实体瘤甲基化标志物及其用途
本申请是申请日为2017年7月6日,申请号为201780002263.8,发明名称为“实体瘤甲基化标志物及其用途”的申请的分案申请。
交叉引用
本申请要求于2016年7月6日提交的美国临时申请号62/358,795的权益,该申请通过引用并入本文。
发明背景
癌症是世界范围内死亡的主要原因,预计在今后二十年内,每年的病例将从2012年的1400万上升至2200万(who)。在一些情况下,仅在患者已经出现症状之后才开始针对实体瘤如食管癌、胰腺癌或胃癌的诊断程序,从而导致程序是昂贵的、侵入性的并且有时是耗时的。此外,无法接近的区域有时会妨碍准确的诊断。另外,高癌症发病率和死亡率与较晚的诊断相关。
技术实现要素:
本文提供了用于将受试者鉴别为患有食管癌、胰腺癌或胃癌的方法和试剂盒。
在某些实施方案中,本文提供了选择疑似患有实体瘤的受试者进行治疗的方法,该方法包括:(a)采用脱氨剂对提取的基因组dna进行处理以生成包含脱氨核苷酸的基因组dna样品,其中所述提取的基因组dna从来自疑似患有实体瘤的受试者的生物样品获得;(b)从所述提取的基因组dna生成包含cg10673833的甲基化谱;(c)将所述生物标志物的甲基化谱与对照进行比较;(d)如果所述甲基化谱与所述对照相关,则将所述受试者鉴别为患有实体瘤;以及(e)如果所述受试者被鉴别为患有实体瘤,则向所述受试者施用有效量的治疗剂;其中所述实体瘤选自食管癌、胰腺癌或胃癌。
在一些实施方案中,所述比较进一步包括生成逐对甲基化差异数据集,该数据集包含:(i)经处理的基因组dna的甲基化谱与第一正常样品的甲基化谱之间的第一差异;(ii)第二正常样品的甲基化谱与第三正常样品的甲基化谱之间的第二差异;以及(iii)第一原发性癌症样品的甲基化谱与第二原发性癌症样品的甲基化谱之间的第三差异。
在一些实施方案中,所述比较进一步包括通过机器学习方法利用对照对所述逐对甲基化差异数据集进行分析,以生成所述甲基化谱。
在一些实施方案中,所述第一原发性癌症样品为食管癌样品、胰腺癌样品或胃癌样品。
在一些实施方案中,所述第二原发性癌症样品为非食管癌样品、非胰腺癌样品或非胃癌样品。
在一些实施方案中,所述对照包含一组甲基化谱,其中每个所述甲基化谱均由从已知癌症类型获得的生物样品生成。
在一些实施方案中,所述已知癌症类型为食管癌、胰腺癌或胃癌。
在一些实施方案中,所述已知癌症类型为复发性或难治性食管癌、复发性或难治性胰腺癌、或复发性或难治性胃癌。
在一些实施方案中,所述已知癌症类型为转移性食管癌、转移性胰腺癌或转移性胃癌。
在一些实施方案中,所述机器学习方法采用选自以下的一项或多项的算法:主成分分析、逻辑回归分析、最近邻分析、支持向量机和神经网络模型。
在一些实施方案中,所述生成进一步包括使所述生物标志物与探针杂交并进行dna测序反应,以对所述生物标志物的甲基化进行定量。
在一些实施方案中,所述生物样品包含循环肿瘤细胞。
在一些实施方案中,所述受试者为人。
在某些实施方案中,本文提供了生成有需要的受试者的生物标志物的甲基化谱的方法,该方法包括:(a)采用脱氨剂对提取的基因组dna进行处理以生成包含脱氨核苷酸的基因组dna样品,其中所述提取的基因组dna从来自所述受试者的生物样品获得;(b)检测所述提取的基因组dna与探针之间的杂交,其中所述探针与cg10673833杂交;以及(c)根据在所述提取的基因组dna与所述探针之间所检测到的杂交来生成甲基化谱。
在一些实施方案中,所述生成进一步包括生成逐对甲基化差异数据集,该数据集包含:(i)经处理的基因组dna的甲基化谱与第一正常样品的甲基化谱之间的第一差异;(ii)第二正常样品的甲基化谱与第三正常样品的甲基化谱之间的第二差异;以及(iii)第一原发性癌症样品的甲基化谱与第二原发性癌症样品的甲基化谱之间的第三差异。
在一些实施方案中,所述生成进一步包括通过机器学习方法利用对照对所述逐对甲基化差异数据集进行分析,以生成所述甲基化谱。
在一些实施方案中,所述第一原发性癌症样品为食管癌样品、胰腺癌样品或胃癌样品。
在一些实施方案中,所述第二原发性癌症样品为非食管癌样品、非胰腺癌样品或非胃癌样品。
在一些实施方案中,所述对照包含一组甲基化谱,其中每个所述甲基化谱均由从已知癌症类型获得的生物样品生成。
在一些实施方案中,所述已知癌症类型为食管癌、胰腺癌或胃癌。
在一些实施方案中,所述已知癌症类型为复发性或难治性食管癌、复发性或难治性胰腺癌、或复发性或难治性胃癌。
在一些实施方案中,所述已知癌症类型为转移性食管癌、转移性胰腺癌或转移性胃癌。
在一些实施方案中,所述已知癌症类型为食管癌。在一些实施方案中,食管癌包括食管鳞状细胞癌、食管腺癌或未分化的食管癌。
在一些实施方案中,所述已知癌症类型为胰腺癌。在一些实施方案中,胰腺癌包括外分泌胰腺癌和胰腺内分泌肿瘤。在一些实施方案中,胰腺癌包括胰腺腺癌、胰腺腺鳞癌、胰腺鳞状细胞癌、印戒细胞癌、未分化的胰腺癌、具有巨细胞的未分化胰腺癌、壶腹癌、胃泌素瘤、胰岛素瘤、胰高糖素瘤(glucagonomas)、生长抑素瘤、舒血管肠肽瘤(vipomas)、胰多肽瘤(ppomas)或类癌瘤。
在一些实施方案中,所述已知癌症类型为胃癌。在一些实施方案中,胃癌包括胃腺癌、胃淋巴瘤、胃肠道间质瘤、类癌瘤、胃原发性鳞状细胞癌、胃小细胞癌或胃平滑肌肉瘤。
在一些实施方案中,所述机器学习方法采用选自以下的一项或多项的算法:主成分分析、逻辑回归分析、最近邻分析、支持向量机和神经网络模型。
在一些实施方案中,所述方法进一步包括进行dna测序反应,以在生成所述甲基化谱之前对所述生物标志物的甲基化进行定量。
在一些实施方案中,所述生物样品包含循环肿瘤细胞。
在一些实施方案中,所述受试者为人。
具体地,本申请提供了以下内容:
1.一种生成有需要的受试者的生物标志物的甲基化谱的方法,该方法包括:
a)采用脱氨剂对提取的基因组dna进行处理以生成包含脱氨核苷酸的基因组dna样品,其中所述提取的基因组dna从来自所述受试者的生物样品获得;
b)检测所述提取的基因组dna与探针之间的杂交,其中所述探针与cg10673833(肌球蛋白ig)杂交;以及
c)根据在所述提取的基因组dna与所述探针之间所检测到的杂交来生成甲基化谱。
2.如项目1所述的方法,其中所述探针包含式i的结构:
其中:
a为第一靶标结合区;
b为第二靶标结合区;并且
l为连接区;
其中a具有与从seqidno:1的5’末端的位置1开始的至少30个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性;b具有与从seqidno:1的3’末端的位置1’开始的至少12个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性;并且
其中l与a相连接;并且b与a或l相连接。
3.如项目2所述的方法,其中所述探针包含式ia的结构:
4.如项目2所述的方法,其中a具有与从seqidno:1的5’末端的位置1开始的至少40个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
5.如项目2所述的方法,其中a具有与从seqidno:1的5’末端的位置1开始的至少50个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
6.如项目2所述的方法,其中b具有与从seqidno:1的3’末端的位置1’开始的至少15个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
7.如项目2所述的方法,其中b具有与从seqidno:1的3’末端的位置1’开始的至少20个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
8.如项目2所述的方法,其中l的长度为约15、20、25、30、35、40、45、50、55或60个核苷酸。
9.如项目1所述的方法,其中所述探针具有与seqidno:1至少80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的序列同一性。
10.如项目1所述的方法,其中所述生成进一步包括生成逐对甲基化差异数据集,该数据集包含:
(i)经处理的基因组dna的甲基化谱与第一正常样品的甲基化谱之间的第一差异;
(ii)第二正常样品的甲基化谱与第三正常样品的甲基化谱之间的第二差异;以及
(iii)第一原发性癌症样品的甲基化谱与第二原发性癌症样品的甲基化谱之间的第三差异。
11.如项目10所述的方法,其中所述生成进一步包括通过机器学习方法利用对照对所述逐对甲基化差异数据集进行分析,以生成所述甲基化谱。
12.如项目10所述的方法,其中所述第一原发性癌症样品为食管癌样品、胰腺癌样品或胃癌样品。
13.如项目10所述的方法,其中所述第二原发性癌症样品为非食管癌样品、非胰腺癌样品或非胃癌样品。
14.如项目11所述的方法,其中所述对照包含一组甲基化谱,其中每个所述甲基化谱均由从已知癌症类型获得的生物样品生成。
15.如项目14所述的方法,其中所述已知癌症类型为食管癌、胰腺癌或胃癌。
16.如项目14所述的方法,其中所述已知癌症类型为复发性或难治性食管癌、复发性或难治性胰腺癌、或复发性或难治性胃癌。
17.如项目14所述的方法,其中所述已知癌症类型为转移性食管癌、转移性胰腺癌或转移性胃癌。
18.如项目14所述的方法,其中所述已知癌症类型为食管癌。
19.如项目18所述的方法,其中食管癌包括食管鳞状细胞癌、食管腺癌或未分化的食管癌。
20.如项目14所述的方法,其中所述已知癌症类型为胰腺癌。
21.如项目20所述的方法,其中胰腺癌包括外分泌胰腺癌和胰腺内分泌肿瘤。
22.如项目20所述的方法,其中胰腺癌包括胰腺腺癌、胰腺腺鳞癌、胰腺鳞状细胞癌、印戒细胞癌、未分化的胰腺癌、具有巨细胞的未分化胰腺癌、壶腹癌、胃泌素瘤、胰岛素瘤、胰高糖素瘤、生长抑素瘤、舒血管肠肽瘤、胰多肽瘤或类癌瘤。
23.如项目14所述的方法,其中所述已知癌症类型为胃癌。
24.如项目23所述的方法,其中胃癌包括胃腺癌、胃淋巴瘤、胃肠道间质瘤、类癌瘤、胃原发性鳞状细胞癌、胃小细胞癌或胃平滑肌肉瘤。
25.如项目11所述的方法,其中所述机器学习方法采用选自以下的一项或多项的算法:主成分分析、逻辑回归分析、最近邻分析、支持向量机和神经网络模型。
26.如项目1-25中任一项所述的方法,其中所述方法进一步包括进行dna测序反应,以在生成所述甲基化谱之前对所述生物标志物的甲基化进行定量。
27.一种选择疑似患有实体瘤的受试者进行治疗的方法,该方法包括:
a)采用脱氨剂对提取的基因组dna进行处理以生成包含脱氨核苷酸的基因组dna样品,其中所述提取的基因组dna从来自疑似患有实体瘤的受试者的生物样品获得;
b)从所述提取的基因组dna生成包含cg10673833(肌球蛋白ig)的甲基化谱;
c)将所述生物标志物的甲基化谱与对照进行比较;
d)如果所述甲基化谱与所述对照相关,则将所述受试者鉴别为患有实体瘤;以及
e)如果所述受试者被鉴别为患有实体瘤,则向所述受试者施用有效量的治疗剂;
其中所述实体瘤选自食管癌、胰腺癌或胃癌。
28.如项目1-27中任一项所述的方法,其中所述生物样品包含循环肿瘤细胞。
29.如项目1-27中任一项所述的方法,其中所述受试者为人。
附图说明
本公开内容的各个方面在所附的权利要求书中具体阐述。通过参考以下对利用本公开内容原理的说明性实施方案加以阐述的详细描述以及附图,将获得对本公开内容的特征和优点的更好的理解,在这些附图中:
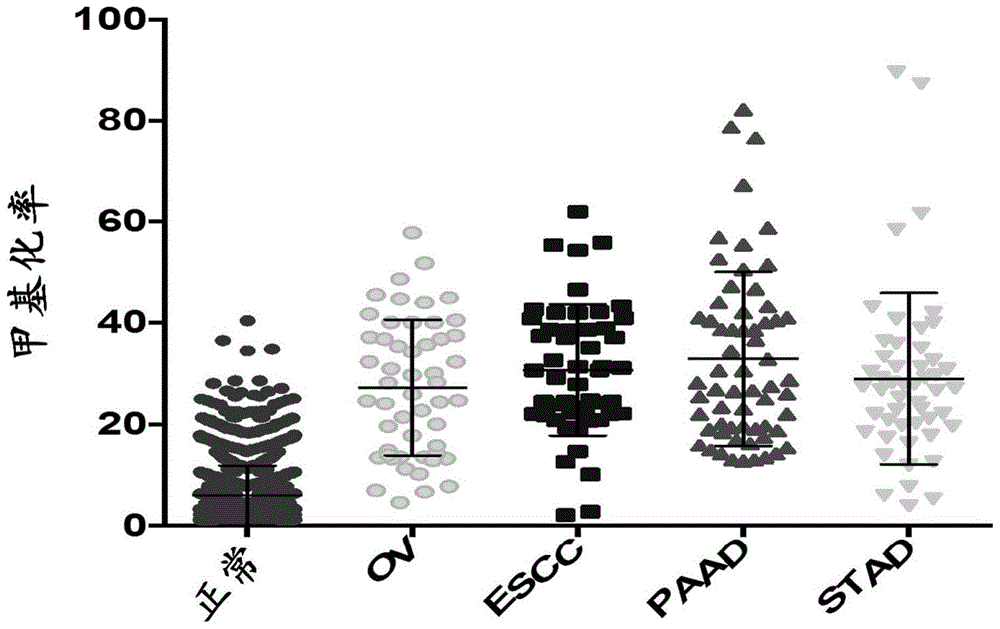
图1示出了不同癌症类型中无细胞dna(cfdna)的甲基化率。
图2a-图2b示出了食管癌的不同反应组中无细胞dna(cfdna)的甲基化率。图2a示出了甲基化率的散点图。图2b示出了甲基化率的箱形图。
图3a-图3b示出了胰腺癌的不同反应组中无细胞dna(cfdna)的甲基化率。图3a示出了甲基化率的散点图。图3b示出了甲基化率的箱形图。
图4a-图4b示出了胃癌的不同反应组中无细胞dna(cfdna)的甲基化率。图4a示出了甲基化率的散点图。图4b示出了甲基化率的箱形图。
具体实施方式
癌症的特征在于由导致细胞增殖和细胞死亡的平衡失调的一个或多个基因突变或修饰引起的细胞异常生长。dna甲基化使肿瘤抑制基因的表达沉默,并且其自身呈现为第一批瘤变化中的一种。在瘤组织和血浆中发现的甲基化模式显示出同质性,并且在一些情况下被用作灵敏的诊断标志物。例如,在一项研究中,cmethdna测定在用于诊断转移性乳腺癌时显示出约91%的灵敏度和96%的特异性。在另一项研究中,循环肿瘤dna(ctdna)在用于鉴别一大群患有转移性结肠癌的患者的kras基因突变时的灵敏度为约87.2%且特异性为约99.2%(bettegowda等人,detectionofcirculatingtumordnainearly-andlate-stagehumanmalignancies.sci.transl.med,6(224):ra24.2014)。相同的研究进一步显示,在>75%的患有晚期胰腺癌、卵巢癌、结直肠癌、膀胱癌、胃食管癌、乳腺癌、黑素瘤、肝细胞癌和头颈癌的患者中可检测到ctdna(bettegowda等人)。
另外的研究显示,cpg甲基化模式与瘤进展相关。例如,在一项乳腺癌甲基化模式的研究中,发现p16过度甲基化与早期乳腺癌相关,而timp3启动子过度甲基化与晚期乳腺癌相关。此外,已显示在乳腺癌中bmp6、cst6和timp3启动子过度甲基化与向淋巴结的转移相关。
在一些实施方案中,对于癌症检测,与体细胞突变分析相比,dna甲基化谱分析提供了更高的临床灵敏度和动态范围。在其他情况下,已显示出改变的dna甲基化特征(signature)与某些癌症的治疗反应的预后相关。例如,一项研究显示,在一组患有晚期直肠癌的患者中,使用十个差异性甲基化的区域来预测患者的预后。类似地,使用血清中的rassf1adna甲基化测量来预测在不同研究中的乳腺癌患者中经历辅助疗法的患者的不良结果。此外,srbc基因过度甲基化与在不同研究中采用奥沙利铂治疗的结直肠癌患者的不良结果相关。另一项研究显示,esr1基因甲基化与接受他莫昔芬的乳腺癌患者的临床反应相关。另外,显示arhi基因启动子过度甲基化是未经他莫昔芬治疗的乳腺癌患者的长期存活的预测因子。
在一些实施方案中,本文公开了基于dna甲基化谱分析诊断食管癌、胰腺癌或胃癌的方法和试剂盒。在一些情况下,本文还提供了基于dna甲基化谱分析鉴别患有食管癌、胰腺癌或胃癌的受试者的方法和试剂盒。
使用方法
诊断受试者的方法
在某些实施方案中,本文公开了诊断食管癌、胰腺癌或胃癌以及选择疑似患有食管癌、胰腺癌或胃癌的受试者进行治疗的方法。在一些情况下,所述方法包括采用一种或多种本文所述的生物标志物。在一些情况下,生物标志物包括胞嘧啶甲基化位点。在一些情况下,胞嘧啶甲基化包括5-甲基胞嘧啶(5-mcyt)和5-羟甲基胞嘧啶。在一些情况下,胞嘧啶甲基化位点出现在cpg二核苷酸基序中。在其他情况下,胞嘧啶甲基化位点出现在chg或chh基序中,其中h为腺嘌呤、胞嘧啶或胸腺嘧啶。在一些情况下,一个或多个cpg二核苷酸基序或cpg位点形成cpg岛——一个富集cpg二核苷酸的短dna序列。在一些情况下,cpg岛的长度通常但不总是在约0.2至约1kb之间。在一些情况下,生物标志物包括cpg岛。
在一些实施方案中,本文公开了选择疑似患有实体瘤的受试者进行治疗的方法,其中该方法包括(a)采用脱氨剂对提取的基因组dna进行处理以生成包含脱氨核苷酸的基因组dna样品,其中所述提取的基因组dna从来自疑似患有实体瘤的受试者的生物样品获得;(b)从所述提取的基因组dna生成包含生物标志物cg10673833的甲基化谱;(c)将所述生物标志物的甲基化谱与对照进行比较;(d)如果所述甲基化谱与所述对照相关,则将所述受试者鉴别为患有实体瘤;以及(e)如果所述受试者被鉴别为患有实体瘤,则向所述受试者施用有效量的治疗剂,其中所述实体瘤选自食管癌、胰腺癌或胃癌。
在一些实施方案中,甲基化谱包含一种或多种本文所述生物标志物的多种cpg甲基化数据。在一些情况下,通过首先从生物样品获得基因组dna(例如,核dna或循环dna)并随后通过脱氨剂对该基因组dna进行处理以生成提取的基因组dna来生成多种cpg甲基化数据。在一些情况下,在提交以进行用于生成cpg甲基化数据的测序分析之前,任选地采用一种或多种限制性酶来处理所提取的基因组dna(例如,提取的核dna或提取的循环dna)以生成一组dna片段。在一些情况下,该测序分析包括使一种或多种本文所述的生物标志物中的每一种与探针杂交,并进行dna测序反应以对该一种或多种生物标志物中每一种的甲基化进行定量。在一些情况下,随后将cpg甲基化数据输入机器学习/分类程序中以生成甲基化谱。
在一些情况下,生成了一组生物样品,并随后将其输入机器学习/分类程序中。在一些情况下,该组生物样品包含2、3、4、5、6、7、8、9、10、20、30个或更多个生物样品。在一些情况下,该组生物样品包含2、3、4、5、6、7、8、9、10、20、30个或更多个正常生物样品。在一些情况下,该组生物样品包含2、3、4、5、6、7、8、9、10、20、30个或更多个癌性生物样品。在一些情况下,该组生物样品包含感兴趣的生物样品、第一原发性癌症样品、第二原发性癌症样品、第一正常样品、第二正常样品和第三正常样品;其中第一和第二原发性癌症样品不同;并且其中第一、第二和第三正常样品不同。在一些情况下,生成了三对差异数据集,其中所述三对数据集包含:感兴趣生物样品的甲基化谱与第一正常样品的甲基化谱之间的第一差异数据集,其中该感兴趣生物样品与第一正常样品来自相同的生物样品源;第二正常样品的甲基化谱与第三正常样品的甲基化谱之间的第二差异数据集,其中第二和第三正常样品不同;以及第一原发性癌症样品的甲基化谱与第二原发性癌症样品的甲基化谱之间的第三差异数据集,其中第一和第二原发性癌症样品不同。在一些情况下,进一步将该差异数据集输入机器学习/分类程序中。在一些情况下,生成了来自第一、第二和第三数据集的逐对甲基化差异数据集,并随后在存在对照数据集或训练数据集的情况下通过机器学习/分类方法对所述逐对甲基化差异数据集进行分析以生成癌症cpg甲基化谱。在一些情况下,第一原发性癌症样品为食管癌样品、胰腺癌样品或胃癌样品。在一些情况下,第二原发性癌症样品为非食管癌样品、非胰腺癌样品或非胃癌样品。在一些情况下,机器学习方法包括根据最高得分(例如,t检验值,β检验值)鉴别多个标志物和多个权重,并根据该多个标志物和多个权重将样品分类。在一些情况下,机器学习方法采用选自以下的一项或多项的算法:主成分分析、逻辑回归分析、最近邻分析、支持向量机和神经网络模型。
在一些实施方案中,cpg甲基化谱包含生物标志物cg10673833。
在一些情况下,受试者被诊断为患有食管癌、胰腺癌或胃癌。在一些情况下,受试者被诊断为患有食管癌。在一些情况下,食管癌进一步包括复发性或难治性食管癌。在其他情况下,食管癌包括转移性食管癌。在一些情况下,受试者被诊断为患有复发性或难治性食管癌。在另外的情况下,受试者被诊断为患有转移性食管癌。
在一些实施方案中,食管癌为任意类型的食管癌。在一些情况下,食管癌包括食管鳞状细胞癌、食管腺癌或未分化的食管癌。
在一些实施方案中,进一步用治疗剂治疗被诊断患有食管癌的受试者。示例性的治疗剂包括但不限于多西他赛、雷莫芦单抗、曲妥珠单抗或其组合。
腺癌进一步包括复发性或难治性胰腺癌。在其他情况下,胰腺癌包括转移性胰腺癌。在一些情况下,受试者被诊断为患有复发性或难治性胰腺癌。在另外的情况下,受试者被诊断为患有转移性胰腺癌。
在一些实施方案中,胰腺癌为任意类型的胰腺癌。在一些情况下,胰腺癌包括外分泌胰腺癌和胰腺内分泌肿瘤。在一些情况下,胰腺癌包括胰腺腺癌、胰腺腺鳞癌、胰腺鳞状细胞癌、印戒细胞癌、未分化的胰腺癌、具有巨细胞的未分化胰腺癌、壶腹癌、胃泌素瘤、胰岛素瘤、胰高糖素瘤、生长抑素瘤、舒血管肠肽瘤、胰多肽瘤或类癌瘤。
在一些实施方案中,进一步用治疗剂治疗被诊断患有胰腺癌的受试者。示例性的治疗剂包括但不限于盐酸厄洛替尼、依维莫司、氟尿嘧啶、盐酸吉西他滨、盐酸伊立替康、醋酸兰瑞肽、丝裂霉素c、紫杉醇、苹果酸舒尼替尼或其组合。
在一些情况下,受试者被诊断为患有胃癌。在一些情况下,胃癌进一步包括复发性或难治性胃癌。在其他情况下,胃癌包括转移性胃癌。在一些情况下,受试者被诊断为患有复发性或难治性胃癌。在另外的情况下,受试者被诊断为患有转移性胃癌。
在一些实施方案中,胃癌为任意类型的胃癌。在一些情况下,胃癌包括胃腺癌、胃淋巴瘤、胃肠道间质瘤、类癌瘤、胃原发性鳞状细胞癌、胃小细胞癌或胃平滑肌肉瘤。
在一些实施方案中,进一步用治疗剂治疗被诊断患有胃癌的受试者。示例性的治疗剂包括但不限于多西他赛、盐酸阿霉素、氟尿嘧啶、醋酸兰瑞肽、丝裂霉素c、雷莫芦单抗、曲妥珠单抗或其组合。
在一些实施方案中,本文还描述了生成生物标志物的甲基化谱的方法。在一些情况下,该方法包括(a)采用脱氨剂对提取的基因组dna进行处理以生成包含脱氨核苷酸的基因组dna样品,其中所述提取的基因组dna从来自所述受试者的生物样品获得;(b)检测所述提取的基因组dna与探针之间的杂交,其中所述探针与cg10673833杂交;以及(c)根据在所述提取的基因组dna与所述探针之间所检测到的杂交来生成甲基化谱。
在一些情况下,如本文其他各处所述,在生成甲基化谱之前生成逐对甲基化差异数据集。在一些情况下,该逐对甲基化差异数据集包含(i)经处理的基因组dna的甲基化谱与第一正常样品的甲基化谱之间的第一差异;(ii)第二正常样品的甲基化谱与第三正常样品的甲基化谱之间的第二差异;以及(iii)第一原发性癌症样品的甲基化谱与第二原发性癌症样品的甲基化谱之间的第三差异。
在一些情况下,通过机器学习方法利用对照来分析所述逐对甲基化差异数据集,以生成甲基化谱。在一些情况下,该机器学习方法采用选自以下的一项或多项的算法:主成分分析、逻辑回归分析、最近邻分析、支持向量机和神经网络模型。
在一些实施方案中,探针包括dna探针、rna探针或其组合。在一些情况下,探针包括天然核酸分子和非天然核酸分子。在一些情况下,探针包括标记的探针,诸如例如,荧光标记的探针或放射性标记的探针。在一些情况下,探针与cpg位点相关联。在一些情况下,将探针用于下一代测序反应以生成cpg甲基化数据。在其他情况下,将探针用于基于溶液的下一代测序反应以生成cpg甲基化数据。在一些情况下,探针包括分子信标探针、taqman探针、锁定核酸探针、持锁探针或scorpion探针。在一些情况下,探针包括持锁探针。
在一些情况下,所述方法进一步包括进行dna测序反应,如本文其他各处所述的那些反应,以在生成甲基化谱之前对生物标志物的甲基化进行定量。
在一些实施方案中,cpg甲基化位点位于启动子区(例如,诱导启动子甲基化)。在一些情况下,启动子甲基化导致其相应基因表达的下调。在一些情况下,一个或多个上文和后文所述的cpg甲基化位点位于启动子区,导致启动子甲基化以及随后的相应基因表达的下调。在一些情况下,cpg甲基化位点如表1所示。在一些情况下,基因表达的增加导致肿瘤体积的减小。
在一些实施方案中,cg10673833是指肌球蛋白ig(myo1g)。在一些实施方案中,本文描述了选择疑似患有实体瘤的受试者进行治疗的方法,该方法包括生成包含肌球蛋白ig(myo1g)的甲基化谱。在一些实施方案中,本文描述了生成有需要的受试者的基因的甲基化谱的方法,该方法包括检测所提取的基因组dna与探针之间的杂交,其中该探针与肌球蛋白ig(myo1g)杂交。
对照
在一些实施方案中,对照为样品的甲基化值、甲基化水平或甲基化谱。在一些情况下,对照包含一组甲基化谱,其中每个所述甲基化谱均由从已知癌症类型获得的生物样品生成。在一些情况下,所述已知癌症类型为食管癌、胰腺癌或胃癌。在一些情况下,所述已知癌症类型为复发性或难治性食管癌、复发性或难治性胰腺癌、或复发性或难治性胃癌。在其他情况下,所述已知癌症类型为转移性食管癌、转移性胰腺癌或转移性胃癌。
在一些情况下,所述已知癌症类型为食管癌。在一些情况下,所述已知癌症类型为食管鳞状细胞癌、食管腺癌或未分化的食管癌。
在一些情况下,所述已知癌症类型为胰腺癌。在一些情况下,所述已知癌症类型为胰腺腺癌、胰腺腺鳞癌、胰腺鳞状细胞癌、印戒细胞癌、未分化的胰腺癌、具有巨细胞的未分化胰腺癌、壶腹癌、胃泌素瘤、胰岛素瘤、胰高糖素瘤、生长抑素瘤、舒血管肠肽瘤、胰多肽瘤或类癌瘤。
在一些情况下,所述已知癌症类型为胃癌。在一些情况下,所述已知癌症类型为胃腺癌、胃淋巴瘤、胃肠道间质瘤、类癌瘤、胃原发性鳞状细胞癌、胃小细胞癌或胃平滑肌肉瘤。
探针
在一些实施方案中,以上描述的一种或多种探针包含式i的结构:
其中:
a为第一靶标结合区;
b为第二靶标结合区;并且
l为连接区;
其中a具有与从seqidno:1的5’末端的位置1开始的至少30个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性;b具有与从同一seqidno:1的3’末端的位置1’开始的至少12个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性;并且其中l与a相连接;并且b与a或l相连接。
在一些情况下,l与a相连接并且b与l相连接。在一些情况下,a、b和l如式ia中所示连接:
在一些实施方案中,a具有与从seqidno:1的5’末端的位置1开始的至少35个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,a具有与从seqidno:1的5’末端的位置1开始的至少40个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,a具有与从seqidno:1的5’末端的位置1开始的至少45个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,a具有与从seqidno:1的5’末端的位置1开始的至少50个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,a具有与从seqidno:1的5’末端的位置1开始的至少55个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,a具有与从seqidno:1的5’末端的位置1开始的至少60个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,a具有与从seqidno:1的5’末端的位置1开始的至少65个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,a具有与从seqidno:1的5’末端的位置1开始的至少70个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,a具有与从seqidno:1的5’末端的位置1开始的至少80个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,a具有与从seqidno:1的5’末端的位置1开始的至少90个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
在一些实施方案中,b具有与从同一seqidno:1的3’末端的位置1’开始的至少14个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少15个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少18个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少20个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少22个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少25个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少28个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少30个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少35个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少40个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少45个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少50个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少55个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少60个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少65个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少70个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少80个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。在一些情况下,b具有与从同一seqidno:1的3’末端的位置1’开始的至少90个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
在一些情况下,将以上描述的探针用于下一代测序反应以生成cpg甲基化数据。在一些情况下,将探针用于基于溶液的下一代测序反应以生成cpg甲基化数据。在一些情况下,下一代测序反应包括454lifesciences平台(roche,branford,ct);lllumina基因组分析仪、goldengate甲基化测定或infinium甲基化测定,即infinium人甲基化27k珠阵列(beadarray)或veracodegoldengate甲基化阵列(illumina,sandiego,ca);来自bio-rad的qx200tmdropletdigitaltmpcr系统;dna连接测序,solid系统(appliedbiosystems/lifetechnologies);helicos真单分子dna测序技术;半导体测序(iontorrent;personalgenomemachine);dna纳米球测序;采用来自doversystems的技术的测序(polonator),以及无需在测序前扩增或以其他方式转化天然dna的技术(例如,pacificbiosciences和helicos),如基于纳米孔的策略(例如,oxfordnanopore、geniatechnologies和nabsys)。在一些情况下,基于溶液的下一代测序反应为小液滴数字pcr测序法。
在一些情况下,每个探针均与cpg位点相关联。在一些情况下,每个探针均与生物标志物(例如,cpg位点)相关联。
在一些情况下,l的长度为10至60、15至55、20至50、25至45以及30至40个核苷酸。在一些情况下,l的长度为约15、20、25、30、35、40、45、50、55或60个核苷酸。
在一些情况下,l进一步包含衔接子区。在一些情况下,该衔接子区包含用于鉴别每个探针的序列。在一些情况下,每个说明性序列中的衔接子区由一系列n表示,其中每个n均为a、t、g或c。
在一些实施方案中,本文所述的探针具有与seqidno:1至少50%、60%、70%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的序列同一性。在一些情况下,该探针具有与seqidno:1至少50%的序列同一性。在一些情况下,该探针具有与seqidno:1至少60%的序列同一性。在一些情况下,该探针具有与seqidno:1至少70%的序列同一性。在一些情况下,该探针具有与seqidno:1至少80%的序列同一性。在一些情况下,该探针具有与seqidno:1至少85%的序列同一性。在一些情况下,该探针具有与seqidno:1至少90%的序列同一性。在一些情况下,该探针具有与seqidno:1至少91%的序列同一性。在一些情况下,该探针具有与seqidno:1至少92%的序列同一性。在一些情况下,该探针具有与seqidno:1至少93%的序列同一性。在一些情况下,该探针具有与seqidno:1至少94%的序列同一性。在一些情况下,该探针具有与seqidno:1至少95%的序列同一性。在一些情况下,该探针具有与seqidno:1至少96%的序列同一性。在一些情况下,该探针具有与seqidno:1至少97%的序列同一性。在一些情况下,该探针具有与seqidno:1至少98%的序列同一性。在一些情况下,该探针具有与seqidno:1至少99%的序列同一性。在一些情况下,该探针与seqidno:1具有100%的序列同一性。在一些情况下,该探针由seqidno:1组成。
在一些情况下,将以上描述的探针用于数字pcr测序方法。在一些情况下,将该探针用于小液滴数字pcr(ddpcr)测序方法。
检测方法
在一些实施方案中,使用多种方法来测量、检测、确定、鉴别和表征基因或生物标志物(例如,含cpg岛的区域/片段)的甲基化状态/水平,以将受试者鉴别为患有食管癌、胰腺癌或胃癌,或区分食管癌、胰腺癌或胃癌的类型。
在一些情况下,从分离自个体的生物样品生成甲基化谱。在一些实施方案中,该生物样品为活检物。在一些情况下,该生物样品为组织样品。在一些情况下,该生物样品为组织活检样品。在一些情况下,该生物样品为血液样品。在其他情况下,该生物样品为无细胞生物样品。在其他情况下,该生物样品为循环肿瘤dna样品。在一个实施方案中,该生物样品为含有循环肿瘤dna的无细胞生物样品。
在一些实施方案中,从液体样品获得生物标志物(或表观遗传标志物)。在一些实施方案中,该液体样品包括血液和其他生物来源的液体样品,包括但不限于,外周血、血清、血浆、腹水、尿液、脑脊髓液(csf)、痰、唾液、骨髓、滑液、房水、羊水、耳垢、乳汁、支气管肺泡灌洗液、精液、前列腺液、考珀液(cowper’sfluid)或射精前流体、女性射出液、汗液、泪液、囊液、胸膜液和腹膜液、心包液、腹水、淋巴液、食糜、乳糜、胆汁、间质液、月经、脓液、皮脂、呕吐物、阴道分泌物/流出物、滑液、粘膜分泌物、粪便水、胰液、来自窦腔的洗液、支气管肺抽吸物、囊胚腔液或脐带血。在一些实施方案中,该生物流体为血液、血液衍生物或血液级分,例如,血清或血浆。在特定实施方案中,该样品包括血液样品。在另一个实施方案中,使用血清样品。在另一个实施方案中,样品包含尿液。在一些实施方案中,该液体样品还包括已在其获得后经任意方式处理的样品,诸如通过离心、过滤、沉淀、透析、层析、利用试剂处理、洗涤或针对某些细胞群富集。
在一些实施方案中,从组织样品获得生物标志物(或表观遗传标志物)。在一些情况下,组织对应于任何细胞。不同类型的组织对应于不同类型的细胞(例如,肝、肺、血液、结缔组织等),而且还对应于健康细胞与肿瘤细胞,或对应于处于瘤形成各个阶段的肿瘤细胞,或对应于移位的恶性肿瘤细胞。在一些实施方案中,组织样品进一步包括临床样品,并且还包括培养中的细胞、细胞上清液、器官等。样品还包括被制备用于病理学分析或免疫组织化学研究的新鲜冷冻和/或福尔马林固定的石蜡包埋的组织块,如从临床或病理学活检物制备的组织块。
在一些实施方案中,在正常样品(例如,没有疾病的正常或对照组织,或正常或对照体液、粪便、血液、血清、羊水)中,最重要地在健康的粪便、血液、血清、羊水或其他体液中,生物标志物(或表观遗传标志物)是甲基化或未甲基化的。在其他实施方案中,在来自患有疾病(例如,一种或多种本文所述的适应症)或处于该疾病风险下的患者的样品中,生物标志物(或表观遗传标志物)是甲基化不足或过度甲基化的;例如,与正常样品相比,减少或增加(分别地)至少约50%、至少约60%、至少约70%、至少约75%、至少约80%、至少约85%、至少约90%、至少约95%或约100%的甲基化频率。在一个实施方案中,与患有疾病(例如,一种或多种本文所述的适应症)或处于该疾病风险下的同一患者的先前获得样品的分析相比,样品也可以是甲基化不足或过度甲基化的,这特别地用于比较疾病的进展。
在一些实施方案中,甲基化组(methylome)包含一组表观遗传标志物或生物标志物,诸如以上描述的生物标志物。在一些情况下,将与生物体(例如,人)的肿瘤的甲基化组相对应的甲基化组分类为肿瘤甲基化组。在一些情况下,采用生物样品中的肿瘤组织或无细胞(或无蛋白质)肿瘤dna来确定肿瘤甲基化组。感兴趣的甲基化组的其他实例包括向体液中贡献dna的器官的甲基化组(例如,诸如脑、乳房、肺、前列腺、和肾、血浆等组织的甲基化组)。
在一些实施方案中,血浆甲基化组是从动物(例如,人)的血浆或血清确定的甲基化组。在一些情况下,血浆甲基化组是无细胞或无蛋白质甲基化组的实例,因为血浆和血清包含无细胞dna。血浆甲基化组也是混合甲基化组的实例,因为其为肿瘤与其他感兴趣甲基化组的混合物。在一些情况下,从受试者的尿液样品确定尿液甲基化组。在一些情况下,细胞甲基化组对应于从患者细胞(例如,血细胞)确定的甲基化组。血细胞的甲基化组被称为血细胞甲基化组(或血液甲基化组)。
在一些实施方案中,通过本领域中的任何标准手段,包括使用可商购的试剂盒,来分离dna(例如,基因组dna,如提取的基因组dna或经处理的基因组dna)。简言之,在感兴趣的dna被封装在细胞膜内时,通过酶手段、化学手段或机械手段破坏并裂解生物样品。在一些情况下,随后通过例如用蛋白酶k消化来清除dna溶液中的蛋白质和其他污染物。随后从溶液中回收dna。在这样的情况下,这通过包括盐析、有机提取或将dna结合至固相支持物在内的多种方法进行。在一些情况下,方法的选择受到包括时间、花费和所需的dna量在内的若干种因素的影响。
在样品dna未包封在膜内时(例如,来自无细胞样品如血液或尿液的循环dna),任选地采用本领域中用于分离和/或纯化dna的标准方法(参见,例如,bettegowda等人,detectionofcirculatingtumordnainearly-andlate-stagehumanmalignancies.sci.transl.med,6(224):ra24.2014)。这样的方法包括使用蛋白质变性试剂,例如,离液盐(例如,盐酸胍或尿素);或去污剂,例如,十二烷基硫酸钠(sds)、溴化氰。备选方法包括但不限于乙醇沉淀或丙醇沉淀、真空浓缩,以及采用离心机的其他方法。在一些情况下,本领域技术人员还使用装置,如过滤装置,例如,超滤、二氧化硅表面或膜、磁性颗粒、聚苯乙烯颗粒、聚苯乙烯表面、带正电荷的表面和带正电荷的膜、带电荷的膜、带电荷的表面、带电荷开关膜、带电荷开关表面。
在一些情况下,一旦提取到核酸,则通过本领域已知的任何手段进行甲基化分析。多种甲基化分析程序是本领域已知的并且可用于实施本文公开的方法。这些测定允许确定组织样品内一个或多个cpg位点的甲基化状态。此外,可将这些方法用于甲基化核酸的绝对或相对定量。这样的甲基化测定涉及除其他技术之外的两个主要步骤。第一步是甲基化特异性反应或分离,如(i)亚硫酸氢盐处理,(ii)甲基化特异性结合,或(iii)甲基化特异性限制性酶。第二个主要步骤涉及(i)扩增和检测,或(ii)通过诸如以下的多种方法的直接检测:(a)pcr(序列特异性扩增)如taqman(r),(b)对未处理和亚硫酸氢盐处理的dna的dna测序,(c)通过连接染料修饰的探针(包括环状连接和切割)进行的测序,(d)焦磷酸测序,(e)单分子测序,(f)质谱或(g)southern印迹分析。
此外,可采用从亚硫酸氢盐转化的dna扩增的pcr产物的限制性酶消化,例如,由sadri和hornsby(1996,nucl.acidsres.24:5058-5059)描述的方法或cobra(combinedbisulfiterestrictionanalysis)(xiong和laird,1997,nucleicacidsres.25:2532-2534)。cobra分析是一种用于确定在少量基因组dna中的特定基因座处的dna甲基化水平的定量甲基化测定。简言之,使用限制性酶消化来揭示经亚硫酸氢钠处理的dna的pcr产物中的甲基化依赖性序列差异。首先根据frommer等人(frommer等人,1992,proc.nat.acad.sci.usa,89,1827-1831)描述的程序,通过标准的亚硫酸氢盐处理将甲基化依赖性序列差异引入基因组dna。然后采用对感兴趣的cpg位点具有特异性的引物进行亚硫酸氢盐转化的dna的pcr扩增,随后进行限制性内切核酸酶消化、凝胶电泳和采用特异性标记杂交探针的检测。原始dna样品中的甲基化水平由在广谱dna甲基化水平内线性定量方式的被消化pcr产物与未消化pcr产物的相对量表示。另外,该技术可以可靠地应用于从微切石蜡包埋组织样品获得的dna。用于cobra分析的典型试剂(例如,如可在典型的基于cobra的试剂盒中找到的)可包括但不限于:针对特定基因(或甲基化改变的dna序列或cpg岛)的pcr引物;限制性酶和合适的缓冲液;基因杂交寡核苷酸;对照杂交寡核苷酸;用于寡核苷酸探针的激酶标记试剂盒;以及放射性核苷酸。此外,亚硫酸氢盐转化试剂可包括:dna变性缓冲液;磺化缓冲液;dna回收试剂或试剂盒(例如,沉淀、超滤、亲和柱);脱磺化缓冲液;和dna回收组分。
在一个实施方案中,采用甲基化特异性pcr(msp)来确定选定cpg位点的甲基化谱。msp允许评估cpg岛内几乎任何组的cpg位点的甲基化状态,而不依赖于甲基化敏感性限制性酶的使用(herman等人,1996,proc.nat.acad.sci.usa,93,9821-9826;美国专利号5,786,146、6,017,704、6,200,756、6,265,171(herman和baylin);美国专利公开号2010/0144836(vanengeland等人))。简言之,通过脱氨剂如亚硫酸氢钠修饰dna,以将未甲基化(而非甲基化)的胞嘧啶转化成尿嘧啶,随后利用相对于未甲基化dna对甲基化dna具有特异性的引物进行扩增。在一些情况下,用于msp分析的典型试剂(例如,如可在典型的基于msp的试剂盒中找到的)包括但不限于:针对特定基因(或甲基化改变的dna序列或cpg岛)的甲基化和未甲基化pcr引物、优化的pcr缓冲液和脱氧核苷酸以及特异性探针。在一些情况下,采用如fackler等人(fackler等人,2004,cancerres.64(13)4442-4452;或fackler等人,2006,clin.cancerres.12(11pt1)3306-3310)所述的定量多重甲基化特异性pcr(qm-pcr)。
在一个实施方案中,采用methylight和/或重甲基(heavymethyl)方法来确定选定cpg位点的甲基化谱。methylight和重甲基测定是采用基于荧光的实时pcr(taqman(r))技术的高通量定量甲基化测定,在pcr步骤后无需进一步操作(eads,c.a.等人,2000,nucleicacidres.28,e32;cottrell等人,2007,j.urology177,1753;美国专利号6,331,393(laird等人))。简言之,methylight方法开始于基因组dna的混合样品,该样品根据标准程序在亚硫酸氢钠反应中转化成甲基化依赖性序列差异的混合池(亚硫酸氢盐方法将未甲基化的胞嘧啶残基转化成尿嘧啶)。然后在“无偏倚”(采用不与已知cpg甲基化位点重叠的引物)pcr反应或“偏倚”(采用与已知cpg二核苷酸重叠的pcr引物)反应中进行基于荧光的pcr。在一些情况下,序列区分在扩增过程的水平或荧光检测过程的水平下发生,或在这两种水平下发生。在一些情况下,使用methylight测定作为对于基因组dna样品中的甲基化模式的定量测试,其中序列区分在探针杂交的水平下发生。在该定量版本中,pcr反应提供在存在与特定假定甲基化位点重叠的荧光探针的情况下的无偏倚扩增。针对输入dna的量的无偏倚对照由其中引物和探针都不与任何cpg二核苷酸重叠的反应提供。或者,通过利用不“覆盖”已知甲基化位点的对照寡核苷酸(“msp”技术的基于荧光的版本)或利用覆盖潜在甲基化位点的寡核苷酸探测偏倚的pcr池来实现对基因组甲基化的定性测试。用于methylight分析的典型试剂(例如,如可在典型的基于methylight的试剂盒中找到的)可包括但不限于:针对特定基因(或甲基化改变的dna序列或cpg岛)的pcr引物;taqman(r)探针;优化的pcr缓冲液和脱氧核苷酸;以及taq聚合酶。
定量methylight使用亚硫酸氢盐来转化基因组dna,并且利用不依赖于甲基化的引物采用pcr对甲基化位点进行扩增。具有两种不同荧光团的对甲基化和未甲基化位点具有特异性的检测探针提供对甲基化的同时定量测量。重甲基技术开始于dna的硫酸氢盐转化。接下来,特异性阻断剂阻止未甲基化dna的扩增。甲基化基因组dna不结合该阻断剂,并且其序列将被扩增。利用甲基化特异性探针来检测经扩增的序列。(cottrell等人,2004,nuc.acidsres.32:e10)。
ms-snupe技术是基于dna亚硫酸氢盐处理和随后的单核苷酸引物延伸,用于评估特定cpg位点处的甲基化差异的定量方法(gonzalgo和jones,1997,nucleicacidsres.25,2529-2531)。简言之,使基因组dna与亚硫酸氢钠反应以将未甲基化的胞嘧啶转化成尿嘧啶,同时保持5-甲基胞嘧啶不变。然后采用对亚硫酸氢盐转化的dna具有特异性的pcr引物进行所需靶序列的扩增,并将所得产物分离并使用该产物作为用于感兴趣cpg位点处甲基化分析的模板。在一些情况下,分析了少量dna(例如,微切的病理学切片),并且该方法避免了使用限制性酶来确定cpg位点处的甲基化状态。用于ms-snupe分析的典型试剂(例如,如在典型的基于ms-snupe的试剂盒中找到的)包括但不限于:针对特定基因(或甲基化改变的dna序列或cpg岛)的pcr引物;优化的pcr缓冲液和脱氧核苷酸;凝胶提取试剂盒;阳性对照引物;针对特定基因的ms-snupe引物;反应缓冲液(针对ms-snupe反应);以及放射性核苷酸。此外,亚硫酸氢盐转化试剂可包括:dna变性缓冲液;磺化缓冲液;dna回收试剂或试剂盒(例如,沉淀、超滤、亲和柱);脱磺化缓冲液;和dna回收组分。
在另一个实施方案中,采用基于差异结合的甲基化检测方法来确定选定cpg位点的甲基化状态。对于差异甲基化区域的鉴别,一种方法是捕获甲基化dna。该方法采用这样的蛋白质,其中mbd2的甲基结合域与抗体的fc片段相融合(mbd-fc)(gebhard等人,2006,cancerres.66:6118-6128;和pct公开号wo2006/056480a2(relhi))。该融合蛋白具有优于常规甲基化特异性抗体的若干种优势。mbdfc对甲基化dna具有更高的亲和力并且结合双链dna。更重要的是,这两种蛋白质结合dna的方式不同。甲基化特异性抗体随机结合dna,这意味着只能获得二元回答(binaryanswer)。另一方面,mbd-fc的甲基结合域结合dna分子,无论该dna分子的甲基化状态如何。这种蛋白质-dna相互作用的强度由dna甲基化的水平限定。在结合基因组dna后,可使用盐浓度提高的洗脱溶液来分级分离未甲基化dna和甲基化dna,从而允许更加受控的分离(gebhard等人,2006,nucleicacidsres.34:e82)。因此,该方法被称为甲基-cpg免疫沉淀(mcip),其不仅富集基因组dna,而且还根据甲基化水平来分级分离该基因组dna,当还应该研究未甲基化dna级分时这是特别有帮助的。
在备选实施方案中,5-甲基胞苷抗体结合甲基化dna并使之沉淀。可从abeam(cambridge,ma)、diagenode(sparta,nj)或eurogentec(c/oanaspec,fremont,ca)获得抗体。一旦分离了甲基化片段,则可采用基于微阵列的技术如甲基化cpg岛回收测定(mira)或甲基化dna免疫沉淀(medip)来对这些甲基化片段进行测序(pelizzola等人,2008,genomeres.18,1652-1659;o’geen等人,2006,biotechniques41(5),577-580;weber等人,2005,nat.genet.37,853-862;horak和snyder,2002,methodsenzymol,350,469-83;lieb,2003,methodsmolbiol,224,99-109)。另一种技术为甲基-cpg结合域柱/部分解链的分子的分离(mbd/spm,shiraishi等人,1999,proc.natl.acad.sci.usa96(6):2913-2918)。
在一些实施方案中,用于检测甲基化的方法包括将基因组dna随机剪切或随机片段化、利用甲基化依赖性或甲基化敏感性限制性酶来切割dna并随后选择性地鉴别和/或分析经切割或未切割的dna。选择性鉴别可包括,例如,将经切割和未切割的dna分离(例如,根据大小)以及对被切割或未被切割的感兴趣序列进行定量。参见例如美国专利号7,186,512。或者,该方法可包括在限制性酶消化后将完整dna进行扩增,由此仅扩增在扩增区域中未被限制性酶切割的dna。参见例如美国专利号7,910,296;7,901,880;和7,459,274。在一些实施方案中,可采用基因特异性引物进行扩增。
例如,存在在其dna识别序列未被甲基化时在该dna识别序列处进行优先或显著切割或消化的甲基敏感性酶。因此,将未甲基化dna样品切割成比甲基化dna样品更小的片段。类似地,未切割过度甲基化的dna样品。相反,存在仅在其dna识别序列被甲基化时才在该dna识别序列处进行切割的甲基敏感性酶。适合用于该技术的方法的消化未甲基化dna的甲基敏感性酶包括但不限于hpall、hhal、maell、bstui和acil。在一些情况下,所使用的酶为hpall,其仅切割未甲基化序列ccgg。在其他情况下,所使用的另一种酶为hhal,其仅切割未甲基化序列gcgc。这两种酶均可从newenglandbiolabs(r),inc.获得。还使用了仅消化未甲基化dna的两种或更多种甲基敏感性酶的组合。仅消化甲基化dna的合适的酶包括但不限于dpnl(其仅在完全甲基化的5’-gatc序列处进行切割)以及mcrbc,即一种切割含有修饰胞嘧啶(5-甲基胞嘧啶或5-羟甲基胞嘧啶或n4-甲基胞嘧啶)的dna并且在识别位点5’...pumc(n4o-3ooo)pumc...3’处进行切割的内切核酸酶(newenglandbiolabs,inc.,beverly,ma)。用于在特定位点切割dna的选定限制性酶的切割方法和程序是技术人员公知的。例如,限制性酶的许多供应商提供关于通过特定限制性酶切割dna序列的条件和类型的信息,这些供应商包括newenglandbiolabs、pro-megabiochems、boehringer-mannheim等。sambrook等人(参见sambrook等人,molecularbiology:alaboratoryapproach,coldspringharbor,n.y.1989)提供了关于使用限制性酶和其他酶的方法的一般性描述。
在一些情况下,甲基化依赖性限制性酶是在甲基化识别序列处或附近切割或消化dna,但在该识别序列未被甲基化时不在同一序列处或附近切割dna的限制性酶。甲基化依赖性限制性酶包括在甲基化识别序列处进行切割的那些酶(例如,dpnl)以及在接近而非在识别序列处的序列处进行切割的酶(例如,mcrbc)。例如,mcrbc的识别序列为5’rmc(n40-3000)rmc3‘,其中“r”为嘌呤并且“mc”为甲基化胞嘧啶,并且“n40-3000”表示观察到限制性事件的两个rmc半位点之间的距离。mcrbc通常在一个一半位点或另一个一半位点附近进行切割,但切割位置通常分布在几个碱基对(来自甲基化碱基的大约30个碱基对)上。mcrbc有时切割两个一半位点的3’,有时切割两个一半位点的5’,而有时在两个位点之间进行切割。示例性甲基化依赖性限制性酶包括,例如,mcrbc、mcra、mrra、bisl、glal和dpnl。本领域技术人员将会理解,包括本文所述限制性酶的同源物和直系同源物在内的任何甲基化依赖性限制性酶也适合与一种或多种本文所述的方法一起使用。
在一些情况下,甲基化敏感性限制性酶是在未甲基化识别序列处或附近切割dna,但在该识别序列被甲基化时不在同一序列处或附近进行切割的限制性酶。示例性甲基化敏感性限制性酶在例如mcclelland等人,22(17)nucleicacidsres.3640-59(1994)中进行了描述。当识别序列内的胞嘧啶在位置c5处被甲基化时,不在其识别序列处或附近切割dna的合适的甲基化敏感性限制性酶包括,例如,aatii、acii、acdi、agei、alui、asci、asei、asisi、bbei、bsaai、bsahi、bsiei、bsiwi、bsrfi、bsshii、bsski、bstbi、bstni、bstui、clai、eaei、eagi、faui、fsei、hhai、hinpli、hincii、hpaii、hpy99i、hpych4iv、kasi、mboi、mlui、mapali、mspi、naei、nari、noti、pmli、psti、pvui、rsrii、sacii、sapi、sau3ai、sfli、sfoi、sgrai、smai、snabi、tsci、xmai和zrai。当识别序列内的腺苷在位置n6处被甲基化时,不在其识别序列处或附近切割dna的合适的甲基化敏感性限制性酶包括,例如,mboi。本领域技术人员将理解,包括本文所述限制性酶的同源物和直系同源物在内的任何甲基化敏感性限制性酶也适合与一种或多种本文所述的方法一起使用。本领域技术人员将进一步理解,在其识别序列处或附近存在胞嘧啶甲基化的情况下无法切割的甲基化敏感性限制性酶可能对其识别序列处或附近腺苷甲基化的存在不敏感。类似地,在其识别序列处或附近存在腺苷甲基化的情况下无法切割的甲基化敏感性限制性酶可能对其识别序列处或附近胞嘧啶甲基化的存在不敏感。例如,sau3ai对其识别序列处或附近的甲基化胞嘧啶的存在敏感(即,无法切割),但对其识别序列处或附近的甲基化腺苷的存在不敏感(即,能够切割)。本领域技术人员还将理解,一些甲基化敏感性限制性酶被包含其识别序列的dna的一条或两条链上的碱基的甲基化阻断,而其他甲基化敏感性限制性酶仅被两条链上的甲基化阻断,并且如果识别位点是半甲基化的,其仍可以切割。
在备选实施方案中,任选地将衔接子添加至随机片段化的dna的末端,然后利用甲基化依赖性或甲基化敏感性限制性酶来消化该dna,并随后使用与衔接子序列杂交的引物扩增完整dna。在这种情况下,进行第二步以确定扩增的dna池中特定基因的存在、不存在或量。在一些实施方案中,采用实时定量pcr来扩增dna。
在其他实施方案中,所述方法包括对基因组dna群体内的靶序列中的平均甲基化密度进行定量。在一些实施方案中,该方法包括在允许基因座中潜在限制性酶切割位点的至少一些拷贝保持未切割的条件下,使基因组dna与甲基化依赖性限制性酶或甲基化敏感性限制性酶接触;对该基因座的完整拷贝进行定量;以及将扩增产物的量与代表对照dna的甲基化的量的对照值进行比较,由此将该基因座中的平均甲基化密度相比于对照dna的甲基化密度进行定量。
在一些情况下,通过提供包含基因座的基因组dna的样品、利用甲基化敏感或甲基化依赖性的限制性酶切割该dna,并随后对完整dna的量进行定量,或对在感兴趣dna基因座处切割的dna的量进行定量,来确定dna的基因座的甲基化的量。完整或切割的dna的量将取决于含有基因座的基因组dna的初始量、基因座中甲基化的量以及在基因组dna中被甲基化的基因座中的核苷酸的数目(即,分数)。可通过将完整dna或切割dna的量与代表经类似处理的dna样品中完整dna或切割dna的量的对照值进行比较来确定dna基因座中甲基化的量。该对照值可代表已知或预测的甲基化核苷酸数目。或者,该对照值可代表来自另一(例如,正常的,无疾病的)细胞中相同基因座或来自第二基因座的完整或切割的dna的量。
通过在允许基因座中潜在限制性酶切割位点的至少一些拷贝保持未切割的条件下使用至少一种甲基化敏感性或甲基化依赖性限制性酶,并随后对剩余的完整拷贝进行定量,并且将该量与对照进行比较,可确定基因座的平均甲基化密度。如果在允许基因座中潜在限制性酶切割位点的至少一些拷贝保持未切割的条件下使甲基化敏感性限制性酶与dna基因座的拷贝相接触,则剩余的完整dna将与甲基化密度成正比,并且因此可与对照相比较以确定样品中基因座的相对甲基化密度。类似地,如果在允许基因座中潜在限制性酶切割位点的至少一些拷贝保持未切割的条件下使甲基化依赖性限制性酶与dna基因座的拷贝相接触,则剩余的完整dna将与甲基化密度成反比,并且因此可与对照相比较以确定样品中基因座的相对甲基化密度。这样的测定在例如美国专利号7,910,296中公开。
甲基化cpg岛扩增(mca)技术是一种可用于筛选基因组dna中改变的甲基化模式并且可用于分离与这些变化相关的特定序列的方法(toyota等人,1999,cancerres.59,2307-2312,美国专利号7,700,324(issa等人))。简言之,在任意机引发的pcr扩增之前,使用对其识别位点中的胞嘧啶甲基化具有不同敏感度的限制性酶消化来自原发性肿瘤、细胞系和正常组织的基因组dna。在高分辨率聚丙烯酰胺凝胶上解析pcr产物后,将显示出差异甲基化的片段进行克隆并测序。然后使用克隆的片段作为用于southern分析的探针,以确认这些区域的差异甲基化。用于mca分析的典型试剂(例如,如可在典型的基于mca的试剂盒中找到的)可包括但不限于:用于任意引发基因组dna的pcr引物;pcr缓冲液和核苷酸、限制性酶和合适的缓冲液;基因杂交寡核苷酸或探针;对照杂交寡核苷酸或探针。
其他甲基化检测方法包括在例如以下文献中描述的方法:美国专利号7,553,627;6,331,393;美国专利系列号12/476,981;美国专利公开号2005/0069879;rein等人,26(10)nucleicacidsres.2255-64(1998);以及olek等人,17(3)nat.genet.275-6(1997)。
在另一个实施方案中,采用甲基化敏感性高分辨率解链(highresolutionmelting,hrm)来确定选定cpg位点的甲基化状态。近期wojdacz等人报道了作为评价甲基化的技术的甲基化敏感性高分辨率解链(wojdacz和dobrovic,2007,nuc.acidsres.35(6)e41;wojdacz等人,2008,nat.prot.3(12)1903-1908;balic等人,2009j.mol.diagn.11102-108;以及美国专利公开号2009/0155791(wojdacz等人))。多种可商购的实时pcr机器具有hrm系统,包括rochelightcycler480、corbettresearchrotorgene6000和appliedbiosystems7500。如candiloro等人(candiloro等人,2011,epigenetics6(4)500-507)所述,hrm还可与其他扩增技术如焦磷酸测序相组合。
在另一个实施方案中,采用引物延伸测定(包括产生扩增的靶标以供使用质谱进行分析的优化的pcr扩增反应)来确定选定cpg基因座的甲基化状态。该测定还可以以多重化的方式进行。质谱法是一种用于检测与差异甲基化调控元件相关的多核苷酸的特别有效的方法。通过将检测到的信号的质量与感兴趣多核苷酸的预期质量进行比较来验证多核苷酸序列的存在。特定多核苷酸序列的相对信号强度(例如,光谱上质量峰)指示特定等位基因的相对群体,从而使得能够直接从数据计算等位基因比率。该方法在pct公开号wo2005/012578a1(beaulieu等人)中进行了详细描述,该pct专利通过引用而全文并入本文。对于甲基化分析,可采用该测定来检测亚硫酸氢盐引入的甲基化依赖性c至t序列变化。这些方法对于在单个孔中进行多重扩增反应和多重引物延伸反应(例如,多重同源引物质量延伸(hme)测定)以进一步提高通量并降低引物延伸反应的每个反应的成本是特别有用的。
用于dna甲基化分析的其他方法包括限制性位标基因组扫描(rlgs,costello等人,2002,meth.molbiol,200,53-70),甲基化敏感性代表性差异分析(ms-rda,ushijima和yamashita,2009,methodsmolbiol507,117-130)。用于相对甲基化的全面高通量阵列(charm)技术在wo2009/021141(feinberg和irizarry)中进行了描述。roche(r)nimblegen(r)微阵列包括芯片上染色质免疫沉淀(chlp芯片)或芯片上甲基化dna免疫沉淀(medip-芯片)。这些工具已用于多种癌症应用,包括黑素瘤、肝癌和肺癌(koga等人,2009,genomeres.,19,1462-1470;acevedo等人,2008,cancerres.,68,2641-2651;rauch等人,2008,proc.nat.acad.sci.usa,105,252-257)。其他人报道了用于高通量甲基化检测的硫酸氢盐转化、持锁探针杂交、环化、扩增和下一代测序或多重测序(deng等人,2009,nat.biotechnol27,353-360;ball等人,2009,nat.biotechnol27,361-368;美国专利号7,611,869(fan))。作为硫酸氢盐氧化的替代,bayeyt等人报道了将5-甲基胞嘧啶氧化而不与胸苷反应(随后进行pcr或焦磷酸测序)的选择性氧化剂(wo2009/049916(bayeyt等人))。
在一些情况下,使用定量扩增方法(例如,定量pcr或定量线性扩增)对限制性酶消化后侧翼为扩增引物的基因座内的完整dna的量进行定量。定量扩增的方法在例如美国专利号6,180,349;6,033,854;和5,972,602,以及例如degraves等人,34(1)biotechniques106-15(2003);deimanb,等人,20(2)mol.biotechnol.163-79(2002);以及gibson等人,6genomeresearch995-1001(1996)中公开。
在以甲基化特异性方式反应或分离核酸之后,在一些情况下对该核酸进行基于序列的分析。例如,一旦确定来自样品的一个特定基因组序列与其对应物相比是过度甲基化或甲基化不足的,则可确定该基因组序列的量。随后,可将该量与标准对照值进行比较,并使用该量确定样品中食管癌、胰腺癌或胃癌的存在。在许多情况下,期望使用本领域公知的几种核酸扩增程序中的任一种来扩增核酸序列。具体而言,核酸扩增是含有与被扩增的核酸序列(模板)互补的序列的核酸拷贝的化学或酶促合成。所述方法和试剂盒可采用本领域技术人员已知的任何核酸扩增或检测方法,诸如在美国专利号5,525,462(takarada等人);6,114,117(hepp等人);6,127,120(graham等人);6,344,317(urnovitz);6,448,001(oku);6,528,632(catanzariti等人);以及pct公开号wo2005/111209(nakajima等人)中所描述的那些。
在一些实施方案中,使用本领域技术人员已知的方法通过pcr扩增来扩增核酸。然而,本领域技术人员将认识到,扩增可通过任何已知的方法来完成,如连接酶链反应(lcr)、q-复制扩增、滚环扩增、转录扩增、自我持续序列复制、基于核酸序列的扩增(nasba),上述每一种方法均提供足够的扩增。还任选地使用分支dna技术来定性地显示代表特定甲基化模式的技术序列的存在,或定量地确定样品中该特定基因组序列的量。nolte综述了用于直接定量临床样品中的核酸序列的分支dna信号扩增(nolte,1998,adv.clin.chem.33:201-235)。
pcr过程是本领域公知的,并且包括,例如,逆转录pcr、连接介导的pcr、数字pcr(dpcr)或小液滴数字pcr(ddpcr)。关于pcr方法和方案的综述,请参见例如innis等人编著,pcrprotocols,aguidetomethodsandapplication,academicpress,inc.,sandiego,calif.1990;美国专利号4,683,202(mullis)。pcr试剂和方案还可从商业供应商如rochemolecularsystems获得。在一些情况下,pcr利用热稳定酶以自动化过程进行。在该过程中,反应混合物的温度自动循环通过变性区、引物退火区和延伸反应区。专门适用于此目的的机器是可商购的。
在一些实施方案中,还采用侵入式切割反应如invader(r)技术来测量扩增的序列(zou等人,2010,2010年7月28日associationofclinicalchemistry(aacc)海报展示,“sensitivequantificationofmethylatedmarkerswithanovelmethylationspecifictechnology;和美国专利号7,011,944(prudent等人))。
合适的下一代测序技术是广泛可用的。实例包括454lifesciences平台(roche,branford,ct)(margulies等人,2005nature,437,376-380);lllumina基因组分析仪、goldengate甲基化测定或infinium甲基化测定,即infinium人甲基化27k珠阵列或veracodegoldengate甲基化阵列(illumina,sandiego,ca;bibkova等人,2006,genomeres.16,383-393;美国专利号6,306,597和7,598,035(macevicz);7,232,656(balasubramanian等人));来自bio-rad的qx200tmdropletdigitaltmpcr系统;或dna连接测序,solid系统(appliedbiosystems/lifetechnologies);美国专利号6,797,470、7,083,917、7,166,434、7,320,865、7,332,285、7,364,858和7,429,453(barany等人);helicos真实单分子dna测序技术(harris等人,2008science,320,106-109;美国专利号7,037,687和7,645,596(williams等人);7,169,560(lapidus等人);7,769,400(harris)),pacificbiosciences的单分子实时(smrttm)技术,以及测序(soni和meller,2007,clin.chem.53,1996-2001);半导体测序(iontorrent;personalgenomemachine);dna纳米球测序;采用来自doversystems的技术的测序(polonator),以及无需在测序前扩增或以其他方式转化天然dna的技术(例如,pacificbiosciences和helicos),如基于纳米孔的策略(例如,oxfordnanopore、geniatechnologies和nabsys)。这些系统允许采用平行方式以高阶多重化对从样品分离的许多核酸分子进行测序。这些平台中的每一种均允许对核酸片段的克隆扩增或未扩增的单分子进行测序。某些平台涉及,例如,(i)染料修饰的探针的连接(包括环状连接和切割)测序,(ⅱ)焦磷酸测序,和(iii)单分子测序。
焦磷酸测序是基于合成测序的核酸测序方法,其依赖于对核苷酸掺入时释放的焦磷酸的检测。通常,合成测序涉及一次一个核苷酸地合成与所寻求的序列的链互补的dna链。可将研究的核酸固定至固体支持物上,与测序引物杂交,与dna聚合酶、atp硫酸化酶、萤光素酶、腺苷三磷酸双磷酸酶、腺苷5'磷酰硫酸(phosphsulfate)和萤光素一起温育。依次添加并除去核苷酸溶液。核苷酸的正确掺入释放焦磷酸,该焦磷酸与atp硫酸化酶相互作用并在腺苷5'磷酰硫酸的存在下产生atp,从而为萤光素反应提供能量,该萤光素反应产生化学发光信号,从而允许序列测定。用于焦磷酸测序的机器和甲基化特异性试剂可从qiagen,inc.(valencia,ca)获得。还参见tost和gut,2007,nat.prot.22265-2275。普通技术人员可以使用的基于焦磷酸测序的系统的实例通常涉及以下步骤:将衔接子核酸与研究的核酸连接并使研究的核酸与珠子杂交;在乳液中扩增研究的核酸中的核苷酸序列;使用皮升的多孔固体支持物分选珠子;并通过焦磷酸测序方法对扩增的核苷酸序列进行测序(例如,nakano等人,2003,j.biotech.102,117-124)。这样的系统可用于指数式扩增由本文所述的方法生成的扩增产物,例如,通过将异源核酸连接至由本文所述的方法生成的第一扩增产物。
cpg甲基化数据分析方法
在某些实施方案中,将针对生物标志物小组中的生物标志物测量的甲基化值以数学方式组合,并且该组合值与潜在的诊断问题相关联。在一些情况下,通过本领域数学方法的任何适当状态将甲基化生物标志物值组合。用于将生物标志物组合与疾病状态关联的公知数学方法采用如下方法:如判别分析(da)(例如,线性da、二次da、正则化da)、判别函数分析(dfa)、核方法(例如,svm)、多维标度(mds)、非参数方法(例如,k-最近邻分类器)、pls(偏最小二乘法)、基于树的方法(例如,逻辑回归、cart、随机森林方法、boosting/bagging方法)、广义线性模型(例如,逻辑回归)、基于主成分的方法(例如,simca)、广义加性模型、基于模糊逻辑的方法、神经网络和基于遗传算法的方法。技术人员在选择合适的方法来评估本文所述的表观遗传标志物或生物标志物组合方面将没有问题。在一个实施方案中,在关联表观遗传标志物或生物标志物组合的甲基化状态中使用以便例如诊断食管癌、胰腺癌或胃癌的方法选自da(例如,线性判别分析、二次判别分析、正则化判别分析)、dfa、核方法(例如,svm)、mds、非参数方法(例如,k-最近邻分类器)、pls(偏最小二乘法)、基于树的方法(例如,逻辑回归、cart、随机森林方法、boosting方法)或广义线性模型(例如,逻辑回归)以及主成分分析。关于这些统计学方法的细节见于以下参考文献:ruczinski等人,12j.ofcomputationalandgraphicalstatistics475-511(2003);friedman,j.h.,84j.oftheamericanstatisticalassociation165-75(1989);hastie,trevor,tibshirani,robert,friedman,jerome,theelementsofstatisticallearning,springerseriesinstatistics(2001);breiman,l.,friedman,j.h.,olshen,r.a.,stone,c.j.classificationandregressiontrees,california:wadsworth(1984);breiman,l.,45machinelearning5-32(2001);pepe,m.s.,thestatisticalevaluationofmedicaltestsforclassificationandprediction,oxfordstatisticalscienceseries,28(2003);以及duda,r.o.,hart,p.e.,stork,d.o.,patternclassification,wileyinterscience,第二版(2001)。
在一个实施方案中,通过例如p-值检验或t-值检验或f-检验,将每个甲基化小组的相关结果根据其与疾病或肿瘤类型阳性状态的相关性来进行评定。随后选择评定的(最好是第一名,即,低p-值或t-值)生物标志物并将其添加至甲基化小组,直到达到某个诊断值。这样的方法包括采用例如随机变量t-检验来鉴别甲基化小组,或者更广义地说,鉴别在几个类别中差异甲基化的基因(wrightg.w.和simonr,bioinformatics19:2448-2455,2003)。其他方法包括指定用于确定将包含在生物标志物小组中的表观遗传标志物的显著性水平的步骤。小组中包括在小于指定阈值的单变量参数显著性水平下的类别之间差异甲基化的表观遗传标志物。指定的显著性水平是否小到足以排除足够的错误发现并不重要。在一些问题中,通过使用作特征的生物标志物小组更开放来实现更好的预测。在一些情况下,如果包含较少的标志物,则这些小组是可生物解释且可临床适用的。与交叉验证类似,对在交叉验证过程中创建的每个训练集重复生物标志物选择。这是为了提供预测误差的无偏倚估计。与新患者样品数据一起使用的甲基化小组是通过应用甲基化选择和“已知”甲基化信息的分类器而得到的甲基化小组,或对照甲基化小组。
也可以使用利用甲基化谱来预测未来样品类别的模型。这些模型可以基于复合协变量预测器(radmacher等人,journalofcomputationalbiology9:505-511,2002)、对角线线性判别分析(dudoit等人,journaloftheamericanstatisticalassociation97:77-87,2002)、最近邻分类(同样是dudoit等人)和具有线性核的支持向量机(ramaswamy等人,pnasusa98:15149-54,2001)。该模型并入在如通过随机变量t-检验评价的给定显著性水平(例如,0.01、0.05或0.1)下差异甲基化的标志物(wrightg.w.和simonr.bioinformatics19:2448-2455,2003)。可评估采用交叉验证(优选留一交叉验证)的各个模型的预测误差(simon等人,journalofthenationalcancerinstitute95:14-18,2003)。对于每个留一交叉验证训练集,重复整个模型构建过程,包括表观遗传标志物选择过程。在一些情况下,还评估了模型的交叉验证误差率估计值是否显著小于从随机预测预期的误差率估计值。在一些情况下,将类别标签随机排列,然后重复整个留一交叉验证过程。显著性水平是使得交叉验证误差率不大于通过真实甲基化数据获得的交叉验证误差率的随机排列的比例。
另一种分类方法是由bo和jonassen描述的贪婪对(greedy-pairs)方法(genomebiology3(4):research0017.1-0017.11,2002)。贪婪对方法从根据训练集上的所有标志物的各自t-得分对所有标志物进行排序开始。这种方法试图选择一起良好工作的标志物对来区分类别。
此外,任选地将采用甲基化谱的二叉树分类器用于预测未来样品的类别。该树的第一个节点包含区分类别的总集中的两个子集的二元分类器。各个二元分类器均基于“支持向量机”,该“支持向量机”并入在如通过随机变量t-检验评价的显著性水平(例如,0.01、0.05或0.1)下在标志物中差异表达的标志物(wrightg.w.和simonr.bioinformatics19:2448-2455,2003)。评估用于所有可能的二元分区的分类器,并且所选择的分区是交叉验证预测误差最小的分区。然后,对于由先前的二元分割确定的两个类别子集依次重复该过程。二叉树分类器的预测误差可通过对整个树构建过程进行交叉验证来评估。这种总体交叉验证包括在每个节点处重新选择最佳分区,以及重新选择用于每个交叉验证训练集的标志物,如simon等人(simon等人,journalofthenationalcancerinstitute95:14-18,2003)所述。在多折交叉验证(several-foldcrossvalidation)中,保留一部分样品,在剩余样品上开发二叉树,随后对被保留的样品预测类别成员。将该过程重复几次,每次保留不同百分比的样品。将样品随机分至部分测试集中(simonr和lama.brb-arraytoolsuserguide,3.2版.biometricresearchbranch,nationalcancerinstitute)。
因此,在一个实施方案中,每个标志物b)的相关结果均通过其与疾病的正确相关性(优选通过p-值检验)来评定。还可包括d)按照其评级顺序来选择标志物的步骤。
在另外的实施方案中,可在向患者施用疗法之前、期间或之后,额外地采用诸如转录速率的值、水平、特点、特征、性质等,mrna水平,翻译速率,蛋白质水平,生物学活性,细胞特征或性质,基因型,表型等因素,以使得能够进一步分析患者的癌症状态。
在一些实施方案中,用于正确预测状态的诊断测试以测定的灵敏度、测定的特异性或接受者操作特征(“roc”)曲线下面积进行测量。在一些情况下,灵敏度是通过测试预测为阳性的真阳性的百分比,而特异性是通过测试预测为阴性的真阴性的百分比。在一些情况下,roc曲线提供了作为1-特异性的函数的测试灵敏度。例如,roc曲线下面积越大,则测试的预测值越准确或有力。测试效用的其他有用量度包括阳性预测值和阴性预测值。阳性预测值是测试阳性为真实阳性的人的百分比。阴性预测值是测试阴性为真实阴性的人的百分比。
在一些实施方案中,本文公开的一种或多种生物标志物在不同样品中显示出至少p<0.05、p<10-2、p<10-3、p<10-4或p<10-5的统计学差异。使用这些生物标志物的诊断测试可显示出至少0.6、至少约0.7、至少约0.8或至少约0.9的roc。在一些情况下,生物标志物在患有或没有食管癌、胰腺癌或胃癌的不同受试者中被差异甲基化。在另外的情况下,针对食管癌、胰腺癌或胃癌的不同亚型的生物标志物被差异甲基化。在某些实施方案中,采用本文所述的方法测量患者样品中的生物标志物,并将其与例如预先确定的生物标志物水平进行比较,并将其用于确定患者是否患有食管癌、胰腺癌或胃癌,并且/或者确定患者患有何种食管癌、胰腺癌或胃癌亚型。在其他实施方案中,将患者样品中的生物标志物的组合的相关性与例如预先确定的生物标志物组进行比较。在一些实施方案中,然后将该测量值与区分食管癌、胰腺癌或胃癌的存在或不存在或区分食管癌、胰腺癌或胃癌亚型的相关诊断量、截止值或多变量模型得分进行比较。如本领域中所熟知的,通过调节测定中所使用的特定诊断截止值,可根据诊断者的偏好提高诊断测定的灵敏度或特异性。在一些实施方案中,例如,通过测量来自患有或没有食管癌、胰腺癌或胃癌的患者以及患有不同食管癌、胰腺癌或胃癌亚型的患者的统计学显著数目的样品中的生物标志物过度甲基化或甲基化不足的量,并且绘制截止值以适应所需的特异性和灵敏度水平,来确定特定诊断截止值。
试剂盒/制品
在一些实施方案中,本文提供了用于检测和/或表征本文所述生物标志物的甲基化谱的试剂盒。在一些情况下,该试剂盒包含多个引物或探针以检测或测量一个或多个样品的甲基化状态/水平。在一些情况下,这样的试剂盒包含与至少一种本文所述的甲基化标志物序列杂交的至少一种多核苷酸,和用于检测基因甲基化的至少一种试剂。用于检测甲基化的试剂包括,例如,硫酸氢钠,被设计用于在标志物序列未被甲基化(例如,含有至少一个c-u转化)时与作为标志物序列的产物的序列杂交的多核苷酸,和/或甲基化敏感性限制性酶或甲基化依赖性限制性酶。在一些情况下,该试剂盒提供固体支持物,该固体支持物为适于在测定中使用的测定装置的形式。在一些情况下,该试剂盒进一步包含可检测标签,该标签任选地连接至试剂盒中的多核苷酸,例如,探针。
在一些实施方案中,所述试剂盒包含能够特异性扩增本文所述生物标志物的dna区域的至少一部分的一个或多个(例如,1、2、3、4个或更多个)不同的多核苷酸(例如,引物和/或探针)。任选地,该试剂盒中还包含能够与扩增部分杂交的一种或多种可检测地标记的多肽。在一些实施方案中,该试剂盒包含足以扩增2、3、4、5、6、7、8、9、10个或更多个不同dna区域或其部分的引物,并且任选地包含能够与每个扩增的dna区域或其部分杂交的可检测地标记的多核苷酸。该试剂盒可进一步包含甲基化依赖性或甲基化敏感性限制性酶和/或亚硫酸氢钠。
在一些实施方案中,所述试剂盒包含亚硫酸氢钠,用于全基因组扩增的引物和衔接子(例如,可连接或以其他方式连至基因组片段的寡核苷酸),以及用于对来自本文所述表观遗传标志物的dna区域的至少一个胞嘧啶的转化的甲基化序列和/或转化的未甲基化序列的存在进行定量的多核苷酸(例如,可检测地标记的多核苷酸)。
在一些实施方案中,所述试剂盒包含甲基化感测限制性酶(例如,甲基化依赖性限制性酶和/或甲基化敏感性限制性酶),用于全基因组扩增的引物和衔接子,以及用于对本文所述表观遗传标志物的dna区域的至少一部分的拷贝数进行定量的多核苷酸。
在一些实施方案中,所述试剂盒包含甲基化结合部分,和用于对本文所述标志物的dna区域的至少一部分的拷贝数进行定量的一种或多种多核苷酸。甲基化结合部分是指与甲基胞嘧啶特异性结合的分子(例如,多肽)。
实例包括缺乏dna切割活性但保留结合甲基化dna的能力的限制性酶或其片段,与甲基化dna特异性结合的抗体等。
在一些实施方案中,所述试剂盒包含封装材料。如本文所用的,术语“封装材料”可指容纳试剂盒组分的物理结构。在一些情况下,封装材料保持试剂盒组分的无菌性,并且由常用于这类目的的材料(例如,纸、波纹纤维、玻璃、塑料、铝箔、安瓿等)制成。所述试剂盒中包含在进行测定时有用的其他材料,包括试管、移液管等。在一些情况下,所述试剂盒还包含关于在本文所述的任何测定中使用这些试剂中的一种或多种的书面说明。
在一些实施方案中,试剂盒还包含缓冲剂、防腐剂或蛋白质/核酸稳定剂。在一些情况下,试剂盒还包含如本文所述的反应混合物的其他组分。例如,试剂盒包含一份或多份如本文所述的热稳定dna聚合酶,和/或一份或多份dntp。在一些情况下,试剂盒还包含已知量的携带基因座的各个等位基因的模板dna分子的对照样品。在一些实施方案中,试剂盒包含阴性对照样品,例如,不含携带基因座的各个等位基因的dna分子的样品。在一些实施方案中,试剂盒包含阳性对照样品,例如,含有已知量的基因座的各个等位基因中的一个或多个的样品。
某些术语
除非另有定义,否则本文使用的所有技术和科学术语都具有与所请求保护的主题所属领域的技术人员通常理解的相同含义。应理解,前文的一般描述和下文的详细描述仅是示例性和解释性的,并非限制任何所请求保护的主题。在本申请中,除非另有特别说明,否则单数的使用包括复数。必须指出,除非上下文另有明确规定,如在说明书和所附权利要求中所使用的,单数形式“一个”、“一种”和“该”包括复数个指代物。在本申请中,除非另有说明,“或”的使用表示“和/或”。此外,术语“包括”以及其他形式如“包含”的使用并不是限制性的。
如本文所用的,范围和量可表示为“约”特定值或范围。约还包括确切的量。因此,“约5μl”意指“约5μl”,也指“5μl”。通常,术语“约”包括预期在实验误差范围内的量。
本文使用的章节标题仅用于组织的目的,不应被解释为限制所描述的主题。
如本文所用,术语“个体”、“受试者”和“患者”意指任何哺乳动物。在一些实施方案中,该哺乳动物为人。在一些实施方案中,该哺乳动物为非人的哺乳动物。所述术语均不要求或限于以医疗保健工作者(例如,医生、注册护士、护士执业者、医师助理、老年或临终关怀工作者)的监督(例如,不断的或间歇的)为特征的情况。
“位点”对应于单个位点,其在一些情况下为单个碱基位置或一组相关的碱基位置,例如,cpg位点。“基因座”对应于包含多个位点的区域。在一些情况下,基因座包含一个位点。
实施例
这些实施例仅为了说明性目的而提供,而非限制本文提供的权利要求的范围。
实施例1
从qiaamp循环核酸试剂盒获得无细胞dna样品。使用生物标志物cp10673833(cob-2)的甲基化谱进行分析。
相对于来自正常受试者的cob-2甲基化率,来自患有食管癌、胰腺癌或胃癌的受试者的cob-2甲基化率较高(图1)。此外,cob-2甲基化率在食管癌、胰腺癌和胃癌之间存在差异。治疗后,观察到所有三种癌症类型的甲基化率在不存在肿瘤负荷的情况下降低:食管癌(图2a-2b)、胰腺癌(图3a-3b)和胃癌(图4a-4b)。然而,在存在肿瘤负荷的情况下,观察到甲基化率相对于不存在肿瘤负荷的情况和正常样品而言较高(图2a-2b、图3a-3b和图4a-4b)。
实施例2.甲基化相关区块(mcb)的鉴别
在一些情况下,由于dna甲基转移酶和脱甲基酶的持续能力和缺乏序列特异性,以及遗传连锁分析中单元型区块的概念,位置靠近的cpg具有相似的甲基化水平。计算彼此位于一千碱基内的任何两个cpg的β值之间的pearson相关系数r2。使用r2>0.5的截止值来鉴别由持锁探针探询的区域内的甲基化相关区块(mcb)(本文中也称为bcm)。使用皮尔逊r<0.5的值来鉴别任何两个相邻标志物之间的过渡点(边界),从而指示不相关的甲基化。将未被边界隔开的标志物合并至甲基化相关区块(mcb)中。该程序在每个区块中在2至22个cpg位置之间进行合并,以鉴别持锁数据(padlockdata)内的每个诊断分类中的bcm总数。通过将bcm内所有探询的cpg位置处c的数目进行加和并除以在那些位置处的c+t总数来计算整个mcb的甲基化频率。分别从来自两个诊断分类中每一个的30个癌症样品和30个相应正常组织样品计算相隔不超过200bp的每一对cpg标志物的甲基化频率之间的pearson相关系数。使用pearsonr<0.5的值鉴别任何两个相邻标志物之间的过渡点(边界),从而指示不相关的甲基化。将未被边界隔开的标志物合并至甲基化相关区块(mcb)中。通过将bcm内所有探询的cpg位置处c的数目进行加和并除以在那些位置处的c+t总数来计算整个mcb的甲基化频率。
实施例3.将差异甲基化的标志物与基因表达相联系
从tcga网站获得胰腺癌样品的tcgadna甲基化和rnaseq表达数据。每个cpg处的dna甲基化程度以β值表示,并且计算为(m/(m+u)),其中m和u分别为代表甲基化等位基因强度和未甲基化等位基因强度的归一化值。β值在0至1的范围内,并且反映每个样品中每个cpg处的甲基化等位基因的分数。对于tcga数据中的胰腺癌样品和匹配的正常样品中的每一个,计算所有485,000个标志物的甲基化β值。选择平均值小于0.05或大于0.95的cpg标志物用于进一步评估。还选择肿瘤组织的平均甲基化值与相应正常组织的平均甲基化值之间的差异大于0.5的标志物。在这两组的交集处,进一步选择正常样品的平均甲基化<0.05并且正常样品与肿瘤样品之间的差异大于0.5的标志物,并鉴别与这些标志物相关的基因。对于每个标志物,随后将胰腺癌样品分成甲基化值大于胰腺癌样品的平均值的样品和甲基化值小于胰腺癌样品的平均值的样品。接下来,检查tcga数据中的rnaseq数据,并计算每个基因的相对表达。由于表达值变化很大,因此如下调整该值:log2(表达值+1)。鉴别甲基化值的差异与相关基因表达水平的变化相关的基因。选择存在相关性的基因以供进一步的功能评估和验证。
dna/rna分离和定量pcr
从患者获得白血病样品和相应的远处样品;将样品冷冻并保存在-80℃下直至使用。采用allprepdna/rnamini试剂盒(qiagen,valencia,ca),根据制造商的建议进行dna和rna从样品中的分离。在rna分离期间,使样品经历柱上dna酶消化。采用nanodrop2000(thermoscientific)对rna进行定量。根据制造商的说明,每个样品使用200ngrna来使用iscriptcdna合成试剂盒(bio-rad,inc)进行cdna合成。在7500实时pcr系统(appliedbiosystems)上,使用基因特异性引物和powersybrgreenpcrmastermix,通过标准40-循环扩增方案进行qpcr。实验一式三份地进行,并相对于内源性actb水平进行归一化。采用δδct方法(循环阈值<30)来计算表达的相对变化倍数。
细胞培养和基因转染
人胰腺癌细胞系panc03.27和人胚胎肾细胞系hek293a从美国模式培养物保藏中心(americantypeculturecollection)(manassas,va,usa)获得,并且根据它们的说明进行培养。本文公开的基因的表达构建体以pcmv6-entry载体中的
通过采用磷酸钙沉淀,用胰腺癌基因mgfp慢病毒载体与第三代包装载体一起共转染hek-293t细胞来制备慢病毒颗粒。在转染后36小时收集病毒上清液。在转染白血病基因mgfp慢病毒载体前一天,将人胰腺癌细胞系panc03.27接种到6孔板中。通过用moi约5的病毒颗粒感染细胞24hr来生成稳定的细胞系,收集该细胞系并采用facs将该细胞系分选至100%gfp-阳性。然后将gfp阳性细胞用于细胞培养中的集落形成测定和裸鼠中的肿瘤异种移植。
集落形成测定
以每孔500个细胞的密度将细胞接种到6孔板中,并在37℃以及5%co2加湿空气下培养14天。用10%甲醛将集落固定5min,然后用0.1%结晶紫染色30秒。对由50个或更多个细胞组成的集落进行计数。该实验一式三份地进行并重复3次。板接种效率=(集落数目/接种的细胞数目)×100%。
肿瘤异种移植
所有动物研究均依照机构及国际动物法规进行。动物方案经中山大学实验动物管理与使用委员会批准。雌性无胸腺balb/c裸鼠(4-5周龄,18-20克)购自供应商(广东省实验动物中心,广东,中国)。
向小鼠皮下注射100μl悬浮在无血清培养基中的肿瘤细胞。通过目测检查,每3天监测一次肿瘤生长。采用卡尺测量肿瘤大小,并根据以下公式计算肿瘤体积:肿瘤体积(mm3)=(长度(mm)×宽度(mm)2)×0.5。在注射后3-4周将所有动物处死,并收获异种移植物。从每个实验组中的五只小鼠获得代表性数据。用单向重复测量anova进行统计学分析。
实施例4
表1示出了本文所述的cpg位点所涉及的基因名称。
实施例5
表2示出了本文所述的探针。
实施方案1涉及一种生成有需要的受试者的生物标志物的甲基化谱的方法,该方法包括:(a)采用脱氨剂对提取的基因组dna进行处理以生成包含脱氨核苷酸的基因组dna样品,其中所述提取的基因组dna从来自所述受试者的生物样品获得;(b)检测所述提取的基因组dna与探针之间的杂交,其中所述探针与cg10673833(肌球蛋白ig)杂交;以及(c)根据在所述提取的基因组dna与所述探针之间所检测到的杂交来生成甲基化谱。
实施方案2:如实施方案1所述的方法,其中所述探针包含式i的结构:
其中:
a为第一靶标结合区;
b为第二靶标结合区;并且
l为连接区;
其中a具有与从seqidno:1的5’末端的位置1开始的至少30
个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性;
b具有与从seqidno:1的3’末端的位置1’开始的至少12个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性;并且
其中l与a相连接;并且b与a或l相连接。
实施方案3:如实施方案2所述的方法,其中所述探针包含式ia的结构:
实施方案4:如实施方案2所述的方法,其中a具有与从seqidno:1的5’末端的位置1开始的至少40个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
实施方案5:如实施方案2所述的方法,其中a具有与从seqidno:1的5’末端的位置1开始的至少50个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
实施方案6:如实施方案2所述的方法,其中b具有与从seqidno:1的3’末端的位置1’开始的至少15个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
实施方案7:如实施方案2所述的方法,其中b具有与从seqidno:1的3’末端的位置1’开始的至少20个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
实施方案8:如实施方案2所述的方法,其中l的长度为约15、20、25、30、35、40、45、50、55或60个核苷酸。
实施方案9:如实施方案1所述的方法,其中所述探针具有与seqidno:1至少80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的序列同一性。
实施方案10:如实施方案1所述的方法,其中所述生成进一步包括生成逐对甲基化差异数据集,该数据集包含:(i)所述经处理的基因组dna的甲基化谱与第一正常样品的甲基化谱之间的第一差异;(ii)第二正常样品的甲基化谱与第三正常样品的甲基化谱之间的第二差异;以及(iii)第一原发性癌症样品的甲基化谱与第二原发性癌症样品的甲基化谱之间的第三差异。
实施方案11:如实施方案10所述的方法,其中所述生成进一步包括通过机器学习方法利用对照对所述逐对甲基化差异数据集进行分析,以生成所述甲基化谱。
实施方案12:如实施方案10所述的方法,其中所述第一原发性癌症样品为食管癌样品、胰腺癌样品或胃癌样品。
实施方案13:如实施方案10所述的方法,其中所述第二原发性癌症样品为非食管癌样品、非胰腺癌样品或非胃癌样品。
实施方案14:如实施方案11所述的方法,其中所述对照包含一组甲基化谱,其中每个所述甲基化谱均由从已知癌症类型获得的生物样品生成。
实施方案15:如实施方案14所述的方法,其中所述已知癌症类型为食管癌、胰腺癌或胃癌。
实施方案16:如实施方案14所述的方法,其中所述已知癌症类型为复发性或难治性食管癌、复发性或难治性胰腺癌、或复发性或难治性胃癌。
实施方案17:如实施方案14所述的方法,其中所述已知癌症类型为转移性食管癌、转移性胰腺癌或转移性胃癌。
实施方案18:如实施方案14所述的方法,其中所述已知癌症类型为食管癌。
实施方案19:如实施方案18所述的方法,其中食管癌包括食管鳞状细胞癌、食管腺癌或未分化的食管癌。
实施方案20:如实施方案14所述的方法,其中所述已知癌症类型为胰腺癌。
实施方案21:如实施方案20所述的方法,其中胰腺癌包括外分泌胰腺癌和胰腺内分泌肿瘤。
实施方案22:如实施方案20所述的方法,其中胰腺癌包括胰腺腺癌、胰腺腺鳞癌、胰腺鳞状细胞癌、印戒细胞癌、未分化的胰腺癌、具有巨细胞的未分化胰腺癌、壶腹癌、胃泌素瘤、胰岛素瘤、胰高糖素瘤、生长抑素瘤、舒血管肠肽瘤、胰多肽瘤或类癌瘤。
实施方案23:如实施方案14所述的方法,其中所述已知癌症类型为胃癌。
实施方案24:如实施方案23所述的方法,其中胃癌包括胃腺癌、胃淋巴瘤、胃肠道间质瘤、类癌瘤、胃原发性鳞状细胞癌、胃小细胞癌或胃平滑肌肉瘤。
实施方案25:如实施方案11所述的方法,其中所述机器学习方法采用选自以下的一项或多项的算法:主成分分析、逻辑回归分析、最近邻分析、支持向量机和神经网络模型。
实施方案26:如实施方案1-25中任一项所述的方法,其中所述方法进一步包括进行dna测序反应,以在生成所述甲基化谱之前对所述生物标志物的甲基化进行定量。
实施方案27涉及一种选择疑似患有实体瘤的受试者进行治疗的方法,该方法包括:(a)采用脱氨剂对提取的基因组dna进行处理以生成包含脱氨核苷酸的基因组dna样品,其中所述提取的基因组dna从来自疑似患有实体瘤的受试者的生物样品获得;(b)从所述提取的基因组dna生成包含cg10673833(肌球蛋白ig)的甲基化谱;(c)将所述生物标志物的甲基化谱与对照进行比较;(d)如果所述甲基化谱与所述对照相关,则将所述受试者鉴别为患有实体瘤;以及(e)如果所述受试者被鉴别为患有实体瘤,则向所述受试者施用有效量的治疗剂;其中所述实体瘤选自食管癌、胰腺癌或胃癌。
实施方案28:如实施方案27所述的方法,其中所述探针包含式i的结构:
其中:
a为第一靶标结合区;
b为第二靶标结合区;并且
l为连接区;
其中a具有与从seqidno:1的5’末端的位置1开始的至少30
个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性;
b具有与从seqidno:1的3’末端的位置1’开始的至少12个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性;并且
其中l与a相连接;并且b与a或l相连接。
实施方案29:如实施方案28所述的方法,其中所述探针包含式ia的结构:
实施方案30:如实施方案28所述的方法,其中a具有与从seqidno:1的5’末端的位置1开始的至少40个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
实施方案31:如实施方案28所述的方法,其中a具有与从seqidno:1的5’末端的位置1开始的至少50个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
实施方案32:如实施方案28所述的方法,其中b具有与从seqidno:1的3’末端的位置1’开始的至少15个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
实施方案33:如实施方案28所述的方法,其中b具有与从seqidno:1的3’末端的位置1’开始的至少20个连续核苷酸至少70%、80%、90%、95%或99%的序列同一性。
实施方案34:如实施方案28所述的方法,其中l的长度为约15、20、25、30、35、40、45、50、55或60个核苷酸。
实施方案35:如实施方案27所述的方法,其中所述探针具有与seqidno:1至少80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的序列同一性。
实施方案36:如实施方案27所述的方法,其中所述比较进一步包括生成逐对甲基化差异数据集,该数据集包含:(i)所述经处理的基因组dna的甲基化谱与第一正常样品的甲基化谱之间的第一差异;(ii)第二正常样品的甲基化谱与第三正常样品的甲基化谱之间的第二差异;以及(iii)第一原发性癌症样品的甲基化谱与第二原发性癌症样品的甲基化谱之间的第三差异。
实施方案37:如实施方案27或36所述的方法,其中所述比较进一步包括通过机器学习方法利用对照对所述逐对甲基化差异数据集进行分析,以生成所述甲基化谱。
实施方案38:如实施方案36所述的方法,其中所述第一原发性癌症样品为食管癌样品、胰腺癌样品或胃癌样品。
实施方案39:如实施方案36所述的方法,其中所述第二原发性癌症样品为非食管癌样品、非胰腺癌样品或非胃癌样品。
实施方案40:如实施方案37所述的方法,其中所述对照包含一组甲基化谱,其中每个所述甲基化谱均由从已知癌症类型获得的生物样品生成。
实施方案41:如实施方案40所述的方法,其中所述已知癌症类型为食管癌、胰腺癌或胃癌。
实施方案42:如实施方案40或41所述的方法,其中所述已知癌症类型为复发性或难治性食管癌、复发性或难治性胰腺癌、或复发性或难治性胃癌。
实施方案43:如实施方案40-42中任一项所述的方法,其中所述已知癌症类型为转移性食管癌、转移性胰腺癌或转移性胃癌。
实施方案44:如实施方案37所述的方法,其中所述机器学习方法采用选自以下的一项或多项的算法:主成分分析、逻辑回归分析、最近邻分析、支持向量机和神经网络模型。
实施方案45:如实施方案27-44中任一项所述的方法,其中所述生成进一步包括使所述生物标志物与探针杂交并进行dna测序反应,以对所述生物标志物的甲基化进行定量。
实施方案46:如实施方案1-45中任一项所述的方法,其中所述生物样品包含循环肿瘤细胞。
实施方案47:如实施方案1-46中任一项所述的方法,其中所述受试者为人。
虽然本文已经示出并描述了本公开内容的优选实施方案,但对于本领域技术人员将显而易见的是,这些实施方案仅作为示例提供。在不偏离本公开内容的情况下,本领域技术人员现将想到许多变化、改变和替换。应理解,本文所述的本公开内容的实施方案的各种替代方案均可用于实施本公开内容。意在用以下权利要求限定本公开内容的范围,并由此涵盖这些权利要求范围内的方法和结构及其等同物。
序列表
<110>优美佳生物技术有限公司
加利福尼亚大学董事会
<120>实体瘤甲基化标志物及其用途
<130>49697-711.601
<140>pct/us2017/040963
<141>2017-07-06
<150>62/358,795
<151>2016-07-06
<160>1
<170>patentin版本3.5
<210>1
<211>112
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>人工序列的描述:合成探针
<220>
<221>修饰的碱基
<222>(89)..(94)
<223>a、c、t、g、未知或其他
<220>
<221>修饰的碱基
<222>(98)..(98)
<223>肌苷
<400>1
aacacaacctccttataaaacctgtctcttatacacatctccgagcccacgagactcgtc60
ggcagcgtcagatgtgtataagagacagnnnnnnaacnaaaaaccctccaaa112
- 还没有人留言评论。精彩留言会获得点赞!