一种TPP核糖开关序列引物和肠道菌群分类方法与流程
本发明涉及一种tpp核糖开关序列引物和肠道菌群分类方法。
背景技术:
目前16srrna基因序列广泛应用在细菌分类的研究,但是16srrna基因序列具有相对的稳定性,使得16srrna基因序列进化速率相对较低,无法分辨近缘菌株之间的进化关系,一般只能分析到属的水平,以及16srrna基因序列在物种内存在种内异质性,这也是细菌分类中的一个重要的误差来源。
技术实现要素:
本发明的目的在于克服现有技术的不足之处,提供了一种tpp核糖开关序列引物和肠道菌群分类方法,解决了上述背景技术中的问题。
本发明解决其技术问题所采用的技术方案是:提供了一种tpp核糖开关序列引物,所述引物为3’端带有接头序列的保守序列,所述保守序列为
seqidno:01:nngctgaga,和
seqidno:02:tycctncgc;
本发明还提供了一种肠道菌群分类方法,设计tpp核糖开关序列引物,以klenowfragment酶构建tpp核糖开关基因序列文库,采用特异性扩增制备人类肠道菌的总tpp核糖开关序列,建立一种新的肠道菌群分类标准;所述tpp核糖开关序列引物包含上述保守序列seqidno:01和seqidno:02。
具体包括如下步骤:
一)构建tpp核糖开关基因序列文库,设计带有接头序列的tpp核糖开关保守序列引物,并以人类肠道菌群dna样本为模板,加入klenowfragment酶、脱氧核糖核苷三磷酸、缓冲液和超纯水构建混合体系,经孵育程序依次合成tpp核糖开关基因dna序列的第一条链和第二条链,得到总tpp核糖开关dna序列;
其中,孵育程序为:
步骤一)具体步骤如下:
1)tpp核糖开关序列引物设计;所述tpp核糖开关序列引物为带有接头序列的tpp核糖开关保守序列,上游引物和下游引物序列分别为
seqidno:03:ttaaccccacaaacacgggagcnngctgaga,和
seqidno:04:atgcttgattctcctcgctacgtycctncgc;
2)tpp核糖开关基因dna序列第一条链的合成;
①取人类肠道菌群dna样本1000ng,加入10μmseqidno:035μl,补充超纯水使总体系达到20μl,得到20μl混合体系;
②将20μl混合体系在95℃孵育5min;
③将孵育后的20μl混合体系置于冰上,并加入以下组分,得到40μl混合体系:
④将40μl混合体系立即放入pcr中,以孵育程序进行孵育,得到第一条链。
3)tpp核糖开关基因dna序列第二条链的合成;
①在上述孵育后的40μl混合体系置于冰上依次加入如下组分,得到50μl混合体系:
②将50μl混合体系立即放入pcr中,进行如下孵育程序,得到第二条链,得到总tpp核糖开关基因dna样本。
二)将步骤一)产物总tpp核糖开关dna序列进行pcr扩增;其中,步骤二)的上游引物、下游引物序列为
seqidno:05:ttaaccccacaaacacgggagc,和
seqidno:06:atgcttgattctcctcgctacg
取上步总tpp核糖开关基因dna样本中10μl,pcr体系以40μl计组分为下表,
进行pcr反应,循环30轮并于4℃下保存产物。
三)构建总tpp核糖开关dna序列pcr扩增文库;
1)设计总tpp核糖开关dna序列pcr建库引物,其中建库的上游引物、下游引物序列为
seqidno:07:
atgatacggcgaccaccgagatctacactctttccctacacgacgctcttccgatctttaaccccacaaacacgggagc,和
seqidno:08:
caagcagaagacggcatacgagatgcatatgtgactggagttcagacgtgtgctcttccgatcatgcttgattctcctcgctacg,
建库的下游引物包括索引序列seqidno:09:gcatat;
2)将步骤二)tpp核糖开关基因的2个样本pcr产物,依次取3μl作为建库模板,组分为下表,
随后进行pcr反应,循环30轮并于4℃下保存产物。
四)illumina二代测序服务。
本技术方案与背景技术相比,它具有如下优点:
1.本方案建立了一种特异性扩增具有短保守dna片段的新方法,并应用该方法特异性扩增出人类肠道菌中总tpp核糖开关序列,可以区分16srrna分不开的物种;
2.核糖开关是调控基因表达的非编码rna,作为细胞核酸组分水平中的分子标准用来区分细菌物种,具有序列较短便于分析的优点,同时核糖开关广泛分布在细菌中,其序列的变异更加丰富,便于和肠道菌功能相结合,能够实现有效区分近缘菌株之间的细小差别。
附图说明
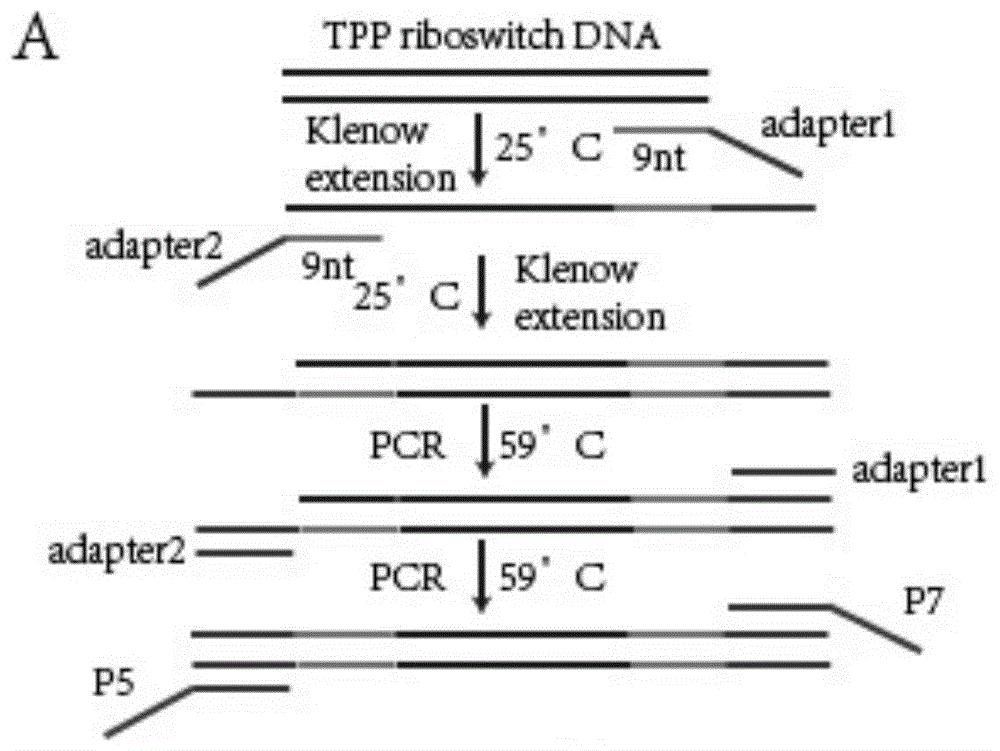
图1为本发明分类方法流程示意图;
图2为16srrna基因v4片段;
图3为tpp核糖开关文库。
具体实施方式
请查阅图1~3,本实施例的一种肠道菌群分类方法,包括如下步骤:
一)tpp核糖开关基因序列文库的构建:
1)tpp核糖开关基因序列引物设计;
所述tpp核糖开关基因序列的保守序列(下划线)5’端接有adapter序列,在本实施例中,adapter序列采用与后续高通量测序机器适配接头序列,具体如下:
2)tpp核糖开关基因dna序列第一条链的合成;
①取肠道菌样品dna1000ng,加入上述tpp核糖开关10μmreverseprimer5μl,补充超纯水使总体系达到20μl,得到20μl混合体系;
②将20μl混合体系在95℃孵育5min;
③将孵育后的20μl混合体系置于冰上,并加入以下组分,得到40μl混合体系:
④将40μl混合体系立即放入pcr中,进行如下孵育程序,得到第一条链:
3)tpp核糖开关基因dna序列第二条链的合成;
①在上述孵育后的40μl混合体系置于冰上依次加入如下组分,得到50μl混合体系:
②将50μl混合体系立即放入pcr中,进行如下孵育程序,得到第二条链,得到总tpp核糖开关基因dna样本:
二)总tpp核糖开关基因dna样本pcr扩增:
1)pcr扩增引物设计;
本实施例采用总tpp核糖开关基因dna样本adapter序列作为引物,
2)取10μl总tpp核糖开关基因dna样本作为pcr模板,依次加入如下组分:
3)将pcr反应管放入普通pcr仪中,pcr反应程序如下设置:
三)总tpp核糖开关dna序列pcr扩增文库制备:
1)总tpp核糖开关dna序列pcr建库引物p5和97的设计(下划波浪线标记为index序列);
2)将步骤二)得到的tpp核糖开关基因2个样本pcr产物,依次取3μl作为建库模板;
四)测序,具体为illumina二代测序服务。
以上所述,仅为本发明较佳实施例而已,故不能依此限定本发明实施的范围,即依本发明专利范围及说明书内容所作的等效变化与修饰,皆应仍属本发明涵盖的范围内。
序列表
<110>华侨大学
<120>一种tpp核糖开关序列引物和肠道菌群分类新方法
<160>9
<170>siposequencelisting1.0
<210>1
<211>9
<212>dna
<213>人工序列(artificialsequence)
<400>1
nngctgaga9
<210>2
<211>9
<212>dna
<213>人工序列(artificialsequence)
<400>2
tycctncgc9
<210>3
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>3
ttaaccccacaaacacgggagcnngctgaga31
<210>4
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>4
atgcttgattctcctcgctacgtycctncgc31
<210>5
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>5
ttaaccccacaaacacgggagc22
<210>6
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>6
atgcttgattctcctcgctacg22
<210>7
<211>79
<212>dna
<213>人工序列(artificialsequence)
<400>7
atgatacggcgaccaccgagatctacactctttccctacacgacgctcttccgatcttta60
accccacaaacacgggagc79
<210>8
<211>85
<212>dna
<213>人工序列(artificialsequence)
<400>8
caagcagaagacggcatacgagatgcatatgtgactggagttcagacgtgtgctcttccg60
atcatgcttgattctcctcgctacg85
<210>9
<211>6
<212>dna
<213>人工序列(artificialsequence)
<400>9
gcatat6
- 还没有人留言评论。精彩留言会获得点赞!