一种高产羟基酪醇的大肠杆菌构建方法及应用与流程
本发明涉及生物工程技术领域,具体涉及一种高产羟基酪醇的大肠杆菌构建方法及应用。
背景技术:
羟基酪醇(hydroxytyrosol)是一种天然多酚类化合物,具有多种生物和药理活性。羟基酪醇具有强效的抗氧作用,可以保护人类红细胞中过氧化氢对dna和细胞膜的损伤,清除紫外线照射下黑素瘤细胞m14产生的自由基,也能够抑制血小板聚集。除此之外,羟基酪醇还有预防炎症、抗肿瘤及抑制微生物活性的作用。因此,羟基酪醇在保健食品、化妆品和制药行业中具有广泛的应用。当前,商业的羟基酪醇主要从天然宿主中提取或通过化学合成获得。研究表明,羟基酪醇大量分布在橄榄的叶和果实当中,可以通过橄榄油或者水解橄榄苦苷获得,甚至也可以通过橄榄油产生的废水中提取得到。尽管橄榄相关的原料丰富且价格便宜,但这些提取方法仍存在以下缺点:操作过程复杂、回收率低、水蒸气强酸性和耗时。另一方面,羟基酪醇也可以通过化学方法合成,但该方法原材料昂贵、工艺复杂、污染环境,难以批量生产。因此,利用可再生廉价原料通过高效的生物合成方式生产高附加值的羟基酪醇,符合新经济形势下的可持续发展,有利于促进羟基酪醇的工业化发展。
生物合成羟基酪醇的研究有:santos等利用乳酸菌降解橄榄苦苷合成羟基酪醇,在有氧和无氧条件下测试了六株细菌对橄榄苦苷的降解效率,分别为植物乳杆菌(lactobacillusplantarum)6907、副干酪乳杆菌(lactobacillusparacasei)9192、干酪乳杆菌(lactobacilluscasei)、乳酸双歧杆菌bo(bififidobacteriumlactis)、粪肠球菌(enterococcusfaecium)32、乳酸杆菌(lactobacillus)lafti10,结果发现最有效的菌株是植物乳杆菌6907,其对橄榄苦苷降解效率最好且达到90%,而羟基酪醇的生成率只达到30%,转化率较低。allouche等人利用黏质沙雷菌(seeratiamarcescens)和铜绿假单胞菌(pseudomousaeruginosa)通过酪醇异构体合成羟基酪醇,利用微生物固相负载技术,将这两种菌固载到海藻酸钙水凝胶上,然后经过固载的细胞实现酪醇向羟基酪醇的转变,结果显示该系统能够在7h内降解4g/l酪醇溶液,羟基酪醇转化率达82%;另外还发现当细胞液质量浓度达到5g/l时,羟基酪醇的转化率提高到96%。brooks等人利用表达酪氨酸酶活性的恶臭假单胞菌(pseudomonasputida)f6细胞提取液催化酪醇合成羟基酪醇,其产率达到77%。bouallagui等人利用微生物固相负载技术将海藻酸钙珠中铜绿假单胞菌(pseudomonasaeruginosa)静息细胞固载在海藻酸钙水凝胶上,该实验够使5g/l酪醇转变为86%的羟基酪醇。然而,以上生物合成都以酪醇为底物,其成本较高,难以大量生产。satoh等人首先报道以l-酪氨酸为底物生物合成羟基酪醇的途径,在该途径中,酪氨酸经小鼠酪氨酸羟化酶羟化,且需要辅因子四氢褐变蛋白(mh4)的参与,但是四氢褐变蛋白目前无法通过任何商业渠道获得,这严重限制了该途径的生物催化效率。最终以葡萄糖作为原料,获得了0.08mm(12.3mg/l)的羟基酪醇。li等人以l-酪氨酸为底物合成中间产物酪醇,然后酪醇再进一步合成羟基酪醇,得率接近50%。chen等人设计了两个以酪氨酸为底物生物合成羟基酪醇的途径,两条路径均需要经过酪氨酸羟化才能进一步合成羟基酪醇,通过突变的羟化酶hpabcs改善酪氨酸的羟化过程,突变的hpabcs替换了该路径两个羟化步骤,最终获得的羟基酪醇转化率为93%。但是,该实验只检测了5mm的l-酪氨酸生产羟基酪醇,并没有扩大底物进一步进行羟基酪醇产量检测。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。为此,本发明的一个目的在于提供一种高产羟基酪醇的大肠杆菌构建方法。该方法可高产羟基酪醇,催化过程简单、环保,具有广阔的工业化应用前景。
为此,在本发明的一方面,本发明提出了一种高产羟基酪醇的大肠杆菌构建方法,其包括以下步骤:
pcr扩增获取hpabc、laad、aro10和par四种基因;将hpabc基因用bamhi和xhoi双酶切后,连接进入经bamhi和xhoi双酶切表达载体pacycduet-1中,得到质粒pacyc-hpabc;将laad和aro10基因双片段分别用bsai酶切,随后连接进入经bamhi和xhoi双酶切的表达载体petduet-1中,得到质粒pet-laad-aro10;将par基因用hindiii和xhoi双酶切后,连接经hindiii和xhoi双酶切的prsfduet-1载体,获得质粒prsf-par;
将质粒pacyc-hpabc、质粒pet-laad-aro10和质粒prsf-par共同转入大肠杆菌bl21(de3)感受态细胞中,得到重组大肠杆菌。
根据本发明实施例的一种高产羟基酪醇的大肠杆菌构建方法,该方法通过大肠杆菌重组菌表达4种酶:大肠杆菌羟化酶(two-componentflavin-dependentmonooxygenase,hpabc)、l-α-氨基酸脱氨酶(l-α-aminoaciddeaminase,laad)、α-酮酸脱羧酶(α-keto-aciddecarboxylase,aro10)、苯乙醛还原酶(phenylacetaldehydereductase,par),易于规模化发酵培养,能够高产羟基酪醇。
在本发明的第二个方面,本发明提出了由上述方法构建的高产羟基酪醇的大肠杆菌。
在本发明的第三个方面,本发明提出由上述高产羟基酪醇的大肠杆菌用于生产羟基酪醇的用途。
在本发明的第四个方面,本发明提出由上述的高产羟基酪醇的大肠杆菌生产羟基酪醇的方法,其包括以下步骤:
将携带有质粒pacyc-hpabc、质粒pet-laad-aro10和质粒prsf-par的重组大肠杆菌于lb培养基中培养,之后按1:100比例接入tb培养液中扩大培养,然后加入诱导剂进行诱导培养,离心收集细胞;
采用10g/l新鲜细胞干重,5mm、10mm、25mm、50mml-酪氨酸底物,20g/l葡萄糖,磷酸盐缓冲液反应体系,在30℃,250rpm下催化1~10h,每隔两小时液相色谱检测羟基酪醇产量。
根据本发明实施例的生产羟基酪醇的方法,其以5mml-酪氨酸为底物催化10h后,生产摩尔得率达93.4%的羟基酪醇,以10mml-酪氨酸为底物催化10h后,生产摩尔得率达94.2%的羟基酪醇,以25mml-酪氨酸为底物催化10h后,生产摩尔得率达97.1%的羟基酪醇,从50mml-酪氨酸中可获得4.99g/l羟基酪醇;利用本发明的重组大肠杆菌生物转化生物基l-酪氨酸合成羟基酪醇,获得已知报道的以l-酪氨酸为底物生产羟基酪醇最高产量4.99g/l,催化过程简单、环保,具有广阔的工业化应用前景。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
图1为根据本发明实施例的hpabc、laad、aro10、par四种酶催化合成羟基酪醇路径;
图2为根据本发明实施例的不同浓度的l-酪氨酸生产羟基酪醇的产量;
图3为根据本发明实施例的重组大肠杆菌菌株bl21(de3)-ht以25mml-酪氨酸为底物生产羟基酪醇的时间曲线图;
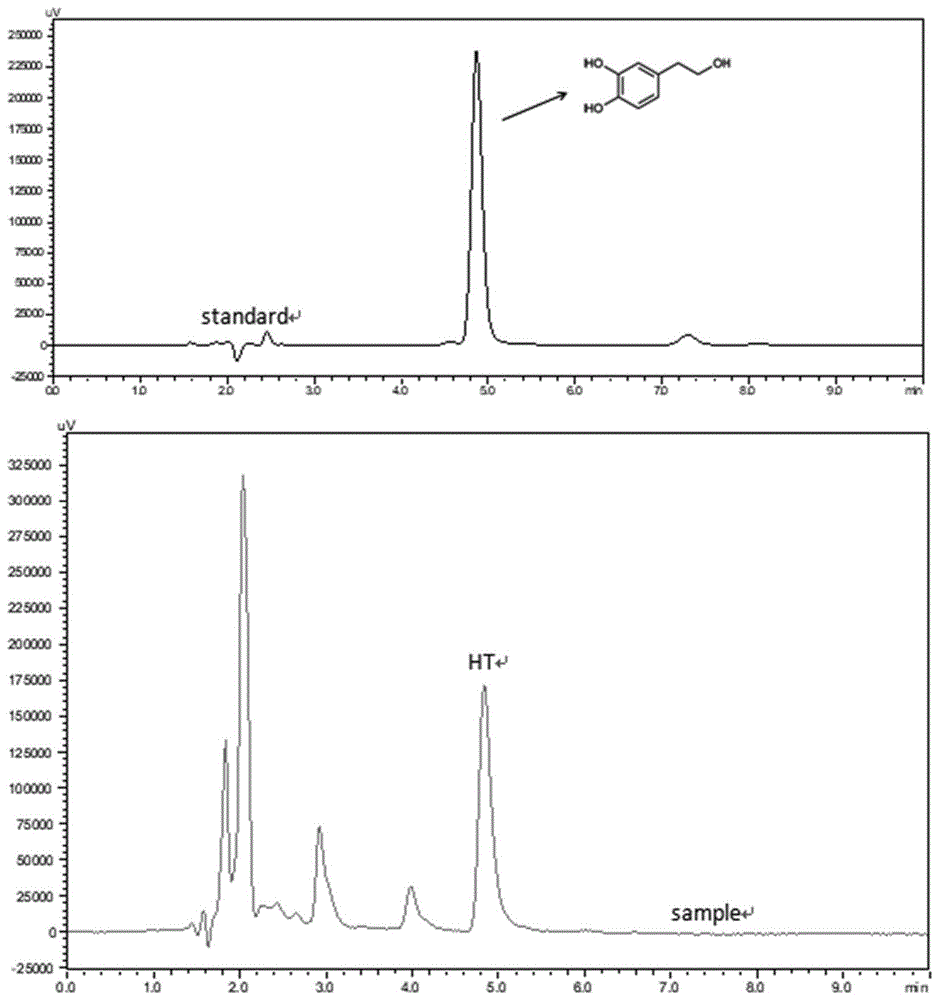
图4为根据本发明实施例的重组大肠杆菌菌株bl21(de3)-ht以5mml-酪氨酸为底物催化反应10h的hplc验证图。
具体实施方式
以下通过特定的具体实例说明本发明的技术方案。应理解,本发明提到的一个或多个方法步骤并不排斥在所述组合步骤前后还存在其他方法步骤或在这些明确提到的步骤之间还可以插入其他方法步骤;还应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。而且,除非另有说明,各方法步骤的编号仅为鉴别各方法步骤的便利工具,而非为限制各方法步骤的排列次序或限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容的情况下,当亦视为本发明可实施的范畴。
为了更好的理解上述技术方案,下面更详细地描述本发明的示例性实施例。虽然显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
本发明采用的试材皆为普通市售品,皆可于市场购得;涉及的实验如无特别说明,均为常规实验方法。
所用材料来源:大肠杆菌菌株bl21(de3)和top10为市售,大肠杆菌菌株bl21(de3)用于本发明中所有基因的表达,top10用于载体构建。大肠杆菌表达载体pacycduet-1,petduet-1,prsfduet-1来源于novagen,phusion高保真dna聚合酶、限制性内切酶购买自厦门鹭隆生物科技发展有限公司。质粒提取试剂盒、dna纯化试剂盒、胶回收试剂盒和细菌基因组dna提取试剂盒购买自上海生物工程有限公司。
lb培养基组成为:10gl-1蛋白胨、5gl-1酵母粉、5gl-1nacl,余量为双蒸水,0.1mpa压力121℃下灭菌20min。
tb培养基组成为:12gl-1蛋白胨、24gl-1酵母粉、2.31gl-1kh2po4、12.54gl-1k2hpo4、0.4%甘油,余量为双蒸水,培养基在0.1mpa压力121℃下灭菌20min。
本发明实施例的羟基酪醇生物合成路径见图1:
以l-酪氨酸为底物,经过大肠杆菌羟化酶hpabc的作用下生成l-多巴,经l-α-氨基酸脱氨酶laad催化合成3,4-二羟基苯丙酮酸,在α-酮酸脱羧酶aro10的作用下生成3,4-二羟基苯乙醛,最后经苯乙醛还原酶par的催化作用下合成羟基酪醇。
下面参考具体实施例,对本发明进行描述,需要说明的是,这些实施例仅仅是描述性的,而不以任何方式限制本发明。
实施例1构建重组大肠杆菌
1、构建pacyc-hpabc质粒:以seqidno:1和seqidno:2所示序列为上、下游引物(表1),以大肠杆菌全基因组为模板扩增hpabc基因,将hpabc基因片段用bamhi和xhoi酶切,随后连接进入经过bamhi和xhoi双酶切的表达载体pacycduet-1中,得到质粒pacyc-hpabc。
2、构建pet-laad-aro10质粒
以核苷酸序列为seqidno:9的合成laad基因为模板,以seqidno:3和seqidno:4为引物(表1),pcr扩增laad所示基因片段;以酿酒酵母的基因组dna为模板,以seqidno:5和seqidno:6为引物pcr扩增aro10基因片段;胶回收目的条带;随后在37℃,bsai酶切2小时后;pcr纯化回收酶切片段;将纯化回收的片段与经过bamhi和xhoi双酶切的表达载体petduet-1连接,16℃连接1小时转入大肠杆菌top10感受态细胞中,之后用t7universival引物验证获取阳性克隆菌落,提取质粒pet-laad-aro10。
3、构建prsf-par质粒
以核苷酸序列为seqidno:10的合成par基因为模板,以seqidno:7和seqidno:8为引物(表1),pcr扩增par所示基因片段,将par基因片段用hindiii和xhoi酶切,随后连接进入经过hindiii和xhoi双酶切的表达载体prsfduet-1,得到质粒prsf-par。
4、获取大肠杆菌重组菌株bl21(de3)
将上述1、2、3获取的pacyc-hpabc、pet-laad-aro10、prsf-par质粒电击法导入大肠杆菌bl21(de3)菌种中,以含有氨苄霉素、卡纳霉素和氯霉素三种抗生素的培养基中筛选,获取阳性克隆bl21(de3)-ht大肠杆菌重组菌株。
表1:pcr扩增所用引物
实施例2全细胞生物转化bl21(de3)菌株
将实施例1制备的bl21(de3)-ht菌株接种在2mllb培养液中,之后按1:100比例接入tb培养液中扩大培养2~3h后,od600达0.4-06后,加入1mmiptg后低温诱导蛋白表达16~24h,离心获取细胞。按2ml的反应体系催化(10g/l细胞干重、5mm、10mm、25mm、50mml-酪氨酸底物、20g/l葡萄糖),最后加入磷酸缓冲液补齐(200mm,ph=8.0),全细胞催化1~10h后,液相色谱检测羟基酪醇产量。
产品定量分析:转化液采用shimadzu高效液相色谱仪检测分析,采用光电二极管阵列检测器(工作波长210nm);色谱条件为:流动相是50%甲醇,30%乙腈(含0.1%三氟乙酸)、采用shimadzuc18色谱柱(4.6×250mm,5μm),流速1ml/min、柱温40℃、进样量10μl;流动相:90%ddh2o,0.1%tfa,10%乙腈。
结果如图2-图4所示,将bl21(de3)-ht菌株以5mml-酪氨酸为底物催化10h后,生产摩尔得率达93.4%的羟基酪醇,以10mml-酪氨酸为底物催化10h后,生产摩尔得率达94.2%的羟基酪醇,以25mml-酪氨酸为底物催化10h后,生产摩尔得率达97.1%的羟基酪醇,从50mml-酪氨酸中可获得4.99g/l羟基酪醇。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不应理解为必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。此外,本领域的技术人员可以将本说明书中描述的不同实施例或示例进行接合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
序列表
<110>厦门大学
<120>一种高产羟基酪醇的大肠杆菌构建方法及应用
<130>无
<160>10
<170>siposequencelisting1.0
<210>1
<211>34
<212>dna
<213>人工序列(artificialsequence)
<400>1
ttggtctcggatccgatgaaaccagaagatttcc34
<210>2
<211>34
<212>dna
<213>人工序列(artificialsequence)
<400>2
ttggtctcatcctttaaatcgcagcttccatttc34
<210>3
<211>37
<212>dna
<213>人工序列(artificialsequence)
<400>3
ttggtctcggatccgatgaacatttcacgtcgcaagc37
<210>4
<211>36
<212>dna
<213>人工序列(artificialsequence)
<400>4
ttggtctcatcctttacttcttaaaacgatccaaac36
<210>5
<211>40
<212>dna
<213>人工序列(artificialsequence)
<400>5
ttggtctcaaggagatatataatggcacctgttacaattg40
<210>6
<211>37
<212>dna
<213>人工序列(artificialsequence)
<400>6
ttggtctcctcgagctattttttatttcttttaagtg37
<210>7
<211>44
<212>dna
<213>人工序列(artificialsequence)
<400>7
agagaaagcttaaggagatatataatgagcgtgaccgcgaaaac44
<210>8
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>8
agagactcgagtcacatgcttgaactcccg30
<210>9
<211>1422
<212>dna
<213>人工序列(artificialsequence)
<400>9
atgaacatttcacgtcgcaagctgctgctgggtgttggtgctgctggtgtgttggcgggt60
ggtgcagctctggttccaatggtgcgtcgtgatggtaaatttgttgaagcaaagagccgt120
gcgagcttcgtggaaggtacccaaggtgcgctgccgaaagaagctgacgttgtgattatc180
ggtgctggtattcagggtatcatgaccgctattaatctggcagaacgtggtatgagcgtt240
accattctggaaaagggtcaaatcgcaggtgaacagagcggtcgtgcgtacagccaaatt300
atcagctatcagaccagcccggaaatttttccgctgcatcactacggtaaaatcctgtgg360
cgtggtatgaacgaaaagattggtgcggataccagctatcgtacccaaggtcgtgttgaa420
gctctggcagatgaaaaagcactggacaaggcgcaggcttggatcaaaaccgcgaaggaa480
gctgcaggttttgacaccccgctgaatacccgtattatcaaaggtgaagaactgagcaac540
cgtctggttggtgctcaaaccccgtggaccgtggctgctttcgaagaagatagcggtagc600
gttgacccggaaaccggtaccccggcactggctcgttacgctaaacagattggtgttaag660
atctataccaactgcgctgtgcgtggtattgaaaccgcgggtggtaaaatcagcgatgtt720
gtgagcgaaaaaggtgcgatcaagaccagccaagtggtgctggcgggtggtatttggagc780
cgtctgtttatgggtaatatgggtattgacatcccgaccctgaacgtttacctgagccaa840
caacgtgttagcggtgtgccaggtgcgccgcgtggtaatgtgcatctgccgaacggtatc900
cactttcgtgaacaagctgatggtacctatgctgttgcaccgcgtattttcaccagcagc960
atcgtgaaagacagctttctgctgggtccgaagttcatgcatctgctgggtggtggtgaa1020
ctgccgctggaattttctatcggtgaagacctgtttaatagcttcaaaatgccgaccagc1080
tggaacctggacgaaaagaccccgtttgaacaattccgtgttgcgaccgctacccaaaat1140
acccagcacctggatgcagtttttcagcgtatgaaaaccgaatttccggtgttcgaaaag1200
agcgaagttgtggaacgttggggtgctgttgtgagcccgaccttcgacgaactgccgatt1260
atcagcgaagttaaggaatacccgggtctggttattaacaccgctaccgtgtggggtatg1320
accgaaggtccggcagcgggtgaagttaccgcagatattgtgatgggtaaaaagccggtt1380
attgatccgaccccgtttagtttggatcgttttaagaagtaa1422
<210>10
<211>987
<212>dna
<213>人工序列(artificialsequence)
<400>10
atgagcgtgaccgcgaaaaccgtgtgtgttaccggcgccagcggctacatcgcctcttgg60
cttgtaaagtttctgttgcactcgggttataacgttaaagcgtcagtccgcgatccgaac120
gacccgaaaaaaacgcagcacctgctgtctctgggcggcgcgaaagaacggctgcacctg180
ttcaaagcgaatctgctggaagaaggttcgttcgatgcggttgttgacggttgcgaaggt240
gtgttccataccgcgtcccctttctactattctgtaaccgatccgcaggccgagcttctg300
gatccggcagtaaaaggcactctgaacctgctcggttcctgtgctaaagcgccttcagtt360
aagcgtgtagtgctcaccagcagcatcgctgccgttgcgtactctggtcaaccacgtact420
cctgaagtagtagtggatgaatcgtggtggacgtctcctgattattgtaaagaaaaacag480
ctgtggtacgtcttaagtaaaacgctggcggaagatgcggcttggaaatttgtgaaagaa540
aaggggattgacatggtcgttgtaaatcctgcaatggtcattggaccgttactgcagcca600
accctcaatacgagcagcgccgcggtgctgtctcttgtaaacggggcggaaacatatcct660
aatagctctttcggctgggttaatgtcaaagatgtggcgaatgcccacattcttgccttt720
gaaaacccaagcgccaacggccgttacttgatggttgaacgtgttgcgcactatagcgac780
atcctgaaaatcctccgcgacctgtaccctactatgcaattgcctgaaaaatgtgcagat840
gataacccgctgatgcagaattaccaggtctcaaaagaaaaagcgaaatcactgggcatc900
gaatttactactcttgaggaaagtattaaagaaacagtagaatccttgaaagaaaaaaaa960
tttttcggcgggagttcaagcatgtga987
- 还没有人留言评论。精彩留言会获得点赞!