一种特异性结合肿瘤坏死因子-α的核酸适配体及其应用的制作方法
本发明涉及生物和医学
技术领域:
,尤其涉及一种特异性结合肿瘤坏死因子-α的核酸适配体及其应用。
背景技术:
:肿瘤坏死因子(tumornecrosisfactoralpha,tnf-α)主要由单核细胞和巨噬细胞产生,包括膜结合前体蛋白和分泌型蛋白两种形式。膜结合前体蛋白在tnf转化酶tace的作用下,切除信号肽,形成成熟的157个氨基酸残基的分泌型tnf-α(17kda)。tnf-α是一种具有广泛生物学作用的细胞因子,通过与细胞表面的tnfi型和ii型受体结合发挥作用,主要作用有杀伤或抑制肿瘤细胞;提高中性粒细胞的吞噬能力;抗感染;促进髓样白血病细胞向巨噬细胞分化;促进细胞增殖和分化等。tnf-α的主要作用是调节免疫细胞。作为内源性热原的tnf-α能够诱导发热,它在许多疾病中,如心血管疾病、恶病质和败血症所致的多器官功能衰竭、类风湿性关节炎、多发性硬化症、炎症性肠病、移植性抗宿主病和骨髓造血紊乱综合征等的病理过程中也起着重要的介质作用。tnf-α产生的调节异常与多种人类疾病有关,包括阿尔茨海默病,癌症,严重抑郁症,牛皮癣和炎症性肠病(ibd)。对于肿瘤,tnf-α除了对肿瘤细胞本身具有细胞毒性之外,它也能摧毁实体瘤周围的血管组织,并通过血栓的形成,来阻断肿瘤的血液营养供应最终导致肿瘤的坏死。一定浓度的tnf-α能明显降低实体瘤周围间隙组织的压力,扩大肿瘤周围上皮组织的间隙,改变周围血管的通透性,使得化疗的药物到达靶组织周围。tnf-α、tnf-α抗体、tnf-α拮抗剂目前均有上市药品用于临床治疗,tnf-α抗体、tnf-α拮抗剂已经被广泛应用于自身免疫疾病且效果明显。tnf-α作为免疫学研究的重要生物学指标之一,建立快速、敏捷且准确检测tnf-α具有重要的临床意义。目前tnf-α测定方法有电化学免疫传感器,无标记电化学阻抗,新型纳米结构氧化铟锡电极检测法,新型计时电流免疫传感器快速检测法,电化学生物传感器平台检法,使用亲和标记配体检测法,表面等离子共振免疫分析法等。但是目前还没有统一的标准测定方法,不同厂家之间,不同方法结果差别较大。很多方法都存在着操作繁琐,检测时间长,不适合大批量检测,结果重复性差等问题,而且所用仪器和试剂价格昂贵,成本高,不适合基层实验室开展,同时不适用于急诊检验。核酸适配体(aptamer)是指通过指数富集的配基系统进化技术(selex)筛选分离得到的dna或者rna分子,它可以与其他靶标如蛋白质、金属离子、小分子、多肽甚至整个细胞进行高亲和力和特异性的结合,因此在生化分析、环境监测、基础医学、新药合成等方面展示广阔的前景。核酸适配体与抗体相比有分子量小,稳定性更好,易改造修饰,无免疫原性,制作周期短,可以通过人工合成等优势,免去了动物免疫、饲养、蛋白提取和纯化等一系列流程。目前已经有一些研究者公布了他们所发现的一些tnf-α蛋白的核酸适配体序列,然而,这些tnf-α蛋白的核酸适配体还没有做到检测试剂盒或者成药的水平。因此,本领域对具有更高的针对tnf-α蛋白的结合亲和力的核酸适配体存在需求。技术实现要素:基于
背景技术:
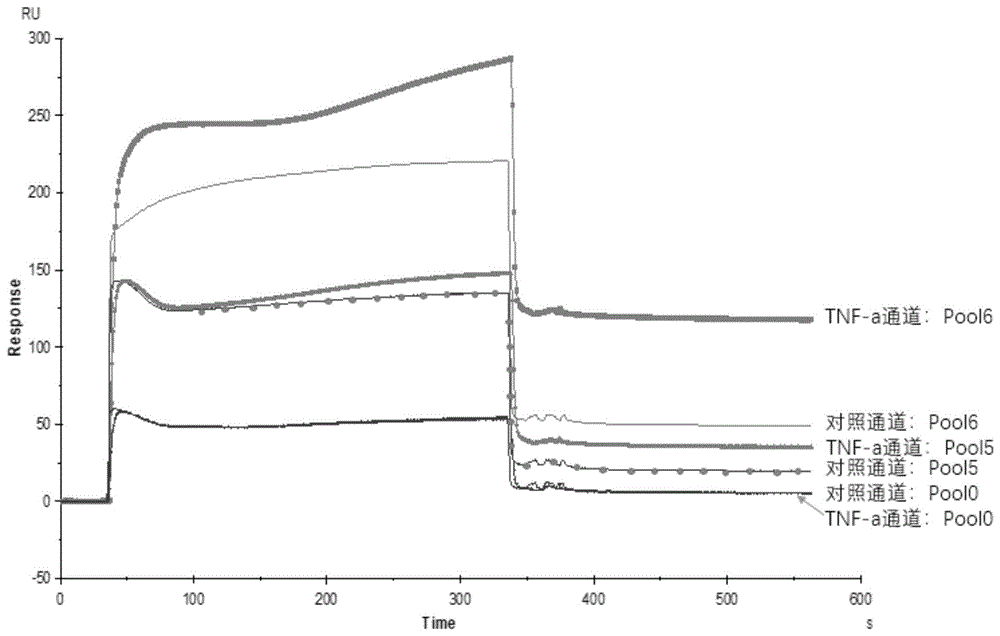
存在的技术问题,本发明提出了一种特异性结合肿瘤坏死因子-α的核酸适配体及其应用,本发明对肿瘤坏死因子-α具有高度特异性,且分子量小,化学性质稳定,易于保存、易于标记。本发明提出的一种特异性结合肿瘤坏死因子-α的核酸适配体,所述核酸适配体序列包含以下核苷酸序列中的至少一种:a、如seqidnos.1-4所示的任意一个dna序列;b、与seqidnos.1-4所示的任意一个dna序列具有60%以上同源性的dna序列;c、在严格条件下与seqidnos.1-4所示的任意一个dna序列杂交的dna序列;d、由seqidnos.1-4所示的任意一个dna序列转录的rna序列;其中,上述核苷酸序列均能够特异性结合肿瘤坏死因子-α。优选地,上述与seqidnos.1-4所示的任意一个dna序列具有60%以上同源性的dna序列,其同源性可以为60%以上、70%以上、80%以上、85%以上、90%以上、92%以上、94%以上、96%以上、98%以上或99%以上。优选地,所述核酸适配体序列被修饰,所述修饰包括磷酸化、甲基化、氨基化、巯基化、用硫取代氧、用硒取代氧或同位素化。优选地,所述核酸适配体序列上连接荧光标记物、放射性物质、治疗性物质、生物素、地高辛、纳米发光材料、小肽、sirna或酶。上述荧光标记物、放射性物质、治疗性物质、生物素、地高辛、纳米发光材料、小肽、sirna、酶为常用的标记、检测、诊断或治疗的物质。以上经修饰或连接处理后的核酸适配体,都具有与原核酸适配体基本相同或类似的分子结构、理化性质和功能,都能与肿瘤坏死因子-α结合;经修饰或连接处理后的核酸适配体可以保持或提高核酸适配体与肿瘤坏死因子-α的亲和力,或可以提高核酸适配体的稳定性。本发明还提出了一种核酸适配体衍生物,所述核酸适配体衍生物是由上述核酸适配体序列的骨架衍生出的硫代磷酸酯骨架序列,或者是由上述核酸适配体改造成的肽核酸。上述核酸适配体衍生物与原核酸适配体具有基本相同或类似的分子结构、理化性质和功能。上述“硫代磷酸酯骨架”具有本领域普通技术人员一般理解的含义,其是指rna和dna核酸适配体的磷酸二酯骨架的非桥键氧原子可以被一个或两个硫原子取代,分别产生具有硫代磷酸酯或二硫代磷酸酯键的硫代磷酸酯骨架。硫代磷酸酯骨架序列对核酸酶降解的抗性更强;对于核酸酶的降解来说,硫代磷酸酯骨架序列更稳定。上述“肽核酸”具有本领域普通技术人员一般理解的含义,其是指一种人工合成dna分子类似物,1991年由nielsen等首次报道。用n-2-(氨乙基)-甘氨酸(n-(2-aminoethyl)-glycine)单位代替糖-磷酸酯骨架作为重复结构单元,合成了以肽键连接的寡核苷酸模拟物,称为肽核酸。由于肽核酸(pna)没有如dna或rna上的磷酸基团,因此pna与dna之间缺乏电性相斥的现象,使两者之间的结合强度大于dna与dna。上述硫代磷酸酯骨架序列和肽核酸可用核酸适配体按照本领域常规方法制得。本发明还提出了上述核酸适配体或上述核酸适配体衍生物在纯化肿瘤坏死因子-α、检测肿瘤坏死因子-α中的应用。肿瘤坏死因子-α的纯化方法有多种,如:将上述核酸适配体或上述核酸适配体衍生物与含有tnf-α蛋白的样品液孵育,使得二者特异性结合形成复合物,回收复合物,通过高盐或者其他方法将结合的tnf-α蛋白洗脱下来,即纯化得到tnf-α蛋白;或者,先将上述核酸适配体或上述核酸适配体衍生物固定到固相基质上,将含有tnf-α蛋白的样品液缓慢流经固相基质,二者会特异性结合,且不会与其它无关蛋白结合,然后用缓冲液清洗固相基质,去除未结合的无关蛋白,再用高盐或者其他方法将结合的tnf-α蛋白洗脱并收集,即纯化得到tnf-α蛋白。本领域技术人员能够依据实际需要选择适当的纯化方法。本发明还提出了上述核酸适配体或上述核酸适配体衍生物在制备检测肿瘤坏死因子-α的试剂盒、检测肿瘤坏死因子-α的分子探针中的应用。可以用上述核酸适配体或上述核酸适配体衍生物来检测受试者血清中tnf-α蛋白的浓度,进而判断受试者是否具有tnf-α表达水平异常相关的疾病例如异常的炎性反应相关的诸如牛皮癣、肿瘤等疾病;纯化所得tnf-α可用于治疗tnf-α蛋白异常的相关疾病,例如促进肿瘤坏死等。本发明人设计并合成了一个随机单链dna文库和相应的引物,经适宜的磁珠法筛选六轮得到特异性结合肿瘤坏死因子-α的核酸适配体,将其分别命名为tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt;tnf-α-12-18nt的序列如seqidno.1所示,其序列为:5’-ggggctgggagtttctgc-3’;tnf-α-03-56nt的序列如seqidno.2所示,其序列为:5’-cacgcataacttcacggccacggttgagctgctggtattggctatcgttatgcgtg-3’;tnf-α-01-56nt的序列如seqidno.3所示,其序列为:5’-cacgcataacatcgcccgcagcacccatttgttttttttttttttggttatgcgtg-3’;tnf-α-72-56nt的序列如seqidno.4所示,其序列为:5’-cacgcataacggggggtgcgccggtaggtgagtggctggtgtttgtgttatgcgtg-3’。与现有技术相比,本发明的优点在于:本发明具有比蛋白抗体易合成,分子量小,可以对不同部位进行修饰和取代,且更稳定,易于保存,无批次间差异等优点;本发明可在常温的血清环境中结合tnf-α蛋白;另外,与目前已经公布的一些tnf-α蛋白的核酸适配体相比,本发明对tnf-α蛋白的亲和力更高,结构更稳定,在dpbs缓冲液和mes缓冲液中均有很强的结合,蛋白点杂交实验中可以识别tnf-α蛋白,可以用于快速、敏捷且准确地检测tnf-α蛋白,并且本发明可以在血清中与tnf-α蛋白结合。附图说明图1为实施例1中第五轮、第六轮所得文库与肿瘤坏死因子-α的亲和力spr检测结果。图2为如seqidnos.1-4所示的dna序列在mes缓冲液中与肿瘤坏死因子-α的亲和力spr检测结果。图3为如seqidnos.1-4所示的dna序列在dpbs缓冲液中与肿瘤坏死因子-α的亲和力spr检测结果。图4为如seqidnos.1-4所示的dna序列与肿瘤坏死因子-α的结合kd值用spr检测的结果。图5为如seqidnos.1-4所示的dna序用蛋白点杂交检测肿瘤坏死因子-α的结果。具体实施方式下面,通过具体实施例对本发明的技术方案进行详细说明。以下实施例中所述实验方法如无特殊说明,均为常规方法;所用的实验材料如无特殊说明,均为常规生化试剂,可通过商业途径购买得到。实施例1特异性结合肿瘤坏死因子-α的核酸适配体的筛选1.合成以下序列所示的随机单链dna文库和引物:随机单链dna文库:5’-tccagcactccacgcataac-36n-gttatgcgtgctaccgtgaa-3’,其中,“36n”表示36个任意的核苷酸碱基连接而成的序列,该文库由生工生物工程(上海)股份有限公司合成;引物由南京金斯瑞生物科技有限公司合成,引物信息如表1所示,表1引物及其序列备注:lib18s1为正向引物;lib20a2为反向引物;lib18s1-fam为荧光标记的正向引物;lib20a2-ploya为连接有polya尾的反向引物,polya为由19个腺苷酸(a)组成的polya尾,“spacer18”为18原子的六乙二醇间臂,其结构式如下:将随机单链dna文库、引物分别用mes缓冲液(mes:100mm,nacl:150mm,kcl:1mm,mgcl2:1mm,cacl2:1mm;ph6.0,25℃)配制成100μm贮存液,依次记为随机单链dna文库储备液、lib18s1储备液、lib20a2储备液、lib18s1-fam储备液、lib20a2-ploya储备液,于-20℃保存备用。2.磁珠法筛选2.1羧基磁珠固定靶标蛋白(tnf-α蛋白):(1)取50μl羧基磁珠(invitrogen,dynabeadstmmyonetmcarboxylicacid,#65012),用200μldpbs缓冲液(cacl2:0.1g/l,kcl:0.2g/l,kh2po4:0.2g/l,mgcl2·6h2o:0.1g/l,nacl:8g/l,na2hpo4:1.15g/l)清洗4遍,磁铁垂钓磁珠,去上清;(2)取配置好的nhs(n-羟基琥珀酰亚胺;0.1m水溶液)和edc(1-(3-二甲氨基丙基)-3-乙基碳二亚胺盐酸盐;0.4m水溶液)各50μl,等体积混合,加入到上一步清洗后的磁珠中,25℃孵育20min活化磁珠表面的羧基,磁珠用mes缓冲液清洗1遍后得到活化后的磁珠,尽快用于下一步;(3)取50μl浓度为0.5mg/ml的tnf-α蛋白(货号:210-ta-02m/cf;r&dsystems),加入ph4.0,10mmnaac溶液100μl混匀,然后加至活化后的磁珠中,室温摇床孵育30min(期间如果磁珠聚集需要不定时摇匀),使得tnf-α蛋白通过蛋白表面的氨基偶联到磁珠表面,磁铁垂钓磁珠,去上清得到固定靶标的磁珠;(4)取100μl1m乙醇胺ph8.5加至固定靶标的磁珠中,室温,摇床孵育10min,封闭磁珠表面未反应的活化位点,磁铁垂钓磁珠,去上清,用200μlmes缓冲液清洗4遍,此磁珠记为mb-tnf-α磁珠,待用;2.2羧基磁珠固定bsa蛋白:方法同2.1,用bsa蛋白替换tnf-α蛋白,其他条件相同,获得的磁珠记为mb-bsa磁珠,待用;2.3磁珠筛选过程:2.3.1文库变复性处理:取1od随机单链dna文库作为起始文库,14000rpm离心10min,将文库粉末离心到管底,用mes缓冲液溶解至10μm,分装到pcr管进行变复性处理,变复性处理过程如下:pcr仪设定程序95℃保持10min,拿出pcr管立即冰水浴5min,然后将pcr管置于室温平衡至室温得到变复性处理后文库,变复性处理目的是使折叠的链解开,然后再折叠成一定的构象;2.3.2反筛:将变复性处理后文库加入到2.2得到的mb-bsa磁珠中,在垂直混合仪上25℃孵育30min,置于磁力架上,收集得到上清a备用;将孵育后的磁珠加入200μlmes缓冲液清洗4次,清洗后的磁珠加入200μlmes缓冲液中,沸水浴10min,收集煮沸后的上清标记为elution-bsa备用,丢弃磁珠;2.3.3正筛:将上清a全部加入到2.1得到的mb-tnf-α磁珠中,室温摇床孵育30min,结束后吸弃上清,保留磁珠,用mes缓冲液清洗磁珠4次,每次200μl,吸弃上清,向清洗后的磁珠中加入200μlmes缓冲液,沸水浴10min,磁铁垂钓磁珠,回收上清标记为elution-tnf-α;2.3.4计算正筛、反筛的文库保留率:取罗氏8联排pcr管,每孔加入28μlq-pcrmix,再分别加入elution-bsa和elution-tnf-α各2μl,进行荧光定量pcr,其程序如下:95℃预变性2min;95℃变性0.5min,60℃退火0.5min,72℃延伸0.5min,共25个循环;然后根据q-pcr的起跳循环数以及标准曲线,分别计算出elution-tnf-α和elution-bsa中的分子数,并分别计算其与投入的起始文库的总分子数的比值即得正筛、反筛的文库保留率,这样可以有效的监测每一轮筛选的效果;其中,q-pcrmix的配方如表2:表2q-pcrmix的配方试剂体积(μl)ddh2o81610*pfu酶缓冲液100dntpmix(10mm)20引物lib18s15引物lib20a25pfu酶4evagreen染料50上述每一轮筛选的条件、文库保留率见表3:表3各轮筛选的条件、各轮文库保留率2.4乳浊液pcr(e-pcr):以elution-tnf-α中的核酸分子为模板,用乳浊液pcr(epcr)进行扩增,方法如下:将全部模板elution-tnf-α加入2mlpcrmix中混匀,加入4倍体积的epcr微液滴生成油,涡旋制备得到乳浊液;将乳浊液分装到pcr管中扩增,100μl/管,扩增条件如下:95℃预变性2min,95℃变性60s,60℃退火60s,72℃延伸60s,共30个循环,4℃保存;其中,epcr微液滴生成油购自安徽省昂普拓迈(aptamy)生物科技有限公司(货号:epo100),pcrmix的配方见表4。表4pcrmix的配方试剂总体积ddh2o866μl10*pfu酶buffer100μldntpmix(10mm)20μllib18s1-fam(100μm)5μllib20a2-polya(100μm)5μlpfu酶4μl(20u)2.5制备单链:收集所有的epcr产物于15ml尖底离心管中,加入2倍体积的正丁醇,在旋涡混合器上震荡以充分混匀;于25℃,9000rpm离心10min;移弃上相(正丁醇和油),得到浓缩的pcr扩增产物,按体积比1:1加入tbe尿素变性缓冲液,煮沸变性15min使dna变性,随后冰浴1min,将所有的样品进行尿素变性聚丙烯酰胺凝胶电泳,于400v电泳至溴酚蓝到达胶底部,使fam标记的单链dna与加长的反向的带有polya的单链dna分开,其中,tbe尿素变性缓冲液和尿素变性聚丙烯酰胺凝胶均购自昂普拓迈生物科技有限责任公司,货号分别为tlb-5、ddp-100;2.6切胶回收fam标记的单链dna:将凝胶取出放在塑料膜上,ex(nm):495,em(nm):517条件下检测fam标记的单链dna;用干净的刀片将目的条带直接切下,将胶条转移至1.5mlep管中并捣碎,加入1mlddh2o后沸水浴10min将胶中的fam标记的单链dna转移至溶液中,离心去除胶的碎片,留上清,上清用正丁醇纯化,纯化方法为:加入2倍体积的正丁醇,在旋涡混合器上震荡以充分混匀;于25℃,9000rpm离心5min;移弃上相(正丁醇),得到浓缩的fam标记的单链dna,用3kd的透析袋透析过夜得到次级文库,透析液为mes缓冲液;3、多轮筛选:重复筛选6轮,每次操作均以前一轮第2.6步操作中得到的次级文库为起始文库,筛选过程中用spr检测每一轮的次级文库对tnf-α蛋白的识别能力变化(第五轮、第六轮筛选得到的次级文库与tnf-α蛋白的亲和力检测的spr结果如图1所示,具体操作步骤见实施例2),当次级文库对tnf-α蛋白的识别能力满足要求(即次级文库与靶标的结合能力高于第一轮投入的随机单链dna文库),将得到的次级文库经克隆测序分析后,挑选若干条序列由上海生工合成,检测亲和力,经过亲和力检测以及序列优化,最后确定了4条dna序列与肿瘤坏死因子-α具有很强的结合能力(参见实施例3-6),即为特异性结合肿瘤坏死因子-α的核酸适配体,将其分别命名为tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt;tnf-α-12-18nt的序列如seqidno.1所示,其序列为:5’-ggggctgggagtttctgc-3’;tnf-α-03-56nt的序列如seqidno.2所示,其序列为:5’-cacgcataacttcacggccacggttgagctgctggtattggctatcgttatgcgtg-3’;tnf-α-01-56nt的序列如seqidno.3所示,其序列为:5’-cacgcataacatcgcccgcagcacccatttgttttttttttttttggttatgcgtg-3’;tnf-α-72-56nt的序列如seqidno.4所示,其序列为:5’-cacgcataacggggggtgcgccggtaggtgagtggctggtgtttgtgttatgcgtg-3’。所述筛选方法中,可逐轮增加筛选压力,以增进筛选核酸适配体的富集程度,缩短筛选进程。所述增加筛选压力包括减少投入起始文库的量、靶标蛋白的用量,缩短起始文库和靶标蛋白的孵育时间,增加磁珠清洗时间、清洗次数(本次筛选详细参数见表3)。实施例2表面等离子共振(spr)检测实施例1中第五轮筛选、第六轮筛选得到的次级文库和tnf-α蛋白的亲和力溶液配制:取实施例1中第一轮筛选的随机单链dna文库、第五轮筛选得到的次级文库、第六轮筛选得到的次级文库,分别用mes缓冲液稀释成浓度为500nm的溶液,依次记为溶液pool0、溶液pool5、溶液pool6。操作:将tnf-α蛋白偶联到cm5芯片(gehealthcare货号:br100399)表面的第3通道上记为tnf-α通道,第4通道不偶联任何蛋白,只做活化和封闭处理记为对照通道;tnf-α通道偶联过程如下:先用50mmnaoh水溶液清洗芯片,进样20μl,流速10μl/min,然后用edc和nhs等体积混合的溶液,进样50μl活化芯片,流速5μl/min;将tnf-α蛋白用ph4.5的10mm醋酸钠稀释至终浓度为50μg/ml后进样,进样体积50μl,流速5μl/min,tnf-α蛋白偶联量为2000ru;然后进乙醇胺封闭芯片,流速5μl/min,进样50μl;对照通道活化和封闭过程如下:先用50mmnaoh水溶液清洗芯片,进样20μl,流速10μl/min,然后用edc和nhs等体积混合的溶液,进样50μl活化芯片,流速5μl/min;然后进乙醇胺封闭芯片,流速5μl/min,进样50μl;上述edc、nhs同实施例1的2.1中的edc、nhs。检测:使用biacoret200设定检测参数,进样流速30μl/min,时间3min,解离条件为流速30μl/min,时间5min;上述所有过程中,仪器运行的缓冲液均为mes缓冲液;取溶液pool0、溶液pool5、溶液pool6依次分别进样tnf-α通道、对照通道,检测结果参见图1,图1为实施例1中第五轮、第六轮所得文库与肿瘤坏死因子-α的亲和力spr检测结果;由图1可以看出,第五轮筛选、第六轮筛选得到的次级文库均与靶标肿瘤坏死因子-α有明显的结合,满足送测序的要求。实施例3表面等离子共振(spr)检测核酸适配体tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt与tnf-α蛋白在mes缓冲液中的亲和力溶液配制:取tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt分别用mes缓冲液稀释成浓度为100nm的溶液,依次记为溶液1、溶液2、溶液3、溶液4。操作:将tnf-α蛋白偶联到cm5芯片(gehealthcare货号:br100399)表面,具体操作同实施例2中的tnf-α通道偶联过程。检测:使用表面等离子共振仪(gehealthcare,型号:biacoret200)设定检测参数,进样30μl/min*3min,解离30μl/min*5min,取溶液1、溶液2、溶液3、溶液4依次进样,检测结果参见图2,图2为如seqidnos.1-4所示的dna序列在mes缓冲液中与肿瘤坏死因子-α的亲和力spr检测结果。由图2可以看出,核酸适配体tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt与靶标肿瘤坏死因子-α在mes缓冲液中的亲和力均非常高,上升的ru值均很高。实施例4表面等离子共振(spr)检测核酸适配体tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt与tnf-α蛋白在dpbs缓冲液中的亲和力溶液配制、操作、检测同实施例3,将mes缓冲液均更换成dpbs缓冲液。检测结果参见图3,图3为如seqidnos.1-4所示的dna序列在dpbs缓冲液中与肿瘤坏死因子-α的亲和力spr检测结果。由图3可以看出,核酸适配体tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt与靶标肿瘤坏死因子-α在dpbs缓冲液中的亲和力均非常高,上升的ru值均很高。实施例5表面等离子共振(spr)检测核酸适配体tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt与tnf-α蛋白的结合kd值溶液配制:取tnf-α-12-18nt用mes缓冲液稀释成一系列不同浓度的溶液,其浓度为:1000nm、500nm、125nm、62.5nm、15.625nm。取tnf-α-03-56nt用mes缓冲液稀释成一系列不同浓度的溶液,其浓度为:125nm、62.5nm、31.25nm、15.625nm、7.813nm。取tnf-α-01-56nt用mes缓冲液稀释成一系列不同浓度的溶液,其浓度为:1000nm、500nm、125nm、62.5nm、15.625nm。取tnf-α-72-56nt用mes缓冲液稀释成一系列不同浓度的溶液,其浓度为:2000nm、1000nm、500nm、250nm、125nm、62.5nm。操作:将tnf-α蛋白偶联到cm5芯片(gehealthcare货号:br100399)表面:tnf-α蛋白用ph4.5的10mm醋酸钠稀释至终浓度为50μg/ml后,进样体积20μl,流速5ul/min,tnf-α蛋白偶联量为600ru,其他同实施例2中的tnf-α通道偶联过程。检测:使用表面等离子共振仪(gehealthcare,型号:biacoret200)设定检测参数,进样10μl/min*3min,解离10μl/min*5min,再生:1mnacl30μl/min*30s,仪器运行的缓冲液为mes缓冲液,取上述各核酸适配的系列溶液从低浓度到高浓度依次进样,检测结果参见图4;图4为如seqidnos.1-4所示的dna序列与肿瘤坏死因子-α的结合kd值用spr检测的结果。由图4可以看出,tnf-α-12-18nt与肿瘤坏死因子-α的结合kd值为1.165e-8m;tnf-α-03-56nt与肿瘤坏死因子-α的结合kd值为:4.049e-10m;tnf-α-01-56nt与肿瘤坏死因子-α的结合kd值为:5.838e-8m,tnf-α-72-56nt与肿瘤坏死因子-α的结合kd值为:2.177e-7m;kd值均在nm级别以上,有的可以达到pm级别,如seqidnos.1-4所示的dna序列与肿瘤坏死因子-α的亲和力很高。实施例6蛋白点杂交实验检测生物素修饰的核酸适配体tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt与tnf-α蛋白的相互作用溶液配制:tnf-α蛋白系列溶液:取tnf-α蛋白分别用pbs缓冲液稀释成浓度为0.5mg/ml、0.167mg/ml、0.056mg/ml、0.018mg/ml、0.006mg/ml的溶液。对照蛋白溶液:取对照蛋白il-12用pbs缓冲液稀释成浓度为0.5mg/ml的溶液。10%bsa溶液:取bsa蛋白用pbs缓冲液稀释成质量分数为10wt%的溶液。pbst缓冲液:取tween20用pbs缓冲液稀释成体积分数为0.5‰的溶液。变复性核酸适配体溶液:取tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt分别用pbs缓冲液稀释成1μm的溶液,分别经变复性处理(95℃保持10min,然后立即冰浴5min,再室温平衡10min)得到各自对应的变复性核酸适配体溶液。hrp-标记的链霉抗生物素蛋白溶液:hrp-标记的链霉抗生物素蛋白(购自碧云天,货号a0303)用pbst缓冲液按照1:10000(v/v)配制得到。显色液:a液:b液=1:1(v/v),(beyoeclstar特超敏ecl化学发光试剂盒,购自碧云天,货号p0018a,a液和b液为试剂盒自带溶液)。操作:取tnf-α蛋白系列溶液、对照蛋白溶液各2μl,分别点样到硝酸纤维素膜上(购自millipore,规格10cm×5cm),自然风干,然后用10%bsa溶液于室温封闭6h,接着用pbst缓冲液清洗3次,吸净;共做4份平行样;将4个变复性核酸适配体溶液分别和硝酸纤维素膜上的蛋白摇床室温孵育2h,然后用pbst缓冲液洗三次,清洗时放置在摇床上,每次10min;加入hrp-标记的链霉抗生物素蛋白溶液室温摇床孵育30min,用pbst缓冲液洗三次,清洗时放置在摇床上,每次10min;加入显色液于室温显色1min,使用仪器(ge医疗生命科学部的imagequanttmlas4000数字成像系统)观察拍照,结果参见图5,图5为如seqidnos.1-4所示的dna序用蛋白点杂交检测肿瘤坏死因子-α的结果。由图5可以看出,图5包含了各蛋白浓度梯度变化的情况以及对照蛋白的情况,可以看出生物素修饰的tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt对tnf-α蛋白显色明显,随着tnf-α蛋白浓度的降低,显色的斑点颜色变浅,而对il-12蛋白没有显色,这说明生物素修饰的tnf-α-12-18nt、tnf-α-03-56nt、tnf-α-01-56nt、tnf-α-72-56nt均可以用于膜杂交tnf-α蛋白的检测,而且灵敏度较高。以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。序列表<110>安徽省昂普拓迈生物科技有限责任公司<120>一种特异性结合肿瘤坏死因子-α的核酸适配体及其应用<130>2019<160>4<170>siposequencelisting1.0<210>1<211>18<212>dna<213>人工合成()<400>1ggggctgggagtttctgc18<210>2<211>56<212>dna<213>人工合成()<400>2cacgcataacttcacggccacggttgagctgctggtattggctatcgttatgcgtg56<210>3<211>56<212>dna<213>人工合成()<400>3cacgcataacatcgcccgcagcacccatttgttttttttttttttggttatgcgtg56<210>4<211>56<212>dna<213>人工合成()<400>4cacgcataacggggggtgcgccggtaggtgagtggctggtgtttgtgttatgcgtg56当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1