益生菌嵌合传感器及其构建方法和应用
本发明涉及生物技术应用领域,具体涉及一种基于双组分系统(组氨酸激酶受体,应答调节因子)两个组成部分进行嵌合重组改造,人工构建针对特定生物大分子的响应传感系统。
背景技术:
双组分系统,包含组氨酸激酶(histidinekinases,hk)及应答调节因子(responseregulator,rr)两个典型的功能蛋白。组氨酸激酶,主要由位于n-端可变的配体结合结构域(ligandbindingdomain,lbd),跨膜结构域(tm),以及位于c-端相对保守的二聚化/磷酸转移结构域(dhp),atp结合/催化结构域(ca)等功能域组成。应答调节因子,则包括两个主要的功能区域,分别是位于n-端的信号接收结构域(receiverdomain,rec),以及位于c-端的dna-结合结构域(dnabindingdomain,dbd)。
当输入信号出现时,通常位于膜外的hk-lbd,从静默构象迅速切换至激活构象,这种构象重排将传递信息至膜内的c端信号转导区,由hk-ca结构域催化从atp获得γ-磷酰基团,再递呈至位于hk-dhp区高度保守的组氨酸残基,完成激酶传感器的磷酸化激活。随后,激活的组氨酸激酶通过hk-dhp区介导,结合胞内的rr,传递磷酰基至n-端的rr-rec,从而使保守的天冬氨酸残基发生磷酸化,再激活位于c端的rr-dbd,完成信号从hk传递激活至rr的过程。激活状态的rr,可实现对下游一个或多个输出启动子的转录调控。
天然存在的双组分系统,响应对象主要为一系列小分子物质,如钾离子,氮离子等(riglardt,giessentw,baymm,etal.engineeredbacteriacanfunctioninthemammaliangutlong-termaslivediagnosticsofinflammation.naturebiotechnology2017,35:653-658.)。目前,未见有针对蛋白质等大分子的双组分系统传感通路,然而,在临床疾病模型中,其特征性标志物常为蛋白质等大分子,此时,若要实现对此类特征性标志物的检测,通常需预先获得针对性的特异性抗体,进一步组装为经典的酶联检测试剂盒,方能实现对标志物分子的定性或定量检测。本方法以溃疡性结肠炎为疾病模型,针对溃疡性结肠炎临床检验使用的钙卫蛋白(calprotectin)炎症因子标志物,利用益生菌株为载体构建了一种全细胞传感器。通过将可表达针对钙卫蛋白的特异性纳米抗体编码序列,活性替换融合天然双组分系统组氨酸激酶受体的配体结合结构域,从而获得由益生菌携带的,针对钙卫蛋白大分子标志物的嵌合型双组分传感系统,有望在肠道共生定殖状态下,以无创、非侵入方式实现对生物大分子标志物的检测响应。
技术实现要素:
为探索创建自然界所不存在的针对蛋白质等生物大分子的肠道益生菌传感器,本发明的首要目的是提供一种通用的功能域融合重组技术,采用针对目标大分子的特异性纳米抗体编码序列,对肠道益生菌内源的双组分系统进行活性融合,构建可响应溃疡性结肠炎钙卫蛋白标志物分子的工程益生菌。具体而言,本发明包括如下技术方案:
根据本发明的第一个方面,提供一种益生菌嵌合传感器构建方法,包括如下步骤:
s1.益生菌载体菌种挑选:选择合适的益生菌株;
s2.准备用于构建传感器的质粒骨架prr-thsr和phk-thss;
s3.依据步骤s2中的质粒骨架,进行双组分系统组氨酸激酶受体的改造:利用可特异性结合目标蛋白的纳米抗体nbcp17的编码序列与计算机模拟分析得到的组氨酸激酶受体结合结构域及两侧位置进行交换融合,构建嵌合型组氨酸激酶受体文库;
s4.利用步骤s3获得的组氨酸激酶嵌合受体文库,构建可检测钙卫蛋白目标分子的组氨酸激酶嵌合受体的益生菌株:与应答调节因子组成杂合双组分系统,从而创建依赖指定目标蛋白激发的嵌合双组分系统,形成益生菌嵌合传感器;
其中,所述嵌合型组氨酸激酶受体为phk-ptac-thss-nbcp,所述应答调节因子为prr-plteto-1-thsr-sfgfp。
所述prr-thsr和phk-thss可通过文献landrybp,palankir,dyulgyarovn,etal.phosphataseactivitytunestwo-componentsystemsensordetectionthreshold.naturecommuncations2018,9:1433,按指示途径获得质粒骨架。
进一步的,所述步骤s1中的益生菌株选自大肠杆菌nissle1917或乳杆菌或双歧杆菌。
进一步的,所述步骤s3中可特异性结合目标蛋白的纳米抗体nbcp17为免疫骆驼获得的针对钙卫蛋白分子的纳米抗体,其获取方式为:
1)使用钙卫蛋白为抗原,与完全弗氏佐剂混合(v/v=1:1),充分乳化,皮下注射免疫双峰驼;从第2次免疫开始,使用不完全弗氏佐剂1:1混合乳化,间隔免疫5次;
2)第5次免疫结束后第7天,采集骆驼颈部静脉血50ml,分离淋巴细胞,提取总rna,反转录成cdna;
3)利用正向引物c-01:gtcctggctgctcttctacaagg(seqidno.1)和反向引物c-02:ggtacgtgctgttgaactgttcc(seqidno.2),扩增获得650-750bp的片段,纯化后作为二轮扩增的模板;根据骆驼vhh片段上下游保守序列设计引物,钓取骆驼源vhhs编码序列,酶切连接噬菌粒载体phen2,电转大肠杆菌tg1感受态,复性,涂板,37℃倒置培养,待菌体长成,洗下菌体;
4)利用碳酸盐缓冲液稀释钙卫蛋白抗原,加入96孔酶联板,4℃过夜孵育制备抗原包被板;以辅助噬菌体m13k07感染tg1展示文库,经4轮筛选,获得亲和力相对最高的子文库,涂布双抗性平板,挑取单克隆,培养12-18小时表达抗体;离心取上清,加入抗原预制板,进行间接elisa评估,选择效价最高的单克隆,测序获得纳米抗体的编码序列。
进一步的,所述步骤s3中构建组氨酸激酶嵌合受体文库的方法如下:通过三维结构模拟比对,分析获得配体结合结构域对应的编码序列范围,随后采用无缝克隆的方式构建组氨酸激酶嵌合受体文库,并分别命名为phk-ptac-thss-nbcp01、phk-ptac-thss-nbcp02、phk-ptac-thss-nbcp03、phk-ptac-thss-nbcp04、phk-ptac-thss-nbcp05、phk-ptac-thss-nbcp06、phk-ptac-thss-nbcp07、phk-ptac-thss-nbcp08、phk-ptac-thss-nbcp09、phk-ptac-thss-nbcp10、phk-ptac-thss-nbcp11、phk-ptac-thss-nbcp12、phk-ptac-thss-nbcp13、phk-ptac-thss-nbcp14、phk-ptac-thss-nbcp15、phk-ptac-thss-nbcp16、phk-ptac-thss-nbcp17、phk-ptac-thss-nbcp18、phk-ptac-thss-nbcp19和phk-ptac-thss-nbcp20。
进一步的,所述步骤s4包括:
1)将prr-plteto-1-thsr-sfgfp电转化导入益生菌株感受态细胞,通过特异性引物扩增筛选得到阳性的转化子;
2)利用步骤1)中的阳性转化子,制作感受态细胞,进一步将嵌合激酶受体文库分别导入已经携带prr-plteto-1-thsr-sfgfp质粒的益生菌株;
3)通过添加iptg、脱水四环素以及钙卫蛋白溶液至步骤2)中的工程化菌株,获得具有荧光响应信号的菌株,即为可响应钙卫蛋白的组氨酸激酶嵌合受体的益生菌株。
本发明的第二个方面是提供了一种益生菌嵌合传感器,其由上述方法构建获得,为包括组氨酸激酶嵌合受体以及应答调节因子双组分系统的益生菌株。
本发明的第三个方面是提供了所述益生菌嵌合传感器的应用,用于制备生物大分子标志物的检测试剂。
进一步的,所述生物大分子为钙卫蛋白。
本发明通过基因功能域融合手段,基于nissle1917益生菌载体,对异源双组分系统组氨酸激酶受体进行融合改造,获得具有应答响应钙卫蛋白能力的嵌合激酶受体,在与同源的应答调节因子组成杂合型双组分系统后,可使nissle1917益生菌株具有检测溃疡性结肠炎钙卫蛋白炎症因子的能力,经深入改造后具有较好应用于临床无创检测的潜力。
附图说明
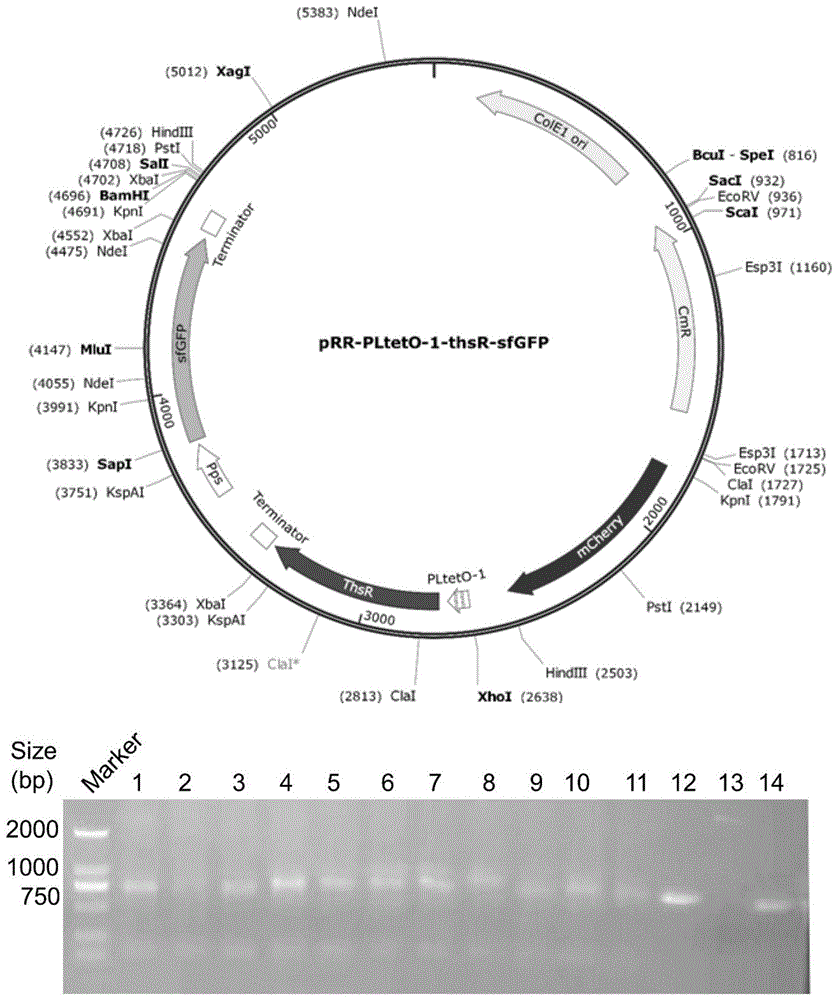
图1为携带应答调节因子单元的prr-plteto-1-thsr-sfgfp质粒图谱示意及构建验证结果
图2为携带嵌合激酶受体的phk-ptac-thss-nbcp质粒图谱示意及构建验证结果
图3为携带嵌合激酶受体和信号报告单元的益生菌钙卫蛋白传感器灵敏度测试结果
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合图示与具体实施例,进一步阐述本发明。
下面实施例中未注明具体实验条件的试验方法,通常按照常规实验条件或按照制造厂所建议的实验条件。所使用的材料、试剂等,如无特殊说明,为从商业途径得到的试剂和材料。
本文中所涉及的各溶液制备方法如下:
磷酸盐缓冲液:磷酸二氢钾0.24g/l,磷酸氢二钠1.42g/l,氯化钠8.0g/l,氯化钾0.2g/l,ph=7.4,121℃灭菌15分钟。
lb培养基:酵母提取物5g/l,胰蛋白胨10g/l,氯化钠10g/l(lb固体培养基则需另加15g/l琼脂粉)。
m9甘油培养基:1×m9盐,0.4%v/v甘油,0.2%酪蛋白氨基酸,2mmmgso4,100umcacl2。配制方法:(1)配制5×浓度的m9盐溶液:七水合磷酸钠64.0g/l,磷酸二氢钾15.0g/l,氯化钠2.5g/l,氯化铵5.0g/l。(2)配制1m的硫酸镁溶液:七水合硫酸镁246.0g/l。(3)配制1m的氯化钙溶液:六水合氯化钙219.1g/l。(4)配制50%的甘油水溶液:量取0.5l甘油,加双蒸水至1.0l。将上述四种试剂,121℃灭菌15分钟,备用。(5)配制20%酪蛋白氨基酸溶液:称2.0g酪蛋白氨基酸,加双蒸水溶解至10ml,0.22微米滤器过滤除菌。(6)按5×m9盐溶液,200ml;1m的硫酸镁溶液,2ml;1m的氯化钙溶液,0.1ml;50%的甘油水溶液,12.5ml;20%酪蛋白氨基酸溶液,10ml。
本发明的方法使用的质粒骨架为prr-thsr和phk-thss,可从北京中源合聚生物科技有限公司购买获得(商品编号分别为:#104336,#90952),亦可通过实施例2所述的方法构建。
实施例1:益生菌载体的选择
益生菌载体菌株的选择:肠道益生菌escherichiacolinissle1917(ecn),具有调节tnf-α、ifn-γ等细胞因子释放,抑制病原菌粘附于肠上皮细胞等作用(albarn,francescaa.,joségm,teresav,etal.theadministrationofescherichiacolinissle1917amelioratesdevelopmentofdss-inducedcolitisinmice.frontiersinpharmacology2018,9:468.)。在欧洲循证医学诊断与管理共识中,甚至认为其具有替代一线药物美沙拉嗪的潜力(harbordm,elliakimr,bettenworthd,etal.thirdeuropeanevidence-basedconsensusonthediagnosisandmanagementofulcerativecolitispart2:currentmanagement.journalofcrohns&colitis,2017,11:769-784.)。因此,我们从北京百欧博伟生物技术有限公司,购买了ecn野生型菌株,经测试其生长状态良好,后续用作构建益生菌传感器的载体菌株。
实施例2:prr-thsr,phk-thss质粒骨架的制备
针对ecn菌株的遗传操作方法可参考如下文献:oub,jiangb,jind,etal.engineeredrecombinantescherichiacoliprobioticstrainsintegratedwithf4andf18fimbriaeclustergenesinthechromosomeandtheirassessmentofimmunogenicefficacyinvivo.acssyntheticbiology2020,9:412-426.
用于构建传感器的prr-thsr,phk-thss质粒骨架,参考文献landrybp,palankir,dyulgyarovn,etal.phosphataseactivitytunestwo-componentsystemsensordetectionthreshold.naturecommuncations2018,9:1433,按文献指示途径获得质粒骨架。
实施例3:phk-ptac-thss-nbcp质粒文库的构建
经密码子优化的thss基因序列如下:
atgtcccgcctgctgctgtgtatctgtgttctgctgttctcttctgtggcgtggtctaaaccgcagcagttttatgtgggcgtactggctaactggggtcatcagcaagccgttgaacgttggaccccgatgatggagtatctgaacgaacatgtgccggacgcggaatttcacgtctacccgggcaacttcaaagcactgaacctggcaatggaactgggccagattcagttcattatcactaacccgggccaatatctgtacctgagcaatcagtacccgctgtcttggctggcgaccatgcgttctaagcgtcacgatggtaccacttctgcgatcggttccgccattattgtccgcgcggacagcgactaccgcaccctgtacgacctgaaaggtaaagtggtggctgcgtccgacccgcatgctctgggtggctaccaagcgaccgtcggtctgatgcattccctgggcatggatccggacaccttcttcggtgaaaccaagtttctgggctttccactggatccgctgctgtaccaagttcgtgatggcaacgttgacgcggccattaccccactgtgcactctggaggacatggttgcacgcggcgtactgaaatcttccgattttcgtgtgctgaaccctagccgcccggatggtgtagaatgccagtgctctaccaccctgtacccgaactggtctttcgctgcgactgagtctgtatccaccgaactgtctaaagaaatcacgcaggcactgctggaactgccatccgacagcccggcagctatcaaagcgcaactgaccggctggaccagcccgatctcccaactggcggtaatcaaactgttcaaagagctgcacgtaaaaaccccggactctagccgttgggaagccgttaagaagtggctggaagaaaaccgtcactggggtatcctgtctgttctggtgttcatcattgcaacgctgtatcacctgtggattgaataccgcttccaccaaaaaagctcttctctgatcgaatctgaacgtcagctgaaacagcaagctgttgccctggaacgtctgcaatctgctagcatcgttggtgaaattggtgcgggtctggcccacgagattaatcagccgatcgctgcaattacctcttattctgaaggtggcatcatgcgcctgcaaggtaaagaacaggcggatacggatagctgcatcgaactgctggaaaaaatccacaaacagagcactcgcgcaggcgaagtggtgcaccgcatccgtggtctgctgaaacgtcgtgaagcggtgatggtagatgttaacatcctgaccctggtggaagaatccatcagcctgctgcgtctggagctggcacgtcgcgaaatccagatcaacactcagatcaaaggtgaaccgttcttcattactgccgaccgcgttggcctgctgcaagttctgattaacctgatcaaaaactccctggacgcgatcgctgaatctgataatgcccgttctggtaaaatcaacatcgaactggactttaaagagtaccaggtaaacgtctccatcatcgataacggtccgggcctggcgatggattctgacactctgatggctacgttttacactaccaaaatggatggcctgggcctgggtctggcaatctgccgcgaagttatcagcaaccacgacggccacttcctgctgtccaaccgtgacgacggcgttctgggctgtgtggcaaccctgaatctgaaaaaacgcggttctgaagtgccgatcgaagtctaa(seqidno.3)
原始的thss基因序列以表达盒形式存在于phk-thss质粒,以此为基础构建phk-ptac-thss-nbcp质粒文库,包括如下步骤:
(1)利用swiss-model和i-tasser三维结构建模软件,对拟进行融合操作的组氨酸激酶受体thss进行同源建模,结合已鉴定的激酶受体功能结构域分布特征,预估激酶受体thss的双跨膜结构域及结合结构域对应编码区域(43-111bp,454-522bp)。
(2)利用无缝克隆的方法,将经密码子偏好性优化的钙卫蛋白特异性纳米抗体编码序列,融合替换预测的组氨酸激酶配体结合结构域编码区域,自第43bp开始,设定15个核苷酸为步移长度,替换所预测的跨膜结构域与结合结构域两侧位置的编码序列,即分别在43bp、58bp、73bp、88bp、103bp、118bp、454bp、469bp、484bp、499bp、514bp以及529bp处,利用纳米抗体编码序列覆盖替换相应的激酶受体结合结构域,构建获得含有12个嵌合激酶受体的文库,开展第一轮的响应性能评估,测试步骤详见实施例4和实施例5的描述。随后,选择响应效果最好的嵌合激酶受体,从其两侧位置设定3个核苷酸为步移长度,构建8个嵌合激酶受体。进而将上述20个嵌合激酶受体分别命名为phk-ptac-thss-nbcp(01~20),即phk-ptac-thss-nbcp01、phk-ptac-thss-nbcp02、phk-ptac-thss-nbcp03、phk-ptac-thss-nbcp04、phk-ptac-thss-nbcp05、phk-ptac-thss-nbcp06、phk-ptac-thss-nbcp07、phk-ptac-thss-nbcp08、phk-ptac-thss-nbcp09、phk-ptac-thss-nbcp10、phk-ptac-thss-nbcp11、phk-ptac-thss-nbcp12、phk-ptac-thss-nbcp13、phk-ptac-thss-nbcp14、phk-ptac-thss-nbcp15、phk-ptac-thss-nbcp16、phk-ptac-thss-nbcp17、phk-ptac-thss-nbcp18、phk-ptac-thss-nbcp19和phk-ptac-thss-nbcp20。
所述可特异性结合目标蛋白的纳米抗体nbcp17为免疫骆驼获得的针对钙卫蛋白分子的纳米抗体,其制备方法为:
1)使用钙卫蛋白为抗原,与完全弗氏佐剂混合(v/v=1:1),充分乳化,皮下注射免疫双峰驼;从第2次免疫开始,使用不完全弗氏佐剂1:1混合乳化,间隔免疫5次;
2)第5次免疫结束后第7天,采集骆驼颈部静脉血50ml,分离淋巴细胞,提取总rna,反转录成cdna;
3)利用正向引物c-01:gtcctggctgctcttctacaagg(seqidno.1)和反向引物c-02:ggtacgtgctgttgaactgttcc(seqidno.2),扩增获得650-750bp的片段,纯化后作为二轮扩增的模板;根据骆驼vhh片段上下游保守序列设计引物,钓取骆驼源vhhs编码序列,酶切连接噬菌粒载体phen2,电转大肠杆菌tg1感受态,复性,涂板,37℃倒置培养,待菌体长成,洗下菌体;
4)利用碳酸盐缓冲液稀释钙卫蛋白抗原,加入96孔酶联板,4℃过夜孵育制备抗原包被板;以辅助噬菌体m13k07感染tg1展示文库,经4轮筛选,获得亲和力相对最高的子文库,涂布双抗性平板,挑取单克隆,培养12-18小时表达抗体;离心取上清,加入抗原预制板,进行间接elisa评估,选择效价最高的单克隆,测序获得纳米抗体nbcp17的编码序列。
经密码子优化的纳米抗体nbcp17编码序列如下:
caatctgttgttggcctggccgaagcgggtaacggtgcggttctggctatgggtagtctgcgtctgttgtgcgcagctccaggcagcaccaaaattaagtctcccatgatttgggagcgtgaagcaacaggctttgaagccgaattgctgcgaaccgcaggtcgaagcgggggcctgacccaatacttagacggtgttcaaggttacttccgtattgaacgtatcaaagcaaaaataaccgcatacaaccagcgcgacacgctgtcaccggatgatagcgcttttgcctatctttgtcaggcggtacgtggt(seqidno.4)。
实施例4:携带prr-plteto-1-thsr-sfgfp质粒的ecn菌株构建
一种携带信号报告单元prr-plteto-1-thsr-sfgfp的益生菌(大肠杆菌nissle1917)的构建方法(质粒图谱如图1所示),包括以下步骤:
(1)将携带信号报告单元的重组质粒prr-thsr甘油管冻存菌液,吸取10μl转接至5mllb培养基,添加氯霉素至25μg/ml的工作浓度,37℃,220r/min振荡培养12-18h,纯化获得质粒产物,重新命名为prr-plteto-1-thsr-sfgfp。
(2)吸取上述质粒产物,加入大肠杆菌nissle1917感受态菌液,混匀,电转(2.5kv,200欧姆,25μf,0.2cm电转化杯,电击时间:4.5-5ms),加入600μllb培养基,转移至1.5ml离心管,37℃,220r/min振荡培养45min。取100μl培养液,涂布至lb固体琼脂平板(氯霉素抗性),37℃倒置培养24-48h。
(3)转化子筛选:待上述平板长出约1mm的单菌落,利用20μllb培养基(氯霉素抗性)混匀单克隆,利用特定的靶序列进行pcr扩增验证,将验证条带大小正确(约800bp)(见图1)的单克隆,送上海华大基因科技有限公司测序验证,确认获得构建成功的epr03菌株。
实施例5:携带phk-ptac-thss-nbcp质粒的ecn菌株构建
一种同时携带信号报告单元和感知单元phk-ptac-thss-nbcp的工程益生菌库的构建方法(质粒图谱如图2所示),包括以下步骤:
(1)将实施例3中所获得的嵌合激酶受体文库质粒,分别电击转化(2.5kv,200欧姆,25μf,0.2cm电转化杯,电击时间:4.5-5ms)导入受试的epr03菌株感受态细胞。随后,向电击杯中加入600μllb无抗培养基,吹吸混匀,转移至1.5ml离心管,37℃,220r/min振荡培养45min。取100μl培养液,涂布至lb固体琼脂平板(氯霉素25μg/ml和壮观霉素50μg/ml),37℃倒置培养24-48h。
(2)待平板长出约1mm菌落后,利用融合构建引物进行扩增验证,扩增出阳性条带的菌落,经加有氯霉素和壮观霉素抗性的培养液,37℃,220r/min振荡培养;同时,取100μl菌液送测序,确认构建序列的正确性,分别命名为epr03-ph-nbcp(01-20),即epr03-ph-nbcp01、epr03-ph-nbcp02、epr03-ph-nbcp03、epr03-ph-nbcp04、epr03-ph-nbcp05、epr03-ph-nbcp06、epr03-ph-nbcp07、epr03-ph-nbcp08、epr03-ph-nbcp09、epr03-ph-nbcp10、epr03-ph-nbcp11、epr03-ph-nbcp12、epr03-ph-nbcp13、epr03-ph-nbcp14、epr03-ph-nbcp15、epr03-ph-nbcp16、epr03-ph-nbcp17、epr03-ph-nbcp18、epr03-ph-nbcp19和epr03-ph-nbcp20。
实施例6:携带嵌合激酶受体及信号报告单元工程益生菌株的测试
(1)分别取epr03-ph-nbcp(01-20)菌株10ul,转接至5mllb培养基(氯霉素25μg/ml和壮观霉素50μg/ml),37℃,220r/min振荡培养12-16h。
(2)吸取上述菌液50ul,转接至3mlm9甘油培养基(氯霉素25μg/ml和壮观霉素50μg/ml),37℃培养3h,至od600=0.2左右。
(3)配制反应体系。以m9甘油培养基(氯霉素25μg/ml和壮观霉素50μg/ml),稀释上述菌液至od600=10-3。吸取1ml,分别加入iptg(工作浓度75um)、四环素(工作浓度50ng/ml)和钙卫蛋白标准品液(工作浓度500mg/l),37℃,220r/min振荡培养6h,至对数期(od600=0.3)
(4)sfgfp荧光测定。取出上述培养管,冰浴,停止反应。取10μl菌液加至200μl经4℃预冷的pbs,利用biotekinstruments公司的cytation3型荧光酶标仪测定sfgfp荧光强度,设定激发光波长488nm,发射光波长530nm。同时,测定组成型表达的mcherry荧光强度,激发光波长552nm,发射光波长625nm,用于荧光信号的标定。选择epr03-ph-nbcp(01-20)中荧光强度较高的工程益生菌株,所对应的嵌合激酶受体即可用于构建钙卫蛋白响应型传感系统。
实施例7:携带阳性嵌合激酶受体和信号报告单元的益生菌传感器检测灵敏度测试
(1)利用实施例6筛选到的携带对钙卫蛋白响应较好的嵌合激酶受体和信号报告单元的工程益生菌株甘油管菌液10ul,转接至5mllb培养基(氯霉素25μg/ml和壮观霉素50μg/ml),37℃,220r/min振荡培养12-16h。
(2)吸取上述菌液50ul,转接至3mlm9甘油培养基(氯霉素25μg/ml和壮观霉素50μg/ml),37℃培养3h,至od600=0.2左右。
(3)配制反应体系。以m9甘油培养基(氯霉素25μg/ml和壮观霉素50μg/ml),稀释上述菌液至od600=10-3。吸取1ml,分别加入iptg(工作浓度75um)、四环素(工作浓度50ng/ml)和梯度稀释的钙卫蛋白标准品溶液(工作浓度0,25,50,75,100,125,150,175,200,250,300,350,400,500,1000mg/l),37℃,220r/min振荡培养6h,至对数期(od600≈0.3)
(4)sfgfp荧光测定。取出上述培养管,冰浴,停止反应。取10μl菌液加至200μl经4℃预冷的pbs,利用biotekinstruments公司的cytation3型荧光酶标仪测定sfgfp荧光强度,设定激发光波长488nm,发射光波长530nm。同时,测定组成型表达的mcherry荧光强度,激发光波长552nm,发射光波长625nm,用于荧光信号的标定。结果见图3,在测定条件下,所构建的钙卫蛋白益生菌传感系统,最大响应信号约为50000(a.u.),信号强度较高,具有应用于临床辅助诊断的前景。
上述实施方式不应理解为对本发明保护范围的限制。本发明的关键是:定制针对生物大分子的纳米抗体,利用其编码序列与双组分系统激酶受体的配体结合域进行替换融合,获得可结合响应目标大分子的融合型激酶受体;进一步地,借助双组分系统原有应答调节因子传递磷酸化信号,激活受控的同源启动子下游报告基因的表达合成。在不脱离本发明精神的情况下,对本发明做出任何形式的改变,均应落入本发明的保护范围之内。
序列表
<110>上海健康医学院
华卫安评医学研究(上海)有限公司
<120>益生菌嵌合传感器及其构建方法和应用
<130>jsp12100763
<160>4
<170>siposequencelisting1.0
<210>1
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>1
gtcctggctgctcttctacaagg23
<210>2
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>2
ggtacgtgctgttgaactgttcc23
<210>3
<211>1785
<212>dna
<213>人工序列(artificialsequence)
<400>3
atgtcccgcctgctgctgtgtatctgtgttctgctgttctcttctgtggcgtggtctaaa60
ccgcagcagttttatgtgggcgtactggctaactggggtcatcagcaagccgttgaacgt120
tggaccccgatgatggagtatctgaacgaacatgtgccggacgcggaatttcacgtctac180
ccgggcaacttcaaagcactgaacctggcaatggaactgggccagattcagttcattatc240
actaacccgggccaatatctgtacctgagcaatcagtacccgctgtcttggctggcgacc300
atgcgttctaagcgtcacgatggtaccacttctgcgatcggttccgccattattgtccgc360
gcggacagcgactaccgcaccctgtacgacctgaaaggtaaagtggtggctgcgtccgac420
ccgcatgctctgggtggctaccaagcgaccgtcggtctgatgcattccctgggcatggat480
ccggacaccttcttcggtgaaaccaagtttctgggctttccactggatccgctgctgtac540
caagttcgtgatggcaacgttgacgcggccattaccccactgtgcactctggaggacatg600
gttgcacgcggcgtactgaaatcttccgattttcgtgtgctgaaccctagccgcccggat660
ggtgtagaatgccagtgctctaccaccctgtacccgaactggtctttcgctgcgactgag720
tctgtatccaccgaactgtctaaagaaatcacgcaggcactgctggaactgccatccgac780
agcccggcagctatcaaagcgcaactgaccggctggaccagcccgatctcccaactggcg840
gtaatcaaactgttcaaagagctgcacgtaaaaaccccggactctagccgttgggaagcc900
gttaagaagtggctggaagaaaaccgtcactggggtatcctgtctgttctggtgttcatc960
attgcaacgctgtatcacctgtggattgaataccgcttccaccaaaaaagctcttctctg1020
atcgaatctgaacgtcagctgaaacagcaagctgttgccctggaacgtctgcaatctgct1080
agcatcgttggtgaaattggtgcgggtctggcccacgagattaatcagccgatcgctgca1140
attacctcttattctgaaggtggcatcatgcgcctgcaaggtaaagaacaggcggatacg1200
gatagctgcatcgaactgctggaaaaaatccacaaacagagcactcgcgcaggcgaagtg1260
gtgcaccgcatccgtggtctgctgaaacgtcgtgaagcggtgatggtagatgttaacatc1320
ctgaccctggtggaagaatccatcagcctgctgcgtctggagctggcacgtcgcgaaatc1380
cagatcaacactcagatcaaaggtgaaccgttcttcattactgccgaccgcgttggcctg1440
ctgcaagttctgattaacctgatcaaaaactccctggacgcgatcgctgaatctgataat1500
gcccgttctggtaaaatcaacatcgaactggactttaaagagtaccaggtaaacgtctcc1560
atcatcgataacggtccgggcctggcgatggattctgacactctgatggctacgttttac1620
actaccaaaatggatggcctgggcctgggtctggcaatctgccgcgaagttatcagcaac1680
cacgacggccacttcctgctgtccaaccgtgacgacggcgttctgggctgtgtggcaacc1740
ctgaatctgaaaaaacgcggttctgaagtgccgatcgaagtctaa1785
<210>4
<211>312
<212>dna
<213>人工序列(artificialsequence)
<400>4
caatctgttgttggcctggccgaagcgggtaacggtgcggttctggctatgggtagtctg60
cgtctgttgtgcgcagctccaggcagcaccaaaattaagtctcccatgatttgggagcgt120
gaagcaacaggctttgaagccgaattgctgcgaaccgcaggtcgaagcgggggcctgacc180
caatacttagacggtgttcaaggttacttccgtattgaacgtatcaaagcaaaaataacc240
gcatacaaccagcgcgacacgctgtcaccggatgatagcgcttttgcctatctttgtcag300
gcggtacgtggt312
- 还没有人留言评论。精彩留言会获得点赞!