串联蛋白表达的制作方法
序列表的引用
本申请包含计算机可读形式的序列表。该计算机可读形式通过引用并入本文。
本发明提供了通过增加每个易位事件中可转运到内质网(er)的多肽的数量来提高多肽表达产量的手段和方法。
背景技术:
工业生物技术中的产品开发包括大规模增加酶产量以降低成本这一持续挑战。在过去的几十年里,已经有两种主要的方法用于此目的。第一种是基于经典的诱变和筛选。在此,特定的基因修饰并未预先定义,并且主要的要求是对检测相对离散的产量增量敏感的筛选测定。高通量筛选使得能够筛选大量的突变体以寻找所需的表型,即,更高的酶产量。第二种方法包括众多策略,这些策略的范围从使用更强的启动子和多拷贝菌株以确保目的基因的高表达到使用密码子优化的基因序列以辅助翻译。然而,蛋白质的高水平产生可能触发细胞机制中用于将目的酶分泌到培养基中的几个瓶颈。
对于其氨基酸序列包含信号肽(sp)的分泌酶,翻译后sp被信号肽酶切割并且成熟蛋白易位进入内质网(er;voss等人,2013;aviram和schuldiner2017)。为了通过er分泌蛋白质,信号识别粒子(srp)以高度保守的方式识别sp。srp与核糖体缔合,并通过疏水裂口识别正在被翻译且具有疏水基序的分泌蛋白,并且与真核生物er膜中存在的srp受体(sr)结合(aviram和schuldiner2017)。因此,蛋白质分泌的限制步骤可能是新生多肽从胞液易位到er。由于该过程非常耗能,每个细胞每时间单位的易位数量存在容量上限。
克服易位上限的手段和方法将构成全新的产量优化方法,因此在工业生物技术中将是非常需要的。
技术实现要素:
本发明提供了通过增加可转移到er的多肽的数量,同时每个易位依赖性事件仍使用一种信号肽,从而增加每个易位事件中可分泌的多肽单元的数量来提高多肽表达产量的手段和方法。
在第一方面,本发明涉及核酸构建体,其包含可操作地连接至以下的异源启动子:
a)编码信号肽的多核苷酸;以及
b)编码一种或多种目的多肽的至少两种多核苷酸;
其中该编码一种或多种目的多肽的至少两种多核苷酸各自被编码包含蛋白水解切割位点的接头多肽的接头多核苷酸分离;并且
其中将该信号肽、该一种或多种目的多肽和该包含蛋白水解切割位点的一个或多个接头多肽框内编码为单个多肽。
在第二方面,本发明涉及表达载体,其包含根据第一方面所述的核酸构建体。
在第三方面,本发明涉及真菌宿主细胞,其包含根据第一方面所述的核酸构建体和/或根据第二方面所述的表达载体。
在第四方面,本发明涉及用于产生一种或多种目的多肽的方法,该方法包括:
a)提供根据第三方面所述的真菌宿主细胞;
b)在有助于该一种或多种目的多肽表达的条件下培养所述宿主细胞;以及任选地
c)回收该一种或多种目的多肽。
附图说明
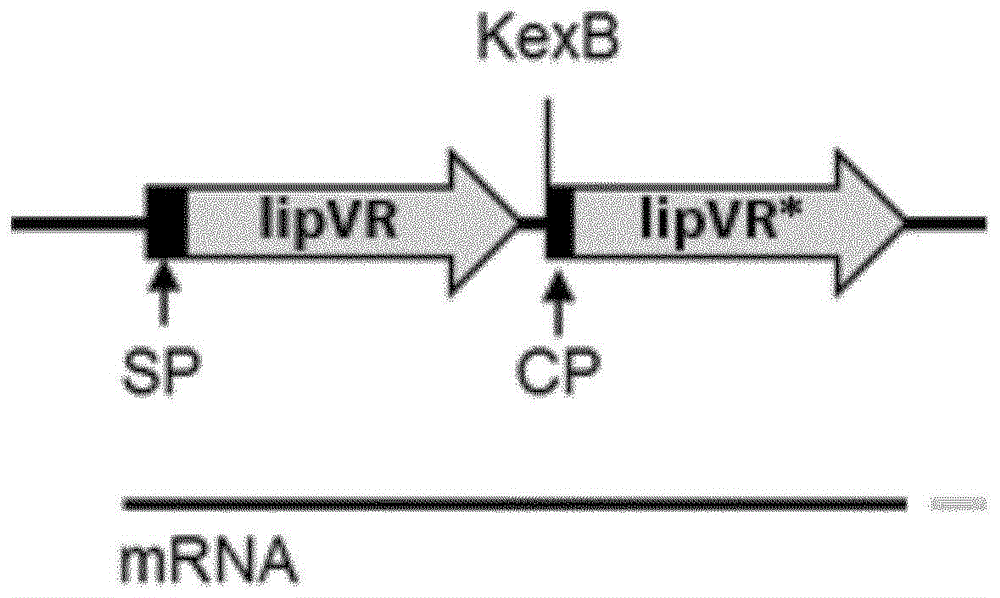
图1示意性地示出了lipvr表达盒。简短地,克隆了lipvr编码序列的一个或多个“单元”(使用不同密码子优化版本的基因、lipvr、lipvr*等),以进行其中lipvr以单线、串联或更多形式转录的基因构建。sp:来自lipvr基因或角质酶prepro编码序列的天然信号肽;cp:角质酶pro编码序列;kexb:kexb切割位点(“kr”)。在所有情况下,单个转录物含有所有“lipvr单元”。
图2示出了用于在米曲霉中表达和分泌lipvr脂肪酶的质粒pat652(单基因构建体)的图谱。
图3示出了用于在米曲霉中表达和分泌lipvr脂肪酶的质粒pat1509(串联基因构建体)的图谱。
图4(左)示出了如通过sdspage证明的lipvr的产生,用于比较发酵结束时(第7天),通过米曲霉菌株at969(泳道1:18个拷贝的单表达质粒pat652)和at1684(泳道2:9个拷贝的pat1509(lipvr串联))单线产生lipvr相比串联产生lipvr。图4(右)示出了菌株at969和at1684在发酵结束时的脂肪分解活性(表示为任意单位,a.u.)。
图5示出了产生完整lipvr分子(在含有lipvr串联盒的米曲霉菌株at1684的补料分批发酵期间产生)的正确加工程度。如所示的,在发酵结束时在30℃或34℃并且在ph6.5或7.4下取样(上清液),并通过质谱法进行分析。串联加工的水平显示为全长lipvr分子的百分比(黑盒)和虽不同但未完全加工的lipvr分子的聚集百分比(灰盒)。
定义
cdna:术语“cdna”意指可以通过从获得自真核或原核细胞的成熟的、剪接的mrna分子进行反转录而制备的dna分子。cdna缺乏可以存在于对应基因组dna中的内含子序列。初始的初级rna转录物是前体mrna,其通过一系列的步骤(包括rna剪接)进行加工,然后呈现为成熟的mrna。
编码序列:术语“编码序列”意指直接指定多肽的氨基酸序列的多核苷酸。编码序列的边界通常由可读框确定,该可读框以起始密码子(例如atg、gtg或ttg)开始并且以终止密码子(例如taa、tag或tga)结束。编码序列可以为基因组dna、cdna、合成dna或其组合。
控制序列:术语“控制序列”意指表达编码本发明的成熟多肽的多核苷酸所必需的核酸序列。每个控制序列对于编码该多肽的多核苷酸来说可以是天然的(即,来自相同基因)或外源的(即,来自不同基因),或相对于彼此是天然的或外源的。此类控制序列包括但不限于前导序列、多腺苷酸化序列、前肽序列、启动子、信号肽序列、以及转录终止子。最少,控制序列包括启动子、以及转录和翻译终止信号。出于引入有利于将控制序列与编码多肽的多核苷酸的编码区连接的特异性限制性位点的目的,这些控制序列可以提供有多个接头。
表达:术语“表达”包括涉及多肽产生的任何步骤,包括但不限于:转录、转录后修饰、翻译、翻译后修饰、以及分泌。
表达载体:术语“表达载体”意指直链或环状dna分子,其包含编码多肽的多核苷酸并且可操作地连接至提供用于其表达的控制序列。
异源启动子:术语“异源启动子”意指对与其可操作地连接的多核苷酸是外源(即,来自不同基因)的启动子。
宿主细胞:术语“宿主细胞”意指易于用包含本发明的多核苷酸的核酸构建体或表达载体进行转化、转染、转导等的任何细胞类型。术语“宿主细胞”涵盖由于复制期间出现的突变而与亲本细胞不相同的任何亲本细胞子代。
分离的:术语“分离的”意指处于自然界中不存在的形式或环境中的物质。
成熟多肽:术语“成熟多肽”意指在翻译和任何翻译后修饰如n-末端加工、c-末端截短、糖基化作用、磷酸化作用等之后处于其最终形式的多肽。在一个方面,成熟多肽是seqidno:5的氨基酸1至289(对应于seqidno:6的氨基酸1至289)。seqidno:5的氨基酸-20至-1是信号肽。在本领域中已知的是,宿主细胞可以产生由相同多核苷酸表达的两种或更多种不同的成熟多肽(即,具有不同的c-末端和/或n-末端氨基酸)的混合物。在本领域中还已知的是,不同的宿主细胞不同地加工多肽,并且因此一个表达多核苷酸的宿主细胞当与另一个表达相同多核苷酸的宿主细胞相比时可以产生不同的成熟多肽(例如,具有不同的c-末端和/或n-末端氨基酸)。
成熟多肽编码序列:术语“成熟多肽编码序列”意指编码如在wo2018/150021中确定的具有脂肪分解活性的成熟多肽的多核苷酸。在一个方面,成熟多肽编码序列是seqidno:3的核苷酸61至1056或其cdna序列(对应于seqidno:4的核苷酸61至927),并且seqidno:3的核苷酸1至60(对应于seqidno:4的核苷酸1至60)编码信号肽。
核酸构建体:术语“核酸构建体”意指单链或双链的核酸分子,该核酸分子是从天然存在的基因中分离的,或以本来不存在于自然界中的方式被修饰成含有核酸的区段,或是合成的,该核酸分子包含一个或多个控制序列。
可操作地连接:术语“可操作地连接”意指如下构型,在该构型中,控制序列被放置在相对于多核苷酸的编码序列适当的位置处,使得该控制序列指导该编码序列的表达。
分泌的:术语“分泌的”意指一种或多种目的多肽被加工并释放到细胞外环境(例如生长培养基)中。在一个实施例中,一种或多种目的多肽经由包含内质网、高尔基体和分泌小泡的常规分泌途径被加工和释放。在另一个实施例中,一种或多种目的多肽经由非常规分泌途径被加工和释放(rabouille,trendsincellbiology[细胞生物学趋势]2017,第27卷,第230-240页;kim等人,journalofcellscience[细胞科学杂志]2018,第131卷,jcs213686)。
序列同一性:两个氨基酸序列之间或两个核苷酸序列之间的关联度通过参数“序列同一性”来描述。
出于本发明的目的,使用如在emboss软件包(emboss:欧洲分子生物学开放软件包(emboss:theeuropeanmolecularbiologyopensoftwaresuite),rice等人,2000,trendsgenet.[遗传学趋势]16:276-277)(优选5.0.0版本或更新版本)的尼德尔程序中所实施的尼德曼-翁施算法(needleman-wunschalgorithm)(needleman和wunsch,1970,j.mol.biol.[分子生物学杂志]48:443-453)来确定两个氨基酸序列之间的序列同一性。所使用的参数是空位开放罚分10、空位延伸罚分0.5和eblosum62(blosum62的emboss版)取代矩阵。使用尼德尔标记的“最长同一性”的输出(使用非简化选项(nobriefoption)获得)作为同一性百分比并且如下计算:
(相同的残基x100)/(比对长度-比对中的空位总数)
出于本发明的目的,使用如在emboss软件包(emboss:欧洲分子生物学开放软件包(emboss:theeuropeanmolecularbiologyopensoftwaresuite),rice等人,2000,同上)(优选5.0.0版本或更新版本)的尼德尔程序中所实施的尼德曼-翁施算法(needleman和wunsch,1970,同上)来确定两个脱氧核糖核苷酸序列之间的序列同一性。所使用的参数是空位开放罚分10、空位延伸罚分0.5和ednafull(ncbinuc4.4的emboss版)取代矩阵。使用尼德尔标记的“最长同一性”的输出(使用非简化选项获得)作为同一性百分比并且如下计算:
(相同的脱氧核糖核苷酸x100)/(比对长度-比对中的空位总数)
变体:术语“变体”意指与相应的天然多肽相比,在一个或多个(例如,几个)位置处包含改变(即,取代、插入和/或缺失)的多肽。取代意指用不同的氨基酸替代占据某一位置的氨基酸;缺失意指去除占据某一位置的氨基酸;而插入意指在邻接并且紧随占据某一位置的氨基酸之后添加氨基酸。
具体实施方式
本发明提供了通过增加可转运到er的多肽的数量,同时每个易位事件仍仅使用一个sp,从而增加每个易位事件中可分泌的多肽单元的数量来提高多肽表达产量的手段和方法。
本发明构思基于核酸构建体的设计,这些核酸构建体包含可操作地连接至编码信号肽的多核苷酸和编码一种或多种目的多肽的至少两种多核苷酸的异源启动子。编码目的多肽的每种多核苷酸被编码接头多肽的接头多核苷酸分离,该接头多肽包含被合适的蛋白酶识别的蛋白水解切割位点(图1)。将信号肽、一种或多种目的多肽和一个或多个接头多肽框内编码,以允许翻译为单个多肽。术语“框内编码”是指在rna剪接和去除前体mrna中存在的任何内含子后获得的成熟mrna。
可以将本发明的核酸构建体转化到合适的宿主细胞中,并且在合适的条件下发酵此类宿主细胞将允许多核苷酸的转录,随后进行所得mrna的核糖体翻译。随后所得多肽(其含有一种信号肽和各自被接头多肽分离的一种或多种目的多肽)作为一个易位事件中的单个单元经靶向进入分泌途径。在通过识别由接头多肽包含的蛋白水解切割位点的蛋白酶进行蛋白水解加工之后,释放一种或多种目的多肽并将其分泌到细胞外培养基中。
如本文披露的实例中所示,在真菌宿主细胞的构建中使用本发明的核酸构建体导致目的多肽的产量增加以及对目的多肽的个别拷贝的均匀加工。后者对于酶等功能多肽尤其重要,因为一级结构的完整性对于三级结构的折叠和正确形成很重要,而该三级结构对于活性很重要。
因此,在第一方面,本发明涉及核酸构建体,其包含可操作地连接至以下的异源启动子:
a)编码信号肽的多核苷酸;以及
b)编码一种或多种目的多肽的至少两种多核苷酸;
其中该编码一种或多种目的多肽的至少两种多核苷酸各自被编码包含蛋白水解切割位点的接头多肽的接头多核苷酸分离;并且
其中将该信号肽、该一种或多种目的多肽和该包含蛋白水解切割位点的一个或多个接头多肽框内编码为单个多肽。
优选地,本发明的核酸构建体包含编码一种或多种,例如1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、20、25、30、35、40或更多种目的多肽的至少两种,例如2、3、4、5、6、7、8、9、10、11、12、13、14、15、20、25、30、35、40或更多种多核苷酸。
信号肽可以是适合于将一种或多种目的多肽靶向至宿主细胞(优选真菌宿主细胞)的分泌途径的任何信号肽。优选地,该信号肽是异源信号肽。
在一个优选的实施例中,该信号肽与seqidno:2具有至少80%,例如至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性,优选地,信号肽包含seqidno:2或由其组成。
在一个优选的实施例中,该编码信号肽的多核苷酸与seqidno:1具有至少80%,例如至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性;优选地,该编码信号肽的多核苷酸包含seqidno:1或由其组成。
该一种或多种目的多肽可以是任何多肽。优选地,该目的多肽包含酶;优选地,该酶选自由以下组成的组:水解酶、异构酶、连接酶、裂解酶、氧化还原酶或转移酶;更优选地是氨肽酶、淀粉酶、糖酶、羧肽酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、几丁质酶、角质酶、环糊精糖基转移酶、脱氧核糖核酸酶、内切葡聚糖酶、酯酶、α-半乳糖苷酶、β-半乳糖苷酶、葡糖淀粉酶、α-葡糖苷酶、β-葡糖苷酶、转化酶、漆酶、脂肪酶、甘露糖苷酶、变聚糖酶、核酸酶、氧化酶、果胶分解酶、过氧化物酶、磷酸二酯酶、植酸酶、多酚氧化酶、蛋白水解酶、核糖核酸酶、转谷氨酰胺酶、木聚糖酶、和β-木糖苷酶;最优选地,该酶是脂肪酶。
在一个优选的实施例中,该一种或多种目的多肽与seqidno:5的成熟多肽具有至少80%,例如至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性;优选地,该一种或多种目的多肽包含seqidno:5的成熟多肽或由其组成。
在一个优选的实施例中,该编码一种或多种目的多肽的至少两种多核苷酸与seqidno:4的成熟多肽编码序列独立地具有至少80%,例如至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性;优选地,该编码一种或多种目的多肽的至少两种多核苷酸包含seqidno:4的成熟多肽编码序列或由其组成;还优选地,该编码一种或多种多肽的至少两种多核苷酸是不同的,即,不具备同一性。
在另一个优选的实施例中,本发明的核酸构建体包含编码具有相同氨基酸序列的至少两种目的多肽的至少两种多核苷酸,并且至少两种目的多肽被分泌为具有相同氨基酸序列的单独多肽。优选地,该至少两种目的多肽与seqidno:5的成熟多肽具有至少80%,例如至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性;优选地,该至少两种目的多肽包含seqidno:5的成熟多肽或由其组成。优选地,该编码至少两种目的多肽的至少两种多核苷酸与seqidno:4的成熟多肽编码序列独立地具有至少80%,例如至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性;优选地,该编码至少两种目的多肽的至少两种多核苷酸包含seqidno:4的成熟多肽编码序列或由其组成;还优选地,该编码至少两种多肽的至少两种多核苷酸是不同的,即,不具备同一性。
应选择接头多核苷酸,使得编码的接头多肽具有足够的长度和柔性以允许识别蛋白水解切割位点的合适的蛋白酶接近蛋白水解切割位点。优选地,该接头多肽包含至少10个氨基酸,例如至少11个氨基酸、至少12个氨基酸、至少13个氨基酸、至少14个氨基酸、至少15个氨基酸、至少16个氨基酸、至少17个氨基酸、至少18个氨基酸、至少19个氨基酸、至少20个氨基酸、至少25个氨基酸、至少30个氨基酸、至少35个氨基酸、至少40个氨基酸、至少45个氨基酸、至少45个氨基酸、至少50个氨基酸、至少55个氨基酸、至少60个氨基酸、至少65个氨基酸、至少70个氨基酸、至少75个氨基酸、至少80个氨基酸、至少85个氨基酸、至少90个氨基酸、至少95个氨基酸、至少100个氨基酸、或更多个氨基酸。
该接头多肽包含由合适的蛋白酶(优选kexb蛋白酶)识别的蛋白水解切割位点。优选地,该蛋白水解切割位点是二元氨基酸基序,例如lys-arg或arg-arg基序。优选地,该蛋白水解切割位点是kexb切割位点。
该一种或多种目的多肽被表达为单个多肽的一部分,但应在将个别目的多肽分泌到胞外培养基之前于细胞内释放。因此,优选地,由该接头多肽编码的蛋白水解切割位点被细胞内蛋白酶识别。优选地,蛋白水解切割发生在细胞内,即包含本发明核酸构建体的合适的宿主细胞内部。可替代地,蛋白水解切割发生在细胞外且在包含本发明核酸构建体的合适的宿主细胞培养期间和/或之后。
核酸构建体
本发明涉及包含编码信号肽、一种或多种目的多肽和一个或多个接头多肽的多核苷酸的核酸构建体,这些多核苷酸可操作地连接至一个或多个控制序列,该一个或多个控制序列在与控制序列相容的条件下指导这些多核苷酸在合适的宿主细胞中的表达。
可以按多种方式操纵多核苷酸,以提供其表达。对多核苷酸进行操纵可能是理想的或必需的,这取决于核酸构建体、表达载体和/或将多核苷酸引入其中的宿主细胞。用于利用重组dna方法修饰多核苷酸的技术是本领域熟知的。
控制序列可为启动子,即,被宿主细胞识别用于表达编码本发明的多肽的多核苷酸的多核苷酸。该启动子包含介导多肽的表达的转录控制序列。该启动子可以是在宿主细胞中显示出转录活性的任何多核苷酸,包括变体、截短型及杂合型启动子,并且可以从编码与该宿主细胞同源或异源的细胞外或细胞内多肽的基因获得。
用于指导本发明的核酸构建体在丝状真菌宿主细胞中的转录的合适启动子的实例是从以下的基因中获得的启动子:构巢曲霉乙酰胺酶、黑曲霉中性α-淀粉酶、黑曲霉酸稳定性α-淀粉酶、黑曲霉或泡盛曲霉葡糖淀粉酶(glaa)、米曲霉taka淀粉酶、米曲霉碱性蛋白酶、米曲霉磷酸丙糖异构酶、尖孢镰孢胰蛋白酶样蛋白酶(wo96/00787)、镶片镰孢淀粉葡糖苷酶(wo00/56900)、镶片镰孢daria(wo00/56900)、镶片镰孢quinn(wo00/56900)、米黑根毛霉(rhizomucormiehei)脂肪酶、米黑根毛霉天冬氨酸蛋白酶、里氏木霉β-葡糖苷酶、里氏木霉纤维二糖水解酶i、里氏木霉纤维二糖水解酶ii、里氏木霉内切葡聚糖酶i、里氏木霉内切葡聚糖酶ii、里氏木霉内切葡聚糖酶iii、里氏木霉内切葡聚糖酶v、里氏木霉木聚糖酶i、里氏木霉木聚糖酶ii、里氏木霉木聚糖酶iii、里氏木霉β-木糖苷酶和里氏木霉翻译延伸因子,以及na2-tpi启动子(来自曲霉属中性α-淀粉酶基因的经修饰的启动子,其中已经用来自曲霉属磷酸丙糖异构酶基因的未翻译的前导序列替代未翻译的前导序列;非限制性实例包括来自黑曲霉中性α-淀粉酶基因的经修饰的启动子,其中已经用来自构巢曲霉或米曲霉丙糖磷酸异构酶基因的未翻译的前导序列替代未翻译的前导序列);及其变体、截短型及杂合型启动子。其他启动子描述于美国专利号6,011,147中。
在酵母宿主中,有用的启动子从以下的基因中获得:酿酒酵母烯醇酶(eno-1)、酿酒酵母半乳糖激酶(gal1)、酿酒酵母醇脱氢酶/甘油醛-3-磷酸脱氢酶(adh1、adh2/gap)、酿酒酵母磷酸丙糖异构酶(tpi)、酿酒酵母金属硫蛋白(cup1)、以及酿酒酵母3-磷酸甘油酸激酶。酵母宿主细胞的其他有用的启动子由romanos等人,1992,yeast[酵母]8:423-488描述。
所选的启动子应为与其可操作地连接的一个或多个多核苷酸是外源(即,来自不同基因)的异源启动子。
控制序列也可为由宿主细胞识别以终止转录的转录终止子。该终止子可操作地连接至编码该多肽的多核苷酸的3'-末端。在宿主细胞中有功能的任何终止子可用于本发明中。
丝状真菌宿主细胞的优选终止子从以下的基因中获得:构巢曲霉乙酰胺酶、构巢曲霉邻氨基苯甲酸合酶、黑曲霉葡糖淀粉酶、黑曲霉α-葡糖苷酶、米曲霉taka淀粉酶、尖孢镰孢胰蛋白酶样蛋白酶、里氏木霉β-葡糖苷酶、里氏木霉纤维二糖水解酶i、里氏木霉纤维二糖水解酶ii、里氏木霉内切葡聚糖酶i、里氏木霉内切葡聚糖酶ii、里氏木霉内切葡聚糖酶iii、里氏木霉内切葡聚糖酶v、里氏木霉木聚糖酶i、里氏木霉木聚糖酶ii、里氏木霉木聚糖酶iii、里氏木霉β-木糖苷酶和里氏木霉翻译延伸因子。
酵母宿主细胞的优选终止子从以下的基因中获得:酿酒酵母烯醇酶、酿酒酵母细胞色素c(cyc1)以及酿酒酵母甘油醛-3-磷酸脱氢酶。酵母宿主细胞的其他有用的终止子由romanos等人(1992,同上)描述。
控制序列也可以是前导序列,即对宿主细胞翻译而言重要的mrna的非翻译区域。该前导序列可操作地连接至编码该多肽的多核苷酸的5'-末端。可以使用在宿主细胞中有功能的任何前导序列。
用于丝状真菌宿主细胞的优选前导序列从米曲霉taka淀粉酶和构巢曲霉磷酸丙糖异构酶的基因中获得。
酵母宿主细胞的合适的前导序列从以下的基因中获得:酿酒酵母烯醇酶(eno-1)、酿酒酵母3-磷酸甘油酸激酶、酿酒酵母α-因子和酿酒酵母醇脱氢酶/甘油醛-3-磷酸脱氢酶(adh2/gap)。
控制序列还可以是多腺苷酸化序列,一种可操作地连接至该多核苷酸的3’-末端并且当转录时由宿主细胞识别为将多腺苷酸残基添加至所转录的mrna的信号的序列。可以使用在宿主细胞中有功能的任何多腺苷酸化序列。
丝状真菌宿主细胞的优选多腺苷酸化序列从以下的基因中获得:构巢曲霉邻氨基苯甲酸合酶、黑曲霉葡糖淀粉酶、黑曲霉α-葡糖苷酶、米曲霉taka淀粉酶和尖孢镰孢胰蛋白酶样蛋白酶。
酵母宿主细胞的有用的多腺苷酸化序列由guo和sherman,1995,mol.cellularbiol.[分子细胞生物学]15:5983-5990描述。
控制序列还可以是编码与多肽的n末端连接的信号肽并指导多肽进入细胞的分泌途径的信号肽编码区。多核苷酸的编码序列的5’端本身可以含有在翻译阅读框中天然与编码多肽的编码序列区段相连接的信号肽编码序列。可替代地,编码序列的5’端可以含有对于该编码序列是外源的信号肽编码序列。在编码序列不天然地含有信号肽编码序列的情况下,可能需要外源信号肽编码序列。可替代地,外源信号肽编码序列可以单纯地替代天然信号肽编码序列以便增强多肽的分泌。然而,可以使用指导已表达多肽进入宿主细胞的分泌途径的任何信号肽编码序列。
用于丝状真菌宿主细胞的有效的信号肽编码序列是从以下酶的基因获得的信号肽编码序列:黑曲霉中性淀粉酶、黑曲霉葡糖淀粉酶、米曲霉taka淀粉酶、特异腐质霉纤维素酶、特异腐质霉内切葡聚糖酶v、柔毛腐质霉脂肪酶和米黑根毛霉天冬氨酸蛋白酶。
用于酵母宿主细胞的有用的信号肽从酿酒酵母α-因子和酿酒酵母转化酶的基因中获得。其他的有用的信号肽编码序列由romanos等人(1992,同上)描述。
在一个优选的实施例中,信号肽与seqidno:2具有至少80%,例如至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性;优选地,该信号肽包含seqidno:2或由其组成。
在一个优选的实施例中,信号肽包含seqidno:2或由其组成。
控制序列还可以是编码位于多肽的n-末端的前肽的前肽编码序列。所得的多肽被称为前体酶(proenzyme)或多肽原(或在一些情况下被称为酶原(zymogen))。多肽原通常是无活性的并且可通过催化切割或自身催化切割来自多肽原的前肽而转化为活性多肽。前肽编码序列可以从以下的基因获得:嗜热毁丝霉(myceliophthorathermophila)漆酶(wo95/33836)、米黑根毛霉天冬氨酸蛋白酶和酿酒酵母α-因子。
在信号肽序列和前肽序列二者都存在的情况下,该前肽序列位于紧邻多肽的n-末端且该信号肽序列位于紧邻前肽序列的n-末端。
还可希望的是添加调节序列,这些调节序列调节宿主细胞生长相关的多肽的表达。调节序列的实例是引起基因表达以响应于化学或物理刺激(包括调节化合物的存在)而开启或关闭的那些。
在酵母中,可以使用adh2系统或gal1系统。
在丝状真菌中,可以使用黑曲霉葡糖淀粉酶启动子、米曲霉takaα-淀粉酶启动子和米曲霉葡糖淀粉酶启动子、里氏木霉纤维二糖水解酶i启动子以及里氏木霉纤维二糖水解酶ii启动子。
调节序列的其他实例是允许基因扩增的那些序列。在真核系统中,这些调节序列包括在甲氨蝶呤存在下扩增的二氢叶酸还原酶基因以及用重金属扩增的金属硫蛋白基因。在这些情况中,编码多肽的多核苷酸会与调节序列可操作地连接。
多核苷酸
本发明还涉及编码信号肽的多核苷酸、编码一种或多种目的多肽的多肽、以及编码一个或多个接头多肽的一个或多个接头多核苷酸。在实施例中,这些多核苷酸已经被分离。
用于分离或克隆多核苷酸的技术是本领域已知的且包括从基因组dna或cdna或其组合进行分离。可以例如通过使用熟知的聚合酶链式反应(pcr)或表达文库的抗体筛选来检测具有共有结构特征的克隆dna片段,实现从基因组dna克隆多核苷酸。参见例如,innis等人,1990,pcr:aguidetomethodsandapplication[pcr:方法和应用指南],academicpress[学术出版社],纽约。可以使用其他核酸扩增程序例如连接酶链式反应(lcr)、连接激活转录(lat)和基于多核苷酸的扩增(nasba)。这些多核苷酸可以克隆自曲霉属菌株或相关有机体,并且因此,例如可以是该多核苷酸的多肽编码区的等位基因变体或物种变体。
编码信号肽、一种或多种目的多肽、或接头多肽的多核苷酸的修饰对于合成基本上类似于这些多肽的多肽可以是必需的。术语“基本上类似”于该多肽是指多肽的非天然存在的形式。
表达载体
在第二方面,本发明还涉及包含本发明的多核苷酸、启动子、以及转录和翻译终止信号的重组表达载体。多个核苷酸和控制序列可连接在一起以产生重组表达载体,该重组表达载体可包括一个或多个便利的限制性位点以允许编码该多肽的多核苷酸在此类位点处的插入或取代。可替代地,可以通过将多核苷酸或包含该多核苷酸的核酸构建体插入用于表达的适当载体中而表达该多核苷酸。在产生表达载体时,编码序列如此位于载体中,使得编码序列与用于表达的适当控制序列可操作地连接。
重组表达载体可以是可以方便地经受重组dna程序并且可以引起多核苷酸表达的任何载体(例如,质粒或病毒)。载体的选择将典型地取决于载体与待引入载体的宿主细胞的相容性。载体可以是直链或闭合环状质粒。
载体可以是自主复制载体,即作为染色体外实体存在的载体,其复制独立于染色体复制,例如质粒、染色体外元件、微染色体或人工染色体。载体可以含有用于确保自我复制的任何手段。可替代地,载体可以是这样的载体,当它引入宿主细胞中时整合入基因组中并与其中已整合了它的一个或多个染色体一起复制。此外,可以使用单独的载体或质粒或两个或更多个载体或质粒,其共同含有待引入宿主细胞基因组的总dna,或可以使用转座子。
载体优选地含有允许方便地选择转化细胞、转染细胞、转导细胞等细胞的一个或多个选择性标记。选择性标记是一种基因,其产物提供了杀生物剂抗性或病毒抗性、对重金属抗性、对营养缺陷型的原养型等。
酵母宿主细胞的合适的选择性标记包括但不限于:ade2、his3、leu2、lys2、met3、trp1和ura3。
用于丝状真菌宿主细胞的合适的选择性标记包括但不限于adea(磷酸核糖酰氨基咪唑-琥珀羧胺合酶)、adeb(磷酸核糖酰-氨基咪唑合酶)、amds(乙酰胺酶)、argb(鸟氨酸氨甲酰基转移酶)、bar(草丁膦乙酰转移酶)、hph(潮霉素磷酸转移酶)、niad(硝酸还原酶)、pyrg(乳清酸核苷-5'-磷酸脱羧酶)、sc(硫酸腺苷基转移酶)以及trpc(邻氨基苯甲酸合酶)连同其等同物。优选的用于曲霉细胞中的是构巢曲霉或米曲霉amds和pyrg基因以及吸水链霉菌(streptomyceshygroscopicus)bar基因。优选的用于木霉属细胞的是adea、adeb、amds、hph以及pyrg基因。
选择性标记可以是如wo2010/039889中所述的双选择性标记系统。在一个方面,双选择性标记是hph-tk双选择性标记系统。
载体优选地含有允许载体整合到宿主细胞的基因组中或载体在细胞中独立于基因组自主复制的一个或多个元件。对于整合到宿主细胞基因组中,载体可以依靠编码多肽的多核苷酸序列或用于通过同源或非同源重组整合到基因组中的载体的任何其他元件。可替代地,载体可以含有用于指导通过同源重组而整合入宿主细胞基因组中的一个或多个染色体中的一个或多个精确位置处的另外的多核苷酸。为了增加在精确位置处整合的可能性,整合元件应当含有足够数目的核酸,例如100至10,000个碱基对、400至10,000个碱基对和800至10,000个碱基对,这些核酸与相应的靶序列具有高度序列同一性以增强同源重组的概率。整合元件可以是与宿主细胞基因组内的靶序列同源的任何序列。此外,整合元件可以是非编码或编码的多核苷酸。另一方面,载体可以通过非同源重组整合入宿主细胞的基因组中。
为了自主复制,载体可以进一步包含复制起点,该复制起点使得载体在讨论中的宿主细胞中自主复制成为可能。复制起点可以是在细胞中发挥作用的介导自主复制的任何质粒复制子。术语“复制起点”或“质粒复制子”意指使质粒或载体能够在体内复制的多核苷酸。
用于酵母宿主细胞中的复制起点的实例是2微米复制起点、ars1、ars4、ars1与cen3的组合、及ars4与cen6的组合。
在丝状真菌细胞中有用的复制起点的实例是ama1和ans1(gems等人,1991,gene[基因]98:61-67;cullen等人,1987,nucleicacidsres.[核酸研究]15:9163-9175;wo00/24883)。可根据wo00/24883中披露的方法完成ama1基因的分离和包含该基因的质粒或载体的构建。
可将本发明多核苷酸的多于一个拷贝插入宿主细胞以增加多肽的产生。通过将序列的至少一个另外的拷贝整合到宿主细胞基因组中或者通过包括与该多核苷酸一起的可扩增的选择性标记基因可以获得多核苷酸的增加的拷贝数目,其中通过在适当的选择性试剂的存在下培养细胞可以选择包含选择性标记基因的经扩增的拷贝以及由此该多核苷酸的另外的拷贝的细胞。
用于连接以上所述的元件以构建本发明的重组表达载体的程序是本领域的普通技术人员熟知的(参见例如,sambrook等人,1989,同上)。
宿主细胞
在第三方面,本发明还涉及包含本发明的核酸构建体或表达载体的重组宿主细胞。将包含多核苷酸的本发明的构建体或载体引入宿主细胞中,这样使得该构建体或载体作为染色体整合体或作为自主复制的染色体外载体维持,如较早前所述。术语“宿主细胞”涵盖由于复制期间出现的突变而与亲本细胞不相同的任何亲本细胞子代。宿主细胞的选择将在很大程度上取决于编码一种或多种目的多肽的多核苷酸及其来源。
宿主细胞可以是可用于重组产生目的多肽的任何细胞,例如真核细胞,优选真菌细胞。
如本文所用的“真菌”包括子囊菌门(ascomycota)、担子菌门(basidiomycota)、壶菌门(chytridiomycota)和接合菌门(zygomycota)以及卵菌门(oomycota)和所有有丝分裂孢子真菌(如由hawksworth等人在以下文献中所定义的:ainsworthandbisby’sdictionaryofthefungi[安斯沃思和拜斯比真菌字典],第8版,1995,cabinternational[国际应用生物科学中心],universitypress[大学出版社],英国剑桥)。
真菌宿主细胞可以为酵母细胞。如本文所用的“酵母”包括产子囊酵母(ascosporogenousyeast)(内孢霉目(endomycetales))、产担子酵母(basidiosporogenousyeast)和属于半知菌纲(fungiimperfecti)(芽孢纲(blastomycetes))的酵母。由于酵母的分类可在将来变化,出于本发明的目的,酵母应当如biologyandactivitiesofyeast[酵母的生物学与活性](skinner,passmore和davenport编辑,soc.app.bacteriol.symposiumseriesno.9[应用细菌学学会专题论文集系列9],1980)中所描述的那样定义。
酵母宿主细胞可以是假丝酵母属、汉逊酵母属、克鲁弗酵母属、毕赤酵母属、酵母属、裂殖酵母属或耶氏酵母属细胞,如乳酸克鲁弗酵母、卡尔酵母、酿酒酵母、糖化酵母、道格拉氏酵母、克鲁弗酵母、诺地酵母、卵形酵母或解脂耶氏酵母细胞。
真菌宿主细胞可为丝状真菌细胞。“丝状真菌”包括真菌门和卵菌门的亚门的所有丝状形式(如由hawksworth等人,1995(同上)所定义的)。丝状真菌通常的特征在于由几丁质、纤维素、葡聚糖、壳聚糖、甘露聚糖和其他复杂多糖构成的菌丝体壁。营养生长是通过菌丝延伸来进行的,而碳分解代谢是专性需氧的。相反,酵母(如酿酒酵母)的营养生长是通过单细胞菌体的出芽(budding)来进行的,而碳分解代谢可以是发酵性的。
丝状真菌宿主细胞可以是枝顶孢霉属、曲霉属、短梗霉属、烟管霉属、拟蜡菌属、金孢子菌属、鬼伞属、革盖菌属、隐球菌属、线黑粉菌科、镰孢属、腐质霉属、梨孢菌属、毛霉属、毁丝霉属、新美鞭菌属、链孢菌属、拟青霉属、青霉属、平革菌属、射脉菌属、瘤胃壶菌属、侧耳属、裂褶菌属、篮状菌属、嗜热子囊菌属、梭孢壳属、弯颈霉属、栓菌属或木霉属细胞。
例如,丝状真菌宿主细胞可以是泡盛曲霉、臭曲霉、烟曲霉、日本曲霉、构巢曲霉、黑曲霉、米曲霉、黑刺烟管菌、干拟蜡菌、卡内基拟蜡菌、浅黄拟蜡孔菌、潘诺希塔拟蜡菌、环带拟蜡菌、微红拟蜡菌、虫拟蜡菌、狭边金孢子菌、嗜角质金孢子菌、卢克诺文思金孢子菌、粪状金孢子菌、租金孢子菌、女王杜香金孢子菌、热带金孢子菌、褐薄金孢子菌、灰盖鬼伞、毛革盖菌、杆孢状镰孢、谷类镰孢、库威镰孢、大刀镰孢、禾谷镰孢、禾赤镰孢、异孢镰孢、合欢木镰孢、尖孢镰孢、多枝镰孢、粉红镰孢、接骨木镰孢、肤色镰孢、拟分枝孢镰孢、硫色镰孢、圆镰孢、拟丝孢镰孢、镶片镰孢、特异腐质霉、柔毛腐质霉、米黑毛霉、嗜热毁丝霉、粗糙链孢菌、产紫青霉、黄孢平革菌、射脉菌、刺芹侧耳、土生梭孢壳霉、长域毛栓菌、变色栓菌、哈茨木霉、康宁木霉、长枝木霉、里氏木霉、或绿色木霉细胞。
可以将真菌细胞通过涉及原生质体形成、原生质体转化、以及细胞壁再生的方法以本身已知的方式转化。用于转化曲霉属和木霉属宿主细胞的适合程序描述于以下文献中:ep238023,yelton等人,1984,proc.natl.acad.sci.usa[美国国家科学院院刊]81:1470-1474以及christensen等人,1988,bio/technology[生物/技术]6:1419-1422。用于转化镰孢属物种的适合方法由malardier等人,1989,gene[基因]78:147-156和wo96/00787描述。可以使用由以下文献描述的程序转化酵母:becker和guarente,在abelson,j.n.和simon,m.i.编辑,guidetoyeastgeneticsandmolecularbiology[酵母遗传学与分子生物学指南],methodsinenzymology[酶学方法],第194卷,第182-187页,academicpress,inc.[学术出版社有限公司],纽约;ito等人,1983,j.bacteriol.[细菌学杂志]153:163;以及hinnen等人,1978,proc.natl.acad.sci.usa[美国国家科学院院刊]75:1920。
产生方法
在第四方面,本发明还涉及用于产生一种或多种目的多肽的方法,该方法包括:
a)提供本发明的真菌宿主细胞;
b)在有助于该一种或多种目的多肽产生的条件下培养该宿主细胞;以及任选地
c)回收该一种或多种目的多肽。
在一个实施例中,宿主细胞是曲霉属细胞。在一个优选的实施例中,宿主细胞是米曲霉细胞。
这些真菌宿主细胞是在适合于使用本领域已知的方法生产该目的多肽的营养培养基中培养的。例如,可以通过摇瓶培养、或在实验室或工业发酵罐中小规模或大规模发酵(包括连续、分批、补料分批或固态发酵)培养细胞,该培养在合适的培养基中并且在允许表达和/或分离目的多肽的条件下进行。使用本领域中已知的程序,培养发生在包含碳和氮来源及无机盐的合适的营养培养基中。合适的培养基可从商业供应商获得或可以根据公开的组成(例如,在美国典型培养物保藏中心的目录中)制备。如果目的多肽被分泌到营养培养基中,那么可以直接从该培养基中回收该目的多肽。如果该目的多肽不进行分泌,那么其可以从细胞裂解液中进行回收。
可以使用特异性针对该多肽的本领域已知的方法来检测该一种或多种目的多肽。这些检测方法包括但不限于:特异性抗体的使用、酶产物的形成或酶底物的消失。例如,可以使用酶测定来确定目的多肽的活性。
可以使用本领域中已知的方法回收该一种或多种目的多肽。例如,可通过常规方法,包括但不限于收集、离心、过滤、提取、喷雾干燥、蒸发或沉淀,从营养培养基回收该一种或多种目的多肽。在一个方面,回收包含该一种或多种目的多肽的发酵液。
可以通过本领域已知的多种程序纯化该一种或多种目的多肽,包括但不限于色谱法(例如,离子交换色谱法、亲和色谱法、疏水色谱法、聚焦色谱法和尺寸排阻色谱法)、电泳程序(例如,制备型等电聚焦电泳)、差异性溶解(例如,硫酸铵沉淀)、sds-page或提取(参见例如,proteinpurification[蛋白质纯化],janson和ryden编辑,vchpublishers[vch出版公司],纽约,1989),以便获得基本上纯的多肽。
在一个替代性方面,不回收该一种或多种目的多肽,而是将表达该一种或多种目的多肽的本发明的宿主细胞用作该一种或多种多肽的来源。
优选的实施例
1)一种核酸构建体,其包含可操作地连接至以下的异源启动子:
a)编码信号肽的多核苷酸;以及
b)编码一种或多种目的多肽的至少两种多核苷酸;
其中该编码一种或多种目的多肽的至少两种多核苷酸各自被编码包含蛋白水解切割位点的接头多肽的接头多核苷酸分离;并且
其中将该信号肽、该一种或多种目的多肽和该包含蛋白水解切割位点的一个或多个接头多肽框内编码为单个多肽。
2)根据权利要求1所述的核酸构建体,其中该至少两种多核苷酸编码具有相同氨基酸序列的至少两种目的多肽,并且其中该至少两种目的多肽被分泌为具有相同氨基酸序列的单独多肽。
3)根据前述实施例中任一项所述的核酸构建体,其中该信号肽与seqidno:2具有至少80%的序列同一性;优选地,该信号肽包含seqidno:2或由其组成。
4)根据前述实施例中任一项所述的核酸构建体,其中该编码信号肽的多核苷酸与seqidno:1具有至少80%的序列同一性;优选地,该编码信号肽的多核苷酸包含seqidno:1或由其组成。
5)根据前述实施例中任一项所述的核酸构建体,其中该一种或目的多肽包含酶;优选地,该酶选自由以下组成的组:水解酶、异构酶、连接酶、裂解酶、氧化还原酶或转移酶;更优选地是氨肽酶、淀粉酶、糖酶、羧肽酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、几丁质酶、角质酶、环糊精糖基转移酶、脱氧核糖核酸酶、内切葡聚糖酶、酯酶、α-半乳糖苷酶、β-半乳糖苷酶、葡糖淀粉酶、α-葡糖苷酶、β-葡糖苷酶、转化酶、漆酶、脂肪酶、甘露糖苷酶、变聚糖酶、核酸酶、氧化酶、果胶分解酶、过氧化物酶、磷酸二酯酶、植酸酶、多酚氧化酶、蛋白水解酶、核糖核酸酶、转谷氨酰胺酶、木聚糖酶、和β-木糖苷酶;最优选地,该目的多肽是脂肪酶。
6)根据前述实施例中任一项所述的核酸构建体,其中该一种或多种目的多肽与seqidno:5的成熟多肽具有至少80%的序列同一性;优选地,该一种或多种目的多肽包含seqidno:5的成熟多肽或由其组成。
7)根据前述实施例中任一项所述的核酸构建体,其中该编码一种或多种目的多肽的至少两种多核苷酸与seqidno:4的成熟多肽编码序列独立地具有至少80%的序列同一性;优选地,该编码一种或多种目的多肽的至少两种多核苷酸包含seqidno:4的成熟多肽编码序列或由其组成。
8)根据前述实施例中任一项所述的核酸构建体,其中该接头多肽包含至少10个氨基酸。
9)根据前述实施例中任一项所述的核酸构建体,其中该蛋白水解切割位点是二元氨基酸基序;优选地,该蛋白水解切割位点是lys-arg基序或arg-arg基序。
10)根据前述实施例中任一项所述的核酸构建体,其中该蛋白水解切割位点是kexb切割位点。
11)一种表达载体,其包含含有可操作地连接至以下的异源启动子的核酸构建体:
a)编码信号肽的多核苷酸;以及
b)编码一种或多种目的多肽的至少两种多核苷酸;
其中该编码一种或多种目的多肽的至少两种多核苷酸各自被编码包含蛋白水解切割位点的接头多肽的接头多核苷酸分离;并且
其中将该信号肽、该一种或多种目的多肽和该包含蛋白水解切割位点的一个或多个接头多肽框内编码为单个多肽。
12)根据权利要求11所述的表达载体,其中该至少两种多核苷酸编码具有相同氨基酸序列的至少两种目的多肽,并且其中该至少两种目的多肽被分泌为具有相同氨基酸序列的单独多肽。
13)根据实施例11-12中任一项所述的表达载体,其中该信号肽与seqidno:2具有至少80%的序列同一性;优选地,该信号肽包含seqidno:2或由其组成。
14)根据实施例11-3中任一项所述的表达载体,其中该编码信号肽的多核苷酸与seqidno:1具有至少80%的序列同一性;优选地,该编码信号肽的多核苷酸包含seqidno:1或由其组成。
15)根据实施例11-14中任一项所述的表达载体,其中该一种或目的多肽包含酶;优选地,该酶选自由以下组成的组:水解酶、异构酶、连接酶、裂解酶、氧化还原酶或转移酶;更优选地是氨肽酶、淀粉酶、糖酶、羧肽酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、几丁质酶、角质酶、环糊精糖基转移酶、脱氧核糖核酸酶、内切葡聚糖酶、酯酶、α-半乳糖苷酶、β-半乳糖苷酶、葡糖淀粉酶、α-葡糖苷酶、β-葡糖苷酶、转化酶、漆酶、脂肪酶、甘露糖苷酶、变聚糖酶、核酸酶、氧化酶、果胶分解酶、过氧化物酶、磷酸二酯酶、植酸酶、多酚氧化酶、蛋白水解酶、核糖核酸酶、转谷氨酰胺酶、木聚糖酶、和β-木糖苷酶;最优选地,该一种或多种目的多肽是脂肪酶。
16)根据实施例11-15中任一项所述的表达载体,其中该一种或多种目的多肽与seqidno:5的成熟多肽具有至少80%的序列同一性;优选地,该一种或多种目的多肽包含seqidno:5的成熟多肽或由其组成。
17)根据实施例11-16中任一项所述的表达载体,其中该编码一种或多种目的多肽的至少两种多核苷酸与seqidno:4的成熟多肽编码序列独立地具有至少80%的序列同一性;优选地,该编码一种或多种目的多肽的至少两种多核苷酸包含seqidno:4的成熟多肽编码序列或由其组成。
18)根据实施例11-17中任一项所述的表达载体,其中该接头多肽包含至少10个氨基酸。
19)根据实施例11-18中任一项所述的表达载体,其中该蛋白水解切割位点是二元氨基酸基序;优选地,该蛋白水解切割位点是lys-arg基序或arg-arg基序。
20)根据实施例11-19中任一项所述的表达载体,其中该蛋白水解切割位点是kexb切割位点。
21)一种真菌宿主细胞,该真菌宿主细胞在其基因组中包含:
i)含有可操作地连接至以下的异源启动子的核酸构建体:
a)编码信号肽的多核苷酸;以及
b)编码一种或多种目的多肽的至少两种多核苷酸;
其中该编码一种或多种目的多肽的至少两种多核苷酸各自被编码包含蛋白水解切割位点的接头多肽的接头多核苷酸分离;并且
其中将该信号肽、该一种或多种目的多肽和该包含蛋白水解切割位点的一个或多个接头多肽框内编码为单个多肽;
和/或
ii)含有所述核酸构建体的表达载体。
22)根据权利要求21所述的真菌宿主细胞,其中该至少两种多核苷酸编码具有相同氨基酸序列的至少两种目的多肽,并且其中该至少两种目的多肽被分泌为具有相同氨基酸序列的单独多肽。
23)根据实施例21-22中任一项所述的真菌宿主细胞,所述真菌宿主细胞是酵母宿主细胞;优选地,该酵母宿主细胞选自由以下组成的组:假丝酵母属、汉逊酵母属、克鲁弗酵母属、毕赤酵母属、酵母属、裂殖酵母属、和耶氏酵母属细胞;更优选地,该酵母宿主细胞选自由以下组成的组:乳酸克鲁弗酵母、卡尔酵母、酿酒酵母、糖化酵母、道格拉氏酵母、克鲁弗酵母、诺地酵母、卵形酵母和解脂耶氏酵母细胞。
24)根据实施例21-22中任一项所述的真菌宿主细胞,所述真菌宿主细胞是丝状真菌宿主细胞;优选地,该丝状真菌宿主细胞选自由以下组成的组:枝顶孢霉属、曲霉属、短梗霉属、烟管霉属、拟蜡菌属、金孢子菌属、鬼伞属、革盖菌属、隐球菌属、线黑粉菌科、镰孢属、腐质霉属、梨孢菌属、毛霉属、毁丝霉属、新美鞭菌属、链孢菌属、拟青霉属、青霉属、平革菌属、射脉菌属、瘤胃壶菌属、侧耳属、裂褶菌属、篮状菌属、嗜热子囊菌属、梭孢壳属、弯颈霉属、栓菌属和木霉属细胞;更优选地,该丝状真菌宿主细胞选自由以下组成的组:泡盛曲霉、臭曲霉、烟曲霉、日本曲霉、构巢曲霉、黑曲霉、米曲霉、黑刺烟管菌、干拟蜡菌、卡内基拟蜡菌、浅黄拟蜡孔菌、潘诺希塔拟蜡菌、环带拟蜡菌、微红拟蜡菌、虫拟蜡菌、狭边金孢子菌、嗜角质金孢子菌、卢克诺文思金孢子菌、粪状金孢子菌、租金孢子菌、女王杜香金孢子菌、热带金孢子菌、褐薄金孢子菌、灰盖鬼伞、毛革盖菌、杆孢状镰孢、谷类镰孢、库威镰孢、大刀镰孢、禾谷镰孢、禾赤镰孢、异孢镰孢、合欢木镰孢、尖孢镰孢、多枝镰孢、粉红镰孢、接骨木镰孢、肤色镰孢、拟分枝孢镰孢、硫色镰孢、圆镰孢、拟丝孢镰孢、镶片镰孢、特异腐质霉、柔毛腐质霉、米黑毛霉、嗜热毁丝霉、粗糙链孢菌、产紫青霉、黄孢平革菌、射脉菌、刺芹侧耳、土生梭孢壳霉、长域毛栓菌、变色栓菌、哈茨木霉、康宁木霉、长枝木霉、里氏木霉、和绿色木霉细胞;甚至更优选地,该丝状真菌宿主细胞选自由以下组成的组:黑曲霉、米曲霉、镶片镰孢和里氏木霉;最优选地,该丝状真菌宿主细胞是米曲霉细胞。
25)根据实施例21-24中任一项所述的真菌宿主细胞,其中该信号肽与seqidno:2具有至少80%的序列同一性;优选地,该信号肽包含seqidno:2或由其组成。
26)根据实施例21-25中任一项所述的真菌宿主细胞,其中该编码信号肽的多核苷酸与seqidno:1具有至少80%的序列同一性;优选地,该编码信号肽的多核苷酸包含seqidno:1或由其组成。
27)根据实施例21-26中任一项所述的真菌宿主细胞,其中该一种或多种目的多肽包含酶;优选地,该酶选自由以下组成的组:水解酶、异构酶、连接酶、裂解酶、氧化还原酶或转移酶;更优选地是氨肽酶、淀粉酶、糖酶、羧肽酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、几丁质酶、角质酶、环糊精糖基转移酶、脱氧核糖核酸酶、内切葡聚糖酶、酯酶、α-半乳糖苷酶、β-半乳糖苷酶、葡糖淀粉酶、α-葡糖苷酶、β-葡糖苷酶、转化酶、漆酶、脂肪酶、甘露糖苷酶、变聚糖酶、核酸酶、氧化酶、果胶分解酶、过氧化物酶、磷酸二酯酶、植酸酶、多酚氧化酶、蛋白水解酶、核糖核酸酶、转谷氨酰胺酶、木聚糖酶、和β-木糖苷酶;最优选地,该目的多肽是脂肪酶。
28)根据实施例21-27中任一项所述的真菌宿主细胞,其中该一种或多种目的多肽与seqidno:5的成熟多肽具有至少80%的序列同一性;优选地,该一种或多种目的多肽包含seqidno:5的成熟多肽或由其组成。
29)根据实施例21-28中任一项所述的真菌宿主细胞,其中该编码一种或多种目的多肽的至少两种多核苷酸与seqidno:4的成熟多肽编码序列独立地具有至少80%的序列同一性;优选地,该编码一种或多种目的多肽的至少两种多核苷酸包含seqidno:4的成熟多肽编码序列或由其组成。
30)根据实施例21-29中任一项所述的真菌宿主细胞,其中该接头多肽包含至少10个氨基酸。
31)根据实施例21-30中任一项所述的真菌宿主细胞,其中该蛋白水解切割位点是二元氨基酸基序;优选地,该蛋白水解切割位点是lys-arg基序或arg-arg基序。
32)根据实施例21-31中任一项所述的真菌宿主细胞,其中该蛋白水解切割位点是kexb切割位点。
33)根据实施例21-32中任一项所述的真菌宿主细胞,其中蛋白水解切割发生在细胞内,或者其中蛋白水解切割发生在细胞外且在真菌宿主细胞培养期间和/或之后。
34)一种产生一种或多种目的多肽的方法,所述方法包括:
a)提供真菌宿主细胞,其包含:
i)含有可操作地连接至以下的异源启动子的核酸构建体:
a)编码信号肽的多核苷酸;以及
b)编码一种或多种目的多肽的至少两种多核苷酸;
其中该编码一种或多种目的多肽的至少两种多核苷酸各自被编码包含蛋白水解切割位点的接头多肽的接头多核苷酸分离;并且
其中将该信号肽、该一种或多种目的多肽和该包含蛋白水解切割位点的一个或多个接头多肽框内编码为单个多肽;
和/或
ii)含有所述核酸构建体的表达载体。
b)在有助于该一种或多种目的多肽表达的条件下培养所述宿主细胞;以及任选地
c)回收该一种或多种目的多肽。
35)根据权利要求34所述的方法,其中该至少两种多核苷酸编码具有相同氨基酸序列的至少两种目的多肽,并且其中该至少两种目的多肽被分泌为具有相同氨基酸序列的单独多肽。
36)根据实施例34-35中任一项所述的方法,其中该一种或多种目的多肽包含酶;优选地,该酶选自由以下组成的组:水解酶、异构酶、连接酶、裂解酶、氧化还原酶或转移酶;更优选地是氨肽酶、淀粉酶、糖酶、羧肽酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、几丁质酶、角质酶、环糊精糖基转移酶、脱氧核糖核酸酶、内切葡聚糖酶、酯酶、α-半乳糖苷酶、β-半乳糖苷酶、葡糖淀粉酶、α-葡糖苷酶、β-葡糖苷酶、转化酶、漆酶、脂肪酶、甘露糖苷酶、变聚糖酶、核酸酶、氧化酶、果胶分解酶、过氧化物酶、磷酸二酯酶、植酸酶、多酚氧化酶、蛋白水解酶、核糖核酸酶、转谷氨酰胺酶、木聚糖酶、和β-木糖苷酶;最优选地,该一种或多种目的多肽是脂肪酶。
37)根据实施例34-36中任一项所述的方法,其中该真菌宿主细胞是酵母宿主细胞;优选地,该酵母宿主细胞选自由以下组成的组:假丝酵母属、汉逊酵母属、克鲁弗酵母属、毕赤酵母属、酵母属、裂殖酵母属、和耶氏酵母属细胞;更优选地,该酵母宿主细胞选自由以下组成的组:乳酸克鲁弗酵母、卡尔酵母、酿酒酵母、糖化酵母、道格拉氏酵母、克鲁弗酵母、诺地酵母、卵形酵母和解脂耶氏酵母细胞。
38)根据实施例34-36中任一项所述的方法,其中该真菌宿主细胞是丝状真菌宿主细胞;优选地,该丝状真菌宿主细胞选自由以下组成的组:枝顶孢霉属、曲霉属、短梗霉属、烟管霉属、拟蜡菌属、金孢子菌属、鬼伞属、革盖菌属、隐球菌属、线黑粉菌科、镰孢属、腐质霉属、梨孢菌属、毛霉属、毁丝霉属、新美鞭菌属、链孢菌属、拟青霉属、青霉属、平革菌属、射脉菌属、瘤胃壶菌属、侧耳属、裂褶菌属、篮状菌属、嗜热子囊菌属、梭孢壳属、弯颈霉属、栓菌属和木霉属细胞;更优选地,该丝状真菌宿主细胞选自由以下组成的组:泡盛曲霉、臭曲霉、烟曲霉、日本曲霉、构巢曲霉、黑曲霉、米曲霉、黑刺烟管菌、干拟蜡菌、卡内基拟蜡菌、浅黄拟蜡孔菌、潘诺希塔拟蜡菌、环带拟蜡菌、微红拟蜡菌、虫拟蜡菌、狭边金孢子菌、嗜角质金孢子菌、卢克诺文思金孢子菌、粪状金孢子菌、租金孢子菌、女王杜香金孢子菌、热带金孢子菌、褐薄金孢子菌、灰盖鬼伞、毛革盖菌、杆孢状镰孢、谷类镰孢、库威镰孢、大刀镰孢、禾谷镰孢、禾赤镰孢、异孢镰孢、合欢木镰孢、尖孢镰孢、多枝镰孢、粉红镰孢、接骨木镰孢、肤色镰孢、拟分枝孢镰孢、硫色镰孢、圆镰孢、拟丝孢镰孢、镶片镰孢、特异腐质霉、柔毛腐质霉、米黑毛霉、嗜热毁丝霉、粗糙链孢菌、产紫青霉、黄孢平革菌、射脉菌、刺芹侧耳、土生梭孢壳霉、长域毛栓菌、变色栓菌、哈茨木霉、康宁木霉、长枝木霉、里氏木霉、和绿色木霉细胞;甚至更优选地,该丝状真菌宿主细胞选自由以下组成的组:黑曲霉、米曲霉、镶片镰孢和里氏木霉;最优选地,该丝状真菌宿主细胞是米曲霉细胞。
39)根据实施例34-38中任一项所述的方法,其中该信号肽与seqidno:2具有至少80%的序列同一性;优选地,该信号肽包含seqidno:2或由其组成。
40)根据实施例34-39中任一项所述的方法,其中该编码信号肽的多核苷酸与seqidno:1具有至少80%的序列同一性;优选地,该编码信号肽的多核苷酸包含seqidno:1或由其组成。
41)根据实施例34-40中任一项所述的方法,其中该一种或多种目的多肽包含酶;优选地,该酶选自由以下组成的组:水解酶、异构酶、连接酶、裂解酶、氧化还原酶或转移酶;更优选地是氨肽酶、淀粉酶、糖酶、羧肽酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、几丁质酶、角质酶、环糊精糖基转移酶、脱氧核糖核酸酶、内切葡聚糖酶、酯酶、α-半乳糖苷酶、β-半乳糖苷酶、葡糖淀粉酶、α-葡糖苷酶、β-葡糖苷酶、转化酶、漆酶、脂肪酶、甘露糖苷酶、变聚糖酶、核酸酶、氧化酶、果胶分解酶、过氧化物酶、磷酸二酯酶、植酸酶、多酚氧化酶、蛋白水解酶、核糖核酸酶、转谷氨酰胺酶、木聚糖酶、和β-木糖苷酶;最优选地,该一种或多种目的多肽是脂肪酶。
42)根据实施例34-41中任一项所述的方法,其中该一种或多种目的多肽与seqidno:5的成熟多肽具有至少80%的序列同一性;优选地,该一种或多种目的多肽包含seqidno:5的成熟多肽或由其组成。
43)根据实施例34-42中任一项所述的方法,其中该编码一种或多种目的多肽的至少两种多核苷酸与seqidno:4的成熟多肽编码序列独立地具有至少80%的序列同一性;优选地,该编码一种或多种目的多肽的至少两种多核苷酸包含seqidno:4的成熟多肽编码序列或由其组成。
44)根据实施例34-43中任一项所述的方法,其中该接头多肽包含至少10个氨基酸。
45)根据实施例34-44中任一项所述的方法,其中该蛋白水解切割位点是二元氨基酸基序;优选地,该蛋白水解切割位点是lys-arg基序或arg-arg基序。
46)根据实施例34-45中任一项所述的方法,其中该蛋白水解切割位点是kexb切割位点。
47)根据实施例34-46中任一项所述的方法,其中蛋白水解切割发生在细胞内,或者其中蛋白水解切割发生在细胞外且在真菌宿主细胞培养期间和/或之后。
通过以下实例进一步描述本发明,这些实例不应理解为对本发明的范围进行限制。
实例
材料与方法
pcr、克隆、连接核苷酸等的一般方法是本领域技术人员熟知的,并且可以例如在以下文献中发现:‘molecularcloning:alaboratorymanual[分子克隆:实验室手册]’,sambrook等人(1988),coldspringharborlab.[冷泉港实验室],冷泉港,纽约州;ausubel,f.m.等人(编辑);‘currentprotocolsinmolecularbiology[分子生物学实验室指南]’,johnwileyandsons[约翰威利父子公司](1995);harwood,c.r.和cutting,s.m.(编辑);‘dnacloning:apracticalapproach[dna克隆:实用方法],第i和ii卷’,d.n.glover编辑(1985);‘oligonucleotidesynthesis[寡核苷酸合成]’,m.j.gait编辑(1984);‘nucleicacidhybridization[核酸杂交]’,b.d.hames和s.j.higgins编辑(1985);‘apracticalguidetomolecularcloning[分子克隆实用指南]’,b.perbal(1984)。
用作缓冲液和底物的化学品是至少试剂级的商业产品。
曲霉属转化
如us9,487,767中所述进行曲霉属转化。针对具有在含硝酸盐作为氮源和硫胺素的基础平板上生长的能力而选择已修复靶标niad基因并包含pyrg基因的转化体(coved.j.,1966.biochem.biophys.acta[生物化学与生物物理学报]113:51-56)。在30℃下生长5-7天后,稳定的转化体看起来强力地生长并且使菌落形成孢子。转化体通过分生孢子生产进行纯化。
菌株培养
使用本领域熟知的方法在适合于产生脂肪酶蛋白的营养培养基中培养转化细胞。例如,可以通过在合适的培养基中并在允许脂肪酶蛋白被表达和回收的条件下进行摇瓶培养(其中用来自转化体的孢子接种10mlypd培养基(2g/l酵母提取物、2g/l蛋白胨和2%葡萄糖)并在30℃下孵育4天)和在实验室或工业发酵罐中进行小规模或大规模发酵(包括例如,分批或补料分批发酵)来培养细胞。使用本领域中已知的程序,培养发生在包含碳和氮来源及无机盐的合适的营养培养基中。合适的培养基可从商业供应商获得或可以根据公开的组成制备。脂肪酶蛋白被分泌到营养培养基中,并且可从该培养基中直接回收。
in-fusion克隆
使用由克罗泰克实验室有限公司(clontechlaboratories,inc)提供的in-fusion克隆试剂盒和手册进行in-fusion克隆。
通过ddpcr确定拷贝数
根据制造商,使用bioradqx200tm液滴发生器和qx200tm液滴读取器,使用bioradquantasofttm版本1.7.4.0917,使用olic作为单拷贝基因,通过ddpcr确定拷贝数。
sds-page
使用criteriontmxt预制凝胶、10%bis-tris(来自伯乐公司(bio-rad))通过sds-page分析使蛋白质产生可视化,并且如制造商推荐地跑胶并且用考马斯蓝染色。
质粒
pat652描述于实例1中。
pat1509描述于实例1中。
菌株
米曲霉宿主菌株衍生自wo2000/39322中描述的bech2。
实例1.使用在一个mrna中包含两个脂肪酶分子的表达盒来增加米曲霉中脂肪酶的产量(串联构建体)
该实验的目的是构建质粒,用于在米曲霉菌株中作为串联构建体表达最初从红聚颈腔菌(wo2018/150021,seqidno:5的成熟多肽)分离的脂肪酶lipvr,即,在单个多肽中含有两个脂肪酶分子(图1)。该实验的基本原理是,如果去除信号肽并将新合成的多肽易位到内质网(er)是真菌中蛋白质分泌的限速步骤,则将一种信号肽与两种或更多种目的多肽偶联应有助于增加分泌。
1a.构建pat652和pat1509用于将lipvr表达为单线或串联
该实验的目的是构建质粒,用于在米曲霉菌株中表达lipvr(wo2018/150021)。
通过使用in-fusion
质粒pat1509在pna2启动子序列下游含有以下元件:1)缺少终止密码子的天然lipvr基因(其中天然信号肽序列被角质酶pre-pro-序列(cpp)的信号肽序列替代),随后是kexb切割序列(编码氨基酸lys-arg),编码不含前区的角质酶pro序列的新dna序列,以及最后是第二个密码子优化的lipvr基因(针对米曲霉进行优化且缺少内含子)(图3)。通过使用引物lipvr-c(seqidno:10)和lipvr-d(seqidno:11)进行重叠延伸扩增的剪接(higuchi等人,1988;horton等人,2013),将lipvr串联表达盒(seqidno:9)构建到衍生自pcols1175的noti+asisi消化的质粒(wo2013/178674)中。
1b.在多拷贝中将lipvr表达为单线或串联的米曲霉菌株的构建与分析
将质粒pat652(单线)和pat1509(串联)单独用于转化米曲霉宿主菌株,并针对具有在补充有硝酸钠(作为氮源)和硫胺素(下调pyrg标记的表达以增加拷贝数偏好)但缺乏尿苷(针对pyrg互补进行选择)的蔗糖培养基上生长的能力选择转化体。
将选择的转化体在10mlypd中于30℃培养4天,并通过sds-page分析上清液中脂肪酶的产生。针对所引入的表达构建体的拷贝数对所鉴定的产生脂肪酶的转化体进行遗传表征,并对其进行选择用于发酵。菌株at969含有插入基因组的单线lipvr盒的18个拷贝(或1个sp/lipvr单元),而菌株at1684含有串联lipvr盒的9个拷贝,因此18个lipvr“单元”由9个具有单个sp的串联分子制成(或1个sp/2个lipvr单元)。通过sds-page和脂肪分解活性测定分析第7天从发酵中收集的样品的脂肪酶产生(图4)。如所示,与单线菌株at969相比,串联菌株at1684中分泌的lipvr显著增加(脂肪分解活性增加75%,图4)。
这些结果有力地表明,在生产菌株背景下,在相关高拷贝数下,在强表达条件下,使用串联lipvr表达盒可显著增加分泌的和功能活性酶的产量。
实例2.增加的酶产生和正确加工酶单元的条件
该实验的目的是研究使用串联表达盒的多个拷贝和合适的启动子(例如pna2启动子)(wo2012/160093)构建的米曲霉菌株(像at1684)是否不仅可用于增加酶产量(参见实例1),也可确保给定的目的多肽的正确加工,从而使该方法能够在工业酶生产中使用,在该工业酶生产中,重要的是所生产的酶分子具有功能性和同一性,以确保均匀的活性。
lipvr是30kda的蛋白质,其在表观分子量为40kda下运行。at1684的发酵在两种不同的温度(30℃和34℃)和两种不同的ph值(6.5和7.4)下进行。对培养物上清液进行ms分析以研究lipvr衍生的分子的组成。如图5中所示,在培养7天后测试的所有条件下,lipvr的正确加工水平都很高。值得注意的是,无论生长温度如何,在ph6.5下获得了lipvr的完整加工,这提供了证据表明这些生长条件足以加工串联蛋白,而无需例如过表达kexb。kexb完整加工所需的确切条件(温度、ph等)将取决于所选的真菌宿主细胞。技术人员将能够使用本领域已知的方法优化所选的任何给定真菌宿主细胞的条件。
结论
当比较含有相同拷贝数的相同目的多肽的米曲霉菌株(其被配置为一种信号肽-一种目的多肽(单线)或一种信号肽-两种目的多肽(串联))时,在串联配置中观察到多肽产量增加了两倍。此外,使用本发明的核酸构建体导致在不同生长条件下目的多肽的每个拷贝的正确且均匀的加工。这些结果提供了明确的证据,表明使用包含一个sp和多于一个cds的目的酶基因(其通过蛋白酶切割识别位点分开)的遗传构建,可以获得工业功能性酶的显著的产量增加。另外,我们证明了多肽的正确且完整的加工可导致单个功能性lipvr分子的产生。
参考文献:
aviramn,schuldinerm(2017).targetingandtranslocationofproteinstotheendoplasmicreticulumataglance.jcellsci130:4079-4085.
higuchir,krummelb,saikir(1988).ageneralmethodofinvitropreparationandspecificmutagenesisofdnafragments:studyofproteinanddnainteractions.nucleicacidsres.16(15):7351-7367.
hortonrm,caiz,hosn,andpeaselr(2013).genesplicingbyoverlapextension:tailor-madegenesusingthepolymerasechainreaction.biotechniques54(3):129-133.
vossm,
序列表
<110>诺维信公司(novozymesa/s)
<120>串联蛋白表达
<130>14646-wo-pct
<160>11
<170>patentin3.5版
<210>1
<211>105
<212>dna
<213>人工序列
<220>
<223>用作信号肽的cpp的dna序列
<400>1
atgaagttcttcaccaccatcctcagcaccgccagccttgttgctgctctccccgccgct60
gttgactcgaaccataccccggccgctcctgaacttgttgcccgg105
<210>2
<211>35
<212>prt
<213>人工序列
<220>
<223>用作信号肽的cpp的氨基酸序列
<400>2
metlysphephethrthrileleuserthralaserleuvalalaala
151015
leuproalaalavalaspserasnhisthrproalaalaprogluleu
202530
valalaarg
35
<210>3
<211>1059
<212>dna
<213>红聚颈腔菌
<400>3
atgaagtccgcttcgatcttactcagggtagctgccctcctcctccctgctgtatctgca60
ctgccacttgaaagaagaggtatggacgaactatcctagcgatcagtgtgtctattttgc120
ctaacctagcaaagctatatccgcggatctcctggcaaccttcagcctcttcgagcagtt180
cgcagccgcagcatattgtccggataacaacgacagtcccgacaccaagcttacttgctc240
tgtcggaaactgcccgcttgtcgaagctgacacgaccagcacggtcactgaattcgaaaa300
gtacatcttacacgaccccgttcacctacagacaaagtcccagctaacgtccacctctat360
ctctgtccctttagctcgctcgaaaccgacgtcactggctacgtcgcgactgacagcaca420
cgagagctcatcgttgtggcattccgcgggagttcctcgatccggaactggatcgccgac480
atcgactttcccttcaccgacaccgacctctgcgatggctgccaggcagcctcgggcttc540
tggacgtcctggacggaggcacggacaggggtgctggcggcggtggcgagcgctgccgcg600
gccaacccgtcctataccgttgccgtgacgggccacagcctcggcggggccgtggccgcg660
ctggccgctggcgccctccggaacgcgggctacacggtcgcgctatacagcttcggagcg720
cctcgcgtgggtgacgagaccctcagcgagtacatcactgcgcaggcgggtggaaactac780
cgcatcacgcacctcaacgacccagtgccgaagctgcccccgctgctcctggggtatcgc840
cacatcagcccggaatactacatcagcagcgggaacaacgtgaccgtgacggcggatgac900
gtggaggagtacaccggcacgatcaacctgagtgggaacacgggcgatctgacgttcgac960
acggatgcgcacagttggtacttcaacgagatcggggcatgcgatgatggtgaggctttg1020
gagtggaagaagcggggggtagaagttcagtgggtttaa1059
<210>4
<211>930
<212>dna
<213>人工序列
<220>
<223>lipvr基因的dna序列的cdna
<220>
<221>cds
<222>(1)..(927)
<220>
<221>信号肽
<222>(1)..(60)
<220>
<221>成熟肽
<222>(61)..(927)
<400>4
atgaagtccgcttcgatcttactcagggtagctgccctcctcctccct48
metlysseralaserileleuleuargvalalaalaleuleuleupro
-20-15-10-5
gctgtatctgcactgccacttgaaagaagagctatatccgcggatctc96
alavalseralaleuproleugluargargalaileseralaaspleu
-11510
ctggcaaccttcagcctcttcgagcagttcgcagccgcagcatattgt144
leualathrpheserleuphegluglnphealaalaalaalatyrcys
152025
ccggataacaacgacagtcccgacaccaagcttacttgctctgtcgga192
proaspasnasnaspserproaspthrlysleuthrcysservalgly
303540
aactgcccgcttgtcgaagctgacacgaccagcacggtcactgaattc240
asncysproleuvalglualaaspthrthrserthrvalthrgluphe
45505560
gaaaactcgctcgaaaccgacgtcactggctacgtcgcgactgacagc288
gluasnserleugluthraspvalthrglytyrvalalathraspser
657075
acacgagagctcatcgttgtggcattccgcgggagttcctcgatccgg336
thrarggluleuilevalvalalapheargglyserserserilearg
808590
aactggatcgccgacatcgactttcccttcaccgacaccgacctctgc384
asntrpilealaaspileasppheprophethraspthraspleucys
95100105
gatggctgccaggcagcctcgggcttctggacgtcctggacggaggca432
aspglycysglnalaalaserglyphetrpthrsertrpthrgluala
110115120
cggacaggggtgctggcggcggtggcgagcgctgccgcggccaacccg480
argthrglyvalleualaalavalalaseralaalaalaalaasnpro
125130135140
tcctataccgttgccgtgacgggccacagcctcggcggggccgtggcc528
sertyrthrvalalavalthrglyhisserleuglyglyalavalala
145150155
gcgctggccgctggcgccctccggaacgcgggctacacggtcgcgcta576
alaleualaalaglyalaleuargasnalaglytyrthrvalalaleu
160165170
tacagcttcggagcgcctcgcgtgggtgacgagaccctcagcgagtac624
tyrserpheglyalaproargvalglyaspgluthrleuserglutyr
175180185
atcactgcgcaggcgggtggaaactaccgcatcacgcacctcaacgac672
ilethralaglnalaglyglyasntyrargilethrhisleuasnasp
190195200
ccagtgccgaagctgcccccgctgctcctggggtatcgccacatcagc720
provalprolysleuproproleuleuleuglytyrarghisileser
205210215220
ccggaatactacatcagcagcgggaacaacgtgaccgtgacggcggat768
proglutyrtyrileserserglyasnasnvalthrvalthralaasp
225230235
gacgtggaggagtacaccggcacgatcaacctgagtgggaacacgggc816
aspvalgluglutyrthrglythrileasnleuserglyasnthrgly
240245250
gatctgacgttcgacacggatgcgcacagttggtacttcaacgagatc864
aspleuthrpheaspthraspalahissertrptyrpheasngluile
255260265
ggggcatgcgatgatggtgaggctttggagtggaagaagcggggggta912
glyalacysaspaspglyglualaleuglutrplyslysargglyval
270275280
gaagttcagtgggtttaa930
gluvalglntrpval
285
<210>5
<211>309
<212>prt
<213>人工序列
<220>
<223>合成构建体
<400>5
metlysseralaserileleuleuargvalalaalaleuleuleupro
-20-15-10-5
alavalseralaleuproleugluargargalaileseralaaspleu
-11510
leualathrpheserleuphegluglnphealaalaalaalatyrcys
152025
proaspasnasnaspserproaspthrlysleuthrcysservalgly
303540
asncysproleuvalglualaaspthrthrserthrvalthrgluphe
45505560
gluasnserleugluthraspvalthrglytyrvalalathraspser
657075
thrarggluleuilevalvalalapheargglyserserserilearg
808590
asntrpilealaaspileasppheprophethraspthraspleucys
95100105
aspglycysglnalaalaserglyphetrpthrsertrpthrgluala
110115120
argthrglyvalleualaalavalalaseralaalaalaalaasnpro
125130135140
sertyrthrvalalavalthrglyhisserleuglyglyalavalala
145150155
alaleualaalaglyalaleuargasnalaglytyrthrvalalaleu
160165170
tyrserpheglyalaproargvalglyaspgluthrleuserglutyr
175180185
ilethralaglnalaglyglyasntyrargilethrhisleuasnasp
190195200
provalprolysleuproproleuleuleuglytyrarghisileser
205210215220
proglutyrtyrileserserglyasnasnvalthrvalthralaasp
225230235
aspvalgluglutyrthrglythrileasnleuserglyasnthrgly
240245250
aspleuthrpheaspthraspalahissertrptyrpheasngluile
255260265
glyalacysaspaspglyglualaleuglutrplyslysargglyval
270275280
gluvalglntrpval
285
<210>6
<211>289
<212>prt
<213>红聚颈腔菌
<400>6
leuproleugluargargalaileseralaaspleuleualathrphe
151015
serleuphegluglnphealaalaalaalatyrcysproaspasnasn
202530
aspserproaspthrlysleuthrcysservalglyasncysproleu
354045
valglualaaspthrthrserthrvalthrgluphegluasnserleu
505560
gluthraspvalthrglytyrvalalathraspserthrarggluleu
65707580
ilevalvalalapheargglyserserserileargasntrpileala
859095
aspileasppheprophethraspthraspleucysaspglycysgln
100105110
alaalaserglyphetrpthrsertrpthrglualaargthrglyval
115120125
leualaalavalalaseralaalaalaalaasnprosertyrthrval
130135140
alavalthrglyhisserleuglyglyalavalalaalaleualaala
145150155160
glyalaleuargasnalaglytyrthrvalalaleutyrserphegly
165170175
alaproargvalglyaspgluthrleuserglutyrilethralagln
180185190
alaglyglyasntyrargilethrhisleuasnaspprovalprolys
195200205
leuproproleuleuleuglytyrarghisileserproglutyrtyr
210215220
ileserserglyasnasnvalthrvalthralaaspaspvalgluglu
225230235240
tyrthrglythrileasnleuserglyasnthrglyaspleuthrphe
245250255
aspthraspalahissertrptyrpheasngluileglyalacysasp
260265270
aspglyglualaleuglutrplyslysargglyvalgluvalglntrp
275280285
val
<210>7
<211>41
<212>dna
<213>人工序列
<220>
<223>引物lipvr-a
<400>7
tacacaactgggggccaccatgaagtccgcttcgatcttac41
<210>8
<211>38
<212>dna
<213>人工序列
<220>
<223>引物lipvr-b
<400>8
gtgtcagtcaccgcgttaaacccactgaacttctaccc38
<210>9
<211>2028
<212>dna
<213>人工序列
<220>
<223>lipvr-串联的dna序列
<400>9
atgaagttcttcaccaccatcctcagcaccgccagccttgttgctgctctccccgccgct60
gttgactcgaaccataccccggccgctcctgaacttgttgcccggctgccacttgaaaga120
agaggtatggacgaactatcctagcgatcagtgtgtctattttgcctaacctagcaaagc180
tatatccgcggatctcctggcaaccttcagcctcttcgagcagttcgcagccgcagcata240
ttgtccggataacaacgacagtcccgacaccaagcttacttgctctgtcggaaactgccc300
gcttgtcgaagctgacacgaccagcacggtcactgaattcgaaaagtacatcttacacga360
ccccgttcacctacagacaaagtcccagctaacgtccacctctatctctgtccctttagc420
tcgctcgaaaccgacgtcactggctacgtcgcgactgacagcacacgagagctcatcgtt480
gtggcattccgcgggagttcctcgatccggaactggatcgccgacatcgactttcccttc540
accgacaccgacctctgcgatggctgccaggcagcctcgggcttctggacgtcctggacg600
gaggcacggacaggggtgctggcggcggtggcgagcgctgccgcggccaacccgtcctat660
accgttgccgtgacgggccacagcctcggcggggccgtggccgcgctggccgctggcgcc720
ctccggaacgcgggctacacggtcgcgctatacagcttcggagcgcctcgcgtgggtgac780
gagaccctcagcgagtacatcactgcgcaggcgggtggaaactaccgcatcacgcacctc840
aacgacccagtgccgaagctgcccccgctgctcctggggtatcgccacatcagcccggaa900
tactacatcagcagcgggaacaacgtgaccgtgacggcggatgacgtggaggagtacacc960
ggcacgatcaacctgagtgggaacacgggcgatctgacgttcgacacggatgcgcacagt1020
tggtacttcaacgagatcggggcatgcgatgatggtgaggctttggagtggaagaagcgg1080
ggggtagaagttcagtgggttaaacgagccgctgttgactcgaaccataccccggccgct1140
cctgaacttgttgcccggttgcctttggaaaggagggcgatttccgcagacctcctcgcg1200
accttctccttgttcgaacagttcgcagcagcagcctactgtcccgacaacaacgactcc1260
cctgatactaagttgacatgttcggtcggcaactgtcctttggtcgaagccgacacaaca1320
tcgaccgtgacagagttcgagaactccctcgagacagacgtcacgggttatgtggcaacc1380
gattccacgcgtgagctcatcgtcgtcgccttcaggggatcctcgtccatccggaactgg1440
attgccgacatcgatttccccttcaccgataccgatctctgtgatggttgtcaggcagca1500
tcgggcttctggacctcgtggacagaagcccgaacaggtgtgctcgcagccgtggcgtcc1560
gcagcagcagcgaacccctcctacacggtggcagtgacaggccattcgttgggtggtgcg1620
gtcgcagccctcgcagcaggtgccttgaggaacgcaggctacacagtggcgttgtactcc1680
ttcggtgcacctcgggtcggcgacgagacattgtcggagtatatcactgcgcaggcaggt1740
ggcaactacaggattactcacctcaacgacccggtccctaagctccctccgttgctcttg1800
ggctatcgacacatttcgcctgagtattacatctcgtccggcaacaacgtcacggtgaca1860
gccgatgatgtggaggagtacactggaacaatcaacttgtcgggtaacacaggcgatttg1920
accttcgacacagacgcccactcgtggtatttcaacgagattggtgcgtgtgatgatggc1980
gaggcattggaatggaagaaacgcggagtcgaagtgcagtgggtctaa2028
<210>10
<211>41
<212>dna
<213>人工序列
<220>
<223>引物lipvr-c
<400>10
tacacaactgggggccaccatgaagttcttcaccaccatcc41
<210>11
<211>36
<212>dna
<213>人工序列
<220>
<223>引物lipvr-d
<400>11
gtgtcagtcaccgcgttagacccactgcacttcgac36
- 还没有人留言评论。精彩留言会获得点赞!