一种抗肿瘤聚酮类化合物及其制备方法和用途
:
1.本发明涉及工业微生物领域,具体涉及streptomyces coelicolor a3(2)-oe1(保藏编号: cctcc m 20211134,保藏日期:2021年09月03日,保藏单位:中国典型培养物保藏中心, 保藏地址:湖北省武汉市武昌区八一路299号武汉大学生命科学学院,430072)生产聚酮类 化合物angumycinones c的方法;本发明还涉及该类化合物在抗肿瘤中的用途。
背景技术:
2.癌症是威胁人类身体健康的恶性肿瘤,是影响人们生活质量的主要难题之一。研究数据 表明,肺癌、前列腺癌以及乳腺癌等占据癌症死亡排行榜的首位。但是迄今为止仍没有一种 治疗显著的药物可以对癌症细胞进行彻底消除,以更好地对抗癌症这一顽疾。活性天然产物 因其结构多样和活性显著等特点,是当今发现药物靶点的一个主要来源,也是当今的一个研 究热点。聚酮类化合物结构复杂、活性多样,特别因其在抗肿瘤领域表现出来的良好应用前 景,颇受研究者们的青睐。
技术实现要素:
3.本发明旨在提供一种具有强烈的细胞毒抑制活性,同时对正常细胞无副作用的新化合物。
4.其结构式是
[0005][0006]
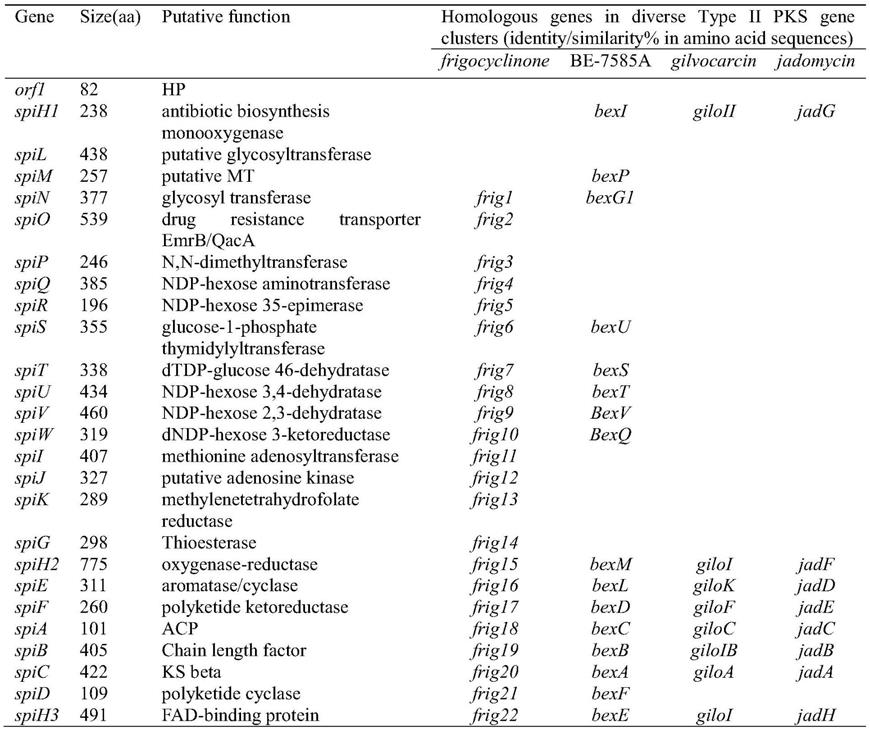
本发明的第一个目的是提供聚酮类化合物angumycinones c的生物合成基因簇spi,其 核苷酸序列如seq id no.1所示,包含25个基因,具体为:
[0007]
负责角蒽醌骨架合成及合成过程中进行修饰的基因,即spi a、spi b、spi c、spi d、spi e、 spi f共6个基因;
[0008]
spi a位于seq id no.1所示序列第23639-23944个碱基处,长度为306个碱基对,编码 酰基载体蛋白,101个氨基酸;
[0009]
spi b位于seq id no.1所示序列第24020-25237个碱基处,长度为1218个碱基对,编码 聚酮链延长因子,405个氨基酸;
[0010]
spi c位于seq id no.1所示序列第25234-26295个碱基处,长度为1062个碱基对,编码 beta-酮基合酶,353个氨基酸;
[0011]
spi d位于seq id no.1所示序列第26540-26869个碱基处,长度为330个碱基对,编码 环化酶,109个氨基酸;
[0012]
spi e位于seq id no.1所示序列第21827-22762个碱基处,长度为936个碱基对,编码 环化酶,311个氨基酸;
[0013]
spi f位于seq id no.1所示序列第22783-23565碱基处,长度为783个碱基对,编码酮 基还原酶,260个氨基酸;
[0014]
编码与糖有关的基因,即spi p、spi q、spi r、spi s、spi t、spi u、spi v、spi w共8个 基因:
[0015]
spi p位于seq id no.1所示序列第6481-7314碱基处,长度为834个碱基对,编码n,n
‑ꢀ
二甲基转移酶,277个氨基酸;
[0016]
spi q位于seq id no.1所示序列第7383-8540碱基处,长度为1158个碱基对,编码ndp
‑ꢀ
己糖转氨酶,385个氨基酸;
[0017]
spi r位于seq id no.1所示序列第8544-9134碱基处,长度为591个碱基对,编码ndp
‑ꢀ
己糖-35-异构酶,196个氨基酸;
[0018]
spi s位于seq id no.1所示序列第9147-10214碱基处,长度为1068个碱基对,编码葡 萄糖-1-磷酸胸腺嘧啶转移酶,355个氨基酸;
[0019]
spi t位于seq id no.1所示序列第10211-11227碱基处,长度为1017个碱基对,编码 dtdp-葡萄糖-4,6-脱水酶,338个氨基酸;
[0020]
spi u位于seq id no.1所示序列第11224-12528碱基处,长度为1305个碱基对,编码 ndp-己糖-3,4-脱水酶,434个氨基酸;
[0021]
spi v位于seq id no.1所示序列第12525-13907碱基处,长度为1383个碱基对,编码 ndp-己糖-2,3-脱水酶,460个氨基酸;
[0022]
spi w位于seq id no.1所示序列第13907-14866碱基处,长度为960个碱基对,编码ndp
‑ꢀ
己糖-3-酮基还原酶,319个氨基酸;
[0023]
编码氧化还原酶的基因是spi h1,spi h2,spi h3:
[0024]
spi h1位于seq id no.1所示序列第269-985碱基处,长度为717个碱基对,编码蒽酮单 加氧酶,238个氨基酸;
[0025]
spi h2位于seq id no.1所示序列第19497-21824碱基处,长度为2328个碱基对,编码 fad依赖的单加氧酶,775个氨基酸;
[0026]
spi h3位于seq id no.1所示序列第27076-28551碱基处,长度为1476个碱基对,编码 fad依赖的单加氧酶,491个氨基酸;
[0027]
编码糖基转移酶的基因是spi l,spi n:
[0028]
spi l位于seq id no.1所示序列第1030-2346碱基处,长度为1317个碱基对,编码假定 的糖基转移酶,438个氨基酸;
[0029]
spi n位于seq id no.1所示序列第3212-4345碱基处,长度为1134个碱基对,编码糖基 转移酶,377个氨基酸;
[0030]
编码与初级代谢相关的基因是spi i,spi j,spi k:
[0031]
spi i位于seq id no.1所示序列第14925-16148碱基处,长度为1224个碱基对,编码甲 硫氨酸腺苷转移酶,407个氨基酸;
[0032]
spi j位于seq id no.1所示序列第16150-17133碱基处,长度为984个碱基对,编码假定 的腺苷酸激酶,327个氨基酸;
[0033]
spi k位于seq id no.1所示序列第17130-17999碱基处,长度为870个碱基对,编码亚 甲基四氢叶酸还原酶,289个氨基酸;
[0034]
spi o位于seq id no.1所示序列第4421-6040碱基处,长度为1620个碱基对,编码自抗 性基因,539个氨基酸;
[0035]
spi m位于seq id no.1所示序列第2343-3116碱基处,长度为774个碱基对,编码甲基 转移酶,257个氨基酸;
[0036]
spi g位于seq id no.1所示序列第18378-19274碱基处,长度为897个碱基对,编码硫 酯酶,298个氨基酸;
[0037]
seq id no.1的第1位到28551位的碱基序列的互补序列可根据dna碱基互补原则随时 得到。seq id no.1的第1位到28551位的的核苷酸序列或部分核苷酸序列可以通过用合适 的限制性内切酶酶切得到。本发明提供了得到至少包含部分seq id no.1的第1位到28551 位中dna序列的重组dna载体的途径。
[0038]
本发明的式ⅰ化合物可通过微生物发酵培养来获取含有该类化合物的发酵物,然后对发 酵粗提物采用sephadex lh20凝胶柱层析、中压mplc和半制备hplc等方法分离纯化得到。
[0039]
本发明的第二个目的是提供新的聚酮类化合物angumycinones c,其结构式如式(i)所示:
[0040][0041]
本发明的三个目的是提供聚酮类化合物angumycinones c或其药用盐在制备抗肿瘤药物 中的应用
[0042]
本发明的下述实施例中列举了利用s.coelicolor a3(2)-oe1制备本发明式ⅰ化合物的实 例。
附图说明:
[0043]
图1是重组菌株a3(2)-oe1粗提物的分析信息;
[0044]
分析条件:色谱柱为capcell park c18柱:5μ,20mm
×
250mm,流动相包括a相和b相, 流动相a相:色谱甲醇+1
‰
(体积分数)的三氟乙酸;流动b相:水+1
‰
(体积分数)的三氟乙酸; 进样程序:0-60min,流动相比例为a相/b相(体积比):95:5-0:100,5-45min,检测波长190-600 nm,流速1ml/min,其中1代表化合物i。
[0045]
图2是angumycinones c的关键的二维信号;
[0046]
图3是angumycinones c的假定生合成路线;
具体实施方式:
[0047]
在如下的实施例中所指的化合物ⅰ的化学结构(结构式中的阿拉伯数字是化学结
构中碳 原子的标位)是:
[0048][0049]
以下实施例是对本发明的进一步说明,而不是对本发明的限制。
[0050]
实施例1聚酮类化合物angumycinones c的生物合成基因簇的异源表达
[0051]
1.streptomyces sp.hdn15129基因组序列扫描及angumycinones c的生物合成基因簇序列 分析和功能分析:
[0052]
通过对streptomyces sp.hdn15129进行全基因组测序,并上传到antismash上进行分析, 同时结合基因注释,在其中找到了29kb的与该化合物生物合成有关的基因簇,包含了20个 开放阅读框(open reading frames,orfs)(表1)。根据生物信息学分析spi a、spi b、spi c、 spi d、spi e、spi f共6个基因负责聚酮链骨架合成及合成过程中的修饰;spi p、spi q、spir、spi s、spi t、spi u、spi v、spi w共8个基因负责编码与糖有关的基因;spi h1,spi h2, spi h3负责编码氧化还原酶的基因。该化合物生物合成途径初步推测如图3所示。
[0053]
表1.angumycinones c生物合成基因簇的基因及其功能分析
[0054][0055]
实施例2化合物ⅰ的重组菌株构建、发酵生产及分离精制
[0056]
1.重组菌株的构建
[0057]
(1)采用放线菌基因组提取的方法来提取streptomyces sp.hdn15129放线菌基因组;
[0058]
(2)使用mfei/msei限制性内切酶酶切基因组,来释放目的基因簇spi;同时将之前构 建好的引物来扩增克隆载体p15a-spi。
[0059]
(3)使用red/et重组工程技术将胶回收后的克隆载体和酶切后的线性基因组构建目 的质粒,并通过转化子筛选得到正确的质粒。而后将正确的质粒重转化至gb05大肠中, 以消除背景的影响。
[0060]
(4)将重转化的正确质粒通过线环重组(linear plus circular homologousrecombination,lchr)的方法添加强启动子kasop*,以启动目的基因簇的表达。并通过该 方法添加位点特异性重组元件pr6k-orit-phic31-kasop*,最后将该质粒电转化入 et12567/puz8002中。
[0061]
(5)链霉菌(s.coelicolor)a3(2)在ms[培养基组成(克/升):豆粉20g,甘露醇20g, 琼脂粉20g,ph调节至7.2]平板中划线培养5-7天,长出的孢子用无菌棉签刮下孢子置 于50ml离心管中,50℃热激10min自然冷却的菌株作为接合转移的受体菌。供体菌e.coliet12567/puz8002/p15a-spi在100m l含50μg/ml卡那霉素、25μg/m l氯霉素和50μg/ml 阿泊拉霉素的lb液体培养基中于37℃生长至od600值约为0.6-0.8时,离心收集菌体 (9500rpm,1min),用无抗lb清洗菌体3遍,悬浮于1ml lb培养基中,作为接合转移 的供体
菌。取上述受体菌400μl和供体菌200μl混合均匀,涂布于不含任何抗生素的 ms固体培养基上,吹干后,于30℃培养16-20h。然后将平板取出,用含有抗生素的水 覆盖平板,其终浓度为50μg/ml阿泊拉霉素和25μg/ml萘啶酮酸,吹干后,于30℃培养 箱中,培养10-20天后观察。
[0062]
(6)当接合转移平板上长出小菌落后,用无菌牙签将其转接到含有25μg/ml阿泊拉霉素和 50μg/ml萘啶酮酸的ms平板上,30℃培养10-15天后,抽取各个突变株的基因组dna, 利用异源表达的检测引物spif/r(引物序列见于表2)通过pcr检测获得阳性克隆,即获得 angumycinones c生物合成基因簇异源表达菌株a3(2)-oe1。
[0063]
表2.检测引物名称和序列
[0064]
primersequences(5
’‑3’
)spifgcaggctgctgacgtgcgtgspirgtgtccgaggtgaccgggag
[0065]
2.发酵生产
[0066]
生产菌的发酵培养:按培养微生物的常规方法,取s.coelicolor a3(2)-oe1适量,接种到 ms-apra[添加阿泊拉霉素终浓度50μg/ml]的固体斜面培养基上,在30℃培养箱中培养10天。
[0067]
取斜面培养10天的s.coelicolor a3(2)-oe1适量,接种到装有100ml培养基[培养基组 成(克/升):可溶性淀粉10g,蛋白胨2g,酵母提取物4g,ph调节至7.2]的500ml锥型 瓶中,在30℃,200rpm条件下摇床培养8天,获得发酵产物。
[0068]
3.浸膏的获得
[0069]
发酵液用纱布过滤得到上清液。用等量乙酸乙酯萃取三次,合并所有乙酸乙酯相,减压 浓缩得到粗浸膏,共12克。
[0070]
4.化合物的分离精制
[0071]
浸膏用甲醇溶解后,使用95%甲醇溶解,使用石油醚萃取,出去油脂成分,蒸干后以甲 醇-水为洗脱体系进行反相层析柱层析,分为7个流份。组分5先以甲醇为流动相进行 sephadexg-200分子筛洗脱,后再经反相半制备高效液相色谱(甲醇:水=46:54)得化合物
ⅰꢀ
(4.6mg)。
[0072]
化合物ⅰ为亮黄色针状固体,分子式c
19h16
o7,hr-esi-ms m/z:355.0824[m-h]-,计算 值355.0823);ir(kbr)ν
max 3399,1699,1683,1653,1577,1541,1488,1207,1136,1027cm-1
。 1
h and 13
c nmr核磁数据归属见表2。
[0073]
表2化合物ⅰ的1h和
13
c nmr数据(600和150mhz,in dmso-d6)a[0074][0075]
a)本表信号归属基于dept、hmqc及hmbc图谱解析结果。碳信号的多重度利用dept 方法确定并分别用s(单重峰)、d(二重峰)、t(三重峰)和q(四重峰)、m(多重峰) 表示。
[0076]
b)此栏中的数字和代号分别代表在1h-1
h cosy谱中与相应行中的1h给出偶合相关信号的 1
h核。
[0077]
c)此栏中的数字和代号分别代表在hmbc谱中与相应行中的1h给出偶合相关信号的
13
c 核。
[0078]
实施例2化合物的细胞毒活性测试
[0079]
1实验样品及实验方法
[0080]
被测样品溶液的配制:测试样品为上述实施例1中分离精制的化合物ⅰ纯品。精密称取 适量样品,用dmso配置成30μm的母液,然后采用二倍稀释法稀释成15,7.5,3.75,1.875,0.9375μm的待测溶液,阳性药阿霉素(adm)配置成1μm,供测活性。
[0081]
供测细胞:l-02、h69ar(srb法)。
[0082]
测试方法:srb实验方法如下检测及数据分析
[0083]
(1)细胞处理:贴壁细胞,胰酶消化对数期细胞,制成细胞悬液。
[0084]
(2)细胞计数:使用计数板和计数器,吸取10-20μl,计四个角上16个方格细胞的平均数x(x 大致20-50比较好),40
÷
x=y,y为一个板需要加的细胞的毫升数,每个板一共需要6ml,6 -y=z,z为需要加的培养基的体积(计数原则,计上不计下,计左不计右)。(每个
96孔板的 细胞数量在38-41万)
[0085]
(3)细胞铺板:96孔板中每孔加入90μl细胞悬液
[0086]
(4)加样品:细胞贴壁生长24h后,每孔加入10μl不同浓度的化合物溶液。
[0087]
(5)细胞放入37℃培养箱培养
[0088]
(6)72h后,去掉培养基,每孔加入100μl tca溶液,4℃固定1h以上,自来水冲洗5-6 遍,自然晾干,每孔加入100μl srb溶液进行染色,染色5-10min后,去除srb,1%的 冰醋酸溶液冲洗5-6遍,自然晾干,干燥之后加入150μltris溶液,震荡摇匀,用酶标仪在 515nm测吸光度。
[0089]
2实验结果
[0090]
在细胞毒活性测试中,不同浓度的化合物i对所测试的肿瘤细胞的实验结果见表3。
[0091]
表3不同浓度的化合物i对h69ar细胞的抑制率
[0092][0093][0094]
3结论
[0095]
化合物ⅰ具有强烈的肿瘤细胞增殖抑制活性,作为新型抗肿瘤化合物结构在癌症治疗领 域具有良好的应用前景。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1