番茄miR482基因在控制植物分枝上的应用方法与流程
本发明涉及植物基因的应用方法,具体涉及番茄mir482基因在控制植物分枝上的应用方法。
背景技术:
植物分枝是形成理想株型的最重要组成部分,在很大程度上,分枝影响植物的形态建成。分枝与植物的产量形成、适应环境能力和竞争能力密切相关。高等植物分枝的多少直接影响其生物量和结实率等经济指标。但侧枝过多不仅会消耗植物养分,减少植株空间密度诱发病虫害,也会影响植株后期的生长。植物分枝受遗传因素、植物激素和环境因素等多重调控,但是遗传因素起主要作用。植物的分枝来源于叶腋中的侧芽。尽管侧生分生组织与茎顶端分生组织具有同样的发育潜力,但是侧芽经常形成具有更少叶片的休眠芽。一旦环境条件适合,休芽便可以被激活,形成分枝。分枝发育的调控赋予植物对于持续变化的环境条件的可塑性,这一过程受到严格而精细的调控。
随着遗传学的发展,基因调控分枝形成的机制正一步步的被揭开。人们已经在豌豆、拟南芥、水稻和矮牵牛等物种的突变体中筛选到除分枝外其他表型正常的突变株系。这些突变体都与依赖于独脚金内酯(sl)的生理反应密切相关。这些突变体都出现多分枝且植株变矮的表型,说明sl是控制植株分枝的关键作用因子。自从2008年发现这种新型的植物激素,独脚金内酯在植物体内信号通路的作用机制便被迅速研究。植物体内的sl受体是一种αβ水解酶,例如矮牵牛花dad2和水稻d14是已经验证的与sl受体直接相关的基因。sl受体能够与max2/d3/rms4等f-box蛋白相互作用来介导响应sl的目标蛋白降解。像水稻中d53蛋白属于smxl(suppressorofmax2)蛋白家族,它便是一种能调控分蘖且属于sl信号通路中的目标蛋白。
近来,中国科学院遗传与发育生物学研究所焦雨铃研究组发现拟南芥中维持顶端分生组织的的同源异型转录因子wuschel(wus)基因也参与分枝的形成。在前期的研究中,焦雨铃研究组发现在分枝起始过程依赖于植物激素细胞分裂素的信号高点。进一步研究发现,细胞分裂素通路的下游转录因子type-barr能够直接激活wus表达。wus的激活具有高度时空特异性,只发生在成熟叶片的叶腋处。进一步研究发现wus的激活与组蛋白修饰的状态相关,特别是受到组蛋白甲基化和乙酰化调控。
mir482是植物中较保守的一个mirna。研究发现:转基因表达mir482不仅导致了豌豆结节数目的显著增加;而且也影响病原菌感染植物的过程。如:shivaprasad等发现mir482通过靶向调节nbs-lrr的表达影响真菌病原菌感染棉花。yang等超表达马铃薯mir482e后提高了植物对黄萎病病原菌的敏感性。番茄mir482对分枝形成过程的具体调控作用至今未见研究报道。
技术实现要素:
本发明的目的是提供番茄mir482基因在控制植物分枝上的应用方法,该方法能够控制mir482的表达,使植物分枝明显增多。
本发明的目的通过如下技术方案实现:
番茄mir482基因在控制植物分枝上的应用方法,利用mir482前体序列以及plp-35s载体来构建番茄mir482基因的超表达载体,然后通过农杆菌介导法转化番茄植株,通过番茄mir482基因调控植株分枝发育;所述mir482前体序列的核苷酸序列如seqidno.1所示。
进一步地,所述农杆菌介导法中采用的基因工程菌为农杆菌gv3101。
进一步地,构建番茄mir482基因的超表达载体使用的引物组为:
mir482-f:ttggagaggacagggtaccctaggttcagtttagcagatctg
mir482-r:gtcgactctagaggatccccggtggctgtgcccctgatcg,
横线内序列为plp-35s载体smai酶切后两端序列。引物mir482-f、mir482-r的序列分别如seqidno.2、seqidno.3所示。
与现有技术相比,本发明的有益效果为:
1.本发明的应用方法表明番茄mir482能够作为调控番茄分枝发育的调控因子,这在一定程度上加深了人们对于植物分枝调控机制的理解,深入研究分枝发育的调控机制可以为作物育种提供一定的借鉴。
2.本发明获得了超表达mir482的转基因番茄,与野生型番茄相比,分枝明显增多。
附图说明
下面结合附图中的具体实施例对本发明的技术方案做进一步的详细说明,但不构成对本发明的任何限制。
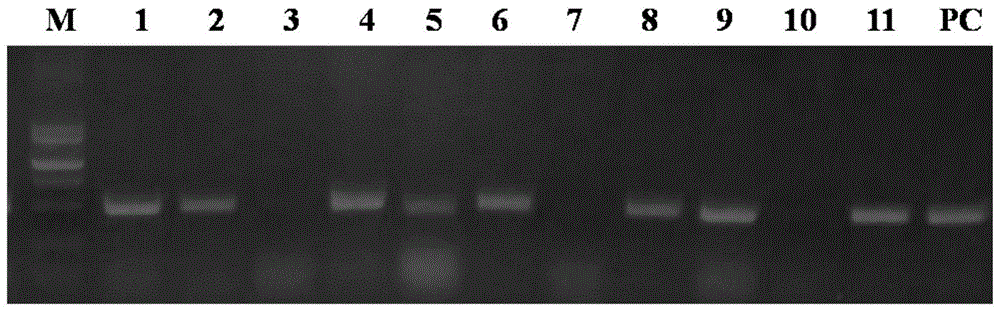
图1为转基因番茄pcr鉴定结果图;
图2为转基因番茄中mir482的表达情况;
图3为转基因番茄植株的分枝表观分析。
具体实施方式
实施例
下述实施例中所使用的方法如无特殊说明,均为常规方法。
下述实施例中所选用的材料、试剂等,如无特别说明,均可以从商业途径中获得。
一、mir482超表达载体的构建
根据植物基因组dna提取试剂盒(tiangen生物公司)提取番茄叶片dna,以叶片dna作为模板,设计引物mir482-f和mir482-r,扩增出183bp的mir482前体序列,经过测序,mir482前体序列的核苷酸序列如seqidno.1所示。
pcr扩增体系为:
pcr扩增程序如下:
pcr产物经1.5%琼脂糖凝胶电泳,利用凝胶回收试剂盒(omega生物公司)回收pcr片段。
提取plp-100-35s质粒,用smai酶切,回收载体大片段。利用peasy-uniseamlesscloningandassemblykit(全式金生物公司)将mir482前体序列与smai酶切回收的plp-100-35s载体大片段连接,转化大肠杆菌dh5a,经菌落pcr筛选阳性后送生工生物科技有限公司测序验证,构建成功的载体命名为plp-35s-mir482。
引物序列如下:
mir482-f:ttggagaggacagggtaccctaggttcagtttagcagatctg
mir482-r:gtcgactctagaggatccccggtggctgtgcccctgatcg
横线上的序列为plp-35s载体smai酶切后两端序列。
二、转基因番茄的获得
1.转化农杆菌获得转基因番茄
将plp-35s-mir482载体转入农杆菌gv3101中,得到重组菌,将重组菌命名为gv3101/plp-35s-mir482。采用农杆菌介导法转化番茄,并通过卡那霉素抗性筛选初步得到t0代转基因番茄。具体实验步骤如下:
将plp-35s-mir482的质粒转化到农杆菌lba4404感受态,利用pcr筛选阳性克隆。然后进行农杆菌侵染,将含相应抗生素的20ml液体培养基+1ml贮备菌液(甘油菌)在28℃暗培养摇菌(一般与外植体同时准备)至od600=1时,收集农杆菌。然后用kcms液体培养基(ms+0.9mg/lvb1+0.1mg/lkt+0.2mg/l2,4-d+0.2mm乙酰丁香酮+2%蔗糖)稀释至od600=0.05~0.1,作为侵染液。
番茄种子用75%乙醇表面消毒30s~2min,无菌水洗3次,再用4%的次氯酸钠溶液表面消毒15~18min,无菌水洗5次。将种子移入无菌水中,置于25℃,30rpm摇床上直至种子萌发后转入到1/2ms固体培养基上,光照培养箱中培养。待到真叶刚长出时的子叶作为外植体,将子叶剪去叶尖和叶柄部,置于kcms固体培养基中,28℃,暗培养24h。
将预培养的番茄外植体置于侵染液中,30rpm摇床上15~30min;移出外植体,滤纸洗掉多余菌液,重新置于kcms固体培养基中,25℃暗培养2~3d。
将外植体转移到2z培养基中(ms+nitsch+2mg/l玉米素核苷+20mg/l潮霉素+400mg/laugmentin+200mg/ltimentin),每天光照18h/黑暗6h,25℃,60%湿度;每两周更换一次培养基。待有小苗分化出来后,将玉米素核苷浓度减半。待芽生长2周左右,将其切下移到生根培养基(1/2ms+nitsch+20mg/l潮霉素+400mg/laugmentin+200mg/ltimentin)中,2~3周移栽至温室。
2.pcr法检测转基因番茄
(1)潮霉素抗性筛选
植物种子和野生型番茄种子分别置于1/2ms(20mg/l卡潮霉素)平板上,经过2~3d后种子萌发。至10d左右,野生型番茄幼苗根几乎停止生长,而转基因植株则能够正常生长。约20d左右,野生型番茄幼苗出现枯死现象,转基因植物幼苗生长旺盛。经过卡那霉素抗性筛选后,转基因幼苗移栽到温室。
(2)pcr筛选转基因番茄植株
目标片段是否整合进植物基因组dna,提取t0代plp-35s-mir482番茄叶片的基因组dna(植物基因组dna提取试剂盒(tiangen生物公司),然后用35s启动子的特异性引物f-35s和plp-35s-mir482的特异性引物mir482-r,进行plp-35s-mir482转基因植物的pcr鉴定,得到482bp的为阳性t0代转plp-35s-mir482番茄植株。f-35s和mir482-r引物序列如下:
f-35s:5'-aacagaactcgccgtaaaga-3',
mir482-r:tcgactctagaggatccccggtggctgtgcccctgatcg。
引物f-35s的序列如seqidno.4所示。
pcr鉴定体系:
pcr反应程序:
pcr产物经1.2%琼脂糖凝胶电泳分析。测试结果如图1所示,其中1-11为11个转基因植物中提取的dna为模板进行的pcr扩增结果,m为marker,pc为阳性对照。从图1结果所示,筛选到了8株阳性苗,然后从中选择编号为9和11的阳性苗作为后续研究对象。
三、转基因番茄的表型分析
1.定量pcr检测
选取阳性t0代转plp-35s-mir482番茄1(plp-35s-mir482-9)、阳性t0代转plp-35s-mir482番茄2(plp-35s-mir482-11)和野生型番茄(wt),利用trizon试剂(invitrogen生物公司)提取90天龄番茄苗叶片rna,反转录成cdna后作为模板,设计定量引物,进行定量pcr扩增。
(1)mirna茎环反转录合成cdna
1)反转录引物设计:对成熟mirna采用茎环反转录合成cdna,在成熟mirna的3’端使用一条50nt可自行折叠成茎环结构的特异性rt引物,序列seqidno.5所示:
mir482a-slr:
gtcgtatccagtgcagggtccgaggtattcgcactggatacgactaggaa。
2)反应体系:在0.2mlpcr反应管中加入,总反应体系为20μl:
3)反应条件:
步骤1:将混匀的反应溶液置于65℃加热5min,之后放入冰中2min。
步骤2:放置pcr仪里16℃热激30min,之后42℃60min,85℃,5min使酶失活停止反转录。
(2)mirna实时荧光定量qrt-pcr
1)定量引物设计:反转录后cdna产物的引物由一条特异性引物和一条通用引物组成,特异性引物基础序列与目标mirna成熟序列互补,根据对引物的长度,tm值及gc含量的要求再用软件进行调整,可在5’端加2-3个gc以增加退火温度,平衡gc含量,u6被作为内参序列。定量引物序列及反转录引物分别如下:
mir482a-slr:gtcgtatccagtgcagggtccgaggtattcgcactggatacgactaggaa
slr-r:gtgcagggtccgaggt
mir482a-slr-f:gcggcgttccaattccacccat。
slr-r和mir482a-slr-f的序列分别如seqidno.6和seqidno.7所示。
2)应用sybr染料法,对mirna采用实时定量检测。反应体系参照
总反应体系为25μl:
3)realtimepcr反应程序:
步骤1:预变性95℃5min;
步骤2:40循环:95℃5s,60℃30s
以上循环结束后进行65℃~95℃的融解曲线分析。为确保实验数据的有效性,每个样品平行三次,溶解曲线为单一峰。按照相对定量算法,目的基因的相对表达量计算公式为:rel.exp=2-δδct,其中δδct=(处理样品δct)-(calibratorqδct),处理样品δct=(内参基因ct)-(目的基因ct),calibratorδct=(参比样内参基因ct)–(参比样目的基因ct)。表达水平的结果如图2所示,与wt相比,plp-35s-mir482-9、plp-35s-mir482-11的植株中mir482的表达量有了一定程度的上升。
3.表型分析
对转基因番茄表型调查结果如图3所示,研究结果是在番茄苗生长大约90天后进行比较,结果表明,与野生型番茄相比,plp-35s-mir482超表达载体转基因番茄表现出矮小、分枝明显增多的表型。
以上实施例为本发明的部分实施方式,并不限制于本发明。对本领域技术人员来说,在不脱离本发明原理的前提下做出的若干改进和变型,也应视为本发明的保护范围。
序列表
<110>玉林师范学院
<120>番茄mir482基因在控制植物分枝中的应用方法
<160>7
<170>siposequencelisting1.0
<210>1
<211>183
<212>dna
<213>番茄(lycopersiconesculentum)
<400>1
taagttcagtttagcagatctgaaattggagatgagtttttcgaaaatctatggggattg60
gtgagttggaaagcttttctttttcttctcttgtgattagctttccaattccacccattc120
ctatggtttttcggtattctctcccttttcgaatgctatcgatcgatcaggggcacagcc180
acc183
<210>2
<211>42
<212>dna
<213>人工序列(artificialsequence)
<400>2
ttggagaggacagggtaccctaggttcagtttagcagatctg42
<210>3
<211>40
<212>dna
<213>人工序列(artificialsequence)
<400>3
gtcgactctagaggatccccggtggctgtgcccctgatcg40
<210>4
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>4
aacagaactcgccgtaaaga20
<210>5
<211>50
<212>dna
<213>人工序列(artificialsequence)
<400>5
gtcgtatccagtgvagggtccgaggtattcgcactggatacgactaggaa50
<210>6
<211>16
<212>dna
<213>人工序列(artificialsequence)
<400>6
gtgcagggtccgaggt16
<210>7
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>7
gcggcgttccaattccacccat22
- 还没有人留言评论。精彩留言会获得点赞!