一种与油茶单果质量相关的DNA片段及其应用的制作方法
一种与油茶单果质量相关的dna片段及其应用
技术领域
1.本发明涉及油茶分子标记及遗传育种技术领域。具体涉及一种与油茶单果质量相关的dna片段、其紧密连锁的分子标记及其应用。
背景技术:
2.油茶(camellia oleifera)作为四大油料(油菜、花生、大豆和油茶)之一,在亚热带地区广泛种植,种植面积达6500万亩以上。油茶籽油不饱和脂肪酸含量达90%以上,且富含角鲨烯、维生素e等营养成分,是一种优质的食用油,被称为“东方橄榄油”。选育高产(油)质优的油茶优良品种一直是油茶产业健康发展的基础和保障。一直以来,以选择和杂交育种为主要手段的油茶育种工作取得了长足的进展,但油茶的常规育种周期长,新品种选育缓慢,良种选育速度还不能满足产业发展的需求,这已成为限制油茶产业发展的重要因素之一。
3.相比于传统育种技术,分子标记辅助育种可从苗期开始选择,大幅缩短育种的周期,对以果实为主要目的的经济林育种优势尤其明显。分子标记辅助育种离不开有效的分子标记,因此,开发与果实大小、油茶果实产量、油脂品质表型相关的分子标记,对于油茶油脂产量和品质的分子标记辅助育种及相关性状的遗传改良具有重要意义。
4.果实大小、果实产量、种仁含油率等指标直接决定单位面积油茶产(油)量,同时,大果型的新品种选育对于提高采摘效率,降低劳动成本具有重要意义。因此,开展油茶大果型新品种选育研究,是提高油茶产量、降低劳动成本的重要途径,对油茶产业的提升和健康发展具有十分重要的意义。
技术实现要素:
5.本发明的目的在于提供一种油茶单果质量基因位点及与基因位点紧密连锁的分子标记,以及所述分子标记在油茶大果型种质表型鉴定和育种中的应用。
6.本发明提供的油茶单果质量基因位点及与所述基因位点紧密连锁的分子标记的开发是基于已建立的油茶f1代杂交群体,开展高密度遗传连锁图构建和单果质量性状的qtl定位实现的。油茶的简化基因组序列为本发明标记开发的区域。
7.本发明中关键基因位点及连锁的snp分子标记的开发过程基本如下:
8.(1)果实大小差异显著的油茶无性系长林53号(20.38g)和长林81号(14.31g)控制授粉,创制果实大小广泛分离的油茶f1代杂交群体。
9.(2)采集杂交群体180个单株的完全成熟果实,测定单个果实重量。
10.(3)采集杂交群体180个单株及两个亲本的幼嫩叶片,采用takara minibest植物基因组dna提取试剂盒(takara,dalian,china)提取dna,利用ecori和nlaiii(hin1ii)双酶切后每样本分别构建简化基因组(ddrad)测序文库,利用illumina hiseqxten平台测序。
11.(4)以二倍体油茶基因组为参考序列,分析(3)中获得的180个样本及2个亲本简化基因组的snp位点。snp数据根据以下原则过滤:亲本测序深度≥10x,子代测序深度≥8x;基
因型缺失率≤30%;snp质量值≥30。过程中用到软件bwa是公开免费的。
12.(5)运用joinmap4.0软件进行连锁图谱构建,参数设置为:rec≤0.4,lod≥3.0,jump=5,作图函数使用kosambi;分析连锁群内标记的排列顺序,计算相邻标记间的遗传距离。
13.(6)运用qtl icimapping软件进行数据分析,采用完备区间作图法(icim)进行qtl定位。扫描步长设置为1cm;逐步回归标记进入的概率(pin)为0.002(pout=2*pin=0.002);lod值为2.5。
14.利用上述技术措施,本发明获得了一个位于10号连锁群(lg10)上的油茶单果质量基因位点wsf.10
‑
2,该基因位点的贡献率为44.3%,与该位点紧密连锁的snp标记为chr10
‑
85853737,其基因型为c/t(表1)。
15.表1基因位点及连锁snp分子标记信息
16.基因位点连锁群位置置信区间连锁snp双亲基因型lod贡献率wsf.10
‑
2lg10205.399cm198.095cm
‑
205.399cmchr10
‑
85853737ct*cc3.8244.3%
17.具体地,本发明提供如下技术方案:
18.第一方面,本发明提供一个与油茶单果质量相关的dna片段,其为位于油茶连锁图谱10号连锁群的wsf.10
‑
2;置信区间为198.095cm
‑
205.399cm。
19.上述dna片段对表型的贡献率为44.3%,可用于图位克隆和分子标记辅助选择。
20.与上述dna片段紧密连锁的snp分子标记为chr10
‑
85853737,所述chr10
‑
85853737位于油茶基因组10号染色体的85853737bp位,多态性为c/t。
21.第二方面,本发明提供与油茶单果质量位点紧密连锁的snp分子标记,其包括snp分子标记chr10
‑
85853737,所述chr10
‑
85853737位于油茶基因组10号染色体的85853737bp位,多态性为c/t。
22.所述snp分子标记与油茶单果质量位点wsf.10
‑
2紧密连锁。
23.具体地,snp分子标记chr10
‑
85853737含有如seq id no.1所示序列第252位的多态性为c/t的核苷酸序列。
24.优选地,所述snp分子标记chr10
‑
85853737含有如seq id no.1所示序列第252位的多态性为c/t的核苷酸序列。
25.seq id no.1:
26.cacagtcattagagttagcacctagtgatgtttctagttcatctcagcctttagtcatcactgcttttgtggaaacttcatccagaattgctcaaagagagacaataatggctaaagatattgtgcaattatttaaatagaacaattatactaatttgtgctttcaaactgtaggaaagcaactaaccagaattgaggtagctataaatacttttaaaaatcataaaatggtacgaccttccacctcaactctttaaccagtaaatagtaaaccacctttagaagtaactaattttaagttacgttttgataaattgggtagtgaattcatggatacccttttacaaaaaatgagtgatttaaatttagggaaatcagcaccaggcagt。
27.进一步地,snp分子标记chr10
‑
85853737由序列如seq id no.2
‑
3所示的引物对以油茶基因组dna为模板经pcr扩增获得。
28.seq id no.2:5
’‑
cacagtcattagagttagca
‑3’
;
29.seq id no.3:5
’‑
actgcctggtgctgatttcc
‑3’
。
30.snp分子标记chr10
‑
85853737,具有所述多态性的位点的基因型为c/t,对应高单
果质量;基因型为c/c,对应低单果质量。本发明所述的单果质量为完全成熟新鲜果实质量,单位克。
31.第三方面,本发明提供用于扩增所述snp分子标记的引物。
32.作为本发明的一种实施方式,所述引物包括如seq id no.2
‑
3所示的引物。
33.本发明还提供含有上述引物的试剂或试剂盒。
34.第四方面,本发明提供的与油茶单果质量相关的dna片段或上述的snp分子标记或上述的引物或上述的试剂或试剂盒的以下任一应用:
35.(1)在鉴定油茶果实大小表型中的应用;
36.(2)在油茶果实质量大小的早期预测中的应用;
37.(3)在油茶果实质量大小改良或油茶果实质量大小分子标记辅助育种中的应用;
38.(4)在筛选大果型油茶中的应用。
39.第五方面,本发明提供一种鉴定油茶果实质量的方法,包括如下步骤:
40.(1)提取待鉴定油茶的基因组dna;
41.(2)以基因组dna为模板,利用序列如seq id no.2
‑
3所示的引物进行pcr扩增;
42.(3)分析pcr扩增产物中上述的snp分子标记的基因型,根据所述基因型判断待鉴定油茶单个果实质量的表型;
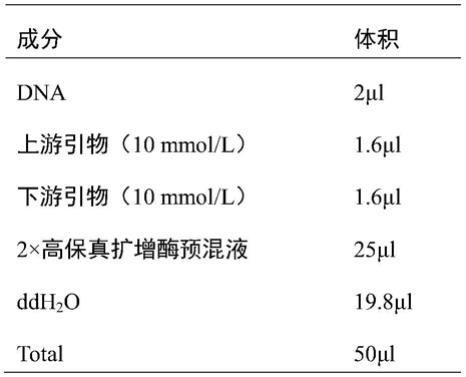
43.在上述方法的步骤(1)中,所述待鉴定油茶具体选自长林53号
×
长林81号的杂种f1代个体。
44.提取油茶基因组dna采用takara minibest植物基因组dna提取试剂盒(takara,dalian,china)。
45.在步骤(2)中,pcr扩增的反应程序为:94
‑
95℃,3
‑
5min;94
‑
95℃,15
‑
30s,65
‑
69℃,40
‑
60s,38
‑
45个循环;67
‑
70℃,3
‑
6min。优选为,95℃,3min,1个循环预变性;95℃,15s变性,68℃,45s延伸,40个循环;68℃,5min,1个循环彻底延伸。
46.在步骤(2)中,在扩增后,通过琼脂糖凝胶电泳检测并回收所得到的pcr产物。
47.作为一种实施方案,琼脂糖凝胶电泳中,琼脂糖凝胶的浓度为1.2%。胶回收使用axyprep dna凝胶回收试剂盒(axygen,code no.ap
‑
gx
‑
50)。
48.步骤(3)中,分析snp分子标记的基因型可采用本领域常规技术手段,例如测序等,可以seq id no.2
‑
3为测序引物进行测序。
49.步骤(3)中所述判断待鉴定油茶单个果实质量大小表型的方法为:
50.若snp分子标记chr10
‑
85853737具有多态性的位点的基因型为c/t,则待鉴定油茶为高单果质量油茶;若基因型为c/c,则待鉴定油茶为低单果质量油茶。
51.本发明提供的鉴定高单果质量油茶的方法,包括:
52.(1)提取待鉴定油茶的基因组dna;
53.(2)以dna为模板,利用上述的引物进行pcr扩增;
54.(3)分析pcr扩增产物中的snp分子标记的基因型,根据所述基因型判断待鉴定油茶是否为高单果质量油茶。
55.若snp分子标记chr10
‑
85853737具有多态性的位点的基因型为c/t,则待鉴定油茶为高单果质量;若基因型为c/c,则待鉴定油茶为低单果质量。
56.本发明的有益效果在于:本发明提供了一个油茶单果质量主效基因位点,对单果
质量表型的贡献率为44.3%,并开发了与基因位点紧密连锁的snp位点。利用这个snp标记对长林53号
×
长林81号的杂种f1代个体进行了辅助选择,结果表明,这位点为高单果质量基因型的单株中,74.68%的个体其单果质量高于群体单果质量平均值(19.25g);低单果质量基因型的个体中,77.22%的个体其单个果实质量低于群体平均值(19.25g)。这表明该标记用于辅助选择是切实有效的。
57.在油茶常规选择育种中,果实大小性状的鉴定需要幼苗造林5
‑
6年才能鉴定,费时费力。本发明中的snp位点位置明确,检测方法方便快速,不受环境影响,目的性更强,工作量小,效率更高,成本低。因此,通过检测所述snp位点,可在苗期进行鉴定和辅助筛选,大大节约生产成本和提高选择效率。在油茶育种中,可选择本发明的分子标记及其检测方法鉴定出高单果质量油茶进行育种,可提高油茶育种的选择效率,加快育种进程。
附图说明
58.图1是本发明实施例3中油茶单果质量基因位点wsf.10
‑
2的位置示意图。
具体实施方式
59.以下实施例用于说明本发明,但不用来限制本发明的范围。在不背离本发明精神和实质的情况下,对本发明方法、步骤或条件所作的修改或替换,均属于本发明的保护范围。
60.若未特别指明,本发明实施例中所用的实验材料、试剂、仪器等均可市售获得;若未具体指明,本发明实施例中所有的技术手段均为本领域技术人员所熟知的常规手段。
61.以下实施例中所用的长林53号
×
长林81号的杂种f1代单株,均由中国林业科学研究院亚热带林业研究所木本油料育种与培育研究组收集、评价,并保存于浙江金华婺城区东方红林场种质资源圃。
62.实施例1油茶单果质量分离群体的构建及性状测定
63.本实施例中使用长林53号和长林81号分别作为母本和父本,采用控制授粉技术,创制了经济性状广泛分离的杂种f1代群体。f1群体采用随机区组3次重复设计保存在浙江省婺城区东方红林场。180个子代个体待果实完全成熟后(5%果实开裂),每样本采集20
‑
30个新鲜果实,测定鲜果质量,计算平均单果质量。结果表明,杂交群体单果质量发生显著分离,说明该性状具有数量性状特点。
64.实施例2油茶连锁图谱构建
65.1、基因组dna提取
66.于3月份采集实施例1中长林53号
×
长林81号家系180个个体及其双亲本的春稍嫩叶,采用kac法(takara试剂盒code no.9768)提取基因组总dna。具体步骤如下:
67.(1)首先在1.5ml离心管中加入500μl的buffer hs ii;准确称取100mg油茶嫩叶进行液氮研磨;迅速将研磨好的粉末加入到离心管中混匀,然后加入10μl的rnase a(10mg/ml),充分振荡混匀,于56℃水浴温育10分钟。
68.(2)加入62.5μl的buffer kac,充分混匀。冰上放置5分钟,12,000rpm离心5分钟。取上清,加入与上清液等体积的buffer gb,充分混匀。
69.(3)将spin column安置于collection tube,溶液移至spin column中(由于溶液
较多,一般需要分两次过柱,每次过柱的体积量不要超过700μl),12,000rpm离心1分钟,弃滤液。
70.(4)将500μl的buffer wa加入至spin column中,12,000rpm离心1分钟,弃滤液。
71.(5)将700μl的buffer wb加入至spin column中,12,000rpm离心1分钟,弃滤液。
72.(6)重复操作步骤(5)。
73.(7)将spin column安置于collection tube上,12,000rpm离心2分钟。
74.(8)将spin column安置于新的1.5ml的离心管上,在spin column膜的中央处加入30~50μl的elution buffer或灭菌蒸馏水,室温静置5分钟。
75.(9)12,000rpm离心2分钟洗脱dna。
76.2、dd
‑
rad简化基因组测序
77.各样本基因组dna经过最佳酶切组合ecori和nlaiii双酶切后连接接头,接头包括3部分,分别为测序引物、分子识别序列(barcode)和与内切酶酶切基因组后产生的粘性末端互补的序列。然后对每个样品进行进行pcr扩增。扩增程序:98℃2min;98℃30s,60℃30s,72℃15s,13个循环;72℃5min。pcr产物用2%琼脂糖凝胶电泳,300
‑
500bp长度的片段用axyprep dna凝胶回收试剂盒从凝胶中回收、纯化。将带有不同barcode的纯化后的dna样本,每12个个体混池为一个样品,构建dd
‑
rad测序文库,利用illumina hiseqxten平台测序。
78.3、snp位点识别和基因分型
79.(1)测序数据过滤,测序获得的原始序列数据首先按照如下步骤过滤:
80.1)根据序列上的barcode,用一个自定义的perl脚本快速的将12个样本的混合数据按个体分开;
81.2)具有barcode,且barcode后面紧跟内切酶的识别位点的序列保留,其余序列舍弃;
82.3)缺失的核苷酸数>3个的序列,舍弃;
83.4)其他低质量的、污染的序列使用ngs qc toolkit软件包(patel r k,jain m.ngs qc toolkit:a platform for quality control of next
‑
generation sequencingdata[m].springer us,2015.)进一步过滤。
[0084]
(2)snp识别与过滤:将每个样本的高质量的reads比对到参考基因组序列上。剔除没有比对上的序列,其余序列识别snp位点。识别的snp位点经过严格过滤,获得高质量的snps数据。过程中用到软件tophat v2.1.1、bcftools v1.9和bwa是公开免费的。snps过滤标准如下:
[0085]
1)亲本测序深度≥10x,子代测序深度≥8x;
[0086]
2)基因型缺失率≤30%;
[0087]
3)snp质量值≥30。
[0088]
4、遗传图谱构建
[0089]
(1)标记分离模式检测:运用joinmap4.0软件中的cp功能,对检测到的所有snp进行分析,标记分离比率用卡方检验计算,确定各个标记的分离模式,如ab
×
cd,ef
×
eg,hk
×
hk,lm
×
ll,nn
×
np,cc
×
ab,ab
×
cc等,过滤、剔除显著不正常分离(p<0.05)或含有非正常碱基的标记。ef
×
eg、hk
×
hk、lm
×
ll和nn
×
np四种类型的标记用于后续连锁图构建。
[0090]
(2)遗传连锁图构建:用joinmap4.0软件构建连锁图,参数设置为:rec≤0.4,lod≥3.0,jump=5,作图函数使用kosambi;分析连锁群内标记的排列顺序,计算相邻标记间的遗传距离。构建的连锁图共有15个连锁群,连锁图上分子标记有2780个,共覆盖3327cm,平均间距为1.20cm。
[0091]
实施例3油茶单果质量基因位点及连锁snp位点挖掘
[0092]
运用qtl icimapping软件进行数据分析,采用完备区间作图法(icim)进行单果质量的qtl定位。扫描步长设置为1cm;逐步回归标记进入的概率(pin)设置为为0.002(pout=2*pin=0.002);lod值设置为2.5。lod显著性阈值通过运行1000次permutation检验确定。在油茶10号染色体上定位到油茶单果质量基因位点wsf.10
‑
2,贡献率为44.3%,与其紧密连锁的snp分子标记为chr10
‑
85853737(见表1,图1)。
[0093]
实施例4高单果质量基因位点与连锁snp分子标记在油茶育种中的应用
[0094]
1、从实施例1得到的长林53号
×
长林81号油茶杂交f1代家系群体中随机挑选158个单株为材料,采集嫩叶提取总dna(提取方法同实施例2)。dna溶液稀释100倍,作为工作液。
[0095]
2、利用seq id no.2
‑
3所示的引物对对dna工作液进行pcr扩增,反应体系如表2所示:
[0096]
表2pcr反应体系
[0097][0098]
pcr扩增程序为:
[0099][0100]
3、pcr扩增产物进行凝胶检测和纯化回收并测序、基因分型。凝胶检测和纯化回收按照axyprep dna凝胶回收试剂盒(axygen,code no.ap
‑
gx
‑
50)说明书进行,其流程如下:
[0101]
(1)配制1.2%的琼脂糖凝胶,将50μl扩增产物全部上样,电泳电压为5v/cm,电泳约20分钟至上样缓冲液中二甲苯青达到距离凝胶前端1cm处时停止电泳。
[0102]
(2)在紫外灯下切下含有目的dna的琼脂糖凝胶,用纸巾吸尽凝胶表面的液体并切
碎。计算凝胶重量,该重量作为一个凝胶体积(例如100mg=100μl体积)。
[0103]
(3)加入3个凝胶体积的buffer de
‑
a,混合均匀后于75℃加热,每2
‑
3分钟间断混合,直至凝胶块完全熔化。
[0104]
(4)加入0.5个buffer de
‑
a体积的buffer de
‑
b,混合均匀。
[0105]
(5)将上述溶液转移到dna制备管中,12000rpm离心1分钟,弃滤液。
[0106]
(6)加入500μl buffer w1,12000rpm离心30秒,弃滤液。
[0107]
(7)加入700μl buffer w2,12000rpm离心30秒,弃滤液。以同样的方法再用700μlbuffer w2洗涤一次,12000rpm离心1分钟,弃滤液。
[0108]
(8)将制备管放回离心管中,12000rpm离心1分钟。
[0109]
(9)将制备管置于洁净的1.5ml离心管中,在制备膜中央加25
‑
30μl去离子水,室温静置1分钟。12000rpm离心1分钟洗脱dna。
[0110]
(10)凝胶回收dna,以对应的扩增引物为测序引物,采用一代测序测定扩增产物核苷酸序列,用chromas软件判读测序峰图上snp位点的基因型。
[0111]
4、分别鉴定所有个体的chr10
‑
85853737位点的基因型。对照各位点的基因型与单果质量高低的关系,若该位点的基因型为c/t,则该油茶个体为高单果质量油茶;若基因型为c/c,则该油茶个体为低单果质量油茶。
[0112]
5、采集158个f1代个体及双亲本完全成熟果实,测定其单果质量。表3结果表明,chr10
‑
85853737位点为高单果质量基因型的单株中,74.68%的个体其果实质量高于群体单果质量平均值(19.25g);基因型为低单果质量基因型的个体中,77.22%的个体其单果质量低于群体平均值(19.25g)。这表明该标记用于辅助选择是切实有效的,可用于早期鉴别或辅助鉴别,可大大节约生产成本,提高选择效率,加快油茶育种进程。
[0113]
表3母本长林53号、父本长林81号及f1单株的单果质量及基因型数据
[0114]
[0115][0116]
虽然,上文中已经用一般性说明及具体实施方案对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1