利用外周血诊断早期肝癌的DNA甲基化标记物及其应用的制作方法
本发明属于生物检测领域,涉及一种用于肝癌的标记物及其应用,具体涉及利用外周血诊断早期肝癌的dna甲基化标记物及其应用。
背景技术:
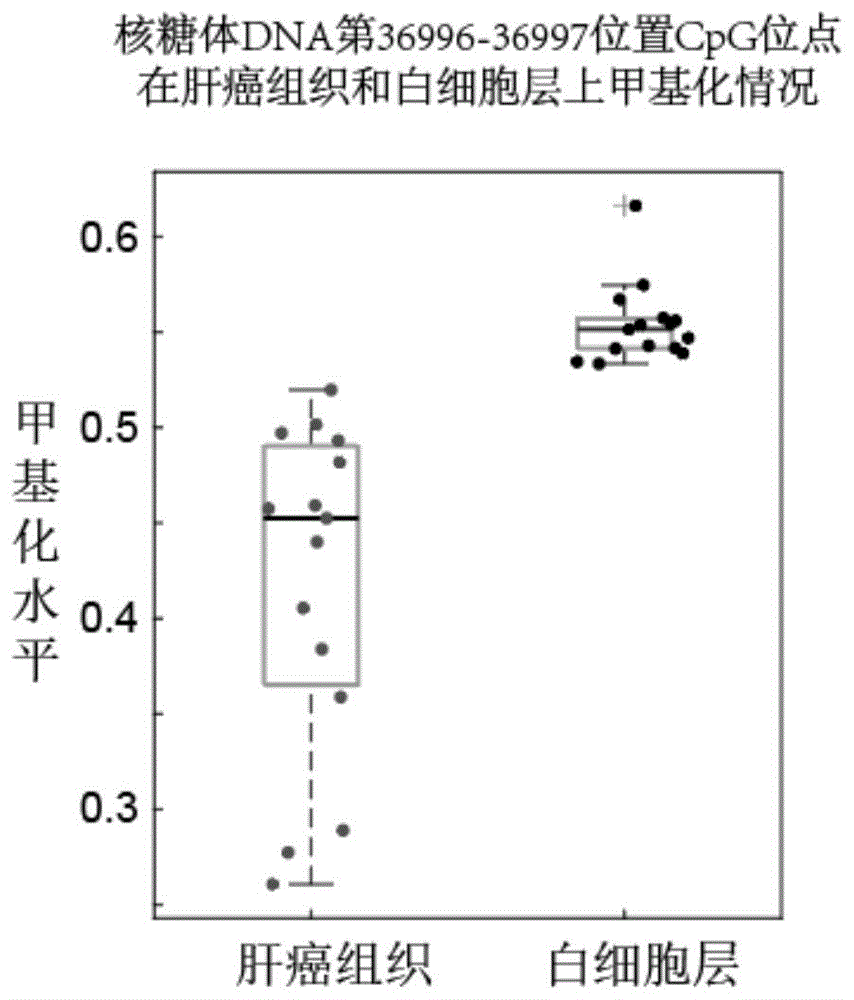
:外周血检测疾病是一种微创甚至无创的检测方式。在外周血中有游离dna,这些游离dna来自于细胞凋亡释放到血液中的dna,因此,通过对游离dna的分析可以鉴别出机体内的出现一些问题。dna甲基化是表观遗传学的重要部分,dna甲基化对基因调控有着至关重要的作用。现有研究表明癌症的发生与基因组dna甲基化非常密切,这使得通过鉴别dna甲基化的变异来检测癌症成为了现实。dna甲基化是指生物体内在dna甲基转移酶的催化下,以s-腺苷甲硫氨酸为甲基供体,将甲基转移到特定的碱基上的过程。在哺乳动物中dna甲基化主要发生在cpg的c上,生成5-甲基胞嘧啶。在基因组中98%以上的cpg位点分布于具有转座潜能的重复序列中。在正常细胞中,这些cpg处于高度甲基化/转录沉默的状态,而在肿瘤细胞中这些cpg发生了广泛的去甲基化,导致重复序列的转录、转座子的活化,增加基因组的不稳定性。余下的占总量2%左右的cpg密集地分布于基因启动子区域的cpg岛。筛选癌症组织特异的甲基化异常位点有助于癌症的检测。肝癌是常见的一种恶性肿瘤,由于现有标记物特异性差(例如甲胎蛋白),许多肝癌患者诊断时往往已是中晚期,丧失了根治切除的机会。因此寻找早期肝癌外周血甲基化灵敏度高的标记物对于肝癌的早发现早治疗具有重要意义。技术实现要素:本发明旨在至少在一定程度上解决相关技术中的技术问题之一。为此,本发明的一个目的在于提出一种能够用于肝癌的标记物。本发明的发明人在研究过程中发现:核糖体dna在生命过程中起到非常重要作用。核糖体dna的转录产物占据细胞rna产量的80%,对于细胞翻译蛋白质过程至关重要。有研究表明,在癌症中核糖体dna转录调控会出现异常。因此,研究癌症中核糖体dna的甲基化异常有助于我们寻找癌症检测的标记物。然而在人参考基因组序列hg19中并不包含核糖体dna的参考序列,因此,常规分析中并不涉及到核糖体dna的甲基化。此外,在人的基因组中常染色体的拷贝数只有2,而核糖体dna的拷贝数却有约400,这使得即使测序深度较浅时,我们也可以有足够的数据分析核糖体dna单个cpg位点的甲基化情况。因此,在核糖体dna上寻找检测癌症的标记物既有机制基础,也有实现基础。具体而言,本发明提供了如下技术方案:根据本发明的第一方面,本发明提供了一种用于肝癌的标记物,所述标记物包括选自以下cpg位点中的至少一个:以人核糖体dna重复片段单元参考序列u13369.1为基准,第24167,36996,37361,37178,39913,30789,37020,36832,34428,或者34805位置处的cpg位点或者经修饰的cpg位点。根据本发明的实施例,以上所述用于肝癌的标记物可以进一步包括如下技术特征:在本发明的一些实施例中,以人核糖体dna重复片段单元参考序列u13369.1为基准,所述标记物包括第24167,36996,37361,37178,39913,30789位置处的cpg位点或者经修饰的cpg位点中的至少一种;以及第37020,36832,34428或者34805位置处的cpg位点或者经修饰的cpg位点中的至少一种。在本发明的一些实施例中,以人核糖体dna重复片段单元参考序列u13369.1为基准,所述标记物包括第24167,36996,37361,37178,39913,30789位置处的cpg位点或者经修饰的cpg位点中的至少两种。在本发明的一些实施例中,以人核糖体dna重复片段单元参考序列u13369.1为基准,所述标记物包括第24167,36996,37361,37178,39913,30789位置处的cpg位点或者经修饰的cpg位点中的至少一种;以及第37020,36832,34428或者34805位置处的cpg位点或者经修饰的cpg位点中的至少两种。在本发明的一些实施例中,所述修饰的cpg位点包括5-甲基化修饰或者5-羟甲基化修饰。根据本发明的第二方面,本发明提供了一种引物序列,所述引物序列以本发明第一方面所述标记物所在核苷酸序列为靶序列,用于靶序列的特异性扩增。根据本发明的第三方面,本发明提供了一种探针,所述探针游离于溶液中或者固定于芯片上,所述探针能够特异性捕获本发明第一方面所述标记物所在的核苷酸序列。根据本发明的第四方面,本发明提供了一种试剂盒,所述试剂盒用于诊断肝癌,所述试剂盒含有用于检测本发明第一方面所述的标记物的试剂。在本发明的一些实施例中,所述试剂盒进一步包括本发明第二方面任一实施例所述的引物序列或者本发明第三方面所述的探针。根据本发明的第五方面,本发明提供了标记物或者引物序列或者探针在制备肝癌诊断试剂盒中的用途,所述标记物为本发明第一方面所述的标记物,所述引物序列为本发明第二方面所述的引物序列,所述探针为本发明第三方面所述的探针。根据本发明的第六方面,本发明提供了一种确定待测样本中目标位点甲基化的方法,所述目标位点为本发明第一方面任一实施例所述标记物中的cpg位点,所述方法包括:(1)对所述待测样本外周血中的游离dna进行甲基化处理,使得未发生甲基化的胞嘧啶转化为胸腺嘧啶,获得经甲基化处理后的样本;(2)基于所述经甲基化处理后的样本,构建测序文库,测序获得测序数据;(3)将所述测序数据与参考序列进行比对,基于比对结果确定所述测序数据中目标位点的甲基化结果。根据本发明的实施例,以上确定待测样本中目标位点甲基化的方法可以进一步包括如下技术特征:在本发明的一些实施例中,所述参考序列为人核糖体dna重复片段单元参考序列u13369.1。在本发明的一些实施例中,所述测序是通过第二代测序方法或第三代测序方法进行的。利用已有的二代测序方法或者三代测序方法均可以实现对待测样本中的cpg位点的甲基化结果进行测定。在本发明的一些实施例中,所述测序是通过选自hiseq2000、solid、454和单分子测序装置的至少一种进行的。根据本发明的第七方面,本发明提供了一种用于诊断肝癌或者预测肝癌患病风险的系统,包括:甲基化处理装置,所述甲基化处理装置用于对来自于待测样本外周血中的游离dna进行甲基化处理,使得未发生甲基化的胞嘧啶转化为胸腺嘧啶,获得经甲基化处理后的样本;测序装置,所述测序装置与所述甲基化处理装置相连,所述测序装置基于所述经甲基化处理后的样本,构建测序文库,测序获得测序数据;比对装置,所述比对装置与所述测序装置相连,所述比对装置用于所述测序数据与参考序列进行比对,基于比对结果确定所述测序数据中标记物中cpg位点的甲基化结果;结果判定装置,所述结果判定装置与所述比对装置相连,所述结果判定装置基于所述测序数据中标记物中cpg位点的甲基化结果,通过统计模型分析,判定所述待测样本是否患有肝癌或者预测所述待测样本是否易患肝癌;其中,所述标记物为本发明第一方面任一实施例所述的标记物。根据本发明的实施例,以上所述诊断系统可以进一步包括如下技术特征:在本发明的一些实施例中,所述参考序列为人核糖体dna重复片段单元参考序列u13369.1。在本发明的一些实施例中,所述统计模型为多元统计模型。利用多元统计模型可以分析多个cpg位点甲基化情况同肝癌的关系,从而利用cpg位点的甲基化结果确定肝癌的患病情况,实现肝癌的早期快速诊断。在本发明的一些实施例中,所述统计模型是基于多个肝癌患者和所述多个肝癌患者中cpg位点的甲基化结果建立的,所述cpg位点为本发明第一方面任一实施例所述标记物。在本发明的一些实施例中,所述多元统计模型为logistic回归模型、随机森林模型中的至少一种,优选为logistic回归模型。回归模型是对统计关系进行定量描述的一种数学模型是,是通过模型研究一个变量关于另一个变量的具体依赖关系的计算模型。通过回归模型分析,可以研究各cpg位点或者多个cpg位点的甲基化结果同肝癌的关系,从而根据cpg位点的甲基化检测结果,即可以确定待测样本的患病情况。logistic回归模型作为一种广义的线性回归模型,可以准确研究疾病和变量的关系。在本发明的一些实施例中,利用软件bs-seeker2进行所述比对,软件所选匹配方式为局部比对(localalignment)。选择bs-seeker2匹配的原因是该软件支持’localalignment’的匹配模式,使用这种匹配模式有助于提高匹配回参考序列的比率,增加分析结果的鲁棒性。本发明所取得的有益效果为:利用本发明提供的各cpg位点或者cpg位点的组合作为标记物,能够以患者外周血为样本,通过检测病人外周血中部分核糖体dna序列的甲基化状态即可实现肝癌的早期诊断,从而在无创或者微创的情况下,即能够实现及时诊断肝癌。而且本发明所提供的标记物检测肝癌,特异性和灵敏性均很高,而且这些标记物在基因组中的拷贝数多,较少标记物即可以实现高精度检测。附图说明图1是根据本发明的实施例提供的核糖体dna第36996位置上cpg位点在肝癌组织和白细胞层上甲基化情况。图2是根据本发明的实施例提供的核糖体dna第36996位置上cpg位点在健康人、hbv感染的非癌患者、早期肝癌患者外周血游离dna的甲基化情况。图3是根据本发明的实施例提供的外周血数据在核糖体dna第36996位置上cpg位点的甲基化水平鉴别非癌患者和癌症患者的roc图。图4是100次训练集和测试集拆分中,在测试集中准确率的箱体图。图5是根据本发明的实施例提供的用于诊断肝癌或者预测肝癌患病风险的系统的结构示意图。具体实施方式下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。为了方便本领域技术人员理解,对本文中出现的某些术语进行解释和说明,需要说明的是,这些解释和说明仅用来帮助本领域技术人员对于本发明进行理解,而不能看做是对本发明保护范围的限制。本文中,cpg位点表示二核苷酸对,碱基鸟嘌呤(g)紧随胞嘧啶(c)之后,cpg是胞嘧啶(c)-磷酸(p)-鸟嘌呤(g)的缩写。本文中,“标记物”是指能够用于指示受试者患有肝癌的情况。这些标记物可以是核酸序列、大分子、小分子等等,例如可以是一定长度的核酸序列,也可以是一个特定位点的核苷酸或者两个特定位点的核苷酸,只要能够用于指示受试者患有肝癌的情况。根据本发明的实施例,本发明提供的标记物指的是能够用于检测或者诊断受试者是否患者肝癌的cpg位点。本发明提供了利用能够用来检测肝癌的标记物及应用。这些标记物是从人核糖体dna参考序列中筛选出来的。本发明揭示了人核糖体dna甲基化异常的序列区域,筛选出了能够利用外周血dna检测肝癌的10个cpg位点。这些区域的甲基化状态在肿瘤组织和非肿瘤组织中存在明显差异,在肿瘤组织中低甲基化,并且可以在外周血中很好地区分包含hbv感染病人在内的非肝癌患者和早期肝癌患者,这些标记物中单个cpg的auc最高可以达到98%,在100%特异性下,可以取得80%的灵敏度。并经过测试集验证,组合应用这些标记物,诊断患者是否患肝癌的准确率达到了95%。根据本发明的一个方面,本发明提供了一种用于肝癌的标记物,所述标记物以人核糖体dna重复片段单元参考序列u13369.1为基准,选自以下cpg位点中的至少一个:第24167,36996,37361,37178,39913,30789,37020,36832,34428,或者34805位置处的cpg位点或者经修饰的cpg位点。用作标记物的cpg位点,可以是这些位点中的任意一个,任意两个,任意三个,任意四个,任意五个,任意六个,任意七个,任意八个,任意九个,甚至是全部十个。当用作标记物的cpg位点越多时,通过这些标记物进行肝癌诊断,所获得的诊断结果越可靠。在至少一些实施方式中,第24167,36996,37361,37178,39913位置处的cpg位点的预测率更加可靠,可以单独使用,或者组合其中两个或者三个应用。在至少一些实施方式中,第30789,37020,36832,34428,或者34805位置处的cpg位点的肝癌诊断率要比其他位点低,可以组合应用,获得更加可靠的诊断结果。本文中,“以人核糖体dna重复片段单元参考序列u13369.1为基准”是指本文在表述这些cpg位点时,是以人核糖体dna重复片段单元参考序列u13369.1中的位置进行的表述。收录于genebank中的人核糖体dna重复片段单元参考序列u13369.1中含有的这些cpg位点可以用作肝癌的标记物,通过对这些cpg位点分析可以预测样本是否易患肝癌或者诊断是否患有肝癌。这些cpg位点的位置也许会随着数据库的数据更新或者因为不同数据库的表征方式的不同而发生变化,但是这些变化不影响这些位点用于诊断肝癌的功能。这些变化也包含在本发明的保护范围之内。在本发明的至少一些实施方式中,所述cpg位点的修饰包括5-甲基化修饰、5-羟甲基化修饰。基于这些标记物,可以通过对外周血dna进行处理,用于肝癌的早期诊断。也可以基于这些标记物,制备检测早期肝癌的检测试剂或者试剂盒。根据本发明的另一方面,本发明提供了一种诊断肝癌的方法,包括:(1)对待测样本外周血中的游离dna进行甲基化处理,使得未发生甲基化的胞嘧啶转化为胸腺嘧啶,获得经甲基化处理后的样本;(2)基于所述经甲基化处理的样本,构建测序文库,测序获得测序数据;(3)将所述测序数据与人核糖体dna参考序列进行比对,基于比对结果确定所述测序数据中标记物中cpg位点的甲基化结果;(4)基于所述测序数据中cpg位点的甲基化结果,通过统计模型分析,判定所述待测样本是否患有肝癌。需要说明的是,该方法不仅可以用来判断待测样本是否患有肝癌,还可以预测待测样本未来患有肝癌的风险,从而实现早点儿治疗或者预防。在对待测样本外周血的游离dna进行建库,测序,来获取各cpg位点的甲基化结果时,可以采用本领域通用的技术手段。在至少一些实施方式中,在至少一些实施方式中,利用全基因组甲基化测序获取各cpg位点的甲基化结果。例如,将患者血液样本通过10分钟1600×g和10分钟16000×g离心过滤得到血浆;通过dspbloodminikit(qiagen)提取dna,每个病人dna样本从4ml的血浆中提取;使用illumina的paired-endsequencingsamplepreparationkit进行甲基化接头;接下来,测序文库使用ampurexpmagneticbeads(beckmancoulter)进行纯化,然后利用epitectplusdnabisulfitekit(qiagen)进行两轮的重亚硫酸氢盐转化;将产物进行10个循环的pcr扩增,最后在hiseq2000(illumina)进行单端测序。本发明还提供了一种用于诊断肝癌或者预测肝癌患病风险的系统,如图5所示,包括:甲基化处理装置、测序装置、比对装置和结果判定装置,所述甲基化处理装置用于对待测样本者外周血中的游离dna进行甲基化处理,使得未发生甲基化的胞嘧啶转化为胸腺嘧啶,获得经甲基化处理后的样本;所述测序装置与甲基化处理装置相连,所述测序装置基于所述甲基化处理后的样本,构建测序文库,在测序平台上获得测序数据;所述比对装置与所述测序装置相连,所述比对装置用于所述测序数据与参考序列进行比对,基于比对结果确定所述测序数据中标记物位置cpg位点的甲基化结果;所述结果判定装置与所述比对装置相连,所述结果判定装置基于所述测序数据中cpg位点的甲基化结果,通过统计模型分析,判定所述待测样本是否患有肝癌或者预测所述待测样本是否易患肝癌。下面将结合实施例对本发明的方案进行解释。本领域技术人员将会理解,下面的实施例仅用于说明本发明,而不应视为限定本发明的范围。实施例中未注明具体技术或条件的,按照本领域内的文献所描述的技术或条件或者按照产品说明书进行。所用试剂或仪器未注明生产厂商者,均为可以通过市购获得的常规产品。实施例1全基因组甲基化测序数据筛选核糖体dna上差异的cpg位点我们使用2013年发表于pnas题为”noninvasivedetectionofcancer-associatedgenome-widehypomethylationandcopynumberaberrationsbyplasmadnabisulfitesequencing”文章中发表的外周血重亚硫酸氢盐测序数据,数据存放于欧洲基因组-表型档案(europeangenome-phenomearchive),检索号为egas00001000566。这里使用到健康人(32个)、hbv感染非癌病人(8个)、早期肝癌病人(i期、ii期,26个)的外周血dna甲基化数据,以及其中15对肝癌组织和白细胞层dna甲基化数据。在genbank中下载人的核糖体dna重复片段单元的参考序列u13369.1,全长共计42999个碱基,3288个cpg位点。利用bs-seeker2软件将测序数据匹配回参考序列上u13369.1,不再去除测序重复,原因在于核糖体dna上的测序覆盖度比较高。计算每个cpg位点的甲基化c个数和未甲基化c个数。接下来,筛除那些匹配次数少的cpg位点,得到2871个有效的cpg位点。这时,随机将病人拆分成两部分,一部分作为训练集,一部分作为测试集,其中,分别分别选择90%的健康人、90%的hbv感染非癌症人、90%的肝癌患者作为训练集,剩余的病人作为测试集。在训练集上筛选标记物,在测试集上进行测试。随机拆分过程重复100次,均进行后续的分析步骤。利用训练集数据在2871个有效的cpg位点上筛选出能够有效区分非癌、癌患者的cpg位点。基本的操作是,利用每个cpg位点的甲基化水平区分非癌、癌患者,绘制每个cpg的roc(receiveroperatingcharacteristic)曲线,计算auc(areaundercurve)。对每个位点的auc从大到小排序,筛选前30个cpg位点,一般前30个cpg位点的auc均可以大于90%。利用筛选出的前30个cpg位点,利用训练集数据训练正则化的logisitc回归模型,其中正则化是一范数约束,即lasso回归,目的是减少过拟合,筛选有效的cpg位点。一范数约束的系数通过十倍交叉验证得到。最终选择出系数不为零的cpg位点,即为目标标记物。通过100次的训练集和测试集的随机拆分,我们得到了100个正则化的logistic回归模型以及对应的cpg位点的组合,计算100次实验中cpg位点被选中的次数,我们可以得到表1的结果。表1中的cpg位点即是用于肝癌诊断的标记物。表1cpg位点选中的次数cpg位置选中的次数369961002416710037361923717871399134730789443702015368321234428113480511进一步地,分析这些cpg位点在15对癌症组织和白细胞层上的甲基化程度,这些位点在癌症组织中均是低甲基化。以核糖体dna参考序列第36996位置处的cpg位点为例,图1示出了核糖体dna参考序列36996位置处cpg位点在癌症组织和白细胞层dna甲基化程度,从图1可以看出,第36996位置处的cpg位点在癌症组织中显著低甲基化。进一步地,比较在癌症和非癌症患者外周血中这些cpg位点的甲基化水平,发现在癌症病人中这些位点低甲基化。图2示出了核糖体dna参考序列第36996位置处cpg位点在健康人、感染hbv的非癌患者、早期肝癌患者外周血游离dna中的甲基化水平。从图2可以看出,相比较于健康人,感染hbv的非癌患者、早期肝癌患者在核糖体dna第36996位置cpg位点的甲基化水平较低。尤其是早期肝癌患者在核糖体dna第36996位置cpg位点的甲基化水平更低。同时,图3示出了利用核糖体dna参考序列第36996位置处cpg位点区分非癌患者和早期肝癌患者的roc曲线图。从图3可以看出,仅依靠第36996位置处cpg位点的甲基化水平即可有效区分癌症患者和非癌症患者,auc=98%,在100%特异性下,可以取得80%的灵敏度。实施例2测试集中测试标记物的效果在100次训练集和测试集的随机拆分中,利用训练集训练了正则化的logistic模型,将模型应用于测试集,计算出在测试集中的准确率,图4给出了在100次数据集随机拆分中,模型在测试集中准确率的箱线图。平均准确率为0.9513,准确率的标准差为0.0686,说明取得了非常好的区分效果。本文中,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接或彼此可通讯;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1