帕金森生物标志物及其在制备检测产品中的应用的制作方法
本发明涉及生物医学领域,涉及帕金森生物标志物及其在制备检测产品中的应用,具体的涉及标志物为txlngy和gmip。
背景技术:
帕金森病(pd)是一种慢性进展的神经系统退行性疾病,目前患病率仅次于阿尔茨海默病,发病率为8-18/10万,主要发生在中老年人群,60岁以上人群患病率约为1%,80岁以上人群患病率约4%(leea,gilbertr1vi.epidemiologyofparkinsondisease[j].neurololin,2016;34(4):955-9b5.)。其进行性恶化的症状主要与中脑腹侧黑质致密部及周围神经系统中多巴胺(da)含量逐步减少有关,在出现典型临床症状以前,脑干、溴球及大脑皮层的非多巴胺能神经元退化就已经产生,而且周围神经系统(如肠道和心脏)也发生类似的da改变(sundbergm,isacsono.advancesinstem-cell-generatedtransplantationtherapyforparkinson'sdisease[j].expertopinbiolther,2014,14(4):437-53.)。躯体运动由黑质纹状体系统的da能神经元进行调控,因此运动相关障碍是帕金森病的主要临床表现,包括运动迟缓、肌肉强直、静止性震颤和姿势不稳。然而,随着疾病进展,其他非运动性症状也开始出现,包括焦虑、抑郁、被动、精神病样状态、痴呆以及睡眠障碍(chaudhurikr,healydg,schapira.ah.non-motorsymptomsofparkinson'sdisease:diagnosisandmanagement[j].lancetneurol,2006,5(3):235-45.)。目前帕金森病多表现为一组临床综合征,存在全身受累和多器官功能障碍。人们研究帕金森病的病因、发病机制及治疗已有近200年历史,目前仍不完全清楚,但一些重要的发病环节已受到研究者关注。
帕金森病的发病可能是遗传、环境、氧化应激、免疫等多种因素共同作用的结果,最终导致黑质区多巴胺能神经元变性坏死。对发病机制的深入研究,更有利于指导临床的对症及对因治疗。
目前帕金森病治疗现状并不理想,多采用对症治疗,主要针对缓解pd运动症状,包括左旋多巴(l-dopa)替代疗法、da受体激动剂、mao-b抑制剂及深部脑刺激术等治疗方法(foltynet,harizmi.surgicalmanagementofparkinson'sdisease[j].expertrevneurother,2010,10(6):903-14.)。在pd的所有阶段,使用药物治疗其运动症状均有强力的证据支持,但药物疗效会随病程进展逐渐减弱,表现为症状波动,如出现开关现象、剂末恶化及异动症(lid),还会出现多种非多巴胺相关的非运动性症状,如抑郁、淡漠、幻觉、多汗等,使用左旋多巴替代治疗无效,可能与乙酰胆碱、5羟色胺等神经递质紊乱失调有关。
阐明pd的发病机制,对于pd的预防、相关药物的设计及合理有效的临床治疗具有重要意义,现已成为生物医学领域亟待解决的重要问题。随着生物学技术的发展,遗传因子在疾病中的研究受到广泛重视,基于基因水平的帕金森发病机理及生物标志物的研究逐步引起学者们的关注。寻找与帕金森相关的基因应用于帕金森的临床诊断,揭示帕金森的发病机制,提高患者的生存质量具有重要的意义。
技术实现要素:
为了弥补现有技术的不足,本发明的目的在于提供与帕金森相关的标志物,采用标志物来诊断疾病具有及时性、特异性和灵敏性,患者在帕金森早期就能知晓风险,针对风险高低,采取相应的预防和治疗措施,从而提高生活质量。
为了实现上述目的,本发明采用如下技术方案:
本发明提供了检测基因的水平的试剂在制备诊断帕金森产品中的应用,所述基因包括txlngy或gmip。
进一步,所述产品包括通过测序技术、核酸杂交技术、核酸扩增技术、蛋白免疫技术检测txlngy或gmip水平的试剂。
进一步,所述试剂包括特异性针对txlngy或gmip的探针、引物或抗体。
进一步,所述特异性针对txlngy的引物序列如seqidno.1~2所示,特异性针对gmip基因的引物序列对如seqidno.3~4所示。
本发明提供了一种检测产品,所述产品包括检测样本中txlngy或gmip基因的试剂。在本发明中,“样本”是包含细胞或细胞物质的可从中获取核酸、多肽、或其它分析物的物质。优选的,所述样本为血液。
进一步,所述产品包括芯片、试剂盒或核酸膜条。
进一步,所述试剂盒包括特异性扩增txlngy或gmip的引物。
进一步,特异性扩增txlngy的引物序列如seqidno.1~2所示,特异性扩增gmip基因的引物序列对如seqidno.3~4所示。
本发明提供了上面所述的检测产品在制备诊断帕金森的疾病工具中的应用。
本发明提供了txlngy或gmip在构建预测帕金森的计算模型中的应用。
本发明提供了txlngy或gmip在制备治疗帕金森的药物组合物中的应用。
进一步,所述药物组合物包括txlngy或gmip的抑制剂,所述抑制剂可以降低txlngy或gmip的表达水平。
进一步,所述抑制剂为sirna。
进一步,针对txlngy和gmip的sirna的序列分别如seqidno.7~8以及seqidno.9~10所示。
本发明提供了一种药物组合物,其特征在于,所述药物组合物包括txlngy或gmip的抑制剂,所述抑制剂可以降低txlngy或gmip的表达水平。
进一步,所述抑制剂为sirna。
进一步,针对txlngy和gmip的sirna的序列分别如seqidno.7~8以及seqidno.9~10所示。
附图说明
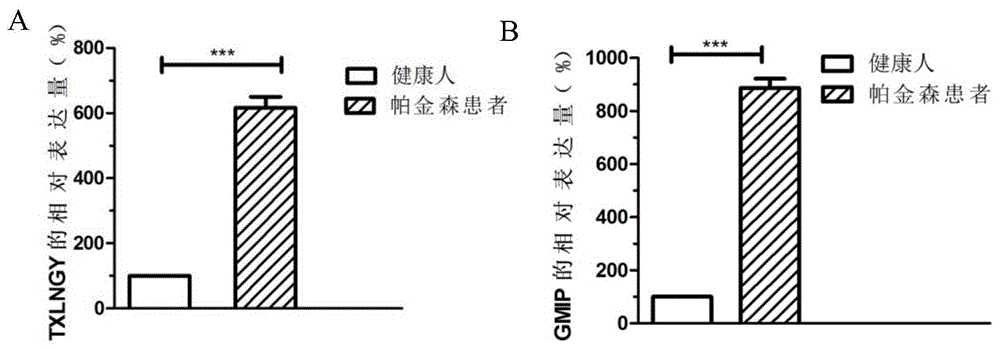
图1是利用qpcr检测txlngy或gmip基因在帕金森患者中的表达情况图,其中图a是txlngy的表达情况图,图b是gmip的表达情况图。
图2是以txlngy和gmip作为检测变量的roc曲线图,其中,图a是txlngy,图b是gmip。
图3是txlngy和gmip的抑制情况图,其中,图a是txlngy,图b是gmip。
图4是帕金森病细胞增殖活性图。
具体的实施方式
本发明利用高通量测序的方法结合生物信息学分析,通过检测帕金森患者和正常人中的差异表达的基因,寻找可用于表征帕金森的标志物。本发明通过检测分析,首次发现了txlngy或gmip在帕金森患者中呈现差异性表达,并通过进一步实验证明了txlngy或gmip在帕金森患者中表达上调,同时,通过细胞实验证明了改变txlngy或gmip的表达水平,可以改变有关细胞的增殖能力,提示txlngy或gmip可作为检测指标应用于帕金森的临床诊断和治疗。
txlngy或gmip
在本发明中,txlngy(geneid:246126)包括人txlngy基因及其表达产物。目前公开的txlngy转录本有2个,序列分别如nr_045128.1、nr_045129.1所示,一种代表性的txlngy基因序列如nr_045128.1所示。
gmip(geneid:51291)包括人gmip基因及其表达产物。目前公开的gmip转录本有3个,序列分别如nm_001288998.2、nm_001288999.2、nm_016573.4所示。一种代表性的gmip的核苷酸序列如目前国际公共核酸数据库genebank中nm_001288998.2所示,其所编码的蛋白序列如np_001275927.1所示。
本发明的实用性并不局限于对本发明的靶标基因的任何特定变体的基因表达进行定量。本领域技术人员知道,进行生物信息学分析时,通常会将测序序列和已知的基因进行比对,只要有关序列可以比对到相关基因上,就可以看做是该基因的表达,因此,在提及差异表达的基因时,该基因的不同的转录本、突变型或其片段也包含在本发明中。
本领域技术人员应当理解,测定基因表达的手段不是本发明的重要方面。本发明可以利用本领域内已知的任何方法测定基因的表达水平。
本文所用术语“差异表达”表示与第二种样品中相同的一种或多种本发明生物标志物的表达水平比较,经测定mrna的量或水平,在一个样品中本发明的一种或多种生物标志物的rna和/或所述生物标志物mrna的一种或多种剪接变体表达水平的差异。“差异表达的”还可以包括与第二种样品或样品群中蛋白质表达量或水平比较,对样品或样品群中本发明生物标志物编码的蛋白质的测定。差异表达可以如本文所述和本领域技术人员理解的方法确定。术语“差异表达”或“表达水平的变化”表示与第二种样品中给定生物标志物的可测定表达水平比较,经测定rna的量和/或蛋白质的量,样品中给定生物标志物可测定表达水平的增加或降低。术语“差异表达”或“表达水平的变化”还可以表示与第二个样品群中生物标志物的可测定表达水平比较,样品群中给定生物标志物可测定表达水平的增加或降低。本文所用“差异表达”可以用给定生物标志物的表达水平相对于对照中给定生物标志物的平均表达水平的比率进行测定,其中比率不等于1.0。还可以用p值测定差异表达。当使用p值时,当p值小于0.1时生物标志物被鉴定为在第一和第二群体之间差异表达。更优选p值小于0.05。甚至更优选p值小于0.01。还更优选p值小于0.005。最优选p值小于0.001。当基于比率确定差异表达时,如果第一种和第二种样品中表达水平的比率大于或小于1.0,则rna或蛋白质是差异表达的。举例来说,大于1.2、1.5、1.7、2、3、4、10、20的比率,或小于1的比率,例如0.8、0.6、0.4、0.2、0.1、0.05。在本发明的另一个实施方案中,如果第一群体的平均表达水平与第二群体的平均表达水平的比率大于或小于1.0,则核酸转录本是差异表达的。举例来说,大于1.2、1.5、1.7、2、3、4、10、20的比率,或小于1的比率,例如0.8、0.6、0.4、0.2、0.1、0.05。在本发明的另一个实施方案中,如果第一个样品中表达水平与第二个群体中平均表达水平的比率大于或小于1.0,例如包括比率大于1.2、1.5、1.7、2、3、4、10、20,或比率小于1,例如0.8、0.6、0.4、0.2、0.1、0.05,则核酸转录本是差异表达的。
“表达差异增加”或“上调”表示基因相对于对照而言,基因表达(以rna表达或蛋白质表达测定)显示增加至少10%或更多,例如20%、30%、40%或50%、60%、70%、80%、90%或更多或1.1倍、1.2倍、1.4倍、1.6倍、1.8倍或更多。
“表达差异降低”或“下调”表示基因相对于对照而言,基因表达(以rna表达或蛋白质表达测定)显示降低至少10%或更多,例如20%、30%、40%或50%、60%、70%、80%、90%或少于1.0倍、0.8倍、0.6倍、0.4倍、0.2倍、0.1倍或更少的基因。例如,上调基因包括与从正常个体分离的mrna或蛋白质的表达相比,从以患有帕金森为特征的个体分离的血中mrna或蛋白质表达水平增加的基因。例如,下调基因包括与从正常个体分离的血相比,从以患有帕金森为特征的个体分离的血中mrna或蛋白质表达水平降低的基因。
本发明的txlngy或gmip使用本领域普通技术人员已知的多种核酸以及蛋白技术进行检测,这些技术包括但不限于:核酸测序、核酸杂交、核酸扩增技术、蛋白免疫技术。
核酸测序技术的示例性非限制性实例包括但不限于链终止子(sanger)测序和染料终止子测序。本领域的普通技术人员将认识到,由于rna在细胞中不太稳定并且在实验中更易受到核酸酶攻击,因此在测序前通常将rna逆转录成dna。
核酸测序技术的另一示例性非限制性实例包括下一代测序(深度测序/高通量测序),高通量测序技术是一种基于单分子簇的边合成边测序技术,基于专有的可逆终止化学反应原理。测序时将基因组的dna的随机片段附着到光学透明的玻璃表面,这些dna片段经过延伸和桥式扩增后,在玻璃表面形成数以亿计的簇,每个簇是具有数千份相同模板的单分子簇,然后利用带荧光基团的四种特殊脱氧核糖核苷酸,通过可逆性的边合成边测序技术对待测的模板dna进行测序。
核酸杂交技术的示例性非限制性实例包括但不限于原位杂交(ish)、微阵列和southern或northern印迹。原位杂交(ish)是一种使用标记的互补dna或rna链作为探针以定位组织一部分或切片(原位)或者如果组织足够小则为整个组织(全组织包埋ish)中的特异性dna或rna序列的杂交。dnaish可用于确定染色体的结构。rnaish用于测量和定位组织切片或全组织包埋内的mrna和其他转录本(例如,ncrna)。通常对样本细胞和组织进行处理以原位固定靶转录本,并增加探针的进入。探针在高温下与靶序列杂交,然后将多余的探针洗掉。分别使用放射自显影、荧光显微术或免疫组织化学,对组织中用放射、荧光或抗原标记的碱基标记的探针进行定位和定量。ish也可使用两种或更多种通过放射性或其他非放射性标记物标记的探针,以同时检测两种或更多种转录本。
核酸扩增技术的示例性非限制性实施例包括但不限于:聚合酶链式反应(pcr)、逆转录聚合酶链式反应(rt-pcr)、转录介导的扩增(tma)、连接酶链式反应(lcr)、链置换扩增(sda)和基于核酸序列的扩增(nasba)。本领域的普通技术人员将认识到,某些扩增技术(例如,pcr)需要在扩增前将rna逆转录成dna(例如,rt-pcr),而其他扩增技术则直接扩增rna(例如,tma和nasba)。
蛋白免疫技术包括夹心免疫测定,例如夹心elisa,其中使用识别生物标志物上不同表位的两种抗体进行该生物标志物的检测;放射免疫测定(ria)、直接、间接或对比酶联免疫吸附测定(elisa)、酶免疫测定(eia)、荧光免疫测定(fia)、蛋白质印迹法、免疫沉淀法和基于任何颗粒的免疫测定(如使用金颗粒、银颗粒或乳胶颗粒、磁性颗粒或量子点)。可例如在微量滴定板或条的形式中实施免疫法。
芯片、试剂盒、核酸膜条
在本发明中芯片包括基因芯片、蛋白芯片;所述基因芯片包括固相载体;以及有序固定在所述固相载体上的寡核苷酸探针,所述的寡核苷酸探针特异性地对应于本发明所述标志物的部分或全部序列。所述蛋白芯片包括固相载体,以及固定在固相载体上的本发明所述标志物的抗体或配体。所述固相载体包括无机载体和有机载体,所述无机载体包括但不限于有硅载体、玻璃载体、陶瓷载体等;所述有机载体包括聚丙烯薄膜、尼龙膜等。
“抗体”在本文中以最广义使用,而且明确覆盖单克隆抗体、多克隆抗体、自至少两种完整抗体形成的多特异性抗体(例如双特异性抗体)、及抗体片段,只要它们展现期望的生物学活性。
术语“单克隆抗体”在用于本文时指从一群基本上同质的抗体获得的抗体,即构成群体的各个抗体相同和/或结合相同表位,除了生产单克隆抗体的过程中可能产生的可能变体外,此类变体一般以极小量存在。此类单克隆抗体典型的包括包含结合靶物的多肽序列的抗体,其中靶物结合多肽序列是通过包括从众多多肽序列中选择单一靶物结合多肽序列在内的过程得到的。例如,选择过程可以是从众多克隆诸如杂交瘤克隆、噬菌体克隆或重组dna克隆的集合中选择独特克隆。应当理解,选定的靶物结合序列可进一步改变,例如为了提高对靶物的亲和力、将靶物结合序列人源化、提高其在细胞培养物中的产量、降低其在体内的免疫原性、创建多特异性抗体等,而且包含改变后的靶物结合序列的抗体也是本发明的单克隆抗体。与典型的包含针对不同决定簇(表位)的不同抗体的多克隆抗体制备物不同,单克隆抗体制备物的每种单克隆抗体针对抗原上的单一决定簇。在它们的特异性以外,单克隆抗体制备物的优势在于它们一般未受到其它免疫球蛋白的污染。修饰语“单克隆”指示抗体从基本上同质的抗体群获得的特征,不应解释为要求通过任何特定方法来生成抗体。
单克隆抗体在本文中明确包括“嵌合”抗体(免疫球蛋白),其中重链和/或轻链的一部分与衍生自特定物种或属于特定抗体类别或亚类的抗体中的相应序列相同或同源,而链的剩余部分与衍生自另一物种或属于另一抗体类别或亚类的抗体中的相应序列相同或同源,以及此类抗体的片段,只要它们展现出期望的生物学活性。
“抗体片段”包含全长抗体的一部分,一般是其抗原结合区或可变区。抗体片段的例子包括fab、fab′、f(ab′)2和fv片段;双抗体;线性抗体;单链抗体分子;及由抗体片段形成的多特异性抗体。
本发明的抗体的“功能性片段”指那些保留与衍生它们的完整全链分子以基本上相同的亲和力结合多肽且在至少一种测定法中有活性(诸如在小鼠模型中,或在体外抑制抗体片段结合的抗原的生物学活性)的片段。
本发明提供了一种试剂盒,所述试剂盒可用于检测txlngy或gmip基因或蛋白的表达水平,包含用于txlngy或gmip检测和/或定量的引物、寡核苷酸探针、配体、和/或芯片。选自下组的一种或多种物质:容器、使用说明书、阳性对照物、阴性对照物、缓冲剂、助剂或溶剂。
本发明的试剂盒中还可附有试剂盒的使用说明书,其中记载了如何采用试剂盒进行检测,和如何利用检测结果对疾病发展进行判断、对治疗方案进行选择。
试剂盒的组分可以以水介质的形式或以冻干的形式来包装。试剂盒中适当的容器通常至少包括一种小瓶、试管、长颈瓶、宝特瓶、针筒或其它容器,其中可放置一种组分,并且优选地,可进行适当地等分。在试剂盒中存在多于一种的组分时,试剂盒中通常也将包含第二、第三或其它附加的容器,其中分离地放置附加的组分。然而,不同组合的组分可被包含在一个小瓶中。本发明的试剂盒通常也将包括一种用于容纳反应物的容器,密封以用于商业销售。这种容器可包括注模或吹模的塑料容器,其中可保留所需的小瓶。
在本发明中,核酸膜条包括基底和固定于所述基底上的特异性识别txlngy或gmip的探针;所述基底可以是任何适于固定探针的基底,例如尼龙膜、硝酸纤维素膜、聚丙烯膜、玻璃片、硅胶晶片、微缩磁珠等。
本发明中诊断帕金森的产品可用于检测包括txlngy或gmip基因在内的多个基因(例如,与帕金森相关的多个基因)的表达水平,将帕金森的多个标志物同时进行检测,可大大提高帕金森诊断的准确率。
本发明提供了txlngy或gmip在构建预测帕金森的计算模型中的应用,可以以不同方式实施和实现将标志物水平与某种可能性或风险关联起来的步骤。优选地,在数学上组合标志物和一种或多种其它标志物的测定浓度,并将组合值与根本的诊断问题关联起来。可以通过任何适宜的现有技术数学方法将标志物值的测定组合。
优选地,在标志物组合中应用的数学算法是一种对数函数。优选地,应用此类数学算法或此类对数函数的结果是单一值。根据根本的诊断问题,能容易地将此类值与例如个体关于帕金森的风险或与有助于评估帕金森患者的其它有意诊断用途关联起来。以一种优选的方式,此类对数函数是如下获得的:a)将个体分类入组,例如正常人、有帕金森风险的个体、具有帕金森的患者等等,b)通过单变量分析来鉴定在这些组之间差异显著的标志物,c)对数回归分析以评估标志物的可用于评估这些不同组的独立差别值,并d)构建对数函数来组合独立差别值。在这种类型的分析中,标志物不再是独立的,而是代表一个标志物组合。
用于将标志物组合与疾病关联起来的对数函数优选采用通过应用统计方法开发和获得的算法。例如,适宜的统计方法是判别分析(da)(即线性、二次、规则da)、kernel方法(即svm)、非参数方法(即k-最近邻居分类器)、pls(部分最小二乘)、基于树的方法(即逻辑回归、cart、随机森林方法、助推/装袋方法)、广义线性模型(即对数回归)、基于主分量的方法(即simca)、广义叠加模型、基于模糊逻辑的方法、基于神经网络和遗传算法的方法。熟练技术人员在选择适宜的统计方法来评估本发明的标志物组合并由此获得适宜的数学算法方面不会有问题。在一个实施方案中,用于获得评估帕金森中使用的数学算法的统计方法选自da(即线性、二次、规则判别分析)、kernel方法(即svm)、非参数方法(即k-最近邻居分类器)、pls(部分最小二乘)、基于树的方法(即逻辑回归、cart、随机森林方法、助推方法)、或广义线性模型(即对数回归)。
下面结合附图和实施例对本发明作进一步详细的说明。以下实施例仅用于说明本发明而不用于限制本发明的范围。实施例中未注明具体条件的实验方法,通常按照常规条件,例如sambrook等人,分子克隆:实验室手册(newyork:coldspringharborlaboratorypress,1989)中所述的条件,或按照制造厂商所建议的条件。
实施例1筛选与帕金森相关的基因标志物
1、样品收集
分别收集5例正常人血液和帕金森患者血液样本,上述所有标本的取得获得伦理委员会的批准。
帕金森患者:
帕金森患者的入组标准:根据英国脑库帕金森病诊断标准,确诊为帕金森病的患者。
排除标准:有自身免疫性疾病史,过敏反应,免疫缺乏症,糖尿病,心脏病,中风,动脉硬化,精神病,恶性肿瘤,严重的认知功能障碍,或中枢神经系统(cns)感染的患者。
正常对照组:
入组标准:年龄、性别和教育程度等与帕金森组病人相匹配的健康人。
排除标准:有神经系统疾病;有精神病史和不良药物史的人。
2、rna样品的制备及质量分析
(1)取血液,加入3倍体积红细胞裂解液,混匀后室温放置10min,10,000rpm离心1min,吸弃上清,收集白细胞沉淀;
(2)加入trizol,室温放置5min,4℃12,000rpm离心10min,取上清;
(3)每1mltrizol加入200μl氯仿,剧烈振荡混匀后室温放置3-5min,4℃12,000rpm离心10-15min,把水相小心的转移到新管中;
(4)在上清中加入等体积冰冷的异丙醇,室温放置10-20min,4℃12,000rpm离心10min,弃上清;
(5)rna沉淀中加入1ml75%乙醇(用rnase-free水配制),温和振荡离心管,悬浮沉淀;
(6)4℃8,000rpm离心1-2min,弃上清;短暂快速离心,用移液器小心吸弃上清,室温放置2min晾干沉淀;
(7)沉淀中加入50μlrnase-free水,轻弹管壁,以充分溶解rna,-70℃保存。
(8)利用琼脂糖凝胶电泳检测rna的完整性,使用安捷伦2100生物分析仪进行rna纯度分析。
3、构建cdna文库
(1)使用illumina的ribo-zero试剂盒除去总rna中的核糖体rna;
(2)利用illumina的truseqrnasampleprepkit进行cdna文库的构建。
4、上机测序
使用hiseq4000测序平台对cdna文库进行测序,具体操作按说明书进行。
5、高通量转录组测序数据分析
对测序结果进行生物信息学分析,采用limma包和metama包分析,meta分析中p值合并所用方法为inversenormalmethod,当p<0.05时,认为mrna显著差异表达。
6、结果
测序结果显示,与健康人相比,txlngy或gmip基因在帕金森患者血液中的表达量显著增加。
实施例2qpcr测序验证txlngy或gmip基因的差异表达
1、根据高通量测序的检测结果选择txlngy或gmip基因进行大样本qpcr验证。按照实施例1中的样本收集方式选择帕金森患者血液和正常人血液各25例。
2、rna提取步骤同实施例1。
3、逆转录:使用takara公司的反转录试剂盒(takaracode:drr047a)进行操作,反应体系和反应条件如表1所示。
表1逆转录反应体系和反应条件
4、qpcr扩增
(1)引物设计
根据genebank中txlngy或gmip基因和管家基因gapdh基因的编码序列设计qpcr扩增引物,其中,对有不同转录本的基因采用对其共同区域进行引物设计,由生工合成。
表2txlngy和gmip的引物序列
(2)qpcr扩增检验
用
表3qpcr扩增反应体系和反应条件
5、统计学分析
实验采用3次重复实验,所有数据采用均数±标准差(mean±sd)表示。两组间比较采用双侧student'st检验,三组及以上采用单因素方差分析。所有结果均采用graphpadsoftware软件进行绘图,p<0.05定义为差异有统计学意义。对变量txlngy和gmip使用spss进行roc分析,判断基因的诊断效能、灵敏度和特异性。
6、结果
结果如图1所示,与正常人血液相比,txlngy或gmip基因在帕金森患者血液中的表达上调,其中txlngy上调约6.2倍,gmip上调约8.9倍,差异具有统计学意义(p<0.05),提示txlngy和gmip基因可作为基因标志物应用于帕金森的诊断。
roc曲线以及特征参数分别如图2和表4所示,本申请的基因txlngy、gmip的auc值分别为0.934(图2a)、0.925(图2b),说明txlngy、gmip应用于帕金森的诊断具有较高的特异性和敏感性,能够有效的区分帕金森患者和正常人。
表4曲线下面积
a.在非参数假设下
b.零假设:实面积=0.5
实施例3txlngy、gmip的抑制
1、细胞培养
pc12细胞培养基为dmem培养基,含有5%新生牛血清、10%胎牛血清、100iu/ml青霉素及100iu/ml链霉素,置于37℃,5%co2培养箱中培养。待细胞长满后去上清,加入0.25%的胰酶消化,1-2min,轻轻晃动,待细胞脱壁,去掉胰酶,加入含有血清的培养液中和终止消化;将细胞吹打均匀,取1/4量细胞进行传代,置37℃下继续培养。
2、sirna的合成
根据txlngy、gmip的序列设计sirna,由上海吉码制药技术有限公司合成,对照为通用的sirna-nc,针对txlngy、gmip的sirna的序列如表5所示。
表5sirna序列
3、转染
正常培养的pc12细胞至汇合度90%时,用0.25%胰酶消化,1400rpm×5min离心,用含10%胎牛血清的dmem培养液重悬,每孔5×105个/ml细胞铺于24孔板中,置37℃,含5%co2的培养箱中培养,18-24h后待细胞长至60%-80%开始转染。将细胞分成三组,空白对照组(pc12)、阴性对照组(sirna-nc)、实验组:转染sirna(sirna-txlngy、sirna-gmip),转染试剂为invitrogen的lipofectamine2000,具体操作按说明书进行。
4、qpcr检测sirna对txlngy、gmip表达的影响
1)细胞总rna的提取
采用trizol法提取细胞总rna
2)qpcr检测步骤同实施例2
5、结果
结果如图3显示,相比对照组,实验组中txlngy(图3a)、gmip(图3b)的表达水平显著降低,差异具有统计学意义(p<0.05),而阴性对照组与空白对照组之间则无显著性差异(p>0.05)。
实施例4txlngy、gmip对细胞的影响
采用cck-8实验检测txlngy、gmip基因对pc12帕金森病细胞模型细胞增殖能力的影响,其中帕金森细胞模型使用mpp+诱导构建。
取对数生长期pc12细胞,制备成单细胞悬液,根据不同的分组将细胞以每孔2.5×103个的浓度接种至96孔板;于细胞培养箱中培养,24h后进行刺激:mpp+组以浓度500μmol/l的mpp+进行诱导。
细胞培养24h后,每孔加入10μlcck8试剂,混匀后继续培养2h;用酶联仪测定各孔在450nm处的吸光度值(od值);检测结束后放回培养箱继续培养。
其中,实验分组情况如下:
空白对照组:不处理;
模型组:加mpp+;
阴性对照组:转染sirna-nc,加mpp+;
治疗组:转染sirna-gmip,加mpp+;
转染sirna-gmip,加mpp+。
其中,sirna转染时间为48h。
实验结果如图4所示,与模型组相比,治疗组抑制基因表达后可引起细胞死亡率降低,差异具有统计学意义(p<0.05),而阴性对照组与空白对照组之间则无显著性差异。上述结果表明,抑制xlngy、gmip的表达,可逆转mpp+诱导的细胞损伤,提示xlngy、gmip可作为分子靶标应用于帕金森的治疗。
上述实施例的说明只是用于理解本发明的方法及其核心思想。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也将落入本发明权利要求的保护范围内。
序列表
<110>河北医科大学第二医院
<120>帕金森生物标志物及其在制备检测产品中的应用
<150>201910239882x
<151>2019-03-27
<160>10
<170>siposequencelisting1.0
<210>1
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>1
ttgtagatgccagacttc18
<210>2
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>2
ttcagttgtgcttcttct18
<210>3
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>3
cgctatgccaaggaactg18
<210>4
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>4
cgatcttcatggtgctctt19
<210>5
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>5
ctctggtaaagtggatattgt21
<210>6
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>6
ggtggaatcatattggaaca20
<210>7
<211>21
<212>rna
<213>人工序列(artificialsequence)
<400>7
uuugaagagccuuguacagcu21
<210>8
<211>21
<212>rna
<213>人工序列(artificialsequence)
<400>8
cuguacaaggcucuucaaaua21
<210>9
<211>21
<212>rna
<213>人工序列(artificialsequence)
<400>9
uguuuuccauaaaucgugcag21
<210>10
<211>21
<212>rna
<213>人工序列(artificialsequence)
<400>10
gcacgauuuauggaaaacaag21
- 还没有人留言评论。精彩留言会获得点赞!