一种试剂盒、复合体系及其在获得个体年龄中的应用的制作方法
1.本发明涉及生物技术领域,具体涉及一种试剂盒、复合体系及其在获得个体年龄中的应用。
背景技术:
2.人类衰老与基因组特定位点的dna甲基化变化有关。这些表观遗传修饰可用于跟踪供体年龄以进行法医分析或评估生物学年龄。相关研究表明,人类基因组中特定cpg位点的甲基化水平会随着年龄发生变化。对于某些cpg位点,其甲基化的程度与年龄几乎呈线性相关,这些cpg位点可以作为预测年龄的生物标志物。血液是犯罪现场中比较常见的生物痕迹,也是基于dna甲基化进行年龄推断研究开展最多的生物检材。通过测定血液中特定cpg位点的甲基化水平来预测年龄在法医学上有着重要的应用价值。
3.1967年,berdyshev gd等首次提出dna的甲基化水平与衰老紧密相关,开辟了dna甲基化与老化的相关性研究的先河。2013年,steve horvath在多组织中通过illumina 27k和450k芯片测序技术筛选了353个年龄相关的甲基化位点,奠定了运用甲基化位点预测年龄的基础。2014年,weidner等在151个血液样本中通过亚硫酸氢盐焦磷酸测序技术筛选得到了3个年龄相关的甲基化位点,用其进行年龄预测的mad(mean absolute deviation,平均绝对偏差)小于5年。2015年,zbiecpiekarska等通过焦磷酸测序技术检测了303份血样的dna甲基化水平,利用7个甲基化位点进行年龄的预测,表型解释方差为0.86,预测的mad为5.03年。同年,中国学者feng等人通过11个cpg位点对49名中国女性的年龄进行了预测,mad为6岁左右。2016年,park等通过对535例韩国人的血液样本进行3个cpg位点甲基化值的测定(elovl2,znf423,ccdc102b),并且建立了年龄预测的模型,结果显示mad为3.16年。mawlood等也通过比较年龄相关基因的启动子区域中cpg岛的甲基化水平,确定了4个年龄相关基因(nptx2、kcnq1dn、gria2和trim58),利用80例年龄分布在18至91岁之间的女性血液dna样本进行年龄的预测,结果显示mad为7.2年。2018年,aliferi等利用大规模平行测序技术测定对110例全血样品的12个cpg位点的甲基化值进行测定,结果预测结果的mad小于4年。同年,中国学者通过83个cpg作为预测因子,能准确预测89例中国儿童和青少年(年龄范围在6-17岁)的生理年龄,mad为0.62年。2019年,jung等通过测定150例韩国人血液样品中5个cpg位点的dna甲基化水平,建立年龄预测模型,结果显示mad为3.48年。同年,feng等也通过测定390名中国北方汉族男性(15-75岁)的外周血样品的cpg位点的甲基化水平,建立了年龄预测的最优模型,mad为2.89年。
4.但是,目前大多数研究都是以欧美人群为研究对象,并且多数采用的都是illumina 27k或450k芯片数据,利用特定甲基化位点构建模型进行年龄的预测。由于亚欧遗传背景的差异,在欧美人群中构建的预测模型不一定准确适用于中国人群。
5.并且,利用芯片数据获取特定位点的甲基化水平用于年龄推断在实际法医学应用中具有一定的挑战性,受到目前技术的限制,芯片技术无法直接获取特定位点的甲基化水平,只能在获取全基因组所有位点甲基化水平的情况下,挑选特定位点的甲基化水平进行
年龄推断。获取全基因组位点的甲基化水平成本高,耗时长,无法在实际法医学应用中普及。目前,针对中国人群的年龄推断,只有面向小样本(49《n《65)的女性、男性的单一性别群体的焦磷酸或质谱试剂盒。尚缺乏男女通用的中国人群年龄预测的试剂盒。而且相比于质谱测序,焦磷酸测序费用高昂,在实际应用中同样受到一定的限制。
6.因此,提供一种针对中国人群的、男女通用的并且检测个体特定位点的甲基化水平就能获得个体年龄的质谱试剂盒迫在眉睫。
技术实现要素:
7.本发明为解决现有的获得个体年龄的试剂盒成本过高、不适用于中国人群、应用性别和年龄过窄等问题,提供了一种试剂盒、复合体系及其在获得个体年龄中的应用。
8.为实现上述目的,本发明采用的技术方案如下:
9.一方面,本发明提供了一种试剂盒,所述试剂盒包括用于扩增样本基因组dna中10个cpg位点中至少一个cpg位点的扩增引物和/或用于获得所述10个cpg位点中至少一个cpg位点的甲基化率的延伸引物。
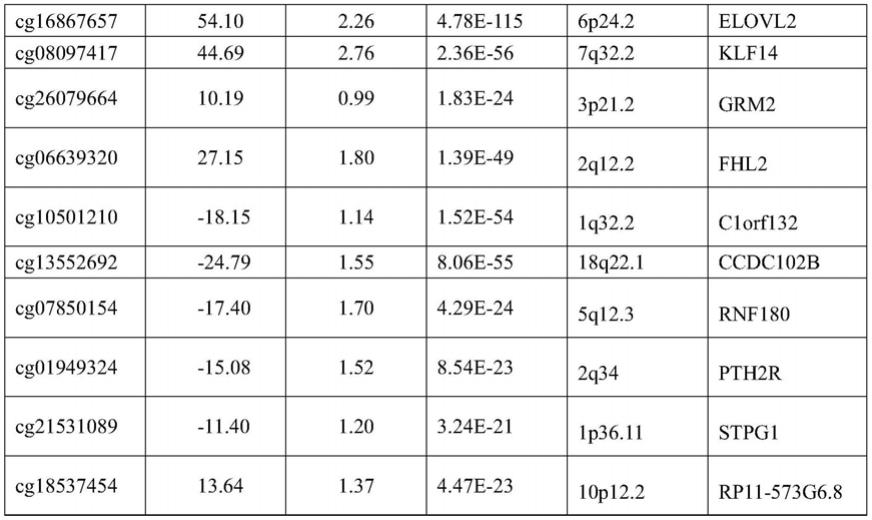
10.具体地,上述样本基因组dna中10个cpg位点包括对应于illumina tm探针id cg16867657、cg08097417、cg13552692、cg10501210、cg06639320、cg26079664、cg07850154、cg18537454、cg01949324和cg21531089的cpg位点。
11.进一步可以解释为:包含用于扩增样本基因组dna中10个cpg位点中至少一个cpg位点的扩增引物的试剂盒在本发明的保护范围内;
12.或,包含用于获得所述10个cpg位点中至少一个cpg位点的甲基化率的延伸引物的试剂盒在本发明的保护范围内;
13.或,既包含用于扩增样本基因组dna中10个cpg位点中至少一个cpg位点的扩增引物又包含用于获得所述10个cpg位点中至少一个cpg位点的甲基化率的延伸引物的试剂盒在本发明的保护范围内。
14.上述10个cpg位点的选择理由如下:(具体见中国专利cn202110191027.3)
15.(1)申请人先前针对2664例来自各个年龄层,不同地区,男女混合的样本使用illumina 850k dna甲基化芯片测定样本的甲基化水平,获得样本数据,将样本数据预处理后,将每个cpg位点的甲基化水平记录为β值,得到阵列甲基化数据;
16.(2)条件表观基因组关联分析:通过年龄、细胞组分、基因组主成分、甲基化组主成分、性别、种族、批次、样板和身体质量指数,构建多重线性回归模型,去除不显著的cpg位点,得到显著cpg位点;
17.(3)将得到的显著cpg位点共同与年龄构建多元回归模型,去除对年龄影响不显著的cpg位点,留下对年龄影响显著的cpg位点;
18.(4)根据bsr算法,在得到的对年龄影响显著的cpg位点中选择10个cpg位点,构建预测年龄的mlr模型。
19.上述10个cpg位点的信息和对年龄的效应值如下表1所示,上述mlr模型为:
20.y1=20.985+54.106
×
cg16867657+44.681
×
cg08097417+10.195
×
cg26079664+27.123
×
cg06639320-18.158
×
cg10501210-24.798
×
cg13552692-17.389
×
cg07850154-15.088
×
cg01949324-11.385
×
cg21531089+13.650
×
cg18537454
21.表1
[0022][0023][0024]
具体地,所述的扩增引物的多核苷酸序列包括seq id no.1-seq id no.20所示的序列和/或由seq id no.1-seq id no.20所示的序列经过替换、缺失、增加、修饰得到的能扩增对应的cpg位点的多核苷酸序列。
[0025]
进一步可以解释为:多核苷酸序列为seq id no.1-seq id no.20所示的序列的扩增引物在本发明的要求保护的范围内;
[0026]
或,多核苷酸序列为由seq id no.1-seq id no.20所示的序列经过替换、缺失、增加、修饰得到的,且能扩增对应的cpg位点的扩增引物在本发明的要求保护的范围内。
[0027]
具体地,所述扩增引物为dna或者rna。
[0028]
具体地,seq id no.1-seq id no.20所示的序列及其对应的cpg位点如下表2所示。
[0029]
表2
[0030]
[0031][0032]
具体地,所述的延伸引物的核苷酸序列为seq id no.21-seq id no.30所示的序列,seq id no.21-seq id no.30所示的序列及其对应的cpg位点如下表3所示。
[0033]
表3
[0034]
cpg位点seq id多核苷酸序列cg26079664seq id no.21tttagaggaggcg18537454seq id no.22cccccttaccaac
cg16867657seq id no.23tggaagttgagtigtcg08097417seq id no.24cacattctttcttctacccg01949324seq id no.25tcaaatatccacttaaaccg13552692seq id no.26gtctccttaaacaatcccccg06639320seq id no.27ttgggagtatagtagttatcg10501210seq id no.28aaaatttaaatctacicaaaccg21531089seq id no.29tgtaagataggtgtaagttttcg07850154seq id no.30tacctaaatttaattttcccttc
[0035]
另一方面,本发明还提供了一种复合体系,包括:基因组dna提取体系,扩增检测体系,数据获取体系;
[0036]
所述基因组dna提取体系用于样本基因组dna的提取;
[0037]
所述扩增检测体系用于获得所述样本基因组dna中10个cpg位点的甲基化率,所述的10个cpg位点包括对应于illumina tm探针id cg16867657、cg08097417、cg13552692、cg10501210、cg06639320、cg26079664、cg07850154、cg18537454、cg01949324和cg21531089的cpg位点;
[0038]
所述数据获取体系用于对所述样本基因组dna中10个cpg位点的甲基化率与所述样本的来源个体的年龄进行多元线性回归分析,构建回归模型,以获得所述样本的来源个体的年龄。
[0039]
具体地,所述样本可以是包含基因组dna的实体组织、血液、尿液、粪便或唾液,优选地,为血液。
[0040]
具体地,所述扩增检测体系用于使用与所述的样本基因组dna中10个cpg位点一一对应的10对扩增引物对其进行扩增以获得扩增产物。
[0041]
具体地,所述扩增检测体系用于获得扩增产物后,使用质谱检测法获得所述样本基因组dna中10个cpg位点的甲基化率。
[0042]
具体地,所述的使用质谱检测法获得所述10个cpg位点的甲基化率是采用与所述样本基因组dna中10个cpg位点一一对应的10对延伸引物对其进行单碱基延伸以获得所述样本基因组dna中10个cpg位点的甲基化率。
[0043]
再一方面,本发明还提供了上述试剂盒和/或上述复合体系在获得个体年龄中的应用。
[0044]
作为优选的但并不限制本发明范围的一些实施方案可以是:
[0045]
本发明样本总量为100例,男性48例,女性52例,年龄分布在23岁至64岁之间,样本信息如下表4所示。
[0046]
表4
[0047]
样本分类数量百分比平均值标准差最大值最小值女性5252%\\\\男性4848%\\\\年龄\\40.6512.07\\年龄\\\\2364
[0048]
针对这批来自各个年龄层,各个地区,男女混合的样本使用质谱测序测定样本的
10个cpg位点甲基化水平。
[0049]
使用dna提取试剂盒(qiagen)分别提取100例样本血液的dna。
[0050]
对提取的dna模板进行多重pcr扩增反应:多重pcr扩增体系如下表5所示,多重pcr扩增条件如下表6所示,多重pcr扩增引物如上表2所示。
[0051]
表5
[0052][0053][0054]
表6
[0055][0056]
进行sap去除未反应的游离核苷酸:通过5’末端切割磷酸基团,使未参加上步反应的dntps去磷酸化。去除扩增产物中剩余的非结合的dntps,以免影响单碱基延伸反应。sap反应体系如下表7所示。将2μlsap体系混合液和5μl上述多重pcr反应体系混合液组成7μl体系,按照下表8的实验条件进行pcr反应。
[0057]
表7
[0058][0059]
表8
[0060][0061][0062]
进行iplex延伸:按照下表9的体系配置iplex混合液,按照下表10的实验条件运行pcr程序。
[0063]
表9
[0064]
试剂体积(μl)mili-q water0.619iplex buffer0.2iplex termination mix0.2iplex enzyme0.041最终体系1.06
[0065]
表10
[0066][0067]
下机后425g离心1min,使溶液集中与反应孔底部。然后进行iplex产物脱盐,延伸序列如上表3所示,加入引物1μl,用massarray核酸质谱分型系统进行质谱检测甲基化水平。
[0068]
基于已有的年龄预测模型y1,运用这100例样本的质谱数据对样本来源个体的年龄进行预测,结果如下表11所示。
[0069]
y1=20.985+54.106
×
cg16867657+44.681
×
cg08097417+10.195
×
cg26079664+27.123
×
cg06639320-18.158
×
cg10501210-24.798
×
cg13552692-17.389
×
cg07850154-15.088
×
cg01949324-11.385
×
cg21531089+13.650
×
cg18537454。
[0070]
表11
[0071]
样本集madr2100例男女混合样本5.700.92男性(48例)6.240.93女性(52例)5.210.93
[0072]
最小平均误差mad为5.7岁,r2为0.92。
[0073]
针对这批来自各个年龄层,各个地区,男女混合的样本使用illumina 850kdna甲基化芯片测定样本的甲基化水平。
[0074]
使用champ包提取甲基化beta值(甲基化信号与总信号比值,表示甲基化程度)以及相应的detection p值(总信号与背景信号比较,表示甲基化质量),进行质量控制:a、去除在20%以上样本中缺失(detection p》0.05)的探针以及5%及以上样本中《3beads的探针;b、删除非cpg的探针和含有snps的探针;c、去除交叉反应(非特异)的探针及性染色体上的探针;d、修正甲基化beta值矩阵中的异常值(小于0的用最小的正值替换,大于1的用小于1的最大值替换)。
[0075]
样本层面的质控包括:a、删除10%以上探针都缺失的样本;b、删除mds图偏离的样本;c、删除450k epic上的65/59个基因型对照探针检测的基因型与现有的基因型数据匹配不上的样本;d、与现有基因型数据相比,两个体间甲基化芯片的基因型数据相关性异常高的样本。并在其中设置了5个重复样本,分析显示重复之间的相关性高于非重复之间的,这
说明了结果的可靠性。用knn方法对缺失值进行填充。
[0076]
使用bmiq方法对ⅱ型探针进行矫正:先通过svd(奇异值分解)分析确认需要校正的批次效应:芯片slide和position,进而使用combat方法去除beta值中的上述批次效应,得到质控后的甲基化beta值矩阵。
[0077]
由于不同血细胞的甲基化水平存在异质性,因此进行细胞异质性校正(epidish包基于上面得到的甲基化数据估计了样本的血细胞组分比例),涉及7个细胞组分(b:b细胞,nk:自然杀伤细胞,cd4t:cd4+t-cells,cd8t:cd8+t-cells,mono:单核细胞,neutro:中性粒细胞,eosino:嗜酸性粒细胞)。
[0078]
每个cpg位点的甲基化水平被记录为beta值,范围从0到1。最后得到了100x751015的阵列甲基化数据,甲基化数据经过标准化处理后进行后续分析。
[0079]
基于已有的年龄预测模型y1,运用这100例样本的illumina 850k dna甲基化芯片数据对样本来源个体的年龄进行预测,结果如下表12所示。
[0080]
表12
[0081]
样本集madr2100例男女混合样本5.240.86男性5.000.89女性5.450.84
[0082]
最小平均误差mad为5.24岁,r2为0.86。
[0083]
综上所述,对于同一批样本,illumina 850k dna甲基化芯片获取的甲基化数据与质谱测序获取的甲基化数据预测的准确性相近,均在5-6岁。这说明已有的基于illumina 850k dna甲基化芯片数据构建的年龄预测模型,同样适用于试剂盒获取的甲基化数据。
[0084]
需要说明的是,本领域技术人员可以根据质谱测序获取的10个cpg位点的甲基化数据来构建其他模型,也可以根据需要从上述10个cpg位点中选择一部分变量来构建其他的模型,只要能满足其对年龄推断准确性的要求即可。
[0085]
相对于现有技术,本发明具有以下有益效果:
[0086]
1.相较于现有技术中使用illumina dna甲基化27k、450k和850k芯片获得个体样本中10个特定cpg位点的甲基化率,本发明提供的试剂盒获得个体样本中10个特定cpg位点的甲基化率的成本更低、速度更快、准确性相似,将其带入现有模型,可快速准确的推断出个体年龄,尤其适合应用于法医、刑侦鉴定领域,可快速为案件侦破提供线索。
[0087]
2.本发明提供的试剂盒可以广泛适用于不同性别,不同地区,不同年龄段的中国人群个体年龄的检测。
[0088]
3.本发明提供的试剂盒为质谱检测试剂盒,与焦磷酸检测试剂盒相比,成本大幅降低,有良好的大规模应用前景。
附图说明
[0089]
图1为本发明中100例样本的年龄分布图;
[0090]
图2为本发明中100例样本基因组dna中cg26079664位点的illumina 850k dna甲基化芯片数据分布;
[0091]
图3为本发明中100例样本基因组dna中cg18537454位点的illumina 850k dna甲
基化芯片数据分布;
[0092]
图4为本发明中100例样本基因组dna中cg16867657位点的illumina 850k dna甲基化芯片数据分布;
[0093]
图5为本发明中100例样本基因组dna中cg08097417位点的illumina 850k dna甲基化芯片数据分布;
[0094]
图6为本发明中100例样本基因组dna中cg01949324位点的illumina 850k dna甲基化芯片数据分布;
[0095]
图7为本发明中100例样本基因组dna中cg13552692位点的illumina 850k dna甲基化芯片数据分布;
[0096]
图8为本发明中100例样本基因组dna中cg06639320位点的illumina 850k dna甲基化芯片数据分布;
[0097]
图9为本发明中100例样本基因组dna中cg10501210位点的illumina 850k dna甲基化芯片数据分布;
[0098]
图10为本发明中100例样本基因组dna中cg21531089位点的illumina 850k dna甲基化芯片数据分布;
[0099]
图11为本发明中100例样本基因组dna中cg07850154位点的illumina 850k dna甲基化芯片数据分布;
[0100]
图12为本发明中100例样本基因组dna中cg26079664位点的质谱检测数据分布;
[0101]
图13为本发明中100例样本基因组dna中cg18537454位点的质谱检测数据分布;
[0102]
图14为本发明中100例样本基因组dna中cg16867657位点的质谱检测数据分布;
[0103]
图15为本发明中100例样本基因组dna中cg08097417位点的质谱检测数据分布;
[0104]
图16为本发明中100例样本基因组dna中cg01949324位点的质谱检测数据分布;
[0105]
图17为本发明中100例样本基因组dna中cg13552692位点的质谱检测数据分布;
[0106]
图18为本发明中100例样本基因组dna中cg06639320位点的质谱检测数据分布;
[0107]
图19为本发明中100例样本基因组dna中cg10501210位点的质谱检测数据分布;
[0108]
图20为本发明中100例样本基因组dna中cg21531089位点的质谱检测数据分布;
[0109]
图21为本发明中100例样本基因组dna中cg07850154位点的质谱检测数据分布;
[0110]
图22为本发明中100例样本的illumina 850k dna甲基化芯片的预测结果散点图;
[0111]
图23为本发明中100例样本的质谱测序数据的预测结果散点图。
具体实施方式
[0112]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
[0113]
在进一步描述本发明具体实施方式之前,应理解,本发明的保护范围不局限于下述特定的具体实施方案;还应当理解,本发明实施例中使用的术语是为了描述特定的具体实施方案,而不是为了限制本发明的保护范围。
[0114]
当实施例给出数值范围时,应理解,除非本发明另有说明,每个数值范围的两个端
点以及两个端点之间任何一个数值均可选用。在通篇说明书及权利要求当中所提及的“包含”或“包括”为一开放式用语,故应解释成“包含但不限定于”。除非另外定义,本文中使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同意义。
[0115]
下列实施例中未注明具体条件的实验方法,按照常规方法和条件,或按照商品说明书选择。本发明中所有使用的试剂和器材均为市售,对其来源不做具体限定,本发明中所使用的引物均由金斯瑞公司合成。
[0116]
实施例1一种试剂盒
[0117]
包含用于扩增样本基因组dna中10个cpg位点的20条扩增引物,其多核苷酸序列为seq id no.1-seq id no.20所示的序列;
[0118]
包含用于获得所述基因组dna中10个cpg位点甲基化率的10条延伸引物,其多核苷酸序列为seq id no.21-seq id no.30所示的序列。
[0119]
上述样本基因组dna中10个cpg位点包括对应于illumina tm探针id cg16867657、cg08097417、cg13552692、cg10501210、cg06639320、cg26079664、cg07850154、cg18537454、cg01949324和cg21531089的cpg位点。
[0120]
实施例2采用本发明提供的试剂盒和复合体系获得中国人群的个体年龄
[0121]
1.样本选择
[0122]
收集了中国人群中14名不同年龄,不同地区,男女混合的无关个体的血液样本,年龄跨度在24-64岁之间,样本具体信息见下表13。
[0123]
表13
[0124]
样本分类数量百分比平均值标准差最大值最小值女性857.14%\\\\男性642.86%\\\\年龄\\33.0710.79\\年龄\\\\2464
[0125]
2.提取上述14个血液样本的基因组dna。
[0126]
3.通过实施例1中的试剂盒获取14个血液样本的基因组dna中上述10个cpg位点的甲基化值。
[0127]
4.将每个样本得到的10个cpg位点的甲基化值带入已有模型y1,分别得到预测的14个个体的年龄。
[0128]
y1=20.985+54.106
×
cg16867657+44.681
×
cg08097417+10.195
×
cg26079664+27.123
×
cg06639320-18.158
×
cg10501210-24.798
×
cg13552692-17.389
×
cg07850154-15.088
×
cg01949324-11.385
×
cg21531089+13.650
×
cg18537454。
[0129]
5.结果如下表14显示。
[0130]
表14
[0131]
样本集样本量mad14例男女混合样本144.82男性65.94女性83.98
[0132]
利用模型y1预测的14人的实际年龄与预测年龄的最小平均误差mad为4.82岁,r2
为0.98。结果显示利用该试剂盒获取的位点的甲基化值能用于构建预测模型,此模型在不同性别的个体中均可准确预测年龄,能为案件侦破提供数据支持。
[0133]
最后应当说明的是,以上内容仅用以说明本发明的技术方案,而非对本发明保护范围的限制,本领域的普通技术人员对本发明的技术方案进行的简单修改或者等同替换,均不脱离本发明技术方案的实质和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1