一种高产雄烯二酮的重组分枝杆菌及构建方法及应用与流程
本发明属于生物技术和生物化工领域,具体涉及一种高产雄烯二酮的重组分枝杆菌及构建方法及应用。
背景技术:
甾体激素类药物是指分子结构中含有甾体结构的激素类药物,是临床上一类重要的药物,主要包括肾上腺皮质激素和性激素两大类。甾体激素类药物因具有众多药理作用,如抗感染、抗过敏、抗病毒和抗休克等,而被广泛用于治疗各种疾病,如风湿病、心血管疾病、癌症、皮肤病以及内分泌失调等。甾体激素类药物经过几十年的研究开发,目前已经形成种类繁多、临床应用广泛和需求旺盛的一大类甾体药物,成为仅次于抗生素的第二大药物。
雄甾-4-烯-3,17-二酮(英文名称:androst-4-ene-3,17-dione,简称:雄烯二酮或4-ad),其外观形状为近白色晶体粉末,无异味,无毒性,不溶于水。雄烯二酮最初是从精巢或尿中提取出的具有雄性激素作用的一种甾类化合物,后经研究发现其对机体起着重要的调节作用。雄烯二酮现已成为制备甾体激素类药物不可替代的中间体,几乎所有的甾体激素类药物都可以4-ad为原料进行生产,可用于生产性激素、孕激素以及蛋白同化激素,又可用于制备氢化可的松、氧化泼尼松及黄体酮等100余种药物。
雄烯二酮的全球市场约为800亿美元并且以每年20%的速度增长。我国制药企业每年对雄烯二酮的需求量约为6000吨,然而我国雄烯二酮的年生产能力仅为1000吨左右,与市场需求有很大差距。
目前,我国雄烯二酮的生产主要存在两种途径,一是薯蓣皂苷元途径,二是微生物转化途径,市场上两种途径生产的雄烯二酮大致各占一半。然而,其中薯蓣皂苷元途径(从薯蓣(黄姜)中分离皂苷生产雄烯二酮)生产过程复杂,成本较高,污染严重,许多地方已禁止生产。微生物转化途径(利用微生物转化植物甾醇或胆固醇生产雄烯二酮)具有生产成本低、生产步骤简化等优势,越来越受到广大厂商的关注和重视。随着生物技术的进一步发展,全球市场上微生物转化法生产雄烯二酮的比例将会快速增长,并且市场前景非常诱人。
由于目前有些微生物制甾药工艺的相对落后以及高效菌株和生产线的引进需要巨额开支,使得大多数企业长期依赖既有的传统生产模式。近年来,随着某些企业开始大力引进优秀甾药转化微生物及发酵工艺,激素类药物的生产模式已大为改观。从1998年以来便开始采用微生物转化植物甾醇生产雄烯二酮的工艺,而攻克微生物发酵生产激素的技术一直是本领域科技人员多年的努力方向,甾药微生物转化技术的改进和发展还有很长的路要走。
目前,微生物转化植物甾醇生产雄烯二酮存在的主要问题有:菌株转化能力较差,甾药在转化工程中易被降解,并有副产物产生等,严重影响生产效益。
技术实现要素:
本发明的目的在于提供一种可减少副产物产生,提高植物甾醇制备雄烯二酮的转化效率的一种高产雄烯二酮的重组分枝杆菌的构建方法。
本发明的第二个目的是提供一种高产雄烯二酮的重组分枝杆菌。
本发明的第三个目的是提供一种高产雄烯二酮的重组分枝杆菌发酵生产雄烯二酮的应用。
本发明的技术方案概述如下:
一种高产雄烯二酮的重组分枝杆菌,用下述方法构建:将胆固醇氧化酶基因chom2、携带有rbs片段的甾酮c27单加氧酶基因smo2和携带有rbs片段的17β-羟固醇脱氢酶基因hsd4a导入新金分枝杆菌(mycobacteriumsp.)cicc21097中,得到高产雄烯二酮的重组分枝杆菌mncsh;
所述胆固醇氧化酶基因chom2的核苷酸序列如seqidno.1所示;
所述rbs片段的核苷酸序列如seqidno.2所示;
所述甾酮c27单加氧酶基因smo2的核苷酸序列如seqidno.3所示;
所述17β-羟固醇脱氢酶基因hsd4a的核苷酸序列如seqidno.4所示。
一种高产雄烯二酮的重组分枝杆菌的构建方法,包括如下步骤:将胆固醇氧化酶基因chom2和质粒pmv261通过酶切,连接,构建单基因过表达重组质粒pmv261-chom2;将携带有rbs片段的甾酮c27单加氧酶基因smo2和重组质粒pmv261-chom2通过酶切,连接,构建双基因过表达重组质粒pmv261-chom2-smo2;将携带有rbs片段的17β-羟固醇脱氢酶基因hsd4a和双基因过表达重组质粒pmv261-chom2-smo2通过酶切,连接,构建三基因过表达重组质粒pmv261-chom2-smo2-hsd4a;
将三基因过表达重组质粒pmv261-chom2-smo2-hsd4a导入新金分枝杆菌感受态细胞中,获得的阳性转化子即为一种高产雄烯二酮的重组分枝杆菌,命名为mncsh;
所述的三基因过表达重组质粒pmv261-chom2-smo2-hsd4a中三个基因chom2、携带有rbs片段的甾酮c27单加氧酶基因smo2和携带有rbs片段的17β-羟固醇脱氢酶基因hsd4a的构建先后顺序互换。
上述一种高产雄烯二酮的重组分枝杆菌发酵生产雄烯二酮的应用。
实验证明一种高产雄烯二酮的重组分枝杆菌转化植物甾醇的主要产物为4-雄烯二酮,收率90%以上,选择性达90%以上,与原始菌株相比,重组菌通过过表达胆固醇氧化酶、甾酮c27单加氧酶以及17β-羟固醇脱氢酶,加大产物代谢流量,从而降低副产物生成,提高雄烯二酮产量。与原始菌株相比,重组菌具有更好的催化转化性能,可以提高生产效率。工艺方法简便,效率高。
附图说明
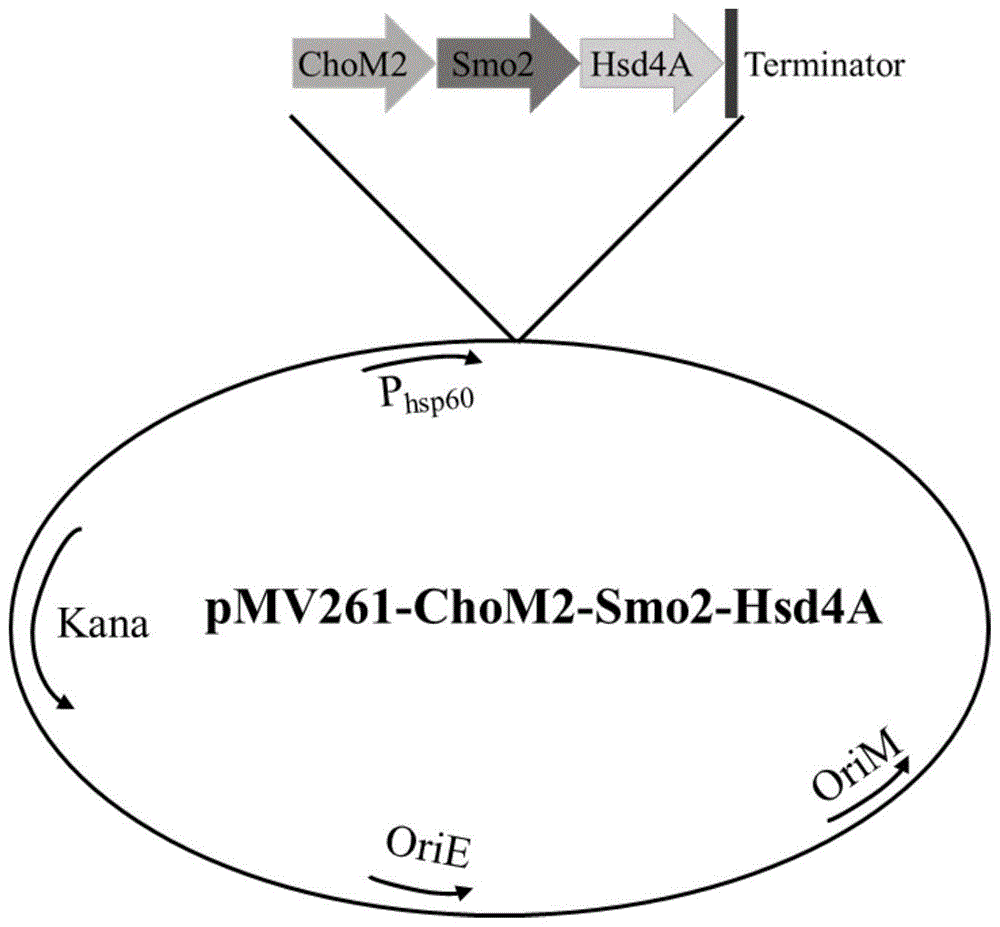
图1重组质粒pmv261-chom2-smo2-hsd4a示意图;
图2高产雄烯二酮的重组菌株mncsh的构建;
图3发酵转化168小时后,提取发酵液检测的液相色谱(hplc)图,图3中(a)为原始菌株(b)为重组菌株;
图4原始菌株及重组菌株阳性转化子mncsh转化生产4-ad动力学曲线;
具体实施方式
宿主细胞优选新金分枝杆菌(mycobacteriumsp.),该菌株于中国工业微生物菌种保藏管理中心(简称cicc21097)购买获得,编号cicc21097;
2018年9月20日;http://www.china-cicc.org/
pmv261(市售)
下面结合具体实施例对本发明做进一步阐述。应当理解,此处所描述的具体实施例仅用以解释本发明并不限定本发明,对本发明内容所做的等同替换,或相应的改进,仍属于本发明的保护范围之内。
实施例1
一种高产雄烯二酮的重组分枝杆菌的构建方法,包括如下步骤:
(1)构建三基因过表达重组质粒pmv261-chom2-smo2-hsd4a:
①合成目的基因,根据胆固醇氧化酶基因chom2(seqidno.1)、携带有rbs片段的甾酮c27单加氧酶基因smo2(rbs片段连接在基因smo2的5'端,rbs片段的序列如seqidno.2所示,基因smo2的序列如seqidno.3所示)以及携带有rbs片段的17β-羟固醇脱氢酶hsd4a(rbs片段连接在基因hsd4a的5'端,基因hsd4a序列如seqidno.4所示)的核苷酸序列,将酶切位点bamhⅰ/ecorⅰ添加于基因chom2序列两端,将酶切位点ecorⅰ添加于携带有rbs片段的基因smo2两端,将酶切位点hindⅲ添加于携带有rbs片段的基因hsd4a两端,将所设计的序列交由金唯智公司进行基因合成;
②pcr扩增步骤①获得的目的基因片段chom2、携带有rbs片段的smo2及携带有rbs片段的hsd4a基因;
③将步骤②获得的目的基因片段chom2及质粒pmv261分别用bamhⅰ/ecorⅰ双酶切,纯化,连接获得单基因过表达重组质粒pmv261-chom2;
将步骤②获得的携带有rbs片段的目的基因片段smo2及单基因过表达重组质粒pmv261-chom2分别用ecorⅰ酶切,纯化,连接获得双基因过表达重组质粒pmv261-chom2-smo2;
将步骤②获得的携带有rbs片段的目的基因片段hsd4a及双基因过表达重组质粒pmv261-chom2-smo2分别用hindⅲ酶切,纯化,连接获得三基因过表达重组质粒pmv261-chom2-smo2-hsd4a,如图1所示。
表1通过pcr获得过表达基因所需引物
(2)构建一种高产雄烯二酮的重组分枝杆菌,命名为mncsh:
①分枝杆菌(cicc21097)感受态细胞制备:
一级种子培养至od600为1.0左右,按10%接种量转接到种子培养基中进行二级种子培养;24h后加入2%甘氨酸继续培养24h。离心收集菌体,分四次用10%预冷甘油冲洗悬浮菌体并离心,最后加入甘油悬浮菌体,并分装保存;
种子培养基组成:0.5g/lk2hpo4,0.5g/lmgso4·7h2o,0.05g/l柠檬酸铁铵,2.0g/l柠檬酸,3.5g/l磷酸氢二铵,20g/l甘油,其余为水,ph7.5。
②电转化:10μl步骤(1)所得三基因过表达重组质粒加入100μl感受态菌体中放置10min,1.5kv条件下电转两次,每次5ms;
③重组子筛选与验证:电转产物加入种子培养基复苏培养2h后,涂布于含有50mg/l卡那霉素的种子培养基平板上,30℃静置培养7d,挑取单菌落至种子培养基培养,利用引物chom2-f及hsd4a-r进行菌液pcr验证,菌液pcr出现3840bp大小的条带,菌液pcr验证正确的阳性转化子即为一种高产雄烯二酮的重组分枝杆菌,命名为mncsh,如图2所示。
实施例2
一种高产雄烯二酮的重组分枝杆菌,命名为mncsh(简称重组菌株)发酵制备雄烯二酮的方法
以1%(v/v)接种量将重组分枝杆菌mncsh菌种接种到5ml种子培养基中,30℃振荡培养(200rpm)48h,之后以10%接种量转接于200ml发酵转化培养基中,37℃,200rpm,转化培养168h。
发酵转化培养基组成为0.5g/lk2hpo4,0.5g/lmgso4·7h2o,0.05g/l柠檬酸铁铵,2.0g/l柠檬酸,3.5g/l磷酸氢二铵,20g/l植物甾醇,60g/l甲基化-β-环糊精,其余为水,ph8.0。
每24h取1ml发酵液,并用2倍体积乙酸乙酯提取,用高效液相色谱检测雄烯二酮产量。如图4所示,不同发酵时间,原始菌株与重组菌株转化生成的雄烯二酮产量对比,发酵转化168小时,重组菌株比原始菌株(cicc21097)雄烯二酮产量提高31.9%,雄烯二酮浓度达到11.1g/l。
发酵168小时后取重组菌株的发酵液,用2倍体积乙酸乙酯提取并用高效液相色谱检测产物含量,结果如图3中(b)所示。原始菌株发酵168小时后采用同样的工艺条件进行提取并检测产物,结果如图3中(a)所示。通过对比可知,重组菌株与原始菌株发酵转化的主要产物均为4-ad,并且重组菌株的4-ad产量远高于原始菌株;此外,重组菌株发酵液中副产物2(21-羟基-20-甲基孕甾-4-烯-3-酮)的含量远低于原始菌株,并且重组菌株的收率和选择性远高于原始菌株。与原始菌株相比,重组菌具有更佳的性能,采用重组菌进行转化可以提高生产效率。
序列表
<110>天津大学
<120>一种高产雄烯二酮的重组分枝杆菌及构建方法及应用
<160>10
<170>siposequencelisting1.0
<210>1
<211>1617
<212>dna
<213>新金色分枝杆菌(mycobacteriumsp.)
<400>1
atgctgacaagacggcggttcctgggtgtcgcgctcggtgcggcggccggtgccggcgcc60
gtggtggcgtgccagcggaccgagtccggcgagcgaccggccgatcgcgcgtttcaccag120
gccatcgtggtcggcagcgggtacggcgggggcgtcagcgcgttgcgtttgggggaggcc180
ggcgtcgaaacgctgatcctggagcgcggtcggctctgggacaccccggacgaggacggt240
aagcggttcagcaaaatgttgcccgccgacacccgggcgggttggttccgcgatgtgcca300
ccgagcctggtgccctcattcggcggcatatcggtcaacgcggtcgctgcccagaatcct360
ggttcgcagccggtccaggcgggcatctgcgacaagatcacctacggcgcccacgaggtc420
ttccgcgggatagcggtcggtggtggctcgatggtgaacgccgcgatcgccgcgataccc480
acgccggatcaggtgcgggcggccttcccggacatcgaccccaacgagttcctcggcacc540
tatgtcgagcgggccaagaccacgctgaagatcagctatcgcgatatgggctggttcgag600
cagaccccctacttccaatatgcgcgggtggggcgcagttatgccgaggcggcaggctac660
ggagtggactacaacggaagcgcctactcgttcgattacatggtctcggaggccgccggc720
caggcgccgaagtcggcactggactgggaatgccagtacggcaacaactacggacgcttc780
ggcagtgtggatcagacctacatcgccgcggcgttggccaccggcaaggtgacgttgcgt840
ccgctgaccgaggtgaccggcatccgccgcgaatcctccggggagtacgtggtgtccatc900
cgcgagatcgatcggtggggcaaagagttgtcgcgcaacgagatcggttgcgagcagctg960
tatctggcggccggcgtggtcgggacggctgagctgctactgcgcgcgcgtgagaacggc1020
gatcttgccgacctgtccgacgaggtcggtgagggttatggcaacaacggggacatcatg1080
gtggcccacaacaccgccgagcaggatccggtgggtaccctgcagtcgctgctgggcatg1140
atcaacctggacggtcgcaacgatccggacaacccggtgtacgccagcatgttctcgcta1200
ccgctgccgctggagacccatgcgctgggctactacgccatggtccgcaccggcgaccgc1260
gcggtgatcagctatgaccgcgcgtccgacgccatctccatcgactggccacagagcaac1320
accgaccgcctgatcgagcgggccaagctggtcttcgacaaggtgacccaggccaacggg1380
gtggactaccgcgatgacctgttcgaggggaaagccttcgcgcccaatactgttcaccca1440
ctgggtgggtgtgtgcggggtgttgccaccgatgccttcgggcgggtcaacgggtacgag1500
aacctctacgtcaacgacgcgtcgctcgttccggggtatatcggctgcaacccgtacatg1560
tcgatcaccgcgctggccgaacgcaatatcgaggcgatcatctcaggccggcgttag1617
<210>2
<211>14
<212>dna
<213>人工序列(artificialsequence)
<400>2
aagaaggagatata14
<210>3
<211>1236
<212>dna
<213>新金色分枝杆菌(mycobacteriumsp.)
<400>3
atgacgacgatggatgcgtgtccgttcggtgcggggtacgacttcaccgaccccgaggtg60
ctgctgcaggggcttccggtcacggagttcgcccacctgcgcaagaccgcaccgatctgg120
tggaacgcccagggtgagtcgatcttcgatgacggcggctattgggtgatcagccggcac180
gaagacgtcaagaccatctcccgcaactcccgcgacatctggtccaccaatgccaaggga240
gcggtcatgcggctgcccgacggcatcaccgccgaccaactcgacctgaccaaggccctg300
ctgatcaatcacgacgccccggagcacacccggctgcgcaagctggtctcgcgcctgttc360
acgccgcgctcggtggccgcgctcgaggagaagctggcggtggcggcacgcgagatcgtg420
gcacgggccgccgaacgcggctccggcaatttcgtcgatgacgtggcgatgccgctgccg480
ctacaggccatcgccgacctgatcggggtgcccgaggcggaccgggagaagatattccac540
tggtcgaactgcatcatgaacaccgacgaccccgatttcgacagcgacccgacgaccgcc600
aacgcggagctgatgggttacgcctacaacatggccgaacaacgccggaagtgcccggcc660
gatgacatcgtcacccgcctggtccaggccgatctgggcggagaagagggcatcaccgaa720
gtggagttcgccttcttcgtgatcctgctggccgtggcaggcaatgagaccacccgcaat780
gcgatgacccacgggatgaacgccttcctcgaaaacccggatcaatgggaacttttcaag840
cgtgagcgccccgataccgccatcgaggagatcatccggtgggccagcccggtgcactgc900
ttccagcgcacggcgctccaggacaccgagatcggcggggtcaccatcaagcaaggccag960
cgggtcgggctgttctacagctcggcaaactacgacgaatccgtgttcaccgacccgttc1020
cggttcgacatcctgcgcaacccgaatccgcatctggccttcggtggcaacggcgcacat1080
ttctgcatcggcgccaacctggcccgcatggagatcaagctgatgttcaacgagatcgcc1140
aaccagatcccggacatctccaaactggctgaaccgcagcgccttcgatccggctggatc1200
aacggcgtgaaggaactgcaggtttcctactcctga1236
<210>4
<211>912
<212>dna
<213>新金色分枝杆菌(mycobacteriumsp.)
<400>4
atgaacgacaacccgatcgacctgtccggaaaggttgccgtcgtcaccggcgcggccgcc60
ggcctgggccgggccgaggcgataggcctggcgcgggccggcgcgacggtcgtggtcaac120
gacatggccggcgcgctggacaactccgacgtgctggccgagatcgaagcggtcgggtcc180
aagggcgtcgcggtcgccggtgatatcagcgcgcgcagcaccgccgacgaactcgtcgag240
acagccgaccggctcgggggactgggcatcgtggtgaacaacgccggcatcacccgggac300
aagatgctgttcaacatgtccgacgaggactgggacgcggtgatcgccgtgcatctgcgc360
ggacacttcctgttgacgcgcaatgctgcggcgtactggaaggcgaaggccaaggagacc420
gccgacggacgggtgtacggacggatcgtcaacacctcctcggaggccgggatcgccgga480
ccggtgggtcaagccaattacggtgccgccaaggccggtatcacggcgttgacgctgtcg540
gcggcgcgcgggttgagcaggtacggggtgcgggccaatgccatcgcaccgcgggcccgc600
accgccatgaccgccggcgtgttcggtgatgcaccggagctggcggacggacaggtcgat660
gccctctcgccggagcatgtcgtcacgctcgtcacctacctgtcctccccggcgtccgag720
gatgtcaacgggcagctgttcatcgtgtacggaccgacggtcaccctggttgcggcgccg780
gttgccgcccaccggttcgatgccgccggtgatgcctgggaccccgcggcgttgagcgac840
acgctcggtgacttctttgctaaaagggatccgaatattgggttctccgcaactgagctc900
atgggttcttga912
<210>5
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>5
ggatccatgctgacaagacgg21
<210>6
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>6
gaattcctaacgccggcctga21
<210>7
<211>35
<212>dna
<213>人工序列(artificialsequence)
<400>7
gaattcaagaaggagatataatgacgacgatggat35
<210>8
<211>26
<212>dna
<213>人工序列(artificialsequence)
<400>8
gaattctcaggagtaggaaacctgca26
<210>9
<211>35
<212>dna
<213>人工序列(artificialsequence)
<400>9
aagcttaagaaggagatataatgaacgacaacccg35
<210>10
<211>26
<212>dna
<213>人工序列(artificialsequence)
<400>10
aagctttcaagaacccatgagctcag26
- 还没有人留言评论。精彩留言会获得点赞!