预测抗精神病药物疗效的DNA甲基化标记物及筛选方法和应用
预测抗精神病药物疗效的dna甲基化标记物及筛选方法和应用
技术领域
1.本发明专利涉及生物技术领域,具体是指一种用于预测抗精神病药物疗效的dna甲基化标记物及其筛选方法和应用。
背景技术:
2.精神分裂症是一种重型精神障碍,多发病于青少年及青年早期,表现为阳性症状、阴性症状及认知功能损害等症状群。该病发病率约为1%,致残率高,相当比例的患者存在症状迁延不愈或渐进性功能衰退的现象。抗精神病药物治疗仍是精神分裂症的主要治疗方法。早期抗精神病药物治疗应答情况是该病长期症状和功能结局的最强有力的预测因素之一。然而,迄今仍缺乏客观的生物学标记物来预测患者的早期治疗应答。目前已有初步的脑结构协变连接研究显示精神分裂症患者可能存在皮层下脑结构同步发育异常,且与患者的行为学表型相关。目前借助“在体”脑影像技术从脑结构及功能网络水平上发现了可预测抗精神病药物早期疗效的神经生物学标记物。然而,脑网络连接是从宏观角度预判抗精神病药早期疗效,微观上,脑网络连接可能受基因表达及神经可塑性变化的影响,而基因表达又在很大程度上受表观遗传的调控。已有研究证实表观遗传学变化与脑结构体积变化之间存在关联。因此我们进一步推测表观遗传或有预判精神分裂症患者早期治疗应答的潜在价值。表观遗传是指dna序列无改变,但基因表达发生变化,进而改变基因功能并引起表型变化。在表观遗传修饰中,dna甲基化是研究得较深入且较重要的调节基因表达的方式之一。目前,已有研究初步揭示抗精神病药物治疗可影响dna甲基化水平,如奥氮平可引起大鼠海马、小脑中编码多巴胺受体、转运体等基因甲基化水平普遍增高;氯氮平可引起小鼠神经发育相关基因甲基化水平改变等。然而,仍未有研究探讨dna甲基化在预判抗精神病药早期疗效中的作用。
3.因此,找到准确的dna甲基化标记物是预测抗精神病药物疗效转归的至关重要的一步。
技术实现要素:
4.本发明旨在至少在一定程度上解决现有技术中存在的技术问题之一,为此,提供一种用于预测抗精神病药物疗效的dna甲基化标记物,本发明还提供上述甲基化标记物在制备用于预测抗精神病药物疗效的诊断试剂和/或辅助诊断试剂和/或诊断试剂盒中的用途。本发明进一步提供上述甲基化标记物的筛选方法。用于预测抗精神病药物疗效的dna甲基化标记物预测抗精神病药物治疗疗效,可以提高抗精神病药物疗效的预测准确率,节约成本,适于推广应用,具有较好的应用前景;本发明甲基化标记物的筛选方法,简单、科学、可靠。通过对dna甲基化数据分析,发现与抗精神病药物疗效预测相关的新的生物标记物。
5.在本发明的第一方面,本发明提供一种用于预测抗精神病药物疗效的dna甲基化标记物,所述用于预测抗精神病药物疗效的dna甲基化标记物选自人第1号染色体上的甲基
化cpg位点cg08348962、第4号染色体上的甲基化cpg位点cg27184628、第5号染色体上的甲基化cpg位点cg19679633、第6号染色体上的甲基化cpg位点cg10652641、第8号染色体上的甲基化cpg位点cg21442626、第12号染色体上的甲基化cpg位点cg09265000、第15号染色体上的甲基化cpg位点cg27079104、第16号染色体上的甲基化cpg位点cg06295223、第19号染色体上的甲基化cpg位点cg07237326中的一个或多个。
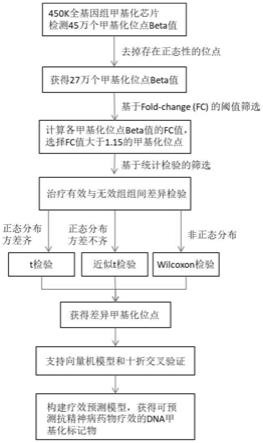
6.优选地,所述标记物选自人第1号染色体上的甲基化cpg位点cg08348962、第4号染色体上的甲基化cpg位点cg27184628、第5号染色体上的甲基化cpg位点cg19679633、第6号染色体上的甲基化cpg位点cg10652641、第8号染色体上的甲基化cpg位点cg21442626、第12号染色体上的甲基化cpg位点cg09265000、第15号染色体上的甲基化cpg位点cg27079104、第16号染色体上的甲基化cpg位点cg06295223中的一个或多个。
7.更优选地,所述甲基化cpg位点cg08348962位于ildr2基因上;所述甲基化cpg位点cg27184628位于med28基因上;所述甲基化cpg位点cg19679633位于c5orf38基因上;所述甲基化cpg位点cg10652641位于c6orf27基因上;所述甲基化cpg位点cg21442626位于atp6v1c1基因上;所述甲基化cpg位点cg09265000位于rarg基因上;所述甲基化cpg位点cg27079104位于hexa基因上;所述甲基化cpg位点cg06295223位于prdm7基因上。
8.在本发明的第二方面,本发明提供一种上述甲基化标记物在制备用于预测抗精神病药物疗效的诊断试剂和/或辅助诊断试剂和/或诊断试剂盒中的用途。
9.在本发明的第三方面,本发明提供一种试剂盒,其将上述甲基化标记物作为抗精神病药物疗效的标记物。
10.在本发明的第四方面,本发明提供一种上述用于预测抗精神病药物疗效的dna甲基化标记物的筛选方法,包括如下步骤:
11.步骤1)、基于甲基化beta值筛选:采用illumina 450k甲基化芯片检测精神分裂症患者治疗有效者与无效者的全基因组45万甲基化cpg位点的甲基化水平即beta值,去掉所检测到的甲基化cpg位点中存多态性的cpg位点,并获得剩余甲基化cpg位点的beta值;
12.步骤2)、基于fold
‑
change(fc)的阈值筛选:根据步骤1)计算得到的剩余甲基化cpg位点的beta值进一步计算各甲基化cpg位点的fc值,进一步筛选出fc值大于1.15的甲基化cpg位点;
13.步骤3)、基于统计检验筛选:根据步骤2)筛选出的甲基化cpg位点的甲基化beta值选择不同的检验方法进行两总体的差异检验,筛选出治疗有效组与无效组两组间有显著差异的甲基化cpg位点;
14.步骤4)、构建疗效预测模型:对步骤3)筛选出的治疗有效组与无效组两组间有显著差异的甲基化cpg位点的beta值,构建抗精神病药物治疗疗效预测模型,通过采用机器学习支持向量机模型和十折交叉验证所述甲基化cpg位点,计算治疗有效者与无效者样本的预测准确率;
15.步骤5)、获得用于预测抗精神病药物疗效的dna甲基化标记物:所述步骤4)的抗精神病药物疗效预测模型中对应的甲基化cpg位点中的一个或多个即为可预测抗精神病药物疗效的dna甲基化标记物。
16.在本发明的技术方案中,所述步骤3)中,若步骤2)筛选出的甲基化cpg位点的甲基化beta值数据服从正态分布且满足方差齐性条件,采用t检验;若步骤2)筛选出的甲基化
cpg位点的甲基化beta值数据服从正态分布但不满足方差齐性条件,采用近似t检验;若步骤2)筛选出的甲基化cpg位点的甲基化beta值数据不服从正态分布,采用wilcoxon秩和检验,并且p值经fdr校正后小于0.05的cpg位点被认为存在显著差异。
17.在本发明的技术方案中,所述步骤4)中,所述机器学习支持向量机模型,使用r语言平台(v3.6.3)进行数据分析,所使用的工具包为e1071(v 1.7.4),并结合十折交叉验证,以上述步骤3)中得到的差异甲基化cpg位点的甲基化beta值构建抗精神病药物疗效预测模型进行相互验证。
18.在本发明的技术方案中,所述步骤4)中,预测准确率的计算公式为:
[0019][0020]
其中,a为预测为治疗应答且实际也为治疗应答患者样本个数,b为预测为治疗应答患者但实际为治疗无应答个数,c为预测为治疗无应答但实际为治疗应答患者样本个数,d为预测为治疗无应答且实际也为治疗无应答样本个数。
[0021]
本发明的有益效果在于:
[0022]
1、本发明提供了一种用于预测抗精神病药物疗效的dna甲基化标记物;用于预测抗精神病药物疗效的dna甲基化标记物包括人第1号染色体上的甲基化cpg位点cg08348962、第4号染色体上的甲基化cpg位点cg27184628、第5号染色体上的甲基化cpg位点cg19679633、第6号染色体上的甲基化cpg位点cg10652641、第8号染色体上的甲基化cpg位点cg21442626、第12号染色体上的甲基化cpg位点cg09265000、第15号染色体上的甲基化cpg位点cg27079104、第16号染色体上的甲基化cpg位点cg06295223、第19号染色体上的甲基化cpg位点cg07237326中的至少一个,也可将该9个甲基化cpg位点联合起来预测抗精神病药物治疗疗效,由此,可提高抗精神病药物疗效的预测准确率,节约成本,适于推广应用,具有较好的应用前景;
[0023]
2、本发明提供一种上述甲基化标记物在制备用于预测抗精神病药物疗效的诊断试剂和/或辅助诊断试剂和/或诊断试剂盒中的用途;可通过dna甲基化标记物的甲基化水平来预测抗精神病药物疗效转归;
[0024]
3、本发明提供一种上述甲基化标记物的筛选方法,通过该方法可筛选出用于预测抗精神病药物疗效的dna甲基化标记物,其简单、科学、可靠。
附图说明
[0025]
图1为可预测抗精神病药物疗效的甲基化cpg位点筛选方法流程图;
[0026]
图2为十折交叉验证在测试集上的平均准确率结果图。
具体实施方式
[0027]
下面将结合实施例对本发明的方案进行解释。本领域技术人员将会理解,下面的实施例仅用于说明本发明,而不应视为限定本发明的范围。实施例中未注明具体技术或条件的,按照本领域内的文献所描述的技术或条件或者按照产品说明书进行。
[0028]
实施例1
[0029]
用于预测抗精神病药物疗效的dna甲基化标记物的筛选方法,包括如下步骤,
[0030]
步骤1):基于甲基化beta值筛选:采用illumina 450k甲基化芯片检测精神分裂症患者治疗有效者与无效者的全基因组甲基化cpg位点的甲基化水平即beta值,去掉所检测到的甲基化cpg位点中存多态性的cpg位点,并获得剩余甲基化cpg位点的beta值;
[0031]
本实施例通过招募首次发作且未经治疗的精神分裂症患者38例,并给予8周利培酮单一抗精神病药物治疗,治疗8周后评估患者疗效,根据andreasen缓解标准,将患者分为缓解与未缓解组。临床症状评估、药物干预、疗效评定如下:
[0032]
临床症状评估:采用阳性和阴性症状量表(positive and negative syndrome scale,panss)评定患者的症状严重程度。panss共包括三个维度:阳性症状(panss
‑
positive symptom,panss
‑
p,由p1,p2,p3,p4,p5,p6,p7组成),阴性症状(panss
‑
negative symptom,panss
‑
n,由n1,n2,n3,n4,n5,n6,n7组成),以及一般精神病理症状(panss
‑
general psychopathological symptom,panss
‑
g,由g1~g16组成)。
[0033]
药物干预:患者接受利培酮单药治疗8周,治疗剂量从1mg/日开始,根据临床表现逐渐加量,在开始治疗的2周内达到并稳定在治疗剂量2
‑
4mg,若患者症状未见明显改善可增加剂量,最高可至6mg/日。所有患者均未使用情绪稳定剂和抗抑郁剂。由两名有经验的医师每周评估利培酮的安全性,分别在基线及治疗8周随访时采用panss量表评估病人的症状严重程度。
[0034]
疗效评定:利培酮治疗8周后疗效评定根据anderson等所成立的精神分裂症缓解工作组(remission in schizophrenia working group,rswg)的缓解标准。rswg组将p1、p2、p3、n1、n4、n6、g5、g9等panss的8项评分均≤3,且维持至少6个月定义为缓解。本研究治疗时间标准定为8周,借助anderson分类标准将患者分为治疗缓解组14例与未缓解组24例。
[0035]
在入组时于固定时间(早上6:30)采集患者治疗前(基线期)的全血dna,基于illumina450k芯片检测所有患者全基因组45万dna甲基化cpg位点的beta值。去掉所检测到的甲基化cpg位点中存多态性的cpg位点,并获得剩余27万甲基化cpg位点的甲基化beta值,在得到的27万甲基化cpg位点基础上分析抗精神病药物治疗8周缓解组与未缓解组基线期(治疗前)cpg位点beta值的差异。
[0036]
步骤2)、基于fold
‑
change(fc)的阈值筛选:根据步骤1)计算得到的剩余27万甲基化cpg位点的beta值进一步计算各甲基化cpg位点的fc值,进一步筛选出fc值大于1.15的甲基化cpg位点9837个;
[0037]
所述步骤2)中,对于来自缓解组、未缓解(分别是以下公式中的a、b两组)两组样本数据,fc值的定义如下:
[0038][0039]
基于fold
‑
change(fc)的阈值筛选,筛选出fc值大于1.15的甲基化cpg位点9837个,对于筛选出的fc值大于1.15的9837个甲基化cpg位点进行进一步的差异分析。
[0040]
步骤3)、基于统计检验筛选:根据步骤2)筛选出的甲基化cpg位点的甲基化beta值选择不同的检验方法进行两总体的差异检验,筛选出治疗有效组与无效组两组间有显著差异的甲基化cpg位点;
[0041]
所述步骤3)中,若步骤2)筛选出的甲基化cpg位点的甲基化beta值数据服从正态分布且满足方差齐性条件,采用t检验;若步骤2)筛选出的甲基化cpg位点的甲基化beta值
数据服从正态分布但不满足方差齐性条件,采用近似t检验;若步骤2)筛选出的甲基化cpg位点的甲基化beta值数据不服从正态分布,采用wilcoxon秩和检验,并且p值经fdr校正后小于0.05的cpg位点被认为存在显著差异。由此,筛选出治疗有效组与无效组两组间有显著差异的甲基化cpg位点9个。
[0042]
步骤4)、构建疗效预测模型:对步骤3)筛选出的治疗有效组与无效组两组间有显著差异的9个甲基化cpg位点cpg位点的beta值,构建抗精神病药物治疗疗效预测模型,通过采用机器学习支持向量机模型和十折交叉验证所述甲基化cpg位点,计算治疗有效者与无效者样本的预测准确率;
[0043]
十折交叉验证(10
‑
fold cross
‑
validation),是常用的测试方法,用来测试算法预测的准确性。将数据集分成十分,轮流将其中9份作为训练数据,1份作为测试数据进行预测。每次试验都会得出相应的准确率。10次的结果的准确率的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计。
[0044]
由上述方法验证所述9个甲基化cpg位点中的一个或多个预测抗精神病药物疗效模型的的准确率高达100%;
[0045]
十次十折交叉验证在测试集的平均准确率为100%,每次十折交叉验证在测试集上的平均准确率如下图2所示。图中,横坐标为次数,纵坐标为准确率。
[0046]
所述步骤4)中,所述机器学习支持向量机模型,使用r语言平台(v3.6.3)进行数据分析,所使用的工具包为e1071(v 1.7.4),并结合十折交叉验证,以上述步骤3)中的9个差异甲基化cpg位点的甲基化beta值构建抗精神病药物疗效预测模型进行相互验证。
[0047]
所述步骤4)中,预测准确率的计算公式为:
[0048][0049]
其中,a为预测为治疗应答且实际也为治疗应答患者样本个数,b为预测为治疗应答患者但实际为治疗无应答个数,c为预测为治疗无应答但实际为治疗应答患者样本个数,d为预测为治疗无应答且实际也为治疗无应答样本个数。
[0050]
所述步骤(4)详细如下:本实施例使用支持向量机方法,使用r语言平台(v3.6.3)进行数据分析,所用工具包为e1071(v 1.7.4),并结合交叉验证,以上述步骤(3)中的9个差异cpg位点的甲基化beta值构建预测模型进行相互验证。
[0051]
本实施例使用r语言平台(v3.6.3)进行数据分析,所用工具包为e1071(v 1.7.4);通过对样本数据进行甲基化分析,获得9个显著(校正后p
‑
value<0.05)、可能与抗精神病药物早期治疗应答相关的甲基化cpg位点(见表1),并计算出所述甲基化cpg位点的甲基化beta值来确定dna甲基化水平,beta值=来自甲基化珠粒类型的强度值/(来自甲基化的强度值+来自未甲基化珠粒类型的强度值+100)。上述cpg位点即为用于预测抗精神病药物早期治疗应答的dna甲基化标记物。用于预测抗精神病药物疗效的dna甲基化标记物的筛选方法得到的用于预测抗精神病药物疗效的dna甲基化标记物如表1所示。
[0052]
表1预测抗精神病药物疗效的dna甲基化标记物
[0053][0054]
本实施例通过机器学习支持向量机(support vector machine,svm)方法,利用这9个cpgcpg位点甲基化水平即beta值对患者疗效进行预测,十次十折交叉验证(10
‑
fold cross
‑
validation)平均准确率为100%。
[0055]
cpg位点以上述甲基化cpg位点的甲基化beta值构建预测模型,通过计算样本预测准确率验证该模型的可行性,样本预测准确率计算公式为:
[0056][0057]
其中,a为预测为治疗应答且实际也为治疗应答患者样本个数,b为预测为治疗应答患者但实际为治疗无应答个数,c为预测为治疗无应答但实际为治疗应答患者样本个数,d为预测为治疗无应答且实际也为治疗无应答样本个数。
[0058]
使用机器学习方法(支持向量机、交叉验证)对上述预测模型进行相互验证:
[0059]
在机器学习方法中,支持向量机(svm)是一种有监督的机器学习方法,通常用于数据的二进制分类。给定分类问题中的输入数据和学习目标x={x1,...,x
n
},y={y1,...,y
n
},输入数据的每个样本都包含多个特征,从而构成一个特征空间:x
i
=[x1,...,x
n
]∈x。学习目标y∈{
‑
1,1}是一个二进制变量,表示负例和正例。
[0060]
若输入数据所在的特征空间存在作为决策边界的超平面将学习目标按正类和负类分开,并使任意样本的点到平面距离大于等于1:
[0061]
决策边界:w
t
x+b=0
[0062]
点到平面距离:y
i
(w
t
x
i
+b)≥1
[0063]
则称该分类问题具有线性可分离性。参数w和b是分别是超平面的法向向量和截距。
[0064]
满足此条件的决策边界实际上构造了两个平行的超平面作为区间边界,以区分样本的分类。
[0065][0066][0067]
在间隔边界以上的样本被判为正例样本,而在间隔边界以下的样本被判为负例样本。将两个间隔边界之间的距离定义为位于间隔边界上的正例样本和负例样本作为支持向量。
[0068]
步骤5)、获得用于预测抗精神病药物疗效的dna甲基化标记物:所述步骤4)的抗精神病药物疗效预测模型中对应的9个甲基化cpg位点中的一个或多个即为可预测抗精神病药物疗效的dna甲基化标记物。
[0069]
由本实施例预测抗精神病药物疗效的dna甲基化标记物的筛选方法得到的两组间差异甲基化cpg位点9个(见表1,对应基因包括rarg、hexa、celf6等,分别参与神经源性分化过程,神经退行性疾病、孤独症的发病机制等)。可预测患者疗效的cpg位点有(见表1):cg19679633、cg27184628、cg06295223、cg27079104、cg21442626、cg07237326、cg09265000、cg10652641、cg08348962。
[0070]
利用这9个cpg位点的甲基化beta值中的一个或多个或联合起来预测精神分裂症早期治疗应答,适于大规模推广应用。
[0071]
实施例2
[0072]
本实施例提供了一种用于预测抗精神病药物疗效的诊断试剂盒,所述诊断试剂盒将上述甲基化标记物作为抗精神病药物疗效的标记物。
[0073]
进一步地,本实施例提供了一种抗精神病药物疗效预测的方法,包括:
[0074]
1、提取待测样本的基因组dna;
[0075]
2、以步骤1中的基因组dna为模板,利用上述试剂盒进行pcr扩增;
[0076]
3、测序;
[0077]
4、得到dna甲基化检测结果;
[0078]
5、根据人第1号染色体上的甲基化cpg位点cg08348962、第4号染色体上的甲基化cpg位点cg27184628、第5号染色体上的甲基化cpg位点cg19679633、第6号染色体上的甲基化cpg位点cg10652641、第8号染色体上的甲基化cpg位点cg21442626、第12号染色体上的甲基化cpg位点cg09265000、第15号染色体上的甲基化cpg位点cg27079104、第16号染色体上的甲基化cpg位点cg06295223、第19号染色体上的甲基化cpg位点cg07237326中的至少一个cpg位点甲基化水平,实现对待测样本抗精神病药物疗效预测。
[0079]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1