表皮毛特异积累花青素调控基因及克隆方法和应用与流程
本发明涉及植物
技术领域:
,尤其涉及一种表皮毛特异积累花青素调控基因及其克隆方法和应用。
背景技术:
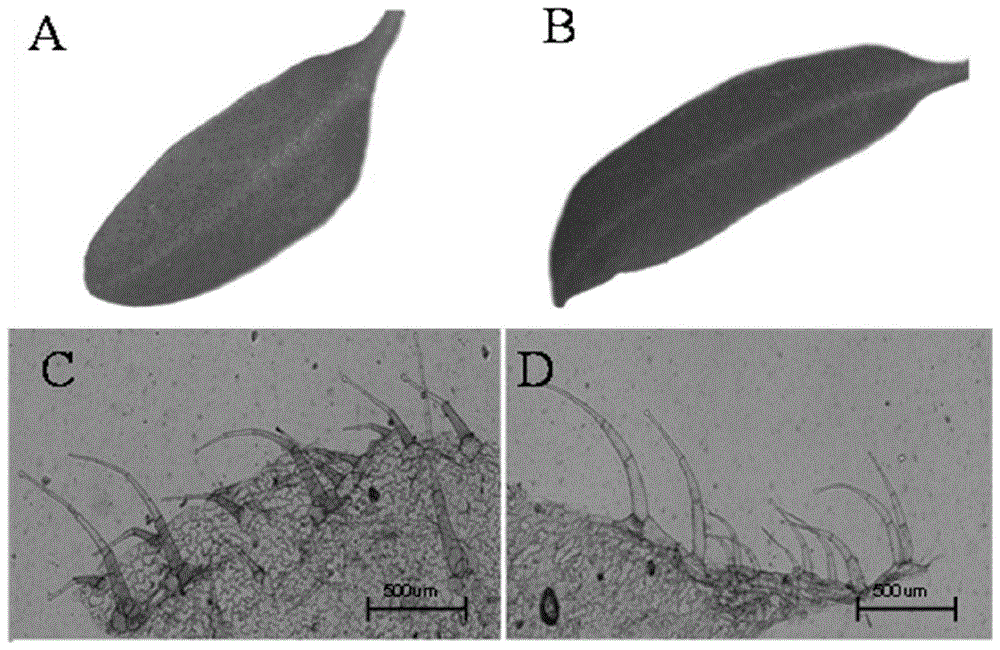
:花青素是植物体内一类重要的次生代谢物质,具有重要的生物学功能,例如可以吸引昆虫传粉、种子传播,还可以提高植物对逆境胁迫的抗性等。植物花青素合成代谢途径主要分为三个阶段,第一个阶段由苯丙氨酸到4-香豆酰辅酶a,受到苯丙氨酸裂解酶(pal)、肉桂酸羟基酶(c4h)、4-香豆酰辅酶a连接酶(4cl)的调控;第二个阶段是由4-香豆酰coa和3个丙二酰coa反应生成二氢山奈酚,受到查尔酮合酶(chs)、查尔酮异构酶(chi)和黄烷酮-3-羟化酶(f3h)的调控;第三个阶段是由二氢山奈酚合成花青素,主要受到二强黄酮醇还原酶(dfr)、花青素合酶(ans)的调控。植物表皮毛是植物表皮细胞所特化的最外层结构,具有很好的抗虫防病毒作用。例如,番茄的表皮毛有多种结构,被分成腺体毛(ⅰ、ⅳ、ⅵ、ⅶ)和非腺体毛(ⅱ、ⅲ、ⅴ)。然而,部分类型番茄的腺体毛出现能够特异积累花青素的情况,但其调控机制并不清楚。技术实现要素:基于此,有必要提供一种表皮毛特异积累花青素调控基因及其克隆方法和应用,该基因能够调控番茄表皮毛特异积累花青素,可以在改良植物表皮毛特异积累花青素或者培育番茄新品种中进行应用。本发明解决上述技术问题的技术方案如下:本发明提供一种表皮毛特异积累花青素调控基因,其cdna序列如seqidno.35所示。本发明提供一种上述所述的表皮毛特异积累花青素调控基因编码的蛋白。本发明提供一种含上述所述的表皮毛特异积累花青素调控基因的表达载体。上述所述的表皮毛特异积累花青素调控基因、上述所述的表皮毛特异积累花青素调控基因编码的蛋白或上述所述的表达载体在改良植物表皮毛特异积累花青素或者培育番茄新品种中的应用。本发明还提供一种表皮毛特异积累花青素调控基因的克隆方法,包括如下步骤:采用番茄突变体la0812为母本、番茄la1589为父本进行杂交得番茄la0812×la1589f1,番茄la0812×la1589f1再自交得番茄la0812×la1589f2群体;从番茄la0812×la1589f2群体中挑选表皮毛特异积累花青素的单株,提取dna,测序;分析确定目标基因位于10号染色体上;在10号染色体上开发亲本间存在多态性的分子标记;进一步扩大番茄la0812×la1589f2群体,利用分子标记、表型和基因型鉴定,确定目标基因位于pn-12和pn86280之间;对pn-12和pn86280区间内的多个orf进行序列差异分析,确定候选基因;确定候选基因在番茄叶片表皮毛中特异积累表达,即得。具体地,pn-12和pn86280区间内具有9个orf,分别为solyc10g086190、solyc10g086200、solyc10g086210、solyc10g086220、solyc10g086230、solyc10g086240、solyc10g086250、solyc10g086260和solyc10g086270。在其中一个实施例中,solyc10g086190所对应的引物序列如seqidno.17和seqidno.18所示,solyc10g086200所对应的引物序列如seqidno.19和seqidno.20所示,solyc10g086210所对应的引物序列如seqidno.21和seqidno.22所示,solyc10g086220所对应的引物序列如seqidno.23和seqidno.24所示,solyc10g086230所对应的引物序列如seqidno.25和seqidno.26所示,solyc10g086240所对应的引物序列如seqidno.27和seqidno.28所示,solyc10g086250所对应的引物序列如seqidno.29和seqidno.30所示,solyc10g086260所对应的引物序列如seqidno.31和seqidno.32所示,solyc10g086270所对应的引物序列如seqidno.33和seqidno.34所示。在其中一个实施例中,在确定目的基因位于pn-12和pn86280之间的步骤之前还包括将目的基因粗定位在pn6363标记和tg233标记之间的步骤。在其中一个实施例中,确定候选基因在番茄叶片表皮毛中特异积累表达的步骤为:构建表达载体,并利用农杆菌介导法转化获得转基因番茄植株。本发明的有益效果是:与现有技术相比,本发明通过研究获取到能够在表皮毛中特异积累表达花青素的基因,该基因可以在改良植物表皮毛特异积累花青素或者培育番茄新品种中进行应用。附图说明图1为番茄pn突变体la0812叶片与ac叶片的对比图;其中,(a)为番茄pn突变体la0812叶片图,(b)为番茄ac叶片图,(c)为番茄pn突变体la0812叶片的光学显微镜图,(d)为番茄ac叶片的光学显微镜图。图2为总花青素含量测试结果统计图。图3为bsa-seq的snp指数图,其中x轴表示12条染色体,y轴表示snp指数数值。图4为分子标记在第10染色体上的位置图。图5为目标基因pn的精确定位图。图6为候选基因表达量测试结果统计图(每个orf从左到右的顺序依次对应m82、il10-3、ac、la0812)。图7为orf8在番茄pn突变体la0812和番茄ac中的核苷酸序列比对图。图8为预测氨基酸序列比对图。图9为转基因番茄植株与ac植株叶片表皮毛花青素对照图。具体实施方式以下对本发明进行举例描述,所举实例只用于解释本发明,并非用于限定本发明的范围。除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的
技术领域:
的技术人员通常理解的含义相同。实施例1突变体表型鉴定获取番茄材料pn突变体la0812(由番茄遗传资源中心(tgrc)引进)、普通栽培番茄ailsacraig(ac)、la1589、加工番茄m82以及渐渗系il10-3(s.pennelli/m82)。将各品种一部分种植于华中农业大学黄土坡基地、另外一部分种植放置于绿化间进行培养(温度25℃,光照160μmolphotonsm-2s-1,昼夜循环为16h/8h,空气相对湿度为55%)。观察番茄材料不同发育阶段的表型。确定番茄pn突变体la0812的下胚轴、叶片表面的表皮毛特异积累花青素。其中,番茄pn突变体la0812叶片与ac叶片的对比图见图1。由图1可以明显看出,与野生型番茄ac的叶片相比,番茄pn突变体la0812叶片表面的表皮毛细胞特异积累花青素。另外,分别采集pn突变体la0812、ac、a1589、加工番茄m82以及渐渗系il10-3的两叶一心时期的幼嫩叶片,每种材料取三株进行混样,三个生物学重复。总花青素的提取测试步骤如下:将叶片组织用液氮研磨,称取0.1g于2ml的离心管中,加入1ml的提取液(1%盐酸甲醇)4℃避光提取24小时,期间晃动,充分提取。13000r/min离心10min,取100μl上清液于酶标板中,加入100ul的ddh2o,取3个技术重复。用酶标仪分别测波长在530nm和657nm测吸光光度值。以提取液做参比。总花青素的相对含量的计算公式:(a/g)=(a530-0.25*a657)/m总花青素含量的测试结果见图2。由图2可以看出,pn突变体la0812的叶片中花青素的含量明显高于其它野生型番茄材料。实施例2pn基因的克隆本实施例提供一种表皮毛特异积累花青素调控基因(命名为pn基因)的克隆方法,包括如下步骤:(1)群体构建:以表皮毛特异积累花青素的番茄材料pn突变体la0812为母本、野生番茄材料la1589为父本进行杂交获得体la0812×la1589f1,然后la0812×la1589f1再自交获得la0812×la1589f2植株,分离群体,并进行普通遗传学规律分析。另外,以番茄m82为母本,il10-3为父本,进行杂交得到番茄m82×il10-3的f1代,自交得到番茄m82×il10-3的f2遗传,分离群体。在135株la0812×la1589f2植株的个体中,有39株叶表皮毛不积累花青素,与野生型la1589的表型一致;而有96株叶表皮毛特异积累花青素,与pn突变体la0812的表型一致,通过卡方检验,结果表明其分离比符合孟德尔遗传规律,说明pn突变体表皮毛特异积累花青素的表型是由显性单基因控制。(2)利用bsa结合基因组测序的方法来进行目标基因的粗定位:从室内种植的la0812×la1589f2植株中分离群体,选取表皮毛特异性积累花青素的各单株,分别采集幼嫩叶片100mg,采用ctab法提取dna。。ctab方法提取番茄材料dna的步骤如下:将100mg新鲜样品置于2ml离心管中,置于冰上,加入750μl含有巯基乙醇的预热的ctab溶液中,置于dna核酸提取仪中,60hz研磨45s。其中,ctab溶液配方含ctab1.4mol/l、nacl1.5%、edta(ph8.0)1.4mol/l、tris-hcl(ph8.0)100mmol/l以及β-巯基乙醇1%(现用现加)。取出离心管置于65℃的恒温水浴箱中,水浴60min-90min左右,期间上下颠倒2-3次,充分抽提。水浴结束后,向离心管中加入750μl氯仿异戊醇混合溶液(v氯仿:v异戊醇=24:1),上下剧烈颠倒100次,使溶液充分混合。10000r/min,离心10min,形成三相。离心结束后,吸取300μl上清液移入新的1.5ml离心管中,同时加入300μl预冷的异丙醇,轻摇后放于-20℃冰箱,静置10min。12000r/min离心5min,弃上清,向离心管中加入1ml75%的乙醇清洗dna沉淀。吸干酒精,使dna彻底风干。待dna风干为透明胶状后,向离心管中加入50μl灭菌ddh2o,常温溶解dna。然后采用超微量分光光度计测量dna浓度,稀释成一定浓度,一部分用于送测序,另一部分放置于-80°冰箱中保存备用。根据la0812×la1589f2分离群体的表型,分别构建两个极端池,包括m(mutant)池和n(normal)池,各包含30个单株,提取dna,等量混池,将样品送至novogene公司,进行文库构建和测序。对获得的原始数据进行质量评估,得到cleandata,将cleandata比对用bwa参考基因组上获得sam文件,用picard软件去掉重复序列获得bam文件,再用gatk和samtools进行callsnp、indel的检测及注释,利用perl脚本算出snp-index,结合r包画出△snp-index在各个染色体上的分布。采用bsa+dna测序的方法,结合snp指数进行基因型的统计分析,确定目的基因的候选区域,结果见图3。由图3分析看出第十号染色体末端出现明显的snp差异位点,表明目标基因pn可能位于第十号染色体。根据sgn中发布的第10染色体中的分子标记信息以及根据栽培番茄heinz1706和野生型番茄la1589的基因组信息开发均匀覆盖在第10染色体末端。以番茄la1589、番茄pn突变体la0812以及la0812×la1589f1代的gdna为模板进行pcr扩增。其中,pcr反应体系:10×pcrbuffer,2μl;dntp(10mm),0.5μl;前引物(10mm),0.5μl;后引物(10mm),0.5μl;taq酶(5u/μl),0.2μl;模板(20-100ng/μl),0.5μl;ddh2o,15.8μl。设置的扩增程序为:94℃,3min;94℃30sec;52℃-56℃30sec;72℃1kb/min;72℃10min;16℃10min,循环数:35个循环。pcr反应结束后,产物用1%琼脂糖凝胶电泳检测,确定在番茄la1589和pn突变体la0812之间具有稳定的多态性分子标记,用于进一步的定位分析。对于琼脂糖胶显示无多态性的一些caps标记,进一步进行酶切筛选多态性。结合pcr扩增和凝胶电泳检测,确定在对亲本之间具有稳定多态性的分子标记,共获得8个分子标记,见下表1:表1用于pn图位克隆所有的分子标记扩增引物信息对384个la0812×la1589f2单株进行基因型分析。按照mapmaker/expversion3.0(landeretal1987)软件的要求,将每个单株的表型和基因型转化可用于分析的数据,进行遗传连锁分析。如图4所示,将目的基因pn定位于pn6363和tg233标记之间,且分别发生1个交换和2个交换,遗传距离为0.77cm,物理距离约为385.67kb。(3)确定候选基因:利用763个la0812×la1589f2分离群体单株,结合新开发的分子标记,选取在两个亲本之间具有多态性的标记共4个,进行表型和基因型鉴定。如图5所示,最终将pn基因定位于pn-12和pn86280,约59.768kb的物理区间。分析pn-12和pn86280之间约59.768kb物理区间序列信息,利用番茄基因组的注释信息(sl2.40),预测候选区域中可能存在的基因。利用在线软件softberry(http://linux1.softberry.com/berry.phtml)对候选基因所在的序列进行分析,初步确定该区域可能存在的基因,去除片段太小的基因,然后利用软件对该区域所有的基因进一步的确认。最后对所编码的氨基酸序列进行比对分析,确定每个基因可能的功能,并进一步确定可能的候选基因。在候选区域发现9个开放阅读框(orf),如下表2所示。在这9个orfs中,前6个分别编码腺苷激酶/生长素诱导的saur样蛋白、黄素氧化/nadh氧化酶、未知蛋白、葡萄糖基转移,后3个为myb串联基因。按照候选基因序列号,在solgenomicsnetwork数据库中查询并下载候选基因全长序列。表2候选区段基因编号基因编号基因功能预测长度(bp)orf1solyc10g086190adenosinekinase4217orf2solyc10g086200auxin-inducedsaur-likeprotein372orf3solyc10g086210translin-likeprotein4825orf4solyc10g086220flavinoxidoreductase/nadhoxidase1333orf5solyc10g086230unknownprotein243orf6solyc10g086240glucosyltransferase1815orf7solyc10g086250mybtranscriptionfactor1558orf8solyc10g086260mybtranscriptionfactor1012orf9solyc10g086270mybtranscriptionfactor950根据9个orfs的序列信息,设计qrt-pcr引物进行定量的分析,确定是否在基因表达方面有差异,具体方法包括如下步骤:s1,番茄叶片rna提取。rna提取方法用的是trizolreagent法进行提取。取播种后约两周左右的番茄幼苗两叶一心大小的叶片。每次提取设置三个生物学重复。其中,trizolreagent法提取rna的步骤如下:取幼嫩组织若干,液氮环境中研磨后分装成100mg至预冷的1.5ml的离心管中,加入1ml的trizol,立即颠倒混匀,抽提几分钟;12000r/min,2-8℃离心10min。吸取上清转移到新的1.5ml离心管中,室温放置5min。加入200μl的氯仿,充分抽提15s(使劲摇匀),室温放置2-3min。12000r/min,2-8℃离心15min。吸取上清,转移至新的1.5ml离心管中,加入500μl预冷的异丙醇,颠倒混匀,室温放置10min。12000r/min,2-8℃离心10min。小心弃上清的胶状rna,加入1ml75%的乙醇。7500r/min离心2min,去掉上清,留下胶状rna。干燥5-10min,溶于depc处理水中,55℃-60℃温育10min,-70℃保存备用。s2,用primer3对候选区域的基因进行实时定量pcr的检测。将抽提的rna反转录成cdna,用于q-rt-pcr检测。所用的体系用actin作为内参基因,配置10μl的体系sybrmix,5μl;cdna,4.0μl;前引物,0.5μl;后引物,0.5μl。扩增体系设置为:预变性95℃,5min;变性95℃,15s,退火58℃,1min,40个循环;溶解曲线:98℃,10s,65℃1min;冷却40℃,1s。每个反应设置3个技术重复,用2-△△ct方法分析数据。其中,所用的引物序列见下表3:表3实时定量pcr所用的引物序列上述9个orfs的表达量统计结果见图6。由图6可以看出,与m82和ac相比,orf7、orf8和orf9表达量显著下调,orf2、orf3和orf5在la0812和il10-3中均上调表达,但上调幅度不太明显,相对于orf1、orf4、orf6和orf7来说两个番茄材料都表现出下调的趋势。orf8和orf9在il10-3材料中上调表达的,而突变体la0812相对于对照ac是下调表达的。预测pn位点可能是一个调控基因,需要进一步进行orf序列差异的分析。进行orf序列差异的分析。采用primer5.0软件设计特异性扩增引物,引物设计原则包含起始密码子和终止密码子。然后,以pn突变体la0812和ac的gdna为模板,进行基因的扩增。连接到peasy-blunt载体上,进行测序。利用mμltalininterfacepage在线软件分析候选基因在pn突变体la0812和ac之间是否存在序列差异。通过序列差异分析发现orf8在ac中的gdna是1012bp,在la0812中扩增的gdna长度为848bp(从atg-tga)。如图7所示,pn突变体la0812中扩增的序列有一段外显子区域的缺失,并且有多个snp位点。结合softberry对pn突变体la0812的gdna进行测序的结果进行氨基酸的预测,如图8所示,结果发现orf8在c端和n端都有一部分氨基酸的缺失。确定orf8为候选基因。番茄突变体中orf8的cdna序列如seqidno.35所示:atgaacagtacatctatgtcttcattgggagtgagaaaaggttcatggactgaagaagaagattttctttaaagaaaatgtattgacaagtatggtgaaggaaaatggcatcttgttcccataagagctggtaattattaaattaatattacataatttctatctgtctgtctgtctcattttatgtaacgttatttggaacatcatccaaaaatgtatgtgcaggtttgaatagatgtcggaaaagttgtagattgaggtggctgaattatctaaggccacatatcaagagaggtgactttgaacaagatgaagtggatctcattttgaggcttcataagctcttaggcaacaggcatgcaagtttatgttgtggcaaaatttgattagtatatattatatatatgtgtgaatatttcatctaaatattacgttattttacgtagatggtcacttattgctggtagacttccaggaaggacagctaacgatgtgaaaaactattggaacactaaccttctaaggaagttaaatactactaaaattgttcttcgtcaaaagattaacaataagtgtggatcaatggtggataaatttactggaaagttgcaatgacgatattgaagaagatgaagaggttgtaattaattatgaaaaaacactaacaagtttgttacatgaagaaatatcaccaccattaaatattggtgaaggtaagtccatgcaacaaggacaaataagtcatgaaaattggggtgaattttctcttaatttaccacccatgcaacaaggagtacaaaatgatgatttttctgctgaaattgacttatggaatctacttgattaa。该突变体中orf8所编码的蛋白序列如seqidno.36所示:mnstsmsslgvrkgswteeedfl。(4)构建表达载体:构建以pn突变体la0812的gdna作为模板,扩增启动子(atg前3kb)和基因的全长序列,连接到peasy-blunt上,热激法转化大肠杆菌感受态dh5α中,进行测序,选取正确的单克隆菌,提取质粒,用sac1和kpn1对表达载体pmv2和连有候选基因的peasy-blunt载体进行双酶切,分别回收pmv2的载体骨架和候选基因片段。然后用t4连接酶将候选基因和载体骨架连接,热激并转化到大肠杆菌感受态中。挑取单克隆,进行pcr阳性检测后,摇菌提取质粒,用saci和kpni对构建好的重组子进行双酶切验证,若能够用双酶切切出目标条带,说明获得了功能互补载体。将构建好的载体通过电击转化的方法转入农杆菌gv3101中。(4)番茄遗传转化选用ac番茄子叶作为外植体,用带有kan抗性的lb培养基进行农杆菌gv3101菌液的培养和收集,将菌液调至合适的od值,侵染4min。将浸染后的外植体放置于kc培养基中,2d后放置于筛选培养基(ms+2.0mg/lzt+500mg/lcef+500mg/lkm+3%sucrose+7.5g/l琼脂)中,筛选15d后,转移到0.2z(ms+0.2mg/lzt+500mg/lcef+500mg/lkm+3%sucrose+7.5g/l琼脂)进行继代培养,继代15d,选取有生长点的外植体放置于生根培养基(1/2ms+2.0mg/liba+3%sucrose)中,15d后移栽到绿化间,便于移栽和阳性检测。由于转基因的过程中,转入的是自身启动子和基因全长序列,本身存在indel,所以通过设计分子标记对两个转基因系进行阳性检测,两个分子标记的引物见下表4。pcr反应后产物经过琼脂凝胶电泳分析并用成像系统进行观察、记录。表4阳性检测所用引物序列表如图9所示,与图a中ac番茄相比,通过对两叶一心的番茄幼苗进行表型观察,发现如图b所示的含候选基因orf8的转基因植株叶片茸毛出现了花青素特异积累,表明orf8即为表皮毛特积累花青素调控基因pn。采用该表皮毛特积累花青素调控基因pn或者含该表皮毛特积累花青素调控基因pn的表达载体可以在改良植物表皮毛特异积累花青素或者培育番茄新品种中进行应用。以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。序列表<110>华中农业大学<120>表皮毛特异积累花青素调控基因及其克隆方法和应用<160>40<170>siposequencelisting1.0<210>1<211>24<212>dna<213>人工序列(artificialsequence)<400>1atcacgaattttgaaaacgttagg24<210>2<211>25<212>dna<213>人工序列(artificialsequence)<400>2aaaagtgttggcttattgttattgg25<210>3<211>24<212>dna<213>人工序列(artificialsequence)<400>3tgaaaaaagtctaagttgctcgga24<210>4<211>25<212>dna<213>人工序列(artificialsequence)<400>4acatttgtgagcttctgttttcgta25<210>5<211>24<212>dna<213>人工序列(artificialsequence)<400>5aaacaaccaaaccccacaaaaact24<210>6<211>24<212>dna<213>人工序列(artificialsequence)<400>6gggtttttacttgtgattcttgga24<210>7<211>25<212>dna<213>人工序列(artificialsequence)<400>7ttggctaatacattcagcaaagcac25<210>8<211>23<212>dna<213>人工序列(artificialsequence)<400>8aaggtctaaggctgcgaacgata23<210>9<211>23<212>dna<213>人工序列(artificialsequence)<400>9atggtactagagcagggtccgtc23<210>10<211>25<212>dna<213>人工序列(artificialsequence)<400>10cactcttgggcctcaaataactaaa25<210>11<211>25<212>dna<213>人工序列(artificialsequence)<400>11tttactataccctccatcaatcacc25<210>12<211>23<212>dna<213>人工序列(artificialsequence)<400>12taggctcaaacaacaccatctcc23<210>13<211>23<212>dna<213>人工序列(artificialsequence)<400>13tacagagccctgaggaaggtaat23<210>14<211>23<212>dna<213>人工序列(artificialsequence)<400>14gcaccaggaaaaggttaaagtgt23<210>15<211>20<212>dna<213>人工序列(artificialsequence)<400>15catgcctttttcttgggatg20<210>16<211>20<212>dna<213>人工序列(artificialsequence)<400>16tggaacccctttaactgtgc20<210>17<211>22<212>dna<213>人工序列(artificialsequence)<400>17tgaaatatcatcggttggctcg22<210>18<211>21<212>dna<213>人工序列(artificialsequence)<400>18ggattgcccatacccaacaga21<210>19<211>23<212>dna<213>人工序列(artificialsequence)<400>19cctagagatgttccaaagggtca23<210>20<211>23<212>dna<213>人工序列(artificialsequence)<400>20cgtctattttttggagatgtggc23<210>21<211>23<212>dna<213>人工序列(artificialsequence)<400>21ctctctactctaatggcgggtgg23<210>22<211>21<212>dna<213>人工序列(artificialsequence)<400>22ctgaatctatctccgtcgcca21<210>23<211>20<212>dna<213>人工序列(artificialsequence)<400>23atgaagcaggggacacgaac20<210>24<211>24<212>dna<213>人工序列(artificialsequence)<400>24atcttctctatcgtaaccaccagc24<210>25<211>23<212>dna<213>人工序列(artificialsequence)<400>25catacaacctcaaagatggctca23<210>26<211>24<212>dna<213>人工序列(artificialsequence)<400>26agaagccaaatttaactaaggtga24<210>27<211>22<212>dna<213>人工序列(artificialsequence)<400>27tggtgctctgttccgtttattt22<210>28<211>20<212>dna<213>人工序列(artificialsequence)<400>28cctctgcttccttgcctttc20<210>29<211>22<212>dna<213>人工序列(artificialsequence)<400>29aggacagcaaacgatgtgaaga22<210>30<211>21<212>dna<213>人工序列(artificialsequence)<400>30cgaggatgagaacgaggacga21<210>31<211>20<212>dna<213>人工序列(artificialsequence)<400>31cgaggctggcaggataggta20<210>32<211>22<212>dna<213>人工序列(artificialsequence)<400>32catgaaccttttctcactccca22<210>33<211>23<212>dna<213>人工序列(artificialsequence)<400>33taaaagagtatctcaaggctggc23<210>34<211>23<212>dna<213>人工序列(artificialsequence)<400>34cgaaccacaaaagtagggagtct23<210>35<211>847<212>dna<213>人工序列(artificialsequence)<400>35atgaacagtacatctatgtcttcattgggagtgagaaaaggttcatggactgaagaagaa60gattttctttaaagaaaatgtattgacaagtatggtgaaggaaaatggcatcttgttccc120ataagagctggtaattattaaattaatattacataatttctatctgtctgtctgtctcat180tttatgtaacgttatttggaacatcatccaaaaatgtatgtgcaggtttgaatagatgtc240ggaaaagttgtagattgaggtggctgaattatctaaggccacatatcaagagaggtgact300ttgaacaagatgaagtggatctcattttgaggcttcataagctcttaggcaacaggcatg360caagtttatgttgtggcaaaatttgattagtatatattatatatatgtgtgaatatttca420tctaaatattacgttattttacgtagatggtcacttattgctggtagacttccaggaagg480acagctaacgatgtgaaaaactattggaacactaaccttctaaggaagttaaatactact540aaaattgttcttcgtcaaaagattaacaataagtgtggatcaatggtggataaatttact600ggaaagttgcaatgacgatattgaagaagatgaagaggttgtaattaattatgaaaaaac660actaacaagtttgttacatgaagaaatatcaccaccattaaatattggtgaaggtaagtc720catgcaacaaggacaaataagtcatgaaaattggggtgaattttctcttaatttaccacc780catgcaacaaggagtacaaaatgatgatttttctgctgaaattgacttatggaatctact840tgattaa847<210>36<211>23<212>prt<213>人工序列(artificialsequence)<400>36metasnserthrsermetserserleuglyvalarglysglysertrp151015thrgluglugluasppheleu20<210>37<211>22<212>dna<213>人工序列(artificialsequence)<400>37tgttcgttagtgggttcggtag22<210>38<211>21<212>dna<213>人工序列(artificialsequence)<400>38atacggataccgatcacccaa21<210>39<211>23<212>dna<213>人工序列(artificialsequence)<400>39aaagttgtagattgaggtggctg23<210>40<211>23<212>dna<213>人工序列(artificialsequence)<400>40ccctaatgaatgtatgtggatgg23当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1