基于CRISPR的改变基因产物表达的方法及其应用与流程
本发明涉及生物医疗领域,具体而言,涉及一种基于crispr的改变基因产物表达的方法及其应用。
背景技术:
近几年基因编辑技术获得突破性发展,尤其是第三代基因编辑技术crispr更具有明显的优势,如构建简单,效率高,操作简便等。crispr系统一般包括以下几个部分:(1)pam位点,位于靶序列的下游,只有几个nt(例如spcas9/ngg;sacas9/nngrrt),根据此位点来选取靶序列;(2)靶序列,识别并与切割位点结合的序列,一般在20nt左右;(3)tracrna,连接与靶序列之后的一段回文rna序列;(4)cas9内切酶,具有独立酶活性。cas9含有2个独特的活性位点,分别为氨基末端的ruvc和蛋白质中部的hnh。cas9中的hnh活性位点剪切grna的互补dna链,ruvc活性位点剪切非互补链。nickase(切口酶)为cas9蛋白的突变体,其ruvc或hnh尖性位点失活,使其只能切割目的序列的其中一条dna链,从而形成dna单链切口。crispr的工作原理通常为,sgrna、tracrrna和cas9组成复合体,识别并结合于crrna互补的序列,然后解开dna双链,形成r-loop,使crrna与互补链杂交,另一条链保持游离的单链状态,然后由cas9中的活性位点剪切dna的两条链或一条链,最终引入dna双链断裂(dsb)或单链断裂(ssb)。dsb有两种修复方式:一种是非源末端连接(nhej),一种是同源重组(hr),当同源重组片段存在的情况下倾向于后者。ssb有两种修复方式:一是以未断裂的互补链为模板进行修复,一种是在同源重组片断存在的情况下以同源重组的方式进行修补。利用上述原理可以对特定的基因进行突变敲除或定点编辑,相较于目前普遍采用的随机整合,定点基因编辑的安全风险更加可控。
il-1β是许多风湿性关节炎的致病因子,因此它也是最受关注的il-1家族成员。
il-1家族成员包括:il-1α、il-1β、il-1ra、il-18、il-33、il-36α、il-36β、il-36γ、il-36ra、il-37、il-38。其中il-1α、il-1β、il-18、il-33、il-36α、il-36β、il-36γ是促炎性因子,而il-1ra、il-36ra、il-37、il-38是抗炎性因子。
il-1β首先与il-1r1受体结合,导致il-1r1结构发生改变,然后il-1β/il-1r1复合物再结合il-1r3,形成il-1β/il-1r1/il-1r3聚合体,激活nf-κb通路。与不同的配体结合,il-1r1会发生不同的变构现象。抗炎性因子il-1ra结合il-1r1后,il-1r1同样变构,但变构后的il-1r1不再结合il-1r3,抑制了nf-κb通路。il-1β同样可以结合il-1r2,但这个受体缺乏胞内区域,不能产生任何信号传导。
il-1β主要由骨髓来源的细胞分泌,像单核细胞和巨噬细胞,但t、b细胞并不分泌il-1β。原始的巨噬细胞并不分泌il-1β,一旦巨噬细胞受到tlr(toll-likereceptor)配体刺激,或者il-1α,或者il-1β刺激下,巨噬细胞会大量表达分泌il-1β。在koa早期,主要表现为滑膜内膜增生,其中主要是巨噬细胞大量聚集,而巨噬细胞是il-1β分泌的主要细胞。随着koa进展,滑膜内膜上的b型滑膜细胞由于炎性环境的刺激,逐渐变为纤维细胞,此后主要由这些纤维细胞分泌il-1β。研究发现,在il-1β拮抗剂存在情况下,体外培养的滑膜细胞、软骨细胞以及体内的小动物模型膝关节滑膜液中,il-1β表达分泌量出现明显下降;基因技术沉默体外培养的软骨细胞膜上的il-1r1后,il-1β表达量同样明显下调。局部关节腔内注射il-1β单克隆抗体后,软骨修复能力得到增强。
tnf-α自1975年发现以来,研究人员对其特性及作用机理有了深入的认知。tnf-α在机体免疫调节反应中起着重要的作用。
tnf超家族成员有19个。tnf主要由单核细胞或巨噬细胞分泌,其它一些细胞像t细胞、b细胞、主细胞、nk细胞、中性粒细胞、纤维细胞以及成骨细胞均可分泌tnf-α,只不过分泌量很少。tnf存在两种形式:一种是膜tnf(mtnf),另一种是可溶性tnf(stnf)。stnf存在于体液中。
tnfr家族成员有29个,其中与tnf-α有关的受体有tnfr1和tnfr2。所有组织细胞均表达tnfr1,而tnfr2主要表达于免疫细胞、神经元、上皮细胞的细胞膜上。这两个受体与tnf结合的胞外结构域相似,不同的是它们的细胞内结构域。tnfr1胞内结构区存在一死亡结构域(tradd);tnfr2胞内区无tradd,而是存在能够招募两个traf1和traf2的结构域。tnfr1和tnfr2均能激活nf-κb通路,而tnfr1还能通过tradd激活细胞程序性死亡过程。
早期和中期关节滑膜液中含有大量的stnf-α,通过tnfr激活nf-κb通路,促使软骨细胞、滑膜细胞及滑膜纤维细胞的促炎性分子表达上调,包括mmp-13、adamts-5、adamts-7等,加速了ecm的降解进程,软骨组织破坏程度加重。yunpengzhao等通过基因技术封闭了体外培养的软骨细胞膜上的tnfr,即使tnf-α存在的情况下,软骨细胞分泌的促炎性因子表达也不会上调。ching-houma等研究发现,tnf-α/tnfr的结合,可激活pkr信号通路,导致软骨细胞内抗氧化酶表达量下调,细胞内氧化应激反应增强,加速了软骨细胞的凋亡。
il-1β、tnf-α可在一些疾病例如类风湿性关节炎和膝关节骨关节炎的治疗中产生负面影响,因而在一些情况下,存在有效抑制il-1β和/或tnf-α生理作用的需要。
技术实现要素:
本发明涉及一种改变基因产物表达的方法,包括提供包含一种或多种载体的非天然存在的核酸酶系统,所述载体包含:
i)选自seqidno:1~9中至少一种的编码核酸酶系统指导rna(grna)或其前体物的核酸序列,以及任选的ii)编码基因组靶向核酸酶的核苷酸序列;
所述grna靶向靶dna,且所述核酸酶切割所述靶dna以改变基因产物的表达。
本发明还涉及一种制备经修饰的细胞的方法,包括使用如上所述的方法以改变基因产物的表达,所述基因产物选自il1r1、tnfr1以及tnfr2中的至少一种。
本发明还涉及如上方法中所涉及的载体,所述载体相关的转录物和/或蛋白质,以及如上方法制备的经修饰的细胞。
本发明还涉及药用组合物,其包括如上所述的载体、如上所述的转录物和/或蛋白质以及如上所述的细胞中的至少一种,以及药学上可接受的载体。
与现有技术相比,本发明的有益效果为:
(1)能够同时改变il1r1、tnfr1以及tnfr2三个基因的基因产物的表达,也可分别有效编辑上述三种基因。
(2)敲除效率高。
(3)脱靶效应不显著,经处理的细胞仍然能够正常存活并分化。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
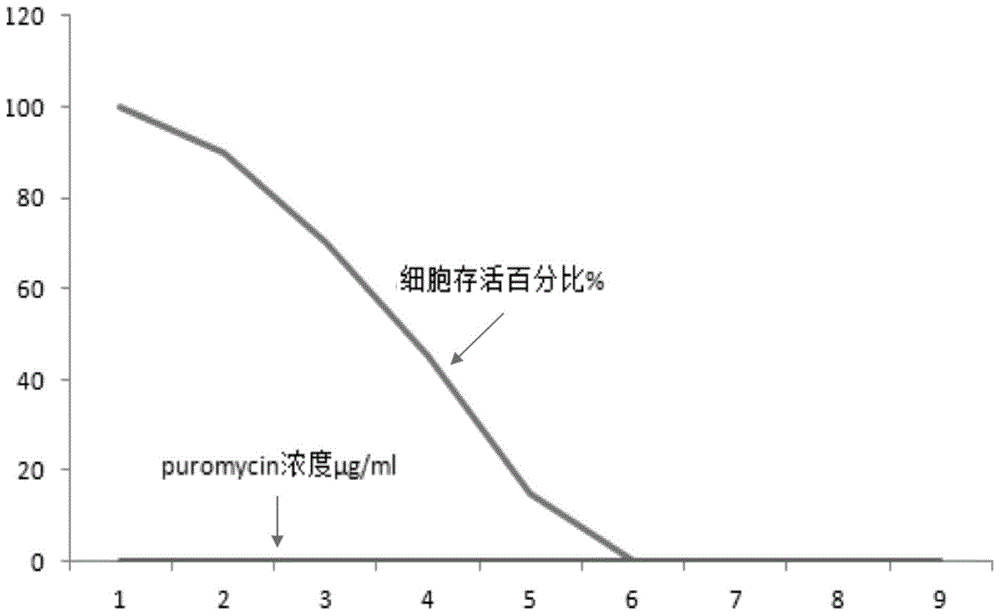
图1为本发明一个实施例中抗生素压力筛选msc趋势图;
图2为本发明一个实施例中t7e1基因突变检测试剂盒检测电泳图;
图3为本发明一个实施例中msc/il1r1-细胞tgf-β表达分析图;
图4为本发明一个实施例中msc/tnfr1-细胞il-8表达分析图;
图5为本发明一个实施例中msc/tnfr2-细胞igf-1表达分析图;
图6为本发明一个实施例中msc/il1r1-/tnfr1-/tnfr2-分化为脂肪细胞、成骨细胞图;
图7为本发明一个实施例中pcr方法检测msc/il1r1-/tnfr1-/tnfr2-分化为脂肪细胞标志物lpl和分化为成骨细胞标志物opn的mrna表达图。
具体实施方式
现将详细地提供本发明实施方式的参考,其一个或多个实例描述于下文。提供每一实例作为解释而非限制本发明。实际上,对本领域技术人员而言,显而易见的是,可以对本发明进行多种修改和变化而不背离本发明的范围或精神。例如,作为一个实施方式的部分而说明或描述的特征可以用于另一实施方式中,来产生更进一步的实施方式。
因此,旨在本发明覆盖落入所附权利要求的范围及其等同范围中的此类修改和变化。本发明的其它对象、特征和方面公开于以下详细描述中或从中是显而易见的。本领域普通技术人员应理解本讨论仅是示例性实施方式的描述,而非意在限制本发明更广阔的方面。
本发明提供了一种改变基因产物表达的方法,包括提供包含一种或多种载体的非天然存在的核酸酶系统,所述载体包含:
i)选自seqidno:1~9中至少一种的编码核酸酶系统指导rna(grna)或其前体物的核酸序列,以及任选的ii)编码基因组靶向核酸酶的核苷酸序列;
所述grna靶向靶dna,且所述核酸酶切割所述靶dna以改变基因产物的表达。
组分i)和ii)可均位于所述载体上,也可以将ii)设置于另一不同的载体上。
在本发明中seqidno:1~9所示核苷酸序列对应的靶点序列特异性好,不易脱靶,基因编辑(例如敲除)效率高。
本发明采用基因编辑系统基于crispr系统,能高效地编辑宿主细胞中的il1r1、tnfr1或tnfr2基因中的一种或多种,从而有效抑制il-1β和/或tnf-α等细胞因子及其所在信号通路的作用,不仅可以用于自身免疫性疾病(特别是关节炎类疾病)的治疗,还可以搭建起自身免疫性疾病的研究平台,促进这些疾病发病机制的研究。
在某些实施方案中,grna的前体物可由dna分子或包含编码grna的核酸的表达载体提供。
在一些实施方式中,所述改变基因产物的表达具体为下调该靶基因的表达。
在一些实施方式中,所述核酸酶非限制性地包含cas1、cas1b、cas2、cas3、cas4、cas5、cas6、cas7、cas8、cas9、cas10、csy1、csy2、csy3、cse1、cse2、csc1、csc2、csa5、csn2、csm2、csm3、csm4、csm5、csm6、cmr1、cmr3、cmr4、cmr5、cmr6、csb1、csb2、csb3、csx1、csx3、csx10、csx14、csx14、csx15、csx17、csax、csf1、csf2、csf3、csf4、cpf1、c2c1、c2c2、c2c3,或上述蛋白的同源物及其修饰形式。这些酶是为本领域技术人员所公知的。
在一些实施方式中,所述核酸酶是cas。
在一些实施方式中,所述核酸酶是cas9。
在一些实施方式中,所述cas9来自化脓性链球菌或肺炎链球菌。
在一些实施方式中,常规的基于病毒的系统可以包括用于基因转移的逆转录病毒、慢病毒、腺病毒、腺相关和单纯疱疹病毒载体;上述病毒通常是复制缺陷的;优选慢病毒。
在一些实施方式中,所述载体为lenticrisprv2。
在一些实施方式中,所述方法在细胞外进行或细胞内进行。
根据本发明的再一方面,本发明还涉及一种制备经修饰的细胞的方法,包括使用如上所述的方法以改变基因产物的表达,所述基因产物选自il1r1、tnfr1以及tnfr2中的至少一种。
在一些实施方式中,所述细胞为真核细胞。
在一些实施方式中,所述细胞为非人的哺乳动物细胞。
在一些实施方案中,所述细胞非限制性地包括牛、马、乳牛、猪、绵羊、山羊、大鼠、小鼠、狗、猫、兔、骆驼、驴、鹿、貂、鸡、鸭、鹅、火鸡、斗鸡等。
在一些实施方式中,所述细胞为人类细胞。
在一些实施方式中,所述细胞非人类的生殖细胞、受精卵或单细胞胚胎。
在一些实施方案中,转染的细胞取自受试者。
在一些实施方案中,所述细胞衍生自取自受试者的细胞,例如细胞系。用于组织培养的多种细胞系是本领域已知的。细胞系的实例包括但不限于c8161,ccrf-cem,molt,mimcd-3,nhdf,hela-s3,huh1,huh4,huh7,huvec,hasmc,hekn,heka,miapacell,panel,pc-3,tf1,ctll-2,c1r,rat6,cv1,rpte,a10,t24,j82,a375,arh-77,calu1,sw480,sw620,skov3,sk-ut,caco2,p388d1,sem-k2,wehi-231,hb56,tib55,jurkat,j45.01,lrmb,bcl-1,bc-3,ic21,dld2,raw264.7,nrk,nrk-52e,mrc5,mef,hepg2,helab,helat4,cos,cos-1,cos-6,cos-m6a,bs-c-1猴肾上皮细胞,balb/3t3小鼠胚胎成纤维细胞,3t3swiss,3t3-l1,132-d5人胎儿成纤维细胞;小鼠成纤维细胞,293-t,3t3,721,9l,a2780,a2780adr,a2780cis,a172,a20,a253,a431,a-549,alc,b16,b35,bcp-1细胞,beas-2b,bend.3,bhk-21,br293,bxpc3,c3h-10t1/2,c6/36,cal-27,cho,cho-7,cho-ir,cho-k1,cho-k2,cho-t,chodhfr-/-,cor-l23,cor-l23/cpr,cor-l23/5010,cor-l23/r23,cos-7,cov-434,cmlt1,cmt,ct26,d17,dh82,du145,ducap,el4,em2,em3,emt6/ar1,emt6/ar10.0,fm3,h1299,h69,hb54,hb55,hca2,hek-293,hela,hepa1c1c7,hl-60,hmec,ht-29,jurkat,jy细胞,k562细胞,ku812,kcl22,kg1,kyo1,lncap,ma-mei1-48,mc-38,mcf-7,mcf-10a,mda-mb-231,mda-mb-468,mda-mb-435,mdckii,mdckii,mor/0.2r,mono-mac6,mtd-1a,myend,nci-h69/cpr,nci-h69/lx10,nci-h69/lx20,nci-h69/lx4,nih-3t3,nalm-1,nw-145,opcn/opct细胞系,peer,pnt-1a/pnt2,renca,rin-5f,rma/rmas,saos-2细胞,sf-9,skbr3,t2,t-47d,t84,thp1细胞系,u373,u87,u937,vcap,vero细胞,wm39,wt-49,x63,yac-1,yar及其转基因品种。细胞系可从本领域技术人员已知的多种来源获得,例如保藏中心。
在一些实施方式中,所述细胞选自全能干细胞、多能干细胞以及单能干细胞中的至少一种。
在一些实施方式中,所述多能干细胞选自间充质干细胞。
在一些实施方式中,所述间充质干细胞选自骨髓间充质干细胞、脂肪间充质干细胞、脐带间充质干细胞、脐带血间充质干细胞、胎盘间充质干细胞以及肝脏间充质干细胞中的至少一种。
在一些实施方式中,所述方法在体内或体外进行。
在一些实施方式中,所述cas蛋白是密码子优化的,用于在所述细胞中更为高效地表达。
密码子的优化可根据宿主的密码子偏好进行操作,其对本领域技术人员是容易的。
根据本发明的再一方面,本发明还涉及如上方法中所定义的载体,以及所述载体制备得到的转录物和/或蛋白质例。
其中转录物一般为rna。
在一些实施方式中,本发明所述载体、转录物中包含基因工程中常用的调控元件,例如增强子、启动子、内部核糖体进入位点(ires)和其他表达控制元件(例如转录终止信号,或者多腺苷酸化信号和多聚u序列等)。
在一些实施方式中,本发明所述载体、转录物中还可以包含筛选所用的基因(例如抗生素抗性基因)、用于生成荧光蛋白的核酸等片段。荧光蛋白可以选择绿色荧光蛋白、蓝色荧光蛋白、黄色荧光蛋白、橙色荧光蛋白或红色荧光蛋白。绿色荧光蛋白可以采用常见的gfp,也可以采用经过改造后的gfp基因,例如增强型gfp基因egfp等;蓝色荧光蛋白可以选自ebfp、azuritc、tagbfp等;黄色荧光蛋白可以选自eyfp、ypct、phiyfp等;橙色荧光蛋白可以选自mko、morange、mbanana等;红色荧光蛋白可以选自tagrfp、mruby、mcherry、mkatc。
根据本发明的再一方面,本发明还涉及通过如上所述的方法制备的经修饰的细胞。
根据本发明的再一方面,本发明还涉及药用组合物,其包括如上所述的载体、如上所述的转录物和/或蛋白质以及如上所述的细胞中的至少一种,以及药学上可接受的载体。
本文中所述载体在重组核酸的技术中经常以质粒的形式被使用。
所述药用组合物可用于治疗免疫疾病,特别适合用于治疗类风湿性关节炎和膝关节骨关节炎。
因而特别地,本发明还是涉及一种用于治疗有此需要的主体中的类风湿性关节炎和膝关节骨关节炎的方法,所述方法包括:
a)提供所述药用组合物;
b)向所述主体的患处施用治疗有效量的所述药用组合物。
在本发明中“主体”、“受试者”、“患者”等词汇可根据需要通用。主体可以为哺乳动物,优选为人。在一些实施方案中,所述药物组合物中所包含的细胞在其天然存在于受试者中时被转染。
在一些实施方式中,治疗可经患处(特别是手足关节及其周围)局部给予至患处表面,或通过植入给予,或通过注射给予等。
在一些方面,当前公开的主题提供包括将一种或多种多核酸,例如一种或多种本文所述的载体,其一种或多种转录物,和/或由其转录的一种或多种蛋白质递送至宿主细胞的方法。在一些方面,当前公开的主题还提供由这些方法产生的细胞,以及包含这些细胞或由这些细胞产生的生物体。上述产物可组成本发明所述的药用组合物。常规的基于病毒和非病毒的基因转移方法可用于在哺乳动物细胞或靶组织中引入核酸。这种方法可用于将编码crispr系统组分的核酸施用到培养中或宿主生物体中的细胞。非病毒载体递送系统包括dna质粒,rna(例如本文所述载体的转录物),裸核酸和与递送媒介物(例如脂质体)复合的核酸。病毒载体递送系统包括dna和rna病毒,其在递送至细胞后具有附加或整合的基因组。
非病毒递送核酸的方法包括脂转染,核转染,微注射,生物射弹,病毒体,脂质体,免疫脂质体,聚阳离子或脂质:核酸缀合物,裸dna,人工病毒粒子和dna的试剂增强摄取。
病毒递送核酸的方法可以直接施用到所述主体或可以用于体外处理细胞,且可以任选地将修饰的细胞施用到所述主体。用载体转染方法可以在宿主基因组中整合,通常导致插入的转基因的长期表达。另外,已经在许多不同细胞类型和靶组织中观察到高转导效率。
下面将结合实施例对本发明的实施方案进行详细描述。
实施例
crispr-cas敲除il1r1和tnfr基因的筛选
1、grna设计与准备
(1)il1r1grna序列(靶向位点位于il1r1第4外显子)。
grnasequence1(seqidno:1)
gaggcttgttctgtagatac
grnasequence2(seqidno:2)
ctctttgtgttgatgaatcc
grnasequence3(seqidno:3)
tcatttgggttaagaggaca
(2)tnfr1grna序列(seqidno:4的靶向位点位于tnfr1第1外显子;seqidno:5的靶向位点位于tnfr1第6外显子;seqidno:6的靶向位点位于tnfr1第10外显子)。
grnasequence4(seqidno:4)
gcaggtcaggcacggtggag
grnasequence5(seqidno:5)
ggcacaacttcgtgcactcc
grnasequence6(seqidno:6)
accacggcgtacagcgtcgc
(3)tnfr2grna序列(靶向位点位于tnfr2的第2外显子)。
grnasequence7(seqidno:7)
ggcatttacaccctacgccc
grnasequence8(seqidno:8)
tctgagccggcatgtgctcc
grnasequence9(seqidno:9)
ggtcatagtattctctgagc
(2)分别合成带粘性末端的靶序列正义链和反义链(正义链的5'-端加cacc,若正义链5'-端第1个核苷酸不是鸟嘌呤g,则在正义链的5'-端加caccg;在反义链的5'-端加aaac,若正义链5'-端第1个核苷酸不是鸟嘌呤g,则在反义链的3'-端加c)。
(3)将上述正义链和反义链等摩尔混合,100℃处理后自然冷却至室温进行退火处理,合成带粘性末端的双链grna。
2、慢病毒载体准备
(1)lenticrisprv2扩增和提取,并测定质粒浓度。
(2)采用限制性内切酶bsmbi对lenticrisprv2进行酶切,37℃酶切1h后加loadingbuffer终止反应。
(3)琼脂糖凝胶电泳回收线性化载体片断,并测定回收产物浓度,-20℃保存备用。
3、连接转化
(1)将切胶回收的线性化lenticrisprv2载体与退火后的grna双链进行连接反应。
(2)连接产物热击法转化dh5α,转化后向每个离心管加入无菌lb培养基(不含抗生素),混匀后置于恒温摇床振荡培养复苏。
(3)将复苏后的dh5α细菌涂布lb固体平板(amp+),倒置于恒温培养箱37℃静置培养12~16h。
(4)从上述平板上分别单菌落接种到lb液体培养(amp+)中扩大培养。
(5)使用human-u6测序引物5'-atggactatcatatgcttaccgta-3'对上述菌液分别测序。
(6)将测序正确的菌液提取质粒并测定质粒浓度后保存备用。
4、包装慢病毒
(1)取1.5ml灭菌ep管,加入1.5μg包装质粒和250μl的无血清培养基。轻柔混匀,室温孵育5min。
(2)取1.5ml灭菌ep管,取9μl脂质体2000溶于250μl无血清培养基中。轻柔混匀,室温孵育5min。
(3)将dna溶液和脂质体溶液轻柔混匀。室温孵育20min。
(4)用胰酶消化并记数293t细胞。用含血清的培养基重悬细胞。
(5)在六孔板中每孔加入1ml含血清的生长培养基,再加入dna-脂质体复合物。
(6)将1ml重悬的293t细胞(1×106个细胞/ml)加入到平板中。37℃,5%co2孵箱中孵育过夜。
(7)移除含有dna-脂质体复合物的培养基移除,代之以dmem完全培养基(含丙酮酸钠和非必须氨基酸)。
(8)转染后48~72h收获含病毒的上清。3000rpm离心20min,去除沉淀。
(9)测定病毒滴度。病毒滴度达到108以上
(10)病毒上清-80℃冻存。
5、puromycin最适压力浓度筛选
(1)取96孔板,将msc以2×104/孔铺到24孔板中,37℃,5%co2过液。
(2)用完全培养基对puromycin按以下浓度稀释0、0.1、0.25、0.75、1、1.5、2、5、10μg/ml至msc培养孔中,平行3孔。37℃,5%co2过液。
(3)每天观察细胞状态及死亡情况。
(4)确定msc完全至死量的最小puromycin浓度。
实验结果如图1所示。
6、慢病毒浸染msc
(1)慢病毒转染前18~24小时,将msc以1×105/孔铺到24孔板中。使细胞在慢病毒转染时的数量为2×105/孔左右。
(2)第二天,用含有6μg/mlpolybrene的2ml新鲜培养基替换原培养基,加入适量病毒悬液。37℃孵育。
(3)4小时后加入2ml新鲜培养基以稀释polybrene。
(4)重复步骤(2)(3)进行第二次慢病毒侵染。
(5)重复步骤(2)(3)进行第三次慢病毒侵染。
(6)继续培养24小时,用新鲜培养基替换含有病毒的培养基。
(7)继续培养msc。
7、t7e1基因突变检测
(1)pcr扩增
il1r1靶点周围序列。
aagaatatgaaagtgttactcagacttatttgtttcatagctctactgatttcttctctggaggctgataaatgcaaggaacgtgaagaaaaaataattttagtgtcatctgcaaatgaaattgatgttcgtccctgtcctcttaacccaaatgaacacaaaggcactataacttggtataaagatgacagcaagacacctgtatctacagaacaagcctccaggattcatcaacacaaagagaaactttggtttgttcctgctaaggtggaggattcaggacattactattgcgtggtaagaaattcatcttactgcctcagaattaaaataagtgcaaaatttgtggagaatgagcctaacttatgttataatgcacaagccatatttaagcagaaactacccgttgcaggagacggaggacttgtgtgcccttatatggagttttttaaaaatgaaaataatgagttacctaaattacagtggtataa
tnfr1靶点周围序列。
actgtcccaactttgcggctccccgcagagaggtggcaccaccctatcagggggctgaccccatccttgcgacagccctcgcctccgaccccatccccaacccccttcagaagtgggaggacagcgcccacaagccacagagcctagacactgatgaccccgcgacgctgtacgccgtggtggagaacgtgcccccgttgcgctggaaggaattcgtgcggcgcctagggctgagcgaccacgagatcgatcggctggagctgcagaacgggcgctgcctgcgcgaggcgcaatacagcatgctggcgacctggaggcggcgcacgccgcggcgcgaggccacgctggagctgctgggacgcgtgctccgcgacatggacctgctgggctgcctggaggacatcgaggaggcgctttgcggccccgccgccctcccgcccgcgcccagtcttctcagatgaggctgcgcccctgcgggcagctctaaggaccgtcctgcga
tnfr2靶点周围序列。
tgcggctccccgcagagaggtggcaccaccctatcagggggctgaccccatccttgcgacagccctcgcctccgaccccatccccaacccccttcagaagtgggaggacagcgcccacaagccacagagcctagacactgatgaccccgcgacgctgtacgccgtggtggagaacgtgcccccgttgcgctggaaggaattcgtgcggcgcctagggctgagcgaccacgagatcgatcggctggagctgcagaacgggcgctgcctgcgcgaggcgcaatacagcatgctggcgacctggaggcggcgcacgccgcggcgcgaggccacgctggagctgctgggacgcgtgctccgcgacatggacctgctgggctgcctggaggacatcgaggaggcgctttgcggccccgccgccctcccgcccgcgcccagtcttctcagatgaggctgc
(2)将基因编辑修饰的msc的pcr产物和未编辑修饰的msc的pcr产物按如下体系进行退火处理(95℃,5min,自然冷却至室温)。
(3)分别加入0.5μlt7e1酶于上述三组处理中,37℃反应30min。
(4)2%琼脂糖凝胶电泳鉴定分析。
实验结果如图2所示。
8、msc基因表达产物分析
(1)将基因编辑修饰的msc/il1r1-、msc/tnfr1--、msc/tnfr2-、msc/il1r1-/tnfr1-、msc/il1r1-/tnfr2-、msc/il1r1-/tnfr1-/tnfr2-和未编辑修饰的msc按1×105/孔铺到24孔板中,37℃,5%co2孵育。
(2)80%融合度时,分别加入适量的il-1β、tnf-α,继续培养4h。
(3)收集细胞,提取总rna。
(4)加入pcr扩增引物:
tgf-βforward:5'-tggaaacccacaacgaaatc-3'
tgf-βreverse:5'-ctaaggcgaaagccctcaat-3'
rt-pcr扩增产物含tgf-β基因片断
tggaaacccacaacgaaatctatgacaagttcaagcagagtacacacagcatatatatgttcttcaacacatcagagctccgagaagcggtacctgaacccgtgttgctctcccgggcagagctgcgtctgctgaggctcaagttaaaagtggagcagcacgtggagctgtaccagaaatacagcaacaattcctggcgatacctcagcaaccggctgctggcacccagcgactcgccagagtggttatcttttgatgtcaccggagttgtgcggcagtggttgagccgtggaggggaaattgagggctttcgccttag
il-8forward:5'-agtgctaaagaacttagatg-3'
il-8reverse:5'-tatgaattatcagccctctt-3'
rt-pcr扩增产物含il-8基因片断
agtgctaaagaacttagatgtcagtgcataaagacatactccaaacctttccaccccaaatttatcaaagaactgagagtgattgagagtggaccacactgcgccaacacagaaattattgtaaagctttctgatggaagagagctctgtctggaccccaaggaaaactgggtgcagagggttgtggagaagtttttgaagagggctgagaattcata
igf-1forward:5'-tggtggatgctcttcagttcg-3'
igf-1reverse:5'-ttagatcacagctccggaagc-3'
rt-pcr扩增产物含igf-1基因片断
tggtggatgctcttcagttcgtgtgtggagacaggggcttttatttcaacaagcccacagggtatggctccagcagtcggagggcgcctcagacaggcatcgtggatgagtgctgcttccggagctgtgatctaa
实验结果分别如图3、图4、图5所示。
9、基因修饰msc分化实验
1)基因修饰msc分化为脂肪细胞
a、常规复苏msc细胞。计数细胞,调整细胞浓度为6×105/ml。
b、将重悬于dmem-h完全培养基的脐带msc以6×104/孔接种于24孔板,每孔体系为1ml。
c、置5%co2,饱和湿度,37℃培养箱培养。
d、当细胞100%融合,小心吸弃培养基,然后每孔添加0.5~1ml脂肪诱导培养基。将此培养基应用日记录为脂肪分化第一天。
e、按下列分化时刻表更换新鲜脂肪诱导或维持培养基。(每次换液必须小心,因为单层的脂肪细胞很容易脱落)
f、诱导分化21天后,小心吸弃培养基,4%多聚甲醛固定细胞,室温孵育30~40分钟。
g、小心吸弃固定液,用1×pbs洗涤三次,每次5~10分钟。
h、用双蒸水洗涤两次。
i、加入0.5ml~1ml油红o,覆盖细胞,室温孵育50分钟。
j、吸弃油红o,双蒸水洗涤三次。
k、加入0.5ml苏木精复染5~15分钟。
l、双蒸水洗涤三次,镜检。
m、未固定、染色细胞用pcr方法检测脂联蛋白酶(lpl)mrna表达情况。
实验结果如图6所示。
2)基因修饰msc分化为成骨细胞
a、用1×pbs分别稀释维甲酸(vitronectin)和i型胶原(collageni),使得终浓度为12μg/ml。
b、24孔板每孔添加0.5mlvitronectin和i型胶原(1:1)混合物,室温孵育过夜。
c、第二天,吸弃,用1×pbs洗涤一次,待用。
d、以6×104/孔浓度将脐带msc加入经维甲酸和i型胶原包被的24孔板中,每孔体系为1ml。
e、置5%co2,饱和湿度,37℃培养箱培养。
f、当细胞100%融合,小心吸弃培养基,然后每孔添加1ml成骨诱导培养基。将此培养基应用日记录为成骨分化第一天。
g、每2-3天更换新鲜成骨诱导培养基。
h、诱导分化17天后,小心吸弃培养基,用4%多聚甲醛固定细胞,室温孵育30-40分钟。
i、小心吸弃固定液,用1×pbs洗涤三次,每次5-10分钟。
j、用双蒸水洗涤两次。
k、5%硝酸银浸泡细胞2小时。
l、紫外光照射1小时。
m、双蒸水冲洗2分钟。
n、5%硫代硫酸钠中和残留的硝酸银。
o、充分水洗,镜检。
p、未固定、染色细胞用pcr方法检测骨桥蛋白(opn)mrna表达情况。
实验结果如图7所示。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
序列表
<110>北京兴元和济生命医学科技有限公司
<120>基于crispr的改变基因产物表达的方法及其应用
<160>9
<170>siposequencelisting1.0
<210>1
<211>20
<212>dna
<213>artificialsequence
<400>1
gaggcttgttctgtagatac20
<210>2
<211>20
<212>dna
<213>artificialsequence
<400>2
ctctttgtgttgatgaatcc20
<210>3
<211>20
<212>dna
<213>artificialsequence
<400>3
tcatttgggttaagaggaca20
<210>4
<211>20
<212>dna
<213>artificialsequence
<400>4
gcaggtcaggcacggtggag20
<210>5
<211>20
<212>dna
<213>artificialsequence
<400>5
ggcacaacttcgtgcactcc20
<210>6
<211>20
<212>dna
<213>artificialsequence
<400>6
accacggcgtacagcgtcgc20
<210>7
<211>20
<212>dna
<213>artificialsequence
<400>7
ggcatttacaccctacgccc20
<210>8
<211>20
<212>dna
<213>artificialsequence
<400>8
tctgagccggcatgtgctcc20
<210>9
<211>20
<212>dna
<213>artificialsequence
<400>9
ggtcatagtattctctgagc20
- 还没有人留言评论。精彩留言会获得点赞!