抗体或抗体组合物的制备方法与流程
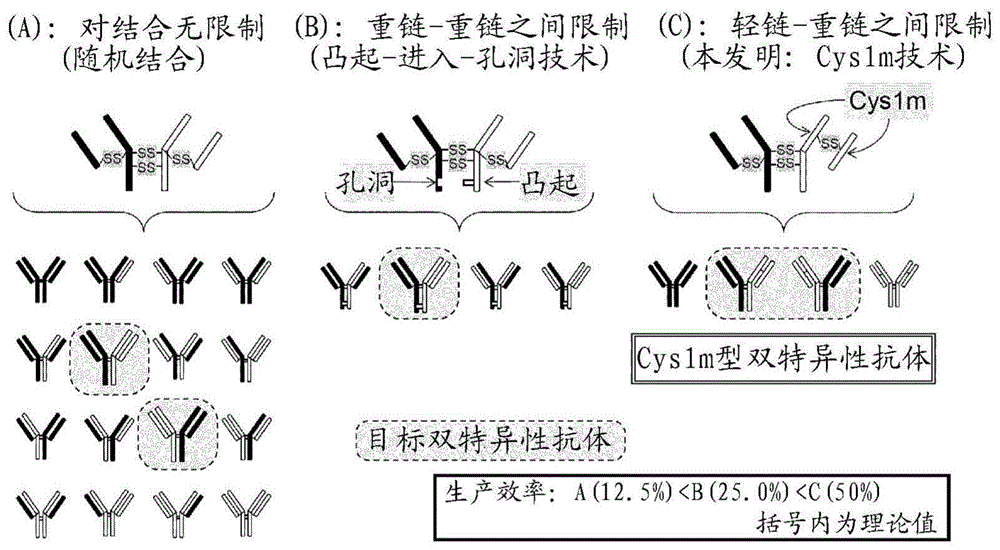
本发明是申请号为“201380057876.3”,申请日为“2013年11月1日”,发明名称为“抗体或抗体组合物的制备方法”的申请的分案申请。本发明涉及含有至少两个不同fab区的抗体,尤其是具有规定的轻链-重链组合的抗体、相应的抗体组合物、或它们的制备方法。
背景技术:
:由于诸如具有两种不同抗原识别位点的双特异性抗体的多特异性抗体具有可同时结合两种以上不同抗原的特异性质,因此其已经预期被开发作为药物或诊断药物。然而,生产率低或纯化的困难成为障碍,并且实用化方面没有进展。另外,虽已知几种有效制备多特异性抗体的方法,但多数是通过限制抗体的重链-重链之间的结合,以有效地制备多特异性抗体(专利文献1-6)。另外,通过引用将以下专利文献的公开内容全部并入本说明书。专利文献1:wo98/50431专利文献2:wo2010/151792专利文献3:美国专利第7,183,076号专利文献4:wo2009/089004专利文献5:wo2007/147901专利文献6:wo2011/034605发明简述本发明人努力研究当制备含有两个不同fab区的抗体;或fab区在至少两种抗体间不同的组合物时的生产率低或纯化困难的问题,并发现通过使用非天然二硫键,可有效地制备它们。换言之,根据本发明,可有效率地制备具有轻链和重链特定组合的抗体。本发明提供了(1)抗体;或(2)含有抗体的组合物;的制备方法;所述方法利用非天然二硫键。上述(1)抗体中含有至少两个fab区,所含fab区中的至少两个不同。另外,上述(2)组合物含有至少二种含fab区的抗体,所含抗体具有的fab区中,至少两个不同。通过此方法,可有效地制备上述抗体或组合物。在一实施方案中,此方法包括在表达抗体的条件下,培养含有编码抗体的核酸的宿主细胞的步骤。另外,在一实施方案中,此方法包括从宿主细胞培养物回收抗体的步骤。在一实施方案中,至少一个fab区含有在轻链与重链之间形成非天然二硫键的半胱氨酸残基。另外,在一实施方案中,某轻链与重链之间的二硫键的位置与抗体或组合物所含的至少一个其它轻链与重链之间的二硫键的位置不同。或者,某fab区在与抗体或组合物所含的至少一个其它fab区不同位置形成二硫键。另外,在一实施方案中,上述非天然二硫键和上述二硫键是cl区与ch1区之间的二硫键。另外,本发明提供了含第一fab区和第二fab区的抗体的制备方法,其是利用非天然二硫键的方法。构成上述第一fab区的轻链和重链与构成上述第二fab区的轻链和重链互不相同。依据此方法,可有效率地制备上述抗体。在一实施方案中,此方法包括在对应目标抗体的亲本抗体中,用形成或可能形成二硫键的半胱氨酸残基取代第一fab区的cl区和ch1区中除半胱氨酸以外的至少一个氨基酸残基的步骤。另外,在一实施方案中,此方法包括通过形成或可能形成二硫键的半胱氨酸残基,在第一fab区中形成非天然二硫键的步骤。另外,在一实施方案中,包含使第一fab区在与第二fab区不同的位置形成二硫键的步骤。另外,本发明提供了通过上述方法所制备的抗体。另外,本发明提供了含有至少两个不同fab区的抗体。在一实施方案中,上述抗体中的至少一个fab区含有在cl区与ch1区之间形成或可能形成非天然二硫键的半胱氨酸残基,从而形成非天然二硫键。另外,在一实施方案中,某cl区与ch1区之间的二硫键的位置与至少一个其它cl区与ch1区之间的二硫键的位置不同。或者,某fab区在与至少一个其它fab区不同的位置形成二硫键。另外,在一实施方案中,抗体含有两个不同fab区。另外,本发明提供了由上述方法所制备的组合物。另外,本发明提供了含有至少两种含fab区的抗体的组合物。此组合物中抗体的fab区中,至少两种fab区不同。在一实施方案中,上述抗体中的至少一个fab区含有在轻链与重链之间形成或可能形成非天然二硫键的半胱氨酸残基,从而形成非天然二硫键。另外,在一实施方案中,某抗体的轻链与重链之间的二硫键的位置与至少一种其它抗体的轻链与重链之间的二硫键的位置不同。或者,某抗体的fab区在与至少一个其它抗体的fab区不同的位置形成二硫键。另外,在一实施方案中,上述非天然二硫键和上述二硫键是cl区与ch1区之间的二硫键。在一实施方案中,此抗体为多特异性抗体。在一实施方案中,此抗体为双特异性抗体。在一实施方案中,此抗体是其中至少两个抗体片段通过接头连接或直接连接的抗体。在一实施方案中,此抗体是抗体片段。在一实施方案中,此抗体为嵌合抗体、人源化抗体或人抗体。在一实施方案中,此抗体是fc区由其它分子所取代的抗体。另外,本发明提供了上述的方法、抗体或组合物,其中通过在选自a)轻链116位置-重链134位置、b)轻链116位置-重链141位置、c)轻链118位置-重链128位置、d)轻链121位置-重链126位置、e)轻链121位置-重链127位置、f)轻链124位置-重链126位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置和i)轻链162位置-重链173位置中的至少一组轻链-重链位置所引入的半胱氨酸残基,形成非天然二硫键。另外,本发明提供了上述的方法、抗体或组合物,其中通过在选自b)轻链116位置-重链141位置、c)轻链118位置-重链128位置、f)轻链124位置-重链126位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置和i)轻链162位置-重链173位置中的至少一组轻链-重链位置所引入的半胱氨酸残基,形成非天然二硫键。另外,本发明提供了上述的方法、抗体或组合物,其中通过在选自轻链为κ链时的b)轻链116位置-重链141位置、f)轻链124位置-重链126位置和g)轻链162位置-重链170位置、以及轻链为λ链时的h)轻链162位置-重链171位置和i)轻链162位置-重链173位置中的至少一组轻链-重链位置所引入的半胱氨酸残基,形成非天然二硫键。另外,本发明提供了上述的方法、抗体或组合物,其中在选自a)f116c-s134c、b)f116c-a141c、c)f118c-l128c、d)s121c-f126c、e)s121c-p127c、f)q124c-f126c、g)s162c-f170c、h)s162c-p171c、i)s162c-v173c、j)f118c-l128c、k)e124c-f126c、l)t162c-f170c、m)t162c-p171c和n)t162c-v173c中的至少一组轻链半胱氨酸-重链半胱氨酸之间,形成非天然二硫键。在一实施方案中,在选自b)f116c-a141c、c)f118c-l128c、f)q124c-f126c、g)s162c-f170c、h)s162c-p171c和i)s162c-v173c中的至少一组轻链半胱氨酸-重链半胱氨酸之间,形成非天然二硫键。另外,在其它实施方案中,在选自轻链为κ链时的b)f116c-a141c、f)q124c-f126c和g)s162c-f170c、以及轻链为λ链时的m)t162c-p171c和n)t162c-v173c中的至少一组轻链半胱氨酸-重链半胱氨酸之间,形成非天然二硫键。另外,本发明提供了上述的方法、抗体或组合物,其中至少一个fab区的cl区与ch1区之间未形成天然二硫键。另外,本发明提供了上述的方法、抗体或组合物,其中某fab区中cl区与ch1区之间的二硫键的位置与至少一个其它fab区中cl区与ch1区之间的二硫键的位置完全不同。另外,本发明提供了上述方法,其中宿主细胞是真核细胞或大肠杆菌。另外,本发明提供了与限制重链-重链间结合的技术组合的上述的方法,或由该方法获得的抗体或组合物。附图简述图1为用以说明本发明(cys1m技术)的有效性的图。图2为在实施例中使用的引物序列的列表。图3为在实施例中使用的cdna序列的列表。图4为在实施例中使用的cdna等转录产物的序列的列表。图5为表示本发明的抗体(cys1m抗体(抗cd20抗体))中ss键的形成的sds-page图。图6为表示本发明的抗体(cys1m抗体(抗cd37抗体))中ss键的形成的sds-page图。图7为表示本发明的抗体(cys1m抗体)中ss键的形成的sds-page图。图8为表示本发明的抗体(cys1m抗体;抗her2抗体、抗egfr抗体、抗cd52抗体)中ss键的形成的sds-page图。图9为表示[cys1m型轻链-野生型重链]抗体(轻链为κ链)中ss键的形成的sds-page图。图10为表示[cys1m型轻链-野生型重链]或[野生型轻链-cys1m型重链]抗体(轻链为λ链)中ss键的形成的sds-page图。图11为表示[野生型轻链-cys1m型重链]抗体(轻链为κ链)中ss键的形成的sds-page图。图12为表示引入非天然二硫键的抗cd20抗体的抗原结合能力(检查对表达cd20抗原的ramos细胞的抗原结合能力的结果)的图。图13为表示引入非天然二硫键的抗cd20抗体的抗原结合能力(检查对表达cd20抗原的ramos细胞的抗原结合能力的结果)的图。图14为表示引入非天然二硫键的抗cd20抗体的抗原结合能力(检查对表达cd20抗原的ramos细胞的抗原结合能力的结果)的图。图15为表示引入非天然二硫键的抗cd20抗体的抗原结合能力(检查对表达cd20抗原的ramos细胞的抗原结合能力的结果)的图。图16为表示引入非天然二硫键的抗cd20抗体的抗原结合能力(检查对表达cd20抗原的ramos细胞的抗原结合能力的结果)的图。图17为表示引入非天然二硫键的抗cd37抗体的抗原结合能力(检查对表达cd37抗原的ramos细胞的抗原结合能力的结果)的图。图18为表示引入非天然二硫键的抗cd37抗体的抗原结合能力(检查对表达cd37抗原的ramos细胞的抗原结合能力的结果)的图。图19为表示引入非天然二硫键的抗cd37抗体的抗原结合能力(检查对表达cd37抗原的ramos细胞的抗原结合能力的结果)的图。图20为表示双特异性抗体αcd20(cys1m)/αdr5的蛋白质a亲和性纯化的结果的图。图21为表示对纯化的αcd20(cys1m)/αdr5进行f(ab')2分析的结果的图。图22为表示对亲本抗体αcd20和αdr5进行f(ab')2分析的结果的图。图23为表示对纯化的αcd20(cys1m)/αcd37进行f(ab')2分析的结果的图。图24为表示对亲本抗体αcd20和αcd37进行f(ab')2分析的结果的图。图25为表示对纯化的αcd20(cys1m)/αdr5进行fab分析的结果的图。图26为表示对亲本抗体αcd20、αdr5和轻链错配体进行fab分析的结果的图。图27为表示对纯化的αcd20(cys1m)/αcd37进行fab分析的结果的图。图28为表示对亲本抗体αcd20、αcd37和轻链错配体进行fab分析的结果的图。图29为表示对αcd20(cys1m)/αdr5中的蛋白质a亲和性纯化样品进行fab分析的结果的图。图30为表示对αcd20(cys1m)/αcd37中的蛋白质a亲和性纯化样品进行fab分析的结果的图。图31为表示对于纯化的αcd20(cys1m)/αcd37对cd20[+]cd37[-]细胞的抗原结合能力进行分析的结果的图。图32为表示对于纯化的αcd20(cys1m)/αcd37对cd20[-]cd37[+]细胞的抗原结合能力进行分析的结果的图。图33为表示对于纯化的αdr5/αcd20(cys1m)对dr5[+]cd20[-]细胞的抗原结合能力进行分析的结果的图。图34为表示对于纯化的αdr5/αcd20(cys1m)对dr5[-]cd20[+]细胞的抗原结合能力进行分析的结果的图。发明实施方式[用语和方面的说明]本说明书中,下述术语具有以下所示的意义,各术语涉及以下所示的各方面。“抗体”是指因抗原抗体反应而显示与抗原的结合性的分子,具有一对或二对或更多对的结合位点(fv)。抗体包括但不限于,例如具有含轻链和重链的一对或二对多肽链的全长抗体,以及其一部分(片段)。各轻链或重链可含有可变区(与对于抗原的识别和结合有关)和恒定区(与定位,补体依赖性细胞毒性和细胞间相互作用有关)。最常见的全长抗体含有2个轻链可变(vl)区、2个轻链恒定(cl)区、2个重链可变(vh)区和2个重链恒定(ch)区。可变区含有互补性决定区(cdr)和骨架区(fr),互补性决定区为向抗体赋予抗原特异性的序列。由上述定义所明确的,除非特别注明,本说明书中“抗体”包括其中两种或三种或更多种抗体(例如,诸如fab区等的抗体片段)通过接头连接或直接连接的抗体(含多个抗体片段的抗体)。作为上述抗体,例如可以例举多个抗体片段以接头连接的抗体,但不限于此。抗体包括单克隆抗体、多克隆抗体、至少2个抗体所形成的多特异性抗体(例如双特异性抗体)、具有所需的生物学活性的抗体片段和fc区由其它分子所取代的抗体等。另外,抗体包括嵌合抗体(例如人源化抗体)、(完全)人抗体、多价抗体、修饰的抗体。对“修饰的抗体”,包括但不限于,在维持结合能力的状态下缺失(缩短)或添加(加长)氨基酸序列的抗体、取代部分氨基酸序列的抗体、缺失或添加糖链的一部分或全长的抗体、和添加其它接头等的抗体,以及这些的组合。另外,尤其当抗体含fc区时,抗体可含糖链。由哺乳动物细胞所生产的天然抗体典型地含有与fc区的ch2结构域的asn297通常n连接的支链寡糖(例如参见wright等,(1997)trendsbiotechnol.15:26-32)。寡糖可含各种碳水化合物,例如甘露糖、n-乙酰葡萄糖胺(glcnac)、半乳糖、和唾液酸、以及结合于二支链寡糖结构的“主干部”的glcnac的果糖。另外,在不损害本发明功效的范围内,抗体可为任何类型(例如igg、iga、igm、igd、ige)和任何亚型(例如igg1、igg2、igg3、igg4)。可变区包含可变区中最高频率变化的被称为高变区(hvr)或互补性决定区(cdr)的区段、和相对高保守的被称为骨架区(fr)的区段。天然抗体的轻链和重链的可变区分别含有3个cdr和4个fr区。各链的cdr与另一链的cdr一同促成抗体的抗原结合位点的形成(例如参见kabat等,sequencesofproteinsofimmunologicalinterest,5thed.publichealthservice,nationalinstitutesofhealth,bethesda,md.(1991))。“互补性决定区”或“cdr”(或“高变区”、“hvr”或“hv”)是指抗体可变区中高频率可变的、形成环的区域。抗体一般在vl中含有3个cdr(cdrl1、cdrl2、cdrl3),并在vh中含有3个cdr(cdrh1、cdrh2、cdrh3)。在不损害本发明功效的范围内,可使用任意定义作为cdr定义。作为cdr定义,例如可使用诸如kabat、chothia、abm、contact等在相关
技术领域:
中所使用的通常的cdr定义,但不限于此。kabat定义基于序列变化,是最常用的(例如参见kabat等,sequencesofproteinsofimmunologicalinterest,5thed.publichealthservice,nationalinstitutesofhealth,bethesda,md.(1991))。对于chothia,还考虑结构的环位置来确定(例如参见chothia和lesk,j.mol.biol.196:901-917(1987))。abm是kabat与chothia结构环的中间定义,通过oxfordmolecular的abm抗体模型软件而使用。contact基于复合物晶体结构的分析(例如参见maccallum等,j.mol.biol.262:732-745(1996))。这些cdr的各个定义如下所示。表1cdr可包含以下中至少一个“延伸的cdr”:vl的24-36或24-34(cdrl1)、46-56或50-56(cdrl2)、89-97或89-96(cdrl3)、vh的26-35(cdrh1)、50-65或49-65(cdrh2)、93-102、94-102或95-102(cdrh3)。可使用“kabat编号系统”(依据kabat的可变区残基编号或kabat的氨基酸位置编号)对抗体的氨基酸残基进行编号(例如参见kabat等,sequencesofimmunologicalinterest,5thed.publichealthservice,nationalinstitutesofhealth,bethesda,md.(1991))。在该编号中,氨基酸序列可含有相当于可变区的fr或cdr内的插入物的添加氨基酸。例如,在重链可变区中,也可包含在重链fr残基82之后(残基82a、82b和82c等)以及在cdrh2的残基52之后(残基52a)的氨基酸插入物。依据标准的kabat编号序列,通过在抗体序列的同源区域相互比较而确定残基的kabat号码。另外,当特别指明时,也可使用诸如chothia进行的编号等的、本领域技术人员已知的其它编号。“eu编号”或“eu索引”一般用于指免疫球蛋白重链恒定区(例如参见国际免疫学信息提供网站(www.imgt.org);edelmang.m.等,thecovalentstructureofanentireγgimmunoglobulinmolecule.,proc.natl.acad.sci.usa,1969,63(1),78-85;kabat等,sequencesofimmunologicalinterest.5thed.publichealthservice,nationalinstitutesofhealth,bethesda,md.(1991))。“kabat的eu编号”或“kabat的eu索引”是组合上述kabat编号和eu编号的编号,广泛地用于对人igg1等进行编号。本说明书中,除非特别指出,否则抗体的氨基酸残基的编号使用通过kabat的eu编号系统进行的残基编号。“fab区”(或“fab部分”)是指将抗体以木瓜酶切割时所得的2种片段中,相当于具有抗原结合能力的片段的区,也指同时含有来自轻链的部分和来自重链的部分的区。通常,fab区含有轻链和重链的可变区(vl和vl区),且含有轻链的恒定(cl)区和重链的第一恒定(ch1)区。fab区是相关
技术领域:
已知的区,可通过常规方法确定。例如可利用与已知抗体等的同源性而确定目的区域是否为fab区,或简单地作为结构域集合表示。由于fab区的边界可以变化,因此,典型地,在人igg1、igg2、igg3、igg4、igm中,fab区由以下组成:包含轻链可变区(长度依抗体克隆而异)的全长轻链(κ链和λ链),和重链可变区(长度依抗体克隆而异)加第一恒定(ch1)区的区域,但不限于此。“两个不同fab区”是指关于构成该fab区的轻链部分和重链部分二者的一级序列、侧链的修饰或构象分别有一个或多个不同点的两个fab区。“接头”是指使某分子与另一分子连接时所使用的连接分子,并且在相关
技术领域:
中公知多种。作为连接对象的分子包括多肽或低分子化合物,例举抗体片段之间、或抗体片段与其它组分之间的连接等作为实例。具体的接头可包括但不限于,例如,诸如gs接头((ggggs)3)等的数个残基至数十个残基长度的肽;和低分子量化合物,例如,n-琥珀酰亚胺基3-(2-吡啶基二硫基)丙酸酯(spdp);琥珀酰亚胺基6-3-[2-吡啶基二硫基]丙酰胺)己酸酯(lc-spdp);磺基琥珀酰亚胺基6-3-[2-吡啶基二硫基]丙酰胺)己酸酯(磺基-lc-spdp);n-琥珀酰亚胺基3-(2-吡啶基二硫基)丁酸酯(spdb);琥珀酰亚胺氧基羰基-α-(2-吡啶基二硫基)甲苯(smpt);琥珀酰亚胺基6-(α-甲基)-[2-吡啶基二硫基]甲酰胺)己酸酯(lc-smpt);磺基琥珀酰亚胺基6-(α-甲基-[2-吡啶基二硫基]丙酰胺)己酸酯(磺基-lc-smpt);琥珀酰亚胺基-4-(对马来酰亚胺苯基)丁酸酯(smpb);磺基琥珀酰亚胺基-4-(对马来酰亚胺苯基)丁酸酯(磺基-smpb);间马来酰亚胺苯甲酰基-n-羟基琥珀酰亚胺酯(mbs);间马来酰亚胺苯甲酰基-n-羟基磺基琥珀酰亚胺酯(磺基-mbs);s-乙酰基巯基琥珀酸酐(samsa);二甲基3,3-二硫双丙酰胺(dtbp);2-亚胺基硫烷盐。另外,接头内或接头与待连接分子之间可含有非共价结合的键。当肽等为“不同”时,不同可包括但不限于氨基酸序列的不同、添加的糖链的不同、化学修饰的不同、二硫键的不同等。另外,本发明中,优选地,用于本发明目的的半胱氨酸残基和/或二硫键的不同不包含在上述不同中(换言之,除了半胱氨酸残基和/或二硫键的不同以外,具有至少一个不同)。“(轻链)cl区”是指轻链的恒定区,是相关
技术领域:
公知的区。cl区可通过常规方法确定,例如可利用与已知抗体等的同源性而确定目的区域是否为cl区。由于cl区的边界可改变,因此,在人κ链中,cl区通常由109-214组成,但不限于此。另外,人λ链中的cl区通常由109-213组成。“(重链)ch1区”是指重链的第一恒定区,其为相关
技术领域:
已知的区。本文定义的ch1区也可含ch1区之后的绞链区的一部分(可包含于fab区的绞链区)。ch1区可通过常规方法确定,例如可利用与已知抗体等的同源性而确定目的区域是否为ch1区。由于ch1区的边界可改变,因此,在人igg1、igg2、igg3、igg4的重链中,本文定义的ch1区通常是由氨基酸残基编号118-215和额外的绞链区的一部分(例如氨基酸残基编号216-224)组成;在igm的重链中,本文定义ch1区域通常是由氨基酸基编号118-216组成,但不限于此。“fc区”是指将抗体以木瓜酶切割时所得的2种片段中,对应于不具有抗原结合能力的片段的区。通常,fc区是指抗体重链的c端区,其一般含有一部分绞链区,由重链的第二恒定(ch2)区和第三恒定(ch3)区组成。重链fc区的边界可改变,例如人igg1重链fc区一般是由thr225的氨基酸残基至ch3区的羧基端组成。依据抗体的重链恒定区的氨基酸序列,抗体分为不同类型(例如iga、igd、ige、igg和igm的5种类型,进而igg1、igg2、igg3、igg4、iga1、和iga2等的亚型)。对应上述5种类型的重链恒定区分别称为α、δ、ε、γ和μ。另外,抗体的轻链基于其氨基酸序列可认为是kappa(κ)或lamda(λ)中任一种。所谓抗体的“效应子功能”是指抗体的fc区具有的生物学活性,并可依抗体的同种型而可改变。抗体的效应子功能的实例包括c1q结合性;补体依赖性细胞毒性(cdc);fc受体结合性;抗体依赖性细胞介导的细胞毒性(adcc);吞噬作用;细菌功能的损害/阻断;毒素的中和;和免疫活性细胞(例如b细胞)的活化。上述的fc区通常为对中性白细胞、巨噬细胞、其它免疫辅助细胞、补体复合体和免疫系统受体的结合位点。此部分也可改变,此改变包括例如抗体的氨基酸序列中的氨基酸添加或缺失、一个或多个氨基酸的取代、和(亚)类型转变。另外,抗体也包含通过任意公知方法进行修饰的修饰抗体。例如糖链修饰(wo0061739等)或fc区的氨基酸突变(us20050054832a1)等增加与fc受体等的结合,可提供更高的治疗效果。“天然抗体”中,人igg是由两种相同的轻链和两种相同的重链组成的分子量约为150kda的异四聚体糖蛋白质。各轻链通过一个二硫键结合于重链。另一方面,重链是通过多个二硫键彼此结合,其数量依igg的亚型而异。在亚型igg1的情况下,重链间存在两个二硫键。因此,参与链间结合的二硫键总数为四个。各链在氨基端侧有可变区,在羧基端侧有恒定区。在重链的中间部分,也即ch1区和ch2区的边界具有高可塑性的绞链区,重链通过铰链区中存在的两个二硫键而彼此结合。另外,ch3区通过疏水的结合力而彼此配对。另一方面,cl区通过疏水结合力与ch1区配对,并且也通过二硫键结合。结果是,vl区与vh区位置接近。“单克隆抗体”是指来自仅一组的抗体基因(1种轻链和1种重链),在蛋白质水平基本上相同的抗体的组。组中所含的各个抗体除了可能少量存在的突变(例如天然产生的突变)以外是相同的。另外,单克隆抗体可依据各种常规方法制备而不局限其具体制备方法。这些制备方法包括例如融合瘤法、dna重组法、噬菌体呈现(phagedisplay)技术、以及在具有编码部分或全部人类免疫球蛋白基因座或人类免疫球蛋白序列的基因的动物中产生人或人样抗体的技术等。“嵌合抗体”是指轻链或重链或其双方部分具有来自特定物种的氨基酸序列,剩余部分由来自其他物种的氨基酸序列组成的抗体。实例包括来自大鼠或小鼠抗体等的来自动物抗体的可变区与其它分子(例如来自人抗体的恒定区)融合的抗体。“人源化抗体”是嵌合抗体的一种,是具有轻链和/或重链的可变区序列经改变以与已知的人可变区序列基本一致的可变区的抗体。这类改变是现有技术上已知的,通常通过诱导突变或cdr移植所进行,但是不限于此。cdr移植是指将具有所需特异性的抗体的cdr移植到人抗体的骨架,从而将大部分的非人序列与人序列交换。例如依据最佳拟合法,将提供者抗体的可变区序列对已知的人可变区序列库的全体进行同源性搜寻,将最接近提供者序列的人序列作为人源化抗体的人骨架使用。其它方法是使用由轻链或重链的特定亚型的全部人抗体的共有序列所得的特定骨架。可将相同骨架用于数种不同的人源化抗体。抗体优选地保持对抗原的亲和性和/或所需的生物学特性并被人源化。因此,例如也可以进行使用亲本抗体序列和人源化序列的三维模型,以分析亲本抗体序列和各种概念上的人源化产物的处理。人源化抗体也可包含在接受者抗体(人抗体)或提供者抗体(例如鼠抗体)中未发现的残基。通过将小鼠单克隆抗体人源化,降低人抗小鼠抗体(hama)反应。“人抗体”是指轻链和重链双方的恒定区和可变区均为来自人或基本上与其相同的抗体,和/或使用在此所公开的用以制备人抗体的任一项技术所制备的抗体。可通过各种传统技术制备人抗体,可举以下方法为例。通过将选自来自人来源的噬菌体呈现库的fv克隆可变区序列与已知的人恒定区序列组合,可制备人抗体。另外,通过将抗原给予响应于抗原刺激并可产生人抗体的完全成分而不产生内源性免疫球蛋白的转基因动物(例如小鼠;例如免疫的转基因鼠(xenomouse)),可制备人抗体(例如参见关于xenomouse技术的美国专利第6075181号和第6150584号)。另外,已知生殖细胞系突变体小鼠的抗体重链结合区(jh)基因的同型纯合子缺失不产生内源性抗体,在向该小鼠移植引入人生殖细胞系免疫球蛋白基因序列的胚性干细胞的小鼠中,通过给予抗原而产生人抗体(例如参见jakobovits等,proc.natl.acad.sci.usa90,2551-2555(1993);jakobovits等,nature362,255-258(1993);bruggermann等,yearinimmunol.,7:33-40(1993))。另外,也可通过人的b细胞融合瘤技术制备人抗体(例如参见li等,proc.natl.acad.sci.usa,103:3557-3562(2006))。用以生产人单克隆抗体的人骨髓瘤或小鼠-人异骨髓瘤细胞系记载于例如kozbor,j.immunol.133,3001-3005(1984);brodeur等,monoclonalantibodyproductiontechniquesandapplications,pp.51-63(marceldekker,inc.,newyork,1987);boerner等,j.immunol.,147:86-95(1991)。另外,在其中人抗体具有与非人亲本抗体(例如小鼠抗体)类似的亲和性的特性时,也可使用基因重排以从非人亲本抗体得到人抗体(也称为表位印记;例如参见wo93/06213)。与通过cdr移植的非人抗体的人源化不同,通过此技术,也可得到完全不具有非人起源的fr或cdr残基的人抗体。“抗体片段”是指含有足以提供抗原结合的可变区序列的抗体的一部分。作为本发明对象所使用时的抗体片段是指含有一对或二对以上的轻链可变区与重链可变区的组合的抗体的一部分。上述的抗体的一部分包括fv、fab、f(ab')2,但是不限于此。这些抗体片段可依常规方法制备,例如可通过胃蛋白酶消化等的抗体的蛋白水解切割法,或操作抗体的轻链和重链的cdna,产生轻链和重链片段的重组法等制备。抗体的胃蛋白酶处理产生“f(ab')2”片段,其具有两个抗原结合位点,可交叉结合抗原。开发各种技术用以产生抗体片段。例如这些片段可通过抗体的蛋白水解(切割、消化)而诱导(例如参见morimoto等,journalofbiochemicalandbiophysicalmethods24:107-117(1992);brennan等,science,229:81-83(1985))。另外,这些片段也可通过重组宿主细胞(例如大肠杆菌)直接产生。另外,通过使从宿主细胞回收的fab'-sh片段化学结合,也可形成f(ab')2片段(例如参考carter等,bio/technology(ny)10:163-167(1992))。“fv片段”是含有完全的抗原结合位点的最小抗体片段。双链fv一般是由一个轻链可变结构域和一个重链可变结构域的二聚体组成。“fab”片段是含轻链和重链的可变区(vl和vh区),具有轻链恒定(cl)区和重链第一恒定(ch1)区的抗体片段。另外,“f(ab')2片段”是之间以铰链半胱氨酸残基形成的二硫键结合的fab'片段对。“多价抗体”是指具有3个或更多个抗原结合位点的抗体。多价抗体一般具有二聚体化结构域(例如fc区或绞链区)和3个或以上(例如3个至8个,尤其4个)的抗原结合位点(例如参见tutt等,j.immunol.147:60-69(1991))。“多特异性抗体”是指对至少两种不同抗原,具有结合特异性的抗体(也含抗体片段),也包括双特异性抗体。可依据已知的方法制备双特异性抗体。例如可通过具有不同特异性的两种免疫球蛋白轻链-重链对的同时表达来制备双特异性抗体(例如参见milstein和cuello,nature,305:537-539(1983);wo93/08829;traunecker等,emboj.10:3655-3659(1991))。此时,因为轻链和重链随机配对,所以这些的融合瘤(四个杂种)产生10个不同抗体的混合物,其中一个具有正确的双特异性结构,通过亲和层析法等分离/纯化。关于此,也已知并可使用更适合得到上述组合的双特异性抗体的方法(例如参见wo94/04690)。关于用以产生双特异性抗体的更详细内容,例如参见suresh等,methodsinenzymology,121:210-228(1986)。“具有结合能力”是指分子(例如抗体)对其结合配偶体(例如抗原)具有结合(主要是非共价结合)的能力,尤其是特异性结合的能力。“结合亲和性”是指分子(例如抗体)的单一结合位点与其结合配偶体(例如抗原)之间的非共价结合的相互作用的综合强度。除非特别指出,否则结合亲和性是指反映结合对的成员(例如抗体与抗原)之间的1:1相互作用的结合亲和性。一般,分子x的对其配偶体y的亲和性以解离常数(kd)表示。亲和性可依据本领域技术人员已知的方法测定。低亲和性抗体趋向于缓慢地结合抗原并迅速地解离,而高亲和性抗体处于与抗原结合更久的状态。抗体也包括与一种或多种与药物偶联的抗体(这种抗体也特别称为“药物结合抗体”或“adc”)。另外,抗体也包括与肽、多肽或蛋白质偶联的抗体。另外,抗体也包括与一种或多种与标示标记(放射性同位素等)偶联并被标示为可检测的抗体。另外,将未与药物、标示标记或多肽等偶联的抗体特别称为裸抗体(nakedantibodies)。在上述偶联抗体中,抗体(ab)是优选通过接头(l)与一种或多种药物部分(d)(或肽、多肽、蛋白质或标示标记部分)偶联的抗体,例如每1个抗体偶联1至20个药物部分。可通过已知的有机化学反应以及试剂的手段制备这样的偶联抗体。偶联抗体可使用上述方法以外的方法制备,也可例如作为通过重组技术的融合蛋白质,或使用多特异性抗体,或通过肽合成制备。“多肽”一般是指含多于约10个氨基酸的肽或蛋白质。多肽可作为抗体的抗原。另外,对于各种多肽的抗体,已知在诸如医疗等许多领域有效。多肽包括哺乳动物多肽(尤其人多肽)、原核生物多肽等,尤其作为在工业上有用的多肽可列举生长因子、激素、细胞因子和这些的受体、凝血因子和抗凝血因子等。多肽包括但不限于,血管紧张肽原酶;生长激素(人生长激素、牛生长激素等);生长激素释出因子;甲状旁腺激素;促甲状腺激素;脂蛋白;α-1抗胰蛋白酶;胰岛素(a链、b链);前胰岛素;促卵泡激素;降钙素(calcitonin);促黄体生成激素;高血糖素;viiic因子;ix因子;组织因子;血管性血友病因子;蛋白质c;心房钠利尿因子;尿激酶;t-pa;蛙皮素;凝血酶;hgf;tnf-α;tnf-β;tnfr(tnfr1、tnfr2等);tgf-α;tgf-β(tgf-β1、tgf-β2、tgf-β3、tgf-β4、tgf-β5等);脑啡肽酶;rantes;mipi-1;血清白蛋白;苗勒抑制物质(mullerianinhibitingsubstance);松弛素(a链、b链);前松弛素;促性腺激素;β-内酰胺酶;dnase;抑制素;活化素;vegf;vegfr;整合素;蛋白质a;蛋白质d;类风湿因子;bdnf;神经营养因子(nt-3、nt-4、nt-5、nt-6等);ngf-β;pdgf;纤维母细胞生长因子(afgf、bfgf)等;egf;egfr;her2;胰岛素样生长因子(igf-i、igfii等);胰岛素样生长因子结合蛋白质;死亡受体(dr3、dr4、dr5等);fas配体;fas受体;cd-3;cd-4;cd-8;cd-10;cd-11;cd-19;cd-20;cd-25;cd-32;cd-30;cd-33;cd-37;cd-52;hla-dr;gpiib;ige;c5;ccr-4;α4-整合素;rankl;ctla4;blys;ngep;muc-1;cea;epcam;促红血球生成素;bmp;免疫毒素;干扰素(ifn-α、ifn-β、ifn-γ等);集落刺激因子(m-csf、gm-csf、g-csf等);白介素(il-1至il-13等);超氧化物歧化酶;t细胞受体;促衰变因子;病毒抗原(hiv被膜等);抗体;和上述多肽的片段。“多核苷酸”或“核酸”是指任意长度的核苷酸聚合物,包含dna和rna。核苷酸包括脱氧核苷酸、核糖核苷酸、经修饰的核苷酸(例如甲基化核苷酸)或碱基,和/或这些的类似物。核苷酸通过dna或rna聚合酶或合成反应被连接。多核苷酸或核酸也可包含核苷酸连接后的修饰(例如与标签或保护基的结合)。另外,“寡核苷酸”是指短,一般为单链的多核苷酸。一般可指未达约200个核苷酸长度的合成多核苷酸,但并不限于此。“载体”是指可输送其它核酸的核酸分子。载体包含质粒(连接添加的dna的环状双链dna)、噬菌体载体(连接添加的多核苷酸的噬菌体)、病毒载体(连接添加的多核苷酸的病毒)等。某些载体可在它们所引入的宿主细胞内进行自我复制(例如具有细菌复制起点的细菌载体与游离基因哺乳动物载体)。其它载体在引入宿主细胞时被整合到宿主细胞的基因组中,与宿主基因组一起复制(例如非游离基因附体哺乳动物载体)。进而,某载体可指导与其可操作地连接的基因的表达。这类载体称作表达载体或重组表达载体。一般,重组dna技术中有用的表达载体多采用质粒的形式。具有一定序列同一性的多肽或核酸相对于作为基本的氨基酸/核苷酸序列,可含几个氨基酸/核苷酸的突变(改变)。在可提升目标分子的特性(例如抗体的结合亲和性和/或生物学的特性)时优选这样的修饰。可通过向多肽的核酸引入适当的核苷酸变化或通过肽合成来制备多肽的氨基酸序列突变体。这类突变包括氨基酸序列内残基的缺失和/或插入和/或取代。只要在目标分子保持所需特征的范围内,可任意组合缺失、插入和取代。向某序列中引入突变的方法包括但不限于,从天然源的分离(天然产生的氨基酸/核苷酸序列突变体时)、位点特异性突变、pcr诱导的突变和盒式突变。可改变多肽以增加或减少糖基化水平。多肽的糖基化通常是n-连接或o-连接中任一种。n-连接是指碳水化合物与天冬酰胺残基侧链的结合。天冬酰胺-x-丝氨酸和天冬酰胺-x-苏氨酸(x是除了脯氨酸以外的任意氨基酸)的三肽序列是用于糖链部分与天冬酰胺侧链的酶促连接的识别序列。因此,当多肽中存在这些三肽序列的任一种时,它们成为潜在的糖基化位点。o-连接糖基化是指糖类、n-乙酰半乳糖胺、半乳糖或木糖之一与羟基氨基酸,最常见为丝氨酸或苏氨酸的连接,但是有时也与5-羟脯氨酸或5-羟赖氨酸发生连接。对多肽的糖基化位点的添加或缺失可通过使氨基酸序列改变从而制备或去除一个或多个上述三肽序列(n-连接糖基化位点)而实现。也可通过对作为基本的多肽序列添加、缺失或取代一个或多个丝氨酸或苏氨酸残基进行这种改变(o-连接糖基化位点时)。另外,具有某些氨基酸序列的多肽也可以包括这样的多肽,连接于该多肽的寡糖(糖链)由天然形式改变。另外,氨基酸残基的优选取代是保守性取代,其实例如表2所示。可以将这类氨基酸取代引入多肽,并对于所需活性/效果(例如抗原结合性、免疫原性、adcc或cdc等)筛选取代体。非保守性取代是将一个分类中的一员交换成其它分类的一员,非保守性取代也可在保持所需特征的范围内进行。表2原始残基示例性取代残基优选取代残基ala(a)val、leu、ilevalarg(r)lys、gln、asnlysasn(n)gln、his、asp、lys、argglnasp(d)glu、asnglucys(c)ser、alasergln(q)asn、gluasnglu(e)asp、glnaspgly(g)alaalahis(h)asn、gln、lys、argargile(i)leu、val、met、ala、phe、正亮氨酸leuleu(l)正亮氨酸、ile、val、met、ala、pheilelys(k)arg、gln、asnargmet(m)leu、phe、ileleuphe(f)trp、leu、val、ile、ala、tyrtyrpro(p)alaalaser(s)thrthrthr(t)val、sersertrp(w)tyr、phetyrtyr(y)trp、phe、thr、serpheval(v)ile、leu、met、phe、ala、正亮氨酸leu对于抗体的突变体,也可改变亲本抗体的互补性决定区(cdr)和/或骨架区(fr)的氨基酸残基。作为从亲本抗体制备突变体的方法,例举亲和力成熟法(例如使用噬菌体呈现法),但是不限于此。另外,也可通过分析抗原抗体复合体的晶体结构,并确定候补突变点,以制备突变体。“天然二硫键”是指通常存在于野生型多肽(抗体等)的半胱氨酸-半胱氨酸间的共价键。“非天然二硫键”是指在上述“天然二硫键”以外的位置所形成的半胱氨酸-半胱氨酸间的共价键。因此,即使当形成二硫键的半胱氨酸残基的一方为天然二硫键残基(通常存在于野生型多肽的半胱氨酸残基),另一方为非天然二硫键(存在于与天然二硫键残基不同位置的半胱氨酸残基)时,作为二硫键整体,可称为非天然二硫键。对于非天然二硫键,优选形成二硫键的两个半胱氨酸残基都是非天然半胱氨酸残基。另外,本说明书中,除非有特别记载,否则只要不违反本发明的目的,“二硫键”的记载就可作为包含“天然二硫键”和“非天然二硫键”双方的总称使用。只要不违反本发明的目的,可以通过任何方法将非天然半胱氨酸残基引入目的轻链或重链,可使用相关领域已知的全部方法。具体地,通过将存在于目的位置的氨基酸残基取代为半胱氨酸残基,或将半胱氨酸残基插入至目的位置,从而可引入半胱氨酸残基。可使用已知的基因修饰技术等修饰氨基酸残基的方法进行这类取代或插入。关于天然二硫键,可进一步由其交联样式分为在同一多肽链内所形成的“链内键”和在异源多肽链间所形成的“链间键”。例如在人igg1抗体的情况下,前者是各结构域内各1条,整个分子合计存在12条。另一方面,对于后者,重链-重链间存在2条,轻链-重链间各存在1条。因此,在人igg1抗体的情况下,每1个分子合计存在16条天然二硫键。此天然二硫键的条数和其位置依抗体的类型和亚型而异,分别为固有的。例如在人igg1抗体的轻链-重链间的链间键的情况下,cl区的氨基酸位置214的半胱氨酸残基和ch1区的氨基酸位置220的半胱氨酸残基间形成二硫键,在igg2、igg3、igg4、igm抗体的轻链-重链间的链间键的情况下,cl区的氨基酸位置214的半胱氨酸残基和ch1区的氨基酸位置131的半胱氨酸残基间形成二硫键。“在不同位置形成二硫键”(二硫键的位置不同)是指当比较存在于两种多肽或其部分的二硫键时,一方以与另一方不同的模式形成二硫键(虽在一方中存在,但在另一方中不存在的二硫键)。此时,两种多肽或其部分之间,可有一致(重复)的二硫键(尤其链内键可一致)。就降低两个多肽或其部分交叉的观点,一致的二硫键数量(链内键除外)优选为2、1或0,最优选为0。另外,关于两种二硫键的异同,当构成各个二硫键的两个半胱氨酸残基双方均为相同或对应的位置时,键为“相同”,当至少一方为基本上不同的位置时,键为“不同”。为减少交叉,优选双方位置均不同,但并不限于此。另外,作为“不形成二硫键的氨基酸残基”,通常包括将半胱氨酸以外的氨基酸残基、和半胱氨酸残基的sh基化学修饰成不能形成二硫键的状态的情况。通过将可形成二硫键的半胱氨酸残基取代成这些氨基酸残基,可防止二硫键的形成。当用不能形成二硫键的氨基酸残基取代半胱氨酸残基时,大多所使用的是取代成丙氨酸或丝氨酸。或者当可维持目的多肽的功能时,通过使半胱氨酸残基缺失也可使得不形成二硫键,这种情况可以说是将半胱氨酸残基改变成“不形成二硫键的氨基酸残基”。“纯化”是指除去杂质使得以包含在样品中的重量计算,目标分子在样品中以至少95%,至少98%,或至少99%的浓度存在。“分离”是指目标分子被从通常伴随天然环境的至少一种其它类似分子(多肽、核酸等)分离和/或回收的状态。通常,分离的分子经过至少一个纯化步骤所制备。关于多肽,例如当被纯化(1)使得以罗氏法(lowrymethod)测定时的纯度超过95或99重量%,(2)使得通过使用氨基酸序列确定装置,足以得到至少15个n端或内部氨基酸序列的残基,或(3)使得通过使用了考马斯蓝(coomasieblue)或银染色的非还原或还原条件下的sds-page而变得均匀时,可称为充分地分离,但不限于此。“组合物”用于本技术实现要素:时是指,i)含至少两种抗体的组合物,或ii)含抗体和其它组分的组合物中任一种,除非特别指出,否则也包括任何实施方案。作为i)的意义所使用的组合物,包括例如使至少两种抗体在同一个细胞中共同表达的细胞、或由该细胞所制备的组合物等。作为其它成份,在不违反使用组合物的目的的范围内,可使用任意组分,但优选使用药学上可接受的载体。“药学上可接受的载体”,可包括例如无菌水或生理盐水、稳定剂、赋形剂、抗氧化剂(抗坏血酸等)、缓冲剂(磷酸、柠檬酸、其它有机酸和其盐等)、防腐剂、表面活性剂(聚山梨醇酯、聚乙二醇等)、螯合剂(edta等)、结合剂、ph调节剂、细胞(哺乳类的红血球等)等。另外,也可含蛋白质(低分子量的多肽、血清白蛋白、明胶、免疫球蛋白等)、氨基酸(甘氨酸、谷氨酰胺、天冬酰胺、精氨酸、组氨酸、赖氨酸等)和其盐、单糖(葡萄糖、甘露糖、半乳糖等)或多糖(麦芽糖、海藻糖、麦芽三糖、糊精、葡聚糖、蔗糖等)等的糖类、糖醇(甘露糖醇或山梨糖醇等)、碳水化合物、合成聚合物(聚烯烃、聚苯乙烯、苯乙烯·二乙烯基苯共聚物、聚甲基丙烯酸酯、聚酰胺等)或天然聚合物(纤维素、琼脂糖、几丁质、壳聚糖等)和这些的交联体,但不限于此。当制备注射用水溶液时,也可与例如含生理盐水、葡萄糖或其它添加物(d-山梨糖醇、d-甘露糖、d-甘露糖醇、氯化钠等)的等张液、适当的助溶剂(例如醇(乙醇等)、多元醇(丙二醇、聚乙二醇等)、非离子型表面活性剂(聚山梨醇酯20、聚山梨醇酯80、聚山梨醇酯120、聚氧乙烯硬化蓖麻油等))等并用。另外,根据需要,也可将本发明的双特异性抗体封入微胶囊(羟甲基纤维素、明胶、聚甲基丙烯酸酯等的微胶囊),或将其制成胶体药物递送系统(脂质体、白蛋白微球、微乳剂、纳米粒子和纳米胶囊等)。“至少一个”是指一个或以上,包含两个、三个、四个或五个、或在组合方面理论可取得的上限值的约5%(或以上)、约10%(或以上)、约20%(或以上)、约50%(或以上)、约80%(或以上)。在不损害本发明的目的、或作为抗体等的该发明对象的功效的范围内,本领域技术人员可适当确定上限。这类上限包括两个、三个、四个或五个、或在组合方面理论可取得的上限值的约5%(或以上)、约10%(或以上)、约20%(或以上)、约50%(或以上)、约80%(或以上)或100%。“至少两个”是将“至少一个”的下限为从一个变更为两个,其它相同。实施方案以下通过使用实施本发明的实施方案详细说明本发明,但本发明并不限于此。这些方面可单独使用,也可组合使用。另外,对于各方面的定义或详细内容,也参照上述的“用语和方面的说明”。本发明涉及通过改变二硫键的形成位置,限制轻链-重链间配对的方法,并且当轻链-重链组合存在多种时,可有效率地制备含轻链和重链的抗体(参照图1)。本发明的一实施方案为含有至少两个不同fab区的抗体;或含有至少两种含fab区的抗体的组合物,所述fab区在至少两种抗体之间不同;的制备方法,所述方法包括i)在表达所述抗体的条件下,培养含有编码所述抗体的核酸的宿主细胞的步骤,和ii)从宿主细胞培养物回收所述抗体的步骤,其中,所述核酸编码至少一个含有半胱氨酸残基的区域,所述半胱氨酸残基在所述fab区的轻链与重链之间形成非天然二硫键,其中,由于所述非天然二硫键的存在,fab区中的轻链与重链之间的二硫键的位置与至少一个其它fab区中的轻链与重链之间的二硫键的位置不同。在一实施方案中,在上述方法中,上述非天然二硫键和上述二硫键是cl区与ch1区之间的二硫键。另外,本发明的一实施方案为抗体的制备方法,所述抗体含有第一fab区和第二fab区,所述第一fab区含有第一轻链和重链,所述第二fab区含有分别与所述第一轻链和重链不同的第二轻链和重链,所述方法包括:a)将所述抗体的亲本抗体的第一fab区的cl区和ch1区中的半胱氨酸以外的至少一个氨基酸残基取代成形成二硫键的半胱氨酸残基的步骤,和b)通过所述形成二硫键的半胱氨酸残基,在第一fab区中形成非天然二硫键的步骤,其中,由于所述非天然二硫键的存在,第一fab区在与第二fab区不同的位置形成二硫键。另外,本发明的其它实施方案为含有至少两个不同fab区的抗体,其中,至少一个fab区含有在cl区与ch1区之间形成非天然二硫键的半胱氨酸残基,从而形成非天然二硫键,其中,由于所述非天然二硫键的存在,fab区中的cl区与ch1区之间的二硫键的位置与至少一个其它fab区中的cl区与ch1区之间的二硫键的位置不同。在一实施方案中,上述抗体含有两个不同fab区。另外,本发明的其它实施方案为含有至少两种含fab区的抗体的组合物,所述fab区在至少两种抗体之间不同,其中,至少一个fab区含有在轻链与重链之间形成非天然二硫键的半胱氨酸残基,从而形成非天然二硫键,其中,由于所述非天然二硫键的存在,fab区中的轻链与重链之间的二硫键的位置与至少一个其它fab区中的轻链与重链之间的二硫键的位置不同。在一实施方案中,在上述组合物中,上述非天然二硫键和上述二硫键是cl区与ch1区之间的二硫键。通常,上述抗体或组合物也可通过前述抗体或组合物的制备方法制备。根据本发明,通过限制各fab区中的轻链-重链的组合,减少前述组合随机性引起的非期待组合的抗体产生量,因此,可有效率地制备含有至少两个不同fab区的抗体(含第一fab区和第二fab区的抗体);或含有至少两个含不同fab区的抗体的组合物。本发明中,通过使轻链-重链(尤其cl区-ch1区)间形成非天然二硫键,使得轻链-重链(尤其cl区-ch1区)间的二硫键的位置在两个fab区之间(第一轻链和重链与第二轻链和重链之间)不完全一致。据此,cl区-ch1区间的结合优选在各fab区为特异的。为使二硫键在两个fab区之间不完全一致,将一方的cl区-ch1区间的二硫键的一部分非天然化(一方为天然二硫键,另一方为非天然二硫键)或在与一方的非天然二硫键不同的位置使另一方形成非天然二硫键(双方均为非天然二硫键)。另外,优选在至少两个不同fab区之间ch1区-cl区间的二硫键不交叉,或优选在上述组合的交叉减少的位置形成二硫键。另外,优选第一轻链和第二重链或第二轻链和第一重链之间不形成二硫键,或优选在上述组合的交叉减少的位置形成二硫键。本发明的一实施方案为任意上述方法、抗体或组合物,其中,一个fab区中的cl区与ch1区之间的二硫键的位置与至少一个其它fab区中的cl区与ch1区之间的二硫键的位置完全不同。基于待形成的目标抗体的构象数据来确定通过取代成半胱氨酸残基而可形成非天然二硫键的氨基酸残基的位置,或形成交叉少的非天然二硫键位置。在大部分的情况,记载所需的各个原子坐标的构象数据可由proteindatabank(pdb)等公开的数据库免费获得。获得的坐标数据使得可以通过使用一般称为计算化学软件的专用软件计算构象,可以对pc显示器等仿真地进行可视化投影。另外,在大部分的情况,也以计算化学软件计算任意原子间的距离或键角度,进而结合能量等。抗体分子内存在的天然二硫键是存在于半胱氨酸残基的侧链末端的硫原子之间的共价键,并且当负责链间键时,预测侧链朝向是彼此相对的趋势。为将此反映于构象计算中,设定两个半胱氨酸残基的β碳间的距离小于其α碳间的距离的条件是适当的。例如,在人igg1抗体的轻链-重链间的链间键的情况下,在cl区的氨基酸位置214的半胱氨酸残基和ch1区的氨基酸位置220的半胱氨酸残基间所形成的二硫键中,计算上述α碳间距离(cα-cα')是上述β碳间距离(cβ-cβ')是(pdb登录:1l7i)。参照关于这些结果和关于二硫键的已知数据,例如若设定cα-cα'为以下,cβ-cβ'为以下,且β碳间距离<α碳间距离,则通过计算从存在于邻近肽链中的氨基酸残基组选出满足这些条件的氨基酸残基对,也即这些氨基酸残基对可以为对半胱氨酸残基的潜在取代候选对。作为cα-cα'和cβ-cβ'计算所使用的值并非局限于上述值,例如,可组合使用分别为以下,以下,以下,以下,以下或以下,以及以下,以下,以下,以下,以下或以下的值。另外,用于实施本发明的氨基酸残基修饰方法并非特别限定,可使用可达成目的的所有方法。通常通过改变编码目的位置氨基酸的核酸,从而通过取代·缺失·添加半胱氨酸残基而进行本发明中氨基酸残基的改变,但并不限于此,也可通过化学的修饰等进行的胱氨酸残基修饰等。另外,“取代氨基酸残基”当然包括取代编码氨基酸残基的核酸,从而导致氨基酸残基取代。在用不能形成二硫键的氨基酸残基取代半胱氨酸残基的情况下,大多所使用的是取代成丙氨酸残基或丝氨酸残基。另外,因为本发明并非受特定的cdr序列等限定,所以本发明作为对象的抗体也可具有与对于任何抗原的抗体对应的fab区。作为容易形成非天然二硫键的位置,可以例举(1)轻链116位置-重链126位置、轻链116位置-重链127位置、轻链116位置-重链128位置、轻链116位置-重链134位置、轻链116位置-重链141位置、轻链118位置-重链126位置、轻链118位置-重链127位置、轻链118位置-重链128位置、轻链118位置-重链134位置、轻链118位置-重链141位置、轻链121位置-重链126位置、轻链121位置-重链127位置、轻链121位置-重链128位置、轻链121位置-重链134位置、轻链121位置-重链141位置、轻链124位置-重链126位置、轻链124位置-重链127位置、轻链124位置-重链128位置、轻链124位置-重链134位置或轻链124位置-重链141位置,和(2)轻链162位置-重链170位置、轻链162位置-重链171位置或轻链162位置-重链173位置间,但是并不限于此。作为更具体的容易形成非天然二硫键的位置的组合,可以例举a)轻链116位置-重链134位置、b)轻链116位置-重链141位置、c)轻链118位置-重链128位置、d)轻链121位置-重链126位置、e)轻链121位置-重链127位置、f)轻链124位置-重链126位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置和i)轻链162位置-重链173位置间。这些位置所引入的半胱氨酸残基以比较接近的位置和侧链方向存在,可形成二硫键。更优选的,当轻链为λ链时,实例可包括c)轻链118位置-重链128位置、f)轻链124位置-重链126位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置和i)轻链162位置-重链173位置间,但是并不限于此。更优选通过向选自a)轻链116位置-重链134位置、b)轻链116位置-重链141位置、c)轻链118位置-重链128位置、f)轻链124位置-重链126位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置和i)轻链162位置-重链173位置中的至少一组轻链-重链位置所引入的半胱氨酸残基来形成非天然二硫键。在这些位置,更确实地,向轻链所引入的半胱氨酸残基将不与重链220位置的半胱氨酸残基交叉。当轻链为λ链时,更优选通过向f)轻链124位置-重链126位置以外的位置所引入的半胱氨酸残基来形成非天然二硫键,更优选通过向c)轻链118位置-重链128位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置或i)轻链162位置-重链173位置所引入的半胱氨酸残基来形成非天然二硫键。更优选通过向选自b)轻链116位置-重链141位置、c)轻链118位置-重链128位置、d)轻链121位置-重链126位置、e)轻链121位置-重链127位置、f)轻链124位置-重链126位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置和i)轻链162位置-重链173位置中的至少一组轻链-重链位置所引入的半胱氨酸残基来形成非天然二硫键。在这些位置,更确实地,向重链所引入的半胱氨酸残基将不与轻链214位置的半胱氨酸残基交叉。当轻链为λ链时,更优选通过向c)轻链118位置-重链128位置、f)轻链124位置-重链126位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置或i)轻链162位置-重链173位置所引入的半胱氨酸残基来形成非天然二硫键。更优选通过向选自b)轻链116位置-重链141位置、c)轻链118位置-重链128位置、f)轻链124位置-重链126位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置和i)轻链162位置-重链173位置中的至少一组轻链-重链位置所引入的半胱氨酸残基来形成非天然二硫键。更确实地,向这些位置所引入的半胱氨酸残基将不与天然二硫键交叉。当轻链为λ链时,更优选通过向f)轻链124位置-重链126位置以外的位置所引入的半胱氨酸残基来形成非天然二硫键。更优选通过向选自b)轻链116位置-重链141位置、f)轻链124位置-重链126位置、g)轻链162位置-重链170位置、h)轻链162位置-重链171位置和i)轻链162位置-重链173位置中的至少一组轻链-重链位置所引入的半胱氨酸残基来形成非天然二硫键。当向这些位置引入半胱氨酸残基以实施本发明时,可达成极佳的产率和交叉反应性。更优选地,当轻链为κ链时,通过向b)轻链116位置-重链141位置、f)轻链124位置-重链126位置或g)轻链162位置-重链170位置所引入的半胱氨酸残基来形成非天然二硫键;当轻链为λ链时,通过向h)轻链162位置-重链171位置和i)轻链162位置-重链173位置所引入的半胱氨酸残基来形成非天然二硫键。另外,就纯化的简便性而言,更优选在f)轻链124位置-重链126位置间或i)轻链162位置-重链173位置间形成非天然二硫键,最优选在f)轻链124位置-重链126位置间形成非天然二硫键。本段落的实施方案中,当轻链为λ链时,优选通过向f)轻链124位置-重链126位置以外的位置所引入的半胱氨酸残基来形成非天然二硫键。对于向上述位置引入的半胱氨酸残基,可例举半胱氨酸取代或插入至以下位置,或通过半胱氨酸取代或插入以下的氨基酸,但并不限于此。轻链(κ链):116位置(f116c)、118位置(f118c)、121位置(s121c)、124位置(q124c)、162位置(s162c)轻链(λ链):118位置(f118c)、124位置(e124c)、162位置(t162c)重链:126位置(f126c)、127位置(p127c)、128位置(l128c)、134位置(s134c)、141位置(a141c)、170位置(f170c)、171位置(p171c)、173位置(v173c)另外,本发明的进一步实施方案是上述任一种方法、抗体或组合物,其中,至少一个fab区的cl区与ch1区之间不形成天然二硫键,或至少一个fab区不含有在轻链与重链之间可形成天然二硫键的半胱氨酸残基。在此实施方案中,在至少一个fab区中不形成天然二硫键,而是仅通过非天然二硫键形成轻链与重链之间的结合。此时,其它fab区可形成天然二硫键,也可形成别的非天然二硫键。作为天然二硫键的一实例,包括但不限于轻链的氨基酸位置214的半胱氨酸残基与重链的氨基酸位置220的半胱氨酸残基之间的二硫键。上述任一实施方案的方法、抗体或组合物可以进一步是包括应用限制重链-重链间组合技术的步骤的方法,或由其制备的抗体或组合物。这类技术包括但不限于,凸起-进入-孔洞(knobs-into-holes)技术(例如美国专利第7,183,076号;wo98/50431(日本专利第4324231号))、通过静电引力的异源结合(例如wo2009/089004、wo2007/147901)、通过带电亮氨酸拉链结构的异源结合(例如wo2011/034605)、通过轻链重链交换表达的有效率的生产法(例如wo2009/0802513)、通过蛋白质a亲和层析法纯化(wo2010/151792)。这些技术的任一项也可与本发明组合使用,在这种情况下,其也包含在本发明的技术范围内。使这些技术与本发明组合时,将可极有效率地制备轻链-重链和重链-重链限制的抗体或组合物(例如多特异性抗体)。另外,本发明的进一步实施方案是上述任一种实施方案的方法、抗体或组合物,其中抗体为多特异性抗体(尤其双特异性抗体)。作为多特异性抗体的制备方法,已知有杂交-杂交瘤技术(milstein和cuello,nature305;537-539(1983))。在此方法中,因为免疫球蛋白的轻链和重链随机组合,所以在双特异性抗体的情况下,这些融合瘤(四源杂交瘤(quadroma))具有产生10种不同抗体分子的混合物的可能性。这些中仅1种具有正确的双特异性结构,所以通过此方法所需的多特异性抗体的产率低(参照图1)。另外,当使用亲和层析等纯化所需的多特异性抗体时,不容易提高一般所需的多特异性抗体的纯度。另外,在多特异性抗体的制备中,虽已知几种以克服因轻链和重链的随机组合而引起的困难为目的的技术,但其大多限制重链-重链间的结合。相比之下,本发明涉及通过使二硫键变化来限制轻链-重链间结合的方法,通过与现有的改良技术不同的机制,可有效率地制备多特异性抗体。因此,也可与限制重链-重链间结合的方法等的现有技术组合使用,此时,将可更有效率地制备多特异性抗体。另外,本发明的进一步实施方案为任一上述方法、抗体或组合物,其中,抗体是通过至少两个抗体片段的接头连接或直接连接的抗体。另外,本发明的进一步实施方案为任一上述方法、抗体或组合物,其中,抗体为抗体片段。当应用本发明以制备单一抗体片段时,优选含有2对以上轻链部分与重链部分的组合的抗体片段,这类抗体片段包括但不限于f(ab')2。另外,当应用本发明以制备含抗体片段的组合物时,优选含有1对以上轻链部分和重链部分的组合的抗体的组合物,这类组合物包括但不限于含fv、fab、f(ab')2的组合物。通过抗体作为抗体片段,使得其生产率优秀,且对表达靶分子的组织或病灶部位的迁移/浸润优秀。另外,本发明的进一步实施方案是上述任一实施方案的方法、抗体或抗体组合物,其中,抗体的fc区被其它分子取代。当本发明的对象为抗体时,抗体可具有fc区,此外,在不违反本发明目的的范围内,fc区可采取任何结构。换言之,本发明的抗体中不仅包括具有突变的fc区的抗体,也包括fc区被正常fc区以外的分子所取代的广义的抗体分子。因抗体的用途/目的,也已知可使用许多分子作为取代分子,实例可包括例如多核苷酸、核苷酸、多肽、肽、聚乙二醇、氨基酸(例如甘氨酸、组氨酸等)、糖链、低分子量化合物、脂质、磷脂质(例如卵磷酯等)、维生素(例如生物素)和酶。另外,本发明的进一步实施方案是上述任一实施方案的方法、抗体或抗体组合物,其中,抗体为igg1、igg2、igg3、igg4或igm抗体。另外,本发明的进一步实施方案是上述任一实施方案的方法、抗体或抗体组合物,其中,抗体的轻链为κ链。本发明的进一步实施方案是上述任一实施方案的方法、抗体或抗体组合物,其中,抗体为嵌合抗体、人源化抗体或人抗体。在不损害发明功效的范围内,嵌合抗体、人源化抗体或人抗体可为前述嵌合抗体、人源化抗体或人抗体中任一种。抗体优选为人抗体。通过作为人抗体,起到降低抗原性和改善体内动力学的功效。另外,通过以人抗体为对象,也可最大极限地应用本说明书所记载的信息。本发明的进一步实施方案是上述任一实施方案的方法,其中,宿主细胞为真核细胞或大肠杆菌。因为本发明并不涉及依赖宿主细胞的方法,所以可使用适合制备抗体的任何宿主细胞,但是作为制备抗体常用的宿主细胞,可适合使用真核细胞或大肠杆菌。真核细胞包括但不限于,例如来自于酵母、真菌、昆虫、植物、动物、人或其它的多细胞生物的有核细胞。抗体的一般制备方法如下简述。上述任一实施方案的方法可还包括一个或多个以下详述的步骤或实施方案。(1)免疫通过将所得的抗原给予哺乳动物进行免疫。抗原也可与佐剂混合使用。作为哺乳动物,适合使用小鼠,更适合使用balb/c小鼠。对相同的哺乳动物可进行单次或多次免疫。(2)筛选依据常规方法从脾细胞制备融合瘤,并且以抗体效价等所需活性为指标进行筛选。也可在得到脾细胞之前,以免疫的哺乳动物单位,以血清抗体效价等血清活性为指标进行筛选。优选使用elisa进行筛选。(3)大量制备将筛选选出的融合瘤给予至小鼠腹腔而产生腹水,收集该含抗体的腹水进行纯化以得到抗体。优选地,使用scid小鼠作为小鼠。对于纯化,优选使用层析法,更优选亲和层析法,例如蛋白质g亲和层析法。(4)重组生产关于筛选所得的抗体,通过从产生该抗体的融合瘤获得cdna等,可在其它细胞制备重组体,这类实施方案也包含在上述制备方法中。使用所得的cdna,在其它细胞中制备重组体的方法的详细内容将在后面描述。本发明的一实施方案是编码上述任一实施方案的抗体的核酸。核酸优选为dna。可通过常规方法对上述任一实施方案的核酸进行分离和测序。例如可使用设计以特异地扩增轻链和/或重链等的寡核苷酸引物而进行测序,但并不限于此。另外,为使分离的核酸克隆和表达,可将其基因转移到原核或真核细胞。这类步骤可参照例如molecularcloning:alaboratorymanual(cshlpress)、currentprotocolsinmolecularbiology(johnwiley&sons,inc.)、antibodyengineering(springer);antibodies:alaboratorymanual(cshlpress)。另外,本发明的一实施方案是含有上述任一实施方案的核酸的载体。通常,可通过常规方法将分离的上述任一实施方案的核酸插入到载体而得到此载体。载体优选为可复制的载体,更优选为具有启动子的载体(表达载体)。通常,载体包含但不限于信号序列、复制起点、一个或多个选择基因、启动子、增强子元件、和终止子序列中的一个或多个组件。对于各组件,描述如下。(1)信号序列不仅可以通过直接重组方法生产目的多肽,作为与信号序列等的融合肽也可以生产目的多肽。信号序列是被宿主细胞识别和加工(即,通过信号肽酶切割)的序列。在原核生物宿主细胞中,可使用例如碱性磷酸酶、青霉素酶、ipp或热稳定的肠毒素ii先导序列等的原核生物信号序列作为信号序列。在酵母中,可使用例如酵母转化酶先导序列、α因子先导序列、酸性磷酸酶先导序列或葡糖糖化酶先导序列、或wo90/13646所记载的信号等作为信号序列。在哺乳动物细胞中,可使用例如单纯疱疹gd信号等的病毒分泌先导序列或哺乳动物的信号序列。(2)复制起点许多载体(例如表达载体和克隆载体)包含使得在一个或多个选择的宿主细胞中可以复制载体的核酸序列。一般,克隆载体中,此序列使载体与宿主染色体dna分开复制,并含复制起点或自主复制序列。对于许多细菌、酵母和病毒,这类序列是公知的。来自质粒pbr322的复制起点适合于大部分的革兰氏阴性细菌,2μ质粒起点适合于酵母,各种病毒起点(sv40、多瘤病毒、腺病毒、vsv、bpv等)对于哺乳动物细胞中的克隆载体有用。一般,哺乳动物的表达载体不需要复制起点(实际上,在许多情况下通常使用sv40起点(作为启动子))。(3)选择基因许多载体(例如表达载体和克隆载体)通常含有也被称为选择标记的选择基因。作为典型的选择基因包括(a)提供对如氨苄青霉素、新霉素、甲氨蝶呤或四环素那样的抗生素或其它毒素的耐性的基因、(b)弥补营养缺陷性的基因、或(c)供给不能从(特定的)培养基得到的重要营养素的基因(例如对芽孢杆菌而言的d-丙氨酸消旋酶)。(4)启动子许多载体(例如表达载体和克隆载体)一般包含被宿主生物体所识别、在编码目的多肽的核酸上游的启动子。作为适合原核生物宿主使用的启动子,包括phoa启动子、β-内酰胺酶和乳糖启动子、碱性磷酸酶、色氨酸(trp)启动子、和融合瘤启动子(例如tac启动子)。但是,其它细菌启动子也适合。例如细菌系统所使用的载体包含编码多肽的核酸上游的夏因-达尔加诺(s.d.)序列。另外,对于真核生物,也已知其启动子序列。基本上所有的真核生物基因具有自转录起始位点上游约25至30个碱基所发现的富at区。许多基因的自转录起始位点上游约70至80个碱基所发现的其它序列是n为任意核苷酸的cncaat区。大部分真核生物基因的3'端具有aataaa序列,其是向mrna的3'端添加polya的信号。这些序列可适当地插入到真核生物的表达载体。(5)增强子元件可通过在载体中插入增强子序列而屡屡增强dna的转录。现在已知来自哺乳动物基因的许多增强子序列(珠蛋白、弹性蛋白酶、白蛋白、α-胎儿蛋白和胰岛素)。然而,通常,多使用来自真核细胞病毒的增强子。例如,复制起点之后期侧的sv40增强子(100-270碱基对)、巨细胞病毒初期启动子增强子、复制起点之后期侧的多瘤病毒增强子和腺病毒增强子(也参见yaniv,nature,297:17-18(1982))。增强子可插入载体中多肽编码序列的5'或3'位置,但优选位于5'位置。(6)终止子序列真核生物宿主细胞(来自酵母、真菌、昆虫、植物、动物、人或其它多细胞生物的有核细胞)所使用的许多载体(例如表达载体)可含终止转录和稳定mrna所需的序列。这类序列一般可自真核生物或病毒的dna或cdna的5',有时是3'的非翻译区获得。关于这些区,编码多肽的mrna的非翻译部分包括作为多腺苷酸化片段转录的核苷酸片段。一个有效的终止子序列是牛生长激素多腺苷酸化区(例如参见wo94/11026)。通常,通过向不产生抗体的宿主细胞(例如大肠杆菌细胞、猴cos细胞、中国仓鼠卵巢(cho)细胞、或骨髓瘤细胞)转导上述任一实施方案的核酸,并通过在适当的营养培养基中进行培养,从而也可生产由该核酸所编码的抗体(例如参见skerra等,curr.opinioninimmunol.,5:256-262(1993);pluckthun,immunol.revs.130:151-188(1992))。之后,例如通过将抗体从宿主细胞糊分离至可溶性部分并纯化(例如根据同种型使用蛋白质a或g柱),可制备抗体。可在各种培养基培养宿主细胞。市售培养基,例如hamf10(sigma)、mem(sigma)、rpmi-1640(sigma)和dmem(sigma)适用于培养宿主细胞。根据需要,可向这些培养基补充激素和/或其它生长因子(例如胰岛素、运铁蛋白、上皮生长因子)、盐类(例如氯化钠、钙、镁、磷酸盐)、缓冲剂(例如hepes)、核苷酸(例如腺苷、胸苷)、抗生素(例如庆大霉素)、微量元素(最终浓度以微摩尔范围通常存在的无机化合物等)和葡萄糖或等效的能源。还可含有本领域技术人员已知的适当浓度的其它必要的补充物质。关于各宿主细胞的适合的培养条件,例如温度、ph等对于本领域技术人员是清楚的,或在简单的条件讨论范围内。当使用重组技术时,抗体在细胞内、周质空间所产生、或直接分泌到培养基中。当抗体在细胞内产生时,第1步骤是通过例如离心分离或超滤去除不需要物质(细胞碎片等)。carter等,bio/technology(ny)10:163-167(1992)记载了分泌到大肠杆菌的周质空间的抗体的分离方法。简言之,在醋酸钠(ph3.5)、edta和苯甲基磺酰氟(pmsf)的存在下,将细胞糊进行冷解冻约30分钟。可以通过离心分离去除细胞碎片。当抗体分泌到培养基中时,一般使用蛋白质浓缩过滤器(例如amicon或pellicon的超滤过滤器)来浓缩来自这类表达系统的上清液。通过在上述的任意步骤包含pmsf等的蛋白酶抑制剂,可抑制抗体降解,并且可使用抗生素防止外来性污染生物的生长。可使用例如羟磷灰石层析、疏水性相互作用层析、凝胶电泳、透析和亲和层析来纯化从细胞制备的抗体组合物。通常,亲和层析为优选的纯化步骤。作为亲和层析的蛋白质a/g的适合性取决于抗体中存在的免疫球蛋白fc区的种类和同种型。蛋白质a可用于纯化基于人γ1、γ2、或γ4重链的抗体(例如参见lindmark等,j.immunol.methods.62:1-13(1983))。蛋白质g可适用于含有所有小鼠同种型和人γ3的所有人γ重链(例如参见guss等,emboj.5:1567-1575(1986))。亲和配体所结合的最常见的基质为琼脂糖,但也可使用其它材料。孔控制玻璃或聚(苯乙烯二乙烯)苯等的机械上稳定的基质可比琼脂糖达成更快流速和更短处理时间。当抗体含ch3结构域时,bakerbondabx树脂(j.t.baker,phillipsburg,nj)可用于纯化。根据待收集的抗体,也可使用利用离子交换柱、乙醇沉淀、反相hplc、二氧化硅层析、肝素层析、层析聚焦、sds-page、和硫酸铵沉淀法。在上述预纯化步骤后,使含目标抗体和混入物的混合溶液接受使用ph约2.5-4.5,优选使用了低盐浓度(例如约0-0.25mnacl)的洗脱缓冲液的低ph疏水性相互作用层析。[其它实施方案]上述任一实施方案的抗体可任选地与药学上可接受的载体等一起制成组合物或制剂等。另外,上述任一实施方案的抗体可应用于一般抗体所使用的各种用途。提供多特异性抗体所使用的代表性用途的实例如下。[检测/诊断]多特异性抗体可有效地用于竞争性结合测定、直接和间接三明治测定法和免疫沉淀法等的已知测定法。另外,也可使用多特异性抗体以固定在酶免疫测定中所使用的酶。通过设计多特异性抗体的一个fab区与不发生酶抑制的酶表面的特定表位结合,并将其它fab区与在所需部位中确保高酶密度的固定化基质结合,可高敏感度地进行酶免疫测定。多特异性抗体还可用于肿瘤等各种疾病的体内免疫诊断或体外免疫诊断(songsivilai等,clin.exp.immunol.79:315-321(1990))。在这种情况下,多特异性抗体的一个fab区可与肿瘤相关抗原结合,其它fab区可与可检测与放射性核素结合的螯合剂等的标记结合。[疾病治疗]通过提供与靶细胞(例如特定器官等)结合的一个fab区以及与药物等(低分子量药物、多肽等)结合的其它fab区,以通过递送靶细胞特异性的药物,可将多特异性抗体用于治疗上。另外,通过提供与靶标(例如病原体或肿瘤细胞)结合的一个fab区以及与t细胞受体或fcγ受体等的细胞毒性诱导因子结合的其它fab区,以通过限定细胞毒性的靶标,可将多特异性抗体用于治疗上。在这种情况下,使用多特异性抗体,可使靶标的细胞性免疫防御机制特异地针对肿瘤细胞或感染性病原体。另外,通过提供与靶标(例如病原体或肿瘤细胞)上的某抗原(例如膜蛋白质、受体蛋白质等)结合的一个fab区以及与同一靶标或同一类型靶标上的其它抗原结合的其它fab区,以通过改变细胞毒性强度(例如adcc增强、诱导细胞凋亡等),可将多特异性抗体用于治疗上。另外,多特异性抗体可作为纤维蛋白溶剂或疫苗佐剂使用。进而,这些抗体可用于治疗感染性疾病(例如将效应细胞靶向被hiv病毒或流感病毒等病毒的细胞或鼠弓形体等的原生动物感染的细胞),或可用于将免疫毒素递送到肿瘤细胞,或可用于使免疫复合体靶向细胞表面受体。上文对本发明的实施方案进行描述,这些是本发明示例性的,也可采用上述以外的各种结构。例如在体外化学交联具有满足本发明条件的结构的多肽链时,或想增加特定的轻链-重链间结合时(制备多特异性抗体时)等,本发明也适用,这类方法也包括在本发明的实施方案中。实施例以下通过实施例说明本发明,但这些实施例并非限定本发明。另外,实施例中提及的市售试剂,若不特别指出,则依据制造商的使用说明或常规方法使用。在本实施例中,首先显示引入非天然二硫键(cys1m)的突变体在分子量和功能上与野生型抗体等同。其次,其显示非天然二硫键具有高结合选择性,即不与天然二硫键交叉。最后,基于各种分析结果证明通过利用cyslm,可简便地制备作为igg型的完全形态的双特异性抗体。实施例1[表达载体的构建]将市售的表达载体pcdna3.1(+)(invitrogen公司)用作表达各种抗体分子的载体。在一个载体上,串联配置轻链的表达单位(启动子、目的基因、polya序列)和重链的表达单位(同),使得以单一载体的基因转移可表达抗体。使用的启动子和克隆而得到的cdna的碱基序列如图2和图3所示,转录产物的氨基酸序列如图4所示。(i-i)非天然二硫键引入位点的搜索使用chemicalcomputinggroup公司的计算化学软件“moe”进行结构搜索。proteindatabank(pdb)内的人fab的构象数据中,轻链为κ链的igg1抗体的初期结构使用重链为γ1型且轻链为κ型,分辨度最高为的pdbid:1l71的数据,轻链为λ型的igg1抗体的初期结构使用重链为γ1型且轻链为λ型,分辨度最高为的pdbid:2fb4的数据。当引入新的二硫键时,突变起点的残基彼此的α碳间距离以及β碳间距离在某程度接近是重要的报告(sowdhaminir,等,proteineng.,95-103,1989),搜索对于κ链α碳间距离为以下,β碳间距离为以下的残基对,对于λ链α碳间距离为以下,β碳间距离为以下的残基对。(i-ii)人轻链基因的获得使用来自健康人(成人)的末梢血白血球的rna而制备的cdna基因库(biochain公司,c1234148-10)为模板,进行pcr克隆而得到人κ型轻链基因。该过程的pcr引物参照genbank登录号:j00241而设计(图2的序列p01和p02)。另外,为容易进行克隆,预先使两个引物之间包含限制酶位点。将pcr产物克隆进克隆载体(pbluescriptii等)后,验证碱基序列,选出两识别序列间的序列与j00241相同的克隆(野生型:图3的序列n01、图4的序列a01)。克隆含有连接于上述序列上游部分的分泌信号序列(与抗dr5抗体的序列一致)的轻链可变区的基因(抗cd20抗体、抗cd37抗体或抗dr5抗体),将其与已经克隆的κ链恒定区以此顺序连接,配置在表达载体的启动子的下游。以与人κ型轻链基因相同的步骤得到人λ型轻链基因。该过程的pcr引物参照genbank登录号:j00252而设计(图2的序列p03和p04)。另外,为使容易克隆,预先使两个引物之间包含限制酶位点。将pcr产物克隆进克隆载体(pbluescriptii等)后,验证碱基序列,选出两识别序列间的序列与j00252相同的克隆。以克隆此λ链恒定区的载体为模板,使用设计轻链可变区与λ链恒定区连接的有义引物(图2的序列p05)和λ链恒定区c端的反义引物(图2的序列p04),再次进行pcr,得到用于连接可变区的λ链恒定区(野生型:图3的序列n02、图4的序列a02)。克隆含有连接于上述序列上游部分的分泌信号序列(与抗dr5抗体的序列一致)的轻链可变区的基因(抗cd20抗体),将其与用于连接可变区的λ链恒定区以此顺序连接,配置在表达载体中启动子的下游。(i-iii)人igg1基因的获得以从健康人(成人)的末梢血白血球提取的rna为材料合成cdna后,进行pcr克隆而得到人igg1重链恒定区(ch1区-ch3区)的基因。该过程的pcr引物参照genbank登录号:j00228而设计(图2的序列p06和p07)。另外,为容易进行克隆,预先使两个引物之间包含限制酶位点。将pcr产物克隆进克隆载体(pbluescriptii等)后,验证碱基序列,选出两识别序列间的序列与j00228相同的克隆(野生型:图3的序列n03、图4的序列a03)。克隆含有连接于上述序列上游部分的分泌信号序列的重链可变区的基因(抗cd20抗体、抗cd37抗体或抗dr5抗体),将其与经克隆的重链恒定区以此顺序连接,配置在表达载体中启动子的下游。(i-iv)非天然二硫键结合抗体表达载体的获得为使轻链-重链间的天然二硫键无效化,同时用ser取代负责的cys(轻链:c214s,重链:c220s)。对于κ型轻链,设计具有c214s突变的有义引物(图2的序列p08)和反义引物(图2的序列p09),适当组合使用在这些的上游侧设计的用于引入cys突变的各种引物(图2的序列p10-p18)、在最上游设计的来自载体序列的有义引物(图2的序列p19)和在最下游设计的来自载体序列的反义引物(图2的序列p20),以人κ型轻链基因(野生型)为模板进行pcr,得到作为目标的引入突变的基因片段群。适当地通过pcr连接它们,进行克隆之后,验证序列(图3的序列n04-n08,图4的序列a04-a08)。接着,将各个与表达载体上的野生型基因的同源区域交换,得到作为目标的引入突变的轻链基因群。对于λ型轻链,设计具有c214s突变的反义引物(图2的序列p21),适当组合使用在这些的上游侧设计的用于引入cys突变的各种引物(图2的序列p22-p26)、和在最上游设计的有义引物(图2的序列p05),以人λ型轻链基因(野生型)为模板进行pcr,得到作为目标的引入突变的基因片段群。适当地通过pcr连接它们,进行克隆之后,验证序列(图3的序列n09-n11,图4的序列a09-a11)。接着,将各个与表达载体上的野生型基因的同源区域交换,得到作为目标的引入突变的轻链基因群。在重链中,使用具有c220s突变的有义引物(图2的序列p27)、反义引物(图2的序列p28)、用于引入cys突变的各种引物(图2的序列p29-p43)、在最上游侧设计的来自抗cd20抗体的重链可变区的序列的有义引物和在最下游设计的来自ch2结构域的序列的反义引物(图2的序列p44),以人igg1基因为模板进行pcr,得到作为目标的引入突变的基因片段群。适当地通过pcr连接它们并进行克隆之后,验证序列(图3和图4的序列n12-n19和a12-a19)。接着,将各个与表达载体上的野生型基因的同源区域交换,得到作为目标的引入突变的重链基因群。(i-v)蛋白质a亲和性缺失型抗体表达载体的获得当制备双特异性抗体时,将一个重链设计为蛋白质a结合能力缺失,从而可以以蛋白质a结合能力的差异为指标而简便且有效地纯化不同序列的重链彼此结合的分子(杂合体)。换言之,将igg1上的负责残基h435和y436,取代成不具有蛋白质a结合能力的igg3型残基(h435r/y436f)。已经验证由野生型重链(记为[1])和该突变体重链(记为[3])组成的杂合体([1]/[3])呈现在野生型纯合体([1]/[1])和突变体纯合体([3]/[3])中间的蛋白质a结合能力,并且因此,可在使用了蛋白质a柱的亲和层析中分别纯化三者。参照对于人igg3型重链的genbank登录号:x03604,设计具有h435r/y436f突变的有义引物(图2的序列p45)和反义引物(图2的序列p46)。使用这些与来自载体序列的有义引物(图2的序列p19)和反义引物(图2的序列p47),以人igg1重链恒定区基因为模板进行pcr,得到突变上游的基因片段和突变下游的基因片段。使两片段以pcr连接。进而,以此为模板,使用上游和下游引物(图2的序列p19、p47)进行pcr,得到作为目标的基因片段后,进行克隆,验证序列(图3的序列n20,图4的序列a20)。接着,经过限制酶处理,在制备sacii-xhol片段后,将其与表达载体上的野生型基因的同源区交换,得到表达作为目标的引入突变的重链基因的载体。[各种抗体的表达与纯化](ii-i)基因转移使用市售试剂组,以基因转移质量纯化各种表达载体后,使用293fectin(invitrogen,12347-019),依照厂商说明书,向freestyle293-f细胞(invitrogen公司,r790-07)导入基因。(ii-ii)通过亲和层析纯化当从培养物上清液纯化亲本抗体(成为形成多特异性抗体基础的各个抗体)等时,使用hitrapprotein-ahp柱或hitrapprotein-ghp柱(gehealthcarebio-sciences公司),依照厂商说明书,进行大量纯化。将所得的纯化部分对pbs-t(10mmna2hpo4,150mmnacl,0.07%的tween-80,ph7.0)进行透析,于4℃保存直至使用。(ii-iii)通过强阳离子交换层析,纯化双特异性抗体使用强阳离子交换柱pl-scx(polymerlaboratories公司,)。于移动相溶液a(10mmmes,ph6.0)、移动相溶液b(500mmnacl的10mmmes,ph6.0)和流速1ml/min,将移动相溶液b的混合率为2%的初始移动相以柱体积换算5倍量以上递送,从而预先平衡柱。加载0.2-1mg的以蛋白质a亲和层析纯化的弱结合部分(重链[1][3]型杂合体=双特异性抗体)(0分钟),并使其与柱静电结合。以上述初始移动相洗涤5分钟后(0→5分钟),将溶液b的混合率以0.8%/分钟增加的直线梯度洗脱47.5分钟(5→52.5分钟,2→40%),按顺序进行结合成分的收集。之后,立即使溶液b混合率为100%,进行柱洗涤。其间,记录在280nm中的吸收,监测蛋白质的洗脱行为。根据需要,使回收的双特异性抗体(主峰)对pbs-t(ph7.0)进行透析,于4℃保存。[抗体的特性分析](iii-i)sds-page在非还原条件下以下述步骤进行sds-page,以验证已纯化的双特异性抗体具有设计的分子量。另外,由该结果也验证了轻链-重链间的结合限定的状态。使用样品处理溶液(cosmobio制造,423420:trissds样品处理溶液等)使各样品形成sds复合物之后,在含有sds的非还原条件下使用具有适当丙烯酰胺浓度的预制凝胶(marisol制造,gm-1020-3n:长生10-20%等)进行电泳。接着,以一般所使用的染色方法对凝胶进行染色,例如使用考马斯亮蓝r250溶液染色,以进行蛋白质条带的可视化。(iii-ii)f(ab')2分析因为双特异性抗体同时具有来自两个亲本抗体的两种fab,所以当从其制备f(ab')2时,其具有呈现两个亲本抗体的性质之间的中间性质的物理化学特征。为验证其结构上确实是双特异性的,使用已纯化的双特异性抗体,按以下述步骤进行胃蛋白酶处理和f(ab')2分析。将50μg的已纯化的双特异性抗体(无透析处理)溶解于含0.07%tween-80的30mm醋酸钠(ph4.0),以获得约10μg/100μl的最终浓度,向每50μg底物添加8.5u的用0.2m醋酸钠(ph4.0)溶胀的固相化胃蛋白酶(sigma公司,来自猪胃粘膜的胃蛋白酶-琼脂糖等)。将其在37℃下以120rpm振荡1小时,以发生切割反应后,以离心分离型过滤器(宝酒造公司制,9040:suprec-01等)处理,收集过滤液。立即添加30%体积量的2.5mtris-hcl(ph8.0)并搅拌,以中和反应溶液。接着,使用向移动相溶液a添加了0.07%的tween-80的缓冲液,该移动相溶液a在使用了强阳离子交换管柱pl-scx的hplc中,进行透析或脱盐柱处理,然后依照上述(ii-iii)通过强阳离子交换层析进行分析。(iii-iii)fab分析因为双特异性抗体同时具有来自两个亲本抗体的两种fab,所以当从其制备fab时,其具有所检测到的来自两个亲本抗体的两种fab的物理化学特征。为验证其结构上确实是双特异性的,使用已纯化的双特异性抗体,按下述步骤进行木瓜酶处理和fab分析。将60μg的已纯化的双特异性抗体溶解于200μl的pbs-t(ph7.0)后,向每60μg底物添加0.12u的以30μl的1mtris-40mmedta(ph7.4)、30μl的10mm半胱氨酸、和0.1mtris-4mmedta(ph7.4)溶胀的固相化木瓜酶(sigma公司,p-4406:papainagarosefrompapayalatex等)。将其以pbs-t(ph7.0)稀释至300μl后,在37℃下以120rpm振荡16小时,发生切割反应。接着,与上述(iii-ii)同样地,以离心分离型过滤器处理混合物并收集过滤液,然后通过透析或脱盐柱处理进行缓冲液交换,依照上述(ii-iii)通过强阳离子交换层析进行分析。(iii-iv)抗原结合能力分析因为双特异性抗体同时具有来自两个亲本抗体的两种fab,所以其具有可结合于表达对应抗原的靶细胞双方的生物学特征。为验证其结构上确实是双特异性的,使用已纯化的双特异性抗体,按下述步骤进行结合能力分析。将靶细胞以2×105细胞/孔接种于96孔板后,添加50μl的溶解于pbs的各浓度的双特异性抗体样品,使细胞分散,该pbs含5%的fbs(5%fbs/pbs)。在冰上进行反应30分钟后,以200μl的5%fbs/pbs洗涤细胞2次。接着,添加50μl的以5%fbs/pbs稀释的藻红蛋白(pe)标示的抗人iggfc抗体(例如rockland公司,709-1817,稀释100倍),再次使细胞分散。在冰上进行反应30分钟后,与先前同样地洗涤细胞2次。最后使其分散于200μl的1%福尔马林后,以流式细胞仪测量各个靶细胞呈现的荧光量,算出平均荧光强度(mfi)。[选择引入非天然二硫键的突变体候补]以计算化学软件“moe”搜索的结果,在κ链中除了具有与存在于野生型抗体的既有cys残基形成二硫键的可能性高的1组以外,发现了9组可引入非天然二硫键的残基对候补。这些位置、α碳间距离(cα-cα')和β碳间距离(cβ-cβ')如表3所示。另外,在λ链中,发现了5组可引入非天然二硫键的残基对候补。这些位置、α碳间距离(cα-cα')和β碳间距离(cβ-cβ')如表4所示。另外,轻链为λ链的氨基酸残基的编码通过与κ链的序列比对而确定。非天然二硫键引入位置的搜索结果列表表3表4表3记载的各突变被实际表达并验证是否在轻链-重链间形成非天然二硫键。向表达载体上的野生型抗cd20抗体基因和野生型抗cd37抗体基因单独引入表3记载的cys1m(a)-(i)的各突变后,使其分别基因转移至freestyle293-f细胞并表达,以hitrap蛋白质a柱简单纯化来自该培养物上清液的抗体成分。使它们接受sds-page的结果如图5和图6所示。在除cys1m(e)以外的突变体中,在显示与野生型同等分子量的约150kda的位置观察到主要条带。另外,表4记载的各突变也被实际表达并验证是否在轻链-重链间形成非天然二硫键。向表达载体上的野生型抗cd20抗体的cl区的基因移植入λ1型cl基因,以形成λ1型cl基因表达载体。向该λ1型cl基因表达载体单独引入表4记载的cys1m(j)-(n)的各突变后,与上述同样地使其基因转移至freestyle293-f细胞并表达,以hitrap蛋白质a柱简单纯化来自该培养物上清液的抗体成分。使它们接受sds-page的结果如图7所示。在所有突变体中,在与野生型同等分子量的约150kda的位置观察到主要条带。因此,验证了通过引入cys1m突变可在轻链-重链间形成非天然二硫键,并且可适用而不依赖抗体的轻链亚型。另一方面,向表达载体上的野生型抗her2抗体基因、抗egfr抗体基因和抗cd52抗体基因引入表3记载的cys1m(f)突变后,与上述同样地使其基因转移至freestyle293-f细胞并表达,以hitrap蛋白质a柱简单纯化来自该培养上清液的抗体成分,使它们接受sds-page。结果如图8所示。在示出引入cys1m(f)型突变的任一抗体都与野生型具有同等分子量的约150kda的位置观察到主要条带,验证了引入cys1m突变可适用而不依赖抗体的可变区的序列。接着,验证轻链或重链的各突变是否不与天然的轻链或重链形成二硫键。向表达载体上的野生型抗cd20抗体的轻链基因或重链基因中任一方引入上述突变,将它们与上述同样地进行表达实验与用以验证的sds-page分析。向轻链引入突变的sds-page的结果如图9和图10所示。在除了κ链s121c(cys1m(d)和(e)中使用)和λ链e124c(cys1m(k)中使用)以外的轻链突变中,在被认为是重链二聚体和轻链的位置观察到条带,在与野生型同等分子量的约150kda的位置未见到主要条带。另一方面,向重链引入突变的sds-page的结果如图10和图11所示。在除了重链s134c(cys1m(a)中使用)以外的重链突变体中,在被认为是轻链的单体、以及重链二聚体和单体的位置观察到条带,在与野生型同等分子量的约150kda的位置未见到主要条带。因此,说明轻链或重链的各突变体不与天然的轻链或重链形成二硫键。最后,验证了引入恒定区的非天然二硫键是否影响抗原结合能力。使用以hitrap蛋白质a柱简单纯化的cys1m型抗cd20抗体,调查对于表达cd20抗原的ramos细胞的抗原结合能力的结果如图12-16所示。cys1m(a)-(n)突变体的抗原结合能力与野生型抗体(wt)的抗原结合能力几乎未见有差异。另外,对具有非天然二硫键的抗cd37抗体(cys1m型抗cd37抗体),使用表达cd37抗原的ramos细胞,与抗cd20抗体的实验同样地调查cys1m(a)-(i)突变体的抗原结合能力,显示与抗cd20抗体同样的结果(图17-19)。综合以上结果,上述实验中形成非天然二硫键的半胱氨酸残基与天然二硫键具有较少交叉,具有高结合选择性。另外,引入的非天然二硫键对抗原结合能力无影响。[双特异性抗体的制备]作为用于表达实验的具有非天然二硫键的抗cd20抗体(αcd20)的组合配偶体,使用抗dr5抗体(αdr5)和抗cd37抗体(αcd37)以制备双特异性抗体。实例使用的cys1m是(b)、(c)、(f)、(g)和(h)5种,并将其引入αcd20。将用于纯化重链杂合体([1][3]偶联物)的蛋白质a亲和性缺失突变引入到αdr5、αcd37或αcd20(记为[3])。制备双特异性抗体αcd20(cys1m)/αdr5时的蛋白质a亲和层析的结果如图20所示。刚加载后的洗涤中观察到的最初大峰是不能结合于蛋白质a的重链[3][3]型纯合体(对应于αdr5)。通过后续的洗脱操作,回收了35-40分钟附近的弱结合性的重链[1][3]型杂合体(对应于αcd20(cys1m)/αdr5,双特异性抗体),接着回收了55-60分钟附近的强结合性的重链[1][1]型纯合体(对应于αcd20)。引入任一非天然二硫键的突变体均具有与野生型(wt)相同的洗脱图谱,引入的突变对该纯化方法不造成不良影响。在相同组合中,即使是向αcd20引入了蛋白质a亲和性缺失突变[3]的αdr5/αcd20(cys1m)的情况,也同样地洗脱成为3个峰(未公开资料)。对于作为另一组合的双特异性抗体αcd20(cys1m)/αcd37的组合也进行同样的实验时,同样地洗脱成为3个峰,从洗脱时间最早的开始,分别对应于αcd37(重链[3][3]型纯合体)、αcd20(cys1m)/αcd37(重链[1][3]型杂合体)、αcd20(重链[1][1]型纯合体)。在各个情况下收集重链[1][3]型杂合体(双特异性抗体)部分,进行缓冲液交换,然后接受强阳离子交换层析,并收集其主要峰。再次进行缓冲液交换,获得双特异性抗体的最终纯化产物。[双特异性抗体的品质验证]可同时结合于两种不同抗原的双特异性抗体同时具有来自可识别各个抗原的两种亲本抗体的fab,所以在其f(ab')2分析中,理论上,在从两个亲本抗体制备的f(ab')2的情况下的洗脱时间之间可检测出1个峰。以胃蛋白酶处理已纯化的双特异性抗体αcd20(cys1m)/αdr5,f(ab')2分析结果如图21所示。在本样品中,在33分钟附近观察到主要峰,这相当于双特异性抗体的f(ab')2。其洗脱时间在图22所示的单独分析的亲本抗体αdr5(30分钟)和αcd20(36分钟)的洗脱时间之间。在作为另一组合的双特异性抗体αcd20(cys1m)/αcd37情况下的结果如图23所示。该组合在超过30分钟时见有f(ab')2的峰。该组合也与先前同样,是在亲本抗体αcd37(25分钟)和αcd20(36分钟)的洗脱时间之间(图24)。可同时结合于两种不同抗原的双特异性抗体同时具有来自可识别各个抗原的两种亲本抗体的fab,所以在其fab分析中,将在分别与从两亲本抗体制备的fab相同的洗脱时间检测到2个峰。以木瓜酶处理已纯化的双特异性抗体αcd20(cys1m)/αdr5,fab分析结果如图25所示。在各样品共同的18分钟附近的峰是通过木瓜酶切割而产生的fc。另一方面,25.5分钟附近的峰是αdr5特异的fab,29-30分钟的峰是αcd20特异的fab(图26)。根据另外制备的强制使轻链错误结合的抗体样品的分析结果,该组合中的轻链错配体的fab在αdr5(轻链)-αcd20(重链)的情况下在22分钟附近洗脱,另一方面,在αcd20(轻链)-αdr5(重链)的情况下在37分钟附近洗脱(图26)。在3种本纯化样品中完全未检测出来自这些错误结合的fab等的杂质的峰。双特异性抗体αcd20(cys1m)/αcd37的fab分析结果如图27所示。另外,分析各个亲本抗体的结果如图27所示。任一双特异性抗体样品均具有与上述同样的结果。换言之,在18分钟附近检测出fc的峰,并且在23分钟附近检测出αcd37的fab的峰,在29-30分钟附近检测出αcd20的fab的峰。另外制备的强制错误结合的抗体的分析结果显示,该组合中的轻链错配体的fab在αcd37(轻链)-αcd20(重链)的情况下在22.5分钟附近洗脱,另一方面,在αcd20(轻链)-αcd37(重链)的情况下在28分钟附近和在31分钟附近洗脱(图28)。在3种本纯化样品中完全未检测出来自这些错误结合的fab等的杂质的峰。以使用蛋白质a亲和性纯化样品的fab分析表示,可直接地显示通过引入非天然二硫键产生的轻链-重链间的结合限定功效。双特异性抗体αcd20(cys1m)/αdr5的结果如图29所示,同时αcd20(cys1m)/αcd37的结果如图30所示。在未引入突变的野生型的情况下,任一组合例均明显地检测出各两种类型错误结合的fab。另一方面,在引入突变的情况下,这些错误结合的fab锐减,特别是在cys1m(f)和(g)的情况下,为稍有检出的程度。图31和32显示了双特异性抗体αcd20(cys1m)/αcd37是功能上的双特异性抗体。在作为阴性对照的亲本抗体αcd37(wt)不能结合的状况下,αcd20(cys1m)/αcd37对cd20阳性cd37阴性细胞(引入cd20基因的sp2/0细胞,以facs确认其表达)明显具有结合能力。对于其它测试细胞即cd20阴性cd37阳性细胞(引入cd37基因得sp2/0细胞,以facs确认其表达),在阴性对照亲本抗体αcd20(wt)不能结合的状况下,αcd20(cys1m)/αcd37具有结合能力。双特异性抗体αdr5/αcd20(cys1m)也同样地可得到的功能上双特异性的结果(图33和34),显示该技术的有效性是普遍的。根据以上所示的结果,验证了通过使用了本发明的非天然二硫键的链间结合限定技术,可有效且简便地制备双特异性抗体等的具有不同fab区的抗体。以上以实施本发明的方案的记载所说明的各种实施方案并非意在限制本发明,而是为了示例性公开本发明。本发明的技术范围是由权利要求书的记载所确定,并且本领域技术人员可在权利要求书所记载的本发明的技术范围内做出各种设计改变。另外,通过引用将本说明书所引用的专利、专利申请和出版物的公开内容全部并入本说明书。序列表<110>全药工业株式会社<120>抗体或抗体组合物的制备方法<130>jp113035<160>53<170>patentinversion3.5<210>1<211>27<212>dna<213>人工序列<220><223>引物<400>1tttcgtacggtggctgcaccatctgtc27<210>2<211>33<212>dna<213>人工序列<220><223>引物<400>2ttttctagatcaacactctcccctgttgaagct33<210>3<211>23<212>dna<213>人工序列<220><223>引物<400>3tttaagcttggtcagcccaaggc23<210>4<211>25<212>dna<213>人工序列<220><223>引物<400>4cgactctagactatgaacattctgt25<210>5<211>30<212>dna<213>人工序列<220><223>引物<400>5aaacgtacggtggccaaccccactgtcact30<210>6<211>29<212>dna<213>人工序列<220><223>引物<400>6tttgctagcaccaagggcccatcggtctt29<210>7<211>30<212>dna<213>人工序列<220><223>引物<400>7aaactcgagtcatttacccggagacaggga30<210>8<211>30<212>dna<213>人工序列<220><223>引物<400>8tcaacaggggagagtcctgatctagagtcg30<210>9<211>30<212>dna<213>人工序列<220><223>引物<400>9cgactctagatcaggactctcccctgttga30<210>10<211>44<212>dna<213>人工序列<220><223>引物<400>10aaacgtacggtggctgcaccatctgtctgcatcttcccgccatc44<210>11<211>30<212>dna<213>人工序列<220><223>引物<400>11catctgtcttcatctgcccgccatctgatg30<210>12<211>30<212>dna<213>人工序列<220><223>引物<400>12catcagatggcgggcagatgaagacagatg30<210>13<211>30<212>dna<213>人工序列<220><223>引物<400>13ttcatcttcccgccatgcgatgagcagttg30<210>14<211>30<212>dna<213>人工序列<220><223>引物<400>14caactgctcatcgcatggcgggaagatgaa30<210>15<211>27<212>dna<213>人工序列<220><223>引物<400>15gatgagtgcttgaaatctggaactgcc27<210>16<211>27<212>dna<213>人工序列<220><223>引物<400>16tttcaagcactcatcagatggcgggaa27<210>17<211>30<212>dna<213>人工序列<220><223>引物<400>17ctcccaggagtgcgtcacagagcaggacag30<210>18<211>30<212>dna<213>人工序列<220><223>引物<400>18ctgtcctgctctgtgacgcactcctgggag30<210>19<211>20<212>dna<213>人工序列<220><223>引物<400>19aattaaccctcactaaaggg20<210>20<211>20<212>dna<213>人工序列<220><223>引物<400>20gtgccacctgacgtctagat20<210>21<211>32<212>dna<213>人工序列<220><223>引物<400>21ccctctagactatgaggattctgtaggggcca32<210>22<211>51<212>dna<213>人工序列<220><223>引物<400>22aaacgtacggtggccaaccccactgtcactctgtgcccgccctcctctgag51<210>23<211>30<212>dna<213>人工序列<220><223>引物<400>23cctctgagtgcctccaagccaacaaggcca30<210>24<211>30<212>dna<213>人工序列<220><223>引物<400>24tggaggcactcagaggagggcgggaacaga30<210>25<211>30<212>dna<213>人工序列<220><223>引物<400>25ggagacctgcaaaccctccaaacagagcaa30<210>26<211>30<212>dna<213>人工序列<220><223>引物<400>26ggagggtttgcaggtctccactcccgcctt30<210>27<211>30<212>dna<213>人工序列<220><223>引物<400>27gttgagcccaaatcttccgacaaaactcac30<210>28<211>30<212>dna<213>人工序列<220><223>引物<400>28gtgagttttgtcggaagatttgggctcaac30<210>29<211>44<212>dna<213>人工序列<220><223>引物<400>29tcagctagcaccaagggcccatcggtctgccccctggcaccctc44<210>30<211>30<212>dna<213>人工序列<220><223>引物<400>30cccatcggtcttctgcctggcaccctcctc30<210>31<211>30<212>dna<213>人工序列<220><223>引物<400>31gaggagggtgccaggcagaagaccgatggg30<210>32<211>30<212>dna<213>人工序列<220><223>引物<400>32catcggtcttcccctgcgcaccctcctcca30<210>33<211>30<212>dna<213>人工序列<220><223>引物<400>33tggaggagggtgcgcaggggaagaccgatg30<210>34<211>27<212>dna<213>人工序列<220><223>引物<400>34tccaagtgcacctctgggggcacagcg27<210>35<211>27<212>dna<213>人工序列<220><223>引物<400>35agaggtgcacttggaggagggtgccag27<210>36<211>27<212>dna<213>人工序列<220><223>引物<400>36acagcgtgcctgggctgcctggtcaag27<210>37<211>27<212>dna<213>人工序列<220><223>引物<400>37gcccaggcacgctgtgcccccagaggt27<210>38<211>27<212>dna<213>人工序列<220><223>引物<400>38gcgtgcacacctgcccggctgtcctac27<210>39<211>27<212>dna<213>人工序列<220><223>引物<400>39gtaggacagccgggcaggtgtgcacgc27<210>40<211>28<212>dna<213>人工序列<220><223>引物<400>40cgtgcacaccttctgcgctgtcctacag28<210>41<211>28<212>dna<213>人工序列<220><223>引物<400>41ctgtaggacagcgcagaaggtgtgcacg28<210>42<211>27<212>dna<213>人工序列<220><223>引物<400>42ccggcttgcctacagtcctcaggactc27<210>43<211>27<212>dna<213>人工序列<220><223>引物<400>43ctgtaggcaagccgggaaggtgtgcac27<210>44<211>26<212>dna<213>人工序列<220><223>引物<400>44tgctcctcccgcggctttgtcttggc26<210>45<211>30<212>dna<213>人工序列<220><223>引物<400>45ggctctgcacaaccgcttcacgcagaagag30<210>46<211>30<212>dna<213>人工序列<220><223>引物<400>46ctcttctgcgtgaagcggttgtgcagagcc30<210>47<211>20<212>dna<213>人工序列<220><223>引物<400>47taatacgactcactataggg20<210>48<211>330<212>dna<213>智人(homosapiens)<400>48cgtacggtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatct60ggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacag120tggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggac180agcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgag240aaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaag300agcttcaacaggggagagtgttgatctaga330<210>49<211>324<212>dna<213>智人<400>49cgtacggtggccaaccccactgtcactctgttcccgccctcctctgaggagctccaagcc60aacaaggccacactagtgtgtctgatcagtgacttctacccgggagctgtgacagtggcc120tggaaggcagatggcagccccgtcaaggcgggagtggagaccaccaaaccctccaaacag180agcaacaacaagtacgcggccagcagctacctgagcctgacgcccgagcagtggaagtcc240cacagaagctacagctgccaggtcacgcatgaagggagcaccgtggagaagacagtggcc300cctacagaatgttcatagtctaga324<210>50<211>999<212>dna<213>智人<400>50gctagcaccaagggcccatcggtcttccccctggcaccctcctccaagagcacctctggg60ggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcg120tggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacagtcctca180ggactctactccctcagcagcgtggtgaccgtgccctccagcagcttgggcacccagacc240tacatctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaagttgagccc300aaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctgggggga360ccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccct420gaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactgg480tacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaac540agcacgtaccgggtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaag600gagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctcc660aaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgag720ctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatc780gccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtg840ctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtgg900cagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacg960cagaagagcctctccctgtctccgggtaaatgactcgag999<210>51<211>107<212>prt<213>智人<400>51argthrvalalaalaproservalpheilepheproproseraspglu151015glnleulysserglythralaservalvalcysleuleuasnasnphe202530tyrproargglualalysvalglntrplysvalaspasnalaleugln354045serglyasnserglngluservalthrgluglnaspserlysaspser505560thrtyrserleuserserthrleuthrleuserlysalaasptyrglu65707580lyshislysvaltyralacysgluvalthrhisglnglyleuserser859095provalthrlysserpheasnargglyglucys100105<210>52<211>105<212>prt<213>智人<400>52argthrvalalaasnprothrvalthrleupheproproserserglu151015gluleuglnalaasnlysalathrleuvalcysleuileseraspphe202530tyrproglyalavalthrvalalatrplysalaaspglyserproval354045lysalaglyvalgluthrthrlysproserlysglnserasnasnlys505560tyralaalasersertyrleuserleuthrprogluglntrplysser65707580hisargsertyrsercysglnvalthrhisgluglyserthrvalglu859095lysthrvalalaprothrglucysser100105<210>53<211>330<212>prt<213>智人<400>53alaserthrlysglyproservalpheproleualaproserserlys151015serthrserglyglythralaalaleuglycysleuvallysasptyr202530pheprogluprovalthrvalsertrpasnserglyalaleuthrser354045glyvalhisthrpheproalavalleuglnserserglyleutyrser505560leuserservalvalthrvalproserserserleuglythrglnthr65707580tyrilecysasnvalasnhislysproserasnthrlysvalasplys859095lysvalgluprolyssercysasplysthrhisthrcysproprocys100105110proalaprogluleuleuglyglyproservalpheleuphepropro115120125lysprolysaspthrleumetileserargthrprogluvalthrcys130135140valvalvalaspvalserhisgluaspprogluvallyspheasntrp145150155160tyrvalaspglyvalgluvalhisasnalalysthrlysproargglu165170175gluglntyrasnserthrtyrargvalvalservalleuthrvalleu180185190hisglnasptrpleuasnglylysglutyrlyscyslysvalserasn195200205lysalaleuproalaproileglulysthrileserlysalalysgly210215220glnproarggluproglnvaltyrthrleuproproserargaspglu225230235240leuthrlysasnglnvalserleuthrcysleuvallysglyphetyr245250255proseraspilealavalglutrpgluserasnglyglnprogluasn260265270asntyrlysthrthrproprovalleuaspseraspglyserphephe275280285leutyrserlysleuthrvalasplysserargtrpglnglnglyasn290295300valphesercysservalmethisglualaleuhisasnhistyrthr305310315320glnlysserleuserleuserproglylys325330当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- OTUD5的单克隆抗体制备及其在癌症治疗中的用途的制造方法与工艺
- 氧化白藜芦醇或氧化白藜芦醇联合抗生素在制备抗真菌感染产品中的应用的制造方法与工艺
- 一种3D打印技术制备治疗高磷血症的口腔速崩片的方法与流程
- 特异性人EWS‑FLI1融合蛋白抗体的制备方法及在制备尤文肉瘤诊断抗体试剂的应用与制造工艺
- 抗下垂基板及其制备和使用的方法与制造工艺
- 用于修饰抗体以制备免疫缀合物的特定位点的制造方法与工艺
- 汉坦病毒S基因克隆、表达、单克隆抗体的制备方法及其应用与制造工艺
- 一种膜蛋白CD14的抗体的制备方法及应用与制造工艺
- 用于治疗癌症的抗CCR4抗体和4‑1BB激动剂的组合的制造方法与工艺
- 一种识别磷铝酸盐矿物浸蚀剂的制备及使用方法与制造工艺