调控基因组的方法和组合物与流程
本申请要求2018年8月28日提交的美国序列号:62/723,886,2018年8月31日提交的美国序列号:62/725,778,2019年5月21日提交的美国序列号:62/850,883和2019年6月21日提交的美国序列号:62/864,924(其各自的全部内容通过引用并入本文)的优先权。
序列表
本申请包含序列表,该序列表已以ascii格式电子提交,并通过引用以其整体并入本文。所述ascii副本创建于2019年8月28日,名为v2065-7000wo_sl.txt,大小为4,004,548字节。
背景技术:
在没有专门的蛋白质来促进插入事件的情况下,目的核酸整合到基因组中的频率较低且位点特异性极低。一些现有的方法、例如crispr/cas9更适合于小型编辑,并且在整合较长序列时效率较低。其他现有的方法、例如cre/loxp需要第一步先将loxp位点插入基因组中,然后第二步将目的序列插入loxp位点中。在本领域中需要用于将目的序列插入基因组中的改进的蛋白质。
技术实现要素:
本公开涉及用于体内或体外改变宿主细胞、组织或受试者中一个或多个位置处的基因组的新颖组合物、系统和方法。特别地,本发明的特征在于用于将外源遗传元件引入宿主基因组中的组合物、系统和方法。
所述组合物或方法的特征可包括以下列举的实施例中的一个或多个。
1.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)编码治疗性多肽或编码哺乳动物(例如人)多肽的异源对象序列,或其片段或变体。
2.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列,其中以下中一项或多项:
i.所述异源对象序列编码蛋白质,例如酶(例如,溶酶体酶)或血液因子(例如,因子i、ii、v、vii、x、xi、xii或xiii);
ii.所述异源对象序列包含组织特异性启动子或增强子;
iii.所述异源对象序列编码大于250、300、400、500或1,000个氨基酸,并且任选地多达7,500个氨基酸的多肽;
iv.所述异源对象序列编码哺乳动物基因的片段,但不编码完整的哺乳动物基因,例如,编码一个或多个外显子,但不编码全长蛋白质;
v.所述异源对象序列编码一个或多个内含子;
vi.所述异源对象序列不同于gfp,例如,不同于荧光蛋白或不同于报道蛋白。
vii.所述异源对象序列不同于t细胞嵌合抗原受体
3.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列。
4.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)靶dna结合结构域,(ii)逆转录酶结构域和(iii)内切核酸酶结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列。
5.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域,其中(i)或(ii)之一或两者均衍生自禽逆转录转座酶,例如具有表2或3的序列或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列。
6.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域,其中所述多肽在37℃下的活性不低于在25℃下在其他方面类似的条件下的活性的70%、75%、80%、85%、90%或95%;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列。
7.如实施例6所述的系统,其中所述多肽衍生自禽逆转录转座酶,例如表3第8列的禽逆转录转座酶,或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性的序列。
8.如实施例6所述的系统,其中所述禽逆转录转座酶是来自斑胸草雀(taeniopygiaguttata)、中地雀(geospizafortis)、白喉带鹀(zonotrichiaalbicollis)或白喉
9.如实施例6所述的系统,其中所述多肽衍生自表3第8列的逆转录转座酶,或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性的序列。
10.如前述实施例中任一项所述的系统,其中所述模板rna包含表3的序列(例如,表3第6列的5'非翻译区和表3第7列的3'非翻译区中的一者或两者)或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性的序列。
11.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列,其中以下中一项或多项:
i.编码所述多肽和所述模板rna的核酸或编码所述模板rna的核酸是分开的核酸;
ii.所述模板rna不编码活性逆转录酶,例如,如实例1-2中所述包含失活的突变逆转录酶,或不包含逆转录酶序列;或
iii.所述模板rna不编码活性内切核酸酶,例如包含失活的内切核酸酶或不包含内切核酸酶;或
iv.所述模板rna包含一个或多个化学修饰。
12.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的5'非翻译序列,(ii)结合所述多肽的3'非翻译序列,(iii)异源对象序列,和(iv)与所述异源对象序列可操作地连接的启动子,
其中所述启动子位于结合所述多肽的5'非翻译序列与所述异源序列之间,或
其中所述启动子位于结合所述多肽的3'非翻译序列与所述异源序列之间。
13.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的5'非翻译序列,(ii)结合所述多肽的3'非翻译序列,以及(iii)异源对象序列,并且
其中所述异源对象序列包含在所述模板rna上以5'至3'取向的开放阅读框(或其反向互补序列);或
其中所述异源对象序列包含在所述模板rna上3'至5'取向的开放阅读框(或其反向互补序列)。
14.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域,其中(i)或(ii)中的至少一个是异源的,和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列。
15.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)靶dna结合结构域,(i)逆转录酶结构域和(iii)内切核酸酶结构域,其中(i)、(ii)或(iii)中的至少一个是异源的,和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列。
16.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)与无嘌呤/无嘧啶内切核酸酶(ape)型非ltr逆转录转座子的逆转录酶结构域至少80%相同(例如,至少85%、90%、95%、97%、98%、99%、100%相同)的序列和(ii)与ape型非ltr逆转录转座子的内切核酸酶结构域至少80%相同(例如,至少85%、90%、95%、97%、98%、99%、100%相同)的序列;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列。
17.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)与限制酶样内切核酸酶(rle)型非ltr逆转录转座子的逆转录酶结构域至少80%相同(例如,至少85%、90%、95%、97%、98%、99%、100%相同)的序列,(ii)与rle型非ltr逆转录转座子的内切核酸酶结构域至少80%相同(例如,至少85%、90%、95%、97%、98%、99%、100%相同)的序列,和(iii)异源靶dna结合结构域(例如,异源锌指dna结合结构域);和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列。
18.如前述实施例中任一项所述的系统,其中所述模板rna包含(iii)可操作地连接至异源对象序列的启动子。
19.如前述实施例中任一项所述的系统,其中所述多肽进一步包含(iii)dna结合结构域。
20.如实施例17所述的系统,其中所述多肽包含与seqidno:1016的序列至少80%相同(例如,至少85%、90%、95%、97%、98%、99%、100%相同)的序列。
21.如前述实施例中任一项所述的系统,其中所述多肽包含与表3第8列中的序列至少80%相同(例如,至少85%、90%、95%、97%、98%、99%、100%相同)的序列。
22.如前述实施例中任一项所述的系统,其中编码所述多肽和所述模板rna的核酸或编码所述模板rna的核酸是共价连接的,例如是融合核酸的一部分。
23.如实施例22所述的系统,其中所述融合核酸包含rna。
24.如实施例22所述的系统,其中所述融合核酸包含dna。
25.如前述实施例中任一项所述的系统,其中(b)包含模板rna。
26.如实施例25所述的系统,其中所述模板rna进一步包含核定位信号。
27.如前述实施例中任一项所述的系统,其中(a)包含编码所述多肽的rna。
28.如实施例27所述的系统,其中(a)的rna和(b)的rna是分开的rna分子。
29.如实施例28所述的系统,其中(a)的rna和(b)的rna以10:1至5:1、5:1至2:1、2:1至1:1、1:1至1:2、1:2至1:5或1:5至1:10的比例存在。
30.如实施例28所述的系统,其中(a)的rna不包含核定位信号。
31.如前述实施例中任一项所述的系统,其中所述多肽进一步包含核定位信号和/或核仁定位信号。
32.如前述实施例中任一项所述的系统,其中(a)包含编码以下的rna:(i)所述多肽和(ii)核定位信号和/或核仁定位信号。
33.如前述实施例中任一项所述的系统,其中所述rna包含假结序列,例如异源对象序列的5’。
34.如实施例33所述的系统,其中所述rna包含假结序列的5'的茎环序列或螺旋。
35.如实施例33或34所述的系统,其中所述rna包含假结序列的3',例如假结序列的3'和异源对象序列的5'的一个或多个(例如2、3或更多个)茎环序列或螺旋。
36.如实施例33-35中任一项所述的系统,其中包含所述假结的模板rna具有催化活性,例如,rna切割活性,例如,顺式-rna切割活性。
37.如前述实施例中任一项所述的系统,其中所述rna包含例如所述异源对象序列的3’的至少一个茎环序列或螺旋,例如1、2、3、4、5或更多个茎环序列、发夹或螺旋序列。
38.任何以上编号的系统,其中所述多肽包含与表1中所列多肽或其逆转录酶结构域或内切核酸酶结构域的序列具有至少80%同一性(例如,至少85%、90%、95%、97%、98%、99%、100%同一性)的至少50个氨基酸(例如,至少100、150、200、300、500个氨基酸)的序列。
39.任何以上编号的系统,其中所述多肽包含与表2-3的任一个中列出的多肽或其逆转录酶结构域、内切核酸酶结构域或dna结合结构域的序列具有至少80%同一性(例如,至少85%、90%、95%、97%、98%、99%、100%同一性)的至少50个氨基酸(例如,至少100、150、200、300、500个氨基酸)的序列。
40.任何以上编号的系统,其中所述多肽包含与表3第8列的氨基酸序列或其逆转录酶结构域、内切核酸酶结构域或dna结合结构域具有至少80%同一性(例如,至少85%、90%、95%、97%、98%、99%、100%同一性)的至少50个氨基酸(例如,至少100、150、200、300、500个氨基酸)的序列。
41.任何以上编号的系统,其中所述模板rna包含表3的序列(例如,表3第6列的5'非翻译区和表3第7列的3'非翻译区中的一者或两者)或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性的序列。
42.如实施例41所述的系统,其中所述模板rna包含来自表3第7列的3'非翻译区的约100-125bp的序列,例如其中所述序列包含表3第7列的3'非翻译区的核苷酸1-100、101-200或201-325,或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性的序列。
43.任何以上编号的系统,其中(a)包含rna,并且(b)包含rna。
44.任何以上编号的系统,其仅包含rna,或其以rna:dna比例为至少10:1、20:1、30:1、40:1、50:1、60:1、70:1、80:1、90:1或100:1包含rna多于dna。
45.任何以上编号的系统,其不包含dna或按质量或摩尔量计不包含超过10%、5%、4%、3%、2%或1%的dna。
46.任何上述编号的系统,其能够通过插入所述异源对象序列来修饰dna,而无需进行(b)的依赖于介入的dna的rna聚合。
47.任何上述编号的系统,其能够在存在dna修复途径抑制剂(例如scr7,一种parp抑制剂)的情况下,或在缺乏dna修复途径的细胞系(例如,缺乏核苷酸切除修复途径或同源性指导的修复途径的细胞系)中通过插入异源对象序列来修饰dna。
48.任何以上编号的系统,其不会引起在靶细胞中形成可检测水平的双链断裂。
49.任何以上编号的系统,其能够利用逆转录酶活性并任选地在没有同源重组活性的情况下修饰dna。
50.任何以上编号的系统,其中所述模板rna已经被处理以减少二级结构,例如,加热至例如减少二级结构的温度,例如加热至至少70、75、80、85、90或95c。
51.如实施例50所述的系统,其中随后将所述模板rna冷却至例如允许二级结构的温度,例如至小于或等于30、25或20c
52.一种用于修饰dna的系统,所述系统包含:
(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列,(ii)异源对象序列,(iii)在所述模板rna的5’末端的与靶dna链具有100%同一性的至少10个碱基的第一同源结构域;和(iv)在所述模板rna的5’末端的与靶dna链具有100%同一性的至少10个碱基的第二同源结构域。
53.如前述实施例中任一项所述的系统,其中(a)和(b)是同一核酸的一部分。
54.如实施例1-52中任一项所述的系统,其中(a)和(b)是分开的核酸。
55.如前述实施例中任一项所述的系统,其中所述模板rna在所述模板rna的5’末端包含与靶dna链(例如,其中所述靶dna链是人dna序列)具有100%同一性的至少10个碱基。
56.如前述实施例中任一项所述的系统,其中所述模板rna在所述模板rna的3’末端包含与靶dna链(例如,其中所述靶dna链是人dna序列)具有100%同一性的至少10个碱基。
57.一种宿主细胞(例如,哺乳动物细胞,例如人细胞),其包含任何前述编号的系统。
58.一种修饰细胞、组织或受试者中的靶dna链的方法,所述方法包括对所述细胞、组织或受试者施用任何前述编号的系统,其中所述系统将所述模板rna序列逆转录成所述靶dna链,从而修饰所述靶dna链。
59.如实施例58所述的方法,其中所述细胞、组织或受试者是哺乳动物(例如人)细胞、组织或受试者。
60.如前述实施例中任一项所述的方法,其中所述细胞是成纤维细胞。
61.如前述实施例中任一项所述的方法,其中所述细胞是原代细胞。
62.如前述实施例中任一项所述的方法,其中所述细胞没有被永生化。
63.一种修饰哺乳动物细胞基因组的方法,所述方法包括使细胞与以下接触:
(a)多肽或编码多肽的核酸,其中该多肽包含(i)逆转录酶结构域,(ii)内切核酸酶结构域,和任选地(iii)dna结合结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列。
64.如实施例63所述的方法,其中所述多肽不包含靶dna结合结构域。
65.如实施例63所述的方法,其中所述多肽衍生自ape型转座子逆转录酶。
66.如实施例63所述的方法,其中(i)逆转录酶结构域(ii)内切核酸酶结构域或(i)和(ii)两者具有表1的序列或与其具有至少80%、85%的序列,90%、95%、97%、98%、99%、100%同一性的序列。
67.如实施例63所述的方法,其中所述多肽进一步包含靶dna结合结构域。
68.一种修饰哺乳动物细胞基因组的方法,所述方法包括使细胞与以下接触:
(a)编码多肽的rna,其中该多肽包含(i)逆转录酶结构域,(ii)内切核酸酶结构域,和任选地(iii)dna结合结构域;和
(b)模板rna,其包含(i)结合所述多肽的序列和(ii)异源对象序列,
其中所述方法不包括使所述哺乳动物细胞与dna接触,或其中(a)和(b)的组合物不包含按核酸的质量或摩尔量计超过1%、0.5%、0.2%、0.1%、0.05%、0.02%或0.01%的dna。
69.如实施例68所述的方法,所述方法导致向所述哺乳动物细胞的基因组添加外源dna序列的至少5、10、20、50、100、200、500、1,000、2,000或5,000个碱基对。
70.如实施例68或69所述的方法,所述方法导致向所述哺乳动物细胞的基因组添加蛋白质编码序列。
71.一种将dna插入哺乳动物细胞基因组的方法,所述方法包括使所述细胞与rna组合物接触,其中所述rna组合物包含:
(a)指导模板rna插入基因组的第一rna,和
(b)包含异源序列的模板rna,
其中所述方法不包括使所述哺乳动物细胞与dna接触,或其中(a)和(b)的组合物不包含按核酸的质量或摩尔量计超过1%、0.5%、0.2%、0.1%、0.05%、0.02%或0.01%的dna,
其中所述方法导致向所述哺乳动物细胞的基因组添加dna(例如外源dna)序列的至少5、10、20、50、100、200、500、1,000、2,000或5,000个碱基对。
72.如实施例71所述的方法,其中所述第一rna编码多肽(例如,本文表1、2或3中的任一个的多肽),其中所述多肽指导所述模板rna插入所述基因组中。
73.如实施例72所述的方法,其中所述模板rna进一步包含结合所述多肽的序列。
74.一种方法,所述方法添加至少5、10、15、20、25、30、35、40、45、50、60、70、80、90、100、150、200、250、300、350、400、500、1000bp的外源dna进入哺乳动物细胞的基因组,而没有将dna递送到所述细胞。
75.一种方法,所述方法添加至少5、10、15、20、25、30、35、40、45、50、60、70、80、90、100、150、200、250、300、350、400、500、1000bp的外源dna进入哺乳动物细胞的基因组,其中所述方法不包括使所述哺乳动物细胞与dna接触,或者其中所述方法包括使所述哺乳动物细胞与组合物接触,所述组合物包含按核酸的质量或摩尔量计少于1%、0.5%、0.2%、0.1%、0.05%、0.02%或0.01%的dna。
76.一种方法,所述方法添加至少5、10、15、20、25、30、35、40、45、50、60、70、80、90、100、150、200、250、300、350、400、500、1000bp的外源dna进入哺乳动物细胞的基因组,所述方法包括仅将rna递送到所述哺乳动物细胞。
77.一种方法,所述方法添加至少5、10、15、20、25、30、35、40、45、50、60、70、80、90、100、150、200、250、300、350、400、500、1000bp的外源dna进入哺乳动物细胞的基因组,所述方法包括将rna和蛋白质递送至所述哺乳动物细胞。
78.如实施例68-77中任一项所述的方法,其中所述模板rna用作插入所述外源dna的模板。
79.如实施例68-78中任一项所述的方法,其不包括外源dna的dna依赖性rna聚合。
80.如实施例58-79中任一项所述的方法,其导致向所述哺乳动物细胞的基因组添加至少5、10、20、50、100、200、500、1,000、2,000或5,000个碱基对的dna。
81.如实施例68-80中任一项所述的方法,其中(a)的rna和(b)的rna共价连接,例如是同一转录物的一部分。
82.如实施例68-80中任一项所述的方法,其中(a)的rna和(b)的rna是分开的rna。
83.如实施例58-82中任一项所述的方法,其不包括使所述哺乳动物细胞与模板dna接触。
84.一种修饰人细胞基因组的方法,所述方法包括使所述细胞与以下接触:
(a)多肽或编码多肽的核酸,其中该多肽包含(i)逆转录酶结构域,(ii)内切核酸酶结构域,和任选地(iii)dna结合结构域;和
(b)模板rna(或编码所述模板rna的dna),所述模板rna包含(i)结合所述多肽的序列和(ii)异源对象序列,
其中所述方法导致将所述异源对象序列插入人细胞的基因组中,
其中所述人细胞不显示任何dna修复基因和/或肿瘤抑制基因的上调,或其中dna修复基因和/或肿瘤抑制基因的上调不超过10%、5%、2%或1%、例如,其中通过rna-seq测量上调,如实例14中所述。
85.一种向细胞(例如哺乳动物细胞)的基因组添加外源编码区的方法,所述方法包括使所述细胞与包含所述外源编码区的非编码链的rna接触,其中任选地,所述rna不包含所述外源编码区的编码链,其中任选地,递送包括非病毒递送。
86.一种在细胞(例如,哺乳动物细胞)中表达多肽的方法,所述方法包括使所述细胞与rna接触,其中所述rna包含非编码链,所述非编码链是将编码所述多肽的序列的反向互补序列,其中任选地,所述rna不包含编码所述多肽的编码链,其中任选地,递送包括非病毒递送。
87.如实施例58-86中任一项所述的方法,其中插入所述哺乳动物基因组中的序列是对所述哺乳动物基因组外源的序列。
88.如实施例58-87中任一项所述的方法,其独立于dna模板运行。
89.如实施例58-88中任一项所述的方法,其中所述细胞是组织的一部分。
90.如实施例58-89中任一项所述的方法,其中所述哺乳动物细胞是整倍体,没有被永生化,是生物体的一部分,是原代细胞,是非分裂的,是肝细胞或来自患有遗传性疾病的受试者。
91.如实施例58-90中任一项所述的方法,其中所述接触包括使所述细胞与质粒、病毒、病毒样颗粒、病毒体、脂质体、囊泡、外来体或脂质纳米颗粒接触。
92.如实施例58-91中任一项所述的方法,其中所述接触包括使用非病毒递送。
93.如实施例58-92中任一项所述的方法,其包括使所述细胞与所述模板rna(或编码所述模板rna的dna)接触,其中所述模板rna包含外源编码区的非编码链,其中任选地,所述模板rna不包含所述外源编码区的编码链,其中任选地,递送包括非病毒递送,从而将所述外源编码区添加至所述细胞的基因组。
94.如实施例58-93中任一项所述的方法,其包括使所述细胞与所述模板rna(或编码所述模板rna的dna)接触,其中所述模板rna包含非编码链,所述非编码链是编码所述多肽的序列的反向互补序列,其中任选地,所述模板rna不包含编码所述多肽的编码链,其中任选地,递送包括非病毒递送,从而在所述细胞中表达所述多肽。
95.如实施例63-94中任一项所述的方法,其中所述接触包括对受试者例如静脉内施用(a)和(b)。
96.如实施例63-95中任一项所述的方法,其中所述接触包括至少两次向受试者施用(a)和(b)的剂量。
97.如实施例的实施例63-96中任一项所述的方法,其中所述多肽将所述模板rna序列逆转录成所述靶dna链,从而修饰所述靶dna链。
98.如实施例63-97中任一项所述的方法,其中(a)和(b)分开施用。
99.如实施例63-97中任一项所述的方法,其中(a)和(b)一起施用。
100.如实施例63-99中任一项所述的方法,其中(a)的核酸未整合到所述宿主细胞的基因组中。
101.任何前述编号的方法,其中结合所述多肽的序列具有以下特征中的一个或多个:
(a)在所述模板rna的3’末端;
(b)在所述模板rna的5'末端;
(b)是非编码序列;
(c)是结构化的rna;或
(d)形成至少1个发夹环结构。
102.任何前述编号的方法,其中所述模板rna进一步包含含有与靶dna链具有至少80%同一性(例如,至少85%、90%、95%、97%、98%、99%、100%同一性)的至少20个核苷酸的序列。
103.任何前述编号的方法,其中所述模板rna进一步包含含有与靶dna链具有至少80%同一性(例如,至少85%、90%、95%、97%、98%、99%、100%同一性)的至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、20、25、30、35、40、45、50、60、70、80、90、100、110、120、130、140、150个核苷酸的序列。
104.任何前述编号的方法,其中包含与靶dna链具有至少80%同一性的至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、20、25、30、35、40、45、50、60、70、80、90、100、110、120、130、140、150个核苷酸,或约:2-10、10-20、20-30、30-40、40-50、50-60、60-70、70-80、80-90、90-100、10-100或2-100个核苷酸的序列在所述模板rna的3’末端。
105.任何前述编号的方法,其中所述模板rna进一步包含含有与靶dna链具有至少80%同一性(例如,至少85%、90%、95%、97%、98%、99%、100%同一性)的至少100个核苷酸的序列,例如在所述模板rna的3’末端。
106.如实施例104或105所述的方法,其中所述序列与其具有至少80%同一性的靶dna链中的位点靠近被包含所述内切核酸酶的多肽识别(例如结合和/或切割)的靶dna链上的靶位点(例如,在约:0-10、10-20、20-30、30-50或50-100个核苷酸内)。
107.任何前述编号的方法,其中包含与靶dna链具有至少80%同一性的至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、20、25、30、35、40、45、50、60、70、80、90、100、110、120、130、140、150个核苷酸,或约:2-10、10-20、20-30、30-40、40-50、50-60、60-70、70-80、80-90、90-100、10-100或2-100个核苷酸的序列在所述模板rna的3’末端;
任选地,其中所述序列与其具有至少80%同一性的靶dna链中的位点靠近被包含所述内切核酸酶的多肽识别(例如结合和/或切割)的靶dna链上的靶位点(例如,在约:0-10、10-20或20-30个核苷酸内)。
108.如实施例107所述的方法,其中所述靶位点是所述人基因组中与包含所述内切核酸酶的多肽的天然靶位点具有最接近同一性的位点,例如其中所述人基因组中的靶位点具有至少约16、17、18、19或20个核苷酸与所述天然靶位点相同。
109.任何前述编号的方法,其中所述模板rna的至少3、4、5、6、7、8、9或10个碱基与所述靶dna链具有100%同一性。
110.任何前述编号的方法,其中与所述靶dna链具有100%同一性的至少3、4、5、6、7、8、9或10个碱基在所述模板rna的3’末端。
111.任何前述编号的方法,其中与所述靶dna链具有100%同一性的至少3、4、5、6、7、8、9或10个碱基在所述模板rna的5’末端。
112.任何前述编号的方法,其中所述模板rna在所述模板rna的5’末端包含与所述靶dna具有100%同一性的至少3、4、5、6、7、8、9或10个碱基并且在所述模板rna的3’末端包含与所述靶dna具有100%同一性的至少3、4、5、6、7、8、9或10个碱基。
113.任何前述编号的方法,其中所述异源对象序列在50-50,000个碱基对之间(例如,在50-40,000bp之间,在500-30,000bp之间,在500-20,000bp之间,在100-15,000bp之间,在500-10,000bp之间,在50-10,000bp之间,在50-5,000bp之间)。
114.任何前述编号的方法,其中所述异源对象序列是至少10、25、50、100、150、200、250、300、400、500、600或700bp。
115.任何前述编号的方法,其中所述异源对象序列是至少715、750、800、950、1,000、2,000、3,000或4,000bp。
116.任何前述编号的方法,其中所述异源对象序列小于5,000、10,000、15,000、20,000、30,000或40,000bp。
117.任何前述编号的方法,其中所述异源对象序列小于700、600、500、400、300、200、150或100bp。
118.任何前述编号的方法,其中所述异源对象序列包含:
(a)开放阅读框,例如编码多肽的序列,例如酶(例如,溶酶体酶)、膜蛋白、血液因子、外显子、细胞内蛋白(例如,胞质蛋白、核蛋白、细胞器蛋白、例如线粒体蛋白或溶酶体蛋白)、细胞外蛋白、结构蛋白、信号传导蛋白、调节蛋白、转运蛋白、感觉蛋白、运动蛋白、防御蛋白、或储存蛋白;
(b)非编码和/或调节序列,例如结合转录调控剂的序列,例如启动子、增强子、绝缘子;
(c)剪接接受位点;
(d)聚a位点;
(e)表观遗传修饰位点;或
(f)基因表达单元。
119.任何前述编号的方法,其中所述靶dna是基因组安全港(gsh)位点。
120.任何前述编号的方法,其中所述靶dna是基因组naturalharbortm位点。
121.任何前述编号的方法,其导致所述异源对象序列以至少0.01、0.025、0.05、0.075、0.1、0.15、0.2、0.25、0.3、0.4,0.5、0.75、1、1.25、1.5、1.75、2、2.5、3、4或5个拷贝/基因组的平均拷贝数插入所述基因组中的靶位点。
122.任何前述编号的方法,其导致进入基因组中的靶位点中的整合子的约25-100%、50-100%、60-100%、70-100%、75-95%、80%-90%是未截短的,如通过本文所述的测定法测量,例如实例6的测定法测定。
123.任何前述编号的方法,其导致所述异源对象序列在所述细胞的基因组中的仅一个靶位点处插入。
124.任何前述编号的方法,其导致所述异源对象序列插入细胞的靶位点中,所述插入的异源序列相对于插入前的异源序列包含少于10%、5%、2%、1%、0.5%、0.2%或0.1%的突变(例如snp或一个或多个缺失(例如截短或内部缺失)),例如,如通过实例12的测定所测量。
125.任何前述编号的方法,其导致所述异源对象序列插入多个细胞的靶位点,其中所述插入的异源序列的少于10%、5%、2%或1%的拷贝包含突变(例如,snp或缺失,例如,截短或内部缺失),例如,如通过实例12的测定所测量。
126.任何前述编号的方法,其导致所述异源对象序列插入靶细胞基因组,并且其中所述靶细胞不显示p53的上调,或显示p53上调少于10%、5%、2%、或1%、例如其中p53的上调是通过p53蛋白水平,例如根据实例30中所述的方法,或通过在ser15和ser20磷酸化的p53的水平来测量。
127.任何前述编号的方法,其导致所述异源对象序列插入靶细胞基因组,并且其中靶细胞不显示任何dna修复基因和/或肿瘤抑制基因的上调,或其中dna修复基因和/或肿瘤抑制基因的上调不超过10%、5%、2%或1%、例如,其中通过rna-seq测量上调,如实例14中所述。
128.任何前述编号的方法,其导致所述异源对象序列插入与所述系统接触的细胞群体中约1%-80%的细胞(例如约1%-10%、10%-20%、20%-30%、30%-40%、40%-50%、50%-60%、60%-70%或70%-80%的细胞)中的靶位点(例如,以1个插入或多于一个插入的拷贝数),例如,如使用单细胞ddpcr所测量的,例如,如实例17中所述。
129.任何前述编号的方法,其导致所述异源对象序列以1个插入的拷贝数插入与所述系统接触的细胞群体中约1%-80%的细胞(例如约1%-10%、10%-20%、20%-30%、30%-40%、40%-50%、50%-60%、60%-70%或70%-80%的细胞)中的靶位点,例如,如使用菌落分离和ddpcr所测量的,例如,如实例18中所述。
130.任何前述编号的方法,其导致所述异源对象序列在细胞群体中以比插入非靶位点(脱靶插入)更高的速率插入靶位点(中靶插入),其中中靶插入与脱靶插入的比率大于10:1、20:1、30:1、40:1、50:1、60:1、70:1、80:1、90:1、100:1、200:1、500:1或1,000:1,例如使用实例11的测定。
131.任何上述编号的系统,其导致在存在dna修复途径抑制剂(例如scr7,一种parp抑制剂)的情况下,或在缺乏dna修复途径的细胞系(例如,缺乏核苷酸切除修复途径或同源性指导的修复途径的细胞系)中异源对象序列的插入。
132.任何前述编号的系统,其可配制成药物组合物。
133.任何前述编号的系统,将其置于药学上可接受的载剂(例如,囊泡、脂质体、天然或合成脂质双层、脂质纳米颗粒、外来体)中。
134.一种制备用于修饰哺乳动物细胞基因组的系统的方法,所述方法包括:
a)提供如前述实施例中任一项所述的模板rna,例如,其中所述模板rna包含(i)结合包含逆转录酶结构域和内切核酸酶结构域的多肽的序列,和(ii)异源对象序列;并且
b)处理所述模板rna以减少二级结构,例如将所述模板rna加热至例如至少70、75、80、85、90或95c,并且
c)随后将所述模板rna冷却至例如允许二级结构的温度,例如至小于或等于30、25或20c。
135.如实施例134所述的方法,其进一步包括使所述模板rna与包含(i)逆转录酶结构域和(ii)内切核酸酶结构域的多肽或编码所述多肽的核酸(例如rna)接触。
136.如实施例134或135所述的方法,其进一步包括使所述模板rna与细胞接触。
137.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列编码治疗性多肽。
138.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列编码哺乳动物(例如人)多肽或其片段或变体。
139.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列编码酶(例如,溶酶体酶),血液因子(例如,因子i、ii、v、vii、x、xi、xii或xiii)、膜蛋白、外显子、细胞内蛋白(例如,胞质蛋白、核蛋白、细胞器蛋白、例如线粒体蛋白或溶酶体蛋白)、细胞外蛋白、结构蛋白、信号传导蛋白、调节蛋白、转运蛋白、感觉蛋白、运动蛋白、防御蛋白、或储存蛋白。
140.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列包含组织特异性启动子或增强子。
141.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列编码大于250、300、400、500或1,000个氨基酸,并且任选地多达1300个氨基酸的多肽。
142.如前述实施例中任一项的系统或方法,其中所述异源对象序列编码哺乳动物基因的片段,但不编码完整的哺乳动物基因,例如,编码一个或多个外显子,但不编码全长蛋白质。
143.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列编码一个或多个内含子。
144.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列不同于gfp,例如,不同于荧光蛋白或不同于报道蛋白。
145.如前述实施例中任一项所述的系统或方法,其中所述多肽包含(i)逆转录酶结构域和(ii)内切核酸酶结构域,其中(i)或(ii)之一或两者均衍生自禽逆转录转座酶,例如具有表2或3的序列或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性。
146.如前述实施例中任一项所述的系统或方法,其中所述多肽在37℃下的活性不低于在25℃下在其他方面类似的条件下的活性的70%、75%、80%、85%、90%或95%。
147.如前述实施例中任一项所述的系统或方法,其中编码所述多肽和所述模板rna的核酸或编码所述模板rna的核酸是分开的核酸。
148.如前述实施例中任一项所述的系统或方法,其中所述模板rna不编码活性逆转录酶,例如,如实例1或2中所述包含失活的突变逆转录酶,或不包含逆转录酶序列。
149.如前述实施例中任一项所述的系统或方法,其中所述模板rna包含一个或多个化学修饰。
150.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列位于所述启动子和结合所述多肽的序列之间。
151.如前述实施例中任一项所述的系统或方法,其中所述启动子位于所述异源对象序列和结合所述多肽的序列之间。
152.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列包含在所述模板rna上以5'至3'取向的开放阅读框(或其反向互补序列)。
153.如前述实施例中任一项所述的系统或方法,其中所述异源对象序列包含在所述模板rna上3'至5'取向的开放阅读框(或其反向互补序列)。
154.如前述实施例中任一项所述的系统或方法,其中所述多肽包含(a)逆转录酶结构域和(b)内切核酸酶结构域,其中(a)或(b)中的至少一个是异源的。
155.如前述实施例中任一项所述的系统或方法,其中所述多肽包含(a)靶dna结合结构域,(b)逆转录酶结构域和(c)内切核酸酶结构域,其中(a)、(b)或(c)中的至少一个是异源的。
156.一种基本上纯的多肽,其包含(a)逆转录酶结构域和(b)异源内切核酸酶结构域。
157.一种基本上纯的多肽,其包含(a)靶dna结合结构域,(b)逆转录酶结构域和(c)内切核酸酶结构域,其中(a)、(b)或(c)中的至少一个是异源的。
158.一种基本上纯的多肽,其包含(a)逆转录酶结构域,(b)内切核酸酶结构域和(c)异源靶dna结合结构域。
159.一种多肽或编码所述多肽的核酸,其中所述多肽包含(a)逆转录酶结构域和(b)内切核酸酶结构域,其中(a)或(b)中的至少一个彼此异源。
160.一种多肽或编码所述多肽的核酸,其中所述多肽包含(a)靶dna结合结构域,(b)逆转录酶结构域和(c)内切核酸酶结构域,其中(a)、(b)或(c)中的至少一个彼此异源。
161.如实施例156-160编号的任何多肽,其中所述逆转录酶结构域与表1-3中任一个的ape型或rle型非ltr逆转录转座子的逆转录酶结构域具有至少80%同一性(例如,至少85%、90%、95%、97%、98%、99%、100%的同一性)。
162.如实施例156-161编号的任何多肽,其中所述内切核酸酶结构域与表1-3中任一个的ape型或rle型非ltr逆转录转座子的内切核酸酶结构域具有至少80%同一性,例如,至少85%、90%、95%、97%、98%、99%、100%的同一性。
163.如实施例156-162编号的任何多肽或如任何前述编号的方法,其中所述dna结合结构域与表1、2或3中列出的序列的dna结合结构域具有至少80%同一性,例如,至少85%、90%、95%、97%、98%、99%、100%同一性。
164.一种编码如任何前述编号的实施例所述的多肽的核酸。
165.一种包含如编号的实施例164所述的核酸的载体。
166.一种包含如编号的实施例164所述的核酸的宿主细胞。
167.一种包含如任何前述编号的实施例所述的多肽的宿主细胞。
168.一种包含如编号的实施例165所述的载体的宿主细胞。
169.一种宿主细胞(例如人细胞),其包含:(i)染色体中靶位点处的异源对象序列(例如,编码治疗性多肽的序列),和(ii)在异源对象序列的一侧(例如上游)的非翻译区(例如,逆转录转座子未翻译序列,例如表3第6列的序列)和在异源对象序列的另一侧(例如下游)的非翻译区(例如逆转录转座子非翻译序列,例如表3第7列的序列)中的一者或两者。
170.一种宿主细胞(例如人细胞),其包含:(i)在染色体的靶位点处的异源对象序列(例如,编码治疗性多肽的序列),其中所述靶位基因座是naturalharbortm位点,例如本文表4的位点。
171.如实施例170所述的宿主细胞,其进一步包含(ii)所述异源对象序列的非翻译区5’和所述异源对象序列的非翻译区3’之一或两者。
172.如实施例170所述的宿主细胞,其进一步包含(ii)在异源对象序列的一侧(例如上游)的非翻译区(例如,逆转录转座子未翻译序列,例如表3第6列的序列)和在异源对象序列的另一侧(例如下游)的非翻译区(例如逆转录转座子非翻译序列,例如表3第7列的序列)中的一者或两者。
173.如实施例169-173中任一项所述的宿主细胞,其仅在所述靶位点处包含异源对象序列。
174.一种药物组合物,其包含任何前述编号的系统、核酸、多肽或载体;和药学上可接受的赋形剂或载剂。
175.如实施例174所述的药物组合物,其中所述药学上可接受的赋形剂或载剂选自载体(例如病毒或质粒载体),囊泡(例如脂质体、外来体、天然或合成脂质双层)、脂质纳米颗粒。
176.如前述实施例中任一项所述的多肽,其中所述多肽进一步包含核定位序列。
177.一种修饰细胞、组织或受试者中的靶dna链的方法,所述方法包括对所述细胞、组织或受试者施用任何前述编号的系统,从而修饰所述靶dna链。
178.任何前述编号的实施例,其中所述多肽包含与表5中列出的氨基酸序列(例如,seqidno:1017-1022中的任何一个)或其功能片段具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
179.任何前述编号的实施例,其中所述逆转录酶结构域包含与表5中列出的氨基酸序列(例如,seqidno:1017-1022中的任何一个)或其功能片段的逆转录酶结构域具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
180.任何前述编号的实施例,其中所述逆转录转座酶包含与表5中列出的氨基酸序列(例如,seqidno:1017-1022中的任何一个)或其功能片段具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
181.任何前述编号的实施例,其中所述多肽包含与氨基酸序列sgsetpgtsesatpes(seqidno:1023)或gggs(seqidno:1024)具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
182.任何前述编号的实施例,其中所述逆转录酶结构域包含与氨基酸序列sgsetpgtsesatpes(seqidno:1023)或gggs(seqidno:1024)具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
183.任何前述编号的实施例,其中所述逆转录转座酶包含与氨基酸序列sgsetpgtsesatpes(seqidno:1023)或gggs(seqidno:1024)具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
184.任何前述编号的实施例,其中所述多肽、逆转录酶结构域或逆转录转座酶包含接头,所述接头包含与氨基酸序列sgsetpgtsesatpes(seqidno:1023)或gggs(seqidno:1024)具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
185.任何前述编号的实施例,其中所述多肽包含通过接头(例如包括至少1、2、3、4、5、6、7、8,9、10、11、12,13、14、15、16、17、18、19、20、25、30、35、40、45、50、60、70、80、90、100、125、150、200、300、400或500个氨基酸的接头)共价附接至所述多肽其余部分的dna结合结构域。
186.编号的实施例185,其中所述接头在所述dna结合结构域、rna结合结构域、逆转录酶结构域或内切核酸酶结构域(例如,如图17a-17f中的任一个所示)中的位置处附接至所述多肽的其余部分。
187.编号的实施例185或186,其中所述接头在所述多肽的α螺旋区的n末端侧的位置处,例如在对应于实例26中所述的版本v1的位置处,附接至所述多肽的其余部分。
188.编号的实施例185或186,其中所述接头在所述多肽的α螺旋区的c末端侧的位置处,例如在rna结合基序之前(例如,-1rna结合基序),例如在对应于实例26中所述的版本v2的位置处,附接至所述多肽的其余部分。
189.编号的实施例185或186,其中所述接头在所述多肽的随机卷曲区的c末端侧的位置处,例如,相对于dna结合基序(例如c-mybdna结合基序)的n末端,例如在对应于实例26中所述的版本v3的位置处,附接至所述多肽的其余部分。
190.编号的实施例185-189中的任一项,其中所述接头包含与氨基酸序列sgsetpgtsesatpes(seqidno:1023)或gggs(seqidno:1024)具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
191.任何前述编号的实施例,其中包含来自所述模板rna序列的5’末端的至少约500、1000、2000、3000、3500、3600、3700、3800、3900或4000个连续核苷酸的多核苷酸序列被整合到靶细胞基因组中。
192.任何前述编号的实施例,其中包含来自所述模板rna序列的3’末端的至少约500、1000、2000、2500、2600、2700、2800、2900或3000个连续核苷酸的多核苷酸序列被整合到靶细胞基因组中。
193.任何前述编号的实施例,其中所述模板rna的核酸序列或其部分(例如,包含至少约100、200、300、400、500、1000、2000、2500、3000、3500或4000个核苷酸的部分)以至少约0.21、0.3、0.4、0.5、0.6、0.7、0.8、0.9或1.0个整合子/基因组的拷贝数整合到靶细胞群体的基因组中。
194.任何前述编号的实施例,其中所述模板rna的核酸序列或其部分(例如,包含至少约100、200、300、400、500、1000、2000、2500、3000、3500或4000个核苷酸的部分)以至少约0.085、0.09、0.1、0.15或0.2个整合子/基因组的拷贝数整合到靶细胞群体的基因组中。
195.任何前述编号的实施例,其中所述模板rna的核酸序列或其部分(例如,包含至少约100、200、300、400、500、1000、2000、2500、3000、3500或4000个核苷酸的部分)以至少约0.036、0.04、0.05、0.06、0.07或0.08个整合子/基因组的拷贝数整合到靶细胞群体的基因组中。
196.任何前述编号的实施例,其中所述多肽包含功能性内切核酸酶结构域(例如,其中所述内切核酸酶结构域不包含消除内切核酸酶活性的突变,例如如本文所述)。
197.任何前述编号的实施例,其中所述多肽包含与来自中嘴地雀例如中地雀的r2多肽(例如,如本文所述,例如,r2-1_gfo)或其功能片段具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
198.任何前述编号的实施例,其中所述逆转录酶结构域包含与来自中嘴地雀例如中地雀的r2多肽(例如,如本文所述,例如,r2-1_gfo)或其功能片段具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
199.任何前述编号的实施例,其中所述逆转录转座酶包含与来自中嘴地雀例如中地雀的r2多肽(例如,如本文所述,例如,r2-1_gfo)或其功能片段具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
200.编号的实施例197-199中的任一项,其中所述模板rna的核酸序列或其部分(例如,包含至少约100、200、300、400、500、1000、2000、2500、3000、3500或4000个核苷酸的部分)以至少约0.21个整合子/基因组的拷贝数整合到靶细胞群体的基因组中。
201.任何前述编号的实施例,其中所述多肽包含与来自大线虫例如人蛔虫的r4多肽(例如,如本文所述,例如,r4_al)或其功能片段具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
202.任何前述编号的实施例,其中所述逆转录酶结构域包含与来自大线虫例如人蛔虫的r4多肽(例如,如本文所述,例如,r4_al)或其功能片段具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
203.任何前述编号的实施例,其中所述逆转录转座酶包含与来自大线虫例如人蛔虫的r4多肽(例如,如本文所述,例如,r4_al)或其功能片段具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
204.编号的实施例201-203中的任一项,其中所述模板rna的核酸序列或其部分(例如,包含至少约100、200、300、400、500、1000、2000、2500、3000、3500或4000个核苷酸的部分)以至少约0.085个整合子/基因组的拷贝数整合到靶细胞群体的基因组中。
205.任何前述编号的实施例,其中将所述系统引入靶细胞不会导致p53和/或p21蛋白水平的改变(例如上调)、h2ax磷酸化(例如γh2ax)、atm磷酸化、atr磷酸化、chk1磷酸化、chk2磷酸化和/或p53磷酸化。
206.任何前述编号的实施例,其中将所述系统引入靶细胞导致所述靶细胞中p53蛋白水平上调至小于通过引入靶向与所述系统相同的基因组位点的位点特异性核酸酶(例如cas9)诱导的p53蛋白水平的约0.001%、0.005%、0.01%、0.05%、0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、30%、40%、45%、50%、55%、60%、70%、80%或90%的水平。
207.编号的实施例205或206,其中所述p53蛋白水平根据实例30中描述的方法确定。
208.任何前述编号的实施例,其中将所述系统引入靶细胞导致所述靶细胞中p53磷酸化水平上调至小于通过引入靶向与所述系统相同的基因组位点的位点特异性核酸酶(例如cas9)诱导的p53磷酸化水平的约0.001%、0.005%、0.01%、0.05%、0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、30%、40%、45%、50%、55%、60%、70%、80%或90%的水平。
209.任何前述编号的实施例,其中将所述系统引入靶细胞导致所述靶细胞中p21蛋白水平上调至小于通过引入靶向与所述系统相同的基因组位点的位点特异性核酸酶(例如cas9)诱导的p53蛋白水平的约0.001%、0.005%、0.01%、0.05%、0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、30%、40%、45%、50%、55%、60%、70%、80%或90%的水平。
210.编号的实施例205或209,其中所述p21蛋白水平根据实例30中描述的方法确定。
211.任何前述编号的实施例,其中将所述系统引入靶细胞导致所述靶细胞中h2ax磷酸化水平上调至小于通过引入靶向与所述系统相同的基因组位点的位点特异性核酸酶(例如cas9)诱导的h2ax磷酸化水平的约0.001%、0.005%、0.01%、0.05%、0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、30%、40%、45%、50%、55%、60%、70%、80%或90%的水平。
212.任何前述编号的实施例,其中将所述系统引入靶细胞导致所述靶细胞中atm磷酸化水平上调至小于通过引入靶向与所述系统相同的基因组位点的位点特异性核酸酶(例如cas9)诱导的atm磷酸化水平的约0.001%、0.005%、0.01%、0.05%、0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、30%、40%、45%、50%、55%、60%、70%、80%或90%的水平。
213.任何前述编号的实施例,其中将所述系统引入靶细胞导致所述靶细胞中atr磷酸化水平上调至小于通过引入靶向与所述系统相同的基因组位点的位点特异性核酸酶(例如cas9)诱导的atr磷酸化水平的约0.001%、0.005%、0.01%、0.05%、0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、30%、40%、45%、50%、55%、60%、70%、80%或90%的水平。
214.任何前述编号的实施例,其中将所述系统引入靶细胞导致所述靶细胞中chk1磷酸化水平上调至小于通过引入靶向与所述系统相同的基因组位点的位点特异性核酸酶(例如cas9)诱导的chk1磷酸化水平的约0.001%、0.005%、0.01%、0.05%、0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、30%、40%、45%、50%、55%、60%、70%、80%或90%的水平。
215.任何前述编号的实施例,其中将所述系统引入靶细胞导致所述靶细胞中chk2磷酸化水平上调至小于通过引入靶向与所述系统相同的基因组位点的位点特异性核酸酶(例如cas9)诱导的chk2磷酸化水平的约0.001%、0.005%、0.01%、0.05%、0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、30%、40%、45%、50%、55%、60%、70%、80%或90%的水平。
定义
结构域:如本文所用,术语“结构域”是指有助于生物分子的特定功能的生物分子的结构。结构域可以包含生物分子的连续区域(例如,连续序列)或不同的非连续区域(例如,非连续序列)。蛋白质结构域的实例包括但不限于内切核酸酶结构域、dna结合结构域、逆转录结构域;核酸的结构域的实例是调节结构域,例如转录因子结合结构域。
外源的:如本文所用,术语外源的,当相对于生物分子(例如核酸序列或多肽)使用时,是指通过人工将生物分子引入宿主基因组、细胞或生物中。例如,使用重组dna技术或其他方法添加到现有基因组、细胞、组织或受试者中的核酸对于现有核酸序列、细胞、组织或受试者而言是外源的。
基因组安全港位点(gsh位点):基因组安全港位点是宿主基因组中的位点,其能够容纳新遗传材料的整合,例如,使得插入的遗传元件不会引起宿主基因组的显著改变对宿主细胞或生物体构成风险。gsh位点通常满足以下条件中的1、2、3、4、5、6、7、8或9个:(i)距癌症相关基因>300kb;(ii)距mirna/其他功能性小rna>300kb;(iii)距5'基因末端>50kb;(iv)距复制起点>50kb;(v)距任何极保守元件>50kb;(vi)转录活性低(即无mrna+/-25kb);(vii)不在拷贝数可变区中;(viii)在开放染色质中;和/或(ix)是唯一的,在人基因组中有1个拷贝。满足一些或所有这些标准的人基因组中gsh位点的实例包括:(i)腺相关病毒位点1(aavs1),它是aav病毒在19号染色体上整合的天然位点;(ii)趋化因子(c-c基序)受体5(ccr5)基因,一种被称为hiv-1共同受体的趋化因子受体基因;(iii)小鼠rosa26基因座的人直系同源物;(iv)rdna基因座。另外的gsh位点是已知的,并且描述于例如pellenz等人,2018年8月20日电子公开(https://doi.org/10.1101/396390)中。
异源的:当用于参考第二元件来描述第一元件时,术语异源的意思是第一元件和第二元件自然界中不以如所描述的布置存在。例如,异源多肽、核酸分子、构建体或序列是指(a)多肽、核酸分子或多肽或核酸分子序列的一部分,其对于表达其的细胞而言不是天然的,(b)相对于其天然状态已发生改变或突变的多肽或核酸分子或多肽或核酸分子的一部分,或(c)具有与在类似条件下的天然表达水平相比改变的表达的多肽或核酸分子。例如,异源调节序列(例如启动子,增强子)可以用于调节基因或核酸分子的表达,其方式不同于基因或核酸分子通常在自然界中表达的方式。在另一个实例中,多肽或核酸序列的异源结构域(例如,多肽的dna结合结构域或编码多肽的dna结合结构域的核酸)可以相对于其他结构域布置,或者可以是不同的序列或相对于多肽的其他结构域或部分或其编码核酸来自不同来源。在某些实施例中,异源核酸分子可以存在于天然宿主细胞基因组中,但是可以具有改变的表达水平或具有不同的序列或两者。在其他实施例中,异源核酸分子对于宿主细胞或宿主基因组可能不是内源的,而是可能是已经通过转化(例如,转染,电穿孔)引入宿主细胞中,其中添加的分子可以整合到宿主基因组中或可以作为染色体外遗传物质短暂(例如mrna)存在或半稳定存在超过一代(例如游离病毒载体、质粒或其他自我复制载体)
突变或突变的:当应用于核酸序列时,术语“突变的”是指与参考(例如天然)核酸序列相比,核酸序列中的核苷酸可以被插入、缺失或改变。可以在基因座处进行单个改变(点突变),或者可以在单个基因座处插入、缺失或改变多个核苷酸。另外,可以在核酸序列内的任何数目的基因座处进行一个或多个改变。核酸序列可以通过本领域已知的任何方法进行突变。
核酸分子:核酸分子是指rna和dna分子两者,包括但不限于cdna、基因组dna和mrna,并且还包括合成的核酸分子,例如化学合成或重组产生的核酸分子,例如如本文所述的rna模板。核酸分子可以是双链或单链、环状或线性的。如果是单链,则核酸分子可以是有义链或反义链。除非另有说明,并且作为本文中以通用格式“seq.idno:”所述的所有序列的实例,“包含seq.idno:1的核酸”是指具有(i)seq.idno:1的序列或(ii)与seq.idno:1互补的序列的核酸、至少一部分。两者之间的选择取决于使用seq.idno:1的上下文。例如,如果将核酸用作探针,则两者之间的选择取决于探针与期望的靶互补的要求。如本领域技术人员将容易理解的,本公开的核酸序列可以被化学或生物化学修饰或可以包含非天然或衍生的核苷酸碱基。此类修饰包括例如标记,甲基化,用类似物取代一个或多个天然核苷酸,核苷酸间修饰,例如不带电荷的连接(例如,甲基膦酸酯、磷酸三酯、氨基磷酸酯、氨基甲酸酯等)、带电荷的连接(例如,硫代磷酸酯、二硫代磷酸酯等),侧链部分(例如,多肽),嵌入剂(例如,吖啶,补骨脂素等),螯合剂,烷基化剂和经修饰的连接(例如,α异头核酸等等)。还包括合成的分子,它们模拟多核苷酸通过氢键和其他化学相互作用与指定序列结合的能力。这样的分子是本领域已知的,并且包括例如其中肽键替代分子主链中的磷酸键的那些。其他修饰可以包括,例如,其中核糖环包含桥接部分或其他结构(例如在“锁定”核酸中发现的修饰)的类似物。
基因表达单元:基因表达单元是核酸序列,其包含与至少一个效应子序列可操作地连接的至少一个调节核酸序列。当第一核酸序列被放置成与第二核酸序列有功能关系时,该第一核酸序列与该第二核酸序列可操作地连接。例如,如果启动子或增强子影响编码序列的转录或表达,则所述启动子或增强子与所述编码序列可操作地连接。可操作地连接dna序列可以是连续的或非连续的。在需要连接两个蛋白质编码区的情况下,可操作地连接的序列可以在同一阅读框中。
宿主:如本文所用,术语宿主基因组或宿主细胞是指已将蛋白质和/或遗传物质引入其中的细胞和/或其基因组。应当理解,这些术语不仅旨在指特定的受试者细胞和/或基因组,而且还指这种细胞的后代和/或这种细胞的后代的基因组。因为由于突变或环境影响,某些修饰可能在后代中发生,所以这样的后代实际上可能与亲本细胞不同,但仍包括在本文所用的术语“宿主细胞”的范围内。宿主基因组或宿主细胞可以是在培养物中生长的分离的细胞或细胞系,或者是从这种细胞或细胞系分离的基因组材料,或者可以是组成活组织或生物体的宿主细胞或宿主基因组。在一些情况下,宿主细胞可以是动物细胞或植物细胞,例如,如本文所述。在某些情况下,宿主细胞可以是牛细胞、马细胞、猪细胞、山羊细胞、绵羊细胞、鸡细胞或火鸡细胞。在某些情况下,宿主细胞可以是玉米细胞、大豆细胞、小麦细胞或稻细胞。
假结:如本文所用,“假结序列”序列是指具有带有合适的自身互补性以形成假结结构的序列的核酸(例如rna),例如具有:第一区段、第一区段和第三区段之间的第二区段,其中第三区段与第一区段互补,以及第四区段,其中第四区段与第二区段互补。假结可以任选地具有另外的二级结构,例如,布置在第二区段中的茎环,布置在第二区段和第三区段之间的茎环,在第一区段之前的序列或在第四区段之后的序列。假结可以在第一区段和第二区段之间,第二区段和第三区段之间或第三区段和第四区段之间具有另外的序列。在一些实施例中,所述区段的排列从5'到3':第一、第二、第三和第四。在一些实施例中,第一和第三区段包含五个完全互补的碱基对。在一些实施例中,第二和第四区段包含10个碱基对,任选地具有一个或多个(例如,两个)凸起。在一些实施例中,第二区段包含一个或多个未配对的核苷酸,例如形成环。在一些实施例中,第三区段包含一个或多个未配对的核苷酸,例如形成环。
茎环序列:如本文所用,“茎环序列”是指具有足够的自身互补性以形成茎-环的核酸序列(例如,rna序列),例如,具有的茎包含至少两个(例如,3、4、5、6、7、8、9或10个)碱基对,以及具有的环具有至少三个(例如,四个)碱基对。茎可能包含不匹配或凸起。
附图说明
图1是genewriting基因组编辑系统的示意图。
图2是genewriter基因组编辑器多肽的结构示意图。
图3是genewriter基因组编辑器多肽的示意图,所述多肽包含设计用于靶向基因组不同位点的异源dna结合结构域。
图4是genewriter基因组编辑器模板rna的结构示意图。
图5是显示genewriting基因组编辑系统将基因表达单元添加到基因组中的安全港位点的示意图。
图6是显示基因编辑基因组编辑以将新的外显子添加到基因组中的特定内含子中并替换下游外显子的示意图。
图7展示了miseq库构建的示意图。使用(1)外部正向引物和带尾的内部反向引物,然后是(2)带尾的内部正向引物和尾反向引物,通过r2tg-rdna连接进行巢式pcr。内部反向引物包含1-4个碱基的错位,8-核苷酸随机umi和多重条形码。umi允许对单个扩增事件进行计数,以消除pcr偏差。
图8a-8b:dna介导的r2tg整合入hek293t细胞的miseq和matlab分析的结果。每个图显示了对(图8a)实验r2tg(图8b)和1bp缺失阴性对照的分析。y轴表示通过matlab找到的唯一umi确定的唯一序列的比对计数。x轴表示序列覆盖的序列位置。图左侧的垂直灰线指示正向引物的位置,而图右侧的垂直灰线指示预期的tg-rdna连接位点。图的右端的柱表示没有截短,而图的左端的柱表示截短。图8a显示大多数序列显示出与预期整合产物的高度对齐。
图9显示了在跨转染条件下人细胞中r2tg-rdna连接的拷贝数变异的ddpcr评估。正向引物和探针预期与r2tg的3’utr结合,而反向引物则靶向人rdna。将所得的ddpcr信号标准化为参考测定rpp30的信号,以确定拷贝数。与以1-bp缺失改变翻译的遗传对照(框移突变体对照,右边的柱组)相比,野生型(wt,左边的柱组)r2tg情况下发现平均拷贝/基因组显著更高。
图10展示了克隆来自实例7的巢式pcr产物的topo的序列比对和覆盖。图右边缘的灰线指示预期的转基因-rdna连接。大多数序列显示出与预期整合产物的高度对齐。
图11是示例性模板rna的示意图。它在中心包含有效载荷结构域(例如,异源对象序列,例如,包含启动子和蛋白质编码序列)。有效载荷结构域的侧翼是5'和3'蛋白质相互作用结构域,例如能够结合genewriter多肽的序列,例如表3中所示的5’和3’utr序列。蛋白质相互作用结构域的侧翼是5’和3’同源翼域,其与基因组中期望的插入区域具有同源性。
图12是显示使用不同转染条件通过ddpcr(数字液滴pcr)测量的逆转座效率的图。柱a-c代表使用0.15μllipofectaminetmrnaimax分别以100ng、250ng或500ng转染的样品。柱d-f代表使用0.3μllipofectaminetmrnaimax分别以100ng、250ng或500ng转染的样品。柱g-i代表使用1μl
图13.反式转基因递送机制的示意图。该示意图展示了具有pcep4主链的驱动质粒(左),所述主链编码逆转录酶r2tg,上游具有启动子和科扎克序列,下游具有聚腺苷酸化信号。驱动质粒可以驱动genewriter蛋白的表达。具有pcdna主链的转基因质粒(右)包含(依次)cmv启动子、rdna同源序列、5’utr、反义取向插入物、3’utr、第二rdna同源序列、第二聚腺苷酸化信号和tk启动子驱动的mkate2标记。反义取向插入物包含ef1α启动子、含内含子的egfp编码区和聚腺苷酸化信号。在转基因质粒中使用cmv启动子可驱动包含rdna同源区、utr和反义取向插入物的模板rna的表达。
图14显示了在跨转染条件下人细胞中转基因-rdna连接的拷贝数变异的ddpcr评估。正向引物和探针被设计为与r2tg的3’utr结合,而反向引物则靶向人rdna。将所得的ddpcr信号标准化为参考测定rpp30的信号,以确定拷贝数。与不涉及r2tg序列的主链构建体相比,野生型(wt)r2tg情况下发现平均拷贝/基因组显著更高。条件1表示驱动质粒:转基因质粒的摩尔比为9:1;条件2表示比例为4:1,条件3表示比例为1:1,条件4表示比例为1:4,并且条件5表示比例为1:9。
图15a和15b.图15a:r2tg的杂交捕获可鉴定人基因组中的中靶整合。与r2核糖体位点中预期的靶整合相对齐的读段覆盖表示在y轴上。rdna和r2tg之间的5'连接由左侧垂直线指示,而3'连接由右侧垂直线指示。下一代测序可鉴定跨预期连接的读段。图15b显示了来自该实验的在整合的序列的5’末端和3'末端被归类为中靶整合或脱靶整合的读段的数目。
图16.3’连接巢式pcr的桑格测序结果。小写核苷酸代表设计的snp。阴影的大写核苷酸代表wt序列。图16公开了seqidno:1538。
图17a-17f是描绘各种共价二聚的genewriter蛋白构型的示意图。描绘的蛋白质是:图17a:野生型全长酶。图17b,通过接头连接的两种全长酶(各自包含dna结合结构域、rna结合结构域、逆转录酶结构域和内切核酸酶结构域)。图17c,通过接头与全长酶连接的dna结合结构域和rna结合结构域。图17d,通过接头与rna结合结构域、逆转录酶结构域和内切核酸酶结构域连接的dna结合结构域和rna结合结构域。图17e,通过第一接头与rna结合结构域连接的dna结合结构域,所述rna结合结构域通过第二接头与第二rna结合结构域、逆转录酶结构域和内切核酸酶结构域连接。图17f,通过第一接头与rna结合结构域连接的dna结合结构域,所述rna结合结构域通过第二接头与多个rna结合结构域(在该图中,分子包含三个rna结合结构域)连接,所述多个rna结合结构域通过接头与逆转录酶结构域和内切核酸酶结构域连接。在一些实施例中,每个r2结合模板rna中的utr。在一些实施例中,至少一个模块包含逆转录酶结构域和内切核酸酶结构域。在一些实施例中,蛋白质包含多个rna结合结构域。在一些实施例中,模块化系统是拆分开的,并且仅当其结合在dna上时才具有活性,其中系统使用两个不同的dna结合模块,例如,第一蛋白(其包含与rna结合模块(其募集rna模板用于靶引发的逆转录)融合的第一dna结合模块)以及第二蛋白(其包含第二dna结合模块,所述第二dna结合模块在整合位点处结合并与逆转录和内切核酸酶模块融合)。在一些实施例中,编码genewriter的核酸包含内含肽,使得genewriter蛋白从两个单独的基因表达并且在翻译后通过蛋白剪接融合。在一些实施例中,genewriter源自非ltr蛋白,例如r2蛋白。
图18a-18f是示出了genewriter蛋白的不同模块组分的示意性示图。描绘的蛋白质是:图18a:野生型全长酶。图18b:genewriter的dna结合结构域可包含锌指、cas9或转录因子,或上述任何一个的片段或变体。图18c:逆转录酶结构域和rna结合结构域一起可以包含与蛋白的一个或多个其他结构域异源的逆转录酶结构域(例如,来自r2蛋白),并且可以任选地进一步包含一个或多个另外的rna结合结构域,或上述中任何的片段或变体。图18d:rna结合结构域可包含例如b盒蛋白、ms2外壳蛋白、dcas蛋白或utr结合蛋白,或上述任何一个的片段或变体。图18e:逆转录酶结构域可包含例如截短的逆转录酶结构域,例如来自r2蛋白;来自病毒(例如,hiv)的逆转录酶结构域,或来自amv(禽成纤维细胞病病毒)的逆转录酶结构域,或上述任何一个的片段或变体。图18f:内切核酸酶结构域可包含例如cas9切口酶、cas直系同源物、foki或限制性内切酶,或上述任何一个的片段或变体。在一些实施例中,可以将单独的dna结合结构域附接至本文所述的多肽(例如,与多肽的现有或先前的dna结合结构域相比,对靶dna序列具有更强的亲和力的dna结合结构域,或者与多肽的现有或先前dna结合结构域相比结合不同靶dna序列的dna结合序列)。在一些实施例中,可以产生dna结合结构域突变体,例如,对靶dna序列具有增加的亲和力。在实施例中,dna结合结构域包含锌指。在实施例中,dna结合结构域通过接头附接至多肽(例如,在n末端或c末端),例如,如本文所述。在实施例中,锌指附接至dna结合结构域突变体(例如,如本文所述),使得多肽表现出与靶dna序列的结合增加(例如,如通过锌指所决定),而不与rdna竞争。
图19是显示接头突变体整合到hek293t细胞基因组中的图,通过ddpcr测定评估r2tg整合的拷贝数/基因组。在v1突变体中,插入位于r2tg的α螺旋区域的n末端侧,所述区域位于预测的-1rna结合基序之前;在v2突变体中,插入位于r2tg的α螺旋区域的c末端侧,所述区域位于预测的-1rna结合基序之前;在v3突变体中,插入位于随机卷曲区域的c末端,所述区域位于r2tg的预测c-mybdna结合基序之后。
图20a-20b是一系列图,其显示了证实r2tg顺式整合的保真度的长读段测序。在预期参考序列上绘制由umi确定的唯一序列覆盖。左侧的垂直柱表示rdna和r2tg的预期5'连接,而右侧的垂直柱表示3'连接。显示了跨5'连接和3'连接的两个单独的扩增子。
图21a-21b是一系列图,其显示了证实r2tg顺式整合的保真度的长读段测序。在预期参考序列上绘制由umi确定的唯一序列缺失(>3bp)。左侧的垂直柱表示rdna和r2tg的预期5'连接,而右侧的垂直柱表示3'连接。显示了跨5'连接和3'连接的两个单独的扩增子。
图22是显示用于r2gfo的顺式整合的示例性质粒图plv033的示意图。
图23是显示hek293t细胞中r2gfo、r4al和r2tg以顺式整合的图。显示了四个重复的平均值;误差棒表示标准偏差。
图24是显示r2tg顺式整合到人成纤维细胞中的图。经四个重复实验绘制了野生型(wt)和内切核酸酶(en)对照r2tg的整合效率,如通过ddpcr在r2tg和rdna靶的3'连接处测量。
图25是显示p53、p21、肌动蛋白和粘着斑蛋白的蛋白质印迹分析的示意图。用指定的化合物或质粒对u2os细胞进行处理:gfp、r2tg-wt(野生型)或r2tg-en(内切核酸酶结构域突变体)。用lipofectamine3000(lipo)或fugenehd(fug)进行质粒转染。处理或转染后24小时分析细胞。
具体实施方式
本公开涉及用于例如体内或体外靶向、编辑、修饰或操纵细胞、组织或受试者中dna序列中的一个或多个位置处的dna序列(例如,将异源对象dna序列插入哺乳动物基因组的靶位点)的组合物、系统和方法。所述靶dna序列可以包括例如编码序列、调节序列、基因表达单元。
更具体地,本公开提供了用于将目的序列插入基因组中的基于反转座子的系统。本公开部分基于生物信息学分析以鉴定逆转录转座酶序列以及来自多种生物的相关的5’utr和3’utr(参见表3)。尽管不希望受到理论的束缚,但在一些实施例中,相对于在较低温度下进化的一些其他酶,在恒温(温血)物种(如鸟类)中鉴定的逆转录转座酶可能具有改善的热稳定性,并且因此热稳定的逆转录转座酶可能更适合用于人体细胞中。本公开内容还提供了实验证据,表明来自不同物种(例如动物的不同物种的和/或逆转录转座子的不同物种和进化枝(例如,按逆转录酶系统发生学分组,例如,如su等人(2019)rna中所述;通过引用以其整体并入本文))的几种逆转录转座酶可用于催化dna插入人细胞中的靶位点(参见实例7和实例28))。
在一些实施例中,相对于各种较早的系统,本文描述的系统可以具有许多优点。例如,本公开描述了能够将异源核酸的长序列(例如,超过3000个核苷酸)插入基因组中的逆转录转座酶(参见,例如,图20a)。另外,本文所述的逆转录转座酶可以将异源核酸插入基因组中的内源位点,例如rdna基因座(参见,例如,实例7)。这与cre/loxp系统相反,cre/loxp系统需要第一步将外源loxp位点插入,然后第二步将目的序列插入loxp位点。
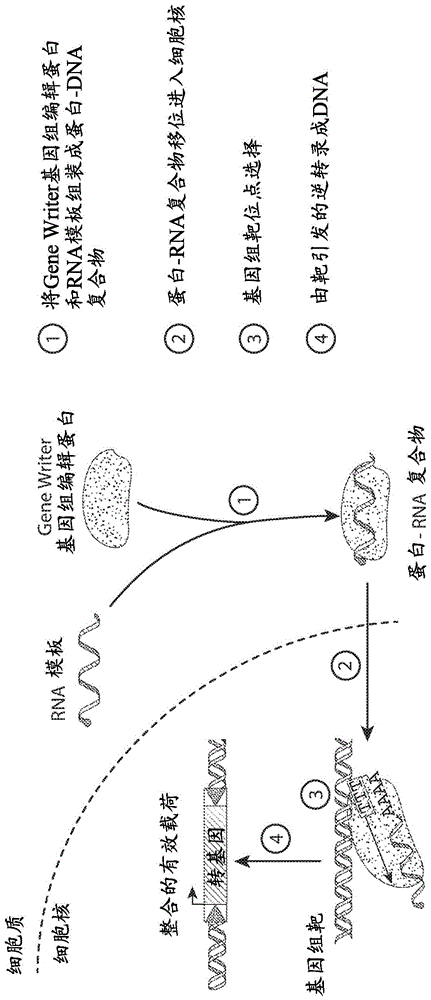
gene-writertm基因组编辑器
非长末端重复(ltr)逆转录转座子是一种类型的在真核生物基因组中广泛分布的移动遗传元件。它们包括两类:无嘌呤/无嘧啶内切核酸酶(ape)型和限制性内切酶样内切核酸酶(rle)型。ape类逆转录转座子由两个功能结构域构成:内切核酸酶/dna结合结构域和逆转录酶结构域。rle类由三个功能结构域构成:dna结合结构域、逆转录结构域和内切核酸酶结构域。非ltr逆转录转座子的逆转录酶结构域通过结合rna序列模板并将其逆转录进入宿主基因组的靶dna发挥功能。rna序列模板具有与转座酶特异性结合的3’非翻译区和通常具有编码转座酶蛋白的一个或多个开放阅读框(“orf”)的可变5’区。rna序列模板还可以包含特异性结合逆转录转座酶的5'非翻译区。
发明人已经发现,出人意料地,此类非ltr逆转录转座子的元件可以在功能上被模块化和/或修饰以靶向,编辑,修饰或操纵靶dna序列,例如以通过逆转录将对象(例如异源)核酸序列插入到靶基因组例如哺乳动物基因组中。这样的经模块化和修饰的核酸、多肽组合物和系统在本文中描述,并称为genewritertm基因编辑器。genewritertm基因编辑器系统包含:(a)多肽或编码多肽的核酸,其中所述多肽包含(i)逆转录酶结构域和(x)含有dna结合功能的内切核酸酶结构域或(y)内切核酸酶结构域和单独的dna结合结构域;和(b)模板rna,其包含(i)结合所述多肽的序列和(ii)异源插入序列。例如,genewriter基因组编辑器蛋白质可包含dna结合结构域、逆转录酶结构域和内切核酸酶结构域。在其他实施例中,genewriter基因组编辑器蛋白质可包含逆转录酶结构域和内切核酸酶结构域。在某些实施例中,genewritertm基因编辑器多肽的元件可以衍生自非ltr逆转录转座子的序列,例如ape型或rle型逆转录转座子或其部分或结构域。在一些实施例中,rle型非ltr逆转录转座子来自r2、nesl、hero、r4或cre进化枝。在一些实施例中,genewriter基因组编辑器衍生自在人基因组中发现的r4元件x4_line。在一些实施例中,ape型非ltr逆转录转座子来自r1或tx1进化枝。在一些实施例中,genewriter基因组编辑器衍生自在人基因组中发现的tx1元件mare6。genewritertm基因编辑器系统的rna模板元件通常与多肽元件异源,并提供要插入(逆转录)到宿主基因组中的对象序列。在一些实施例中,genewriter基因组编辑器蛋白能够靶向引发的逆转录。
在一些实施例中,genewriter基因组编辑器与第二多肽组合。在一些实施例中,第二多肽衍生自ape型非ltr逆转录转座子。在一些实施例中,第二多肽具有锌指节样基序。在一些实施例中,第二多肽是gag蛋白的同源物。
genewriter基因编辑器系统的多肽组分
rt结构域:
在本发明的某些方面,genewriter系统的逆转录酶结构域是基于ape型或rle型非ltr逆转录转座子的逆转录酶结构域。ape型或rle型非ltr逆转录转座子的野生型逆转录酶结构域可用于genewriter系统或可被修饰(例如,通过插入、缺失或取代一个或多个残基)以改变靶dna序列的逆转录酶活性。在一些实施例中,逆转录酶从其天然序列改变为具有改变的密码子使用,例如,针对人细胞进行改善。在一些实施例中,逆转录酶结构域是来自不同逆转录病毒、ltr-逆转录转座子或非ltr逆转录转座子的异源逆转录酶。在某些实施例中,genewriter系统包含多肽,所述多肽包含来自r2、nesl、hero、r4或cre进化枝的rle型非ltr逆转录转座子的或来自r1或tx1进化枝的ape型非ltr逆转录转座子的逆转录酶结构域。在某些实施例中,genewriter系统包括多肽,所述多肽包含表1、表2或表3中所列的逆转录转座子的逆转录酶结构域。在实施例中,genewriter系统的逆转录酶结构域的氨基酸序列与表1、表2或表3中所引用的dna序列的逆转录转座子的逆转录酶结构域的氨基酸序列至少约50%、至少约60%、至少约70%、至少约80%、至少约85%、至少约90%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%相同。本领域普通技术人员能够使用常规工具作为基本局部比对搜索工具(blast),基于与其他已知逆转录结构域的同源性来鉴定逆转录结构域。在一些实施例中,逆转录酶结构域被修饰,例如通过位点特异性突变。在实施例中,逆转录酶结构域被工程化以结合异源模板rna。
内切核酸酶结构域:
在某些实施例中,在本文描述的genewriter系统中可以使用或可以修饰ape型逆转录转座子的内切核酸酶/dna结合结构域或rle型逆转录转座子的内切核酸酶结构域(例如,通过插入、缺失或取代一个或多个残基)。在一些实施例中,内切核酸酶结构域或内切核酸酶/dna结合结构域被从其天然序列改变为具有改变的密码子使用,例如,针对人细胞进行改善。在一些实施例中,内切核酸酶元件是异源内切核酸酶元件,例如fok1核酸酶,ii型限制性l样内切核酸酶(rle型核酸酶)或另一rle型内切核酸酶(也称为rel)。在一些实施例中,异源内切核酸酶活性具有切口酶活性,并且不形成双链断裂。本文描述的genewriter系统的内切核酸酶结构域的氨基酸序列可以与表1、2或3中所引用的dna序列的逆转录转座子的内切核酸酶结构域的氨基酸序列至少约50%、至少约60%、至少约70%、至少约80%、至少约85%、至少约90%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%相同。本领域普通技术人员能够使用工具作为基本局部比对搜索工具(blast),基于与其他已知内切核酸酶结构域的同源性来鉴定内切核酸酶结构域。在某些实施例中,异源内切核酸酶是fok1或其功能片段。在某些实施例中,异源内切核酸酶是霍利迪(holliday)连接解离酶或其同源物,例如来自硫磺矿硫化叶菌(sulfolobussolfataricus)-ssolhje的霍利迪连接解离酶(govindaraju等人,nucleicacidsresearch[核酸研究]44:7,2016)。在某些实施例中,异源内切核酸酶是剪接体蛋白诸如prp8的大片段的内切核酸酶(mahbub等人,mobiledna[移动dna]8:16,2017)。例如,本文所述的genewriter多肽可包含来自ape或rle型逆转录转座子的逆转录酶结构域和包含fok1或其功能片段的内切核酸酶结构域。在其他实施例中,同源内切核酸酶结构域被修饰,例如通过位点特异性突变,以改变dna内切核酸酶活性。在其他实施例中,内切核酸酶结构域被修饰以去除任何潜在的dna序列特异性。
dna结合结构域:
在某些方面,选择、设计或构建本文所述的genewriter多肽的dna结合结构域以结合期望的宿主dna靶序列。在某些实施例中,工程化的rle的dna结合结构域是相对于天然逆转录转座子序列的异源dna结合蛋白或结构域。在一些实施例中,异源dna结合元件是锌指元件或tal效应子元件,例如锌指或tal多肽或其功能片段。在一些实施例中,异源dna结合元件是序列指导的dna结合元件,例如cas9、cpf1或其他已被改变为不具有内切核酸酶活性的crispr相关蛋白。在一些实施例中,异源dna结合元件保留内切核酸酶活性。在一些实施例中,异源dna结合元件替代多肽的内切核酸酶元件。在特定实施例中,异源dna结合结构域可以是cas9、tal结构域、zf结构域、myb结构域、其组合或其倍数中的任何一个或多个。在某些实施例中,异源dna结合结构域是表1、表2或表3中所述的逆转录转座子的dna结合结构域。本领域普通技术人员能够使用工具作为基本局部比对搜索工具(blast),基于与其他已知dna结合结构域的同源性来鉴定dna结合结构域。在其他实施例中,例如通过位点特异性突变、增加或减少dna结合元件(例如锌指的数量和/或特异性)等来修饰dna结合结构域,以改变dna结合特异性和亲和力。在一些实施例中,dna结合结构域从其天然序列改变为具有改变的密码子使用,例如,针对人细胞有进行改善
在本发明的某些方面,由genewriter系统整合的宿主dna结合位点可以在基因中、内含子中、外显子中、orf中、在任何基因的编码区之外、在调节子中、在基因的调节区域内、或在基因的调节区域外。在其他方面,工程化的rle可以结合一个或多于一个宿主dna序列。
在某些实施例中,genewritertm基因编辑器系统rna进一步包含细胞内定位序列,例如,核定位序列。核定位序列可以是促进rna输入细胞核中的rna序列。在某些实施例中,核定位信号位于模板rna上。在某些实施例中,逆转录转座酶多肽被编码在第一rna上,并且模板rna是第二单独rna,并且核定位信号位于模板rna上而不是在编码逆转录转座酶多肽的rna上。尽管不希望受到理论的束缚,但是在一些实施例中,编码逆转录转座酶的rna主要靶向细胞质以促进其翻译,而模板rna主要靶向核以促进其逆转座进入基因组。在一些实施例中,核定位信号在模板rna的3’末端、5'末端或内部。在一些实施例中,核定位信号在异源序列的3’(例如,直接在异源序列的3’)或在异源序列的5’(例如,直接在异源序列的5’)。在一些实施例中,核定位信号被置于模板rna的5’utr之外或3’utr之外。在一些实施例中,核定位信号放置在5’utr和3’utr之间,其中任选地,核定位信号不随转基因转录(例如,核定位信号是反义取向或在转录终止信号或聚腺苷酸化信号的下游)。在一些实施例中,核定位序列位于内含子内部。在一些实施例中,多个相同或不同的核定位信号在rna中,例如在模板rna中。在一些实施例中,核定位信号的长度小于5、10、25、50、75、100、150、200、250、300、350、400、450、500、600、700、800、900或1000bp。可以使用各种rna核定位序列。例如,lubelsky和ulitsky,nature[自然]555(107-111),2018描述了rna序列,其驱动rna定位进入细胞核。在一些实施例中,核定位信号是sine衍生的核rna定位(sirloin)信号。在一些实施例中,核定位信号结合核富集蛋白。在一些实施例中,核定位信号结合hnrnpk蛋白。在一些实施例中,核定位信号富含嘧啶,例如是富含c/t、富含c/u、富含c、富含t或富含u的区域。在一些实施例中,核定位信号衍生自长非编码rna。在一些实施例中,核定位信号衍生自malat1长非编码rna或是malat1的600个核苷酸的m区(在miyagawa等人,rna18,(738-751),2012中描述)。在一些实施例中,核定位信号衍生自borg长非编码rna或为agccc基序(在zhang等人,molecularandcellularbiology[分子和细胞生物学]34,2318-2329(2014)中描述。在一些实施例中,核定位序列在shukla等人,theembojournal[embo杂志]e98452(2018)中描述。在一些实施例中,核定位信号衍生自非ltr逆转录转座子、ltr逆转录转座子、逆转录病毒或内源逆转录病毒。
在某些实施例中,genewritertm基因编辑器系统多肽进一步包含细胞内定位序列,例如,核定位序列和/或核仁定位序列。核定位序列和/或核仁定位序列可以是促进蛋白质输入到核和/或核仁中的氨基酸序列,其中它可以促进异源序列整合到基因组中。在某些实施例中,genewriter基因编辑器系统多肽(例如,逆转录转座酶,例如,根据本文表1、2或3中的任一项的多肽)进一步包含核仁定位序列。在某些实施例中,逆转录转座酶多肽编码在第一rna上,模板rna是第二单独rna,并且核仁定位信号编码在编码逆转录转座酶多肽的rna上,而不在模板rna上。在一些实施例中,核仁定位信号位于多肽的n末端、c末端或内部。在一些实施例中,使用多个相同或不同的核仁定位信号。在一些实施例中,核定位信号的长度小于5、10、25、50、75或100个氨基酸。可以使用各种多肽核仁定位信号。例如,yang等人,journalofbiomedicalscience[生物化学科学杂志]22,33(2015)描述了一种核定位信号,其也起着核仁定位信号的作用。在一些实施例中,核仁定位信号也可以是核定位信号。在一些实施例中,核仁定位信号可以与核定位信号重叠。在一些实施例中,核仁定位信号可包含碱性残基区段。在一些实施例中,核仁定位信号可以富含精氨酸和赖氨酸残基。在一些实施例中,核仁定位信号可以衍生自在核仁中富集的蛋白质。在一些实施例中,核仁定位信号可以衍生自在核糖体rna基因座处富集的蛋白质。在一些实施例中,核仁定位信号可以衍生自结合rrna的蛋白质。在一些实施例中,核仁定位信号可以衍生自msp58。在一些实施例中,核仁定位信号可以是单组分基序。在一些实施例中,核仁定位信号可以是两组分基序。在一些实施例中,核仁定位信号可以由多个单组分或两组分基序组成。在一些实施例中,核仁定位信号可以由单组分和两组分基序的混合物组成。在一些实施例中,核仁定位信号可以是双重两组分基序。在一些实施例中,核仁定位基序可以是krassqalgtipkrrsssrfikrkk(seqidno:1530)。在一些实施例中,核仁定位信号可以衍生自核因子-κb诱导激酶。在一些实施例中,核仁定位信号可以是rkkrkkk基序(seqidno:1531)(在birbach等人,journalofcellscience[细胞科学杂志],117(3615-3624),2004中描述)。
在一些实施例中,本文所述的核酸(例如,编码genewriter多肽的rna或编码该rna的dna)包含微小rna结合位点。在一些实施例中,微小rna结合位点用于增加genewriter系统的靶细胞特异性。例如,可以基于在非靶细胞类型中存在但在靶细胞类型中不存在(或相对于非靶细胞而言以降低的水平存在)的mirna的识别来选择微小rna结合位点。因此,当编码genewriter多肽的rna存在于非靶细胞中时,它将与mirna结合,而当编码genewriter多肽的rna存在于靶细胞中时,它将不会与mirna结合(或结合,但相对于非靶细胞而言以降低的水平结合)。尽管不希望受到理论的束缚,但是mirna与编码genewriter多肽的rna的结合可例如通过降解编码多肽的mrna或通过干扰翻译来减少genewriter多肽的产生。因此,异源对象序列将比非靶细胞的基因组更有效地插入靶细胞的基因组中。也可以将在编码genewriter多肽的(或在编码rna的dna中编码的)rna中具有微小rna结合位点的系统与受第二微小rna结合位点调节的模板rna组合使用,例如,如本文标题为“genewritertm基因编辑器系统的模板rna组分”中所述。
表1:ape型非ltr逆转录转座子元件
表2:rle型非ltr逆转录转座子元件
技术人员可以基于表1-3中提供的登录号,例如通过使用常规序列分析工具(如基本局部比对搜索工具(blast)或cd-搜索(用于保守结构域分析)),来确定每个逆转录转座子及其结构域的核酸和相应的多肽序列。其他序列分析工具是已知的并且可以在例如https://molbiol-tools.ca,例如在https://molbiol-tools.ca/motifs.htm上找到。seqidno1-112与表1中的每一行对齐,并且seqidno113-1015与表2中的前903行对齐。
本文的表1-3提供了示例性转座子的序列,包括逆转录转座酶的氨基酸序列,以及允许逆转录转座酶与模板rna结合的5'和3'非翻译区的序列,以及完整的转座子核酸序列。在一些实施例中,表1-3中任一个的5’utr允许逆转录转座酶结合模板rna。在一些实施例中,表1-3中任一个的3’utr允许逆转录转座酶结合模板rna。因此,在一些实施例中,用于本文所述的任何系统中的多肽可以是本文表1-3中的任一个的多肽,或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%的同一性的序列。在一些实施例中,系统还包含本文表1-3中任一个的5'或3'非翻译区中的一个或两个(或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%的同一性的序列),例如来自与前一句中提到的多肽相同的转座子,如上表同一行所示。在一些实施例中,系统包含本文表1-3中任一个的5'或3'非翻译区中的一个或两个,例如,完整转座子序列的片段(其编码能够结合逆转录转座酶的rna)和/或标题列预测的5’utr或预测的3’utr列中提供的子序列。
在一些实施例中,用于本文描述的任何系统中的多肽可以是基于多个逆转录转座子的对齐的多肽序列的分子重建或遗传重建。在一些实施例中,用于本文描述的任何系统中的5'或3'非翻译区可以是基于多个逆转录转座子的对齐的5'或3'非翻译区的分子重建。基于本文提供的登录号,技术人员可以例如通过使用常规序列分析工具(如基本局部比对搜索工具(blast)或cd-搜索(用于保守结构域分析))来比对多肽或核酸序列。可以基于共有序列创建分子重构建,例如使用在ivics等人,cell[细胞]1997,501-510;wagstaff等人,molecularbiologyandevolution[分子生物学与进化]2013,88-99中描述的方法。在一些实施例中,如通过诸如boissinot等人,molecularbiologyandevolution[分子生物学与进化]2000,915-928中所述的系统发育方法所评估的,衍生出5'或3'非翻译区或多肽的逆转录转座子是年轻的或最近活跃的移动元件。
表3(如下)显示了示例性的genewriter蛋白和来自使用数据挖掘鉴定的各种逆转录转座酶的相关序列。第1列表示逆转录转座子所属的家族。第2列列出了元件名称。第3列表示登录号(如果有)。第4列列出了在其中发现逆转录转座酶的生物。第5列列出了逆转录转座子的dna序列。第6列列出了预测的5'非翻译区,第7列列出了预测的3'非翻译区;两者都是第5列的序列的片段,预测其允许模板rna结合第8列的逆转录转座酶。(应理解,第5-7列显示了dna序列,并且根据第5-7列中的任何一个的rna序列通常会包括尿嘧啶而不是胸苷)第8列列出了在第5列的逆转录转座子中编码的预测逆转录转座酶序列。
genewriter,例如热稳定genewriter
尽管不希望受到理论的束缚,但在某些实施例中,在冷环境中进化的逆转录转座酶在人体温度下可能无法正常发挥作用。该申请提供了许多热稳定的genewriter,包括衍生自禽逆转录转座酶的蛋白质。表3中的示例性禽转座酶序列包括斑胸草雀(锦花雀;转座子名称r2-1_tg)、中地雀(中嘴地雀;转座子名称r2-1_gfo)、白喉带鹀(白喉麻雀;转座子名称r2-1_za)和白喉
可以例如通过测试genewriter在高温(例如37℃)和低温(例如25℃)下体外聚合dna的能力来测量热稳定性。用于测定体外dna聚合活性(例如,可加工性)的合适条件描述于例如bibillo和eickbush,“highprocessivityofthereversetranscriptasefromanon-longterminalrepeat逆转录转座子[非长末端重复逆转录转座子的逆转录酶的高生产力]”(2002)jbc277,34836-34845。在一些实施例中,热稳定的genewriter多肽在37℃时具有的活性例如dna聚合活性不低于其在25℃时在其他方面相似的条件下的活性的70%、75%、80%、85%、90%或95%。
在一些实施例中,genewriter多肽(例如表1、2或3的序列或与其具有至少70%、75%、80%、85%、90%、95%、96%、97%、在98%或99%同一性的序列)在选自哺乳动物(例如人)或鸟的受试者中是稳定的。在一些实施例中,本文所述的genewriter多肽在37℃下起作用。在一些实施例中,本文所述的genewriter多肽在37℃下具有比在较低温度例如在30℃、25℃或20℃下更高的活性。在一些实施例中,本文所述的genewriter多肽在人细胞中比在斑马鱼细胞中具有更高的活性。
在一些实施例中,genewriter多肽在37℃培养的人细胞中是有活性的,例如,使用本文实例6或实例7的测定。
在一些实施例中,所述测定包括以下步骤:(1)将hek293t细胞以10,000个细胞/孔引入一个或多个直径为6.4mm的孔中,(2)将细胞在37℃下孵育24小时,(3)提供包含以下的转染混合物:0.5μl如果
在一些实施例中,genewriter多肽导致异源对象序列(例如,gfp基因)以至少0.01、0.025、0.05、0.075、0.1、0.15、0.2、0.25、0.3、0.4、0.5、0.75、1、1.25、1.5、1.75、2、2.5、3、4或5个拷贝/基因组的平均拷贝数插入靶基因座(例如,rdna)中。在一些实施例中,本文所述的细胞(例如,在靶插入位点包含异源序列的细胞)包含异源对象序列,其平均拷贝数是至少0.01、0.025、0.05、0.075、0.1、0.15、0.2、0.25、0.3、0.4,0.5、0.75、1、1.25、1.5、1.75、2、2.5、3、4或5个拷贝/基因组。
在一些实施例中,genewriter引起靶rna中序列的整合,其中在末端具有相对少的截短事件。例如,在一些实施例中,genewriter蛋白(例如,seqidno:1016的)导致进入靶位点的整合子的约25%-100%、50%-100%、60%-100%、70%-100%、75%-95%、80%-90%或86.17%未被截短,如本文所述的测定(例如实例6和图8的测定)所测量的。在一些实施例中,genewriter蛋白(例如,seqidno:1016的蛋白)导致进入靶位点的整合子的至少约30%、40%、50%、60%、70%、80%或90%未被截短。如本文所述的测定所测量的。在一些实施例中,使用测定将整合子分为截短的和未被截短的,所述测定包含扩增,所述扩增使用包含距元件(例如,野生型转座子序列,例如斑胸草雀)的末端565bp的正向引物和位于靶插入位点的基因组dna(例如rdna)中的反向引物。在一些实施例中,靶插入位点中的全长整合子的数目大于靶插入位点中的被截短300-565个核苷酸的整合子的数目,例如,全长整合子的数目是截短的整合子的数目的至少1.1x、1.2x、1.5x、2x、3x、4x、5x、6x、7x、8x、9x或10x,或全长整合子的数目是截短的整合子的数目的至少1.1x-10x、2x-10x、3x-10x或5x-10x。
在一些实施例中,本文描述的系统或方法导致异源对象序列在靶细胞的基因组中的仅一个靶位点处插入。插入可以例如使用如实例8中所述的大于1%、1.5%、2%、2.5%、3%、3.5%、4%、4.5%、5%的阈值来测量。在一些实施例中,本文所述的系统或方法导致异源对象序列的插入,其中少于1%、1.5%、2%、2.5%、3%、3.5%、4%、4.5%、5%、10%、20%、30%、40%或50%的插入是在靶位点以外的其他位点,例如,使用本文所述的测定,例如,实例8的测定。
在一些实施例中,本文所述的系统或方法导致异源对象序列的“无痕”插入,而在一些实施例中,由于插入异源序列,靶位点可显示出内源dna的缺失或重复。不同逆转录转座子的机制可能导致在宿主基因组中在逆转座过程中发生的在靶位点处的不同的复制或缺失模式。在一些实施例中,系统导致无痕插入,在周围的基因组dna中没有重复或缺失。在一些实施例中,系统导致在插入上游缺失小于1、2、3、4、5、10、50或100bp的基因组dna。在一些实施例中,系统导致在插入下游缺失小于1、2、3、4、5、10、50或100bp的基因组dna。在一些实施例中,系统导致在插入上游重复小于1、2、3、4、5、10、50或100bp的基因组dna。在一些实施例中,系统导致在插入下游重复小于1、2、3、4、5、10、50或100bp的基因组dna。
在一些实施例中,本文所述的genewriter或其dna结合结构域特异性结合其靶位点,例如,如使用实例21的测定所测量的。在一些实施例中,genewriter或其dna结合结构域与其靶位点的结合以比与人基因组中任何其他结合位点的结合更强。例如,在一些实施例中,在实例21的测定中,靶位点代表genewriter或其dna结合结构域与人基因组dna的结合事件的大于50%、60%、70%、80%、90%或95%。
基因工程化,例如二聚化的genewriter
一些非ltr逆转录转座子利用两个亚基来完成逆转座(christensen等人pnas[美国国家科学院院刊]2006)。在一些实施例中,本文所述的逆转录转座酶包含两个连接的亚基作为单个多肽。例如,可以将两个野生型逆转录转座酶用接头连接起来以形成共价的“二聚化的”蛋白(参见图17)。在一些实施例中,编码逆转录转座酶的核酸编码作为单个多肽表达的两个逆转录转座酶亚基。在一些实施例中,亚基通过肽接头连接,如本文在标题为“接头”的部分中所描述的,以及例如在chen等人advdrugdelivrev[先进药物输送评论]2013中所描述的。在一些实施例中,多肽中的两个亚基通过刚性接头连接。在一些实施例中,刚性接头由基序(eaaak)n(seqidno:1534)组成。在其他实施例中,多肽中的两个亚基通过柔性接头连接。在一些实施例中,柔性接头由基序(gly)n组成。在一些实施例中,柔性接头由基序(ggggs)n(seqidno:1535)组成。在一些实施例中,刚性或柔性接头由长度1、2、3、4、5、10、15或更多个氨基酸组成,以使得能够进行逆转座。在一些实施例中,接头由刚性和柔性接头基序的组合组成。
基于机制,两个逆转录转座酶亚基并不需要全部功能。在一些实施例中,融合蛋白可以由完全功能性亚基和缺少一个或多个功能性结构域的第二亚基组成。在一些实施例中,一个亚基可缺少逆转录酶功能。在一些实施例中,一个亚基可缺少逆转录酶结构域。在一些实施例中,一个亚基可仅具有内切核酸酶活性。在一些实施例中,一个亚基可仅具有内切核酸酶结构域。在一些实施例中,构成单个多肽的两个亚基可以提供互补的功能。
在一些实施例中,一个亚基可缺少内切核酸酶功能。在一些实施例中,一个亚基可缺少内切核酸酶结构域。在一些实施例中,一个亚基可仅具有逆转录酶活性。在一些实施例中,一个亚基可仅具有逆转录酶结构域。在一些实施例中,一个亚基可仅具有dna依赖性dna合成功能。
接头:
在一些实施例中,本文所述的组合物和系统的结构域(例如,多肽的内切核酸酶和逆转录酶结构域或多肽的dna结合结构域和逆转录酶结构域)可以通过接头连接。本文所述的包含接头元件的组合物具有s1-l-s2的一般形式,其中s1和s2可以相同或不同,并代表通过接头彼此缔合的两个结构域部分(例如,各自是多肽或核酸结构域)。在一些实施例中,接头可以连接两个多肽。在一些实施例中,接头可以连接两个核酸分子。在一些实施例中,接头可以连接多肽和核酸分子。接头可以是化学键,例如一个或多个共价键或非共价键。接头可以是柔性的、刚性的和/或可切割的。在一些实施例中,接头是肽接头。通常,肽接头的长度是至少2、3、4、5、6、7、8、9、10或更多个氨基酸,例如,长度是2-50个氨基酸,长度是2-30个氨基酸。
最常用的柔性接头具有的序列主要由gly和ser残基(“gs”接头)段组成。柔性接头可以有用于连接需要一定程度的移动或相互作用的结构域,并且可以包括小的、非极性的(例如gly)或极性的(例如ser或thr)氨基酸。ser或thr的掺入还可以通过与水分子形成氢键来维持接头在水溶液中的稳定性,且因此减少了接头与其他部分之间的不利相互作用。这样的接头的实例包括具有结构[ggs]>1或[gggs]>1(seqidno:1536)的那些。刚性接头有用于保持各结构域之间的固定距离并维持它们的独立功能。当结构域的空间分离对于保持试剂中一种或多种组分的稳定性或生物活性至关重要时,刚性接头也可以是有用的。刚性接头可以具有α螺旋结构或富含脯氨酸的序列(pro-rich序列)、(xp)n,其中x表示任何氨基酸,优选ala、lys或glu。可裂解接头可以在体内释放游离的功能性结构域。在一些实施例中,接头可以在特异性条件下(例如在还原剂或蛋白酶的存在下)切割。体内可裂解接头可利用二硫键的可逆性质。一个实例包括两个cys残基之间的凝血酶敏感性序列(例如,prs)。cprsc(seqidno:1537)的体外凝血酶处理导致凝血酶敏感性序列的切割,而可逆的二硫键保持完整。此类接头是已知的并且描述于,例如,chen等人,2013.fusionproteinlinkers:property,designandfunctionality[融合蛋白接头:特性、设计和功能].advdrugdelivrev.[先进药物输送评论]65(10):1357-1369。本文所述组合物中接头的体内裂解也可以通过蛋白酶进行,该蛋白酶在病理条件下(例如癌症或炎症)在体内、在特定细胞或组织中、或在受限的某些细胞区室内表达。许多蛋白酶的特异性在受限的区室中提供了对接头的缓慢切割。
在一些实施例中,氨基酸接头是存在于天然多肽的此类结构域之间的内源氨基酸(或与之同源)。在一些实施例中,存在于此类结构域之间的内源氨基酸被取代,但是长度与天然长度没有变化。在一些实施例中,将另外的氨基酸残基添加至结构域之间的天然存在的氨基酸残基。
在一些实施例中,氨基酸接头被计算地设计或筛选以最大化蛋白质功能(anad等人,febsletters[febs通讯],587:19,2013)。
genewritertm基因编辑器系统的模板rna组分
本文所述的genewriter系统可通过靶引发的逆转录将rna序列模板转录进入宿主靶dna位点。通过将rna序列模板直接逆转录到宿主基因组中来编写一个或多个dna序列,genewriter系统可以将对象序列插入靶基因组中,而不需要将外源dna序列引入宿主细胞中(不同于例如crispr系统)以及消除外源dna插入步骤。因此,genewriter系统提供了使用定制的rna序列模板的平台,所述模板包含对象序列,例如,包含异源基因编码和/或功能信息的序列。
在一些实施例中,模板rna编码与异源对象序列处于顺式的genewriter蛋白。各种顺式构建体描述于例如kuroki-kami等人(2019)mobiledna[移动dna]10:23(通过引用以其整体并入本文),并且可以与本文所述的任何实施例组合使用。例如,在一些实施例中,模板rna包含异源对象序列,编码genewriter蛋白的序列(例如,包含(i)逆转录酶结构域和(ii)内切核酸酶结构域的蛋白质,例如本文所述),5'非翻译区和3'非翻译区。组件可以以各种顺序包括。在一些实施例中,例如使用kuroki-kami等人,同上的图3a中所示的布置,genewriter蛋白和异源对象序列以不同方向被编码(有义相比于反义)。在一些实施例中,genewriter蛋白和异源对象序列以相同方向被编码。在一些实施例中,编码多肽和模板rna的核酸或编码模板rna的核酸是共价连接的,例如是融合核酸的一部分和/或同一转录物的一部分。在一些实施例中,融合核酸包含rna或dna。
在某些情况下,编码genewriter多肽的核酸可以在异源对象序列的5'。例如,在一些实施例中,模板rna从5'至3'包含5'非翻译区、有义编码的genewriter多肽、有义编码的异源对象序列和3'非翻译区。在一些实施例中,模板rna从5'至3'包含5'非翻译区、有义编码的genewriter多肽、反义编码的异源对象序列和3'非翻译区。
在一些实施例中,rna进一步包含与dna靶位点的同源性。
应当理解,当将模板rna描述为包含开放阅读框或其反向互补序列时,在一些实施例中,必须先将模板rna转化成双链dna(例如,通过逆转录),然后开放阅读框可以被转录和翻译。
在某些实施例中,可以鉴定、设计、工程化和构建定制的rna序列模板,以包含改变或指定宿主基因组功能的序列,例如通过将异源编码区引入基因组;影响或引起外显子结构/选择性剪接;引起内源基因的破坏;引起内源基因的转录激活;引起内源dna的表观遗传调节;引起可操作地连接的基因上调或下调,等等。在某些实施例中,可以将定制的rna序列模板工程化以包含编码外显子和/或转基因的序列,提供与转录因子激活剂、阻遏物、增强子等及其组合的结合位点。在其他实施例中,编码序列可以进一步用剪接受体位点、聚a尾部定制。在某些实施例中,rna序列可包含编码与rle转座酶同源的rna序列模板的序列,经工程化以包含异源编码序列或其组合。
模板rna可与靶dna具有某些同源性。在一些实施例中,模板rna具有在所述rna的3’末端的与靶dna完全同源的至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、20、25、30、35、40、45、50、60、70、80、90、100、110、120、130、140、150、175、200或更多个碱基。在一些实施例中,模板rna具有例如在所述模板rna的5’末端的与靶dna至少50%、60%、70%、80%、85%、90%、95%、97%、98%、99%或100%同源的至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、20、25、30、35、40、45、50、60、70、80、90、100、110、120、130、140、150、160、175、180或200或更多个碱基。在一些实施例中,模板rna具有衍生自非ltr逆转录转座子(例如,本文所述的非ltr逆转录转座子)的3’非翻译区。在一些实施例中,模板rna具有与非ltr逆转录转座子(例如本文所述的非ltr逆转录转座子)(例如表1、2或3中的非ltr逆转录转座子)的3’序列至少50%、60%、70%、80%、85%、90%、95%、97%、98%、99%或100%同源的至少10、15、20、25、30、40、50、60、80、100、120、140、160、180、200或更多个碱基的3’区。在一些实施例中,模板rna具有衍生自非ltr逆转录转座子(例如,本文所述的非ltr逆转录转座子)的5’非翻译区。在一些实施例中,模板rna具有与非ltr逆转录转座子(例如本文所述的非ltr逆转录转座子)(例如表2或3中所述的非ltr逆转录转座子)的5’序列至少40%、50%、60%、70%、80%、90%、95%或更高同源的至少10、15、20、25、30、40、50、60、80、100、120、140、160、180或200或更多个碱基的5’区。
本文所述的genewriter基因组编辑系统的模板rna组分通常能够结合系统的genewriter基因组编辑蛋白。在一些实施例中,模板rna具有3'区,其能够结合genewriter基因组编辑蛋白。结合区,例如3’区,可以是结构化的rna区,例如具有至少1、2或3个发夹环,其能够结合系统的genewriter基因组编辑蛋白。
本文所述的genewriter基因组编辑系统的模板rna组分通常能够结合系统的genewriter基因组编辑蛋白。在一些实施例中,模板rna具有5'区,其能够结合genewriter基因组编辑蛋白。结合区,例如5’区,可以是结构化的rna区,例如具有至少1、2或3个发夹环,其能够结合系统的genewriter基因组编辑蛋白。在一些实施例中,5’非翻译区包含假结,例如能够结合至genewriter蛋白的假结。
在一些实施例中,模板rna(例如发夹rna的非翻译区,例如5’非翻译区)包含茎环序列。在一些实施例中,模板rna(例如发夹rna的非翻译区,例如5’非翻译区)包含发夹。在一些实施例中,模板rna(例如发夹rna的非翻译区,例如5’非翻译区)包含螺旋。在一些实施例中,模板rna(例如发夹rna的非翻译区,例如5’非翻译区)包含假结。在一些实施例中,模板rna包含核酶。在一些实施例中,核酶类似于丁型肝炎病毒(hdv)核酶,例如具有类似于hdv核酶的二级结构和/或具有hdv核酶的一种或多种活性,例如自我切割活性。参见,例如,eickbush等人,molecularandcellularbiology[分子和细胞生物学],2010,3142-3150。
在一些实施例中,模板rna(例如发夹rna的非翻译区,例如3’非翻译区)包含一个或多个茎环或螺旋。r23’utr的示例性结构例如在以下中示出:ruschak等人“secondarystructuremodelsofthe3′untranslatedregionsofdiverser2rnas[r2rna的3'非翻译区的二级结构模型]”rna.2004年6月;10(6):978-987,例如在其中的图3中,以及eikbush和eikbush,“r2andr2/r1hybridnon-autonomousretrotransposonsderivedbyinternaldeletionsoffull-lengthelements[r2和r2/r1杂合非自主逆转录转座子通过全长元件的内部缺失而产生]”mobiledna[移动dna](2012)3:10;例如在其中的图3中,所述文章通过引用以其整体并入本文。
在一些实施例中,本文描述的模板rna包含能够结合本文描述的genewriter蛋白的序列。例如,在一些实施例中,模板rna包含能够与genewriter蛋白中的ms2外壳蛋白序列结合的ms2rna序列。在一些实施例中,模板rna包含能够结合b盒序列的rna序列。在一些实施例中,模板rna包含能够与genewriter蛋白中的dcas序列结合的rna序列(例如,crrna序列和/或tracrrna序列)。在一些实施例中,除了utr或代替utr,模板rna(例如,共价地)连接至非rnautr,例如蛋白质或小分子。
在一些实施例中,模板rna在3'末端具有聚a尾。在一些实施例中,模板rna在3'末端不具有聚a尾。
在一些实施例中,模板rna具有与非ltr逆转录转座子(例如本文所述的非ltr逆转录转座子)的5’序列至少40%、50%、60%、70%、80%、90%、95%或更高同源的至少10、15、20、25、30、40、50、60、80、100、120、140、160、180、200或更多个碱基的5’区。
系统的模板rna通常包含用于插入靶dna的对象序列。对象序列可以是编码的或非编码的。
在一些实施例中,本文所述的系统或方法包含单个模板rna。在一些实施例中,本文所述的系统或方法包含多个模板rna。
在一些实施例中,对象序列可以包含开放阅读框。在一些实施例中,模板rna具有科扎克序列。在一些实施例中,模板rna具有内部核糖体进入位点。在一些实施例中,模板rna具有自切割肽,例如t2a或p2a位点。在一些实施例中,模板rna具有起始密码子。在一些实施例中,模板rna具有剪接受体位点。在一些实施例中,模板rna具有剪接供体位点。在一些实施例中,模板rna在终止密码子的下游具有微小rna结合位点。在一些实施例中,模板rna在开放阅读框的终止密码子下游具有聚a尾。在一些实施例中,模板rna包含一个或多个外显子。在一些实施例中,模板rna包含一个或多个内含子。在一些实施例中,模板rna包含真核转录终止子。在一些实施例中,模板rna包含增强的翻译元件或翻译增强元件。在一些实施例中,rna包含人t细胞白血病病毒(htlv-1)r区。在一些实施例中,rna包含增强核输出的转录后调节元件,例如乙型肝炎病毒(hpre)或土拨鼠肝炎病毒(wpre)的转录后调节元件。在一些实施例中,在模板rna中,异源对象序列编码多肽,并相对于5'和3’utr以反义方向编码。在一些实施例中,在模板rna中,异源对象序列编码多肽,并相对于5'和3’utr以有义方向编码。
在一些实施例中,本文所述的核酸(例如,模板rna或编码模板rna的dna)包含微小rna结合位点。在一些实施例中,微小rna结合位点用于增加genewriter系统的靶细胞特异性。例如,可以基于在非靶细胞类型中存在但在靶细胞类型中不存在(或相对于非靶细胞而言以降低的水平存在)的mirna的识别来选择微小rna结合位点。因此,当模板rna存在于非靶细胞中时,它将与mirna结合,而当模板rna存在于靶细胞中时,它将不会与mirna结合(或结合,但相对于非靶细胞而言以降低的水平结合)。尽管不希望受到理论的束缚,但mirna与模板rna的结合可能会干扰异源对象序列插入基因组。因此,异源对象序列将比非靶细胞的基因组更有效地插入靶细胞的基因组中。在模板rna(或编码它的dna)中具有microrna结合位点的系统也可以与编码genewriter多肽的核酸组合使用,其中genewriter多肽的表达受第二microrna结合位点的调节,例如如本文所述,例如在标题为“genewriter基因编辑器系统的多肽组分”的部分中所述。
在一些实施例中,对象序列可以包含非编码序列。例如,模板rna可以包含启动子或增强子序列。在一些实施例中,模板rna包含组织特异性启动子或增强子,其中的每个可以是单向的或双向的。在一些实施例中,启动子是rna聚合酶i启动子、rna聚合酶ii启动子或rna聚合酶iii启动子。在一些实施例中,启动子包含tata元件。在一些实施例中,启动子包含b识别元件。在一些实施例中,启动子具有针对转录因子的一个或多个结合位点。在一些实施例中,相对于5’和3’utr以反义方向转录非编码序列。在某些情况下,相对于5'和3’utr以有义方向转录非编码序列。
在一些实施例中,本文所述的核酸(例如,模板rna或编码模板rna的dna)包含启动子序列,例如组织特异性启动子序列。在一些实施例中,组织特异性启动子用于增加genewriter系统的靶细胞特异性。例如,可以基于启动子在靶细胞类型中有活性但在非靶细胞类型中无活性(或在较低水平上有活性)来选择启动子。因此,即使启动子整合到非靶细胞的基因组中,它也不会驱动整合基因的表达(或仅驱动低水平表达)。如本文所述,在模板rna中具有组织特异性启动子序列的系统也可与微小rna结合位点(例如在模板rna或编码genewriter蛋白的核酸中)组合使用。在模板rna中具有组织特异性启动子序列的系统也可与由组织特异性启动子驱动的编码genewriter多肽的dna组合使用,例如,以在靶细胞中获得比非靶细胞中更高水平的genewriter蛋白。
在一些实施例中,模板rna包含微小rna序列、sirna序列、指导rna序列、piwirna序列。
在一些实施例中,模板rna包含协调表观遗传修饰的位点。在一些实施例中,模板rna包含抑制例如防止表观遗传沉默的元件。在一些实施例中,模板rna包含染色质绝缘子。例如,模板rna包含ctcf位点或靶向用于dna甲基化的位点。
为了促进更高水平或更稳定的基因表达,模板rna可以包括防止或抑制基因沉默的特征。在一些实施例中,这些特征防止或抑制dna甲基化。在一些实施例中,这些特征促进dna去甲基化。在一些实施例中,这些特征防止或抑制组蛋白脱乙酰化。在一些实施例中,这些特征防止或抑制组蛋白甲基化。在一些实施例中,这些特征促进组蛋白乙酰化。在一些实施例中,这些特征促进组蛋白去甲基化。在一些实施例中,可以将多种特征掺入模板rna中以促进这些修饰中的一种或多种。cpg二核苷酸通过宿主甲基转移酶进行甲基化。在一些实施例中,模板rna缺乏cpg二核苷酸,例如,与相应的未改变的序列相比,其不包含cpg核苷酸或包含减少数量的cpg二核苷酸。在一些实施例中,从整合的dna驱动转基因表达的启动子缺乏cpg二核苷酸。
在一些实施例中,模板rna包含由至少一个可操作地连接至效应子序列的调节区构成的基因表达单元。效应子序列可以是转录成rna的序列(例如,编码序列或非编码序列,例如编码微小rna的序列)。
在一些实施例中,将模板rna的对象序列插入靶基因组的内源内含子中。在一些实施例中,将模板rna的对象序列插入靶基因组中,从而充当新的外显子。在一些实施例中,将对象序列插入靶基因组导致天然外显子的替换或天然外显子的跳过。
在一些实施例中,将模板rna的对象序列插入靶基因组的基因组安全港位点中,例如aavs1、ccr5或rosa26中。在一些实施例中,将模板rna的对象序列添加到基因组的基因间区域或基因内区域中。在一些实施例中,将模板rna的对象序列添加到基因组的内源活性基因的5’或3’的0.1kb、0.25kb、0.5kb、0.75kb,1kb、2kb、3kb、4kb、5kb、7.5kb、10kb、15kb、20kb、25kb、50、75kb或100kb之内。在一些实施例中,将模板rna的对象序列添加到基因组的内源启动子或增强子的5’或3’的0.1kb、0.25kb、0.5kb、0.75kb,1kb、2kb、3kb、4kb,5kb、7.5kb、10kb、15kb、20kb、25kb、50、75kb或100kb之内。在一些实施例中,模板rna的对象序列可以是例如在50-50,000个碱基对之间(例如,在50-40,000bp之间,在500-30,000bp之间,在500-20,000bp之间,在100-15,000bp之间,在500-10,000bp之间,在50-10,000bp之间,在50-5,000bp之间。在一些实施例中,异源对象序列的长度小于1,000、1,300、1500、2,000、3,000、4,000、5,000或7,500个核苷酸。
在一些实施例中,基因组安全港位点是naturalharbortm位点。在一些实施例中,naturalharbortm位点是核糖体dna(rdna)。在一些实施例中,naturalharbortm位点是5srdna、18srdna、5.8srdna或28srdna。在一些实施例中,naturalharbortm位点是5srdna中的mutsu位点。在一些实施例中,naturalharbortm位点是28srdna中的r2位点、r5位点、r6位点、r4位点、r1位点、r9位点或rt位点。在一些实施例中,naturalharbortm位点是18srdna中的r8位点或r7位点。在一些实施例中,naturalharbortm位点是编码转移rna(trna)的dna。在一些实施例中,naturalharbortm位点是编码trna-asp或trna-glu的dna。在一些实施例中,naturalharbortm位点是编码剪接体rna的dna。在一些实施例中,naturalharbortm位点是编码小核rna(snrna)例如u2snrna的dna。
因此,在一些方面,本公开提供了将异源对象序列插入naturalharbortm位点的方法。在一些实施例中,所述方法包括使用本文所述的genewriter系统,例如,使用表1-3中任一项的多肽或与其具有序列相似性,例如与其具有至少80%、85%、90%或95%同一性的多肽。在一些实施例中,所述方法包括使用酶,例如逆转录转座酶,将异源对象序列插入naturalharbortm位点。在一些方面,本公开提供了宿主人细胞,其包含位于细胞基因组中的naturalharbortm位点的异源对象序列(例如,编码治疗性多肽的序列)。在一些实施例中,naturalharbortm位点是在下表4中描述的位点。在一些实施例中,将异源对象序列插入表4所示序列的20、50、100、150、200、250、500或1000个碱基对内。在一些实施例中,将异源对象序列插入表4所示序列的0.1kb、0.25kb、0.5kb、0.75、kb、1kb、2kb、3kb、4kb、5kb、7.5kb、10kb、15kb、20kb、25kb、50、75kb或100kb内。在一些实施例中,将异源对象序列插入与表4所示序列具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性的位点。在一些实施例中,将异源对象序列插入与表4所示序列具有至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同一性的位点的20、50、100、150、200、250、500或1000个碱基对内,或0.1kb、0.25kb、0.5kb、0.75、1kb、2kb、3kb、4kb、5kb、7.5kb、10kb、15kb、20kb、25kb、50、75kb或100kb内。在一些实施例中,将异源对象序列插入表4第5列所示的基因内,或所述基因的20、50、100、150、200、250、500或1000个碱基对内,或0.1kb、0.25kb、0.5kb、0.75、kb、1kb、2kb、3kb、4kb、5kb、7.5kb、10kb、15kb、20kb、25kb、50、75kb或100kb内。
表4.naturalharbortm位点。第1列指示插入naturalharbortm位点的逆转录转座子。第2列指示在naturalharbortm位点处的基因。第3列和第4列显示了插入位点5'和3'的示例性人基因组序列(例如250bp)。第5列和第6列列出了实例基因符号和相应的基因id。
在一些实施例中,本文所述的系统或方法导致异源序列插入人基因组中的靶位点。在一些实施例中,人基因组中的靶位点与天然的生物体基因组中的相应野生型逆转录转座酶(例如genewriter从其衍生的逆转录转座酶)的相应靶位点具有序列相似性。例如,在一些实施例中,以插入位点为中心的人基因组序列的40个核苷酸与以插入位点为中心的天然生物体基因组序列的40个核苷酸之间的同一性小于99.5%、99%、98%、97%、96%、95%、90%、85%、80%、75%、70%、60%或50%、或50%-60%、60%-70%、70%-80%、80%-90%或90-100%。在一些实施例中,以插入位点为中心的人基因组序列的100个核苷酸与以插入位点为中心的天然生物体基因组序列的100个核苷酸之间的同一性小于99.5%、99%、98%、97%、96%、95%、90%、85%、80%、75%、70%、60%或50%、或50%-60%、60%-70%、70%-80%、80%-90%或90-100%。在一些实施例中,以插入位点为中心的人基因组序列的500个核苷酸与以插入位点为中心的天然生物体基因组序列的500个核苷酸之间的同一性小于99.5%、99%、98%、97%、96%、95%、90%、85%、80%、75%、70%、60%或50%、或50%-60%、60%-70%、70%-80%、80%-90%或90-100%。
组合物和系统的产生
如本领域技术人员将理解的那样,设计和构建核酸构建体和蛋白质或多肽(例如本文所述的系统、构建体和多肽)的方法在本领域中是常规的。通常,可以使用重组方法。通常,参见smales和james(编辑),therapeuticproteins:methodsandprotocols[治疗性蛋白:方法和方案](methodsinmolecularbiology[分子生物学方法]),humanapress[胡玛纳出版社](2005);以及crommelin,sindelar和meibohm(编辑),pharmaceuticalbiotechnology:fundamentalsandapplications[药物生物技术:基础与应用],springer[斯普林格出版社](2013)。设计、制备、评估、纯化和操作核酸组合物的方法描述于green和sambrook(编辑),molecularcloning:alaboratorymanual[分子克隆:实验室手册](第四版),coldspringharborlaboratorypress[冷泉港实验室出版社](2012)。
产生本文所述的治疗性药物蛋白质或多肽的示例性方法涉及在哺乳动物细胞中表达,尽管也可以使用昆虫细胞、酵母、细菌、或其他细胞,在适当的启动子控制下,产生重组蛋白。哺乳动物表达运载体可以包含非转录元件,如复制起点、合适的启动子、以及其他5'或3’侧翼非转录序列、以及5'或3'非翻译序列,如必要的核糖体结合位点、聚腺苷酸化位点、剪接供体和接受位点、以及终止序列。源自sv40病毒基因组的dna序列,例如sv40起点、早期启动子、剪接和聚腺苷酸化位点可以用于提供异源dna序列表达所需的其他遗传元件。在以下文献中描述了用于与细菌、真菌、酵母、和哺乳动物细胞宿主一起使用的适当的克隆和表达运载体:green&sambrook,molecularcloning:alaboratorymanual[分子克隆:实验室手册](第四版),coldspringharborlaboratorypress[冷泉港实验室出版社](2012)。
不同哺乳动物细胞培养系统可以用于表达和制造重组蛋白。哺乳动物表达系统的实例包括cho、cos、hek293、hela和bhk细胞系。在以下文献中描述了用于生产蛋白治疗剂的宿主细胞培养的过程:zhou和kantardjieff(编辑),mammaliancellculturesforbiologicsmanufacturing[用于生物制品制造的哺乳动物细胞培养](advancesinbiochemicalengineering/biotechnology[生物化学工程/生物科技的进展]),springer[斯普林格出版社](2014)。本文所述的组合物可包括载体,例如编码重组蛋白的病毒载体,例如慢病毒载体。在一些实施例中,载体,例如病毒载体,可以包含编码重组蛋白的核酸。
在以下文献中描述了蛋白治疗剂的纯化:franks,proteinbiotechnology:isolation,characterization,andstabilization[蛋白生物技术:分离、表征、和稳定化],humanapress[胡玛纳出版社](2013);以及cutler,proteinpurificationprotocols[蛋白纯化方案](methodsinmolecularbiology[分子生物学方法]),humanapress[胡玛纳出版社](2010)。
应用
通过将编码基因整合到rna序列模板中,genewriter系统可以满足治疗需求,例如,通过在具有功能丧失性突变的个体中提供治疗性转基因的表达,通过以正常转基因代替功能获得性突变,通过提供调节序列以消除功能获得性突变表达,和/或通过控制可操作地连接的基因、转基因及其系统的表达。在某些实施例中,rna序列模板编码对宿主细胞的治疗需要具有特异性的启动子区,例如组织特异性启动子或增强子。在又其他实施例中,启动子可以可操作地连接至编码序列。
在实施例中,genewritertm基因编辑器系统可以提供治疗性转基因,其表达例如替换型血液因子或替换型酶例如溶酶体酶。例如,本文所述的组合物、系统和方法可用于在靶人基因组中表达半乳糖苷酶α或β以治疗法布里病;针对戈谢病的伊米苷酶、塔格苷酶(taliglucerase)α、维拉苷酶(velaglucerase)α或阿糖脑苷酶;针对溶酶体酸性脂肪酶缺乏症(沃尔曼病(wolmandisease)/cesd)的sebelipaseα;针对黏多醣贮积症的拉罗尼酶(laronidase)、艾度硫酸酯酶(idursulfase)、elosulfaseα、或加硫酶(galsulfase);针对庞贝病的阿糖苷酶α(alglucosidasealpha)。例如,本文所述的组合物、系统和方法可用于在靶人基因组中表达因子i、ii、v、vii、x、xi、xii或xiii,以改善血液因子缺陷。
在一些实施例中,异源对象序列编码细胞内蛋白(例如,细胞质蛋白、核蛋白、细胞器蛋白如线粒体蛋白或溶酶体蛋白或膜蛋白)。在一些实施例中,异源对象序列编码膜蛋白,例如除car以外的膜蛋白和/或内源人膜蛋白。在一些实施例中,异源对象序列编码细胞外蛋白。在一些实施例中,异源对象序列编码酶,结构蛋白,信号传导蛋白、调节蛋白、转运蛋白、感觉蛋白、运动蛋白、防御蛋白或储存蛋白。
施用
本文所述的组合物和系统可以在体外或体内使用。在一些实施例中,例如在体外或体内将系统或系统组分递送至细胞(例如,哺乳动物细胞,例如人细胞)。在一些实施例中,细胞是真核细胞,例如多细胞生物的细胞,例如动物,例如哺乳动物(例如人、猪、牛)、鸟(例如家禽,例如鸡、火鸡、或鸭)或鱼。在一些实施例中,细胞是非人动物细胞(例如,实验动物、牲畜或伴侣动物)。在一些实施例中,细胞是干细胞(例如,造血干细胞)、成纤维细胞或t细胞。在一些实施例中,细胞是非分裂细胞,例如非分裂成纤维细胞或非分裂t细胞。在一些实施例中,细胞是hsc,并且p53没有被上调或被上调例如少于10%、5%、2%或1%、例如,根据实例30中所述的方法测定。本领域技术人员将理解,可以以多肽、核酸(例如,dna、rna)及其组合的形式递送genewriter系统的组分。
例如,递送可以使用以下任何组合来递送逆转录转座酶(例如,作为编码逆转录转座酶蛋白的dna,作为编码逆转录转座酶蛋白的rna或作为蛋白本身)和模板rna(例如,作为编码rna的dna,或作为rna):
1.逆转录转座酶dna+模板dna
2.逆转录转座酶rna+模板dna
3.逆转录转座酶dna+模板rna
4.逆转录转座酶rna+模板rna
5.逆转录转座酶蛋白+模板dna
6.逆转录转座酶蛋白+模板rna
7.逆转录转座酶病毒+模板病毒
8.逆转录转座酶病毒+模板dna
9.逆转录转座酶病毒+模板rna
10.逆转录转座酶dna+模板病毒
11.逆转录转座酶rna+模板病毒
12.逆转录转座酶蛋白+模板病毒
如上所述,在一些实施例中,使用病毒递送编码逆转录转座酶蛋白的dna或rna,并且在一些实施例中,使用病毒递送模板rna(或编码模板rna的dna)。
在一个实施例中,系统和/或系统的组分以核酸的形式递送。例如,genewriter多肽可以以编码所述多肽的dna或rna的形式递送,并且模板rna可以以rna或其有待转录成rna的互补dna的形式递送。在一些实施例中,系统或系统的组分在1、2、3、4或更多个不同的核酸分子上递送。在一些实施例中,系统或系统的组分作为dna和rna的组合递送。在一些实施例中,系统或系统的组分作为dna和蛋白质的组合递送。在一些实施例中,系统或系统的组分作为rna和蛋白质的组合递送。在一些实施例中,genewriter基因组编辑器多肽作为蛋白质递送。
在一些实施例中,使用载体将系统或系统的组分递送到细胞,例如哺乳动物细胞或人细胞。载体可以是例如质粒或病毒。在一些实施例中,递送是体内、体外、离体或原位的。在一些实施例中,病毒是腺相关病毒(aav)、慢病毒、腺病毒。在一些实施例中,系统或系统的组分与病毒样颗粒或病毒体一起被递送至细胞。在一些实施例中,递送使用一种以上的病毒、病毒样颗粒或病毒体。
在一个实施例中,本文所述的组合物和系统可以配制在脂质体或其他类似的囊泡中。脂质体是球形囊泡结构,所述球形囊泡结构由围绕内部水性隔室的单层或多层的脂质双层和相对不可渗透的外部亲脂性磷脂双层构成。脂质体可以是阴离子的、中性的或阳离子的。脂质体具有生物相容性,无毒,可以递送亲水性和亲脂性药物分子,保护其货物免受血浆酶的降解,并将其负载运输穿过生物膜和血脑屏障(bbb)(关于综述,参见,例如,spuch和navarro,journalofdrugdelivery[药物递送杂志],第2011卷,文章id469679,第12页,2011.doi:10.1155/2011/469679)。
囊泡可由几种不同类型的脂质制成;然而,磷脂最常用于产生脂质体作为药物载剂。制备多层囊泡脂质的方法是本领域已知的(参见例如美国专利号6,693,086,其关于多层囊泡脂质制备的教导通过引用并入文中)。尽管当脂质膜与水溶液混合时,囊泡的形成是自发的,但也可以通过使用均质器、超声仪或挤压装置以振荡的形式施加力来加快囊泡的形成(关于综述,参见,例如,spuch和navarro,journalofdrugdelivery[药物递送杂志],第2011卷,文章id469679,第12页,2011.doi:10.1155/2011/469679)。可通过挤出通过具有减小尺寸的过滤器来制备挤出的脂质,如templeton等人,naturebiotech[自然生物技术],15:647-652,1997中所述,其关于挤出脂质制备的教导通过引用并入文中。
脂质纳米颗粒是为本文所述的药物组合物提供生物相容性和可生物降解的递送系统的载剂的另一个实例。纳米结构化的脂质载剂(nlc)是经修饰的固体脂质纳米颗粒(sln),其保留了sln的特性,提高了药物的稳定性和载药量,并防止了药物泄漏。聚合物纳米颗粒(pnp)是药物递送的重要组成部分。这些纳米颗粒可以有效地将药物递送引导至特定靶并改善药物稳定性和受控的药物释放。也可以使用脂质聚合物纳米颗粒(pln),其是一种组合了脂质体和聚合物的新型载剂。这些纳米颗粒具有pnp和脂质体的互补优势。pln由核-壳结构构成;聚合物核提供了稳定的结构,磷脂壳提供了良好的生物相容性。这样,这两种组分提高了药物包封有效率,促进了表面修饰,并防止了水溶性药物的泄漏。对于综述,参见例如li等人2017,nanomaterials[纳米材料]7,122;doi:10.3390/nano7060122。
外来体也可用作本文所述的组合物和系统的药物递送媒剂。对于综述,参见ha等人2016年7月.actapharmaceuticasinicab.[药学学报]第6卷,第4期,第287-296页;https://doi.org/10.1016/j.apsb.2016.02.001。
可以将genewriter系统引入细胞、组织和多细胞生物中。在一些实施例中,系统或系统的组分通过机械手段或物理手段递送至细胞。
以下文献中描述了蛋白治疗剂的配制品:meyer(编辑),therapeuticproteindrugproducts:practicalapproachestoformulationinthelaboratory,manufacturing,andtheclinic[治疗性蛋白药物产品:实验室、制造和临床中配制品的实践方法],woodheadpublishingseries[伍德海德出版系列](2012)。
所有的公开物、专利申请、专利、以及在此引用的其他出版物和参考文献(例如,序列数据库参考数字)通过引用以其整体并入本文。例如,本文例如在本文的任何表中提及的所有genbank、unigene和entrez序列都通过引用并入本文。除非另有说明,否则本文指定的序列登录号(包括本文的任何表中的序列登录号)是指截至2018年8月27日的当前数据库条目。当一个基因或蛋白质引用多个序列登录号时,所有序列变体都包括在内。
实例
通过以下实例进一步说明本发明。提供这些实例仅出于说明目的,而不应以任何方式解释为限制本发明的范围或内容。
实例1:将genewritertm系统递送至哺乳动物细胞
该实例描述了将genewritertm基因组编辑系统递送至哺乳动物细胞,用于将外源dna位点特异性地插入哺乳动物细胞基因组中。
在该实例中,genewritertm系统的多肽组分是来自家蚕的r2bm蛋白;模板rna组分是来自家蚕的r2bm逆转录转座酶的rna,其在逆转录酶结构域中包含突变,使得逆转录转座酶失活。
hek293t细胞用以下测试试剂转染:
1.乱序rna对照
2.编码上述多肽的rna
3.上述模板rna
4.2和3的组合
转染后,将hek293t细胞培养至少4天,然后分析位点特异性基因组编辑。从每组hek293细胞中分离基因组dna。使用位于28srrna基因中的r2bm整合位点侧翼的引物进行pcr。pcr产物在琼脂糖凝胶上电泳以测量扩增的dna的长度。
仅在用以上第4组的完整genewritertm系统转染的细胞中观察到预期长度的pcr产物,其表明可将突变的r2bm逆转录转座酶的序列插入靶基因组中的成功的genewritingtm基因组编辑事件。
实例2:将genewritertm系统位点特异性靶向递送至昆虫细胞中
该实例描述了genewritertm基因组编辑系统,所述系统被递送到昆虫细胞的基因组特异性靶位点处。
在该实例中,genewritertm系统的多肽组分衍生自家蚕的r2bm,其通过用异源锌指dna结合结构域代替其在多肽氨基末端的dna结合结构域进行修饰。已知锌指dna结合结构域与家蚕细胞的bmblos2基因座中的dna结合(takasu等人,insectbiochemistryandmolecularbiology[昆虫生物化学与分子生物学]40(10):759-765,2010)。模板rna是来自家蚕的r2bm逆转录转座酶的rna,其在逆转录酶结构域中包含突变,使得逆转录转座酶失活。此外,模板rna在5’末端进行了修饰,并且与靶dna位点具有180个碱基的同源性。
家蚕昆虫细胞系用以下测试试剂转染:
1.乱序rna对照
2.编码上述多肽组分的rna
3.上述模板rna
4.2和3的组合
转染后,将细胞培养至少4天,并分析位点特异性genewritingtm基因组编辑。从细胞中分离出基因组dna,并使用位于基因组中靶整合位点侧翼的引物进行pcr。pcr产物在琼脂糖凝胶上电泳以测量dna的长度。仅在用以上第4组的完整genewritertm系统转染的细胞中观察到预期长度的pcr产物,其表明可将突变的r2bm逆转录转座酶的序列插入靶昆虫细胞基因组中的成功的genewritingtm基因组编辑事件。
实例3:将genewritertm系统位点特异性靶向递送至哺乳动物细胞中
该实例描述了genewritertm基因组编辑器系统,所述系统用于将异源序列插入哺乳动物基因组的特定位点。
在该实例中,系统的多肽是来自家蚕的r2bm蛋白,模板rna组分是编码gfp蛋白的rna,并且在5’末端侧接5’utr,在3’末端侧接来自家蚕r2bm逆转录转座酶的3’utr。gfp基因在其起始密码子上游具有内部核糖体进入位点,在其终止密码子下游具有聚a尾。
hek293细胞用以下测试试剂转染:
1.乱序rna对照
2.编码上述多肽的rna
3.编码上述gfp的模板rna
4.2和3的组合
转染后,将hek293细胞培养至少4天,并且然后分析位点特异性genewritingtm基因组编辑事件。从hek293细胞中分离基因组dna,并使用位于28srrna基因中r2bm整合位点侧翼的引物进行pcr。pcr产物在琼脂糖凝胶上电泳以测量dna的长度。在用第4组测试试剂(完整的genewritertm系统)转染的细胞中检测到预期长度的pcr产物,其指示成功的genewritingtm基因组编辑事件。该结果表明genewriting基因组编辑系统可以将新转基因插入哺乳动物细胞基因组中。
将转染的细胞再培养10天,然后在多个细胞培养传代后通过流式细胞术测定gfp表达。计算来自每个细胞群体的gfp阳性细胞的百分比。在用第4组测试试剂(完整的genewritertm系统)转染的hek293细胞群体中检测到gfp阳性细胞。该结果表明表达了写入哺乳动物细胞基因组的新转基因。
实例4:使用genewritertm系统将基因表达单元靶向递送至哺乳动物细胞中
该实例描述了genewriter基因组编辑器的制备和使用,以将异源基因表达单元插入哺乳动物基因组。
在该实例中,genewriter系统的多肽衍生自家蚕的r2bm多肽,如通过用异源锌指dna结合结构域代替其在多肽氨基末端的dna结合结构域进行了修饰。已知锌指dna结合结构域与人细胞的aavs1基因座中的dna结合(hockemeyer等人,naturebiotechnology[自然生物技术]27(9):851-857,2009)。模板rna包含基因表达单元。基因表达单元包含与至少一个编码序列可操作地连接的至少一个调节序列。在该实例中,调节序列包括cmv启动子和增强子、增强的翻译元件和wpre。编码序列是gfp开放阅读框。基因表达单元的5’末端侧翼是与靶dna位点同源的180个碱基,并且3’末端侧翼是来自家蚕的r2bm逆转录转座酶的3’utr。
hek293细胞用以下测试试剂转染:
1.乱序对照rna
2.编码上述多肽组分的rna
3.包含基因表达单元(如上所述)的模板rna
4.完整的genewriter系统,其包含(2)和(3)
转染后,将hek293细胞培养至少4天,并分析位点特异性genewriting基因组编辑。从hek293细胞中分离出基因组dna,并使用位于基因组中靶整合位点侧翼的引物进行pcr。pcr产物在琼脂糖凝胶上电泳以测量dna的长度。在用第4组测试试剂(完整的genewritertm系统)转染的细胞中检测到预期长度的pcr产物,其指示成功的genewritingtm基因组编辑事件。
将转染的细胞再培养10天,然后在多个细胞培养传代后通过流式细胞术测定gfp表达。计算来自每个细胞群体的gfp阳性细胞的百分比。在用第4组测试试剂转染的hek293细胞群体中检测到gfp阳性细胞,表明表达了通过genewriting基因组编辑添加到哺乳动物细胞基因组中的基因表达单元。
实例5:使用genewritertm系统将基因表达单元靶向递送至哺乳动物细胞的内含子区
该实例描述了genewriting基因组编辑系统的制造和使用,以将异源序列添加到内含子区中,充当上游外显子的剪接受体。
靶整合位点是白蛋白基因座的第一内含子。将新外显子剪接到所述第一内含子中(所述新外显子在5’末端包含剪接受体位点,在3’末端包含聚a尾)将产生成熟的mrna,其包含与新外显子剪接的白蛋白基因座的第一天然外显子。因为白蛋白的第一外显子是在蛋白质加工后去除的,所以表达新形成的基因单元的细胞将分泌仅包含新外显子的成熟蛋白质。
在该实例中,genewriter基因组编辑器多肽衍生自家蚕的r2bmgenewriter基因组编辑器,如通过用异源锌指dna结合结构域代替其在多肽氨基末端的dna结合结构域进行了修饰。已知锌指dna结合结构域与白蛋白基因座的第一内含子紧密结合,如sarma等人,blood[血液]126,15:1777-1784,2015中所述。模板rna是编码epo的rna,其具有紧接成熟epo的第一个氨基酸5’的剪接受体位点(起始密码子和信号肽被去除),和终止密码子下游的3’聚a尾。此外,eporna的5’末端侧翼是与靶dna位点同源的180个碱基,并且3’末端侧翼是来自家蚕的r2bm逆转录转座酶的3’utr。
hek293细胞用以下测试试剂转染:
1.乱序对照rna
2.编码上述多肽的rna
3.包含上述epo剪接受体的模板rna
4.完整的genewriter系统,其包含(2)和(3)
转染后,将hek293细胞培养至少4天,并分析位点特异性genewriting基因组编辑和适当的mrna加工。从hek293细胞分离基因组dna。进行逆转录pcr以测量包含白蛋白基因座的第一天然外显子和新外显子的成熟mrna。rt-pcr反应使用与白蛋白基因座的第一个天然外显子结合的正向引物和与epo结合的反向引物进行。rt-pcr产物在琼脂糖凝胶上电泳以测量dna的长度。在用第4组测试剂转染的细胞中检测到预期长度的pcr产物,其表明成功的genewriting基因组编辑事件和成功的剪接事件。该结果表明genewriting基因组编辑系统可以将编码基因的异源序列添加到内含子区中,以充当上游外显子的剪接受体。
将转染的细胞再培养10天,并在多个细胞培养传代后测定细胞上清液中的epo分泌。通过epoelisa试剂盒测量上清液中epo的量。在用第4组测试试剂转染的hek293细胞中检测到epo,表明可以通过genewriting基因组编辑将异源序列添加到内含子区中,以充当上游外显子的剪接受体并被活跃表达。
实例6:将r2tg逆转录转座子靶向递送至哺乳动物细胞
该实例描述了通过dna或rna递送将r2tg逆转录转座子元件(参见本文表3的第一行)靶向整合至哺乳动物细胞。
r2tg是来自锦花雀(斑胸草雀)的内源逆转录转座子。由于非ltrr2元件不存在于人基因组中,并且被认为具有很高的位点特异性,因此r2tg准确有效地将自身整合到人基因组中的能力将证明其具有进行基因组靶向整合并有可能实现人基因治疗的能力。
在dna递送方法中,设计并合成了带有r2tg的质粒(plv014),以便对r2tg元件进行密码子优化,并使其侧翼为其天然非翻译区(utr),进一步地,侧翼具有或不具有与rdna靶基因座的100bp同源性。r2tg元件的表达是由哺乳动物cmv启动子驱动的。此外,将在逆转录转座酶的编码序列中具有移码的1bp缺失突变体(678*)构建为失活对照(“移码突变体”)。每种质粒通过
接下来,评估了r2tg转座酶至人基因组中的整合。基于与雀类基因组的同源性,测试了人rdna中的推定整合位点。高级miseq和ddpcr测定用于评估整合。
通过在初始pcr中引入随机唯一分子指数(umi),消除了miseq文库构建中的偏倚(图7)。通过首先将r2tg和rdna基因座的预期3'连接扩增30个循环来进行巢式pcr。在此步骤中,引入了一个miseq衔接子,多路复用条形码和8bpumi。使用第二pcr进一步富集预期的产物并添加第二miseq衔接子。样品在miseq上测序300个循环。解复用后,通过matlab分析样品。首先,通过搜索相邻序列来定位每个序列上的umi。创建了umi数据库,并且接下来通过唯一性将其折叠。对于每个唯一的读段,进行搜索以寻找预期的rdna整合位点的序列以及比对的人基因组dna和外源dna的分离序列。然后将外源dna与预期的整合序列进行比对。miseq分析流程的结果如图8a-8b所示。在用野生型r2tg构建体(其侧翼是与靶rdna基因座具有同源性的100bp)处理的细胞中发现了到预测的整合位点中的广泛唯一性整合,但移码突变体对照情况下没有发现。大多数整合事件都有完整的模板rna序列,整合在最接近整合位点的565bp中,如通过与预期序列完美比对的测序读段所证实的。基于直接与靶位点相邻的缺口后的预期序列比对的测序读段,实验性r2tg情况下整合事件的子集具有约300bp或约450的截短(图8a)。更具体地说,观察到的86.17%的整合子在最靠近整合位点的565bp中未被截短。相反,图8b示出未检测到整合事件。没有侧翼rdna同源性的构建体显示接近噪声的微不足道整合信号。
接下来执行ddpcr以确认整合并评估整合效率。针对r2tg元件的3'utr部分设计taqman探针。合成正向引物以直接结合在探针的上游,并且合成反向引物以结合rdna。因此,跨整合连接的预期产物的扩增会使探针降解并产生荧光信号。在上述质粒的几次重复实验中进行了ddpcr,以确定r2tg整合事件的平均拷贝数。ddpcr拷贝数分析的结果(与参考基因rpp30相比)如图9所示。在几种质粒转染条件下,当在同源性情况下递送时,注意到在靶位点平均整合了5个或更多个r2tg拷贝/基因组,显著增加高于对照构建体。相反,移码突变体阴性对照中的平均拷贝数/基因组通常低于1。当没有同源性的构建体被递送到细胞中时,可以看到微不足道的信号。实验共同表明,r2tg逆转录转座子有效整合到人细胞中的靶位点处。
在rna递送方法中,设计了r2tgrna(rnav019),以使r2tg元件经密码子优化,并侧翼是其天然非翻译区(utr)。更具体地说,构建体按顺序包括:t7启动子,长度为100个核苷酸的5’28s靶同源区,r2tg野生型5’utr,r2tg密码子优化的编码序列,r2tg野生型3’utr和长度为100个核苷酸的3’28s靶同源区。将100bp的28s同源序列添加到utr之外以增强整合。合成了r2tgrna,并添加了帽和聚a尾。r2tg元件的转录是由t7启动子驱动的。通过lipofectaminetmrnaimax或
ddpcr拷贝数分析的结果(标准化为参考基因rpp30)如图12所示。在几种转染条件下,平均整合测量为0.01个r2tg拷贝/基因组,显著高于检测限。结果表明,使用rna递送方法将r2tg逆转录转座子成功整合到人细胞中。
实例7:使用r2tg逆转录转座子将异源对象序列靶向递送至哺乳动物细胞
该实例描述了通过利用具有多种递送机制的r2tg逆转录转座子系统将转基因递送至人细胞,包括通过利用r2tg逆转录转座子系统将异源对象序列经rna介导递送至人细胞。
r2蛋白在每个元件的非翻译区(utr)中识别其模板rna结构,以形成核糖核蛋白颗粒,所述核糖核蛋白颗粒充当下游整合入宿主基因组的中间体。因此,利用r2tg机制,进行工程化,将utr与其天然背景脱钩并且将utr引入替代的外源序列中,以将期望的核酸递送至基因组中。
通过将1)r2tg编码序列和2)转基因盒(其侧翼是r2tgutr序列以及与28srdna同源的100bp)分别构建到单独的驱动子和转基因质粒中,测试了转基因整合。图13说明了双质粒系统。将双质粒通过
类似于质粒的反式转基因递送,通过构建r2tg的编码序列(其前是t7启动子序列)的扩增子来进行rna递送。所构建的扩增子包含实验性r2tg元件以及1bp缺失移码突变体对照。分别地,构建了扩增子,所述扩增子包含编码gfp的外源序列和egf1-α报道分子(其侧翼区足以驱动通过r2tg整合入基因组)。更具体地说,构建体包括:t7启动子,其驱动rna的转录,其中所述rna从5'到3'包含(a)长度为10nt的5’28s同源区,(b)5'非翻译区,(c)反义tkpa聚a序列,(d)编码gfp的反义异源对象序列,(e)反义科扎克序列,(f)反义ef1α启动子,(g)3'非翻译区,其结合genewriter蛋白,以及(h)长度为10nt的3’28s同源区。通过新英格兰实验室hiscribet7arca试剂盒转录每种rna,并通过zymorna清洁与浓缩器纯化。
通过
巢式pcr是通过以下进行:跨预期的转基因-rdna连接的3’末端的前30轮pcr,然后使用内部引物组再进行20轮pcr扩增。对从用野生型转座酶反应处理的细胞中提取的基因组dna进行的巢式pcr的三个重复实验之一产生了预期大小(约596bp)的pcr产物。相反,在用移码失活的r2tg突变体对照或无转染对照处理的细胞中提取的基因组dna中未观察到pcr产物。通过zero
实例8:将r2tg逆转录转座子靶向递送至哺乳动物细胞
该实例描述了通过dna递送将r2tg逆转录转座子元件靶向整合至哺乳动物细胞。
如上文实例6中所述设计和合成带有r2tg的质粒(plv014)和对照质粒。每种质粒通过
针对hg38参考人基因组和rdna基因座序列hsu13369(genbank:u13369.1)进行靶基因座扩增。使用两个独立的引物组进行靶向基因座扩增。两个引物组情况下的分析均表明,28srdna基因座序列是唯一检测到高于1%阈值的整合位点。因此,r2tg转座子在哺乳动物细胞中的整合对这个靶位点是特异性的。
实例9:通过rna重折叠或驱动子比模板rna的比例来改善反式rna模板化整合入哺乳动物细胞
rna模板的设计与之前的实例相同。由驱动子和转基因有效载荷组成的两种rna被传递到哺乳动物细胞。为了更好地促进折叠,通过加热至95c并冷却至室温来使有效载荷rna变性以促进适当的二级结构形成。在一些实施例中,将rna冷却至室温将增加整合效率。
转基因比驱动子的摩尔比也可变化以评估合适的组分化学计量。通过ddpcr和测序分析整合。在一些实施例中,使用更高比例的驱动子比转基因。在一些实施例中,使用更高比例的转基因比驱动子。
类似地,分析了具有顺式转基因整合的先前实例的驱动子比有效载荷的化学计量。通过ddpcr和测序分析整合。在一些实施例中,更高比例的驱动子转录或翻译比转基因转录将导致更高的整合效率。在一些实施例中,更高比例的转基因转录比驱动子转录和翻译的将导致更高的整合效率。
实例10:杂交捕获测定
进行杂交捕获实验以获得逆转录转座子整合到靶位点的特异性的公正观点。如前实例所述,通过整合侧翼为其天然utr和与预期r2rdna靶任一侧具有同源性的100bp的r2tg进行逆转录转座子实验。rdna靶位点具有与相应的天然靶位点有100个核苷酸的同一性的两个侧翼集。逆转录转座子通过质粒或mrna被递送至人293t细胞。72小时后提取基因组dna。提取后,根据方案使用定制探针组(twist)对每个基因组dna样品进行杂交捕获。设计生物素化探针,使约120bp探针跨r2tg编码序列和utr两者的链。首先,根据twist的方案,通过基因组dna的片段化和测序衔接子的连接创建了下一代文库(可从以下万维网获得:twistbioscience.com/ngs_protocol_custompanel_hybridcap)。接下来,将探针与基因组dna文库杂交,并扩增富集的样品。使用300bp的配对末端读段在miseq上测序最终文库。自定义matlab脚本用于分析读段。所得的分析示于图15a和15b中,用于rna递送。杂交捕获表明r2tg到预期基因座的中靶整合。进行rna递送后,在数据的非预期3'连接处鉴定出单个读段的1次可能脱靶,相比之下在预期的基因座上则是100个以上的读段,表明特异性大于100:1。在5'连接处,所有50个读段均位于预期的基因座处,表明特异性大于50:1。该实验表明整合的高度特异性。
实例11:长读段pacbio分析
可以进行远距离pcr扩增,以测量期望的全长序列整合到人基因组靶位点中,并测量在插入过程中是否引入了突变。逆转录转座子整合实验如先前实例中所述进行。在一个实例中,通过设计一种靶向基因组整合位点的引物和一种靶向整合子序列的引物,pcr扩增被用于产生扩增子。在该实例中,设计这些引物以使与整合子序列融合的扩增的基因组基因座的长度最大化。通过合并跨整合子两端的扩增子并执行长读段下一代测序,可以评估每个整合的保真度。
在另一个实例中,如先前实例中所述执行杂交捕获,但是在初始库生成期间具有较大的靶文库长度。然后对生成的文库进行长读段下一代测序。
在一些实施例中,长读段下一代测序将显示在跨样品在整合的dna中存在少于10%、5%、2%、1%、0.5%、0.2%或0.1%的snp。在一些实施例中,长读段下一代测序将显示整合的dna中少于10%、5%、2%或1%具有snp。在一些实施例中,长读段下一代测序将显示整合的dna中少于10%、5%、2%或1%具有内部缺失。在一些实施例中,长读段下一代测序将显示跨群体的总共的整合的dna中少于10%、5%、2%、1%、0.5%、0.2%或0.1%被缺失。在一些实施例中,长读段下一代测序将显示整合的dna中少于10%、5%、2%或1%被截短。
实例12:不同的同源性长度和同源性中的点突变的实验
在该实例中,设计实验以表征与靶位点同源的合适的长度和起始位置,以进行有效的逆转录转座子整合。同样,同源性用于支持逆转录驱动的整合机制。
通过修饰质粒plv014,在r2tg质粒的100bp下游同源性中引入了一系列snp。图16列出了snp的设计。转染后,使用巢式pcr回收3'整合连接位点,产生预期扩增子大小约为738bp的pcr产物,并对pcr产物进行桑格测序,以检查是否掺入了任何snp。在该实验中,缺少并入到连接序列中的snp遗传标记表明整合是由逆转录驱动的。snp设计和测序结果如图16所示。对于设计的18个遗传标记,未观察到snp引入,这与通过逆转录指导的r2tg整合相一致。
该实例还描述了评估靶位点的不同同源性区域,以鉴定促进有效整合到基因组中的较短区域。本实例描述了两种方法。首先,测试与靶位点具有同源性的100bp的不同窗口,从靶位点3'的bp1-100开始,然后测试靶位点3'的2-101,靶位点3’的3-103,依此类推,直到靶位点3'的bp30-131。其次,测试与靶位点具有同源性的足以进行dna整合的较短长度,从靶位点3'的bp0-100开始,然后测试靶位点3’的0-95,靶位点3’的0-90,等等,直到目标位点的靶位点3’的bp0-10。在将每种质粒转染到293t细胞后,使用ddpcr来测量逆转录转座效率。
在该实例中,评估具有不同长度的不同utr区域以鉴定用以有效整合到基因组中的较短序列。通过将该325bp的序列分为3个区域(1-100bp,101-200bp和201-325bp)来测试3’utr。生成包含每个截短的3’utr的r2tg的构建体,以分别测试整合效率。
实例13:评估p53或其他修复途径是否被上调
该实例描述了外源r2tg逆转录转座对基因表达,特别是肿瘤抑制基因和dna修复基因表达的影响的评估。表达r2tg的质粒被递送至多种癌细胞系,包括293t、mcf-7和t47d。在确认在每个细胞系中的整合后,进行rna-seq以评估对基因表达谱的影响。然后应用基因集富集分析来评估逆转录转座后是否有任何dna修复途径上调。mcf-7和t47d分别是具有野生型和突变型p53的乳腺癌细胞系,其用于专门评估p53与逆转录转座之间的关系。在一些实施例中,当逆转录转座子genewriter整合到基因组中时,p53不被上调。在一些实施例中,当逆转录转座子genewriter整合到基因组中时,没有dna修复基因被上调。在一些实施例中,当逆转录转座子genewriter整合到基因组中时,没有肿瘤抑制基因被上调。
实例14:dna修复抑制剂存在下的逆转录转座
在该实例中,实验将通过应用dna修复途径抑制剂或dna修复途径缺陷细胞系来测试不同dna修复途径对r2tg逆转录转座的影响。当应用dna修复途径抑制剂时,首先进行prestoblue细胞生存力测定,以确定抑制剂的毒性以及随后的测定是否应进行任何归一化。scr7是nhej的抑制剂,其可在r2tg递送过程中以一系列稀释度使用。parp蛋白是核酶,其作为同二聚体与单链和双链断裂结合。因此,其抑制剂可用于相关dna修复途径的测试,包括同源重组修复途径和碱基切除修复途径。实验程序与scr7的实验程序相同。具有核苷酸切除修复(ner)途径的核心蛋白缺陷的细胞系用于测试ner对r2tg逆转录转座的影响。在将r2tg元件递送到细胞中之后,将ddpcr用于评估在抑制dna修复途径的情况下的逆转录转座。还进行测序分析以评估某些dna修复途径是否在整合连接的改变中起作用。在一些实施例中,r2tg到基因组中的整合不会被敲低任何dna修复途径降低,表明r2tg不依赖于宿主细胞途径进行dna整合。
实例15:在成纤维细胞和t细胞中的逆转录转座
在此实例中,在未分裂的细胞(包括成纤维细胞和t细胞)中重复了先前对293t细胞进行的r2tg逆转录转座分析。与293t细胞相比,非分裂细胞有时更难用脂质试剂转染。因此,核转染用于递送r2tg元件。如本文针对293t细胞所述,将进行随后的整合效率的逆转录转座分析和测序分析。在一些实施例中,r2tg整合到成纤维细胞和t细胞的基因组中。
实例16:单细胞ddpcr
在该实例中,定量测定法被用于确定在单细胞水平上靶向基因组整合的频率,并且该信息可以与从基因组dna定量的靶向基因组整合的拷贝数/基因组进行比较。
收集约5000个经转染的细胞,并与ddpcr反应混合物混合,然后分配到约20,000个液滴中,目的是每个液滴仅包含一个细胞或不包含细胞。如上所述,将进行ddpcr测定(包括5’utr和3’utr测定),以确定单细胞水平上r2或转基因整合的频率。将使用从相同数量的细胞中收获的基因组dna并行进行对照实验,以确定靶向基因组整合效率/基因组。在一些实施例中,在单细胞水平上靶向基因组整合的频率经计算为1%-80%,例如25%,其中所示百分比的细胞具有转基因的一个或多个拷贝整合到期望的基因座中。
实例17:通过集落分离进行单细胞分析
在该实例中,定量测定法用于确定衍生自单细胞的细胞集落中的基因组整合拷贝数。
单细胞集落将通过集落拾取或有限稀释来分离,并以96孔格式进行培养。当细胞达到>80%汇合度时,一半细胞将被冷冻以备后用,另一半细胞的基因组dna将被收获用于ddpcr。如前所述,将进行优化的ddpcr测定(包括5’utr和3’utr测定),以确定r2或转基因整合的频率。使用适当的对照,将针对每个r2元件筛选至少96个集落。如果适用,将通过单细胞ddpcr数据或第一组单细胞集落筛选数据确定待筛选的集落总数。在一些实施例中,在单细胞水平上靶向基因组整合的频率经计算为1%-80%,例如25%,其中所示百分比的细胞具有转基因的单拷贝整合到期望的基因座中。该测定还可用于确定具有转基因的多于一个拷贝整合到期望基因座中的集落的百分比。
实例18:dna结合亲和力和/或重新靶向
野生型r2的dna靶向模块由半胱氨酸-组氨酸锌指和c-myb转录因子结合基序构成。该n末端模块可以被不同的dna结合模块取代,例如一个或多个dna结合蛋白(例如,转录因子),一个或多个锌指(例如,天然或设计的基序)和/或核酸指导的催化上失活的内切核酸酶(例如,与指导rna(例如sgrna)结合形成cas9-rnp的cas9)。将该dna结合模块交换为天然存在的模块,在一些情况下,将其与可将其附接到rna结合/rt模块的柔性接头一起放置。另外,在一些构建中,该新的dna结合模块与相同和/或不同的dna结合模块串联放置。此外,一些构建可能会拆分genewriter蛋白,其中一个蛋白分子包含rna结合模块,另一个蛋白分子包含rt和内切核酸酶模块。在一些实施例中,dna模块的交换增加了对基因组位置的特异性和/或亲和力,并且在一些情况下允许新基因组位置的特异性靶向。
实例19:测量dna结合亲和力的测定
例如,如本实例中所述,可以测试本文描述的genewriters的dna结合活性(以及其dna结合结构域)。dna结合模块通过在细胞(例如大肠杆菌)中重组表达而纯化,或者在无细胞转录和翻译反应(例如,t7rna聚合酶+小麦胚芽提取物)中表达。通过在结合测定(例如,emsa、荧光各向异性、双滤膜结合、fret、spr或热泳(温度相关强度变化))中测量kd,测试纯化的一个或多个dna结合模块的结合亲和力。蛋白质(dna结合模块)被标记和/或dna分子被与上述结合测定兼容的分子(例如染料,放射性同位素(例如蛋白质:35s-甲硫氨酸,马来酰亚胺染料,dna:32p末端或内部标记,带有连接胺的dna与nhs-酯染料反应)进行标记。通过改变分子的浓度并拟合至计算结合亲和力的结合曲线来测量分子。在一些测定中,通过对dna序列进行突变分析或经由对蛋白质-核酸复合物(例如,cas9-rnpdna结合模块)的氨基酸变化或改变对dna结合模块进行突变来测试核酸序列特异性。在一些实施例中,增加dna结合模块的kd将减少脱靶插入,并且在一些情况下,将通过增加r2-rna复合物在特定基因组位置的停留时间来增加中靶位点的活性。
实例20:确定从头开始的整体特异性的测定
在全长逆转录转座子r2的情况下或没有逆转录转座酶的对照中,dna结合模块在细胞(例如动物细胞,例如人细胞)中作为单独的dna结合模块表达。使用递送dna、rna或蛋白质的常规方法,将模块或逆转录转座子的表达递送至细胞。该复合物是交联的(例如,使用化学或紫外光)或未交联的。裂解细胞并用dna酶i处理,以便仅保护结合的dna免于降解。提取dna,类似于chip-seq或dig-seq,鉴定dna片段的ngs文库制备和从头结合位点。在一些实施例中,鉴定潜在的脱靶位点,其可以被追踪以去除假阳性。在其他实施例中,该测定证实了关于dna结合模块结合于其预期位点而不是其他位点的特异性的体外测定。
以高通量鉴定dna结合位点的正交试验使用boyle等人,pnas[美国国家科学院院刊]2017中描述的方法,其中dna结合结构域在无细胞环境中进行测试以确定特异性,并系统分析与新的dna结合模块有关的序列突变体。
实例21:rna分子的模块性
rna分子通过在逆转录酶模块中发现的相互作用(称为子模块“rna结合”)与r2蛋白结合。所述蛋白识别5'和/或3’utr中的特定结构以与rna相互作用。在一些实施例中,utr模块的交换增加了蛋白相互作用,改变了结合utr的蛋白特异性,针对核酸酶进行了稳定,和/或改善了细胞耐受性(例如,导致先天免疫应答降低)。在其他实施例中,r2蛋白的rna结合模块的添加和/或交换与连接至rna的转基因和/或元件模块的不同序列或配体的使用相容。在一些实施例中,代替utr的新配体的组合将对r2的rna结合结构域具有更好的亲和力,并导致更好的插入效率。在一些实施例中,utr的序列的改变或utr的碱基修饰的改变将增加二级结构稳定性,其导致与rna结合模块更好的相互作用。
实例22:测量与新序列的rna结合亲和力的测定
在结合测定中测试新的utr模块。对于新的rna,可以通过以下来合成:使用合成的dna模板通过无细胞体外转录或通过全长的rna的化学合成或连接在一起形成单个rna分子的片段的化学合成。在结合测定(例如,emsa、荧光各向异性、双滤膜结合、fret、spr或热泳(温度相关强度变化))中测量纯化的utr的结合亲和力。使用或不使用上面描述的用于标记rna的标记来检测utr模块和/或rna结合模块/rt模块。进行不同浓度的分子的测量以确定结合亲和力。在一些实施例中,与野生型r2蛋白或utr相比,对5’和/或3’utr结合模块的改变/交换和/或对rna结合/rt模块的改变将导致更好的相互作用。在一些实施例中,增加的相互作用将导致逆转录转座效率的提高,并且在一些情况下,增加r2蛋白与rna相互作用的特异性。
实例23:替代性utr
尽管不希望受到理论的束缚,但在一些实施例中,utr充当r2蛋白与rna相互作用的柄,所述rna用作rt的模板(与其结合基因组位置相一致),用其内切核酸酶模块使dna产生切口,然后使用结合的rna作为模板在dna中的切割位点处进行rt插入。对于保持模板与rt模块非常接近的utr,可以将utr模块替换为不同的配体,这些配体将与工程化进入r2蛋白的特定rna结合模块结合。因此,在一些实施例中,替代性非rnautr是蛋白、小分子或通过蛋白-蛋白相互作用、小分子-蛋白相互作用或通过杂交共价附接的其他化学实体。在一些实施例中,rna结合模块特异性结合配体,所述配体不是附接至转基因模块rna(其增加逆转录转座的效率、稳定性和/或速率)的rna。
实例24:测量utr构建体活性的测定
如上所述进行结合测定以测量r2蛋白与工程化的utr的亲和力,例如,对于蛋白-核酸相互作用。在蛋白-蛋白或蛋白-小分子相互作用的情况下,所述测定在附接有utr模块的rna转基因模块上使用标记。
实例25:靶向基因组整合
在该实例中,genewriting技术被递送到靶细胞和非靶细胞,并且新的dna以比非靶细胞更高的频率被整合到靶细胞中的基因组中。如下文更详细描述的,该方法利用具有靶细胞所不具有(或具有较低水平)的内源mirna的非靶细胞的优势。内源mirna用于减少非靶细胞中的dna整合。
使用的多肽是r2tg蛋白,模板rna组分是编码gfp蛋白的rna,并且在5’末端侧接5’utr,在3’末端侧接r2tg逆转录转座酶的3’utr。5’utr侧翼是与r2tg28srdna靶位点5'具有同源性的100bp,并且3’utr侧翼是与r2tg28srdna靶位点3’具有同源性的100bp。gfp基因相对于5'和3’utr处于反义方向,并具有自己的启动子和聚腺苷酸化信号。
模板rna进一步包含微小rna识别序列。该微小rna识别序列与非靶细胞中的微小rna结合,导致在基因组整合之前抑制(例如降解)模板rna。
在该实例中,靶细胞是肝细胞,并且非靶细胞是来自造血谱系的巨噬细胞。靶细胞和非靶细胞分开培养。可以如本文所述将模板rna和逆转录转座酶蛋白递送至细胞,例如作为rna或使用病毒载体(例如,腺相关病毒载体),其中模板rna从病毒载体dna转录。
处理细胞后三天,测定gfp表达和基因组整合。
通过流式细胞术测定gfp表达。在一些实施例中,肝细胞群体中的gfp表达将比巨噬细胞群体中的gfp表达更高。
使用本文所述的方法,通过液滴数字pcr测定基因组整合(就相对于参考基因标准化的拷贝数/细胞而言)。在一些实施例中,肝细胞群体中的基因组整合将比巨噬细胞群体中的基因组整合更高。
实例26:测试dna结合结构域的模块性
在该实例中,进行了一系列实验以测试各种突变逆转录转座酶的活性,并获得有关这些蛋白质的结构知识。该实验在不同的位置和长度上测试了柔性接头,以确定dna结合结构域(dbd)是否是模块化的。这些实验还为能够将dbd与其余r2tg分离并用任何靶向dna的蛋白序列替代dbd提供了支持。因此,该实例支持这样的理解,即本文所述的转座酶可以在通过结构建模鉴定的多个位置(例如,在预测的-1rna结合基序中、在α螺旋中和位于预测的c-mybdna结合基序c末端的螺旋区中,例如如下所述)上经受住测试的序列差异水平,同时保持功能
简而言之,两个接头(接头a:sgsetpgtsesatpes(seqidno:1023)和接头b:gggs(seqidno:1024))插入了3个位置,此处标记为版本v1、v2和v3。v1位于r2tg的α螺旋区域的n末端侧,所述区域位于预测的-1rna结合基序之前,v2位于r2tg的α螺旋区域的c末端侧,所述区域位于预测的-1rna结合基序之前,并且v3位于随机卷曲区域的c末端,所述区域位于r2tg的预测c-mybdna结合基序之后。对于v1、v2和v3中的每一个,通过pcr将接头a或b中的一个添加到表达r2tg的dna质粒中,从而产生序列v1a(v1+接头a),v1b(v1+接头b),v1c(v1+接头c),v2a(v2+接头a),v2b(v2+接头b)和v2c(v2+接头c),如下表5中所示。通过桑格测序验证了接头的插入,并纯化了dna质粒用于转染。
表5.r2tg突变体的氨基酸序列,在dna结合结构域(dbd)中具有接头
将hek293t细胞铺板在96孔板中,并在37℃,5%co2下生长过夜。用表达r2tg(野生型)、r2内切核酸酶突变体和接头突变体的质粒转染hek293t细胞。根据生产商的建议,使用fugenehd转染试剂进行转染,其中每个孔接受80ng质粒dna和0.5μl转染试剂。所有转染均一式两份进行,并在基因组dna提取之前将细胞孵育72小时。
通过ddpcr测定法测量突变体的活性,所述测定法定量r2tg整合的拷贝数/基因组。通过在每个末端产生两个不同的扩增子来定量5’和3’连接。
v3(在dbd中的c-myb结合基序附近)降低了与接头a或b的整合活性。与接头a(16aa)相比于较短接头b(4aa)一起使用时,v1(在-1rna结合基序之前的α螺旋的n末端)具有与野生型相当的活性。这可能与氨基酸的选择、长度或三维结构有关。v2(在-1rna结合基序之前的α螺旋的c末端)不耐受接头a;但是,接头b的活性与野生型相当,并且略好于野生型。因此,v1和v2被认为是添加接头的优选位置,所述接头可以分开r2tg的dna结合结构域和蛋白的其余部分。
实例27:长读段测序以确定整合保真度
逆转录转座子整合实验如先前实例中所述进行。在一个实例中,通过设计一种靶向基因组整合位点的引物和一种靶向整合子序列的引物,pcr扩增被用于产生扩增子。在该实例中,设计这些引物以使与整合子序列融合的扩增的基因组基因座的长度最大化。通过合并跨整合子两端的扩增子并执行长读段下一代测序,可以评估每个整合的保真度。
如本文所述,通过质粒转染将r2tg的顺式构建体整合到293t细胞中。用侧翼随机umi生成跨整合各末端的扩增子,以控制pcr偏倚。这些扩增子用pacbio下一代测序进行测序。折叠所得序列以去除具有相同umi的读段。通过比对唯一读段,构建了覆盖图,如图20a-20b所示。序列覆盖大部分显示跨扩增子的均匀覆盖,表明整合的高保真度。相关的逆转录酶缺陷突变体对照未产生信号。在图21a-21b中还分析了内部缺失。相对于整体唯一读段计数,内部缺失通常较低,其中一些在rdna-r2tg的5'连接处聚簇。
在另一个实例中,可以如先前实例中所述执行杂交捕获,但是在初始库生成期间具有较大的靶文库长度。然后可以对生成的文库进行长读段下一代测序。
实例28:将r2gfo和r4al逆转录转座子靶向递送至哺乳动物细胞
该实例描述了通过dna递送将r2gfo和r4al逆转录转座子元件靶向整合至哺乳动物细胞。
在一个实例中,我们测定了来自中嘴地雀(中地雀)的完整r2元件r2-1_gfo(“r2gfo”)(kojima等人plosone[公共科学图书馆·综合]11,e0163496(2015))。在另一个实例中,我们测定了来自大线虫(人蛔虫)的完整r4元件r4_al(r4al)(repbase;burke等人nucleicacidsres.[核酸研究]23,4628-34(1995))。由于非ltrr2和r4元件不存在于人基因组中,并且被认为具有很高的位点特异性,因此逆转录转座子准确有效地将自身整合到人基因组中的能力将证明其进行基因组靶向整合的能力。
如先前的实例一样,设计具有r2gfo(plv033)或r4al(plv462)的质粒以用于r2gfo或r4al元件的顺式整合。合成质粒,使得野生型元件的侧翼是其天然非翻译区(utr)和与其rdna靶具有同源性的100bp(图22)。元件的表达是由哺乳动物cmv启动子驱动的。我们使用
执行ddpcr以确认整合并评估整合效率。针对每种元件的3'utr部分设计taqman探针。合成正向引物以直接结合在探针的上游,并且合成反向引物以结合rdna。因此,跨整合连接的预期产物的扩增会使探针降解并产生荧光信号。ddpcr拷贝数分析的结果(与参考基因rpp30相比)如图23所示。在此实验中,r2gfo整合达到平均拷贝数为0.21个整合子/基因组。r4al达到平均拷贝数为0.085个整合子/基因组。
实例29:逆转录转座子整合到人成纤维细胞中
该实例描述了r2tg顺式整合到人成纤维细胞中。简言之,合成了设计用于以顺式整合r2tg的质粒,使得r2tg的侧翼是其天然utr和与其rdna靶同源的序列,如前述实例。使用neon转染系统分别将0.5μgplv014(野生型)和plv072(en突变体)质粒转染到从新生儿包皮中分离的100,000个人皮肤成纤维细胞(hdfn,c0045c,赛默飞世尔科技公司(thermofisherscientific))中。执行了两个程序,每个程序一式两份。程序1的设置为1700v脉冲电压,20ms脉冲宽度和1个脉冲数。程序2的设置为1400v脉冲电压,20ms脉冲宽度和2个脉冲数。使用编码egfp的质粒,两种程序都实现了95%的转染效率。转染后三天,提取基因组dna用于ddpcr测定。
执行ddpcr以确认整合并评估整合效率。针对r2tg元件的3’utr部分设计taqman探针。合成正向引物以直接结合在探针的上游,并且合成反向引物以结合rdna。因此,跨整合连接的预期产物的扩增会使探针降解并产生荧光信号。ddpcr拷贝数分析的结果(与参考基因rpp30相比)如图24所示。在该实验中,野生型(wt)r2tg整合达到平均拷贝数为0.036个整合子/基因组,显著高于具有消除内切核酸酶活性(en)的点突变的对照r2tg质粒。
实例30:逆转录转座子转染后dna损伤反应的评估
dna损伤(例如,由于dsb形成或复制叉折叠导致的损伤)导致p53激活,这在许多其他转录反应中导致p21的上调,导致细胞周期停滞或凋亡。使用crisrp/cas9进行基因组编辑已显示可激活p53和p21,这是基于crispr/疗法的潜在安全性和功效问题。为了确定r2tg递送到细胞是否导致p53和p21激活,以4x104细胞/孔的密度接种u2os细胞,并在24小时后使用fugenehd和lipofectamine试剂与500ngr2tg-wt质粒或500ngr2tg-en(r2tg的一种变体,在内切核酸酶(en)结构域中具有突变,导致r2tg失活)进行转染。为了控制转染效率,还用表达gfp的质粒转染了u2os细胞。最后,作为p53和p21激活的阳性对照,用dna损伤诱导剂依托泊苷(20μm)或博来霉素(10μg/ml)中的一种处理u2os细胞。转染/处理后24小时收集u2os细胞。在ripa缓冲液中制备蛋白裂解物,并在sds-page凝胶上电泳,然后转移至硝酸纤维素,然后用针对p53和p21以及肌动蛋白和粘着斑蛋白的抗体进行探测。如图25所示,在任一转染条件下均未检测到r2tg诱导的超过gfp质粒对照的p53或p21上调。
- 还没有人留言评论。精彩留言会获得点赞!