修饰的人可变域的制作方法
1.本发明提供了包含修饰的人、人源化或嵌合免疫球蛋白重链可变域的多肽。还提供了相应抗体、变体、片段、核酸、载体、噬菌体、文库、方法和试剂盒。
背景技术:
2.治疗性蛋白,如抗体含有一些翻译后修饰,它们中的一些对蛋白具有潜在不希望的影响。例如,焦谷氨酸(pyroglutamate,焦谷氨酸盐)(通常缩写为pe、pyroe或pyroglu)可以在多肽链的n-末端体外和体内形成。焦谷氨酸的形成通过在该位置最初合成的谷氨酸或谷氨酰胺残基的重排发生(参见图1)。
3.如通过种系vh基因节段重排所编码的人、人源化或嵌合抗体重链可变(vh)域的n-末端的第一个残基通常是谷氨酰胺或谷氨酸。抗体n-末端的谷氨酰胺和谷氨酸两者已显示体外自发环化为焦谷氨酸。当通过谷氨酰胺环化形成焦谷氨酸时,所产生的抗体变得酸性更强。相反地,当通过谷氨酸环化形成焦谷氨酸时,所产生的抗体变得酸性降低。随时间,这可能导致抗体制备中的电荷不均一,这在多种背景中可能是不期望的。降低抗体制备中的这种可变性可以是有益的。
4.然而,谷氨酰胺或谷氨酸在vh域的n-末端的存在可以是重要的。的确,在抗体从原核和真核细胞分泌期间,通过信号肽和重链可变域之间的切割,从未成熟的重链的n-末端除去信号肽(sp;也称为前导肽)。信号肽切割效率取决于信号肽序列以及vh域的序列。信号肽肽酶(如spasei)所识别的肽节段延伸至成熟蛋白的起始(choo等人,2008)。vh域中的侧接残基因此可以影响信号肽酶处理并有助于非典型切割位点。
技术实现要素:
5.本文已意外地发现可以向人、人源化或嵌合vh域的n-末端引入氨基酸改变,同时保留相应未修饰的人、人源化或嵌合vh域所要求的亲和性(affinity,亲和力)、特异性和/或结构相互作用。有利地,这降低了包含修饰的人、人源化或嵌合vh域的蛋白制剂(例如,抗体制剂)中的可变性(例如,电荷不均一性)。
6.因此,本文首次提供了新的抗体、重链可变区、变体、片段、核酸、载体、噬菌体、文库、方法和试剂盒,其包含缺少谷氨酰胺或谷氨酸的修饰的n末端残基,同时不会有害地影响信号肽切割或蛋白表达。此外,描述了抗体产生方法,其中可以修饰人、人源化或嵌合抗体、重链可变区和编码它们的核酸的整个组以普遍除去n末端谷氨酰胺或谷氨酸,从而允许这些人抗体、重链可变区的整个组从头开始展示、测定和评价,没有这种残基,避免了先导候选鉴定(lead candidate identification)时实施下游修饰的任务,节约时间并减少工作,并且优选地同时不会有害地影响信号肽切割或蛋白表达。
7.此外,当通过展示技术或者在功能测定中产生要对于活性进行筛选的重链或抗体组时,期望测试这些蛋白,因为它们将处于其最终形式以避免这种分析中的结果的可变性并且基于可以在下游生产中使用的变体,避免不得不进行多轮相同分析。然而,常规做法是
分析重链或抗体以除去可以仅在前导,如抗体已鉴别后并且在进行了功能性表征后导致翻译后修饰的残基。然后,可以通过本领域中已知的多种重组技术,包括通过核酸突变或通过核酸合成,从而导致编码改变否则在储存期间将产生潜在改变的残基的变化的新序列,改变具体残基。例如,在免疫动物(或另外的转基因动物)的b细胞的免疫和收集后或者在分析所产生的抗体的杂交瘤或文库产生前,必须特异性改变由抗体产生所产生的每种蛋白是费力且费时的方法。因此,在本文中已开发了通过改变n末端谷氨酰胺和谷氨酸来修饰整个包含人、人源化或嵌合vh域的抗体、重链或可变区的组的新型方式。
8.其它优势在于可以使用包含编码信号肽的核酸和包含vh域的第一或前两个氨基酸的标准载体,所述vh域的第一氨基酸不是谷氨酰胺或谷氨酸,并且其中至少所述第一或前两个氨基酸不同于未修饰的vh域,在本文中其也称为参考亲代可变区或常规人、人源化或嵌合vh域。这种载体可以用于宿主细胞以产生包含如本文所描述的修饰的vh域的抗体或重链组,并且进一步改善生产抗体的稳健性和效率。
9.修饰在免疫和组产生后并且在产生展示文库前所产生的每个抗体或重链的另一种复杂性在于以下考虑:这样做,可以阻碍负责抗体或重链在细胞表面展示的信号肽,从而损害展示温度的宽度和稳健性。
10.可以将氨基酸变化引入人、人源化或嵌合vh域的n-末端的事实允许更有效的产生抗体的方法,因为与已选择一个或多个前导候选之后相反,可以在抗体组产生期间进行修饰。
11.如本文所示,除去人、人源化或嵌合vh域n-末端的谷氨酰胺或谷氨酸并用另一种氨基酸(如丙氨酸)替换该残基消除了任何蛋白,如抗体n-末端的自发焦谷氨酸形成,从而引入了修饰的可变域。有利地,引入修饰的人、人源化或嵌合vh域的fabs和噬菌体展示文库的成功产生证实修饰的人、人源化或嵌合vh域保留了相应未修饰的人、人源化或嵌合vh域的所需要的亲和性、特异性和/或结构相互作用。此外,通过使用通用引物,所使用的方法允许产生整个人重链可变区或抗体组,其n-末端的这种谷氨酰胺或谷氨酸被除去,而不考虑哪种v基因节段产生了所述可变区,从而允许对这些组进行均一测试并引入高通量筛选。
12.一些优势可以与消除焦谷氨酸形成有关。如上所述,焦谷氨酸的存在可以改变抗体酸度,其可以导致抗体降解或影响货架期。此外,已报道一旦在患者中输注,具有超过特定阈值水平的低ph的抗体将引起疼痛。消除焦谷氨酸形成将消除这些潜在不利的性质。此外,出于调控目的,焦谷氨酸的消除也是有益的,因为,例如,欧洲药品管理局(european medical agency)指南要求生物制品的申请人监测一些结构特征,包括聚集状态,n-和c-末端(重链n-末端的焦谷氨酸和c-末端的赖氨酸)。n末端焦谷氨酸的消除将通过消除这种监测变化而使得管理审查变得容易。n末端焦谷氨酸的不存在还可以导致抗体货架期增加。消除焦谷氨酸形成还提供了更大的过程控制并且可以对与这种n末端谷氨酰胺或谷氨酸残基有关的疾病具有益处。n末端焦谷氨酸的不存在还确保抗体中电荷不均一性的降低并因此使得基于电荷的纯化和分离更有效。在不存在焦谷氨酸的情况下,n末端修饰的添加以及后续分析还可以更容易。
13.本发明人还意外地鉴别这种氨基酸变化可以改善信号肽从未成熟的人、人源化或嵌合vh域的n-末端的有效切割。例如,丙氨酸残基(任选地与其它第二残基,例如,丙氨酸-脯氨酸、丙氨酸-天冬氨酸、丙氨酸-谷氨酸、丙氨酸-苏氨酸、丙氨酸-缬氨酸、丙氨酸-丝氨
酸或者丙氨酸-亮氨酸一起)在人、人源化或嵌合vh域的n-末端的引入可以提高vh域及其上游信号肽之间的切割,因此不会不利地影响修饰的人、人源化或嵌合vh域以及包含这些域的抗体或抗体片段,例如,fabs的表达和分泌并且优选地提高了有效表达和分泌。
14.本文提供了可以用于扩增和修饰编码人、人源化或嵌合vh域的核酸的一些通用引物(具体地,修饰在vh域的n-末端编码的第一(和任选地第二)氨基酸)。有利地,以某些组合,本文所提供的通用引物可以无偏好地扩增和修饰从存在于人基因组样品的每个vh基因家族中的任何功能性vh基因节段产生的人、人源化或嵌合重链的整个组库。这些通用引物能够在任何所产生的人、人源化或嵌合可变区组中产生这些修饰,而不考虑已重组或重排以形成可变区的vh基因节段。通过使用共有人重链组库,这些通用引物能够产生这些修饰。
15.本发明提供了包含人、人源化或嵌合免疫球蛋白重链可变域的多肽,其中可变域包含选自由下述组成的组的n末端氨基酸:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸。
16.适当地,人、人源化或嵌合免疫球蛋白重链可变域可以包含选自由下述组成的组的n末端氨基酸:精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸和酪氨酸。
17.适当地,人、人源化或嵌合免疫球蛋白重链可变域可以包含选自由下述组成的组的n末端氨基酸:精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、色氨酸和酪氨酸。
18.适当地,人、人源化或嵌合免疫球蛋白重链可变域可以包含选自由下述组成的组的n末端氨基酸:天冬酰胺、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、丝氨酸、苏氨酸、色氨酸和酪氨酸。
19.适当地,人、人源化或嵌合免疫球蛋白重链可变域可以包含n末端丙氨酸。
20.适当地,人、人源化或嵌合免疫球蛋白重链可变域可以包含选自由下述组成的组的n末端序列:丙氨酸-脯氨酸、丙氨酸-天冬氨酸、丙氨酸-谷氨酸、丙氨酸-苏氨酸、丙氨酸-缬氨酸、丙氨酸-丝氨酸和丙氨酸-亮氨酸。
21.适当地,人、人源化或嵌合免疫球蛋白重链可变域可以包含n末端序列丙氨酸-脯氨酸。
22.适当地,多肽可以包含人、人源化或嵌合免疫球蛋白重链可变域的n末端氨基酸上游的信号肽。
23.适当地,信号肽可以包含氨基酸序列aqpama(seq id no:5)。
24.本发明还提供了包含如本文所描述的多肽的抗体、抗体变体或抗体片段。
25.本发明还提供了编码如本文所描述的多肽、抗体、抗体变体或抗体片段的核酸。
26.此外,本发明提供了包含如本文所描述的核酸的载体。
27.本发明还提供了包含编码如本文所描述的人、人源化或嵌合免疫球蛋白重链的信号肽和第一个氨基酸或前两个氨基酸的核酸序列的模板或标准载体。这些模板载体不包含编码人、人源化或嵌合免疫球蛋白重链的核酸。
28.适当地,载体包含编码信号肽和n末端氨基酸的核酸序列,所述n末端氨基酸选自由下述组成的组:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、
chain,共同轻链)。
51.适当地,可以修饰编码来自b细胞的人、人源化或嵌合免疫球蛋白重链可变域的所有核酸以编码:
[0052]-包含选自由下述组成的组的n末端氨基酸的人、人源化或嵌合免疫球蛋白重链可变域:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸;或者
[0053]-包含选自由下述组成的组的n末端序列的人、人源化或嵌合免疫球蛋白重链可变域:丙氨酸-脯氨酸、丙氨酸-天冬氨酸、丙氨酸-谷氨酸、丙氨酸-苏氨酸、丙氨酸-缬氨酸、丙氨酸-丝氨酸和丙氨酸-亮氨酸。
[0054]
适当地,步骤(a)可以包括提供至少一种重组人基因节段所编码或基于所述节段的多个不同的核酸,所述基因节段选自以下人基因家族中的每一个:ighv1、ighv2、ighv3、ighv4、ighv5、ighv6和ighv7。
[0055]
适当地,所述方法可以包括:
[0056]
(a)使用选自1308ap、1308ap2、2020ap2、2018ap或2018ap2的5’引物,扩增和修饰ighv1家族基因所编码的核酸;和/或
[0057]
(b)使用选自1310ap2、1310ap3、1310ap4或1310ap5的5’引物,扩增和修饰ighv2家族基因所编码的核酸;和/或
[0058]
(c)使用选自0508ap、0508ap2、2018ap、2018ap2、2021ap、2021ap2、2021ap3、2021ap4或2021ap5的5’引物,扩增和修饰ighv3家族基因所编码的核酸;和/或
[0059]
(d)使用1312ap作为5’引物,扩增和修饰ighv4家族基因所编码的核酸;和/或
[0060]
(e)使用选自1313ap或1313ap2的5’引物,扩增和修饰ighv5家族基因所编码的核酸;
[0061]
(f)使用选自1310ap2、1310ap3、1310ap4、1310ap5或1312ap2的5’引物,扩增和修饰ighv6家族基因所编码的核酸;和/或
[0062]
(g)使用选自1314ap或1314ap2的5’引物,扩增和修饰ighv7家族基因所编码的核酸。
[0063]
适当地,所述方法可以包括:
[0064]
(a)使用选自1308ap2、2020ap2或2018ap2的5’引物,扩增和修饰ighv1家族基因所编码的核酸;和/或
[0065]
(b)使用1310ap5作为5’引物,扩增和修饰ighv2家族基因所编码的核酸;和/或
[0066]
(c)使用选自0508ap;2021ap2或2018ap2]的5’引物,扩增和修饰ighv3家族基因所编码的核酸;和/或
[0067]
(d)使用选自1312ap2或2019ap2的5’引物,扩增和修饰ighv4家族基因所编码的核酸;和/或
[0068]
(e)使用1313ap2作为5’引物,扩增和修饰ighv5家族基因所编码的核酸;
[0069]
(f)使用选自1310ap2、1310ap3、1310ap4、1310ap5或1312ap2的5’引物,扩增和修饰ighv6家族基因所编码的核酸;和/或
[0070]
(g)使用1314ap2作为5’引物,扩增和修饰ighv7家族基因所编码的核酸。
[0071]
适当地,可以对修饰的人、人源化或嵌合免疫球蛋白重链可变域进行频率分析以
用于先导鉴定。
[0072]
适当地,所述方法还可以包括将每个扩增并修饰的核酸引入载体。
[0073]
适当地,载体包含编码信号肽的核酸序列。
[0074]
适当地,载体中的核酸序列所编码的信号肽包含氨基酸序列aqpama(seq id no:5)。
[0075]
适当地,载体可以是噬粒或质粒。
[0076]
适当地,所述方法还可以包括将每个载体转化或转染到细胞中以产生文库。
[0077]
适当地,细胞可以是噬菌体感受态细胞。
[0078]
适当地,可以将修饰的人、人源化或嵌合免疫球蛋白重链可变域整合到噬菌体中以用于筛选结合特异性和/或亲和性。
[0079]
适当地,所述方法可以用于减少人、人源化或嵌合免疫球蛋白重链可变域中的焦谷氨酸形成。
[0080]
因此,本发明还提供了用于减少人、人源化或嵌合免疫球蛋白重链可变域中焦谷氨酸形成的方法,所述方法包括:修饰编码人、人源化或嵌合免疫球蛋白重链可变域的核酸,从而修饰的核酸编码包含选自由下述组成的组的n末端氨基酸的人、人源化或嵌合免疫球蛋白重链可变域:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸。
[0081]
适当地,修饰的核酸可以编码包含n末端丙氨酸的人、人源化或嵌合免疫球蛋白重链可变域。
[0082]
适当地,修饰的核酸编码包含选自由下述组成的组的n末端序列的人、人源化或嵌合免疫球蛋白重链可变域:丙氨酸-脯氨酸、丙氨酸-天冬氨酸、丙氨酸-谷氨酸、丙氨酸-苏氨酸、丙氨酸-缬氨酸、丙氨酸-丝氨酸和丙氨酸-亮氨酸。
[0083]
适当地,修饰的核酸可以编码包含n末端序列丙氨酸-脯氨酸的人、人源化或嵌合免疫球蛋白重链可变域。
[0084]
本发明还提供了用于扩增和修饰编码人、人源化或嵌合免疫球蛋白重链可变域的任何核酸的5’引物,所述核酸选自或基于以下人vh基因家族中的一种或多种:ighv1、ighv2、ighv3、ighv4、ighv5、ighv6和ighv7,其中引物包含在扩增的核酸中引入修饰的修饰位点,从而扩增的核酸编码包含选自由下述组成的组的n末端氨基酸的人、人源化或嵌合免疫球蛋白重链可变域:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸。
[0085]
适当地,修饰位点可以使得扩增的核酸编码包含n末端丙氨酸的人、人源化或嵌合免疫球蛋白重链可变域。
[0086]
适当地,修饰位点可以使得扩增的核酸编码包含选自由下述组成的组的n末端序列的人、人源化或嵌合免疫球蛋白重链可变域:丙氨酸-脯氨酸、丙氨酸-天冬氨酸、丙氨酸-谷氨酸、丙氨酸-苏氨酸、丙氨酸-缬氨酸、丙氨酸-丝氨酸和丙氨酸-亮氨酸。
[0087]
适当地,修饰位点可以使得扩增的核酸编码包含n末端丙氨酸-脯氨酸的人、人源化或嵌合免疫球蛋白重链可变域。
[0088]
适当地,引物可以编码修饰位点上游的信号肽或信号肽的一部分。
[0089]
本发明还提供了包含至少一种5’引物的试剂盒,所述5'引物选自以下组中的每一
个:
[0090]
(a)1308ap、1308ap2、2020ap2、2018ap或2018ap2;
[0091]
(b)1310ap2、1310ap3、1310ap4或1310ap5;
[0092]
(c)0508ap、0508ap2、2018ap、2018ap2、2021ap、2021ap2、2021ap3、2021ap4或2021ap5;
[0093]
(d)1312ap2;
[0094]
(e)1313ap或1313ap2;
[0095]
(f)1310ap2、1310ap3、1310ap4、1310ap5或1312ap2;
[0096]
和
[0097]
(g)1314ap2或1314ap。
[0098]
适当地,试剂盒可以包含选自以下组中的每一个的至少一种5’引物:
[0099]
(a)1308ap2、2020ap2或2018ap2;
[0100]
(b)1310ap5;
[0101]
(c)0508ap、2021ap2或2018ap2;
[0102]
(d)1312ap2或2019ap2;
[0103]
(e)1313ap2;
[0104]
(f)1310ap2、1310ap3、1310ap4、1310ap5或1312ap2;和
[0105]
(g)1314ap2。
[0106]
本发明还提供了用于产生抗体、抗体变体或抗体片段的方法,所述方法包括:
[0107]-修饰编码人、人源化或嵌合免疫球蛋白重链可变域的核酸,从而修饰的核酸编码包含选自由下述组成的组的n末端氨基酸的人、人源化或嵌合免疫球蛋白重链可变域:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸;
[0108]-随后使用抗体筛选技术来识别包含选自下列的n末端氨基酸的人、人源化或嵌合免疫球蛋白重链可变域:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸,以用于结合至靶标抗原;
[0109]-选择结合靶标抗原的人、人源化或嵌合免疫球蛋白重链可变域;和
[0110]-使用所述人、人源化或嵌合免疫球蛋白重链可变域来开发治疗性抗体、抗体变体或抗体片段,而无需进一步修饰n末端氨基酸。
[0111]
适当地,修饰的核酸可以编码包含n末端丙氨酸的人、人源化或嵌合免疫球蛋白重链可变域。
[0112]
适当地,修饰的核酸编码包含选自由下述组成的组的n末端序列的人、人源化或嵌合免疫球蛋白重链可变域:丙氨酸-脯氨酸、丙氨酸-天冬氨酸、丙氨酸-谷氨酸、丙氨酸-苏氨酸、丙氨酸-缬氨酸、丙氨酸-丝氨酸和丙氨酸-亮氨酸。
[0113]
适当地,修饰的核酸编码包含n末端序列丙氨酸-脯氨酸的人、人源化或嵌合免疫球蛋白重链可变域。
[0114]
适当地,抗体筛选技术包括当与轻链配对时,人、人源化或嵌合免疫球蛋白重链可变域的筛选。
[0115]
适当地,抗体筛选技术包括当与共有轻链配对时,人、人源化或嵌合免疫球蛋白重链可变域的筛选。
[0116]
在本说明书的整个描述和权利要求中,词语“包含”和“含有”及其变化形式表示“包括,但不限于”,并且它们不意欲(并且不)排除其它部分、添加剂、组分、整数或步骤。
[0117]
在本说明书的整个描述和权利要求中,除非上下文另外要求,否则单数涵盖了复数。具体地,当使用不定冠词时,除非上下文另外要求,否则说明书应被理解为考虑了多个以及单一。
[0118]
结合本发明的具体方面、实施方式或实施例描述的特性、整数、特征、化合物、化学部分或基团将理解为除非与之矛盾,否则适用于本文所述的任何其它方面、实施方式或实施例。
[0119]
以下将进一步详细描述本发明的多个方面。
附图说明
[0120]
在下文中参考附图进一步描述了本发明的实施方式,其中:
[0121]
图1显示了在蛋白质的n-末端的焦谷氨酸(pyroglu)形成。
[0122]
图2显示了使用signalp的sp切割预测分析结果。对于360个所分析的序列中的每一个,对vh位置1的每个氨基酸提供d得分,以及平均(avg.)d得分。在左侧提供了具有原核(p)sp的序列的数据;在右侧提供了具有真核(e)sp的序列的数据。对于每个数据组的右侧,列
‘
天然频率(nat.freq.)(%)’列出了革兰氏阴性和真核含sp蛋白组的位置1处的氨基酸频率[choo和ranganathan,2008]。
[0123]
图3显示了对于1170条序列,使用signalp的sp切割预测分析结果。对于1170条所分析的序列,对vh位置2的每个氨基酸提供d得分,以及平均(avg.)d得分。在左侧提供了具有原核(p)sp的序列的数据;在右侧提供了具有真核(e)sp的序列的数据。对于每个数据组的右侧,列
‘
天然频率(%)’列出了革兰氏阴性和真核含sp蛋白组的位置2处的氨基酸频率[choo和ranganathan,2008]。
[0124]
图4显示了使用signalp的sp切割预测分析结果。对于sp和vh起始的18个组合中的每一个,对在位置1和2具有变化的1170条序列亚组提供了d得分。在左侧提供了具有原核(p)sp的序列的数据;在右侧提供了具有真核(e)sp的序列的数据。对于两个sp,还提供了平均(avg.)d得分。上面的行显示了wt序列结果。中间行显示了最佳变体的结果,即具有最高d得分的序列。下面的行显示了最佳变体的共有性(consensus)结果,即当与细菌sp组合并且当与真核sp组合时,d得分高于wt序列的序列;还提供了与wt相比的d得分差异(最后一行)。
[0125]
图5显示了新的5’ap引物的比对(前两个vh密码子加粗并加下划线)。
[0126]
图6显示了退火至通过两个merus小鼠系表达的vh基因节段的起始的新设计的5’引物的蛋白翻译。将改变为ap的vh区的前两个残基加粗并加下划线。
[0127]
图7显示了ap 5’引物的扩增效率(琼脂糖凝胶上pcr产物得率的比较)。
[0128]
图8显示了新的ap和ap2引物的比对。
[0129]
图9显示了ap2 5’引物的扩增效率(琼脂糖凝胶上pcr产物得率的比较)。
[0130]
图10显示了平行测试的所有新的引物(ap和ap2)的扩增效率。
[0131]
图11显示了1310ap引物的5种不同的变体以及2021ap引物的5种不同的变体的扩
增效率。
[0132]
图12显示了新的引物1308ap2与所有功能性ighv1序列的比对。
[0133]
图13显示了新的引物2020ap2与所有功能性ighv1序列的比对。
[0134]
图14显示了新的引物2018ap2与所有功能性ighv1序列的比对。
[0135]
图15显示了ighv1的新的引物1308ap2、2018ap2和2020ap2的比对。
[0136]
图16显示了新的引物1310ap5与所有功能性ighv2序列的比对。
[0137]
图17显示了新的引物0508ap与所有功能性ighv3序列的比对。
[0138]
图18显示了新的引物2021ap2与所有功能性ighv3序列的比对。
[0139]
图19显示了新的引物2018ap2与所有功能性ighv3序列的比对。
[0140]
图20显示了对ighv3特异的3种新的引物的比对。
[0141]
图21显示了新的引物1312ap2与所有功能性ighv4序列的比对。
[0142]
图22显示了新的引物2019ap2与所有功能性ighv4序列的比对。
[0143]
图23显示了新的引物1313ap2与所有功能性ighv5序列的比对。
[0144]
图24显示了新的引物与ighv6-1的比对。
[0145]
图25显示了新的引物1314ap2与功能性ighv7基因节段的比对。
[0146]
本文所提供的附图显示了每个家族内的特异性vh基因节段与它们相应的引物的序列比对。本领域的常规技术人员将清楚由于等位变化vh基因节段的序列可以改变,并且本文所描述的本发明还涵盖了每个家族内不同的vh基因节段序列的相应引物。
[0147]
本文中所提及的专利、科技文献建立了在提交时本领域技术人员可获得的知识。本文所引用的授权的专利、公开和申请中的专利申请和其它专利公开的全部公开内容以它们分别具体且单独表示作为参考并入的相同程度作为参考并入本文。在任何不一致的情况下,将以本公开为准。
[0148]
以下将进一步详细描述本发明的多个方面。
具体实施方式
[0149]
本发明提供了包含修饰的人、人源化或嵌合免疫球蛋白重链可变(vh)域的多肽。
[0150]
术语“免疫球蛋白重链可变域”和“vh域”在本文中是可互换使用的。该术语在本文中一般用于表示人、人源化或嵌合vh域(除非上下文另外明确指明)。
[0151]
术语“肽”、“蛋白”和“多肽”在本文中是可互换使用的。蛋白序列的n-末端(也称为氨基-末端、nh2-末端、n末端或胺-末端)是蛋白序列的开始。按照惯例,肽序列从n-末端至c-末端(从左至右)书写。c-末端(也称为羧基末端、羧基末端、c末端尾、c末端或cooh-末端)是由游离羧基(-cooh)终止的氨基酸链(蛋白或多肽)的末端。
[0152]
与常规人或亲代人源化或嵌合vh域相比,本文所描述的修饰的人、人源化或嵌合可变域(在本文中也称为修饰的vh域)包含氨基酸修饰,即修饰的vh域的n末端氨基酸选自由下述组成的组:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸。这不同于常规人或亲代人源化或嵌合vh域(在本文中也称为未修饰的vh域),因为常规人和人源化或嵌合亲代vh域在n-末端具有谷氨酰胺或谷氨酸残基。
[0153]
不考虑多肽内可以存在的其它肽域和序列,如本文所使用的,vh域的“n-末端”(或
者vh域的“n末端氨基酸”)是指vh域氨基酸序列的开始(即vh域的第一氨基酸(从左至右))。因此,为了避免引起怀疑,vh域的“n-末端”(或者vh域的“n-末端氨基酸”)是指成熟vh域氨基酸序列的第一个氨基酸并且不考虑所述多肽中可以作为例如信号肽序列的一部分存在的任何上游氨基酸。因此,vh域的“n-末端”(或者vh域的“n-末端氨基酸”)实际上可以不是多肽链的开始(它可以在其上游具有其它氨基酸残基)。换言之,对于包含位于vh域氨基酸序列直接上游和邻近的信号肽的多肽,vh域的“n-末端”是指vh域的第一个氨基酸(即信号肽序列之后的第一个氨基酸)。作为非限制性实例,如序列mkyllptaaagllllaaqpamaqvqlvqsg(seq id no:3)
……
所示,当多肽包含信号肽(mkyllptaaagllllaaqpama(seq id no:1)+vh域(qvqlvqsg(seq id no:2)
……
(根据ighv1-3*01_x62109.1_homo))时,对vh域的n末端氨基酸加下划线。
[0154]
vh域由4个框架区和3个高变区(也称为cdr)组成,具有fr1-cdr1-fr2-cdr2-fr3-cdr3-fr4(n-末端至c-末端)的布置。框架区占可变区的约85%并且起到vh域的cdr的支架的作用。与cdr相比,框架区在它们的氨基酸序列中可变性较低。fr1区的第一个氨基酸也是vh域的n末端氨基酸。kabat编号方案广泛用于对抗体序列中的残基编号。(kabat,e.a.等人,nih公开号(publication no.)91-3242(1991))。
[0155]
尽管认为人、人源化或嵌合vh域的n末端残基谷氨酰胺或谷氨酸在抗体的抗原亲和性、抗原特异性和/或结构相互作用中起到重要(或关键)作用,但是目前已意外地发现可以耐受该位置处的氨基酸变化。有利地,这允许用另一种(优选的)氨基酸修饰谷氨酰胺或谷氨酸,所述氨基酸如丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸或者缬氨酸之一。以这种方式,人、人源化或嵌合vh域的n末端氨基酸的修饰消除了焦谷氨酸的形成(并因此避免了在本文其它处详细讨论的与焦谷氨酸形成有关的潜在有害影响)。
[0156]
根据它们的生物化学性质(例如,电荷、疏水性、尺寸等),可以对氨基酸分组。例如,酸性残基包括天冬氨酸和谷氨酸,具有极性侧链的非酸性残基的实例包括天冬酰胺和谷氨酰胺。在一个实例中,因此,人、人源化或嵌合vh域的n末端残基谷氨酰胺或谷氨酸被酸性或极性残基,如天冬氨酸或天冬酰胺替代。这些氨基酸具有与谷氨酰胺或谷氨酸类似的生物化学性质,并因此可以是有用的选择,照此变化保留了类似的生物化学性质,同时除去了重链可变区中随时间可能来自谷氨酰胺或谷氨酸向焦谷氨酸转变的潜在下游可变性。
[0157]
已在本文中分析了每种氨基酸变化(即n末端丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸或缬氨酸)对人、人源化或嵌合vh域上游信号肽切割位点的识别的潜在影响。已发现人、人源化或嵌合vh域中n末端谷氨酸或谷氨酰胺残基被丙氨酸的修饰是特别有用的,因为它消除了焦谷氨酸形成并且还维持(例如,改善)了信号肽切割位点在原核生物和真核生物中的识别。基于平均d得分的计算机审查,消除焦谷氨酸形成同时维持原核生物中信号肽切割位点的相对识别的其它氨基酸是甘氨酸、蛋氨酸、天冬酰胺、丝氨酸、苏氨酸、缬氨酸和酪氨酸。基于平均d得分的计算机审查,消除焦谷氨酸形成同时维持真核生物中信号肽切割位点的相对识别的其它氨基酸包括苯丙氨酸、异亮氨酸、亮氨酸、缬氨酸和色氨酸。因此,这些氨基酸中的每一个对于n末端谷氨酸或谷氨酰胺残基的修饰也是有用的。基于未修饰的残基频率,评价焦谷氨酸形成的消除同时维持原核生物和真核生物两者中信号
肽切割位点的相对识别表明优选的残基是丙氨酸、门冬氨酸和丝氨酸。
[0158]
丙氨酸是脂族残基。因此,在另一个实例中,人、人源化或嵌合vh域的n末端残基谷氨酰胺或谷氨酸被脂族残基替换,如丙氨酸、甘氨酸、缬氨酸、亮氨酸或异亮氨酸。
[0159]
还在本文中研究了用另一种(优先的)氨基酸替换vh域n-末端的第二氨基酸的影响。为了避免引起怀疑,“vh域的n-末端处的第二氨基酸”是指与vh域的n末端氨基酸直接相邻(在n末端至c末端方向)的氨基酸(换言之,vh域氨基酸序列中位置2处的氨基酸,其中n末端氨基酸(如未修饰的人、人源化或嵌合vh域中的q或e)位于位置1)。
[0160]
意外地,已发现基于这些残基在具有信号肽的革兰氏阴性细菌的成熟蛋白中的未修饰频率,将vh域n-末端的第二个氨基酸(在n末端至c末端方向)改变为脯氨酸、天冬氨酸、谷氨酸、苏氨酸、缬氨酸、丝氨酸或亮氨酸之一促进vh域上游信号肽切割位点的切割(choo和ranganathan,2008)。特别是当将脯氨酸选择为vh域n-末端处的第二氨基酸时就是这种情况。
[0161]
因此,本文所描述的修饰的人、人源化或嵌合vh域可以包括选自由下述组成的组的第一n末端氨基酸:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸;和选自由下述组成的组的第二氨基酸:脯氨酸、天冬氨酸、谷氨酸、丝氨酸、苏氨酸、缬氨酸或亮氨酸。在一个具体实例中,将vh域n-末端的第二氨基酸选择为脯氨酸,其中优选的第一和第二位置包含“丙氨酸-脯氨酸”或“ap”。优选地,避免了本文中的半胱氨酸残基,因为它在n-末端引入了高反应性基团,其可能在生产和储存中引起开发责任。
[0162]
如以下所提供的数据所示,修饰的vh域的n末端的氨基酸的特别有用的组合是丙氨酸-脯氨酸、丙氨酸-天冬氨酸、丙氨酸-谷氨酸、丙氨酸-丝氨酸、丙氨酸-苏氨酸、丙氨酸-缬氨酸和丙氨酸-亮氨酸。如本文所使用的,用于“丙氨酸-脯氨酸”或“ap”等的形式是指修饰的人vh域的n末端的两个相邻的氨基酸(即vh域的n-末端的“第一-第二”氨基酸(以n末端至c末端方向))。
[0163]
使用signalp从sp切割预测分析推断替代优选组合。基于图3中的数据,其它优选的组合包括以下中的每一种:甘氨酸-脯氨酸、甘氨酸-天冬氨酸、甘氨酸-谷氨酸、甘氨酸-丝氨酸、甘氨酸-苏氨酸、甘氨酸-亮氨酸、甘氨酸-缬氨酸、蛋氨酸-脯氨酸、蛋氨酸-天冬氨酸、蛋氨酸-谷氨酸、蛋氨酸-丝氨酸、蛋氨酸-苏氨酸、蛋氨酸-亮氨酸、蛋氨酸-缬氨酸、天冬酰胺-脯氨酸、天冬酰胺-天冬氨酸、天冬酰胺-谷氨酸、天冬酰胺-丝氨酸、天冬酰胺-苏氨酸、天冬酰胺-亮氨酸、天冬酰胺-缬氨酸、丝氨酸-脯氨酸、丝氨酸-天冬氨酸、丝氨酸-谷氨酸、丝氨酸-丝氨酸、丝氨酸-苏氨酸、丝氨酸-亮氨酸、丝氨酸-缬氨酸、苏氨酸-脯氨酸、苏氨酸-天冬氨酸、苏氨酸-谷氨酸、苏氨酸-丝氨酸、苏氨酸-苏氨酸、苏氨酸-亮氨酸、苏氨酸-缬氨酸、缬氨酸-脯氨酸、缬氨酸-天冬氨酸、缬氨酸-谷氨酸、缬氨酸-丝氨酸、缬氨酸-苏氨酸、缬氨酸-亮氨酸、缬氨酸-缬氨酸、酪氨酸-脯氨酸、酪氨酸-天冬氨酸、酪氨酸-谷氨酸、酪氨酸-丝氨酸、酪氨酸-亮氨酸、酪氨酸-缬氨酸和酪氨酸-苏氨酸。
[0164]
已在本文中研究了将人、人源化或嵌合vh域的n-末端的前两个氨基酸修饰为丙氨酸-脯氨酸的影响。据发现这种组合对于促进信号肽切割效率是特别有利的。因此,当与和上游信号肽一起在细胞中表达的修饰的人、人源化或嵌合vh域一起使用时,本文所描述的本发明是特别有利的。在这方面,“上游”是指相对于修饰的vh域信号肽在多肽中的定位。换
言之,当作为整体观察多肽时,当与修饰的vh域的氨基酸序列相比更接近于多肽的n-末端时,所述信号肽位于修饰的vh域的上游。
[0165]
一些不同的信号肽是本领域那些技术人员已知的。如本文所使用的,术语“信号肽”是指确保进入分泌途径的前导序列。信号肽是位于分泌蛋白n-末端的相对短的肽,其指导蛋白进入内质网腔内以用于后续从细胞中排除。例如,在真核生物中,通过胞液中的信号识别颗粒(srp)识别含有位于新生蛋白n-末端的5-30个氨基酸的信号肽,而蛋白仍在核糖体上合成。然后,在内质网(er)膜中,srp将srp-核糖体-新生链(srp-rnc)复合物递送至srp-受体(sr)。然后,gtp-依赖性机制将rnc复合物递送至膜-结合易位子,其允许生长的多肽链易位至er腔内。在跨过er膜后,通过信号肽肽酶(spp)切掉信号肽。一些适合于在真核细胞中蛋白表达的信号肽是本领域那些技术人员已知的。免疫球蛋白重链和轻链的n-末端具有天然信号肽或前导序列(nucl.acids res.(2005),33,d256-d261)。其它信号肽序列在本领域中是熟知的,如nucleic acid research(1984)12,5145-5164中所列。膜蛋白和分泌蛋白的信号肽的实例包括在酵母中,在常规膜和分泌蛋白表达系统中使用的来源于酿酒酵母(saccharomyces cerevisiae)或酵母病毒的那些,其包括来源于α-因子、α-因子受体、前毒素原、suc2蛋白和pho5蛋白、bgl2蛋白和aga2蛋白的分泌信号肽。已提供了预测分泌信号肽序列的计算机程序。signalp(http://www.cbs.dtu.dk/services/signalp/)、psort(http://psort.nibb.ac.jp/)和phobius(http://phobius.cgb.ki.se/)。这些计算机程序的使用允许分泌信号的序列预测。
[0166]
可以用于真核细胞中vh域表达的信号肽的具体实例(其在以下实施例部分中使用)是mgwsciilflvlllaqpama(seq id no:4)。应注意这是非限制性实例,因为基于它们的常规特征,srp选择性结合信号肽,尽管它们在一级序列中具有可变性。因此,还可以在本文中使用其它适合的信号肽。
[0167]
在细菌中输送至胞质外环境的大部分蛋白使用所谓的sec途径进行靶向。当seca(仅在原核生物和原核来源的细胞器,如线粒体中发生的蛋白)识别新合成的前体蛋白上的信号肽时,起始该途径。
[0168]
可以用于原核细胞中vh域表达的信号肽的具体实例(其在以下实施例部分中使用)是mkyllptaaagllllaaqpama(seq id no:1)。应注意这是非限制性实例,因为基于它们的常规特征,seca选择性结合信号肽,尽管它们在一级序列中具有可变性。因此,还可以在本文中使用其它适合的信号肽。代表性信号序列包括来自pelb、ompa、phoa、木聚糖内切酶和stii的信号序列(appl.microbiol.biotechnol(2004)64:625-635)。
[0169]
应注意在以下实施例部分中使用的两个(非限制性)信号肽两者均具有位于信号肽c末端的序列aqpama(seq id no:5)(换言之,紧邻vh域n-末端上游的氨基酸序列是
…
aqpama(seq id no:5))。因此,在一个实例中,信号肽包含氨基酸序列aqpama(seq id no:5)。
[0170]
如上所述,信号肽切割效率基于信号肽切割位点处的信号肽序列以及vh的信号肽序列。因此,侧接信号肽切割位点的vh域和信号肽的残基可以影响信号肽酶处理并且有助于非典型切割位点。优选地,这些残基因此是aqpamaa(seq id no:6)或者aqpamaap(seq id no:7)(信号肽c末端的序列加粗,并且修饰的人、人源化或嵌合vh域的n末端氨基酸加下划线)。
[0171]
在另一个实例中,具体地对于原核宿主细胞中的表达,侧接信号肽切割位点的vh域和信号肽的氨基酸残基因此可以是mkyllptaaagllllaaqpamaa(seq id no:8)或者mkyllptaaagllllaaqpamaap(seq id no:9)(信号肽c末端序列加粗,并且修饰的人、人源化或嵌合vh域的n末端氨基酸加下划线)。
[0172]
在另一个实例中,具体地对于真核宿主细胞中的表达,侧接信号肽切割位点的vh域和信号肽的氨基酸残基因此可以是mgwsciilflvlllaqpamaa(seq id no:10)或者mgwsciilflvlllaqpamaap(seq id no:11)(信号肽c末端序列加粗,并且修饰的人、人源化或嵌合vh域的n末端氨基酸加下划线)。
[0173]
本文所描述的多肽包含修饰的vh域。所述多肽可以是包含本文所描述的修饰的vh域的任何蛋白。例如,它可以是包含本文所描述的修饰的vh域的抗体、抗体变体或抗体片段。
[0174]
抗体、抗体变体和抗体片段
[0175]“抗体”是属于免疫球蛋白类型蛋白的蛋白质分子,其含有结合抗原上的表位的一个或多个域,其中这些域来源于抗体的可变区或者与抗体的可变区共有序列同源性。抗体结合具有不同的质量,包括特异性和亲和性。特异性决定结合域特异性结合它的哪个抗原或表位。亲和性是结合至特定抗原或表位的强度的量度。在本文中方便地指出抗体的
‘
特异性’是指它对特定抗原的选择性,然而
‘
亲和性’是指抗体的抗原结合位点和它所结合的表位之间的相互作用强度。因此,如本文所使用的“结合特异性”是指各个抗体结合位点与抗原决定簇反应的能力。通常,本发明所述的抗体的结合位点位于fab部分中并且由重链和轻链的高变区构成。
[0176]
如本文所使用的,“抗体片段”是指包含抗体的功能性部分(在这种情况下,至少本文所描述的修饰的vh域)的蛋白质部分。抗体片段可以是任何结合试剂,其包括但不限于单链fv、单链或串联双链抗体vhh、fab、锚蛋白重复序列蛋白或dart、tcr-样抗体、样抗体、microproteins、或
[0177]“亲和性”是单个抗原结合位点及其抗原之间的相互作用强度。对于抗原,可以用平衡解离常数(kd),也称为亲合常数来表示本发明的抗体的单个抗原结合位点。通常,用于治疗应用的抗体可以具有微摩尔(10-6
m;低亲和性)至皮摩尔(10-12
m;高亲和性)范围的kd值的亲和性。
[0178]“抗原”是能够在宿主生物中引起免疫应答(以生产抗体)和/或被抗体靶向的分子。在分子水平,抗原的特征在于其能够被抗体的抗原结合位点结合。另外,可以将抗原的混合物认为是
‘
抗原’,即技术人员将理解有时可以将肿瘤细胞的裂解液或病毒颗粒表示为
‘
抗原’,然而存在具有多种抗原决定簇的这些肿瘤细胞裂解液或病毒颗粒制剂。抗原包含至少一种,但是通常更多表位。
[0179]“表位”或“抗原决定簇”是免疫球蛋白或抗体特异性结合的抗原上的位点。可以由邻接氨基酸或通过蛋白的三级折叠并置的非邻接氨基酸形成表位(分别为所谓的直链和构象表位)。通常在暴露于变性溶剂时保留由邻接、直链氨基酸所形成的表位,而通常在用变
性溶剂处理时失去通过三级折叠、构象所形成的表位。表位通常可以包括处于独特空间构象的3、4、5、6、7、8、9、10、11、12、13、14或15个氨基酸。
[0180]
术语“重链”或“免疫球蛋白重链”包括来自任何生物的免疫球蛋白重链恒定区序列,并且除非另作说明,包括重链可变域(vh)。除非另作说明,否则重链可变域包括3个重链cdr和4个骨架(fr)区。重链片段包括cdr和fr,及其组合。在可变域(从n末端至c末端)之后,典型的重链具有ch1域、铰链、ch2域和ch3域。重链的功能性片段包括能够特异性识别抗原并且包含至少一个cdr的片段。
[0181]
术语“轻链”包括来自任何生物的免疫球蛋白轻链可变域,或者v
l
(或其功能性片段);和免疫球蛋白恒定域,或者c
l
(或其功能性片段)序列。除非另作说明,否则术语轻链可以包括选自人κ、λ及其组合的轻链。除非另作说明,否则轻链可变(v
l
)域通常包括3个轻链cdr和4个fr区。一般地,全长轻链从n-末端至c-末端包括v
l
域和轻链恒定域,所述v
l
域包括fr1-cdr1-fr2-cdr2-fr3-cdr3-fr4。本发明可以使用的轻链包括例如不选择性结合所述重链选择性结合的表位的那些。
[0182]
适合在本发明的抗体中使用的轻链包括共有轻链(clc),如可以通过在现有抗体文库中对最常用的轻链的筛选所鉴别的那些(湿文库或在计算机中模拟),其中所述轻链基本上不干扰表位-重链结合域的亲和性和/或选择性,而且还适合于与一系列重链配对。例如,适合的轻链包括来自转基因动物的一种轻链,如其具有整合至其基因组中的共有轻链并且可以用于产生在重链具有多样性并且一旦暴露于抗原,则能够特异性结合所述抗原的大型共有轻链抗体组。
[0183]
术语“共有轻链”是指可以是相同的或者具有一些氨基酸序列差异,同时本发明的抗体的结合特异性不受影响,即所述差异不实质影响功能性结合区的形成的轻链。例如,在如本文所使用的共有链的定义的范围内,有可能例如通过引入和测试保守氨基酸变化、当与同源链配对时,在对结合特异性无贡献或仅有部分贡献的区域中的氨基酸变化来制备或发现不相同但仍功能等效的可变链。这些变体因此也能够结合不同的同源链并形成功能性抗原结合域。因此,如本文所使用的术语
‘
共有轻链’是指可以是相同的或者具有一些氨基酸序列差异,同时在与重链配对后保留所得抗体的结合特异性的轻链。特定共有轻链和这些功能等效变体的组合涵盖在术语“共有轻链”的范围内。对于共有轻链的使用和适合性的详细描述,参见wo 2004/009618、wo 2009/157771和wo 2020/141973。
[0184]“fab”表示包含可变区的结合域,通常包含成对的重链可变域和轻链可变域的结合域。fab可以包含恒定区的域,包括与轻链恒定域(cl)和vl域配对的ch1和vh域。例如,可以作为共价键通过ch1和cl域处的二硫桥键发生这种配对。
[0185]“单-链可变片段”(scfv)表示包含通过接头,例如肽接头,例如约10至约25个氨基酸长的肽接头连接的vh域和vl域的结合域。在本文中,术语“连接的”是指通过它们的一级氨基酸序列彼此连接的域。例如,可以通过接头将基础抗体部分连接至其它结合域(或者将其它结合域连接至其它结合域)。类似地,可以将ch1域连接至重链可变区并且可以将cl域连接至轻链可变区。“配对”则表示本发明的多肽之间的相互作用,从而可以使它们多聚化。例如,其它结合域可以包含与轻链区(cl-vl)配对的重链区(ch1-vh),其中通常通过二硫键的形成使(重链区的)ch1和(轻链区的)cl配对。抗体链或多肽的域,如混合的结合域还可以通过共价或非共价相互作用,例如,通过范德华力、氢键、水-介导的氢键、盐桥或其它静电
力、芳族侧链之间的相互吸引、二硫键的形成或者本领域技术人员已知的其它作用力进一步相互作用和配对以形成界面。
[0186]
当表示核酸或氨基酸序列时,在本文中将“同一性百分比(%)”定义为在出于最优比较目的进行序列比对后,与所选序列中的残基相同的候选序列中的残基的百分比。使用vector nti program advance 11.5.2软件的alignx应用,使用缺省设置,确定了比较核酸的序列同一性百分比,该应用使用了改良的clustalw算法(thompson,j.d.,higgins,d.g.和gibson t.j.(1994)nuc.acid res.22:4673-4680)、swgapdnamt得分矩阵、15分的空位开放罚分和6.66分的空位延伸罚分。使用vector nti program advance 11.5.2软件的alignx应用,使用缺省设置比对氨基酸序列,该应用使用了改良的clustalw算法(thompson,j.d.,higgins,d.g.,和gibson t.j.1994)、blosum62mt2得分矩阵、10分的空位开放罚分和0.1分的空位延伸罚分。
[0187]“多个”表示两个或更多个。
[0188]
如本文所描述的抗体的“变体”可以包括抗体的功能性部分、功能性衍生物、衍生物和/或类似物。这包括抗体模拟物、单体和适体。变体通常维持抗体的结合特异性,例如双重特异性抗体的特异性。如本文所描述的抗体的功能性衍生物是包含通过连接区所连接的结合一个靶标的可变域和结合第二靶标的可变域的蛋白。所述可变域可以是照此的可变域,或者fab片段或可变域样分子,如包含通过接头连接在一起的vh和vl的单链fv(scfv)片段。可变域样分子的其它实例是所谓的单域抗体片段。单-域抗体片段(sdab)是具有单一单体抗体可变区的抗体片段。像完整抗体一样,它能够选择性结合至特异性抗原。通过仅12-15kda的分子量,单-域抗体片段比由两条蛋白重链和两条轻链组成的一般抗体(150-160kda)小得多,并且甚至比fab片段(~50kda,一条轻链和半条重链)和单-链可变片段(~25kda,两个可变区,一个来自轻链并且一个来自重链)也小得多。单域抗体本身不比正常抗体(通常90-100kda)小得多。单-域抗体片段大部分从骆驼科动物中存在的重链抗体工程化得到;这些被称为vhh片段一些鱼类也具有仅有重链的抗体(ignar,
‘
免疫球蛋白新型抗原受体’),从中可以获得被称为vnar片段的单-域抗体片段。替代方法是将来自人或小鼠的常规免疫球蛋白g(igg)的二聚化可变域分成单体。尽管有关单-域抗体的大部分研究目前基于重链可变域,但是来源于轻链的纳米抗体也已显示特异性结合至靶标表位。可变域-样分子的其它非限制性实例是vhh,人域抗体(dabs)和迷你抗体(unibodies)。优选的功能性部分是包含含有重链可变区和轻链可变区的可变域的部分。这些可变域的非限制性实例是f(ab)-片段和单链fv片段。可变域(-样)连接的双重特异性形式是例如结合至两个不同的scfv的人血清白蛋白(hsa);包含通过二聚化基序或自结合二级结构,如螺旋束或卷曲螺旋结合在一起以使得scfv片段二聚化的两个不同的scfv的双重特异性微型抗体(morrison(2007)nat.biotechnol.25:1233-34)。适合于将scfv偶联至接头的hsa接头和方法的实例描述于wo2009/126920。
[0189]
功能性衍生物可以是抗体模拟物、多肽、适体或其组合。这些蛋白或适体通常结合至一个靶标。本发明所述的蛋白结合至两个或更多个靶标。应理解可以通过本领域中已知的方法将这些抗体、抗体模拟物、多肽和适体的任意组合连接在一起。例如,在一些实施方式中,本发明的结合分子是缀合物或融合蛋白。抗体模拟物是像抗体一样可以特异性结合抗原,但是在结构上与抗体无关的多肽。抗体模拟物通常是摩尔质量为约3至20kda的人工
肽或蛋白。优于抗体的一般优势在于更好的溶解度、组织渗透性、对热和酶的稳定性以及相对低的生产成本。抗体模拟物的非限制性实例是亲和体(affibody)分子(通常基于蛋白a的z域)、人泛素(affilins)(通常基于γ-b晶体或泛素);粘合素(通常基于胱抑素);亲和素(affitins)(通常基于来自嗜酸热硫化叶菌(sulfolobus acidocaldarius)的sac7d);阿尔法体(通常基于三股螺旋卷曲螺旋);抗运载蛋白(通常基于脂质运载蛋白);高亲和性多聚体(avimer)(通常基于多种膜受体的a域);darpin(通常基于锚蛋白重复序列基序);菲诺体(fynomers)(通常基于fyn 7的sh3域);kunitz结构域肽(通常基于多种蛋白酶抑制剂的kunitz域);和单体(通常基于纤连蛋白的iii型域)。
[0190]
单体是使用纤连蛋白iii型域(fn3)作为分子骨架构建的合成结合蛋白。单体是产生靶标结合蛋白的简单且稳健的抗体的替代。术语“单体”是koide小组于1998年创造的,该小组发表了第一篇使用人纤连蛋白的第十fn3域证实单体概念的论文。单体及其它抗体模拟物通常产生自组合文库,其中使用分子展示和定向进化技术,如噬菌体展示、mrna展示和酵母表面显示使所述骨架部分多样化。大量抗体模拟物对它们各自的靶标具有高亲和性和高特异性。适体是结合至特定靶标分子的寡核苷酸或肽分子。通常通过从大型随机序列池选择它们来产生适体,但是天然适体也存在于核糖开关中。适体可以作为大分子用于基础研究和临床目的。“非键合相互作用”在不通过共价键连接的原子之间起作用。因此,这些是不包括电子共有,而是包括分子之间或分子内电磁相互作用的更分散的变化的键。非键合相互作用包括静电相互作用,如氢键作用、离子相互作用和卤素键合。范德华力是包括永久偶极子或感生偶极子(或多极子)的静电相互作用的亚组。这些包括下列:永久偶极子-偶极子相互作用、偶极子-感生偶极子相互作用和感生偶极子-感生偶极子相互作用。盐桥是两种非共价相互作用:氢键和离子键的组合。疏水相互作用是由于更强的水:水相互作用而迫使在一起的非极性(非电离)烃分子的相互作用。
[0191]
核酸和载体
[0192]
本发明还提供了编码本发明的多肽、抗体、抗体变体或抗体片段的核酸。
[0193]
本文所描述的核酸可以用于生产本发明的多肽、抗体、抗体变体或抗体片段。因此,还提供了包含这些核酸的载体(例如,表达载体),其可以用于生产本发明的多肽、抗体、抗体变体或抗体片段。
[0194]
通常,通过包含编码一起组装以形成抗体的多肽的核酸的细胞来生产抗体。可以将用于制备抗体的多肽的核酸置于任何适合的表达载体中,并且在适合的情况下,可以将两种或更多种载体置于单一宿主细胞中。一般地,可以将编码修饰的vh域的核酸与适合的接头和/或恒定区一起克隆,并且可以将所述序列在适合于表达的细胞系中在适合的表达构建体中置于与启动子可操作地连接。
[0195]
其中可以例如通过克隆或合成引入编码修饰的vh域的核酸的载体dna优选地包含编码vh域的信号肽和第一或前两个氨基酸的核酸。照此,可以将载体dna用作用于如本文所描述的修饰的抗体或重链的生产的标准载体,借此省略对于必须改变每个单个vh域的第一或前两个氨基酸的需要。因此,这种载体dna不包含编码修饰的vh域的核酸。本领域技术人员知道如何将编码修饰的vh域的核酸引入该载体dna,从而产生功能性抗体或重链,例如,通过省略编码核酸的第一或前两个氨基酸的密码子,所述核酸编码已存在于载体dna中的修饰的vh域。
[0196]
载体可以是任何适合的载体,例如,噬粒(用于噬菌体中的表达)或者质粒(用于细菌或真核细胞中的表达)。
[0197]
噬粒是dna基克隆载体,其具有噬菌体和质粒两者的性质。噬粒具有质粒复制起点和来源于噬菌体的复制起点。噬粒可以与丝状噬菌体m13组合用作一类克隆载体,并且可以包装到噬菌体衣壳中。噬粒在多种生物技术应用中使用;例如,它们可以用于噬菌体展示(在本文其它处提供了其详细信息)。一些不同的噬粒是可商购的并且可以在本发明的背景中使用。
[0198]
本发明还提供了包含本发明的核酸或载体的噬菌体。这种噬菌体可以是文库的一部分,例如,噬菌体展示文库。
[0199]
质粒也是熟知的。可以构建用于免疫球蛋白重链和轻链基因的细菌或哺乳动物表达的质粒,如在本文其它地方所描述的,通过聚合酶链反应(pcr)生产(和修饰)其可变区。一些不同的质粒是可商购的并且可以在本发明的背景中使用。
[0200]
筛选、宿主细胞和生产本发明的多肽的方法
[0201]
本发明还提供了制备包含本文其它处所述的修饰的vh域的多肽的方法。可以通过用抗原免疫非人动物,优选地转基因非人动物来提供编码vh域的vh核酸,借此产生对于抗原特异的vh域并且导致产生这些vh域的b细胞的克隆扩增。然后,可以分离编码vh域的核酸用于cdna合成并且在本文所述的方法中使用所述核酸。
[0202]
在一种方法中,这种cdna可以用于产生噬菌体展示文库以筛选显示出所期望的结合性质的vh域。在选择后,可以将所期望的vh核酸转染到宿主细胞中用于抗体生产。
[0203]
在另一种方法中,在频率分析中使用cdna,其中对编码重链可变区的cdna进行高通量测序,并且选择cdna用于转染至宿主细胞中以用于抗体生产,包括基于所使用的可变区基因节段的频率、总可变区序列、hcdr3或技术人员所期望的其它特征。
[0204]
可以如本领域中已知的并且如本文进一步描述的实施向宿主细胞的转染。例如,如本文所描述的任何载体可以用于转染。还考虑宿主细胞包含整合到其基因组中的编码修饰的vh域的核酸,所述核酸包含编码优选地第一和第二氨基酸位置的变体,并且还可以包含其它下游变化。
[0205]
其它方法包括:提供包含编码能够组装到本发明的抗体中的多肽的一个或多个核酸的细胞;并且在提供用于多肽表达和用于它们向抗体组装的条件下培养所述细胞。
[0206]
编码本文所描述的修饰的vh域的核酸分子可以作为染色体外拷贝存在和/或可以稳定整合到宿主细胞的染色体中。在可以靶向已知缺少基因沉默的基因座的情况下,后者是优选的。
[0207]
为了获得编码包含ch3域的多肽的核酸的表达,本领域技术人员熟知能够驱动这种表达的序列可以功能上连接至编码包含ch3域的多肽的核酸。功能上连接的表示描述编码包含ch3域的多肽或其前体的核酸与能够驱动表达,从而这些序列可以驱动包含ch3域的多肽或其前体的表达的序列连接。有用的表达载体在本领域中可用,例如,invitrogen的pcdna载体系列。当编码目标多肽的序列相对于控制所编码的多肽的转录和翻译的序列正确整合时,所产生的表达盒对于产生目标多肽,称为表达有用。驱动表达的序列可以包括启动子、增强子等,及其组合。这些应能够在宿主细胞中起作用,借此驱动功能上与它们连接的核酸的表达。启动子可以是组成型的或可以被调控,并且可以得自多种来源,包括病毒、
原核或真核来源或者是人工设计的。目标核酸的表达可以来自天然启动子或其衍生物或者来自完全异源的启动子。用于在真核细胞中表达的一些熟知且常用的启动子包括来源于病毒,如腺病毒的启动子,例如,e1a启动子、来源于巨细胞病毒(cmv)的启动子,如cmv即早(ie)启动子、来源于猿猴病毒40(sv40)的启动子等。适合的启动子还可以来源于真核细胞,如金属硫蛋白(mt)启动子、延伸因子1α(ef-1α)启动子、肌动蛋白启动子、免疫球蛋白启动子、热冲击启动子等。能够驱动目标序列在宿主细胞中表达的任何启动子或增强子/启动子在本发明中是适合的。在一个实施方式中,能够驱动表达的序列包含来自cmv启动子的区域,优选地包含cmv即早基因增强子/启动子的核苷酸-735至+95的区域。技术人员将知道在本发明中使用的表达序列可以适当地与可以稳定或提高表达的元件,如绝缘子、基质附着区、star元件(wo 03/004704)等组合。这可以提高表达稳定性和/或水平。
[0208]
重组宿主细胞的蛋白质生产已广泛描述于,例如,current protocols in protein science,1995,coligan je,dunn bm,ploegh hl,speicher dw,wingfield pt,isbn 0-471-11184-8;bendig,1988。进行细胞培育以使其能够代谢,和/或生长,和/或分化,和/或生产目标重组蛋白。这可以通过本领域技术人员熟知的方法完成,并且所述方法包括但不限于为细胞提供营养物。所述方法包括贴壁生长、悬浮生长或其组合。可以通过本领域中熟知的方法优化一些培养条件以优化蛋白质生产得率。可以在例如培养皿、滚瓶或生物反应器中,使用分批、补料分批、连续系统、中空纤维等进行培养。为了通过细胞培养实现重组蛋白的大规模(连续)生产,使用能够悬浮生长的细胞,并且细胞能够在不存在动物-或人-来源的血清或者动物-或人-来源的血清组分的情况下培养。因此,由于不存在来源于培养基的其它动物或人蛋白,因此纯化更容易并且安全性得到提高,同时所述系统也是非常可靠的,因为合成培养基的可重复性最好。
[0209]
在宿主细胞中表达免疫球蛋白-样多肽,并且通过本领域技术人员常规已知的方法,从细胞收获,或者优选地,从细胞培养基收获。在收获后,可以通过使用本领域中已知的方法纯化这些ig-样多肽。这些方法可以包括沉淀、离心、过滤、尺寸-排阻色谱、亲合色谱、阳离子-和/或阴离子交换色谱、疏水相互作用色谱等。对于包含igg多肽的抗体混合物,可以适当地使用蛋白a或蛋白g亲合色谱(参见例如,美国专利4,801,687和5,151,504)。
[0210]
在使用亲合色谱捕获后,使用正交精制(orthogonal polishing)步骤除去任何残留的方法-相关和/或产物-相关杂质,其可以包括同型二聚体、电荷变体、宿主细胞蛋白(hcp)和宿主细胞dna。通常,为了获得纯化的双重特异性抗体或多价多聚体,实施以下步骤,包括宿主细胞培养、收获澄清、随后是蛋白捕获、阴离子交换色谱法,包括除去宿主细胞dna,然后将阳离子交换色谱(ciex)用于除去宿主细胞蛋白,沥滤蛋白a、可能的聚集体和可能的产物相关杂质,随后是额外的步骤,如纳滤作为最终的病毒去除方法步骤。本领域技术人员意识到可以改变这些步骤的顺序或者替换单一步骤。例如,第二精制步骤的替代包括疏水相互作用色谱和混合-模式色谱。
[0211]
通过根据本发明的方法生产的免疫球蛋白-样多肽和/或其混合物优选地具有共有轻链。因此,还提供了根据本发明的方法,其还包括向所述宿主细胞提供编码共有轻链的核酸。这是能够与至少两种不同的重链配对的轻链,借此形成功能性抗原结合域。功能性抗原结合域能够特异性结合至抗原。在一个实施方式中,使用能够与通过根据本发明的方法生产的所有种类配对的共有轻链,借此形成功能性抗原结合域,从而避免不匹配的重链和
轻链的错配。在一个方面,仅使用具有一个相同氨基酸序列的共有轻链。作为另外一种选择,本领域技术人员将认识到“共有”还表示氨基酸序列不相同的轻链的功能等价物。存在所述轻链的多种变体,其中存在不会实质影响功能性结合区形成的突变(缺失、替换、添加)。这些变体因此也能够结合不同的重链并形成功能性抗原结合域。因此,如本文所使用的术语“共有轻链”是指可以是相同的或者具有一些氨基酸序列差异,同时在与重链配对后保留所得抗体的结合特异性的轻链。例如,有可能例如通过引入和测试保守氨基酸变化和/或当与重链配对时,在对结合特异性无贡献或仅有部分贡献的区域中的氨基酸变化来制备或发现不相同但仍功能等效的轻链。特定共有轻链和这些功能等效变体的组合涵盖在术语“共有轻链”的范围内。有关共有轻链的使用的详细描述,参考wo2004/009618。优选地,在本发明中使用共有轻链,所述轻链是种系-样轻链,更优选地,还可以使用种系轻链,优选地重排种系人κ轻链,最优选地重排种系人κ轻链igvκ1-39/jκ、igvκ3-15/jκ或者igvκ3-20/jκ、重排种系人λ轻链。优选的重排种系人λ轻链包含igvl3-21/jl。
[0212]
作为另外一种选择,作为使用共有链和避免不相配的重链和轻链的错配的替代,技术人员可以选择通过本领域的常规技术人员已知的方式,迫使重链和轻链配对的方式。
[0213]
本文还提供了表达本发明的多肽的宿主细胞。根据本发明的“宿主细胞”可以是能够表达重组dna分子的任何宿主细胞,其包括细菌,诸如,例如埃希氏菌属(escherichia)(例如,大肠杆菌(e.coli))、肠杆菌属(enterobacter)、沙门氏菌属(salmonella)、芽孢杆菌属(bacillus)、假单胞菌属(pseudomonas)、链霉菌属(streptomyces)、酵母如酿酒酵母(s.cerevisiae)、乳酸克鲁维酵母(k.lactis)、巴斯德毕赤酵母(p.pastoris)、假丝酵母属(candida)或亚罗酵母属(yarrowia)、丝状真菌如脉孢菌属(neurospora)、米曲霉(aspergillus oryzae)、构巢曲霉(aspergillus nidulans)和黑曲霉(aspergillus niger)、昆虫细胞如草地贪夜蛾(spodoptera frugiperda)sf-9或sf-21细胞,并且优选地哺乳动物细胞如中国仓鼠卵巢(cho)细胞、bhk细胞、小鼠细胞包括sp2/0细胞和ns-0骨髓瘤细胞、灵长类动物细胞如cos和vero细胞、mdck细胞、brl 3a细胞、杂交瘤、肿瘤-细胞、永生原代细胞、人细胞如w138、hepg2、hela、hek293、ht1080或胚胎视网膜细胞如per.c6等。通常,所选的表达系统将包括哺乳动物细胞表达载体和宿主,从而所述抗体可以是适当糖基化的。人细胞系可以用于获得具有完全人糖基化模式的抗体。用于生长或增殖细胞的条件(参见,例如,tissue culture,academic press,kruse和paterson主编(1973))和用于重组产物表达的条件可以稍微不同,并且根据本领域技术人员一般已知的方法,通常实施所述方法优化以相对于彼此提高产物比例和/或细胞生长。通常,对于最大化哺乳动物细胞培养的生产能力的原理、规程和实用技术可见于mammalian cell biotechnology:a practical approach(m.butler主编,irl press,1991)。本领域已广泛描述了重组宿主细胞中抗体的表达。编码轻链和重链的核酸可以作为染色体外拷贝存在和/或可以稳定整合到宿主细胞的染色体中。
[0214]
文库
[0215]
本发明提供了本发明的不同的核酸、载体或噬菌体的文库(即集合)。所述文库可以包括至少约106个不同的本发明的核酸、载体或噬菌体。
[0216]
根据本发明的文库的实例是展示文库。制备展示文库的方法在本领域中是熟知的。例如,用于展示本发明的多种修饰的vh域的展示文库的制备方法可以包括将本发明的
核酸(例如,以本文其它处所述的载体形式)整合到生物中,如噬菌体或酵母,或者用于肽展示的其它载体中,其中所述生物在所述生物或载体的表面上表达和展示所述修饰的vh域。可以通过使用噬菌体展示文库在多个生物,如噬菌体(每个噬菌体展示一个修饰的vh域)的表面上展示多个修饰的vh域,通常多个不同的修饰的vh域。因此,在展示文库中,通过本发明的核酸所编码的多种修饰的vh域可以与人共有链可变区配对。所述展示文库可以是例如fab噬菌体展示文库。
[0217]
展示文库技术
[0218]
用于本文所描述的修饰的vh域的展示技术的多种形式,包括噬菌体展示、酵母展示、核糖体展示、mrna展示等在本领域中是已知的并且涵盖在本文所描述的本发明内。以下讨论集中在噬菌体展示上,但是这种描述不是限制性的并且基于本文所提供的描述,其可以容易地应用于其它形式的展示技术。噬菌体展示是所使用的重要技术,其包括使用作为感染细菌的病毒的噬菌体,用于蛋白-蛋白、蛋白-肽和蛋白-dna相互作用的研究。本文所描述的多种规程是构建噬菌体展示文库和淘选与目标抗原结合的噬菌体的标准规程并且描述于antibody phage display:methods and protocols(主编:philippa m.o’brien,robert aitken)。可以根据本领域中已知的程序,例如,如kramer等人2003(kramer等人2003.nucleic acids res.31(11):e59)所述,使用vcsm13(stratagene)作为辅助噬菌体株生长和收获文库。可以根据本领域中已知的程序,例如,如kramer等人2003(kramer等人2003.nucleic acids res.31(11):e59)所述,使用vcsm13作为辅助噬菌体株生长和处理噬菌体。
[0219]
在示例性技术中,将编码目标蛋白的核酸,例如编码修饰的vh域的核酸整合到噬菌体外壳蛋白基因中,从而导致噬菌体在其外部“展示”蛋白,同时在其内部包含编码所述蛋白的核酸。以这种方式,在基因型和表型之间建立联系。对于抗体发现,在噬菌体展示中,可以在丝状噬菌体颗粒的表面上表达vh和/或vl域的大型集合(文库),从而它们配对以形成结合域。根据这些文库,可以通过与抗原的结合相互作用和展示的结合域选择噬菌体。因此,可以对其它蛋白、肽或dna序列或者其它形式的靶标部分筛选展示噬菌体,以检测所展示的vh、vl或结合域以及那些其它部分之间的相互作用。以这种方式,可以在称为体外选择的过程中筛选和扩增vh、vl或结合域的大型文库,该过程类似于自然选择。因此,可以在噬菌体上展示本发明的修饰的vh域。
[0220]
本文所描述的本发明提供了从免疫动物,包括转基因动物获得基本上所有编码重链可变区的核酸并且将编码修饰的重链可变区的核酸整合到展示技术(例如,噬菌体、酵母、核糖体等)中的有效的组装线过程(assembly-line process),其中所述核酸中的每一个在所述修饰的重链可变区的n-末端编码非谷氨酸和非谷氨酰胺氨基酸残基,借此允许测试基本所有来自缺少这种残基的免疫动物的重链可变区,而不考虑人可变区基因节段或者在所述动物中所述可变区所来源的部分。
[0221]
作为另外一种选择,本发明提供了产生包含n末端修饰的重链可变区的结合分子的限定群体的方法,从而获得了表达有限vl组库,优选地单一或共有轻链并且表达对目标抗原特异的多种重链可变区的b细胞群体。可以在用目标抗原使具有人免疫球蛋白基因座的转基因动物免疫后获得所述b细胞。对来自所述b细胞的核酸(rna或dna)测序,其编码部分并且优选地基本所有所述重链可变区。优选地,扩增所述样品中编码免疫球蛋白重链可
变区的所述核酸,并对其进行频率分析,其中分析了所述群体对v基因节段的使用,分析了vh序列,hcdr3以及技术人员目标组库的其它质量。
[0222]
然后,选择来自该频率分析的所述重链可变区并以本文所描述的方式将其提供给宿主细胞以生产包含至少一种vh序列的可变区的第一或者第一和第二编码氨基酸的变化,优选地将两个或更多个与所述有限vl组库或共有轻链的至少一种vl序列一起进一步提供至所述宿主细胞。此后,培养所述宿主细胞以使得修饰的vh和vl多肽表达,其中将一个修饰的vh与一个vl提供至所述宿主细胞以生产单特异性抗体,并且其中将两个或更多个修饰的vh序列与一个vl提供至所述宿主细胞以生产多重特异性抗体。
[0223]
同时扩增并修饰核酸的方法
[0224]
本文还提供了同时扩增和修饰编码人免疫球蛋白重链可变域的核酸的方法。由于将靶标模板的扩增与模板序列的修饰在单一步骤中组合,从而使得所述扩增的核酸编码本发明的新型多肽(即包含如在本文其它地方所描述的修饰的人vh域的多肽),所述方法是特别有用的。
[0225]
本文所描述的方法包括提供编码人免疫球蛋白重链可变域(在本文中也称为人vh域)的核酸的步骤。在本文中还可以将提供用于在所述方法中使用的核酸称为模板序列,它是要扩增和修饰的序列。
[0226]
模板核酸可以得自任何适合的来源。通常,所述模板核酸可以是cdna,例如,已通过rna样品的逆转录产生的cdna。所述rna样品可以是得自表达包含人免疫球蛋白重链可变域的多肽的细胞的总rna或mrna。
[0227]
本文所描述的任何宿主细胞可以用于获得模板核酸(例如,对应于通过编码人免疫球蛋白重链可变域的细胞所产生的rna序列的cdna序列)。在特别有利的实例中,所述模板核酸得自包含人免疫球蛋白可变区基因节段的人细胞或转基因动物细胞。在另一个实例中,所述转基因动物包含人免疫球蛋白重链基因座或其部分(例如,人免疫球蛋白重链微小基因座)。
[0228]
可以使用任何适合的包含人可变区基因节段的转基因动物,例如,转基因绵羊、兔、大鼠、小鼠、鸟,包括鸡等,其形成了在重链可变域的n-末端包含谷氨酸或谷氨酰胺的人、人源化或嵌合抗体或重链。
[0229]
先前已描述了具有人可变区基因节段的转基因动物。可以在本文所描述的方法中使用这些转基因动物。适用于在本文所描述的发明中使用的转基因动物具有编码包含重排可变轻链和重链的人共有免疫球蛋白链和编码如wo2009/157771中所述的这些动物的种系中的同源链的非重排可变区的核酸。这些转基因动物能够产生具有通过免疫球蛋白的两条同源链,例如,未重排的重链或轻链之一所产生的多样性的抗体,其在b细胞发育以及抗原暴露后的亲合力成熟期间经历了体细胞重组。这些转基因动物,如能够产生抗一系列抗原的抗体的多种组库。
[0230]
可以用目标抗原或表位使人转基因动物免疫。适合的免疫规程通常是导致b细胞选择性扩增的规程,其表示设计初次免疫和加强免疫以引起产生结合至目标抗原或表位的抗体的b细胞的选择性扩增。所述免疫规程可以例如在初次免疫和每次后续加强免疫期间使用不同的抗原形式或片段。例如,所述抗原可以在细胞膜、脂肪颗粒、胶束、重组蛋白、融合至另一蛋白的重组蛋白、蛋白域或蛋白的肽上表达。所述免疫规程可以包括在初次和/或
末端的修饰,则适合引物的设计是可能的。
[0239]
在本发明所述的方法中使用的至少一种5’引物可以包括在所编码的模板核酸的vh域中引入修饰,从而在所述扩增的核酸中所述编码的人、人源化或嵌合vh域的n末端残基谷氨酰胺或谷氨酸被酸性或极性残基,如天冬氨酸或天冬酰胺替换的序列。这些氨基酸具有与谷氨酰胺或谷氨酸类似的生物化学性质并因此可以是有用的选择。
[0240]
在具体的实例中,在本发明所述的方法中使用的至少一种5’引物可以包括在所编码的模板核酸的vh域中引入修饰,从而在所述扩增的核酸中所编码的人、人源化或嵌合vh域的n末端残基谷氨酰胺或谷氨酸被丙氨酸替换的序列。这种修饰是特别有用的,因为它消除了焦谷氨酸形成并且还维持(例如,改善)了信号肽切割效率。
[0241]
丙氨酸是脂族残基。因此,在另一个实例中,在本发明所述的方法中使用的至少一种5’引物可以包括在所编码的模板核酸的vh域中引入修饰,从而在所述扩增的核酸中所编码的人、人源化或嵌合vh域的n末端残基谷氨酰胺或谷氨酸被脂族残基,如丙氨酸、甘氨酸、丙氨酸、缬氨酸、亮氨酸或异亮氨酸替换的序列。
[0242]
在本发明所述的方法中使用的至少一种5’引物可以包括在所编码的模板核酸的vh域中引入两个修饰,从而在所述扩增的核酸中所编码的人、人源化或嵌合vh域的n末端序列被选自下列的(第一)n末端氨基酸:丙氨酸、精氨酸、天冬酰胺、天冬氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸和缬氨酸;和选自下列的(第二)氨基酸(如根据vh域的n-末端所计算的):脯氨酸、缬氨酸、天冬氨酸、谷氨酸、丝氨酸、亮氨酸或苏氨酸替换的序列。在一个具体实例中,将所述vh域的n-末端的第二氨基酸选择为脯氨酸。
[0243]
在一个具体实例中,在本发明所述的方法中使用的至少一种5’引物可以包括在所编码的模板核酸的vh域中引入两个修饰,从而在所述扩增的核酸中所编码的人、人源化或嵌合vh域的n末端序列被丙氨酸-脯氨酸、丙氨酸-天冬氨酸、丙氨酸-谷氨酸、丙氨酸-苏氨酸、丙氨酸-缬氨酸、丙氨酸-丝氨酸和丙氨酸-亮氨酸替换的序列。如本文所使用的,用于“丙氨酸-脯氨酸”等的形式是指修饰的人vh域的n末端的两个相邻的氨基酸(即vh域的n-末端的“第一-第二”氨基酸(以n末端至c末端方向))。
[0244]
在优选实例中,在本发明所述的方法中使用的至少一种5’引物包括在所编码的模板核酸的人、人源化或嵌合vh域中引入两个修饰,从而在所述扩增的核酸中所编码的人、人源化或嵌合vh域的n末端的前两个氨基酸是丙氨酸-脯氨酸的序列。据发现这种组合对于促进信号肽切割效率是特别有利的。
[0245]
在本发明所述的方法中使用的至少一种5’引物可以包括编码信号肽或信号肽部分,从而在所述扩增(和修饰)的核酸中,在所编码的修饰的人、人源化或嵌合vh域上游编码信号肽的序列。在本文其它处详细描述了在所编码的多肽中信号肽和所述修饰的vh域的n-末端之间的空间关系并且其在本文中同样适用。
[0246]
在本发明所述的方法中使用的至少一种5’引物因此可以包括编码包含修饰位点上游的序列
……
aqpama(seq id no:5)的信号肽或信号肽部分的序列(即从而在所编码的多肽中,信号肽的序列
…
aqpama(seq id no:5)与修饰的vh域的修饰的n-末端直接相邻(并且位于其上游))。例如,所述至少一种5’引物可以包括在通过所扩增的核酸编码的修饰的vh域的n-末端引入丙氨酸(或丙氨酸-脯氨酸组合)并且在所编码的修饰的vh域的上游引入
信号肽,从而在所修饰的vh域中侧接信号肽切割位点的残基包含aqpamaa(seq id no:6)或aqpamaap(seq id no:7)的序列(其中信号肽的c末端的序列加粗,并且vh域的n末端氨基酸加下划线)。
[0247]
在另一个实例中,在本发明所述的方法中使用的至少一种5’引物可以包括编码包含修饰位点上游的序列
……
aqpama(seq id no:5)的信号肽或信号肽部分的序列(即从而在所编码的多肽中,信号肽的序列
…
aqpama(seq id no:5)与修饰的vh域的修饰的n-末端直接相邻(并且位于其上游))。例如,所述至少一种5’引物可以包括在通过所扩增的核酸编码的修饰的vh域的n-末端引入丙氨酸(或丙氨酸-脯氨酸组合)并且在所编码的修饰的vh域的上游引入信号肽,从而在所修饰的人、人源化或嵌合vh域中侧接信号肽切割位点的残基包含mkyllptaaagllllaaqpamaa(seq id no:8)或mkyllptaaagllllaaqpamaap(seq id no:9)的序列(其中信号肽的c末端的序列加粗,并且vh域的n末端氨基酸加下划线)。
[0248]
在另一个实例中,在本发明所述的方法中使用的至少一种5’引物可以包括编码包含修饰位点上游的序列
……
aqpama(seq id no:5)的信号肽或信号肽部分的序列(即从而在所编码的多肽中,信号肽的序列
…
aqpama(seq id no:5)与修饰的vh域的修饰的n-末端直接相邻(并且位于其上游))。例如,所述至少一种5’引物可以包括在通过所扩增的核酸编码的修饰的vh域的n-末端引入丙氨酸(或丙氨酸-脯氨酸组合)并且在所编码的修饰的vh域的上游引入信号肽,从而在所修饰的人、人源化或嵌合vh域中侧接信号肽切割位点的残基包含mgwsciilflvlllaqpamaa(seq id no:10)或mgwsciilflvlllaqpamaap(seq id no:11)的序列(其中信号肽的c末端的序列加粗,并且vh域的n末端氨基酸加下划线)。
[0249]
下表中提供了修饰人、人源化或嵌合vh域的n-末端的前两个密码子(以编码丙氨酸-脯氨酸)并且在直接紧邻所编码的修饰的vh域并且位于其上游的位置引入信号肽的适合的5’引物序列的实例。如根据表将看出的,将举例说明的5’引物设计用于从每个基因家族扩增每个功能性人ighv基因节段。这基于引物中修饰位点之后的序列,其与在所列的人vh基因节段中的这些位置所发现的未修饰的核酸(至少部分)互补。
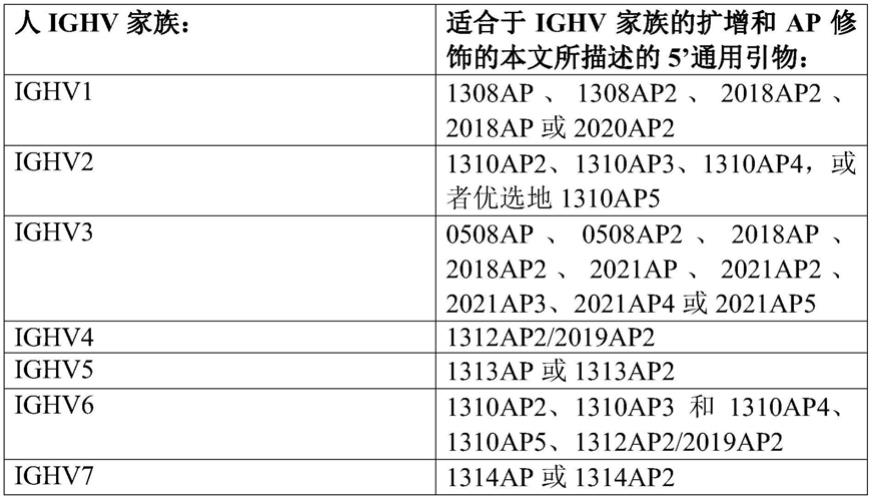
[0250][0251]
表1:5’通用引物和它们的靶标人ighv家族的列表。
[0252]
本文所描述的方法因此可以包括:
[0253]
(a)使用选自1308ap、1308ap2、2018ap、2018ap2或2020ap2的5’引物,扩增并修饰ighv1家族基因所编码的核酸;和/或
[0254]
(b)使用选自1310ap2、1310ap3、1310ap4或1310ap5的5’引物,扩增并修饰ighv2家族基因所编码的核酸;和/或
[0255]
(c)使用选自0508ap、0508ap2、2018ap、2018ap2、2021ap2、2021ap、2021ap3、2021ap4或2021ap5的5’引物扩增并修饰ighv3家族基因所编码的核酸;和/或
[0256]
(d)使用选自1312ap2作为5’引物,扩增并修饰ighv4家族基因所编码的核酸;和/或
[0257]
(e)使用选自1313ap或1313ap2的5’引物,扩增并修饰ighv5家族基因所编码的核酸;
[0258]
(f)使用选自1310ap2、1310ap3、1310ap4、1310ap5或1312ap2的5’引物,扩增并修饰ighv6家族基因所编码的核酸;和/或
[0259]
(g)使用选自1314ap或1314ap2的5’引物,扩增并修饰ighv7家族基因所编码的核酸。
[0260]
在本文中注意到引物1312ap2和2019ap2具有相同的序列,因此这些术语可以互换使用。在本文中,这也通过使用术语“1312ap2/2019ap2”表示。
[0261]
如以下实施例部分中所示,可以优选地使用本文所公开的某些5’引物。
[0262]
例如,当扩增和修饰来自ighv1基因家族的基因节段所编码的核酸时,可以使用选自1308ap、1308ap2、2018ap、2018ap2或2020ap2的5’引物。作为另外一种选择,可以使用类似地修饰人可变区的前两个n末端氨基酸的引物以编码ap。一个具体实例包括选自1308ap2、2018ap2或2020ap2的5’引物。
[0263]
此外,当扩增和修饰来自ighv2基因家族的基因节段所编码的核酸时,可以使用选自1310ap2、1310ap3、1310ap4或1310ap5的5’引物,或者作为另外一种选择,可以使用类似地修饰人可变区的前两个n末端氨基酸的引物以编码ap。一个具体实例包括作为1310ap5的5’引物。
[0264]
此外,当扩增和修饰来自ighv3基因家族的基因节段所编码的核酸时,可以使用选自0508ap、0508ap2、2018ap、2018ap2、2021ap、2021ap2、2021ap3、2021ap4或2021ap5的5’引物,或者作为另外一种选择,可以使用类似地修饰人可变区的前两个n末端氨基酸的引物以编码ap。一个具体实例包括选自0508ap、2021ap2或2018ap2的5’引物。
[0265]
此外,当扩增和修饰来自ighv4基因家族的基因节段所编码的核酸时,可以使用作为1312ap2的5’引物,或者作为另外一种选择,可以使用类似地修饰人可变区的前两个n末端氨基酸的引物以编码ap。
[0266]
此外,当扩增和修饰来自ighv5基因家族的基因节段所编码的核酸时,可以使用作为1313ap或1313ap2的5’引物,或者作为另外一种选择,可以使用类似地修饰人可变区的前两个n末端氨基酸的引物以编码ap。一个具体实例包括作为1313ap2的5’引物。
[0267]
此外,当扩增和修饰来自ighv6基因家族的基因节段所编码的核酸时,可以使用作为1310ap2、1310ap3、1310ap4、1310ap5或1312ap2的5’引物,或者作为另外一种选择,可以使用类似地修饰人可变区的前两个n末端氨基酸的引物以编码ap。一个具体实例包括选自
1312ap2和1310ap5的5’引物。
[0268]
此外,当扩增和修饰来自ighv7家族的基因节段所编码的核酸时,可以使用作为1314ap或1314ap2的5’引物,或者作为另外一种选择,可以使用类似地修饰人可变区的前两个n末端氨基酸的引物以编码ap。一个具体实例包括作为1314ap2的5’引物。
[0269]
如本领域的常规技术人员将清楚的,存在其中将对于同时扩增和修饰编码不同人vh域的多个不同模板核酸有益的情况。例如,使用本文所描述的方法扩增(和修饰)人和/或人转基因动物细胞样品内所编码的不同的人vh域的部分或完整组库可以是有益的。
[0270]
举例来说,本文所描述的方法可以用于同时修饰和扩增在转基因动物(例如,具有人免疫球蛋白重链基因座或其部分的转基因鼠科或禽类生物;如小鼠)中编码人vh域的核酸的组库。本文所提供的方法使得能够例如使用其中使用几种不同的5’引物的多路pcr反应同时扩增和修饰不同的ighv基因节段。
[0271]
术语“多路聚合酶链反应”或者“多路pcr”在本文中是可互换使用的以表示在单一pcr反应/混合物中使用多个独特的引物通过不同序列产生扩增的核酸的聚合酶链反应。通过一次靶向多个基因,可以从单一测试运行中获得额外的信息,这些信息是否则需要数倍试剂和更长时间来进行的。必须优化每个引物组的退火温度以在单一反应内正确起作用。
[0272]
因此,所述方法可以包含提供通过至少一种人基因节段所编码的多个不同的核酸的步骤,所述基因节段选自以下人基因家族中的每一个:ighv1、ighv2、ighv3、ighv4、ighv5、ighv6、ighv7。有利地,可以在一个pcr反应中同时扩增和修饰所提供的多个不同的核酸(作为模板核酸)。
[0273]
例如,可以选择并在本发明所述的方法中使用来自表1中每一行的至少一种引物以同时扩增和修饰编码以下人基因家族ighv1、ighv2、ighv3、ighv4、ighv5、ighv6和ighv7内的功能性基因节段的模板核酸。
[0274]
如以下实施例部分中所示,可以优选地使用本文所公开的某些5’引物。
[0275]
例如,可以选择来自以下类别中的每一个的至少一种引物的组合以在本发明所述的方法中使用(从而基于v基因家族的数目,导致产生了在一个反应中使用的至少6种不同的5’引物的混合物,其产生了vh组库):
[0276]
a)选自1308ap、1308ap2、2020ap2、2018ap或2018ap2的5’引物;
[0277]
b)选自1310ap2、1310ap3、1310ap4或1310ap5的5’引物;
[0278]
c)选自0508ap、0508ap2、2018ap、2018ap2、2021ap、2021ap2、2021ap3、2021ap4或2021ap5的5’引物;
[0279]
d)作为1312ap2的5’引物;
[0280]
e)选自1313ap或1313ap2的5’引物;
[0281]
f)选自1310ap2、1310ap3、1310ap4、1310ap5或1312ap2的5’引物;和
[0282]
g)选自1314ap或1314ap2的5’引物。
[0283]
如本领域的常规技术人员将清楚的,来自以上a)至g)中每一种的至少一种引物的组合将是特别有利的,因为它将提供将在一个反应中同时扩增和修饰编码人ighv1、ighv2、ighv3、ighv4、ighv5、ighv6和ighv7基因节段的模板核酸的通用5’引物混合物。
[0284]
还可以存在以下情况,其中可以优选表1所列(或者以上a)至g)所列)的引物亚组。例如,当关注仅编码人ighv1、ighv2、ighv3的模板核酸时,仅选择表1相应的列中(或者以上
(a)至(c)中)的引物组合可以是有用的。要使用的引物的优选性与例如用于抗体或重链产生的平台内的基因家族相关。例如,当使用具有包含来自基因家族ighv1、ighv5和ighv7的vh基因节段的人微小基因座的转基因宿主时,优选地使用表1中所列的对应于所述基因家族的引物以产生在n-末端包含变体的一组重链。除了以上所提供的引物,基于本文所描述的教导内容,技术人员可以进一步开发对每个vh基因家族应用以扩增任何人vh域的引物,其同样包括在本发明内。
[0285]
本文所描述的方法包括使用至少一种5’引物、至少一种3’引物和核酸进行聚合酶链反应(pcr)以产生扩增的核酸。以上详细讨论了至少一种5’引物和(模板)核酸。
[0286]
可以使用任何适合的3’引物或3’引物的混合物。如本领域的常规技术人员将清楚的,这包括与编码所编码的人、人源化或嵌合vh域的fr4区域的核酸互补的3’引物或者与编码人重链恒定域的核酸互补的3’引物。对于人vh域,通过重排的人j基因节段(或者在共有重链的背景中j基因节段)编码fr4区。因此,适合的3’引物的设计是常规技术人员熟知的。
[0287]
以下提供了示例性引物,其包括与fr4末端互补的区域并且包括限制性位点bsteii和xhoi。
[0288]
hujh1/2xho=tattgttacctcgagacggtgaccagggtgcc(seq id no:12)
[0289]
hujh3xho=tattgttacctcgagacggtgaccattgtccc(seq id no:13)
[0290]
hujh4/5xho=tattgttacctcgagacggtgaccagggttcc(seq id no:14)
[0291]
hujh6xho=tattgttacctcgagacggtgaccgtggtccc(seq id no:15)
[0292]
本文所描述的方法还可以包括将每个扩增和修饰的核酸引入载体的步骤。用于将核酸引入载体的方法是熟知的并且包括限制性内切酶消化和连接。在本文其它处描述了适合的载体并且其包括噬粒或质粒。
[0293]
本文所描述的方法还可以进一步包括将每个载体转化或转染到细胞中以产生文库。用于将载体引入细胞的方法是熟知的。在本文其它处描述了适合的宿主细胞并且其包括噬菌体感受态细胞,如噬菌体感受态大肠杆菌(e.coli)或者噬菌体感受态酵母。还在本文其它处描述了相应文库。
[0294]
试剂盒
[0295]
本文还提供了试剂盒。所述试剂盒包括本文所描述的多种5’引物。所述试剂盒可以包括至少2个、至少3个、至少4个、至少5个、至少6个、至少7个、至少8个、至少9个等本文所描述的不同的5’引物。任选地,基于人、人源化或嵌合vh域组库的性质,所述试剂盒还包括至少一种本文所描述的3’引物。以上提供了适合的引物的详细信息并且在本文中同样适用。
[0296]
可以将所述试剂盒的组分放在适合于运输的容器中。
[0297]
另外,所述试剂盒可以包括用于所述试剂盒中所提供的材料的使用的说明材料,包括指导(即规程)。尽管说明材料通常包含书面或印刷材料,但是它们可以在能够储存这些指导并将它们传递给终端用户的任何媒介中提供。适合的媒介包括但不限于电子存储媒介(例如,磁盘、磁带、卡带、芯片)和光学媒介(例如,cd rom)。所述媒介可以包括登录提供说明材料的因特网站点。这些说明可以根据本文详细说明的任何方法或用途。
[0298]
药物组合物和使用方法
[0299]
通过本发明还提供了药物组合物,其包含抗体、抗体片段或抗体变体和药物可用
的载体和/或稀释剂。因此,本发明提供了如本文所描述的用于通过疗法治疗人或者动物体的抗体、抗体片段或抗体变体。通过本发明还提供了用于治疗患有医学病况的人或动物的方法,所述方法包括向所述人或动物施用治疗有效量的如本文所描述的抗体、抗体片段或抗体变体。要施用于患者的根据本发明的抗体、抗体片段或抗体变体的量通常在治疗窗中,这表示使用足够的量以获得治疗效果,而所述量不超过导致不可接受的副作用程度的阈值。获得所期望的治疗效果所需的抗体、抗体片段或抗体变体的量越低,则治疗窗通常将越大。因此,优选以低剂量发挥足够治疗效果的根据本发明的抗体、抗体片段或抗体变体。
[0300]
在本文中,对作为现有技术提供的专利文档或其它材料的引用不应被视为截至任何权利要求的优先日期,对该文档或材料是已知的或者它所包含的信息是一般常识的一部分的承认。
[0301]
除非本文另外定义,否则本文所使用的所有技术和科学术语具有与本发明所属领域的技术人员通常理解的含义相同的含义。尽管在本发明的实践中使用与本文所描述的那些类似或等价的任何方法和材料,但是本文描述了优选的方法和材料。因此,通过作为整体参考本说明书,更全面地描述了以下马上定义的术语。另外,除非上下文中明确指出,否则如本文所使用的,单数术语“一个”、“一种”包括多个对象。除非另外说明,否则分别以5'至3'取向从左到右书写核酸;以氨基至羧基取向从左到右书写氨基酸序列。应理解本发明不局限于所描述的具体方法、规程和试剂,因为这些可以基于本领域技术人员使用它们的背景而改变。
[0302]
通过以下非限制性实例证实了本发明的方面。
[0303]
实施例
[0304]
已鉴别了可以扩增从每个人vh基因家族内的每个功能性vh基因节段所产生的整个可变区的新的引物。新的引物借助于任何功能性人vh基因节段的重组修饰所产生的任何人vh域的任何n-末端,从而导致防止n末端焦谷氨酸形成和/或提高表达。
[0305]
以下实施例证实本发明使用通过merus的小鼠所产生的dna编码可变区并将该dna整合到载体中,同时改变人免疫球蛋白重链可变域的第一(或第一和第二)n末端编码氨基酸。将通过两种不同的小鼠所产生的dna编码可变区组成功整合到具有第一(或第一和第二)n末端编码氨基酸改变的载体中。这种小鼠具有含有来自人vh基因家族的代表性vh基因节段的合成重链微小基因座。显示引物在所有vh基因亚家族中起作用。已对于vh扩增效率和vh多样性优化了引物。它们已用于成功产生噬菌体展示文库和后续fab表达。
[0306]
研究原理
[0307]
先前描述的merus小鼠系表达具有人vh区的抗体。在这些小鼠免疫后,可以分离rna,随后是vh区的cdna合成和pcr扩增。值得注意的,vh序列从e或q开始。
[0308]
现已设计了在扩增期间替换所有vh序列n-末端的e或q的pcr引物。已特异性设计了引物以扩增由人组库内的任何人重组功能性v基因节段和功能性基因家族组成的任何重链可变区的无偏vh组库。
[0309]
当改变vh的n-末端序列时,应小心不要影响抗体性质样结构、抗原结合和稳定性和信号肽(sp)切割。已分析了来自真核生物、革兰氏阳性细菌和革兰氏阴性细菌的2352个
分泌蛋白的sp和相关成熟蛋白的各个位置处的氨基酸频率[choo和ranganathan,2008]。这种分析显示了物种组之间的相似性和差异。整体上,主要在sp内观察到氨基酸偏好,然而对于成熟肽的前几个残基也观察到了某些偏好:
[0310]
通过审查这些数据,应注意在真核(25%a或q)和革兰氏阴性(54%a或q)成熟蛋白的第一位置,优选a和q。在真核生物中,在第二(16%)和第四(11%)位置相对频繁存在p。在革兰氏阴性细菌中,在第二位置频繁观察到d、e、p和t(所有分析的蛋白中56%具有这4个残基之一)。对于第三和第四位置,t在第三(11%)和第四(13%)位置是普遍的。
[0311]
另一方面,在某些位置一些氨基酸明显较少存在。例如,在真核生物和革兰氏阴性细菌中,w以仅约1%的频率存在于第一位置。因此,结论如下:由于特定氨基酸是有利或不利的,因此通过改变成熟肽的前几个残基序列,sp切割的优化可以是可能的。
[0312]
当改变vh n-末端序列时,修饰的序列应与原核(细菌)以及真核sp良好组合。
[0313]
细菌sp包括例如mkyllptaaagllllaaqpama(seq id no:1)。真核sp包括例如mgwsciilflvlllaqpama(seq id no:4)。这些信号肽用作以下代表性、非限制性实例。
[0314]
为了能够计算机检查从修饰的vh的sp切割至少与相应野生型(wt)vh一样好,产生了一组18个代表性序列,其分别含有sp和vh区的前20个n末端氨基酸(9个vh区与2种不同的sp序列组合=18个代表性序列)。将所选择的vh区序列对于所有vh基因亚家族选择作为代表性序列。应理解vh区中位置20以外的vh残基不显著影响sp切割[choo和ranganathan,2008]。
[0315]
改变18条序列中每一个的第一vh残基(“位置1”)以包括所有20种可能的氨基酸,借此导致产生了18
×
20=360条序列。为所有序列提供样式p#x或e#x的编码,其中:
[0316]
p=原核sp;e=真核sp
[0317]
#=内部标号
[0318]
x=vh位置1处的氨基酸
[0319]
例如,p1a包含原核sp并且20-残基vh序列具有转变为a的第一vh编码的氨基酸e。
[0320]
为了研究第一vh残基对sp切割的影响,使用www.cbs.dtu.dk/services/signalp上的预测工具signalp 4.1[petersen等人,2011],使用以下参数计算机分析了所有360条序列:
[0321]
生物组:对于p#x序列为
‘
革兰氏阴性细菌’并且对于e#x序列为
‘
真核生物’[0322]
输出格式:
‘
短(无图示)’[0323]
所有其它参数:标准/缺省
[0324]
对于所有360条序列,正确预测了sp切割位点的位置。对于所有360条序列,比较了预测的所谓d(区别)得分(参见图2)。高d得分表示在vh区之前的序列实际上为信号肽的高概率。在本文中,认为更高的d得分对应于有效切割sp的概率更高。图2还列出了对于含有n末端sp的307个革兰氏阴性和1877个真核蛋白组在位置1处的未修饰的氨基酸的频率[choo和ranganathan,2008;其它文件2]。在本文中,认为更高的频率对应于有效切割sp的概率更高。在p#x序列中,对于x=a观察到最高的d得分(平均0.911),并且a是原核分泌蛋白中最常见的氨基酸(41.7%)。作为另一个实例,在e#x序列中,对于x=p观察到了最低的d得分(平均0.863),并且p是真核分泌蛋白中最不常见的氨基酸(0.3%)。
[0325]
基于d得分,将具有最高得分的以下3个残基选择作为第一vh位置处潜在的替代残
基:
[0326]
a:与e和q相比,大部分得分/频率高(得多);它是目前在未修饰的sp中最常见的氨基酸
[0327]
d:侧链化学类似于e;得分/频率与e和q相当
[0328]
s:部分得分/频率稍高于e和/或q
[0329]
与在位置1处含有e或q的序列一起,这留下了5
×9×
2=90条序列用于进一步分析(位置1处5种氨基酸
×
9条vh区序列
×
2个sp)。
[0330]
对于90条序列中的每一个(即在位置1处具有a、d、e、q或s),改变第二vh残基(
‘
位置2’)。省略以下7个残基,因为这些在未修饰的sp中很少或完全不存在[choo和ranganathan,2008];括号之间是革兰氏阴性/真核sp在位置2处的频率:
[0331]
c(0.0%/1.9%)
[0332]
f(1.0%/2.2%)
[0333]
h(0.3%/2.5%)
[0334]
m(0.0%/0.7%)
[0335]
r(0.3%/4.7%)
[0336]
w(1.6%/0.9%)
[0337]
y(0.3%/2.5%)
[0338]
这留下了在位置2处要改变的以下13种残基:
[0339]
a(5.9%/3.7%)
[0340]
d(17.3%/8.0%)
[0341]
e(16.9%/8.8%)
[0342]
g(6.5%/5.0%)
[0343]
i(2.9%/3.7%)
[0344]
k(1.6%/5.0%)
[0345]
l(1.6%/4.6%)
[0346]
n(5.9%/4.3%)
[0347]
p(10.8%/15.8%)
[0348]
q(4.9%/4.9%)
[0349]
s(5.5%/9.0%)
[0350]
t(10.8%/5.6%)
[0351]
v(5.9%/6.3%)
[0352]
以上导致产生了90
×
13=1170条要分析的序列。
[0353]
产生了1170条序列。为所有序列提供样式p#xz或e#xz的编码,其中:
[0354]
p=原核sp;e=真核sp
[0355]
#=内部标号
[0356]
x=vh位置1处的氨基酸
[0357]
z=vh位置2处的氨基酸
[0358]
例如,p1ad包含原核sp并且20-残基vh序列具有转变为a的第一vh编码的氨基酸e和转变为d的第二vh编码的氨基酸v。
[0359]
为了研究前两个不同的vh残基对sp切割的影响,以本文进一步提供的参数,使用预测工具signalp 4.1计算机分析所有1170条序列。
[0360]
对于所有1170条序列,正确预测了sp切割位点的位置。比较了1170条序列的d得分(图3)。据观察整体上,位置2处残基的种类对sp切割的影响不严重取决于位置1处残基的种类。例如,在位置2对于k观察到了相对低的d得分,不管位置1处的残基是a、d、e、q或s。此外,通常对于在位置1具有a的序列获得最高得分。
[0361]
如下使用图3中的结果以限定对于9种引物中的每一种,在位置1和2处的残基的最优组合,如图4所总结的。
[0362]
首先,对于sp和vh基因节段的18种组合中的每一种,鉴别了具有最高d得分的变体。例如,对于编码p1xz的65条序列,在位置1+2处具有av的变体具有最高的d得分(0.907)。有趣地,具有细菌sp的序列的最佳变体均在位置1+2处具有av(或者有时也具有at)。类似地,具有真核sp的序列的最佳变体均在位置1+2处具有ap(或者有时也具有av)。
[0363]
应理解基于本文所提供的教导内容,本领域的常规技术人员还可以识别用于和原核或真核信号肽一起使用的单独的引物。
[0364]
优选地,对于要与原核或真核sp一起使用的vh不需要单独的引物,它是对于9种引物中的每一种所确定的处于位置1+2处的共有序列,该序列与两种sp组合提供了高于相应wt序列的更高的得分/频率。基于数据,将这种共有序列定义为ap:
[0365]
与细菌sp组合,位置1+2处的ap提供了比wt序列高0.030至0.065(平均0.040)的d得分。
[0366]
与真核sp组合,位置1+2处的ap提供了比wt序列高0.002至0.005(平均0.003)的d得分。
[0367]
当与未修饰的细菌(41.7%)和真核(13.5%)sp组合时,a是位置1处最常见的氨基酸(参见图3)。
[0368]
当与未修饰的细菌sp组合时,p是位置2处第三最常见的氨基酸(10.8%),并且当与未修饰的真核sp组合时,是位置2处最常见的氨基酸(15.8%;参见图3)。
[0369]
设计了与图5中所列的引物相同的新的fw(5’)引物,除了在所有新的fw引物中,改变前两个vh密码子,从而这些编码ap而不是ev、eq、qi或ql(称为0508ap、1308ap、1310ap等)。由于遗传密码的简并度,对于a(gcn)和p(ccn)存在4种不同的密码子。对于引物,选择与当前引物中的密码子最相同的密码子(这根据引物而改变)。应小心不要引入sfii、bsteii和xhoi的新的克隆位置3。图5提供了所产生的9种新的引物序列;图6提供了这些引物的蛋白翻译。
[0370]
与不修饰vh区所编码的第一和第二氨基酸的当前引物平行测试所设计的引物。结果总结如下所示:
[0371]
实验结果
[0372]
引物设计和扩增效率分析。
[0373]
使用了两种不同的示例性小鼠系。使用新的引物和当前引物,将基于这些小鼠内的核酸的cdna用于vh扩增。通过比较琼脂糖凝胶上的pcr产物得率,分析了每种引物的扩增效率,参见图7。
[0374]
以下引物显示获得了足够的pcr产物:
[0375]
对于ighv1家族:1308ap;2018ap
[0376]
对于ighv3家族:0508ap;2018ap
[0377]
对于igvh4家族:1312ap;2019ap
[0378]
对于ighv5家族:1313ap
[0379]
对于ighv7家族:1314ap
[0380]
以下引物产生了低或无得率:
[0381]
对于ighv1家族:2020ap(无得率)
[0382]
对于ighv2家族:1310ap(低得率)
[0383]
3种新的(ap)引物在pcr中从cdna扩增vh基因节段中表现不好,因此重新考虑引物设计。可以通过序列基序,如长g/c延伸引起不良结果,这可以引起不期望的二级结构,如二聚体和发夹。所使用的引物序列的检查显示突变的引入导致产生了10-11bp的相对长的g/c延伸,这部分是由于对于ala密码子gcg和对于pro密码子ccc/ccg的使用。尽管这些延伸也存在于未获得良好结果的引物中,但是任何副作用可以取决于引物中其它处的序列性质,其根据引物是不同的。
[0384]
遗传密码的简并度允许通过选择其它密码子来减少g/c延伸的长度。因此,设计了新的引物(版本2;ap2;称为0508ap2、1310ap2等),其中将密码子gca和cct分别用于ala和pro。这不仅用于表现不好的3种引物,而且还用于其它6种引物。
[0385]
为了计算机检查版本2/ap2引物是否预计表现更好,使用vector nti软件的oligo分析功能分析了亚组。例如,对于引物do_2020及其更新的版本,预测了以下数目的可能的不希望的二聚体和发夹:
[0386]
2020ap:65个二聚体和26个发夹(总计91个)。这是相对高的并且可以(部分地)解释为什么这种引物表现不好。
[0387]
2020ap2:49个二聚体和19个发夹(总计68个)。这比2020ap低得多。这表明2020ap2可能表现的比2020ap更好。
[0388]
还检查了进一步降低g/c含量是否可以导致甚至更少的预测的二级结构:
[0389]
当在引物2020ap2中用gct或gca替换vh之前的ala密码子gcc时,预测了55或54个可能的二聚体和22个可能的发夹(总计77或76个)。这比2020ap2的多,因此将该ala密码子维持为gcc。
[0390]
对于其它引物获得了类似的预测结果(未显示)。
[0391]
图8显示了新的(ap)和优化的(ap2)引物的比对。
[0392]
大部分ap2引物显示获得了足够的pcr产物。参见图9。然而,引物0508ap2和1310ap2;(对于小鼠1,泳道#2&4)似乎对上述设计未显示出(较大)改善。引物2020ap2(对于小鼠2,泳道#5)目前起作用,然而上述设计(2020ap)不起作用。阴性对照(-)是阴性的。
[0393]
平行测试了所有新的引物(ap和ap2)版本以分析扩增效率,参见图10。如前所示,引物2020ap2(#8,小鼠2)起作用,然而2020ap(#7,小鼠2)不起作用。对于两种小鼠,引物0508ap(#1)似乎比0508ap2(#2)的作用好一些。在所有其它反应中,ap2的得率与ap类似或稍微更好。
[0394]
起始了对1310ap引物的进一步优化。另外,测试了ighv3家族的其它引物(2021ap)。测试了1310ap引物的5种不同的变体以及2021ap引物的5种不同的变体,参见图
11。新的引物1310ap5(#6,小鼠1)提供了比先前表现最好的引物1310ap2(#3,小鼠1)明显更好的结果。新的引物2021ap至2021ap5(#8至12)均类似地表现良好。
[0395]
整体上,以下引物能够获得足够的pcr产物:
[0396]
对于ighv1家族:1308ap、1308ap2、2020ap2、2018ap、2018ap2
[0397]
对于ighv2家族:1310ap2、1310ap3、1310ap4、1310ap5
[0398]
对于ighv3家族:0508ap、0508ap2、2018ap、2018ap2、2021ap、2021ap2、2021ap3、2021ap4、2021ap5
[0399]
对于igvh4家族:1312ap2/2019ap2
[0400]
对于ighv5家族:1313ap、1313ap2
[0401]
对于ighv6家族:1310ap2、1310ap3、1310ap4、1310ap5、1312ap2/2019ap2
[0402]
对于ighv7家族:1314ap、1314ap2
[0403]
纯化多种上述引物的pcr产物并连接至载体以用于转化到噬菌体感受态细菌细胞。产生了噬菌体展示文库。实施菌落pcr和测序以确定插入频率和序列多样性。
[0404]
vh多样性的分析
[0405]
通过将所扩增的vh基因节段克隆至fab-噬菌体载体构建噬菌体展示文库(大小约1e6-1e7)。对来自这些文库的单个克隆测序以确定多种vh基因家族的表示。分析所产生的序列以确定多种vh基因家族的表示。发现这种表示(即每种vh在所扩增的vh基因节段总数中的百分比)对于新的变体诱导引物以及扩增未改变的vh序列的引物类似,这表明产生包含vh序列的前两个位置的变体的引物不影响相应v基因节段和vh家族在所产生的噬菌体文库中的表示。
[0406]
fab表达的分析
[0407]
将来自文库的单个克隆用于产生含有可溶性fab的非纯化的胞质提取物。使用octet定量确定这些fab的浓度。发现大部分生产具有处于相同范围(约10-15μg/ml)的fab得率(数据未显示)。所产生的具有ap突变的fab良好且整体导致了比wt fab更高的平均得率(11.4与10.0μg/ml),这表明变体产生引物和n末端可变区中的变化的实用性。
[0408]
fab完整性的分析
[0409]
对所产生的可溶性fab亚组进行sds-page和免疫印迹。具有预期尺寸的条带在所产生的印迹上是明显的(数据未显示)。
[0410]
结果总结
[0411]
实验显示本文所描述的发明的引物可以用于产生具有不同vh组库的噬菌体展示文库并且可以通过来自这些文库的成员表达fab。新的引物可以用于扩增完整人可变区基因节段组库内编码vh基因节段的cdna,同时修饰所编码的可变域的n-末端以防止n末端焦谷氨酸形成和/或提高fab表达。
[0412]
读者关注与本发明申请相关的本说明书同时或在本说明书之前提交的所有文件,并且其对于本说明书的公共审查是开放的,并且所有这些文件的内容作为参考并入本文。
[0413]
在本说明书(包括任何所附权利要求、摘要和附图)中所公开的所有特性和/或因此所公开的任何方法或过程的所有步骤可以以任意组合合并,除了其中这些特性和/或步骤中的至少一些互相排斥的组合。
[0414]
除非另外明确表示,否则在本说明书(包括任何所附权利要求、摘要和附图)中所
公开的每种特征可以被起相同、等价或类似目的的替代特征代替。因此,除非另外明确表示,否则所公开的每种特征仅是等价或类似特征的一般系列的一个实例。
[0415]
本发明不局限于任何以上实施方式的详细信息。本发明延伸至在本说明书(包括任何所附权利要求、摘要和附图)中所公开的特性的任何一个新颖特性或任何新颖特性的组合,或者延伸至因此所公开的任何方法或过程的步骤的任何一个新颖步骤或任何新颖步骤的组合。
[0416]
参考文献
[0417]
choo,k.h.,and ranganathan,s.(2008).flanking signal and mature peptide residues influence signal peptide cleavage.bmc bioinformatics 9 suppl 12,s15.
[0418]
fowler,e.,moyer,m.,krishna,r.g.,chin,c.c.q.,and wold,f.(1996).removal of n-terminal blocking groups from proteins,currentprotocols in protein science.
[0419]
jefferis,r.(2016).review article.posttranslational modifications and the immunogenicity of biotherapeutics.journal of immunology research 2016.
[0420]
liu yd,goetze am,bass rb,flynn gc(2011).n-terminal glutamate to pyroglutamate conversion in vivo for human igg2 antibodies.j biol chem.2011 apr 1;286(13):11211-7.
[0421]
petersen,t.n.,brunak,s.,von heijne,g.,and nielsen,h.(2011).signalp 4.0:discriminating signal peptides from transmembrane regions.nature methods 8,785-786.
[0422]
yu l.,vizel a.,huff m.b.,young m.,remmele r.l.jr,he b.(2006).investigation of n-terminal glutamate cyclization of recombinant monoclonal antibody in formulation development.j.pharm.biomed.anal.42(4):455-63.
[0423]
ambrogelly a.,gozo s.,katiyar a.,dellatore s.,kune y.,bhat r.,sun j.,li n.,wang d.,nowak c.,neill a.,ponniah g.,king c.,mason b.,beck a,liu h.(2018).analytical comparability of recombinant monoclonal antibody therapeutics.mabs 10(4):513-538。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1