重组表达载体、靶向性的T细胞及它们的应用的制作方法
本发明属于肿瘤生物制品领域,具体地,涉及一种重组表达载体、含有该重组表达载体靶向性的T细胞及其应用。
背景技术:
肿瘤是严重威胁人类健康的常见病和多发病,已成为威胁人类健康的第一“杀手”。肿瘤不仅严重威胁人类的健康,同时会给患病家庭和社会带来沉重的负担。因此,研发或改进新的肿瘤治疗手段具有重要的临床意义和社会意义。
肿瘤的发生和进展与诸多因素有关,累积的基因突变是肿瘤发生的内在因素。在正常状态下,突变的肿瘤细胞会被免疫系统及时识别并清除。当人体免疫力下降或存在缺陷时,免疫系统无法及时识别和杀伤肿瘤细胞,便会引起肿瘤的发生。免疫治疗作为一种新的肿瘤治疗手段,正是通过改善和指导人体免疫系统对肿瘤的杀伤来达到治愈肿瘤的目的。
免疫治疗的手段有很多,如细胞因子激活的杀伤性(cytokine induced killer,CIK)细胞、树突状细胞(dentritic cells,DC)疫苗、自然杀伤性(natural killer,NK)细胞及嵌合型抗原受体修饰的T(chimeric antigen receptor modified T cells,CART)细胞等。其中,CART疗法以其精准、特异、直接的特点,取得了令人鼓舞的临床效果。嵌合性抗原受体由识别肿瘤抗原的单链抗体(scfv)、激活T细胞CD3-zeta链以及共刺激信号CD28或CD137组成。该受体可直接介导T细胞对肿瘤的识别及杀伤,不依赖于传统TCR与MHC的结合,从而有效规避了肿瘤细胞低表达MHC分子造成的T细胞对肿瘤细胞的识别障碍。例如,以CD19为靶点的CART-19对于急性B细胞白血病可以取得90%以上的临床有效率。
CART疗法进展很快,但其对于某些病种的治疗效果仍然不理想。其中,肿瘤微环境中存在多种抑制免疫系统的机制,例如肿瘤会分泌TGF-β、白介素6(interleukin-6,IL-6)或表达免疫监测点蛋白配体PD-L1等抑制T细胞的激活并诱导产生抑制型免疫细胞,从而起到保护肿瘤不受免疫细胞杀伤的作用。
PD-1是由人PDCD1基因编码的由268个氨基酸组成的跨膜蛋白,PD-1在激活的T细胞、B细胞和巨噬细胞表面有表达,是免疫检验点蛋白之一。当T细胞激活后,其激活的TCR/ZAP70、PI3K/AKT等信号通路会上调PD-1分子的表达。PD-1有PD-L1和PD-L2两种配体,PD-L1在多种免疫细胞和人体组织中有低表达,在几乎所有的肿瘤组织中高表达;PD-L2主要在DC和少数肿瘤中有表达。与配体结合后,PD-1会通过抑制T细胞受体(T cell receptor,TCR)信号激活而影响T细胞的活化和扩增,并促进效应T细胞的凋亡。通常,PD-1信号通路在抑制T细胞过度激活、下调免疫系统活性、避免自身免疫疾病和促进免疫耐受中扮演着重要的角色。
由于PD-L1在肿瘤组织中的高表达,PD-1通路也成为参与肿瘤微环境对T细胞免疫抑制的一个重要机制。已经有研究表明,肿瘤组织中PD-L1的表达与肿瘤的预后相关。因此,阻断PD-1信号通路,削减肿瘤微环境对T细胞的免疫抑制作用,被认为是提高肿瘤免疫治疗效果的一种有效手段。最近的临床研究也证实,通过单克隆抗体来阻断PD-1信号通路对于非小细胞肺癌、黑色素瘤、肾癌、胰腺癌、淋巴瘤等肿瘤均有良好的疗效,是30年来临床效果最好的免疫治疗手段,其相关药物也已经走向临床。理论和实践都证明,抑制PD-1信号通路,对于解除肿瘤微环境的抑制作用,提高免疫治疗对肿瘤的杀伤效果具有非常重要的意义。因此,PD-1信号通路的阻断联合其他免疫治疗手段被认为可以取得更大的突破。
目前PD-1信号通路的阻断,主要是通过PD-L1或PD-L2单克隆抗体实现的。然而,抗体药物存在一定的局限性,如代谢快、需多次输注、价格昂贵、难以在肿瘤部位形成有效浓度及潜在抗药性的产生等。
技术实现要素:
本发明的目的是为了克服现有技术中的上述缺陷,提供一种重组表达载体、含有该重组表达载体靶向性的T细胞及其应用,含有本发明重组表达载体靶向性的T细胞能够有效的表达嵌合抗原受体ScFv-CD8-CD137-CD3ζ(简称为CAR,下同),且能够有效的沉默PD-1,增强了对PD-1介导的免疫抑制的抵抗。
第一方面,本发明提供了一种重组表达载体,所述重组表达载体含有能够表达RNAi的核苷酸序列1和能够表达嵌合抗原受体的核苷酸序列2;
其中,所述RNAi能够沉默PD-1;
其中,所述嵌合抗原受体为ScFv-CD8-CD137-CD3ζ,包括依次串联的单链抗体ScFv、CD8的铰链区和跨膜区、CD137的胞内信号结构域和CD3ζ的胞内信号结构域。
第二方面,本发明提供了一种工程化的靶向性的T细胞,所述靶向性的T细胞含有如上所述的重组表达载体。
第三方面,本发明提供了如上所述的工程化靶向性的T细胞的制备方法,所述方法包括:
包装携带如上所述的重组表达载体的慢病毒,得到病毒原液;利用得到的病毒原液感染T细胞,使T细胞表达RNAi和表达所述嵌合抗原受体。
第四方面,本发明提供了上述工程化靶向性的T细胞在制备用于治疗B细胞系恶性血液系统肿瘤的制剂中的应用。
本发明通过基因工程的方法将T细胞内的PD-1基因表达抑制,从而阻断PD-1信号通路,且实验表明CART细胞中的PD-1的敲低可能改变了细胞因子分泌模式,但是增强了对PD-1介导的免疫抑制的抵抗。此外,本发明通过基因工程手段制备的PD-1沉默的CART细胞既结合了T细胞治疗的优点,又解除了免疫检验点的调控,可很大程度上解除肿瘤微环境对CART细胞免疫功能的抑制。同时,本发明通过基因工程的方法将T细胞内的PD-1基因表达抑制,与封闭抗体相比,T细胞具有体内生存周期长、可有效推广、制备成本低、有效靶向肿瘤位置等优势。因此,本发明将为临床上CART治疗提供一种新的细胞药物。
本发明的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
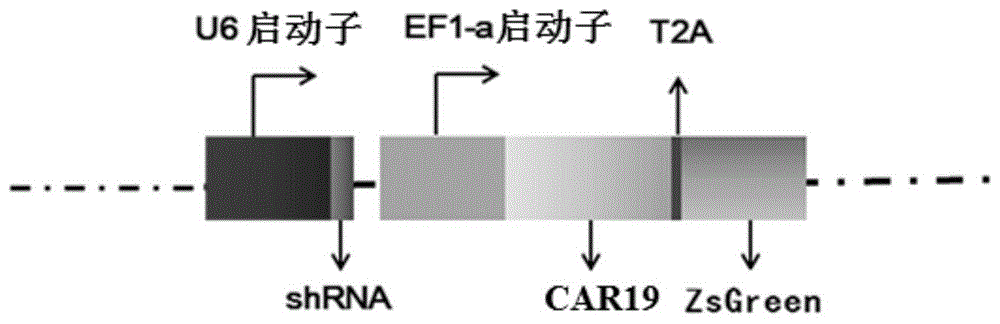
图1为本发明提供的一种重组表达载体的示意图。
图2为通过蛋白质免疫印迹(WB)验证的感染本发明的RNAi修饰的CART-19细胞中CAR19的表达情况;其中,空载对照为未携带本发明重组表达载体的慢病毒,CAR19为携带本发明重组表达载体的慢病毒。
图3为通过免疫荧光法验证的感染本发明的RNAi修饰的CART-19细胞中CAR19的表达情况;其中,空载对照为未携带本发明重组表达载体的慢病毒,CAR19为携带本发明重组表达载体的慢病毒。
图4为通过流式细胞术验证的RNAi修饰的CART-19细胞中CAR19分子的表达与ZsGreen的表达的相关性。
图5为通过实时荧光定量PCR测定在Jurkat细胞(PD-1阳性)中不同shRNA对PD-1的沉默效果。
图6为通过蛋白质免疫印迹(WB)测定在Jurkat细胞(PD-1阳性)中不同shRNA对PD-1的沉默效果。
图7为通过流式细胞仪测定在Jurkat细胞(PD-1阳性)中不同shRNA对PD-1的沉默效果。
图8为S3和S4修饰的CART-19(S3-CART-19和S4-CART-19)细胞中PD-1阳性率。
图9为在靶细胞刺激后的CART-19细胞中PD-1表达水平快速上调的过程中S3和S4对PD-1的抑制情况。
图10为S4-CART-19细胞与IFN-γ刺激的表达CD19的A549细胞(IFN-γ刺激会上调细胞中PD-L1的表达)共培养24小时后,S4-CART-19细胞释放的几种炎性细胞因子水平。
具体实施方式
以下对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
第一方面,本发明提供了一种重组表达载体,所述重组表达载体含有能够表达RNAi的核苷酸序列1和能够表达嵌合抗原受体的核苷酸序列2;
其中,所述RNAi能够沉默PD-1;
其中,所述嵌合抗原受体CAR为ScFv-CD8-CD137-CD3ζ,包括依次串联的单链抗体ScFv、CD8的铰链区和跨膜区、CD137的胞内信号结构域和CD3ζ的胞内信号结构域。
根据本发明,所述RNAi可以为任意的能够干扰PD-1基因表达的干扰RNA,例如,可以为siRNA、miRNA或shRNA。根据本发明一种优选的实施方式,所述RNAi为shRNA。
更为优选的,所述shRNA序列为shRNA-3和/或shRNA-4;其中,shRNA-3的序列如SEQ ID NO.1所示(其反义链如SEQ ID NO.2);shRNA-4的序列如SEQ ID NO.3所示(其反义链如SEQ ID NO.4所示)。
根据本发明,所述RNAi的表达受启动子的调控,因此,在所述重组表达载体中,在所述核苷酸序列1的上游,还含有启动子,以驱动RNA干扰序列的表达。其中,所述启动子可以为本领域公知的任意能够调控RNAi表达的启动子,优选的,所述启动子为U6启动子。
根据本发明,所述单链抗体ScFv可以为现有的能够用于构建嵌合抗原受体的单链抗体,例如,选自CD19、CD20、CD22、CD30、CD33、CD133、CD138、HER1和HER2中的至少一种。优选情况下,所述嵌合抗原受体为CD19ScFv-CD8-CD137-CD3ζ(简称CAR19),具有SEQ ID NO.5所示的氨基酸序列,更优选,所述嵌合抗原受体的氨基酸序列如SEQ ID NO.5所示。
根据本发明,所述嵌合抗原受体是指成熟蛋白,其前体蛋白还可以含有信号肽结构域,所述信号肽结构域位于所述嵌合抗原受体的最上游。所述信号肽可以为本领域公知的各种信号肽,例如,大鼠生长激素信号肽。
根据本发明,在了解了如上所述的嵌合抗原受体的氨基酸序列的情况下,本领域技术人员根据本领域的公知常识,其能够获得编码如上嵌合抗原受体的基因,并且由于密码子的简并性所获得的不同核苷酸序列的基因均应该视为在本发明的保护范围之内。
优选情况下,编码上述嵌合抗原受体CAR19的基因具有如SEQ ID NO.6所示的核苷酸序列,更优选编码上述嵌合抗原受体CAR19的基因的核苷酸序列如SEQ ID NO.6所示。
根据本发明,所述核苷酸序列2的表达受启动子的调控,因此,在所述重组表达载体中,在所述核苷酸序列2的上游,还含有启动子,以驱动核苷酸序列2的表达。其中,所述启动子可以为本领域公知的任意能够调控核苷酸序列2的表达启动子,优选的,所述启动子为延伸因子1-α(EF1-a)。
根据本发明,优选的,所述重组表达载体还含有通过T2A基序连接在核苷酸序列2下游的表达ZsGreen的核苷酸序列3。其中,所述ZsGreen为绿色荧光蛋白,其可以通过免疫荧光法来监测CAR的表达情况。
根据本发明,可用的负载载体可以为本领域公知的各种能够携带外来基因的载体,优选情况下,所述重组表达载体为慢病毒表达载体。对于慢病毒表达载体没有特别的限定,只要能够与辅助载体共转染包装细胞如293T包装细胞,获得病毒原液及RNAi和嵌合抗原受体修饰的T细胞(例如,RNAi-CART-19)即可。
根据本发明一种具体的实施情况,慢病毒表达载体为plvx-RNAi-ScFv-CD8-CD137-CD3ζ。其中,慢病毒表达载体plvx的启动子为U6启动子和EF1a启动子。其中,U6启动子位于EF1a启动子的上游。U6启动子在所述核苷酸序列1的上游,以驱动RNAi的表达;EF1a启动子在所述核苷酸序列2的上游,以驱动所述核苷酸序列2的表达。并且所述慢病毒表达载体还含有通过T2A基序连接在核苷酸序列2下游的表达ZsGreen的核苷酸序列3,以来监测CAR的表达情况。
对于慢病毒表达载体的制备方法没有特别的限定,可以为本领域技术人员能够想到的各种方法,优选情况下,以慢病毒表达载体plvx-RNAi-CD19ScFv-CD8-CD137-CD3ζ为例,慢病毒载体的制备方法包括以下步骤:
(1)从T细胞cDNA中分别扩增CD8的铰链区和跨膜区结构域、CD137的胞内信号结构域和CD3ζ的胞内信号结构域,或者全基因合成CD8的铰链区和跨膜区结构域、CD137的胞内信号结构域和CD3ζ的胞内信号结构域的融合基因,并克隆至载体plvx(慢病毒表达载体plvx含有U6启动子和EF1a启动子)EF1a启动子的下游,构建得到plvx-EF1a启动子-CD8-CD137-CD3ζ;
(2)全基因合成编码大鼠生长激素信号肽和编码CD19ScFv的核苷酸序列,并克隆至plvx-EF1a启动子-CD8-CD137-CD3ζ中,构建得到plvx-EF1a启动子-CD19ScFv-CD8-CD137-CD3ζ。
(3)全基因合成靶向人源PD-1基因的shRNA序列,并克隆至plvx-EF1a启动子-CD19ScFv-CD8-CD137-CD3ζ中U6启动子的下游,构建得到慢病毒表达载体plvx-U6启动子-RNAi-EF1a启动子-CD19ScFv-CD8-CD137-CD3。
经测序验证后得到序列正确的慢病毒载体plvx-U6启动子-RNAi-EF1a启动子-CD19ScFv-CD8-CD137-CD3ζ(以下简称plvx-RNAi-CD19ScFv-CD8-CD137-CD3ζ)。
步骤(1)中,优选采用全基因组合成的方法合成CD8的铰链区和跨膜区结构域(SEQ ID NO:7)、CD137的胞内信号结构域(SEQ ID NO:8)和CD3ζ的胞内信号结构域(SEQ ID NO:9)的融合基因,其5’端含有NcoI酶切位点,3’端含有SalI酶切位点。将获得的融合基因克隆至质粒pGSI中,得到pGSI-CD8a-CD137-CD3ζ质粒,然后将其进行NcoI/SalI酶切,再与NcoI/SalI双酶切后的慢病毒表达载体plvx连接。
步骤(2)中,对于合成编码大鼠生长激素信号肽和CD19ScFv的核苷酸序列的方法没有特别的限定,可以为本领域常用的各种方法,例如可以通过全基因合成技术合成。
具体地,得到序列正确的慢病毒表达载体的方法可以包括:通过全基因合成技术合成编码大鼠生长激素信号肽(编码序列SEQ ID NO:11)和CD19ScFv(编码序列SEQ ID NO:12)融合基因的核苷酸序列,其5’端含有EcoR1、kozak序列,3’端含有NcoI酶切位点,克隆至质粒pGSI中,得到pGSI-CD19ScFv;然后将pGSI-CD19ScFv进行EcoRI/NcoI双酶切,与EcoRI/NcoI双酶切后的步骤(1)得到的重组质粒plvx-EF1a启动子-CD8-CD137-CD3ζ连接,经测序鉴定,得到序列正确的plvx-EF1a启动子-CD19ScFv-CD8-CD137-CD3ζ。
步骤(3)中,可以通过全基因组合成的方法获得靶向人源PD-1基因的shRNA序列,并使得5’含有BamHI酶切位点,3’含有MluI酶切位点。经BamHI/MluI双酶切,再与同样经过经BamHI/MluI双酶切的plvx-EF1a启动子-CD19ScFv-CD8-CD137-CD3ζ连接,从而将shRNA序列连接至plvx-EF1a启动子-CD19ScFv-CD8-CD137-CD3ζ中U6启动子的下游,经测序鉴定,得到序列正确的慢病毒表达载体plvx-U6启动子-RNAi-EF1a启动子-CD19ScFv-CD8-CD137-CD3ζ(以下简称plvx-RNAi-CD19ScFv-CD8-CD137-CD3ζ)。
其中,在所述慢病毒表达载体中,嵌合抗原受体连接在EF1a启动子的下游受其调控,在嵌合抗原受体的下游还具有通过T2A基序连接的ZsGreen基序,可作为检测嵌合抗原受体是否表达的标签,此外,RNAi连接在U6启动子的下游受其调控。
第二方面,本发明还提供了一种工程化靶向性的T细胞,所述T细胞含有如上所述的重组表达载体。
如上所述的工程化靶向性的T细胞的制备方法可以包括:包装携带如上所述的重组表达载体的慢病毒,得到病毒原液;利用得到的病毒原液感染T细胞,使T细胞表达嵌合抗原受体。
根据本发明,对于包装携带如上所述的重组表达载体的慢病毒的方法没有特别的限定,可以为本领域技术人员常用的各种方法,本发明一种优选的包装携带如上所述的重组表达载体的慢病毒的方法包括,将重组表达载体与辅助质粒(如psPAX2、pMD2.G)共转染293T包装细胞,转染48-72h时收集病毒上清,离心、过滤,获得病毒原液。
根据本发明,对于所述T细胞的制备方法没有特别限定,可以为本领域常用的各种方法,优选情况下,该方法包括:(1)在CD3单克隆抗体、白介素-2、重组人纤维蛋白和血清的存在下,将单个T细胞进行第一阶段培养;(2)在CD3单克隆抗体、白介素-2、重组人纤维蛋的存在下,将所述第一阶段培养的细胞进行第二阶段培养。
具体的,将全血进行离心处理,得到上层血浆和下层沉淀,下层沉淀采用分离液对细胞进行分离,得到单个核细胞。上层血浆于50-60℃水浴灭火并离心后取上清液即为血清。然后将所述单个核细胞与白介素-2、血清、T细胞培养液(例如,X-VIVO15TM)混合,并将得到的混合液置于包被有重组人纤维蛋白和CD3单克隆抗体的培养容器中,于30-37℃、饱和湿度为3-6%的CO2培养箱中进行第一阶段培养70-80h,使细胞贴壁。之后将培养容器中的旧液弃去,更换新的T细胞培养液,并转移至未包被的培养容器中,在30-37℃、饱和湿度为3-6%的CO2培养箱中进行第二阶段培养,培养的过程中不断补充白介素-2。
优选的,第一阶段培养中,在第一T细胞培养液中,所述白介素-2的浓度为250-350U/mL,血清的浓度为0.4-0.6体积%。
优选的,第二阶段培养中,补加白介素-2的量使得,相对于100ml的第二T细胞培养液中,所述白介素-2的浓度维持在250-350U/mL。
其中,根据本发明,将培养容器进行包被的方法可以为,将混有重组人纤维蛋白和CD3单克隆抗体的PBS缓冲液(包被液)加入到待培养的培养容器中,并在4-37℃的条件下静置1-12小时,之后弃去培养容器中的包被液。优选的,在弃去包被液之后,还包括使用PBS缓冲液对培养容器洗涤1-3次,使用T细胞培养液洗涤1-2次。其中,相对于10ml的所述包被液,所述人纤维蛋白的量可以为80-120μL,所述CD3单克隆抗体的量可以为40-60μL。
根据本发明,对于制备慢病毒感染T细胞的方法没有特别限定,可以为本领域常用的各种方法,优选情况下,该方法包括:(1)在病毒原液、白介素-2、聚凝胺(Polybrene)和重组人纤维蛋白存在下,将T细胞进行第一阶段感染培养;(2)在白介素-2下,将所述第一阶段感染培养的细胞进行第二阶段感染培养。
具体的,将300-800μL病毒原液添加至包被有重组人纤维蛋白的培养容器中,1800-2200g离心1.5-2.5h后,再向所述培养容器中添加300-800μL含有3×105-8×105个T细胞的新鲜T细胞培养液,250-350U/mL的白介素-2,0.3-1.0μg/mL聚凝胺置于30-37℃、饱和湿度为3-6%的CO2培养箱中进行第一阶段感染培养12-16h后,弃培养液,将细胞转至未包被的培养容器中,加入T细胞培养液、白介素-2,使T细胞的密度为1×106-5×106,白介素-2的浓度为250-350U/mL,于30-37℃、饱和湿度为3-6%的CO2培养箱中进行第二阶段感染培养50-60h,获得RNAi和CAR19修饰的T细胞。
其中,将培养容器进行包被的方法可以为,将混有重组人纤维蛋白的PBS缓冲液(包被液)加入到待培养的培养容器中,并在4-37℃的条件下静置1-12小时,之后弃去培养容器中的包被液。优选的,在弃去包被液之后,还包括使用PBS缓冲液对培养容器洗涤1-3次,使用T细胞培养液洗涤1-2次。其中,相对于10ml的所述包被液,所述人纤维蛋白的量可以为80-120μL。
优选的,RNAi和CAR19修饰的T细胞表达的嵌合抗原受体的成熟蛋白氨基酸序列优选如SEQ ID NO.5所示。其中,本领域技术人员应该理解的是,嵌合抗原受体前体蛋白由大鼠生长激素信号肽、CD19ScFv、CD8的铰链区和跨膜区、CD137的胞内信号结构域和CD3ζ的胞内信号结构域串联构成,蛋白质翻译后在细胞内粗面型内质网切除信号肽后成为成熟嵌合抗原受体蛋白,分泌输出后并定位于T细胞的细胞膜上。该嵌合抗原受体的成熟蛋白氨基酸序列对应的基因编码序列如SEQ ID NO.6所示。该嵌合抗原受体以CD8的铰链区和跨膜区及CD137和CD3ζ的胞内信号结构域串联而成的结构为信号传导结构域,其氨基酸序列如SEQ ID NO.13所示,对应的基因编码序列如SEQ ID NO.14所示。大鼠生长激素信号肽和CD19ScFv的融合基因如SEQ ID NO.10所示。
第三方面,本发明还提供了所述的工程化靶向性的T细胞在制备用于治疗B细胞系恶性血液系统肿瘤的制剂中的应用。
优选的,所述B细胞系恶性血液系统肿瘤包括非霍奇金淋巴瘤、B细胞慢性淋巴细胞白血病和B细胞急性淋巴细胞白血病中的至少一种。
实施例
以下的实施例将对本发明作进一步的说明,但并不因此限制本发明。
以下实施例中的实验方法,如无特殊说明,均为本领域常规方法。下述实施例中所用的实验材料,如无特殊说明,均为自常规生化试剂商店购买得到,其中:
T细胞培养液X-VIVO 15TM无血清细胞培养基购自美国Lonza公司。
淋巴细胞分离液购自TBD公司。
CD3单克隆抗体、重组纤维连接蛋白(retronectin),PD-1抗体均购自美国BD公司。
重组人白介素2购自protech公司。
总RNA提取试剂盒RNAiso Reagent、高保真DNA聚合酶(HS DNA Polymerase)、T4DNA连接酶购自TaKaRa公司。
RevertAidTM First Strand cDNA Synthesis Kit购自Fermentas公司。
EcoRI、MluI、BamHI、SalI、NcoI购自Thermo公司。
琼脂糖凝胶DNA回收试剂盒、普通DNA产物纯化试剂盒、质粒小提试剂盒均购自天根生化科技有限公司。
Plvx购自百恩维生物科技有限公司,含有U6启动子,EF1a启动子以及ZsGreen基序。
psPAX2、pMD2.G均购自Addgene公司。
pGSI购自北京天一辉远生物科技有限公司。
Trans1-T1Phage Resistant化学感受态细胞购自北京全式金生物技术有限公司。
LipofectamineTM 2000Transfection Reagent转染试剂购自Invitrogen公司。
Polybrene购自Sigma公司
293T包装细胞,Jurkat细胞(PD-1阳性)及A549细胞购自美国ATCC。
所有引物均由北京天一辉远生物科技有限公司合成。
实施例1
本实施例用于说明T细胞的制备
(1)取人静脉血于含肝素的真空管中。采用淋巴细胞分离液,通过密度梯度离心方法分离获得单个核细胞(PBMCs)。
(2)PBMCs洗三次后,采用含有0.5体积%的人自体血清的X-VIVO 15TM无血清T细胞培养液调整细胞终浓度为2×106个细胞/mL;将细胞接种于预先经过终浓度为10μg/mL的retronectin和50ng/ml CD3单克隆抗体包被的75cm2细胞培养瓶中。然后在培养基里加入终浓度为300U/mL的重组人白介素2,在37℃、饱和湿度为5%的CO2培养箱中培养。
(3)培养第4天,将细胞转移至未包被的培养瓶中,每2天按照细胞生长数量加入T细胞培养液X-VIVO 15TM,控制细胞浓度为1×108个细胞/mL,并加入终浓度为300U/ml的重组人白介素2;培养至第12天,得到T细胞。
实施例2
本实施例用于说明慢病毒表达载体的构建
(1)慢病毒表达载体(Plvx-EF1a启动子-CD19ScFv-CD8a-CD137-CD3ζ)的制备
委托北京天一辉远生物科技有限公司全基因合成融合基因CD8a-CD137-CD3ζ的核苷酸序列,其5’端含有NcoI酶切位点,3’端含有SalI酶切位点,将前述融合基因分别克隆在质粒pGSI中,命名为pGSI-CD8a-CD137-CD3ζ质粒。经NcoI/SalI双酶切,酶切产物经1%琼脂糖凝胶进行分离,用琼脂糖凝胶DNA回收试剂盒回收第一目的片段备用。
慢病毒表达载体Plvx用NcoI/SalI双酶切,酶切产物经1%的琼脂糖凝胶进行分离,用琼脂糖凝胶DNA回收试剂盒回收大的载体片段,然后与之前回收的第一目的片段通过T4DNA连接酶连接,连接产物转化Trans1-T1Phage Resistant化学感受态细胞,37℃培养16h后挑取单克隆,37℃,250rpm培养12h后用质粒小提试剂盒提取质粒。将质粒送北京天一辉远生物科技有限公司对插入的融合基因片段进行测序。将测序结果正确的重组质粒命名为Plvx-CD8a-CD137-CD3ζ。
(3)慢病毒表达载体(Plvx-CD19ScFv-CD8a-CD137-CD3ζ)的制备
委托北京天一辉远生物科技有限公司全基因合成编码人源CD8a信号肽(SEQ ID NO:12)和CD19ScFv(SEQID NO.13)的融合基因的核苷酸序列,其5’端含有EcoR1、kozak序列,3’端含有NcoI酶切位点,将前述融合基因分别克隆在质粒pGSI中,命名为pGSI-CD19ScFv质粒。经EcoRI/NcoI双酶切,酶切产物经1%琼脂糖凝胶进行分离,用琼脂糖凝胶DNA回收试剂盒回收第二目的片段备用。
Plvx-CD8a-CD137-CD3ζ质粒经限制性内切酶EcoRI/NcoI酶切,酶切产物经1%琼脂糖凝胶进行分离,用琼脂糖凝胶DNA回收试剂盒回收载体片段备用。然后分别与回收的第二目的片段通过T4DNA连接酶进行连接,具体方法见说明书。将连接产物转化Trans1-T1Phage Resistant化学感受态细胞,37℃培养16h后挑取单克隆,37℃,250rpm培养12h后,用质粒小提试剂盒提取质粒。提取的质粒分别经限制性内切酶EcoRI/NcoI和EcoRI/SalI双酶切鉴定,选择正确的质粒,命名为Plvx-CD19ScFv-CD8a-CD137-CD3ζ,简称CAR19。
(4)慢病毒载体(Plvx-PD-1-RNAi-CD19ScFv-CD8a-CD137-CD3ζ)的制备。
全基因合成靶向人源PD-1基因的shRNA序列,shRNA-3(S3,核苷酸序列如SEQ ID NO.1所示,其反义链的核苷酸序列如SEQ ID NO.2所示)和shRNA-4(S4,核苷酸序列如SEQ ID NO.3所示,其反义链的核苷酸序列如SEQ ID NO.4所示),由北京天一辉远生物科技有限公司合成,5’含有BamHI酶切位点,3’含有MluI酶切位点。经BamHI/MluI双酶切,酶切产物用DNA回收试剂盒回收备用。
Plvx-CD19ScFv-CD8a-CD137-CD3ζ质粒经限制性内切酶BamHI/MluI酶切,酶切产物经1%琼脂糖凝胶进行分离,用琼脂糖凝胶DNA回收试剂盒回收载体片段备用。然后分别与回收的含有S3和S4的片段连接,具体方法见说明书。将连接产物转化Trans1-T1Phage Resistant化学感受态细胞,37℃培养16h后挑取单克隆,37℃,250rpm培养12h后,用质粒小提试剂盒提取质粒。提取的质粒分别经限制性内切酶BamHI/MluI双酶切鉴定,选择正确的质粒,命名为Plvx-S3-CD19ScFv-CD8a-CD137-CD3ζ和Plvx-S4-CD19ScFv-CD8a-CD137-CD3ζ,简称S3-CAR19和S4-CAR19。
(5)将鉴定正确的质粒送北京天一辉远生物科技有限公司对插入的融合基因片段进行测序。将测序结果正确的慢病毒表达载体命名为Plvx-S3-CAR19和Plvx-S4-CAR19,如图1所示,其中,该嵌合抗原受体以基因CD8的铰链区和跨膜区及CD137和CD3ζ的胞内信号结构域串联而成的结构为信号传导结构域,其氨基酸序列如SEQID NO.14所示,对应的基因编码序列如SEQID NO.15所示。
按照如上的方法制备如下:
·慢病毒表达载体Plvx-S1-CAR19;shRNA-1(S1)的核苷酸序列如SEQ ID NO.15所示,其反义链的核苷酸序列如SEQ ID NO.16所示;
·慢病毒表达载体Plvx-S2-CAR19;shRNA-2(S2)的核苷酸序列如SEQ ID NO.17所示,其反义链的核苷酸序列如SEQ ID NO.18所示;
·慢病毒表达载体Plvx-S5-CAR19;shRNA-5(S5)的核苷酸序列如SEQ ID NO.19所示,其反义链的核苷酸序列如SEQ ID NO.20所示;
·慢病毒表达载体Plvx-S6-CAR19;shRNA-6(S6)的核苷酸序列如SEQ ID NO.21所示,其反义链的核苷酸序列如SEQ ID NO.22所示;
·慢病毒表达载体Plvx-CSR-CAR19;SCR为随机引物,SCR的核苷酸序列如SEQ ID NO.23所示,其反义链的核苷酸序列如SEQ ID NO.24所示。
(6)慢病毒的包装
用分光光度计分别测定慢病毒表达载体Plvx、Plvx-S1-CAR19、Plvx-S2-CAR19、Plvx-S3-CAR19、Plvx-S4-CAR19、Plvx-S5-CAR19、Plvx-S6-CAR19和Plvx-CSR-CAR19和辅助质粒psPAX2、pMD2.G的浓度,慢病毒表达载体、辅助质粒psPAX2、pMD2.G分别以4:2:1的质量比用LipofectamineTM 2000Transfection Reagent转染试剂共转染293T包装细胞。分别在转染48h、72h时收集病毒,用4.5μm滤器过滤收集病毒上清。即分别得修饰有如上慢病毒载体的病毒原液,按每管500μL进行分装,-80℃保存备用。
实施例3
本实施例用于说明慢病毒表达载体对PD-1的沉默效果
(1)使用实时定量聚合酶链反应(qRT-PCR)分析PD-1沉默的效率
将实施例2制备的含有Plvx-S1-CAR19、Plvx-S2-CAR19、Plvx-S3-CAR19、Plvx-S4-CAR19、Plvx-S5-CAR19、Plvx-S6-CAR19和Plvx-CSR-CAR19的病毒分别感染Jurkat细胞(PD-1阳性)并于37℃、饱和湿度为5%的CO2培养箱中培养。为了测试shRNA的沉默效率,分别使用PD-1primer-1、PD-1primer-2和PD-1primer-3来检测Jurkat细胞中的PD-1水平,用于检测PD-1(Hs01550088_m1)表达的以下引物由LifeTechnologies设计和合成;
PD-1primer-1:
正向引物SEQ ID NO.25(AGATCAAAGAGAGCCTGCGG),
反向引物SEQ ID NO.26(CTCCTATTGTCCCTCGTGCG);
PD-1primer-2:
正向引物SEQ ID NO.27(GTGTCACACAACTGCCCAAC),
反向引物SEQ ID NO.28(CTGCCCTTCTCTCTGTCACC);
PD-1Primer-3:
正向引物SEQ ID NO.29(TGCAGCTTCTCCAACACATC),
反向引物SEQ ID NO.30(CACGCTCATGTGGAAGTCAC)。
具体检测方法:使用Transcriptor First Strand cDNA Synthesis Kit(Roche)将来自ZsGreen阳性分选的Jurkat细胞的mRNA逆转成cDNA。PCR采用10μL的体系,加入2X Power SYBR Grenn PCR Master Mix 5μL,DEPC水4μL,模板0.5μL,上下游引物共计1μL,混匀,离心,放入实时定量PCR仪。反应条件为:95℃反应10分钟;95℃反应0.15分钟,72℃条件下延伸1分钟,一共为45个循环反应;95℃反应0.15分钟,60℃条件下延伸0.15分钟,再95℃退火15分钟。
每组设3个平行样。使用Applied Biosystems 7500系统进行定量实时PCR。将PD-1基因的比较Ct标准化为β-肌动蛋白管家基因:ΔCt(样品)=Ct(PD-1)-Ct(β-肌动蛋白)。然后,如下计算与对照相比的相对表达倍数:2-ΔΔCt=2-(ΔCt[样品]-ΔCt[对照])。
结果如图5所示,由图5可以看出,除shRNA-5(S5)外的所有shRNA序列均可有效下调PD-1的mRNA水平。
(2)使用蛋白质免疫印迹(WB)分析PD-1沉默的效率
为了验证PD-1基因的表达,通过FACS对如上(1)中感染的Jurkat细胞(除感染Plvx-S5-CAR19病毒的Jurkat细胞)进行ZsGreen阳性分选,获得纯度大于95%的ZsGreen阳性细胞。37℃、饱和湿度为5%的CO2培养箱中培养扩增后,将细胞离心收集,用PBS清洗一遍,离心收集,加入适量蛋白裂解液,冰上裂解半小时,12000g、4℃离心半小时。收集上清即为蛋白裂解液,-80℃冰箱保存。使用BCA试剂盒测定蛋白浓度。首先制作BSA标准液的浓度与吸光度的标准曲线,然后根据目的蛋白溶液的吸光度值换算出浓度。以每个样本40ug总蛋白的量进行上样,进行SDS-PAGE凝胶电泳,并采用蛋白质免疫印迹(WB)测定PD-1的表达水平。
结果如图6所示,除shRNA-1(S1)和shRNA-2(S1)外,shRNA-3(S3)、shRNA-4(S4)和shRNA-6(S6)均可有效下调PD-1蛋白的表达量。
(3)使用流式检测分析PD-1沉默的效率
为了验证PD-1基因的表达,通过FACS再次验证如上步骤(2)中通过验证的Jurkat细胞中PD-1的表达情况,按照步骤(2)的方法获得PBS洗涤后的细胞沉淀,加入PBS缓冲液调整细胞浓度至1×106/ml,每100ul为一个样本,加入5ul的PD-1抗体室温染色30分钟。PBS冲洗两遍后,利用BD的CaliberII流式细胞仪对PD-1的表达进行检测。
结果如图7所示,除shRNA-6(S6)外,shRNA-3(S3)和shRNA-4(S4)均能有效的沉默PD-1的表达。
由以上可以看出,本发明提供了shRNA-3和shRNA-4在各组检测条件下都可以有效地沉默PD-1表达。
实施例4
本实施例用于说明嵌合抗原受体修饰的T细胞的制备及其表达CAR19的情况
(1)慢病毒感染T细胞及感染后细胞的扩增培养
在6mlPBS中混合60μL retroNectin,形成包被液,加入12孔板中进行包被,每孔500ml溶液,37℃放置1h;之后弃12孔板中中包被液,PBS洗两遍,X-VIVO 15TM洗一遍,得到包被的12孔板。
取实施例1的在75cm2培养瓶中培养的5×105个T细胞,弃掉旧的培养液,加入500μL新鲜T细胞培养液、300U/mL的重组人白介素2、500μL实施例2得到的病毒原液,8μg/mL Polybrene添加至如上的包被的12孔板中,置于37℃、饱和湿度为5%的CO2培养箱中感染12小时后,弃培养液,将感染后的细胞转至未进行任何包被的6孔板中,加入新鲜的T细胞培养液,300U/mL的重组人白介素2,使T细胞的浓度为1×106/ml,于37℃、饱和湿度为5%的CO2培养箱中继续培养,得到的T细胞称为RNAi和嵌合抗原受体修饰,也即,S3-CAR19T细胞、S4-CAR19T细胞、CSR-CAR19T细胞、Plvx T细胞。
(2)按照免疫印迹法检测S4-CAR19T细胞中CAR19的表达水平。如图2所示,由图2可以看出,未经修饰的T细胞中(阴性对照)以及修饰有Plvx空载体的T细胞(空载对照)中均没有CAR19的表达,而修饰有S4-CAR19T细胞中能够有效表达CAR19。说明本发明的重组质粒在修饰T细胞后能够在T细胞中高效表达CAR19。
(4)免疫荧光法证实CAR19的表达,结果如图3所示,修饰有S4-CAR19T细胞能够表达CD3ζ和ZsGreen两种荧光,而感染了空载体的T细胞只表达ZsGreen荧光。说明本发明的重组表达载体在修饰T细胞后能够在T细胞中高效表达CAR19。
(5)通过流式细胞术对S4-CAR19T细胞中CAR19分子的表达情况进行了检测,如图4所示,结果证实CAR19分子的表达与ZsGreen的表达呈现出良好的一一对应关系,证实了利用ZsGreen来追踪CART细胞的可靠性。
实施例5
本实施例用于说明在RNAi-CAR19T细胞中PD-1的表达
实施例1中新分离的T细胞中PD-1的阳性率约为10%,在激活(IFN-γ刺激)和病毒感染两天后迅速增加至约25%。在接下来的一周内,PD-1的表达维持在相似的水平,然后随着培养的延长逐渐降低。流式细胞仪检测PD-1表达水平,结果如图8所示。
如图8所示,直到慢病毒感染后第4天,S3或S4对PD-1表达表现出明显的抑制作用,随后沉默效率逐渐升高。在病毒感染后第7天,也就是培养周期的第9天,S3和S4修饰的CART-19(S3-CART19和S4-CART19)细胞中PD-1阳性率分别下降了约78%和87%,与SCR修饰的CART-19(SCR-CART19)细胞相比。
实施例6
本实施例用于说明在靶细胞刺激后PD-1表达水平
分别将实施例4制备的S4-CAR19T细胞和CSR-CAR19T细胞(效应细胞)与等量的IFN-γ刺激的表达CD19的A549细胞(靶细胞,IFN-γ刺激会上调细胞里PD-L1的表达)细胞按照效靶比1:1于37℃,5%CO2共培养24小时,之后采用ELISA测定RNAi-CAR19T细胞释放的几种炎性细胞因子水平,结果如图10所示。
ELISA测定结果表明,在靶细胞刺激后,S4-CART19细胞分泌的IL-2比SCR-CART19细胞更多。然而,S4-CART19细胞中其他测试因子的分泌量低于SCR-CART19细胞的分泌。此外,SCR-CART19细胞的细胞因子分泌显着受到PD-L1表达的抑制,但S4-CART19细胞几乎不受影响。这表明CART细胞中的PD-1的敲低可能改变了细胞因子分泌模式,但是增强了对PD-L1介导的免疫抑制的抵抗。
以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
SEQUENCE LISTING
<110> 中国人民解放军总医院
<120> 重组表达载体、靶向性的T细胞及它们的应用
<130> I55748RMJ
<160> 30
<170> PatentIn version 3.3
<210> 1
<211> 68
<212> DNA
<213> shRNA-3
<400> 1
gatcccggat ttccagtggc gagagaattc aagagattct ctcgccactg gaaatccttt 60
tttggaaa 68
<210> 2
<211> 68
<212> DNA
<213> shRNA-3的反义链
<400> 2
cgcgtttcca aaaaaggatt tccagtggcg agagaatctc ttgaattctc tcgccactgg 60
aaatccgg 68
<210> 3
<211> 68
<212> DNA
<213> shRNA-4
<400> 3
gatcccgacg gagtatgcca ccattgtttc aagagaacaa tggtggcata ctccgtcttt 60
tttggaaa 68
<210> 4
<211> 68
<212> DNA
<213> shRNA-4的反义链
<400> 4
cgcgtttcca aaaaagacgg agtatgccac cattgttctc ttgaaacaat ggtggcatac 60
tccgtcgg 68
<210> 5
<211> 491
<212> PRT
<213> CD19ScFv-CD8-CD137-CD3ζ的氨基酸序列
<400> 5
Glu Val Lys Leu Gln Glu Ser Gly Pro Gly Leu Val Ala Pro Ser Gln
1 5 10 15
Ser Leu Ser Val Thr Cys Thr Val Ser Gly Val Ser Leu Pro Asp Tyr
20 25 30
Gly Val Ser Trp Ile Arg Gln Pro Pro Arg Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Gly Ser Glu Thr Thr Tyr Tyr Asn Ser Ala Leu Lys
50 55 60
Ser Arg Leu Thr Ile Ile Lys Asp Asn Ser Lys Ser Gln Val Phe Leu
65 70 75 80
Lys Met Asn Ser Leu Gln Thr Asp Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Lys His Tyr Tyr Tyr Gly Gly Ser Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Thr Thr Ser
130 135 140
Ser Leu Ser Ala Ser Leu Gly Asp Arg Val Thr Ile Ser Cys Arg Ala
145 150 155 160
Ser Gln Asp Ile Ser Lys Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Asp
165 170 175
Gly Thr Val Lys Leu Leu Ile Tyr His Thr Ser Arg Leu His Ser Gly
180 185 190
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Ser Leu
195 200 205
Thr Ile Ser Asn Leu Glu Gln Glu Asp Ile Ala Thr Tyr Phe Cys Gln
210 215 220
Gln Gly Asn Thr Leu Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu
225 230 235 240
Ile Thr Thr Arg Leu Ser Asn Ser Ile Met Tyr Phe Ser His Phe Val
245 250 255
Pro Val Phe Leu Pro Ala Lys Pro Thr Thr Thr Pro Ala Pro Arg Pro
260 265 270
Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro
275 280 285
Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu
290 295 300
Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys
305 310 315 320
Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Arg Ser Lys
325 330 335
Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg
340 345 350
Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro
355 360 365
Glu Glu Glu Glu Gly Gly Cys Glu Leu Glu Phe Arg Val Lys Phe Ser
370 375 380
Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr
385 390 395 400
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
405 410 415
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn
420 425 430
Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
435 440 445
Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
450 455 460
His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr
465 470 475 480
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 6
<211> 1476
<212> DNA
<213> CD19ScFv-CD8-CD137-CD3ζ的核算序列
<400> 6
gaggtgaaac tgcaggagtc aggacctggc ctggtggcgc cctcacagag cctgtccgtc 60
acatgcactg tctcaggggt ctcattaccc gactatggtg taagctggat tcgccagcct 120
ccacgaaagg gtctggagtg gctgggagta atatggggta gtgaaaccac atactataat 180
tcagctctca aatccagact gaccatcatc aaggacaact ccaagagcca agttttctta 240
aaaatgaaca gtctgcaaac tgatgacaca gccatttact actgtgccaa acattattac 300
tacggtggta gctatgctat ggactactgg ggtcaaggaa cctcagtcac cgtctcctca 360
ggtggaggcg gttcaggcgg aggtggctct ggcggtggcg gatcggacat ccagatgaca 420
cagactacat cctccctgtc tgcctctctg ggagacagag tcaccatcag ttgcagggca 480
agtcaggaca ttagtaaata tttaaattgg tatcagcaga aaccagatgg aactgttaaa 540
ctcctgatct accatacatc aagattacac tcaggagtcc catcaaggtt cagtggcagt 600
gggtctggaa cagattattc tctcaccatt agcaacctgg agcaagaaga tattgccact 660
tacttttgcc aacagggtaa tacgcttccg tacacgttcg gaggggggac taagttggaa 720
ataacaacgc gtctgagcaa ctccatcatg tacttcagcc acttcgtgcc ggtcttcctg 780
ccagcgaagc ccaccacgac gccagcgccg cgaccaccaa caccggcgcc caccatcgcg 840
tcgcagcccc tgtccctgcg cccagaggcg tgccggccag cggcgggggg cgcagtgcac 900
acgagggggc tggacttcgc ctgtgatatc tacatctggg cgcccttggc cgggacttgt 960
ggggtccttc tcctgtcact ggttatcacc ctttactgca gatctaaacg gggcagaaag 1020
aaactcctgt atatattcaa acaaccattt atgagaccag tacaaactac tcaagaggaa 1080
gatggctgta gctgccgatt tccagaagaa gaagaaggag gatgtgaact ggaattcaga 1140
gtgaagttca gcaggagcgc agacgccccc gcgtaccagc agggccagaa ccagctctat 1200
aacgagctca atctaggacg aagagaggag tacgatgttt tggacaagag acgtggccgg 1260
gaccctgaga tggggggaaa gccgagaagg aagaaccctc aggaaggcct gtacaatgaa 1320
ctgcagaaag ataagatggc ggaggcctac agtgagattg ggatgaaagg cgagcgccgg 1380
aggggcaagg ggcacgatgg cctttaccag ggtctcagta cagccaccaa ggacacctac 1440
gacgcccttc acatgcaggc cctgccccct cgctaa 1476
<210> 7
<211> 287
<212> DNA
<213> CD8的核酸序列
<400> 7
gatcacgcgt ctgagcaact ccatcatgta cttcagccac ttcgtgccgg tcttcctgcc 60
agcgaagccc accacgacgc cagcgccgcg accaccaaca ccggcgccca ccatcgcgtc 120
gcagcccctg tccctgcgcc cagaggcgtg ccggccagcg gcggggggcg cagtgcacac 180
gagggggctg gacttcgcct gtgatatcta catctgggcg cccttggccg ggacttgtgg 240
ggtccttctc ctgtcactgg ttatcaccct ttactgcaga tctgatc 287
<210> 8
<211> 146
<212> DNA
<213> CD137的核算序列
<400> 8
gatcagatct aaacggggca gaaagaaact cctgtatata ttcaaacaac catttatgag 60
accagtacaa actactcaag aggaagatgg ctgtagctgc cgatttccag aagaagaaga 120
aggaggatgt gaactggaat tcgatc 146
<210> 9
<211> 359
<212> DNA
<213> CD3 ζ的核算序列
<400> 9
gatcgaattc agagtgaagt tcagcaggag cgcagacgcc cccgcgtacc agcagggcca 60
gaaccagctc tataacgagc tcaatctagg acgaagagag gagtacgatg ttttggacaa 120
gagacgtggc cgggaccctg agatgggggg aaagccgaga aggaagaacc ctcaggaagg 180
cctgtacaat gaactgcaga aagataagat ggcggaggcc tacagtgaga ttgggatgaa 240
aggcgagcgc cggaggggca aggggcacga tggcctttac cagggtctca gtacagccac 300
caaggacacc tacgacgccc ttcacatgca ggccctgccc cctcgctaag tcgacgatc 359
<210> 10
<211> 801
<212> DNA
<213> 大鼠生长激素信号肽和CD19ScFv的融合基因
<400> 10
ggatccgcca ccatggcctt accagtgacc gccttgctcc tgccgctggc cttgctgctc 60
cacgccgcca ggccggaggt gaaactgcag gagtcaggac ctggcctggt ggcgccctca 120
cagagcctgt ccgtcacatg cactgtctca ggggtctcat tacccgacta tggtgtaagc 180
tggattcgcc agcctccacg aaagggtctg gagtggctgg gagtaatatg gggtagtgaa 240
accacatact ataattcagc tctcaaatcc agactgacca tcatcaagga caactccaag 300
agccaagttt tcttaaaaat gaacagtctg caaactgatg acacagccat ttactactgt 360
gccaaacatt attactacgg tggtagctat gctatggact actggggtca aggaacctca 420
gtcaccgtct cctcaggtgg aggcggttca ggcggaggtg gctctggcgg tggcggatcg 480
gacatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 540
atcagttgca gggcaagtca ggacattagt aaatatttaa attggtatca gcagaaacca 600
gatggaactg ttaaactcct gatctaccat acatcaagat tacactcagg agtcccatca 660
aggttcagtg gcagtgggtc tggaacagat tattctctca ccattagcaa cctggagcaa 720
gaagatattg ccacttactt ttgccaacag ggtaatacgc ttccgtacac gttcggaggg 780
gggactaagt tggaaataac a 801
<210> 11
<211> 75
<212> DNA
<213> 大鼠生长激素信号肽的核算序列
<400> 11
ggatccgcca ccatggcctt accagtgacc gccttgctcc tgccgctggc cttgctgctc 60
cacgccgcca ggccg 75
<210> 12
<211> 726
<212> DNA
<213> CD19ScFv的核算序列
<400> 12
gaggtgaaac tgcaggagtc aggacctggc ctggtggcgc cctcacagag cctgtccgtc 60
acatgcactg tctcaggggt ctcattaccc gactatggtg taagctggat tcgccagcct 120
ccacgaaagg gtctggagtg gctgggagta atatggggta gtgaaaccac atactataat 180
tcagctctca aatccagact gaccatcatc aaggacaact ccaagagcca agttttctta 240
aaaatgaaca gtctgcaaac tgatgacaca gccatttact actgtgccaa acattattac 300
tacggtggta gctatgctat ggactactgg ggtcaaggaa cctcagtcac cgtctcctca 360
ggtggaggcg gttcaggcgg aggtggctct ggcggtggcg gatcggacat ccagatgaca 420
cagactacat cctccctgtc tgcctctctg ggagacagag tcaccatcag ttgcagggca 480
agtcaggaca ttagtaaata tttaaattgg tatcagcaga aaccagatgg aactgttaaa 540
ctcctgatct accatacatc aagattacac tcaggagtcc catcaaggtt cagtggcagt 600
gggtctggaa cagattattc tctcaccatt agcaacctgg agcaagaaga tattgccact 660
tacttttgcc aacagggtaa tacgcttccg tacacgttcg gaggggggac taagttggaa 720
ataaca 726
<210> 13
<211> 249
<212> PRT
<213> 信号传导结构域氨基酸序列
<400> 13
Thr Arg Leu Ser Asn Ser Ile Met Tyr Phe Ser His Phe Val Pro Val
1 5 10 15
Phe Leu Pro Ala Lys Pro Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr
20 25 30
Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala
35 40 45
Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe
50 55 60
Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val
65 70 75 80
Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Arg Ser Lys Arg Gly
85 90 95
Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val
100 105 110
Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu
115 120 125
Glu Glu Gly Gly Cys Glu Leu Glu Phe Arg Val Lys Phe Ser Arg Ser
130 135 140
Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu
145 150 155 160
Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg
165 170 175
Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln
180 185 190
Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr
195 200 205
Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp
210 215 220
Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala
225 230 235 240
Leu His Met Gln Ala Leu Pro Pro Arg
245
<210> 14
<211> 750
<212> DNA
<213> 信号传导结构域核苷酸序列
<400> 14
acgcgtctga gcaactccat catgtacttc agccacttcg tgccggtctt cctgccagcg 60
aagcccacca cgacgccagc gccgcgacca ccaacaccgg cgcccaccat cgcgtcgcag 120
cccctgtccc tgcgcccaga ggcgtgccgg ccagcggcgg ggggcgcagt gcacacgagg 180
gggctggact tcgcctgtga tatctacatc tgggcgccct tggccgggac ttgtggggtc 240
cttctcctgt cactggttat caccctttac tgcagatcta aacggggcag aaagaaactc 300
ctgtatatat tcaaacaacc atttatgaga ccagtacaaa ctactcaaga ggaagatggc 360
tgtagctgcc gatttccaga agaagaagaa ggaggatgtg aactggaatt cagagtgaag 420
ttcagcagga gcgcagacgc ccccgcgtac cagcagggcc agaaccagct ctataacgag 480
ctcaatctag gacgaagaga ggagtacgat gttttggaca agagacgtgg ccgggaccct 540
gagatggggg gaaagccgag aaggaagaac cctcaggaag gcctgtacaa tgaactgcag 600
aaagataaga tggcggaggc ctacagtgag attgggatga aaggcgagcg ccggaggggc 660
aaggggcacg atggccttta ccagggtctc agtacagcca ccaaggacac ctacgacgcc 720
cttcacatgc aggccctgcc ccctcgctaa 750
<210> 15
<211> 68
<212> DNA
<213> shRNA-1
<400> 15
gatcccgagc tcagggtgac agagagattc aagagatctc tctgtcaccc tgagctcttt 60
tttggaaa 68
<210> 16
<211> 68
<212> DNA
<213> shRNA-1的反义链
<400> 16
cgcgtttcca aaaaagagct cagggtgaca gagagatctc ttgaatctct ctgtcaccct 60
gagctcgg 68
<210> 17
<211> 68
<212> DNA
<213> shRNA-2
<400> 17
gatcccgcct gtgttctctg tggactattc aagagatagt ccacagagaa cacaggcttt 60
tttggaaa 68
<210> 18
<211> 68
<212> DNA
<213> shRNA-2反义链
<400> 18
cgcgtttcca aaaaagcctg tgttctctgt ggactatctc ttgaatagtc cacagagaac 60
acaggcgg 68
<210> 19
<211> 68
<212> DNA
<213> shRNA-5
<400> 19
gatcccgagg atggacactg ctcttggttc aagagaccaa gagcagtgtc catcctcttt 60
tttggaaa 68
<210> 20
<211> 68
<212> DNA
<213> shRNA-5的反义链
<400> 20
cgcgtttcca aaaaagagga tggacactgc tcttggtctc ttgaaccaag agcagtgtcc 60
atcctcgg 68
<210> 21
<211> 59
<212> DNA
<213> shRNA-6
<400> 21
gccaacacat cggagagctt ttcaagagaa agctctccga tgtgttggtt ttttggaag 59
<210> 22
<211> 67
<212> DNA
<213> shRNA-6的反义链
<400> 22
gatccttcca aaaaaccaac acatcggaga gctttctctt gaaaagctct ccgatgtgtt 60
ggctgca 67
<210> 23
<211> 65
<212> DNA
<213> CSR
<400> 23
gatcccgcgc gatagcgcta ataatttctc gagaaattat tagcgctatc gcgctttttt 60
ggaaa 65
<210> 24
<211> 65
<212> DNA
<213> CSR的反义链
<400> 24
cgcgtttcca aaaaagcgcg atagcgctaa taatttctcg agaaattatt agcgctatcg 60
cgcgg 65
<210> 25
<211> 20
<212> DNA
<213> PD-1 primer-1正向引物
<400> 25
agatcaaaga gagcctgcgg 20
<210> 26
<211> 20
<212> DNA
<213> PD-1 primer-1反向引物
<400> 26
ctcctattgt ccctcgtgcg 20
<210> 27
<211> 20
<212> DNA
<213> PD-1 primer-2正向引物
<400> 27
gtgtcacaca actgcccaac 20
<210> 28
<211> 20
<212> DNA
<213> PD-1 primer-2反向引物
<400> 28
ctgcccttct ctctgtcacc 20
<210> 29
<211> 20
<212> DNA
<213> PD-1 primer-3正向引物
<400> 29
tgcagcttct ccaacacatc 20
<210> 30
<211> 20
<212> DNA
<213> PD-1 primer-3反向引物
<400> 30
cacgctcatg tggaagtcac 20
- 还没有人留言评论。精彩留言会获得点赞!
- 基于lmp-1抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图
- 基于bcg1抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图
- 基于pap抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图
- 基于hm1.24抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图
- 基于hcv1抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图
- 基于afp抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图
- 基于hpve6抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图
- 基于hbv2抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图
- 基于hbv1抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图
- 基于ck19抗原的dc细胞、靶向性免疫细胞群及其制备方法和用图