一种DNA和RNA共建库的方法及试剂盒与流程
本发明涉及生物技术领域,具体涉及一种dna和rna同时构建测序文库的方法。
背景技术:
目前针对不同的核酸样本是采用不同的建库策略。普通dna样本首先经过末端修复及加a,然后进行接头连接,最后通过pcr扩增完成dna测序文库的构建,耗时3h左右。普通rna样本首先需要进行poly(a)的捕获或者核糖体rna的去除,然后进行cdna的合成,最后通过dna样本建库策略完成rna测序文库的构建,耗时8h。宏基因组测序在新病原体的诊断、检测、跟踪及溯源起到关键的作用。传统的建库方式无法真正做到dna和rna样本共同建库,目前出现的一种dna/rna共建库的方法是:rna经过oligo-dt引物反转录后,tn5转座酶随机对rna/dna杂合链进行切割,在片段化之后,转座酶会在杂合链两端加上接头,之后进行pcr扩增。此种方法的核心点在于使用tn5转座酶对rna/cdna复合双链和dna双链进行打断和添加部分接头,该方法虽然可以很大程度上的优化了建库步骤,节省建库时间,但是tn5转座酶打断建库依然存在着一些不可避免的缺陷:1)tn5转座酶打断识别具有特异性,其测序的前9个bp有明显的偏好性,即使是突变的tn5转座酶也无法完全消除bais;2)tn5建库是酶量依赖型,对dna的定量要求高,酶和dna的比例不准确会影响打断;3)对dna溶液杂质不耐受,会影响打断效果;4)tn5建库无法适用于降解性的样本或者分子片段较小的核酸。
因此,有必要针对现有技术的缺陷,采用单链建库的原理,提出一种不同与tn5转座酶建库的dna/rna共建库的方法,简化建库流程,减少建库时间,同时也可以解决测序偏好性的问题,并能适应于降解样本和不同分子片段大小的核酸样本的新型高效共建库方法。
技术实现要素:
针对现有技术的缺陷,本发明基于单链建库的原理,提出一种dna和rna共建库的方法,以达到有效的简化建库流程,减少建库时间,解决测序偏好性的问题,也能适应于降解样本和不同分子片段大小的核酸样本的目的。
为了达到上述目的,本发明提出一种dna和rna共建库的方法,包括以下步骤:
1.对rna和dna混合样本进行rna片段化及dna变性;
2.基于s1产物,利用随机引物进行dna的链置换反应,将dna片段带上5'接头,形成5'trunctedadapter-dna;将rna逆转录成一链cdna,带上5'接头,形成5'trunctedadapter-cdna;
3.使用外切酶对多余的引物进行消化,再利用磁珠对产物进行纯化;
4.对带5'接头的dna及带有5'接头的一链cdna的3'末端添加一段多聚寡核苷酸ployc,得到5'trunctedadapter-dna-多聚寡核苷酸结构,利用dna修复酶、dna聚合酶及dna连接酶将所述5'trunctedadapter-dna-多聚寡核苷酸的3'末端和p7接头连接;
5.通过pcr文库扩增,得到上机测序文库。
进一步地,所述步骤1中包括对混合样本中的dna进行片段化。
进一步地,所述随机引物为t5trunctedadapter+n6,所述随机引物核苷酸序列如seqidno:1所示。
进一步地,所述步骤s2在klenow(exo-)聚合酶和逆转录酶及rnainhibitor条件下进行一链cdna的合成及链置换反应。
进一步地,所述逆转录酶为hiscriptii逆转录酶、hiscriptiii逆转录酶、hiscriptiv逆转录酶中的一种。
进一步地,所述步骤3使用exoi外切酶对残留引物进行消化。
进一步地,所述dna聚合酶选自klenow(exo-)聚合酶、bsudna聚合酶、phi29聚合酶、taq聚合酶、a家族dna聚合酶、b家族高保真聚合酶中的一种。
本发明的另一目的在于,提供一种dna和rna共建库的试剂盒,包括如下组分:
1)工具酶:所述工具酶包括逆转录酶、末端转移酶、dna修复酶、dna聚合酶、dna连接酶;
2)工具酶反应体系:各个工具酶对应的反应所需要的缓冲液;
3)接头体系:随机引物及t7truncatedadapter;
4)外切酶消化体系;
5)pcr反应体系;
6)low-edta-te。
进一步地,所述随机引物核苷酸序列如seqidno:1所示。
进一步地,所述逆转录酶为hiscriptii逆转录酶、hiscriptiii逆转录酶、hiscriptiv逆转录酶中的一种;
进一步地,所述dna连接酶为t4dna连接酶、taqdna连接酶及e.colidna连接酶中的一种;
进一步地,所述聚合酶为klenow(exo-)聚合酶、bsudna聚合酶、phi29聚合酶、taq聚合酶、a家族dna聚合酶、b家族高保真聚合酶中的一种。
与现有技术相比,本发明的有益效果为:
1)本发明实现了dna/rna样本同时完成测序文库的建库。打破了常规的建库策略,不依赖样本的完整性,适用于各种dna及rna样本建库。本发明可以用于宏基因测序,对病毒微生物等具有良好的实用性;
2)本发明实验步骤简单,用时短,可以有效的降低成本。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
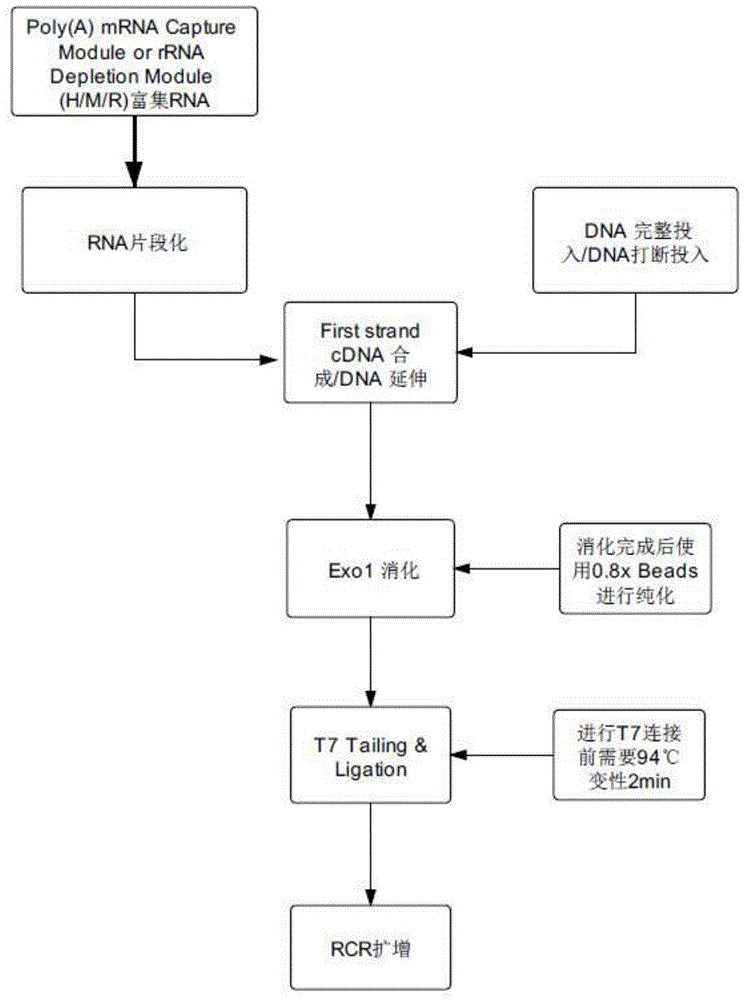
图1是本发明一种dna/rna共建库的方法流程图;
图2是本发明一种dna/rna共建库的原理图;
图3是t7truncatedadapter结构示意图;
图4是实施例1中rna样本的建库的一链cdna合成效率分析图;
图5是实施例1中rna样本的文库制备示意图;
图6是实施例2中dna样本的文库制备示意图;
图7是实施例3中dna和rna混合样本的文库制备示意图。
具体实施方式
以下实例用于说明本发明,但不限制本发明的范围。在不背离本发明精神和实质的前提下,对本发明的方法、步骤或条件所作的修改或替换,均属于本发明的范围。
本发明的建库原理为:通过对样本中rna的打断及dna变性,一链cdna合成及链置换反应、dna3'接头的连接并形成单链,通过pcr扩增快速地来实现rna和dna混合样本的建库。以达到有效的简化建库流程,减少建库时间,解决测序偏好性的问题,也能适应于降解样本和不同分子片段大小的核酸样本的目的,所述共建库的方法流程图如图1所示,所述建库的原理图如图2所示。
实施例1rna样本的建库
本实施例中,使用小鼠的50ngmrna和大鼠的50ngmrna分别进行建库测试,通过rna片段化、一链cdna合成及链置换反应、dna3'接头的连接及文库扩增完成rna的建库,为了检测可靠性,每个样本设置了两个重复。
1)rna的片段化:
配制反应体系如下:
fragmentbuffer的组成是:320mmtris-hcl,800mmkcl,240mmmgcl2,ph为7.9。运行反应程序:94℃/10min,4℃/hold。
2)链置换反应:
通过随机引物对片段化的rna进行一链cdna的合成。随机引物是在n6的5'端加上t5trunctedadapter,引物序列是:
5'-acactctttccctacacgacgctcttccgatctnnnnnn-3',使用的混合酶1stcdna/dnasynthesisenzymemix是:20uklenow(exo-),200uscriptiirt,20urnaseinhibitor。对照是没有在n6的5'端加上t5trunctedadapter,引物序列是:5'-nnnnnn-3'。
配制反应体系如下:
运行反应程序:25℃/10min,37℃/30min,42℃/30min,70℃/10min,4℃/hold。待反应结束,使用小鼠和大鼠的内参基因mugapdh、muβ-actin、rngapdh、rnβ-actin定量检测一链cdna的合成效率。引物序列如下:
mugapdhf:5'-aggtcggtgtgaacggatttg-3'
mugapdhr:5'-tgtagaccatgtagttgaggtca-3'
muβ-actinf:5'-ggagattactgccctggctccta-3'
muβ-actinr:5'-gactcatcgtactcctgcttgctg-3'
rngapdhf:5'-agtgccagcctcgtctcata-3'
rngapdhr:5'-agagaaggcagccctggtaa-3'
rnβ-actinf:5'-gcagttggttggagcaa-3'
rnβ-actinr:5'-atgccgtggatacttgga-3'
将一链cdna的合成反应液200倍稀释,取1μl反应液+199μlh2o,然后进行定量pcr检测。使用takara的tbgreentmpremixextaqtm(tlirnasehplus)(rr420a)配置反应体系如下:
运行反应程序:95℃预变性30s;95℃变性5s,60℃退火10s,72℃延伸20s,65℃到95℃,0.5℃/s,4℃hold。
实验结果是:使用随机引物和n6的一链cdna的合成效率一致。图3是一链cdna的合成效率分析,a图是小鼠的mugapdh,b图是小鼠的muβ-actin,c图是大鼠的rngapdh,d图是大鼠的rnβ-actin,相比n6,随机引物的一链cdna的合成效率没有发生变化。
3)一链cdna的纯化
按照1.0×ampurexp磁珠比例进行dna纯化。21μllowedtate洗脱磁珠。取20μldna上清,再用1.0×ampurexp磁珠纯化一次,17μl的lowedtate洗脱磁珠,取15μl用于dna3'接头连接。
4)dna3'接头连接
首先将15μl的一链cdna进行95℃变性2min,然后立即置于冰上,待加入dna3'接头连接反应液。使用的试剂t7buffer:700mmtris-hcl,100mmmg(ac)2,260umnad+,10mmdtt,10mmatp,500mmnacl,500mmkac;t7enzymemix:10utdt(neb,m0315),60ue.colidnaligase(neb,m0205),10ut4pnk(t4polynucleotidekinase,neb,m0201),10uklenow(neb,m0212);t7truncatedadapter接头结构如图3所示,采用专利公开文件cn110607353a中的t7truncatedadapter接头。
配置反应体系如下:
运行反应程序:37℃,预变性15min;95℃,2min,4℃hold。
5)文库扩增
使用商业化的试剂2×kapahifihotstartreadymix(kapa,km2618)进行pcr的扩增。扩增引物是universalpcr引物(universalpcrprimer,rm20248,abclonal)和index引物(index,rm22201,abclonal)。
配制反应体系如下:
反应条件如下:
11个循环反应结束,1.0×ampurexp磁珠捕获,使用21μl的low-edta-te洗脱;
建库产量如下:
实验结果:如图4所示,其中a为小鼠的rna的pcr文库峰图,11cycles,文库产量23ng/ul,21ul水洗脱,主峰在500bp左右;b为大鼠的rna的pcr文库峰图,11cycles,文库产量17.2ng/ul,21ul水洗脱,主峰在500bp左右。可见此方法可以完成对rna的测序文库的构建。
实施例2dna样本的建库
本实施例中,使用human的未片段化的基因组dna和200bp片段化的dna分别进行建库测试,通过dna的变性、一链cdna合成、dna3'接头的连接及文库扩增完成dna的建库,为了检测可靠性,每个样本设置了两个重复。
1)dna的变性:
配制反应体系如下:
fragmentbuffer的组成是:320mmtris-hcl,800mmkcl,240mmmgcl2,ph7.9。运行反应程序:94℃/10min,4℃/hold。
2)链置换反应:
通过随机引物对dna进行链置换反应。随机引物是在n6的5'端加上t5trunctedadapter,引物序列是:
5'-acactctttccctacacgacgctcttccgatctnnnnnn-3',使用的混合酶1stcdna/dnasynthesisenzymemix是:20uklenow(exo-),200uscriptiirt,20urnaseinhibitor。
配制反应体系如下:
运行反应程序:25℃/10min,37℃/30min,42℃/30min,70℃/10min,4℃/hold。
3)链置换dna的纯化
按照1.0×ampurexp磁珠比例进行dna纯化。21μllowedtate洗脱磁珠。取20μldna上清,再用1.0×ampurexp磁珠纯化一次,17μl的lowedtate洗脱磁珠,取15μl用于dna3'接头连接。
4)dna3'接头连接
首先将15μl的一链cdna进行95℃变性2min,然后立即置于冰上,待加入dna3'接头连接反应液。使用的试剂t7buffer:700mmtris-hcl,100mmmg(ac)2,260umnad+,10mmdtt,10mmatp,500mmnacl,500mmkac;t7enzymemix:10utdt(neb,m0315),60ue.colidnaligase(neb,m0205),10ut4pnk(t4polynucleotidekinase,neb,m0201),10uklenow(neb,m0212);t7truncatedadapter采用专利公开文件cn110607353a中的t7truncatedadapter接头。
配置反应体系如下:
运行反应程序:37℃,预变性15min;95℃,2min,4℃hold。
5)文库扩增
使用商业化的试剂2×kapahifihotstartreadymix(kapa,km2618)进行pcr的扩增。扩增引物是universalpcr引物(universalpcrprimer,rm20248,abclonal)和index引物(index,rm22201,abclonal)。
配制反应体系如下:
反应条件如下:
8/9个循环反应结束,1.0×ampurexp磁珠捕获,使用21μl的low-edta-te洗脱;
建库产量如下:
实验结果:如图6所示,其中a为human的未片段化的dna的pcr文库扩增,b为human的片段化的dna的pcr文库扩增,图a为human的未片段化的dna样本的pcr文库峰图,9cycles,文库产量25ng/ul21ul水洗脱,主峰在350bp左右,b为human的片段化的dna样本的pcr文库峰图,8cycles,文库产量24.8ng/ul21ul水洗脱,主峰在350bp左右可见此方法可以完成对dna的测序文库的构建。
实施例3:dna/rna样本的建库
本实施例采用上述的一种dna/rna共建库的方法,对常见的dna/rna混合样本进行建库测试。我们测试了两种样本:包括human片段化的dna和ratrna的混合样本和未片段化的humandna和ratrna样本。以下是所示的是基本的dna/rna文库构建步骤,为了检测可靠性,每个样本设置了两个重复。
1)rna的片段化及dna变性
配制反应体系如下:
fragmentbuffer的组成是:320mmtris-hcl,800mmkcl,240mmmgcl2,ph7.9。运行反应程序:94℃/10min,4℃/hold。运行反应程序:94℃/10min,4℃/hold。
2)一链cdna的合成及链置换反应
配制反应体系如下:
随机引物是在n6的5'端加上t5trunctedadapter,引物序列是:5'-acactctttccctacacgacgctcttccgatctnnnnnn-3',使用的混合酶1stcdna/dnasynthesisenzymemix是:20uklenow(exo-),200uscriptiirt,20urnaseinhibitor。对照是没有在n6的5'端加上t5trunctedadapter,引物序列是:5'-nnnnnn-3'。
1stcdna/dnasynthesisenzymemix为klenow(exo-)聚合酶、逆转录酶及rnainhibitor,其中逆转录酶可以选择市售产品中的hiscriptii逆转录酶、hiscriptiii逆转录酶、hiscriptiv逆转录酶。
运行反应程序:25℃/10min,37℃/30min,42℃/30min,70℃/10min,4℃/hold。反应结束后,按照1.0×ampurexp磁珠比例进行两次纯化,选用exoi外切酶对残留引物进行消化。17μl的lowedtate洗脱磁珠,取15μl用于dna3'接头连接。
3)dna3'接头连接
首先将15μl的一链cdna进行95℃变性2min,然后立即置于冰上,使用t7truncatedadapter进行dna3'接头的连接,t7truncatedadapter采用专利公开文件cn110607353a中的t7truncatedadapter接头。
待加入dna3'接头连接反应液。
配置反应体系如下:
使用的试剂t7buffer:700mmtris-hcl,100mmmg(ac)2,260umnad+,10mmdtt,10mmatp,500mmnacl,500mmkac;
t7enzymemix包含dna聚合酶、dna连接酶、dna修复酶。聚合酶可以选择以下市售中的一种:klenow(exo-)聚合酶、bsudna聚合酶、phi29聚合酶、taq聚合酶、a家族dna聚合酶、b家族高保真聚合酶;连接酶可以选择以下市售中的一种:t4dna连接酶、taqdna连接酶及e.colidna连接酶。
本实施例中t7enzymemix包含有:10utdt(neb,m0315),60ue.colidnaligase(neb,m0205),10ut4pnk(t4polynucleotidekinase,neb,m0201),10uklenow(neb,m0212)。
运行反应程序:37℃,预变性15min;95℃,2min,4℃hold。
3.4)文库扩增
配制反应体系如下:
反应条件如下:
7/8个循环反应结束,1.0×ampurexp磁珠捕获,使用21μl的low-edta-te洗脱;
建库产量如下:
实验结果:如图7所示,其中a为human的未片段化的dna和rna共建库的pcr文库扩增,b为human的片段化的dna和rna共建库的pcr文库扩增,其中a为human的未片段化的dna和rna共建库的pcr文库峰图,7cycles,文库产量31.3ng/ul,21ul水洗脱,主峰在400bp左右;b为human的片段化的dna和rna共建库的pcr文库峰图,8cycles,文库峰型28.5ng/ul21ul水洗脱,主峰在400bp左右。从所建立的文库来看,此方法可以同时完成对dna/rna的测序文库的构建,对于混合样本中dna是否片段化均可实现,本次建库过程所需时间仅为3.5小时。
从以上实施例来看,本发明提供的一种dna和rna共建库的方法,该方法可以有效的将dna样本和rna样本结合到一起进行建库,对于简化建库流程,减少建库时间有重要意义,同时也可以解决测序偏好性的问题,并且该方法对样本的投入量没有要求,能适应各种环境样本,降解样本和不同分子片段大小的核酸样本,是一种新型高效共建库方法。
本发明并不仅仅限于说明书和实施方式中所描述,因此对于熟悉领域的人员而言可容易地实现另外的优点和改进,故在不背离权利要求及等同范围所限定的一般概念的精神和范围的情况下,本发明并不限于特定的细节、代表性的方案和这里示出与描述的图示示例。
序列表
<110>上海英基生物科技有限公司
<120>一种dna和rna共建库的方法
<141>2020-09-15
<160>1
<170>siposequencelisting1.0
<210>1
<211>39
<212>dna
<213>artificialsequence
<400>1
acactctttccctacacgacgctcttccgatctnnnnnn39
- 还没有人留言评论。精彩留言会获得点赞!