一种提高嘌呤操纵子pur基因表达量的突变体及其构建方法与应用
本发明涉及一种提高嘌呤操纵子pur基因表达量的突变体及其构建方法与应用,属于基因工程技术领域。
背景技术:
嘌呤类化合物是细胞内重要生命活性物质,在细胞内遗传物质的合成与传递、信号转导、能量供应等均具有重要作用。另外,嘌呤类化合物作为前体可以合成多种药物,在疾病的诊断和治疗以及生命科学研究等领域也有广泛的应用。例如早期的巯基嘌呤类药物,以及后期的氟达拉滨、克罗拉滨等嘌呤类核苷药物在癌症治疗方面发挥重要作用。
嘌呤的从头合成路线早已探明,嘌呤的从头合成主要以谷氨酰胺和5-磷酸核糖焦磷酸(prpp)为前体,经过10步反应合成第一个带有嘌呤环的化合物次黄嘌呤核苷酸(imp),imp进一步转化为不同的嘌呤化合物及嘌呤类核苷酸。大肠杆菌中imp生物合成的相关基因大部分以嘌呤操纵子pur形式存在。嘌呤的从头合成受到转录阻遏调控、关键酶的反馈抑制调控等多层次、不同水平的严密调控,导致细胞内嘌呤的积累非常低。其中嘌呤操纵子pur的转录抑制是限制嘌呤合成基因表达和嘌呤化合物积累的重要因素。因此提高嘌呤pur操纵子的基因表达水平是提高嘌呤类化合物及其衍生物生物合成的重要途径。
dna结合转录二组分调控因子arca在嘌呤操纵子pur基因表达的调控作用和在嘌呤生物合成中的应用暂无报道。
技术实现要素:
针对嘌呤从头合成途径中,嘌呤操纵子pur的转录抑制以及嘌呤化合物难以积累的问题,本发明将全局调控因子arca首次应用于嘌呤操纵子pur的调控,提高嘌呤操纵子pur的基因表达水平和嘌呤化合物的生物合成,技术方案如下:
首先本发明提供了一种提高嘌呤操纵子pur基因表达量的突变体,所述突变体是通过敲除大肠杆菌中的dna结合转录二组分调控因子arca构建获得的,所述dna结合转录二组分调控因子arca,genbank登录号为948874。
本发明还提供了上述突变体的构建方法,利用p1噬菌体转导法在大肠杆菌基因组中敲除dna结合转录二组分调控因子arca,构建获得突变菌株e.coli△arca。
优选地,所述大肠杆菌为e.coliw3110。
本发明还提供了一种高产次黄嘌呤的重组菌,所述重组菌过表达突变的prpp合成酶基因prs和突变的prpp转酰胺酶基因purf,出发菌株为上述的敲除了大肠杆菌中的dna结合转录二组分调控因子arca的大肠杆菌突变体。
进一步地限定,所述突变的prpp合成酶基因prs,其核苷酸序列如seqidno.1所示;所述突变的prpp转酰胺酶基因purf如seqidno.2所示。
本发明还提供了上述高产次黄嘌呤的重组菌的构建方法,步骤如下:
1)突变的prpp转酰胺酶基因purf的制备:
以大肠杆菌的基因组dna为模板,以引物seqidno.4和seqidno.6克隆获得k326q突变的prpp转酰胺酶基因purf的上游片段,以引物seqidno.5和seqidno.7克隆获得k326q突变的prpp转酰胺酶基因purf的下游片段,以引物seqidno.4和seqidno.5,利用片段搭桥法搭桥k326q突变的prpp转酰胺酶基因purf的上游和下游片段,获得如seqidno.3所示的k326q突变的prpp转酰胺酶基因purf;
以k326q突变的prpp转酰胺酶基因purf为模板,以引物seqidno.4和seqidno.8克隆获得p410w突变的prpp转酰胺酶基因purf的上游片段,以引物seqidno.5和seqidno.9克隆获得p410w突变的prpp转酰胺酶基因purf的下游片段,以引物seqidno.4和seqidno.5,利用片段搭桥法搭桥p410w突变的prpp转酰胺酶基因purf的上游和下游片段,获得如seqidno.2所示的k326q、p410w双突变的prpp转酰胺酶基因purf;所述k326q是指prpp转酰胺酶基因purf编码的第326位赖氨酸突变为谷氨酰胺,所述p410w是指prpp转酰胺酶基因purf编码的第410位脯氨酸突变为色氨酸;
2)将步骤1)所得的k326q、p410w双突变的prpp转酰胺酶基因purf连接到中间载体上,获得重组质粒i;
3)突变的prpp合成酶基因prs的构建:以大肠杆菌的基因组dna为模板,以引物seqidno.10和seqidno.11克隆获得d128a突变的prpp合成酶基因prs的上游片段,以引物seqidno.12和seqidno.13克隆获得d128a突变的prpp合成酶基因prs的下游片段,以引物seqidno.10和seqidno.13,利用片段搭桥法搭桥d128a突变的prpp合成酶基因prs的上游和下游片段,获得如seqidno.1所示的d128a突变的prpp合成酶基因prs;所述d128a是指prpp合成酶基因prs编码的第128位的天冬氨酸突变为丙氨酸;
4)将步骤3)所得的d128a突变的prpp合成酶基因prs连接到步骤2)所得的重组质粒i中,获得过表达突变的prpp合成酶基因prs和突变的prpp转酰胺酶基因purf的重组质粒ii;
5)将步骤4)所得的重组质粒ii导入前述的突变体中,获得高产次黄嘌呤的重组菌。
进一步地限定,步骤2)所述中间载体为pacycduet-1。
进一步地限定,步骤5)所述重组质粒ii导入突变体的方法为热激转化法。
本发明还提供了上述重组菌在合成次黄嘌呤或次黄嘌呤衍生物中的应用。
进一步地限定,所述次黄嘌呤或次黄嘌呤衍生物的合成方法如下:在发酵培养基中,接种上述的高产次黄嘌呤的重组菌,以葡萄糖为碳源,37℃,180rpm的条件下发酵48h。
本发明中prpp合成酶基因prs来源于大肠杆菌(escherichiacoli),在genbank上记载的全名为ribose-phosphatediphosphokinase,为磷酸核糖二磷酸激酶,geneid为945772。d128a突变的prpp合成酶基因prs即prpp合成酶基因prs中含有d128a突变,其核苷酸序列如seqidno.1所示。d128a即表示第128位的氨基酸d突变为a。
本发明中prpp转酰胺酶基因purf来源于大肠杆菌(escherichiacoli),在genbank上记载的全名为amidophosphoribosyltransferase,为磷酸核糖氨基转移酶,geneid为946794。
k326q、p410w双突变的prpp转酰胺酶基因purf即prpp转酰胺酶基因purf中含有k326q、p410w双突变,其核苷酸序列如seqidno.2所示。k326q、p410w双突变即表示第326位的氨基酸k突变为q,且第410位的氨基酸p突变为w。
本发明所述的p1噬菌体转导法是本领域基因敲除的常用技术之一,按照标准的操作方法操作即可。
本发明中所涉及的定义和缩写对照如下:
dna结合转录二组分调控因子:arca
磷酸核糖焦磷酸:prpp
prpp合成酶基因:prs
prpp转酰胺酶基因:purf
大肠杆菌(escherichiacoli):e.coli
本发明中“热激转化”或“热转化”指分子生物学中转染技术的一种,用来将外来基因整合到宿主基因中并稳定表达,其利用受到热激后,细胞膜出现裂隙,将外来基因导入宿主基因或将外来质粒导入宿主原生质体,又热激转化或热转化等。
本发明中“过量表达”或“过表达”指特定的基因在生物体中大量表达,表达量超过正常水平(即,野生型表达水平),可以通过增强内源表达或引入外源基因来实现。
本发明中通过失活dna结合转录二组分调控因子arca提高嘌呤操纵子pur的基因表达水平以及该调控方法在合成次黄嘌呤和衍生物中的应用在本发明的保护范围之内。
有益效果
本发明首次实现了dna结合转录二组分调控因子arca在嘌呤操纵子pur基因表达的调控和在嘌呤生物合成中的应用。失活dna结合转录二组分调控因子arca后,嘌呤操作子pur的基因表达水平均发生显著提高。以敲除arca基因的大肠杆菌突变体为出发菌株,过表达突变的prpp合成酶基因prs和突变的prpp转酰胺酶基因purf能够将次黄嘌呤的产量提高2.29倍。本发明提供的提高嘌呤操纵子pur基因表达的调控方法,应用于次黄嘌呤的生物合成,能够将次黄嘌呤的产量提高2.29倍。
附图说明
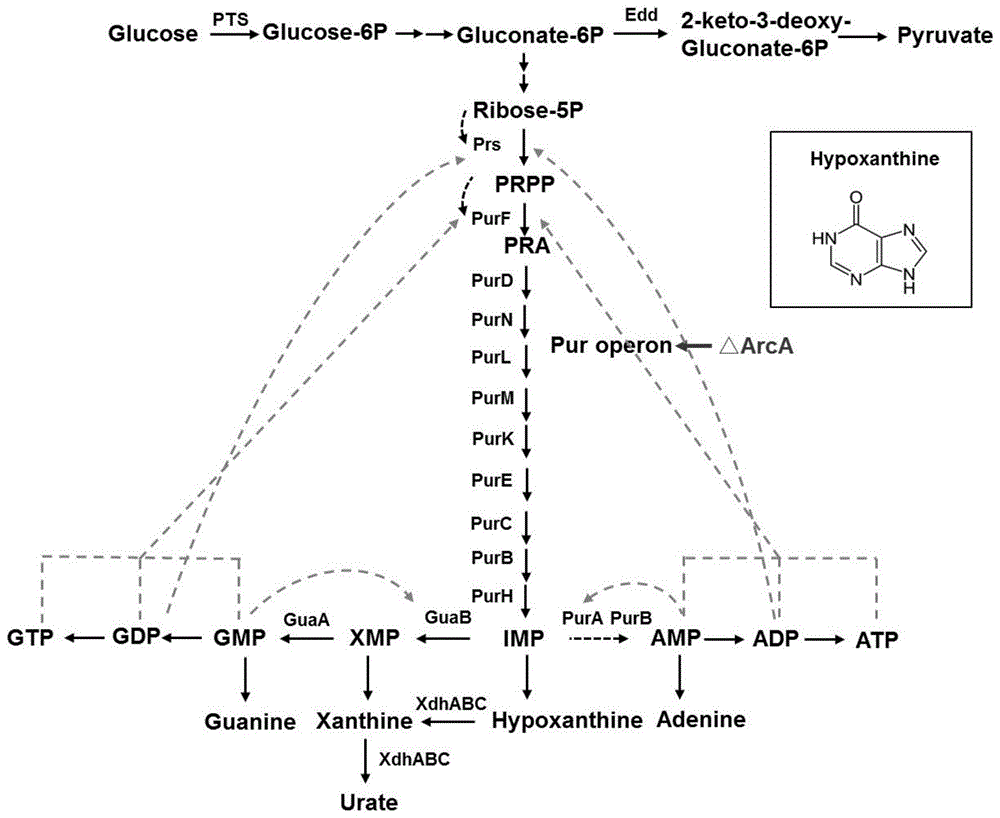
图1为葡萄糖为碳源嘌呤的从头合成途径;
图2为定量pcr技术检测失活arca对嘌呤操纵子pur基因表达水平的影响;
图3为次黄嘌呤的摇瓶发酵检测结果。
具体实施方式
下面结合具体实施例对本发明做进一步说明,但本发明不受实施例的限制。
以下实施例中所用材料、试剂、仪器和方法,未经特殊说明,均为本领域中的常规材料、试剂、仪器和方法,均可通过商业渠道获得。
所用酶试剂购自mbifermentas公司,提取质粒所用的试剂盒和回收dna片段所用的试剂盒购自美国omega公司,相应的操作步骤按照产品说明书进行;所有培养基如无特别说明均用去离子水配制。
培养基配方:
1)lb培养基:5g/l酵母粉,10g/lnacl,10g/l蛋白胨,其余为水,121℃,20min灭菌。
2)发酵生产培养基(发酵培养基):5g/l酵母粉,10g/lnacl,10g/l蛋白胨,20g/l葡萄糖(glucose)。
在实际培养过程中,可向上述培养基中添加一定浓度的抗生素以维持质粒的稳定性,如50mg/l的氯霉素。
以下实验过程中所涉及的引物的核苷酸序列如表1所示。
表1本发明重组菌构建所用的引物的核苷酸序列
实施例1:提高嘌呤操纵子pur基因表达量的突变体e.coliw3110△arca的构建。
利用p1噬菌体转导法敲除大肠杆菌e.coliw3110基因组的dna结合转录二组分调控因子arca(所述arca的geneid:948874),构建突变菌株e.coliw3110△arca。具体步骤如下:
1)供体菌株裂解文库的制备
10ml无菌的ep管中加入4ml加热融化的0.4%琼脂培养基,加入400μl过夜培养的供体菌株jw4364(该供体菌株来源于keiocollection文库,可以通过商业途径购买,keiocollection文库构建方法如“babat,etal.constructionofescherichiacolik-12in-frame,single-geneknockoutmutants:thekeiocollection.molecularsystemsbiology2006,2(1):1-11”中所述),加入10μl存储的噬菌体原液,将溶液混匀后倒于lb无抗平板上,37℃湿润环境下培养,直至出现不规则噬菌斑。
2)噬菌体裂解文库的收集
刮取平板上所有半固体培养基至10ml无菌ep管,加入3mllb液体培养基,同时加入400μl氯仿,震荡后离心收集上清至另一无菌ep管,同时加入400μl氯仿,此溶液即为jw43640供体菌裂解文库。
3)转导
过夜培养受体菌e.coliw3110,将步骤2)制备的jw4364供体菌裂解文库以不同浓度与受体菌e.coliw3110混合后进行转导,涂布卡那抗性平板,过夜培养至生长出单克隆后,以引物seqidno.14和seqidno.15进行阳性克隆的验证,获得基因组失活dna结合转录二组分调控因子arca的突变菌株e.coliw3110△arca。
实施例2.嘌呤操作子pur基因表达水平的检测。
本实施例利用定量pcr技术检测实施例1构建的突变菌株e.coliw3110△arca和野生菌株e.coliw3110的嘌呤操纵子pur的基因相对表达水平。具体步骤如下;
1)利用easyspinplus艾德莱细菌rna快速提取试剂盒分别提取突变菌株e.coliw3110△arca和野生菌株e.coliw3110的总rna;
2)分别检测野生菌株和突变菌株抽提的总rna的260nm吸光值,确定rna的浓度;
3)将rna浓度调成一致后,利用primerscripttmrtreagentkit试剂盒中的gdnaerase去除rna中残留的基因组dna,并进行反转录为cdna;
4)以组成型表达基因rpod作为内参,利用tbgreentmpremixextaqtmii试剂盒,以cdna为模板,进行定量pcr的检测。其中,purd的扩增引物为:seqidno.16和seqidno.17,purn的扩增引物为:seqidno.18和seqidno.19,purl的扩增引物为:seqidno.20和seqidno.21,purm的扩增引物为:seqidno.22和seqidno.23,purk的扩增引物为:seqidno.24和seqidno.25,pure的扩增引物为:seqidno.26和seqidno.27,purc的扩增引物为:seqidno.28和seqidno.29,purb的扩增引物为:seqidno.30和seqidno.31,purh的扩增引物为:seqidno.32和seqidno.33。
定量pcr的检测结果(图2)说明:失活dna结合转录二组分调控因子arca后,嘌呤操作子pur的基因表达水平均发生显著提高。将野生菌株w3110的pur操纵子基因表达水平定为1,突变菌株e.coliw3110△arca的嘌呤操纵子pur的基因:purd(geneid:948504)的表达水平提高2.01倍,purn(geneid:946973)的表达水平提高1.98倍,purl(geneid:947032)的表达水平提高2.07倍,purm(geneid:946975)的表达水平提高2.11倍,purk(geneid:945153)的表达水平提高2.24倍,pure(geneid:949031)的表达水平提高2.24倍,purc(geneid:946957)的表达水平提高2.18倍,purb(geneid:945695)的表达水平提高1.86倍,purh(geneid:948503)的表达水平提高2.03倍。
实施例3.次黄嘌呤合成菌株的构建。
1)突变的prpp转酰胺酶基因purf的制备:
以大肠杆菌的基因组dna为模板,以引物seqidno.4和seqidno.6克隆获得k326q突变的prpp转酰胺酶基因purf的上游片段,以引物seqidno.5和seqidno.7克隆获得k326q突变的prpp转酰胺酶基因purf的下游片段,利用片段搭桥法以引物seqidno.4和seqidno.5搭桥k326q突变的prpp转酰胺酶基因purf的上游和下游片段,获得如seqidno.3所示的k326q突变的prpp转酰胺酶基因purf;
以k326q突变的prpp转酰胺酶基因purf为模板,以引物seqidno.4和seqidno.8克隆获得p410w突变的prpp转酰胺酶基因purf的上游片段,以引物seqidno.5和seqidno.9克隆获得p410w突变的prpp转酰胺酶基因purf的下游片段,利用片段搭桥法以引物seqidno.4和seqidno.5搭桥p410w突变的prpp转酰胺酶基因purf的上游和下游片段,获得如seqidno.2所示的k326q、p410w双突变的prpp转酰胺酶基因purf;
2)步骤1)所得的k326q、p410w双突变的prpp转酰胺酶基因purf(k326q、p410w)与载体pacycduet-1经saci、hindiiii双酶切后,利用回收试剂盒回收酶切后目的片段purf(k326q、p410w)和载体pacycduet-1,再利用t4dna连接酶进行连接,连接产物转化e.colidh5α,筛选阳性克隆,得到重组质粒pacycduet1-purf(k326q、p410w);
3)突变的prpp合成酶基因prs的构建:以大肠杆菌的基因组dna为模板,以引物seqidno.10和seqidno.11克隆获得d128a突变的prpp合成酶基因prs的上游片段,以引物seqidno.12和seqidno.13克隆获得d128a突变的prpp合成酶基因prs的下游片段,利用片段搭桥法以引物seqidno.10和seqidno.13搭桥d128a突变的prpp合成酶基因prs的上游和下游片段,获得如seqidno.1所示的d128a突变的prpp合成酶基因prs;
4)将步骤3)所得的d128a突变的prpp合成酶基因prs(d128a)与步骤2)所得重组质粒pacycduet1-purf(k326q、p410w)经bamhi、saci双酶切后,利用回收试剂盒回收酶切后目的片段prs(d128a)和载体pacycduet1-purf(k326q、p410w),再利用t4dna连接酶进行连接,连接产物转化e.colidh5α,筛选阳性克隆,得到重组质粒pacycduet1-prs(d128a)-purf(k326q、p410w)。
5)利用takara感受态试剂盒制备突变菌株w3110△arca和对照菌株w3110的感受态,将重组质粒pacycduet1-prs(d128a)-purf(k326q、p410w)通过热激法转化至突变菌株w3110△arca感受态细胞,得到次黄嘌呤生产菌株:
e.coliw3110△arca/pacycduet1-prs(d128a)-purf(k326q、p410w)(简称为hx-a),同时将重组质粒pacycduet1-prs(d128a)-purf(k326q、p410w)转化至野生菌株e.coliw3110,获得对照菌株e.coliw3110/pacycduet1-prs(d128a)-purf(k326q、p410w)(简称为hx-w)。
实施例4.次黄嘌呤的摇瓶发酵试验。
本实施例共进行二组实验,以说明本发明所能够获得的效果,具体实验方法如下:
对照组:e.coliw3110/pacycduet1-prs(d128a)-purf(k326q、p410w)(hx-w),
实验组:实施例3制备次黄嘌呤生产菌株e.coliw3110△arca/pacycduet1-prs(d128a)-purf(k326q、p410w)(hx-a)。
1)将对照菌株hx-w和实验菌株hx-a分别接种至3mllb试管中,37℃过夜培养。
2)将过夜培养后的对照菌株hx-w和实验菌株hx-a按1:100的体积比例接种到含有50ml发酵培养基的250ml摇瓶中(内含50mg/l的氯霉素),37℃、180rpm条件下发酵48h。
3)取1ml发酵液,4℃,12000rpm离心10min,取上清,0.22μm滤膜过滤后,利用lc-ms检测发酵产物。
4)lc-ms检测结果(图3)发现,对照菌株hx-w的次黄嘌呤产量为35.38mg/l,而实验组hx-a的次黄嘌呤产量为81.26mg/l。由此表明,以敲除arca基因的大肠杆菌突变体为出发菌株,过表达突变的prpp合成酶基因prs和突变的prpp转酰胺酶基因purf能够将次黄嘌呤的产量提高2.29倍。本发明提供的提高嘌呤操纵子pur基因表达的调控方法,应用于次黄嘌呤的生物合成(代谢路径如图1所示),能够将次黄嘌呤的产量提高2.29倍。
本领域技术人员应该理解,上述各个步骤均按照标准的分子克隆技术进行。
虽然本发明已以较佳的实施例公开如上,但其并非用以限定本发明,任何熟悉此技术的人,在不脱离本发明精神和范围内,都可以做各种的改动与修饰,因此,本发明的保护范围应该以权利要求书所界定的为准。
核苷酸序列表
<110>中国科学院青岛生物能源与过程研究所
<120>一种提高嘌呤操纵子pur基因表达量的突变体及其构建方法与应用
<130>
<160>33
<170>patentinversion3.5
<210>1
<211>948
<212>dna
<213>d128a突变的prpp合成酶基因prs(含自身启动子序列)
<400>1
gtgcctgatatgaagctttttgctggtaacgccaccccggaactagcacaacgtattgcc60
aaccgcctgtacacttcactcggcgacgccgctgtaggtcgctttagcgatggcgaagtc120
agcgtacaaattaatgaaaatgtacgcggtggtgatattttcatcatccagtccacttgt180
gcccctactaacgacaacctgatggaattagtcgttatggttgatgccctgcgtcgtgct240
tccgcaggtcgtatcaccgctgttatcccctactttggctatgcgcgccaggaccgtcgc300
gtccgttccgctcgtgtaccaatcactgcgaaagtggttgcagacttcctctccagcgtc360
ggtgttgaccgtgtgctgacagtggcgctgcacgctgaacagattcagggtttcttcgac420
gttccggttgataacgtatttggtagcccgatcctgctggaagacatgctgcagctgaat480
ctggataacccaattgtggtttctccggacatcggcggcgttgtgcgtgcccgcgctatc540
gctaagctgctgaacgataccgatatggcaatcatcgacaaacgtcgtccgcgtgcgaac600
gtttcacaggtgatgcatatcatcggtgacgttgcaggtcgtgactgcgtactggtcgat660
gatatgatcgacactggcggtacgctgtgtaaagctgctgaagctctgaaagaacgtggt720
gctaaacgtgtatttgcgtacgcgactcacccgatcttctctggcaacgcggcgaacaac780
ctgcgtaactctgtaattgatgaagtcgttgtctgcgataccattccgctgagcgatgaa840
atcaaatcactgccgaacgtgcgtactctgaccctgtcaggtatgctggccgaagcgatt900
cgtcgtatcagcaacgaagaatcgatctctgccatgttcgaacactaa948
<210>2
<211>1518
<212>dna
<213>k326q、p410w双突变的prpp转酰胺酶基因purf
<400>2
atgtgcggtattgtcggtatcgccggtgttatgccggttaaccagtcgatttatgatgcc60
ttaacggtgcttcagcatcgcggtcaggatgccgccggcatcatcaccatagatgccaat120
aactgcttccgtttgcgtaaagcgaacgggctggtgagcgatgtatttgaagctcgccat180
atgcagcgtttgcagggcaatatgggcattggtcatgtgcgttaccccacggctggcagc240
tccagcgcctctgaagcgcagccgttttacgttaactccccgtatggcattacgcttgcc300
cacaacggcaatctgaccaacgctcacgagttgcgtaaaaaactgtttgaagaaaaacgc360
cgccacatcaacaccacttccgactcggaaattctgcttaatatcttcgccagcgagctg420
gacaacttccgccactacccgctggaagccgacaatattttcgctgccattgctgccaca480
aaccgcttaatccgcggcgcgtatgcctgtgtggcgatgattatcggccacggtatggtt540
gctttccgcgatccaaacgggattcgtccgctggtactgggaaaacgtgatattgacgag600
aaccgtacagaatatatggtcgcttccgaaagcgtagcgctcgatacgctgggctttgat660
ttcctgcgtgacgtcgcgccgggcgaagcgatttacatcactgaagaagggcagttgttt720
acccgtcaatgtgctgacaatccggtcagcaatccgtgcctgtttgagtatgtatacttt780
gcccgcccggactcgtttatcgacaaaatttccgtttacagcgcgcgtgtgaatatgggc840
acgaaactgggcgagaaaattgcccgcgaatgggaagatctggatatcgacgtggtgatc900
ccgatcccagaaacctcgtgtgatatcgcgctggaaattgctcgtattctgggcaaaccg960
taccgccagggcttcgttcagaaccgctatgttggccgcacctttatcatgccgggccag1020
cagctgcgtcgtaagtccgtgcgccgtaaactgaatgccaaccgcgccgagttccgcgat1080
aaaaacgtcctgctggtcgacgactccatcgtccgtggcaccacttctgagcagattatc1140
gagatggcacgcgaagccggagcgaagaaagtgtacctcgcttctgcggcaccggaaatt1200
cgcttcccgaacgtttatggtattgatatgtggagcgccacggaactgatcgctcacggt1260
cgcgaagttgatgaaattcgccagatcatcggtgctgacgggttgattttccaggatctg1320
aacgatctgatcgacgccgttcgcgctgaaaatccggatatccagcagtttgaatgctcg1380
gtgttcaacggcgtctacgtcaccaaagatgttgatcagggctacctcgatttcctcgat1440
acgttacgtaatgatgacgccaaagcagtgcaacgtcagaacgaagtggaaaatctcgaa1500
atgcataacgaaggatga1518
<210>3
<211>1518
<212>dna
<213>k326q突变的prpp转酰胺酶基因purf
<400>3
atgtgcggtattgtcggtatcgccggtgttatgccggttaaccagtcgatttatgatgcc60
ttaacggtgcttcagcatcgcggtcaggatgccgccggcatcatcaccatagatgccaat120
aactgcttccgtttgcgtaaagcgaacgggctggtgagcgatgtatttgaagctcgccat180
atgcagcgtttgcagggcaatatgggcattggtcatgtgcgttaccccacggctggcagc240
tccagcgcctctgaagcgcagccgttttacgttaactccccgtatggcattacgcttgcc300
cacaacggcaatctgaccaacgctcacgagttgcgtaaaaaactgtttgaagaaaaacgc360
cgccacatcaacaccacttccgactcggaaattctgcttaatatcttcgccagcgagctg420
gacaacttccgccactacccgctggaagccgacaatattttcgctgccattgctgccaca480
aaccgcttaatccgcggcgcgtatgcctgtgtggcgatgattatcggccacggtatggtt540
gctttccgcgatccaaacgggattcgtccgctggtactgggaaaacgtgatattgacgag600
aaccgtacagaatatatggtcgcttccgaaagcgtagcgctcgatacgctgggctttgat660
ttcctgcgtgacgtcgcgccgggcgaagcgatttacatcactgaagaagggcagttgttt720
acccgtcaatgtgctgacaatccggtcagcaatccgtgcctgtttgagtatgtatacttt780
gcccgcccggactcgtttatcgacaaaatttccgtttacagcgcgcgtgtgaatatgggc840
acgaaactgggcgagaaaattgcccgcgaatgggaagatctggatatcgacgtggtgatc900
ccgatcccagaaacctcgtgtgatatcgcgctggaaattgctcgtattctgggcaaaccg960
taccgccagggcttcgttcagaaccgctatgttggccgcacctttatcatgccgggccag1020
cagctgcgtcgtaagtccgtgcgccgtaaactgaatgccaaccgcgccgagttccgcgat1080
aaaaacgtcctgctggtcgacgactccatcgtccgtggcaccacttctgagcagattatc1140
gagatggcacgcgaagccggagcgaagaaagtgtacctcgcttctgcggcaccggaaatt1200
cgcttcccgaacgtttatggtattgatatgccgagcgccacggaactgatcgctcacggt1260
cgcgaagttgatgaaattcgccagatcatcggtgctgacgggttgattttccaggatctg1320
aacgatctgatcgacgccgttcgcgctgaaaatccggatatccagcagtttgaatgctcg1380
gtgttcaacggcgtctacgtcaccaaagatgttgatcagggctacctcgatttcctcgat1440
acgttacgtaatgatgacgccaaagcagtgcaacgtcagaacgaagtggaaaatctcgaa1500
atgcataacgaaggatga1518
<210>4
<211>70
<212>dna
<213>purf-up-5’
<400>4
ccggagctcctttacactttaagctttttatgtttatgttgtgtggaattgagcaaatca60
cagctgatcc70
<210>5
<211>29
<212>dna
<213>purf-down-3’
<400>5
ccgaagcttcgcagaacctgtaataagcg29
<210>6
<211>20
<212>dna
<213>purf-up(k326q)-3’
<400>6
aacgaagccctggcggtacg20
<210>7
<211>42
<212>dna
<213>purf-down(k326q)-5’
<400>7
cgtaccgccagggcttcgttcagaaccgctatgttggccgca42
<210>8
<211>20
<212>dna
<213>purf-up(p410w)-3’
<400>8
catatcaataccataaacgt20
<210>9
<211>43
<212>dna
<213>purf-down(p410w)-5’
<400>9
acgtttatggtattgatatgtggagcgccacggaactgatcgc43
<210>10
<211>30
<212>dna
<213>prs(d128a)-up-5’
<400>10
ccgggatccgccattgcacagagccatgct30
<210>11
<211>20
<212>dna
<213>prs(d128a)-up-3’
<400>11
ccactgtcagcacacggtca20
<210>12
<211>42
<212>dna
<213>prs(d128a)-down-5’
<400>12
tgaccgtgtgctgacagtggcgctgcacgctgaacagattca42
<210>13
<211>29
<212>dna
<213>prs(d128a)-down-3’
<400>13
ccggagctcccagcaagcgtcgatcagag29
<210>14
<211>20
<212>dna
<213>kan-3’
<400>14
ggtgagatgacaggagatcc20
<210>15
<211>20
<212>dna
<213>id-arca-5’
<400>15
acgttgatggaaagtgcatc20
<210>16
<211>20
<212>dna
<213>qpcr-purd-5’
<400>16
gattgatctgaccatcgtcg20
<210>17
<211>22
<212>dna
<213>qpcr-purd-3’
<400>17
cgcttttgagccttccagttgg22
<210>18
<211>20
<212>dna
<213>qpcr-purn-5’
<400>18
caggcaattattgacgcctg20
<210>19
<211>20
<212>dna
<213>qpcr-purn-3’
<400>19
agcgtatgcgttgcaatacc20
<210>20
<211>20
<212>dna
<213>qpcr-purl-5’
<400>20
gagcacgcacaacttgaacg20
<210>21
<211>20
<212>dna
<213>qpcr-purl-3’
<400>21
tatgggcaatatcggtcgct20
<210>22
<211>20
<212>dna
<213>qpcr-purm-5’
<400>22
gcgtcgtccggaagtgatgg20
<210>23
<211>20
<212>dna
<213>qpcr-purm-3’
<400>23
agtccattgccagacgcagc20
<210>24
<211>20
<212>dna
<213>qpcr-purk-5’
<400>24
cattgctgtctggccagtcg20
<210>25
<211>20
<212>dna
<213>qpcr-purk-3’
<400>25
cacatcgcggttcacaaagg20
<210>26
<211>20
<212>dna
<213>qpcr-pure-5’
<400>26
cgactgggctaccatgcagt20
<210>27
<211>20
<212>dna
<213>qpcr-pure-3’
<400>27
cctgataaccgttctcttcg20
<210>28
<211>20
<212>dna
<213>qpcr-purc-5’
<400>28
gatacgtcagcaggggatgg20
<210>29
<211>20
<212>dna
<213>qpcr-purc-3’
<400>29
gtatcggagagcagacgctc20
<210>30
<211>20
<212>dna
<213>qpcr-purb-5’
<400>30
cagcgaatatggtttgctga20
<210>31
<211>20
<212>dna
<213>qpcr-purb-3’
<400>31
gcatcaaggtaaccgattgc20
<210>32
<211>20
<212>dna
<213>qpcr-purh-5’
<400>32
cgcaatgatacgtcagcagg20
<210>33
<211>20
<212>dna
<213>qpcr-purh-3’
<400>33
tccatttgagtcgggatacc20
- 还没有人留言评论。精彩留言会获得点赞!