)于特定的功能。
有三大类干细胞:(i)成体或体干细胞(出生后),其存在于所有出生后生物中;(ii)胚胎干细胞,其可来源于胚胎前或胚胎发育阶段,以及(iii)胎儿干细胞(fetalstemcell)(出生前),其可分离自发育中的胎儿。
涉及分离和使用人胚胎干细胞的干细胞技术已成为医学研究的重要主题。人胚胎干细胞具有分化为人体任何和所有细胞类型(包括复杂组织)的潜力。预期由细胞功能障碍引起的许多疾病可通过施用人胚胎干细胞或人胚胎干细胞来源细胞来进行治疗。多能胚胎干细胞分化并产生多种特化的成熟细胞的能力揭示了这些细胞作为替代、恢复或补充受损或患病的细胞、组织和器官的手段的潜在应用。然而,科学和伦理学的考虑减慢了使用从流产胚胎或利用体外受精技术形成的胚胎中回收的胚胎干细胞的研究的进展。
成体干细胞仅以低频率存在,并显示出有限的分化潜力和较差的生长。与使用成体干细胞相关的另一个问题是,这些细胞在移植之后不是免疫豁免的,或者可失去其免疫豁免,其中术语“免疫豁免”用于表示接受者的免疫系统不将细胞识别为异物的状态。因此,当使用成体干细胞时,在大多数情况下仅可进行自体移植。大部分目前预期的干细胞治疗形式基本上是定制的医学程序(medicalprocedure),并因此与这样的程序相关的经济因素限制了其广泛的潜力。
已在与胚胎干细胞融合之后的体细胞中观察到至少一些所测量的胚胎特异性基因的表达恢复。但是,所得细胞是杂交体(hybrid),通常具有四倍体基因型,并因此不适合作为正常或组织相容性细胞用于移植目的。
体细胞核转移的使用已被示出为充分地重编程体细胞核内容物以过继多能性,但是,引起了超出道德状态的一系列担忧。施加在卵细胞和所引入的细胞核二者上的应激巨大,导致所得细胞大量损失。此外,该程序必须在显微镜下手动进行,并且因此,体细胞核转移是非常耗费资源的。此外,并非供体细胞的遗传信息全部被转移,因为供体细胞的含有其自身线粒体dna的线粒体被保留下来。所得杂交细胞保留了最初属于卵的线粒体结构。结果,克隆不是核(nucleus)供体的完美拷贝。
takahashi等人在2006年取得了迈向患者来源的多能细胞的一大步。表明已知调节和维持干细胞多能性的限定的转录因子(tf)(takahasietal.,2006,cell126,663-676;schulz&hoffmann,2007,epigenetics2,37-42)的过表达可诱导鼠体成纤维细胞的多能状态,被称为诱导多能干(inducedpluripotentstem,ips)细胞。在这项研究中,作者将oct3/4、sox2、klf4和c-myc鉴定为ips细胞产生所需要的(takahasietal.,2006)。在随后的研究中,作者表明相同的tf能够对成人成纤维细胞进行重编程(takahasietal.,2007,cell131,861-872),而另一些人则将关于人(yuetal.,2007,science318,1917)或鼠成纤维细胞(wemigetal.,2007,nature448,318-324)的这种活性归因于由oct3/4、sox2、nanog和lin28构成的修改的tf混合物(tf-cocktail)。对于那些最初的研究以及大多数随后的研究,使用逆转录病毒或慢病毒载体过表达重编程tf。由于病毒启动子的沉默,这些研究可再现地表明外源tf的表达在重编程过程期间被关闭(hotta&ellis,2008,j.cellbiochem.105,940-948综述)。因此,多能状态通过激活的内源转录因子来维持。此外,病毒表达的tf的沉默是随后ips细胞再分化为组织特异性前体的前提(yuetal.,2007)。病毒递送的主要缺点是编码有效癌基因的整合逆转录病毒的随机再激活,其在c-myc的情况下导致嵌合小鼠中肿瘤的诱导(okitaetal.,2007,nature448,313-317)。同时,已经示出在不存在myc的情况下可以产生ips细胞(nakagawaetal.,2008,nat.biotechnol.,26(1),101-106)。总体而言,仅oct4和sox2被报道为对重编程是必需的,癌基因(如myc和klf4)似乎起着增强子的作用(mcdevitt&palecek,2008,curr.opin.biotechnol.19,527-33)。相应地,已经显示其他转化基因产物(如sv40大t抗原或htert)可提高ips产生的效率(malietal.,2008,stemcells26,1998-2005)。由于表观遗传重编程涉及染色质重塑,因此添加组蛋白脱乙酰酶(histonedeacetylase,hdac)抑制剂(如丙戊酸)或dna甲基转移酶抑制剂(如5’-azac)极大改善了重编程效率(huangfuetal.,2008,nat.biotechnol.26,795-797)并降低了oct4和sox2对tf的需要(huangfuetal.,2008,nat.biotechnol.26,1269-1275)。
降低与逆转录病毒整合入宿主基因组中相关的风险的另一种策略是使用非整合型腺病毒载体,其介导足以进行重编程的瞬时转基因表达(stadtfeldetal.,2008,322,945-949)。还通过使用导致瞬时基因表达的常规真核表达质粒避免了转基因整合。到目前为止,通过这种策略,已成功地将mef重编程为ips细胞(okitaetal.,2008,science322,949-53)。在这项研究中尚未检测到基因组整合,但是,不能完全排除转染的质粒dna在一小部分细胞中稳定的基因组整合。
成人成纤维细胞容易来源于健康的供体,或者在未来的临床应用中来源于患者而没有危险的手术干预。然而,最近的研究表明,人角质形成细胞更容易且更有效地重编程为ips细胞,并且例如毛囊来源的角质形成细胞可能是患者来源的ips细胞的更好的选择来源(aasenetal.,2008,nat.biotechnol.26(11),1276-84)。
仍然需要用于将分化的体细胞重编程以产生大量且高质量的去分化或重编程细胞的技术。
多年来,在生物医学研究中已经研究了包含编码用于预防和治疗目的的一种或更多种多肽的外来遗传信息的核酸分子。受与使用脱氧核糖核酸(dna)分子相关的安全问题的影响,近年来,核糖核酸(rna)分子受到越来越多的关注。已经提出了多种方法,包括以裸rna形式或以复合或包装形式(例如在非病毒或病毒递送载剂)中施用单链或双链rna。在病毒和在病毒递送载剂中,遗传信息通常被蛋白质和/或脂质(病毒颗粒)包封。例如,已经提出了将来源于rna病毒的工程rna病毒颗粒作为用于治疗植物(wo2000/053780a2)或用于哺乳动物的疫苗接种(tubulekasetal.,1997,gene,vol.190,pp.191-195)的递送载剂。通常来说,rna病毒是具有rna基因组的多种感染性颗粒。rna病毒可细分为单链rna(single-strandedrna,ssrna)和双链rna(double-strandedrna,dsrna)病毒,并且ssrna病毒通常可进一步分为正链[(+)链]和/或负链[(-)链]病毒。正链rna病毒作为生物医学中的递送系统初步(primafacie)具有吸引力,因为它们的rna可直接用作用于在宿主细胞中翻译的模板。
甲病毒是正链rna病毒的典型代表。甲病毒的宿主包括多种生物,包括昆虫、鱼类和哺乳动物,例如驯养的动物和人。甲病毒在受感染细胞的细胞质中复制(关于甲病毒生命周期的综述,请参见joséetal.,futuremicrobiol.,2009,vol.4,pp.837-856)。许多甲病毒的总基因组长度通常为11,000至12,000个核苷酸,并且基因组rna通常具有5’帽和3’poly(a)尾。甲病毒的基因组编码非结构蛋白(参与病毒rna的转录、修饰和复制以及蛋白质修饰)和结构蛋白(形成病毒颗粒)。基因组中通常有两个开放阅读框(openreadingframe,orf)。四种非结构蛋白(nsp1-nsp4)通常一起由在基因组5’末端附近开始的第一orf编码,而甲病毒结构蛋白一起由存在于第一orf下游并延伸到基因组3’末端附近的第二orf编码。通常来说,第一orf大于第二orf,比例为大约2∶1。
在被甲病毒感染的细胞中,仅编码非结构蛋白的核酸序列才从基因组rna翻译,而编码结构蛋白的遗传信息可从亚基因组转录物翻译,后者是类似于真核信使rna(mrna)的rna分子(mrna;gouldetal.,2010,antiviralres.,vol.87pp.111-124)。在感染之后,即在病毒生命周期的早期,(+)链基因组rna直接充当信使rna,用于编码非结构多蛋白(nsp1234)的开放阅读框的翻译。在一些病毒中,在nsp3和nsp4的编码序列之间存在乳白终止密码子(opalstopcodon):当翻译在乳白终止密码子处终止时,产生包含nsp1、nsp2和nsp3的多蛋白p123,并且在通读该乳白密码子之后产生另外包含nsp4的多蛋白p1234(strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562;ruppetal.,2015,j.gen.virology,vol.96,pp.2483-2500)。nsp1234被自动蛋白水解切割成片段nsp123和nsp4。多肽nsp123和nsp4缔合形成(-)链复制酶复合物,其使用(+)链基因组rna作为模板转录(-)链rna。通常在随后的阶段,nsp123片段被完全切割成个体蛋白质nsp1、nsp2和nsp3(shirako&strauss,1994,j.virol.,vol.68,pp.1874-1885)。所有四种蛋白质形成(+)链复制酶复合物,其使用基因组rna的(-)链互补链作为模板来合成新的(+)链基因组(kimetal.,2004,virology,vol.323,pp.153-163,vasiljevaetal.,2003,j.biol.chem.vol.278,pp.41636-41645)。
在受感染的细胞中,亚基因组rna和新的基因组rna由nsp1提供5’帽(petterssonetal.1980,eur.j.biochem.105,435-443;rozanovetal.,1992,j.gen.virology,vol.73,pp.2129-2134),并且由nsp4提供聚腺苷酸[poly(a)]尾(rubachetal.,virology,2009,vol.384,pp.201-208)。因此,亚基因组rna和基因组rna二者类似于信使rna(mrna)。
甲病毒结构蛋白(核心核衣壳蛋白c、包膜蛋白e2和包膜蛋白e1,病毒颗粒的所有成分)通常由处于亚基因组启动子控制下的一个单一开放阅读框编码(strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562)。亚基因组启动子被顺式作用的甲病毒非结构蛋白识别。特别地,甲病毒复制酶使用基因组rna的(-)链互补链作为模板来合成(+)链亚基因组转录物。(+)链亚基因组转录物编码甲病毒结构蛋白(kimetal.,2004,virology,vol.323,pp.153-163,vasiljevaetal.,2003,j.biol.chem.vol.278,pp.41636-41645)。亚基因组rna转录物充当模板,用于翻译编码作为一种多蛋白的结构蛋白的开放阅读框,并且多蛋白(poly-protein)被切割以产生结构蛋白。在宿主细胞中甲病毒感染的后期,位于nsp2编码序列内的包装信号确保将基因组rna选择性包装到由结构蛋白包装的出芽病毒体(buddingviron)中(whiteetal.,1998,j.virol.,vol.72,pp.4320-4326)。
在受感染的细胞中,(-)链rna的合成通常仅在感染之后的前3-4小时中观察到,并且在后期无法检测到,后期仅观察到(+)链rna(基因组和亚基因组二者)的合成。根据frolovetal.,2001,rna,vol.7,pp.1638-1651,用于调节rna合成的流行模型表明对非结构多蛋白的加工的依赖性:非结构多蛋白nsp1234的初始切割产生nsp123和nsp4;nsp4充当rna依赖性rna聚合酶(rdrp),其对(-)链合成具有活性,但对于(+)链rna的产生是低效的。多蛋白nsp123的进一步加工(包括在nsp2/nsp3连接处的切割)改变复制酶的模板特异性以提高(+)链rna的合成并降低或终止(-)链rna的合成。
甲病毒rna的合成也受顺式作用rna元件(包括四个保守序列元件)的调节(conservedsequenceelement,cse;strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562;andfrolov,2001,rna,vol.7,pp.1638-1651)。
通常来说,甲病毒基因组的5’复制识别序列的特征是不同甲病毒之间的较低总体同源性,但具有保守的预测二级结构。甲病毒基因组的5’复制识别序列不仅参与翻译起始,而且还包括包含参与病毒rna合成的两个保守序列元件cse1和cse2的5’复制识别序列。对于cse1和2的功能,认为二级结构比线性序列更重要(strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562)。
相比之下,甲病毒基因组的3’末端序列(即poly(a)序列立即上游的序列)的特征在于保守的一级结构,特别是保守的序列元件4(cse4),也被称为“19-nt保守序列”,其对于启动(-)链合成是重要的。
cse3,也被称为“连接序列(junctionsequence)”,是甲病毒基因组rna的(+)链上的保守序列元件,(-)链上的cse3的互补序列充当亚基因组rna转录的启动子(strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562;frolovetal.,2001,rna,vol.7,pp.1638-1651)。cse3通常与编码nsp4的c末端片段的区域重叠。
除甲病毒蛋白外,宿主细胞因子(推测是蛋白质)也可与保守序列元件结合(strauss&strauss,同上)。
已经提出了将甲病毒来源的载体用于将外来遗传信息递送到靶细胞或靶生物中。在简单的方法中,将编码甲病毒结构蛋白的开放阅读框替换为编码目的蛋白质的开放阅读框。基于甲病毒的反式复制系统依赖于两个分开的核酸分子上的甲病毒核苷酸序列元件:一个核酸分子编码病毒复制酶(通常为多蛋白nsp1234),并且另一个核酸分子能够被所述复制酶反式复制(因此称为反式复制系统)。反式复制需要在给定的宿主细胞中存在这两种核酸分子。能够被复制酶反式复制的核酸分子必须包含某些甲病毒序列元件,以允许通过甲病毒复制酶进行识别和rna合成。
如本文中所述,本发明的方面和实施方案解决了对提供用于使分化体细胞重编程以产生大量且高质量的去分化或重编程细胞的技术的需求。
发明概述
本发明提供了使用编码重编程因子的rna复制子产生重编程细胞的技术。这些技术使用无限量的容易且廉价获得的细胞,并且提供了可用于细胞治疗的重编程细胞。根据本发明的方法打开了在不修饰宿主基因组的情况下重编程的可能性。
本发明利用这样的事实:当提供适当的因子时,可将终末分化细胞的命运重定向至多能性。具体地,本发明提供了用于将动物分化体细胞重编程为具有干细胞特征的细胞的技术。该方法允许使用限定的系统在体外将一种类型的体细胞去分化为多能干细胞样细胞。在一个实施方案中,本发明的方法提供了自体(同基因)细胞类型,用于在捐赠初始体细胞样品的同一个体中进行细胞移植。
根据本发明,向一种或更多种体细胞提供一种或更多种rna复制子,所述rna复制子能够表达诱导体细胞重编程为具有干细胞特征的细胞的一种或更多种因子。这些因子的表达将未分化细胞的特征赋予体细胞,并促进体细胞的重编程。
根据本发明,可使用不同类型的rna复制子。在一种类型的rna复制子中,甲病毒来源的rna载体的编码甲病毒结构蛋白的开放阅读框被编码重编程因子的开放阅读框替换。相应复制子在图1中示出为“顺式复制子;wt-rrs”。根据本发明的另一些类型的rna复制子涉及基于甲病毒的反式复制系统。相应复制子在图1中示出为“反式复制子;wt-rrs”。这样的复制子的优点是允许在亚基因组启动子的控制下扩增编码重编程因子的开放阅读框。
编码nsp1234的开放阅读框通常与甲病毒基因组的5’复制识别序列重叠(nsp1的编码序列),并且通常还与包含cse3的亚基因组启动子重叠(nsp4的编码序列)。因此,在这样的“反式复制子”中,rna复制所需的5’复制识别序列包含nsp1的aug起始密码子并且因此与甲病毒非结构蛋白的n末端片段的编码序列重叠,并且包含5’复制识别序列的复制子通常编码甲病毒非结构蛋白的(至少)一部分,通常是nsp1的n末端片段。这在几个方面是不利的:在顺式复制子的情况下,这种重叠限制了例如将复制酶orf的密码子使用适应于不同的哺乳动物靶细胞(人、小鼠、农场动物)。可以想到,存在于病毒中的5’复制识别序列的二级结构并非在每种靶细胞中都是最佳的。然而,二级结构不能自由改变,因为必须考虑复制酶orf中可能产生的氨基酸变化,并测试其对复制酶功能的影响。也不可能将完整的复制酶orf交换为异源来源的复制酶,因为这可导致5’复制识别序列结构的破坏。在反式复制子的情况下,由于5’复制识别序列需要保留在反式复制子中,因此这种重叠导致nsp1蛋白片段的合成。nsp1片段通常是不需要和不希望的:不希望的翻译给宿主细胞带来不必要的负担,并且除了药物活性蛋白外还编码nspl片段的旨在用于治疗用途的rna复制子可能面临监管问题。例如,必须证明截短的nsp1不会产生有害的副作用。此外,5’复制识别序列内nsp1的aug起始密码子的存在阻止了以如下方式设计编码目的异源基因的反式复制子:其中用于目的基因翻译的起始密码子位于核糖体翻译起始可接近的最5’位置。继而,来自现有技术反式复制子rna的转基因的5’-帽依赖性翻译具有挑战,除非编码为与nsp1的起始密码子同框的融合蛋白(这样的融合构建体由例如micheletal.,2007,virology,vol.362,pp.475-487描述)。这样的融合构建体导致上述的nsp1片段同样的不必要翻译,引起与上述相同的问题。而且,融合蛋白引起额外的问题,因为其可能改变目的融合转基因的功能或活性,或者当用作疫苗载体时,跨越融合区的肽可能改变融合抗原的免疫原性。
因此,本发明提供了另一种类型rna复制子,其包含复制酶复制所需的序列元件,但是这些序列元件不编码任何蛋白质或其片段,例如甲病毒非结构蛋白或其片段。因此,复制酶复制所需的序列元件与蛋白质编码区解偶联。相应复制子在图1中示出为“反式复制子;δ5atg-rrsδsgp”。与天然甲病毒基因组rna相比,通过去除至少一个起始密码子来实现解偶联。复制酶可由rna复制子或单独的核酸分子编码。在一个特别优选的实施方案中,这样的复制子不包含亚基因组启动子,并且编码重编程因子的开放阅读框的翻译起始密码子在核糖体翻译起始可接近的最5’位置。
在第一方面,本发明提供了包含编码重编程因子的开放阅读框的rna复制子。在一个实施方案中,rna复制子包含一个或更多个编码相同或不同的重编程因子的另外的开放阅读框。在一个实施方案中,rna复制子包含编码功能性重编程因子集合(setofreprogrammingfactors)的开放阅读框,所述功能性重编程因子集合是可用于将体细胞重编程为具有干细胞特征的细胞的重编程因子集合,即当在体细胞中表达时足以实现将体细胞重编程为具有干细胞特征的细胞的重编程因子集合。
在一个实施方案中,重编程因子选自:oct4、sox2、klf4、c-myc、lin28和nanog。
在一个实施方案中,rna复制子是顺式复制子或反式复制子。
在一个实施方案中,rna复制子包含编码功能性甲病毒非结构蛋白或重编程因子的第一开放阅读框。
在一个实施方案中,rna复制子包含5’复制识别序列,其中所述5’复制识别序列的特征在于,与天然甲病毒5’复制识别序列相比,所述5’复制识别序列包含至少一个起始密码子的去除。
在一个实施方案中,第一开放阅读框不与5’复制识别序列重叠。
在一个实施方案中,第一开放阅读框的起始密码子是rna复制子的5’→3’方向上的第一个功能性起始密码子。
在一个实施方案中,特别是如果rna复制子是顺式复制子,则rna复制子包含编码功能性甲病毒非结构蛋白的开放阅读框。rna复制子可包含编码一种或更多种重编程因子的一个或更多个开放阅读框。
在一个实施方案中,特别是如果rna复制子是反式复制子,则rna复制子不包含编码功能性甲病毒非结构蛋白的开放阅读框。在该实施方案中,可以如本文中所述反式提供用于复制子复制的功能性甲病毒非结构蛋白。rna复制子可包含编码一种或更多种重编程因子的一个或更多个开放阅读框。因此,在一个实施方案中,rna复制子可仅包含编码一种重编程因子的一个开放阅读框。多个这样的rna复制子可以形成rna复制子集合(setofrnareplicaons),例如本文中所述的功能性rna复制子集合。
在一个实施方案中,rna复制子包含编码目的蛋白质(例如功能性甲病毒非结构蛋白或重编程因子)的第一开放阅读框。在一个实施方案中,第一开放阅读框不与5’复制识别序列重叠。
如果rna复制子是顺式复制子,则第一开放阅读通常是编码功能性甲病毒非结构蛋白的开放阅读框。在该实施方案中,rna复制子通常包含处于亚基因组启动子控制下的至少一个另外的编码重编程因子的开放阅读框。如果rna复制子是反式复制子,则第一开放阅读通常是编码重编程因子的开放阅读,并且rna复制子优选不包含编码功能性甲病毒非结构蛋白的开放阅读框。
在一个实施方案中,rna复制子包含(经修饰的)5’复制识别序列和位于5’复制识别序列下游的编码目的蛋白质(例如功能性甲病毒非结构蛋白或重编程因子)的第一开放阅读框,其中5’复制识别序列和编码目的蛋白质的第一开放阅读框不重叠,并且优选地5’复制识别序列不与rna复制子的任何开放阅读框重叠,例如5’复制识别序列不包含功能性起始密码子,并且优选不包含任何起始密码子。最优选地,第一开放阅读框的起始密码子是rna复制子5’→3’方向上的第一个功能性起始密码子,优选第一个起始密码子。在一个实施方案中,第一开放阅读框并且优选整个rna复制子不表达非功能性甲病毒非结构蛋白,例如甲病毒非结构蛋白的片段,特别是nsp1和/或nsp4的片段。在一个实施方案中,功能性甲病毒非结构蛋白与5’复制识别序列是异源的。在一个实施方案中,第一开放阅读框不受亚基因组启动子的控制。
在一个实施方案中,第一开放阅读框编码功能性甲病毒非结构蛋白,并且rna复制子包含处于亚基因组启动子控制下的至少一个另外的编码重编程因子的开放阅读框。在一个实施方案中,亚基因组启动子和第一开放阅读框不重叠。
在另一个实施方案中,第一开放阅读框编码重编程因子,并且rna复制子优选不包含编码功能性甲病毒非结构蛋白的开放阅读框。rna复制子可包含处于亚基因组启动子控制下的至少一个另外的开放阅读框,其编码一种或更多种重编程因子(例如,与由第一开放阅读框编码的重编程因子一起形成功能性的重编程因子集合的一种或更多种重编程因子)。在一个实施方案中,亚基因组启动子和第一开放阅读框不重叠。
在一个特别优选的实施方案中,位于5’复制识别序列下游的第一开放阅读框编码重编程因子,5’复制识别序列和第一开放阅读框不重叠,5’复制识别序列不包含功能性起始密码子,并且优选地不包含任何起始密码子,并且rna复制子不包含编码功能性甲病毒非结构蛋白的开放阅读框。在该实施方案中,第一开放阅读框的起始密码子是rna复制子的5’→3’方向上是第一个功能起始密码子,优选第一个起始密码子,使得rna复制子不表达非功能性甲病毒非结构蛋白,例如甲病毒非结构蛋白的片段,特别是nsp1和/或nsp4的片段。rna复制子可包含处于亚基因组启动子控制下的至少一个另外的开放阅读框,其编码一种或更多种重编程因子(例如,与由第一开放阅读框编码的重编程因子一起形成功能性的重编程因子集合的一种或更多种重编程因子)。在一个实施方案中,亚基因组启动子和第一开放阅读框不重叠。
在一个实施方案中,以去除至少一个起始密码子为特征的rna复制子的5’复制识别序列包含与甲病毒的5’端的约250个核苷酸同源的序列。在一个优选的实施方案中,其包含与甲病毒的5’端的约300至500个核苷酸同源的序列。在一个优选的实施方案中,其包含载体系统亲本的特定甲病毒物种的有效复制所需的5’-末端序列。
在一个实施方案中,rna复制子的5’复制识别序列包含与甲病毒的保守序列元件1(cse1)和保守序列元件2(cse2)同源的序列。
在一个优选的实施方案中,rna复制子包含cse2,并且进一步的特征在于其包含来自甲病毒的非结构蛋白的开放阅读框的片段。在一个更优选的实施方案中,非结构蛋白的开放阅读框的所述片段不包含任何起始密码子。
在一个实施方案中,5’复制识别序列包含与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列,其中与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列的特征在于,与天然甲病毒序列相比,其包含至少一个起始密码子的去除。
在一个优选的实施方案中,与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列的特征在于,其包含非结构蛋白的开放阅读框的至少天然起始密码子的去除。
在一个优选的实施方案中,与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列的特征在于,其包含非结构蛋白的开放阅读框的天然起始密码子以外的一个或更多个起始密码子的去除。在一个更优选的实施方案中,所述核酸序列的特征还在于非结构蛋白(优选nsp1)的开放阅读框的天然起始密码子的去除。
在一个优选的实施方案中,5’复制识别序列包含一个或更多个茎环,其为5’复制识别序列提供关于rna复制的功能。在一个优选的实施方案中,5’复制识别序列的一个或更多个茎环未缺失或破坏。更优选地,茎环1、3和4中的一个或更多个,优选所有茎环1、3和4,或茎环3和4未缺失或破坏。更优选地,5’复制识别序列没有茎环缺失或破坏。
在一个优选的实施方案中,rna复制子包含一个或更多个核苷酸变化,以补偿通过去除至少一个起始密码子而引入的一个或更多个茎环内的核苷酸配对破坏。
在一个实施方案中,rna复制子不包含编码截短的甲病毒非结构蛋白的开放阅读框。
在一个实施方案中,rna复制子包含3’复制识别序列。
在一个实施方案中,rna复制子的特征在于由第一开放阅读框编码的目的蛋白质可从rna复制子作为模板表达。在一个实施方案中,rna复制子包含亚基因组启动子,控制包含第一开放阅读框的亚基因组rna的产生。
在一个实施方案中,rna复制子的特征在于其包含亚基因组启动子。通常来说,亚基因组启动子控制包含编码目的蛋白质的开放阅读框的亚基因组rna的产生。
在一个实施方案中,由第一开放阅读框编码的目的蛋白质可从rna复制子作为模板表达。在一个更优选的实施方案中,由第一开放阅读框编码的目的蛋白质可另外从亚基因组rna表达。
在一个优选的实施方案中,rna复制子的特征还在于其包含亚基因组启动子,所述亚基因组启动子控制包含编码目的蛋白质的第二开放阅读框的亚基因组rna的产生。所述目的蛋白质可以是与由第一开放阅读框编码的目的蛋白质相同或不同的第二蛋白质。
在一个更优选的实施方案中,亚基因组启动子和编码目的蛋白质的第二开放阅读框位于编码目的蛋白质的第一开放阅读框的下游。
在一实施方案中,rna复制子可通过功能性甲病毒非结构蛋白复制。
在第二方面,本发明提供了rna复制子集合,即,包含至少2个,例如2、3、4、5、6或更多个rna复制子的集,其中每个rna复制子包含至少一个编码重编程因子的开放阅读框,并且所述rna复制子集合编码重编程因子集合。
在一个实施方案中,每个rna复制子包含一个编码重编程因子的开放阅读框。
在一个实施方案中,所述重编程因子集合是功能性重编程因子集合,即,其可用于和/或足以将体细胞重编程为具有干细胞特征的细胞。
在一个实施方案中,重编程因子集合包含oct4和sox2。在一个实施方案中,重编程因子集合还包含klf4和/或c-myc。在一个实施方案中,重编程因子集合还包含nanog和/或lin28。
在一个实施方案中,重编程因子集合包含oct4、sox2、klf4和c-myc。在一个实施方案中,重编程因子集合还包含lin28和任选的nanog。
在一个实施方案中,重编程因子集合包含oct4、sox2、nanog和lin28。
在一个实施方案中,该集中的至少一个rna复制子是根据本发明的rna复制子。在一个实施方案中,该集中的每个rna复制子是根据本发明的rna复制子。
在第三方面,本发明提供了一种系统,其包含:
用于表达功能性甲病毒非结构蛋白的rna构建体,
根据本发明第一方面的rna复制子或根据本发明第二方面的rna复制子集合,其可通过所述功能性甲病毒非结构蛋白反式复制。优选地,rna复制子或rna复制子集合的特征还在于其不编码功能性甲病毒非结构蛋白。
在一个实施方案中,根据第一方面的rna复制子、根据第二方面的rna复制子集合或根据第三方面的系统的特征在于,甲病毒是委内瑞拉马脑炎病毒(venezuelanequineencephalitisvirus)。
在第四方面,本发明提供了dna(即一个或更多个dna分子),其包含编码根据第一方面的rna复制子、根据第二方面的rna复制子集合或根据第三方面的系统的核酸序列。
在另一方面,本发明提供了产生具有干细胞特征的细胞的方法,其包括将一种或更多种根据本发明的rna复制子引入到体细胞中的步骤。
在另一方面,本发明提供了用于提供具有干细胞特征的细胞的方法,其包括以下步骤:
(i)提供包含体细胞的细胞群,
(ii)提供一个或更多个rna复制子,其中所述一个或更多个rna复制子中的每一个包含编码功能性甲病毒非结构蛋白的开放阅读框,可被所述功能性甲病毒非结构蛋白复制并且包含至少一个编码重编程因子的开放阅读框,(iii)将所述一个或更多个rna复制子引入到所述体细胞中,使得所述细胞表达可用于将体细胞重编程为具有干细胞特征的细胞的重编程因子集合,以及
(iv)允许具有干细胞特征的细胞发育。
在另一方面,本发明提供了用于提供具有干细胞特征的细胞的方法,其包括以下步骤:
(i)提供包含体细胞的细胞群,
(ii)提供用于表达功能性甲病毒非结构蛋白的rna构建体,
(iii)提供一个或更多个rna复制子,其中所述一个或更多个rna复制子中的每一个可被所述功能性甲病毒非结构蛋白反式复制,并且包含至少一个编码重编程因子的开放阅读框,
(iv)将所述rna构建体和所述一个或更多个rna复制子引入到所述体细胞中,使得所述细胞表达可用于将体细胞重编程为具有干细胞特征的细胞的重编程因子集合,以及
(v)允许具有干细胞特征的细胞发育。
根据本发明,优选通过电穿孔或脂质体转染将一个或更多个rna复制子和任选地用于表达功能性甲病毒非结构蛋白的rna构建体引入到体细胞中。
在一个实施方案中,rna复制子包含编码功能性的重编程因子集合的开放阅读框。在一个实施方案中,不同的rna复制子包含编码不同重编程因子的开放阅读框。在后一实施方案中,这些不同的rna复制子可在相同时间点或在不同时间点共引入(任选地与表达功能性甲病毒非结构蛋白的rna构建体一起)细胞中以提供功能性重编程因子集合。
在一个实施方案中,细胞表达一种或更多种重编程因子。
在一个实施方案中,一个或更多个rna复制子编码重编程因子集合。
在一个实施方案中,一个或更多个rna复制子的每一个包含一个编码重编程因子的开放阅读框。
在一个实施方案中,由一个或更多个rna复制子编码的重编程因子集合是功能性重编程因子集合,即,可用于和/或足以将体细胞重编程为具有干细胞特征的细胞的重编程因子集合。
在一个实施方案中,重编程因子集合包含oct4和sox2。在一个实施方案中,重编程因子集合还包含klf4和/或c-myc。在一个实施方案中,重编程因子集合还包含nanog和/或lin28。
在一个实施方案中,重编程因子集合包含oct4、sox2、klf4和c-myc。在一个实施方案中,重编程因子集合还包含lin28和任选的nanog。
在一个实施方案中,重编程因子集合包含oct4、sox2、nanog和lin28。
在一个实施方案中,本发明的方法还包括向体细胞中引入增强将体细胞重编程为具有干细胞特征的细胞的mirna。
在一个实施方案中,本发明的方法还包括在至少一种组蛋白脱乙酰酶抑制剂的存在下培养体细胞。在一个实施方案中,至少一种组蛋白脱乙酰酶抑制剂包含丙戊酸。
在一个实施方案中,允许具有干细胞特征的细胞发育的步骤包括在胚胎干细胞培养条件下,优选在适于将多能干细胞维持在未分化状态的条件下培养体细胞。
在一个实施方案中,干细胞特征包括胚胎干细胞形态,其中所述胚胎干细胞形态优选包括选自紧凑集落、高细胞核细胞质比例和突出的核仁的形态标准。在某些实施方案中,具有干细胞特征的细胞具有正常核型,表达端粒酶活性,表达胚胎干细胞特征性的细胞表面标志物和/或表达胚胎干细胞特征性的基因。胚胎干细胞特征性的细胞表面标志物可选自阶段特异性胚胎抗原3(ssea-3)、ssea-4、肿瘤相关抗原-1-60(tra-1-60)、tra-1-81和tra-2-49/6e,并且胚胎干细胞特征性的基因可选自内源性oct4、内源性nanog、生长和分化因子3(gdf3)、降低的表达1(reducedexpression1,rex1)、成纤维细胞生长因子4(fgf4)、胚胎细胞特异性基因1(esg1)、发育多能性相关2(dppa2)、dppa4和端粒酶逆转录酶(tert)。
在一实施方案中,具有干细胞特征的细胞是去分化和/或重编程的体细胞。优选地,具有干细胞特征的细胞表现出胚胎干细胞的本质特征,例如多能状态。优选地,具有干细胞特征的细胞具有分化为所有三个原胚层的晚期衍生物的发育潜力。在一个实施方案中,原胚层是内胚层,并且晚期衍生物是肠样上皮组织。在另一个实施方案中,原胚层是中胚层,并且晚期衍生物是横纹肌和/或软骨。在另一个实施方案中,原胚层是外胚层,并且晚期衍生物是神经组织和/或表皮组织。在一个优选的实施方案中,具有干细胞特征的细胞具有分化为神经元细胞和/或心脏细胞的发育潜力。
在一个实施方案中,体细胞是具有间充质表型的胚胎干细胞来源体细胞。在一个优选的实施方案中,体细胞是成纤维细胞,例如胎儿成纤维细胞或产后成纤维细胞,或者角质形成细胞,优选毛囊来源的角质形成细胞。在另一些实施方案中,所述成纤维细胞是肺成纤维细胞、包皮成纤维细胞或真皮成纤维细胞。在特定的实施方案中,所述成纤维细胞是保藏在美国典型培养物保藏中心(atcc)的目录编号为ccl-186或保藏在美国典型培养物保藏中心(atcc)的目录编号为crl-2097的成纤维细胞。在一实施方案中,成纤维细胞是成人真皮成纤维细胞。优选地,体细胞是人细胞。根据本发明,可对体细胞进行遗传修饰。
在一个实施方案中,一个或更多个rna复制子中的至少一个rna复制子是根据本发明的rna复制子。在一个实施方案中,一个或更多个rna复制子的每个rna复制子是根据本发明的rna复制子。在一个实施方案中,一个或更多个rna复制子包含根据本发明的rna复制子集合。
本发明方法的特定实施方案还包括培养、繁殖和冷冻保存具有干细胞特征的细胞的一个或更多个步骤。
在另一方面,本发明提供了通过本发明的方法产生的具有干细胞特征的细胞。在一个实施方案中,所述细胞是重组细胞。
在另一方面,本发明提供了表达一种或更多种重编程因子,优选功能性重编程因子的细胞,其包含一种或更多种本发明的rna复制子,所述rna复制子包含编码一种或更多种重编程因子的开放阅读框。本发明还提供了这样的细胞的群体。
在另一方面,本发明提供了用于提供分化的细胞类型的方法,其包括以下步骤:(i)使用本发明的方法提供具有干细胞特征的细胞,以及(ii)在诱导或指导部分或完全分化为分化的细胞类型的条件下培养所述具有干细胞特征的细胞。
在另一方面,本发明涉及提供分化的细胞类型的方法,其包括在诱导或指导部分或完全分化为分化的细胞类型的条件下培养本发明的具有干细胞特征的细胞的步骤。
在一个实施方案中,诱导或指导部分或完全分化成分化的细胞类型的条件包括至少一种分化因子的存在。优选地,根据本发明获得的分化细胞的体细胞类型不同于用于去分化的体细胞的体细胞类型。优选地,去分化细胞来源于成纤维细胞,并且所述再分化细胞类型不同于成纤维细胞。在另一个实施方案中,去分化细胞来源于角质形成细胞,并且所述再分化细胞类型不同于角质形成细胞。
在另一方面,本发明涉及用于产生具有干细胞特征的细胞的试剂盒,其包含根据第一方面的rna复制子、根据第二方面的rna复制子集合或根据第三方面的系统。试剂盒可还包含胚胎干细胞培养基。
在另一方面,本发明提供了药物组合物,其包含本发明的具有干细胞特征的细胞,例如,包含本发明的rna复制子集合,每个rna复制子编码功能性重编程因子集合中的一种重编程因子。
在甚至另一方面,本发明涉及药物组合物,其包含根据第一方面的rna复制子、根据第二方面的rna复制子集合或根据第三方面的系统。
在另一方面,本发明提供了本发明的药物组合物,其用作药物。
在另一些方面,本发明涉及本发明的细胞或药物组合物在医学中(特别是在移植医学中)的用途。
在另一方面,本发明提供了用于治疗疾病的方法,其包括向对象施用治疗有效量的本发明的药物组合物。
在另一方面,本发明提供了治疗患有疾病的对象的方法,所述方法包括向对象施用通过本发明的方法产生的具有干细胞特征的细胞。
在一个实施方案中,细胞对于所述对象可以是自体的、同种异体的或同基因的。
在本发明所有方面的一个实施方案中,治疗方法还包括从对象获得体细胞样品,并且通过本发明的方法处理所述细胞以提供具有干细胞特征的细胞。在本发明所有方面的一个实施方案中,用编码一种或更多种重编程因子的核酸瞬时转染具有干细胞特征的细胞。因此,编码一种或更多种重编程因子的核酸没有整合到细胞的基因组中。在本发明所有方面的一个实施方案中,体细胞来自施用具有干细胞特征的细的对象。在本发明所有方面的一个实施方案中,体细胞来自与施用具有干细胞特征的细胞的哺乳动物不同的哺乳动物。
在本发明的一个实施方案中,治疗包括细胞治疗,例如细胞移植治疗。
在另一方面,本发明提供了本文中所述的剂和组合物,其用于本文中所述的方法。
通过以下详细描述和权利要求,本发明的其他特征和优点将变得明显。
附图简述
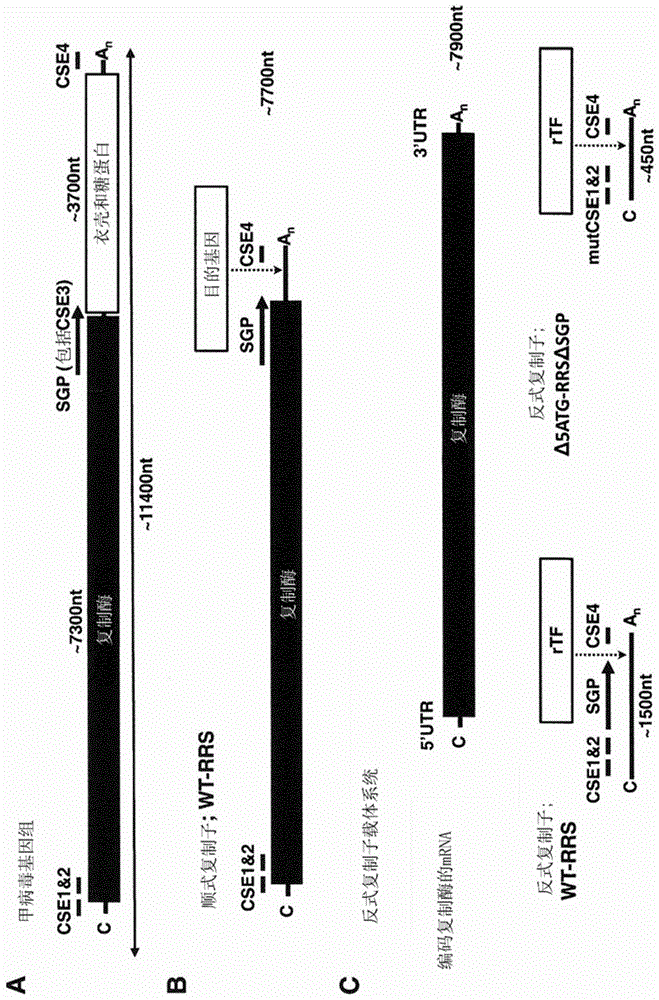
图1:亲本病毒基因组和载体顺式和反式复制rna
(a)甲病毒基因组的一般结构。两个大的开放阅读框(orf)被亚基因组启动子(subgenomicpromoter,sgp)隔开。5’orf编码用于rna扩增的酶复合物(复制酶),3’orf编码病毒结构基因(衣壳和包膜糖蛋白)。在5’-端,两个保守序列元件(cse)构成了5’-复制识别序列(rrs),其与复制酶编码区部分重叠。3’rrs由cse4(3’-末端19个核苷酸)和poly-a尾(an)的约15个核苷酸构成。(b)顺式复制子载体保留了rrs和sgp的wt序列,它们缺少结构基因的orf,并且用目的基因代替。(c)反式复制子(tr)载体系统。顺式复制子分成编码复制酶但不能复制的mrna,和被复制酶反式扩增的短rna。这些所谓的反式复制子具有两种不同的设计,一种包含wt序列中与顺式复制子相同的所有病毒rrs。另一种版本包含缩短的5’cse,其经突变以去除了可用作翻译起始密码子的任何aug密码子。5’aug的去除确保了仅利用插入在突变的5’cse下游的目的orf的起始密码子开始翻译。本发明中的目的基因是六种促进多能性的重编程转录因子(rtf)(oct4、sox2、myc、klf4、nanog、lin28)和痘苗病毒(vacciniavirus)的三种干扰素逃逸蛋白(interferonescapeprotein)(e3、k3、b18)。
图2:使用反式复制子技术(wt-rrs)的rna重编程
图3:使用反式复制子技术(δ5atg-rrsδsgp)的rna重编程
图4:使用反式复制子技术(wt-rss)通过一次转染的基于rna的重编程
图5:根据本发明有用的包含未经修饰的或经修饰的5’复制识别序列的rna复制子的示意图
缩写:aaaa=poly(a)尾;atg=起始密码子(startcodon/initiationcodon)(dna水平为atg;rna水平为aug);5xatg=包含编码nsp1*的核酸序列中所有起始密码子的核酸序列(在编码来自塞姆利基森林病毒(semlikiforestvirus)的nsp1*的核酸序列的情况下,5xatg对应于五个特定起始密码子);δ5atg=对应于编码nsp1*的核酸序列的核酸序列,但是不包含自然界中存在的甲病毒中编码nsp1*的核酸序列的任何起始密码子(在来源于塞姆利基森林病毒的nsp1*的情况下,“δ5atg”对应于与塞姆利基森林病毒相比去除了五个特定起始密码子);ecorv=ecorv限制位点;nsp=编码甲病毒非结构蛋白(例如nsp1、nsp2、nsp3、nsp4)的核酸序列;nsp1*=编码nsp1的片段的核酸序列,其中该片段不包含nsp1的c-末端片段;*nsp4=编码nsp4的片段的核酸序列,其中该片段不包含nsp4的n-末端片段;rrs=5’复制识别序列;sali=sali限制位点;sgp=亚基因组启动子;sl=茎环(例如sl1、sl2、sl3、sl4);sl1-4的位置如图示;utr=非翻译区(例如5’-utr、3’-utr);wt=野生型;转基因优选地涉及编码重编程因子的开放阅读框。
顺式复制子wt-rrs:基本上对应于甲病毒基因组的rna复制子,不同之处在于编码甲病毒结构蛋白的核酸序列已被编码目的基因(“转基因”)的开放阅读框替代。当将“复制子wt-rrs”引入细胞后,编码复制酶(nsp1234或其片段)的开放阅读框的翻译产物可顺式驱动rna复制子复制,并驱动亚基因组启动子(sgp)下游的核酸序列的合成(亚基因组转录物)。
反式复制子或模板rnawt-rrs:基本上对应于“复制子wt-rrs”的rna复制子,不同之处在于编码甲病毒非结构蛋白nsp1-4的核酸序列的大部分已被去除。更具体地,编码nsp2和nsp3的核酸序列已经完全去除;编码nsp1的核酸序列已截短,使得“模板rnawt-rrs”编码nsp1的片段,该片段不包含nsp1的c-末端片段(但其包含nsp1的n-末端片段;nsp1*);编码nsp4的核酸序列已截短,使得“模板rnawt-rrs”编码nsp4的片段,该片段不包含nsp4的n-末端片段(但其包含nsp4的c-末端片段;*nsp4)。这种截短的nsp4序列与完全活性的亚基因组启动子部分重叠。编码nsp1*的核酸序列包含在自然界中存在的甲病毒中编码nsp1*的核酸序列的所有起始密码子(在来自塞姆利基森林病毒的nsp1*的情况下,为五个特定的起始密码子)。
δ5atg-rrs:基本上对应于“模板rnawt-rrs”的rna复制子,不同之处在于其不包含自然界中存在的甲病毒中编码nsp1*的核酸序列的任何起始密码子(在塞姆利基森林病毒的情况下,与自然界中发现的塞姆利基森林病毒相比,“δ5atg-rrs”对应于五个特定的起始密码子的去除。)引入以去除起始密码子的所有核苷酸变化均被其他核苷酸变化所补偿,以保留rna的预期二级结构。
δ5atg-rrsδsgp:基本上对应于“δ5atg-rrs”的rna复制子,不同之处在于其不包含亚基因组启动子(sgp)并且不包含编码*nsp4的核酸序列。“转基因1”=目的基因。
δ5atg-rrs-双顺反子:基本上对应于“δ5atg-rrs”的rna复制子,不同之处在于其包含在亚基因组启动子上游的编码第一目的基因(“转基因1”)的第一开放阅读框和在亚基因组启动子下游的编码第二目的基因(“转基因2”)的第二开放阅读框。第二开放阅读框的定位对应于rna复制子“δ5atg-rrs”中目的基因(“转基因”)的定位。
顺式复制子δ5atg-rrs:基本上对应于“δ5atg-rrs-双顺反子”的rna复制子,不同之处在于编码第一目的基因的开放阅读框编码功能性甲病毒非结构蛋白(通常是编码多蛋白nsp1-nsp2-nsp3-nsp4(即nsp1234)的一个开放阅读框)。“顺式复制子δ5atg-rrs”中的“转基因”对应于“δ5atg-rrs-双顺反子”中的“转基因2”。功能性甲病毒非结构蛋白能够识别亚基因组启动子并合成包含编码目的基因(“转基因”)的核酸序列的亚基因组转录物。“顺式复制子δ5atg-rrs”与“顺式复制子wt-rrs”一样顺式编码功能性甲病毒非结构蛋白;然而,由“顺式复制子δ5atg-rrs”编码的nsp1的编码序列不需要包含所有茎环的“顺式复制子wt-rrs”的精确核酸序列。
图6.帽二核苷酸的结构。顶部:天然帽二核苷酸,m7gpppg。底部:硫代磷酸酯帽类似物β-s-arca二核苷酸:由于立体异构p中心,β-s-arca有两种非对映体,根据其在反相hplc中的洗脱特性,分别命名为d1和d2。
发明详述
尽管以下详细描述了本发明,但是应当理解,本发明不限于本文描述的特定方法、方案和试剂,因为这些可以改变。还应理解,本文所使用的术语仅出于描述特定实施方案的目的,并不旨在限制本发明的范围,本发明的范围仅由所附权利要求书来限制。除非另有定义,否则本文中使用的所有技术和科学术语具有与本领域普通技术人员通常理解的相同含义。
优选地,本文中使用的术语如以下中所述:“amultilingualglossaryofbiotechnologicalterms:(iupacrecommendations)”,h.g.w.leuenberger,b.nagel,andh.
除非另有说明,否则本发明的实施将采用化学、生物化学、细胞生物学、免疫学和重组dna技术的常规方法,这些方法在本领域的文献中有解释(参见例如molecularcloning:alaboratorymanual,2ndedition,j.sambrooketal.eds.,coldspringharborlaboratorypress,coldspringharbor1989)。
在下文中,将描述本发明的要素。这些要素与特定实施方案一起列出,但是,应该理解,它们可以以任何方式和任何数量组合以产生另外的实施方案。各种描述的实例和优选实施方案不应被解释为将本发明限制于仅明确描述的实施方案。该描述应理解为公开和涵盖了将明确描述的实施方案与任何数量的公开和/或优选要素相组合的实施方案。此外,除非上下文另有指示,否则应认为本描述公开了本申请中所有描述的元件的任何排列和组合。
术语“约”是指近似或接近,并且在本文阐述的数值或范围的情况下优选地是指所记载或要求保护的数值或范围的+/-10%。
在描述本发明的上下文中(特别是在权利要求的上下文中)使用的没有数量词修饰的名词表示一个/种或更多个/种,除非本文另外指出或与上下文明显矛盾。本文中数值范围的记载仅旨在用作单独提及落入该范围内的每个单独数值的速记方法。除非本文另外指出,否则每个单独的值都被并入说明书中,就如同其在本文中被单独记载一样。除非本文另外指出或与上下文明显矛盾,否则本文描述的所有方法可以以任何合适的顺序执行。本文提供的任何和所有实例或示例性语言(例如,“例如”)的使用仅旨在更好地说明本发明,并且不对以其他方式要求保护的本发明的范围构成限制。说明书中的任何语言都不应解释为指示任何未要求保护的要素对于实施本发明是必不可少的。
除非另有明确说明,否则在本文件的上下文中使用术语“包含”来表示除由“包含”引入的列表的成员以外,还可以任选地存在其他成员。但是,作为本发明的特定实施方案,术语“包含”涵盖不存在其他成员的可能性,即,对于该实施方案而言,“包含”应理解为具有“由…组成”的含义。
对以一般术语表征的组分的相对量的指示意在是指由所述一般术语涵盖的所有特定变体或成员的总量。如果由一般术语限定的某组分被指出以某相对量存在,并且如果将组分还被表征为由一般术语涵盖的特定变体或成员,则意指没有额外存在由一般术语涵盖的其他变体或成员而使得由一般术语涵盖的组分的总相对量超过指出的相对量;更优选地,完全不存在由一般术语涵盖的其他变体或成员。
在本说明书的全文中引用了一些文件。无论是上文还是下文,本文引用的每个文件(包括所有专利、专利申请、科学出版物、制造商的说明书、说明书等)均通过引用全文并入本文。本文中的任何内容均不应解释为承认本发明无权先于这样的公开内容。
本文中使用的诸如“降低”或“抑制”的术语是指引起水平总体降低优选5%或更多、10%或更多、20%或更多、更优选50%或更多、并且最优选75%或更多的能力。术语“抑制”或类似短语包括完全或基本上完全抑制,即降低至零或基本上至零。
诸如“提高”或“增强”的术语优选地涉及提高或增强至少约10%、优选至少20%、优选至少30%、更优选至少40%、更优选至少50%、甚至更优选至少80%、最优选至少100%。
术语“净电荷”是指整个物体(例如化合物或颗粒)上的电荷。
具有总净正电荷的离子是阳离子,而具有总净负电荷的离子是阴离子。因此,根据本发明,阴离子是具有比质子更多的电子,使得其具有净负电荷的离子;并且阳离子是具有比质子更少的电子,使得其具有净正电荷的离子。
关于给定化合物或颗粒,术语“带电”、“净电荷”、“带负电”或“正电”是指给定化合物或颗粒在溶解或悬浮在ph7.0的水中时的净电荷。
根据本发明,核酸是脱氧核糖核酸(dna)或核糖核酸(rna)。一般来说,核酸分子或核酸序列是指优选为脱氧核糖核酸(dna)或核糖核酸(rna)的核酸。根据本发明,核酸包括基因组dna、cdna、mrna、病毒rna、重组制备和化学合成的分子。根据本发明,核酸可以是单链或双链以及线性或共价闭合的环状分子的形式。根据本发明的术语“核酸”还包括核酸在核苷酸碱基、糖或磷酸上的化学衍生化,以及包含非天然核苷酸和核苷酸类似物的核酸。
根据本发明,“核酸序列”是指核酸(例如核糖核酸(rna)或脱氧核糖核酸(dna))中的核苷酸序列。该术语可以指整个核酸分子(例如整个核酸分子的单链)或其一部分(例如片段)。
根据本发明,术语“rna”或“rna分子”涉及包含核糖核苷酸残基并且优选完全或基本上由核糖核苷酸残基构成的分子。术语“核糖核苷酸”是指在β-d-呋喃核糖基的2’-位具有羟基的核苷酸。术语“rna”包括双链rna、单链rna、分离的rna,例如部分或完全纯化的rna、基本上纯的rna、合成rna,以及重组产生的rna,例如通过添加、缺失、置换和/或改变一个或更多个核苷酸而不同于天然存在的rna的经修饰的rna。这样的改变可包括将非核苷酸材料添加到例如rna的末端或内部,例如在rna的一个或更多个核苷酸处。rna分子中的核苷酸还可包含非标准核苷酸,例如非天然存在的核苷酸或化学合成的核苷酸或脱氧核苷酸。这些改变的rna可称为类似物,特别是天然存在的rna的类似物。
根据本发明,rna可以是单链或双链的。在本发明的一些实施方案中,单链rna是优选的。术语“单链rna”通常是指没有互补核酸分子(通常没有互补rna分子)与其结合的rna分子。单链rna可包含自补序列,其允许rna的一部分折叠回来并形成二级结构基序,包括但不限于碱基对、茎、茎环和凸起。单链rna可作为负链[(-)链]或正链[(+)链]存在。(+)链是包含或编码遗传信息的链。遗传信息可以是例如编码蛋白质的多核苷酸序列。当(+)链rna编码蛋白质时,(+)链可直接充当翻译(蛋白质合成)的模板。(-)链是(+)链的互补链。在双链rna的情况下,(+)链和(-)链是两个独立的rna分子,并且这两个rna分子彼此缔合以形成双链rna(“双链体rna”)。
术语rna的“稳定性”涉及rna的“半衰期”。“半衰期”涉及消除分子的活性、量或数量的一半所需的时间。在本发明的上下文中,rna的半衰期指示所述rna的稳定性。rna的半衰期可能会影响rna的“表达持续时间”。可以预期,半衰期长的rna将在延长的时间内表达。
术语“翻译效率”涉及在特定时间段内由rna分子提供的翻译产物的量。
关于核酸序列,“片段”涉及核酸序列的一部分,即代表在5’-和/或3’-末端缩短的核酸序列的序列。优选地,核酸序列的片段包含来自所述核酸序列的核苷酸残基的至少80%、优选至少90%、95%、96%、97%、98%或99%。在本发明中,优选的是rna分子的保留rna稳定性和/或翻译效率的那些片段。
关于氨基酸序列(肽或蛋白质),“片段”是指氨基酸序列的一部分,即代表在n-末端和/或c-末端缩短的氨基酸序列的序列。可例如通过翻译缺少开放阅读框的3’末端的截短的开放阅读框来得到在c末端缩短的片段(n末端片段)。可例如通过翻译缺少开放阅读框的5’末端的截短的开放阅读框来得到在n末端缩短的片段(c末端片段),只要截短的开放阅读框包含用于开始翻译的起始密码子即可。氨基酸序列的片段包含来自氨基酸序列的氨基酸残基的例如至少1%、至少2%、至少3%、至少4%、至少5%、至少10%、至少20%、至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%。
关于例如根据本发明的核酸和氨基酸序列,术语“变体”包括任何变体,特别是突变体、病毒株变体、剪接变体、构象、同种型、等位基因变体、物种变体和物种同源物,尤其是天然存在的那些。等位基因变体涉及基因正常序列的改变,其重要性通常不清楚。完整的基因测序通常鉴定给定基因的许多等位基因变体。关于核酸分子,术语“变体”包括简并核酸序列,其中根据本发明的简并核酸是由于遗传密码的简并性而在密码子序列上不同于参考核酸的核酸。物种同源物是与给定核酸或氨基酸序列具有不同起源物种的核酸或氨基酸序列。病毒同源物是与给定核酸或氨基酸序列具有不同起源病毒的核酸或氨基酸序列。
根据本发明,与参考核酸相比,核酸变体包括单个或多个核苷酸的缺失、添加、突变、置换和/或插入。缺失包括从参考核酸中去除一个或更多个核苷酸。添加变体包括一个或更多个核苷酸例如1、2、3、5、10、20、30、50或更多个核苷酸的5’-和/或3’-末端融合。在置换的情况下,序列中的至少一个核苷酸被去除,并且至少一个其他核苷酸被插入其位置(例如颠换和转换)。突变包括无碱基位点、交联位点和化学改变或修饰的碱基。插入包括向参考核酸中添加至少一个核苷酸。
根据本发明,“核苷酸变化”可以指与参考核酸相比单个或多个核苷酸的缺失、添加、突变、置换和/或插入。在一些实施方案中,“核苷酸变化”选自与参考核酸相比单个核苷酸的缺失、单个核苷酸的添加、单个核苷酸的突变、单个核苷酸的置换和/或单个核苷酸的插入。根据本发明,与参考核酸相比,核酸变体可包含一个或更多个核苷酸变化。
特定核酸序列的变体优选具有所述特定序列的至少一种功能性质,并且优选在功能上等同于所述特定序列,例如,具有与特定核酸序列相同或相似的特性的核酸序列。
如下所述,本发明的一些实施方案的特征尤其在于与甲病毒(例如自然界中存在的甲病毒)的核酸序列同源的核酸序列。这些同源序列是甲病毒(例如自然界中存在的甲病毒)的核酸序列的变体。
给定核酸序列与作为所述给定核酸序列的变体的核酸序列之间的同一性程度优选为至少70%,优选至少75%,优选至少80%,更优选至少85%,甚至更优选至少90%或最优选至少95%、96%、97%、98%或99%。优选给出至少约30、至少约50、至少约70、至少约90、至少约100、至少约150、至少约200、至少约250、至少约300或至少约400个核苷酸的区域的同一性程度。在一些优选的实施方案中,给出了参考核酸序列的整个长度的同一性程度。
“序列相似性”表示相同或代表保守氨基酸置换的氨基酸的百分比。两个多肽或核酸序列之间的“序列同一性”表示序列之间相同的氨基酸或核苷酸的百分比。
术语“%同一性”尤其意指待比较的两个序列之间在最佳比对中相同的核苷酸的百分比,所述百分比是纯粹统计的,并且两个序列之间的差异可随机分布在序列的整个长度上,并且待比较序列与参考序列相比可包含添加或缺失,以获得两个序列之间的最佳比对。两个序列的比较通常在关于片段或“比较窗口”最佳比对以鉴定相应序列的局部区域之后通过比较所述序列来进行。用于比较的最佳比对可以手动进行,或者借助于smithandwaterman,1981,adsapp.math.2,482的局部同源性算法,借助于needlemanandwunsch,1970,j.mol.biol.48,443的局部同源性算法,以及借助于pearsonandlipman,1988,proc.natlacad.sci.usa85,2444的相似性搜索算法,或借助于使用所述算法的计算机程序(gap、bestfit、fasta、blastp、blastn和tfasta,wisconsingeneticssoftwarepackage,geneticscomputergroup,575sciencedrive,madison,wis)。
通过确定待比较的序列所对应的相同位置的数目,用该数目除以比较的位置数目,然后将此结果乘以100来得出百分比同一性。
例如,可使用blast程序″blast2sequences″,其可在网站http://www.ncbi.nlm.nih.gov/blast/bl2seq/wblast2.cgi获得。
如果核酸与另一个核酸彼此互补,则两个序列“能够杂交”或“杂交”。如果核酸与另一核酸能够彼此形成稳定的双链体,则这两个序列“互补”。根据本发明,杂交优选在允许多核苷酸之间特异性杂交的条件(严格条件)下进行。严格条件在例如以下中进行了描述:molecularcloning:alaboratorymanual,j.sambrooketal.,editors,2ndedition,coldspringharborlaboratorypress,coldspringharbor,newyork,1989orcurrentprotocolsinmolecularbiology,f.m.ausubeletal.,editors,johnwiley&sons,inc.,newyork,并且是指例如在杂交缓冲液(3.5xssc,0.02%ficoll,0.02%聚乙烯吡咯烷酮,0.02%牛血清白蛋白,2.5mmnah2po4(ph7),0.5%sds,2mmedta)中在65℃下杂交。ssc为0.15m氯化钠/0.15m柠檬酸钠,ph7。杂交之后,洗涤转移了dna的膜,例如在室温下在2×ssc中,然后在高至68℃的温度下在0.1-0.5×ssc/0.1×sds中。
百分比互补性表示核酸分子中可与第二核酸序列形成氢键(例如,watson-crick碱基配对)的连续残基的百分比(例如,10个中的5、6、7、8、9、10为50%、60%、70%、80%、90%和100%互补)。“完美互补”或“完全互补”是指核酸序列的所有连续残基与第二核酸序列中相同数目的连续残基氢键键合。优选地,根据本发明的互补度为至少70%,优选至少75%,优选至少80%,更优选至少85%,甚至更优选至少90%或最优选至少95%、96%、97%、98%或99%。最优选地,根据本发明的互补度是100%。
术语“衍生物”包括核酸在核苷酸碱基、糖或磷酸上的任何化学衍生化。术语“衍生物”还包括含有非天然存在的核苷酸和核苷酸类似物的核酸。优选地,核酸的衍生化提高其稳定性。
根据本发明,“来源于核酸序列的核酸序列”是指作为来源核酸的变体的核酸。优选地,当作为关于特定序列的变体的序列代替rna分子中的特定序列时,其保留了rna稳定性和/或翻译效率。
“nt”是核苷酸,或核酸分子中的的核苷酸,优选连续核苷酸的缩写。
根据本发明,术语“密码子”是指编码核酸中的碱基三联体,其在核糖体的蛋白质合成期间指示接下来将添加哪个氨基酸。
术语“转录”涉及这样的过程,在该过程中由rna聚合酶读取具有特定核酸序列的核酸分子(“核酸模板”),从而使rna聚合酶产生单链rna分子。在转录过程中,核酸模板中的遗传信息被转录。核酸模板可以是dna;但是,例如在从甲病毒核酸模板转录的情况下,模板通常是rna。随后,可将转录的rna翻译成蛋白质。根据本发明,术语“转录”包括“体外转录”,其中术语“体外转录”涉及其中在无细胞系统中体外合成rna,特别是mrna的过程。优选地,将克隆载体应用于转录物的产生。这些克隆载体通常被称为转录载体,并且根据本发明被术语“载体”所涵盖。克隆载体优选是质粒。根据本发明,rna优选是体外转录的rna(ivt-rna),并且可通过合适的dna模板的体外转录获得。用于控制转录的启动子可以是任何rna聚合酶的任何启动子。通过克隆核酸,特别是cdna,并且将其引入用于体外转录的合适载体中,可以获得用于体外转录的dna模板。cdna可通过rna的逆转录获得。
在转录过程中产生的单链核酸分子通常具有作为模板的互补序列的核酸序列。
根据本发明,术语“模板”或“核酸模板”或“模板核酸”通常是指可被复制或转录的核酸序列。
“从核酸序列转录的核酸序列”和类似术语是指作为模板核酸序列的转录产物的核酸序列,适当时为完整rna分子的一部分。通常来说,转录的核酸序列是单链rna分子。
根据本发明,“核酸的3’末端”是指具有游离羟基的末端。在双链核酸(特别是dna)的示意图中,3’末端始终在右侧。根据本发明,“核酸的5’末端”是指具有游离磷酸基团的末端。在双链核酸(特别是dna)的示意图中,5’末端始终在左侧。
5′末端5′--p-nnnnnnn-oh-3′3′末端
3′-ho-nnnnnnn-p--5′
“上游”描述了核酸分子的第一元件相对于核酸分子的第二元件的相对定位,其中两个元件包含在同一核酸分子中,并且其中第一元件比核酸分子的第二元件更靠近核酸分子的5’末端。然后,说第二元件在核酸分子的第一元件的“下游”。可将位于第二元件“上游”的元件同义地称为位于第二元件的“5”’。对于双链核酸分子,关于(+)链给出了如“上游”和“下游”的指示。
根据本发明,“功能性连接”或“功能性连接的”涉及处于功能关系内的连接。如果核酸与另一核酸序列功能相关,则该核酸是“功能性连接的”。例如,如果启动子影响编码序列的转录,则启动子与所述编码序列功能性连接。功能性连接的核酸通常彼此相邻,在适当情况下被另外的核酸序列隔开,并且在特定的实施方案中,通过rna聚合酶转录得到单个rna分子(共同转录物)。
在特定的实施方案中,根据本发明将核酸与表达控制序列功能性连接,所述表达控制序列相对于该核酸可以是同源的或异源的。
根据本发明,术语“表达控制序列”包括启动子、核糖体结合序列和其他控制基因的转录或来源rna的翻译的控制元件。在本发明的特定实施方案中,可以调节表达控制序列。表达控制序列的精确结构可根据物种或细胞类型而变化,但是通常包括分别参与起始转录和翻译的5’-非转录序列以及5’-和3’-非翻译序列。更具体地,5’-非转录表达控制序列包括启动子区,所述启动子区包含用于功能性连接的基因的转录控制的启动子序列。表达控制序列还可包括增强子序列或上游激活子序列。dna分子的表达控制序列通常包括5’-非转录序列以及5’-和3’-非翻译序列,例如tata盒、加帽序列、caat序列等。甲病毒rna的表达控制序列可包括亚基因组启动子和/或一个或更多个保守序列元件。如本文中所述,根据本发明的特定表达控制序列是甲病毒的亚基因组启动子。
本文指定的核酸序列(特别是可转录和编码核酸序列)可与任何表达控制序列(特别是启动子)组合,所述表达控制序列对于所述核酸序列可以是同源的或异源的,术语“同源”是指核酸序列也与表达控制序列是天然功能性连接的事实,术语“异源”是指核酸序列并非与表达控制序列是天然功能性连接的事实。
如果可转录核酸序列(特别是编码肽或蛋白质的核酸序列)与表达控制序列彼此共价连接,使得可转录序列并且特别是编码核酸序列的转录或表达处于表达控制序列的控制之下或影响之下,则它们彼此“功能性”连接。如果要将核酸序列翻译成功能性肽或蛋白质,则诱导表达控制序列功能性连接至编码序列会导致所述编码序列的转录,而不会导致编码序列发生移码或编码序列无法翻译成期望的肽或蛋白质。
术语“启动子”或“启动子区”是指通过提供对于rna聚合酶的识别和结合位点来控制转录物(例如包含编码序列的转录物)的合成的核酸序列。启动子区可包含针对参与所述基因转录调节的另外的因子的另外的识别或结合位点。启动子可控制原核或真核基因的转录。启动子可以是“诱导型”并响应于诱导物而启动转录,或者如果转录不受诱导物控制,则可以是“组成型”。如果不存在诱导物,则诱导型启动子仅在很小的程度上表达或完全不表达。在诱导物的存在下,基因被“打开”或转录水平升高。这通常通过特定转录因子的结合来介导。根据本发明的特定启动子是如本文中所述的甲病毒的亚基因组启动子。另一些特定启动子是甲病毒的基因组正链或负链启动子。
术语“核心启动子”是指启动子所包含的核酸序列。核心启动子通常是正确启动转录所需的启动子的最小部分。核心启动子通常包含转录起始位点和rna聚合酶的结合位点。
“聚合酶”通常是指能够催化由单体结构单元合成聚合物分子的分子实体。“rna聚合酶”是能够催化由核糖核苷酸结构单元合成rna分子的分子实体。“dna聚合酶”是能够催化由脱氧核糖核苷酸结构单元合成dna分子的分子实体。对于dna聚合酶和rna聚合酶,分子实体通常是蛋白质或多个蛋白质的组装体或复合物。通常来说,dna聚合酶基于模板核酸合成dna分子,所述模板核酸通常是dna分子。通常来说,rna聚合酶基于模板核酸合成rna分子,所述模板分子是dna分子(在这种情况下,rna聚合酶是dna依赖性rna聚合酶,ddrp),或者是rna分子(在这种情况下,rna聚合酶是rna依赖性rna聚合酶,rdrp)。
“rna依赖性rna聚合酶”或“rdrp”是催化从rna模板的rna转录的酶。在甲病毒rna依赖性rna聚合酶的情况下,基因组rna的(-)链互补链和(+)链基因组rna的顺序合成导致rna复制。因此,甲病毒rna依赖性rna聚合酶被同义地称为“rna复制酶”。实际上,rna性rna聚合酶通常由除逆转录病毒以外的所有rna病毒编码。编码rna依赖性rna聚合酶的病毒的典型代表是甲病毒。
根据本发明,“rna复制”通常是指基于给定rna分子(模板rna分子)的核苷酸序列合成的rna分子。合成的rna分子可以例如与模板rna分子相同或互补。通常来说,rna复制可通过dna中间体的合成发生,或者可通过rna依赖性rna聚合酶(rdrp)介导的rna依赖性rna复制直接发生。在甲病毒的情况下,rna复制不是通过dna中间体发生的,而是由rna依赖性rna聚合酶(rdrp)介导的:模板rna链(第一rna链)或其一部分充当模板,用于合成与第一rna链或其一部分互补的第二rna链。第二rna链或其一部分可继而任选地充当模板,用于合成与第二rna链或其一部分互补的第三rna链。因此,第三rna链与第一rna链或其一部分相同。因此,rna依赖性rna聚合酶能够直接合成模板的互补rna链,并且能够间接合成相同的rna链(通过互补中间链)。
根据本发明,术语“模板rna”是指可被rna依赖性rna聚合酶转录或复制的rna。
根据本发明,术语“基因”是指负责产生一种或更多种细胞产物和/或实现一种或更多种细胞间或细胞内功能的特定核酸序列。更具体地,所述术语涉及核酸部分(通常为dna;但是在rna病毒的情况下为rna),其包含编码特定蛋白质或功能性或结构性rna分子的核酸。
如本文所用,“分离的分子”旨在指基本上不含其他分子(例如其他细胞物质)的分子。根据本发明,术语“分离的核酸”是指核酸已经(i)在体外扩增,例如通过聚合酶链式反应(pcr),(ii)通过克隆重组产生,(iii)纯化,例如通过切割和凝胶电泳分级分离,或(iv)合成,例如通过化学合成。分离的核酸是可用于通过重组技术进行操作的核酸。
术语“载体”在本文中以其最一般的含义使用,并且包括核酸的任何媒介载剂,其例如能够将所述核酸引入原核和/或真核宿主细胞中,并且在适当的情况下被整合到基因组中。这样的载体优选在细胞中复制和/或表达。载体包括质粒、噬菌粒、病毒基因组及其级分。
在本发明的上下文中,术语“重组”是指“通过基因工程制备”。优选地,在本发明的上下文中,“重组对象”(例如重组细胞)不是天然存在的。
本文中使用的术语“天然存在”是指对象可在自然界中存在的事实。例如,存在于生物体(包括病毒)中且可以从自然来源中分离并且未在实验室中故意人为修饰的肽或核酸是天然存在的。术语“在自然界中存在”是指“存在于自然界中”,并且包括已知对象以及尚未从自然界中存在和/或分离但将来可能会从自然源中发现和/或分离的对象。
根据本发明,术语“表达”以其最一般的含义使用,并且包括产生rna或者rna和蛋白质。其还包括核酸的部分表达。此外,表达可以是瞬时的或稳定的。对于rna,术语“表达”或“翻译”是指细胞核糖体中的过程,通过该过程,编码rna(例如信使rna)链指导氨基酸序列的组装,以产生肽或蛋白。
根据本发明,术语“mrna”是指“信使rna”,并且涉及通常通过使用dna模板产生并编码肽或蛋白质的转录物。通常来说,mrna包含5’-utr、蛋白质编码区、3’-utr和poly(a)序列。mrna可以从dna模板通过体外转录而产生。体外转录方法是技术人员已知的。例如,存在许多可商购的体外转录试剂盒。根据本发明,可通过稳定修饰和加帽来对mrna进行修饰。
根据本发明,术语“poly(a)序列”或“poly(a)尾”是指通常位于rna分子的3’末端的腺苷酸残基的不间断的或间断的序列。不间断的序列的特征是连续的腺苷酸残基。实际上,不间断的poly(a)序列是典型的。尽管poly(a)序列在真核dna中通常不编码,而是在细胞核中真核转录期间在转录之后通过不依赖于模板的rna聚合酶连接至rna的游离3’末端,但是本发明涵盖了由dna编码的poly(a)序列。
根据本发明,关于核酸分子的术语“一级结构”是指核苷酸单体的线性序列。
根据本发明,关于核酸分子的术语“二级结构”是指核酸分子的二维表示,其反映了碱基配对;例如在单链rna分子的情况下,特别是分子内碱基配对。尽管每个rna分子具有仅一条多核苷酸链,但分子通常以(分子内)碱基对区域为特征。根据本发明,术语“二级结构”包括结构基序,其包括但不限于碱基对、茎、茎环、凸起、环(例如内部环和多分支环)。核酸分子的二级结构可用显示碱基配对的二维图(平面图)表示(关于rna分子二级结构的更多详细信息,参见auberetal.,j.graphalgorithmsappl.,2006,vol.10,pp.329-351)。如本文中所述,某些rna分子的二级结构在本发明的上下文中是相关的。
根据本发明,通过使用用于rna二级结构预测的网络服务器(http://rna.urmc.rochester.edu/rnastructureweb/servers/predict1/predict1.html)进行预测来确定核酸分子,特别是单链rna分子的二级结构。优选地,根据本发明,关于核酸分子的“二级结构”特别是指通过所述预测确定的二级结构。也可使用mfold结构预测(http://unafold.rna.albany.edu/?q=mfold)执行或确认该预测。
根据本发明,“碱基对”是二级结构的结构基序,其中两个核苷酸碱基通过碱基上的供体和受体位点之间的氢键彼此缔合。互补碱基a:u和g:c通过碱基上供体和受体位点之间的氢键形成稳定的碱基对;a:u和g:c碱基对称为watson-crick碱基对。通过碱基g和u(g:u)形成较弱的碱基对(称为wobble碱基对)。碱基对a:u和g:c被称为规范碱基对。其他碱基对如g:u(在rna中经常出现)和其他稀有碱基对(例如a:c;u:u)被称为非规范碱基对。
根据本发明,“核苷酸配对”是指彼此缔合以使其碱基形成碱基对(规范或非规范碱基对,优选规范碱基对,最优选watson-crick碱基对)的两个核苷酸。
根据本发明,关于核酸分子的术语“茎环”或“发夹”或“发夹环”全部可互换地是指核酸分子(通常是单链核酸分子,例如单链rna)的特定二级结构。由茎环代表的特定二级结构由包含茎和(末端)环(也称为发夹环)的连续核酸序列组成,其中茎由两个相邻的完全或部分互补的序列元件形成,它们被形成茎环结构的环的短序列(例如3-10个核苷酸)隔开。两个相邻的完全或部分互补的序列可以定义为例如茎环元件茎1和茎2。茎环如下形成:这两个相邻的完全或部分反向互补的序列(例如茎环元件茎1和茎2)彼此形成碱基对,得到双链核酸序列,所述双链核酸序列包含位于其末端结尾处的由位于茎环元件茎1和茎2之间的短序列形成的未配对环。因此,茎环包含两个茎(茎1和茎2),其在核酸分子的二级结构水平上彼此形成碱基对,并且在核酸分子的一级结构水平上被不是茎1或茎2的一部分的短序列隔开。为说明起见,茎环的二维表示类似于棒棒糖形结构。茎环结构的形成需要自身可折回以形成配对双链的序列的存在;配对双链由茎1和茎2形成。配对茎环元件的稳定性通常取决于能够与茎2的核苷酸形成碱基对(优选规范碱基对,更优选watson-crick碱基对)的茎1的长度、核苷酸数目,对比于不能与茎2的核苷酸形成这样的碱基对(错配或凸起)的茎1的核苷酸数目。根据本发明,最佳环长度为3-10个核苷酸,更优选4-7个核苷酸,例如4个核苷酸、5个核苷酸、6个核苷酸或7个核苷酸。如果给定核酸序列以茎环为特征,则相应互补核酸序列通常也以茎环为特征。茎环通常由单链rna分子形成。例如,甲病毒基因组rna的5’复制识别序列中存在数个茎环(如图5所示)。
根据本发明,关于核酸分子的特定二级结构(例如茎环)的“破坏”是指特定二级结构不存在或被改变。通常来说,二级结构可因作为二级结构的一部分的至少一个核苷酸的改变而被破坏。例如,可通过改变形成茎的一个或更多个核苷酸以使得不能进行核苷酸配对来破坏茎环。
根据本发明,“二级结构破坏的补偿”或“补偿二级结构破坏”是指核酸序列中的一个或更多个核苷酸变化;更通常是指核酸序列中的一个或更多个第二核苷酸变化,所述核酸序列还包含一个或更多个第一核苷酸变化,其特征在于:尽管在不存在一个或更多个第二核苷酸变化的情况下一个或更多个第一核苷酸变化造成核酸二级结构破坏,但是一个或更多个第一核苷酸变化和一个或更多个第二核苷酸变化的共存不造成核酸二级结构破坏。共存是指一个或更多个第一核苷酸变化和一个或更多个第二核苷酸变化二者的存在。通常来说,一个或更多个第一核苷酸变化和一个或更多个第二核苷酸变化一起存在于同一核酸分子中。在一个具体的实施方案中,补偿二级结构破坏的一个或更多个核苷酸变化是补偿一个或更多个核苷酸配对破坏的一个或更多个核苷酸变化。因此,在一个实施方案中,“补偿二级结构破坏”是指“补偿核苷酸配对破坏”,即一个或更多个核苷酸配对破坏,例如一个或更多个茎环内的一个或更多个核苷酸配对破坏。可通过去除至少一个起始密码子来引入一个或更多个一个或更多个核苷酸配对破坏。补偿二级结构破坏的一个或更多个核苷酸变化中的每一个都是这样的核苷酸变化,其可以各自独立地选自一个或更多个核苷酸的缺失、添加、置换和/或插入。在一个示例性实例中,当核苷酸配对a:u被a到c的置换破坏(c和u通常不适合形成核苷酸对)时,则补偿核苷酸配对破坏的核苷酸变化可以是将u置换为g,从而能够形成c:g核苷酸配对。因此将u置换为g补偿了核苷酸配对破坏。在一个替代实例中,当核苷酸配对a:u被a到c的置换破坏时,则补偿核苷酸配对破坏的核苷酸变化可以是将c置换为a,从而恢复原始a:u核苷酸配对的形成。一般来说,在本发明中,补偿二级结构破坏的那些核苷酸变化优选既不恢复原始核酸序列,也不产生新aug三联体。在以上实例集中,相对于c到a的置换,u到g的置换是优选的。
根据本发明,关于核酸分子的术语“三级结构”是指由原子坐标所限定的核酸分子的三维结构。
根据本发明,核酸(例如rna,例如mrna)以编码肽或蛋白质。因此,可转录的核酸序列或其转录物可包含编码肽或蛋白质的开放阅读框(orf)。
根据本发明,术语“编码肽或蛋白质的核酸”是指这样的核酸,如果存在于合适的环境中,优选存在于细胞内,其可在翻译过程中指导氨基酸的组装以产生肽或蛋白质。优选地,根据本发明的编码rna能够与细胞翻译机器相互作用,从而允许编码rna的翻译以产生肽或蛋白质。
根据本发明,术语“肽”包括寡肽和多肽,并且是指包含通过肽键彼此连接的两个或更多个、优选3个或更多个、优选4个或更多个、优选6个或更多个、优选8个或更多个、优选10个或更多个、优选为13个或更多个、优选为16个或更多个、优选为20个或更多个、并且直至优选50个、优选100个或优选150个连续氨基酸的物质。术语“蛋白质”是指大的肽,优选具有至少151个氨基酸的肽,但是术语“肽”和“蛋白质”在本文中通常用作同义词。
根据本发明,术语“肽”和“蛋白质”包括不仅包含氨基酸组分而且还包含非氨基酸组分(例如糖和磷酸结构)的物质,并且还包括包含键(例如酯、硫醚或二硫键)的物质。
根据本发明,术语“起始密码子(initiationcodon和startcodon)”同义地指rna分子的密码子(碱基三联体),其可能是由核糖体翻译的第一个密码子。这样的密码子通常在真核生物中编码氨基酸甲硫氨酸,并且在原核生物中编码经修饰的甲硫氨酸。真核生物和原核生物中最常见的起始密码子是aug。除非在本文中特别指出是指除aug以外的起始密码子,否则关于rna分子的术语“起始密码子”是指密码子aug。根据本发明,术语“起始密码子”也用于指脱氧核糖核酸的相应碱基三联体,即编码rna的起始密码子的碱基三联体。如果信使rna的起始密码子是aug,则编码aug的碱基三联体是atg。根据本发明,术语“起始密码子”优选是指功能性起始密码子,即,指被核糖体用作或将用作启动翻译的密码子的起始密码子。rna分子中可能存在未被核糖体用作开始翻译的密码子的aug密码子,例如由于密码子与帽的距离很短。术语功能性起始密码子不包括这些密码子。
根据本发明,术语“开放阅读框的起始密码子”是指在编码序列(例如自然界中存在的核酸分子的编码序列)中用作蛋白质合成的起始密码子的碱基三联体。在rna分子中,开放阅读框的起始密码子通常前面是5’非翻译区(5’-utr),尽管并非严格要求。
根据本发明,术语“开放阅读框的天然起始密码子”是指在天然编码序列中用作蛋白质合成的起始密码子的碱基三联体。天然编码序列可以是例如自然界中存在的核酸分子的编码序列。在一些实施方案中,本发明提供了自然界中存在的的核酸分子的变体,其特征在于天然起始密码子(存在于天然编码序列中)已被去除(从而其不存在于变体核酸分子中)。
根据本发明,“第一aug”是指信使rna分子的最上游的aug碱基三联体,优选被核糖体用作或将要被核糖体用作开始翻译的密码子的信使rna分子最上游的aug碱基三联体。相应地,“第一atg”是指编码第一aug的编码dna序列的atg碱基三联体。在一些情况下,mrna分子的第一aug是开放阅读框的起始密码子,即在核糖体蛋白质合成过程中用作起始密码子的密码子。
根据本发明,关于核酸变体的某元件的术语“包括去除…”或“以去除…为特征”和类似术语是指与参考核酸分子相比,在核酸变体中所述某元件不是功能性的或不存在。不受限制地,去除可由某元件的全部或一部分的缺失、某元件的全部或一部分的置换、或某元件的功能或结构性质的改变组成。核酸序列的功能元件的去除要求包含去除的核酸变体在该位置处不表现功能。例如,以去除某起始密码子为特征的rna变体要求以去除为特征的rna变体在该位置处不启动核糖体蛋白质合成。核酸序列的结构元件的去除要求包含去除的核酸变体在该位置处不存在该结构元件。例如,以去除某aug碱基三联体(即,某位置处的aug碱基三联体)为特征的rna变体的特征可在于,例如该某aug碱基三联体的一部分或全部的缺失(例如,δaug),或者该某aug碱基三联体的一个或更多个核苷酸(a、u、g)被任意一个或更多个不同的核苷酸置换,使得所得变体的核苷酸序列不包含所述aug碱基三联体。一个核苷酸的合适置换是将aug碱基三联体转化为gug、cug或uug碱基三联体,或转化为aag、acg或agg碱基三联体,或转化为aua、auc或auu碱基三联体的那些。可以相应地选择更多核苷酸的合适置换。
根据本发明,术语“甲病毒”应被广义地理解,并且包括具有甲病毒特征的任何病毒颗粒。甲病毒的特征包括存在(+)链rna,其编码适合在宿主细胞中复制的遗传信息,包括rna聚合酶活性。在strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562中描述了许多甲病毒的另外的特征。术语“甲病毒”包括自然界中存在的的甲病毒及其任何变体或衍生物。在一些实施方案中,变体或衍生物在自然界中不存在。
在一个实施方案中,甲病毒是自然界中存在的的甲病毒。通常来说,自然界中存在的甲病毒可感染任一种或更多种真核生物,例如动物(包括脊椎动物(例如人)和节肢动物(例如昆虫))。
自然界中存在的甲病毒优选地选自以下:巴马森林病毒复合体(包含巴马森林病毒(barmahforestvirus));东部马脑炎复合体(包含七种抗原类型的东部马脑炎病毒(easternequineencephalitisvirus));米德尔堡病毒复合体(包含米德尔堡病毒(middelburgvirus));恩杜姆病毒复合体(包含恩杜姆病毒(ndumuvirus));塞姆利基森林病毒复合体(包含贝巴鲁病毒(bebaruvirus)、基孔肯亚病毒(chikungunyavirus)、马雅罗病毒(mayarovirus)及其亚型乌纳病毒(unavirus)、阿良良病毒(o’nyongnyongvirus)及其亚型伊博-奥拉病毒(igbo-oravirus)、罗斯河病毒(rossrivervirus)及其亚型比巴鲁病毒(bebaruvirus)、盖塔病毒(getahvirus)、鹭山病毒(sagiyamavirus)、塞姆利基森林病毒(semlikiforestvirus)及其亚型metri病毒);委内瑞拉马脑炎复合体(包含卡巴斯欧病毒(cabassouvirus)、沼泽地病毒(evergladesvirus)、莫斯达斯佩德拉斯病毒(mossodaspedrasvirus)、穆坎布病毒(mucambovirus)、帕拉马纳病毒(paramanavirus)、那皮舒纳病毒(pixunavirus)、里奥内格罗病毒(rionegrovirus)、特罗卡拉病毒(trocaravirus)及其亚型比朱布里奇病毒(bijoubridgevirus)、委内瑞拉马脑炎病毒(venezuelanequineencephalitisvirus);西部马脑炎复合体(包含奥拉病毒(auravirus)、巴班肯病毒(babankivirus)、孜拉加奇病毒(kyzylagachvirus)、辛德比斯病毒(sindbisvirus)、奥克尔布病毒(ockelbovirus)、沃达罗河病毒(whataroavirus)、博吉河病毒(buggycreekvirus)、摩根堡病毒(fortmorganvirus)、高地j病毒(highlandsjvirus)、西部马脑炎病毒(westernequineencephalitisvirus);以及一些未分类的病毒,包括鲑鱼胰腺疾病病毒(salmonpancreaticdiseasevirus);睡眠疾病病毒(sleepingdiseasevirus);南部象海豹病毒(southernelephantsealvirus);图那特病毒(tonatevirus)。更优选地,甲病毒选自由以下:塞姆利基森林病毒复合体(包含如上所述的病毒类型,包括塞姆利基森林病毒)、西方马脑炎复合体(包含如上所述的病毒类型,包括辛德比斯病毒)、东部马脑炎病毒(包含如上所述的病毒类型)、委内瑞拉马脑炎复合体(包含如上所述的病毒类型,包括委内瑞拉马脑炎病毒)。
在另一个优选的实施方案中,甲病毒是塞姆利基森林病毒。在另一个优选实施方案中,甲病毒是辛德比斯病毒。在另一个替代的优选实施方案中,甲病毒是委内瑞拉马脑炎病毒。
在本发明的一些实施方案中,甲病毒不是自然界中存在的甲病毒。通常来说,非自然界中存在的甲病毒是自然界中存在的甲病毒的变体或衍生物,其通过核苷酸序列(即基因组rna)中的至少一个突变而区别于自然界中存在的甲病毒。与自然界中存在的甲病毒相比,核苷酸序列中的突变可选自一个或更多个核苷酸的插入、置换或缺失。核苷酸序列中的突变可与由核苷酸序列编码的多肽或蛋白质中的突变相关或不相关。例如,非自然界中存在的甲病毒可以是减毒甲病毒。非自然界中存在的减毒甲病毒是这样的甲病毒,其通常在核苷酸序列中具有至少一个突变,通过该突变,其区别于自然界中存在的甲病毒,其没有完全没有感染性,或者具有感染性但具有较低疾病产生能力或完全没有疾病产生能力。作为说明性实例,tc83是区别于自然界中存在的委内瑞拉马脑炎病毒(veev)的减毒甲病毒(mckinneyetal.,1963,am.j.trop.med.hyg.,1963,vol.12;pp.597-603)。
甲病毒属的成员也可根据其在人类中的相对临床特征进行分类:主要与脑炎相关的甲病毒,以及主要与发热、皮疹和多关节炎相关的甲病毒。
术语“甲病毒的”是指在存在于甲病毒中,或来源于甲病毒或来源于甲病毒(例如通过基因工程)。
根据本发明,“sfv”代表塞姆利基森林病毒。根据本发明,“sin”或“sinv”代表辛德比斯病毒。根据本发明,“vee”或“veev”代表委内瑞拉马脑炎病毒。
根据本发明,术语“甲病毒的”是指来源于甲病毒的实体。为了说明,甲病毒的蛋白质可以指存在于甲病毒中的蛋白质和/或由甲病毒编码的蛋白质;并且甲病毒的核酸序列可以指存在于甲病毒中的核酸序列和/或由甲病毒编码的核酸序列。优选地,“甲病毒的”核酸序列是指“甲病毒的基因组的”和/或“甲病毒的基因组rna的”核酸序列。
根据本发明,术语“甲病毒rna”是指以下任意一种或更多种:甲病毒基因组rna(即(+)链)、甲病毒基因组rna的互补链(即(-)链)、和亚基因组转录物(即(+)链)或其任何片段。
根据本发明,“甲病毒基因组”是指甲病毒的基因组(+)链rna。
根据本发明,术语“天然甲病毒序列”和类似术语通常是指天然存在的甲病毒(自然界中存在的的甲病毒)的(例如核酸)序列。在一些实施方案中,术语“天然甲病毒序列”也包括减毒甲病毒的序列。
根据本发明,术语“5’复制识别序列”优选是指与甲病毒基因组的5’片段相同或同源的连续核酸序列,优选核糖核酸序列。“5’复制识别序列”是可被甲病毒复制酶识别的核酸序列。术语5’复制识别序列包括天然的5’复制识别序列及其功能等同物,例如自然界中存在的甲病毒的5’复制识别序列的功能变体。根据本发明,功能等同物包括如本文中所述的以除去至少一个起始密码子为特征的5’复制识别序列的衍生物。5’复制识别序列是合成甲病毒基因组rna的(-)链互补链所必需的,并且是基于(-)链模板合成(+)链病毒基因组rna所必需的。天然5’复制识别序列通常至少编码nsp1的n末端片段;但不包含编码nsp1234的整个开放阅读框。考虑到天然的5’复制识别序列通常至少编码nsp1的n末端片段的事实,天然5’复制识别序列通常包含至少一个起始密码子,通常为aug。在一个实施方案中,5’复制识别序列包含甲病毒基因组的保守序列元件1(cse1)或其变体和甲病毒基因组的保守序列元件2(cse2)或其变体。5’复制识别序列通常能够形成四个茎环(sl),即sl1、sl2、sl3、sl4。这些茎环的编号从5’复制识别序列的5’端开始。
根据本发明,术语“在甲病毒的5’末端”是指甲病毒基因组的5’末端。在甲病毒5’末端的核酸序列包含位于甲病毒基因组rna5’末端的核苷酸,加上任选的其他核苷酸的连续序列。在一个实施方案中,甲病毒的5’末端的核酸序列与甲病毒基因组的5’复制识别序列相同。
术语“保守序列元件”或“cse”是指存在于甲病毒rna中的核苷酸序列。这些序列元件被称为“保守的”,因为在不同甲病毒的基因组中存在直系同源物,并且不同甲病毒的直系同源cse优选具有高百分比的序列同一性和/或相似的二级或三级结构。术语cse包括cse1、cse2、cse3和cse4。
根据本发明,术语“cse1”或“44-ntcse”同义地是指从(-)链模板合成(+)链所需的核苷酸序列。术语“cse1”是指(+)链上的序列;并且cse1的互补序列(在(-)链上)用作(+)链合成的启动子。优选地,术语cse1包括甲病毒基因组的最5’核苷酸。cse1通常形成保守的茎环结构。不希望受特定理论的束缚,据信对于cse1,二级结构比一级结构(即线性序列)更重要。在模型甲病毒辛德比斯病毒的基因组rna中,cse1由44个核苷酸的连续序列组成,该序列由基因组rna的最5’的44个核苷酸形成(strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562)。
根据本发明,术语“cse2”或“51-ntcse”同义地是指从(+)链模板合成(-)链所需的核苷酸序列。(+)链模板通常是甲病毒基因组rna或rna复制子(应注意,不包含cse2的亚基因组rna转录物不用作(-)链合成的模板)。在甲病毒基因组rna中,cse2通常位于nsp1的编码序列内。在模型甲病毒辛德比斯病毒的基因组rna中,51-ntcse位于基因组rna的核苷酸位置155-205(frolovetal.,2001,rna,vol.7,pp.1638-1651)。cse2通常形成两个保守的茎环结构。这些茎环结构被命名为茎环3(sl3)和茎环4(sl4),因为它们分别是从甲病毒基因组rna的5’末端开始计数的甲病毒基因组rna的第三和第四个保守茎环。不希望受特定理论的束缚,据信对于cse2,二级结构比一级结构(即线性序列)更重要。
根据本发明,术语“cse3”或“连接序列”同义地指来源于甲病毒基因组rna并包含亚基因组rna的起始位点的核苷酸序列。(-)链中该序列的互补序列起促进亚基因组rna转录的作用。在甲病毒基因组rna中,cse3通常与编码nsp4的c末端片段的区域重叠,并延伸到位于编码结构蛋白的开放阅读框上游的短非编码区。
根据本发明,术语“cse4”或“19-nt保守序列”或“19-ntcse”同义地指来自甲病毒基因组rna的核苷酸序列,其在甲病毒基因组的3’非翻译区中的poly(a)序列的立即上游。cse4通常由19个连续核苷酸组成。不希望受特定理论的束缚,cse4被理解为充当启动(-)链合成的核心启动子(joséetal.,futuremicrobiol.,2009,vol.4,pp.837-856);和/或甲病毒基因组rna的cse4和poly(a)尾被理解为共同作用以有效进行(-)链合成(hardy&rice,j.virol.,2005,vol.79,pp.4630-4639)。
根据本发明,术语“亚基因组启动子”或“sgp”是指核酸序列(例如编码序列)上游(5’)的核酸序列,其通过提供对于rna聚合酶,通常是rna依赖性rna聚合酶,特别是功能性甲病毒非结构蛋白的识别和结构位点来控制所述核酸序列的转录。sgp可包含对于另外的因子的另外的识别或结合位点。亚基因组启动子通常是正链rna病毒(例如甲病毒)的遗传元件。甲病毒的亚基因组启动子是病毒基因组rna中包含的核酸序列。亚基因组启动子的一般特征在于,其允许在rna依赖性rna聚合酶(例如功能性甲病毒非结构蛋白)的存在下开始转录(rna合成)。rna(-)链(即甲病毒基因组rna的互补链)充当用于合成(+)链亚基因组转录物的模板,并且(+)链亚基因组转录物的合成通常在亚基因组启动子处或附近开始。本文所用的术语“亚基因组启动子”不限于在包含这样的亚基因组启动子的核酸中的任何特定定位。在一些实施方案中,sgp与cse3相同或与cse3重叠或包含cse3。
术语“亚基因组转录物”或“亚基因组rna”同义地是指使用rna分子作为模板(“模板rna”)的转录可获得的rna分子,其中模板rna包含控制亚基因组转录物的转录的亚基因组启动子。亚基因组转录物可在存在rna依赖性rna聚合酶,特别是功能性甲病毒非结构蛋白的情况下获得。例如,术语“亚基因组转录物”可以是指在甲病毒感染的细胞中使用甲病毒基因组rna的(-)链互补链作为模板制备的rna转录物。然而,本文使用的术语“亚基因组转录物”不限于此,并且还包括通过使用异源rna作为模板可获得的转录物。例如,也可通过使用根据本发明的含有sgp的复制子的(-)链互补链作为模板来获得亚基因组转录物。因此,术语“亚基因组转录物”可以指通过转录甲病毒基因组rna的片段可获得的rna分子,以及通过转录根据本发明的复制子的片段可获得的rna分子。
术语“自体”用于描述源自相同对象的任何事物。例如,“自体细胞”是指源自相同对象的细胞。将自体细胞引入对象是有利的,因为这些细胞克服了免疫学屏障,否则会导致排斥。
术语“同种异体”用于描述源自相同物种的不同个体的任何事物。当一个或更多个基因座上的基因不相同时,两个或多个个体被认为是同种异体。
术语“同基因的”用于描述源自具有相同基因型的个体或组织(即相同双胞胎或相同近交系的动物,或者其组织或细胞)的任何事物。
术语“异源”用于描述由多个不同元件组成的事物。例如,将一个个体的细胞引入不同个体就构成了异源移植。异源基因是源自对象以外的来源的基因。
以下提供了本发明的各个特征的具体和/或优选的变型。本发明还考虑了通过将对于本发明的两种或更多种特征描述的两种或更多种具体和/或优选变体进行组合产生的那些实施方案作为一些特别优选的实施方案
rna复制子
能够被复制酶(优选甲病毒复制酶)复制的核酸构建体称为复制子。根据本发明,术语“复制子”定义了可通过rna依赖性rna聚合酶复制的rna分子,其在没有dna中间体的情况下产生复制子的一个或更多个相同或基本相同的拷贝。“没有dna中间体”是指在形成rna复制子的拷贝的过程中没有形成复制子的脱氧核糖核酸(dna)拷贝或互补链,和/或在形成rna复制子的拷贝或其互补链的过程中没有将脱氧核糖核酸(dna)分子用作模板。复制酶功能通常由功能性甲病毒非结构蛋白提供。
根据本发明,术语“可被复制”和“能够被复制”通常描述了可以制备核酸的一个或更多个相同或基本相同的拷贝。当与术语“复制酶”一起使用时,例如在“可被复制酶复制”中,术语“可被复制”和“能够被复制”描述了核酸分子(例如rna复制子)关于复制酶的功能特征。这些功能特征包括以下至少一种:(i)复制酶能够识别复制子和(ii)复制酶能够充当rna依赖性rna聚合酶(rdrp)。优选地,复制酶能够(i)识别复制子并且(ii)充当rna依赖性rna聚合酶。
表述“能够识别”描述复制酶能够与复制子物理缔合,并且优选地,复制酶能够与复制子结合(通常为非共价)。术语“结合”可以表示复制酶具有与以下任一种或更多种结合的能力:保守序列元件1(cse1)或其互补序列(如果被复制子包含)、保守序列元件2(cse2)或其互补序列(如果被复制子包含)、保守序列元素3(cse3)或其互补序列(如果被复制子包含)、保守序列元素4(cse4)或其互补序列(如果被复制子包含)。优选地,复制酶能够与cse2[即,(+)链]和/或cse4[即(+)链]结合,或者与cse1的互补序列[即(-)链)和/或cse3的互补序列[即(-)链]结合。
表述“能够充当rdrp”是指复制酶能够催化甲病毒基因组(+)链rna的(-)链互补链的合成,其中(+)链rna具有模板功能,和/或复制酶能够催化(+)链甲病毒基因组rna的合成,其中(-)链rna具有模板功能。通常来说,表述“能够充当rdrp”也可包括复制酶能够催化(+)链亚基因组转录物的合成,其中(-)链rna具有模板功能,并且其中(+)链亚基因组转录物的合成通常在甲病毒亚基因组启动子处开始。
表述“能够结合”和“能够充当rdrp”是指在正常生理条件下的能力。特别地,其指表达功能性甲病毒非结构蛋白或已被编码功能性甲病毒非结构蛋白的核酸转染的细胞内部的条件。细胞优选是真核细胞。结合的能力和/或充当rdrp的能力可通过实验来测试,例如在无细胞的体外系统或真核细胞中。任选地,所述真核细胞是来自以下物种的细胞:对于所述物种,代表复制酶起源的特定甲病毒具有感染性。例如,当使用来自对人具有感染性的特定甲病毒的甲病毒复制酶时,正常生理条件是人细胞中的条件。更优选地,真核细胞(在一个实例中是人细胞)来自代表复制酶起源的特定甲病毒对其具有感染性的同一组织或器官。
根据本发明,“与天然甲病毒序列相比”和类似的术语是指作为天然甲病毒序列的变体的序列。该变体本身通常不是天然甲病毒序列。
本发明的rna复制子包含5’复制识别序列。5’复制识别序列是可被功能性甲病毒非结构蛋白识别的核酸序列。换句话说,功能性甲病毒非结构蛋白能够识别5’复制识别序列。
在一个实施方案中,本发明的rna复制子包含5’复制识别序列,其中5’复制识别序列的特征在于与天然甲病毒5’复制识别序列相比包含至少一个起始密码子的去除。
根据本发明的特征在于与天然甲病毒5’复制识别序列相比包含至少一个起始密码子的去除的5’复制识别序列在本文中可以称为“经修饰的5’复制识别序列”或“根据本发明的5’复制识别序列”。如下文所述,根据本发明的5’复制识别序列可以任选地以一个或更多个另外的核苷酸变化的存在为特征。
在一个实施方案中,rna复制子包含3’复制识别序列。3’复制识别序列是可被功能性甲病毒非结构蛋白识别的核酸序列。换句话说,功能性甲病毒非结构蛋白能够识别3’复制识别序列。优选地,3’复制识别序列位于复制子的3’末端(如果复制子不包含poly(a)尾),或在poly(a)尾的立即上游(如果复制子包含poly(a)尾)。在一实施方案中,3’复制识别序列由cse4组成或包含cse4。
在一个实施方案中,5’复制识别序列和3’复制识别序列能够在功能性甲病毒非结构蛋白的存在下指导根据本发明的rna复制子的复制。因此,当单独存在或优选一起存在时,这些识别序列在功能性甲病毒非结构蛋白的存在下指导rna复制子的复制。
优选地,以顺式(通过复制子上的开放阅读框编码为目的蛋白质)或以反式(通过第二方面所述的单独的复制酶构建体上的开放阅读框编码为目的蛋白质)提供能够识别复制子的任选修饰的5’复制识别序列和3’复制识别序列的功能性甲病毒非结构蛋白。在一个实施方案中,当5’复制识别序列和3’复制识别序列对于得到功能性甲病毒非结构蛋白的甲病毒是天然的,或者当3’复制识别序列对于得到功能性甲病毒非结构蛋白的甲病毒是天然的并且5’复制识别序列是得到功能性甲病毒非结构蛋白的甲病毒天然的5’复制识别序列的变体时,实现这一点。天然是指这些序列的天然来源是相同的甲病毒。在一个替代实施方案中,(经修饰的)5’复制识别序列和/或3’复制识别序列对于得到功能性甲病毒非结构蛋白的甲病毒不是天然的,条件是功能性甲病毒非结构蛋白能够识别复制子的(经修饰的)5’复制识别序列和3’复制识别序列二者。换句话说,功能性甲病毒非结构蛋白与(经修饰的)5’复制识别序列和3’复制识别序列二者相容。当非天然功能性甲病毒非结构蛋白能够识别相应的序列或序列元件时,则该功能性甲病毒非结构蛋白被认为是相容的(跨病毒相容性)。(3’/5’)复制识别序列和cse分别与功能性甲病毒非结构蛋白的任何组合都是可能的,只要存在跨病毒相容性即可。通过在适合于rna复制子的条件下,例如在合适的宿主细胞中将待测试的功能性甲病毒非结构蛋白与rna一起孵育,本发明的技术人员可以容易地测试跨病毒相容性,其中所述rna具有待测试的3’和(任选修饰的)5’复制识别序列。如果发生复制,则确定(3’/5’)复制识别序列与功能性甲病毒非结构蛋白是相容的。
去除至少一个起始密码子提供了多个优点。编码nsp1*的核酸序列中起始密码子的缺少通常导致nsp1*(nsp1的n端片段)不翻译。此外,由于nsp1*不翻译,编码目的蛋白质的开放阅读框(“转基因”)是核糖体可接近的最上游的开放阅读框;因此,当复制子存在于细胞中时,翻译在编码目的基因的开放阅读框(rna)的第一aug处开始。这代表了优于现有技术的反式复制子的优势,例如spuul等人(j.virol.,2011,vol.85,pp.4739-4751)所述:根据spuul等人的复制子指导nsp1的n末端部分(74个氨基酸的肽)的表达。从现有技术中还已知,从全长病毒基因组构建rna复制子不是一件容易的事,因为某些突变可使rna不能被复制(wo2000/053780a2),并且去除对于甲病毒的复制重要的5’结构的一些部分会影响复制效率(kamrudetal.,2010,j.gen.virol.,vol.91,pp.1723-1727)。
与常规顺式复制子相比的优势在于,至少一个起始密码子的去除使甲病毒非结构蛋白的编码区与5’复制识别序列解偶联。这使得能够对顺式复制子进行进一步的工程改造,例如通过将天然5’复制识别序列交换为人工序列、突变序列或取自另一rna病毒的异源序列。常规顺式复制子中的这样的序列操作受到nsp1氨基酸序列的限制。任何点突变或点突变簇都需要进行实验评估,以确定复制是否受到影响,并且由于其对蛋白质的不利影响,不可能进行导致移码突变的小插入或缺失。
根据本发明,至少一个起始密码子的去除可通过本领域已知的任何合适的方法来实现。例如,可在计算机上(insilico)设计编码根据本发明的复制子(即特征在于起始密码子的去除)的合适的dna分子,并且然后在体外合成(基因合成);或者,可通过编码复制子的dna序列的定点诱变获得合适的dna分子。在任何情况下,相应的dna分子可用作体外转录的模板,从而提供根据本发明的复制子。
与天然甲病毒5’复制识别序列相比,至少一个起始密码子的去除没有特别限制,并且可选自任何核苷酸修饰,包括一个或更多个核苷酸的置换(包括在dna水平上,起始密码子的a和/或t和/或g的置换);一个或更多个核苷酸的缺失(包括在dna水平上,起始密码子的a和/或t和/或g的缺失),以及一个或更多个核苷酸的插入(包括在dna水平上,一个或更多个核苷酸的插入在起始密码子的a和t之间和/或t和g之间)。不管核苷酸修饰是置换、插入还是缺失,核苷酸修饰都不得导致形成新的起始密码子(作为说明性示例:在dna水平上,插入必须不是atg的插入)。
以至少一个起始密码子的去除为特征的rna复制子的5’复制识别序列(即,根据本发明的经修饰的5’复制识别序列)优选是自然界中存在的甲病毒的基因组的5’复制识别序列的变体。在一个实施方案中,根据本发明的经修饰的5’复制识别序列优选地特征在于,与自然界中存在的至少一种甲病毒的基因组的5’复制识别序列具有80%或更高、优选85%或更高、更优选90%或更高、甚至更优选95%或更高的序列同一性程度。
在一个实施方案中,以去除至少一个起始密码子为特征的rna复制子的5’复制识别序列包含与甲病毒的5’末端(即甲病毒基因组的5’末端)的约250个核苷酸同源的序列。在一个优选的实施方案中,其包含与甲病毒的5’末端(即甲病毒基因组的5’末端)的约250至500个,优选约300至500个核苷酸同源的序列。“甲病毒基因组的5’末端”是指从甲病毒基因组的最上游核苷酸处开始并包括其的核酸序列。换句话说,甲病毒基因组的最上游核苷酸指定为核苷酸号1,并且例如“甲病毒基因组的5’末端的250个核苷酸”是指甲病毒基因组的核苷酸1至250。在一个实施方案中,以去除至少一个起始密码子为特征的rna复制子的5’复制识别序列的特征在于与自然界中存在的至少一种甲病毒的基因组的5’末端的至少250个核苷酸具有80%或更高、优选85%或更高、更优选90%或更高、甚至更优选95%或更高的序列同一性程度。至少250个核苷酸包括例如250个核苷酸,300个核苷酸,400个核苷酸,500个核苷酸。
自然界中存在的甲病毒的5’复制识别序列通常特征在于至少一个起始密码子和/或保守的二级结构基序。例如,塞姆利基森林病毒(sfv)的天然5’复制识别序列包含五个特定的aug碱基三联体。根据frolov等人(2001,rna,vol.7,pp.1638-1651)mfold分析显示,预计不同的甲病毒辛德比斯病毒的天然5’复制识别序列形成四个茎环:sl1、sl2、sl3、sl4。
已知甲病毒基因组的5’末端包含能够通过功能性甲病毒非结构蛋白复制甲病毒基因组的序列元件。在本发明的一个实施方案中,rna复制子的5’复制识别序列包含与甲病毒的保守序列元件1(cse1)和/或保守序列元件2(cse2)同源的序列。
甲病毒基因组rna的保守序列元件2(cse2)通常由sl3和sl4代表,其前面是至少包含编码甲病毒非结构蛋白nsp1的第一个氨基酸残基的天然起始密码子的sl2。但是,在本说明书中,在一些实施方案中,甲病毒基因组rna的保守序列元件2(cse2)是指跨越sl2至sl4并且包含编码甲病毒非结构蛋白nsp1的第一个氨基酸残基的天然起始密码子的区域。在一个优选的实施方案中,rna复制子包含cse2或与cse2同源的序列。在一个实施方案中,rna复制子包含与cse2同源的序列,所述序列的特征在于与自然界中存在的至少一种甲病毒的cse2的序列具有80%或更高、优选85%或更高、更优选90%或更高、甚至更优选95%或更高的序列同一性程度。
在一个优选的实施方案中,5’复制识别序列包含与甲病毒的cse2同源的序列。甲病毒的cse2可包含来自甲病毒的非结构蛋白的开放阅读框的片段。
因此,在一个优选的实施方案中,rna复制子的特征在于其包含与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列。与非结构蛋白或其片段的开放阅读框同源的序列通常是自然界中存在的甲病毒的非结构蛋白或其片段的开放阅读框的变体。在一个实施方案中,与非结构蛋白或其片段的开放阅读框同源的序列优选地特征在于与自然界中存在的至少一种甲病毒的非结构蛋白或其片段的开放阅读框具有80%或更高、优选85%或更高、更优选90%或更高、甚至更优选95%或更高的序列同一性程度。
在一个更优选的实施方案中,与本发明的复制子所包含的非结构蛋白的开放阅读框同源的序列不包含非结构蛋白的天然起始密码子,更优选地,不包含非结构蛋白的任何起始密码子。在一个优选的实施方案中,与cse2同源的序列的特征在于与天然甲病毒cse2序列相比去除了所有起始密码子。因此,与cse2同源的序列优选不包含任何起始密码子。
当与开放阅读框同源的序列不包含任何起始密码子时,与开放阅读框同源的序列本身不是开放阅读框,因为其不能充当翻译模板。
在一个实施方案中,5’复制识别序列包含与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列,其中与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列的特征在于,与天然甲病毒序列相比,其包含至少一个起始密码子的去除。
在一个优选的实施方案中,与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列的特征在于,其包含非结构蛋白的开放阅读框的至少天然起始密码子的去除。优选地,其特征在于,其包含编码nsp1的开放阅读框的至少天然起始密码子的去除。
天然起始密码子是aug碱基三联体,当宿主细胞中存在rna时,宿主细胞中核糖体的在此处开始翻译。换句话说,天然起始密码子是例如已经用包含天然起始密码子的rna接种的宿主细胞中核糖体蛋白质合成过程中翻译的第一个碱基三联体。在一个实施方案中,宿主细胞是来自真核物种的细胞,所述真核物种是包含天然甲病毒5’复制识别序列的特定甲病毒的天然宿主。在一个优选的实施方案中,宿主细胞是bhk21细胞,其来自可在美国典型培养物保藏中心(americantypeculturecollection,manassas,virginia,usa)获得的细胞系“bhk21[c13](
许多甲病毒的基因组已经完全测序并且可以公开获得,而且由这些基因组编码的非结构蛋白序列也可以公开获得。这样的序列信息允许在计算机上确定天然起始密码子。
在一个实施方案中,天然起始密码子包含在kozak序列或功能上等同的序列中。kozak序列是kozak最初描述的序列(1987,nucleicacidsres.,vol.15,pp.8125-8148)。mrna分子上的kozak序列被核糖体识别为翻译起始位点。根据该参考文献,kozak序列包含aug起始密码子,紧随其后的是高度保守的g核苷酸:augg。在本发明的一个实施方案中,与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列的特征在于其包括作为kozak序列一部分的起始密码子的去除。
在本发明的一个实施方案中,复制子的5’复制识别序列的特征在于在rna水平上至少去除了作为augg序列的一部分的所有那些起始密码子。
在一个优选的实施方案中,与来自甲病毒的非结构蛋白或其片段的开放阅读框同源的序列的特征在于,其包含非结构蛋白的开放阅读框的天然起始密码子以外的一个或更多个起始密码子的去除。在一个更优选的实施方案中,所述核酸序列的特征还在于天然起始密码子的去除。例如,除了去除天然起始密码子之外,还可以去除任意一个或两个或三个或四个或多于四个(例如五个)起始密码子。
如果复制子的特征在于去除非结构蛋白的开放阅读框的天然起始密码子并且任选地去除天然起始密码子以外的一个或更多个起始密码子,则与开放阅读框同源的序列本身不是开放阅读框,因为其不能用作翻译模板。
优选地除了去除天然起始密码子之外,去除的天然起始密码子以外的一个或更多个起始密码子优选地选自具有开始翻译的潜力的aug碱基三联体。具有开始翻译的潜力的aug碱基三联体可以称为“潜在起始密码子”。给定的aug碱基三联体是否具有开始翻译的潜力可在计算机上或在基于细胞的体外测定中确定。
在一个实施方案中,在计算机上确定给定的aug碱基三联体是否具有开始翻译的潜力:在该实施方案中,检查核苷酸序列,并且如果aug碱基三联体是augg序列的一部分,优选kozak序列的一部分,则确定其具有开始翻译的潜力。
在一个实施方案中,在基于细胞的体外测定中确定给定的aug碱基三联体是否具有开始翻译的潜力:将特征在于去除了天然起始密码子并且在去除天然起始密码子的位置下游包含给定的aug碱基三联体的rna复制子引入宿主细胞。在一个实施方案中,宿主细胞是来自真核物种的细胞,所述真核物种是包含天然甲病毒5’复制识别序列的特定甲病毒的天然宿主。在一个优选的实施方案中,宿主细胞是bhk21细胞,其来自可在美国典型微生物保藏中心(americantypeculturecollection,manassas,virginia,usa)获得的细胞系“bhk21[c13](
优选地,根据本发明的复制子的特征在于去除了在天然起始密码的去除位置下游并且位于甲病毒非结构蛋白或其片段的开放阅读框内的所有潜在的起始密码子。因此,根据本发明,5’复制识别序列优选不包含可以翻译成蛋白质的开放阅读框。
在一个优选的实施方案中,根据本发明的rna复制子的5’复制识别序列的特征在于与甲病毒基因组rna的5’复制识别序列的二级结构等同的二级结构。在一个优选的实施方案中,根据本发明的rna复制子的5’复制识别序列的特征在于与甲病毒基因组rna的5’复制识别序列的预测的二级结构等同的预测的二级结构。根据本发明,rna分子的二级结构优选地由用于rna二级结构预测的网络服务器预测,http://rna.urmc.rochester.edu/rnastructureweb/servers/predict1/predict1.html.。
通过与天然甲病毒5’复制识别序列相比比较以去除了至少一个起始密码子为特征的rna复制子的5’复制识别序列的二级结构或预测的二级结构,可确定核苷酸配对破坏的存在或不存在。例如,与天然甲病毒5’复制识别序列相比,给定位置处至少一个碱基对可能不存在,例如茎环中的,特别是茎环的茎中的碱基对。
在一个优选的实施方案中,5’复制识别序列的一个或更多个茎环不被缺失或破坏。更优选地,茎环3和4不被缺失或破坏。更优选地5’复制识别序列的茎环都不被缺失或破坏。
在一个实施方案中,至少一个起始密码子的去除不破坏5’复制识别序列的二级结构。在一个替代实施方案中,至少一个起始密码子的去除确实破坏了5’复制识别序列的二级结构。在该实施方案中,与天然甲病毒5’复制识别序列相比,至少一个起始密码子的去除可以是给定位置处的至少一个碱基对(例如茎环中的碱基对)不存在的原因。与天然甲病毒5’复制识别序列相比,如果茎环中的碱基对不存在,则至少一个起始密码子的去除被确定为在茎环内引入了核苷酸碱基配对破坏。茎环中的碱基对通常是茎环的茎中的碱基对。
在一个优选的实施方案中,rna复制子包含一个或更多个核苷酸变化以补偿通过去除至少一个起始密码子而引入的一个或更多个茎环内的核苷酸配对破坏。
如果与天然甲病毒5’复制识别序列相比,至少一个起始密码子的去除在茎环内引入了核苷酸配对破坏,则可以引入预期补偿核苷酸配对破坏的一个或更多个核苷酸变化,并且可将由此获得的二级结构或预测的二级结构与天然甲病毒5’复制识别序列进行比较。
基于公知常识和本文中的公开内容,技术人员可以预期某些核苷酸变化以补偿核苷酸配对破坏。例如,与天然甲病毒5’复制识别序列相比,如果以至少一个起始密码子的去除为特征的rna复制子的给定5’复制识别序列的二级结构或预测的二级结构的给定位置处的碱基对被破坏,则恢复该位置处的碱基对并且优选不重新引入起始密码子的核苷酸变化预期将补偿核苷酸配对破坏。
在一个优选的实施方案中,复制子的5’复制识别序列不与可翻译的核酸序列(即可翻译成肽或蛋白质,特别是nsp,特别是nsp1,或其任一个的片段)重叠或不包含该可翻译的核酸序列。对于“可翻译”的核苷酸序列,需要存在起始密码子;起始密码子编码肽或蛋白质的最n末端的氨基酸残基。在一个实施方案中,复制子的5’复制识别序列不与编码nsp1的n末端片段的可翻译的核酸序列重叠或不包含该可翻译的核酸序列。
在下文中详细描述的一些情况下,rna复制子包含至少一个亚基因组启动子。在一个优选的实施方案中,复制子的亚基因组启动子不与可翻译的核酸序列(即可翻译成肽或蛋白质,特别是nsp,特别是nsp4,或其任一个的片段)重叠或不包含该可翻译的核酸序列。在一个实施方案中,复制子的亚基因组启动子不与编码nsp4的c-末端片段的可翻译核酸序列重叠或不包含该可翻译核酸序列。通过缺失nsp4的编码序列的一部分(通常是编码nsp4的n末端部分的部分)和/或通过去除nsp4编码序列的未缺失的部分中的aug碱基三联体,可以产生具有亚基因组启动子的rna复制子,所述亚基因组启动子不与例如可翻译成nsp4的c末端片段的可翻译的核酸序列重叠或不包含该可翻译的核酸序列。如果去除nsp4或其一部分的编码序列中的aug碱基三联体,则去除的aug碱基三联体优选是潜在的起始密码子。或者,如果亚基因组启动子不与编码nsp4的核酸序列重叠,则可以缺失编码nsp4的整个核酸序列。
在一个实施方案中,rna复制子不包含编码截短的甲病毒非结构蛋白的开放阅读框。在该实施方案的上下文中,特别优选地,rna复制子不包含编码nsp1的n末端片段的开放阅读框,并且任选地不包含编码nsp4的c末端片段的开放阅读框。nsp1的n端片段是截短的甲病毒蛋白;nsp4的c末端片段也是截短的甲病毒蛋白。
在一些实施方案中,根据本发明的复制子不包含甲病毒基因组5’末端的茎环2(sl2)。根据frolov等人(同上),茎环2是存在于甲病毒基因组的5’末端cse2上游的保守二级结构,但对于复制来说是非必要的。
在一个实施方案中,复制子的5’复制识别序列不与编码甲病毒非结构蛋白或其片段的核酸序列重叠。因此,本发明包括这样的复制子,与基因组甲病毒rna相比,其特征在于,如本文中所述去除了至少一个起始密码子,任选地与一种或更多种甲病毒非结构蛋白或其一部分的编码区的缺失相结合。例如,可以缺失nsp2和nsp3的编码区,或者可以缺失nsp2和nsp3的编码区同时缺失nsp1的c末端片段的编码区和/或nsp4的n末端片段的编码区,并且如本文中所述可以去除一个或更多个剩余的起始密码子,即在所述去除之后剩余的。
可通过标准方法来实现一种或更多种甲病毒非结构蛋白的编码区的缺失,例如在dna水平上,通过限制酶切割,优选识别开放阅读框中的唯一的限制位点的限制酶。任选地,可通过诱变(例如定点诱变)将唯一的限制位点引入开放阅读框。相应dna可用作体外转录的模板。
限制位点是对于指导通过特定的限制酶限制(切割)包含限制位点的核酸分子(例如dna分子)来说必要并且充分的核酸序列,例如dna序列。如果在核酸分子中存在一个拷贝的限制位点,则该限制位点对于给定的核酸分子是唯一的。
限制酶是在限制位点处或附近切割核酸分子(例如dna分子)的内切核酸酶。
或者,可通过合成方法获得以缺失开放阅读框的一部分或全部为特征的核酸序列。
根据本发明的rna复制子优选是单链rna分子。根据本发明的rna复制子通常是(+)链rna分子。在一个实施方案中,本发明的rna复制子是分离的核酸分子。
重编程因子和细胞重编程
本发明提供了将一种类型的高度特化的体细胞(例如成纤维细胞或角质形成细胞)通过多能细胞中间体转变成另一种类型(例如神经元细胞)的技术。
具体来说,通过向分化的体细胞提供优选存在于多能细胞类型,优选干细胞,更优选胚胎干细胞中的重编程因子,本发明将细胞的表观遗传记忆恢复到类似于多能干细胞的状态。利用本发明,不必使用、产生或破坏胚胎来产生具有干细胞特征(特别是多能性)的细胞,因此消除了道德上的顾虑。此外,本发明不需要使用整合到基因组中的载体,例如可能在插入位点引入突变的病毒载体。
根据本发明使用的体细胞作为诱导重编程的手段具有优于卵母细胞的重要优点,在于其可在体外容易地扩增数量。另外,本发明允许使用患者特异性的体细胞,因此,在很大程度上消除了对免疫排斥的担忧以及与患者免疫抑制相关的问题。将根据本发明产生的细胞用于自体细胞移植不太可能引起不利的副作用和/或抗性。如果需要,重复进行细胞移植是可行的。然而,由于本发明显著降低了对患者进行免疫抑制以降低急性和超急性排斥的需要,因此也降低了对重复移植程序的需要,降低了疾病治疗的成本。
术语“具有干细胞特征的细胞”在本文中用于表示尽管其源自分化的体非干细胞但仍表现出干细胞(特别是胚胎干细胞)典型的一种或更多种特征的细胞。这样的特征包括胚胎干细胞形态,例如紧凑集落,高细胞核细胞质比例和突出的核仁,正常核型,表达端粒酶活性,表达胚胎干细胞特征性的细胞表面标志物和/或表达胚胎干细胞特征性的基因。胚胎干细胞的特征性的细胞表面标志物例如选自阶段特异性胚胎抗原-3(ssea-3)、ssea-4、肿瘤相关抗原-1-60(tra-1-60)、tra-1-81和tra-2-49/6e。胚胎干细胞特征性的基因选自例如内源性oct4、内源性nanog、生长和分化因子3(gdf3)、降低的表达1(rex1)、成纤维细胞生长因子4(fgf4)、胚胎细胞特异性基因1(esg1)、发育多能性相关2(dppa2)、dppa4和端粒酶逆转录酶(tert)。在一格实施方案中,干细胞典型的一种或更多种特征包括多能性。在一实施方案中,具有干细胞特征的细胞表现出多能状态。在一个实施方案中,具有干细胞特征的细胞具有分化为所有三个原胚层的晚期衍生物的发育潜力。在一个实施方案中,原胚层是内胚层,并且晚期衍生物是肠样上皮组织。在另一个实施方案中,原胚层是中胚层,并且晚期衍生物是横纹肌和/或软骨。在另一个实施方案中,原胚层是外胚层,并且晚期衍生物是神经组织和/或表皮组织。在一个优选的实施方案中,具有干细胞特征的细胞具有分化为神经元细胞和/或心脏细胞的发育潜力。根据本发明,通常术语“具有干细胞特征的细胞”、“具有干细胞特性的细胞”、“干细胞样细胞”、“重编程细胞”和“去分化细胞”或类似术语具有相似的含义并且在本文中可互换使用。
“干细胞”是具有自我更新、保持未分化和开始分化的能力的细胞。干细胞至少在其天然存在的动物的生命中可以无限分裂。干细胞不会终末分化,其不是分化途径的末端。当干细胞分裂时,每个子细胞可保持为干细胞,或者走上导致终末分化的过程。
全能干细胞是具有全能分化特性并能够发育成完整生物体的细胞。在精子使卵母细胞受精之后,直至8细胞阶段的细胞具有这种特性。当这些细胞被分离并移植到子宫中时,它们可以发育成完整的生物体。
多能干细胞是能够发育成源自外胚层、中胚层和内胚层的多种细胞和组织的细胞。来自位于受精后4-5天产生的胚泡内部的内细胞团的多能干细胞被称为“胚胎干细胞”,其可以分化为多种其他组织细胞,但不能形成新的活生物体。
专能干细胞是通常仅分化为其组织和器官特有的细胞类型的干细胞。专能干细胞不仅参与胎儿、新生儿和成年期多种组织和器官的生长和发育,而且还涉及维持成年组织的稳态和组织受损时诱导再生的功能。组织特异性专能细胞统称为“成体干细胞”。
“胚胎干细胞”是存在于或分离自胚胎的干细胞。其可以是多能的,具有分化为生物体中存在的每个和每种细胞的能力,也可以是专能的,具有分化为多于一种细胞类型的能力。
如本文所用,“胚胎”是指处于其发育早期的动物。这些阶段的特征在于着床和原肠胚形成,其中定义和建立了三个胚层,并且在于胚层分化为相应的器官和器官系统。三个胚层是内胚层、外胚层和中胚层。
“胚泡”是处于发育早期的胚胎,其中受精卵已经分裂,并且正在形成或已经形成了围绕着填充有流体的腔的球形细胞层。这种球形细胞层是滋养外胚层。滋养外胚层内部是称为内细胞团(innercellmass,icm)的细胞簇。滋养外胚层是胎盘的前体,而icm是胚胎的前体。
成体干细胞也称为体细胞干细胞,是存在于成体中的干细胞。成年干细胞存在于分化的组织中,可以自我更新,并且可以分化(具有一些限制)以产生其起源组织的特化细胞类型。实例包括间充质干细胞、造血干细胞和神经干细胞。
“分化的细胞”是已经经历了进行性发育变化,成为更特化的形式或功能的成熟细胞。细胞分化是细胞成熟为明显特化的细胞类型时所经历的过程。分化的细胞具有独特的特征,执行特定的功能,并且与分化程度较低的细胞相比,分裂的可能性较小。
“未分化的”细胞(例如未成熟、胚胎或原始细胞)通常具有非特异性的外观,可以执行多种非特异性的活性,并且可能较差地执行(如果有的话)由分化的细胞通常执行的功能。
“体细胞”是指任何和所有分化的细胞,并且不包括干细胞、生殖细胞或配子。优选地,本文所用的“体细胞”是指终末分化细胞。在一实施方案中,体细胞是成纤维细胞(例如肺成纤维细胞、包皮成纤维细胞或真皮成纤维细胞)或角质形成细胞。
在一个实施方案中,体细胞是具有间充质表型的胚胎干细胞来源的体细胞。在一个优选的实施方案中,体细胞是成纤维细胞,例如胎儿成纤维细胞或产后成纤维细胞,或者角质形成细胞,优选毛囊来源的角质形成细胞。在另一些实施方案中,成纤维细胞是肺成纤维细胞、包皮成纤维细胞或真皮成纤维细胞。在特定的实施方案中,所述成纤维细胞是保藏在美国典型培养物保藏中心(atcc)的目录编号为ccl-186、保藏在美国典型培养物保藏中心(atcc)的目录编号为crl-2097或保藏在美国典型培养物保藏中心(atcc)的目录编号为crl-2522、保藏在sbisystembiosciences的目录编号为pc501a-hff、或保藏在innoprot的目录编号为p10857的成纤维细胞。在一实施方案中,成纤维细胞是成人真皮成纤维细胞。优选地,体细胞是人细胞。根据本发明,可对体细胞是经遗传修饰的。
如本文所用,“定向(committed)”是指被认为永久地定向至特定功能的细胞。定向细胞也称为“终末分化细胞”。
如本文所用,“分化”是指细胞适应于编特定形式或功能。在细胞中,分化导致更加定向的细胞。
如本文所用,“去分化”是指形式或功能的特化丧失。在细胞中,去分化导致较低定向的细胞。
如本文所用,“重编程”是指细胞遗传程序的重新设置。重编程细胞优选表现出多能性。
术语“去分化的”和“重编程的”或类似术语在本文中可互换使用,以表示具有干细胞特征的体细胞来源的细胞。然而,所述术语无意通过机械或功能上的考虑来限制本文所公开的主题。
如本文所用,“生殖细胞”是指生殖细胞,例如精母细胞或卵母细胞,或将发育成生殖细胞的细胞。
如本文所用,“多能”是指可以得到除胎盘的细胞或子宫的其他支持细胞以外的任何细胞类型的细胞。
根据本发明,优选地,将能够表达本文所公开的重编程因子的rna复制子引入到体细胞中会导致所述因子表达一段时间以完成重编程过程并导致具有干细胞特征的细胞的发育。优选地,将能够表达本文公开的某些因子的rna引入到体细胞中导致所述因子表达延长的时间,优选至少10天,优选至少11天,更优选至少12天。为了实现这种长期表达,优选将rna定期地引入细胞超过一次,优选使用电穿孔或脂质体转染(lipofection)。优选地,将rna引入细胞至少两次,更优选至少3次,更优选至少4次,甚至更优选至少5次,优选至多6次,更优选至多7次或甚至至多8、9或10次,优选持续至少10天、优选至少11天并且更优选至少12天的一段时间,以确保长时间表达一种或更多种因子。优选地,重复引入rna之间的时间间隔为24小时至120小时,优选48小时至96小时。在一个实施方案中,重复引入rna之间的时间间隔的时间不超过72小时,优选地不超过48小时或36小时。在一个实施方案中,在下一次电穿孔之前,使细胞从先前的电穿孔中恢复。在该实施方案中,重复引入rna之间的时间间隔为至少72小时,优选至少96小时,更优选为至少120小时。在任何情况下,都应选择条件,以使得以支持重编程过程的数量和时间在细胞中表达因子。然而,在一个实施方案中,单次引入rna复制子对于重编程过程和具有干细胞特征的细胞的发育可以是足够的。
对于每种因子,每次转染使用优选至少0.01μg、优选至少0.05μg、优选至少0.1μg、优选至少0.2μg、更优选至少0.3μg、优选至多5μg、更优选至多2μg、更优选至多1μg、更优选至0.5μg、优选0.05至1μg、甚至更优选0.05至0.7μg、或0.05至0.5μg的rna复制子。
优选地,允许具有干细胞特征的细胞发育的步骤包括在胚胎干细胞培养条件下,优选在适于将多能干细胞维持在未分化状态的条件下培养体细胞。
优选地,为了允许具有干细胞特征的细胞发育,在一种或更多种dna甲基转移酶抑制剂和/或一种或更多种组蛋白脱乙酰酶抑制剂的存在下培养细胞。优选的化合物选自5’-氮杂胞苷(5’-azac)、辛二酰苯胺异羟肟酸(saha)、地塞米松、曲古抑菌素a(tsa)、丁酸钠(nabu)、scriptaid和丙戊酸(vpa)。优选地,在丙戊酸(vpa)的存在下培养细胞,丙戊酸的浓度优选为0.5至10mm,更优选为1至5mm,最优选浓度为约2mm。
在本发明的一个优选实施方案中,通过重复电穿孔将rna引入到体细胞中。优选地,如果发生细胞活力损失,则添加先前未电穿孔的细胞作为载体细胞。优选地,在第4次及以后,优选第5次及以后的电穿孔中的一个或更多个之前、期间或之后,例如第4次和第6次电穿孔之前、期间或之后添加先前未电穿孔的细胞。优选地,在第4次或第5次以及每个随后的电穿孔之前、期间或之后添加先前未电穿孔的细胞。优选地,先前未电穿孔的细胞是与引入rna的细胞相同的细胞。
优选地,将能够表达一种或更多种重编程因子的rna复制子引入细胞引起该一种或更多种重编程因子在细胞中的表达。
根据本发明的术语“重编程因子”包括诱导将体细胞重编程为具有干细胞特征的细胞的蛋白质和肽及其衍生物和变体,任选地与其他试剂(例如其他重编程因子)一起。例如,术语“重编程因子”包括oct4、sox2、nanog、lin28、klf4和c-myc。
重编程因子可以是任何动物物种(例如,哺乳动物和啮齿动物)的。哺乳动物的实例包括但不限于人和非人灵长类。灵长类包括但不限于人、黑猩猩、狒狒、食蟹猴和任何其他新世界或旧世界猴(neworoldworldmonkey)。啮齿动物包括但不限于小鼠、大鼠、豚鼠、仓鼠和沙鼠。
在本发明的一个实施方案中,能够允许体细胞重编程为具有干细胞特征的细胞的重编程因子包括选自以下的因子的集合:(i)oct4和sox2,(ii)oct4、sox2、以及nanog和lin28之一或二者,(iii)oct4、sox2、以及klf4和c-myc之一或二者。在一个实施方案中,所述重编程因子包括oct4、sox2、nanog和lin28,oct4、sox2、klf4和c-myc,或者oct4、sox2、klf4、c-myc、nanog和lin28。
oct4是真核pou转录因子的转录因子,并且是胚胎干细胞多能性的指标。其为母体表达的八聚体结合蛋白。已经观察到其存在于卵母细胞、胚细胞的内细胞团以及原始生殖细胞中。基因pou5f1编码oct4蛋白。该基因名称的同义词包括oct3、oct4、otf3和mgc22487。特定浓度oct4的存在对于使胚胎干细胞保持未分化状态是必要的。优选地,“oct4蛋白”或简单地“oct4”涉及人oct4。
sox2是sox(sry相关的hmg盒)基因家族的成员,该家族编码具有单个hmgdna结合结构域的转录因子。已发现sox2通过抑制神经祖细胞的分化能力来控制它们。该因子的抑制导致从心室区分层,随后退出细胞周期。这些细胞还通过丧失祖细胞和早期神经元分化标志物而丧失其祖细胞特征。优选地,“sox2蛋白”或简单地“sox2”涉及人sox2。
nanog是nk-2型同源结构域基因,并且被认为在维持干细胞多能性中起关键作用,大概是通过调节对胚胎干细胞更新和分化至关重要的基因的表达。nanog充当转录激活因子,具有嵌入在其c末端的两个异常强的激活结构域。nanog表达的降低诱导胚胎干细胞的分化。优选地,“nanog蛋白”或简单地“nanog”涉及人nanog。
lin28是一种保守的胞质蛋白,具有不寻常的rna结合基序对:冷休克结构域和一对逆转录病毒型cchc锌指。在哺乳动物中,其在多种类型的未分化细胞中是丰富的。在多能哺乳动物细胞中,在与poly(a)结合蛋白的rnase敏感复合物中以及在蔗糖梯度的多聚核糖体级分(polysomalfraction)中观察到lin28,表明其与翻译mrna相关。优选地,“lin28蛋白”或简单地“lin28”涉及人lin28。
krueppel样因子(klf4)是一种锌指转录因子,其在不同组织(例如结肠、胃和皮肤)的有丝分裂后上皮细胞中强烈表达。klf4对于这些细胞的终末分化是必需的,并且参与细胞周期调节。优选地,“klf4蛋白”或简单地“klf4”涉及人klf4。
myc(cmyc)是在多种人癌症中过表达的原癌基因。当其特异性突变或过表达时,其提高细胞增殖并充当癌基因。myc基因编码转录因子,该转录因子通过结合在增强子盒序列(e-box)以及募集组蛋白乙酰转移酶(hat)来调节所有基因中15%的表达。myc属于myc转录因子家族,该家族还包括n-myc和l-myc基因。myc家族转录因子包含bhlh/lz(基本螺旋-环-螺旋(helix-loop-helix)亮氨酸拉链)结构域。优选地,“cmyc蛋白”或简单地“cmyc”涉及人cmyc。
术语“mirna”(microrna)是指存在于真核细胞中的21-23个核苷酸长的非编码rna,其通过诱导靶mrna的降解和/或阻止其翻译来调节过多的细胞功能,包括与esc自我更新/分化和细胞周期进程相关的那些。mirna是转录后调节因子,其与靶信使rna转录物(mrna)上的互补序列结合,通常导致翻译抑制或靶标降解和基因沉默。已经发现,正确组合的mirna能够在体外诱导体细胞直接细胞重编程为具有干细胞特征的细胞。例如,已经观察到mirna簇302-367(例如簇302a-d/367)增强体细胞重编程。
本文中对特定因子例如oct4、sox2、nanog、lin28、klf4或c-myc的提及应理解为也包括这些因子的所有变体。特别地,应理解为还包括细胞天然表达的这些因子的所有剪接变体、翻译后修饰的变体、构象、同种型和物种同源物。
出于本发明的目的,蛋白质或肽或氨基酸序列的“变体”包括氨基酸插入变体、氨基酸缺失变体和/或氨基酸置换变体。
氨基酸插入变体包括氨基末端和/或羧基末端融合,以及在特定氨基酸序列中插入单个或两个或更多个氨基酸。对于具有插入的氨基酸序列变体,一个或更多个氨基酸残基插入在氨基酸序列的特定位点,尽管随机插入连同所得产物的适当筛选也是可能的。
氨基酸缺失变体的特征在于从序列中去除一个或更多个氨基酸。
氨基酸置换变体的特征在于除去序列中的至少一个残基,并在其位置插入另一个残基。优选地,修饰发生在氨基酸序列中在同源蛋白质或肽之间不保守的位置处和/或将氨基酸置换成具有相似性质的其他氨基酸。
可例如基于所涉及残基的极性、电荷、溶解性、疏水性、亲水性和/或两亲性质的相似性来进行“保守置换”。例如:(a)非极性(疏水)氨基酸包括丙氨酸、亮氨酸、异亮氨酸、缬氨酸、脯氨酸、苯丙氨酸、色氨酸和甲硫氨酸;(b)极性中性氨基酸包括甘氨酸、丝氨酸、苏氨酸、半胱氨酸、酪氨酸、天冬酰胺和谷氨酰胺;(c)带正电荷的(碱性)氨基酸包括精氨酸、赖氨酸和组氨酸;(d)带负电的(酸性)氨基酸包括天冬氨酸和谷氨酸。置换通常可在组(a)-(d)中进行。另外,基于其破坏α-螺旋的能力,甘氨酸和脯氨酸可以彼此置换。一些优选置换可在以下组中进行:(i)s和t;(ii)p和g;以及(iii)a、v、l和i。考虑到已知的遗传密码以及重组和合成dna技术,熟练的科学家可以容易地构建编码保守氨基酸变体的dna。
优选地,本文中所述的特定氨基酸序列与作为所述特定氨基酸序列的变体的氨基酸序列之间的相似性、优选同一性的程度为至少70%,优选至少80%,优选至少85%,甚至更优选至少90%或最优选至少95%、96%、97%、98%或99%。优选对于至少约20、至少约40、至少约60、至少约80、至少约100、至少约120、至少约140、至少约160、至少约200或250个氨基酸的区域给出相似性或同一性的程度。在优选的实施方案中,对于参考氨基酸序列的整个长度给出相似性或同一性的程度。
根据本发明,蛋白质或肽的变体优选具有其来源的蛋白质或肽的功能特性。上面分别针对oct4,sox2,nanog,lin28,klf4和c-myc描述了这样的功能特性。优选地,蛋白质或肽的变体与得到他们的蛋白质或肽在动物分化细胞的重编程中具有相同的性质。优选地,该变体诱导或增强动物分化细胞的重编程。
本发明的方法可用于实现任何类型的体细胞的去分化。可使用的细胞包括可通过本发明的方法去分化或重编程的细胞,特别是完全或部分分化,更优选地终末分化的细胞。优选地,体细胞是来源于胚胎前、胚胎、胎儿和出生后多细胞生物的二倍体细胞。可使用的细胞的实例包括但不限于成纤维细胞,例如胎儿和新生儿成纤维细胞或成体成纤维细胞,角质形成细胞,特别是原代角质形成细胞,更优选来源于以下的角质形成细胞:毛发、b细胞、t细胞、树突状细胞、脂肪细胞、上皮细胞、表皮细胞、软骨细胞、卵丘细胞、神经细胞、胶质细胞、星形胶质细胞、心脏细胞、食管细胞、肌肉细胞、黑素细胞、造血细胞、骨细胞、巨噬细胞、单核细胞和单个核细胞。可使用的细胞的实例包括血液来源的内皮细胞和内皮祖细胞,以及尿来源的上皮细胞。
可用于本发明方法的细胞可以是任何动物物种(例如,哺乳动物和啮齿动物)的。可通过本发明去分化和再分化的哺乳动物细胞的实例包括但不限于人和非人灵长类细胞。可执行本发明的灵长类细胞包括但不限于人、黑猩猩、狒狒、食蟹猴和任何其他新大陆或旧世界猴的细胞。可执行本发明的啮齿动物细胞包括但不限于小鼠、大鼠、豚鼠、仓鼠和沙鼠细胞。
根据本发明的术语“生物”涉及任何能够繁殖或传递遗传物质的生物单位,并且包括植物和动物以及微生物,例如细菌、酵母、真菌和病毒。术语“生物”包括但不限于人类,非人灵长类或其他动物,特别是哺乳动物,例如牛、马、猪、绵羊、山羊、狗、猫或啮齿动物,例如小鼠和鼠。在一个特别优选的实施方案中,生物是人。
预期根据本发明制备的去分化细胞显示出与多能干细胞许多相同的要求,并且可在用于胚胎干细胞的条件下扩增和维持,例如es细胞培养基或支持胚胎细胞生长的任何培养基。当维持在灭活的胎儿成纤维细胞,例如经辐射的小鼠胚胎成纤维细胞或人成纤维细胞(例如人包皮成纤维细胞、人真皮成纤维细胞、人子宫内膜成纤维细胞、人输卵管成纤维细胞)上时,胚胎干细胞在体外保持其多能性。在一个实施方案中,人饲养细胞可以是通过直接分化来源于重编程细胞的相同培养物的自体饲养细胞。
此外,人胚胎干细胞可在小鼠胎儿成纤维细胞调节的培养基中在基质胶上成功繁殖。在特定培养条件下,人干细胞可在培养物中长时间生长并且保持未分化。
在某些实施方案中,细胞培养条件可包括使细胞与可抑制分化或以其他方式增强细胞去分化的因子接触,例如防止细胞分化为非es细胞、滋养外胚层或其他细胞类型。
根据本发明制备的去分化细胞可通过包括监测细胞表型变化和表征其基因和蛋白质表达的方法进行评估。基因表达可通过rt-pcr确定,翻译产物可通过免疫细胞化学和蛋白质印迹确定。特别地,可使用已知的技术(包括转录组学)表征去分化细胞,以确定基因表达的模式,以及重编程的细胞是否显示出与未分化的多能对照细胞(例如胚胎干细胞)预期的表达模式相似的基因表达模式。
在这方面,可评估去分化细胞的以下基因的表达:oct4、nanog、lin28、生长和分化因子3(gdf3)、降低的表达1(rex1)、成纤维细胞生长因子4(fgf4)、胚胎细胞特异性基因1(esg1)、发育多能相关2(dppa2)、dppa4、端粒酶逆转录酶(tert)、胚胎抗原3(ssea-3),ssea-4、肿瘤相关抗原-1-60(tra-1-60)、tra-1-81和tra-2-49/6e。
可与重编程细胞进行比较的未分化或胚胎干细胞可来自与分化的体细胞相同的物种。或者,可与重编程的细胞进行比较的未分化或胚胎干细胞可来自与分化的体细胞不同的物种。
在一些实施方案中,如果在未分化细胞中特异性表达的某些基因也在重编程细胞中表达,则在重编程细胞与未分化细胞(例如胚胎干细胞)之间存在基因表达模式的相似性。例如,在分化的体细胞中通常无法检测到的某些基因(例如端粒酶)可用于监测重编程的程度。同样,对于某些基因,表达的缺失可用于评估重编程的程度。
以端粒酶活性的诱导为标志的自我更新能力是干细胞的另一个特征,其可在去分化细胞中监测。
核型分析可通过有丝分裂细胞的染色体铺展(chromosomespread)、光谱核型分析、端粒长度测定、总基因组杂交或本领域熟知的其他技术来进行。
复制子包含至少一个开放阅读框
根据本发明的rna复制子包含编码重编程因子的开放阅读框,作为编码目的肽或目的蛋白质的开放阅读框,并且可包含编码目的肽或目的蛋白质(例如一种或更多种另外的重编程因子)的一个或更多个另外的开放阅读框,所述一种或更多种另外的重编程因子与第一重编程因子一起形成功能性重编程因子集合。优选地,目的蛋白质由异源核酸序列编码。编码目的肽或蛋白质的基因同义地称为“目的基因”或“转基因”。在多种实施方案中,目的肽或蛋白质由异源核酸序列编码。根据本发明,术语“异源”是指核酸序列不是天然功能上或结构上与甲病毒核酸序列连接的事实。根据本发明的复制子可以编码单一多肽(即重编程因子)或多个多肽(例如多个重编程因子或重编程因子和另一种多肽)。多个多肽可以编码为单个多肽(融合多肽)或分开的多肽。在一些实施方案中,根据本发明的复制子可包含多于一个开放阅读框,每个开放阅读框可以独立地选择为处于亚基因组启动子的控制之下或不受其控制。或者,多蛋白或融合多肽包含由任选的自催化蛋白酶切割位点(例如口蹄疫病毒2a蛋白)或内含肽分隔的单个多肽。
目的蛋白质可例如选自报道蛋白、药物活性肽或蛋白、细胞外ifn与ifn受体结合的抑制剂、细胞内干扰素(ifn)信号转导的抑制剂和功能性甲病毒非结构蛋白。
干扰素(ifn)信号转导抑制剂
由开放阅读框编码的另一合适的目的蛋白质是干扰素(ifn)信号转导的抑制剂。虽然已经报道引入rna以表达的细胞的活力可能降低,特别是如果用rna多次转染细胞的话,但是发现ifn抑制剂增强其中将要表达rna的细胞的活力(wo2014/071963a1)。优选地,抑制剂是i型ifn信号转导的抑制剂。防止细胞外ifn与ifn受体的结合和/或抑制细胞中的细胞内ifn信号转导可使rna在细胞中稳定表达。替代地或另外地,防止细胞外ifn与ifn受体的结合和/或抑制细胞内ifn信号转导可提高细胞的存活,特别是如果用rna重复转染细胞的话。
在一个实施方案中,防止细胞外ifn与ifn受体的结合包括提供细胞外ifn的结合剂,例如细胞外ifn的病毒结合剂。在一实施方案中,细胞外ifn的病毒结合剂是病毒干扰素受体。在一实施方案中,细胞外ifn的病毒结合剂是痘苗病毒b18r。b18r蛋白是痘苗病毒编码的i型干扰素受体,对小鼠、人、兔、猪、大鼠和牛的i型干扰素具有特异性,其具有强大的中和活性。由westernreserve痘苗病毒株的b18r基因编码的b18r蛋白。60-65kd糖蛋白与白介素1受体相关,并且是免疫球蛋白超家族的成员,这与属于ii类细胞因子受体家族的其他i型ifn受体不同。b18r蛋白对人ifnα具有高亲和力(kd,174pm)。在病毒宿主反应调节剂中,b18r蛋白的独特之处在于它以可溶性细胞外和细胞表面蛋白质存在,从而能够阻断自分泌和旁分泌ifn功能。
不希望受理论的束缚,设想细胞内ifn信号转导可导致翻译和/或rna降解的抑制。这可通过抑制一种或更多种ifn诱导型抗病毒活性效应蛋白来解决。ifn诱导型抗病毒活性效应蛋白可选自rna依赖性蛋白激酶(pkr)、2′,5′-寡腺苷酸合成酶(oas)和rnasel。抑制细胞内ifn信号转导可包括抑制pkr依赖性途径和/或oas依赖性途径。合适的目的蛋白质是能够抑制pkr依赖性途径和/或oas依赖性途径的蛋白质。抑制pkr依赖性途径可包括抑制eif2-α磷酸化。抑制pkr可包括用至少一种pkr抑制剂处理细胞。pkr抑制剂可以是pkr的病毒抑制剂。pkr的优选的病毒抑制剂是痘苗病毒e3。如果肽或蛋白质(例如e3、k3)抑制细胞内ifn信号转导,则肽或蛋白质的细胞内表达是优选的。痘苗病毒e3是25kda的dsrna结合蛋白(由基因e3l编码),其结合并隔离dsrna,以阻止pkr和oas的激活。e3可直接与pkr结合并抑制其活性,从而导致eif2-α的磷酸化降低。痘苗病毒基因k3l编码eif2-α亚基的10.5kda同源物,该亚基充当pkr的不可磷酸化伪底物,并竞争性地抑制eif2-α的磷酸化。ifn信号转导的其他合适的抑制剂是单纯疱疹病毒(herpessimplexvirus)icp34.5、托斯卡纳病毒(toscanavirus)nss、家蚕核多角体病毒(bombyxmorinucleopolyhedrovirus)pk2和hcvns34a。
在一个实施方案中,本发明可包括为细胞提供痘苗病毒b18r或其功能变体和痘苗病毒e3或其功能变体或痘苗病毒k3或其功能变体,或二者。托斯卡纳病毒的病毒逃逸蛋白nss(n)是ifn反应的有效抑制剂,并且可用于替代ekb(e3、k3、b18r)以成功进行基于rna的重编程
ifn信号转导的抑制剂可以以编码ifn信号转导的抑制剂的核酸序列(例如rna)的形式提供给细胞。
在一实施方案中,细胞内或细胞外ifn信号转导的抑制剂由mrna分子编码。该mrna分子可包含如本文中所述的非多肽序列修饰性修饰,例如帽(cap)、5’-utr、3’-utr、poly(a)序列、密码子使用的适应。
在一个替代实施方案中,细胞内或细胞外ifn信号转导的抑制剂由复制子编码,优选地反式复制子或如本文中所述的反式复制子。复制子包含允许通过甲病毒复制酶进行复制的核酸序列元件,通常为cse1、cse2和cse4;并且优选地还有允许产生亚基因组转录物的核酸序列元件,即亚基因组启动子,通常包含cse3。复制子可另外包含一种或更多种如本文中所述的非多肽序列修饰性修饰,例如帽、poly(a)序列、密码子使用的适应。如果复制子上存在多个开放阅读框,则ifn信号转导的抑制剂可由它们中的任何一个编码,任选地在亚基因组启动子的控制下或不受其控制。在一个优选的实施方案中,ifn信号转导的抑制剂由rna复制子的最上游开放阅读框编码。当ifn信号转导的抑制剂由rna复制子的最上游开放阅读框编码时,编码ifn信号转导的抑制剂的遗传信息将在rna复制子引入宿主细胞后的早期翻译,并且所得蛋白质可随后抑制ifn信号转导。
功能性甲病毒非结构蛋白
由开放阅读框编码的另一种合适的目的蛋白质是功能性甲病毒非结构蛋白。术语“甲病毒非结构蛋白”包括甲病毒非结构蛋白的每种共翻译或翻译后修饰形式,包括碳水化合物修饰(例如糖基化)和脂质修饰形式。
在一些实施方案中,术语“甲病毒非结构蛋白”是指甲病毒来源的个体非结构蛋白(nsp1、nsp2、nsp3、nsp4)中的任何一个或更多个,或指包含甲病毒来源的多于一种非结构蛋白的多肽序列的多蛋白。在一些实施方案中,“甲病毒非结构蛋白”是指nsp123和/或nsp4。在另一些实施方案中,“甲病毒非结构蛋白”是指nsp1234。在一个实施方案中,由开放阅读框编码的目的蛋白质由全部nsp1、nsp2、nsp3和nsp4组成,成为一个单个的任选可切割的多蛋白:nsp1234。在一个实施方案中,由开放阅读框编码的目的蛋白质由nsp1、nsp2和nsp3组成,成为一个单个的任选可切割的多蛋白:nsp123。在该实施方案中,nsp4可以是另外的目的蛋白质,并且可由另外的开放阅读框编码。
在一些实施方案中,甲病毒非结构蛋白能够例如在宿主下细胞中形成复合物或缔合体(association)。在一些实施方案中,“甲病毒非结构蛋白”是指nsp123(同义为p123)和nsp4的复合物或缔合体。在一些实施方案中,“甲病毒非结构蛋白”是指nsp1、nsp2和nsp3的复合物或缔合体。在一些实施方案中,“甲病毒非结构蛋白”是指nsp1、nsp2、nsp3和nsp4的复合物或缔合体。在一些实施方案中,“甲病毒非结构蛋白”是指选自nsp1、nsp2、nsp3和nsp4的任一种或更多种的复合物或缔合体。在一些实施方案中,甲病毒非结构蛋白至少包含nsp4。
术语“复合物”或“缔合体”是指在空间上邻近的两个或更多个相同或不同的蛋白质分子。复合物的蛋白质优选彼此直接或间接物理或物理化学接触。复合物或缔合体可由多种不同的蛋白质(异多聚体)和/或一种特定蛋白质的多份拷贝组成(同多聚体)组成。在甲病毒非结构蛋白的上下文中,术语“复合物或缔合”描述了至少两个蛋白质分子的多个,其中至少一个是甲病毒非结构蛋白。复合物或缔合体可由一种特定蛋白质的多个拷贝(同多聚体)和/或多种不同蛋白质(异多聚体)组成。在多聚体的情况下,“多”是指多于一个,例如两个、三个、四个、五个、六个、七个、八个、九个、十个或多于十个。
术语“功能性甲病毒非结构蛋白”包括具有复制酶功能的甲病毒非结构蛋白。因此,“功能性甲病毒非结构蛋白”包括甲病毒复制酶。“复制酶功能”包括rna依赖性rna聚合酶(rdrp)的功能,即能够基于(+)链rna模板催化(-)链rna的合成的酶,和/或以基于(-)链rna模板催化(+)链rna的合成的酶。因此,术语“功能性甲病毒非结构蛋白”可以指使用(+)链(例如基因组)rna作为模板合成(-)链rna的蛋白质或复合物,使用基因组rna的(-)链互补链作为模板合成新的(+)链rna的蛋白质或复合物,和/或使用基因组rna的(-)链互补链的片段作为模板合成亚基因组转录物的蛋白质或复合物。功能性甲病毒非结构蛋白可以另外具有一种或更多种其他功能,例如蛋白酶(用于自裂解)、解旋酶、末端腺苷酸转移酶(用于poly(a)尾添加)、甲基转移酶和胍基转移酶(用于为核酸提供5’-帽)、核定位位点、三磷酸酶(gouldetal.,2010,antiviralres.,vol.87pp.111-124;ruppetal.,2015,j.gen.virol.,vol.96,pp.2483-500)。
根据本发明,术语“甲病毒复制酶”是指甲病毒rna依赖性rna聚合酶,包括来自天然存在的甲病毒(存在于自然界中的甲病毒)的rna依赖性rna聚合酶,以及来自甲病毒的变体或衍生物(例如来自减毒甲病毒)的rna依赖性rna聚合酶。在本发明的上下文中,术语“复制酶”和“甲病毒复制酶”可互换使用,除非上下文指示任何特定的复制酶不是甲病毒复制酶。
术语“复制酶”包括甲病毒复制酶的所有变体,特别是翻译后修饰的变体、构象、同种型和同源物,其由甲病毒感染的细胞表达或由已经用编码甲病毒复制酶的核酸转染的细胞表达。此外,术语“复制酶”包括通过重组方法已经产生和可以产生的所有形式的复制酶。例如,可通过重组方法产生包含有助于在实验室中检测和/或纯化复制酶的标签(例如myc-tag、ha-tag或低聚组氨酸标签(his-tag))的复制酶。
任选地,甲病毒复制酶还通过与以下任一种或更多种结合的能力在功能上限定:甲病毒保守序列元件1(cse1)或其互补序列,保守序列元件2(cse2)或其互补序列,保守序列元件3(cse3)或其互补序列,保守序列元件4(cse4)或其互补序列。优选地,复制酶能够与cse2[即,(+)链]和/或cse4[即(+)链]结合,或与cse1的互补序列[即,(-)链]和/或cse3的互补序列[即,(-)链]结合。
复制酶的来源不限于任何特定的甲病毒。在一个优选的实施方案中,甲病毒复制酶包含来自塞姆利基森林病毒,包括天然存在的塞姆利基森林病毒和塞姆利基森林病毒的变体或衍生物(例如减毒塞姆利基森林病毒)的非结构蛋白。在一个替代实施方案中,甲病毒复制酶包含来自辛德比斯病毒,包括天然存在的辛德比斯病毒和辛德比斯病毒的变体或衍生物(例如减毒辛德比斯病毒)的非结构蛋白。在一个替代实施方案中,甲病毒复制酶包含来自委内瑞拉马脑炎病毒(veev),包括天然存在的veev和veev的变体或衍生物(例如减毒veev)的非结构蛋白。在一个替代实施方案中,甲病毒复制酶包含来自基孔肯亚病毒(chikv),包括天然存在的chikv和chikv的变体或衍生物(例如减毒chikv)的非结构蛋白。
复制酶也可包含来自多于一种甲病毒的非结构蛋白。因此,本发明同样包括包含甲病毒非结构蛋白并具有复制酶功能的异源复合物或缔合体。仅出于说明目的,复制酶可包含来自第一甲病毒的一种或更多种非结构蛋白(例如nsp1、nsp2)和来自第二甲病毒的一种或更多种非结构蛋白(nsp3、nsp4)。来自多于一种不同的甲病毒的非结构蛋白可由分开的开放阅读框编码,或可由单一开放阅读框编码为多蛋白,例如nsp1234。
在一些实施方案中,功能性甲病毒非结构蛋白能够在表达功能性甲病毒非结构蛋白的细胞中形成膜复制复合物和/或液泡。
如果功能性甲病毒非结构蛋白(即具有复制酶功能的甲病毒非结构蛋白)由本发明的核酸分子编码,则优选地复制子的亚基因组启动子(如果存在)与所述复制酶相容。在这种情况下相容是指甲病毒复制酶能够识别亚基因组启动子(如果存在)。在一个实施方案中,当亚基因组启动子对于获得复制酶的甲病毒是天然的,即这些序列的天然来源是相同的甲病毒时,可以实现这一点。在一个替代实施方案中,亚基因组启动子不是获得甲病毒复制酶的甲病毒天然的,条件是甲病毒复制酶能够识别亚基因组启动子。换句话说,复制酶与亚基因组启动子相容(跨病毒相容性)。关于源自不同甲病毒的亚基因组启动子和复制酶的跨病毒相容性的实例是本领域已知的。只要存在跨病毒相容性,亚基因组启动子和复制酶的任何组合都是可能的。本发明的技术人员可通过在适合于由亚基因组启动子合成rna的条件下将待测试的复制酶与rna一起孵育来容易地测试跨病毒相容性,其中rna具有待测试的亚基因组启动子。如果产生了亚基因组转录物,则确定亚基因组启动子和复制酶是相容的。跨病毒相容性的多种实例是已知的(strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562的综述)。
在一个实施方案中,甲病毒非结构蛋白不与异源蛋白(例如泛素)编码为融合蛋白。
在本发明中,编码功能性甲病毒非结构蛋白的开放阅读框可提供在rna复制子上,或者可作为单独的核酸分子(例如mrna分子)提供。独立的mrna分子可任选地包含,例如帽、5’-utr、3’-utr、poly(a)序列和/或密码子使用的适应性。如本文针对本发明的系统所述,mrna分子可反式提供。
当在rna复制子上提供编码功能性甲病毒非结构蛋白的开放阅读框时,复制子可以优选地被功能性甲病毒非结构蛋白复制。特别地,编码功能性甲病毒非结构蛋白的rna复制子可被复制子编码的功能性甲病毒非结构蛋白复制。当没有反式提供编码功能性甲病毒非结构蛋白的核酸分子时,该实施方案是特别优选的。在该实施方案中,针对复制子的顺式复制。在一个优选的实施方案中,rna复制子包含编码功能性甲病毒非结构蛋白的开放阅读框以及编码目的蛋白质的另一开放阅读框,并且可被功能性甲病毒非结构蛋白复制。该实施方案特别适用于根据本发明产生目的蛋白质的一些方法。在图5中示出了相应复制子的实例(“顺式复制子δ5atg-rrs”)。
如果复制子包含编码功能性甲病毒非结构蛋白的开放阅读框,则优选地,编码功能性甲病毒非结构蛋白的开放阅读框不与5’复制识别序列重叠。在一个实施方案中,编码功能性甲病毒非结构蛋白的开放阅读框不与亚基因组启动子(如果存在)重叠。在图5中示出了相应复制子的实例(“顺式复制子δ5atg-rrs”)。
如果复制子上存在多个开放阅读框,则功能性甲病毒非结构蛋白可由它们中的任一个编码,任选地处于亚基因组启动子的控制下或不在亚基因组启动子的控制下,优选不在亚基因组启动子的控制下。在一个优选的实施方案中,功能性甲病毒非结构蛋白由rna复制子的最上游开放阅读框编码。当功能性甲病毒非结构蛋白由rna复制子的最上游开放阅读框编码时,编码功能性甲病毒非结构蛋白的遗传信息将在将rna复制子引入宿主细胞后的早期翻译,并且在宿主细胞中,所得蛋白质可随后驱动复制,任并且任选地产生亚基因组转录物。在图5中示出了相应复制子的实例(“顺式复制子δ5atg-rrs”)。
由复制子包含或由反式提供的单独核酸分子包含的编码功能性甲病毒非结构蛋白的开放阅读框的存在允许复制子被复制,并且随后以高水平表达由复制子编码(任选在亚基因组启动子的控制下)的目的基因。与其他转基因表达系统相比,这具有成本优势。因为本发明的复制子可在功能性甲病毒非结构蛋白的存在下复制,所以即使施用相对少量的复制子rna,也可以实现目的基因的高水平表达。少量的复制子rna会积极影响成本。
rna复制子中至少一个开放阅读框的位置
rna复制子适合于任选在亚基因组启动子的控制下表达一种或更多种编码目的肽或目的蛋白质的基因。多种实施方案是可能的。rna复制子上可存在一个或更多个开放阅读框,每个开放阅读框编码目的肽或目的蛋白质。rna复制子的最上游开放阅读框称为“第一开放阅读框”。在一些实施方案中,“第一开放阅读框”是rna复制子的唯一开放阅读框。任选地,在第一开放阅读框的下游可存在一个或更多个另外的开放阅读框。第一开放阅读框下游的一个或更多个另外的开放阅读框以其存在于第一开放阅读框下游的顺序(5’至3’)可称为“第二开放阅读框”、“第三开放阅读框”,依此类推。优选地,每个开放阅读框包含起始密码子(碱基三联体),通常为aug(在rna分子中),对应于atg(在各自的dna分子中)。
如果复制子包含3’复制识别序列,则优选地所有开放阅读框都位于3’复制识别序列的上游。
当将包含一个或更多个开放阅读框的rna复制子引入宿主细胞时,优选地,由于从5’复制识别序列中去除了至少一个起始密码子,因此优选不在第一开放阅读框上游的任何位置起始翻译。因此,复制子可直接用作第一开放阅读框翻译的模板。优选地,复制子包含5’-帽。这有助于直接从复制子表达由第一开放阅读框编码的基因。
在一些实施方案中,复制子的至少一个开放阅读框在亚基因组启动子,优选甲病毒亚基因组启动子的控制下。甲病毒亚基因组启动子非常有效,并且因此适合高水平表达异源基因。优选地,亚基因组启动子是甲病毒中亚基因组转录物的启动子。这意味着亚基因组启动子是甲病毒天然的并且优选控制所述甲病毒中编码一种或更多种结构蛋白的开放阅读框的转录。或者,亚基因组启动子是甲病毒的亚基因启动子的变体;充当宿主细胞中亚基因组rna转录的启动子的任何变体都是合适的。如果复制子包含亚基因组启动子,则优选地复制子包含保守序列元件3(cse3)或其变体。
优选地,在亚基因组启动子控制下的至少一个开放阅读框位于亚基因组启动子的下游。优选地,亚基因组启动子控制包含开放阅读框的转录物的亚基因组rna的产生。
在一些实施方案中,第一开放阅读框在亚基因组启动子的控制下。当第一开放阅读框处于亚基因组启动子的控制下时,其定位类似于在甲病毒基因组中编码结构蛋白的开放阅读框的定位。当第一开放阅读框处于亚基因组启动子的控制下时,由第一开放阅读框编码的基因既可以从复制子中表达,也可以从其亚基因组转录物中表达(后者在存在功能性甲病毒非结构蛋白的存在下)。相应的实施方案由图5中的复制子“δ5atg-rrs”举例说明。优选地,“δ5atg-rrs”在编码nsp4的c-末端片段(*nsp4)的核酸序列中不包含任何起始密码子。分别处于亚基因组启动子控制下的一个或更多个另外的开放阅读框可存在于亚基因组启动子控制下的第一开放阅读框的下游(图5中未显示)。由一个或更多个另外的开放阅读框(例如由第二开放阅读框)编码的基因可从分别处于亚基因组启动子的控制下的一个或更多个亚基因组转录物翻译。例如,rna复制子可包含亚基因组启动子,其控制编码目的第二蛋白的转录物的产生。
在另一些实施方案中,第一开放阅读框不受亚基因组启动子的控制。当第一开放阅读框不受亚基因组启动子控制时,由第一开放阅读框编码的基因可以从复制子表达。相应的实施方案由图5中的复制子“δ5atg-rrsδsgp”例示。分别处于亚基因组启动子的控制下的一个或更多个另外的开放阅读框可存在于第一开放阅读框的下游(对于两种示例性实施方案的示例,参见图5中的“δ5atg-rrs-双顺反子”和“顺式复制子δ5atg-rrs”。可从亚基因组转录物表达由一个或更多个另外的开放阅读框编码的基因。
在包含根据本发明的复制子的细胞中,复制子可通过功能性甲病毒非结构蛋白扩增。另外,如果复制子包含在亚基因组启动子的控制下的一个或更多个开放阅读框,则预期功能性甲病毒非结构蛋白产生一种或更多种亚基因组转录物。功能性甲病毒非结构蛋白可以反式提供,也可由复制子的开放阅读框编码。
如果复制子包含多于一个编码目的蛋白质的开放阅读框,则优选每个开放阅读框编码不同的蛋白质。例如,第二开放阅读框编码的蛋白质不同于第一开放阅读框编码的蛋白质。
在一些实施方案中,由第一和/或另一个开放阅读框,优选由第一开放阅读框编码的目的蛋白质是功能性甲病毒非结构蛋白。在一些实施方案中,由第一和/或另一个开放阅读框,例如,第二个开放阅读框编码的目的蛋白质是重编程因子。
在一个实施方案中,由第一开放阅读框编码的目的蛋白质是功能性甲病毒非结构蛋白。在该实施方案中,复制子优选包含5’-帽。特别地,当由第一开放阅读框编码的目的蛋白质是功能性甲病毒非结构蛋白,并且优选地,当复制子包含5’-帽时,编码功能性甲病毒非结构性蛋白的核酸序列可有效地从复制子翻译,并且所得蛋白质随后可驱动复制子的复制并驱动亚基因组转录物的合成。当不使用或没有与复制子一起存在的码功能性甲病毒非结构蛋白的其他核酸分子时,该实施方案可以是优选的。在该实施方案中,针对复制子的顺式复制。
其中第一开放阅读框编码功能性甲病毒非结构蛋白的一个实施方案通过图5中的“顺式复制子δ5atg-rrs”示例。在编码nsp1234的核酸序列翻译之后,翻译产物(nsp1234或其片段)可充当复制酶并驱动rna合成,即复制子的复制和包含第二开放阅读框(图5中的“转基因”)的亚基因组转录物的合成。
反式复制系统
在另一方面,本发明提供了一种系统,其包含:
表达功能性甲病毒非结构蛋白的rna构建体,
根据本发明的第一方面的rna复制子,其可被功能性甲病毒非结构蛋白反式复制。
在这方面,优选地rna复制子不包含编码功能性甲病毒非结构蛋白的开放阅读框。
因此,本发明提供了包含两种核酸分子的系统:用于表达功能性甲病毒非结构蛋白(即编码功能性甲病毒非结构蛋白)的第一rna构建体;和第二rna分子rna复制子。用于表达功能性甲病毒非结构蛋白的rna构建体在本文中被同义地称为“用于表达功能性甲病毒非结构蛋白的rna构建体”或“复制酶构建体”。
功能性甲病毒非结构蛋白如上文所定义,并且通常由复制酶构建体所包含的开放阅读框编码。由复制酶构建体编码的功能性甲病毒非结构蛋白可以是能够复制复制子的任何功能性甲病毒非结构蛋白。
当将本发明的系统引入细胞,优选真核细胞中时,可以翻译编码功能性甲病毒非结构蛋白的开放阅读框。翻译之后,功能性甲病毒非结构蛋白能够反式复制单独的rna分子(rna复制子)。因此,本发明提供了用于反式复制rna的系统。因此,本发明的系统是反式复制系统。根据第二方面,复制子是反式复制子。
在本文中,反式(例如在反式作用、反式调节的情况下)通常是指“来自不同分子的作用”(即分子间)。其与顺式(例如,在顺式作用、顺式调节的情况下)相反,后者通常意指“来自相同分子的作用”(即,分子内)。在rna合成(包括转录和rna复制)的情况下,反式作用元件包括包含编码能够进行rna合成的酶(rna聚合酶)的基因的核酸序列。rna聚合酶使用第二核酸分子(即编码其的核酸分子以外的核酸分子)作为合成rna的模板。rna聚合酶和包含编码rna聚合酶的基因的核酸序列均被称为“反式”作用于第二核酸分子。在本发明的上下文中,由反式作用rna编码的rna聚合酶是功能性甲病毒非结构蛋白。功能性甲病毒非结构蛋白能够使用为rna复制子的第二核酸分子作为合成rna(包括rna复制子的复制)的模板。可被根据本发明的复制酶反式复制的rna复制子在本文中被同义地称为“反式复制子”。
在本发明的系统中,功能性甲病毒非结构蛋白的作用是扩增复制子和制备亚基因组转录物(如果复制子上存在亚基因组启动子)。如果复制子编码用于表达的目的基因,则可通过改变功能性甲病毒非结构蛋白的水平来反式调节目的基因的表达水平和/或表达持续时间。
最初在1980年代就发现了甲病毒复制酶通常能够反式识别和复制模板rna的事实,但是并未认识到反式复制对于生物医学应用的潜力,尤其是因为反式复制的rna被认为抑制有效复制:其是在被感染细胞中缺陷干扰(defectiveinterfering,di)rna与甲病毒基因组共复制的情况下发现的(barrettetal.,1984,j.gen.virol.,vol.65(pt8),pp.1273-1283;lehtovaaraetal.,1981,proc.natl.acad.sci.u.s.a,vol.78,pp.5353-5357;pettersson,1981,proc.natl.acad.sci.u.s.a,vol.78,pp.115-119)。dirna是在高病毒载量的细胞系感染过程中可能天然存在的反式复制子。di元件非常高效地共复制,使得其降低了亲本病毒的毒力,因此充当了抑制性寄生rna(barrettetal.,1984,j.gen.virol.,vol.65(pt11),pp.1909-1920)。尽管尚未认识到对于生物医学应用的潜力,但是反式复制现象被用在了一些基础研究中,所述研究旨在阐明复制机制,而无需从相同分子顺式表达复制酶;此外,复制酶和复制子的分离也允许涉及病毒蛋白突变体的功能研究,即使各个突变体是功能丧失的突变体(lemmetal.,1994,emboj.,vol.13,pp.2925-2934)。这些功能丧失研究和dirna并未表明基于甲病毒的反式激活系统可最终可适用于治疗目的。
本发明的系统包含至少两种核酸分子。因此,其可包含两种或更多种,三种或更多种,四种或更多种,五种或更多种,六种或更多种,七种或更多种,八种或更多种,九种或更多种或十种或更多种核酸分子,所述核酸分子优选为rna分子。在一个优选的实施方案中,该系统由恰好两种rna分子组成:复制子和复制酶构建体。在替代的优选实施方案中,该系统包含多于一个的复制子,每个复制子优选地编码至少一种目的蛋白质,并且还包含复制酶构建体。在这些实施方案中,由复制酶构建体编码的功能性甲病毒非结构蛋白可作用于每个复制子以分别驱动亚基因组转录物的复制和产生。例如,每个复制子可编码重编程因子。例如,这是有利的,例如如果期望在细胞中表达多于一种重编程因子以形成功能性重编程因子集合的话。
优选地,复制酶构建体缺少至少一个保守序列元件(cse),所述保守序列元件(cse)对于基于(+)链模板的(-)链合成和/或基于(-)链模板的(+)链合成是必需。更优选地,复制酶构建体不包含任何甲病毒保守序列元件(cse)。特别是在甲病毒的四种cse中(strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562;joséetal.,futuremicrobiol.,2009,vol.4,pp.837-856),复制酶构建体上优选不存在以下cse中的任一种或更多种:cse1;cse2;cse3;cse4。特别地,在不存在任何一种或更多种甲病毒的cse的情况下,本发明的复制酶构建体与典型的真核mrna的相似程度远高于其与甲病毒基因组rna的相似程度。
优选地,本发明的复制酶构建体与甲病毒基因组rna的区别至少在于,其不能自我复制和/或不包含在亚基因组启动子的控制下的开放阅读框。当不能自我复制时,复制酶构建体也可以称为“自杀构建体”。
反式复制系统具有以下优点:
首先并且最重要的是,反式复制系统的多功能性使得可在不同时间和/或不同位置设计和/或制备复制子和复制酶构建体。在一个实施方案中,在第一时间点制备复制酶构建体,并在随后的时间点制备复制子。例如,在其制备之后,复制酶构建体可被存储以在以后的时间点使用。与顺式复制子相比,本发明提供了提高的灵活性:本发明的系统可通过将编码新的重编程因子的核酸克隆到复制子中而设计用于治疗。可以从存储中恢复先前制备的复制酶构建体。换句话说,可以独立于任何特定的复制子来设计和制备复制酶构建体。
第二,根据本发明的反式复制子通常是比典型的顺式复制子短的核酸分子。这使得能够更快地克隆编码目的蛋白质的复制子,并提供高产率的目的蛋白质。
本发明系统的另外的优点包括不受核转录以及在两个分开的rna分子上关键遗传信息的存在的影响,这提供了前所未有的设计自由度。考虑到其可相互组合的通用元件,本发明允许针对期望的rna扩增水平、期望的靶生物、期望的目的蛋白质产生水平等优化复制酶表达。对于任何给定的细胞类型-静息或循环、体外或体内,根据本发明的系统允许共转染不同数量或比例的复制子和复制酶构建体。
根据本发明的复制酶构建体优选是单链rna分子。根据本发明的复制酶构建体通常是(+)链rna分子。在一个实施方案中,本发明的复制酶构建体是分离的核酸分子。
根据本发明的rna分子的优选特征
根据本发明的rna分子可任选地以其他特征为特征,例如,5’-帽、5’-utr、3’-utr、poly(a)序列和/或密码子使用的适应。下面描述了细节。
帽
在一些实施方案中,根据本发明的复制子包含5’帽。
在一些实施方案中,根据本发明的复制酶构建体包含5’帽。
术语“5’-帽”、“帽”、“5’-帽结构”、“帽结构”同义使用,是指在存在于某些真核初级转录物(例如前体信使)的5’末端的二核苷酸rna。5’-帽是这样的结构,其中(任选修饰的)鸟苷通过5’至5’三磷酸键(或在某些帽类似物的情况下为经修饰的三磷酸键)结合至mrna分子的第一核苷酸。该术语可以指代常规帽或帽类似物。为了举例说明,一些特定的帽二核苷酸(包括帽类似物二核苷酸)显示在图6中。
“包含5’-帽的rna”或“提供有5’-帽的rna”或“经5’-帽修饰的rna”或“加帽的rna”是指包含5’-帽的rna。例如,提供具有5’-帽的rna可通过在所述5’-帽的存在下dna模板的体外转录来实现,其中所述5’-帽被共转录并入到产生的rna链中,或者可例如通过体外转录产生rna,并且可使用加帽酶(例如痘苗病毒的加帽酶)将5’-帽在转录后连接至rna。在加帽rna中,(加帽)rna分子第一碱基的3’位置通过磷酸二酯键与rna分子的后续碱基(“第二个碱基”)的5’位置相连。
如果期望在将各个rna引入宿主细胞或宿主生物后的早期翻译编码蛋白质的核酸序列,则在rna分子上存在帽是特别优选的。例如,帽的存在允许由rna复制子编码的目的基因在将各个rna引入宿主细胞后的早期被有效地翻译。“早期”通常是指在引入rna后的前1小时内,或前2小时内,或前3小时内。
如果希望在不存在功能性复制酶或者在宿主细胞中仅存在少量水平的复制酶的情况下进行翻译,rna分子上帽的存在也是优选的。例如,即使将编码复制酶的核酸分子引入宿主细胞,在引入后的早期阶段,复制酶的水平通常也较小。
在根据本发明的系统中,优选地,用于表达功能性甲病毒非结构蛋白的rna构建体包含5’-帽。
特别是当根据本发明的rna复制子不是与编码功能性甲病毒非结构蛋白的第二核酸分子(例如mrna)一起使用或提供时,优选地rna复制子包含5’-帽。独立地,当rna复制子与编码功能性甲病毒非结构蛋白的第二核酸分子一起使用或提供时,rna复制子也可包含5’-帽。
术语“常规5’帽”是指天然存在的5’帽,优选7-甲基鸟苷帽。在7-甲基鸟苷帽中,帽的鸟苷是经修饰的鸟苷,其中修饰由7-位的甲基化组成(图6的顶部)。
在本发明的上下文中,术语“5’-帽类似物”是指类似于常规5’-帽但是被修饰以具有稳定rna的能力(如果连接至其的话,优选在体内或细胞中)的分子结构。帽类似物不是常规5’帽。
对于真核mrna,5’-帽已被描述为参与mrna的有效翻译:通常来说,在真核生物中,翻译仅在信使rna(mrna)分子的5’末端开始,除非存在内部核糖体进入位点(ires)。真核细胞能够在细胞核转录过程中提供具有5’-帽的rna:新合成的mrna通常被修饰具有5’-帽结构,例如当转录物达到20至30个核苷酸的长度时。首先,通过具有rna5’-三磷酸酶和鸟苷酸转移酶活性的加帽酶将5’末端核苷酸pppn(ppp代表三磷酸;n代表任何核苷)在细胞中转化为5’gpppn。gpppn随后可在细胞中被具有(鸟嘌呤-7)-甲基转移酶活性的第二种酶甲基化,形成单甲基化的m7gpppn帽。在一个实施方案中,本发明中使用的5’帽是天然5’帽。
在本发明中,天然5’-帽二核苷酸通常选自非甲基化的帽二核苷酸(g(5′)ppp(5′)n;也称为gpppn)和甲基化的帽二核苷酸((m7g(5′)ppp(5′)n;也称为m7gpppn)。m7gpppn(其中n为g)由以下式表示:
本发明的加帽rna可在体外制备,因此不依赖于宿主细胞中的加帽机制。在体外制备加帽rna的最常用方法是在所有四种核糖核苷三磷酸和帽二核苷酸(例如m7g(5′)ppp(5′)g(也称为m7gpppg))的存在下,用细菌或噬菌体rna聚合酶转录dna模板。rna聚合酶通过m7gpppg的鸟苷部分的3’-oh对下一个模板核苷三磷酸(pppn)的亲核攻击而开始转录,产生中间体m7gpppgpn(其中n是rna分子的第二个碱基)。通过在体外转录过程中将帽与gtp的摩尔比设置为5至10,可以抑制竞争性gtp起始产物pppgpn的形成。
在本发明的一些优选实施方案中,5’帽(如果存在的话)是5’帽类似物。如果rna是通过体外转录获得的,例如为体外转录的rna(ivt-rna),则这些实施方案是特别合适的。最初已经描述了帽类似物通过体外转录来促进rna转录物的大规模合成。
对于信使rna,迄今为止一般已经描述了一些帽类似物(合成帽),并且它们都可在本发明的上下文中使用。理想地,选择与较高的翻译效率和/或提高的体外降解抗性和/或提高的体内降解抗性相关的帽类似物。
优选地,使用仅以一种方向并入rna链的帽类似物。pasquinelli等(1995,rnaj.,vol.,1,pp.957-967)表明,在体外转录过程中,噬菌体rna聚合酶使用7-甲基鸟苷单元来起始转录,其中约40-50%的具有帽的转录物具有反向的帽二核苷酸(即初始反应产物为gpppm7gpn)。与具有正确帽的rna相比,具有反向帽的rna在核酸序列翻译成蛋白质方面不起作用。因此,期望以正确的方向并入帽,即产生具有基本上对应于m7gpppgpn等的结构的rna。已经表明,帽-二核苷酸的反向整合被甲基化鸟苷单元的2’-或3’-oh基的取代所抑制(stepinskietal.,2001;rnaj.,vol.7,pp.1486-1495;pengetal.,2002;org.lett.,vol.24,pp.161-164)。与在常规5’-帽m7gpppg的存在下体外转录的rna相比,在这种“抗反向帽类似物”的存在下合成的rna的翻译效率更高。为此,描述了一种帽类似物,其中甲基化鸟苷单元的3’oh基被och3取代,例如holtkampetal.,2006,blood,vol.108,pp.4009-4017(7-甲基(3’-o-甲基)gpppg;抗反向帽类似物(arca))。arca是根据本发明的合适的帽二核苷酸。
在本发明的一个优选的实施方案中,本发明的rna基本上不易脱帽。这很重要,因为通常来说,从引入培养的哺乳动物细胞的合成mrna产生的蛋白质的量受到mrna天然降解的限制。一种用于mrna降解的体内途径始于mrna帽的去除。这种去除由异二聚焦磷酸酶催化,该酶含有调节亚基(dcpl)和催化亚基(dcp2)。催化亚基在三磷酸桥的α和β磷酸酯基团之间切割。在本发明中,可以选择或存在对这种类型的切割不敏感或较不敏感的帽类似物。为此目的合适的帽类似物可选自根据式(i)的帽二核苷酸:
其中r1选自任选取代的烷基、任选取代的烯基、任选取代的炔基、任选取代的环烷基、任选取代的杂环基、任选取代的芳基和任选取代的杂芳基,
r2和r3独立地选自h、卤素、oh和任选取代的烷氧基,或r2和r3一起形成o-x-o,其中x选自任选取代的ch2、ch2ch2、ch2ch2ch2、ch2ch(ch3)和c(ch3)2,或者r2与r2所连接的环的4′位的氢原子组合形成-o-ch2-或-ch2-o-,
r5选自s、se和bh3,
r4和r6独立地选自o、s、se和bh3。
n是1、2或3。
r1、r2、r3、r4、r5、r6的优选实施方案公开在wo2011/015347a1,并且可在本发明中相应地选择。
例如,在本发明的一个优选实施方案中,本发明的rna包含硫代磷酸酯帽类似物。硫代磷酸酯-帽类似物是特定的帽类似物,其中三磷酸链中三个非桥连的o原子之一被s原子替换,即式(i)中的r4、r5或r6之一是s。硫代磷酸酯-帽类似物已经由j.kowalskaetal.,2008,rna,vol.14,pp.1119-1131描述为不希望的脱盖过程的解决方案,从而提高了rna在体内的稳定性。特别地,在5’-帽的β-磷酸酯基团上用硫原子置换氧原子导致针对dcp2的稳定。在本发明优选的该实施方案中,式(i)中的r5为s;并且r4和r6为o。
在本发明的另一个优选实施方案中,本发明的rna包含硫代磷酸酯-帽类似物,其中rna5’-帽的硫代磷酸酯修饰与“抗反向帽类似物”(arca)修饰组合。相应的arca-硫代磷酸酯-帽类似物描述于wo2008/157688a2中,并且它们都可用于本发明的rna中。在该实施方案中,式(i)中的r2或r3中的至少一个不是oh,优选地r2和r3中的一个为甲氧基(och3),并且r2和r3中的另一个优选为oh。在一个优选的实施方案中,β-磷酸酯基团上氧原子被硫原子置换(使得式(i)中的r5为s;并且r4和r6为o)。相信arca的硫代磷酸酯修饰确保了α、β和γ硫代磷酸酯基团在翻译和脱盖机器中都精确定位在帽结合蛋白的活性位点内。这些类似物中的至少一些基本对焦磷酸酶dcp1/dcp2具有抗性。硫代磷酸酯修饰的arca被描述为具有比缺少硫代磷酸酯基团的相应arca高得多的对eif4e的亲和力。
在本发明中特别优选的相应帽类似物(即m2’7,2’-ogppspg)被称为β-s-arca(wo2008/157688a2;kuhnetal.,genether.,2010,vol.17,pp.961-971)。因此,在本发明的一个实施方案中,本发明的rna用β-s-arca修饰。beta-s-arca由以下结构表示:
通常来说,在桥接的磷酸酯处将氧原子替换为硫原子得到硫代磷酸酯非对映体,其基于在hplc上的洗脱模式称为d1和d2。简单地说“β-s-arca的d1非对映体”或“β-s-arca(d1)”是β-s-arca的d2非对映体(β-s-arca(d2))相比首先在hplc柱上洗脱的β-s-arca的非对映体,因此表现出较短的保留时间。wo2011/015347a1中描述了通过hplc确定立体化学构型。
在本发明的第一个特别优选的实施方案中,本发明的rna用β-s-arca(d2)非对映体修饰。β-s-arca的两种非对映体对核酸酶的敏感性不同。已显示具有β-s-arca的d2非对映体的rna几乎完全抵抗dcp2切割(与在未经修饰的arca5’-帽存在下合成的rna相比,只有6%的切割),而具有β-s-arca(d1)5’-帽的rna对dcp2切割表现出中等敏感性(71%切割)。进一步显示,针对dcp2切割的提高的稳定性与哺乳动物细胞中蛋白质表达的增加相关。特别地,已经显示,与就有β-s-arca(d1)帽的rna相比,具有β-s-arca(d2)帽的rna在哺乳动物细胞中更高效地翻译。因此,在本发明的一个实施方案中,本发明的rna用根据式(i)的帽类似物修饰,其特征在于式(i)中包含取代基r5的p原子处的立体化学构型,其对应于β-s-arca的d2非对映异构体的pβ原子处的立体化学构型。在该实施方式中,式(i)中的r5为s;并且r4和r6为o。另外,式(i)中的r2或r3中的至少一个不是oh,优选地r2和r3中的一个为甲氧基(och3),并且r2和r3中的另一个优选为oh。
在第二个特别优选的实施方案中,本发明的rna用β-s-arca(d1)非对映体修饰。已经证明,在将相应加帽的rna转移到未成熟的抗原呈递细胞中时,β-s-arca(d1)非对映体特别适合于提高rna的稳定性,提高rna的翻译效率,延长rna的翻译,提高rna的总蛋白质表达,和/或提高针对所述rna编码的抗原或抗原肽的免疫应答(kuhnetal.,2010,genether.,vol.17,pp.961-971)。因此,在本发明的替代实施方案中,本发明的rna用根据式(i)的帽类似物修饰,其特征在于式(i)中包含取代基r5的p原子处的立体化学构型,其对应于β-s-arca的d1非对映异构体的pβ原子处的立体化学构型。相应的帽类似物及其实施方案描述于wo2011/015347a1和kuhnetal.,2010,genether.,vol.17,pp.961-971中。在wo2011/015347a1中描述其中包含取代基r5的p原子处的立体化学构型对应于对应于β-s-arca的d1非对映异构体的pβ原子处的立体化学构型的任何帽类似物都可用于本发明。优选地,式(i)中的r5为s;并且r4和r6为o。另外,式(i)中的r2或r3中的至少一个不是oh,优选地r2和r3中的一个为甲氧基(och3),并且r2和r3中的另一个优选为oh。
在一个实施方案中,本发明的rna用根据式(i)的5’-帽结构修饰,其中任何一个磷酸酯基团被boranophosphate基团或phosphoroselenoate基团取代。这样的帽在体外和体内都具有提高的稳定性。任选地,相应化合物具有2’-o-或3’-o-烷基(其中烷基优选为甲基);相应的帽类似物称为bh3-arca或se-arca。如wo2009/149253a2中所述,特别适合于mrna加帽的化合物包括β-bh3-arca和β-se-arca。对于这些化合物,优选地是在式(i)中包含取代基r5的p原子处的立体化学构型对应于β-s-arca的d1非对映体的pβ原子处的构型。
utr
术语“非翻译区”或“utr”是指dna分子中转录但不翻译成氨基酸序列的区域,或涉及rna分子(例如mrna分子)中的相应区域。非翻译区(utr)可位于开放阅读框的5’(上游)(5’-utr)和/或开放阅读框的3’(下游)(3’-utr)。
如果存在,则3’-utr位于基因的3’末端,在蛋白质编码区的终止密码子的下游,但是术语“3’-utr”优选不包括poly(a)尾。因此,3’-utr位于poly(a)尾(如果存在)的上游,例如紧邻poly(a)尾。
如果存在,5’-utr位于基因的5’末端,即蛋白质编码区起始密码子的上游。5’-utr位于5’-帽(如果存在)的下游),例如紧邻5’帽。
根据本发明,可将5’和/或3’非翻译区功能性地连接至开放阅读框,从而使这些区域与开放阅读框相关联,方式为使得包含所述开放阅读框的rna的稳定性和/或翻译效率提高。
在一些实施方案中,根据本发明的复制酶构建体包含5’-utr和/或3’-utr。
在一个优选的实施方案中,根据本发明的复制酶构建体包含
(1)5’-utr,
(2)开放阅读框,以及
(3)3’-utr。
utr与rna的稳定性和翻译效率相关。除了涉及本文中所述的5’-帽和/或3’poly(a)尾的结构修饰外,通过选择特定的5’和/或3’非翻译区(utr)可以改善这二者。通常认为utr中的序列元件会影响翻译效率(主要是5’-utr)和rna稳定性(主要是3’-utr)。优选存在具有活性的5’-utr,以提高复制酶构建体的翻译效率和/或稳定性。独立地或另外地,优选存在具有活性的3’-utr,以提高复制酶构建体的翻译效率和/或稳定性。
关于第一核酸序列(例如utr)的术语“为了提高翻译效率而具有活性”和/或“为了提高稳定性而具有活性”是指第一核酸序列能够在与第二核酸序列的共同转录物中改变所述第二核酸序列的翻译效率和/或稳定性,其方式为与不存在所述第一核酸序列时所述第二核酸序列的翻译效率和/或稳定性相比,所述翻译效率和/或稳定性提高。
在一个实施方案中,根据本发明的复制酶构建体包含与对于得到功能性甲病毒非结构蛋白的甲病毒来说异源或非天然的5’-utr和/或3’-utr。这允许根据期望的翻译效率和rna稳定性来设计非翻译区。因此,异源或非天然utr允许高度的灵活性,并且与天然甲病毒utr相比,这种灵活性是有利的。特别地,虽然已知甲病毒(天然)rna也包含5’-utr和/或3’-utr,但是甲病毒utr具有双重功能,即(i)驱动rna复制以及(ii)驱动翻译。尽管甲病毒utr被报道为对于翻译是效率低下的(berben-bloemheuveletal.,1992,eur.j.biochem.,vol.208,pp.581-587),但由于双重功能,其不通常可能不容易被更有效的utr代替。在本发明中,可以选择包含在用于反式复制的复制酶构建物中的5’-utr和/或3’-utr,而独立于其对rna复制的潜在影响。
优选地,根据本发明的复制酶构建体包含不是病毒来源,特别不是甲病毒来源的5’-utr和/或3’-utr。在一个实施方案中,复制酶构建体包含来源于真核5’-utr的5’-utr和/或来源于真核3’-utr的3’-utr。
根据本发明的5’-utr可包含任选地通过接头分开的多于一个核酸序列的任意组合。根据本发明的3’-utr可包含任选地通过接头分开的多于一个核酸序列的任意组合。
根据本发明的术语“接头”涉及添加在两个核酸序列之间以连接所述两个核酸序列的核酸序列。关于接头序列没有特别限制。
3’-utr的长度通常为200至2000个核苷酸,例如500至1500个核苷酸。免疫球蛋白mrna的3’非翻译区相对较短(少于约300个核苷酸),而其他基因的3’非翻译区相对较长。例如,tpa的3’-非翻译区的长度为约800个核苷酸,因子viii的3’-非翻译区的长度为约1800个核苷酸,并且促红细胞生成素的3’-非翻译区的长度为约560个核苷酸。哺乳动物mrna的3’非翻译区通常具有被称为aauaaa六核苷酸序列的同源区域。该序列可以是poly(a)附着信号,通常位于poly(a)附着位点上游10至30个碱基处。3’-非翻译区可包含一个或更多个反向重复序列,其可折叠形成茎环结构,该结构充当外切核糖核酸酶的屏障或与已知提高rna稳定性的蛋白质(例如rna结合蛋白质)相互作用。
人β-珠蛋白3’utr,特别是人β-珠蛋白3’-utr的两个连续的相同拷贝有助于高转录物稳定性和翻译效率(holtkampetal.,2006,blood,vol.108,pp.4009-4017)。因此,在一个实施方案中,根据本发明的复制酶构建体包含人β-珠蛋白3’-utr的两个连续的相同拷贝。因此,其在5’→3’方向包含:(a)任选的5’-utr;(b)开放阅读框;(c)3’-utr;所述3’-utr包含人β-珠蛋白3’-utr、其片段、或人β-珠蛋白3’-utr的变体或其片段的两个连续的相同拷贝。
在一个实施方案中,根据本发明的复制酶构建体包含3’-utr,其具有活性以提高翻译效率和/或稳定性,但不是人β-珠蛋白3’-utr、其片段、或人β-珠蛋白3’-utr的变体或其片段。
在一个实施方案中,根据本发明的复制酶构建体包含5’-utr,其具有活性以提高翻译效率和/或稳定性。
可例如通过体外转录制备含有utr的复制酶构建体。这可通过以允许具有5’-utr和/或3’-utr的rna转录的方式对模板核酸分子(例如dna)进行遗传修饰来实现。
如图5所示,复制子的特征还可在于5’-utr和/或3’-utr。复制子的utr通常是甲病毒utr或其变体。
poly(a)序列
在一些实施方案中,根据本发明的复制子包含3’-poly(a)序列。如果复制子包含保守序列元件4(cse4),则复制子的3’-poly(a)序列优选存在于cse4的下游,最优选紧邻cse4。
在一些实施方案中,根据本发明的复制酶构建体包含3’-poly(a)序列。
根据本发明,在一个实施方案中,poly(a)序列包含以下或基本上由以下组成或由以下组成:至少20个、优选至少26个、优选至少40个、优选至少80个、优选至少100个,并且优选至多500个、优选至多400个、优选至多300个、优选至多200个、特别是至多150个a核苷酸,特别是约120个a核苷酸。在本文中,“基本上由…组成”是指poly(a)序列中的大多数核苷酸,通常按“poly(a)序列”中核苷酸的数量计至少50%、优选至少75%是a核苷酸(腺苷酸),但允许其余核苷酸是a核苷酸以外的核苷酸,例如u核苷酸(尿苷酸)、g核苷酸(鸟苷酸)、c核苷酸(胞苷酸)。在本文中,“由…组成”是指poly(a)序列中的所有核苷酸,即按poly(a)序列中核苷酸的数量计100%是a核苷酸。术语“a核苷酸”或“a”是指腺苷酸。
实际上,已证明约120个a核苷酸的3’poly(a)序列对转染的真核细胞中rna的水平以及从存在于3’poly(a)序列的上游(5’)的开放阅读框翻译的蛋白质的水平具有有益的影响(holtkampetal.,2006,blood,vol.108,pp.4009-4017)。
在甲病毒中,认为至少11个连续的腺苷酸残基或至少25个连续的腺苷酸残基的3’poly(a)序列对于有效合成负链很重要。特别是在甲病毒中,至少25个连续的腺苷酸残基的3’poly(a)序列被理解为与保守序列元件4(cse4)一起起作用以促进(-)链的合成(hardy&rice,j.virol.,2005,vol.79,pp.4630-4639)。
本发明提供了基于在编码链的互补链中包含重复的dt核苷酸(脱氧胸苷酸)dna模板的rna转录过程中(即体外转录的rna的制备过程中)待连接的3’poly(a)序列。编码poly(a)序列的dna序列(编码链)称为poly(a)盒。
在本发明的一个优选实施方案中,存在于dna的编码链中的3’poly(a)盒基本上由da核苷酸组成,但是被具有四种核苷酸(da、dc、dg、dt)的相等分布的随机序列中断。这样的随机序列的长度可以是5至50、优选10至30、更优选10至20个核苷酸。这样的盒在wo2016/005004a1中公开。wo2016/005004a1中公开的任何poly(a)盒都可用于本发明。基本上由da核苷酸组成但是被具有四种核苷酸(da、dc、dg、dt)的相等分布并且长度为例如5至50个核苷酸的poly(a)盒在dna水平上显示质粒dna在大肠杆菌中的恒定繁殖,而在rna水平上仍与支持rna稳定性和翻译效率的有益特性相关。
因此,在本发明的一个优选实施方案中,本文中所述的rna分子中包含的3’poly(a)序列基本上由a核苷酸组成,但是被具有四种核苷酸(a、c、g、u)的相等分布的随机序列中断。这样的随机序列的长度可以是5至50、优选10至30、更优选10至20个核苷酸。
密码子使用
通常来说,遗传密码的简并性将允许rna序列中存在的某些密码子(编码氨基酸的碱基三联体)被其他密码子(碱基三联体)置换,同时保持相同的编码能力(这样替换密码子与被替换密码子编码相同的氨基酸)。在本发明的一些实施方案中,由rna分子包含的开放阅读框的至少一个密码子与该开放阅读框所起源的物种的相应开放阅读框中的相应密码子不同。在该实施方案中,开放阅读框的编码序列被称为是“适应的”或“修饰的”。可以适应复制子包含的开放阅读框的编码序列。替代地或另外地,可以适应由复制酶构建体包含的功能性甲病毒非结构蛋白的编码序列。
例如,当适应开放阅读框的编码序列时,可以选择常用的密码子:wo2009/024567a1描述了核酸分子的编码序列的适应,涉及将稀有密码子置换为更常用的密码子。由于密码子使用的频率取决于宿主细胞或宿主生物,因此这种适应类型适合使核酸序列适合在特定宿主细胞或宿主生物中表达。一般而言,尽管并不总是需要适应开放阅读框的所有密码子,但更常用的密码子通常在宿主细胞或宿主生物中更高效地翻译。
例如,当适应开放阅读框的编码序列时,可通过为每个氨基酸选择具有最高gc富集含量的密码子来改变g(鸟苷酸)残基和c(胞苷酸)残基的含量。据报道,具有富含gc的开放阅读框的rna分子具有降低免疫活化以及改善rna翻译和半衰期的潜力(thessetal.,2015,mol.ther.23,1457-1465)。
当根据本发明的复制子编码甲病毒非结构蛋白时,甲病毒非结构蛋白的编码序列可根据需要进行适应。由于编码甲病毒非结构蛋白的开放阅读框不与复制子的5’复制识别序列重叠,这种自由是可能的。
本发明实施方案的安全特性
单独或以任何合适的组合的以下特性在本发明中是优选的:
优选地,本发明的复制子或系统不是颗粒形成的。这意味着,在通过本发明的复制子或系统接种宿主细胞之后,宿主细胞不产生病毒颗粒,例如下一代病毒颗粒。在一个实施方案中,根据本发明的所有rna分子完全不含编码任何甲病毒结构蛋白(例如核心核衣壳蛋白c、包膜蛋白p62和/或包膜蛋白e1)的遗传信息。在安全性方面,与其中在反式复制辅助rna上编码结构蛋白的现有技术系统相比,本发明的这一方面提供了附加价值(例如,bredenbeeketal.,j.virol,1993,vol.67,pp.6439-6446)。
优选地,本发明的系统不包含任何甲病毒结构蛋白,例如核心核衣壳蛋白c、包膜蛋白p62和/或包膜蛋白e1。
优选地,本发明系统的复制子和复制酶构建体彼此不同。在一实施方案中,复制子不编码功能性甲病毒非结构蛋白。在一个实施方案中,复制酶构建体缺少基于(+)链模板的(-)链合成和/或基于(-)链模板的(+)链合成所需的至少一个序列元件(优选至少一个cse)。在一实施方案中,复制酶构建体不包含cse1和/或cse4。
优选地,根据本发明的复制子或根据本发明的复制酶构建体均不包含甲病毒包装信号。可以去除例如包含在sfv的nsp2的编码区中的甲病毒包装信号(whiteetal.1998,j.virol.,vol.72,pp.4320-4326),例如,通过缺失或突变。去除甲病毒包装信号的合适方法包括nsp2编码区的密码子使用的适应。遗传密码的简并性可允许删除包装信号的功能,而不影响编码的nsp2的氨基酸序列。
在一个实施方案中,本发明的系统是分离的系统。在该实施方案中,该系统不存在于细胞内部,例如哺乳动物细胞内部,或者不存在于病毒衣壳内部,例如在包含甲病毒结构蛋白的衣壳内部。在一个实施方案中,本发明的系统存在于体外。
dna
在另一方面,本发明提供了dna,其包含编码根据本发明的rna复制子,rna复制子集合或系统的核酸序列。根据本发明,代替使用rna,例如用于细胞转染,可使用编码rna的dna,例如用于细胞转染,从而在细胞中产生rna。
优选地,dna是双链的。
在一个优选的实施方案中,dna是质粒。本文中使用的术语“质粒”通常涉及染色体外遗传物质的构建体,通常是环状dna双链体,其可以独立于染色体dna复制。
本发明的dna可包含可被dna依赖性rna聚合酶识别的启动子。这允许编码的rna(例如本发明的rna)在体内或体外转录。ivt载体可以标准化方式用作体外转录的模板。根据本发明优选的启动子的实例是sp6、t3或t7聚合酶的启动子。
在一个实施方案中,本发明的dna是分离的核酸分子。
制备rna的方法
根据本发明的任何rna分子,无论是否是本发明系统的一部分,都可通过体外转录获得。体外转录的rna(ivt-rna)在本发明中特别令人感兴趣。ivt-rna可通过从核酸分子(特别是dna分子)转录获得。本发明的dna分子适合于这样的目的,特别是如果包含可被dna依赖性rna聚合酶识别的启动子时。
根据本发明的rna可在体外合成。这允许在体外转录反应中添加帽类似物。通常来说,poly(a)尾由dna模板上的poly-(dt)序列编码。或者,可在转录后通过酶促实现加帽和poly(a)尾添加。
体外转录方法是技术人员已知的。例如,如wo2011/015347a1中所述,多种体外转录试剂盒是可商购的。
用于产生细胞的方法及由此产生的细胞
在另一些方面,本发明提供了用于产生具有干细胞特征的细胞的方法,其包括用一种或更多种本发明的rna复制子和任选地用于表达功能性甲病毒非结构蛋白的rna构建体转导体细胞。
在一个实施方案中,本发明提供了用于提供具有干细胞特征的细胞的方法,其包括以下步骤:
(i)提供包含体细胞的细胞群,
(ii)提供一个或更多个rna复制子,其中所述一个或更多个rna复制子中的每一个包含编码功能性甲病毒非结构蛋白的开放阅读框,可被所述功能性甲病毒非结构蛋白复制并且包含至少一个编码重编程因子的开放阅读框,(iii)将所述一个或更多个rna复制子引入到所述体细胞中,使得所述细胞表达可用于将体细胞重编程为具有干细胞特征的细胞的重编程因子集合,以及
(iv)允许具有干细胞特征的细胞发育。
在另一个实施方案中,本发明提供了用于提供具有干细胞特征的细胞的方法,其包括以下步骤:
(i)提供包含体细胞的细胞群,
(ii)提供用于表达功能性甲病毒非结构蛋白的rna构建体,
(iii)提供一个或更多个rna复制子,其中所述一个或更多个rna复制子中的每一个可被所述功能性甲病毒非结构蛋白反式复制,并且包含至少一个编码重编程因子的开放阅读框,
(iv)将所述rna构建体和所述一个或更多个rna复制子引入到所述体细胞中,使得所述细胞表达可用于将体细胞重编程为具有干细胞特征的细胞的重编程因子集合,以及
(v)允许具有干细胞特征的细胞发育。
根据本发明,术语“将rna引入到体细胞中”包括并优选涉及其中仅将rna引入一部分细胞并且一部分细胞保持未转染的实施方案。如果将多于一种rna分子引入细胞中,例如多于一种rna复制子或用于表达功能性甲病毒非结构蛋白的rna构建体和一种或更多种rna复制子,则该术语包括并优选涉及其中全部rna仅引入一部分细胞并且一部分细胞保持未被转染或者保持未被全部所述rna分子转染。在任何情况下,如果根据本发明将多于一种rna分子引入细胞,例如,多于一种表达功能性重编程因子的rna复制子或用于表达功能性甲病毒非结构蛋白的rna构建体和一种或更多种rna复制子,则目的是将所有rna分子引入细胞,例如在单个细胞内表达功能性的重编程因子集合。
在一个实施方案中,转染的细胞表达由一种或更多种转染的复制子和/或转染的复制酶构建体编码的功能性甲病毒非结构蛋白和/或由一种或更多种转染的复制子编码的重编程因子。不同的重编程因子可由位于相同rna复制子或不同rna复制子上的不同开放阅读框编码。在后一实施方案中,优选将不同的复制子共转染到细胞中。
在该方法的多种实施方案中,用于表达功能性甲病毒非结构蛋白的rna构建体和/或rna复制子如上文对于本发明的系统所限定,只要rna复制子可被功能性甲病毒非结构蛋白反式复制并包含编码重编程因子的开放阅读框即可。表达功能性甲病毒非结构蛋白的rna构建体和一种或更多种rna复制子可在相同的时间点接种,或者可在不同的时间点接种。在第二种情况下,通常在第一时间点接种用于表达功能性甲病毒非结构蛋白的rna构建体,并且通常在第二随后的时间点接种一种或更多种复制子。在那种情况下,由于复制酶已经在细胞中合成,所以设想了一个或更多个复制子将被立即复制。第二时间点通常在第一时间点之后不久,例如第一时间点后1分钟至24小时。
可接种或转染一种或更多种核酸分子的细胞可以称为“宿主细胞”。根据本发明,术语“宿主细胞”是指可用外源核酸分子转化或转染的任何细胞。术语“细胞”优选是完整细胞,即具有完整膜的细胞,该膜尚未释放其正常的细胞内组分,例如酶、细胞器或遗传物质。完整细胞优选是活细胞,即能够执行其正常代谢功能的活细胞。根据本发明,术语“宿主细胞”包括原核细胞(例如大肠杆菌)或真核细胞(例如人和动物细胞、植物细胞、酵母细胞和昆虫细胞)。特别优选哺乳动物细胞,例如来自人、小鼠、仓鼠、猪、家养动物(包括马、牛、绵羊和山羊)以及灵长类的细胞。这些细胞可以源自多种组织类型,并且包括原代细胞和细胞系。具体的实例包括角质形成细胞、外周血白细胞、骨髓干细胞和胚胎干细胞。在另一些实施方案中,宿主细胞是抗原呈递细胞,特别是树突细胞、单核细胞或巨噬细胞。核酸可以单个或多个拷贝存在于宿主细胞中,并且在一个实施方案中,在宿主细胞中表达。
细胞可以是原核细胞或真核细胞。原核细胞在本文中适合于例如繁殖根据本发明的dna,并且真核细胞在本文中适合于例如表达复制子的开放阅读框。
出于本发明的目的,诸如“转导”或“转染”的术语是指在体外或体内将核酸引入或并入细胞或者核酸被细胞摄取。根据本发明,用本发明核酸转染的细胞可存在于体外或体内,例如细胞可形成患者的器官、组织和/或生物体的一部分。根据本发明,转染可以是瞬时的或稳定的。对于转染的一些应用,转染的遗传物质仅瞬时表达就足够了。由于在转染过程中引入的核酸通常不整合到核基因组中,因此外来核酸将通过有丝分裂被稀释或降解。允许核酸的附加扩增(episomalamplification)的细胞极大降低了稀释率。如果希望转染的核酸实际上保留在细胞及其子细胞的基因组中,则必须进行稳定的转染。rna可以转染到细胞中以瞬时表达其编码蛋白。
根据本发明,可使用任何可用于将核酸引入(即并入、转移或转染)到细胞中的技术。优选地,通过标准技术将核酸(例如rna)转染到细胞中。这样的技术包括电穿孔、脂质体转染和显微注射。在本发明的一个特别优选的实施方案中,通过电穿孔将rna引入细胞。电穿孔或电透化涉及由外部施加的电场引起的细胞质膜的电导率和渗透性的显着增加。其通常在分子生物学中用作将某些物质引入细胞的方式。根据本发明,优选地,将编码蛋白质或肽的核酸引入细胞中导致所述蛋白质或肽的表达。
对于体内细胞的转染,可使用包含核酸的药物组合物。将核酸靶向特定细胞的递送载体可被施用于患者,导致在体内发生转染。
在一个实施方案中,产生细胞的方法是体外方法。在一个实施方案中,产生细胞的方法包括或不包括通过手术或治疗从人或动物对象中去除细胞。
在该实施方案中,可将根据本发明产生的细胞施用于对象。对于对象,细胞可以是自体的、同基因的、同种异体的或异源的。可使用本领域已知的任何方法将细胞(重新)引入对象。
在另一些实施方案中,体细胞可存在于对象(例如患者)中。在这些实施方案中,用于产生具有干细胞特征的细胞的方法是体内方法,其包括向对象施用rna和/或dna分子。
在这方面,本发明还提供了用于在对象中产生具有干细胞特征的细胞的方法,包括以下步骤:
(i)提供一个或更多个rna复制子,其中所述一个或更多个rna复制子中的每一个均包含编码功能性甲病毒非结构蛋白的开放阅读框,可被功能性甲病毒非结构蛋白复制,并且包含至少一个编码重编程因子的开放阅读框,
(ii)向对象施用所述一个或更多个rna复制子,以及
(iii)允许具有干细胞特征的细胞发育。
在该方法的多种实施方案中,rna复制子如上文对本发明的rna复制子所限定,只要rna复制子包含编码功能性甲病毒非结构蛋白的开放阅读框和编码重编程因子的开放阅读框并且可被功能性甲病毒非结构蛋白复制即可。
本发明还提供了用于在对象中产生具有干细胞特征的细胞的方法,其包括以下步骤:
(i)提供用于表达功能性甲病毒非结构蛋白的rna构建体,
(ii)提供一个或更多个rna复制子,其中所述一个或更多个rna复制子中的每一个可被所述功能性甲病毒非结构蛋白反式复制,并且包含至少一个编码重编程因子的开放阅读框,
(iii)向对象施用所述rna构建体和所述一个或更多个rna复制子,以及
(v)允许具有干细胞特征的细胞发育。
在该方法的多种实施方案中,用于表达功能性甲病毒非结构蛋白的rna构建体和/或rna复制子如上文对于本发明的系统中所限定,只要rna复制子可被功能性甲病毒费结构蛋白复制并且包含编码重编程因子的开放阅读框即可。用于表达功能性甲病毒非结构蛋白的rna构建体和一个或更多个rna复制子可在相同的时间点施用,或者替代地可在不同的时间点施用。在第二种情况下,通常在第一时间点施用用于表达功能性甲病毒非结构蛋白的rna构建体,并且通常在第二随后的时间点施用一个或更多个rna复制子。在那种情况下,由于复制酶已经在细胞中合成,所以设想了一个或更多个复制子将被立即复制。第二时间点通常在第一时间点之后不久,例如,第二时间点。第一个时间点后1分钟到24小时。优选地,与用于表达功能性甲病毒非结构蛋白的rna构建体的施用在相同的位点和通过相同的施用途径进行一个或更多个rna复制子的施用,以提高一个或更多个rna复制子和用于表达功能性甲病毒非结构蛋白的rna构建体到达相同的靶组织或细胞的前景。“位点”是指对象身体的位置。合适的位点是例如左臂、右臂等。
在一个实施方案中,可以向对象施用另外的rna分子,优选mrna分子。任选地,另外的rna分子编码适合于抑制ifn的蛋白质,例如e3。任选地,可在施用一种或更多种复制子或复制酶构建体或根据本发明的系统之前施用另外的rna分子。
根据本发明的rna复制子、根据本发明的集、根据本发明的系统、根据本发明的试剂盒或根据本发明的药物组合物中的任一种都可用于根据本发明在对象中产生细胞的方法中。例如,在本发明的方法中,rna可以以如本文中所述的药物组合物的形式或作为裸rna使用。
在本发明的一个实施方案中,功能性重编程因子集合可包含多于一种重编程因子,其必须全部存在于细胞中以实现重编程。因此,本发明涉及其中rna复制子集合编码不同的重编程因子的实施方案。例如,不同的rna复制子可包含编码不同的重编程因子的不同的开放阅读框。可将这些不同的rna复制子(即rna复制子集合)共接种(任选地与用于表达功能性甲病毒非结构蛋白的rna构建体一起)到细胞中,以提供功能性重编程因子集合。
试剂盒
本发明还提供了包含根据本发明的rna复制子、根据本发明的集合或根据本发明的系统的试剂盒。
在一个实施方案中,试剂盒的成分作为单独的实体存在。例如,试剂盒的一种核酸分子可存在于一个实体中,并且试剂盒的另一种核酸可存在于单独的实体中。例如,打开或封闭的容器是合适的实体。封闭的容器是优选的。所使用的容器应优选无rna酶或基本上无rna酶。
在一个实施方案中,本发明的试剂盒包含用于细胞接种和/或施用于人或动物对象的rna。
根据本发明的试剂盒任选地包含标签或其他形式的信息元素,例如电子数据载体。标签或信息元素优选地包含说明书,例如印刷的书面说明书或电子形式的说明书,其任选地可印刷。说明书可涉及试剂盒的至少一种合适的可能用途。
重编程细胞的用途
使用本发明,将编码合适的因子的rna复制子引入一种或更多种体细胞中,例如通过电穿孔或脂质体转染。引入后,优选使用支持维持去分化细胞的条件(即干细胞培养条件)培养细胞。然后可例如在细胞治疗中将去分化细胞施用给对象,或者任选地扩增并且诱导再分化成体细胞,其然后可例如在细胞治疗中施用给对象。因此,可在体外或体内诱导根据本发明获得的去分化细胞分化为一种或更多种期望的体细胞类型。
术语“细胞治疗”(也称为细胞的治疗或细胞疗法)是其中在患者中提供并且优选地向患者施用细胞材料(通常是完整活细胞)的治疗。该术语包括其中供体是与细胞接受者是不同人的同种异体细胞治疗,以及自体细胞治疗。细胞治疗针对多种器官中的许多临床指征,并通过多种细胞递送方式进行。因此,治疗中涉及的具体作用机制是广泛的。但是,细胞通过两种主要原理促进治疗作用:(1)细胞替代受损的组织,从而促进器官或组织功能的改善。这样的一个实例是在心肌梗死后使用细胞替代心肌细胞。(2)细胞具有释放以旁分泌或内分泌方式作用的可溶因子(例如细胞因子、趋化因子和生长因子)的能力。这些因素有助于器官或部位的自愈。这样的实例包括分泌促进血管生成、抗炎和抗凋亡的因子的细胞。
优选地,根据本发明获得的去分化细胞可产生来自三个胚层(即内胚层、中胚层和外胚层)中的任何一个的细胞。例如,去分化细胞可分化为骨骼肌、骨骼、皮肤真皮、结缔组织、泌尿生殖系统、心脏、血液(淋巴细胞)和脾(中胚层);胃、结肠、肝、胰腺、膀胱;尿道内层、气管上皮部分、肺、咽、甲状腺、甲状旁腺、肠(内胚层);或中枢神经系统、视网膜和晶状体、颅和感觉、神经节和神经、色素细胞、头结缔组织、表皮、毛发、乳腺(外胚层)。根据本发明获得的去分化细胞可使用本领域已知的技术在体外或体内进行再分化。
在本发明的一个实施方案中,由本发明的方法得到的重编程的细胞用于产生分化的后代。因此,一方面,本发明提供了用于产生分化细胞的方法,其包括:(i)使用本发明的方法获得重编程的细胞;以及(ii)诱导重编程的细胞分化以产生分化细胞。步骤(ii)可在体内或体外进行。此外,可通过已引入重编程细胞的身体、器官或组织中添加的或原位存在的适当的分化因子的存在来诱导分化。分化细胞可用于获得细胞、组织和/或器官,其有利地用于细胞、组织和/或器官移植的领域。如果需要,可在重编程之前将遗传修饰引入例如体细胞中。本发明的分化细胞优选不具有胚胎干细胞或胚胎生殖细胞的多能性,并且实质上是组织特异性的部分或完全分化细胞。
本发明方法的一个优点是,可在不进行事先选择或纯化或建立细胞系就的情况下使通过本发明获得的重编程细胞分化。因此,在某些实施方案中,使包含重编程细胞的异质细胞群分化成期望的细胞类型。在一个实施方案中,将从本发明的方法获得的细胞混合物暴露于一种或更多种分化因子并在体外培养。
使通过本文公开的方法获得的重编程细胞分化的方法可包括使重编程细胞透化的步骤。例如,在暴露于一种或更多种分化因子或包含分化因子的细胞提取物或其他制剂之前,可使通过本文中所述的重编程技术产生的细胞或包含重编程的细胞的异质混合物透化。
例如,可通过在至少一种分化因子的存在下培养未分化的重编程细胞并从培养物中选择分化细胞来获得分化细胞。分化细胞的选择可以基于表型,例如分化细胞上存在的某些细胞标志物的表达,或通过功能测定(例如,特定分化细胞类型执行一种或更多种功能的能力)。
在另一个实施方案中,通过其dna序列的添加、缺失或修饰对根据本发明重编程的细胞进行了遗传修饰。
根据本发明制备的重编程或去分化细胞或来源自重编程或去分化细胞的细胞可用于研究和治疗。重编程的多能细胞可分化为体内的任何细胞,包括但不限于皮肤细胞、软骨细胞、骨骼肌细胞、心肌细胞、肾细胞、肝细胞、血液细胞和血液形成细胞、血管前体细胞和血管内皮细胞、胰腺β细胞、神经元细胞、神经胶质细胞、视网膜细胞、神经元细胞、肠细胞、肺细胞和肝细胞。
重编程的细胞可用于再生/修复治疗,并可移植到有此需要的患者中。在一实施方案中,细胞是患者自体的。
根据本发明提供的重编程的细胞可用于例如治疗心脏、神经、内分泌、血管、视网膜、皮肤病、肌肉骨骼疾病和其他疾病的治疗策略。
例如但不作为限制,本发明的重编程细胞可用于补充动物中的细胞,这些动物的天然细胞由于年龄或消融治疗(例如癌症放射治疗和化学治疗)而被耗尽。在另一个非限制性实例中,本发明的重编程细胞可用于器官再生和组织修复。在本发明的一个实施方案中,重编程的细胞可用于使受损的肌肉组织恢复活力,包括营养不良的肌肉和由于缺血性事件(例如心肌梗死)而受损的肌肉。在本发明的另一个实施方案中,本文公开的重编程细胞可用于减轻创伤或手术后动物(包括人)的瘢痕形成。在该实施方案中,将本发明的重编程细胞全身施用(例如静脉内施用),并且其通过受损细胞分泌的循环细胞因子被而募集迁移至新受创组织的部位。在本发明的另一个实施方案中,可将重编程的细胞局部施用于需要修复或再生的治疗部位。
药物组合物
本文中所述的试剂和组合物(例如核酸和细胞)可以以任何合适的药物组合物的形式施用。
本发明的药物组合物优选是无菌的,并包含有效量的本文中所述的试剂和任选地本文中所述的其他试剂以产生期望的反应或期望的效果。
药物组合物通常以均匀剂型提供,并且可以以本身已知的方式制备。药物组合物可例如是溶液或混悬液的形式。
药物组合物可包含盐、缓冲物质、防腐剂、载体、稀释剂和/或赋形剂,所有这些优选是可药用的。术语“可药用的”是指不与药物组合物的活性成分的作用相互作用的无毒材料。
非可药用盐可用于制备可药用盐,并且包括在本发明中。这种可药用盐包括但不限于由以下酸制备的那些盐:盐酸、氢溴酸、硫酸、硝酸、磷酸、马来酸、乙酸、水杨酸、柠檬酸、甲酸、丙二酸、琥珀酸等。可药用盐也可以制备为碱金属盐或碱土金属盐,例如钠盐、钾盐或钙盐。
用于药物组合物中的合适的缓冲物质包括乙酸盐、柠檬酸盐、硼酸盐和磷酸盐。
用于药物组合物中的合适的防腐剂包括苯扎氯铵、氯丁醇、对羟基苯甲酸酯和硫柳汞。
注射剂可包含可药用赋形剂,例如乳酸林格液。
术语“载体”是指天然或合成性质的有机或无机组分,活性成分组合在其中以促进、增强或能够施用。根据本发明,术语“裁体”还包括一种或更多种适合施用于患者的相容的固体或液体填充剂、稀释剂或包囊物质。
用于肠胃外施用的可能的载体物质是例如无菌水、林格液、乳酸林格液、无菌氯化钠溶液、聚亚烷基二醇、氢化萘,并且尤其是生物相容性丙交酯聚合物、丙交酯/乙交酯共聚物或聚氧乙烯/聚氧丙烯共聚物。
当在本文中使用时,术语“赋形剂”旨在表示可能存在于药物组合物中且不是活性成分的所有物质,例如载体、黏合剂、润滑剂、增稠剂、表面活性剂、防腐剂、乳化剂、缓冲剂、矫味剂或着色剂。
在一个实施方案中,如果药物组合物包含核酸,则其包含至少一种阳离子实体。通常来说,阳离子脂质、阳离子聚合物和其他带有正电荷的物质可与带负电荷的核酸形成复合物。通过与阳离子化合物,优选聚阳离子化合物,例如阳离子或聚阳离子肽或蛋白质复合,可使根据本发明的rna稳定。在一个实施方案中,根据本发明的药物组合物包含选自鱼精蛋白、聚乙烯亚胺、聚-l-赖氨酸、聚-l-精氨酸、组蛋白或阳离子脂质的至少一种阳离子分子。
根据本发明,阳离子脂质是阳离子两亲性分子,例如包含至少一个亲水和亲脂部分的分子。阳离子脂质可以是单阳离子或聚阳离子的。阳离子脂质通常具有亲脂性部分,例如固醇、酰基或二酰基链,并且具有总的净正电荷。脂质的头基通常带有正电荷。阳离子脂质优选具有1至10价的正电荷,更优选具有1至3价的正电荷,并且更优选具有1价的正电荷。阳离子脂质的实例包括但不限于1,2-二-o-十八碳烯基-3-三甲基铵丙烷(dotma);二甲基双十八烷基铵(ddab);1,2-二油酰基-3-三甲基铵丙烷(dotap);1,2-二油酰基-3-二甲基铵丙烷(dodap);1,2-二酰氧基-3-二甲基铵丙烷;1,2-二烷氧基-3-二甲基铵丙烷;双十八烷基二甲基氯化铵(dodac),1,2-二肉豆蔻酰氧基丙基-1,3-二甲基羟乙基铵(dmrie)和2,3-二油酰氧基-n-[2(精胺羧酰胺)乙基]-n,n-二甲基-1-丙烷三氟乙酸盐(dospa)。阳离子脂质还包括具有叔胺基的脂质,包括1,2-dilinoleyl氧基-n,n-二甲基-3-氨基丙烷(dlindma)。阳离子脂质适合于在本文中所述的脂质制剂中配制rna,例如脂质体、乳剂和脂质复合物。通常来说,正电荷由至少一种阳离子脂质贡献,并且负电荷由rna贡献。在一个实施方案中,药物组合物除阳离子脂质外还包含至少一种辅助脂质。辅助脂质可以是中性或阴离子脂质。辅助脂质可以是天然脂质,例如磷脂,或天然脂质的类似物,或完全合成的脂质,或与天然脂质没有相似性的类脂质分子。在药物组合物同时包含阳离子脂质和辅助脂质的情况下,可以考虑制剂的稳定性等适当确定阳离子脂质与中性脂质的摩尔比。
在一个实施方案中,根据本发明的药物组合物包含鱼精蛋白。根据本发明,鱼精蛋白可用作阳离子载体剂。术语“鱼精蛋白”是指多种相对低分子量的强碱性蛋白质中的任一种,其富含精氨酸,并且被发现特别是与dna相关联,以代替动物(例如鱼)的精细胞中的体细胞组蛋白。特别地,术语“鱼精蛋白”是指存在于鱼精液中的蛋白质,其是强碱性的,可溶于水,不被热凝结并且包含多个精氨酸单体。根据本发明,本文所用的术语“鱼精蛋白”意指包括从天然或生物来源获得或来源的任何鱼精蛋白氨基酸序列,包括其片段和所述氨基酸序列或其片段的多聚体形式。此外,该术语涵盖(合成的)多肽,这些多肽是人工的并且是为特定目的而专门设计的,并且不能从天然或生物学来源中分离。
可以缓冲根据本发明的药物组合物(例如,用乙酸盐缓冲液、柠檬酸盐缓冲液、琥珀酸盐缓冲液、tris缓冲液、磷酸盐缓冲液)。
含rna的颗粒
在一些实施方案中,由于未保护的rna的不稳定性,所以有利的是以复合或包封形式提供本发明的rna分子。本发明提供了相应的药物组合物。特别地,在一些实施方案中,本发明的药物组合物包含含核酸的颗粒,优选含rna的颗粒。相应的药物组合物称为颗粒制剂。在根据本发明的颗粒制剂中,颗粒包含根据本发明的核酸和适合于递送核酸的可药用载体或可药用载剂。含核酸的颗粒可以是例如蛋白质颗粒的形式或含脂质的颗粒的形式。合适的蛋白质或脂质称为颗粒形成剂。先前已经描述了蛋白质颗粒和含脂质颗粒适于以颗粒形式递送甲病毒rna(例如strauss&strauss,microbiol.rev.,1994,vol.58,pp.491-562)。特别地,甲病毒结构蛋白(例如由辅助病毒提供)是用于以蛋白质颗粒形式递送rna的合适载体。
当将根据本发明的系统配制为颗粒制剂时,可将每种rna物质(例如复制子、复制酶构建体和任选的附加rna物质,例如编码适合抑制ifn的蛋白质的rna)分别配制为个体颗粒制剂。在那种情况下,每种个体颗粒制剂将包含一种rna物质。个体颗粒制剂可以作为分开的实体存在,例如在分开的容器中。通过分别将每种rna物质(通常各自以含rna溶液的形式)与颗粒形成剂一起提供以允许形成颗粒,可获得这样的制剂。各颗粒将仅包含形成颗粒时提供的特定rna物质(单独颗粒制剂)。
在一个实施方案中,根据本发明的药物组合物包含多于一种个体颗粒制剂。相应药物组合物称为混合颗粒制剂。通过分别形成如上所述的个体颗粒制剂然后将个体颗粒制剂混合在一起的步骤,可获得根据本发明的混合颗粒制剂。通过混合步骤,可获得包含混合的含rna的颗粒群的一种制剂(举例说明:例如,第一颗粒群可包含根据本发明的复制子,并且第二颗粒制剂可包含根据本发明的复制酶构建体)。个体颗粒群可以一起在包含个体颗粒制剂的混合群的一个容器中。
或者,可将药物组合物的所有rna物质(例如复制子、复制酶构建体和任选的其他物质,例如编码适合抑制ifn的蛋白质的rna)一起配制为组合颗粒制剂。这样的制剂可通过提供所有rna物质和颗粒形成剂一起的组合制剂(通常为组合溶液)以形成颗粒制剂来形成。与混合颗粒制剂相反,组合颗粒制剂通常将包含含有多于一种rna物质的颗粒。在组合的微粒组合物中,不同的rna物质通常一起存在于单个颗粒中。
在一个实施方案中,本发明的颗粒制剂是纳米颗粒制剂。在该实施方案中,根据本发明的集合物包含纳米颗粒形式的根据本发明的核酸。纳米颗粒制剂可通过各种方案和各种络合化合物获得。脂质、聚合物、低聚物或两亲性物质是纳米微粒制剂的典型成分。
如本文所用,术语“纳米颗粒”是指具有使颗粒适合于全身,尤其是肠胃外施用的直径的任何颗粒,特别是直径通常为1000纳米(nm)或更小的核酸。在一个实施方案中,纳米颗粒的平均直径为约50nm至约1000nm,优选约50nm至约400nm,优选约100nm至约300nm,例如约150nm至约200nm。在一个实施方案中,纳米颗粒的直径为约200至约700nm,约200至约600nm,优选约250至约550nm,特别是约300至约500nm或约200至约400nm。
在一个实施方案中,通过动态光散射测量的本文中所述的纳米颗粒的多分散指数(pi)为0.5或更小,优选0-4或更小,或者甚至更优选0.3或更小。“多分散指数”(pi)是颗粒混合物中单个颗粒(例如脂质体)的均匀或不均匀尺寸分布的量度,并指示混合物中颗粒分布的宽度。例如,可以如wo2013/143555a1中所述确定pi。
如本文所用,术语“纳米颗粒制剂”或类似术语是指包含至少一个纳米颗粒的任何颗粒制剂。在一些实施方案中,纳米颗粒组合物是纳米颗粒的均匀集合。在一些实施方案中,纳米颗粒组合物是含脂质的药物制剂,例如脂质体制剂或乳剂。
含脂质药物组合物
在一个实施方案中,本发明的药物组合物包含至少一种脂质。优选地,至少一种脂质是阳离子脂质。所述含脂质的药物组合物包含根据本发明的核酸。在一个实施方案中,根据本发明的药物组合物包含包封在囊泡(例如脂质体)中的rna。在一个实施方案中,根据本发明的药物组合物包含乳剂形式的rna。在一个实施方案中,根据本发明的药物组合物包含与阳离子化合物复合的rna,从而形成例如所谓的脂质复合物(lipoplex)或多聚复合物(polyplex)。rna包封在载剂(例如脂质体)中不同于例如脂质/rna复合物。脂质/rna复合物可例如在rna例如与预先形成的脂质体混合时获得
在一个实施方案中,根据本发明的药物组合物包含包封在囊泡中的rna。这样的制剂是根据本发明的特定的颗粒制剂。囊泡是卷成球形壳的脂双层,其封闭小的空间并且将该空间与囊泡外部的空间分隔开。通常来说,囊泡内部的空间是水性空间,即包含水。通常来说,囊泡外部的空间是水性空间,即包含水。脂质双层由一种或更多种脂质(形成囊泡的脂质)形成。包围囊泡的膜是层状相,类似于质膜。根据本发明的囊泡可以是多层囊泡、单层囊泡或其混合物。当包封在囊泡中时,rna通常与任何外部介质分离。因此,其以受保护的形式存在,功能上等同于天然甲病毒中的受保护形式。合适的囊泡是如本文中所述的颗粒,特别是纳米颗粒。
例如,rna可被包封在脂质体中。在该实施方案中,药物组合物是或包含脂质体制剂。脂质体中的包封通常会保护rna免受rnase消化。脂质体可包含一些外部rna(例如在其表面上),但是至少一半的rna(理想地是全部)包封在脂质体的核心内。
脂质体是微观的脂质囊泡,通常具有形成囊泡的脂质(例如磷脂)的一个或更多个双层,并且能够包封药物,例如rna。在本发明的上下文中可使用不同类型的脂质体,包括但不限于多层囊泡(multilamellarvesicle,mlv)、小单层囊泡(smallunilamellarvesicle,suv)、大单层囊泡(largeunilamellarvesicle,luv)、空间稳定脂质体(stericallystabilizedliposome,ssl)、多囊囊泡(multivesicularvesicle,mv)和大多囊囊泡(largemultivesicularvesicle,lmv)以及本领域已知的其他双层形式。脂质体的大小和层状性(lamellarity)将取决于制备方式。存在超分子组织的多种其他形式的,其中脂质可存在于水性介质中,包括由单层构成的层状相、六方相和反六方相、立方相、胶束、反胶束。这些相也可与dna或rna组合获得,并且与rna和dna的相互作用可能会显着影响相态。这样的相可存在于本发明的纳米颗粒rna制剂中。
可使用技术人员已知的标准方法形成脂质体。相应方法包括反向蒸发法、乙醇注入法、脱水-再水化法、超声处理或其他合适的方法。在脂质体形成之后,可对脂质体进行大小调整以获得具有基本均一大小范围的脂质体群体。
在本发明的一个优选的实施方案中,rna存在于包含至少一种阳离子脂质的脂质体中。相应脂质体可由单一脂质或脂质混合物形成,只要使用至少一种阳离子脂质即可。优选的阳离子脂质具有能够被质子化的氮原子。优选地,这样的阳离子脂质是具有叔胺基的脂质。具有叔胺基的特别合适的脂质是1,2-dilinoleyl氧基-n,n-二甲基-3-氨基丙烷(dlindma)。在一个实施方案中,根据本发明的rna存在于如wo2012/006378a1中所述的脂质体制剂中:具有脂双层的脂质体,所述脂双层包封包含rna的水性核心,其中脂双层包含pka为5.0至7.6的脂质,其优选具有叔胺基。具有叔胺基的优选的阳离子脂质包括dlindma(pka5.8),并且一般在wo2012/031046a2中描述。根据wo2012/031046a2,包含相应化合物的脂质体特别适合于rna的包封,并因此适合rna的脂质体递送。在一个实施方案中,根据本发明的rna存在于脂质体制剂中,其中脂质体包含至少一种阳离子脂质,其阳离子基团包含至少一个能够被质子化的氮原子(n),其中脂质体和rna的n∶p比率为1∶1至20∶1。根据本发明,“n∶p比率”是指包含脂质的颗粒(例如脂质体)中包含的阳离子脂质中的氮原子(n)与rna中的磷酸盐原子(p)的摩尔比,如wo2013/006825a1。n∶p比率1∶1至20∶1与脂质体的净电荷和rna向脊椎动物细胞的递送效率相关。
在一个实施方案中,根据本发明的rna存在于脂质体制剂中,所述脂质体制剂包含至少一种脂质,所述脂质包含聚乙二醇(peg)部分,其中rna被包封在peg化脂质体中,使得peg部分存在于脂质体外部,如wo2012/031043a1和wo2013/033563a1中所述。
在一个实施方案中,根据本发明的rna存在于脂质体制剂中,其中脂质体的直径为60-180nm,如wo2012/030901a1中所述。
在一个实施方案中,根据本发明的rna存在于脂质体制剂中,其中含rna的脂质体的净电荷接近于零或为负,如wo2013/143555a1中所公开。
在另一些实施方案中,根据本发明的rna以乳剂的形式存在。先前已经描述了乳剂用于将核酸分子(例如rna分子)递送至细胞。本文优选的是水包油乳剂。相应乳剂颗粒包含油核心和阳离子脂质。更优选阳离子水包油乳剂,其中根据本发明的rna与乳剂颗粒复合。乳剂颗粒包含油核心和阳离子脂质。阳离子脂质可与带负电荷的rna相互作用,从而将rna锚定至乳剂颗粒。在水包油乳剂中,乳剂颗粒分散在水连续相中。例如,乳剂颗粒的平均直径通常可以为约80nm至180nm。在一个实施方案中,本发明的药物组合物是阳离子水包油乳剂,其中乳剂颗粒包含油核心和阳离子脂质,如wo2012/006380a2中所述。根据本发明的rna可以以包含阳离子脂质的乳剂形式存在,其中乳剂的n∶p比率为至少4∶1,如wo2013/006834a1中所述。根据本发明的rna可以如wo2013/006837a1中所述的阳离子脂质乳剂的形式存在。特别地,组合物可包含与阳离子水包油乳剂颗粒复合的rna,其中油/脂质的比率为至少约8∶1(摩尔:摩尔)。
在另一些实施方案中,根据本发明的药物组合物包含脂质复合物形式的rna。术语“脂质复合物”或“rna脂质复合物”是指脂质与核酸(例如rna)的复合物。脂质体可由阳离子(带正电)脂质体和阴离子(带负电)核酸形成。阳离子脂质体还可包括中性的“辅助”脂质。在最简单的情况下,通过以一定的混合方案将核酸与脂质体混合而自发形成脂质复合物,但是可以应用多种其他方案。应当理解,带正电荷的脂质体和带负电荷的核酸之间的静电相互作用是脂质复合物形成的驱动力(wo2013/143555a1)。在本发明的一个实施方案中,rna脂质复合物颗粒的净电荷接近零或为负。已知rna和脂质体的电中性或带负电荷的脂质复合物在全身施用后导致脾树突状细胞(dc)中大量rna表达,并且与对于带正电荷的脂质体和脂质复合物已报道的升高的毒性无关(参见wo2013/143555a1)。因此,在本发明的一个实施方案中,根据本发明的药物组合物包含纳米颗粒,优选脂质复合物纳米颗粒形式的rna,其中(i)纳米颗粒中的正电荷数量不超过纳米颗粒中的负电荷数量,和/或(ii)纳米粒子具有中性或净负电荷,和/或(iii)纳米颗粒中正电荷与负电荷的电荷比为1.4∶1或更小,和/或(iv)纳米粒子的ζ电势为0或更小。如wo2013/143555a1中所述,ζ电势是胶体系统中电动势的科学术语。在本发明中,可以如wo2013/143555a1中公开的那样计算纳米颗粒中的(a)ζ电势和(b)阳离子脂质与rna的电荷比二者。总之,如wo2013/143555a1中公开的具有限定的粒径并且其中颗粒的净电荷接近接近零或为负的纳米颗粒脂质复合物制剂是本发明上下文中优选的药物组合物。
治疗性治疗
考虑到向对象施用的能力,根据本发明的每种rna复制子、根据本发明的集合、根据本发明的系统、根据本发明的dna、根据本发明的细胞、根据本发明的试剂盒或根据本发明的药物组合物可被称为“药物”等。本发明预见了提供本发明的rna复制子、集合、系统、dna、细胞、试剂盒或药物组合物以用作药物。
该药物可用于治疗对象。“治疗”是指向对象施用本文中所述的化合物或组合物或其他实体。该术语包括通过治疗治疗人体或动物体的方法。
术语“治疗”或“治疗性治疗”优选地涉及改善个体的健康状况和/或延长(提高)个体的寿命的任何治疗。所述治疗可消除个体中的疾病,阻止或减缓个体中疾病的发展,抑制或减缓个体中疾病的发展,降低个体中症状的频率或严重性,和/或降低当前患有或先前患有疾病的个体中的复发。
术语“预防性治疗”或“预防治疗”涉及旨在防止疾病在个体中发生的任何治疗。术语“预防性治疗”或“预防治疗”在本文中可互换使用。
特别地,细胞(例如本文中所述的去分化细胞或分化细胞)可用于细胞移植,并且特别是治疗疾病,其中提供这些细胞可导致对疾病的预防性或预防治疗。
因此,本文中所述的试剂、组合物和方法可用于治疗患有疾病(例如以细胞损失或变性为特征的疾病)的对象。本文中所述的试剂、组合物和方法也可用于预防本文中所述的疾病。
术语“疾病”是指影响个体身体的异常状况。疾病通常被解释为与特定症状和体征相关的医学状况。疾病可由最初来自外部来源的因素引起,例如感染性疾病,或者其可由内部功能障碍引起,例如自身免疫病。在人类中,“疾病”通常被更广泛地用于指引起受影响个体的疼痛、功能障碍、痛苦、社会问题或死亡或者与所述个体接触的人的类似问题的状况。从广义上讲,其有时包括伤害、残疾、障碍、综合症、感染、孤立的症状、行为异常以及结构和功能的非典型变化,而在其他情况下和出于其他目的,这些可能被视为可区分的类别。疾病通常不仅会在身体上而且会在情感上影响个人,因为感染以及在许多疾病下生活改变个人对生活的观点,以及个人的性格。
术语“个体”和“对象”在本文中可互换使用。他们是指人类、非人灵长类或其他哺乳动物(例如小鼠、大鼠、兔、狗、猫、牛、猪、绵羊、马或灵长类),其可能遭受或易感于疾病或障碍(例如癌症),但是可能患有或未患有疾病或障碍。在许多实施方案中,个体是人类。除非另有说明,否则术语“个体”和“对象”不表示特定年龄,因此包括成年人、老年人、儿童和新生儿。在本发明的优选实施方式中,“个体”或“对象”是“患者”。根据本发明,术语“患者”是指待治疗的对象,特别是患病的对象。
预防性施用本发明的试剂或组合物优选地保护接受者免于出现疾病。本发明的试剂或组合物的治疗性施用可导致疾病进展的抑制。这包括疾病进展的减速,特别是疾病进展的中断,其优选导致疾病的消除。
本文中所述的试剂和组合物可通过任何常规途径施用,例如通过肠胃外施用,包括通过注射或输注。施用优选是肠胃外的,例如肠胃外、静脉内、动脉内、皮下、皮内或肌内。
适用于肠胃外施用的组合物通常包含活性化合物的无菌水性或非水性制剂,其优选与接受者的血液等渗。相容的载体和溶剂的实例是林格液和等渗氯化钠溶液。另外,通常使用无菌的不挥发性油作为溶液或悬浮介质。
本文中所述的试剂和组合物以有效量施用。“有效量”是指单独或与另外剂量一起达到期望的反应或期望的效果的量。在治疗特定疾病或特定病症的情况下,期望的反应优选地涉及对疾病进程的抑制。这包括减慢疾病的进展,特别是中断或逆转疾病的进展。在疾病或病症的治疗中的期望反应也可以是所述疾病或病症的发作的延迟或发作的阻止。
本文中所述的试剂或组合物的有效量将取决于待治疗的病症,疾病的严重程度,患者的个体参数,包括年龄、生理状况、大小和体重,治疗的持续时间,伴随治疗(如果有)的类型,具体施用途径和类似因素。因此,本文描述的药剂的施用剂量可取决于多种这样的参数。在患者对初始剂量的反应不足的情况下,可使用更高的剂量(或通过不同的更局部的施用途径有效地获得更高的剂量)。
可将本文中所述的试剂和组合物例如在体内施用给患者,以治疗或预防多种疾病,例如本文中所述的那些。优选的患者包括患有可通过施用本文中所述的试剂和组合物来纠正或改善的疾病的人患者。
药物组合物可局部或全身施用,优选全身施用。
术语“全身施用”是指药剂的施用,以使该药剂以显著量广泛分布于个体体内并产生期望的作用。例如,药剂可在血管中发展其期望的作用和/或通过血管系统到达其期望的作用部位。典型的全身性施用途径包括通过将试剂直接引入血管系统的施用或经口、肺或肌内施用,其中该试剂被吸收,进入血管系统并通过血液被携带至一个或更多个期望作用位点。
根据本发明,优选地,全身给药是通过肠胃外施用。术语“肠胃外施用”是指药剂的施用,使得药剂不通过肠。术语“肠胃外施用”包括静脉内施用、皮下施用、皮内施用或动脉内施用,但不限于此。
施用也可例如经口、腹膜内或肌内进行。
本文提供的药剂和组合物可以单独或与常规治疗方案组合使用。
实施例
实施例
材料和方法:
编码复制子和反式复制子构建体的dna:本文中使用的载体系统是从委内瑞拉马脑炎病毒(veev;登录号l01442)改造而成的,总体载体设计类似于之前产生的塞姆利基森林病毒载体系统(图1)。第一步,通过基因合成从商业供应商获得编码基于veev的自复制rna(顺式复制子)的质粒。该构建体缺少veev结构基因,但包含veev的所有保守序列元件(cse),这些元件用作复制-识别序列(rrs)并控制病毒复制在t7噬菌体rna聚合酶启动子的转录控制下进入pst1质粒骨架中(holtkampetal.,2006,blood,vol.108,pp.4009-4017)。在veev3’cse的最后一个核苷酸的立即下游添加了由30个和70个腺苷酸残基组成的质粒编码的poly(a)盒(polya30-70),它们被10个核苷酸的随机序列隔开(wo2016/005004a1)。用于质粒线性化的sapi限制位点设置在poly(a)盒的立即下游。使用进一步的基因合成和基于pcr的无缝克隆/重组技术,我们产生了一种质粒,其用作在将编码veev复制酶的完整开放阅读框的mrna体外转录到pst1质粒骨架中的模板(holtkampetal.,2006,blood,vol.108,pp.4009-4017)。该载体包含在复制酶orf上游的人α珠蛋白5’utr,和在其下游的质粒编码的poly(a30-70)盒。再次将sapi限制位点设置在poly(a)盒的立即下游以用于质粒线性化。体外转录后,所得mrna缺乏veev的功能性rrs并且无法复制。对于反式(反式-复制子)中复制的rna的体外转录,产生了模板质粒的两种不同的变体。对于第一种变体,通过从顺式复制子中除去veev-复制子编码序列的大部分同时仅保留包含功能性rrs(5’-cse和亚基因组启动子)的那些来获得编码具有wt-rrs(未经修饰的5’cse、亚基因组启动子、3’cse)的反式复制子的质粒。由于去除了复制酶orf的大部分,当存在于宿主细胞中时,由相应质粒编码的rna不能顺式驱动复制,但复制需要存在反式功能性甲病毒非结构蛋白,目的基因插入在亚基因组启动子的下游。
对于第二种反式形式,去除了包含亚基因组启动子的序列,并将5’rrs缩短至veev基因组的前约270nt。此外,对5’rrs进行了突变以除去可用作翻译起始密码子的所有aug密码子。引入了补偿核苷酸变化以确保5’rrs的正确折叠和功能,该反式复制子为δ5atg-rrsδsgp。5’aug地去除确保了翻译仅利用插入在突变的5’cse下游的目的orf的起始密码子开始。
反式复制rna的两种变体之间的主要生物学差异是具有wt-rrs和亚基因组启动子的反式复制子在亚基因组转录物上产生,所述亚基因组转录物仅在复制时产生。这意味着在不存在反式表达的复制酶的情况下,没有目的蛋白质被翻译。相反,如果使用合成帽类似物进行体外转录,则即使没有复制酶也可将δ5atg-rrsδsgp反式复制子翻译成蛋白质。
本文的目的基因是六种增强多能性的重编程转录因子(rtf)(oct4、sox2、myc、klf4、nanog、lin28)和痘苗病毒的三种干扰素逃逸蛋白(e3、k3和b18)。
实施例1:使用反式复制子技术(wt-rrs)的rna重编程
将原代人真皮成纤维细胞(hdf,innoprot)铺入6孔(100,000个细胞/孔)中,并在4小时之后使用每6孔6μlrnaimax(invitrogen)和0.7μg未经修饰的合成tr-wt-rrsmrna混合物以及0.7μg复制酶mrna和由mirna302a-d和367(1∶1∶1∶1∶1∶1)构成的0.4μgmirna混合物进行脂质体转染。因此,tr-wt-rrsmrna混合物由0.4μg编码重编程tfoskmnl(1∶1∶1∶1∶1∶1)的合成mrna和0.1μg每种ekb构成。96小时之后(第5天),第二次使用1.7μlrnaimax和0.4μg复制酶mrna对细胞进行脂质体转染。将细胞培养在补充有10ng/mlbfgf(invitrogen)和0.5μm硫唑菌素(stemgent)的人胚胎干(hes)细胞培养基(nutristemmedia,stemgent)中,并且按照制造商的说明进行所有脂质体转染。从d12开始观察到集落形成,并描述了实验程序的时间轴(图2a)。图2b显示了从d1到d18的集落形成的显微镜分析。使用tr-wt-rrsmrna产生的ips细胞集落的集落形态和生长行为呈hes细胞样,具有在不同集落中的紧紧包裹的小细胞和明确的边界。集落可被染色为hes细胞表面标志物tra-1-81阳性(灰色/绿色)。根据制造商的说明,使用stain-alivetra-1-81抗体(stemgent)进行tra-1-81活体染色。集落的代表性图片如图2c所示。为了进一步评估集落的多能性,在d18使细胞沉淀,分离总rna并且通过qrt-pcr对hes标志物oct4(内源)、nanog(内源)、lin28(内源)、tert和rex1的mrna表达进行定量。mrna表达相对于hprt的表达归一化,并且在图2d中显示为与输入细胞的转录水平相比的诱导倍数。与输入细胞相比,所有分析的标志物均高表达,表明重编程细胞具有多能性。
数据表明,tr-wt-rrs技术可用于基于rna的ips细胞产生。通过hes细胞样形态和生长行为以及所得ips细胞集落的hes细胞表面和内源标志物的表达证实了细胞的成功重编程。
实施例2:使用反式复制子技术(δ5atg-rrsδsgp)的rna重编程
图3a显示了原代人真皮成纤维细胞(hdf,innoprot)的重编程的时间轴。将40,000个细胞平板接种到12孔板中,并且随后使用每12孔2.5μlrnaimax(invitrogen)和mrna混合物进行脂质体转染4小时,所述mrna混合物由0.33μg编码重编程tfoskmnl(1∶1∶1∶1∶1∶1)的未经修饰的合成tr-δ5atg-rrsδsgpmrna和0.02μg的每种ekb(+”ekb”)的合成mrna或者0.25μg编码oskmnl(1∶1∶1∶1∶1∶1)的未经修饰的合成tr-δ5atg-rrsδsgpmrna和0.04μg的单独n(“+n”)的合成mrna(来自托斯卡纳病毒的病毒逃逸蛋白nss(n)是有效的ifn反应抑制剂,可用于替代ekb成功的基于rna的重编程)构成。两种混合物均与0.3μg复制酶mrna和0.17μg由mirna302a-d和367(1∶1∶1∶1∶1∶1)构成的mirna混合物组合。72小时(第4天)之后,使用与d1相同的确切程序和混合物第二次对细胞进行脂质体转染。在整个实验过程中,将细胞培养在补充有10ng/mlbfgf(invitrogen)和0.5μm硫唑菌素(stemgent)的人胚胎干(hes)细胞培养基(nutristemmedia,stemgent)中,并按照制造商的说明进行了所有脂质体转染。如所示,从d15开始可以观察到集落形成。图3b显示了从d12开始的集落形成的显微镜分析。使用tr-δ5atg-rrsδsgpmrna和ekbmrna或nmrna产生的ips细胞集落的集落形态和生长行为为hes细胞样,具有在不同集落中的紧紧包裹的小细胞和明确的边界。集落可被染色为hes细胞表面标志物tra-1-81阳性(灰色/绿色)。根据制造商的说明,使用stain-alivetra-1-81抗体(stemgent)进行tra-1-81活体染色。集落的代表性图片如图3c所示。为了进一步评估集落的多能性,在d22使细胞沉淀,分离总rna并且通过qrt-pcr对hes标志物oct4(内源)、nanog(内源)、lin28(内源)、tert和rex1的mrna表达进行定量。mrna表达相对于hprt的表达归一化,并且在图3d中显示为与输入细胞的转录水平相比的诱导倍数。与输入细胞相比,所有分析的标志物在使用δ5atg-rrsδsgpmrna和ekbmrna或nmrna产生的ips细胞集落中均高表达,表明重编程细胞具有多能性。
数据表明tr技术(δ5atg-rrsδsgp)可用于基于rna的ips细胞产生。由此,可通过使用ekb或nmrna来阻断对未经修饰的合成rna的ifn应答,从而导致ips集落的形成。通过hes细胞样形态和生长行为以及所得ips细胞集落的hes细胞表面和内源标志物的表达证实了细胞的成功重编程。
实施例3:使用反式复制子技术(wt-rss)通过一次转染的基于rna的重编程
将原代人真皮成纤维细胞(hdf,innoprot)铺入6孔(100,000个细胞/孔)中,并在4小时之后使用每6孔6μlrnaimax(invitrogen)和0.7μg未经修饰的合成tr-wt-rrsmrna混合物以及0.7μg复制酶mrna和由mirna302a-d和367(1∶1∶1∶1∶1∶1)构成的0.4μgmirna混合物进行脂质体转染。因此,tr-wt-rrsmrna混合物由0.4μg编码重编程tfoskmnl(1∶1∶1∶1∶1∶1)的合成mrna和0.1μg每种ekb构成。将细胞培养在补充有10ng/mlbfgf(invitrogen)和0.5μm硫唑菌素(stemgent)的人胚胎干(hes)细胞培养基(nutristemmedia,stemgent)中,并且按照制造商的说明进行所有脂质体转染。从d11天开始观察到集落形成,并描述了实验程序的时间轴(图4a)。图4b显示了从d1到d14的集落形成的显微镜分析。使用tr-wt-rrsmrna产生的ips细胞集落的集落形态和生长行为呈hes细胞样,具有在不同集落中的紧紧包裹的小细胞和明确的边界。集落可被染色为hes细胞表面标志物tra-1-81阳性(灰色/绿色)。根据制造商的说明,使用stain-alivetra-1-81抗体(stemgent)进行tra-1-81活体染色。集落的代表性图片如图4c所示。为了进一步评估集落的多能性,在d18使细胞沉淀,分离总rna并且通过qrt-pcr对hes标志物oct4(内源)、nanog(内源)、lin28(内源)、tert和rex1的mrna表达进行定量。mrna表达相对于hprt的表达归一化,并且在图4d中显示为与输入细胞的转录水平相比的诱导倍数。与输入细胞相比,所有分析的标志物均高表达,表明重编程细胞具有多能性。
数据表明,tr技术(wt-rss)可甚至在仅单次转染的情况下用于基于rna的ips细胞产生。通过hes细胞样形态和生长行为以及所得ips细胞集落的hes细胞表面和内源标志物的表达证实了细胞的成功重编程。
- 还没有人留言评论。精彩留言会获得点赞!