控制脂肽脂链长度改变的关键交换结构域及其突变体和应用的制作方法
本发明涉及一种控制脂肽脂链长度改变的关键结构域及其突变体和应用,属于生物技术领域。
背景技术:
非核糖体肽类是一类重要的微生物天然产物,其具有广泛的生物活性,如抗菌,抗肿瘤,免疫抑制等。非核糖体肽的基因簇主要通过迭代型的模块结构(module)合成不同长度的肽链,而模块可进一步细分为结构域(domain),主要包括:缩合结构域(condensationdomain:cdomain),腺苷酰化结构域(adenylationdomain:adomain),硫醇化结构域(thiolationdomain:tdomain)。这三个结构域构成了一个基本的模块,并由多个模块构成了巨大的非核糖体肽酶体,其中初始的硫醇化结构域经磷酸泛酰巯基乙胺基转移酶活化以后,转化为带磷酸泛酰巯基乙胺长臂的活化态形式,随即作为模块内或模块间的“机械臂”进行底物转移。在模块内,其将由腺苷酰化结构域活化的下游底物-腺苷酰化氨基酸转移至缩合结构域,并随之与上游底物发生缩合,上游底物包括由上一个模块合成的中间产物或由相关基因合成的起始底物(起始缩合结构域),如脂肪酸等。缩合产物随后被长臂转移至下一个模块,作为下一个模块的上游底物,进行下一轮的缩合循环。最终,由多模块循序渐进,逐步合成了完整的非核糖体肽类产物。
脂肽类化合物是非核糖体肽类化合物中非常重要的一类,已经成药的如达托霉素(daptomycin)在抗感染方面至今依然发挥着重要作用。多数情况下,在起始阶段,其合成基因簇由一个起始缩合结构域(condensationstarterdomain:csdomain)负责缩合下游腺苷酰化氨基酸与酰基载体蛋白形式(acylcarrierprotein:acp)或酰基辅酶a形式的上游起始底物。研究表明,起始阶段引入的脂肪酸链对很多脂肽的生物学活性发挥着极其关键的作用,其脂肪酸链长度与天然产物稳定性及活性强弱息息相关。而与其脂肪酸链衍生化相关的生物学研究几乎空白。目前,人们对脂肽脂链的改造手段主要是化学半合成以及前体喂养,如达托霉素,其原产基因簇的最适产物并非十碳酰基长度的达托霉素,而是名为a21978c的产物,主要有反异十一烷酰基的a21978c1,异十二烷酰基的a21978c2以及反异十三烷酰基的a21978c3。研究表明,当这类产物n端的脂链长度超过c11时,对人体毒性较大(16311632,15907192)。达托霉素最初是通过半合成方式获得的,应用于临床后,人们则通过底物喂养以及宿主更换的方式生产毒性较小和活性较强的饱和十碳烷酰基达托霉素,即便如此,达托霉素产量较其他副产物依然不具优势。因此探索定向改造脂肽的脂链长度的关键交换结构域,或能对潜力脂肽甚至已经成药的脂肽的改造提供极大益助,如使达托霉素生物合成时其脂酰基底物具有竞争优势。另一方面,迄今为止,未有cs结构域与其脂酰基底物共结晶结构的报道,因此难以通过理性的改造,定向控制其cs结构域的底物特异性,并进一步定向改造脂肽。
综上所述,本领域迫切需要提供一种控制脂肽脂链长度改变的关键结构域及其突变体和应用,以实现新型脂肽类抗生素的开发或成药脂肽的进一步优化。
技术实现要素:
针对现有技术的不足,本发明要解决的问题是提供一种控制脂肽脂链长度改变的关键交换结构域及其突变体和应用。
为了实现上述发明目的,本发明提供了如下的技术方案。
本发明所述的控制脂肽脂链长度改变的关键交换结构域,其中所述的关键交换结构域为起始缩合结构域及其与临近的腺苷酰化结构域的交界,该起始缩合结构域名为cs结构域,该腺苷酰化结构域名为a结构域;所述的cs结构域与a结构域的交界名为cs-alinker区域;其中所述cs结构域是指在脂肽的生物合成过程中负责催化起始的脂酰基底物与第一个氨酰基底物进行缩合的结构域,所述cs结构域对脂肽的脂链具有特异性并介导脂肽生物合成的起始;所述的a结构域是指催化游离氨基酸形成上游cs结构域的氨酰基底物,该氨酰基底物为氨酰基-肽载体蛋白;所述的交换结构域是cs结构域及cs-alinker区域,命名为cs-al结构域;
其特征在于:
所述控制脂肽脂链长度改变的关键交换结构域是指根霉酰胺的cs-al结构域与根霉肽的cs-al结构域进行互换后的cs-al结构域;其中所述根霉酰胺的cs-al结构域是指含控制脂酰基底物特异性的关键氨基酸位点q36、y138、r148的cs结构域以及cs-alinker区域,该根霉酰胺的cs-al结构域的氨基酸序列如seqno.1所示;其中所述根霉肽的cs-al结构域是指含控制脂酰基底物特异性的关键氨基酸位点q37、y139、a149的cs结构域以及cs-alinker区域,该根霉肽的cs-al结构域的氨基酸序列如seqno.2所示;其中所述根霉酰胺缩写为rzma,根霉肽缩写为hola,其生物合成基因簇均来源于细菌paraburkholderiarhizoxinicahki454;
或者,所述控制脂肽脂链长度改变的关键交换结构域是指滑杆菌素的cs-al结构域被根霉肽的cs-al结构域替换后的cs-al结构域;其中所述滑杆菌素的cs-al结构域是指含控制脂酰基底物特异性的关键氨基酸位点g36、g139、l149的cs结构域以及cs-alinker区域,该滑杆菌素的cs-al结构域的氨基酸序列如seqno.3所示;其中所述根霉肽的cs-al结构域是指含控制脂酰基底物特异性的关键氨基酸位点q37、y139、a149的cs结构域以及cs-alinker区域,该根霉肽的cs-al结构域的氨基酸序列如seqno.2所示;其中所述滑杆菌素缩写为glba,其生物合成基因簇来源于细菌schlegelellabrevitaleadsm7029;
或者,所述控制脂肽脂链长度改变的关键交换结构域是指滑杆菌素的cs-al结构域被滑杆菌肽的cs-al结构域替换后的cs-al结构域;其中所述滑杆菌素的cs-al结构域是指含控制脂酰基底物特异性的关键氨基酸位点g36、g139、l149的cs结构域以及cs-alinker区域,该滑杆菌素的cs-al结构域的氨基酸序列如seqno.3所示;其中所述滑杆菌肽的cs-al结构域是指含控制脂酰基底物特异性的关键氨基酸位点a51、m154、v164的cs结构域以及cs-alinker区域,该滑杆菌肽的cs-al结构域的氨基酸序列如seqno.4所示;其中所述滑杆菌素缩写为glba,滑杆菌肽缩写为glpa,其生物合成基因簇均来源于细菌schlegelellabrevitaleadsm7029。
本发明提供了利用对上述控制脂肽脂链长度改变的关键交换结构域进行cs-al结构域的交换后获得的突变体,其特征在于:根霉酰胺的cs-al结构域与根霉肽的cs-al结构域进行互换后获得的带根霉肽cs-al结构域的根霉酰胺生物合成基因簇突变体,命名为rzmacshola;根霉肽的cs-al结构域被根霉酰胺的cs-al结构域替换后获得的带根霉酰胺cs-al结构域的根霉肽生物合成基因簇突变体,命名为holacsrzma;滑杆菌素的cs-al结构域被根霉肽的cs-al结构域替换后获得的带根霉肽cs-al结构域的滑杆菌素生物合成基因簇突变体,命名为glbacshola;滑杆菌素的cs-al结构域被滑杆菌肽的cs-al结构域替换后获得的带滑杆菌肽cs-al结构域的滑杆菌素生物合成基因簇突变体,命名为glbacsglpa;其中,所述根霉酰胺cs-al结构域的氨基酸序列如seqno.1所示,所述根霉肽cs-al结构域的氨基酸序列如seqno.2所示,所述滑杆菌素的cs-al结构域的氨基酸序列如seqno.3所示,所述滑杆菌肽的cs-al结构域的氨基酸序列如seqno.4所示。
本发明所述突变体在制备带有不同脂链长度脂肽衍生物中的应用。
其中:突变体rzmacshola在异源宿主schlegelellabrevitaleadsm7029中催化c8脂链长度rzma衍生物的合成;突变体holacsrzma在异源宿主schlegelellabrevitaleadsm7029中催化c2脂链长度hola衍生物的合成;突变体glbacshola在同源宿主schlegelellabrevitaleadsm7029中催化c8脂链长度glba衍生物的合成;突变体glbacsglpa在同源宿主schlegelellabrevitaleadsm7029中催化c10脂链长度glba衍生物的合成。
本发明提供了控制脂肽脂链长度改变的关键交换结构域,即对脂肽的cs-al结构域进行交换,用于定向改造脂肽的脂链链长度,为改造潜力脂肽,增加其活性,降低其毒副作用,促进脂肽的临床成药,或指导成药脂肽的进一步优化,如达托霉素的产量优化提供了技术支持。在本发明实施例中,利用cs-al区域的交换,成功实现了将脂肽rzma的c2酰基延长至c8酰基长度,将hola的c8酰基缩短至c2酰基长度,并将glba由原始的c12-2,4不饱和双键酰基定向改造为c8饱和及c10饱和酰基的衍生物。
本发明具有的有益效果和显著的优点是:1)本发明利用cs-al结构域进行交换,对衍生物产量的影响较小,甚至有所提升;2)本发明适用于不同种属的细菌;3)本发明为非核糖体脂肽脂链的改造提供了依据,为后续成药的化合物如达托霉素的进一步优化及潜力药物的进一步开发和改造提供了借鉴和技术方法。
附图说明
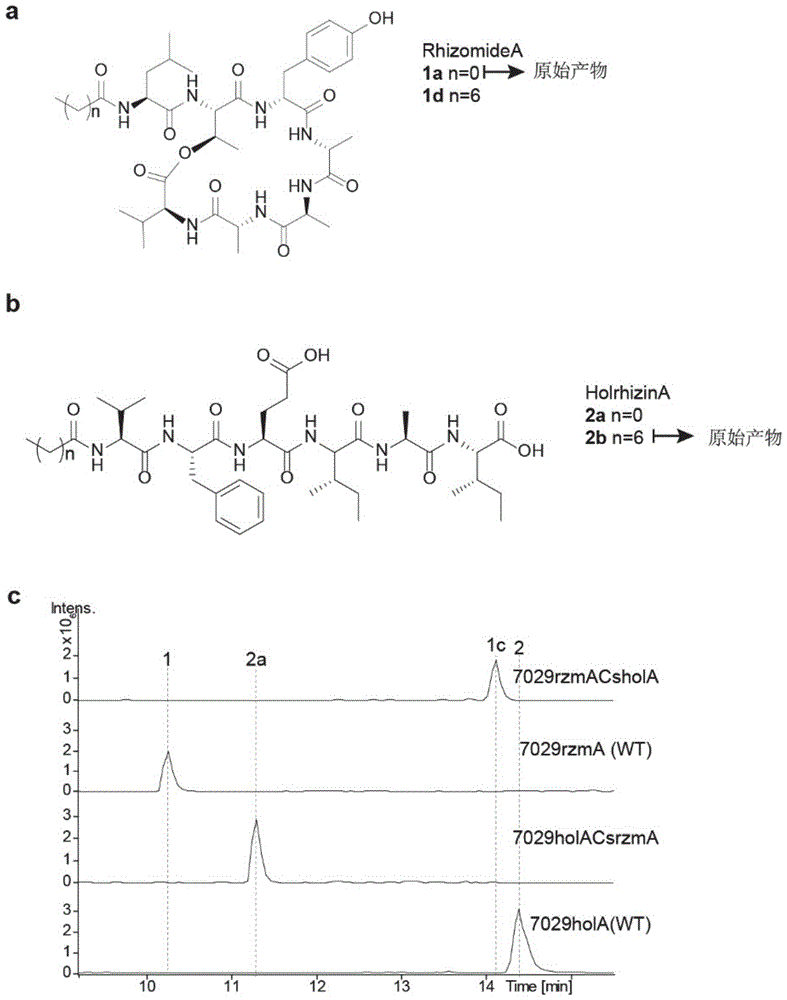
图1:a为根霉酰胺(rhizomidea)所有产物,包括原始产物和突变产生的衍生产物,其中1a(c2-rzma)为原始基因簇rzma产生的原始产物,1d(c8-rzma)为突变体产生的产物;b为根霉肽(holrhizin)所有产物,包括原始产物和突变产生的衍生产物,其中2b(c8-hola)为原始基因簇hola产生的原始产物,2a(c2-hola)为突变体产生的产物;c为lc-ms检测结果,从上至下分别为突变体rzmacshola产生的衍生物c8-rzma,rzma野生型产物c2-rzma,holacsrzma产生的衍生物c2-hola,以及hola野生型产物c8-hola。
图2:a为滑杆菌素基因簇(glba基因簇)的原始产物;b为突变体产生的glba衍生产物;c为lc-ms检测结果,从上至下分别为突变体glbacsglpa产生的衍生物c10-glba,glbacshola产生的衍生物c8-glba,以及glba野生型的产物c12-2,4δδ-glba。
具体实施方式
下面结合具体附图和实施例对本发明内容进行详细说明。如下所述例子仅是本发明的较佳实施方式而已,应该说明的是,下述说明仅仅是为了解释本发明,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对实施方式所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。
下述实施例中,所使用的材料、试剂等,如无特殊说明,均从商业途径得到。未注明具体条件的实验方法,通常按照常规条件,例如sambrook等人,分子克隆:实验室手册(newyork:coldspringharborlaboratorypress,1989)中所述的条件,或按照试剂厂商所建议的条件。
所有涉及在大肠杆菌中分子操作,如直接克隆,突变,质粒构建等均使用red/et重组工程技术。包括exocet直接克隆技术,ccdb反向筛选技术,线环重组,线线重组等。具体实施步骤参照文献1.wangh,liz,jiar,etal.exocet:exonucleaseinvitroassemblycombinedwithrecetrecombinationforhighlyefficientdirectdnacloningfromcomplexgenomes[j].nucleicacidsresearch2018mar16;46(5):e28.doi:10.1093/nar/gkx1249.以及文献2.wangh,bianx,xial,etal.improvedseamlessmutagenesisbyrecombineeringusingccdbforcounterselection[j].nucleicacidsresearch2014mar;42(5):e37.doi:10.1093/nar/gkt1339。实施例中重组涉及的gb2005-dir,gb2005-red-gyra4622,gb2005,及载体p15a-cm-hyg-ccdb,pr6k-amp-ccdb,pr6k-tnpa-km,pr6k-apra-phic31构建见上文。所用抗生素及浓度也均按照上述文献操作,所用抗生素缩写分别为卡那霉素:km,氯霉素:cm,阿伯拉霉素:apra,庆大霉素:genta。
实施例涉及的限制性内切酶均购置newenglandbiolabs(neb)。聚合酶链式反应(pcr)涉及的聚合酶均购自takara。菌株schlegelellabrevitaleadsm7029及paraburkholderiarhizoxinicahki454(dsm19002)均购自德国菌种保藏中心dsmz。
所述如涉及schlegelellabrevitaleadsm7029中的red/et同源重组,则按照文献3.wangx,zhouh,chenh,etal.discoveryofrecombinasesenablesgenomeminingofcrypticbiosyntheticgeneclustersinburkholderialesspecies[j].proceedingsofthenationalacademyofsciences,2018,115(18):201720941.进行操作,涉及菌株redαβdsm7029的构建见上文。引物合成:本发明实施例中所使用的引物均由生工生物工程(上海)有限公司制备。universaldna纯化回收试剂盒购自天根生化科技(北京)有限公司。
实施例中对于大肠杆菌的培养均使用低盐的luria-bertani培养基(lb培养基),配方为:胰蛋白胨(tryptone)10g,酵母提取物(yeastextract)5g,氯化钠(nacl)1g,固体培养基另加12%的琼脂粉,加双蒸水至1000ml,121℃灭菌20min。对于schlegelellabrevitaleadsm7029及paraburkholderiarhizoxinicahki454(dsm19002)的培养均使用cymg培养基,配方为:8g/l酪蛋白胨(caseinpeptone),4g/l酵母提取物,4.06g/lmgcl2·2h2o,10ml/l甘油,固体培养基另加12%的琼脂粉,加双蒸水至1000ml,115℃灭菌30min。相应培养基成分均购自oxiod。
实施例1:
对rzma以及hola的cs-al区域进行互换,获得突变体rzmacshola,holacsrzma且从体内外水平对突变体的催化活性进行验证。即以全长的rzma/hola基因簇及相应突变体催化形成最终产物rzma/hola及其衍生物的能力为准(结构如图1,a,b所示),定量采用绝对定量,分离纯化衍生物及野生型脂肽产物后,以其为标准品,对突变体进行定量,定量仪器为液质联用(lc-ms)。
具体实施步骤如下:
(1)根据antismash(https://antismash.secondarymetabolites.org/#!/start)预测rzma以及hola的cs-al区域,确定其氨基酸序列如seqidno:1和seqidno:2所示。
(2)利用exocet直接克隆技术,操作步骤如文献1所述,(1.wangh,liz,jiar,etal.exocet:exonucleaseinvitroassemblycombinedwithrecetrecombinationforhighlyefficientdirectdnacloningfromcomplexgenomes[j].nucleicacidsresearch2018mar16;46(5):e28.doi:10.1093/nar/gkx1249)以p15a-cm-hyg-ccdb为模板pcr获得带同源臂的p15a-cm载体后,引物为p1-p2forrzmap3-p4forhola(如seqidno:5-8所示),与酶切的dsm19002基因组进行直接克隆,(scai/sali酶切rzma基因簇,ecorv酶切hola基因簇),全长基因组序列可通过gnenbank号nc_014718.1于ncbi网站获取,rzma基因簇的位置为rbrh_rs12370,hola基因簇的位置为rbrh_rs16800,获得带rzma及hola全长基因簇的质粒p15a-cm-rzma以及p15a-cm-hola。再使用red/et线环重组技术,具体步骤依照文献2,(2.wangh,bianx,xial,etal.improvedseamlessmutagenesisbyrecombineeringusingccdbforcounterselection[j].nucleicacidsresearch2014mar;42(5):e37.doi:10.1093/nar/gkt1339.),将pcr获得的tnpa-ir-km基因盒插入p15a-cm-rzma/hola质粒上,引物为p5-p6(如seqidno:9-10所示),模板为pr6k-tnpa-km。此基因盒可表达转座酶,用于将带基因簇的质粒插入宿主菌的基因组上,以方便基因簇进行稳定表达。合成带同源臂的引物p7,p8以及p7,p9(如seqidno:11-13所示)分别用于pcr扩增rzma及hola的cs-al区域,模板分别为p15a-tnpa-km-rzm及p15a-tnpa-km-hol,此步骤可分别获得带同源臂以及km抗性的rzma和hola的cs-al区域,其中rzma-cs-al区域的同源臂可用于与带hola基因簇的质粒p15a-cm-hola进行线环重组,hola-cs-al区域的同源臂可用于与带rzma基因簇的质粒p15a-cm-rzma进行线环重组,red/et线环重组的宿主菌为大肠杆菌gb2005-red-gyra462,构建突变体质粒分别为:嵌合hola的cs-al区域的突变体质粒p15a-tnpa-km-rzmacshola以及嵌合rzma的cs-al区域的突变体质粒p15a-tnpa-km-holacsrzma。
将上述突变体以及野生型质粒分别电转化于dsm7029wt中进行异源表达,电转化电压为1250v,操作步骤均按照eppendorfeporator电转化仪的操作说明进行,加入dna的量为5μg。构建的菌株分别为突变体7029-rzmacshola、7029-holacsrzma以及野生型7029-rzma、7029-hola。
将突变体和野生型进行发酵表达,产物鉴定及定量后可从体内水平(invivo)验证cs-al区域交换的效果。对菌株进行发酵的步骤为,500μl过夜菌转接于50mlcymg液体培养基中,发酵72小时后,向发酵液中加入吸附树脂xad-16(2%)吸附一天后,离心收集菌体及树脂,倒掉上清后,加入40ml甲醇洗脱2h,使用旋转蒸发仪蒸干甲醇后,加入1ml进口甲醇,使用液质联用(lc-ms)检测产物。发酵及定量结果如表1及图1a、b、c所示。
表1:突变体rzmacshola,holacsrzma以及野生型rzma和野生型hola异源表达于dsm7029后的绝对定量
结论:对于rzma而言,当将其cs-al区域被hola的替换时,可定向获得c8-rzma的衍生物,且其产量相对于野生型降低幅度较小。而对于hola而言,当将其cs-al区域被rzma的替换时,可定向获得c2-hola的衍生物,且其产量与野生型相当。综合以上结果可知,在体内实验水平上,cs-al区域的替换可实现对脂肽脂链的定向操纵,获得脂链延长或缩短的衍生物。
实施例2:
进一步,对来源于dsm7029的glba基因簇进行操纵,将glba的cs-al区域替换为来自异源菌ds19002的hola的cs-al,以及来自同源菌dsm7029的glpa的cs-al。获得的突变体分别为glbacshola,glbacsglpa且从体内外水平对突变体的催化活性进行验证。即以全长的glba基因簇及相应突变体催化形成最终产物glba及其衍生物的能力为准(结构如图2,a、b所示),定量采用绝对定量,分离纯化衍生物及野生型脂肽产物后,以其为标准品,对突变体进行定量,定量仪器为液质联用(lc-ms)。
实施例2中涉及的dsm7029中的red/et重组系统及操作均采用文献3(wangx,zhouh,chenh,etal.discoveryofrecombinasesenablesgenomeminingofcrypticbiosyntheticgeneclustersinburkholderialesspecies[j].proceedingsofthenationalacademyofsciences,2018,115(18):201720941.)所述操作,所用菌株为带redαβ的dsm7029(redαβ7029)。
具体实施步骤如下:
(1)滑杆菌素的cs被根霉肽的cs和滑杆菌肽的cs替换直接在redαβ7029中进行,因需要使用apra抗性,所以首先给前述质粒p15a-tnpa-km-hola在大肠杆菌gb2005-red中进行线环重组,插入apra抗性,获得质粒p15a-tnpa-km-hola-apra,引物对为p10、p11(如seqidno:14-15所示),模板为pr6k-apra-phic31质粒。随后,使用带同源臂的引物对p12、p13(如seqidno:16-17所示),以p15a-tnpa-km-hola-apra为模板,pcr扩增带apra抗性的hola-cs-al片段。
带apra抗性的glpa-cs-al片段的获得则使用重叠pcr的方法,apra片段扩增自前述质粒p15a-p15a-tnpa-km-hola-apra,引物为p14、p15(如seqidno:18-19所示),glpa-cs片段pcr自dsm7029基因组,引物为p16、p17(如seqidno:20-21所示),分别获得两个片段后,再使用p15、p16以及两个片段互为引物和模板,进行重叠pcr扩增,扩增方法按照takara公司的primerstarmax的说明书进行操作。
glba-cs-apra片段的获得与glpa-cs-apra的获得类似,apra片段的扩增引物为p18-19(如seqidno:22-23所示),glba-cs片段扩增引物为p20-p21(如seqidno:24-25所示),再使用p19、p20以及两个片段互为引物和模板,进行重叠pcr扩增,扩增方法按照takara公司的primerstarmax的说明书进行操作。
以上三个带apra抗性的片段,包括hola-cs-al,glpa-cs-al及glba-cs-al均将cs置于km抗性的组成型启动子ptn5-km的控制之下。因插入glpa-cs-apra时,原始glpa-cs的存在会干扰重组,因此需要构建删除了glpa-cs的redαβdsm7029菌株,命名为redαβdsm7029δglpacs,构建流程为:pcr扩增带同源臂的genta抗性片段,引物对为p22、p23(如seqidno:26-27所示),按照文献3(wangx,zhouh,chenh,etal.discoveryofrecombinasesenablesgenomeminingofcrypticbiosyntheticgeneclustersinburkholderialesspecies[j].proceedingsofthenationalacademyofsciences,2018,115(18):201720941.)所述操作进行重组,构得敲除菌株redαβdsm7029δglpacs,菌株使用引物对p24、p25(如seqidno:28-29所示)进行菌落pcr鉴定,pcr流程参照takara公司的primerstarmax的说明书进行操作,敲除成功的组扩增片段长度为1.3kb。随后将前述cs-al片段包括hola-cs-al,glpa-cs-al及glba-cs-al电转化于菌株redαβdsm7029δglpacs中,按照文献3所述操作进行重组,分别获得重组菌株为glba的cs-al被hola的cs-al替换的菌株7029-glbacshola;glba的cs-al被glpa的cs-al替换的菌株7029-glbacsglpa;野生型glba的cs-al被带apra抗性及ptn5-km启动子的glba的cs-al替换的菌株7029-glbacs,其作为突变体定量的对照,方便进行比较。
将这些突变体菌株进行发酵表达,产物鉴定及定量后可从体内水平(invivo)验证关键交换结构域的作用。对菌株进行发酵的步骤为,500μl过夜菌转接于50mlcymg液体培养基中,发酵72小时后,向发酵液中加入吸附树脂xad-16(2%)吸附一天后,离心收集菌体及树脂,倒掉上清后,加入40ml甲醇洗脱2h,使用旋转蒸发仪蒸干甲醇后,加入1ml进口甲醇,使用液质联用(lc-ms)检测产物。发酵结果如表2及图2,a-c所示。
表2:从体内外水平验证关键交换结构域在glba中的作用
结论:对于glba而言,当将其cs-al区域被hola的替换时,可定向获得c8-glba的衍生物,且其产量相对于野生型大幅提升(增加了约16倍);当其cs-al区域被glpa的替换时,可定向获得c10-glba的衍生物,且其产量也有很大提高(约8倍)。
综合以上结果可知,在体内实验水平上,cs-al区域的替换可实现对脂肽脂链的定向操纵,且其衍生物的产量较优,有利于工程菌的构建。
序列表
<110>山东大学
<120>控制脂肽脂链长度改变的关键交换结构域及其突变体和应用
<141>2020-12-07
<160>27
<210>1
<211>479
<212>prt
<213>paraburkholderiarhizoxinicahki454
<221>rzma的cs-al区域的氨基酸序列
<222>(1)…(479)
<400>1
mdasvmsttyalsaaqteiwlaqqlypdspvyniaqytviegviepavfeaalrqvidea60
dtlrlqfidsddglrqrigtpawsmpvldltaqadpqaaaqawmradyqqpvnltqgplf120
cyallkvapaqwmwyqryhhimmdgygryliaqrvayvysalcegttpaecdfgsilqll180
esdaqyqisaqraqdeaywlkhcanwsepatlasrsapvlqqrlrqttylaiqalgdtap240
darrlaqfmtaamaaylyrftgeqdvvlglpvkvrfgadrhipgmksntlplrltmrpgm300
nlsslmqqaaqemqsglrhqrypsealrrqlgmpsgqrlfgttvnvmpfdldlsfggysa360
tnhnllngpaedlmlgvywtpgshqlridfdanpacytpeglgahqrrfirfmqvlaada420
tqpidsidlldanerhrllvewnatqrdypahlcvhqlfeaqvertpkatalvyedqtl479
<210>2
<211>479
<212>prt
<213>paraburkholderiarhizoxinicahki454
<221>hola的cs-al区域的氨基酸序列
<222>(1)…(479)
<400>2
msagaislttyplssaqteiwlaqqlhsgspvyniaqytviegaidptvfeaalrqvide60
adslrlqfveseaglrqrigspawsmpvlnltaeaesqavaqawmrtdyeepvdlmqgpl120
fqyallkvapkqwiwyqryhhimmdgygavliaqrvaqvysalcaerepapctfgsvlkl180
lesdaqyrasaqrekdeaywlkhcahwpvpatlagraapalqhrlrqtaylatqalgdaa240
sdvgrlaqfltaalatylhrmtraqdvalglpvtarlganrhipgvvsntvplrftfeak300
mtlasllqqatqiqrgfryqrypsealrrklelmpgqalfgatvnvmpfdydlsfdgyps360
snhnllngpvedlmlavywtpdnpqlridfdvnpacytaeeleahrcrfvrfmqalaadv420
tqpigeidlldteerhrlliewnatqqdypahqcihqlfeaqvehtpeamalvyeeqtl479
<210>3
<211>489
<212>prt
<213>dsm7029
<221>glba的cs-al区域的氨基酸序列
<222>(1)…(489)
<400>3
mqanhntpsyplspaqqeiwiaeqlnpgtgvyntagyadirgpvdvarfgaalrqtmaea60
dclravfhdhgegprqtpndtmawpfplidvsgepdpqaaaeawmqadlaqppdfahgpl120
frmalfraapdrffwylcghhlvadafgltllmhrlaeiysalmlqqapppawfgkledm180
iaadrdyhtsdalehdrtywisrlagcpeavslstgtaaaaaappgkfhrqwaelpaatg240
dalraiardngagvppllialvaaylyrmtgqedlvlglpvtgrpgrelrripgmlanvl300
plrfemtpnlgfgalfqqtarevrqalrhqryrgetmlrdlqqagavarlyahnvnvmaf360
dsevwfaghagrtcnlsngpvddlsltiyddgegkglriafdapaalytedelsghrerf420
irlantlvadlgapiaavdlmaaeerqrlltdwnvaepsprrttlaslfeqqagrapdav480
alvaseerl489
<210>4
<211>507
<212>prt
<213>dsm7029
<221>glpa的cs-al区域的氨基酸序列
<222>(1)…(507)
<400>4
mfpsrqdptassppraaaadaptlhelasvqqvvwldqvldpgvpsynlgamwqiegdld60
pvlfesvlnelaaahdalrlvlqleagvarqrvlpelevklpvidlsmhddardrawqha120
qtsfatpfqlygeplwqtqllrvgpssfywlhrmhhvigdgatvsltylaawdlykrrla180
gdttplepgpsylefldddsaylrspryqrdeqfwkqryaqlpapllpvregveqrqalp240
sgqtslyierprlrrfkalaarfgctlphamlallaayfarahqapevvigvpvhnrgta300
rqkrtwgmfssiipvaidvdpaqsfaalmqgvaaelkrcyrhqrfpiadinralrlgqhg360
rkqlfdvtlaleeypmdiylgdrklrvtkmysgfeqtplavclcdyhedepvavrfnynt420
gafeheaaedlprrigvlldavldagddrplddlrwfddaereqvlhtwnataqryaehd480
rclhemfeaqvqrtpdavavvageqrv507
<210>5
<211>93
<212>dna
<213>人工序列
<221>p1
<222>(1)…(93)
<400>5
tgatgctgtgattggcttgcgtgaatttatccggcgtctggagagggatttaatcccata60
cgcgctaaccgatcttaaggatctccaggca93
<210>6
<211>91
<212>dna
<213>人工序列
<221>p2
<222>(1)…(91)
<400>6
acaatcggtcaagcaagacagttaaaaagaacagggcaagccagtacgtcgcacaggcgc60
ggcgccattgtaagacgtcgatatctggcga91
<210>7
<211>91
<212>dna
<213>人工序列
<221>p3
<222>(1)…(91)
<400>7
caaagtggaaaatgcacgcatttctcagcagccgggaaaacccacaaatgaattgcacgt60
cagcagttggtaagacgtcgatatctggcga91
<210>8
<211>91
<212>dna
<213>人工序列
<221>p4
<222>(1)…(91)
<400>8
ggcagcatcttcatcggcggcgctgtggtgcaatggctgcgcgacgggctgggaatcatc60
aaacaggcgggatcttaaggatctccaggca91
<210>9
<211>70
<212>dna
<213>人工序列
<221>p5
<222>(1)…(70)
<400>9
ctgaggtcattactggatctatcaacaggagtccaagcgagctcgatatctgcatccgat60
gcaagtgtgt70
<210>10
<211>89
<212>dna
<213>人工序列
<221>p6
<222>(1)…(89)
<400>10
gtttgggcagcggataatgcatacgtagtggacatgacgctagcgtccataatctgtacc60
tccttaagtcagaagaactcgtcaagaag89
<210>11
<211>25
<212>dna
<213>人工序列
<221>p7
<222>(1)…(25)
<400>11
ctgaggtcattactggatctatcaa25
<210>12
<211>70
<212>dna
<213>人工序列
<221>p8
<222>(1)…(70)
<400>12
atgagctggtgtgccaagcggttggcctgcgcattcagttgcgtatagctgagcgtttgc60
tcctcgtaga70
<210>13
<211>75
<212>dna
<213>人工序列
<221>p9
<222>(1)…(75)
<400>13
atcagctgatgcgccagacggttggcccgcgcattcagctcagcgtaactcagtgtttga60
tcttcatagaccaac75
<210>14
<211>75
<212>dna
<213>人工序列
<221>p10
<222>(1)…(75)
<400>14
atctcttcaaatgtagcacctgaagtcagccccatacgatataagttgtttgatcatatg60
cggattagaaaaaca75
<210>15
<211>74
<212>dna
<213>人工序列
<221>p11
<222>(1)…(74)
<400>15
ttccgcttcctttagcagcccttgcgccctgagtgcttgcggcagcgtgatagtgcttgg60
attctcaccaataa74
<210>16
<211>95
<212>dna
<213>人工序列
<221>p12
<222>(1)…(95)
<400>16
ccgggccgacccccaggccgatcaggtggtgcgccaggcggttggcgcgctcgttgagcg60
cggcataggtgagcgtttgctcctcgtagaccaac95
<210>17
<211>93
<212>dna
<213>人工序列
<221>p13
<222>(1)…(93)
<400>17
gcgcactggaccgacctgcgcccacgcagcgtggcccgccgcgcacacgcccaaccggag60
gcctgaggactcatctcgttctccgctcatgag93
<210>18
<211>34
<212>dna
<213>人工序列
<221>p14
<222>(1)…(34)
<400>18
gaacacaatctgtacctccttaagtcagaagaac34
<210>19
<211>96
<212>dna
<213>人工序列
<221>p15
<222>(1)…(96)
<400>19
gcgcactggaccgacctgcgcccacgcagcgtggcccgccgcgcacacgcccaaccggag60
gcctgaggactcatctcgttctccgctcatgagctc96
<210>20
<211>90
<212>dna
<213>人工序列
<221>p16
<222>(1)…(90)
<400>20
ccgggccgacccccaggccgatcaggtggtgcgccaggcggttggcgcgctcgttgagcg60
cggcataggtcacgcgctgctcgccggcca90
<210>21
<211>41
<212>dna
<213>人工序列
<221>p17
<222>(1)…(41)
<400>21
aggaggtacagattgtgttcccttcccgacaagatcccacc41
<210>22
<211>43
<212>dna
<213>人工序列
<221>p18
<222>(1)…(43)
<400>22
gtgattcgcttgcataatctgtacctccttaagtcagaagaac43
<210>23
<211>93
<212>dna
<213>人工序列
<221>p19
<222>(1)…(93)
<400>23
gcgcactggaccgacctgcgcccacgcagcgtggcccgccgcgcacacgcccaaccggag60
gcctgaggacatgcaagcgaatcacaacacccc93
<210>24
<211>90
<212>dna
<213>人工序列
<221>p20
<222>(1)…(90)
<400>24
ccgggccgacccccaggccgatcaggtggtgcgccaggcggttggcgcgctcgttgagcg60
cggcataggtgaggcgctcttctgacgcga90
<210>25
<211>37
<212>dna
<213>人工序列
<221>p21
<222>(1)…(37)
<400>25
aggaggtacagattatgcaagcgaatcacaacacccc37
<210>26
<211>90
<212>dna
<213>人工序列
<221>p22
<222>(1)…(90)
<400>27
gcaccggcgcgccggcctgccgcggtccgcgttccagcgacgtccctgccaggagtgttt60
cgtggttgctgaattacattcccaaccgcg90
<210>27
<211>89
<212>dna
<213>人工序列
<221>p23
<222>(1)…(89)
<400>27
tcggccccaccccgcggcggcgcagttctcgcgccagctggttggcccgcgcgttcagct60
cggcatagctcgaaacgacctgcaactta89
- 还没有人留言评论。精彩留言会获得点赞!