用于抗体优化的变异核酸文库的制作方法
用于抗体优化的变异核酸文库
交叉引用
1.本技术要求2019年2月26日提交的第62/810,379号美国临时专利申请和2019年4月5日提交的第62/830,296号美国临时专利申请的权益,所述临时申请中的每一个均通过引用而整体并入。
背景技术:
2.抗体具有以高特异性和亲和力与生物靶标结合的能力。然而,由于免疫效应与功效的平衡,治疗性抗体的设计具有挑战性。因此,需要开发用于优化抗体性质的组合物和方法。援引并入
3.本说明书中所提及的所有出版物、专利和专利申请均通过引用并入本文,其程度犹如具体地且单独地指出每个单独的出版物、专利或专利申请均通过引用而并入。
技术实现要素:
4.本文提供用于优化抗体的方法、组合物和系统。
5.本文提供了包含编码抗体或抗体片段的多个序列的核酸文库,其中所述多个序列中的每个序列相对于输入序列包含预定数目的突变;所述文库包含至少5,000个变异序列,其中所述至少5,000个变异序列中的每一个以不超过所述文库中其他任何变异序列的量的50%的量呈现;并且至少一个序列编码具有比所述输入序列更高的结合亲和力的抗体或抗体片段。本文进一步提供了核酸文库,其中所述文库包含至少50,000个变异序列。本文进一步提供了核酸文库,其中所述文库包含至少100,000个变异序列。本文进一步提供了核酸文库,其中至少一些所述序列编码抗体轻链。本文进一步提供了核酸文库,其中至少一些所述序列编码抗体重链。本文进一步提供了核酸文库,其中所述多个序列中的每个序列相对于所述输入序列在重链或轻链的每个cdr中包含至少一个突变。本文进一步提供了核酸文库,其中所述多个序列中的每个序列相对于所述输入序列在重链或轻链的每个cdr中包含至少两个突变。本文进一步提供了核酸文库,其中至少一个所述突变存在于至少两个个体中。本文进一步提供了核酸文库,其中至少一个所述突变存在于至少三个个体中。本文进一步提供了核酸文库,其中所述多个序列中的每个序列相对于所述输入序列的种系序列在重链或轻链的每个cdr中包含至少一个突变。
6.本文提供了抗体,其中所述抗体包含cdr
‑
h3,该cdr
‑
h3包含seq id no:1
‑
35中的任一个的序列。本文提供了抗体,其中所述抗体包含cdr
‑
h3,该cdr
‑
h3包含seq id no:1
‑
35中的任一个的序列;并且其中所述抗体是单克隆抗体、多克隆抗体、双特异性抗体、多特异性抗体、移植抗体、人抗体、人源化抗体、合成抗体、嵌合抗体、骆驼化抗体、单链fv(scfv)、单链抗体、fab片段、f(ab')2片段、fd片段、fv片段、单结构域抗体、分离的互补决定区(cdr)、双抗体、仅由单个单体可变域组成的片段、二硫键连接的fv(sdfv)、胞内抗体、抗独特型(抗
‑
id)抗体,或它们的抗原结合片段。
7.本文提供了抑制pd
‑
1活性的方法,其包括施用如本文所述的抗体。本文提供了治疗增生性病症的方法,其包括向有需要的受试者施用如本文所述的抗体。本文进一步提供了治疗增生性病症的方法,其中所述增生性病症是癌症。本文进一步提供了治疗增生性病症的方法,其中所述癌症是肺癌、头颈部鳞状细胞癌、结直肠癌、黑素瘤、肝癌、经典霍奇金淋巴瘤、肾癌、胃癌、宫颈癌、merkel细胞癌、b细胞淋巴瘤或膀胱癌。
8.本文提供了包含多个核酸的核酸文库,其中所述多个核酸中的每个核酸编码当翻译时编码抗体的序列,其中所述抗体包含cdr
‑
h3环,该cdr
‑
h3环包含pd
‑
1结合域,并且其中所述多个核酸中的每个核酸包含编码所述pd
‑
1结合域的序列变体的序列。本文进一步提供了核酸文库,其中所述cdr
‑
h3环当翻译时的长度为约20至约80个氨基酸。本文进一步提供了核酸文库,其中所述cdr
‑
h3环的长度为约80至约230个碱基对。本文进一步提供了核酸文库,其中所述抗体进一步包含一个或多个选自轻链可变域(vl)、重链可变域(vh)、轻链恒定域(cl)和重链恒定域(ch)的结构域。本文进一步提供了核酸文库,其中所述vh结构域的长度为约90至约100个氨基酸。本文进一步提供了核酸文库,其中所述vl结构域的长度为约90至约120个氨基酸。本文进一步提供了核酸文库,其中所述vh结构域的长度为约280至约300个碱基对。本文进一步提供了核酸文库,其中所述vl结构域的长度为约300至约350个碱基对。本文进一步提供了核酸文库,其中所述文库包含至少10
10
个不相同的核酸。本文进一步提供了核酸文库,其中所述文库包含至少10
12
个不相同的核酸。本文进一步提供了核酸文库,其中所述抗体包含单个免疫球蛋白结构域。本文进一步提供了核酸文库,其中所述抗体包含至多100个氨基酸的肽。本文进一步提供了核酸文库,其中所述pd
‑
1结合域包含拟肽或小分子模拟物。
9.本文提供了包含多个蛋白质的蛋白质文库,其中所述多个蛋白质中的每个蛋白质包含抗体,其中所述抗体包含cdr
‑
h3环,该cdr
‑
h3环包含pd
‑
1结合域的序列变体。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述cdr
‑
h3环的长度为约20至约80个氨基酸。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述抗体进一步包含一个或多个选自轻链可变域(vl)、重链可变域(vh)、轻链恒定域(cl)和重链恒定域(ch)的结构域。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述vh结构域的长度为约90至约100个氨基酸。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述vl结构域的长度为约90至约120个氨基酸。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述多个蛋白质用来生成拟肽文库。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述蛋白质文库包含抗体。
10.本文提供了包含多个蛋白质的蛋白质文库,其中所述多个蛋白质中的每个蛋白质包含编码不同pd
‑
1结合域的序列,并且其中每个pd
‑
1结合域的长度为约20至约80个氨基酸。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述蛋白质文库包含肽。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述蛋白质文库包含免疫球蛋白。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述蛋白质文库包含抗体。本文进一步提供了包含多个蛋白质的蛋白质文库,其中所述多个蛋白质用来生成拟肽文库。
11.本文提供了包含如本文所述的核酸文库的载体文库。本文提供了包含如本文所述的核酸文库的细胞文库。本文提供了包含如本文所述的蛋白质文库的细胞文库。
12.本文提供了包含编码抗体或抗体片段的多个序列的核酸文库,其中所述多个序列
中的每个序列相对于输入序列包含预定数目的突变;所述文库包含至少30,000个变异序列;并且至少一些所述抗体或抗体片段以小于50nm的k
d
与pd
‑
1结合。本文进一步提供了核酸文库,其中所述文库包含seq id no:1
‑
35中的任一个的cdr序列。本文进一步提供了核酸文库,其中所述文库包含seq id no:1
‑
35中的任一个的cdrh1、cdrh2或cdrh3序列。本文进一步提供了核酸文库,其中所述文库包含至少一个编码以小于10nm的k
d
与pd
‑
1结合的抗体或抗体片段的序列。本文进一步提供了核酸文库,其中所述文库包含至少一个编码以小于5nm的k
d
与pd
‑
1结合的抗体或抗体片段的序列。本文进一步提供了核酸文库,其中所述文库包含至少五个编码以小于10nm的k
d
与pd
‑
1结合的抗体或抗体片段的序列。本文进一步提供了核酸文库,其中所述文库包含至少50,000个变异序列。本文进一步提供了核酸文库,其中所述文库包含至少100,000个变异序列。
13.本文提供了用于抗体优化的计算机化系统,其包括:(a)通用计算机;和(b)包含功能模块的计算机可读介质,所述功能模块包括用于所述通用计算机的指令,其中所述计算机化系统被配置用于以包括以下步骤的方法运行:(i)接收操作指令,其中所述操作指令包含编码抗体或抗体片段的多核苷酸序列;(ii)生成抗体文库,其中该抗体文库包含所述多核苷酸序列的多个变异序列;以及(iii)合成所述多个变异序列。本文进一步提供了用于抗体优化的计算机化系统,其中所述抗体文库包含至少30,000个序列。本文进一步提供了用于抗体优化的计算机化系统,其中所述抗体文库包含至少50,000个序列。本文进一步提供了用于抗体优化的计算机化系统,其中所述抗体文库包含至少100,000个序列。本文进一步提供了用于抗体优化的计算机化系统,其中所述系统进一步包括富集所述变异序列的子集。本文进一步提供了用于抗体优化的计算机化系统,其中所述系统进一步包括表达对应于所述变异序列的抗体或抗体片段。本文进一步提供了用于抗体优化的计算机化系统,其中所述多核苷酸序列是鼠、人或嵌合抗体序列。本文进一步提供了用于抗体优化的计算机化系统,其中所述抗体文库包含各自以不超过所述抗体文库中其他任何变异序列量的50%的量呈现的变异序列。本文进一步提供了用于抗体优化的计算机化系统,其中所述多个变异序列中的每个序列相对于所述输入序列在重链或轻链的每个cdr中包含至少一个突变。本文进一步提供了用于抗体优化的计算机化系统,其中所述多个变异序列中的每个序列相对于所述输入序列在重链或轻链的每个cdr中包含至少两个突变。本文进一步提供了用于抗体优化的计算机化系统,其中所述多个变异序列中的每个序列相对于所述输入序列的种系序列在重链或轻链的每个cdr中包含至少一个突变。本文进一步提供了用于抗体优化的计算机化系统,其中所述抗体文库具有至少10
12
个序列的理论多样性。本文进一步提供了用于抗体优化的计算机化系统,其中所述抗体文库具有至少10
13
个序列的理论多样性。
14.本文提供了优化抗体的方法,其包括:(a)提供编码抗体或抗体片段的多核苷酸序列;(b)生成抗体文库,其中该抗体文库包含所述多核苷酸序列的多个变异序列;以及(c)合成所述多个变异序列。本文进一步提供了优化抗体的方法,其中所述抗体文库包含至少30,000个序列。本文进一步提供了优化抗体的方法,其中所述抗体文库包含至少50,000个序列。本文进一步提供了优化抗体的方法,其中所述抗体文库包含至少100,000个序列。本文进一步提供了优化抗体的方法,其中所述方法进一步包括富集所述变异序列的子集。本文进一步提供了优化抗体的方法,其中所述方法进一步包括表达对应于所述变异序列的抗体或抗体片段。本文进一步提供了优化抗体的方法,其中所述多核苷酸序列是鼠、人或嵌合抗
体序列。本文进一步提供了优化抗体的方法,其中所述抗体文库包含各自以不超过所述抗体文库中其他任何变异序列量的50%的量呈现的变异序列。本文进一步提供了优化抗体的方法,其中所述多个变异序列中的每个序列相对于所述输入序列在重链或轻链的每个cdr中包含至少一个突变。本文进一步提供了优化抗体的方法,其中所述多个变异序列中的每个序列相对于所述输入序列在重链或轻链的每个cdr中包含至少两个突变。本文进一步提供了优化抗体的方法,其中每个序列相对于所述输入序列的种系序列在重链或轻链的每个cdr中包含至少一个突变。本文进一步提供了优化抗体的方法,其中所述抗体文库具有至少10
12
个序列的理论多样性。本文进一步提供了优化抗体的方法,其中所述抗体文库具有至少10
13
个序列的理论多样性。
15.本文提供了核酸文库,其包含:多个序列,所述多个序列包含当翻译时编码抗体或抗体片段的核酸,其中每个序列相对于抗体的输入序列在cdr内包含预定数目的突变;其中所述文库包含至少50,000个变异序列,每个变异序列以平均频率的1.5倍内的量呈现;并且其中至少一个序列当翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少2.5倍。本文进一步提供了核酸文库,其中所述文库包含至少100,000个变异序列。本文进一步提供了核酸文库,其中至少一些所述序列编码抗体轻链。本文进一步提供了核酸文库,其中至少一些所述序列编码抗体重链。本文进一步提供了核酸文库,其中所述多个序列中的每个序列相对于所述输入序列在重链或轻链的cdr中包含至少一个突变。本文进一步提供了核酸文库,其中所述多个序列中的每个序列相对于所述输入序列在重链或轻链的cdr中包含至少两个突变。本文进一步提供了核酸文库,其中至少一个所述突变存在于至少两个个体中。本文进一步提供了核酸文库,其中至少一个所述突变存在于至少三个个体中。本文进一步提供了核酸文库,其中至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少5倍。本文进一步提供了核酸文库,其中至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少25倍。本文进一步提供了核酸文库,其中至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少50倍。本文进一步提供了核酸文库,其中所述多个序列中的每个序列相对于所述输入序列的种系序列在重链或轻链的cdr中包含至少一个突变。本文进一步提供了核酸文库,其中所述cdr是重链上的cdr1、cdr2和cdr3。本文进一步提供了核酸文库,其中所述cdr是轻链上的cdr1、cdr2和cdr3。本文进一步提供了核酸文库,其中所述至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的至少70倍。本文进一步提供了核酸文库,其中所述至少一个序列当翻译时编码k
d
小于50nm的抗体或抗体片段。本文进一步提供了核酸文库,其中所述至少一个序列当翻译时编码k
d
小于25nm的抗体或抗体片段。本文进一步提供了核酸文库,其中所述至少一个序列当翻译时编码k
d
小于10nm的抗体或抗体片段。本文进一步提供了核酸文库,其中所述至少一个序列当翻译时编码k
d
小于5nm的抗体或抗体片段。本文进一步提供了核酸文库,其中所述文库包含seq id no:1
‑
6或9
‑
70中的任一个的cdr序列。本文进一步提供了核酸文库,所述文库包含seq id no:1
‑
6或9
‑
70中的任一个的cdrh1、cdrh2或cdrh3序列。本文进一步提供了核酸文库,其中所述文库包含至少一个编码以小于10nm的k
d
与pd
‑
1结合的抗体或抗体片段的序列。本文进一步提供了核酸文库,其中
所述文库包含至少一个编码以小于5nm的k
d
与pd
‑
1结合的抗体或抗体片段的序列。本文进一步提供了核酸文库,其中所述文库包含至少五个编码以小于10nm的k
d
与pd
‑
1结合的抗体或抗体片段的序列。本文进一步提供了核酸文库,其中所述文库包含至少100,000个变异序列。
16.本文提供了抗体,其中所述抗体包含seq id no:1
‑
6或9
‑
70中的任一个的序列。本文提供了抗体,其中所述抗体包含seq id no:1
‑
6或9
‑
34中的任一个的序列;并且其中所述抗体是单克隆抗体、多克隆抗体、双特异性抗体、多特异性抗体、移植抗体、人抗体、人源化抗体、合成抗体、嵌合抗体、骆驼化抗体、单链fv(scfv)、单链抗体、fab片段、f(ab')2片段、fd片段、fv片段、单结构域抗体、分离的互补决定区(cdr)、双抗体、仅由单个单体可变域组成的片段、二硫键连接的fv(sdfv)、胞内抗体、抗独特型(抗
‑
id)抗体,或它们的抗原结合片段。
17.本文提供了抑制pd
‑
1活性的方法,其包括施用本文所述的抗体。本文提供了治疗增生性病症的方法,其包括向有需要的受试者施用本文所述的抗体。本文进一步提供了方法,其中所述增生性病症是癌症。本文进一步提供了方法,其中所述癌症是肺癌、头颈部鳞状细胞癌、结直肠癌、黑素瘤、肝癌、经典霍奇金淋巴瘤、肾癌、胃癌、宫颈癌、merkel细胞癌、b细胞淋巴瘤或膀胱癌。
18.本文提供了用于抗体优化的计算机化系统,其包括:(a)通用计算机;和(b)包含功能模块的计算机可读介质,所述功能模块包括用于所述通用计算机的指令,其中所述计算机化系统被配置用于以包括以下步骤的方法运行:(i)接收操作指令,其中所述操作指令包含编码抗体或抗体片段的多个序列;(ii)生成包含所述多个序列的核酸文库,所述多个序列包含当翻译时编码抗体或抗体片段的核酸,其中每个序列相对于抗体的输入序列在cdr内包含预定数目的突变;其中所述文库包含至少50,000个变异序列,每个变异序列以平均频率的1.5倍内的量呈现;并且其中至少一个序列当翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少2.5倍;以及(iii)合成所述至少50,000个变异序列。本文进一步提供了用于抗体优化的计算机化系统,其中所述核酸文库包含至少100,000个序列。本文进一步提供了用于抗体优化的计算机化系统,其中所述系统进一步包括富集所述变异序列的子集。本文进一步提供了用于抗体优化的计算机化系统,其中所述系统进一步包括表达对应于所述变异序列的抗体或抗体片段。本文进一步提供了用于抗体优化的计算机化系统,其中所述多核苷酸序列是鼠、人或嵌合抗体序列。本文进一步提供了用于抗体优化的计算机化系统,其中所述多个变异序列中的每个序列相对于所述输入序列在重链或轻链的cdr中包含至少一个突变。本文进一步提供了用于抗体优化的计算机化系统,其中所述多个变异序列中的每个序列相对于所述输入序列在重链或轻链的cdr中包含至少两个突变。本文进一步提供了用于抗体优化的计算机化系统,其中至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少5倍。本文进一步提供了用于抗体优化的计算机化系统,其中至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少25倍。本文进一步提供了用于抗体优化的计算机化系统,其中至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少50倍。本文进一步提供了用于抗体优化的计算机化系
统,其中所述多个变异序列中的每个序列相对于所述输入序列的种系序列在重链或轻链的cdr中包含至少一个突变。本文进一步提供了用于抗体优化的计算机化系统,其中所述cdr是重链上的cdr1、cdr2和cdr3。本文进一步提供了用于抗体优化的计算机化系统,其中所述cdr是轻链上的cdr1、cdr2和cdr3。本文进一步提供了用于抗体优化的计算机化系统,其中所述抗体文库具有至少10
12
个序列的理论多样性。本文进一步提供了用于抗体优化的计算机化系统,其中所述抗体文库具有至少10
13
个序列的理论多样性。
19.本文提供了优化抗体的方法,其包括:(a)提供编码抗体或抗体片段的多个多核苷酸序列;(b)生成包含所述多个序列的核酸文库,所述多个序列包含当翻译时编码抗体或抗体片段的核酸,其中每个序列相对于抗体的输入序列在cdr内包含预定数目的突变;其中所述文库包含至少50,000个变异序列,每个变异序列以平均频率的1.5倍内的量呈现;并且其中至少一个序列当翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少2.5倍;以及(c)合成所述至少50,000个变异序列。本文进一步提供了优化抗体的方法,其中所述抗体文库包含至少100,000个序列。本文进一步提供了优化抗体的方法,其中所述方法进一步包括富集所述变异序列的子集。本文进一步提供了优化抗体的方法,其中所述方法进一步包括表达对应于所述变异序列的抗体或抗体片段。本文进一步提供了优化抗体的方法,其中所述多核苷酸序列是鼠、人或嵌合抗体序列。本文进一步提供了优化抗体的方法,其中所述多个变异序列中的每个序列相对于所述输入序列在重链或轻链的每个cdr中包含至少一个突变。本文进一步提供了优化抗体的方法,其中所述多个变异序列中的每个序列相对于所述输入序列在重链或轻链的每个cdr中包含至少两个突变。本文进一步提供了优化抗体的方法,其中至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少5倍。本文进一步提供了优化抗体的方法,其中至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少25倍。本文进一步提供了优化抗体的方法,其中至少一个序列在翻译时编码这样的抗体或抗体片段,该抗体或抗体片段的结合亲和力是所述输入序列的结合亲和力的至少50倍。本文进一步提供了优化抗体的方法,其中每个序列相对于所述输入序列的种系序列在重链或轻链的每个cdr中包含至少一个突变。本文进一步提供了优化抗体的方法,其中所述核酸文库具有至少10
12
个序列的理论多样性。本文进一步提供了优化抗体的方法,其中所述核酸文库具有至少10
13
个序列的理论多样性。
附图说明
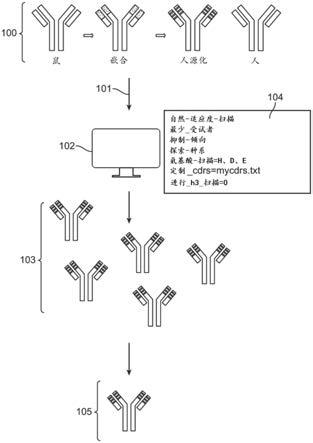
20.图1描绘了抗体优化的工作流程。
21.图2a描绘了免疫球蛋白支架的第一示意图。
22.图2b描绘了免疫球蛋白支架的第二示意图。
23.图3a描绘了文库中优化的抗体输入序列的示例性序列,显示了序列区域中的突变数。
24.图3b显示了抗体优化的工作流程。
25.图4a描绘了1
‑
5轮淘选后可变重链的读取长度。
26.图4b描绘了1
‑
5轮淘选后可变重链的克隆频率。
27.图4c描绘了1
‑
5轮淘选后可变重链的克隆积累。
28.图4d是突变数相对于不同淘选条件的图示。
29.图4e是富集的克隆关于与pd
‑
1结合的序列分析的图示。
30.图5a是第五轮淘选时抗scfv elisa相对于富集的图示。
31.图5b是抗scfv elisa结合pd
‑
1的图示。
32.图6a描绘了与比较物pd
‑
1结合的优化igg的序列。
33.图6b描绘了与亲本抗体(330nm)相比,优化抗体(4.5nm)的亲和力增加。
34.图6c
‑
6d描绘了cdr的序列比对。
35.图6e描绘了剂量依赖性噬菌体pd
‑
1elisa。
36.图6f描绘了等亲和力图。
37.图7a是优化igg的pd
‑
1/pdl
‑
1阻断分析的图示。
38.图7b显示了优化igg的结合亲和力和效力。
39.图7c是优化igg的pd
‑
1/pdl
‑
1阻断ic50(nm,y轴)相对于spr单价结合亲和力(kd(nm),x轴)的图示。
40.图7d是数种igg(x轴)的bvp评分(y轴)的图示。
41.图8呈现了说明如本文所公开的基因合成的示例性处理工作流程的步骤图。
42.图9示出了计算机系统的示例。
43.图10是示出计算机系统的架构的框图。
44.图11是说明网络的示图,该网络被配置用于并入多个计算机系统、多个蜂窝电话和个人数据助理,以及网络附加存储(nas)。
45.图12是使用共享虚拟地址存储空间的多处理器计算机系统的框图。
具体实施方式
46.除非另有说明,否则本公开采用在本领域技术范围内的常规分子生物学技术。除非另有定义,否则本文使用的所有技术和科学术语具有与本领域普通技术人员通常理解的相同的含义。
47.定义
48.贯穿本公开内容,多个实施方案以范围格式给出。应当理解,范围格式的描述只是为了方便和简明,而不应被解释为对任何实施方案的范围的硬性限制。因此,除非上下文另有明确规定,否则对范围的描述应被认为明确公开了所有可能的子范围以及该范围内精确到下限单位十分之一的各个数值。例如,对诸如从1至6的范围的描述应被认为已经明确公开了诸如从1至3、从1至4、从1至5、从2至4、从2至6、从3至6等子范围,以及该范围内的各个值,例如,1.1、2、2.3、5和5.9。无论范围的宽度如何,这都是适用的。这些中间范围的上限和下限可独立地包括在更小的范围内,并且也被涵盖于本公开内容中,受所述范围中任何具体排除的限值所约束。除非上下文另有明确规定,否则在所述范围包括限值之一或两者的情况下,排除了这些所包含的限值中的任一个或两者的范围也被包括在本公开内容中。
49.本文使用的术语仅用于描述特定实施方案的目的,而非旨在限制任何实施方案。除非上下文另有明确规定,否则如本文所用的单数形式“一个”、“一种”和“该”也意欲包括复数形式。进一步应当理解,术语“包括”和/或“包含”在本说明书中使用时指代所述特征、
整数、步骤、操作、元件和/或组分的存在,但不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组分和/或其群体。如本文所用的,术语“和/或”包括一个或多个相关所列项目的任何及所有组合。
50.除非具体说明或从上下文中可以明显看出,否则如本文所用的,关于数字或数字范围的术语“约”应被理解为表示所述数字及其+/
‑
10%的数字,或者对于范围列出的值,表示低于所列下限的10%至高于所列上限的10%。
51.除非具体说明,否则如本文所用的,术语“核酸”涵盖双链或三链核酸以及单链分子。在双链或三链核酸中,核酸链不必共同延伸(即,双链核酸不必沿两条链的全长都是双链的)。当提供时,核酸序列以5’至3’的方向列出,除非另有说明。本文所述的方法提供了分离的核酸的生成。本文所述的方法另外提供了分离并纯化的核酸的生成。本文提及的“核酸”在长度上可包含至少5、10、20、30、40、50、60、70、80、90、100、125、150、175、200、225、250、275、300、325、350、375、400、425、450、475、500、600、700、800、900、1000、1100、1200、1300、1400、1500、1600、1700、1800、1900、2000个或更多个碱基。而且,本文提供了合成任意数目的编码多肽区段的核苷酸序列的方法,该序列包括编码非核糖体肽(nrp)的序列,编码以下物质的序列:非核糖肽合成酶(nrps)模块和合成变体、其它模块化蛋白质如抗体的多肽区段、来自其它蛋白质家族的多肽区段,包括非编码dna或rna,如调节序列,例如启动子、转录因子、增强子、sirna、shrna、rnai、mirna、衍生自微小rna的核仁小rna,或任何感兴趣的功能性或结构性dna或rna单元。以下是多核苷酸的非限制性实例:基因或基因片段的编码区或非编码区、基因间dna、由连锁分析限定的基因座(多个基因座)、外显子、内含子、信使rna(mrna)、转移rna、核糖体rna、短干扰rna(sirna)、短发夹rna(shrna)、微小rna(mirna)、核仁小rna、核酶、互补dna(cdna)(其为mrna的dna呈现形式,通常通过信使rna(mrna)的逆转录或通过扩增来获得);经合成或通过扩增产生的dna分子、基因组dna、重组多核苷酸、支链多核苷酸、质粒、载体、任何序列的分离的dna、任何序列的分离的rna、核酸探针和引物。编码本文提及的基因或基因片段的cdna可包含至少一个编码外显子序列的区域,而没有基因组等同序列中的间插内含子序列。
52.抗体优化
53.本文提供用于优化抗体的方法、组合物和系统。在一些情况下,通过设计包含输入抗体序列的变异序列的计算机模拟文库来优化抗体(图1)。在一些情况下,输入序列100用一个或多个突变在计算机中修饰102,以生成优化序列的文库103。在一些情况下,合成这样的文库,将其克隆到表达载体中,并评价翻译产物(抗体)的活性。在一些情况下,合成序列的片段,随后进行装配。在一些情况下,使用表达载体展示并富集所需的抗体,如噬菌体展示。在一些情况下,在富集过程中使用的选择压力包括结合亲和力、毒性、免疫耐受性、稳定性或其他因素。此类表达载体允许选择(“淘选”)具有特定性质的抗体,并且此类序列的后续增殖或扩增使文库富含这些序列。淘选轮次可以重复任意次数,如1、2、3、4、5、6、7轮或超过7轮。在一些情况下,利用一轮或多轮的测序来鉴定文库中富集了哪些序列105。
54.本文描述了计算机模拟文库设计的方法和系统。例如,抗体或抗体片段序列用作输入。在一些情况下,任何抗体序列都用于输入本文所述的方法和系统中。查询101包含来自生物体的已知突变的数据库102,并且生成包含这些突变的组合的序列文库103。在一些情况下,本文所述的抗体包含cdr区。在一些情况下,来自cdr的已知突变用来构建序列文
库。在一些情况下,使用过滤器104或排除标准为序列文库的成员选择特定类型的变体。例如,如果数据库中最小数目的生物体具有突变,则添加具有该突变的序列。在一些情况下,指定额外的cdr以包含在数据库中。在一些情况下,特定突变或突变组合被排除在文库之外(例如,已知的免疫原性位点、结构位点等)。在一些情况下,将输入序列中的特定位点系统地替换为组氨酸、天冬氨酸、谷氨酸或其组合。在一些情况下,指定了抗体每个区域允许的最大或最小突变数。在一些情况下,相对于输入序列或输入序列的相应种系序列来描述突变。例如,通过优化生成的序列包含至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16个或超过16个来自输入序列的突变。在一些情况下,通过优化生成的序列包含不超过1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16个或不超过18个来自输入序列的突变。在一些情况下,通过优化生成的序列包含约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16个或约18个相对于输入序列的突变。在一些情况下,通过优化生成的序列在第一cdr区中包含约1、2、3、4、5、6或7个来自输入序列的突变。在一些情况下,通过优化生成的序列在第二cdr区中包含约1、2、3、4、5、6或7个来自输入序列的突变。在一些情况下,通过优化生成的序列在第三cdr区中包含约1、2、3、4、5、6或7个来自输入序列的突变。在一些情况下,通过优化生成的序列在重链的第一cdr区中包含约1、2、3、4、5、6或7个来自输入序列的突变。在一些情况下,通过优化生成的序列在重链的第二cdr区中包含约1、2、3、4、5、6或7个来自输入序列的突变。在一些情况下,通过优化生成的序列在重链的第三cdr区中包含约1、2、3、4、5、6或7个来自输入序列的突变。在一些情况下,通过优化生成的序列在轻链的第一cdr区中包含约1、2、3、4、5、6或7个来自输入序列的突变。在一些情况下,通过优化生成的序列在轻链的第二cdr区中包含约1、2、3、4、5、6或7个来自输入序列的突变。在一些情况下,通过优化生成的序列在轻链的第三cdr区中包含约1、2、3、4、5、6或7个来自输入序列的突变。在一些情况下,第一cdr区是cdr1。在一些情况下,第二cdr区是cdr2。在一些情况下,第三cdr区是cdr3。在一些情况下,合成计算机模拟抗体文库,装配,并针对所需序列进行富集。
55.还可以修饰对应于输入序列的种系序列,以在文库中生成序列。例如,通过本文所述的优化方法生成的序列包含至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16个或超过16个来自种系序列的突变。在一些情况下,通过优化生成的序列包含不超过1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16个或不超过18个来自种系序列的突变。在一些情况下,通过优化生成的序列包含约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16个或约18个相对于种系序列的突变。
56.本文提供了用于抗体优化的方法、系统和组合物,其中输入序列包含抗体区域中的突变。抗体的示例性区域包括但不限于互补决定区(cdr)、可变域或恒定域。在一些情况下,该cdr是cdr1、cdr2或cdr3。在一些情况下,该cdr是重链结构域,包括但不限于cdr
‑
h1、cdr
‑
h2和cdr
‑
h3。在一些情况下,该cdr是轻链结构域,包括但不限于cdr
‑
l1、cdr
‑
l2和cdr
‑
l3。在一些情况下,该可变域是轻链可变域(vl)或重链可变域(vh)。在一些情况下,该vl结构域包含κ或λ链。在一些情况下,该恒定域是轻链恒定域(cl)或重链恒定域(ch)。在一些情况下,通过优化生成的序列在第一cdr区中包含约1、2、3、4、5、6或7个来自种系序列的突变。在一些情况下,通过优化生成的序列在第二cdr区中包含约1、2、3、4、5、6或7个来自种系序列的突变。在一些情况下,通过优化生成的序列在第三cdr区中包含约1、2、3、4、5、6或7个来自种系序列的突变。在一些情况下,通过优化生成的序列在重链的第一cdr区中包含约1、2、
3、4、5、6或7个来自种系序列的突变。在一些情况下,通过优化生成的序列在重链的第二cdr区中包含约1、2、3、4、5、6或7个来自种系序列的突变。在一些情况下,通过优化生成的序列在重链的第三cdr区中包含约1、2、3、4、5、6或7个来自种系序列的突变。在一些情况下,通过优化生成的序列在轻链的第一cdr区中包含约1、2、3、4、5、6或7个来自种系序列的突变。在一些情况下,通过优化生成的序列在轻链的第二cdr区中包含约1、2、3、4、5、6或7个来自种系序列的突变。在一些情况下,通过优化生成的序列在轻链的第三cdr区中包含约1、2、3、4、5、6或7个来自种系序列的突变。在一些情况下,第一cdr区是cdr1。在一些情况下,第二cdr区是cdr2。在一些情况下,第三cdr区是cdr3。
57.抗体文库
58.本文提供了从本文所述的抗体优化方法生成的文库。本文所述的抗体导致改善的功能活性、结构稳定性、表达、特异性或其组合。
59.如本文所用的,术语抗体将被理解为包括具有典型抗体分子的特征性双臂、y形的蛋白质以及保留与抗原特异性结合的能力的抗体的一个或多个片段。示例性抗体包括但不限于单克隆抗体、多克隆抗体、双特异性抗体、多特异性抗体、移植抗体、人抗体、人源化抗体、合成抗体、嵌合抗体、骆驼化抗体、单链fv(scfv)(包括这样的片段,其中vl和vh使用重组方法通过合成或天然连接体连接,该连接体使它们能够成为单蛋白质链,其中vl和vh区配对形式单价分子,包括单链fab和scfab)、单链抗体、fab片段(包括包含vl、vh、cl和ch1结构域的单价片段)、f(ab
′
)2片段(包括包含在铰链区通过二硫键连接的两个fab片段的二价片段)、fd片段(包括包含vh和ch1片段的片段)、fv片段(包括包含抗体单臂的vl和vh结构域的片段)、单结构域抗体(dab或sdab)(包括包含vh结构域的片段)、分离的互补决定区(cdr)、双抗体(包括包含二价二聚体的片段,该二聚体例如是彼此结合并识别两种不同抗原的两个vl和vh结构域)、仅由单个单体可变域组成的片段、二硫键连接的fv(sdfv)、胞内抗体、抗独特型(抗
‑
id)抗体,或它们的ab抗原结合片段。在一些情况下,本文公开的文库包含编码抗体的核酸,其中该抗体是fv抗体,包括由包含完整抗原识别和抗原结合位点的最小抗体片段组成的fv抗体。在一些实施方案中,该fv抗体由紧密、非共价缔合的一个重链可变域和一个轻链可变域的二聚体组成,并且每个可变域的三个高变区相互作用以在该vh
‑
vl二聚体的表面上限定抗原结合位点。在一些实施方案中,这六个高变区为抗体赋予抗原结合特异性。在一些实施方案中,单个可变域(或仅包含对抗原为特异性的三个高变区的fv的一半,包括包含一个重链可变域的从骆驼科动物分离的单结构域抗体,如vhh抗体或纳米抗体)具有识别并结合抗原的能力。在一些情况下,本文公开的文库包含编码抗体的核酸,其中该抗体是单链fv或scfv,包括包含vh、vl或vh和vl结构域两者的抗体片段,其中这两个结构域均存在于单个多肽链中。在一些实施方案中,fv多肽在vh与vl结构域之间进一步包含多肽连接体,从而允许scfv形成用于抗原结合的所需结构。在一些情况下,scfv连接至fc片段,或vhh连接至fc片段(包括小抗体)。在一些情况下,所述抗体包含免疫球蛋白分子和免疫球蛋白分子的免疫活性片段,例如,含有抗原结合位点的分子。免疫球蛋白分子是任何类型(例如igg、ige、igm、igd、iga和igy)、类别(例如igg 1、igg 2、igg 3、igg 4、iga 1和iga 2)或亚类的。
60.在一些实施方案中,文库包含适用于预期治疗靶标的种类的免疫球蛋白。通常,这些方法包括“哺乳动物化”,并且包括将供体抗原结合信息转移到免疫原性较低的哺乳动物
抗体接受体以生成有用的治疗性处理的方法。在一些情况下,该哺乳动物是小鼠、大鼠、马、绵羊、牛、灵长类动物(例如黑猩猩、狒狒、大猩猩、猩猩、猴)、狗、猫、猪、驴、兔和人。在一些情况下,本文提供了用于抗体的猫科动物化和犬科动物化的文库和方法。
61.非人抗体的“人源化”形式可以是含有衍生自非人抗体的最小序列的嵌合抗体。人源化抗体通常是人抗体(接受体抗体),其中来自一个或多个cdr的残基被替换为来自非人抗体(供体抗体)的一个或多个cdr的残基。供体抗体可以是任何合适的非人抗体,如具有所需特异性、亲和力或生物学效应的小鼠、大鼠、兔、鸡或非人灵长类动物抗体。在一些情况下,接受体抗体的选定框架区残基被替换为来自供体抗体的相应框架区残基。人源化抗体还可包含在接受体抗体或供体抗体中均未发现的残基。在一些情况下,进行这些修饰以进一步改进抗体性能。
[0062]“犬科动物化”可包括将非犬抗原结合信息从供体抗体转移到免疫原性较低的犬抗体接受体以生成可在狗中用作治疗剂的治疗的方法。在一些情况下,本文提供的非犬抗体的犬科动物化形式是含有衍生自非犬抗体的最小序列的嵌合抗体。在一些情况下,犬科动物化抗体是犬抗体序列(“接受体”或“受体”抗体),其中接受体的高变区残基被替换为来自非犬物种(“供体”抗体)如小鼠、大鼠、兔、猫、狗、山羊、鸡、牛、马、美洲驼、骆驼、单峰驼、鲨鱼、非人灵长类动物、人、人源化、重组序列或具有所需性质的工程化序列的高变区残基。在一些情况下,犬抗体的框架区(fr)残基被替换为相应的非犬fr残基。在一些情况下,犬科动物化抗体包括在接受体抗体或供体抗体中未发现的残基。在一些情况下,进行这些修饰以进一步改进抗体性能。犬科动物化抗体还可包含犬抗体的免疫球蛋白恒定区(fc)的至少一部分。
[0063]“猫科动物化”可包括将非猫抗原结合信息从供体抗体转移到免疫原性较低的猫抗体接受体以生成可在猫中用作治疗剂的治疗的方法。在一些情况下,本文提供的非猫抗体的猫科动物化形式是含有衍生自非猫抗体的最小序列的嵌合抗体。在一些情况下,猫科动物化抗体是猫抗体序列(“接受体”或“受体”抗体),其中接受体的高变区残基被替换为来自非猫物种(“供体”抗体)如小鼠、大鼠、兔、猫、狗、山羊、鸡、牛、马、美洲驼、骆驼、单峰驼、鲨鱼、非人灵长类动物、人、人源化、重组序列或具有所需性质的工程化序列的高变区残基。在一些情况下,猫抗体的框架区(fr)残基被替换为相应的非猫fr残基。在一些情况下,猫科动物化抗体包括在接受体抗体或供体抗体中未发现的残基。在一些情况下,进行这些修饰以进一步改进抗体性能。猫科动物化抗体还可包含猫抗体的免疫球蛋白恒定区(fc)的至少一部分。
[0064]
本文所述的方法可用于优化编码非免疫球蛋白的文库。在一些情况下,所述文库包含抗体模拟物。示例性抗体模拟物包括但不限于anticalins、affilins、affibody分子、affimers、affitins、alphabodies、avimers、atrimers、darpins、fynomers、基于kunitz结构域的蛋白质、单抗体(monobodies)、anticalins、knottins、基于犰狳重复蛋白的蛋白质和双环肽。
[0065]
本文所述的包含编码抗体的核酸的文库在该抗体的至少一个区域中包含变异。用于变异的抗体的示例性区域包括但不限于互补决定区(cdr)、可变域或恒定域。在一些情况下,该cdr是cdr1、cdr2或cdr3。在一些情况下,该cdr是重链结构域,包括但不限于cdr
‑
h1、cdr
‑
h2和cdr
‑
h3。在一些情况下,该cdr是轻链结构域,包括但不限于cdr
‑
l1、cdr
‑
l2和cdr
‑
l3。在一些情况下,该可变域是轻链可变域(vl)或重链可变域(vh)。在一些情况下,该vl结构域包含κ或λ链。在一些情况下,该恒定域是轻链恒定域(cl)或重链恒定域(ch)。
[0066]
本文所述的方法提供了合成包含编码抗体的核酸的文库,其中每个核酸编码至少一个预定参考核酸序列的预定变体。在一些情况下,该预定参考序列是编码蛋白质的核酸序列,并且该变体文库包含编码至少单个密码子的变异的序列,使得由合成核酸编码的后续蛋白质中单个残基的多个不同变体通过标准翻译过程生成。在一些情况下,该抗体文库包含共同编码多个位置处的变异的变化的核酸。在一些情况下,该变体文库包含编码cdr
‑
h1、cdr
‑
h2、cdr
‑
h3、cdr
‑
l1、cdr
‑
l2、cdr
‑
l3、vl或vh结构域的至少单个密码子的变异的序列。在一些情况下,该变体文库包含编码cdr
‑
h1、cdr
‑
h2、cdr
‑
h3、cdr
‑
l1、cdr
‑
l2、cdr
‑
l3、vl或vh结构域的多个密码子的变异的序列。在一些情况下,该变体文库包含编码框架元件1(fw1)、框架元件2(fw2)、框架元件3(fw3)或框架元件4(fw4)的多个密码子的变异的序列。用于变异的密码子的示例性数目包括但不限于至少或大约1、5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、225、250、275、300个或超过300个密码子。
[0067]
在一些情况下,用于变异的抗体的至少一个区域来自重链v基因家族、重链d基因家族、重链j基因家族、轻链v基因家族或轻链j基因家族。在一些情况下,轻链v基因家族包含免疫球蛋白κ(igk)基因或免疫球蛋白λ(igl)。
[0068]
本文提供了包含编码抗体的核酸的文库,其中所述文库用各种数目的片段合成。在一些情况下,所述片段包含cdr
‑
h1、cdr
‑
h2、cdr
‑
h3、cdr
‑
l1、cdr
‑
l2、cdr
‑
l3、vl或vh结构域。在一些情况下,所述片段包含框架元件1(fw1)、框架元件2(fw2)、框架元件3(fw3)或框架元件4(fw4)。在一些情况下,用至少或大约2个片段、3个片段、4个片段、5个片段或多于5个片段合成所述抗体文库。每个核酸片段的长度或合成的核酸的平均长度可以是至少或大约50、75、100、125、150、175、200、225、250、275、300、325、350、375、400、425、450、475、500、525、550、575、600个或超过600个碱基对。在一些情况下,该长度是大约50至600、75至575、100至550、125至525、150至500、175至475、200至450、225至425、250至400、275至375或300至350个碱基对。
[0069]
当翻译时,包含编码如本文所述的抗体的核酸的文库包含各种长度的氨基酸。在一些情况下,每个氨基酸片段的长度或合成的氨基酸的平均长度可以是至少或大约15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、105、110、115、120、125、130、135、140、145、150个或超过150个氨基酸。在一些情况下,该氨基酸长度是大约15至150、20至145、25至140、30至135、35至130、40至125、45至120、50至115、55至110、60至110、65至105、70至100或75至95个氨基酸。在一些情况下,该氨基酸长度是约22个氨基酸至约75个氨基酸。在一些情况下,该抗体包含至少或大约100、200、300、400、500、600、700、800、900、1000、2000、3000、4000、5000个或超过5000个氨基酸。
[0070]
使用本文所述的方法为用于变异的抗体的至少一个区域从头合成大量变异序列。在一些情况下,为cdr
‑
h1、cdr
‑
h2、cdr
‑
h3、cdr
‑
l1、cdr
‑
l2、cdr
‑
l3、vl、vh或其组合从头合成大量变异序列。在一些情况下,为框架元件1(fw1)、框架元件2(fw2)、框架元件3(fw3)或框架元件4(fw4)从头合成大量变异序列。参见图2a。变异序列的数目可以是至少或大约5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、200、
225、250、275、300、325、350、375、400、425、450、475、500个或超过500个序列。在一些情况下,变异序列的数目是至少或大约500、600、700、800、900、1000、2000、3000、4000、5000、6000、7000、8000个或超过8000个序列。在一些情况下,变异序列的数目是大约10至500、25至475、50至450、75至425、100至400、125至375、150至350、175至325、200至300、225至375、250至350或275至325个序列。
[0071]
在一些情况下,用于抗体的至少一个区域的变异序列在长度或序列上是各不相同的。在一些情况下,从头合成的至少一个区域是用于cdr
‑
h1、cdr
‑
h2、cdr
‑
h3、cdr
‑
l1、cdr
‑
l2、cdr
‑
l3、vl、vh或其组合。在一些情况下,从头合成的至少一个区域是用于框架元件1(fw1)、框架元件2(fw2)、框架元件3(fw3)或框架元件4(fw4)。在一些情况下,该变异序列与野生型相比包含至少或大约1、2、3、4、5、6、7、8、9、10、15、20、25、30、35、40、45、50个或超过50个变异核苷酸或氨基酸。在一些情况下,该变异序列与野生型相比包含至少或大约1、2、3、4、5、6、7、8、9、10、15、20、25、30、35、40、45或50个额外的核苷酸或氨基酸。在一些情况下,该变异序列包含比野生型少至少或大约1、2、3、4、5、6、7、8、9、10、15、20、25、30、35、40、45或50个的核苷酸或氨基酸。在一些情况下,该文库包含至少或大约101、102、103、104、105、106、107、108、109、10
10
个或超过10
10
个变体。
[0072]
在合成抗体文库之后,可以将抗体文库用于筛选和分析。例如,分析抗体文库的文库可展示性和淘选。在一些情况下,使用选择性标签分析可展示性。示例性标签包括但不限于放射性标记、荧光标记、酶、化学发光标签、比色标签、亲和标签或本领域已知的其他标记或标签。在一些情况下,该标签是组氨酸、聚组氨酸、myc、血凝素(ha)或flag。在一些情况下,通过使用各种方法的测序对抗体文库进行分析,所述方法包括但不限于单分子实时(smrt)测序、聚合酶克隆(polony)测序、连接测序、可逆终止子测序、质子检测测序、离子半导体测序、纳米孔测序、电子测序、焦磷酸测序、maxam
‑
gilbert测序、链终止(例如,sanger)测序、+s测序或合成测序。在一些情况下,抗体文库展示在细胞或噬菌体的表面上。在一些情况下,使用噬菌体展示针对具有所需活性的序列富集抗体文库。
[0073]
在一些情况下,分析抗体文库的功能活性、结构稳定性(例如,热稳定或ph稳定)、表达、特异性或其组合。在一些情况下,分析抗体文库中能够折叠的抗体。在一些情况下,分析抗体区域的功能活性、结构稳定性、表达、特异性、折叠或其组合。例如,分析vh区或vl区的功能活性、结构稳定性、表达、特异性、折叠或其组合。
[0074]
通过如本文所述的方法生成的抗体或igg具有改进的结合亲和力。在一些情况下,该抗体具有小于1nm、小于1.2nm、小于2nm、小于5nm、小于10nm、小于11nm、小于13.5nm、小于15nm、小于20nm、小于25nm或小于30nm的结合亲和力(例如kd)。在一些情况下,该抗体具有小于1nm的kd。在一些情况下,该抗体具有小于1.2nm的kd。在一些情况下,该抗体具有小于2nm的kd。在一些情况下,该抗体具有小于5nm的kd。在一些情况下,该抗体具有小于10nm的kd。在一些情况下,该抗体具有小于13.5nm的kd。在一些情况下,该抗体具有小于15nm的kd。在一些情况下,该抗体具有小于20nm的kd。在一些情况下,该抗体具有小于25nm的kd。在一些情况下,该抗体具有小于30nm的kd。
[0075]
在一些情况下,通过如本文所述的方法生成的抗体或igg的亲和力是与比较抗体相比改善至少或大约1.5x、2.0x、5x、10x、20x、30x、40x、50x、60x、70x、80x、90x、100x、200x或超过200x的结合亲和力。在一些情况下,通过如本文所述的方法生成的抗体或igg的亲和
力是与比较抗体相比改善至少或大约1.5x、2.0x、5x、10x、20x、30x、40x、50x、60x、70x、80x、90x、100x、200x或超过200x的功能。在一些情况下,该比较抗体是具有类似的结构、序列或抗原靶标的抗体。
[0076]
表达系统
[0077]
本文提供了包含编码含有结合域的抗体的核酸的文库,其中所述文库具有改善的特异性、稳定性、表达、折叠或下游活性。在一些情况下,本文所述的文库用于筛选和分析。
[0078]
本文提供了包含编码含有结合域的抗体的核酸的文库,其中所述核酸文库用于筛选和分析。在一些情况下,筛选和分析包括体外、体内或离体测定。用于筛选的细胞包括取自活受试者的原代细胞或细胞系。细胞可以来自原核生物(例如细菌和真菌)或真核生物(例如动物和植物)。示例性的动物细胞包括但不限于来自小鼠、兔、灵长类动物和昆虫的动物细胞。在一些情况下,用于筛选的细胞包括细胞系,包括但不限于中国仓鼠卵巢(cho)细胞系、人胚肾(hek)细胞系或幼仓鼠肾(bhk)细胞系。在一些情况下,本文所述的核酸文库也可以被递送至多细胞生物体。示例性的多细胞生物体包括但不限于植物、小鼠、兔、灵长类动物和昆虫。
[0079]
可以针对各种药理学或药代动力学性质筛查本文所述的核酸文库。在一些情况下,使用体外测定、体内测定或离体测定来筛查文库。例如,所筛查的体外药理学或药代动力学性质包括但不限于结合亲和力、结合特异性和结合亲合力。所筛查的本文所述文库的示例性体内药理学或药代动力学性质包括但不限于治疗功效、活性、临床前毒性性质、临床功效性质、临床毒性性质、免疫原性、效力和临床安全性性质。
[0080]
本文提供了核酸文库,其中所述核酸文库可以在载体中表达。用于插入本文公开的核酸文库的表达载体可包括真核或原核表达载体。示例性的表达载体包括但不限于哺乳动物表达载体:psf
‑
cmv
‑
neo
‑
nh2
‑
ppt
‑
3xflag、psf
‑
cmv
‑
neo
‑
cooh
‑
3xflag、psf
‑
cmv
‑
puro
‑
nh2
‑
gst
‑
tev、psf
‑
oxb20
‑
cooh
‑
tev
‑
flag(r)
‑
6his、pcep4 pdest27、psf
‑
cmv
‑
ub
‑
kryfp、psf
‑
cmv
‑
fmdv
‑
dagfp、pef1a
‑
mcherry
‑
n1载体、pef1a
‑
tdtomato载体、psf
‑
cmv
‑
fmdv
‑
hygro、psf
‑
cmv
‑
pgk
‑
puro、pmcp
‑
tag(m)和psf
‑
cmv
‑
puro
‑
nh2
‑
cmyc;细菌表达载体:psf
‑
oxb20
‑
betagal、psf
‑
oxb20
‑
fluc、psf
‑
oxb20和psf
‑
tac;植物表达载体:pri 101
‑
an dna和pcambia2301;和酵母表达载体:ptyb21和pklac2,以及昆虫载体:pac5.1/v5
‑
his a和pdest8。在一些情况下,该载体是pcdna3或pcdna3.1。
[0081]
本文描述了在载体中表达以生成包含抗体的构建体的核酸文库。在一些情况下,该构建体的大小各不相同。在一些情况下,该构建体包含至少或大约500、600、700、800、900、1000、1100、1300、1400、1500、1600、1700、1800、2000、2400、2600、2800、3000、3200、3400、3600、3800、4000、4200,4400、4600、4800、5000、6000、7000、8000、9000、10000个或超过10000个碱基。在一些情况下,该构建体包含约300至1,000、300至2,000、300至3,000、300至4,000、300至5,000、300至6,000、300至7,000、300至8,000、300至9,000、300至10,000、1,000至2,000、1,000至3,000、1,000至4,000、1,000至5,000、1,000至6,000、1,000至7,000、1,000至8,000、1,000至9,000、1,000至10,000、2,000至3,000、2,000至4,000、2,000至5,000、2,000至6,000、2,000至7,000、2,000至8,000、2,000至9,000、2,000至10,000、3,000至4,000、3,000至5,000、3,000至6,000、3,000至7,000、3,000至8,000、3,000至9,000、3,000至10,000、4,000至5,000、4,000至6,000、4,000至7,000、4,000至8,000、4,000至9,000、4,
000至10,000、5,000至6,000、5,000至7,000、5,000至8,000、5,000至9,000、5,000至10,000、6,000至7,000、6,000至8,000、6,000至9,000、6,000至10,000、7,000至8,000、7,000至9,000、7,000至10,000、8,000至9,000、8,000至10,000或9,000至10,000个碱基的范围内。
[0082]
本文提供了包含编码抗体的核酸的文库,其中所述核酸文库在细胞中表达。在一些情况下,合成所述文库以表达报告基因。示例性的报告基因包括但不限于乙酰羟酸合酶(ahas)、碱性磷酸酶(ap)、β
‑
半乳糖苷酶(lacz)、β
‑
葡糖苷酸酶(gus)、氯霉素乙酰转移酶(cat)、绿色荧光蛋白(gfp)、红色荧光蛋白(rfp)、黄色荧光蛋白(yfp)、青色荧光蛋白(cfp)、天蓝色荧光蛋白、黄水晶荧光蛋白、橙色荧光蛋白、樱桃荧光蛋白、绿松石荧光蛋白、蓝色荧光蛋白、辣根过氧化物酶(hrp)、萤光素酶(luc)、胭脂碱合酶(nos)、章鱼碱合酶(ocs)、萤光素酶及其衍生物。确定报告基因的调节的方法是本领域公知的、并且包括但不限于荧光光度法(例如,荧光光谱法、荧光激活细胞分选(facs)、荧光显微术)和抗生素抗性确定。
[0083]
pd
‑
1文库
[0084]
本文提供了与程序性细胞死亡蛋白1(pd
‑
1)结合文库有关的方法和组合物,所述文库包含编码pd
‑
1抗体的核酸。在一些情况下,此类方法和组合物通过本文所述的抗体优化方法和系统生成。如本文所述的抗体可以稳定地支撑pd
‑
1结合域。可以基于pd
‑
1配体与pd
‑
1的表面相互作用来设计pd
‑
1结合域。如本文所述的文库可以进一步被斑驳化(variegated),以提供包含各自编码至少一个预定参考核酸序列的预定变体的核酸的变体文库。本文进一步描述了可以在翻译所述核酸文库时生成的蛋白质文库。在一些情况下,将如本文所述的核酸文库转移到细胞中以生成细胞文库。本文还提供了使用本文所述的方法合成的文库的下游应用。下游应用包括鉴定具有增强的生物学相关功能(例如,改善的稳定性、亲和力、结合、功能活性)和用于治疗或预防与pd
‑
1信号传导相关的疾病状态的变异核酸或蛋白质序列。在一些情况下,本文所述的抗体包含seq id no:1
‑
35中的任一个的cdrh1序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh1序列至少80%相同的序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh1序列至少85%相同的序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh1序列至少90%相同的序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh1序列至少95%相同的序列。在一些情况下,本文所述的抗体包含seq id no:1
‑
35中的任一个的cdrh2序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh2序列至少80%相同的序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh2序列至少85%相同的序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh2序列至少90%相同的序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh2序列至少95%相同的序列。在一些情况下,本文所述的抗体包含seq id no:1
‑
35中的任一个的cdrh3序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh3序列至少80%相同的序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh3序列至少85%相同的序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh3序列至少90%相同的序列。在一些情况下,本文所述的抗体包含与seq id no:1
‑
35中的任一个的cdrh3序列至少95%相同的序列。
[0085]
术语“序列同一性”是指两个多核苷酸序列在比较窗口内是相同的(即,在逐个核苷酸的基础上)。术语“序列同一性百分比”如下计算:在比较窗口内比较两个最佳比对的序列,确定相同核酸碱基(例如,a、t、c、g、u或i)在两个序列中均出现的位置的数目以产生匹配位置的数目,将匹配位置的数目除以比较窗口内的位置总数(即窗口大小),并将结果乘以100以得到序列同一性的百分比。
[0086]
术语两种蛋白质之间的“同源性”或“相似性”通过将一个蛋白质序列的氨基酸序列及其保守氨基酸置换物与第二个蛋白质序列进行比较来确定。相似性可以通过本领域公知的程序来确定,例如blast程序(国家生物信息中心的基本局部比对搜索工具)。
[0087]
本文提供了包含编码pd
‑
1抗体的核酸的文库。本文所述的抗体允许提高一系列pd
‑
1结合域编码序列的稳定性。在一些情况下,该pd
‑
1结合域编码序列由pd
‑
1配体与pd
‑
1之间的相互作用来决定。
[0088]
使用各种方法分析基于pd
‑
1配体与pd
‑
1之间表面相互作用的pd
‑
1结合域的序列。例如,进行多物种计算分析。在一些情况下,进行结构分析。在一些情况下,进行序列分析。可以使用本领域已知的数据库进行序列分析。数据库的非限制性实例包括但不限于ncbi blast(blast.ncbi.nlm.nih.gov/blast.cgi)、ucsc genome browser(genome.ucsc.edu/)、uniprot(www.uniprot.org/)和iuphar/bps guide to pharmacology(guidetopharmacology.org/)。
[0089]
本文描述了基于各种生物体之间的序列分析设计的pd
‑
1结合域。例如,进行序列分析以鉴定不同生物中的同源序列。示例性的生物包括但不限于小鼠、大鼠、马、绵羊、牛、灵长类动物(例如黑猩猩、狒狒、大猩猩、猩猩、猴)、狗、猫、猪、驴、兔、鱼、苍蝇和人。在一些情况下,同源序列跨个体在同一生物体中鉴定。
[0090]
在鉴定pd
‑
1结合域之后,可以生成包含编码pd
‑
1结合域的核酸的文库。在一些情况下,pd
‑
1结合域文库包含基于构象配体相互作用、肽配体相互作用、小分子配体相互作用、pd
‑
1的胞外域或靶向pd
‑
1的抗体设计的pd
‑
1结合域序列。pd
‑
1结合域的文库可以被翻译以生成蛋白质文库。在一些情况下,翻译pd
‑
1结合域的文库以生成肽文库、免疫球蛋白文库、其衍生物或它们的组合。在一些情况下,翻译pd
‑
1结合域的文库以生成蛋白质文库,进一步修饰所述蛋白质文库以生成拟肽文库。在一些情况下,翻译pd
‑
1结合域的文库以生成用于生成小分子的蛋白质文库。
[0091]
本文所述的方法提供了pd
‑
1结合域文库的合成,该文库包含各自编码至少一个预定参考核酸序列的预定变体的核酸。在一些情况下,该预定参考序列是编码蛋白质的核酸序列,并且该变体文库包含编码至少单个密码子的变异的序列,使得由合成核酸编码的后续蛋白质中单个残基的多个不同变体通过标准翻译过程生成。在一些情况下,该pd
‑
1结合域文库包含共同编码多个位置处的变异的变化的核酸。在一些情况下,该变体文库包含编码pd
‑
1结合域中的至少单个密码子的变异的序列。在一些情况下,该变体文库包含编码pd
‑
1结合域中的多个密码子的变异的序列。用于变异的密码子的示例性数目包括但不限于至少或大约1、5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、225、250、275、300个或超过300个密码子。
[0092]
本文所述的方法提供了合成包含编码pd
‑
1结合域的核酸的文库,其中该文库包含编码该pd
‑
1结合域的长度变异的序列。在一些情况下,该文库包含编码与预定参考序列相
比少至少或大约1、5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、225、250、275、300个或超过300个密码子的长度变异的序列。在一些情况下,该文库包含编码与预定参考序列相比多至少或大约1、5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、200、225、250、275、300个或超过300个密码子的长度变异的序列。
[0093]
在鉴定pd
‑
1结合域之后,可以设计并合成包含pd
‑
1结合域的抗体。可以基于结合、特异性、稳定性、表达、折叠或下游活性来设计包含pd
‑
1结合域的抗体。在一些情况下,包含pd
‑
1结合域的抗体使得能够与pd
‑
1接触。在一些情况下,包含pd
‑
1结合域的抗体使得能够与pd
‑
1高亲和力结合。pd
‑
1结合域的示例性氨基酸序列包含seq id no:1
‑
70中的任一个。
[0094]
在一些情况下,pd
‑
1抗体对pd
‑
1具有小于1nm、小于1.2nm、小于2nm、小于5nm、小于10nm、小于11nm、小于13.5nm、小于15nm、小于20nm、小于25nm或小于30nm的结合亲和力(例如kd)。在一些情况下,该pd
‑
1抗体具有小于1nm的kd。在一些情况下,该pd
‑
1抗体具有小于1.2nm的kd。在一些情况下,该pd
‑
1抗体具有小于2nm的kd。在一些情况下,该pd
‑
1抗体具有小于5nm的kd。在一些情况下,该pd
‑
1抗体具有小于10nm的kd。在一些情况下,该pd
‑
1抗体具有小于13.5nm的kd。在一些情况下,该pd
‑
1抗体具有小于15nm的kd。在一些情况下,该pd
‑
1抗体具有小于20nm的kd。在一些情况下,该pd
‑
1抗体具有小于25nm的kd。在一些情况下,该pd
‑
1抗体具有小于30nm的kd。
[0095]
在一些情况下,通过如本文所述的方法生成的pd
‑
1抗体的亲和力是与比较抗体相比改善至少或大约1.5x、2.0x、5x、10x、20x、30x、40x、50x、60x、70x、80x、90x、100x、200x或超过200x的结合亲和力。在一些情况下,通过如本文所述的方法生成的pd
‑
1抗体具有与比较抗体相比改善至少或大约1.5x、2.0x、5x、10x、20x、30x、40x、50x、60x、70x、80x、90x、100x、200x或超过200x的功能。在一些情况下,该比较抗体是具有类似的结构、序列或抗原靶标的抗体。
[0096]
本文提供了pd
‑
1结合文库,其包含编码包含pd
‑
1结合域的抗体的核酸,所述抗体包含结构域类型、结构域长度方面的变异或残基变异。在一些情况下,该结构域是包含pd
‑
1结合域的抗体中的区域。例如,该区域是vh、cdr
‑
h3或vl结构域。在一些情况下,该结构域是pd
‑
1结合域。
[0097]
本文所述的方法提供了合成各自编码至少一个预定参考核酸序列的预定变体的核酸的pd
‑
1结合文库。在一些情况下,该预定参考序列是编码蛋白质的核酸序列,并且该变体文库包含编码至少单个密码子的变异的序列,使得由合成核酸编码的后续蛋白质中单个残基的多个不同变体通过标准翻译过程生成。在一些情况下,该pd
‑
1结合文库包含共同编码多个位置处的变异的变化的核酸。在一些情况下,该变体文库包含编码vh、cdr
‑
h3或vl结构域的至少单个密码子的变异的序列。在一些情况下,该变体文库包含编码pd
‑
1结合域中的至少单个密码子的变异的序列。例如,pd
‑
1结合域的至少一个单密码子是各不相同的。在一些情况下,该变体文库包含编码vh、cdr
‑
h3或vl结构域的多个密码子的变异的序列。在一些情况下,该变体文库包含编码pd
‑
1结合域中的多个密码子的变异的序列。用于变异的密码子的示例性数目包括但不限于至少或大约1、5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、225、250、275、300个或超过300个密码子。
[0098]
本文所述的方法提供了合成各自编码至少一个预定参考核酸序列的预定变体的
核酸的pd
‑
1结合文库,其中该pd
‑
1结合文库包含编码结构域的长度变异的序列。在一些情况下,该结构域是vh、cdr
‑
h3或vl结构域。在一些情况下,该结构域是pd
‑
1结合域。在一些情况下,该文库包含编码与预定参考序列相比少至少或大约1、5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、225、250、275、300个或超过300个密码子的长度变异的序列。在一些情况下,该文库包含编码与预定参考序列相比多至少或大约1、5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、200、225、250、275、300个或超过300个密码子的长度变异的序列。
[0099]
本文提供了pd
‑
1结合文库,其包含编码包含pd
‑
1结合域的抗体的核酸,其中所述pd
‑
1结合文库用各种数目的片段合成。在一些情况下,所述片段包含vh、cdr
‑
h3或vl结构域。在一些情况下,所述pd
‑
1结合文库用至少或大约2个片段、3个片段、4个片段、5个片段或多于5个片段合成。每个核酸片段的长度或合成的核酸的平均长度可以是至少或大约50、75、100、125、150、175、200、225、250、275、300、325、350、375、400、425、450、475、500、525、550、575、600个或超过600个碱基对。在一些情况下,该长度是大约50至600、75至575、100至550、125至525、150至500、175至475、200至450、225至425、250至400、275至375或300至350个碱基对。
[0100]
当翻译时,如本文所述的包含编码含有pd
‑
1结合域的抗体的核酸的pd
‑
1结合域文库包含各种长度的氨基酸。在一些情况下,每个氨基酸片段的长度或合成的氨基酸的平均长度可以是至少或大约15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、105、110、115、120、125、130、135、140、145、150个或超过150个氨基酸。在一些情况下,该氨基酸长度是大约15至150、20至145、25至140、30至135、35至130、40至125、45至120、50至115、55至110、60至110、65至105、70至100或75至95个氨基酸。在一些情况下,该氨基酸长度是约22个至约75个氨基酸。
[0101]
包含从头合成的编码含有pd
‑
1结合域的抗体的变异序列的pd
‑
1结合文库包含大量变异序列。在一些情况下,为cdr
‑
h1、cdr
‑
h2、cdr
‑
h3、cdr
‑
l1、cdr
‑
l2、cdr
‑
l3、vl、vh或其组合从头合成大量变异序列。在一些情况下,为框架元件1(fw1)、框架元件2(fw2)、框架元件3(fw3)或框架元件4(fw4)从头合成大量变异序列。在一些情况下,为pd
‑
1结合域从头合成大量变异序列。变异序列的数目可以是至少或大约5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、200、225、250、275、300、325、350、375、400、425、450、475、500个或超过500个序列。在一些情况下,变异序列的数目是约10至300、25至275、50至250、75至225、100至200或125至150个序列。
[0102]
包含从头合成的编码含有pd
‑
1结合域的抗体的变异序列的pd
‑
1结合文库具有改善的多样性。在一些情况下,变体包括亲和力成熟变体。备选地或组合地,变体包括抗体的其他区域中的变体,该区域包括但不限于cdr
‑
h1、cdr
‑
h2、cdr
‑
l1、cdr
‑
l2和cdr
‑
l3。在一些情况下,pd
‑
1结合文库的变体的数目是至少或大约104、105、106、107、108、109、10
10
、10
11
、10
12
、10
13
、10
14
或超过10
14
个不相同的序列。
[0103]
在合成包含编码含有pd
‑
1结合域的抗体的核酸的pd
‑
1结合文库之后,可将文库用于筛选和分析。例如,分析文库的文库可展示性和淘选。在一些情况下,使用选择性标签分析可展示性。示例性标签包括但不限于放射性标记、荧光标记、酶、化学发光标签、比色标签、亲和标签或本领域已知的其他标记或标签。在一些情况下,该标签是组氨酸、聚组氨酸、
myc、血凝素(ha)或flag。例如,pd
‑
1结合文库包含编码抗体的核酸,所述抗体包含具有多个标签如gfp、flag和lucy以及dna条形码的pd
‑
1结合域。在一些情况下,通过使用各种方法的测序对文库进行测定,所述方法包括但不限于单分子实时测序(smrt)、聚合酶克隆(polony)测序、连接测序、可逆终止子测序、质子检测测序、离子半导体测序、纳米孔测序、电子测序、焦磷酸测序、maxam
‑
gilbert测序、链终止(例如,sanger)测序、+s测序或合成测序。
[0104]
疾病和病症
[0105]
本文提供了包含编码含有pd
‑
1结合域的抗体的核酸的pd
‑
1结合文库,其可具有治疗效果。在一些情况下,所述pd
‑
1结合文库当翻译时产生蛋白质,该蛋白质用于治疗疾病或病症。在一些情况下,该蛋白质是免疫球蛋白。在一些情况下,该蛋白质是拟肽。示例性的疾病包括但不限于癌症、炎性疾病或病症、代谢疾病或紊乱、心血管疾病或病症、呼吸系统疾病或病症、疼痛、消化系统疾病或病症、生殖系统疾病或病症、内分泌疾病或病症或者神经系统疾病或病症。在一些情况下,该癌症是实体癌或血液系统癌症。在一些情况下,该癌症是肺癌、头颈部鳞状细胞癌、结直肠癌、黑素瘤、肝癌、经典霍奇金淋巴瘤、肾癌、胃癌、宫颈癌、merkel细胞癌、b细胞淋巴瘤或膀胱癌。在一些情况下,该癌症是msi
‑
h/dmmr癌症。在一些情况下,如本文所述的pd
‑
1程序性细胞死亡蛋白1的抑制剂用于治疗代谢紊乱。在一些情况下,该受试者是哺乳动物。在一些情况下,该受试者是小鼠、兔、狗或人。通过本文描述的方法治疗的受试者可以是婴儿、成人或儿童。包含本文所述的抗体或抗体片段的药物组合物可以静脉内或皮下施用。在一些情况下,药物组合物包含本文所述的包含cdr
‑
h3的抗体或抗体片段,该cdr
‑
h3包含seq id no:1
‑
70中的任一个的序列。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗癌症。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗肺癌。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗头颈部鳞状细胞癌。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗结直肠癌。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗黑素瘤。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗肝癌。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗经典霍奇金淋巴瘤。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗肾癌。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗胃癌。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗宫颈癌。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗merkel细胞癌。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗b细胞淋巴瘤。在一些情况下,使用seq id no:1
‑
70中的任一个的序列治疗膀胱癌。
[0106]
变体文库
[0107]
密码子变异
[0108]
本文所述的变异核酸文库可包含多个核酸,其中每个核酸编码与参考核酸序列相比的变异密码子序列。在一些情况下,第一核酸群体中的每个核酸在单变异位点处含有变体。在一些情况下,第一核酸群体在单变异位点处含有多个变体,使得第一核酸群体在相同变异位点处含有超过一个变体。第一核酸群体可包含在相同变异位点处共同编码多个密码子变体的核酸。第一核酸群体可包含在相同位置处共同编码多达19个或更多个密码子的核酸。第一核酸群体可包含在相同位置处共同编码多达60个变异三联体的核酸,或者第一核酸群体可包含在相同位置处共同编码多达61个不同密码子三联体的核酸。每个变体可编码
在翻译过程中产生不同氨基酸的密码子。表1提供了对于变异位点可能的每个密码子(和代表性氨基酸)的列表。表1.密码子和氨基酸列表表1.密码子和氨基酸列表
[0109]
核酸群体可包含在多个位置处共同编码至多20个密码子变异的改变的核酸。在这类情况下,该群体中的每个核酸包含在相同核酸中超过一个位置处的密码子变异。在一些情况下,该群体中的每个核酸包含在单个核酸中的1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20个或更多个密码子处的密码子变异。在一些情况下,每个变异长核酸包含在单个长核酸中的1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30个或更多个密码子处的密码子变异。在一些情况下,该变异核酸群体包含在单个核酸中的1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30个或更多个密码子处的密码子变异。在一些情况下,该变异核酸群体包含在单个长核酸中的至少约10、20、30、40、50、60、70、80、90、100个或更多个密码子处的密码子变异。
[0110]
高度平行的核酸合成
[0111]
本文提供了一种平台方法,其利用从多核苷酸合成到硅上纳米孔内基因装配的端到端过程的小型化、平行化及垂直整合来创建革命性的合成平台。本文所述的装置采用与96孔板相同的占地面积(footprint)提供了这样一种硅合成平台,与传统合成方法相比,该
硅合成平台能够将通量提高高达1,000倍或更多,其中在单次高度平行化运行中产生高达约1,000,000个或更多个多核苷酸或10,000个或更多个基因。
[0112]
随着新一代测序的出现,高分辨率基因组数据已成为深入研究各种基因在正常生物学和疾病发病机理中的生物学作用的研究的重要因素。本研究的核心是分子生物学的中心法则和“连续信息的逐残基转移”的概念。将dna中编码的基因组信息转录成信息,随后将其翻译成蛋白质,该蛋白质是给定生物学途径内的活性产物。
[0113]
另一个令人兴奋的研究领域是关于着眼于高度特异性细胞靶标的治疗性分子的发现、研发和制备。高度多样性的dna序列文库是靶向治疗剂的开发流程的核心。在设计、构建和测试蛋白质工程循环中使用基因突变体表达蛋白质,在理想情况下该循环得到针对对其治疗靶标具有高亲和力的蛋白质的高度表达而优化的基因。作为实例,考虑受体的结合口袋。同时测试结合口袋内所有残基的所有序列排列的能力将允许进行彻底的探索,从而增加成功的可能性。饱和诱变(其中研究人员试图在受体内的特定位点处生成所有可能的突变)代表了针对这种开发挑战的一种方法。虽然其成本高、耗时且耗力,但它能够将每个变体引入到每个位置。相反,组合诱变(其中几个选定的位置或短dna段可得到广泛修饰)生成具有偏向呈现的变体的不完全组库。
[0114]
为了加速药物开发流程,具有在可用于测试的正确位置处以预期频率可获得的所需变体的文库(换言之,精确文库)使得能够降低成本以及筛选的周转时间。本文提供了用于合成核酸合成变体文库的方法,其能够以所需的频率精确引入每种期望的变体。对于最终用户来说,这意味着不仅能够彻底对序列空间进行采样,而且能够以有效的方式查询这些假设,从而降低成本和筛选时间。全基因组编辑可以阐明重要的途径,可以检测每个变体和序列排列以获得最佳功能性的文库,并且可以使用数以千计的基因重建整个途径和基因组,以重新改造生物系统以供药物发现。
[0115]
在第一个实例中,药物本身可以使用本文所述的方法进行优化。例如,为了改善抗体的指定功能,设计并合成编码抗体一部分的变异多核苷酸文库。然后可以通过本文所述的过程(例如,pcr诱变之后插入载体中)生成抗体的变异核酸文库。然后在生产细胞系中表达该抗体,并针对增强的活性进行筛选。示例筛选包括检查对抗原的结合亲和力、稳定性或效应物功能(例如,adcc、补体或凋亡)的调节。用来优化抗体的示例性区域包括但不限于fc区、fab区、fab区的可变区、fab区的恒定区、重链或轻链的可变域(v
h
或v
l
)以及v
h
或v
l
的特定互补决定区(cdr)。
[0116]
通过本文所述的方法合成的核酸文库可以在与疾病状态相关的各种细胞中表达。与疾病状态相关的细胞包括细胞系、组织样品、来自受试者的原代细胞、从受试者扩充的培养细胞或模型系统中的细胞。示例性的模型系统包括但不限于疾病状态的植物和动物模型。
[0117]
为了鉴定与疾病状态的预防、减轻或治疗相关的变异分子,本文所述的变异核酸文库在与疾病状态相关的细胞中表达,或者在可以诱发细胞疾病状态的细胞中表达。在一些情况下,使用药剂在细胞中诱发疾病状态。用于疾病状态诱发的示例性工具包括但不限于cre/lox重组系统、lps炎症诱发和用来诱发低血糖的链脲佐菌素。与疾病状态相关的细胞可以是来自模型系统的细胞或培养的细胞,以及来自具有特定疾病状况的受试者的细胞。示例性疾病状况包括细菌、真菌、病毒、自身免疫性或增生性病症(例如,癌症)。在一些
情况下,所述变异核酸文库在模型系统、细胞系或来源于受试者的原代细胞中表达,并针对至少一种细胞活性的改变进行筛选。示例性的细胞活性包括但不限于增殖、周期进展、细胞死亡、粘附、迁移、复制、细胞信号传导、能量产生、氧利用、代谢活性和老化、对自由基损伤的响应或其任意组合。
[0118]
基底
[0119]
用作多核苷酸合成表面的装置可以是基底的形式,其包括但不限于均质阵列表面、图案化的阵列表面、通道、珠子、凝胶等。本文提供了包含多个簇的基底,其中每个簇包含多个支持多核苷酸附着和合成的座位。在一些情况下,基底包含均匀的阵列表面。例如,该均匀的阵列表面是均匀的板。如本文所用的术语“座位”是指结构上的离散区域,其提供了对编码单个预定序列的多核苷酸从该表面延伸的支持。在一些情况下,座位在二维表面(例如,基本上为平面的表面)上。在一些情况下,座位在三维表面(例如,孔、微孔、通道或柱杆)上。在一些情况下,座位的表面包含这样的材料,该材料被活化官能化,以附着至少一个核苷酸以供多核苷酸合成,或者优选地,附着相同核苷酸的群体以供多核苷酸群体合成。在一些情况下,多核苷酸是指编码相同核酸序列的多核苷酸群体。在一些情况下,基底的表面包括基底的一个或多个表面。使用所提供的系统和方法在本文所述的文库内合成的多核苷酸的平均错误率通常小于1/1000、小于约1/2000、小于约1/3000或更低,通常没有错误校正。
[0120]
本文提供了支持在共同支持物上的可寻址位置处平行合成具有不同预定序列的多个多核苷酸的表面。在一些情况下,基底为合成超过50、100、200、400、600、800、1000、1200、1400、1600、1800、2,000、5,000、10,000、20,000、50,000、100,000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1,000,000、1,200,000、1,400,000、1,600,000、1,800,000、2,000,000、2,500,000、3,000,000、3,500,000、4,000,000、4,500,000、5,000,000、10,000,000个或更多个不同的多核苷酸提供支持。在一些情况下,该表面为合成超过50、100、200、400、600、800、1000、1200、1400、1600、1800、2,000、5,000、10,000、20,000、50,000、100,000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1,000,000、1,200,000、1,400,000、1,600,000、1,800,000、2,000,000、2,500,000、3,000,000、3,500,000、4,000,000、4,500,000、5,000,000、10,000,000个或更多个编码不同序列的多核苷酸提供支持。在一些情况下,至少一部分多核苷酸具有相同的序列或被配置为用相同的序列合成。在一些情况下,该基底提供用于增长具有至少80、90、100、120、150、175、200、225、250、275、300、325、350、375、400、425、450、475、500个或更多个碱基的多核苷酸的表面环境。
[0121]
本文提供了在基底的不同座位上合成多核苷酸的方法,其中每个座位支持合成多核苷酸群体。在一些情况下,每个座位支持合成与在另一座位上增长的多核苷酸群体具有不同序列的多核苷酸群体。在一些情况下,每个多核苷酸序列被合成为在用于多核苷酸合成的表面上同一座位簇内的不同座位上具有1、2、3、4、5、6、7、8、9或更多的冗余度。在一些情况下,基底的座位位于多个簇内。在一些情况下,基底包含至少10、500、1000、2000、3000、4000、5000、6000、7000、8000、9000、10000、11000、12000、13000、14000、15000、20000、30000、40000、50000个或更多个簇。在一些情况下,基底包含超过2,000、5,000、10,000、100,000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1,
000,000、1,100,000、1,200,000、1,300,000、1,400,000、1,500,000、1,600,000、1,700,000、1,800,000、1,900,000、2,000,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1,000,000、1,200,000、1,400,000、1,600,000、1,800,000、2,000,000、2,500,000、3,000,000、3,500,000、4,000,000、4,500,000、5,000,000或10,000,000个或更多个不同的座位。在一些情况下,基底包含约10,000个不同的座位。单簇内的座位的量在不同情况下是不同的。在一些情况下,每个簇包含1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、120、130、150、200、300、400、500个或更多个座位。在一些情况下,每个簇包含约50
‑
500个座位。在一些情况下,每个簇包含约100
‑
200个座位。在一些情况下,每个簇包含约100
‑
150个座位。在一些情况下,每个簇包含约109、121、130或137个座位。在一些情况下,每个簇包含约19、20、61、64个或更多个座位。备选地或组合地,多核苷酸合成在均匀的阵列表面上进行。
[0122]
在一些情况下,在基底上合成的不同多核苷酸的数目取决于基底中可用的不同座位的数目。在一些情况下,基底的簇或表面内的座位密度至少是或约为1、10、25、50、65、75、100、130、150、175、200、300、400、500、1,000个或更多个座位/mm2。在一些情况下,基底包含10
‑
500、25
‑
400、50
‑
500、100
‑
500、150
‑
500、10
‑
250、50
‑
250、10
‑
200或50
‑
200mm2。在一些情况下,簇或表面内两个相邻座位的中心之间的距离为约10
‑
500、约10
‑
200或约10
‑
100um。在一些情况下,相邻座位的两个中心之间的距离大于约10、20、30、40、50、60、70、80、90或100um。在一些情况下,两个相邻座位的中心之间的距离小于约200、150、100、80、70、60、40、30、20或10um。在一些情况下,每个座位具有约0.5、1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90或100um的宽度。在一些情况下,每个座位具有约0.5
‑
100、0.5
‑
50、10
‑
75或0.5
‑
50um的宽度。
[0123]
在一些情况下,基底内的簇的密度是至少或大约1个簇/100mm2、1个簇/10mm2、1个簇/5mm2、1个簇/4mm2、1个簇/3mm2、1个簇/2mm2、1个簇/1mm2、2个簇/1mm2、3个簇/1mm2、4个簇/1mm2、5个簇/1mm2、10个簇/1mm2、50个簇/1mm2或更高。在一些情况下,基底包含约1个簇/10mm2至约10个簇/1mm2。在一些情况下,两个相邻簇的中心之间的距离至少为或约为50、100、200、500、1000、2000或5000um。在一些情况下,两个相邻簇的中心之间的距离约为50
‑
100、50
‑
200、50
‑
300、50
‑
500和100
‑
2000um。在一些情况下,两个相邻簇的中心之间的距离约为0.05
‑
50、0.05
‑
10、0.05
‑
5、0.05
‑
4、0.05
‑
3、0.05
‑
2、0.1
‑
10、0.2
‑
10、0.3
‑
10、0.4
‑
10、0.5
‑
10、0.5
‑
5或0.5
‑
2mm。在一些情况下,每个簇具有约0.5至约2、约0.5至约1或约1至约2mm的横截面。在一些情况下,每个簇具有约0.5、0.6、0.7、0.8、0.9、1、1.1、1.2、1.3、1.4、1.5、1.6、1.7、1.8、1.9或2mm的横截面。在一些情况下,每个簇具有约0.5、0.6、0.7、0.8、0.9、1、1.1、1.15、1.2、1.3、1.4、1.5、1.6、1.7、1.8、1.9或2mm的内部横截面。
[0124]
在一些情况下,基底是大约标准96孔板的大小,例如,约100至约200mm乘以约50至约150mm。在一些情况下,基底具有小于或等于约1000、500、450、400、300、250、200、150、100或50mm的直径。在一些情况下,基底的直径约为25
‑
1000、25
‑
800、25
‑
600、25
‑
500、25
‑
400、25
‑
300或25
‑
200mm。在一些情况下,基底具有至少约100、200、500、1,000、2,000、5,000、10,000、12,000、15,000、20,000、30,000、40,000、50,000mm2或更大的平面表面积。在一些情况下,基底的厚度约为50
‑
2000、50
‑
1000、100
‑
1000、200
‑
1000或250
‑
1000mm。
[0125]
表面材料
[0126]
本文提供的基底、装置和反应器由适合于本文描述的方法、组合物和系统的任何种类的材料制成。在某些情况下,将基底材料制造成表现出低水平的核苷酸结合。在一些情况下,修饰基底材料以生成表现出高水平的核苷酸结合的不同表面。在一些情况下,基底材料对可见光和/或紫外线是透明的。在一些情况下,基底材料具有足够的导电性,例如,能够跨整个基底或其一部分形成均匀的电场。在一些情况下,导电材料在电气上接地。在一些情况下,该基底是导热的或隔热的。在一些情况下,该材料是耐化学的且耐热的,以支持化学或生化反应,例如多核苷酸合成反应过程。在一些情况下,基底包含柔性材料。对于柔性材料而言,材料可包括但不限于:改性及未改性的尼龙、硝酸纤维素、聚丙烯等。在一些情况下,基底包含刚性材料。对于刚性材料而言,材料可包括但不限于:玻璃;熔融石英;硅、塑料(例如,聚四氟乙烯、聚丙烯、聚苯乙烯、聚碳酸脂,及其混合物等);金属(例如,金、铂等)。基底、固体支持物或反应器可由选自硅、聚苯乙烯、琼脂糖、葡聚糖、纤维素聚合物、聚丙烯酰胺、聚二甲基硅氧烷(pdms)和玻璃的材料制成。基底/固体支持物或者其中的微结构、反应器可使用本文所列材料或本领域中已知的任何其他适当材料的组合制成。
[0127]
表面架构
[0128]
本文提供了用于本文描述的方法、组合物和系统的基底,其中所述基底具有适合于本文描述的方法、组合物和系统的表面架构。在一些情况下,基底包含凸起和/或凹陷特征。具有这类特征的一个益处是用来支持多核苷酸合成的表面积增大。在一些情况下,具有凸起和/或凹陷特征的基底被称为三维基底。在一些情况下,三维基底包含一个或多个通道。在一些情况下,一个或多个座位包含通道。在一些情况下,通道可通过沉积装置如材料沉积装置进行试剂沉积。在一些情况下,试剂和/或流体收集在与一个或多个通道流体连通的较大的孔中。例如,基底包含与具有簇的多个座位相对应的多个通道,并且所述多个通道与该簇的一个孔流体连通。在一些方法中,多核苷酸文库在簇的多个座位中合成。
[0129]
本文提供用于本文描述的方法、组合物和系统的基底,其中该基底被配置用于多核苷酸合成。在一些情况下,该结构被配制为允许用于表面上多核苷酸合成的受控的流动和质量传递路径。在一些情况下,基底的构造允许在多核苷酸合成过程中质量传递路径、化学暴露次数和/或洗涤功效的受控且均匀的分布。在一些情况下,基底的构造允许增加扫描效率,例如通过提供足以用于增长多核苷酸的体积,使得由增长的多核苷酸所排除的体积占可用于或适合于增长多核苷酸的初始可用体积的不超过50%、45%、40%、35%、30%、25%、20%、15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%或更少。在一些情况下,三维结构允许流体的受管控的流动,从而允许化学暴露的快速交换。
[0130]
本文提供了用于本文描述的方法、组合物和系统的基底,其中所述基底包含适合于本文描述的方法、组合物和系统的结构。在一些情况下,通过物理结构实现隔离。在一些情况下,通过表面的差异官能化以生成用于多核苷酸合成的活化和钝化区域来实现隔离。在一些情况下,差异官能化通过在整个基底表面上交替呈现疏水性,从而造成可引起沉积的试剂结珠或润湿的水接触角效应来实现。采用较大的结构可减少飞溅和邻近斑点的试剂对不同的多核苷酸合成位置的交叉污染。在一些情况下,使用装置如材料沉积装置将试剂沉积到不同的多核苷酸合成位置。具有三维特征的基底以允许以低错误率(例如,小于约1:500、1:1000、1:1500、1:2,000;1:3,000;1:5,000;或1:10,000)合成大量多核苷酸(例如,超过约10,000个)的方式配置。在一些情况下,基底包含密度为大约或大于约1、5、10、20、30、
40、50、60、70、80、100、110、120、130、140、150、160、170、180、190、200、300、400或500个特征/mm2的特征。
[0131]
基底的孔可具有与基底的另一个孔相同或不同的宽度、高度和/或容积。基底的通道可具有与基底的另一个通道相同或不同的宽度、高度和/或容积。在一些情况下,簇的直径或包含簇的孔的直径或两者约为0.05
‑
50、0.05
‑
10、0.05
‑
5、0.05
‑
4、0.05
‑
3、0.05
‑
2、0.05
‑
1、0.05
‑
0.5、0.05
‑
0.1、0.1
‑
10、0.2
‑
10、0.3
‑
10、0.4
‑
10、0.5
‑
10、0.5
‑
5或0.5
‑
2mm。在一些情况下,簇或孔或两者的直径小于或约为5、4、3、2、1、0.5、0.1、0.09、0.08、0.07、0.06或0.05mm。在一些情况下,簇或孔或两者的直径为约1.0mm至1.3mm。在一些情况下,簇或孔或两者的直径约为1.150mm。在一些情况下,簇或孔或两者的直径约为0.08mm。簇的直径是指二维或三维基底内的簇。
[0132]
在一些情况下,孔的高度约为20
‑
1000、50
‑
1000、100
‑
1000、200
‑
1000、300
‑
1000、400
‑
1000或500
‑
1000um。在一些情况下,孔的高度小于约1000、900、800、700或600um。
[0133]
在一些情况下,基底包含与簇内的多个座位相对应的多个通道,其中通道的高度或深度为5
‑
500、5
‑
400、5
‑
300、5
‑
200、5
‑
100、5
‑
50或10
‑
50um。在一些情况下,通道的高度小于100、80、60、40或20um。
[0134]
在一些情况下,通道、座位(例如,在基本上平坦的基底中)或通道和座位两者(例如,在其中座位对应于通道的三维基底中)的直径约为1
‑
1000、1
‑
500、1
‑
200、1
‑
100、5
‑
100或10
‑
100um,例如约90、80、70、60、50、40、30、20或10um。在一些情况下,通道、座位或通道和座位两者的直径小于约100、90、80、70、60、50、40、30、20或10um。在一些情况下,两个相邻通道、座位或通道和座位的中心之间的距离约为1
‑
500、1
‑
200、1
‑
100、5
‑
200、5
‑
100、5
‑
50或5
‑
30,例如约20um。
[0135]
表面修饰
[0136]
本文提供了用于在表面上合成多核苷酸的方法,其中该表面包含各种表面修饰。在一些情况下,采用表面修饰通过加成工艺或减成工艺对表面进行化学和/或物理改变,以改变基底表面或基底表面的选定位点或区域的一种或多种化学和/或物理性质。例如,表面修饰包括但不限于:(1)改变表面的润湿性质;(2)对表面进行官能化,即,提供、修改或取代表面官能团;(3)对表面进行去官能化,即,移除表面官能团;(4)以其他方式例如通过刻蚀来改变表面的化学组成;(5)增大或减小表面粗糙度;(6)在表面上提供涂层,例如,展现出与表面的润湿性质不同的润湿性质的涂层;和/或(7)在表面上沉积微粒。
[0137]
在一些情况下,在表面顶部添加化学层(被称为粘附促进剂)有利于基底表面上的座位的结构化图案化。用于施加粘附促进剂的示例性表面包括但不限于玻璃、硅、二氧化硅和氮化硅。在一些情况下,该粘附促进剂是具有高表面能的化学品。在一些情况下,在基底的表面上沉积第二化学层。在一些情况下,第二化学层具有低表面能。在一些情况下,涂覆在表面上的化学层的表面能支持小液滴在表面上的定位。根据所选择的图案化布置,座位的接近度和/或在座位处的流体接触面积是可改变的。
[0138]
在一些情况下,(例如为了多核苷酸合成)核酸或其他部分所沉积到的基底表面或解析座位是光滑的或基本上为平面的(例如,二维的),或者具有不规则性,诸如凸起或凹陷特征(例如,三维特征)。在一些情况下,用一个或多个不同的化合物层来修饰基底表面。感兴趣的此类修饰层包括但不限于无机层和有机层,如金属、金属氧化物,聚合物、有机小分
子等。
[0139]
在一些情况下,使用增大和/或减小表面能的一个或多个部分对基底的解析座位进行官能化。在一些情况下,部分是化学惰性的。在一些情况下,部分被配置为支持所需的化学反应,例如在多核苷酸合成反应中的一个或多个过程。表面的表面能或疏水性是决定核苷酸附着到该表面上的亲和力的因素。在一些情况下,基底官能化方法包括:(a)提供具有包含二氧化硅的表面的基底;和(b)使用本文所述的或本领域已知的合适的硅烷化剂(例如,有机官能烷氧基硅烷分子)对所述表面进行硅烷化。方法和官能化剂在通过引用整体并入本文的美国专利5474796中有描述。
[0140]
在一些情况下,基底表面通常经由存在于基底表面上的反应性亲水部分,在有效地将硅烷偶联至基底表面的反应条件下,使基底表面与含有硅烷混合物的衍生化组合物相接触来进行官能化。硅烷化一般通过使用有机官能烷氧基硅烷分子自装配来覆盖表面。还可使用本领域当前已知的多种硅氧烷官能化试剂,例如用于降低或增大表面能。有机官能烷氧基硅烷根据其有机官能来分类。
[0141]
多核苷酸合成
[0142]
用于多核苷酸合成的本公开的方法可包括涉及亚磷酰胺化学法的过程。在一些情况下,多核苷酸合成包括将碱基与亚磷酰胺偶联。多核苷酸合成可包括通过在偶联条件下沉积亚磷酰胺来偶联碱基,其中相同的碱基任选地与亚磷酰胺沉积超过一次,即双偶联。多核苷酸合成可包括未反应位点的加帽。在一些情况下,加帽是可选的。多核苷酸合成还可包括氧化或氧化步骤或多个氧化步骤。多核苷酸合成可包括解封闭、脱三苯甲基化和硫化。在一些情况下,多核苷酸合成包括氧化或硫化。在一些情况下,在多核苷酸合成反应期间的一个步骤或每个步骤之间,例如使用四唑或乙腈来洗涤所述装置。亚磷酰胺合成方法中任一步骤的时间范围可小于约2min、1min、50sec、40sec、30sec、20sec和10sec。
[0143]
使用亚磷酰胺方法的多核苷酸合成可包括随后将亚磷酰胺构件(例如,核苷亚磷酰胺)添加至增长的多核苷酸链以形成亚磷酸三酯键。亚磷酰胺多核苷酸合成沿3’至5’方向进行。亚磷酰胺多核苷酸合成允许在每个合成循环中将一个核苷酸受控添加至增长的核酸链。在一些情况下,每个合成循环包括偶联步骤。亚磷酰胺偶联包括在活化的核苷亚磷酰胺与(例如通过连接体)结合至基底的核苷之间形成亚磷酸三酯键。在一些情况下,将核苷亚磷酰胺提供给活化的装置。在一些情况下,将核苷亚磷酰胺提供给具有活化剂的装置。在一些情况下,核苷亚磷酰胺以相对于与基底结合的核苷1.5、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、25、30、35、40、50、60、70、80、90、100倍或更多倍的过量来提供给装置。在一些情况下,核苷亚磷酰胺的添加在无水环境中(例如,在无水乙腈中)进行。添加核苷亚磷酰胺后,任选地洗涤该装置。在一些情况下,偶联步骤额外重复一次或多次,任选地在向基底添加核苷亚磷酰胺之间进行洗涤步骤。在一些情况下,本文使用的多核苷酸合成方法包括1、2、3个或更多个连续的偶联步骤。在许多情况下,在偶联之前,与装置结合的核苷通过去除保护基团来脱保护,其中该保护基团起到防止聚合的作用。常见的保护基团为4,4
’‑
二甲氧基三苯甲基(dmt)。
[0144]
偶联后,亚磷酰胺多核苷酸合成方法任选地包括加帽步骤。在加帽步骤中,用加帽剂处理增长的多核苷酸。加帽步骤可用来在偶联后封闭未反应的与基底结合的5
’‑
oh基团以防止进一步链延伸,从而防止形成具有内部碱基缺失的多核苷酸。此外,用1h
‑
四唑活化
的亚磷酰胺可以在很小的程度上与鸟苷的o6位置反应。不受理论的束缚,在用i2/水氧化后,该副产物(可能经由o6
‑
n7迁移)可经历脱嘌呤。无嘌呤位点可终止在多核苷酸的最终脱保护过程中被切割,从而降低全长产物的产率。o6修饰可通过在用i2/水氧化之前用加帽试剂处理而去除。在一些情况下,与没有加帽的合成相比,在多核苷酸合成过程中包括加帽步骤会降低错误率。作为实例,加帽步骤包括用乙酸酐和1
‑
甲基咪唑的混合物处理与基底结合的多核苷酸。在加帽步骤之后,任选地洗涤所述装置。
[0145]
在一些情况下,在添加核苷亚磷酰胺之后,并且任选地在加帽和一个或多个洗涤步骤之后,对与装置结合的增长的核酸进行氧化。氧化步骤包括将亚磷酸三酯氧化成四配位的磷酸三酯——天然存在的磷酸二酯核苷间连接的受保护的前体。在一些情况下,增长的多核苷酸的氧化通过任选地在弱碱(例如,吡啶、二甲基吡啶、三甲吡啶)的存在下用碘和水处理来实现。氧化可在无水条件下采用例如叔丁基过氧化氢或(1s)
‑
(+)
‑
(10
‑
樟脑磺酰基)
‑
氧杂吖丙啶(cso)进行。在一些方法中,在氧化之后进行加帽步骤。第二个加帽步骤允许装置干燥,因为可能持续存在的来自氧化的残余水可以抑制随后的偶联。氧化后,任选地洗涤装置和增长的多核苷酸。在一些情况下,氧化步骤用硫化步骤来代替,以获得多核苷酸硫代磷酸,其中任何加帽步骤均可在硫化之后进行。许多试剂能够进行有效的硫转移,包括但不限于3
‑
(二甲基氨基亚甲基)氨基)
‑
3h
‑
1,2,4
‑
二噻唑
‑3‑
硫酮、ddtt、3h
‑
1,2
‑
苯并二噻戊环
‑3‑
酮1,1
‑
二氧化物(也被称为beaucage试剂)和n,n,n'n'
‑
四乙基秋兰姆二硫化物(tetd)。
[0146]
为了使后续核苷掺入循环通过偶联而发生,除去与装置结合的增长的多核苷酸的受保护的5’末端,使得伯羟基与下一个核苷亚磷酰胺反应。在一些情况下,保护基团为dmt,并且用在二氯甲烷中的三氯乙酸进行解封闭。进行延长时间的脱三苯甲基化或者使用比推荐的酸溶液更强的酸溶液进行脱三苯甲基化可导致与固体支持物结合的多核苷酸的脱嘌呤增加,并因此降低了所需全长产物的产率。本文所述的本公开的方法和组合物提供了受控的解封闭条件,从而限制不希望的脱嘌呤反应。在一些情况下,与装置结合的多核苷酸在解封闭后洗涤。在一些情况下,解封闭后的有效洗涤有助于以低错误率合成多核苷酸。
[0147]
多核苷酸合成方法一般包括一系列迭代的以下步骤:将受保护的单体施加至活化官能化的表面(例如,座位)以与活化的表面、连接体或与预先脱保护的单体连接;使所施加的单体脱保护,使其可与随后施加的受保护的单体反应;以及施加另一种受保护的单体以供连接。一个或多个中间步骤包括氧化或硫化。在一些情况下,在一个或全部步骤之前或之后有一个或多个洗涤步骤。
[0148]
基于亚磷酰胺的多核苷酸合成方法包括一系列化学步骤。在一些情况下,合成方法的一个或多个步骤涉及试剂循环,其中该方法的一个或多个步骤包括向该装置施加对该步骤有用的试剂。例如,试剂通过一系列液相沉积和真空干燥步骤进行循环。对于包含诸如孔、微孔、通道等三维特征的基底,试剂任选地经由孔和/或通道穿过该装置的一个或多个区域。
[0149]
本文所述的方法和系统涉及用于合成多核苷酸的多核苷酸合成装置。该合成可以是平行的。例如,可以平行合成至少或大约至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45、50、100、150、200、250、300、350、400、450、500、550、600、650、700、750、800、850、900、1000、10000、50000、75000、100000个或更多个多
核苷酸。可以平行合成的多核苷酸的总数可以是2
‑
100000、3
‑
50000、4
‑
10000、5
‑
1000、6
‑
900、7
‑
850、8
‑
800、9
‑
750、10
‑
700、11
‑
650、12
‑
600、13
‑
550、14
‑
500、15
‑
450、16
‑
400、17
‑
350、18
‑
300、19
‑
250、20
‑
200、21
‑
150、22
‑
100、23
‑
50、24
‑
45、25
‑
40、30
‑
35个。本领域技术人员知晓,平行合成的多核苷酸的总数可处于由这些值中的任何值所限定的任何范围内,例如25
‑
100。平行合成的多核苷酸的总数可处于由充当范围端点的任何值所限定的任何范围内。在装置内合成的多核苷酸的总摩尔质量或每种多核苷酸的摩尔质量可以是至少或至少约10、20、30、40、50、100、250、500、750、1000、2000、3000、4000、5000、6000、7000、8000、9000、10000、25000、50000、75000、100000皮摩尔或更大。每种多核苷酸的长度或装置内多核苷酸的平均长度可以是至少或大约至少10、15、20、25、30、35、40、45、50、100、150、200、300、400、500个或更多个核苷酸。每种多核苷酸的长度或装置内多核苷酸的平均长度可以是至多或大约至多500、400、300、200、150、100、50、45、35、30、25、20、19、18、17、16、15、14、13、12、11、10个或更少的核苷酸。每种多核苷酸的长度或装置内多核苷酸的平均长度可以处于10
‑
500、9
‑
400、11
‑
300、12
‑
200、13
‑
150、14
‑
100、15
‑
50、16
‑
45、17
‑
40、18
‑
35、19
‑
25之间。本领域技术人员知晓,每种多核苷酸的长度或装置内多核苷酸的平均长度可处于由这些值中的任何值所限定的任何范围内,例如100
‑
300。每种多核苷酸的长度或装置内多核苷酸的平均长度可处于由充当范围端点的任何值所限定的任何范围内。
[0150]
本文提供的在表面上合成多核苷酸的方法允许以较快的速度合成。作为实例,每小时合成至少3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、35、40、45、50、55、60、70、80、90、100、125、150、175、200个或更多个核苷酸。核苷酸包括腺嘌呤、鸟嘌呤、胸腺嘧啶、胞嘧啶、尿苷构件,或其类似物/修饰形式。在一些情况下,多核苷酸文库在基底上平行合成。例如,包含大约或至少约100、1,000、10,000、30,000、75,000、100,000、1,000,000、2,000,000、3,000,000、4,000,000或5,000,000个解析座位的装置能够支持合成至少相同数目的不同的多核苷酸,其中编码不同序列的多核苷酸在解析座位上合成。在一些情况下,在少于约三个月、两个月、一个月、三周、15天、14天、13天、12天、11天、10天、9天、8天、7天、6天、5天、4天、3天、2天、24小时或更短的时间内,以本文所述的低错误率在装置上合成多核苷酸文库。在一些情况下,使用本文所述的基底和方法从以低错误率合成的多核苷酸文库装配的较大核酸在少于约三个月、两个月、一个月、三周、15天、14天、13天、12天、11天、10天、9天、8天、7天、6天、5天、4天、3天、2天、24小时或更短的时间内制备。
[0151]
在一些情况下,本文所述的方法提供了生成包含在多个密码子位点处不同的变异核酸的核酸文库。在一些情况下,核酸可具有1个位点、2个位点、3个位点、4个位点、5个位点、6个位点、7个位点、8个位点、9个位点、10个位点、11个位点、12个位点、13个位点、14个位点、15个位点、16个位点、17个位点、18个位点、19个位点、20个位点、30个位点、40个位点、50个位点或更多个变异密码子位点。
[0152]
在一些情况下,变异密码子位点的一个或多个位点可以是相邻的。在一些情况下,变异密码子位点的一个或多个位点可以是不相邻的,并且由1、2、3、4、5、6、7、8、9、10个或更多个密码子隔开。
[0153]
在一些情况下,核酸可包含变异密码子位点的多个位点,其中所有变异密码子位点彼此相邻,形成一段变异密码子位点。在一些情况下,核酸可包含变异密码子位点的多个
位点,其中所述变异密码子位点彼此均不相邻。在一些情况下,核酸可包含变异密码子位点的多个位点,其中一些变异密码子位点彼此相邻,形成一段变异密码子位点,而一些变异密码子位点彼此不相邻。
[0154]
参见附图,图8示出了用于从较短核酸合成核酸(例如,基因)的示例性处理工作流程。该工作流程大致分为以下阶段:(1)从头合成单链核酸文库,(2)连接核酸以形成更大的片段,(3)错误校正,(4)质量控制,以及(5)运输。在从头合成之前,预先选择预期的核酸序列或一组核酸序列。例如,预先选择一组基因用于生成。
[0155]
一旦选择用于生成的大核酸,则针对从头合成来设计预定的核酸文库。用于生成高密度多核苷酸阵列的各种合适的方法是已知的。在该工作流程示例中,提供了装置表面层。在该示例中,改变表面的化学性质,以改进多核苷酸合成过程。生成低表面能区域以排斥液体,同时生成高表面能区域以吸引液体。表面本身可以是平面表面的形式或者包含形状的变化,例如增加表面积的突起或微孔。在该工作流程示例中,如在通过引用整体并入本文的国际专利申请公开wo/2015/021080中所公开的,所选择的高表面能分子发挥支持dna化学过程的双重功能。
[0156]
多核苷酸阵列的原位制备在固体支持物上进行,并利用单核苷酸延伸过程平行延伸多个寡聚物。沉积装置如材料沉积装置被设计为以逐步方式释放试剂,使得多个多核苷酸平行地一次延伸一个残基,以生成具有预定核酸序列的寡聚物802。在一些情况下,多核苷酸在该阶段从表面上切下。切割包括例如采用氨或甲胺的气体切割。
[0157]
将生成的多核苷酸文库放置于反应室中。在该示例性工作流程中,反应室(也被称为“纳米反应器”)为硅涂覆的孔,其含有pcr试剂并下降到多核苷酸文库803上。在多核苷酸密封804之前或之后,添加试剂以从基底释放多核苷酸。在该示例性工作流程中,多核苷酸在纳米反应器密封805之后释放。一旦释放,单链多核苷酸的片段即发生杂交,以跨越整个长程dna序列。部分杂交805是可能的,因为每个合成的多核苷酸被设计为具有与池中的至少一个其他多核苷酸重叠的一小部分。
[0158]
杂交后,开始pca反应。在聚合酶循环过程中,多核苷酸与互补片段退火,并且用聚合酶补平缺口。根据哪些多核苷酸彼此发现,每个循环随机增加各个片段的长度。片段之间的互补性允许形成完整的大跨度的双链dna806。
[0159]
在pca完成之后,将纳米反应器与装置分开807,并定位成与具有pcr引物的装置相互作用808。密封后,纳米反应器经历pcr 809并扩增较大的核酸。在pcr之后810,打开纳米室811,添加错误校正试剂812,将腔室密封813并进行错误校正反应,以从双链pcr扩增产物中去除具有较差互补性的错配碱基对和/或链814。打开并分离纳米反应器815。错误校正产物接下来经历另外的处理步骤,如pcr和分子条形码化,随后包装822以供运输823。
[0160]
在一些情况下,采取质量控制措施。在错误校正之后,质量控制步骤包括例如与具有用于扩增错误校正产物的测序引物的晶片进行相互作用816,将晶片密封到含有错误校正扩增产物的腔室中817,并进行另一轮扩增818。打开纳米反应器819,合并产物820并进行测序821。在得到可接受的质量控制结果之后,包装的产物822准许运输823。
[0161]
在一些情况下,通过诸如图8中的工作流程生成的核酸使用本文公开的重叠引物进行诱变。在一些情况下,通过在固体支持物上原位制备来生成引物文库,并利用单核苷酸延伸过程平行延伸多个寡聚物。沉积装置如材料沉积装置被设计为以逐步方式释放试剂,
使得多个多核苷酸平行地一次延伸一个残基,以生成具有预定核酸序列的寡聚物802。
[0162]
计算机系统
[0163]
本文所述的任何系统均可以可操作地连接至计算机,并且可以本地或远程地通过计算机进行自动化。在各种情况下,本公开的方法和系统可进一步包括计算机系统上的软件程序及其使用。因此,对于分配/抽真空/再填充功能的同步(如编排和同步材料沉积装置运动、分配动作和真空致动)的计算机化控制处于本公开内容的范围内。计算机系统可被编程为在用户指定的碱基序列与材料沉积装置的位置之间接合,以将正确的试剂递送至基底的指定区域。
[0164]
图9中示出的计算机系统900可被理解为能够从介质911和/或网络端口905读取指令的逻辑设备,其可任选地连接至具有固定介质912的服务器909。诸如图9示出的系统可包括cpu 901、磁盘驱动器903、可选的输入设备如键盘915和/或鼠标916以及可选的监视器907。可通过示出的通信媒介实现与本地或远程位置处的服务器的数据通信。通信媒介可包括传输和/或接收数据的任何手段。例如,通信媒介可以是网络连接、无线连接或因特网连接。这样的连接可提供经由万维网的通信。可以设想有关本公开的数据可经过这样的网络或连接而传输,以便由图9所示的用户方922接收和/或审阅。
[0165]
图10是示出可与本公开的示例实例结合使用的计算机系统1000的第一示例架构的框图。如图10所示,该示例计算机系统可包括用于处理指令的处理器1002。处理器的非限制性示例包括:intel xeontm处理器、amd opterontm处理器、samsung 32
‑
位risc arm 1176jz(f)
‑
sv1.0tm处理器、arm cortex
‑
a8 samsung s5pc100tm处理器、arm cortex
‑
a8 apple a4tm处理器、marvell pxa930tm处理器或功能上等效的处理器。多个执行线程可用于并行处理。在一些情况下,也可以使用多个处理器或具有多个核的处理器,无论是在单一计算机系统中,在群集中,还是通过包含多个计算机、蜂窝电话和/或个人数据助理设备的网络跨系统分布。
[0166]
如图10所示,高速缓冲存储器1004可连接至或并入处理器1002,以提供由处理器1002新近或频繁使用的指令或数据的高速存储器。处理器1002通过处理器总线1008连接至北桥1006。北桥1006通过存储器总线1012连接至随机存取存储器(ram)1010,并管理处理器1002对ram 1010的访问。北桥1006还通过芯片集总线1016连接至南桥1014。南桥1014又连接至外围总线1018。外围总线可以是例如pci、pci
‑
x、pci express或其他外围总线。北桥和南桥通常被称为处理器芯片集,并管理在处理器、ram与外围总线1018上的外围组件之间的数据传送。在一些备选的架构中,北桥的功能性可以并入处理器中,而不是使用单独的北桥芯片。在一些情况下,系统1000可包括附接至外围总线1018的加速器卡1022。加速器可包括现场可编程门阵列(fpga)或用于加速某个处理的其他硬件。例如,加速器可用于适应性数据重建或用来评价在扩展集处理中使用的代数表达式。
[0167]
软件和数据存储在外部存储器1024中,并可加载至ram 1010和/或高速缓冲存储器1004中,以供处理器使用。系统1000包括用于管理系统资源的操作系统;操作系统的非限制性实例包括:linux、windowstm、macostm、blackberry ostm、iostm和其他功能上等效的操作系统,以及在操作系统顶部运行的、用于根据本公开的示例情况管理数据存储和优化的应用软件。在该实例中,系统1000还包括与外围总线连接的网络接口卡(nic)1020和1021,以提供与外部存储如网络附加存储(nas)和可用于分布式并行处理的其他计算机系
统的网络接口。
[0168]
图11是显示了具有多个计算机系统1102a和1102b、多个蜂窝电话和个人数据助理1102c以及网络附加存储(nas)1104a和1104b的网络1100的示图。在示例实例中,系统1102a、1102b和1102c可管理数据存储并优化对存储在网络附加存储(nas)1104a和1104b中的数据的数据访问。数学模型可用于该数据,并使用跨计算机系统1102a和1102b和蜂窝电话以及个人数据助理系统1102c的分布式并行处理进行评价。计算机系统1102a和1102b和蜂窝电话以及个人数据助理系统1102c也可提供对存储在网络附加存储(nas)1104a和1104b中的数据的适应性数据重建的并行处理。图11仅示出了一个实例,而多种多样的其他计算机架构和系统可与本公开的多个实例一起使用。例如,刀片服务器可以用来提供并行处理。处理器刀片可通过背板连接,以提供并行处理。存储还可通过单独的网络接口连接至背板或作为网络附加存储(nas)。在一些示例实例中,处理器可维持单独的存储空间,并通过网络接口、背板或其他连接器传输数据以便由其他处理器并行处理。在其他情况下,部分或全部处理器可使用共享的虚拟地址存储空间。
[0169]
图12是根据示例情况使用共享虚拟地址存储空间的多处理器计算机系统的框图。该系统包括可访问共享的存储器子系统1204的多个处理器1202a
‑
f。该系统中在存储器子系统1204中并入多个可编程硬件存储算法处理器(map)1206a
‑
f。每个map 1206a
‑
f可以包含存储器1208a
‑
f以及一个或多个现场可编程门阵列(fpga)1210a
‑
f。map提供可配置的功能单元,并且可以向fpga1210a
‑
f提供特定算法或算法的部分,以供与相应的处理器密切协同地进行处理。例如,在示例情况中,map可用来评价与数据模型相关的代数表达式以及用来进行适应性数据重建。在该示例中,每个map可被用于这些目的的所有处理器全局访问。在一种配置中,每个map可使用直接存储器访问(dma)来访问相关联的存储器1208a
‑
f,使其独立于且异步于各自的微处理器1202a
‑
f而执行任务。在这一配置中,map可将结果直接馈送至另一map以用于流水处理和并行执行算法。
[0170]
以上计算机架构和系统仅为实例,并且多种多样的其他计算机、蜂窝电话和个人数据助理架构和系统可与示例实例结合使用,包括使用通用处理器、协处理器、fpga和其他可编程逻辑设备、芯片上系统(soc)、专用集成电路(asic)和其他处理和逻辑元件的任何组合的系统。在一些情况下,全部或部分计算机系统可用软件或硬件来实现。任何种类的数据存储介质可与示例实例结合使用,包括随机存取存储器、硬盘驱动器、闪速存储器、磁带驱动器、磁盘阵列、网络附加存储(nas)和其他的本地或分布式数据存储设备和系统。
[0171]
在示例实例中,计算机系统可使用在任何上述或其他计算机架构和系统上执行的软件模块来实现。在其他实例中,该系统的功能可部分或完全地在固件、可编程逻辑设备如图10提到的现场可编程门阵列(fpga)、芯片上系统(soc)、专用集成电路(asic)或其他处理和逻辑元件中实现。例如,集处理器(set processor)和优化器可通过使用硬件加速器卡如图10所示的加速器卡1022用硬件加速方式实现。
[0172]
阐述以下实施例是为了向本领域技术人员更清楚地说明本文所公开的实施方案的原理和实践,而不应解释为限制任何请求保护的实施方案的范围。除非另有说明,否则所有份数和百分比均以重量计。实施例
[0173]
给出以下实施例是为了说明本公开的多个实施方案的目的,而并非意图以任何方
式限制本发明。这些实施例以及目前代表优选实施方案的本文所述方法是示例性的,而非旨在限制本公开的范围。本领域技术人员将会想到其变化以及包含在由权利要求的范围所限定的本公开的精神之内的其他用途。
[0174]
实施例1:装置表面的官能化
[0175]
对装置进行官能化以支持多核苷酸文库的附接和合成。首先使用包含90%h2so4和10%h2o2的水虎鱼溶液(piranha solution)将装置表面润湿清洗20分钟。将该装置在含有去离子水的数个烧杯中冲洗,在去离子水鹅颈旋塞下保持5min,并用n2干燥。随后将该装置在nh4oh(1:100;3ml:300ml)中浸泡5min,使用手持式喷枪(handgun)用去离子水冲洗,在连续三个含有去离子水的烧杯中各浸泡1min,然后再使用手持式喷枪用去离子水冲洗。然后通过将装置表面暴露于o2来等离子体清洗该装置。使用samco pc
‑
300仪器在下游模式下以250瓦进行o2等离子体蚀刻1min。
[0176]
使用具有以下参数的yes
‑
1224p气相沉积烘箱系统,用包含n
‑
(3
‑
三乙氧基甲硅烷基丙基)
‑4‑
羟基丁酰胺的溶液对清洁的装置表面进行活化官能化:0.5至1托,60min,70℃,135℃汽化器。使用brewer science 200x旋涂仪对装置表面进行抗蚀剂涂覆。将spr
tm
3612光致抗蚀剂以2500rpm旋涂在装置上40sec。该装置在brewer热板上以90℃预烘30min。使用karl suss ma6掩模对准仪对装置进行光刻。将该装置暴露2.2sec并在msf 26a中显影1min。剩余的显影剂用手持式喷枪冲洗,并将装置在水中浸泡5min。该装置在烘箱中以100℃烘烤30min,随后使用nikon l200目视检查光刻缺陷。采用预清除(descum)工艺利用samco pc
‑
300仪器以250瓦进行o2等离子体蚀刻1min来去除残余抗蚀剂。
[0177]
用与10μl轻质矿物油混合的100μl全氟辛基三氯硅烷溶液对装置表面进行钝化官能化。将该装置放置于腔室中,泵送10min,随后关闭通往泵的阀门并静置10min。使该腔室排气。该装置通过在70℃下在500ml nmp中进行两次5min浸泡并同时以最大功率(在crest系统上的9)进行超声波处理来剥离抗蚀剂。然后将该装置在室温下在500ml异丙醇中浸泡5min,同时以最大功率进行超声波处理。将该装置浸入300ml的200标准酒精度(proof)的乙醇中并用n2吹干。活化该官能化表面以充当多核苷酸合成的支持物。
[0178]
实施例2:在寡核苷酸合成装置上合成50
‑
聚体序列
[0179]
将二维寡核苷酸合成装置组装至流动池中,其与流动池(applied biosystems(abi394 dna合成仪")连接。该二维寡核苷酸合成装置用n
‑
(3
‑
三乙氧基甲硅烷基丙基)
‑4‑
羟基丁酰胺(gelest)均匀地官能化,并用来使用本文所述的多核苷酸合成方法合成50bp的示例性多核苷酸("50
‑
聚体多核苷酸”)。
[0180]
所述50
‑
聚体的序列如下所述。5'agacaatcaaccatttggggtggacagccttgacctctagacttcggcat##tttttttttt3',其中#表示胸苷
‑
琥珀酰己酰胺ced亚磷酰胺(来自chemgenes的clp
‑
2244),它是能够在脱保护过程中使寡核苷酸从表面上释放的可切割的连接体。
[0181]
根据表2中的方案和abi合成仪,使用标准dna合成化学法(偶联、加帽、氧化和解封闭)完成合成。表2:合成方案
[0182]
亚磷酰胺/活化剂组合以类似于本体试剂通过流动池递送的方式进行递送。当在全部时间内保持环境被试剂“润湿”时,不进行干燥步骤。
[0183]
从abi 394合成仪中去除限流器,以使得能够更快速流动。在没有限流器的情况下,酰胺类(amidites)(在acn中0.1m)、活化剂(在acn中的0.25m苯甲酰基硫基四唑(“btt”;来自glenresearch的30
‑
3070
‑
xx))和ox(在20%吡啶、10%水和70%thf中的0.02m i2)的流速大致为约100ul/sec,乙腈(“acn”)和加帽试剂(帽a和帽b的1:1混合物,其中帽a是在thf/吡啶中的乙酸酐,帽b是在thf中的16%1
‑
甲基咪唑(1
‑
methylimidizole))的流速大致为约200ul/sec,而解封闭剂(在甲苯中的3%二氯乙酸)的流速大致为约300ul/sec(相比之下,在有限流器的情况下,所有试剂的流速均为约50ul/sec)。观测完全排出氧化剂的时间,相应地调整化学品流动时间的时间选择,并在不同的化学品之间引入额外的acn洗涤。在多核苷酸合成后,将芯片在75psi下在气态氨中脱保护过夜。将五滴水施加到表面上以回收多核苷酸。然后在bioanalyzer小rna芯片上分析所回收的多核苷酸。
[0184]
实施例3:在寡核苷酸合成装置上合成100
‑
聚体序列
[0185]
使用实施例2中描述的用于合成50
‑
聚体序列的相同过程,在两个不同的硅芯片上合成100
‑
聚体多核苷酸(“100
‑
聚体多核苷酸”;5'cgggatccttatcgtcatcgtcgtacagatcccgacccatttgctgtccaccagtcatgctagccataccatgatgatgatgatgatgagaaccccgcat##tttttttttt3',其中#表示胸苷
‑
琥珀酰基己酰胺ced亚磷酰胺(来自chemgenes的clp
‑
2244),第一个用n
‑
(3
‑
三乙氧基甲硅烷基丙基)
‑4‑
羟基丁酰胺均匀地官能化,而第二个用11
‑
乙酰氧基十一烷基三乙氧基硅烷和正癸基三乙氧基硅烷的5/95混合物官能化,并在bioanalyzer仪器上分析从表面提取的多核苷酸。
[0186]
使用下列热循环程序,在50ul pcr混合物(25ul neb q5主混合物,2.5ul 10um正向引物,2.5ul 10um反向引物,1ul从表面提取的多核苷酸,用水加至50ul)中使用正向引物(5'atgcggggttctcatcatc3')和反向引物(5'cgggatccttatcgtcatcg3')进一步pcr扩增来自两个芯片的全部十个样品:98℃,30sec98℃,10sec;63℃,10sec;72℃,10sec;重复12个循环72℃,2min
[0187]
pcr产物还在bioanalyzer上运行,在100
‑
聚体位置处显示出尖锐峰。然后,对pcr扩增的样品进行克隆,并进行sanger测序。表3总结了从来自芯片1的斑点1
‑
5采集的样品和从来自芯片2的斑点6
‑
10采集的样品的sanger测序结果。表3:测序结果表3:测序结果
[0188]
因此,合成的多核苷酸的高质量和均匀性在具有不同表面化学的两个芯片上重现。总体上,所测序的100
‑
聚体中有89%是没有错误的完美的序列,对应于262个中的233个。
[0189]
表4总结了从来自斑点1
‑
10的多核苷酸样品中获得的序列的错误特征。表4:错误特征
[0190]
实施例4:抗体优化
[0191]
从亲本序列生成的文库
[0192]
靶向pd
‑
1的抗体序列通过在计算机上生成包含来自12个个体的突变的文库来设计。重链和轻链突变空间来源于亲本序列和最接近的种系序列,以生成ngs数据库。ngs数据库包含轻链cdr1
‑
3和重链cdr1
‑
3的序列,所述序列与亲本参考序列或种系序列相比包含突变。所有cdr序列都在来自ngs数据库的两个或更多个个体中呈现。输入序列在图3a中示出。该文库含有5.9x107个不同的重链和2.9x106个轻链(图3b)。
[0193]
基于珠子的选择
[0194]
c末端生物素化的pd
‑
1抗原与链霉亲和素包被的磁珠结合,以进行五轮选择。在每轮之间消耗珠子结合变体。选择的严格性随着每个后续轮次而增加,并且富集比跟踪中靶结合。
[0195]
elisa和下一代测序
[0196]
合成表达重链和轻链组合的构建体,并进行噬菌体展示以鉴定改进的pd
‑
1结合物。该池用1000万个读取进行测序,并鉴定了400,000个独特的克隆。读取长度分布是高度均匀的(图4a)。在每一轮淘选时测量克隆频率和积累(图4b和4c)。四种不同的严格条件用
于淘选(图4d)。高严格性选择在重复选择中富集相同的结合物池。低严格性选择回收与高严格性选择相同的70个克隆中的44个(63%),具有更宽范围的低亲和力结合物。大多数scfv结合物在第5轮富集(图5a)。在测量scfv与pd
‑
1的结合的elisa实验中,超过90%(68/75)的克隆的存在5倍于背景,并且被富集到超过0.01%。
[0197]
用三种不同的初始选择条件完成了五轮选择。通过ngs经连续的每一轮跟踪克隆富集。去除针对脱靶或背景结合物而富集的序列。在第5轮中呈现的大约1000个克隆被富集到超过群体的0.01%。序列分析显示,在不同的选择条件下,绝大多数针对与pd
‑
1的结合而富集的克隆(>95%)被同样地捕获(图4e)。
[0198]
高通量igg表征
[0199]
克隆在expi293中瞬时转染,并通过kingfisher和hamilton自动化平台纯化。收率和纯度通过perkin elmer labchip和分析型hplc来确认。使用carterra lsa系统评估>170个igg变体的结合亲和力和表位分箱(binning)(数据未示出)。
[0200]
优化的igg以相似或改善的亲和力与具有对应于派姆单抗的序列(比较物1)和对应于纳武单抗的序列(比较物2)的比较抗体结合(数据未示出)。还测量了scfv与pd
‑
1的结合,如图5b所示。相比于具有对应于派姆单抗的序列(比较物1)和对应于纳武单抗的序列(比较物2)的比较抗体,优化抗体的序列含有更少的种系突变(图6a和表5a)。优化抗体的轻链是高度多样性的,超过90%的克隆含有从未重复的独特轻链(表5b)。与亲本序列相比,优化的igg显示出单价结合亲和力的100倍改善。pd1
‑
1克隆以4.52nm的k
d
与pd
‑
1结合,而其他几个克隆显示结合亲和力<10nm。图6b显示了使用本文所述的方法优化后的亲和力增加。这些高亲和力结合物各自包含独特的cdrh3,并且不按序列谱系聚类。还观察到各种cdr之间的多样性,如图6c
‑
6d所示。与野生型相比,pd
‑
1抗体表现出改善的结合亲和力(图6e
‑
6f和表5c)。表5a.pd
‑
1变体序列
表5b.
表5c.
[0201]
功能和可开发性分析
[0202]
测试通过本文所述方法优化的igg对pd
‑
1/pd
‑
l1相互作用的功能阻断。图7a显示,与野生型以及具有对应于纳武单抗的序列的比较抗pd1抗体相比,高亲和力变体显示出改
善的ic50。ic50和单价结合亲和力高度相关。如图7b所示,优化的igg表现出改善的结合亲和力(高达72倍),并且功能也增加了9.5倍。与具有对应于纳武单抗的序列的抗体相比,鉴定出具有更高结合亲和力和功能的六种抗体。如图7c所示,添加抗pd
‑
1igg阻断了pd
‑
1/pdl
‑
1相互作用,释放抑制信号,并导致tcr活化和nfat
‑
re介导的发光(ru)。另外,所有结合物也保留了与食蟹猴pd
‑
1的结合。如通过bvp结合elisa所测量的,几种高亲和力igg表现出低多特异性评分(图7d)。另外,还针对tm和tagg在unchained uncle机器上以及在分析型hplc上测试了igg。
[0203]
虽然本文已经示出并描述了本公开的优选实施方案,但对于本领域技术人员明显的是,这些实施方案仅以示例的方式提供。在不脱离本公开内容的情况下,本领域技术人员将会想到许多变化、改变和替换。应当理解,在实施本公开时可以采用本文所述本公开的实施方案的各种替代方案。旨在以所附权利要求书限定本公开的范围,并且由此涵盖这些权利要求范围内的方法和结构及其等同物。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1