一种基于力编码的肿瘤标志物检测试剂盒及其应用的制作方法
本发明涉及生化分析技术领域,具体涉及一种基于力编码的肿瘤标志物检测试剂盒及其应用。
背景技术:
癌症是严重威胁人类健康的疾病,全世界每年有几百万人死于癌症疾病,其发病率逐年上升,尤其是肺癌、乳腺癌、胃癌、肝癌和结直肠癌等发病率高居榜首。据统计,目前,每年新增的所有癌症疾病患者中,女性乳腺癌患疾病的发病率已经占比所有肿瘤疾病的四分之一,造成的死亡率也是恶性癌症之最。
muc1是黏蛋白家族中的一员,其编码基因定位于人染色体1q21位点。muc1是一类具有复杂糖基结构的多功能大分子糖蛋白,主要分布于各种黏膜上皮细胞和造血细胞的表面,并在多种上皮来源的恶性肿瘤中出现异常糖基化和过量表达。her2(人表皮生长因子受体2)是跨膜受体酪氨酸激酶家族的成员,其在肿瘤发生发展过程中起重要作用,是一个得到广泛研究的肿瘤标志物。
muc1和her2分别存在于乳腺癌的两种细胞亚型中,mcf-7亚型和sk-br-3亚型,其中前者细胞表面过表达muc1,而不表达her2;后者细胞表面过表达her2,而不表达muc1。临床上通过其肿瘤标志物的种类和浓度对肿瘤进行早期诊断。
核酸适配体是一段由几十个碱基组成的单链寡聚核苷酸,它能通过“假碱基对”的堆积、氢键作用、静电作用和形状匹配等方式与各种目标分子特异性、紧密地结合。这些目标分子可以是各种小分子、氨基酸、病毒、蛋白质和染料,甚至可以是亚细胞器和细胞。一般,目标分子可以诱导它形成一些特定的空间结构,如g-四链体、发卡、t结、茎环等。它能特异性识别靶分子,因此,它和传统的化学抗体相似,但是与抗体相比,它又表现出许多优势,如活性稳定、易修饰、成本低、分子量小和易于长期储存等特点。因此,基于核酸适配体的传感器在很多方面都有很好的应用,如食品检测、药物分析、环境监控及生化分析等方面。例如,由于凝血酶蛋白与其核酸适配体具有非常高的亲和力,能够以g-四链体的形式与凝血酶蛋白发生特异性结合,因此利用它们之间的特异性相互作用,可以在分子水平上对凝血酶蛋白进行含量的监测,这对临床疾病的诊断、疾病的发展、疗效的评估等都具有十分重要的意义。
目前基于核酸适配体检测muc1和her2的方法主要有荧光共振能量转移、电化学法、表面等离子共振技术和吸光度法等,但这些方法技术要求高,灵敏度较低,很难满足实际检测的要求。而且,基于这些方法的检测,不能对检测物范围进行很好的调控。并且同时检测多种蛋白时,由于这些蛋白在体内的含量差别较大(从pm级别到um级别),限制了这些方法的实际应用。
技术实现要素:
为了解决上述技术问题,本发明的目的在于提供一种基于力编码的肿瘤标志物检测试剂盒及其应用。
为此,第一方面,本发明提供了一种试剂盒,包括,
一种或多种纳米传感器,磁珠,偶联或固定所述纳米传感器的固相基底;
所述磁珠偶联于所述纳米传感器;
每种所述纳米传感器包括核酸适配体,力编码序列,互补dna序列;
每种所述纳米传感器中的所述核酸适配体、力编码序列和互补dna序列均为单链寡聚核酸;
每种所述纳米传感器中的所述核酸适配体可与目标分子特异性结合;
每种所述纳米传感器中,所述互补dna序列与所述核酸适配体有第一互补配对区,所述第一互补配对区中碱基对的个数为5-25个,优选为12-20个,具体可为12个、13个、14个、15个、16个、17个、18个、19个、20个;
所述互补dna序列与所述力编码序列之间有第二互补配对区;
所述第一互补配对区与第二互补配对区有重叠区。
进一步,所述重叠区中碱基对的个数为1-5个,具体可为1个、2个、3个、4个、5个。
本发明的试剂盒中,纳米传感器的数量一般根据待检测的目标分子的种类的数量而定,一般而言,一种纳米传感器特异性检测一种目标分子。
本发明所述的目标分子是任意可被核酸适配体识别的类型,并不仅限于下文列举的muc1和her2,还可以是其它小分子、氨基酸、病毒、蛋白质或染料等。
进一步,所述目标分子包括muc1和her2中的至少一种,相对应地,所述纳米传感器包括muc1纳米传感器和her2纳米传感器中的至少一种;
所述muc1纳米传感器包括muc1核酸适配体,muc1力编码序列,muc1互补dna序列;
所述her2纳米传感器包括her2核酸适配体,her2力编码序列,her2互补dna序列。
进一步,所述muc1核酸适配体的核酸序列为5’-gcagttgatcctttggataccctg-3’(seqidno:1)。
进一步,所述muc1力编码序列的核酸序列为5’-tttttttttttgtcactgtgca-3’(seqidno:3)。
在一个具体的实施方式中,所述muc1互补dna序列的核酸序列为5’-ttttttttttaaggatcaactgcacagtgaca-3’(命名为com-13,seqidno:4)。在另一个具体的实施方式中,所述muc1互补dna序列的核酸序列为5’-ttttttttttcaaaggatcaactgcacagtgaca-3’(命名为com-15,seqidno:5)。
进一步,由于所述力编码序列和互补dna序列的5’端约10个核苷酸的功能在于使所述纳米传感器与固相基底和磁珠之间保持合理的空间距离,所以该段区域的核苷酸序列不应受到限定,所以,在另一个实施方式中,
所述muc1力编码序列的核酸序列为:将seqidno:3自5’端起第1个-第10个核苷酸进行替换,且替换后第1个-第10个核苷酸在所述纳米传感器中不会形成二级结构;所述muc1互补dna序列的核酸序列为:将seqidno:4或seqidno:5自第1个-第10个核苷酸进行替换,且替换后第1个-第10个核苷酸在所述纳米传感器中不会形成二级结构。
进一步,所述her2核酸适配体的核酸序列为5’-agccgcgaggggagggauaggguagggcgcggcu-3’(seqidno:2)。
进一步,所述her2力编码序列的核酸序列为5’-ttttttttttcactgtcactgtagc-3’(seqidno:6)。
在一个具体的实施方式中,所述her2互补dna序列的核酸序列为5’-ttttttttttccctcccctcgcggctacagtgacagtg-3’(命名为com-16,seqidno:7)。在另一个具体的实施方式中,所述her2互补dna序列的核酸序列为5’-ttttttttttatccctcccctcgcggctacagtgacagtg-3’(命名为com-18,seqidno:8)。
在另一个实施方式中,所述her2力编码序列的核酸序列为:将seqidno:6自5’端起第1个-第10个核苷酸进行替换,且替换后第1个-第10个核苷酸在所述纳米传感器中不会形成二级结构;所述her2互补dna序列的核酸序列为:将seqidno:7或seqidno:8自第1个-第10个核苷酸进行替换,且替换后第1个-第10个核苷酸在所述纳米传感器中不会形成二级结构。
进一步,当所述纳米传感器包括muc1纳米传感器和her2纳米传感器时,所述muc1纳米传感器和her2纳米传感器的摩尔比为1-20:1-20,更优选为1-5:1-5,进一步优选为1:1。
进一步,所述互补dna序列5’端修饰有生物素(biotin),所述磁珠表面修饰有链霉亲和素(streptavidin)。当然,互补dna序列和磁珠也可以采用其它化学修饰方法互连。
进一步,所述固相基底为玻璃基底或pdms基底。
进一步,所述固相基底的表面被醛基修饰。
第二方面,本发明提供所述试剂盒的制备方法,包括以下步骤:
s1、制备偶联或固定所述纳米传感器的固相基底;
s2、组装纳米传感器:将力编码序列加入所述步骤s1制备的固相基底表面,进行第一孵育,使力编码序列连接在固相基底表面;将核酸适配体与互补dna序列进行杂交,得到第一杂交核酸,将第一杂交核酸加入到连接有所述力编码序列的固相基底,进行第二孵育,得到由第一杂交核酸与力编码序列形成的双链的第二杂交核酸,即为所述纳米传感器;
s3、连接磁珠:向所述步骤s2组装有纳米传感器的固相基底加入磁珠,孵育,使磁珠连接于所述纳米传感器的互补dna序列;
s4、磁化:对连接至所述纳米传感器的磁珠进行磁化。
在具体的实施方式中,当所述试剂盒包括多种纳米传感器时,所述步骤s2具体为:将每种纳米传感器的力编码序列加入所述步骤s1制备的固相基底表面,进行第一孵育,使力编码序列连接在固相基底表面;分别将每种纳米传感器中的核酸适配体与互补dna序列进行杂交,分别得到每种纳米传感器的第一杂交核酸,将得到的第一杂交核酸加入到连接有所述力编码序列的固相基底,进行第二孵育,得到由每种纳米传感器的第一杂交核酸与该种纳米传感器的力编码序列形成的双链的第二杂交核酸,即分别得到了每种所述纳米传感器。
其中,磁珠连接于所述纳米传感器的互补dna序列的步骤可以改变顺序,例如先将磁珠连接(或偶联)在互补dna序列上,然后再杂交获得第一杂交核酸,再连接到已固定的力编码序列上,但优选采用上文的方案(即最后偶联磁珠)。
进一步,步骤s1包括,对固相基底的表面依次进行羟基化修饰、氨基化修饰和醛基化修饰,得到醛基修饰的固相基底。
进一步,步骤s1具体包括:
1)用食人鱼溶液(piranha溶液,体积比,98%浓硫酸:30%h2o2=7:3)对固相基底的表面进行羟基化修饰,得到羟基修饰的固相基底;
2)用体积分数为1%的3-氨丙基三乙氧基硅烷的甲苯溶液对所述羟基修饰的固相基底进行氨基化修饰,得到氨基修饰的固相基底;
3)用含有戊二醛的tris-hcl缓冲溶液对所述氨基修饰的固相基底进行醛基化修饰,其中,所述含有戊二醛的tris-hcl缓冲溶液为tris-hcl缓冲溶液中添加体积分数1%戊二醛的溶液制成,得到所述醛基修饰的固相基底。
进一步,步骤2)氨基化修饰的时间为1-10h,具体可为1-3h,3-10h,或2-8h。在具体的实施方式中,为2h。
进一步,步骤3)醛基化修饰的时间为1-10h,具体可为1-3h,3-10h,或2-8h。在具体的实施方式中,为3h。
进一步,步骤s2中,所述第一孵育的温度为0-60℃,优选为0-40℃,具体可为4℃;时间为1-60h,优选为5-40h,具体可为12h。
进一步,步骤s2中,所述杂交的温度为50-95℃,优选80-95℃,具体可为90℃。
进一步,步骤s2中,所述第二孵育的温度为0-60℃,优选为25-60℃,更优选30-50℃,具体可为37℃;时间为1-60h,优选为1-40h,更优选为1-10h,具体可为2h。
进一步,当所述目标肿瘤标志物包括muc1和her2时,所述试剂盒的制备方法的步骤s2具体为:
将muc1力编码序列和her2力编码序列加入到醛基修饰的固相基底表面,使力编码序列的5’端连接在固相基底表面;将muc1核酸适配体与muc1互补dna序列进行杂交,得到muc1第一杂交核酸;将her2核酸适配体与her2互补dna序列进行杂交,得到her2第一杂交核酸;将muc1第一杂交核酸和her2第一杂交核酸加入到固相基底表面,进行孵育;得到由muc1第一杂交核酸与muc1力编码序列形成的双链的muc1第二杂交核酸,即为muc1纳米传感器,得到由her2第一杂交核酸与her2力编码序列形成的双链的her2第二杂交核酸,即为her2纳米传感器。
进一步,步骤s3中,所述磁珠的浓度为1-20mg/ml,优选为1-10mg/ml,具体可为5mg/ml。
进一步,步骤s3中,所述孵育的时间为0.5-3h,具体可为1h、2h。
进一步,步骤s4中,所述磁化的具体步骤包括,使用磁铁进行磁化,所述磁铁的强度为0.8-1t,具体可为0.8t、1t;磁铁与所述磁珠的距离可为0.5-10cm,优选1-5cm,具体可为2cm。
第三方面,本发明提供了所述试剂盒在制备检测待测样本中所述目标分子含量的产品中的应用;或,
所述试剂盒在制备检测待测样本中表达或高表达所述目标分子的肿瘤细胞的产品中的应用;
优选地,所述目标分子为muc1和/或her2。
进一步,所述待测样品为外周血全血,血清,血浆或细胞培养液。
第四方面,本发明提供本发明所述试剂盒用于检测目标分子含量的用途。
进一步,所述目标分子的特征在于,根据所述目标分子的含量无法直接获得疾病的诊断结果或健康状况。
与现有技术相比,本发明具有以下优点:
1、本发明所采用的信号源是磁信号,与传统荧光信号相比,不受环境光线及溶液颜色的干扰,因此检测更灵敏,使用范围更加广泛。
2、本发明实现了对多种目标分子的检测,具有高通量的特点,例如对muc1和her2的无标记检测,待测样品中的muc1和her2处于完全自由的状态,没有经过任何化学修饰,这极大简化了样品的处理工序。
3、本发明可通过序列调控的手段,通过改变互补dna的长度,调节对muc1和her2的检测范围,与传统的固定互补dna序列的长度相比,拓展了其动态检测范围。
4、本发明可以通过力编码的方法,同时对多种目标蛋白进行检测,克服了不同蛋白在体内浓度含量差异较大,无法进行临床检测的难题。
5、通过在基底表面固定更多的纳米传感器,通过力编码的方法,可以同时进行更多种蛋白的检测。
6、通过对病人临床上血清中标志性蛋白质含量的检测,可以从分子水平上,对癌症病人进行早期的、无创的诊断和预后监测。
7、本发明提供的试剂盒除了能检测蛋白质以外,还能够实现对小分子,核酸等的检测,进一步拓展其应用范围。
附图说明
通过阅读下文优选实施方式的详细描述,各种其它的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。在附图中:
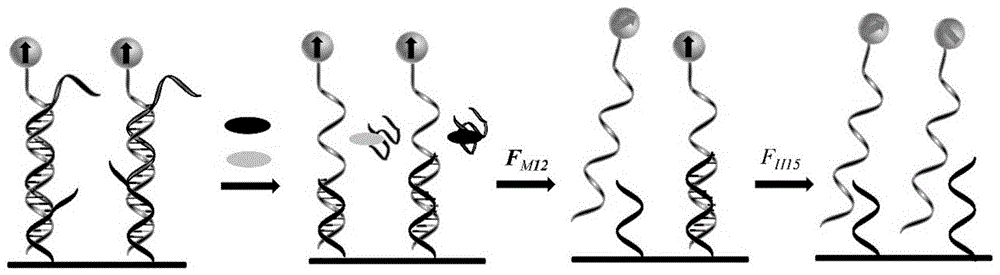
图1为本发明利用力编码同时检测muc1和her2的原理图;
图2为本发明中双链m9(a)和双链m12(b)解离的力谱图;
图3为本发明中双链h12(a)和双链h15(b)解离的力谱图;
图4为同时检测缓冲溶液中的muc1和her2,磁信号变化与muc1或her2浓度的关系;其中,muc1核酸适配体与muc1互补dna互补碱基个数为13;her2核酸适配体与her2互补dna互补碱基个数为16。
图5为同时检测人血清中的muc1和her2,磁信号变化与muc1或her2浓度的关系;
图6为改变核酸适配体与互补dna序列之间的配对碱基个数,对muc1浓度检测的结果。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施方式。虽然附图中显示了本公开的示例性实施方式,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
术语
为了可以更容易地理解本公开,首先定义某些术语。如本公开所使用的,除非本文另有明确规定,否则以下每一个术语具有其下面给出的含义。
核酸适配体(aptamer)指能够与目标分子特异性、高亲和地结合的单链寡聚dna或rna,它能通过自身的结构与目标分子相互作用。核酸适配体一般由25-80个碱基组成,其与靶分子发生特异性识别是基于寡链核苷酸可以形成各种各样的空间构型,如g-四链体(g-quadruplex)、发卡(hairpin)、t结(t-junction)、茎环(stem-loop)等。核酸适配体与目标分子特异性结合时,它们的作用力的方式有“假碱基对”的堆积、氢键作用、静电作用和形状匹配效应等。一般,目标分子可以诱导核酸适配体形成这些特定的二级结构。
在本发明中,所述核酸适配体可与目标肿瘤标志物特异性结合。
在具体的实施方式中,muc1核酸适配体可特异性与muc1结合,所述muc1的核酸序列为seqidno:1;
her2核酸适配体可特异性与her2结合,所述her2核酸适配体的核酸序列为seqidno:2。
杂交,本文所述杂交为核酸分子杂交,是核酸研究中的一项最基本的实验技术,指具有互补序列的单链核酸在一定条件下按碱基配对原则形成双链核酸结构。
纳米传感器,本发明提供的纳米传感器包括核酸适配体,力编码序列,互补dna序列。所述互补dna序列与所述核酸适配体有第一互补配对区,所述互补dna序列与所述力编码序列之间有第二互补配对区,且所述第一互补配对区与第二互补配对区有重叠区(将第二互补配对区除去重叠区的部分,称为稳定结合区)。因此,所述互补dna序列与所述核酸适配体通过第一互补配对区中的碱基配对,可杂交得到部分结构为双链的第一杂交核酸;由于互补dna序列上的重叠区已被核酸适配体所结合,所以,所述第一杂交核酸与所述力编码序列杂交时,通过稳定结合区中的碱基配对,可杂交得到部分结构/全部结构为双链的第二杂交核酸,即纳米传感器。
在具体的实施方式中,检测muc1的纳米传感器由muc1核酸适配体、muc1力编码序列、muc1互补dna序列(com-13或com15)三段核酸组成。检测her2的纳米传感器由her2核酸适配体、her2力编码序列、her2互补dna序列(com-16或com-18)三段核酸组成。
在一个优选的实施例中,所用的核酸序列如表1:
表1
其中,粗体部分示出了第一互补配对区,下划线部分示出了第二互补配对区,双下划线部分示出了稳定结合区。
在另一个优选的实施例中,所用的核酸序列如表2:
其中,粗体部分示出了第一互补配对区,下划线部分示出了第二互补配对区,双下划线部分示出了稳定结合区。
在另一个优选的实施例中,所用的核酸序列如表3:
表3
其中,粗体部分分别示出了muc1第一互补配对区、her2第一互补配对区;下划线部分分别示出了muc1第二互补配对区、her2第二互补配对区;双下划线部分分别示出了muc1稳定结合区、her3稳定结合区。
检测原理
以同时检测muc1和her2(所用核酸序列见表3)为例,说明本发明试剂盒的检测原理,原理图如图1所示。
将分别检测muc1和her2蛋白的纳米传感器同时固定在基底上,在纳米传感器的互补dna序列的5’端标记上磁珠。此时,com-13与muc1力编码序列通过稳定结合区(9个碱基对)形成双链结构,解离所需力为fm9;com-16与her2力编码序列通过稳定结合区(12个碱基对)形成双链结构,解离所需力为fh12。
加入muc1和her2蛋白反应后,muc1结合muc1核酸适配体,使其从双链dna上解离,双链dna的结构发生转换,com-13与muc1力编码序列通过第二互补配对区(12个碱基对)形成双链结构,解离所需力为fm12;同理,her2蛋白结合her2核酸适配体,使其从双链dna上解离,双链dna的结构发生转换,com-16与her2力编码序列通过第二互补配对区(15个碱基对)形成双链结构,解离所需力为fh15。
由小到大依次施加特定大小的作用力,结构变化的双链dna逐个解离,一旦发生解离,磁性粒子将会发生布朗运动,磁偶极发生改变,磁信号就会下降。通过每次施加作用力后,磁信号的变化,来达到检测不同目标蛋白的目的。
通过上述力编码的方式,可以对多种蛋白质进行同时检测。该方法可以通过改变核酸适配体与互补dna序列的配对碱基个数来对目标检测物的范围进行动态调控,以此来拓宽目标物的浓度检测范围,提高其灵敏度。其中,核酸适配体与互补dna序列的配对碱基个数为5-25个,优选为12-20个,因为配对碱基过多,则目标蛋白的加入不能诱导核酸适配体从双链dna上解离;配对碱基过少,核酸适配体不能有效结合到互补dna链上。
下述实施例中所使用的实验方法如无特殊说明,均为常规方法。
下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
下述实施例中的核酸序列由上海生工生物工程有限公司合成,其中互补dna序列的5’端标记有生物素(biotin),力编码序列的5’端修饰有氨基。
下述实施例中的磁珠m-280购自invitrogen公司。
下述实施例中,基准缓冲液(tris-hclbuffer,即tris-hcl缓冲溶液):20mmtris-hcl,140mmnacl,5mmkcl,1mmcacl2,1mmmgcl2,ph=7.4。
dna杂交缓冲液:10mmtris-hcl,1mmedta,1mnacl,ph=8.0。
dna固定缓冲液:20mmtris-hcl,140mmnacl,5mmkcl,1mmcacl2,1mmmgcl2,0.05%tween-20,1%bsa,ph=7.4。
实施例1:醛基化玻璃基底的制备
将切割好的玻璃片先用丙酮超声洗涤2次,然后用超纯水再超声洗涤3次,用1mol/l的naoh溶液超声洗涤10min,然后用超纯水和无水乙醇分别清洗2次,放在250℃的干燥箱中处理3h,去除表面的细菌。
将灭菌处理过的玻璃基底加入刚配制好的piranha溶液烧杯中(98%浓h2so4:30%h2o2=7:3,两者体积比),将上述烧杯放在90℃恒温水浴中让其浸泡30min,玻璃片表面发生羟基化。
将以上刚刚羟基化的玻璃基底加入含1%aptes的甲苯溶液中,室温浸泡3个小时,对玻璃基底进行氨基化。用甲苯溶液清洗表面3次,再用无水乙醇清洗,氮气流吹干,得到氨基化的玻璃基底。
将上述刚刚氨基化处理好的玻璃基底放入有1%戊二醛的基准缓冲溶液体系(体积比)中,在37℃下浸泡2-3小时,再用基准缓冲溶液反复洗涤2-3次,即得到醛基修饰的玻璃基底。
实施例2纳米传感器的固定
将20μl体积比为1:1的3μm氨基化的muc1力编码序列和3μm氨基化的her2力编码序列加入实施例1制备的醛基化玻璃基底表面,用硼氢化钠还原,4℃过夜孵育。
将3μm的muc1核酸适配体与3μm的互补dna序列(com13)等体积混合,在金属浴中90℃反应5min,然后让其自然冷却到室温,得到杂交好的muc1第一杂交核酸(以下简称dna1)。将3μm的her2核酸适配体与3μm的互补dna序列(com16)等体积混合,在金属浴中90℃反应5min,然后让其自然冷却到室温,得到杂交好的her2第一杂交核酸(以下简称dna2)。
取20μl体积比为1:1的dna1和dna2加入到上述固定好muc1力编码序列和her2力编码序列的基底的样品池中,在37℃孵育,第一杂交核酸中互补dna序列与基底上的力编码序列通过第二互补配对区中的碱基配对,结合成为双链核酸。再将含有m280磁珠(磁珠的浓度为5mg/ml)的dna固定缓冲溶液加入样品池中,37℃孵育1h,使磁珠偶联于纳米传感器中互补dna序列的5’端。将固定有纳米传感器且连有磁珠的玻璃基底在磁铁(0.8t)下磁化2min。
实施例3力谱测量
本实施例提供了力谱测量的方法:
(1)固定muc1纳米传感器:
具体步骤同实施例2,区别在于,不包含her2纳米传感器,仅将muc1传感器固定在基底上。
(2)测量muc1的力谱:
将步骤(1)得到的固定有纳米传感器的玻璃基底在1500rpm/min下离心5min(纳米传感器受到的离心力方向由基底指向纳米传感器),去除物理吸附。然后在超低场原子磁力仪上检测磁信号。逐渐增加离心力的大小,每次离心时间仍为5min,记录每次离心力对应的磁信号强度。由于双链dna之间是非共价键结合,在逐渐增加离心力的情况下,最先发生解离的为结合力比较小的双链dna。一旦解离发生,磁性粒子将会发生布朗运动,磁偶极发生改变,磁信号就会下降。通过测量不同离心力作用下磁信号的变化,就可以获得不同双链dna之间的解离力。
磁珠所受离心力大小可由公式精确得到:f=(ρm-ρb)vmω2r;
上述公式中,ρm是磁性粒子的密度,ρb是缓冲液的密度(1.0g·cm-3),vm是磁性粒子的体积,ω是旋转速度,r是样品到旋转中心的距离。
未加muc1蛋白时,纳米传感器组成的双链dna由9个碱基对与固定在基底的力编码序列连接,其解离力谱如图2a所示,其解离力fm9为26pn。加入一定浓度muc1后,37℃孵育30min,再测量其双链dna的解离力谱,结果如图2b所示,可知其解离力fm12为50pn。
(3)固定her2纳米传感器:
具体步骤同实施例2,区别在于,不包含muc1纳米传感器,仅将her2传感器固定在基底上。
(4)测量her2的力谱:
具体步骤同步骤(2),区别在于,所用蛋白为her2。
未加her2蛋白时,纳米传感器组成的双链dna由12个碱基对与固定在基底的力编码序列连接,其解离力谱如图3a所示,其解离力fh12为41pn。加入一定浓度her2后,37℃孵育30min,再测量其双链dna的解离力谱,结果如图3b所示,可知其解离力fh15为73pn。
实施例4检测muc1和her2
将实施例2制备得到的固定有纳米传感器的基底放入样品池中,分别将不同浓度的muc1和her2混合溶液(基准缓冲液配制)加入样品池,37℃孵育30min。首先用fh12(41pn)的力作用于纳米传感器(力的方向由基底指向纳米传感器),去除未反应的双链dna分子。然后将作用力变更为fm12(50pn),用原子磁力仪记录施加作用力前后磁信号的值;再将作用力变更为fh15(73pn),用原子磁力仪记录施加作用力前后磁信号的值。得到磁信号变化随muc1和her2蛋白浓度变化的曲线,如图4所示,磁信号与log蛋白浓度之间的线性关系良好,对muc1蛋白浓度的检测范围为500pm-1μm,对her2蛋白浓度的检测范围为20pm-8nm。
本实施例以50pn和73pn为力编码,通过施加50pn的作用力前后和73pn的作用力前后磁信号的变化,实现了对混合溶液中muc1和her2蛋白浓度的同时检测。检测的动态范围达到5个数量级。
本发明提供的检测试剂盒可实现对体内含量差别较大的不同蛋白进行同时检测。而且通过调节核酸适配体与互补dna配对碱基的个数,基于力编码的动态检测范围可以进一步拓宽。
实施例5血清中对muc1和her2同时检测
本实施例对人血清中的muc1和her2进行了同时检测,检测方法同实施例4,区别在于,本实施例中不同浓度的muc1和her2混合溶液用稀释人血清配制,所述稀释人血清的制备方法为:将新鲜血液(北京人民医院提供)在100rpm/min的转速下离心5min,去上清液后用基准缓冲液稀释100倍。
检测结果见图5,其中对muc1的检测限为1.2nm,相关系数r2=0.988;对her2的检测限为0.1nm,相关系数r2=0.962。可见,本发明的试剂盒应用于人血清样本的检测时,也可取得优良的应用效果,检测灵敏度高,动态检测范围大。
实施例6拓展对目标分子的检测范围
通过序列调控,即改变核酸适配体与互补dna序列之间的配对碱基个数,可以拓展对相应目标分子的检测范围。本实施例以muc1的检测为例,通过序列调控,以拓展对muc1的检测范围。
按照实施例2的制备方法(区别在于,不包含her2纳米传感器),分别制备实验组1和实验组2两个muc1检测试剂盒,二者的区别是:实验组1的纳米传感器由表3中的muc1核酸适配体、com-13和muc1力编码序列组成;实验组2的纳米传感器由表1中的muc1核酸适配体、com-15和muc1力编码序列组成。
分别将制备得到的实验组1和实验组2试剂盒的基底放入样品池中,分别将不同浓度的muc1溶液加入样品池,37℃孵育30min。首先用fm9(26pn)的力作用于纳米传感器(力的方向由基底指向纳米传感器),去除未反应的双链dna分子。然后将作用力变更为fm12(50pn),用原子磁力仪记录施加作用力前后磁信号的值。得到磁信号随muc1浓度变化的曲线,如图6所示,实验组1中,核酸适配体与互补dna序列之间的配对碱基数为13个,其线性检测范围为0.1nm-50nm;实验组2中,核酸适配体与互补dna序列之间的配对碱基数为15个,其线性检测范围为10nm-10μm。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
序列表
<110>中国科学院化学研究所
<120>一种基于力编码的肿瘤标志物检测试剂盒及其应用
<160>8
<170>siposequencelisting1.0
<210>1
<211>24
<212>dna/rna
<213>人工序列(artificialsequence)
<400>1
gcagttgatcctttggataccctg24
<210>2
<211>34
<212>dna/rna
<213>人工序列(artificialsequence)
<400>2
agccgcgaggggagggauaggguagggcgcggcu34
<210>3
<211>22
<212>dna/rna
<213>人工序列(artificialsequence)
<400>3
tttttttttttgtcactgtgca22
<210>4
<211>32
<212>dna/rna
<213>人工序列(artificialsequence)
<400>4
ttttttttttaaggatcaactgcacagtgaca32
<210>5
<211>34
<212>dna/rna
<213>人工序列(artificialsequence)
<400>5
ttttttttttcaaaggatcaactgcacagtgaca34
<210>6
<211>25
<212>dna/rna
<213>人工序列(artificialsequence)
<400>6
ttttttttttcactgtcactgtagc25
<210>7
<211>38
<212>dna/rna
<213>人工序列(artificialsequence)
<400>7
ttttttttttccctcccctcgcggctacagtgacagtg38
<210>8
<211>40
<212>dna/rna
<213>人工序列(artificialsequence)
<400>8
ttttttttttatccctcccctcgcggctacagtgacagtg40
- 还没有人留言评论。精彩留言会获得点赞!