一种基于线性双链DNA分子连接的与门逻辑运算方法及应用与流程
本发明涉及合生生物领域,具体涉及一种基于线性双链dna分子连接的与门逻辑运算方法。
背景技术:
合成生物学(syntheticbiology)是21世纪的新兴交叉学科,强调“设计”和“重设计”,其目的是通过人工设计和构建自然界不存在的生物系统来解决健康、环保和能源等问题。近年来诸如j.d.keasling课题组的青蒿酸微生物合成工厂、c.a.voigt课题组的大肠杆菌成像系统、j.c.venter及g.church课题组创造的新菌种等重大突破展示了合成生物学改变世界的巨大潜能。合成生物学将对人类认识生命、揭示生命奥秘、重新设计及改造生命等方面产生重大的科学意义。合成生物学的发展受到多个国家政府和研究团体的高度重视,美、欧等国均投入大量资本支持合成生物学的研究与工业化。通过前瞻性布局与重点投入,我国已成为合成生物学领域中的重要力量之一,产生了一批代表性研究成果。合成生物学的“重设计”指对模块、组件、系统的重新设计。模块“重设计”:通过对天然蛋白进行基因工程改造以产生具有新功能的蛋白分子。经典例子是通过对绿色荧光蛋白(gfp)、红色荧光蛋白(rfp)的改造以产生系列不同吸收/发射波长的新荧光蛋白(bfp、cfp、yfp、mcherry、mtomato等)。近年来,得益于基因组学、计算机科学的快速发展,大量非天然蛋白被设计出来在医药、材料等不同领域发挥作用。2017年美国华盛顿大学的davidbaker研究团队通过rosetta蛋白设计模型、寡核苷酸合成技术、酵母展示筛选技术、深度测序技术,以流感病毒ha和神经毒素为靶点,设计并测试了超过两万个蛋白质抑制多肽。通过这样的从头设计策略,与以前的研究相比,他们将此类抑制多肽数量提高了两个数量级,并且这些抑制多肽非常稳定,在小鼠实验中可以很好的阻断流感病毒的传播。组件、系统“重设计”:天然存在或经重设计的模块经过重组合、重设计可形成新组件、新系统从而实现合成生物学新功能。加州大学伯克利分校j.d.keasling教授通过将相关基因植入大肠杆菌和酿酒酵母中实现青蒿酸的微生物合成,极大提高了产量缩短了生产周期。此外通过设计基于各种“与”、“非”门逻辑的人工基因线路(artificialgeneticcircuits),研究者实现了生物对不同刺激信号(inputs)的不同反应(outputs)。通过设计包含18个基因和32个调节元件的人工基因线路,麻省理工学院c.a.voigt教授开发出大肠杆菌rgb成像系统,可通过不同逻辑门实现大肠杆菌对不同波长光刺激的不同颜色反应。
通过构建人工基因线路实现精准基因表达调控,合成生物学也在疾病诊断、治疗方面展现出广阔的应用前景。例如近期麻省理工学院卢冠达课题组利用肿瘤特异性启动子(tumor-specificpromoter)、小rna海绵(mirnasponge)、小rna靶向调控(mirna-targetregulation)等基因模块(geneticmodule)设计出复杂的基于rna的免疫调控基因线路。小鼠成瘤实验表明此基因线路可实现免疫因子的肿瘤组织特异性表达,进而诱导t细胞对肿瘤细胞的靶向杀伤,从而增强免疫治疗效果。
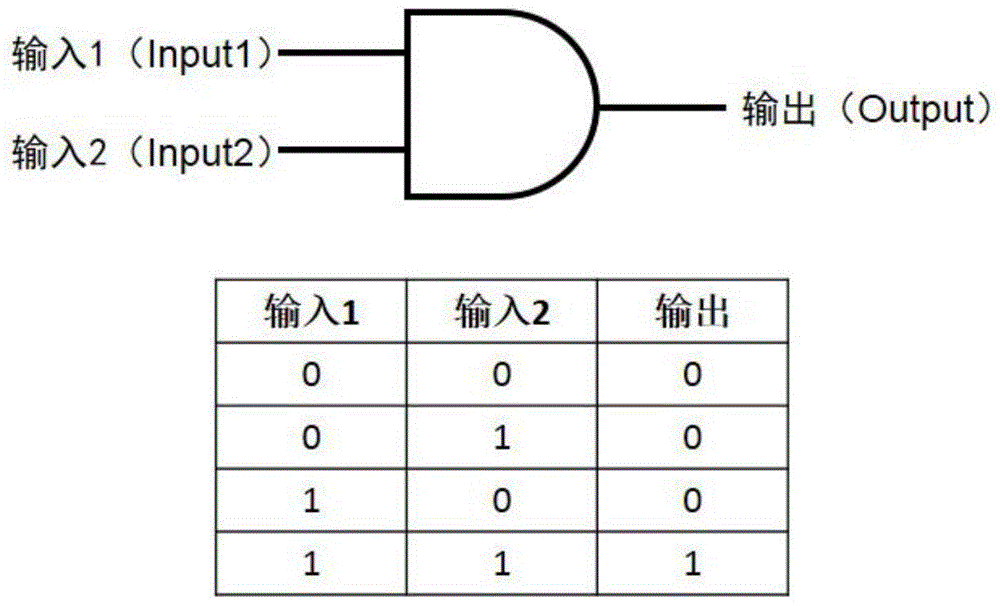
与门逻辑运算(andgatelogiccomputation)是一种最基本的逻辑门,指仅在所有输入信号(inputsignal)都为阳性时,产生阳性输出信号(outputsignal);任何一个输入信号为阴性时,则输出信号为阴性(如图1所示)。在生物医学领域与门逻辑基因线路被用来实现“特异性”,即在所有输入信号都存在的情况下实现信号输出。
现有技术中,存在的缺陷和不足主要包括:(1)现有与门逻辑基因线路构建策略较复杂,首先需要细胞表达多种蛋白或rna分子,在此基础上通过这些分子及dna分子之间的相互作用实现与门运算。在逻辑运算前表达蛋白或rna分子增加了细胞的负担;(2)目前的与门逻辑基因线路设计策略无法实现高信噪比,即在[0,0][0,1][1,0]的情况下实现接近背景的信号输出,在[1,1]的情况下有较强信号输出;(3)目前的与门逻辑基因线路设计策略没有利用拆分基因表达核心组件(启动子-基因编码区-polya信号,promoter-gene-polyasignal)来实现高信噪比输出。
技术实现要素:
本发明设计开发了一种基于线性双链dna分子连接的与门逻辑运算方法,本发明的目的是通过线性双链dna产物的不同组合进行与门逻辑运算进而确定线性双链dna产物作为分子元件在细胞水平构建与门逻辑基因线路的可行性。
本发明还提供了基于线性双链dna分子连接的与门逻辑运算方法的应用,可广泛应用于合成生物学、生物计算。
本发明提供的技术方案为:
一种基于线性双链dna分子连接的与门逻辑运算方法,包括如下过程:
通过pcr扩增反应将含有启动子、基因编码区、polya信号的基因表达核心组件序列拆分成2~3个线性双链dna分子作为输入,转染入细胞中;
在所有线性双链dna分子同时出现时,通过细胞内的连接反应,这些线性双链dna分子重新形成完整的基因表达核心组件序列并进行基因表达。
优选的是,包括:
步骤一、以报告基因表达质粒为模板,通过pcr扩增得到含有cmv启动子序列和/或含有polyasignal序列的多个线性双链dna分子;
步骤二、将所述线性双链dna分子进行1%琼脂糖凝胶电泳,根据产物大小切胶以去除模板质粒,产物回收后,测定浓度;
步骤三、将所述线性双链dna分子不同分组进行转染细胞,转染48小时后采用流式细胞术检测与门逻辑运算输出信号蛋白表达;
当所述转染细胞同时包括所述线性双链dna分子包含cmv启动子序列组成的dna片段和包含polyasignal序列组成的dna片段时,检测到蛋白表达。
优选的是,在所述步骤一中,以报告基因表达质粒为模板,分别利用序列表中的seqidno.11和seqidno.12所示的引物序列通过pcr扩增得到含有序列表中的seqidno.1所示序列和/或序列表中的seqidno.13和seqidno.14所示的引物序列通过pcr扩增得到含有序列表中的seqidno.2所示序列的多个线性双链dna分子。
优选的是,在所述步骤一中,以报告基因表达质粒为模板,分别利用序列表中的seqidno.15和seqidno.16所示的引物序列通过pcr扩增得到含有序列表中的seqidno.3所示序列和/或序列表中的seqidno.17和seqidno.18所示的引物序列通过pcr扩增得到含有序列表中的seqidno.4所示序列的多个线性双链dna分子。
优选的是,在所述步骤一中,以报告基因表达质粒为模板,分别利用序列表中的seqidno.19和seqidno.20所示的引物序列通过pcr扩增得到含有序列表中的seqidno.5所示序列和/或序列表中的seqidno.21和seqidno.22所示的引物序列通过pcr扩增得到含有序列表中的seqidno.6所示序列的多个线性双链dna分子。
优选的是,在所述步骤一中,以报告基因表达质粒为模板,分别利用序列表中的seqidno.23和seqidno.24所示的引物序列通过pcr扩增得到含有序列表中的seqidno.7所示序列和/或序列表中的seqidno.25和seqidno.26所示的引物序列通过pcr扩增得到含有序列表中的seqidno.8所示序列的多个线性双链dna分子。
优选的是,在所述步骤一中,以报告基因表达质粒为模板,分别利用序列表中的seqidno.27和seqidno.28所示的引物序列通过pcr扩增得到含有序列表中的seqidno.9所示序列、序列表中的seqidno.29和seqidno.30所示的引物序列通过pcr扩增得到含有序列表中的seqidno.10所示序列和/或序列表中的seqidno.32和seqidno.33所示的引物序列通过pcr扩增得到含有序列表中的seqidno.31所示序列的多个线性双链dna分子。
优选的是,所述报告基因为荧光素酶。
优选的是,所述报告基因为绿色荧光蛋白。
基于线性双链dna分子连接的与门逻辑运算方法的应用,用于合成生物学、生物计算。
本发明与现有技术相比较所具有的有益效果:本发明以线性双链dna(pcr扩增产物)为元件在细胞水平构建与门逻辑基因线路,通过将基因表达序列拆分成2~3个线性双链dna分子以作为输入,利用细胞内的dna分子连接反应重新形成完整基因表达模块(启动子-基因编码区-polya信号),新基因线路设计原则实现了低噪信比与门逻辑运算,同时在与门逻辑运算过程中不需要先行表达蛋白或rna,本发明的设计思路降低了细胞负担。
附图说明
图1为本发明所述的与门逻辑运算示意图。
图2为本发明所述的实施例1中2输入线性双链dna与门逻辑基因线路示意图。
图3为本发明所述的实施例1中线性双链dna(pcr产物)以不同组合[0,0]、[0,1]、[1,0]、[1,1]转入hek293t细胞(24孔板,100ng/pcr产物/孔),48小时后双荧光素酶报告基因实验检测与门计算输出信号示意图。
图4为本发明所述的实施例2中2输入线性双链dna与门逻辑基因线路示意图。
图5为本发明所述的实施例2中线性双链dna(pcr产物)以不同组合[0,0]、[0,1]、[1,0]、[1,1]转入hek293t细胞(24孔板,100ng/pcr产物/孔),48小时后流式细胞术检测与门计算输出信号示意图。
图6为本发明所述的实施例3中3输入与门运算示意图(cmv:cmv启动子、gfpcds:gfp编码区、sv40:sv40polya信号序列)。
图7为本发明所述的实施例3中流式细胞术检测gfp表达示意图。
图8为本发明所述的实施例3中不同输入所产生gfp阳性细胞比例。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
本发明利用线性双链dna(pcr扩增产物)作为分子元件构建与门逻辑基因线路,在细胞水平实现基于线性双链dna的与门逻辑运算,为合成生物学基因线路的设计提供全新分子元件与策略。本发明利用荧光素酶(luciferase)、绿色荧光蛋白(gfp)作为演示分子(报告分子),表明利用线性双链dna(pcr扩增产物)作为分子元件在细胞水平构建与门逻辑基因线路的可行性,本发明可扩展应用到其它基因。
实验材料和仪器
1、质粒和细胞
hek293t细胞购自中科院上海细胞库;pcdna3.0-luc质粒购自addgene质粒库;pegfp-c1质粒购自clontech公司;prl-cmv质粒购自promega公司。
2、试剂、酶与药品
koddnapolymerase、dntps、10×kodbuffer、mgso4购自toyobo公司;琼脂糖凝胶(agarose)购自生工生物工程(上海)股份有限公司;dna纯化回收试剂盒购自天跟生化科技(北京)有限公司;lipo2000转染试剂购自invitrogen公司;双荧光素酶报告基因检测试剂盒购自promega公司。
利用基于线性双链dna分子连接的与门逻辑运算方法实现细胞水平荧光素酶报告基因表达。
1、pcr扩增得到cmv启动子和polyasignal引物序列
以pcdna3.0-luc质粒或者pegfp-c1质粒为模板,通过pcr扩增得到包含cmv启动子和/或包含polyasignal序列的dna片段;pcr反应条件为:94℃,2min;94℃,30sec;55℃,30sec;68℃,2min,35个循环;68℃,10min。
2、pcr产物的电泳及回收
上述pcr产物用1%琼脂糖凝胶进行电泳,电泳后将切下的目的胶块,利用dna纯化回收试剂盒回收pcr产物。具体步骤如下:向胶块中加入等倍体积溶胶溶液pc,50℃水浴放置10min使胶块溶解;12000rpm离心1min使以上溶液通过吸附柱cb2,弃去收集管中的液体;向吸附柱cb2中加入600μl漂洗液pw,12000rpm离心1min,弃去收集管中的液体,重复漂洗一次;12000rpm离心2min以去除吸附柱上残余漂洗液;将吸附柱cb2放入新的1.5mlep管,向其中加入50μl无菌水溶解pcr产物,12000rpm离心2min收集pcr产物;测定pcr产物浓度,-20℃保存备用。
3、hek293t细胞的转染
取生长状态良好的hek293t细胞,以传代培养细胞第二天细胞密度达到60%-80%为宜;将扩增获得的线性双链dna以不同组合转入细胞。每组线性双链dna以不同组合转入细胞中,包括四种组合:第1组[0,0]为无线性双链dna转染组,第2或3组[0,1],[1,0]只转染一种线性双链dna,第4组[1,1]同时转染两种线性双链dna;转染步骤如下:24孔板细胞的转染体系(50μl/孔):在无菌的1.5ml离心管2个,每个离心管中加入25μl无血清培养基。在其中一管加入转染试剂lipo20001μl;另一管加入100ng线性双链dna,10ng内参质粒prl-cmv,每管都充分混匀。最后两管合并到一管,充分吹打混匀后,室温静置20min。之后将离心管中的液体逐滴加入到细胞中,混匀。将细胞置于37℃、5%co2培养箱中继续培养48h。
4、荧光素酶活性的测定
细胞转染48h后,弃去旧培养基,加适量pbs洗2遍,吸去pbs,每孔细胞加入100μl1×plb细胞裂解液(passivelysisbuffer);水平振荡器60rpm裂解15min;转移裂解液到一个新的ep管中,8000rpm离心3min;在另一个新的ep管中加入50μllarⅱ试剂(不要加到管壁上);取50μl细胞裂解液加到以上larⅱ管中轻轻混匀(不要吹到管壁上),检测、记录;以上ep管中加入50μlstop&glo试剂混匀,检测、记录;计算larⅱ读数和stop&glo读数的比值,每组实验重复四次,结果取平均值。
5、流式细胞术检测绿色荧光蛋白表达
细胞转染48h后,弃去旧培养基,加适量pbs洗2遍,吸去pbs,胰酶消化收集细胞,离心后用含1%血清的pbs重悬细胞,流失细胞仪检测绿色荧光蛋白表达。
在另一种实施例中,报告基因为荧光素酶或者绿色荧光蛋白。
在另一种实施例中,报告基因为pcdna3.0-luc。
在另一种实施例中,报告基因为pegfp-c1。
实施例1
细胞水平2输入线性双链dna与门逻辑运算及其实验结果
如图2、图3所示,以pcdna3.0-luc表达质粒为模板,利用下述引物进行pcr扩增获得三组线性双链dna产物,包括:
第一组:cmv-luc[1-205](即序列表中的seqidno.1所示的碱基序列)和luc[206-1653]-bghpolyasignal(即序列表中的seqidno.2所示的碱基序列);
以pcdna3.0-luc质粒为模板,利用seqidno.11和seqidno.12所示的引物序列通过pcr扩增得到seqidno.1所示的核苷酸序列的dna片段,即为cmv-luc[1-205];pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到cmv-luc[1-205]的上游端引物:
5'-caaggcttgaccgacaattgcatga-3'(序列表中seqidno.11所示的碱基序列);
得到cmv-luc[1-205]的下游端引物:
5'-gtttcatagcttctgccaaccgaac-3'(序列表中seqidno.12所示的碱基序列);
以pcdna3.0-luc质粒为模板,利用seqidno.13和seqidno.14所示的引物序列通过pcr扩增得到seqidno.2所示的核苷酸序列的dna片段,即为luc[206-1653]-bghpolyasignal片段;pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到luc[206-1653]-bghpolyasignal的上游端引物:
5'-gatatgggctgaatacaaatcacag-3'(序列表中seqidno.13所示的碱基序列);
得到luc[206-1653]-bghpolyasignal的下游端引物:
5'-aagtgtagcggtcacgctgcgcgta-3'(序列表中seqidno.14所示的碱基序列)
第二组:cmv-luc[1-158](即序列表中的seqidno.3所示的碱基序列)、luc[159-1653]-bghpolyasignal(即序列表中的seqidno.4所示的碱基序列);
以pcdna3.0-luc质粒为模板,利用seqidno.15和seqidno.16所示的引物序列通过pcr扩增得到seqidno.3所示的核苷酸序列的dna片段,即为cmv-luc[1-158];pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到cmv-luc[1-158]的上游端引物:
5'-caaggcttgaccgacaattgcatga-3'(序列表中seqidno.15所示的碱基序列);
得到cmv-luc[1-158]的下游端引物:
5'-taagtgatgtccacctcgatatgtg-3'(序列表中seqidno.16所示的碱基序列);
以pcdna3.0-luc质粒为模板,利用seqidno.17和seqidno.18所示的引物序列通过pcr扩增得到seqidno.4所示的核苷酸序列的dna片段,即为luc[159-1653]-bghpolyasignal片段。pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到luc[159-1653]-bghpolyasignal的上游端引物:
5'-cgctgagtacttcgaaatgtccgtt-3'(序列表中seqidno.17所示的碱基序列);
得到luc[159-1653]-bghpolyasignal的下游端引物:
5'-aagtgtagcggtcacgctgcgcgta-3'(序列表中seqidno.18所示的碱基序列);
第三组:cmv(即序列表中的seqidno.5所示的碱基序列)、luc[1-1653]-bghpolyasignal(即序列表中的seqidno.6所示的碱基序列);
以pcdna3.0-luc质粒为模板,利用seqidno.19和seqidno.20所示的引物序列通过pcr扩增得到seqidno.5所示的核苷酸序列的dna片段,即为cmv;pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到cmv的上游端引物:
5'-caaggcttgaccgacaattgcatga-3'(序列表中seqidno.19所示的碱基序列);
得到cmv的下游端引物:
5'-ccaacagtaccgaagcccaaagctg-3'(序列表中seqidno.20所示的碱基序列);
以pcdna3.0-luc质粒为模板,利用seqidno.21和seqidno.22所示的引物序列通过pcr扩增得到seqidno.6所示的核苷酸序列的dna片段,即为luc[1-1653]-bghpolyasignal片段;pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到luc[1-1653]-bghpolyasignal的上游端引物:
5'-taagccaccatggaagacgccaaaa-3'(序列表中seqidno.21所示的碱基序列);
得到luc[1-1653]-bghpolyasignal的下游端引物:
5'-aagtgtagcggtcacgctgcgcgta-3'(序列表中seqidno.22所示的碱基序列);
将上述三组线性双链dna产物分别以[0,0](无pcr产物)、[0,1](含有ployasignal序列)、[1,0](含有cmv启动子序列)、[1,1](同时含有cmv启动子序列和ployasignal序列)不同组合pcr产物作为输入信号转入hek293t细胞,检测萤光素酶活性,与无pcr产物转染组[0,0]相比,pcr产物共转染组[1,1]的萤光素酶活性提高了数千至上万倍,而单pcr产物转染组([0,1],[1,0])没有产生显著高于[0,0]组的报告基因信号。
实施例2
利用2输入基于线性双链dna分子连接的与门逻辑运算方法实现细胞水平绿色荧光蛋白表达。
如图4、图5所示,根据pegfp-c1绿色荧光蛋白表达质粒dna序列,pcr扩增获取以下2种线性双链dna:
以pegfp-c1质粒为模板,利用seqidno.23和seqidno.24所示的引物序列通过pcr扩增得到seqidno.7所示的核苷酸序列的dna片段,即为cmv;pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到cmv的上游端引物:
5'-ctttcctgcgttatcccctgattct-3'(序列表中seqidno.23所示的碱基序列);
得到cmv的下游端引物:
5'-agcgctagcggatctgacggttcac-3'(序列表中seqidno.24所示的碱基序列);
以pegfp-c1质粒为模板,利用seqidno.25和seqidno.26所示的引物序列通过pcr扩增得到seqidno.8所示的核苷酸序列的dna片段,即为gfp-sv40pas片段;pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到gfp-sv40pas的上游端引物:
5′-accggtcgccaccatggtgagcaag-3′;(序列表中seqidno.25所示的碱基序列);
得到gfp-sv40pas的下游端引物:
5′-cggcctattggttaaaaaatgagct-3′;(序列表中seqidno.26所示的碱基序列)
将上述线性双链dna产物分别以[0,0](无pcr产物)、[0,1](含有ployasignal序列)、[1,0](含有cmv启动子序列)、[1,1](同时含有cmv启动子序列和ployasignal序列)不同组合pcr产物作为输入信号转入hek293t细胞,检测萤光素酶活性,与无pcr产物转染组[0,0]相比,pcr产物共转染组[1,1]的萤光素酶活性提高了数千至上万倍,而单pcr产物转染组([0,1],[1,0])没有产生显著高于[0,0]组的报告基因信号。
实施例3
根据pegfp-c1绿色荧光蛋白表达质粒dna序列,pcr扩增获取以下3种线性双链dna:
如图6、图7、图8所示,以pegfp-c1质粒为模板,利用seqidno.27和seqidno.28所示的引物序列通过pcr扩增得到seqidno.9所示的核苷酸序列的dna片段,即为cmv;pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到cmv的上游端引物:
5'-ctttcctgcgttatcccctgattct-3'(序列表中seqidno.27所示的碱基序列);
得到cmv的下游端引物:
5'-agcgctagcggatctgacggttcac-3'(序列表中seqidno.28所示的碱基序列);
以pegfp-c1质粒为模板,利用seqidno.29和seqidno.30所示的引物序列通过pcr扩增得到seqidno.10所示的核苷酸序列的dna片段,即为gfp片段;pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到gfpcds的上游端引物:
5′-accggtcgccaccatggtgagcaag-3′(序列表中seqidno.29所示的碱基序列);
得到gfpcds的下游端引物:
5′-gtacagctcgtccatgccgagagtg-3′(序列表中seqidno.30所示的碱基序列);
以pegfp-c1质粒为模板,利用seqidno.32和seqidno.33所示的引物序列通过pcr扩增得到seqidno.31所示的核苷酸序列的dna片段,即为sv40片段;pcr反应体系(50μl):koddnapolymerase(1unit/μl),1μl;10×kodbuffer,5μl;2mmdntps,5μl;25mmmgso4,3μl;20μmforwardprimer,1μl;20μmreverseprimer,1μl;pcdna3.0-luc(10ng/μl),1μl;h2o,33μl。pcr反应条件为:94℃,2min;(94℃,30sec;55℃,30sec;68℃,2min),35个循环;68℃,10min;
得到sv40的上游端引物:
5′-agatctcgagctcaagcttcga-3′(序列表中seqidno.32所示的碱基序列);
得到sv40的下游端引物:
5′-cggcctattggttaaaaaatgagct-3′(序列表中seqidno.33所示的碱基序列);
如图6~8所示,以gfp表达质粒pegfp-c1为模板,pcr扩增获得3种线性双链dna分子:cmv启动子(即序列表中的seqidno.9所示的碱基序列)、gfp编码区(即序列表中的seqidno.10所示的碱基序列)、sv40polya信号序列(即序列表中的seqidno.31所示的碱基序列),以[0,0,0](无pcr产物)、[1,0,0](含有cmv启动子序列)、[0,1,0](含有绿色荧光蛋白编码序列)、[0,0,1](含有ployasignal序列)、[1,1,0](含有cmv启动子序列和绿色荧光蛋白编码序列)、[1,0,1](同时含有cmv启动子序列和ployasignal序列)、[0,1,1](含有ployasignal序列和绿色荧光蛋白编码序列)、[1,1,1](同时含有cmv启动子序列和ployasignal序列)不同组合转入hek293t细胞中,细胞流式结果显示[1,1,1]输入状态可产生gfp蛋白信号。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
sequencelisting
<110>天津达济科技有限公司
<120>一种基于线性双链dna分子连接的与门逻辑运算方法及应用
<130>2018
<160>33
<170>patentinversion3.3
<210>1
<211>982
<212>dna
<213>人工序列
<220>
<223>cmv-luc[1-205]基因的编码序列
<400>1
caaggcttgaccgacaattgcatgaagaatctgcttagggttaggcgttttgcgctgctt60
cgcgatgtacgggccagatatacgcgttgacattgattattgactagttattaatagtaa120
tcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacg180
gtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacg240
tatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggactattta300
cggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctatt360
gacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggac420
tttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttt480
tggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccac540
cccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgt600
cgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctat660
ataagcagagctctctggctaactagagaacccactgcttactggcttatcgaaattaat720
acgactcactatagggagacccaagcttggcattccggtactgttggtaaagccaccatg780
gaagacgccaaaaacataaagaaaggcccggcgccattctatccgctggaagatggaacc840
gctggagagcaactgcataaggctatgaagagatacgccctggttcctggaacaattgct900
tttacagatgcacatatcgaggtggacatcacttacgctgagtacttcgaaatgtccgtt960
cggttggcagaagctatgaaac982
<210>2
<211>1910
<212>dna
<213>人工序列
<220>
<223>luc[206-1653]-bghpolyasignal基因的编码序列
<400>2
gatatgggctgaatacaaatcacagaatcgtcgtatgcagtgaaaactctcttcaattct60
ttatgccggtgttgggcgcgttatttatcggagttgcagttgcgcccgcgaacgacattt120
ataatgaacgtgaattgctcaacagtatgggcatttcgcagcctaccgtggtgttcgttt180
ccaaaaaggggttgcaaaaaattttgaacgtgcaaaaaaagctcccaatcatccaaaaaa240
ttattatcatggattctaaaacggattaccagggatttcagtcgatgtacacgttcgtca300
catctcatctacctcccggttttaatgaatacgattttgtgccagagtccttcgataggg360
acaagacaattgcactgatcatgaactcctctggatctactggtctgcctaaaggtgtcg420
ctctgcctcatagaactgcctgcgtgagattctcgcatgccagagatcctatttttggca480
atcaaatcattccggatactgcgattttaagtgttgttccattccatcacggttttggaa540
tgtttactacactcggatatttgatatgtggatttcgagtcgtcttaatgtatagatttg600
aagaagagctgtttctgaggagccttcaggattacaagattcaaagtgcgctgctggtgc660
caaccctattctccttcttcgccaaaagcactctgattgacaaatacgatttatctaatt720
tacacgaaattgcttctggtggcgctcccctctctaaggaagtcggggaagcggttgcca780
agaggttccatctgccaggtatcaggcaaggatatgggctcactgagactacatcagcta840
ttctgattacacccgagggggatgataaaccgggcgcggtcggtaaagttgttccatttt900
ttgaagcgaaggttgtggatctggataccgggaaaacgctgggcgttaatcaaagaggcg960
aactgtgtgtgagaggtcctatgattatgtccggttatgtaaacaatccggaagcgacca1020
acgccttgattgacaaggatggatggctacattctggagacatagcttactgggacgaag1080
acgaacacttcttcatcgttgaccgcctgaagtctctgattaagtacaaaggctatcagg1140
tggctcccgctgaattggaatccatcttgctccaacaccccaacatcttcgacgcaggtg1200
tcgcaggtcttcccgacgatgacgccggtgaacttcccgccgccgttgttgttttggagc1260
acggaaagacgatgacggaaaaagagatcgtggattacgtcgccagtcaagtaacaaccg1320
cgaaaaagttgcgcggaggagttgtgtttgtggacgaagtaccgaaaggtcttaccggaa1380
aactcgacgcaagaaaaatcagagagatcctcataaaggccaagaagggcggaaagatcg1440
ccgtgtaattctagactgcagattcgatgaattctgcagatatccatcacactggcggcc1500
gctcgagcatgcatctagagggccctattctatagtgtcacctaaatgctagagctcgct1560
gatcagcctcgactgtgccttctagttgccagccatctgttgtttgcccctcccccgtgc1620
cttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattg1680
catcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagca1740
agggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggctt1800
ctgaggcggaaagaaccagctggggctctagggggtatccccacgcgccctgtagcggcg1860
cattaagcgcggcgggtgtggtggttacgcgcagcgtgaccgctacactt1910
<210>3
<211>935
<212>dna
<213>人工序列
<220>
<223>cmv-luc[1-158]基因的编码序列
<400>3
caaggcttgaccgacaattgcatgaagaatctgcttagggttaggcgttttgcgctgctt60
cgcgatgtacgggccagatatacgcgttgacattgattattgactagttattaatagtaa120
tcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacg180
gtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacg240
tatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggactattta300
cggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctatt360
gacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggac420
tttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttt480
tggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccac540
cccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgt600
cgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctat660
ataagcagagctctctggctaactagagaacccactgcttactggcttatcgaaattaat720
acgactcactatagggagacccaagcttggcattccggtactgttggtaaagccaccatg780
gaagacgccaaaaacataaagaaaggcccggcgccattctatccgctggaagatggaacc840
gctggagagcaactgcataaggctatgaagagatacgccctggttcctggaacaattgct900
tttacagatgcacatatcgaggtggacatcactta935
<210>4
<211>1957
<212>dna
<213>人工序列
<220>
<223>luc[159-1653]-bghpolyasignal基因的编码序列
<400>4
cgctgagtacttcgaaatgtccgttcggttggcagaagctatgaaacgatatgggctgaa60
tacaaatcacagaatcgtcgtatgcagtgaaaactctcttcaattctttatgccggtgtt120
gggcgcgttatttatcggagttgcagttgcgcccgcgaacgacatttataatgaacgtga180
attgctcaacagtatgggcatttcgcagcctaccgtggtgttcgtttccaaaaaggggtt240
gcaaaaaattttgaacgtgcaaaaaaagctcccaatcatccaaaaaattattatcatgga300
ttctaaaacggattaccagggatttcagtcgatgtacacgttcgtcacatctcatctacc360
tcccggttttaatgaatacgattttgtgccagagtccttcgatagggacaagacaattgc420
actgatcatgaactcctctggatctactggtctgcctaaaggtgtcgctctgcctcatag480
aactgcctgcgtgagattctcgcatgccagagatcctatttttggcaatcaaatcattcc540
ggatactgcgattttaagtgttgttccattccatcacggttttggaatgtttactacact600
cggatatttgatatgtggatttcgagtcgtcttaatgtatagatttgaagaagagctgtt660
tctgaggagccttcaggattacaagattcaaagtgcgctgctggtgccaaccctattctc720
cttcttcgccaaaagcactctgattgacaaatacgatttatctaatttacacgaaattgc780
ttctggtggcgctcccctctctaaggaagtcggggaagcggttgccaagaggttccatct840
gccaggtatcaggcaaggatatgggctcactgagactacatcagctattctgattacacc900
cgagggggatgataaaccgggcgcggtcggtaaagttgttccattttttgaagcgaaggt960
tgtggatctggataccgggaaaacgctgggcgttaatcaaagaggcgaactgtgtgtgag1020
aggtcctatgattatgtccggttatgtaaacaatccggaagcgaccaacgccttgattga1080
caaggatggatggctacattctggagacatagcttactgggacgaagacgaacacttctt1140
catcgttgaccgcctgaagtctctgattaagtacaaaggctatcaggtggctcccgctga1200
attggaatccatcttgctccaacaccccaacatcttcgacgcaggtgtcgcaggtcttcc1260
cgacgatgacgccggtgaacttcccgccgccgttgttgttttggagcacggaaagacgat1320
gacggaaaaagagatcgtggattacgtcgccagtcaagtaacaaccgcgaaaaagttgcg1380
cggaggagttgtgtttgtggacgaagtaccgaaaggtcttaccggaaaactcgacgcaag1440
aaaaatcagagagatcctcataaaggccaagaagggcggaaagatcgccgtgtaattcta1500
gactgcagattcgatgaattctgcagatatccatcacactggcggccgctcgagcatgca1560
tctagagggccctattctatagtgtcacctaaatgctagagctcgctgatcagcctcgac1620
tgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccct1680
ggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtct1740
gagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattg1800
ggaagacaatagcaggcatgctggggatgcggtgggctctatggcttctgaggcggaaag1860
aaccagctggggctctagggggtatccccacgcgccctgtagcggcgcattaagcgcggc1920
gggtgtggtggttacgcgcagcgtgaccgctacactt1957
<210>5
<211>767
<212>dna
<213>人工序列
<220>
<223>cmv基因的编码序列-1
<400>5
caaggcttgaccgacaattgcatgaagaatctgcttagggttaggcgttttgcgctgctt60
cgcgatgtacgggccagatatacgcgttgacattgattattgactagttattaatagtaa120
tcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacg180
gtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacg240
tatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggactattta300
cggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctatt360
gacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggac420
tttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttt480
tggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccac540
cccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgt600
cgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctat660
ataagcagagctctctggctaactagagaacccactgcttactggcttatcgaaattaat720
acgactcactatagggagacccaagcttggcattccggtactgttgg767
<210>6
<211>2125
<212>dna
<213>人工序列
<220>
<223>luc[1-1653]-bghpolyasignal基因的编码序列
<400>6
taaagccaccatggaagacgccaaaaacataaagaaaggcccggcgccattctatccgct60
ggaagatggaaccgctggagagcaactgcataaggctatgaagagatacgccctggttcc120
tggaacaattgcttttacagatgcacatatcgaggtggacatcacttacgctgagtactt180
cgaaatgtccgttcggttggcagaagctatgaaacgatatgggctgaatacaaatcacag240
aatcgtcgtatgcagtgaaaactctcttcaattctttatgccggtgttgggcgcgttatt300
tatcggagttgcagttgcgcccgcgaacgacatttataatgaacgtgaattgctcaacag360
tatgggcatttcgcagcctaccgtggtgttcgtttccaaaaaggggttgcaaaaaatttt420
gaacgtgcaaaaaaagctcccaatcatccaaaaaattattatcatggattctaaaacgga480
ttaccagggatttcagtcgatgtacacgttcgtcacatctcatctacctcccggttttaa540
tgaatacgattttgtgccagagtccttcgatagggacaagacaattgcactgatcatgaa600
ctcctctggatctactggtctgcctaaaggtgtcgctctgcctcatagaactgcctgcgt660
gagattctcgcatgccagagatcctatttttggcaatcaaatcattccggatactgcgat720
tttaagtgttgttccattccatcacggttttggaatgtttactacactcggatatttgat780
atgtggatttcgagtcgtcttaatgtatagatttgaagaagagctgtttctgaggagcct840
tcaggattacaagattcaaagtgcgctgctggtgccaaccctattctccttcttcgccaa900
aagcactctgattgacaaatacgatttatctaatttacacgaaattgcttctggtggcgc960
tcccctctctaaggaagtcggggaagcggttgccaagaggttccatctgccaggtatcag1020
gcaaggatatgggctcactgagactacatcagctattctgattacacccgagggggatga1080
taaaccgggcgcggtcggtaaagttgttccattttttgaagcgaaggttgtggatctgga1140
taccgggaaaacgctgggcgttaatcaaagaggcgaactgtgtgtgagaggtcctatgat1200
tatgtccggttatgtaaacaatccggaagcgaccaacgccttgattgacaaggatggatg1260
gctacattctggagacatagcttactgggacgaagacgaacacttcttcatcgttgaccg1320
cctgaagtctctgattaagtacaaaggctatcaggtggctcccgctgaattggaatccat1380
cttgctccaacaccccaacatcttcgacgcaggtgtcgcaggtcttcccgacgatgacgc1440
cggtgaacttcccgccgccgttgttgttttggagcacggaaagacgatgacggaaaaaga1500
gatcgtggattacgtcgccagtcaagtaacaaccgcgaaaaagttgcgcggaggagttgt1560
gtttgtggacgaagtaccgaaaggtcttaccggaaaactcgacgcaagaaaaatcagaga1620
gatcctcataaaggccaagaagggcggaaagatcgccgtgtaattctagactgcagattc1680
gatgaattctgcagatatccatcacactggcggccgctcgagcatgcatctagagggccc1740
tattctatagtgtcacctaaatgctagagctcgctgatcagcctcgactgtgccttctag1800
ttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccac1860
tcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtca1920
ttctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatag1980
caggcatgctggggatgcggtgggctctatggcttctgaggcggaaagaaccagctgggg2040
ctctagggggtatccccacgcgccctgtagcggcgcattaagcgcggcgggtgtggtggt2100
tacgcgcagcgtgaccgctacactt2125
<210>7
<211>651
<212>dna
<213>人工序列
<220>
<223>cmv基因的编码序列-2
<400>7
ctttcctgcgttatcccctgattctgtggataaccgtattaccgccatgcattagttatt60
aatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacat120
aacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaa180
taatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtgg240
agtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgc300
cccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgacct360
tatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtga420
tgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaa480
gtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttc540
caaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtggg600
aggtctatataagcagagctggtttagtgaaccgtcagatccgctagcgct651
<210>8
<211>1125
<212>dna
<213>人工序列
<220>
<223>gfp-sv40pas基因的编码序列
<400>8
accggtcgccaccatggtgagcaagggcgaggagctgttcaccggggtggtgcccatcct60
ggtcgagctggacggcgacgtaaacggccacaagttcagcgtgtccggcgagggcgaggg120
cgatgccacctacggcaagctgaccctgaagttcatctgcaccaccggcaagctgcccgt180
gccctggcccaccctcgtgaccaccctgacctacggcgtgcagtgcttcagccgctaccc240
cgaccacatgaagcagcacgacttcttcaagtccgccatgcccgaaggctacgtccagga300
gcgcaccatcttcttcaaggacgacggcaactacaagacccgcgccgaggtgaagttcga360
gggcgacaccctggtgaaccgcatcgagctgaagggcatcgacttcaaggaggacggcaa420
catcctggggcacaagctggagtacaactacaacagccacaacgtctatatcatggccga480
caagcagaagaacggcatcaaggtgaacttcaagatccgccacaacatcgaggacggcag540
cgtgcagctcgccgaccactaccagcagaacacccccatcggcgacggccccgtgctgct600
gcccgacaaccactacctgagcacccagtccgccctgagcaaagaccccaacgagaagcg660
cgatcacatggtcctgctggagttcgtgaccgccgccgggatcactctcggcatggacga720
gctgtacaagtccggactcagatctcgagctcaagcttcgaattctgcagtcgacggtac780
cgcgggcccgggatccaccggatctagataactgatcataatcagccataccacatttgt840
agaggttttacttgctttaaaaaacctcccacacctccccctgaacctgaaacataaaat900
gaatgcaattgttgttgttaacttgtttattgcagcttataatggttacaaataaagcaa960
tagcatcacaaatttcacaaataaagcatttttttcactgcattctagttgtggtttgtc1020
caaactcatcaatgtatcttaacgcgtaaattgtaagcgttaatattttgttaaaattcg1080
cgttaaatttttgttaaatcagctcattttttaaccaataggccg1125
<210>9
<211>651
<212>dna
<213>人工序列
<220>
<223>cmv基因的编码序列-3
<400>9
ctttcctgcgttatcccctgattctgtggataaccgtattaccgccatgcattagttatt60
aatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacat120
aacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaa180
taatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtgg240
agtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgc300
cccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgacct360
tatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtga420
tgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaa480
gtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttc540
caaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtggg600
aggtctatataagcagagctggtttagtgaaccgtcagatccgctagcgct651
<210>10
<211>727
<212>dna
<213>人工序列
<220>
<223>gfpcds基因的编码序列
<400>10
accggtcgccaccatggtgagcaagggcgaggagctgttcaccggggtggtgcccatcct60
ggtcgagctggacggcgacgtaaacggccacaagttcagcgtgtccggcgagggcgaggg120
cgatgccacctacggcaagctgaccctgaagttcatctgcaccaccggcaagctgcccgt180
gccctggcccaccctcgtgaccaccctgacctacggcgtgcagtgcttcagccgctaccc240
cgaccacatgaagcagcacgacttcttcaagtccgccatgcccgaaggctacgtccagga300
gcgcaccatcttcttcaaggacgacggcaactacaagacccgcgccgaggtgaagttcga360
gggcgacaccctggtgaaccgcatcgagctgaagggcatcgacttcaaggaggacggcaa420
catcctggggcacaagctggagtacaactacaacagccacaacgtctatatcatggccga480
caagcagaagaacggcatcaaggtgaacttcaagatccgccacaacatcgaggacggcag540
cgtgcagctcgccgaccactaccagcagaacacccccatcggcgacggccccgtgctgct600
gcccgacaaccactacctgagcacccagtccgccctgagcaaagaccccaacgagaagcg660
cgatcacatggtcctgctggagttcgtgaccgccgccgggatcactctcggcatggacga720
gctgtac727
<210>11
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv-luc[1-205]基因的编码序列的上游引物
<400>11
caaggcttgaccgacaattgcatga25
<210>12
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv-luc[1-205]基因的编码序列的下游引物
<400>12
gtttcatagcttctgccaaccgaac25
<210>13
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到luc[206-1653]-bghpolyasignal基因的编码序列的上游引物
<400>13
gatatgggctgaatacaaatcacag25
<210>14
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到luc[206-1653]-bghpolyasignal基因的编码序列的下游引物
<400>14
aagtgtagcggtcacgctgcgcgta25
<210>15
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv-luc[1-158]基因的编码序列的上游引物
<400>15
caaggcttgaccgacaattgcatga25
<210>16
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv-luc[1-158]基因的编码序列的下游引物
<400>16
taagtgatgtccacctcgatatgtg25
<210>17
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到luc[159-1653]-bghpolyasignal基因的编码序列的上游引物
<400>17
cgctgagtacttcgaaatgtccgtt25
<210>18
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到luc[159-1653]-bghpolyasignal基因的编码序列的下游引物
<400>18
aagtgtagcggtcacgctgcgcgta25
<210>19
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv基因的编码-1序列的上游引物
<400>19
caaggcttgaccgacaattgcatga25
<210>20
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv基因的编码-1序列的下游引物
<400>20
ccaacagtaccgaagcccaaagctg25
<210>21
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到luc[1-1653]-bghpolyasignal基因的编码序列的上游引物
<400>21
taagccaccatggaagacgccaaaa25
<210>22
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到luc[1-1653]-bghpolyasignal基因的编码序列的下游引物
<400>22
aagtgtagcggtcacgctgcgcgta25
<210>23
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv基因的编码-2序列的上游引物
<400>23
ctttcctgcgttatcccctgattct25
<210>24
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv基因的编码-2序列的下游引物
<400>24
agcgctagcggatctgacggttcac25
<210>25
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到gfp-sv40pas基因的编码序列的上游引物
<400>25
accggtcgccaccatggtgagcaag25
<210>26
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到gfp-sv40pas基因的编码序列的下游引物
<400>26
cggcctattggttaaaaaatgagct25
<210>27
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv基因的编码-3序列的上游引物
<400>27
ctttcctgcgttatcccctgattct25
<210>28
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到cmv基因的编码-3序列的下游引物
<400>28
agcgctagcggatctgacggttcac25
<210>29
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到gfpcds基因的编码序列的上游引物
<400>29
accggtcgccaccatggtgagcaag25
<210>30
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到gfpcds基因的编码序列的下游引物
<400>30
gtacagctcgtccatgccgagagtg25
<210>31
<211>386
<212>dna
<213>人工序列
<220>
<223>sv40基因的编码序列
<400>31
agatctcgagctcaagcttcgaattctgcagtcgacggtaccgcgggcccgggatccacc60
ggatctagataactgatcataatcagccataccacatttgtagaggttttacttgcttta120
aaaaacctcccacacctccccctgaacctgaaacataaaatgaatgcaattgttgttgtt180
aacttgtttattgcagcttataatggttacaaataaagcaatagcatcacaaatttcaca240
aataaagcatttttttcactgcattctagttgtggtttgtccaaactcatcaatgtatct300
taacgcgtaaattgtaagcgttaatattttgttaaaattcgcgttaaatttttgttaaat360
cagctcattttttaaccaataggccg386
<210>32
<211>22
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到sv40基因的编码序列的上游引物
<400>32
agatctcgagctcaagcttcga22
<210>33
<211>25
<212>dna
<213>人工序列
<220>
<223>人工合成,以用作得到sv40基因的编码序列的下游引物
<400>33
cggcctattggttaaaaaatgagct25
- 还没有人留言评论。精彩留言会获得点赞!