一种MALDI-TOF质谱检测密集单核苷酸变异位点的引物和探针的设计方法与流程
本发明属于核酸检测技术领域,具体涉及一种maldi-tof质谱检测密集单核苷酸变异位点的引物和探针的设计方法。
背景技术:
在基因组dna序列上,个体间同一位置单个核苷酸存在差别的现象,统称为单核苷酸变异(singlenucleotidevariants,snv)。人基因组上平均约每1000个核苷酸即可能出现1个单核苷酸多态性的变化,其中有些在rna转录、蛋白质表达等生物过程中起调控作用,并与人类的表型性状和疾病密切相关。这种差别的基因座、dna序列等可作为基因组作图的标志,对个体间的遗传关系调查、表型的遗传背景分析、疾病的预测与诊断、个体化用药策略等均有着重要的意义。snv是研究人类家族和动植物品系遗传变异的重要依据。
随着科技的发展和研究的深入,越来越多的表型性状或人类疾病相关的snv位点被发现。从基础研究而言,通过检测更多的样本、更多的snv位点,可加深对某种疾病或表型性状的进一步认识;从临床实践而言,通过对受检个体可疑疾病的多个致病基因、多个snv位点检测,可为明确诊断、风险评估、预防控制、个体化治疗等提供依据。由此可见,以snv检测为主题的理论策略与创新技术研究,其发展趋势必然为尽可能低的检测成本而实现“多”(位点更多)、“快”(速度更快)、“全”(通量更大)的检测目标。
snv检测的发展历程,从限制性片段长度多态性(rflp)、特异性寡核苷酸杂交等分析单一基因单个突变,反向点杂交(rdb)、多重pcr检测单一或多个基因的多个突变,发展到目前可实现基因panel(大量基因突变)分析的高密度基因芯片和二代测序(ngs)。
基因芯片(microarray/arrary-cgh/cma)可快速准确地同时分析数以千计的基因组snv信息,但在样品制备、探针合成与固定、分子标记、数据读取与分析等方面,技术成本昂贵、操作复杂、检测时间长、检测灵敏度较低、重复性差、分析范围较窄。二代测序(ngs)可一次对几十到几百万条dna分子进行序列测定,但测序读长短导致数据分析时存在无法精确定位基因组位置而结果不确定,需核苷酸片段化、目标序列捕获、建库等一系列繁琐的样品前处理,尤其是只有通过生物信息学工具对原始数据进行分析才能得到有生物意义的结果。
生活水平的提高和健康意识的增强,基因检测需求快速增长且样本量日益增加,需同时检测的snv位点也越来越多,在一定程度上具有技术优势的基因芯片和ngs平台需特殊设备和人员配置,方法学研发难度大、投入高、周期长,近期内难以满足实践要求。以高分辨熔链分析和毛细管电泳技术为平台的方法学,其检测容量与灵活性局限了项目研发的进度和难度。操作简单、结果准确、高通量低成本而适合常规应用的snv快速检测方法,是当前现实所需。
基质辅助激光解吸电离飞行时间质谱(matrix-assistedlaserdesorption/ionizationtimeofflightmassspectrometry,maldi-tof-ms)是近年来发展起来的一种新型生物质谱,该技术采用“软电离”方式而产生稳定分子离子,在核酸分析研究方面已取得了突破性进展。其原理为某一dna片段有其特有的分子量,当此序列中增加或减少一个碱基,甚至其中某个碱基替换成另外一个碱基,其分子量即发生了变化,即可通过maldi-tof-ms检测到这种差异,实现定性鉴别和定量分析。maldi-tof-ms是以待测物质的分子量为分析原理,不需对dna分子进行荧光、生物素等标记,飞行时间质量分析(tof)的检测时间极短,特别是近年来检测灵敏度与分析范围的显著提高,以及上样检测和结果分析的自动化,不仅大大增加了单个测试的检测容量而实现了多基因、多snv位点同时分析,而且大大解放了人力而实现了自动化与标准化。
snv质谱检测主要基于pcr和单碱基延伸技术。针对待测的snv位点,于5’端设计一条延伸探针。目标序列pcr完成后,于反应液中加入snv位点延伸探针及ddntp,延伸探针即与待测snv位点5′端序列结合,并延伸一个碱基。所延伸碱基的不同,可得到不同分子量的延伸产物,即可实现snv的基因分型。例如,snv位点模板为胞嘧啶(c),则延伸鸟嘌呤(g);snp模板为腺嘌呤(a),则延伸胸腺嘧啶(t)。由于所延伸的碱基不同,则延伸产物分子量不同,因此可以根据在各自的分子量位置是否出现检测峰,而判断该样品的snv基因型。
在人类基因组中,多个单核苷酸变异位点集中在一段非常短的dna序列中的情况比较常见,如beta地中海贫血-28、-29、-30、-31、-32突变,egfr基因δe746-a750、δe746-t751、δe746-a750(insrp)、δe746-t751(insa/i)、δe746-t751(insva)、δe746-s752(insa/v)、δl747-e749(a750p)、δl747-a750(insp)、δl747-t751、δl747-t751(insp/s)、δl747-s752、δl747-752(e746v)、δl747-752(p753s)、δl747-s752(insq)、δl747-p753、δl747-p753(inss)突变等。通常,在一个探针覆盖范围内,有2个或2个以上的突变位点,就存在探针间的竞争,就被认为是密集分布的单核苷酸变异位点。针对这种密集snv位点,按常规maldi-tof-ms的检测策略所设计的延伸探针必然为序列高同源性,因此,大量多重检测延伸探针存在于一个单独的反应体系中,不可避免的会产生探针之间的非特异性杂交,尤其是探针对模板的竞争性结合,导致随之而来的不均衡杂交效率及单碱基延伸效果。因此局限了检测的snv位点的数量,如中国专利cn201910866308.7一种检测地贫基因突变的试剂盒。cn201610023226.2一种用于肺癌风险预测的基因检测引物组和试剂盒等。有鉴于此,目前常用的策略是采用多个反应管,对密集snv位点进行分管组合单碱基延伸及检测,虽然保证了各位点的检出,但增加了操作过程的复杂性和检测成本,降低了检测通量。
技术实现要素:
本发明是针对目前密集单核苷酸变异位点检测的方法学局限,发明了一种maldi-tof质谱检测密集单核苷酸变异位点的方法,以解决密集snv位点高通量检测难题,开发基于maldi-tof-ms技术平台的密集snv位点快速检测方法,对表型及疾病遗传背景分析的snv常规检测及大规模人群分型的实践应用与基础研究均有重要的意义。
本发明的第一个目的在于提供一种maldi-tof质谱检测单核苷酸变异位点的引物和探针设计方法。
本发明的第二个目的在于提供一种maldi-tof质谱检测单核苷酸变异位点的方法。
本发明的第三个目的所述的设计方法设计得到的引物和探针。
本发明的第四个目的所述引物和探针在maldi-tof质谱检测单核苷酸变异位点中的应用。
本发明的第五个目的一种maldi-tof质谱检测地中海贫血基因分型的单核苷酸变异位点的引物。
本发明的第六个目的一种maldi-tof质谱检测地中海贫血基因分型的单核苷酸变异位点的探针。
本发明的第七个目的所述的引物和所述的探针中的任意一条或几条在制备地中海贫血基因分型试剂盒中的应用。
本发明的第八个目的一种maldi-tof质谱检测酪氨酸激酶受体相关的肺癌基因突变的单核苷酸变异位点的引物。
本发明的第九个目的一种maldi-tof质谱检测酪氨酸激酶受体相关的肺癌基因突变的单核苷酸变异位点的探针。
本发明的第十个目的所述的引物和所述的探针中的任意一条或几条在制备检测酪氨酸激酶受体相关的肺癌基因突变的试剂盒中的应用。
本发明的上述目的是通过以下方案予以实现的:
发明要求保护一种maldi-tof质谱检测单核苷酸变异位点的引物和探针设计方法,需要同时满足以下条件:
各单核苷酸变异位点均只以正向链或只以反向链为模板进行引物的设计;针对每一单核苷酸变异位点各基因型的单碱基延伸探针,snv位点位于探针中央5个碱基范围;
针对每一单核苷酸变异位点各基因型的单碱基延伸探针的tm值比拟设定的检测体系单碱基延伸杂交工作温度高3℃~5℃;
针对每一单核苷酸变异位点各基因型的单碱基延伸探针,以单核苷酸变异位点所处具体位点为界,两端序列的tm值差异不超过5℃;
针对每一单核苷酸变异位点各基因型的单碱基延伸探针,以snv所处具体位点为界,两端序列的tm值均需低于拟设定检测体系杂交工作温度差5℃以上。
针对多个密集分布的单核苷酸变异位点设计各单核苷酸变异位点的引物,不能针对不同突变类型分别以不同模板链设计探针,以避免探针间形成引物间杂交二聚体。
优选地,当引物的分子量在maldi-tof质谱检测的分子量范围内,引物的5’端增加一段接头。
更优选地,接头的序列为acgttggatg,其具有很好的特异性,可以有效的避免跟基因组的其他序列发生非特异性的结合,且不对后续延伸产物的检测产生干扰。
本发明还要求保护一种maldi-tof质谱检测单核苷酸变异位点的方法,包括以下步骤:
根据需检测单核苷酸变异位点,向变异位点的上游和下游进行截取15~30个碱基,确定靶序列扩增子范围,在扩增范围内,按照所述方法设计用于maldi-tof质谱检测的引物和探针;
使用设计的引物进行pcr扩增;
虾碱性磷酸酶处理pcr扩增产物;
加入各特异性单碱基延伸探针及ddntps进行单碱基延伸;
碱基延伸产物采用maldi-tof质谱分析而进行目标snv位点的定性/定量检测。
pcr扩增产物经虾碱性磷酸酶(sap)处理而消除残留的dntps。
以上所述的引物和探针的设计方法,以及maldi-tof质谱检测单核苷酸变异位点的方法均适用于密集分布的单核苷酸变异位点的检测,可以检测出连续相连的很多个位点的变异的,以此方法针对地中海贫血的相连的3个位点的单核苷酸变异,19bp内存在5个位点的单核苷酸变异和179bp内存在14个位点的单核苷酸变异,均能够完美的设计出有效的检测引物和探针;针对酪氨酸激酶受体相关的肺癌基因突变的23bp内存在13个位点单核苷酸变异,也均能够完美的设计出有效的检测引物和探针。
具体的,本发明要求保护以下内容:
一种maldi-tof质谱检测地中海贫血基因分型的单核苷酸变异位点的引物,其核苷酸序列如seqidno:1~11所示。
一种maldi-tof质谱检测地中海贫血基因分型的单核苷酸变异位点的探针,其核苷酸序列如seqidno:12~50所示。
所述的引物和所述的探针中的任意一条或几条在制备地中海贫血基因分型试剂盒中的应用。
以上引物和探针可以用于密集分布的相连的3个位点单核苷酸变异、19bp内存在5个位点的单核苷酸变异和179bp内存在14个位点的变异的检测,可以达到很好的检测效果。
同时,本发明要求保护以下内容:
一种maldi-tof质谱检测酪氨酸激酶受体相关的肺癌基因突变的单核苷酸变异位点的引物,其核苷酸序列如seqidno:51~66所示。
一种maldi-tof质谱检测酪氨酸激酶受体相关的肺癌基因突变的单核苷酸变异位点的探针,其核苷酸序列如seqidno:67~99所示。
所述的引物和所述的探针中的任意一条或几条在制备检测酪氨酸激酶受体相关的肺癌基因突变的试剂盒中的应用。
以上引物和探针可以用于密集分布的23bp内存在13个位点的单核苷酸变异的检测,可以达到很好的检测效果。
与现有技术相比,本发明具有以下有益效果:
通过本发明提供的一种设计maldi-tof质谱检测平台的密集snv位点各突变类型特异性检测杂交探针的方法,利用该方法设计的引物,可以快速准确地对密集单碱基突变位点进行检测,对突变序列具有高度的特异性,并且能用于突变序列丰度的定量检测。
附图说明
图1为hbb基因的-32、-31、-30、-29、-28位点非突变检测图。
图2为hbb基因的-32位点突变检测图。
图3为hbb基因的-31位点突变检测图。
图4为hbb基因的-30位点突变检测图。
图5为hbb基因的-29位点突变检测图。
图6为hbb基因的-28位点突变检测图。
图7为hbb基因的ivs-i-1、cd30、ivs-i-5位点非突变检测图。
图8为hbb基因的ivs-i-1位点突变检测图。
图9为hbb基因的cd30位点突变检测图。
图10为hbb基因的ivs-i-5位点突变检测图。
图11为egfr基因的g719a位点野生型检测图。
图12为egfr基因的g719a位点突变检测图。
图13为egfr基因的g719s和g719c位点野生检测图。
图14为egfr基因的g719s位点突变检测图。
图15为egfr基因的g719c位点突变检测图。
图16为egfr基因的l747-t751>s_2240_2251del12位点野生型检测图。
图17为egfr基因的l747-t751>s_2240_2251del12位点突变检测图。
图18为kras基因的g12c和g12s位点野生型检测图。
图19为kras基因的g12c位点突变检测图。
图20为kras基因的g12s位点突变检测图。
图21为pik3ca基因的e542k位点野生型检测图。
图22为pik3ca基因的e542k位点突变检测图。
具体实施方式
下面结合具体实施例对本发明做出进一步地详细阐述,所述实施例只用于解释本发明,并非用于限定本发明的范围。下述实施例中所使用的试验方法如无特殊说明,均为常规方法;所使用的材料、试剂等,如无特殊说明,为可从商业途径得到的试剂和材料。
dna聚合酶(hataq)、经典苯酚-氯仿抽提试剂购于上海生工生物公司;dntps购于宝生物工程(大连)有限公司;去dntp的碱性磷酸酶试剂、ddntp单碱基延伸试剂、maldi-tof-ms基质芯片等由广州市达瑞生物技术股份有限公司提供;96孔板购于美国axygen公司;封口膜购于美国thermo公司;maldi-tofdna质谱分析仪为广州达瑞生物技术股份有限公司生产的飞行时间质谱检测系统,其分析范围4000-10000daltons。pcr扩增反应、去dntp混合物反应、单碱基延伸反应所用pcr仪器为abi2720或bio-radc1000。
实施例1一种基于maldi-tof质谱平台的密集单核苷酸变异位点快速检测方法应用于地中海贫血基因分型
地中海贫血(简称“地贫”)是一组对人类健康影响最大的遗传性溶血性疾病,分子机理是源于α珠蛋白基因簇(16p13.3)或β珠蛋白基因簇(11p15.5)的基因缺失或突变。重型α-地贫胎死腹中并给孕妇带来严重并发症;重型β-地贫患儿出生后3~6个月出现慢性进行性贫血,终生依赖输血及除铁治疗,多于未成年死亡,极少数患者可采用骨髓移植治疗。此病为常染色体隐性遗传方式,通过人群分子筛查和基因诊断,对双方均为致病基因携带者的高风险孕妇进行胎儿产前诊断,从而避免重型患儿的出生是目前国际上公认的地贫防治首要措施。然而,实现有效防控目标的前提,就是采用准确实用的基因检测方法进行分子筛查和基因诊断。检测方法操作越简单、成本越低,则推广容易而惠及面广;检测位点越多、范围越全,则灵敏度高而漏检率低。
目前临床上的地贫基因检测常规方法有跨越断裂点pcr(gap-pcr)和pcr反向点杂交(reversedot-blot,rdb)。基于这两种方法的商品化试剂盒,检测通量和检测容量有限、操作繁琐耗时长。尤其是当前世界范围内人群的迁移增加导致基因突变谱愈加复杂,地贫人群防控的广泛实施也需要操作简单、检测位点多的方法,以满足当前大规模人群分子筛查和常规分子诊断的方法学要求。maldi-tof-ms是以待测物质的分子量为分析原理,实现了多基因、多snv位点同时分析。但是,人类beta珠蛋白基因序列短、突变会点多且集中,如beta地中海贫血-28(a>g)、-29(a>g)、-30(t>c)、-31(a>c)、-32(c>a),cd14-15(+g)、cd15-16(+g)、cd17(a>t)。这些密集snv位点,以常规maldi-tof-ms检测策略所设计的延伸探针必然为序列高同源、高竞争性。因此,采用本发明所提供的密集snv位点各突变类型特异性杂交探针的设计策略,避免了上述问题,实现了对密集碱基突变位点的快速准确检测。
一、引物设计
基于地贫基因突变热点所包含的缺失突变截短目的序列、点突变物理位置目的基因序列设计了扩增引物和延伸探针。
根据需检测单核苷酸变异位点,向变异位点的上游和下游进行截取15~30个碱基,确定靶序列扩增子范围,在扩增范围内,按照下面的方法设计用于maldi-tof质谱检测的引物和探针:
各单核苷酸变异位点均只以正向链或只以反向链为模板进行引物的设计;针对每一单核苷酸变异位点各基因型的单碱基延伸探针,snv位点位于探针中央5个碱基范围;
针对每一单核苷酸变异位点各基因型的单碱基延伸探针的tm值比拟设定的检测体系单碱基延伸杂交工作温度高3℃-5℃;
针对每一单核苷酸变异位点各基因型的单碱基延伸探针,以单核苷酸变异位点所处具体位点为界,两端序列的tm值差异不超过5℃;
针对每一单核苷酸变异位点各基因型的单碱基延伸探针,以snv所处具体位点为界,两端序列的tm值均需低于拟设定检测体系杂交工作温度差5℃以上。
其中,扩增引物包括:
(1)一对特异性扩增α2珠蛋白基因z-box区域的引物中,
上游引物序列为:5’-gaacccctcgccaccacagtcc-3’(seqidno:1),下游引物序列为:5’-gcagaccaggaaccgggggtg-3’(seqidno:2);
(2)一对特异性扩增--sea地贫基因缺失截短序列的引物中,
上游引物序列为:5’-gcaagcgatctgtgtgggctctt-3’(seqidno:3),下游引物序列为:5’-ggagcccacgttgtcatggttgc-3’(seqidno:4);
(3)一对特异性扩增-α4.2地贫基因缺失截短序列的引物中,
上游引物序列为:5’-cgaccagtttacccaggtgtgtc-3’(seqidno:5),下游引物序列为:5’-cgacccgttggatctcattttct-3’(seqidno:6);
(4)一对特异性扩增-α3.7地贫基因缺失截短序列的引物中,
上游引物序列为:5’-gaacccctcgccaccacagtcc-3’(seqidno:1),下游引物序列为:5’-gcaggcaaacctgcaatcttgat-3’(seqidno:7);
(5)一对特异性扩增--thai地贫基因缺失截短序列的引物中,
上游引物序列为:5’-cctcagcctcctccactcatcac-3’(seqidno:8),
下游引物序列为:5’-gatctgcacctctgggtttctagggtac-3’(seqidno:9);
(6)一对特异性扩增β珠蛋白基因序列的引物中,
上游引物序列为:5’-ggaaggacaggtacctgtggcat-3’(seqidno:10),
下游引物序列为:5’-cggctgtgggaggaagaaggtattaaggaac-3’(seqidno:11);
延伸探针可分为两类:
分布零散的snp位点可采用传统的策略进行设计延伸探针,即延伸探针设计在snp位点前,延伸反应中在snp位点上延伸一个碱基(如cd142(taa>caa)、ivs-2-654(c>t)、cd71/72(+a)、cd31(-c)、int(atg>agg)等突变),根据延伸产物的分子量来判断是否发生突变;或者采用本发明的策略设计延伸探针(如cap+1(a>c)、cd37(tgg>tag)等突变),根据每个位点对应的突变型延伸探针的产物和野生型延伸探针的产物的有无来判断是否发生突变。
分布密集的snp位点采用本发明的策略设计延伸探针(如cd122(cac>cag)、cd125(ctg>ccg);-28(a>g)、-29(a>g)、-30(t>c)、-31(a>c)、-32(c>a);cd17(a>t)、cd14-15(+g);ivs-i-1(g>t)、cd30(agg>ggg)、ivs-i-5(g>c);cd41/42(-tctt)、cd43(g>t);ivs-ii-2(-t)、ivs-ii-5(g>c)等突变),每组分布密集的突变位点共用一条野生型延伸探针,每个突变位点各有一条相应的突变型延伸探针,结合每个位点对应的突变型延伸探针的产物和野生型延伸探针的产物的有无来判断是否发生突变。包括:
(7)特异性检测α地贫基因z-box区域的质谱分析探针为:5’-gggcctgaccgcacc-3’(seqidno:12);
(8)特异性检测α地贫基因--sea缺失的质谱分析探针为:5’-tgcaaactcatccacactacc-3’(seqidno:13);
(9)特异性检测α地贫基因-α4.2缺失的质谱分析探针为:5’-aggagaagtcagtaggcgcagc-3’(seqidno:14);
(10)特异性检测α地贫基因-α3.7缺失的质谱分析探针为:5’-ggagagggaaggagcagtcac-3’(seqidno:15);
(11)特异性检测α地贫基因--thai缺失的质谱分析探针为:5’-atgcctgtgaagcgtcatct-3’(seqidno:16);
(12)特异性检测α地贫基因αwsα(cd122(cac>cag))和αqsα(cd125(ctg>ccg))点突变的共用野生型质谱分析探针为:5’-gcacgccctctcgg-3’(seqidno:17);
(13)特异性检测α地贫基因αwsα点突变的突变型质谱分析探针为:5’-tgcagctccgcctg-3’(seqidno:18);
(14)特异性检测α地贫基因αqsα点突变的突变型质谱分析探针为:5’-cgcctccggaccca-3’(seqidno:19);
(15)特异性检测α地贫基因αcsα(cd142(taa>caa))点突变的质谱分析探针为:5’-gctgacctccatacaacgt-3’(seqidno:20);
(16)特异性检测β地贫基因–32(c>a)、-31(a>c)、-30(t>c)、-28(a>g)和-29(a>g)点突变的共用野生型质谱分析探针为:5’-gctgggcataagtaacagg-3’(seqidno:21);
(17)特异性检测β地贫基因–32(c>a)点突变的质谱分析探针为:5’-ggctgggaataagtaacag-3’(seqidno:22);
(18)特异性检测β地贫基因-30(t>c)点突变的突变型质谱分析探针为:5’-ttgggcacaagtcagaag-3’(seqidno:23);
(19)特异性检测β地贫基因-28(a>g)点突变的突变型质谱分析探针为:5’-tgggcatagtcaagaggg-3’(seqidno:24);
(20)特异性检测β地贫基因-29(a>g)点突变的突变型质谱分析探针为:5’-tgggcatgaagtcaagg-3’(seqidno:25);
(21)特异性检测β地贫基因-31(a>c)点突变的突变型质谱分析探针为:5’-ctgggcctaagtcaaagg-3’(seqidno:26);
(22)特异性检测β地贫基因cap+1(a>c)点突变的野生型质谱分析探针为:5’-ccatctattgctttgttacacttct-3’(seqidno:27);
(25)特异性检测β地贫基因cap+1(a>c)点突变的突变型质谱分析探针为:5’-tctattgcttctttgcactt-3’(seqidno:28);
(23)特异性检测β地贫基因cd37(tgg>tag)点突变的野生型质谱分析探针为:5’-ccgtggtctcttaccggacc-3’(seqidno:29);
(24)特异性检测β地贫基因cd37(tgg>tag)点突变的质谱分析突变型型探针为:5’-ttggtggtctacccttagacc-3’(seqidno:30);
(26)特异性检测β地贫基因int(atg>agg)点突变的质谱分析探针为:5’-caacctcaagaaaccacca-3’(seqidno:31);
(26)特异性检测β地贫基因cd17(a>t)和cd14-15(+g)点突变的共用野生型质谱分析探针为:5’-gtggggtgacaaggacg-3’(seqidno:32);
(27)特异性检测β地贫基因cd17(a>t)点突变的突变型质谱分析探针为:5’-tgtggggcttgaaggacg-3’(seqidno:33);
(28)特异性检测β地贫基因cd14-15(+g)点突变的突变型质谱分析探针为:5’-gccctggggtggc-3’(seqidno:34);
(30)特异性检测β地贫基因cd26(g>a)和cd27/28(+c)点突变的共用野生型质谱分析探针为:5’-aggtgggagtgccctg-3’(seqidno:35);
(31)特异性检测β地贫基因cd26(g>a)点突变的突变型质谱分析探针为:5’-tggtggtagccagctg-3’(seqidno:36);
(32)特异性检测β地贫基因cd27/28(+c)点突变的突变型质谱分析探针为:5’-gtggtgaggctcccg-3’(seqidno:37);
(33)特异性检测β地贫基因ivs-i-1(g>t)、cd30(agg>ggg)和ivs-i-5(g>c)点突变的共用野生型质谱分析探针为:5’-gcaggttggtaggtatcatac-3’(seqidno:38);
(34)特异性检测β地贫基因ivs-i-1(g>t)点突变的突变型质谱分析探针为:5’-gcagtttggtagttatcaagca-3’(seqidno:39);
(35)特异性检测β地贫基因cd30(agg>ggg)点突变的突变型质谱分析探针为:5’-agcgggttatcaggtagg-3’(seqidno:40);
(36)特异性检测β地贫基因ivs-i-5(g>c)点突变的突变型质谱分析探针为:5’-gcaggttgaggctatcatta-3’(seqidno:41);
(37)特异性检测β地贫基因cd41/42(-tctt)和cd43(g>t)点突变的共用野生型质谱分析探针为:5’-cagaggtgtccttctttgattgg-3’(seqidno:42);
(38)特异性检测β地贫基因cd41/42(-tctt)点突变的突变型质谱分析探针为:5’-gaggttgttgagtcctgg-3’(seqidno:43);
(39)特异性检测β地贫基因cd43(g>t)点突变的质谱分析探针为:5’-ggttcttttattggtcctggg-3’(seqidno:44);
(40)特异性检测β地贫基因ivs-ii-2(-t)和ivs-ii-5(g>c)点突变的共用野生型质谱分析探针为:5’-taacttagtccagggtgtatgg-3’(seqidno:45);
(41)特异性检测β地贫基因ivs-ii-2(-t)点突变的突变型质谱分析探针为:5’-aaaacttcagtctggggaatgg-3’(seqidno:46);
(42)特异性检测β地贫基因ivs-ii-5(g>c)点突变的突变型质谱分析探针为:5’-taacttcgtctagggtgaatgg-3’(seqidno:47);
(43)特异性检测β地贫基因ivs-2-654(c>t)点突变的质谱分析探针为:5’-acagtgataattgttatctggagg-3’(seqidno:48);
(44)特异性检测β地贫基因cd71/72(+a)点突变的质谱分析探针为:5’-agtgctcgcttgtgcta-3’(seqidno:49);
(45)特异性检测β地贫基因cd31(-c)点突变的质谱分析探针为:5’-gtctattttccttaccaccgg-3’(seqidno:50)。
二、检测方法
(1)pcr反应:根据检测的样本数目,按照表1配制好pcr反应混合物(模板gdna除外),混匀后分装于96孔板相应的孔中,最后加入模板gdna用封口膜将96孔板封住,震荡混匀后瞬时离心,放入pcr扩增仪。pcr扩增体系如表1所示。
表1本实例pcr反应体系:
pcr扩增程序为:95℃预变性8min;95℃45sec+66℃1min,72℃1min30sec,40个循环;72℃5min;4℃保存。
(2)去dntps反应:向每孔pcr产物中加入2.00μl如表2所示的去dntps反应体系,更换新的膜将96孔板封住,震荡混匀后瞬时离心。
表2去dntps反应体系:
(3)单碱基延伸反应:按照表4配制延伸探针混合液,震荡混匀后瞬时离心,然后依次按照表3反应体系顺序分别加入各组成分,配制成单碱基延伸反应混合液。向去dntps反应后的每孔产物中加入上述2.00μl单碱基延伸反应混合液,用新的膜将96孔板封住,震荡混匀后瞬时离心。
表3本实例单碱基延伸反应体系:
其中,每100.00μl延伸探针混合液的组成如表4所示
表4延伸探针混合液体系:
单碱基延伸反应程序为:95℃预变性5min;95℃30sec,(58℃5sec,80℃5sec,5个循环),40个循环;72℃3min;4℃保存。
(4)反应结束后,2000rpm瞬时离心,每孔加入30μl的灭菌双蒸水,换新的膜将96孔板封住,震荡混匀后,瞬时离心。
(5)质谱检测:打开“板管理系统”软件,编辑实验计划文件,包括样本的位置,样本名称和所用的引物,连接质谱仪与所建立的实验计划文件。其中,质谱检测程序的参数如表5所示。
表5质谱检测程序设置参数:
(8)数据分析和结果判断:利用typer4.0软件,根据延伸探针及探针延伸后分子量大小(如表6)判读目标位点的基因型。
对于缺失型α-地贫基因位点(表6中编号2-5突变):当突变型峰值/延伸探针峰值≥0.5的样本为突变阳性;反之为阴性。其中为突变阳性的样本,若α2内参基因位点(表6中编号1位点)峰值≥2时,判别为杂合缺失;若α2内参基因位点(表6中编号1位点)峰值<2时,判别为纯合缺失。
对于表6中编号6-10点突变位点,判断原则为当峰值≥2时,突变型峰值/野生型峰值≥0.5的样本为突变阳性,提示该样本存在相应的基因突变,当峰值≥2时,突变型峰值/野生型峰值<0.5的样本为突变阴性,样本不存在相应的突变位点。
对于表6中编号11-30突变位点,判断原则为当峰值≥2时,突变峰值/突变型延伸探针峰值≥0.5的样本为突变阳性,提示该样本存在相应的基因突变,反之为阴性;野生峰值/野生型延伸探针峰值≥0.5时,提示该样本存在相应的野生型基因,反之为无野生型基因。即若突变型基因和野生型基因都被检测到,则该样本为杂合突变;若仅检测到突变型基因,则该样本为杂合突变;若仅检测到野生型基因,则该样本为野生型。
表6各突变位点质谱探针、野生型和突变型对应分子量表
三、结果的灵敏性与准确性分析
(1)样本来源及类型:选取已确诊的α地贫和β地贫gdna标本,基因型分别为-α3.7/αα、-α4.2/αα、--sea/αα、--thai/αα、--thai/-α3.7、--thai/-α4.2、--sea/-α4.2、--sea/--sea、--sea/-α3.7、-α3.7/-α3.7、-α4.2/-α4.2、αα/αwsα、αα/αqsα、αα/αcsα、αwsα/αwsα、αcsα/αcsα、αqsα/αqsα、βn/βcd41-42、βcd41-42/βcd41-42、βn/βivs-ii-654、βivs-ii-654/βivs-ii-654、βn/β-28、β-28/β-28、βn/βcd71-72(+a)、βcd71-72(+a)/βcd71-72(+a)、βn/βcd17、βcd17/βcd17、βn/βcd26、βcd26/βcd26、βn/βivs-i-1、βivs-i-1/βivs-i-1、βn/βcd43、βcd43/βcd43、βn/β-32、β-32/β-32、βn/β-29、β-29/β-29、βn/βcd2728、βcd2728/βcd2728、βn/βcd14-15、βcd14-15/βcd14-15、βn/βcap+1、βcap+1/βcap+1、βn/βint、βint/βint、βn/β-31、β-31/β-31、βn/β-30、β-30/β-30、βn/βivs-i-5、βivs-i-5/βivs-i-5、βn/βcd30、βcd30/βcd30、βn/βcd31、βcd31/βcd31、βn/βivs-ii-2、βivs-ii-5/βivs-ii-5各1份(共57份),用灭菌双蒸水将gdna标本稀释至15-200ng/μl备用。
(2)样本检测:将上述待检gdna标本,2份α和β珠蛋白基因均无突变的正常对照gdna样本,以及1-2份质量控制标本,按照表1配制pcr扩增体系,在体系中分别加入5ng、15ng、30ng、60ng、120ng、240ng,按照反应程序:95℃预变性8min;95℃45sec+66℃1min,72℃1min30sec,40个循环;72℃5min,进行pcr扩增。扩增完成后,按表2于每个反应管加入去dntp反应体系并按反应条件(37℃40min;85℃5min)于bio-radc1000pcr仪上去除残留的dntps;然后再按表3及表4于每个反应管中加入各目的基因及突变位点质谱延伸探针及ddntps单碱基延伸试剂,按反应条件(95℃预变性5min;95℃30sec,(58℃5sec,80℃5sec,5个循环),40个循环;72℃3min)于bio-radc1000pcr仪上进行单碱基延伸。反应完成后,于达瑞生物飞行时间质谱检测系统上,用树脂封片去除体系中的盐离子,后将延伸产物点样至芯片,按表5设置质谱参数进行质谱分析。
(3)检测结果:
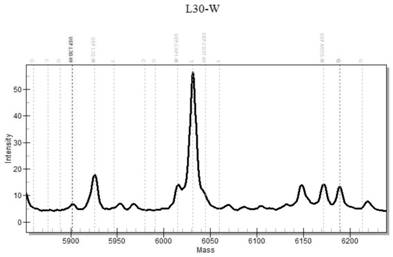
所检标本已知的基因型与本实例分析的结果相比较,结果显示本实例方法的准确性达到100%,灵敏度达15ng/t。hbb基因的-32、-31、-30、-29、-28位点非突变检测质谱图如图1所示,hbb基因的-32、-31、-30、-29、-28位点突变检测质谱图分别如图2、3、4、5、6所示;hbb基因的ivs-i-1、cd30、ivs-i-5位点非突变检测质谱图如图7所示,hbb基因的ivs-i-1、cd30、ivs-i-5位点突变检测质谱图如图8、9、10所示。
四、结果的灵敏性与准确性分析
(1)样本来源及类型:收集218例经gap-pcr和rdb检测的已知基因型gdna标本,此批标本包含-α3.7/αα、-α4.2/αα、--sea/αα、--thai/αα、αα/αwsα、αα/αqsα、αα/αcsα、βn/βcd41-42、βn/βivs-ii-654、βn/β-28、βn/βcd71-72(+a)、βn/βcd17、βn/βcd26、βn/βivs-i-1、βn/βcd43、βn/β-32、βn/β-29、βn/βcap+1、βn/βint、βn/βcd2728、βn/βcd14-15、βn/β-30、βn/βivs-i-5、βn/βcd30、βn/βcd31、βn/βivs-ii-2、βn/βivs-ii-5、βn/βcd30、βn/βcd3129种基因型,用灭菌双蒸水将gdna标本稀释至15-200ng/μl备用。
(2)样本检测:将上述待检gdna标本,2份α和β珠蛋白基因均无突变的正常对照gdna样本,以及1-2份质量控制标本,按照表1配制pcr扩增体系,按照反应程序:95℃预变性8min;95℃45sec+66℃1min,72℃1min30sec,40个循环;72℃5min,进行pcr扩增。扩增完成后,按表2于每个反应管加入去dntp反应体系并按反应条件(37℃40min;85℃5min)于abi2720pcr仪上去除残留的dntps;然后再按表3及表4于每个反应管中加入各目的基因及突变位点质谱延伸探针及ddntps单碱基延伸试剂,按反应条件(95℃预变性5min;95℃30sec,(58℃5sec,80℃5sec,5个循环),40个循环;72℃5min)于abi2720pcr仪上进行单碱基延伸。反应完成后,于飞行时间质谱检测系统上,用树脂封片去除体系中的盐离子,后将延伸产物点样至芯片,按表5设置质谱参数进行质谱分析。每个样本进行16次重复性试验;同时,对该体系稳定性做评价,在24天内,每隔2天将29种基因型各取一管进行检测,共检测12次,通过统计各个位点每次检测的突变型峰值和野生型峰值的比值或突变型峰值和延伸探针峰值的比值,进行稳定性分析。
(3)检测结果:29种基因型批内重复性评价检测结果每个样本16次重复性试验结果均一致,结果表明本试剂盒的检测体系具有良好的重复性;29种基因型批间稳定性评价检测结果,每个样本隔天12次检测结果均一致,结果表明本实例的检测体系具有良好的稳定性。
实施例2一种基于maldi-tof质谱平台的密集单核苷酸变异位点快速检测方法应用于检测酪氨酸激酶受体相关的肺癌基因突变热点
非小细胞肺癌(no-smallcelllungcancer,nsclc)患者可从相应的靶向药物如针对egfr和alk基因突变的酪氨酸激酶抑制剂(tyrosinekinaseinhibitors,tki)吉非替尼/厄洛替尼和克唑替尼等治疗中获益,但是大部分患者接受tki治疗后会因继发突变而导致耐药且不断有新突变位点的发现。因此,肿瘤靶点分子分型的复杂性决定了开展同步多基因检测的必要性。
massarray平台可以实现经济简便的多重扩增反应基因型检测。通过延伸碱基的分子量,从而判断目的基因是否突变。该技术分型结果准确,实验设计灵活,是多基因平行检测的理想平台。因此对于egfr基因δe746-a750、δe746-t751、δe746-a750(insrp)、δe746-t751(insa/i)、δe746-t751(insva)、δe746-s752(insa/v)、δl747-e749(a750p)、δl747-a750(insp)、δl747-t751、δl747-t751(insp/s)、δl747-s752、δl747-752(e746v)、δl747-752(p753s)、δl747-s752(insq)、δl747-p753、δl747-p753(inss)突变等密集snv位点,通过本发明所提供的密集snv位点各突变类型特异性杂交探针的设计延伸探针,实现对egfr基因密集突变位点的快速准确分型。
一、引物设计
基于酪氨酸激酶受体相关的肺癌基因突变热点所包含的点突变物理位置目的基因序列设计了扩增引物和延伸探针。
根据需检测单核苷酸变异位点,向变异位点的上游和下游进行截取15~30个碱基,确定靶序列扩增子范围,在扩增范围内,按照下面的方法设计用于maldi-tof质谱检测的引物和探针:
各单核苷酸变异位点均只以正向链或只以反向链为模板进行引物的设计;针对每一单核苷酸变异位点各基因型的单碱基延伸探针,snv位点位于探针中央5个碱基范围;
针对每一单核苷酸变异位点各基因型的单碱基延伸探针的tm值比拟设定的检测体系单碱基延伸杂交工作温度高3℃~5℃;
针对每一单核苷酸变异位点各基因型的单碱基延伸探针,以单核苷酸变异位点所处具体位点为界,两端序列的tm值差异不超过5℃;
针对每一单核苷酸变异位点各基因型的单碱基延伸探针,以snv所处具体位点为界,两端序列的tm值均需低于拟设定检测体系杂交工作温度差5℃以上。
由于因为maldi-tof质谱平台检测分子量范围是4000~10000da,相当于15~30个碱基的单链寡核苷酸聚合物,当pcr引物为20bp左右,如pcr反应没有能将所有的pcr引物消耗完全,存在反应体系里面,会被当成产物被检测到,干扰检测。
所以,为了避免由于引物的分子量是在质谱检测的分子量范围内,造成干扰后面的检测,在引物的5’端增加一段接头,接头的序列为acgttggatg。
其中,扩增引物包括:
(1)一对特异性扩增egfr基因19号外显子的引物中,
上游引物序列为:5’-acgttggatgtctctctgtcggactatagctgg-3’(seqidno:51),
下游引物序列为:5’-acgttggatggtgggaggttcctgcaga-3’(seqidno:52);
(2)一对特异性扩增egfr基因20号外显子的引物中,
上游引物序列为:5’-acgttggatgaccaagccactgcgaact-3’(seqidno:53),
下游引物序列为:5’-acgttggatggcagccgagcatgagga-3’(seqidno:54);
(3)一对特异性扩增egfr基因18号外显子的引物中,
上游引物序列为:5’-acgttggatgctcccaactctcccaagttga-3’(seqidno:55),
下游引物序列为:5’-acgttggatggtgccagggaccaccttttatac-3’(seqidno:56);
(4)一对特异性扩增egfr基因21号外显子的引物中,
上游引物序列为:5’-acgttggatggccaggactggtgaacgtaaa-3’(seqidno:57),
下游引物序列为:5’-acgttggatgcctccttactctcctttgctct-3’(seqidno:58);
(5)一对特异性扩增braf基因15号外显子的引物中,
上游引物序列为:5’-acgttggatgtttcttcatgaagcagtaacctcaa-3’(seqidno:59),
下游引物序列为:5’-acgttggatgtcaattcttaccacaacatcaatg-3’(seqidno:60);
(6)一对特异性扩增braf基因2号外显子的引物中,
上游引物序列为:5’-acgttggatgatttttattatacctgaggctga-3’(seqidno:61),
下游引物序列为:5’-acgttggatgcgtccacagattcaaattga-3’(seqidno:62);
(7)一对特异性扩增pik3ca基因21号外显子的引物中,
上游引物序列为:5’-acgttggatgtgagcaattgggaggctagt-3’(seqidno:63),
下游引物序列为:5’-acgttggatgtgtggaatgagtgccaagctt-3’(seqidno:64);
(8)一对特异性扩增pik3ca基因10号外显子的引物中,
上游引物序列为:5’-acgttggatggctagagattaaggcaatgaagaaa-3’(seqidno:65),
下游引物序列为:5’-acgttggatgctccattttacttacctgcagtgac-3’(seqidno:66)。
延伸探针可分为两类:
对于分布零散的突变位点,突变位点是单碱基突变时,根据一条延伸探针的产物进行maldi-tof-ms检测(如g719a、g719s、g719c、l858r、l861q、s768i、t790m、v600e、g12r、g12s、g12c、g12a,g12v和g12d等),就可以判断是否发生突变;当突变位点发生多碱基的插入或者缺失时(如d770-n771insg、h773-v774insh和v769-d770insasv),则根据引物设计的需要分别对插入或者缺失片段的一端或两端进行单碱基延伸,单探针延伸的位点分析与单碱基突变的相同,对于两端延伸的位点需要对两条单碱基延伸的引物延伸结果同时进行分析,才能判断是否发生突变。
对于分布密集的位点,采用本发明的策略设计延伸探针(如l747-a750>p_2239_2248ttaagagaag>c、l747-t751del_2240_2254del15、e746-s752>v_2237_2255>t、l747-t751>s_2240_2251del12、l747-s752del_2239_2256del18、e746-t751>a_2237_2251del15、l747-t751>p_2239_2251>c、l747-e749del_2239_2247delttaagagaa、e746-a750del_2235_2249del15、l747-t751del_2239_2253del15和l747-p753>s_2240_2257del18等),每组分布密集的突变位点共用一条野生型延伸探针,每个突变位点各有一条相应的突变型延伸探针,结合每个位点对应的突变型延伸探针的产物和野生型延伸探针的产物的有无来判断是否发生突变。包括:
(9)特异性检测egfr基因g719a点突变的质谱分析探针为:
5’-gccaccggcgaacgag-3’(seqidno:67);
(10)特异性检测egfr基因g719s和g719c点突变的质谱分析探针为:5’-aagaagtgcatcatg-3’(seqidno:68);
(11)特异性检测egfr基因l858r点突变的质谱分析探针为:5’-tgtcaagatcgattttgacaggc-3’(seqidno:69);
(12)特异性检测egfr基因l861q点突变的质谱分析探针为:5’-ttctgcacccttcccagc-3’(seqidno:70);
(13)特异性检测egfr基因d770-n771insg点突变的质谱分析探针1为:5’-gtgcagcgtggatggcac-3’(seqidno:71);
(14)特异性检测egfr基因d770-n771insg点突变的质谱分析探针2为:5’-cgcacgtggggcaggtt-3’(seqidno:72)。
(15)特异性检测egfr基因h773-v774insh点突变的质谱分析探针1为:5’-gtggcccacaaccac-3’(seqidno:73);
(16)特异性检测egfr基因h773-v774insh点突变的质谱分析探针2为:5’-agggcacacgcgtgg-3’(seqidno:74)。
(17)特异性检测egfr基因v769-d770insasv点突变的质谱分析探针1为:5’-tgacagctggcgtgg-3’(seqidno:75);
特异性检测egfr基因v769-d770insasv点突变的质谱分析探针2为:5’-tgtccggacgctcca-3’(seqidno:76)。
(18)特异性检测egfr基因s768i点突变的质谱分析探针为:5’-agccgatggctacgtca-3’(seqidno:77)。
(19)特异性检测egfr基因t790m点突变的质谱分析探针为:5’-ccgtgcaaccgctcatca-3’(seqidno:78)。
(20)特异性检测braf基因v600e点突变的质谱分析探针为:5’-tgatttctagcttggtacag-3’(seqidno:79)。
(21)特异性检测kras基因g12r、g12s和g12c点突变的质谱分析探针为:5’-actggtagttgttggagct-3’(seqidno:80)。
(22)特异性检测kras基因g12a、g12v和g12d点突变的质谱分析探针为:5’-acttgtgtggagtagtgctg-3’(seqidno:81)。
(23)特异性检测kras基因g13d点突变的质谱分析探针为:5’-tggtagctgggttggatg-3’(seqidno:82)。
(24)特异性检测pik3ca基因h1047r点突变的质谱分析探针为:5’-tgttgtcccatcagccaga-3’(seqidno:83)。
(25)特异性检测pik3ca基因e542k点突变的质谱分析探针为:5’-ccagtgatgctcttt-3’(seqidno:84)。
(26)特异性检测pik3ca基因e545k点突变的质谱分析探针为:5’-attctctaacctcaatcact-3’(seqidno:85)。
(25)特异性检测egfr基因l747-a750>p_2239_2248ttaagagaag>c、l747-t751del_2240_2254del15、e746-s752>v_2237_2255>t、l747-t751>s_2240_2251del12、l747-s752del_2239_2256del18、e746-t751>a_2237_2251del15、l747-t751>p_2239_2251>c、l747-e749del_2239_2247delttaagagaa、e746-a750del_2235_2249del15、l747-t751del_2239_2253del15、l747-p753>s_2240_2257del18的野生型质谱分析探针为:5’-aaggaattaagcaacgagaaatctc-3’(seqidno:86)。
(26)特异性检测egfr基因l747-a750>p_2239_2248ttaagagaag>c的突变型质谱分析探针为:5’-atcaaggacatcacaatcc-3’(seqidno:87)。
(27)特异性检测egfr基因l747-t751del_2240_2254del15的突变型质谱分析探针为:5’-ctatcaaggatctcacgaa-3’(seqidno:88)。
(28)特异性检测egfr基因e746-s752>v_2237_2255>t的突变型质谱分析探针为:5’-tatcaaggtcaagccgaca-3’(seqidno:89)。
(29)特异性检测egfr基因l747-t751>s_2240_2251del12的突变型质谱分析探针为:5’-ctcaaggaatctctcacgaa-3’(seqidno:90)。
(30)特异性检测egfr基因l747-s752del_2239_2256del18的突变型质谱分析探针为:5’-gctatcaaggcatccgtcaaa-3’(seqidno:91)。
(31)特异性检测egfr基因e746-t751>a_2237_2251del15的突变型质谱分析探针为:5’-gctatcaatctaggcccgaaa-3’(seqidno:92)。
(32)特异性检测egfr基因l747-t751>p_2239_2251>c的突变型质谱分析探针为:5’-tatcaaggaacctccatgaaa-3’(seqidno:93)。
(33)特异性检测egfr基因l747-e749del_2239_2247delttaagagaa的突变型质谱分析探针为:5’-gctatcaagcaacgaagatct-3’(seqidno:94)。
(34)特异性检测egfr基因e746-a750del_2235_2249del15的突变型质谱分析探针为:5’-ccgctatcacatctaaaccgaa-3’(seqidno:95)。
(35)特异性检测egfr基因l747-t751del_2239_2253del15的突变型质谱分析探针为:5’-atcaaggaatgaaatctccgcc-3’(seqidno:96)。
(36)特异性检测egfr基因l747-p753>s_2240_2257del18的突变型质谱分析探针为:5’-atcaaggaaagcctcgaaaaca-3’(seqidno:97)。
(37)特异性检测egfr基因l747-p753>q_2239_2258>c的突变型质谱分析探针为:5’-ttcccgtcgtcaactaggaa-3’(seqidno:98)。
(38)特异性检测egfr基因e746-a750del_2236_2250del15的突变型质谱分析探针为:5’-atcaagcaagcatcgaaaaccca-3’(seqidno:99)。
二、检测方法
(1)pcr反应:按照表7配制好pcr反应混合物(模板gdna除外),混匀后分装于96孔板相应的孔中,最后加入模板gdna用封口膜将96孔板封住,震荡混匀后瞬时离心,放入pcr扩增仪。pcr扩增体系如表8所示。
表7本实例pcr扩增引物混合液体系:
表8本实例pcr反应体系:
pcr扩增程序为:95℃预变性2min;95℃30sec+56℃30sec,72℃1min,45个循环;72℃5min;4℃保存。
(2)去dntps反应:向每孔pcr产物中加入2.00μl如表9所示的去dntps反应体系,更换新的膜将96孔板封住,震荡混匀后瞬时离心。
表9去dntps反应体系:
(3)单碱基延伸反应:按照表11配制延伸探针混合液,震荡混匀后瞬时离心,然后依次按照表10反应体系顺序分别加入各组成分,配制成单碱基延伸反应混合液。向去dntps反应后的每孔产物中加入上述2.00μl单碱基延伸反应混合液,用新的膜将96孔板封住,震荡混匀后瞬时离心。
表10本实例单碱基延伸反应体系:
其中,每100.00μl延伸探针混合液的组成如表11所示
表11延伸探针混合液体系:
单碱基延伸反应程序为:95℃预变性30sec;95℃5sec,(52℃5sec,80℃5sec,5个循环),40个循环;72℃3min;4℃保存。
(4)反应结束后,2000rpm瞬时离心,每孔加入30μl的灭菌双蒸水,换新的膜将96孔板封住,震荡混匀后,瞬时离心。
(5)质谱检测:所用软件及程序参数设置同实例1“二、检测方法(5)”。
(8)数据分析和结果判断:利用typer4.0软件,根据延伸探针及探针延伸后分子量大小(如表12)及峰值强度的信噪比计算z值。判读目标位点的基因型。
对于非密集位点,即传统策略设计探针的位点,若为单探针延伸的位点,某基因位点的z值≥3时,表明该基因位点发生了突变;若为双探针延伸的位点,z值≥3且第二条延伸探针的检测结果为相应型别,则该位点发生突变。
对于密集位点,即采用本发明策略设计探针的位点,突变型探针z值≥3时,检测结果为相应的型别,则该位点发生突变。计算公式如下:
x:某个基因位点信噪比
medium:参考数据库中的中位数
std:参考数据库中的方差
表12各突变位点质谱探针峰、野生型峰和突变型峰对应分子量表:
三、小规模人群筛查检测评价
1、样本收集:
随机收集92份石蜡组织样本和新鲜组织样本,男女各56份,年龄20-50岁。用广州达瑞生物技术股份有限公司的核酸提取或纯化试剂盒抽提gdna,以灭菌双蒸水将gdna标本稀释至5-200ng/μl备用。
2、样本检测:
将上述92份待检gdna标本,采用双盲的方法,同时应用测序法及本实例方法平行检测。本实例方法的检测方法为:将上述待检gdna标本,2份egfr、kras、braf和pik3ca基因均无突变的正常对照gdna样本,以及1-2份质量控制标本,应用上述本实例方法的反应体系(表8),以及反应程序(95℃预变性2min;95℃30sec+56℃30sec,72℃1min,45个循环;72℃5min)进行pcr扩增。扩增完成后,按表9于每个反应管加入去dntp反应体系并按反应条件(37℃40min;85℃5min)于bio-radc1000pcr仪上去除残留的dntps;然后再按表11及表10于每个反应管中加入各目的基因及突变位点质谱延伸探针及ddntps单碱基延伸试剂,按反应条件(95℃预变性30sec;95℃5sec,(52℃5sec,80℃5sec,5个循环),40个循环;72℃3min)于bio-radc1000pcr仪上进行单碱基延伸。反应完成后,于达瑞生物飞行时间质谱检测系统上,用树脂封片去除体系中的盐离子,后将延伸产物点样至芯片,按表5设置质谱参数进行质谱分析。
3、检测结果:
如表9所示,两种检测方法均检出4例标本有egfr基因缺失,2例有kras基因点突变,1例有pik3ca基因点突变,85例无上述突变,阴性与阳性符合率100%。egfr的g719a、g719s、g719c和l747-t751>s_2240_2251del12的野生型质谱图分别如图11、13、13和16所示,kras的g12c、g12s野生型质谱图如18所示,pik3ca的e542k野生型质谱图如图21所示。egfr的g719a、g719s、g719c、l747-t751>s_2240_2251del12的突变阳性质谱图分别如图12、14、15、17所示,kras的g12c、g12s突变阳性质谱图如19、20所示,pik3ca的e542k突变阳性质谱图如图22所示。
表992例随机样本egfr、kras、braf和pik3ca基因突变筛查阳性检测结果
四、检测egfr、kras、braf、pik3ca基因位点突变5%的情况
1、样本收集
选取4份由相应基因相应突变型别的细胞株dna和野生型人类基因组dna混合制备而成且突变比例为5%的样本。
2、样本检测
将上述4份待检dna标本,同时应用测序法及本实例方法平行检测。按照前文进行多重pcr扩增、sap处理和单碱基延伸反应,最后进行质谱仪检测并数据分析。
3、检测结果:
4份样本分别为egfr、kras、braf、pik3ca这4个基因的4个位点突变阳性,具体见表10。
表104例egfr、kras、braf、pik3ca基因突变比例为5%的样本检测结果:
最后所应当说明的是,以上实施例仅用以说明本发明的技术方案而非对本发明保护范围的限制,对于本领域的普通技术人员来说,在上述说明及思路的基础上还可以做出其它不同形式的变化或变动,这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
序列表
<110>周万军
广州市达瑞生物技术股份有限公司
<120>一种maldi-tof质谱检测密集单核苷酸变异位点的引物和探针的设计方法
<160>99
<170>siposequencelisting1.0
<210>1
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>1
gaacccctcgccaccacagtcc22
<210>2
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>2
gcagaccaggaaccgggggtg21
<210>3
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>3
gcaagcgatctgtgtgggctctt23
<210>4
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>4
ggagcccacgttgtcatggttgc23
<210>5
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>5
cgaccagtttacccaggtgtgtc23
<210>6
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>6
cgacccgttggatctcattttct23
<210>7
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>7
gcaggcaaacctgcaatcttgat23
<210>8
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>8
cctcagcctcctccactcatcac23
<210>9
<211>28
<212>dna
<213>人工序列(artificialsequence)
<400>9
gatctgcacctctgggtttctagggtac28
<210>10
<211>28
<212>dna
<213>人工序列(artificialsequence)
<400>10
gatctgcacctctgggtttctagggtac28
<210>11
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>11
cggctgtgggaggaagaaggtattaaggaac31
<210>12
<211>15
<212>dna
<213>人工序列(artificialsequence)
<400>12
gggcctgaccgcacc15
<210>13
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>13
tgcaaactcatccacactacc21
<210>14
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>14
aggagaagtcagtaggcgcagc22
<210>15
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>15
ggagagggaaggagcagtcac21
<210>16
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>16
atgcctgtgaagcgtcatct20
<210>17
<211>14
<212>dna
<213>人工序列(artificialsequence)
<400>17
gcacgccctctcgg14
<210>18
<211>14
<212>dna
<213>人工序列(artificialsequence)
<400>18
tgcagctccgcctg14
<210>19
<211>14
<212>dna
<213>人工序列(artificialsequence)
<400>19
cgcctccggaccca14
<210>20
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>20
gctgacctccatacaacgt19
<210>21
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>21
gctgggcataagtaacagg19
<210>22
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>22
ggctgggaataagtaacag19
<210>23
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>23
ttgggcacaagtcagaag18
<210>24
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>24
tgggcatagtcaagaggg18
<210>25
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>25
tgggcatgaagtcaagg17
<210>26
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>26
ctgggcctaagtcaaagg18
<210>27
<211>25
<212>dna
<213>人工序列(artificialsequence)
<400>27
ccatctattgctttgttacacttct25
<210>28
<211>25
<212>dna
<213>人工序列(artificialsequence)
<400>28
ccatctattgctttgttacacttct25
<210>29
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>29
ccgtggtctcttaccggacc20
<210>30
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>30
ttggtggtctacccttagacc21
<210>31
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>31
caacctcaagaaaccacca19
<210>32
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>32
gtggggtgacaaggacg17
<210>33
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>33
tgtggggcttgaaggacg18
<210>34
<211>13
<212>dna
<213>人工序列(artificialsequence)
<400>34
gccctggggtggc13
<210>35
<211>16
<212>dna
<213>人工序列(artificialsequence)
<400>35
aggtgggagtgccctg16
<210>36
<211>16
<212>dna
<213>人工序列(artificialsequence)
<400>36
tggtggtagccagctg16
<210>37
<211>15
<212>dna
<213>人工序列(artificialsequence)
<400>37
gtggtgaggctcccg15
<210>38
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>38
gcaggttggtaggtatcatac21
<210>39
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>39
gcagtttggtagttatcaagca22
<210>40
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>40
agcgggttatcaggtagg18
<210>41
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>41
gcaggttgaggctatcatta20
<210>42
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>42
cagaggtgtccttctttgattgg23
<210>43
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>43
gaggttgttgagtcctgg18
<210>44
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>44
ggttcttttattggtcctggg21
<210>45
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>45
taacttagtccagggtgtatgg22
<210>46
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>46
aaaacttcagtctggggaatgg22
<210>47
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>47
taacttcgtctagggtgaatgg22
<210>48
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>48
acagtgataattgttatctggagg24
<210>49
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>49
agtgctcgcttgtgcta17
<210>50
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>50
gtctattttccttaccaccgg21
<210>51
<211>33
<212>dna
<213>人工序列(artificialsequence)
<400>51
acgttggatgtctctctgtcggactatagctgg33
<210>52
<211>28
<212>dna
<213>人工序列(artificialsequence)
<400>52
acgttggatggtgggaggttcctgcaga28
<210>53
<211>28
<212>dna
<213>人工序列(artificialsequence)
<400>53
acgttggatgaccaagccactgcgaact28
<210>54
<211>27
<212>dna
<213>人工序列(artificialsequence)
<400>54
acgttggatggcagccgagcatgagga27
<210>55
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>55
acgttggatgctcccaactctcccaagttga31
<210>56
<211>33
<212>dna
<213>人工序列(artificialsequence)
<400>56
acgttggatggtgccagggaccaccttttatac33
<210>57
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>57
acgttggatggccaggactggtgaacgtaaa31
<210>58
<211>32
<212>dna
<213>人工序列(artificialsequence)
<400>58
acgttggatgcctccttactctcctttgctct32
<210>59
<211>35
<212>dna
<213>人工序列(artificialsequence)
<400>59
acgttggatgtttcttcatgaagcagtaacctcaa35
<210>60
<211>34
<212>dna
<213>人工序列(artificialsequence)
<400>60
acgttggatgtcaattcttaccacaacatcaatg34
<210>61
<211>33
<212>dna
<213>人工序列(artificialsequence)
<400>61
acgttggatgatttttattatacctgaggctga33
<210>62
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>62
acgttggatgcgtccacagattcaaattga30
<210>63
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>63
acgttggatgtgagcaattgggaggctagt30
<210>64
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>64
acgttggatgtgtggaatgagtgccaagctt31
<210>65
<211>35
<212>dna
<213>人工序列(artificialsequence)
<400>65
acgttggatggctagagattaaggcaatgaagaaa35
<210>66
<211>35
<212>dna
<213>人工序列(artificialsequence)
<400>66
acgttggatgctccattttacttacctgcagtgac35
<210>67
<211>16
<212>dna
<213>人工序列(artificialsequence)
<400>67
gccaccggcgaacgag16
<210>68
<211>15
<212>dna
<213>人工序列(artificialsequence)
<400>68
aagaagtgcatcatg15
<210>69
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>69
tgtcaagatcgattttgacaggc23
<210>70
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>70
ttctgcacccttcccagc18
<210>71
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>71
gtgcagcgtggatggcac18
<210>72
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>72
cgcacgtggggcaggtt17
<210>73
<211>15
<212>dna
<213>人工序列(artificialsequence)
<400>73
gtggcccacaaccac15
<210>74
<211>15
<212>dna
<213>人工序列(artificialsequence)
<400>74
agggcacacgcgtgg15
<210>75
<211>15
<212>dna
<213>人工序列(artificialsequence)
<400>75
tgacagctggcgtgg15
<210>76
<211>15
<212>dna
<213>人工序列(artificialsequence)
<400>76
tgtccggacgctcca15
<210>77
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>77
agccgatggctacgtca17
<210>78
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>78
ccgtgcaaccgctcatca18
<210>79
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>79
tgatttctagcttggtacag20
<210>80
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>80
actggtagttgttggagct19
<210>81
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>81
acttgtgtggagtagtgctg20
<210>82
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>82
tggtagctgggttggatg18
<210>83
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>83
tgttgtcccatcagccaga19
<210>84
<211>15
<212>dna
<213>人工序列(artificialsequence)
<400>84
ccagtgatgctcttt15
<210>85
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>85
attctctaacctcaatcact20
<210>86
<211>25
<212>dna
<213>人工序列(artificialsequence)
<400>86
aaggaattaagcaacgagaaatctc25
<210>87
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>87
atcaaggacatcacaatcc19
<210>88
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>88
ctatcaaggatctcacgaa19
<210>89
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>89
tatcaaggtcaagccgaca19
<210>90
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>90
ctcaaggaatctctcacgaa20
<210>91
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>91
gctatcaaggcatccgtcaaa21
<210>92
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>92
gctatcaatctaggcccgaaa21
<210>93
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>93
tatcaaggaacctccatgaaa21
<210>94
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>94
gctatcaagcaacgaagatct21
<210>95
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>95
ccgctatcacatctaaaccgaa22
<210>96
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>96
atcaaggaatgaaatctccgcc22
<210>97
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>97
atcaaggaaagcctcgaaaaca22
<210>98
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>98
ttcccgtcgtcaactaggaa20
<210>99
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>99
atcaagcaagcatcgaaaaccca23
- 还没有人留言评论。精彩留言会获得点赞!