用于DNA循环迭代组装的系统及方法与流程
本发明涉及生物
技术领域:
,特别涉及用于dna循环迭代组装的系统及方法。
背景技术:
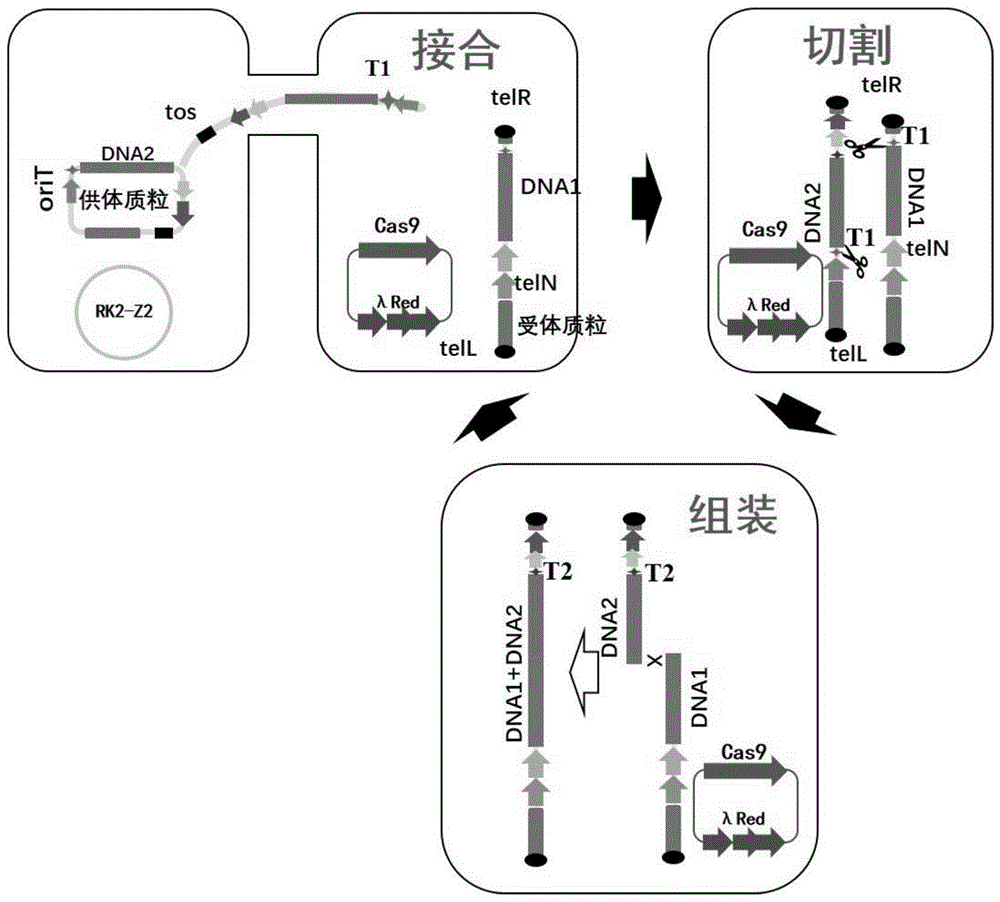
:dna组装技术是将2或多个dna片段按照即定的顺序连接成1条dna片段的技术,它是合成生物学的关键技术,目前发展了多种基于胞外和胞内的dna组装技术,而实现dna组装技术的自动化、高通量、低成本是未来的发展趋势。胞外的dna组装技术有聚合酶链式组装法(pca)、连接酶链式组装法(lca)、biobrick、goldengateassembly、gibosnassembly等,以上方法可以将2或多个dna片段连接成1条长dna。基于以上组装技术的原理,目前已经发展了自动化组装设备或装置。2017年,合成基因组学公司(syntheticgenomics,sg)研究团队发布了一款数字生物转换器(digital-to-biologicalconverter),能够自动化组装5.4kb长的dna。tecan等厂商则开发了针对酶法反应、克隆验证的自动化移液和克隆筛选等商品化设备。而这些方法最长只能将dna片段组装到几十kb,并且随着组装长度的增加,dna组装的效率越来越低。胞内的dna组装方法最常用的是利用酿酒酵母同源重组组装,可以实现100kb以上长度dna的组装。2008年,gibson等在酿酒酵母体内成功组装580kb的生殖道支原体基因组,为了寻求更精简支原体的组装方法,研究者直接将生殖道支原体jcvi-1.0的基因组分为25个dna片段,转化酿酒酵母一步完成支原体基因组的组装。但酿酒酵母组装体系需要繁琐高成本的制备酿酒酵母原生质体和体外操作大片段dna等过程,使得大片段dna的组装难以实现自动化、高通量、低成本。综上所述,避开胞内组装体系制作原生质体和体外操作大片段dna的过程,降低大片段dna的组装成本和提高自动化程度,具有重要的现实意义。技术实现要素:有鉴于此,本发明提供了用于dna循环迭代组装的系统及方法。针对现有胞外和胞内dna组装技术需要抽提质粒、dna酶切、胶回收和需要制作感受态(如原生质体等)等操作过程,存在操作繁琐、自动化程度低、成本高的问题,本发明组装dna不需要制备原生质体、避开体外繁琐的操作dna,便于实现大片段dna自动化、低成本组装。为了实现上述发明目的,本发明提供以下技术方案:本发明提供了用于dna循环迭代组装的系统,包括供体系统和受体系统;所述供体系统包括接合转移辅助元件和供体元件;所述接合转移辅助元件包括氨苄青霉素抗性质粒;所述供体元件为环形质粒,包括下一轮待组装dna片段、本轮组装cas9切割位点、下一轮组装cas9切割位点、sgrna元件和筛选标记;所述受体系统包括切割重组辅助质粒和受体元件;所述切割重组辅助质粒包括卡那霉素抗性质粒;所述受体元件为线形质粒,包括细菌人工染色体(bac)骨架、teln基因、cat筛选标记、本轮待组装dna片段、本轮组装cas9切割位点、端粒结构。在本发明的一些具体实施方案中,所述氨苄青霉素抗性质粒包括rk2-z2;所述卡那霉素抗性质粒包括pcas;所述供体元件或所述受体元件包括质粒或菌体;所述受体元件的端粒结构包括tell和telr。在本发明的一些具体实施方案中,所述供体元件包括第一供体元件、第二供体元件、第三供体元件或第四供体元件中的一个或多个;所述第一供体元件包括下一轮待组装dna片段dna2、本轮组装cas9切割位点t1、下一轮组装cas9切割位点t2、sgrna元件sgrnat1和筛选标记aada;所述第二供体元件包括下一轮待组装dna片段dna3、本轮组装cas9切割位点t2、下一轮组装cas9切割位点t3、sgrna元件sgrnat2和筛选标记aac(3)iv;所述第三供体元件包括下一轮待组装dna片段dna4、本轮组装cas9切割位点t3、下一轮组装cas9切割位点t4、sgrna元件sgrnat3和筛选标记aada;所述第四供体元件包括下一轮待组装dna片段dna5、本轮组装cas9切割位点t4、下一轮组装cas9切割位点t1、sgrna元件sgrnat4和筛选标记aac(3)iv。在本发明的一些具体实施方案中,所述供体元件还包括复制起始位点和接合转移起始位点;所述复制起始位点包括p15a;所述接合转移起始位点包括orit。在本发明的一些具体实施方案中,所述本轮待组装dna片段与所述下一轮待组装dna片段含有100bp~500bp的同源序列。在本发明的一些具体实施方案中,所述rk2-z2在rk2质粒基础上敲除了卡那霉素抗性基因和四环素抗性基因。在本发明的一些具体实施方案中,t1具有如seqidno.1所示序列;t2具有如seqidno.2所示序列;t3具有如seqidno.3所示序列;t4具有如seqidno.4所示序列。基于上述研究,本发明还提供了所述的系统在dna组装中的应用。本发明还提供了dna组装的方法,基于所述的系统,通过接合转移作用将所述供体元件从所述供体系统转移到所述受体系统中,所述供体元件在teln/tos的作用下变成线形元件,sgrna表达,引导cas9切割所述供体元件和所述受体元件的相应切割位点,利用λred同源重组,本轮待组装dna片段和下一轮待组装dna片段借助其同源序列重组dna,完成一轮dna的组装,得到的系统和线形元件分别可以作为下一轮dna组装的受体系统和受体元件;通过设计四组cas9切割位点t1-t4,sgrnat1-sgrnat4和两组筛选标记aada、aac(3)iv的供体元件可以实现dna片段的循环迭代组装。在本发明的一些具体实施方案中,所述方法包括如下步骤:第一轮dna组装:通过接合转移作用,将第一供体元件转移到受体系统中,在teln的作用下,所述第一供体元件线形化,sgrnat1表达,引导cas9切割t1位点,本轮待组装dna片段dna1和下一轮待组装dna片段dna2借助其同源序列组装成1条dna,获得第二受体元件;第二轮dna组装:通过接合转移作用,将第二供体元件转移到受体系统中,在teln的作用下,所述第二供体元件线形化,sgrnat2表达,引导cas9切割t2位点,本轮待组装dna片段dna1+dna2与下一轮待组装dna片段dna3借助其同源序列组装成1条dna,获得第三受体元件;第三轮dna组装:通过接合转移作用,将第三供体元件转移到受体系统中,在teln的作用下,所述第三供体元件线形化,sgrnat3表达,引导cas9切割t3位点,本轮待组装dna片段dna1+dna2+dna3与下一轮待组装dna片段dna4借助其同源序列组装成1条dna,获得第三受体元件;第四轮dna组装:通过接合转移作用,将第四供体元件转移到受体菌中,在teln的作用下,所述第四供体元件线形化,sgrnat4表达,引导cas9切割t4位点,本轮待组装dna片段dna1+dna2+dna3+dna4与下一轮待组装dna片段dna5借助其同源序列组装成1条dna,获得第四受体元件;基于上述步骤完成四轮dna循环组装,通过供体元件、切割位点t1~t4、筛选标记的循环利用,组装过程可以继续循环进行。在本发明的一些具体实施方案中,所述方法中t1具有如seqidno.1所示序列;t2具有如seqidno.2所示序列;t3具有如seqidno.3所示序列;t4具有如seqidno.4所示序列。本发明的有益效果包括但不限于:本发明的循环迭代策略采用四个供体质粒(pdonorr1-pdonorr4)循环利用,采用四个cas9切割位点和两个筛选标记的设计;采用三个cas9切割位点和三个筛选标记的设计,同样可以实现循环迭代组装。本发明中cas9基因、λred系统、teln基因是采用质粒形式实现,cas9基因、λred系统、teln基因整合到大肠杆菌基因组上可以的达到同样dna组装的效果。切割位点t1-t4的序列是非唯一的,任何能被cas9切割且不切割待组装dna的23bp序列都可以作为切割序列。该方法一方面不需要对dna进行繁琐的体外抽提、酶切、回收等操作,另一方面避免传统大片段dna组装需要做原生质体等感受态细胞过程,具有操作简单自动化程度高、成本低等优点。该方法连续组装4轮后,5个dna片段的组装阳性率可达98.4%,具有dna组装阳性率高的优点。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。图1示细菌接合组装技术原理图;图2示pdonor1-pdnonor4四种供体质粒示意图;图3示受体质粒preceptor1结构示意图;图4示四轮dna循环组装流程图;图5示紫色杆菌素生物合成途径,a-e五段dna;图6示紫色杆菌素生物合成途径第四轮组装筛选平板图。菌落表现紫色说明5段dna组装成功;图7示210kb组装质粒(载体10kb+组装片段200kb)脉冲场凝胶电泳验证图;图8示对比例的脉冲场凝胶电泳验证图;其中,2号克隆为正确的组装160kb质粒。具体实施方式本发明公开了用于dna循环迭代组装的系统及方法,本领域技术人员可以借鉴本文内容,适当改进工艺参数实现。特别需要指出的是,所有类似的替换和改动对本领域技术人员来说是显而易见的,它们都被视为包括在本发明。本发明的方法及应用已经通过较佳实施例进行了描述,相关人员明显能在不脱离本
发明内容、精神和范围内对本文所述的方法和应用进行改动或适当变更与组合,来实现和应用本发明技术。本发明利用大肠杆菌的接合转移作用,将供体质粒从供体菌转移到受体菌中,供体质粒在teln/tos的作用下变成线形质粒,同时sgrna开始表达,引导cas9切割供体质粒和受体质粒的相应切割位点,利用λred同源重组,待组装的两dna片段借助其同源序列重组成1条dna(图1),此时,完成一轮dna的组装,得到的菌株和线形质粒分别可以作为下一轮dna组装的受体菌和受体质粒。通过设计四组切割位点(t1-t4,sgrnat1-sgrnat4)和两组筛选标记(aada、aac(3)iv)的供体质粒可以实现dna片段的循环迭代组装。本发明涉及两株大肠杆菌——供体菌和受体菌。供体菌含有一个接合转移辅助质粒rk2-z2和一个供体质粒pdonorr1或pdonorr2或pdonorr3或pdonorr4。rk2-z2为氨苄青霉素抗性质粒,其功能为辅助供体质粒接合转移到受体菌株中;供体质粒pdonorr1-pdonorr4含有不同的元件(图2,表1),包括的本轮组装切割位点(t1-t4)、预留的下一轮组装切割位点、sgrna元件(sgrnat1-t4)和筛选标记(aada、aac(3)iv),这些元件循环利用可实现dna循环迭代组装。表1pdonor1-pdnonor4四种供体质粒所含元件受体菌含有一个切割重组辅助质粒pcas和一个受体质粒preceptor1(图3)。pcas为卡那霉素抗性质粒,能组成型表达cas9蛋白和阿拉伯糖诱导表达λred蛋白,可有效提高dna组装效率;受体质粒preceptor1包括细菌人工染色体(bac)骨架、teln基因、cat筛选标记、dna1待组装dna片段、t1切割位点、tell和telr端粒结构。待组装的两个dna片段之间含有100bp-500bp的同源序列。具体操作步骤涉及接合转移的实验操作,详细如下:1)接单克隆供体菌到3ml含有100mg/l的氨苄青霉素和合适浓度的相应筛选抗生素的lb试管中;2)接单克隆受体菌到3ml含有50mg/l的卡那霉素、10mm的阿拉伯糖和合适浓度的相应筛选抗生素的lb试管中;3)1)和2)试管放30摄氏度摇床培养4-6小时;4)当od值到0.6-1.5之间时,分别收取1.5ml菌液,10000rpm离心1分钟,弃上清;5)用1mllb培养基重悬沉淀菌体,10000rpm离心1分钟,弃上清;6)重复步骤5)一次;7)菌体沉淀用100ullb培养基重悬,混合20ul受体菌和80ul供体菌在一个1.5ml离心管中;8)取100ul混合菌液,分5-8个点滴在无抗固体lb培养基上;9)放置30摄氏度培养箱2小时;10)用1ml无抗液体lb培养基吹洗固体培养基上的菌体,吸到无菌1.5ml离心管中;11)分别将菌液稀释10、100倍,取50ul涂布含有卡那青霉素、氯霉素和壮观霉素或阿伯拉霉素的lb固体平板中;12)30摄氏度培养14-20小时,pcr或抽提质粒、酶切验证组装片段的正确性。dna循环组装的设计流程(图4)如下:第一轮dna组装:通过接合转移实验步骤,将供体质粒pdonorr1转移到受体菌中,在teln的作用下,pdonorr1线形化,同时sgrnat1表达,引导cas9切割t1位点,待组装片段dna1和dna2借助其同源序列组装成1条dna,获得preceptor2质粒,成为第二轮组装的受体载体,此轮dna组装用卡那霉素、氯霉素和壮观霉素lb平板筛选;第二轮dna组装:通过接合转移实验步骤,将供体质粒pdonorr2转移到受体菌中,在teln的作用下,pdonorr2线形化,同时sgrnat2表达,引导cas9切割t2位点,待组装片段dna3与dna1+dna2借助其同源序列组装成1条dna,获得preceptor3质粒,成为第三轮组装的受体载体,此轮dna组装用卡那霉素、氯霉素和阿伯拉霉素lb平板筛选;第三轮dna组装:通过接合转移实验步骤,将供体质粒pdonorr3转移到受体菌中,在teln的作用下,pdonorr3线形化,同时sgrnat3表达,引导cas9切割t3位点,待组装片段dna4与dna1+dna2+dna3借助其同源序列组装成1条dna,获得preceptor4质粒,成为第四轮组装的受体载体,此轮dna组装用卡那霉素、氯霉素和壮观霉素lb平板筛选;第四轮dna组装:通过接合转移实验步骤,将供体质粒pdonorr4转移到受体菌中,在teln的作用下,pdonorr4线形化,同时sgrnat4表达,引导cas9切割t4位点,待组装片段dna5与dna1+dna2+dna3+dna4借助其同源序列组装成1条dna,获得preceptor4质粒,成为第五轮组装的受体载体,此轮dna组装用卡那霉素、氯霉素和阿伯拉霉素lb平板筛选;至此,完成四轮dna循环组装,通过供体载体pdonorr1-r4、切割位点t1-t4、筛选标记的循环利用,组装过程可以继续循环进行。表2t1-t4序列名称序号序列t1seqidno.1ttgagagcagcggtagctgtaggt2seqidno.2catgcttgcaaggcatccaaaggt3seqidno.3gtaaccatgatcgtccatggaggt4seqidno.4ctgtcatcatgtccagctcgagg本发明提供的用于dna循环迭代组装的系统及方法中,所用原料及试剂均可由市场购得。下面结合实施例,进一步阐述本发明:实施例1以分别克隆在preceptor1和pdonorr1-pdonorr4紫色杆菌素生物合成途径的5个dna片段组装成4860bp完整紫色杆菌素生物合成途径(图5)为例。1)紫色杆菌素生物合成途径基因如图5所示,a-e五个dna片段分别克隆在preceptor1和pdonorr1-r4上,具体为:preceptor1-a、pdonror1-b、pdonorr2-c、pdonorr3-d、pdonorr4-e。2)第一轮组装:供体菌(含pdonorr1-b)与受体菌(preceptor1-a)接合转移,卡那霉素、氯霉素和壮观霉素三抗lb平板筛选,获得含有preceptor1-ab的受体菌;第二轮组装:供体菌(含pdonorr2-c)与受体菌(preceptor1-ab)接合转移,卡那霉素、氯霉素和阿伯拉霉素三抗lb平板筛选,获得含有preceptor1-abc的受体菌;第三轮组装:供体菌(含pdonorr3-d)与受体菌(preceptor1-abc)接合转移,卡那霉素、氯霉素和壮观霉素三抗lb平板筛选,获得含有preceptor1-abcd的受体菌;第四轮组装:供体菌(含pdonorr4-e)与受体菌(preceptor1-abcd)接合转移,卡那霉素、氯霉素和阿伯拉霉素三抗lb平板筛选,获得含有preceptor1-abcde的受体菌;3)经过四轮dna组装,组装成功的dna会在大肠杆菌中表达,产生紫色杆菌素,菌落颜色表现为紫色(图6)。经过三次平行实验,平均阳性率达98.4%(表3)。表3.三次平行实验紫色和白色克隆菌落数(稀释100倍涂50ul菌液)和阳性率实施例2以连续迭代循环组装210kb(组装的四个片段大小分别是80kb40kb、40kb、40kb,组成完成后片段大小是200kb,加上载体的10kb是210kb)大片段dna为例。1)4个dna大片段分别连接在pdonorr1-pdonorr4上,分别为pdonorr1-pic(80kb)、pdonorr2-gm1(40kb)、pdonorr3-gm2(40kb)、pdonorr4-gm3(40kb)。2)线形质粒preceptor-43为受体载体(10kb)。3)第一轮组装:供体菌(含pdonorr1-pic)与受体菌(preceptor-43)接合转移,卡那霉素、氯霉素和壮观霉素三抗lb平板筛选,获得含有preceptor-46的受体菌;第二轮组装:供体菌(含pdonorr2-gm1)与受体菌(preceptor-46)接合转移,卡那霉素、氯霉素和阿伯拉霉素三抗lb平板筛选,获得含有preceptor-47的受体菌;第三轮组装:供体菌(含pdonorr3-gm2)与受体菌(preceptor-47)接合转移,卡那霉素、氯霉素和壮观霉素三抗lb平板筛选,获得含有preceptor-48的受体菌;第四轮组装:供体菌(含pdonorr4-gm3)与受体菌(preceptor-48)接合转移,卡那霉素、氯霉素和阿伯拉霉素三抗lb平板筛选,获得含有preceptor-49的受体菌;4)经过四轮dna组装,选取8个克隆,制作大肠杆菌低熔点琼脂糖胶块,脉冲场凝胶电泳验证dna大小,如图7所示,连同载体dna总长度210kb,8个克隆均组装正确,故组装阳性率8/8。质粒说明:1.preceptor1-a:线形质粒,共8926bp;1-187bp为tell序列;188-4844bp为细菌人工染色体载体骨架;4845-4905bp为j23100启动子序列;4906-6821bp为teln基因;6822-7591bp为氯霉素抗性基因(cat);7592-7617bp为b0034rbs序列;7618-8565bp待组装dna片段a;8566-8588bp为t1切割位点;8589-8926bp为telr序列。2.pdonorr1-b:环形质粒,共4776bp;1-907bp为p15a复制起始位点;908-1691bp为orit接合转移起始位点;1692-1714bp为t1切割位点;1715-2773bp为待组装dna片段b;2774-2796bp为t2切割位点;2797-2948bp为sgrnat1元件;2949-3954bp为壮观霉素抗性基因(aada);3955-4473bp为tos位点;4474-4776bp为质粒间隔序列。3.pdonorr2-c:环形质粒,共4821bp;1-907bp为p15a复制起始位点;908-1691bp为orit接合转移起始位点;1692-1714bp为t2切割位点;1715-2856bp为待组装dna片段c;2857-2879bp为t3切割位点;2880-3031bp为sgrnat2元件;3032-3999bp为阿伯拉霉素抗性基因(aac(3)iv);4000-4518bp为tos位点;4519-4821为质粒间隔序列。4.pdonorr3-d:环形质粒,共4777bp;1-907bp为p15a复制起始位点;908-1691bp为orit接合转移起始位点;1692-1714bp为t3切割位点;1715-2574bp为待组装dna片段d;2575-2597bp为t4切割位点;2598-2749bp为sgrnat3元件;2750-3755bp为壮观霉素抗性基因(aada);3756-4274bp为tos位点;4275-4577bp为质粒间隔序列。5.pdonorr4-e:环形质粒,共5017bp;1-907bp为p15a复制起始位点;908-1691bp为orit接合转移起始位点;1692-1714bp为t4切割位点;1715-3075bp为待组装dna片段e;3076-3227bp为sgrnat4元件;3228-4195bp为阿伯拉霉素抗性基因(aac(3)iv);4196-4714bp为tos位点;4715-5017为质粒间隔序列。6.preceptor-43:线形质粒,共8926bp;1-187bp为tell序列;188-4844bp为细菌人工染色体载体骨架;4845-4905bp为j23100启动子序列;4906-6821bp为teln基因;6822-7594bp为氯霉素抗性基因(cat);7595-8094bp为下一组装片段(pic)的同源序列;8095-8117bp为t1切割位点;8118-8455bp为telr序列。7.pdonorr1-pic:环形质粒,共86521bp;1-907bp为p15a复制起始位点;908-1691bp为orit接合转移起始位点;1692-1714bp为t1切割位点;1715-83270bp为待组装dna片段pic;83271-83293bp为t2切割位点;83294-84541bp为ura3筛选标记元件;84542-84693bp为为sgrnat1元件;84694-85669bp为壮观霉素抗性基因(aada);85670-86218bp为tos位点;86219-86521bp为质粒间隔序列。8.pdonorr2-gm1:环形质粒,共45892bp;1-907bp为p15a复制起始位点;908-1691bp为orit接合转移起始位点;1692-1714bp为t2切割位点;1715-42679bp为待组装dna片段gm1;42680-42702bp为t3切割位点;42703-43950bp为ura3筛选标记元件;43951-44102bp为sgrnat2元件;44103-45070bp为阿伯拉霉素抗性基因(aac(3)iv);45071-45589bp为tos位点;45590-45892为质粒间隔序列。9.pdonorr3-gm2:环形质粒,共46466bp;1-907bp为p15a复制起始位点;908-1691bp为orit接合转移起始位点;1692-1714bp为t3切割位点;1715-43215bp为待组装dna片段gm2;43216-43238bp为t4切割位点;43239-44486bp为ura3筛选标记元件;44487-44638bp为sgrnat3元件;44639-45644bp为壮观霉素抗性基因(aada);44655-46163bp为tos位点;46164-46466bp为质粒间隔序列。10.pdonorr4-gm3:环形质粒,共46400bp;1-907bp为p15a复制起始位点;908-1691bp为orit接合转移起始位点;1692-1714bp为t4切割位点;1715-43187bp为待组装dna片段gm3;43188-43210bp为t1切割位点;43211-44458为ura3筛选标记元件;44459-44610bp为sgrnat4元件;44411-45578bp为阿伯拉霉素抗性基因(aac(3)iv);455579-46097bp为tos位点;46098-46400为质粒间隔序列。11.rk2-z2:环形质粒,共56758bp,5639-6499bp为氨苄霉抗性基因(bla);11864-12943bp为oriv复制起始位点;36242-45386bp为接合转移操纵子tragfedcba;45154-47987bp为接合转移操纵子trajxih;47976-49737bp为接合转移操纵子traklm;其余序列为间隔序列。12.pcas质粒:环形质粒,共12542bp,100-4206bp为cas9基因;4336-7453bp为阿拉伯糖操纵子的λred系统;9425-10375bp为rep101(ts)复制蛋白基因;10423-10645bp为psc101复制起始位点;11297-12112bp为卡那霉素抗性基因。对比例:以用传统酿酒酵母原生质体转化方法将4个40kbdna组装成160kb(pgm160)的大片段为例。4个40kb的片段分别在质粒pgm1、pgm2、pgm3、pgm4上,片段两端含有noti位点。具体过程如下:1)准备线性化组装载体linear-pcc1。a.以pcc1质粒为模板,以(a160-f:ttccagtctacaaatcctcgggcctacaggctaaccaagatatggacccgagtccgggcggccgcggtatgtgctcttcttatctcctt,如seqidno.5所示;a160-r:tggagagttgcgacgaaaaagagcaccgctcggtttcttgacgatacgagtacattcatgcggccgcggtcggtcatccggatatagtt,如seqidno.6所示)为引物,用kodfxpcr扩增线性化载体linear-pcc1。b.pcr产物经过琼脂糖凝胶电泳,切割10kb大小凝胶条带,用天根凝胶回收试剂盒回收pcr产物。c.nanodrop或酶标仪定量dna浓度。2)准备待组装dna线性片段。a.向5ml含有氯霉素的lb中分别接菌含有四个质粒(pgm1、pgm2、pgm3、pgm4)的菌株,加终浓度为10mm的阿拉伯糖诱导质粒高考贝复制,37度、220转过夜培养,用hipurebacminikit(magen,p1151-03)抽提质粒。nanodrop或酶标仪定量dna浓度。b.pgm1、pgm2、pgm3、pgm4各取500ng混合,noti酶切,酶切体系如下:a为pgm1、pgm2、pgm3、pgm4四种质粒混合后的体积。37摄氏度酶切30分钟。c.用200ul酚/氯仿溶液抽提一次,取上清,加入200ul异丙醇,12000转,离心10分钟。去掉上清,沉淀用70%的冷的乙醇洗两次,去掉乙醇,室温放置约30分钟,用15ul无菌水溶解沉淀。nanodrop或酶标仪定量dna浓度。3)原生质体转化方法组装大片段dnaa.接vl6-48单克隆在3mlypad培养基中,30度,220转过夜培养;b.转接50mlypad摇瓶,使终od600=0.2,30度,220转培养5-6小时,使终od600=0.8-1.0。c.4000转速离心收菌,用30ml无菌水重悬菌体,然后4000转速离心收菌,再用30ml1m的山梨醇重悬菌体,4000转速离心收菌,去掉上清。d.用20mlspe缓冲液重悬菌体,加入20ulzymlyase-20t和40ulβ-巯基乙醇,30度轻摇孵育30-40分钟。e.1000g离心力离心收集菌体,用50ml山梨醇重悬-离心清洗菌体2次,用200ulstc溶液重悬菌体;f.混合步骤1)中200ng线性化载体linear-pcc1和步骤2)中1ugnoti混合酶切产物,加入200ulstc重悬菌体中,室温静止10分钟;g.加入800ul20%peg8000,混合均匀,室温放置10分钟;h.1000g离心力离心5分钟收集菌体,800ulsos溶液重悬菌体,30度放置40分钟。i.涂布sc-his平板,30度培养3-7天;j.长出的单克隆经过pcr验证,从96个克隆中筛选到8个正确的组装质粒。k.接菌其中的3个克隆到5mlsc-his液体培养基中,30度过夜培养;l.从酵母中抽提质粒<分子克隆实验指南>,电转大肠杆菌感受态,涂氯霉素lb平板。m.氯霉素平板长出的克隆,接5ml含氯霉素的lb液体培养基,抽提质粒,参照<分子克隆实验指南>;n.取适量dnanoti酶切,脉冲场凝胶电泳验证,2号克隆为正确大小的组装dna。结果如图8所示。综上所述,本发明和传统组装方法的操作步骤、所用试剂及估计成本对比如下表:表4“*”本发明的成本计算包含4轮接合转移的成本。比较了传统酿酒酵母原生质体转化方法和本发明的实验步骤、主要用到的试剂和成本,如上表所示,本发明的实验步骤省去了繁琐、高成本的体外操作大片段dna和制作原生质体的过程,操作过程简单,成本比下降近10倍。以上所述仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。序列表<110>天津大学<120>用于dna循环迭代组装的系统及方法<130>mp2020913<160>6<170>siposequencelisting1.0<210>1<211>23<212>dna<213>人工序列(artificialsequence)<400>1ttgagagcagcggtagctgtagg23<210>2<211>23<212>dna<213>人工序列(artificialsequence)<400>2catgcttgcaaggcatccaaagg23<210>3<211>23<212>dna<213>人工序列(artificialsequence)<400>3gtaaccatgatcgtccatggagg23<210>4<211>23<212>dna<213>人工序列(artificialsequence)<400>4ctgtcatcatgtccagctcgagg23<210>5<211>89<212>dna<213>人工序列(artificialsequence)<400>5ttccagtctacaaatcctcgggcctacaggctaaccaagatatggacccgagtccgggcg60gccgcggtatgtgctcttcttatctcctt89<210>6<211>89<212>dna<213>人工序列(artificialsequence)<400>6tggagagttgcgacgaaaaagagcaccgctcggtttcttgacgatacgagtacattcatg60cggccgcggtcggtcatccggatatagtt89当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1