一种C5aR抗体及其制备方法和应用与流程
本申请是优先权日为2016年1月12日、申请号为201780003251.7、发明创造名称为“一种c5ar抗体及其制备方法和应用”的专利申请的分案申请。本发明涉及抗体领域,具体涉及一种c5ar抗体及其制备方法和应用。
背景技术:
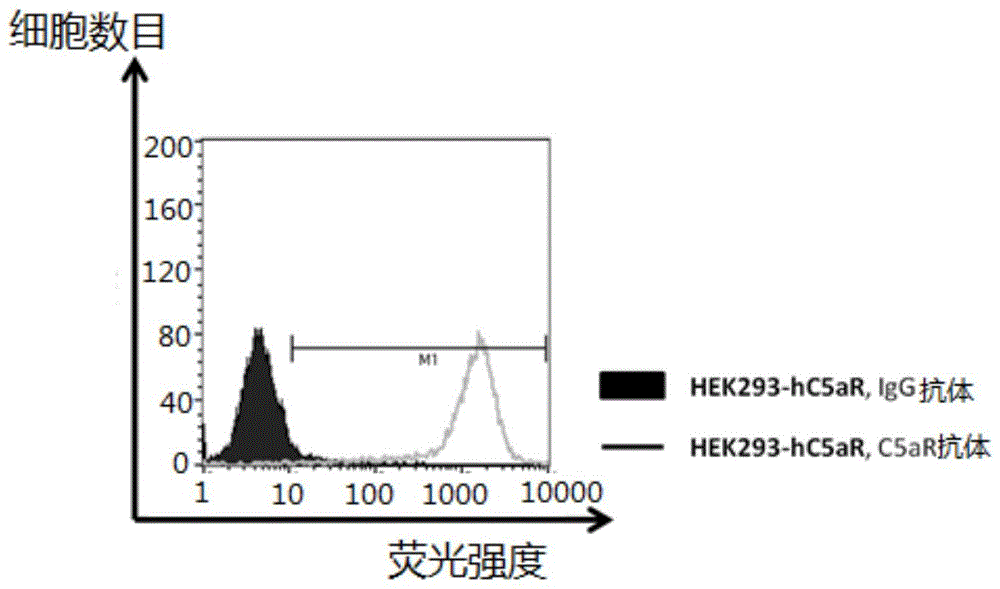
:补体系统是由30多种血浆蛋白和膜蛋白组成,广泛存在于血液、组织液和细胞表面的、具有精密调控机制的蛋白反应系统。补体的主要生理功能是促进吞噬细胞的吞噬能力和溶解靶细胞,因此是机体免疫防御机制的重要组成部分。c5ar的配体c5a,是补体系统活化产物,是炎症反应的重要介质和趋化因子。c5ar与配体c5a结合后诱导炎症反应并影响凝血及纤溶系统,导致正常组织细胞的损伤,其参与多种疾病的病理过程。c5a是补体裂解片段中显示过敏毒素作用最强的介质,其过敏毒素作用分别为c3a和c4a作用的20倍和2500倍。此外,c5a还可以增加血管的通透性,刺激平滑肌收缩。高浓度的c5a是中性粒细胞、嗜酸粒细胞和单核细胞的趋化剂,可诱导这些细胞顺浓度梯度方向移动。c5a对免疫应答有明显增强作用,可诱导单核细胞分泌白介素il-l、il-6、il-8及肿瘤坏死因子α(tnf-α)等细胞因子的表达,促进抗原及同种异体抗原诱导的t细胞增殖及促进b细胞产生抗体等。c5ar属于七次跨膜的g-蛋白偶联受体家族。c5ar是对c5a具有高亲和力的受体,其中kd约为1nm,其位于包括白细胞在内的不同类型的细胞上。每个细胞的受体数量都非常高,每个白细胞可高达200000个位点。c5a还有另外一个受体,称为c5a样受体(c5alikereceptor,c5l2),但由于其不含g蛋白,又称gpr77。gpr77属于c5a受体亚家族成员,在氨基酸序列上与cd88有35%的同源性,目前其生物学功能仍不明确。c5ar参与包括风湿性关节炎、牛皮癣、败血症、再灌注损伤和成年呼吸窘迫综合症在内的各种疾病的发病机制(gerardandgerard,1994;murdochandfinn,2000)。如何阻断c5ar信号的向下游信号通路传导,从而减轻炎症反应一直是免疫学研究的热点问题。目前c5ar和c5a的拮抗剂主要分为抗c5a抗体、抗c5ar抗体、小分子拮抗剂、c5a反义肽、c5a突变体或细菌来源的趋化抑制蛋白等。但是目前仍未有上市的、针对c5ar及其配体的相关拮抗剂新药。技术实现要素:本发明所要解决的技术问题是为了克服目前缺少c5ar抗体的不足,提供一种亲和力高、特异性强的c5ar抗体及其制备方法和应用。所述的c5ar抗体与人源c5ar蛋白具有高度亲和力;能够高效地抑制或阻断c5ar与c5a的结合,显著降低钙流信号,从而下调或切断相应的信号通路,中止体外中性粒细胞的c5a定向迁移;并能够显著抑制中性粒细胞的趋化作用;从而给炎症、血管或神经系统的疾病的治疗带来希望。本发明人以人源c5ar蛋白作为免疫原,采用优化的杂交瘤技术,克隆抗体重链可变区和轻链可变区基因,可变区基因可以嫁接到人源抗体恒定区基因从而形成人鼠嵌合抗体,即获得c5ar抗体的先导抗体。再通过一系列的对先导抗体的初步生产、纯化和检定,获得与人源c5ar蛋白等蛋白具有高度亲和力;能够高效地抑制或阻断c5ar与c5a的结合,显著降低钙流信号;并且能够显著抑制中性粒细胞的趋化作用的c5ar抗体。然后通过分子生物学方法测序获知c5ar抗体的重链可变区和c5ar抗体的轻链可变区的氨基酸序列。本发明提供一种分离的蛋白质,其包括c5ar抗体的重链cdr1、重链cdr2和重链cdr3中的一种或多种,和/或,c5ar抗体的轻链cdr1、轻链cdr2和轻链cdr3中的一种或多种,所述重链cdr1的氨基酸序列如序列表中seqidno:2、seqidno:10、seqidno:18、seqidno:26、seqidno:34、seqidno:42或seqidno:50所示;所述重链cdr2的氨基酸序列如序列表seqidno:3、seqidno:11、seqidno:19、seqidno:27、seqidno:35、seqidno:43或seqidno:51所示;所述重链cdr3的氨基酸序列如序列表中seqidno:4、seqidno:12、seqidno:20、seqidno:28、seqidno:36、seqidno:44或seqidno:52所示;所述轻链cdr1的氨基酸序列如序列表中seqidno:6、seqidno:14、seqidno:22、seqidno:30、seqidno:38、seqidno:46或seqidno:54所示;所述轻链cdr2的氨基酸序列如序列表中seqidno:7、seqidno:15、seqidno:23、seqidno:31、seqidno:39、seqidno:47或seqidno:55所示;所述轻链cdr3的氨基酸序列如序列表中seqidno:8、seqidno:16、seqidno:24、seqidno:32、seqidno:40、seqidno:48或seqidno:56所示;或者,所述重链cdr1的氨基酸序列与如序列表中seqidno:2、seqidno:10、seqidno:18、seqidno:26、seqidno:34、seqidno:42或seqidno:50所示的氨基酸序列至少有80%的序列同源性的氨基酸序列所示;所述重链cdr2的氨基酸序列与如序列表中seqidno:3、seqidno:11、seqidno:19、seqidno:27、seqidno:35、seqidno:43或seqidno:51所示的氨基酸序列至少有80%的序列同源性的氨基酸序列所示;所述重链cdr3的氨基酸序列与如序列表中seqidno:4、seqidno:12、seqidno:20、seqidno:28、seqidno:36、seqidno:44或seqidno:52所示的氨基酸序列至少有80%的序列同源性的氨基酸序列所示;所述轻链cdr1的氨基酸序列与如序列表中seqidno:6、seqidno:14、seqidno:22、seqidno:30、seqidno:38、seqidno:46或seqidno:54所示的氨基酸序列至少有80%的序列同源性的氨基酸序列所示;所述轻链cdr2的氨基酸序列与如序列表中seqidno:7、seqidno:15、seqidno:23、seqidno:31、seqidno:39、seqidno:47或seqidno:55所示的氨基酸序列至少有80%的序列同源性的氨基酸序列所示;所述轻链cdr3的氨基酸序列与如序列表中seqidno:8、seqidno:16、seqidno:24、seqidno:32、seqidno:40、seqidno:48或seqidno:56所示的氨基酸序列至少有80%的序列同源性的氨基酸序列所示。较佳地,所述重链cdr1的氨基酸序列如序列表seqidno:2所示,所述重链cdr2的氨基酸序列如序列表seqidno:3所示且所述重链cdr3的氨基酸序列如序列表seqidno:4所示;所述重链cdr1的氨基酸序列如序列表seqidno:10所示,所述重链cdr2的氨基酸序列如序列表seqidno:11所示且所述重链cdr3的氨基酸序列如序列表seqidno:12所示;所述重链cdr1的氨基酸序列如序列表seqidno:18所示,所述重链cdr2的氨基酸序列如序列表seqidno:19所示且所述重链cdr3的氨基酸序列如序列表seqidno:20所示;所述重链cdr1的氨基酸序列如序列表seqidno:26所示,所述重链cdr2的氨基酸序列如序列表seqidno:27所示且所述重链cdr3的氨基酸序列如序列表seqidno:28所示;所述重链cdr1的氨基酸序列如序列表seqidno:34所示,所述重链cdr2的氨基酸序列如序列表seqidno:35所示且所述重链cdr3的氨基酸序列如序列表seqidno:36所示;所述重链cdr1的氨基酸序列如序列表seqidno:42所示,所述重链cdr2的氨基酸序列如序列表seqidno:43所示且所述重链cdr3的氨基酸序列如序列表seqidno:44所示;所述重链cdr1的氨基酸序列如序列表seqidno:50所示,所述重链cdr2的氨基酸序列如序列表seqidno:51所示且所述重链cdr3的氨基酸序列如序列表seqidno:52所示;所述轻链cdr1的氨基酸序列如序列表seqidno:6所示,所述轻链cdr2的氨基酸序列如序列表seqidno:7所示且所述轻链cdr3的氨基酸序列如序列表seqidno:8所示;所述轻链cdr1的氨基酸序列如序列表seqidno:14所示,所述轻链cdr2的氨基酸序列如序列表seqidno:15所示且所述轻链cdr3的氨基酸序列如序列表seqidno:16所示;所述轻链cdr1的氨基酸序列如序列表seqidno:22所示,所述轻链cdr2的氨基酸序列如序列表seqidno:23所示且所述轻链cdr3的氨基酸序列如序列表seqidno:24所示;所述轻链cdr1的氨基酸序列如序列表seqidno:30所示,所述轻链cdr2的氨基酸序列如序列表seqidno:31所示且所述轻链cdr3的氨基酸序列如序列表seqidno:32所示;所述轻链cdr1的氨基酸序列如序列表seqidno:38所示,所述轻链cdr2的氨基酸序列如序列表seqidno:39所示且所述轻链cdr3的氨基酸序列如序列表seqidno:40所示;所述轻链cdr1的氨基酸序列如序列表seqidno:46所示,所述轻链cdr2的氨基酸序列如序列表seqidno:47所示且所述轻链cdr3的氨基酸序列如序列表seqidno:48所示;或,所述轻链cdr1的氨基酸序列如序列表seqidno:54所示,所述轻链cdr2的氨基酸序列如序列表seqidno:55所示且所述轻链cdr3的氨基酸序列如序列表seqidno:56所示。本发明提供一种分离的蛋白质,其包括c5ar抗体的重链可变区和/或c5ar抗体的轻链可变区,所述重链可变区的氨基酸序列如序列表中seqidno:1、seqidno:9、seqidno:17、seqidno:25、seqidno:33、seqidno:41或seqidno:49所示;所述轻链可变区的氨基酸序列如序列表中seqidno:5、seqidno:13、seqidno:21、seqidno:29、seqidno:37、seqidno:45或seqidno:53所示。较佳地,所述重链可变区的氨基酸序列如序列表seqidno:1所示且所述轻链可变区的氨基酸序列如序列表seqidno:5所示;所述重链可变区的氨基酸序列如序列表seqidno:9所示且所述轻链可变区的氨基酸序列如序列表seqidno:13所示;所述重链可变区的氨基酸序列如序列表seqidno:17所示且所述轻链可变区的氨基酸序列如序列表seqidno:21所示;所述重链可变区的氨基酸序列如序列表seqidno:25所示且所述轻链可变区的氨基酸序列如序列表seqidno:29所示;所述重链可变区的氨基酸序列如序列表seqidno:33所示且所述轻链可变区的氨基酸序列如序列表seqidno:37所示;所述重链可变区的氨基酸序列如序列表seqidno:41所示且所述轻链可变区的氨基酸序列如序列表seqidno:45所示;或,所述重链可变区的氨基酸序列如序列表seqidno:49所示且所述轻链可变区的氨基酸序列如序列表seqidno:53所示。综上所述,上述氨基酸序列的编号如表1所示:表1c5ar抗体蛋白序列编号其中,表1中的数字即为序列表“seqidno:”编号,如5f8e2c11的重链蛋白可变区的氨基酸序列为序列表seqidno:1,而5f8e2c11的重链蛋白可变区中cdr1域的氨基酸序列为序列表seqidno:2。较佳地,所述的蛋白质还包括抗体重链恒定区和/或抗体轻链恒定区,所述的抗体重链恒定区为本领域常规,较佳地为小鼠源抗体重链恒定区。所述的抗体轻链恒定区为本领域常规,较佳地为小鼠源轻链抗体恒定区。所述的蛋白质为本领域常规的蛋白质,较佳地为c5ar抗体,更佳地为抗体全长蛋白、抗原抗体结合域蛋白质片段、双特异性抗体、多特异性抗体、单链抗体(singlechainantibodyfragment,scfv)、单域抗体(singledomainantibody,sdab)和单区抗体(signle-domainantibody)中的一种或多种,以及上述抗体所制得的单克隆抗体或多克隆抗体。所述单克隆抗体可以由多种途径和技术进行研制,包括杂交瘤技术、噬菌体展示技术、单淋巴细胞基因克隆技术等,主流是通过杂交瘤技术从野生型或转基因小鼠制备单克隆抗体。所述的抗体全长蛋白为本领域常规的抗体全长蛋白,其包括重链可变区、轻链可变区、重链恒定区和轻链恒定区。所述的蛋白质的重链可变区和轻链可变区也可与人源重链恒定区和人源轻链恒定区构成全人源抗体全长蛋白。较佳地,所述的抗体全长蛋白为igg1、igg2、igg3或igg4。所述的单链抗体为本领域常规的单链抗体,其包括重链可变区、轻链可变区和15~20个氨基酸的短肽。所述的抗原抗体结合域蛋白质片段为本领域常规的抗原抗体结合域蛋白质片段,其包括轻链可变区、轻链恒定区和重链恒定区的fd段。较佳地,所述的抗原抗体结合域蛋白质片段为fab和f(ab’)。所述的单域抗体为本领域常规的单域抗体,其包括重链可变区和重链恒定区。所述的单区抗体为本领域常规的单区抗体,其仅包括重链可变区。其中,所述蛋白质的制备方法为本领域常规的制备方法。所述制备方法较佳地为:从重组表达该蛋白质的表达转化体中分离获得或者通过人工合成蛋白质序列获得。所述的从重组表达该蛋白质的表达转化体中分离获得优选如下方法:将编码所述蛋白质并且带有点突变的核酸分子克隆到重组载体中,将所得重组载体转化到转化体中,得到重组表达转化体,通过培养所得重组表达转化体,即可分离纯化获得所述蛋白质。本发明还提供一种核酸,其编码上述的蛋白质。较佳地,编码所述重链可变区的核酸如序列表seqidno:57、序列表seqidno:59、序列表seqidno:61、序列表seqidno:63、序列表seqidno:65、序列表seqidno:67或序列表seqidno:69所示;和/或,编码所述轻链可变区的核酸的核苷酸序列如序列表seqidno:58、序列表seqidno:60、序列表seqidno:62、序列表seqidno:64、序列表seqidno:66、序列表seqidno:68或序列表seqidno:70所示。更佳地,编码所述重链可变区的核酸如序列表seqidno:57所示且编码所述轻链可变区的核酸如序列表seqidno:58所示;编码所述重链可变区的核酸如序列表seqidno:59所示且编码所述轻链可变区的核酸如序列表seqidno:60所示;编码所述重链可变区的核酸如序列表seqidno:61所示且编码所述轻链可变区的核酸如序列表seqidno:62所示;编码所述重链可变区的核酸如序列表seqidno:63所示且编码所述轻链可变区的核酸如序列表seqidno:64所示;编码所述重链可变区的核酸如序列表seqidno:65所示且编码所述轻链可变区的核酸如序列表seqidno:66所示;编码所述重链可变区的核酸如序列表seqidno:67所示且编码所述轻链可变区的核酸如序列表seqidno:68所示;或,编码所述重链可变区的核酸如序列表seqidno:69所示且编码所述轻链可变区的核酸如序列表seqidno:70所示。上述核苷酸序列的编号如表2所示:表2c5ar抗体基因序列编号克隆号重链蛋白可变区轻链蛋白可变区5f8e2c11575842b5g7d1596043e8f5b6616246h2a11c763642a12b2b265668b5d1a967689d5a12g76970其中,表2中的数字即为序列表“seqidno:”编号,如编码5f8e2c11的重链蛋白可变区的核苷酸序列为序列表seqidno:33。其中,编码5f8e2c11的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:57中的第76位至第105位;编码5f8e2c11的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:57中的第148位至第195位;编码5f8e2c11的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:57中的第292位至第321位;编码5f8e2c11的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:58中的第70位至第120位;编码5f8e2c11的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:58中的第166位至第186位;编码5f8e2c11的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:58中的第283位至第306位;编码42b5g7d1的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:59中的第76位至第105位;编码42b5g7d1的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:59中的第148位至第198位;编码42b5g7d1的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:59中的第295位至第336位;编码42b5g7d1的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:60中的第70位至第117位;编码42b5g7d1的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:60中的第163位至第183位;编码42b5g7d1的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:60中的第280位至第306位;编码43e8f5b6的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:61中的第76位至第105位;编码43e8f5b6的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:61中的第148位至第198位;编码43e8f5b6的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:61中的第295位至第339位;编码43e8f5b6的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:62中的第70位至第105位;编码43e8f5b6的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:62中的第151位至第171位;编码43e8f5b6的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:62中的第268位至第294位。编码46h2a11c7的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:63中的第76位至第105位;编码46h2a11c7的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:63中的第148位至第198位;编码46h2a11c7的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:63中的第295位至第306位;编码46h2a11c7的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:64中的第70位至第117位;编码46h2a11c7的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:64中的第163位至第183位;编码46h2a11c7的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:64中的第280位至第306位。编码2a12b2b2的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:65中的第76位至第105位;编码2a12b2b2的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:65中的第148位至第198位;编码2a12b2b2的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:65中的第295位至第303位;编码2a12b2b2的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:66中的第70位至第102位;编码2a12b2b2的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:66中的第148位至第168位;编码2a12b2b2的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:66中的第265位至第291位。编码8b5d1a9的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:67中的第76位至第105位;编码8b5d1a9的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:67中的第148位至第198位;编码8b5d1a9的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:67中的第295位至第324位;编码8b5d1a9的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:68中的第70位至第120位;编码8b5d1a9的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:68中的第166位至第189位;编码8b5d1a9的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:68中的第286位至第312位。编码9d5a12g7的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:69中的第76位至第105位;编码9d5a12g7的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:69中的第148位至第195位;编码9d5a12g7的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:69中的第292位至第321位;编码9d5a12g7的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:70中的第70位至第120位;编码9d5a12g7的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:70中的第166位至第186位;编码9d5a12g7的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:70中的第283位至第306位。所述核酸的制备方法为本领域常规的制备方法,较佳地,包括以下的步骤:通过基因克隆技术获得编码上述蛋白质的核酸分子,或者通过人工全序列合成的方法得到编码上述蛋白质的核酸分子。本领域技术人员知晓,编码上述蛋白质的氨基酸序列的碱基序列可以适当引入替换、缺失、改变、插入或增加来提供一个多聚核苷酸的同系物。本发明中多聚核苷酸的同系物可以通过对编码该蛋白序列基因的一个或多个碱基在保持抗体活性范围内进行替换、缺失或增加来制得。本发明还提供一种包含所述核酸的重组表达载体。其中所述重组表达载体可通过本领域常规方法获得,即:将本发明所述的核酸分子连接于各种表达载体上构建而成。所述的表达载体为本领域常规的各种载体,只要其能够容载前述核酸分子即可。所述载体较佳地包括:各种质粒、粘粒、噬菌体或病毒载体等。本发明还提供一种包含上述重组表达载体的重组表达转化体。其中,所述重组表达转化体的制备方法为本领域常规的制备方法,较佳地为:将上述重组表达载体转化至宿主细胞中制得。所述的宿主细胞为本领域常规的各种宿主细胞,只要能满足使上述重组表达载体稳定地自行复制,且所携带所述的核酸可被有效表达即可。较佳地,所述宿主细胞为e.colitg1或bl21细胞(表达单链抗体或fab抗体),或者cho-k1细胞(表达全长igg抗体)。将前述重组表达质粒转化至宿主细胞中,即可得本发明优选的重组表达转化体。其中所述转化方法为本领域常规转化方法,较佳地为化学转化法,热激法或电转法。本发明提供一种c5ar抗体的制备方法,其包括如下步骤:培养上述的重组表达转化体,从培养物中获得c5ar抗体。本发明还提供一种检测过表达c5ar蛋白的细胞的方法,包括如下的步骤:上述的蛋白质与待检样品在体外接触,检测上述的蛋白质与所述待检样品的结合即可。所述的过表达的含义为本领域常规,指c5ar蛋白在待检样品中的rna或蛋白质的过表达(由于转录增加、转录后加工、翻译、翻译后加工以及蛋白质降解改变),以及由于蛋白质运送模式改变(核定位增加)而导致的局部过表达和功能活性提高(如在底物的酶水解作用增加的情况下)。较佳地,过表达也指相比对照样品或正常细胞,c5ar蛋白的rna或蛋白质的表达水平提高50%、60%、70%、80%、90%或更高。所述结合的检测方式是本领域常规的检测方式,较佳地为facs检测。本发明提供上述蛋白质在制备药物中的应用。较佳地,所述的药物是用于抗炎症、血管疾病或神经系统疾病的药物。本发明还提供一种药物组合物,其活性成分包括上述的蛋白质。较佳地,所述的药物组合物是用于抗炎症、血管疾病或神经系统疾病的药物组合物。本发明所述的药物组合物的给药途径较佳的为注射给药或口服给药。所述注射给药较佳的包括静脉注射、肌肉注射、腹腔注射、皮内注射或皮下注射等途径。所述的药物组合物为本领域常规的各种剂型,较佳的为固体、半固体或液体的形式,可以为水溶液、非水溶液或混悬液,更佳的为片剂、胶囊、颗粒剂、注射剂或输注剂等。较佳地,本发明所述的药物组合物还包括一种或多种药用载体。所述的药用载体为本领域常规药用载体,所述的药用载体可以为任意合适的生理学或药学上可接受的药物辅料。所述的药物辅料为本领域常规的药物辅料,较佳的包括药学上可接受的赋形剂、填充剂或稀释剂等。更佳地,所述的药物组合物包括0.01~99.99%的上述蛋白质和0.01~99.99%的药用载体,所述百分比为占所述药物组合物的质量百分比。较佳地,所述的药物组合物的施用量为有效量,所述有效量为能够缓解或延迟疾病、退化性或损伤性病症进展的量。所述有效量可以以个体基础来测定,并将部分基于待治疗症状和所寻求结果的考虑。本领域技术人员可以通过使用个体基础等上述因素和使用不超过常规的实验来确定有效量。本发明提供上述蛋白质在抗炎症、血管疾病或神经系统疾病中的应用。本发明提供上述药物组合物在抗炎症、血管疾病或神经系统疾病中的应用。在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。本发明所用试剂和原料均市售可得。本发明的积极进步效果在于:本发明所述的蛋白质是一种c5ar抗体,其与c5ar蛋白具有高度亲和力(亲和力kd<1*10-8m),能够高效地抑制或阻断c5ar与c5a的结合,显著降低钙流信号,从而下调或切断相应的信号通路,中止体外中性粒细胞的c5a定向迁移;并能够显著抑制中性粒细胞的趋化作用。因此该c5ar抗体能够运用于治疗炎症、血管疾病或神经系统疾病等药物的制备中。附图说明图1为c5ar蛋白转染的hek293细胞facs筛选检测结果。图2为elisa检测c5ar多肽免疫后小鼠血清抗体效价。图3为elisa检测c5ar抗体与c5ar特定表位的结合。图4为facs检测c5ar抗体与chok1-hc5ar的结合反应。图5为flipr检测c5ar抗体阻断c5a介导的钙流信号。图6为人中性粒细胞趋化实验检测c5ar抗体阻断c5a诱导的细胞迁移。具体实施方式下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。下列实施例中未注明具体条件的实验方法,按照常规方法和条件,或按照商品说明书选择。实施例中所述的室温为本领域常规的室温,一般为10~30℃。实施例1c5ar抗体的制备(一)、免疫原a的制备c5ar是一个7次跨膜蛋白,它的胞外结构域包括1个n末端和3个胞外环。设计下列分别针对c5ar蛋白的n末端和3个胞外环的5条多肽,具体序列见表3。表3所示的多肽由吉尔生化上海有限公司合成。将这些多肽与钥孔血蓝蛋白(keyholelimpethemocyanin,klh)偶联后即得到免疫原a。偶联的方法参见《prrs抗体间接elisa检测方法的建立及应用》[j].中国兽医科技,2005(6)。表3免疫原a的多肽序列编号胞外结构域序列c5ar多肽-01c5ar胞外n末端-1参见序列表seqidno:43c5ar多肽-02c5ar胞外n末端-2参见序列表seqidno:44c5ar多肽-03c5ar胞外环-1参见序列表seqidno:45c5ar多肽-04c5ar胞外环-2参见序列表seqidno:46c5ar多肽-05c5ar胞外环-3参见序列表seqidno:47(二)免疫原b的制备免疫原b所用到的稳定细胞系采用慢病毒感染法。编码人源c5ar全长氨基酸序列(如序列表seqidno:72所示)的核苷酸序列被克隆到慢病毒载体plvx-ires载体(购自clontech)并制备质粒。采用脂质体转染法将质粒转染(转染使用x-tremegenehpdnatransfectionreagent,购自roche公司,货号cat#06366236001,并按说明书操作)到hek293细胞系中进行病毒包装,收集病毒悬液对hek293细胞系和chok1细胞系(均购自invitrogen)进行感染。感染方法如下:将hek293细胞系和chok1细胞系的细胞以1e5/孔的浓度铺入含10%(w/w)胎牛血清的完全培养基的6孔板,其中针对hek293的完全培养基为dmem培养基(购自gibco),针对chok1的完全培养基为ham'sf-12nutrientmixture培养基(购自gibco),37℃,5%(v/v)co2条件下置于培养箱中过夜培养。第二天弃去培养基,加入1ml/孔的病毒悬液,过夜孵育后弃去病毒感染液。再加入2ml含800μg/ml的潮霉素b(hygromycinb)和10%(w/w)胎牛血清的dmem培养基(购自invitrogen),选择性培养2周,用有限稀释法在96孔培养板中进行亚克隆,并置于37℃,5%(v/v)co2条件下培养,大约2周后选择部分单克隆孔扩增到6孔板中。对扩增后的克隆用已知的c5ar抗体(购自abcam)经流式细胞分析法进行筛选。选择长势较好、荧光强度较高、单克隆的细胞系继续扩大培养并液氮冻存,即获得免疫原b。具体选择结果如表4和图1所示,表4中阳性细胞(%)指阳性细胞占总细胞数目的百分比。表4说明,已经制得一系列c5ar阳性表达的hek293细胞系,因此获得了免疫原b。表4c5ar蛋白转染的hek293细胞facs筛选检测结果(三)、免疫原c的制备人源c5ar全长氨基酸序列cdna(如序列表seqidno:71所示)被克隆到pcdna3.1载体(购自invitrogen)并包被到1.0μm金胶体子弹(购自bio-rad),并用helios基因枪免疫(heliosgenegunsystem,bio-rad,货号165-2431),即得免疫原c。其中,包被到1.0μm金胶体子弹和免疫的方法参见helios基因枪说明书进行制定。a、免疫原a免疫采用6~8周龄balb/c和sjl小鼠(购自上海斯莱克公司),小鼠在spf条件下饲养。初次免疫时,免疫原a用弗氏完全佐剂乳化后腹腔注射0.25毫升,即每只小鼠注射50微克免疫原a。加强免疫时,免疫原a用弗氏不完全佐剂乳化后腹腔注射0.25毫升,即每只小鼠注射50微克免疫原a。初次免疫与第一次加强免疫之间间隔2周,以后每次加强免疫之间间隔3周。每次加强免疫1周后采血,用elisa和facs检测血清中免疫原a的抗体效价和特异性,结果如图2和表5所示。表5说明,经c5ar胞外区多肽免疫的小鼠的免疫后血清对免疫原均有不同程度的结合,呈现抗原抗体反应,其中最高稀释度为106左右。其中空白对照为1%(w/w)bsa,其中批次指第三次加强免疫后第七天的小鼠血清,表中的数据为od450nm值。表5elisa检测c5ar多肽免疫后小鼠血清抗体效价b、免疫原b免疫采用6~8周龄balb/c和sjl小鼠(购自上海斯莱克公司),小鼠在spf条件下饲养。含有编码人源c5ar全长氨基酸序列的核苷酸序列的pires质粒[参见实施例1步骤(二)]转染hek293细胞系,得含人源c5ar的hek293稳定细胞系(转染使用x-tremegenehpdnatransfectionreagent,购自roche公司,货号cat#06366236001,并按说明书操作)在t-75细胞培养瓶中扩大培养至90%汇合度,吸尽培养基,用dmem基础培养基洗涤2次,然后用无酶细胞解离液(购自invitrogen)37℃处理直至细胞从培养皿壁上可脱落,收集细胞。用dmem基础培养基洗涤2次,进行细胞计数后将细胞用磷酸盐缓冲液(ph7.2)稀释至2×107细胞每毫升。每只小鼠每次免疫时腹腔注射0.5毫升细胞悬液。第一次与第二次免疫之间间隔2周,以后每次免疫间隔3周。除第一次免疫以外,每次免疫1周后采血,用facs检测血清中抗体效价和特异性。在第二次加强免疫后,facs检测血清抗体效价达到1:1000以上。c、免疫原c免疫采用6~8周龄balb/c和sjl小鼠(购自上海斯莱克公司),小鼠在spf条件下饲养。所有小鼠经腹部用helios基因枪免疫4次,每次4枪,每枪1.0微克cdna。初次免疫与第一次加强免疫之间隔2周,以后每次加强免疫间隔3周。每次加强免疫1周后采血,用elisa或facs检测血清中抗体效价。在第二次加强免疫后,facs检测血清抗体效价达到1:1000以上,elisa效价在1:10000以上。通常以免疫原a~c进行免疫,大部分小鼠经3次免疫后facs效价均可达到1:1000以上。在细胞融合前3-5天,将所选择的小鼠进行最终加强免疫。其中用免疫原a进行免疫的小鼠用如表3所示相应的多肽进行最终免疫;用免疫原b和免疫原c进行免疫的小鼠用表达人c5ar的hek293稳定细胞系进行最终免疫。(3-5天后处死小鼠,收集脾细胞。加入nh4oh至终浓度1%(w/w),裂解脾细胞中参杂的红细胞,获得脾细胞悬液。用dmem基础培养基1000转每分钟离心清洗细胞3次,然后按活细胞数目5:1比率与小鼠骨髓瘤细胞sp2/0(购自atcc)混合,采用高效电融合方法(参见methodsinenzymology,vol.220)进行细胞融合。融合后的细胞稀释到含20%胎牛血清、1×hat的dmem培养基中,所述百分比为质量百分比。然后按1×105/200微升每孔加入到96孔细胞培养板中,放入5%co2、37℃培养箱中,所述百分比为体积百分比。14天后用acumen(微孔板细胞检测法)筛选细胞融合板上清,将acumen中mfi值>100的阳性克隆扩增到24孔板,在含10%(w/w)ht胎牛血清的dmem的培养基中,于37℃、5%(v/v)co2条件下扩大培养。培养3天后取24孔板中扩大培养的培养液进行离心,收集上清液,对上清液进行抗体亚型分析,用facs确定对c5ar阳性细胞的结合活性(结合活性的检测方法请分别参见实施例3a和实施例3b)。根据24孔板筛选结果,挑选facs实验中mfi值>50的杂交瘤细胞为符合条件的阳性克隆。选择符合条件的杂交瘤细胞用有限稀释法在96孔板进行亚克隆,在含10%(w/w)fbs的dmem培养基中(购自invitrogen)37℃、5%(v/v)co2条件下培养。亚克隆后10天用acumen进行初步筛选,挑选单个阳性单克隆扩增到24孔板继续培养。3天后用facs确定抗原结合阳性并用c5ar受体配体结合实验评估生物活性(评估标准为facs实验中mfi值>50)。根据24孔板样品检测结果,挑选出最优的克隆,并于含10%(w/w)fbs的dmem培养基中(购自invitrogen)在37℃、5%(v/v)co2条件下将该最优的克隆进行扩大培养,液氮冻存即得本发明杂交瘤细胞,并可用于后续的抗体生产和纯化。实施例2先导抗体的生产和纯化杂交瘤细胞产生的抗体浓度较低,大约仅1-10μg/毫升,浓度变化较大。且培养基中细胞培养所产生的多种蛋白和培养基所含胎牛血清成分对很多生物活性分析方法都有不同程度的干扰,因此需要进行小规模(1-5毫克)抗体生产纯化。将实施例1所得的杂交瘤细胞接种到t-75细胞培养瓶并用生产培养基(hybridomaserumfreemedium,购自invitrogen公司)驯化传代3代。待其生长状态良好,接种细胞培养转瓶。每个2升的培养转瓶中加入500毫升生产培养基,接种细胞密度为1.0×105/毫升。盖紧瓶盖,将转瓶置于37℃培养箱中的转瓶机上,转速3转/分钟。连续旋转培养14天后,收集细胞培养液,过滤去除细胞,并用0.45微米的滤膜过滤至培养上清液澄清。澄清的培养上清液可马上进行纯化或-30℃冻存。澄清的杂交瘤细胞的培养上清液(300ml)中的单克隆抗体用2ml蛋白g柱(购自gehealthcare)纯化。蛋白g柱先用平衡缓冲液(pbs磷酸缓冲液,ph7.2)平衡,然后将澄清的培养上清液上样到蛋白g柱,控制流速在3ml/分钟。上样完毕后用平衡缓冲液清洗蛋白g柱,平衡缓冲液的体积为4倍蛋白g柱柱床体积。用洗脱液(0.1m甘氨盐酸缓冲液,ph2.5)洗脱结合在蛋白g柱上的c5ar抗体,用紫外检测器监测洗脱情况(a280紫外吸收峰)。收集洗脱的抗体,加入10%1.0mtris-hcl缓冲液中和ph,所述百分比为体积百分比,然后立即用pbs磷酸缓冲液透析过夜,第二天换液1次并继续透析3小时。收集透析后的c5ar抗体,用0.22微米的滤器进行无菌过滤,无菌保存,即得纯化的c5ar抗体。将纯化的c5ar抗体进行蛋白浓度(a280/1.4)、纯度、内毒(lonza试剂盒)等检测分析,结果如表6所示,结果发现,抗体最终产品内毒素浓度在1.0eu/毫克以内,得到了纯化的c5ar抗体。表6纯化的c5ar抗体检测分析实施例3先导抗体的检定a、酶联免疫吸附实验(elisa)检测抗体与c5ar蛋白的结合。对实施例2所得的纯化的c5ar抗体与c5ar胞外结构域的5条多肽,即实施例1获得的纯化的免疫原a分别进行交叉反应。将实施例1获得的纯化的免疫原a的5条多肽分别用pbs稀释至终浓度1.0μg/ml,然后以100μl每孔加到96孔elisa板。用塑料膜封好4℃孵育过夜,第二天用洗板液[含有0.01%(v/v)tween20的pbs]洗板2次,加入封闭液[含有0.01%(v/v)tween20和1%(v/v)bsa的pbs]室温封闭2小时。倒掉封闭液,加入实施例2所得的纯化的c5ar抗体100μl每孔。37℃孵育2小时后,用洗板液[含有0.01%(v/v)tween20的pbs]洗板3次。加入hrp(辣根过氧化物酶)标记的二抗(购自sigma),37℃孵育2小时后,用洗板液[含有0.01%(v/v)tween20的pbs]洗板3次。加入tmb底物100μl每孔,室温孵育30分钟后,加入终止液(1.0nhcl)100μl每孔。用elisa读板机(spectramax384plus,购自moleculardevice)读取a450nm数值,结果如图3和表7所示,表7说明,纯化后的抗体与c5ar的结合位点主要在n末端和第二个胞外环(ecl#2)。其中igg对照为人igg,表中的数据为od450nm值。表7elisa检测c5ar抗体与c5ar特定表位的结合b、流式细胞实验(facs)检测抗体与c5ar表达细胞的结合将实施例1步骤(二)中所述含有编码人源c5ar全长氨基酸序列的核苷酸序列导入chok1细胞株得含人c5ar的chok1稳定细胞株(此处称为chok1-hc5ar稳定细胞株),然后在t-75细胞培养瓶中扩大培养至90%汇合度,吸尽培养基,用pbs缓冲液(phosphatebuffersaline,购自invitrogen)洗涤2次,然后用无酶细胞解离液(versenesolution,购自lifetechnology公司)处理和收集细胞。用pbs缓冲液洗涤细胞2次,进行细胞计数后将细胞用pbs缓冲液稀释至2×106细胞每毫升,加入2%小牛血清封闭液,所述百分比为质量百分比。室温孵育15分钟,然后用pbs缓冲液离心洗涤2次。将收集的细胞用facs缓冲液(含有2%fbs的pbs,所述百分比为质量百分比)悬浮至3×106细胞/ml。按每孔100微升加入到96孔facs反应板中,加入实施例2所得的纯化的c5ar抗体待测样品每孔100微升,4℃孵育1小时。用facs缓冲液离心洗涤2次,加入每孔100微升荧光(alexa488)标记的二抗(购自invitrogen),4℃孵育1小时。用facs缓冲液离心洗涤3次,加入每孔100微升固定液[4%(v/v)多聚甲醛]悬浮细胞,10分钟后用facs缓冲液离心洗涤2次。用100微升facs缓冲液悬浮细胞,用facs(facscalibur,购自bd公司)检测和分析结果。结果如图4和表8所示,表8说明,待测抗体可结合细胞表面的c5ar。其中migg对照为鼠igg,作为阴性对照。表8中的数据为mfi所测细胞群的平均荧光强度值。表8facs检测c5ar抗体与chok1-hc5ar的结合反应实施例4flipr钙检测实验检测c5ar抗体阻断c5a-c5ar介导的下游信号通路flipr钙检测试剂盒(calciumassayevaluationkit,product#r8172)购自moleculardevices,具体实验步骤按照试剂盒说明书进行。将实施例1步骤(二)中得到的chok1-hc5ar稳定细胞株进一步改造,导入ga15蛋白(其中,ga15蛋白在ncbi数据库的登录号为nm002068);转染使用x-tremegenehpdnatransfectionreagent,购自roche公司,货号cat#06366236001,并按说明书操作),经过抗生素筛选得到chok1-ga15-hc5ar稳定细胞株。chok1-ga15-hc5ar细胞在t-75细胞培养瓶中扩大培养至90%汇合度,吸尽培养基,用pbs缓冲液洗涤2次,然后用无酶细胞解离液(versenesolution:购自lifetechnology公司)处理和收集细胞。进行细胞计数后将细胞用含10%(w/w)小牛血清的f-12k培养基稀释至2×105细胞每毫升,按每孔50微升加入到384孔板中,放置在5%co2、37℃培养箱中过夜培养。第二天取出384孔板,弃去培养基,加入40微升荧光染料(购自calciumassayevaluationkit,product#r8172)后于室温避光放置1小时。将实施例2所得的纯化的c5ar抗体用缓冲液[含20mmhepes和0.1%(w/w)bsa的hbss缓冲液]稀释至150μg/ml,得抗体稀释溶液。再向384孔板中加入抗体稀释溶液每孔10微升,再于室温避光放置1小时。将384孔板和每孔装有30微升稀释至1nm的c5a溶液的384孔板一起放置在flipr仪器中进行检测。结果如图5和表9所示,表9说明,待测抗体可结合细胞表面的c5ar,从而阻断c5a介导的钙流信号。其中migg对照为鼠igg,表中的数据为mfi所测细胞群的平均荧光强度值。表9flipr检测c5ar抗体阻断c5a介导的钙流信号实施例5人中性粒细胞趋化实验检测c5ar抗体阻断c5a诱导的细胞迁移(一)ficoll分离全血获取外周血中性粒细胞pmns。将新鲜获取的全血用磷酸缓冲液pbs以1:1的体积比例稀释得稀释后的全血,用无菌吸管轻轻将稀释后的全血铺平在ficoll液面(购自gehealthcare),ficoll与稀释后的全血的体积比为3:4,避免震荡混匀,以400g转速室温20℃梯度离心30分钟,离心后的离心管分为四层,上层为血浆,中间白膜层为单核淋巴细胞,下面两层分别为ficoll和红细胞-中性粒细胞层。弃掉血浆、白膜层、ficoll,留红细胞-中性粒细胞层沉淀,用pbs稀释至25ml,再加入25ml3%(w/w)葡聚糖(dextran,分子量500,000,购自上海源叶生物科技有限公司),室温静置20分钟进行红细胞沉降。然后取上清液,500g转速室温离心10分钟,弃上清,取细胞沉淀。将细胞沉淀用无菌水重悬至25ml,颠倒离心管使之充分混匀,反应28秒后加入等体积1.8%(w/w)氯化钠溶液(购自sigma)终止红细胞裂解。500g转速室温离心5分钟,弃上清。将细胞沉淀用趋化缓冲液(49%rpmi1640、49%m199和2%透析的fbs的混合液,所述百分比为质量百分比)重悬至25ml,计数并离心,最后将中性粒细胞重悬至趋化缓冲液,细胞浓度调整为2×107细胞每毫升,得人外周血中性粒细胞。(二)人外周血中性粒细胞趋化实验将实施例5步骤(一)获得的人外周血中性粒细胞以2×106个细胞100微升每孔,铺至96孔细胞培养板。然后将浓度范围从0.5μg/ml到10μg/ml的c5ar抗体[将实施例2所得的纯化的c5ar抗体用趋化缓冲液稀释,趋化缓冲液包含:49%(v/v)rpmi1640、49%(v/v)m199和0.02%(v/v)bsa]加入到该96孔细胞培养板中,于37℃、5%(v/v)co2培养箱孵育20分钟。然后将孵育后的细胞加入到3.0μm孔径的24孔transwell(购自corning)的上室中,再将transwell的上室放置到含有10nmc5a蛋白的下室,在37℃、5%(v/v)co2培养箱中孵育30分钟,期间有细胞迁移进入下室。将迁移进入下室的细胞转移到另一个96孔板,然后加入100μlcelltiter-glo(购自promega)进行测量。结果如图6和表10所示。图6的数据说明,待测抗体均具有抑制人中性粒细胞迁移的活性。表10说明,待测抗体可阻断c5a诱导的细胞迁移。其中igg对照为鼠igg,表中的数据为celltiter-glo所测的荧光强度值。表10人中性粒细胞趋化实验检测c5ar抗体阻断c5a诱导的细胞迁移实施例6轻重链可变区氨基酸序列测定总rna分离:将实施例1亚克隆培养所得的上清液检验过抗原结合后(即经过实施例3~5的检定和活性测定后),通过离心搜集5×107个杂交瘤细胞,加入1mltrizol混匀并转移到1.5ml离心管中,室温静置5分钟。加0.2ml氯仿,振荡15秒,静置2分钟后于4℃,12000g离心5分钟,取上清转移到新的1.5ml离心管中。加入0.5ml异丙醇,将管中液体轻轻混匀,室温静置10分钟后于4℃,12000g离心15分钟,弃上清。加入1ml75%乙醇(所述百分比为体积百分比),轻轻洗涤沉淀,4℃,12000g离心5分钟后弃上清,将沉淀物晾干,加入depc处理过的h2o溶解(55℃水浴促溶10分钟),即得总rna。逆转录与pcr:取1μg总rna,配置20μl体系,加入逆转录酶后于42℃反应60分钟,于7℃反应10分钟终止反应。配置50μlpcr体系,包括1μlcdna、每种引物25pmol、1μldna聚合酶以及相配的缓冲体系、250μmoldntps。设置pcr程序,预变性95℃3分钟,变性95℃30秒,退火55℃30秒,延伸72℃35秒,35个循环后再额外于72℃延伸5分钟,得pcr产物。其中逆转录所用的试剂盒为primescriptrtmastermix,购自takara,货号rr036;pcr所用的试剂盒为q5超保真酶,购自neb,货号m0492。克隆与测序:取5μlpcr产物进行琼脂糖凝胶电泳检测,将检测阳性样品使用柱回收试剂盒纯化,其中回收试剂盒为gel&pcrclean-up,购自macherey-nagel,货号740609。进行连接反应:样品50ng,t载体50ng,连接酶0.5μl,缓冲液1μl,反应体系10μl,于16℃反应半小时得连接产物,其中连接的试剂盒为t4dna连接酶,购自neb,货号m0402;取5μl连接产物加入100μl的感受态细胞(ecos101competentcells,购自yeastern,货号fye607)中,冰浴5分钟。而后于42℃水浴热激1分钟,放回冰上1分钟后加入650μl无抗生素soc培养基,于37℃摇床上以200rpm的速度复苏30分钟,取出200μl涂布于含抗生素的lb固体培养基上于37℃孵箱过夜培养。次日,使用t载体上引物m13f和m13r配置30μlpcr体系,进行菌落pcr,用移液器枪头蘸取菌落于pcr反应体系中吹吸,并吸出0.5μl点于另一块含100nm氨苄青霉素的lb固体培养皿上以保存菌株。pcr反应结束后,取出5μl进行琼脂糖凝胶电泳检测,将阳性样品进行测序。其中,测序的步骤参见kabat,sequencesofproteinsofimmunologicalinterest,nationalinstitutesofhealth,bethesda,md.(1991)。测序结果如表11~12所示:表11c5ar抗体蛋白序列编号其中,表11中的数字即为序列表“seqidno:”编号,如5f8e2c11的重链蛋白可变区的氨基酸序列为序列表seqidno:1,而5f8e2c11的重链蛋白可变区中cdr1域的氨基酸序列为序列表seqidno:2。表12c5ar抗体基因序列编号克隆号重链蛋白可变区轻链蛋白可变区5f8e2c11575842b5g7d1596043e8f5b6616246h2a11c763642a12b2b265668b5d1a967689d5a12g76970其中,表12中的数字即为序列表“seqidno:”编号,如编码5f8e2c11的重链蛋白可变区的核苷酸序列为序列表seqidno:33。其中,编码5f8e2c11的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:57中的第76位至第105位;编码5f8e2c11的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:57中的第148位至第195位;编码5f8e2c11的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:57中的第292位至第321位;编码5f8e2c11的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:58中的第70位至第120位;编码5f8e2c11的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:58中的第166位至第186位;编码5f8e2c11的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:58中的第283位至第306位;编码42b5g7d1的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:59中的第76位至第105位;编码42b5g7d1的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:59中的第148位至第198位;编码42b5g7d1的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:59中的第295位至第336位;编码42b5g7d1的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:60中的第70位至第117位;编码42b5g7d1的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:60中的第163位至第183位;编码42b5g7d1的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:60中的第280位至第306位;编码43e8f5b6的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:61中的第76位至第105位;编码43e8f5b6的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:61中的第148位至第198位;编码43e8f5b6的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:61中的第295位至第339位;编码43e8f5b6的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:62中的第70位至第105位;编码43e8f5b6的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:62中的第151位至第171位;编码43e8f5b6的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:62中的第268位至第294位。编码46h2a11c7的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:63中的第76位至第105位;编码46h2a11c7的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:63中的第148位至第198位;编码46h2a11c7的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:63中的第295位至第312位;编码46h2a11c7的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:64中的第70位至第117位;编码46h2a11c7的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:64中的第163位至第183位;编码46h2a11c7的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:64中的第280位至第306位。编码2a12b2b2的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:65中的第76位至第105位;编码2a12b2b2的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:65中的第148位至第198位;编码2a12b2b2的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:65中的第295位至第303位;编码2a12b2b2的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:66中的第70位至第102位;编码2a12b2b2的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:66中的第148位至第168位;编码2a12b2b2的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:66中的第265位至第291位。编码8b5d1a9的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:67中的第76位至第105位;编码8b5d1a9的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:67中的第148位至第198位;编码8b5d1a9的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:67中的第295位至第324位;编码8b5d1a9的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:68中的第70位至第120位;编码8b5d1a9的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:68中的第166位至第189位;编码8b5d1a9的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:68中的第286位至第312位。编码9d5a12g7的重链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:69中的第76位至第105位;编码9d5a12g7的重链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:69中的第148位至第195位;编码9d5a12g7的重链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:69中的第292位至第321位;编码9d5a12g7的轻链蛋白可变区中cdr1的核苷酸序列为序列表seqidno:70中的第70位至第120位;编码9d5a12g7的轻链蛋白可变区中cdr2的核苷酸序列为序列表seqidno:70中的第166位至第186位;编码9d5a12g7的轻链蛋白可变区中cdr3的核苷酸序列为序列表seqidno:70中的第283位至第306位。应理解,在阅读了本发明的上述内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。<110>尚华科创投资管理(江苏)有限公司<120>一种c5ar抗体及其制备方法和应用<130>p20135608cpd<150>cn201610018727.1<151>2016-1-12<160>72<170>patentinversion3.5<210>1<211>118<212>prt<213>homosapiens<400>1glnvalglnleuargglnserglyproglyleuvalglnprosergln151015serleuserilethrcysthrvalserglypheserleuthrsertyr202530glyvalhistrpvalargglnserproglylysglyleuglutrpleu354045glyvaliletrpserglyglyserthrasptyrasnalaalapheile505560serargleuserileserlysasptyrserlysserglnilepheleu65707580thrmetasnserleuglnthraspaspthralailetyrtyrcysala859095argasnserargleuglyasncyspheasptyrtrpglyglnglythr100105110thrleuthrvalserser115<210>2<211>10<212>prt<213>homosapiens<400>2glypheserleuthrsertyrglyvalhis1510<210>3<211>16<212>prt<213>homosapiens<400>3valiletrpserglyglyserthrasptyrasnalaalapheileser151015<210>4<211>10<212>prt<213>homosapiens<400>4asnserargleuglyasncyspheasptyr1510<210>5<211>112<212>prt<213>homosapiens<400>5aspilevalmetserglnserproserserleualavalseralagly151015glulysvalthrmetsercyslysserserglnserleuleuasnser202530argthrarglysasntyrleualatrptyrglnglnlysproglygln354045serprolysleuleuiletyrtrpalaserthrarggluserglyval505560proaspargphethrglyserglyserglythraspphethrleuthr65707580ileserservalglnalagluaspleualavaltyrtyrcyslysgln859095sertyrasnleuproalapheglyglyglythrlysleugluilelys100105110<210>6<211>17<212>prt<213>homosapiens<400>6lysserserglnserleuleuasnserargthrarglysasntyrleu151015ala<210>7<211>7<212>prt<213>homosapiens<400>7trpalaserthrarggluser15<210>8<211>8<212>prt<213>homosapiens<400>8lysglnsertyrasnleuproala15<210>9<211>123<212>prt<213>homosapiens<400>9glnvalglnleuglnglnserglyprogluleuvallysproglyala151015servallysilesercyslysalaserglytyrvalpheserasnser202530trpmetasntrpvallysglnargproglylysglyleuglutrpile354045glyargileaspproglyaspglyaspthrlystyrasnglylysphe505560lysglylysalathrleuthralaasplysserserserthralatyr65707580metglnleuserserleuthrsergluaspseralavaltyrphecys859095valargphetyrtyrglyserasntyrvalglytyrtyrpheasptyr100105110trpglyglnglythrthrleuthrvalserser115120<210>10<211>10<212>prt<213>homosapiens<400>10glytyrvalpheserasnsertrpmetasn1510<210>11<211>17<212>prt<213>homosapiens<400>11argileaspproglyaspglyaspthrlystyrasnglylysphelys151015gly<210>12<211>14<212>prt<213>homosapiens<400>12phetyrtyrglyserasntyrvalglytyrtyrpheasptyr1510<210>13<211>112<212>prt<213>homosapiens<400>13aspvalleumetthrglnthrproleuserleuprovalserleugly151015aspglnalaserilesercysargserserglnserilevalglnser202530asnglyasnthrtyrleuglutrptyrleuglnlysproglyglnser354045prolysleuleuiletyrlysvalserasnargpheserglyvalpro505560aspargpheserglyserglyserglythraspphethrleulysile65707580serargvalglualagluaspleuglyvaltyrtyrcyspheglngly859095serleuvalproprothrpheglyglyglythrlysleugluilelys100105110<210>14<211>16<212>prt<213>homosapiens<400>14argserserglnserilevalglnserasnglyasnthrtyrleuglu151015<210>15<211>7<212>prt<213>homosapiens<400>15lysvalserasnargpheser15<210>16<211>9<212>prt<213>homosapiens<400>16pheglnglyserleuvalproprothr15<210>17<211>124<212>prt<213>homosapiens<400>17gluvalglnleuglnglnserglyprogluleuvallysproglyala151015servallysilesercyslysalaserglytyrthrphethrasptyr202530tyrmetsertrpmetlysglnserhisglylysserleuglutrpile354045glyaspileasnproasnasnglyaspasniletyrasnglnlysphe505560lysglylysalathrleuthrvalaspargserserserthralatyr65707580metaspleuargserleuthrsergluaspseralavaltyrtyrcys859095alaargtrptyrtyrtyrvalserserphesertyrtrptyrpheasp100105110valtrpglythrglythrthrvalthrvalserser115120<210>18<211>10<212>prt<213>homosapiens<400>18glytyrthrphethrasptyrtyrmetser1510<210>19<211>17<212>prt<213>homosapiens<400>19aspileasnproasnasnglyaspasniletyrasnglnlysphelys151015gly<210>20<211>15<212>prt<213>homosapiens<400>20trptyrtyrtyrvalserserphesertyrtrptyrpheaspval151015<210>21<211>108<212>prt<213>homosapiens<400>21gluilevalleuthrglnserprothrthrmetalaalaserprogly151015glulysilethrilethrcysseralathrserserileasnserasn202530tyrleuhistrptyrglnglnlysproglypheserprolysleuleu354045iletyrargthrserasnleualaserglyvalproalaargpheser505560glyserglyserglythrsertyrserleuthrileglythrmetglu65707580alagluaspvalalathrtyrtyrcysglnglnglyargthrilepro859095argthrpheglyserglythrlysleugluilelys100105<210>22<211>12<212>prt<213>homosapiens<400>22seralathrserserileasnserasntyrleuhis1510<210>23<211>7<212>prt<213>homosapiens<400>23argthrserasnleualaser15<210>24<211>9<212>prt<213>homosapiens<400>24glnglnglyargthrileproargthr15<210>25<211>115<212>prt<213>homosapiens<400>1glnvalglnleulysglnserglyalagluleuvallysproglyala151015servallysilesercysargalaserglytyrthrphethrasptyr202530pheileasntrpvallysglnargproglyglnglyleuglutrpile354045glylysileglyproglyserglyasniletyrglnasnglulysphe505560lysasplysalathrleuthrthraspthrserserserthralatyr65707580metglnleuserserleuthrsergluaspseralavaltyrphecys859095alaargtrpglyileglnargglytrpglyglnglythrthrleuthr100105110valserser115<210>26<211>10<212>prt<213>homosapiens<400>26glytyrthrphethrasptyrpheileasn1510<210>27<211>17<212>prt<213>homosapiens<400>27lysileglyproglyserglyasniletyrglnasnglulysphelys151015asp<210>28<211>6<212>prt<213>homosapiens<400>28trpglyileglnarggly15<210>29<211>112<212>prt<213>homosapiens<400>29aspvalvalmetthrglnthrproleuthrleuservalthrilegly151015glnproalaserilesercyslysserserglnserleuleuaspser202530aspglylysthrtyrleuasntrpleuleuglnargproglyglnser354045prolysargleuphepheleuvalserlysargaspsergluvalpro505560aspargphethrglyserglyserglythraspphethrleulysile65707580serargvalglualagluaspleuglyvaltyrtyrcystrpglnval859095thrhispheprotyrthrpheglyglyglythrlysleugluilelys100105110<210>30<211>16<212>prt<213>homosapiens<400>30lysserserglnserleuleuaspseraspglylysthrtyrleuasn151015<210>31<211>7<212>prt<213>homosapiens<400>31leuvalserlysargaspser15<210>32<211>9<212>prt<213>homosapiens<400>32trpglnvalthrhispheprotyrthr15<210>33<211>112<212>prt<213>homosapiens<400>1glnvalglnleuglnglnproglyalaaspleuvallysproglyala151015servallysmetsercyslysalaserglytyrileleuthrthrtyr202530trpilethrtrpvallysglnargproglyglnglyleuglutrpile354045glyaspilehisproglyserglyserthrlystyrasnglulysphe505560lysserlysalathrleuthrvalaspthrserserserthralatyr65707580metglnleuthrargleusersergluaspseralavaltyrtyrcys859095alaargargasptyrtrpglyglnglythrthrleuthrvalserser100105110<210>34<211>10<212>prt<213>homosapiens<400>2glytyrileleuthrthrtyrtrpilethr1510<210>35<211>17<212>prt<213>homosapiens<400>3aspilehisproglyserglyserthrlystyrasnglulysphelys151015<210>36<211>3<212>prt<213>homosapiens<400>4argasptyr1<210>37<211>107<212>prt<213>homosapiens<400>37aspileglnmetthrglnthrthrserserleuseralaserleugly151015asplysvalthrilesercysargalaserglnaspileserasntyr202530leusertrptyrglnglnlysproaspglythrvallysleuleuile354045tyrtrpileserargleuhisserglyvalproserargphesergly505560serglyserglythrasppheserleuthrileserasnleuglugln65707580gluaspilealathrtyrphecysglnglnglyasnserleupropro859095thrpheglyglyglythrlysleugluvallys100105<210>38<211>11<212>prt<213>homosapiens<400>38argalaserglnaspileserasntyrleuser1510<210>39<211>7<212>prt<213>homosapiens<400>39trpileserargleuhisser15<210>40<211>9<212>prt<213>homosapiens<400>40glnglnglyasnserleuproprothr15<210>41<211>119<212>prt<213>homosapiens<400>41glnvalglnleulysglnserglyalagluleuvallysproglyala151015servallysilesercyslysthrserglytyrilephethrasptyr202530tyrileasntrpmetlysglnargproglyglnglyleuglutrpile354045glylysileglyproglyserglythrthrphetyrasnglulysphe505560lysglylysalathrleuthralaasplysserserthrthrleutyr65707580metglnleuserserleuthralagluaspseralavaltyrphecys859095thrargargglytyrtyrsersersertyrphetyrtrpglyglngly100105110thrthrleuthrvalserser115<210>42<211>10<212>prt<213>homosapiens<400>42glytyrilephethrasptyrtyrileasn1510<210>43<211>17<212>prt<213>homosapiens<400>43lysileglyproglyserglythrthrphetyrasnglulysphelys151015gly<210>44<211>10<212>prt<213>homosapiens<400>44argglytyrtyrsersersertyrphetyr1510<210>45<211>113<212>prt<213>homosapiens<400>45aspilevalmetthrglnserproserserleuservalseralagly151015glulysvalilemetsercyslysserserglnserleuleuasnser202530gluargglnlysasntyrleualatrptyrglnglnlysproglygln354045serprolysleuleuiletyrglyalaserthrarggluserglyval505560proaspargphethrglyserglyserglythraspphethrleuthr65707580ileserservalglnalagluaspleualavaltyrtyrcysleuasn859095asphissertyrproleuthrpheglyalaglythrlysleugluleu100105110lys<210>46<211>17<212>prt<213>homosapiens<400>46lysserserglnserleuleuasnsergluargglnlysasntyrleu151015ala<210>47<211>7<212>prt<213>homosapiens<400>47glyalaserthrarggluser15<210>48<211>9<212>prt<213>homosapiens<400>48leuasnasphissertyrproleuthr15<210>49<211>118<212>prt<213>homosapiens<400>49glnvalglnleulysglnserglyproglyleuvalglnprosergln151015serleuserilethrcysthrvalserglypheserleuthrsertyr202530glyvalhistrpvalargglnserproglylysglyleuglutrpleu354045glyvaliletrpserglyglyserthrasptyrasnalaalapheile505560serargleuserileserlysaspasnserlysserglnvalphephe65707580lysmetasnserleuglnalaaspaspthralailetyrtyrcysala859095argasnglyleuleuglyasnalametasptyrtrpglyglnglythr100105110servalthrvalserser115<210>50<211>10<212>prt<213>homosapiens<400>50glypheserleuthrsertyrglyvalhis1510<210>51<211>16<212>prt<213>homosapiens<400>51valiletrpserglyglyserthrasptyrasnalaalapheileser151015<210>52<211>10<212>prt<213>homosapiens<400>52asnglyleuleuglyasnalametasptyr1510<210>53<211>112<212>prt<213>homosapiens<400>53aspilevalmetserglnserproserserleualavalseralagly151015glulysvalthrmetsercyslysserserglnserleuleuserser202530argthrarglysasntyrleualatrptyrglnglnlysproglygln354045serprolysleuleuiletyrtrpalaserthrarggluserglyval505560proaspargphethrglyserglyserglythraspphethrleuthr65707580ileserservalglnthrgluaspleualavaltyrtyrcyslysgln859095sertyrasnleuleuthrpheglyalaglythrthrleugluleulys100105110<210>54<211>17<212>prt<213>homosapiens<400>54lysserserglnserleuleuserserargthrarglysasntyrleu151015ala<210>55<211>7<212>prt<213>homosapiens<400>55trpalaserthrarggluser15<210>56<211>8<212>prt<213>homosapiens<400>56lysglnsertyrasnleuleuthr15<210>57<211>354<212>dna<213>homosapiens<400>57caggtgcagctgaggcagtcaggacctggcctagtgcagccctcacagagcctgtccatc60acctgcacagtctctggtttctcattaactagttatggtgttcactgggttcgccagtct120ccaggaaagggtctggagtggctgggagtgatatggagtggtggaagcacagactataat180gcagctttcatatccagactgagcatcagcaaggactattccaagagccaaattttcctt240acaatgaacagtctacaaactgatgacacagccatatattactgtgccagaaattcgaga300ctgggaaactgctttgactactggggccaaggcaccactctcacagtctcctca354<210>58<211>336<212>dna<213>homosapiens<400>58gacattgtgatgtcacagtctccatcctccctggctgtgtcagcaggagagaaggtcact60atgagctgcaaatccagtcagagtctgctcaacagtagaacccgaaagaactacttggct120tggtaccagcagaaaccagggcagtctcctaaactgctgatctactgggcatccactagg180gaatctggggtccctgatcgcttcacaggcagtggatctgggacagatttcactctcacc240atcagcagtgtgcaggctgaagacctggcagtttattactgcaagcaatcttataatctt300cccgcgttcggaggggggaccaagctggaaataaaa336<210>59<211>369<212>dna<213>homosapiens<400>59caggttcagctgcagcagtctggacctgagctggtgaagcctggggcctcagtgaagatt60tcctgcaaggcttctggctacgtattcagtaactcctggatgaactgggtgaagcagagg120cctggaaagggtcttgagtggattggacggattgatcctggagatggagatactaaatac180aatgggaagttcaagggcaaggccacactgactgcagacaaatcctccagcacagcctac240atgcaactcagcagcctgacatctgaggactctgcggtctacttctgtgtaagattttac300tacggcagtaactacgtagggtactactttgactattggggtcaaggcaccactctcaca360gtctcctca369<210>60<211>336<212>dna<213>homosapiens<400>60gatgttttgatgacccaaactccactctccctgcctgtcagtcttggagatcaagcctcc60atctcttgcagatctagtcagagcattgtacaaagtaatggaaacacctatttagaatgg120tacctgcagaaaccaggccagtctccaaagctcctgatctacaaagtttccaaccgattt180tctggggtcccagacaggttcagtggcagtggatcagggacagatttcacactcaagatc240agcagagtggaggctgaggatctgggagtttattactgctttcaaggttcccttgttcct300ccgacgttcggtggaggcaccaagctggaaatcaaa336<210>61<211>372<212>dna<213>homosapiens<400>61gaggtccagctgcaacaatctggacctgagctggtgaagcctggggcttcagtgaagata60tcctgtaaggcttctggatacacgttcactgactactacatgagctggatgaagcagagc120catggaaagagccttgagtggattggagatattaatcctaacaatggtgataatatctac180aatcagaagttcaagggcaaggccacattgactgtagacaggtcctccagcacagcctac240atggacctccgcagcctgacatctgaggactctgcagtctattactgtgcaagatggtat300tactacgttagtagcttcagctactggtacttcgatgtctggggcacagggaccacggtc360accgtctcctca372<210>62<211>324<212>dna<213>homosapiens<400>62gaaattgtgctcacccagtctccaaccaccatggctgcatctcccggggagaagatcact60atcacctgcagtgccacctcaagtataaattccaattacttgcattggtatcagcagaag120ccaggattctcccctaaactcttgatttataggacatccaatctggcttctggagtccca180gctcgcttcagtggcagtgggtctgggacctcttactctctcacaattggcaccatggag240gctgaagatgttgccacttactactgccagcagggtcgtactataccacgcacgttcggc300tcggggacaaagttggaaataaaa324<210>63<211>345<212>dna<213>homosapiens<400>63caggtccaactgaagcagtctggagctgagctggtgaagcctggggcttcagtgaagata60tcctgcagggcttctggctacaccttcactgactactttataaactgggtgaagcagagg120cctggacagggccttgagtggattggaaagattggtcctggaagtggtaatatttatcag180aatgagaagtttaaggacaaggccacactgactacagacacatcctccagcacagcctac240atgcagctcagcagtctaacatctgaggactctgcagtctatttctgtgcaagatgggga300atacaacgagggtggggccaaggcaccactctcacagtctcctca345<210>64<211>336<212>dna<213>homosapiens<400>64gatgttgtgatgacccagactccactcactttgtcggttaccattggacaaccagcctcc60atctcttgcaagtcaagtcagagcctcttagatagtgatgggaagacatatttgaattgg120ttgttacagaggccaggccagtctccaaagcgcctattctttctggtgtctaaacgggac180tctgaagtccctgacaggttcactggcagtggatctgggacagatttcacactgaaaatc240agcagagtggaggctgaagatttgggagtttattattgctggcaagttacacattttccg300tacacgttcggaggggggaccaagctggaaataaaa336<210>65<211>336<212>dna<213>homosapiens<400>65caggtccaactgcagcagcctggggctgaccttgtgaagcctggggcctcagtgaagatg60tcctgtaaggcttctggctacatcctcaccacctattggataacctgggtgaagcagagg120cctggacaaggccttgagtggattggagatattcatcctggtagtggtagtacaaagtac180aatgagaaattcaagagtaaggccacactgactgtagacacatcctccagcacagcctac240atgcagctcaccagactgtcatctgaggactctgcggtctattactgtgcaagaagggac300tactggggccaaggcaccactctcacagtctcctca336<210>66<211>321<212>dna<213>homosapiens<400>66gatatccagatgacacagactacatcctccctgtctgcctctctgggagacaaagtcacc60atcagttgcagggcaagtcaggacattagcaattatttaagctggtatcagcagaaacca120gatggaactgttaaactcctgatctactggatctcaagattacactcaggagtcccatca180aggttcagtggcagtgggtctggaacagatttttctctcaccattagcaacctggagcaa240gaagatattgccacttacttttgccaacagggtaattcgcttcctccgacgttcggtgga300ggcaccaagctggaagtcaaa321<210>67<211>357<212>dna<213>homosapiens<400>67caggtccagctgaagcagtctggagctgagctggtgaagcctggggcttcagtgaagata60tcctgcaagacttctggctacatcttcactgactactacataaactggatgaaacaaagg120cctggacagggccttgagtggattggaaagattggtcctggaagtggtactactttctac180aatgagaagttcaagggcaaggccacactgactgcagacaaatcctccaccacactttat240atgcagctcagcagcctgacagctgaggactctgcagtctatttctgtacaagaaggggt300tactacagtagtagctacttttactggggccaaggcaccactctcacagtctcctca357<210>68<211>339<212>dna<213>homosapiens<400>68gacatagtgatgacacagtctccatcctccctgagtgtgtcagcaggagagaaggtcata60atgagctgcaagtccagtcagagtctgttaaacagtgaaagacaaaagaactacttggcc120tggtaccagcagaagccagggcagtctcctaaactgttgatctacggggcatccactagg180gaatcgggggtccctgatcgcttcacaggcagtggatctggaaccgatttcactcttacc240atcagcagtgtgcaggctgaagacctggcagtttattactgtctgaatgatcatagttat300ccgctcacgttcggtgctgggaccaagctggaactgaaa339<210>69<211>354<212>dna<213>homosapiens<400>69caggtgcagctgaagcagtcaggacctggcctagtgcagccctcacagagcctgtccatc60acctgcacagtctctggtttctcattgactagctatggtgtacactgggttcgccagtct120ccaggaaagggtctggagtggctgggagtcatatggagtggtggaagcacagactataat180gcagctttcatatccagactgagcatcagcaaggacaattccaagagccaagttttcttt240aaaatgaacagtctgcaagctgatgacacagccatatattactgtgccagaaatggatta300cttgggaatgctatggactactggggtcaaggaacctcagtcaccgtctcctca354<210>70<211>336<212>dna<213>homosapiens<400>70gacattgtgatgtcacagtctccatcctccctggctgtgtcagcaggagagaaggtcact60atgagctgcaaatccagtcagagtctgctcagcagtagaacccgaaaaaactacttggct120tggtaccagcagaaaccagggcagtctcctaaactgctgatctactgggcatccactagg180gagtctggggtccctgatcgcttcacaggcagtggatctgggacagatttcactctcacc240atcagcagtgtgcagactgaagacctggcagtttattactgcaagcaatcttataatctg300ctcacgttcggtgctgggaccacgctggagctgaaa336<210>71<211>1050<212>dna<213>homosapiens<400>71atgaactccttcaattataccacccctgattatgggcactatgatgacaaggataccctg60gacctcaacacccctgtggataaaacttctaacacgctgcgtgttccagacatcctggcc120ttggtcatctttgcagtcgtcttcctggtgggagtgctgggcaatgccctggtggtctgg180gtgacggcattcgaggccaagcggaccatcaatgccatctggttcctcaacttggcggta240gccgacttcctctcctgcctggcgctgcccatcttgttcacgtccattgtacagcatcac300cactggccctttggcggggccgcctgcagcatcctgccctccctcatcctgctcaacatg360tacgccagcatcctgctcctggccaccatcagcgccgaccgctttctgctggtgtttaaa420cccatctggtgccagaacttccgaggggccggcttggcctggatcgcctgtgccgtggct480tggggtttagccctgctgctgaccataccctccttcctgtaccgggtggtccgggaggag540tactttccaccaaaggtgttgtgtggcgtggactacagccacgacaaacggcgggagcga600gccgtggccatcgtccggctggtcctgggcttcctgtggcctctactcacgctcacgatt660tgttacactttcatcctgctccggacgtggagccgcagggccacgcggtccaccaagaca720ctcaaggtggtggtggcagtggtggccagtttctttatcttctggttgccctaccaggtg780acggggataatgatgtccttcctggagccatcgtcacccaccttcctgctgctgaataag840ctggactccctgtgtgtctcctttgcctacatcaactgctgcatcaaccccatcatctac900gtggtggccggccagggcttccagggccgactgcggaaatccctccccagcctcctccgg960aacgtgttgactgaagagtccgtggttagggagagcaagtcattcacgcgctccacagtg1020gacactatggcccagaagacccaggcagtg1050<210>72<211>350<212>prt<213>homosapiens<400>72metasnserpheasntyrthrthrproasptyrglyhistyraspasp151015lysaspthrleuaspleuasnthrprovalasplysthrserasnthr202530leuargvalproaspileleualaleuvalilephealavalvalphe354045leuvalglyvalleuglyasnalaleuvalvaltrpvalthralaphe505560glualalysargthrileasnalailetrppheleuasnleualaval65707580alaasppheleusercysleualaleuproileleuphethrserile859095valglnhishishistrppropheglyglyalaalacysserileleu100105110proserleuileleuleuasnmettyralaserileleuleuleuala115120125thrileseralaaspargpheleuleuvalphelysproiletrpcys130135140glnasnpheargglyalaglyleualatrpilealacysalavalala145150155160trpglyleualaleuleuleuthrileproserpheleutyrargval165170175valarggluglutyrpheproprolysvalleucysglyvalasptyr180185190serhisasplysargarggluargalavalalailevalargleuval195200205leuglypheleutrpproleuleuthrleuthrilecystyrthrphe210215220ileleuleuargthrtrpserargargalathrargserthrlysthr225230235240leulysvalvalvalalavalvalalaserphepheilephetrpleu245250255protyrglnvalthrglyilemetmetserpheleugluproserser260265270prothrpheleuleuleuasnlysleuaspserleucysvalserphe275280285alatyrileasncyscysileasnproileiletyrvalvalalagly290295300glnglypheglnglyargleuarglysserleuproserleuleuarg305310315320asnvalleuthrglugluservalvalarggluserlysserphethr325330335argserthrvalaspthrmetalaglnlysthrglnalaval340345350当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1