能够在微藻类的叶绿体中产生胶原蛋白、弹性蛋白及其衍生物的肽、多肽或蛋白质的重组微藻类及其相关方法与流程
1.本发明涉及重组微藻类,其包括编码包括氨基酸重复单元的重组蛋白质、多肽或肽的核酸序列,所述重组蛋白质、多肽或肽选自胶原蛋白、弹性蛋白和它们的衍生物,所述核酸序列位于微藻类的叶绿体基因组中。本发明还涉及用于在微藻类的叶绿体中产生包括氨基酸重复单元的重组蛋白质、多肽或肽的方法,所述重组蛋白质、多肽或肽选自胶原蛋白、弹性蛋白和它们的衍生物,其中所述方法包括用编码所述重组蛋白质、多肽或肽的核酸序列转化微藻类的叶绿体基因组。
背景技术:
2.近年来,由于重组蛋白在如个人护理、化妆品、医疗保健、组织工程、生物材料、农业和造纸工业的广泛行业的高价值应用,对重组蛋白的需求越来越大。已经推出了在各种重组系统中产生的大量商业药用蛋白的示例,例如,胰岛素、人生长激素、促红细胞生成素和干扰素。
3.另外,这些各种工业应用需要大量的蛋白质和肽。
4.最当前的工业表达系统包括大肠杆菌、酵母(酿酒酵母(s.cerevisiae)和毕赤酵母(p.pastoris))和哺乳动物细胞系。新兴技术是昆虫细胞培养、植物和微藻类。
5.然而,重组肽和蛋白质的表达仍然受到限制,因为需要大量努力以便获得具有天然构象、大量和高纯度的所需肽和蛋白质。即使是当前的细菌系统比如大肠杆菌在表达重组肽/多肽/蛋白质方面也具有局限性。事实上,不溶性聚集体(或包涵体)的形成由于缺乏成熟的机制来进行翻译后修饰,例如二硫键形成或糖基化而出现。这导致感兴趣的蛋白质溶解度差和/或缺乏蛋白质活性。
6.近年来,已经增长了微藻类作为重组蛋白产生的可选平台的兴趣。
7.相对于其他重组蛋白产生平台,重组藻类提供多项优势。微藻类是光合作用的单细胞微生物,生长所需的营养物质少。它们能够光合自养、混养或异养生长。藻类中蛋白质产生的成本远低于光营养缺陷型生长(photoauxotrophic growth)的其他产生系统。从藻类纯化的蛋白质,与从植物中纯化的蛋白质一样,应不含毒素和病毒试剂,其可存在于细菌或哺乳动物细胞培养物的制剂中。事实上,一些微藻类物种具有fda授予的gras状态(通常被认为是安全的),例如微藻类,小球藻(chlorella vulgaris)、原始小球藻s106(chlorella protothecoides s106)、巴氏杜氏藻(dunaliella bardawil)、莱茵衣藻(chlamydomonas reinhardtii)和蓝藻细菌,钝顶节螺藻(arthrospira plantesis)。
8.如在转基因植物中,藻类已经被工程化,以表达来自核和叶绿体基因组二者的重组基因。
9.此外,包括特定氨基酸序列的重复单元的肽和多肽的重组合成是困难的,因为编码肽或多肽的dna序列经常进行基因重组,导致基因不稳定,并且通常导致产生小于天然蛋白质的蛋白质。
10.相对小的肽的重组产生也可能具有挑战性,因为它们可以自组装或受到蛋白水解降解。
11.而且,与植物表达系统相比,藻类是具有竞争力的生产成本的坚固的工业机箱(industrial chassis),可在光生物反应器和发酵罐内在可重现、无菌和良好控制的产生条件下或在一次性波浪生物反应器(wave bag)中以工业规模达到。另外,它们可以在细胞外,并且因此在培养基中分泌重组蛋白,从而简化后续的纯化步骤。藻类没有季节性,并且不使用耕地。
12.开发在藻类中进行叶绿体转化以产生感兴趣的蛋白质比在植物中更新,并且需要改进。事实上,重组蛋白的产量通常在莱茵衣藻叶绿体中的总可溶性蛋白的0.5%和5%之间,与已建立的微生物平台相比仍然很低。
13.另外,一些哺乳动物蛋白不容易表达(rasala等,2010)。
14.本发明的发明人出人意料地能够在微藻类的叶绿体中产生包括几个氨基酸重复单元的重组蛋白质、多肽或肽,所述重组蛋白质、多肽或肽选自胶原蛋白、弹性蛋白和它们的衍生物。
15.事实上,相似或相同序列之间的同源重组现象在叶绿体基因组中非常有效,具有重复序列的转基因非常不稳定。
16.通过使用所述方法,允许对蛋白质、肽和多肽稳定性和活性以及蛋白质、肽和多肽积累的增加所必需的内源二硫键形成。
技术实现要素:
17.因此,本发明涉及包括编码包括氨基酸重复单元的重组蛋白质、多肽或肽的核酸序列的重组微藻类,所述蛋白质、多肽或肽选自胶原蛋白、弹性蛋白和它们的衍生物,并且所述核酸序列位于微藻类的叶绿体基因组中。
18.本发明还涉及所述重组藻类用于产生包括氨基酸重复单元的重组蛋白质、多肽或肽中的用途,所述蛋白质、多肽或肽选自胶原蛋白、弹性蛋白和它们的衍生物。
19.本发明进一步涉及用于在微藻类的叶绿体中产生包括重复氨基酸单元的重组蛋白质、多肽或肽的方法,所述重组蛋白质、多肽或肽选自胶原蛋白、弹性蛋白和它们的衍生物,其中所述方法包括用编码所述重组蛋白质、多肽或肽的核酸序列转化微藻类的叶绿体基因组。
20.特别地,所述方法包括:
21.(i)提供编码所述重组蛋白质、多肽或肽的核酸序列;
22.(ii)将根据(i)的核酸序列引入能够在微藻类宿主细胞中表达核酸序列的表达载体中;和
23.(iii)通过表达载体转化微藻类宿主细胞的叶绿体基因组。
24.特别地,所述方法还包括:
25.(iv)鉴定转化的微藻类宿主细胞;
26.(v)表征用于产生由所述核酸序列表达的重组蛋白质、多肽或肽的微藻宿主细胞;
27.(vi)提取重组蛋白质、多肽或肽;以及任选地
28.(vii)纯化重组蛋白质、多肽或肽。
29.更特别地,根据本发明的方法允许增加微藻类的叶绿体中的包括氨基酸重复单元的重组肽、多肽或蛋白质的积累和/或稳定性和/或溶解度和/或折叠和/或活性。
30.特别地,所述方法进一步包括步骤(vii)的进一步步骤(viii),其中多肽被切割以允许肽单元的释放。
31.所述切割可以通过本领域技术人员已知的任何方法,比如使用合适的胞内蛋白酶进行。
32.在一个实施方式中,通过根据本发明的方法获得的重组蛋白质、多肽或肽在它们的n-或c-末端被化学修饰,例如通过添加棕榈酰基基团、羟基基团、烷酰基(alkoyl)链(即包括羟基基团的烷基链)或生物素基团。
33.在本领域中和在本发明的上下文中,“重组肽/多肽/蛋白质”意思是由重组基因(或重组核酸序列)即来自不同物种(异源)或来自相同物种(同源)的外源基因(或外源核酸序列)表达的外源肽/多肽/蛋白质。
[0034]“重组微藻类”意思是包括编码重组蛋白质、多肽或肽的核酸序列的微藻类。在本发明的上下文中,重组微藻类被转化,如以下进一步详述的。
[0035]“肽”、“多肽”、“蛋白质”意思是本发明所属领域的技术人员通常理解的含义。特别地,肽、多肽和蛋白质是经肽(酰胺)键连接的氨基酸聚合物。
[0036]
更特别地,根据本发明的蛋白质具有独特且稳定的三维结构并且包括超过50个氨基酸,如54、60、66、72、75、78、84、90、96、100、102、108、114、120、150、180、200、300、350或更多个氨基酸的蛋白质;根据本发明的肽是短寡肽,例如2至10个氨基酸的肽,如4、5、6、7、8、9或10个氨基酸的肽;根据经典含义的多肽可包括11至50个氨基酸,如11、12、15、18、20、24、25、30、35、36、40、42、45、48或50个氨基酸的多肽;但是在本发明的上下文中,多肽是n个单位的相同或不同氨基酸序列的重复,或n个单位的相同或不同肽的重复,n为2至400,特别是2至100。
[0037]
在本发明的上下文中,根据本发明的重组蛋白质、多肽或肽是选自包括氨基酸重复单元的胶原蛋白、弹性蛋白和它们的衍生物的重组蛋白质、多肽或肽。
[0038]
弹性蛋白是细胞外基质的主要结构蛋白。它存在于所有脊椎动物的结缔组织中,为组织提供弹性。弹性蛋白首先被合成为可溶性单体前体,原弹性蛋白,它随后被组装成成熟的弹性蛋白,一种稳定的聚合结构。
[0039]
这种蛋白质在本领域中是众所周知的。弹性蛋白和原弹性蛋白的氨基酸序列含有短的重复氨基酸基序和许多疏水残基。在衰老过程期间或暴露于uvb照射后或在病理过程中,弹性蛋白被降解为短肽,称为“弹性蛋白肽”,其发挥促进例如细胞增殖的信号肽的作用。这些弹性蛋白肽是基质肽(matricins peptide)的一部分。
[0040]
弹性蛋白肽被认为是在天然弹性蛋白中发现的组成部分,并且具有短的氨基酸序列。
[0041]
根据本发明的弹性蛋白肽的示例是五肽:kggvg(seq id n
°
1)、vggvg(seq id n
°
2)、gvgvp(seq id n
°
3)、vpgxg(x为v、i或k)(seq id n4
°
);六肽:vgvapg(seq id n
°
5);七肽:lgaggag(seq id n6);或九肽:lgaggagvl(seq id n
°
7)。
[0042]
在本发明的上下文中,包括弹性蛋白的重复单元的重组肽、多肽或蛋白质包括弹性蛋白肽的重复单元(相同的或不同的),并且特别是seq id n
°
1至7的那些(相同的或不同
的)。弹性蛋白蛋白质/多肽/肽的“衍生物”涵盖弹性蛋白样蛋白质/多肽/肽和其中天然弹性蛋白蛋白质/多肽/肽的氨基酸序列突变或在n-或c-末端处含有一个或多个氨基酸的蛋白质/多肽/肽。补充氨基酸可以是任何氨基酸。弹性蛋白蛋白质/多肽/肽的衍生物还涵盖弹性蛋白样蛋白质/多肽/肽的衍生物。弹性蛋白样蛋白质/多肽/肽的“衍生物”涵盖其中天然弹性蛋白样蛋白质/多肽/肽的氨基酸序列突变或在n-或c-末端处含有一个或多个氨基酸的蛋白质/多肽/肽。
[0043]
因此,根据本发明的肽、多肽和弹性蛋白的肽以及它们的衍生物还涵盖弹性蛋白样肽、多肽、肽和它们的衍生物。
[0044]
弹性蛋白样蛋白质、多肽或肽(elp)是合成分子,主要包括数倍重复单元的肽或衍生物。
[0045]“突变的”肽、多肽或蛋白质意思是突变的肽、多肽或蛋白质的核酸或氨基酸序列含有一个或多个突变。这些突变包括一个或多个核酸或氨基酸的缺失、取代、插入和/或切割。
[0046]
有许多弹性蛋白样多肽的变体,包括重复单元的不同弹性蛋白肽,比如seq id n
°
1至7的那些。
[0047]
本发明中描述的弹性蛋白样多肽或蛋白质因此可以例如包括n倍重复的五肽:(kggvg)n、(vggvg)n、(gvgvp)n、(vpgxg)n;六肽:(vgvapg)n;七肽:(lgaggag)n;或九肽:(lgaggagvl)n;或它们的衍生物。数字n可以是例如2至200,优选的2至100。
[0048]
作为示例,本发明中描述的弹性蛋白肽是seq id n
°
5(vgvapg)的六肽或其衍生物。
[0049]
本发明中描述的弹性蛋白样多肽或蛋白质因此可以例如包括n倍重复的六肽:(vgvapg)n或其衍生物。数字n可以是例如2至200,优选的2至100。
[0050]
特别地,seq id n
°
5的肽衍生物含有在其n-和/或c-末端具有一个或多个氨基酸的vgvapg序列。
[0051]
特别地,seq id n
°
5的肽衍生物中的补充氨基酸是天冬氨酸或谷氨酸。
[0052]
更特别地,所述衍生物可以是seq id n
°
8(vgvapgd)或seq id n
°
9(vgvapge)。
[0053]
仍特别地,本发明中描述的弹性蛋白样多肽包括重复的seq id n
°
5的六肽,更特别地,4倍的该六肽(在本发明中命名为elp4并且具有seq id n
°
81:vgvapgvgvapgvgvapgvgvapg的)。本发明中描述的弹性蛋白样多肽衍生物的另一示例包括重复的seq id n
°
9的六肽,更特别地,4倍的该六肽(在本发明中命名为elpe4并且具有seq id n
°
80:vgvapgevgvapgevgvapgevgvapge)。
[0054]
elp的有趣特征是它们可以随着温度的升高或ph和离子强度的改变而自聚集。该特征可以促进在宿主细胞中产生后elp的纯化步骤。
[0055]
胶原蛋白是结构上相关蛋白质的超家族,构成结缔组织的基本构成元素且参与动物的许多生物功能。这些蛋白质表现出由包括重复氨基酸序列gly-x-y(或gxy)的三个多肽链缔合产生的特征性三螺旋三级结构,其中氨基酸x和y通常是参与三螺旋形成的脯氨酸或4-羟脯氨酸。
[0056]
在人类中,至少有27种不同类型的胶原蛋白存在于不同组织(如骨骼、骨骼、皮肤、肌腱、血管、眼睛等
……
)中。
[0057]
在本发明的上下文中,胶原的重组肽、多肽或蛋白质包括胶原基序的重复单元中,即序列gxy的重复单元中。
[0058]
胶原蛋白蛋白质/多肽/肽的“衍生物”涵盖胶原蛋白样蛋白质/多肽/肽和其中天然胶原蛋白蛋白质/多肽/肽的氨基酸序列突变或在其n-或c-末端处含有一个或多个氨基酸的蛋白质/多肽/肽。这种补充氨基酸可以是任何氨基酸。胶原蛋白蛋白质/多肽/肽的“衍生物”还涵盖胶原蛋白样蛋白质/多肽/肽的衍生物。胶原蛋白样蛋白质/多肽/肽的“衍生物”涵盖其中天然胶原蛋白样蛋白质/多肽/肽的氨基酸序列突变或在其n-或c-末端处含有一个或多个氨基酸的蛋白质/多肽/肽。这种补充氨基酸可以是任何氨基酸。
[0059]
胶原蛋白样蛋白质、肽或多肽主要包括数倍重复单元的胶原基序,即重复单元的序列gxy(而胶原蛋白的肽、多肽或蛋白质仅含有那些重复单元)。
[0060]
所述重复单元被称为“胶原蛋白样结构域”,并且能够形成三螺旋(作为胶原蛋白),例如参与宿主防御机制的c型凝集素(胶原凝素(collectin))。
[0061]
此外,编码含有重复gxy基序的胶原蛋白样序列的基因的基因组数据库的筛选,已鉴定细菌和噬菌体基因组中的基因。然而,这些生物体似乎缺乏脯氨酸羟化酶。最近的研究显示,作为模型的两种最近鉴定的链球菌胶原蛋白样蛋白质scl1和scl2能够形成稳定的三螺旋而不具有脯氨酸残基的羟基化。
[0062]
特别地,胶原蛋白样蛋白质、肽或多肽在本发明中特别地是和/或源自微藻类,例如,蓝隐藻(guillardia theta)的ccmp2712蛋白质(称为gtclp)(的一个或多个氨基酸)。
[0063]
在一个实施方式中,根据本发明的衍生物包括与根据本发明的重组肽、多肽或蛋白质的氨基酸序列至少80%同一性的氨基酸序列。
[0064]“至少80%同一性的氨基酸序列”特别地意指81、82、85、90、91、92、93、94、95、96、97、98或99%同一性的氨基酸序列。通过与本发明的查询(query)氨基酸序列至少95%“同一性”的氨基酸序列,旨在所述肽、多肽或蛋白质的氨基酸序列与查询序列相同,除了所述氨基酸序列可包括每查询氨基酸序列的100个氨基酸多达五个氨基酸改变。换句话说,为了获得与查询氨基酸序列至少95%同一性的氨基酸序列,所述序列中多达5%(100个中的5个)的氨基酸残基可以插入、缺失或用另一个氨基酸取代。
[0065]
在本技术的框架中,同一性的百分比是使用全局比对计算的(即在它们的整个长度内比较两个序列)。用于比较两个或更多个序列的同一性的方法是本领域众所周知的。例如,可以使用“needle”程序,其使用needleman-wunsch全局比对算法(needleman and wunsch(1970)j.mol.biol.48:443-453)在考虑两个序列的整个长度时找到它们的最佳比对(包括空位)。例如,needle程序可在ebi.ac.uk万维网网站上获得。优选地使用emboss::needle(全局)程序(其中“空位打开”参数等于10.0,“空位扩展”参数等于0.5)和blosum62矩阵,计算根据本发明的同一性的百分比。
[0066]
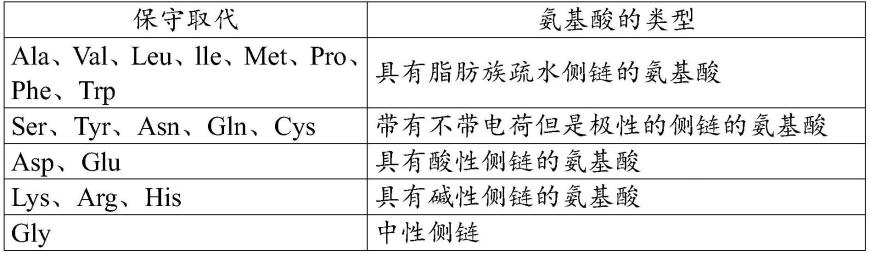
与参考序列“至少80%、85%、90%、95%或99%同一性”的氨基酸序列与参考序列相比可包括突变,比如缺失、插入和/或取代。在取代的情况下,与参考序列至少80%、85%、90%、95%或99%同一性的氨基酸序列可以对应于源自除参考序列之外的另一个物种的同源序列。在另一优选的实施方式中,取代优选地对应于以下表中所示的保守取代。
参数等于10.0、“空位扩展”参数等于0.5)和blosum 62矩阵计算。例如,needle程序可在ebi.ac.uk万维网站点上获得。
[0076]
在一个实施方式中,根据本发明的编码包括氨基酸重复单元的蛋白质、多肽或肽的核酸序列被密码子优化以在微藻类宿主细胞的叶绿体基因组中表达。
[0077]
如以上提到的,根据本发明的核酸序列被引入能够表达核酸序列的表达载体中。
[0078]“引入”意思是用技术人员熟知的方法和以导致编码重组蛋白/多肽/肽的核酸序列表达的方式将该核酸序列克隆到表达载体内。
[0079]“表达载体”或“转化载体”或“重组dna构建体”或类似术语在本文中定义为在微藻类宿主细胞中重组基因转录和它们的mrna翻译所需的dna序列。“表达载体”包括一种或多种用于表达重组基因(一种或多种编码感兴趣的蛋白质、肽或多肽和通常的可选择标志物的基因)的表达盒。在叶绿体基因组转化的情况下,表达载体还含有用于在叶绿体基因组内整合表达盒的同源重组区。
[0080]
在本发明的上下文中,表达载体可以特别地是环状分子,其具有含有两个同源重组区并且位于表达盒两侧的质粒骨架;或线性化分子,其对应于通过酶消化线性化的表达载体或对应于仅含有两侧为两个同源重组区的表达盒的pcr片段。
[0081]
特别地,本发明的表达载体包括至少一个表达盒并且是例如载体pco86、pco96、pco26、pco28、pla01、pla02、pal03或pal04。
[0082]“表达盒”含有与一个或多个调控元件或调控序列可操作地融合(例如,在其5'端融合至启动子和/或5'utr和/或在其3'端融合至3'utr)的编码序列。
[0083]“编码序列”是基因及其相应转录的mrna的一部分,其被翻译成重组蛋白质/多肽/肽。编码序列包括,例如,翻译起始控制序列和终止密码子。在一些实施方式中,表达盒可以含有包括多于一个编码序列的多顺反子,所述编码序列在仅一个启动子/5'utr和3'utr的控制下编码几种蛋白质。
[0084]
所述表达盒的两侧是与叶绿体基因组中靶向整合位点周围的序列相同的左(lhrr)和右(rhrr)内源序列。这些左(lhrr)和右(rhrr)同源区域允许在同源区域之间进行同源重组交换后整合表达盒。
[0085]
同源重组是互补dna序列比对和交换同源区域的能力。将含有与被靶向的基因组序列(“模板”)同源的序列的转基因dna(“供体”)引入生物体,并且然后在相应基因组同源序列的位点进行重组到基因组中。
[0086]
就其本质而言,同源重组是精确的基因靶向事件,因此,大多数用相同靶向序列产生的转基因品系在表型方面基本相同,因此需要筛选的转化事件要少得多。
[0087]
在微藻类的叶绿体基因组转化的情况下,表达盒在叶绿体基因组内的整合发生在表达载体的内源同源序列之间的同源重组之后,其中基因组序列与叶绿体基因组中的靶向整合位点周围的序列相同或相似。
[0088]
在本发明的上下文中,可以在基因rbcl和atpa,或psab和trng,或atpb和16s rdna,或psaa外显子3和trne,或trne和psbh,或psbn和psbt,或psbb和trnd之间使用不同的整合位点。
[0089]
在一些实施方式中,为了增强其积累,可以将重组蛋白质或多肽或肽融合至内源蛋白,例如融合至核酮糖二磷酸羧化酶(rubisco lsu)的大亚单位。在这种情况下,在转化
载体同源重组到叶绿体基因组后,启动子和5'utr将是内源rbcl基因的那些。
[0090]
根据所选的处理系统,感兴趣的蛋白质、肽或多肽将在体内(使用自切割肽)或体外(通过位点特异性蛋白水解)进一步与rbcl分离。
[0091]
在一个实施方式中,根据本发明的表达盒的所述编码序列还包括编码表位标签,特别地flag表位标签,更特别地flag表位标签重复3次(3xflag标签)的核酸序列,以便鉴定和/或纯化重组蛋白质、多肽或肽。
[0092]
特别地,所述表位标签序列位于蛋白质、肽或多肽的n-末端。更特别地,可以将另一表位标签序列单独放置在根据本发明的蛋白质、肽或多肽的c-末端,或除了在n-末端的一个之外,还可以将另一表位标签序列放置在根据本发明的蛋白质、肽或多肽的c-末端,以便监测释放感兴趣的肽/多肽/蛋白质,以遵循其切割,例如通过内切蛋白酶。
[0093]
表位标签序列的示例是flag标签(seq id n
°
24:dykddddk)、3xflag标签(seq id n
°
25:dykddddkdykddddkdykddddk)、ha标签(seq id n
°
26:ypydvpdya)、3xha标签(seq id n
°
27:ypydvpdyaypydvpdyaypydvpdya)、his标签(seq id n
°
28:hhhhhh),其在本发明的实验部分中描述。
[0094]
在一个实施方式中,表达盒中的所述编码序列包括不仅编码所述重组蛋白质、多肽或肽而且还编码允许在特定细胞区室中产生所述重组蛋白质、多肽或肽的氨基酸序列的核酸序列。
[0095]
如本文使用的,“启动子”是指指导核酸转录的核酸控制序列。
[0096]“5'utr”或5'非翻译区(也称为前导序列或前导rna)是直接在起始密码子上游的mrna区域。
[0097]“3'utr”或3'非翻译区是紧跟翻译终止密码子的信使rna(mrna)的部分。
[0098]
5'utr和3'utr是转录(mrna)稳定性和翻译启动所必需的。
[0099]
对于微藻类叶绿体表达,可以在本发明的上下文中使用的启动子、5'utr和3'utr是例如:基因psbd、psba、psaa、atpa和atpb的启动子和5'utr;与5'utr融合的16s rrna启动子(prrn)启动子;psba 3'utr;atpa 3'utr;或rbcl 3'utr。
[0100]
来自外源的5'utr,例如噬菌体t7的基因10l的5'utr,也可以在微藻类启动子下游融合使用。特别地,核酸序列在其5'-端可操作地连接到莱茵衣藻16s rrna启动子(prrn)。
[0101]
根据本发明的核酸序列的稳定表达和翻译可以例如由来自psbd的启动子和5'utr以及atpa 3'utr控制。
[0102]
此外,在根据本发明的重组微藻类或方法的一个实施方式中,编码重组蛋白质、多肽或肽的核酸序列与至少一种选自下述的调控序列可操作地连接:psbd启动子和5'utr(seq id n
°
29);或与atpa 5'utr融合的16srrna启动子(prrn)启动子(seq id n
°
30);psaa启动子和5'utr;atpa启动子和5'utr;来自atpa(seq id n
°
31)和rbcl(seq id n
°
32)的3'utr。
[0103]
在一个实施方式中,编码感兴趣的蛋白质、肽或多肽的无启动子基因可以在叶绿体基因组内的同源重组区之后刚好在天然启动子下游整合。
[0104]
如以上提到的,微藻类宿主细胞的叶绿体基因组被表达载体转化。通过根据本发明的表达载体对微藻类宿主细胞,并且更特别地微藻类的叶绿体基因组的基因转化可以根据本领域技术人员熟知的任何合适的技术进行,包括但不限于基因枪法(boynton等,1988;
goldschmidt-clermont,1991)、电穿孔(fromm等,(1985)proc.natl.acad.sci.(usa)82:5824-5828;参见maruyama等,(2004)biotechnology techniques 8:821-826)、玻璃珠转化(purton等,revue)、用cacl2和聚乙二醇(peg)处理的原生质体(参见kim等,(2002)mar.biotechnol.4:63-73)或显微注射。
[0105]
特别地,所述转化使用与转化dna复合的金微粒的氦枪轰击技术。
[0106]
为了鉴定微藻类转化株,可以使用可选择标志物基因。可以提及例如编码氨基糖苷3
″‑
腺苷酸转移酶并且在莱茵衣藻叶绿体转化的情况下赋予对壮观霉素和链霉素的抗性的aada基因。在另一实施方式中,可选择标志物基因可以是编码3'-氨基糖苷磷酸转移酶vi型并且赋予卡那霉素抗性的鲍曼不动杆菌apha-6ab基因。
[0107]
因此,可以使用赋予抗生素抗性的可选择性标志物基因或使用光合突变体的拯救来进行叶绿体基因组工程化。
[0108]
特别地,在一个实施方式中,用于叶绿体基因组转化的表达载体包括两个表达盒,其包括编码根据本发明的重组蛋白质、多肽或肽或可选择标志物基因的核酸序列。
[0109]
更特别地,用于叶绿体基因组转化的表达载体包括一个包含编码根据本发明的重组蛋白质、多肽或肽的核酸序列的表达盒和一个包括编码氨基糖苷3
″‑
腺苷酸转移酶的aada基因的表达盒。
[0110]
在本发明的另一实施方式中,对应于拯救对光敏感的光合突变体的情况,表达载体包括在突变株中缺失的野生型rhrr区。在同源重组后,缺失的区域在光合突变体的基因组中恢复,所述光合突变体然后能够在光照下生长。
[0111]
特别地,根据本发明的表达盒的编码序列还包括编码信号肽的核酸序列。“信号肽”(sp)在本发明中意思是位于新合成的重组蛋白质或多肽或肽的n-末端的氨基酸序列。该信号肽应该允许蛋白质在叶绿体类囊体的腔内而不是在叶绿体基质内易位。信号肽在穿过类囊体膜易位后被切割。
[0112]
例如,这种信号肽序列选自使用双精氨酸蛋白易位(tat)途径或sec途径在类囊体的腔内易位的已知蛋白质。
[0113]
例如,信号肽可以来源于位于类囊体腔内的藻类蛋白,如来自光系统ii的放氧复合物的莱茵衣藻16和23kda亚单位,或b6f复合物的莱茵衣藻rieske亚单位,或隐藻藻红蛋白α亚单位(例如来自蓝隐藻)的信号肽。
[0114]
特别地,信号肽可以从编码三甲胺-n-氧化物还原酶1(uniprot编号p33225)的大肠杆菌tora基因的序列中提取(sp;seq id n
°
33:nnndlfqaasrrrflaqlggltvagmlgpslltprrataaqa;编码sp的核酸序列是seq id n
°
34)。该信号肽使用了tat系统。在后者穿过类囊体膜后,该氨基酸序列从蛋白质上切割。
[0115]
可以使用在重组蛋白的n-末端不留下补充氨基酸的其他信号肽,特别地例如来自藻类,并且特别地来自莱茵衣藻的信号肽。
[0116]
在一个实施方式中,重组蛋白质或多肽或肽可以作为融合蛋白产生。
[0117]
因此,本发明还涉及根据本发明的重组微藻类或方法,其中编码重组蛋白质、多肽或肽的核酸序列在其5'或3'端可操作地融合至编码载体的核酸序列。
[0118]
已经在重组蛋白产生中开发了融合配偶体或载体以增加积累产量和/或溶解度和/或折叠和/或促进蛋白质纯化。不同大小(或分子量)的融合配偶体已用于各种产生系
统,以增强蛋白质溶解度和积累(麦芽糖结合蛋白(mbp)、谷胱甘肽-s-转移酶(gst)、硫氧还蛋白、gb1、n-利用物质a(nusa)、泛素、小泛素样修饰剂(sumo)、fh8)并且促进检测和纯化(例如但不限于mbp、gst和小表位标签肽,如c-myc标签、聚组氨酸标签(his tag)、flag标签、ha标签。用于纯化的另一类型的融合标签是刺激响应标签(或环境响应多肽),其当调整刺激作为温度或溶液离子强度的修改时,允许融合蛋白沉淀。
[0119]
特别地,根据本发明的载体是抑肽酶。
[0120]
载体与重组蛋白质、多肽或肽融合在一起以形成融合蛋白。
[0121]“抑肽酶”意思是碱性胰蛋白酶抑制剂(bpti),一种通过三个二硫桥交联的小单链蛋白,其包括58个氨基酸残基,具有6.5kda的分子量和10.9的等电点。
[0122]
所述蛋白质是本领域技术人员所熟知的并且是可商业上获得的。例如,它可以在重组系统比如植物中(通过核转化在细胞质中(pogue等,2010),或通过叶绿体转化在类囊体腔中(tissot等,2008)产生。
[0123]
其分子式是c
284h432n84o79
s7,并且其摩尔质量6511.51g/mol。
[0124]
来自bos taurus(牛)的抑肽酶的氨基酸序列是rpdfc leppy tgpck ariir yfyna kaglc qtfvy ggcra krnnf ksaed cmrtc gga(seq id n
°
35)。编码该氨基酸序列的核酸序列是seq id n
°
36。
[0125]
在本发明的上下文中,术语“抑肽酶”还涵盖嵌合抑肽酶和突变抑肽酶。
[0126]“嵌合抑肽酶”意思是抑肽酶在其n-末端和/或在其c-末端与表位标签肽和/或信号肽和/或蛋白酶识别切割位点连接。
[0127]
嵌合抑肽酶可以是例如称为ha-apro(的蛋白质seq id n
°
37),其包括在其
[0128]
n-末端与ha表位标签融合的抑肽酶;或3f-apro(seq id n
°
39),其包括在其n-末端与3xflag表位标签(3f)融合的抑肽酶。
[0129]
嵌合抑肽酶的其他示例可以是称为ha-sp-3f-fx-apro的蛋白质(seq id n
°
41和42),其包括在其n-末端融合到由ha表位标签(ha),随后信号肽(sp)、3xflag表位标签(3f)和因子xa(fx;iegr)的切割位点制成的氨基酸序列的抑肽酶;或称为ha-sp-3f-apro的抑肽酶(seq id n
°
43和44),其包括在其n-末端融合到ha表位标签,随后信号肽sp和3xflag表位标签(3f)的抑肽酶;或称为ha-sp-apro的嵌合抑肽酶(seq id n
°
45和46),其包括在其-n末端融合到ha表位标签,随后信号肽sp的抑肽酶。
[0130]“突变的”抑肽酶意思是“突变的”抑肽酶的核酸或氨基酸序列在抑肽酶或嵌合抑肽酶的核酸或氨基酸序列中含有一个或多个突变。这些突变包括一个或多个核酸或氨基酸的缺失、取代、插入和/或切割。
[0131]
信号肽如先前描述的。
[0132]
可以使用不会在重组蛋白质的n-末端留下补充氨基酸的其他信号肽。如果信号肽在易位到叶绿体类囊体的内腔(或穿过类囊体膜)后被切割,则可以在体内产生另外两种嵌合抑肽酶3f-apro或3f-fx-apro(seq id n
°
47)。
[0133]
特别地,根据本发明,融合配偶体用于改善重组肽、多肽和蛋白质的积累和/或稳定性。
[0134]
仍特别地,并且如上所述,所述融合蛋白还包括被特定蛋白酶识别的切割位点。
[0135]
被特定蛋白酶识别的切割位点是本领域技术人员所熟知的。它们用于将抑肽酶与
感兴趣的重组蛋白质、多肽或肽分离,如果载体可能干扰所述蛋白质、多肽或肽的活性或结构并且因此干扰其用途,则应将其除去。
[0136]
特别地,所述切割位点是内切蛋白酶和/或胞内蛋白酶识别序列(或蛋白酶切割位点或蛋白酶识别位点)。更特别地,所述切割位点的序列位于两个编码序列(抑肽酶之一和根据本发明的感兴趣的重组蛋白质、多肽或肽之一)之间。
[0137]
融合蛋白的切割可以在体内进行(在提取前在重组宿主细胞中,或在用于美容肽的皮肤上时)或在提取和纯化后通过添加蛋白酶在体外进行。
[0138]
蛋白酶的非限制性示例是因子xa(fx)、烟草边缘病毒蛋白酶(tev)、肠激酶(ek)、sumo蛋白酶、凝血酶、人鼻病毒3c蛋白酶(hrv 3c)、胞内蛋白酶arg-c、胞内蛋白酶asp-c、胞内蛋白酶asp-n、胞内蛋白酶lys-c、胞内蛋白酶glu-c、蛋白酶k、iga-蛋白酶、胰蛋白酶、糜蛋白酶和嗜热菌蛋白酶。
[0139]
也可以使用自切割肽,例如介素系统(yang等,2003)、病毒2a系统(rasala等,2012)或来自衣藻的preferredoxin位点(muto等,2009)。
[0140]
在一个实施方式中,连接体可以放置在抑肽酶和蛋白酶切割位点之间。连接体可分为三种类型:柔性、刚性和可切割的。连接体的通常功能是融合融合蛋白的两个配偶体(例如柔性连接体或刚性连接体)或在特定条件下释放它们(可切割的连接体)或在药物设计中提供蛋白质的其他功能,比如改善它们的生物活性或它们的靶向递送。
[0141]
在本发明的一个实施方式中,如果需要,连接体还可以使蛋白酶切割位点更容易接近酶。
[0142]
在一个实施方式中,柔性连接体含有小的非极性(例如gly)或极性(例如ser或thr)氨基酸。chen等,2013中给出了这种连接体的示例。
[0143]
根据本发明的柔性连接体可以是lg(seq id n
°
49:rsggggsggggsgs)或lgm(seq id n
°
50:rsggggssggggggssrs)。
[0144]
当涉及具有载体的融合蛋白时,根据本发明的方法的步骤(vii)是纯化融合蛋白的步骤。
[0145]
在那种情况下,方法任选地包括其中融合蛋白被切割的步骤(viii)。
[0146]
所述切割可以通过本领域技术人员已知的任何方法进行,比如使用合适的蛋白酶来释放重组肽、多肽或蛋白质。
[0147]
所述步骤(viii)之后任选地是重组蛋白质、多肽或肽的纯化步骤(ix)。
[0148]
特别地,所述方法进一步包括在步骤(viii)和步骤(ix)之间的步骤(viii'),其中多肽被切割以允许释放肽单元。
[0149]
所述切割可以通过本领域技术人员已知的任何方法进行,例如使用合适的胞内蛋白酶。
[0150]
产生重组蛋白质、多肽或肽的微藻类宿主细胞的表征可以通过本领域技术人员已知的技术进行,例如通过抗生素抗性转化株的pcr筛选或对总蛋白提取物进行的蛋白质印迹分析。
[0151]
总蛋白的提取可以使用众所周知的技术(离心、裂解、超声等)进行。
[0152]
融合蛋白或重组蛋白质的鉴定可以通过蛋白质印迹使用特异性抗体进行。
[0153]
可以使用众所周知的技术进行纯化。在一个实施方式中,它包括亲和色谱和/或将
根据本发明的肽、多肽或蛋白质与载体分离的步骤(例如通过肠激酶蛋白酶消化)和/或尺寸排阻色谱。
[0154]
在一个实施方式中,亲和色谱的步骤可以被离子交换色谱取代,对于大规模纯化来说成本较低。
[0155]
根据本发明,“微藻类”是含有叶绿体或质体并且任选地能够进行光合作用的真核微生物生物体,或是能够进行光合作用的原核微生物生物体(蓝藻细菌)。
[0156]
特别地,所述微藻类选自绿藻门(chlorophyta)(绿藻类)、红藻门(rhodophyta)(红藻类)、不等鞭毛类(stramenopiles)(长短鞭毛体(heterokonts))、黄藻纲(xanthophyceae)(黄绿藻类)、灰胞藻纲(glaucocystophyceae)(灰胞藻类)、绿蜘藻(chlorarachniophyceae)(chlorarachniophytes)、眼虫目(euglenida)(眼虫)、定鞭藻纲(haptophyceae)(球石藻类)、金藻纲(chrysophyceae)(金藻类)、隐藻门(cryptophyta)(隐藻)、沟鞭藻科(dinophyceae)(鞭毛藻类)、定鞭藻类(haptophyceae)(球石藻类)、硅藻门(bacillariophyta)(硅藻类(diatoms))、真眼点藻纲(eustigmatophyceae)(真眼点藻门(eustigmatophytes))、针胞藻纲(raphidophyceae)(针胞藻(raphidophytes))、栅藻科(scenedesmaceae)、褐藻纲(phaeophyceae)(褐藻类)。
[0157]
更具体地,所述微藻选自衣藻(chlamydomonas)、小球藻属(chlorella)、杜氏藻属(dunaliella)、红球藻属(haematococcus)、硅藻类(diatoms)、栅藻科、四爿藻(tetraselmis)、ostreococcus、紫球藻属(porphyridium)和微拟球藻属(nannochloropsis)。
[0158]
甚至更特别地,所述微藻类选自由衣藻,更特别地莱茵衣藻,甚至更特别地莱茵衣藻137c或作为莱茵衣藻cw15的缺陷菌株组成的组。
[0159]
特别地,所述微藻类在本领域技术人员已知的经典条件下培养。例如,莱茵衣藻生长在tap(tris乙酸盐磷酸盐(tris acetate phosphate))培养基至对数中期(约1-2x106细胞/ml的密度),和/或在23℃至25℃之间(理想情况下25℃)的温度,和/或在恒定光照(70-150μe/m2/s)存在下在旋转振动筛上。实验部分阐释了培养的条件。
[0160]
在本发明的上下文中提到的所有实施方式都可以组合。
[0161]
本发明将通过以下附图和实施例进一步阐释。
附图说明
[0162]
图1:莱茵衣藻叶绿体基因组中的密码子使用
[0163]
图2:用于产生蓝隐藻(g.theta)ccmp2712蛋白(gtclp)、蓝隐藻ccmp2712的天然和嵌合胶原蛋白样结构域(gtcld)的叶绿体转化载体的示意图。
[0164]
图3:使用单克隆抗flag m2抗体,表达来自藻类叶绿体基因组的蓝隐藻ccmp2712蛋白(a)的基因和蓝隐藻ccmp2712(b)的嵌合胶原蛋白样结构域的独立藻类转化株cw-co86和cw-co96的蛋白质印迹分析。在15%sds聚丙烯酰胺凝胶上分离用sds缓冲液裂解从野生型(wt)cw15和转化株cw-co86和cw-co96中提取的100μg的每种总可溶性蛋白样品。mw:分子量标准。箭头表示重组蛋白的位置。
[0165]
图4:使用单克隆抗flag m2(a)或抗ha(b)抗体对137c-co96-4转化株进行蛋白质印迹分析。通过超声处理提取的137c-co96转化株中的50μg的总可溶性蛋白质被肠激酶
(ek)消化(+ek;a:泳道4;b:泳道5)或不消化(a:泳道2和3;b:3和4)。50μg的来自野生型(wt)137c的总可溶性蛋白质用sds缓冲液裂解提取。mw:分子量标准。箭头表示带有或不带有flag标签的重组蛋白质的位置。
[0166]
图5:使用单克隆抗ha抗体对来自137c-co96-4的蛋白质提取物进行来自抗ha亲和色谱的不同洗脱级分的蛋白质印迹分析。将蛋白质样品(50μg的通过超声处理野生型(wt)137c提取的蛋白质或25μg的洗脱或洗涤级分)加载到15%sds聚丙烯酰胺凝胶上。mw:分子量标准。加载:在用抗ha树脂孵育之前通过超声处理提取的总可溶性蛋白质。ft:流过。ea:洗脱分级。w:洗涤分级。箭头表示纯化重组蛋白质的位置。
[0167]
图6:用于弹性蛋白多肽和肽生产的叶绿体转化载体的示意图。
[0168]
图7:使用单克隆抗flag(a)或抗ha(b)抗体对用pla01转化的藻类细胞进行蛋白质印迹分析。用sds缓冲液裂解从野生型(wt)cw15细胞和独立的cw-la01转化株中提取的50μg的总可溶性蛋白质样品在15%sds聚丙烯酰胺凝胶上分离。mw:分子量标准。箭头表示重组蛋白质的位置。
实施例
[0169]
实施例1
[0170]
材料和方法
[0171]
所有寡核苷酸和合成基因都购自eurofins。所有酶都购自neb、promega、invitrogen和sigma aldrich/merck。所有质粒都建立在pbluescript ii骨架上。
[0172]
藻类菌株和生长条件
[0173]
使用的两种藻类菌株是莱茵衣藻野生型(137c;mt+)和细胞壁缺陷型菌株cw15(cc-400;mt+),获得自衣藻资源中心,明尼苏达大学)。
[0174]
转化之前,所有菌株都在包括23℃至25℃之间(理想情况下25℃)的温度,在有恒定光照(70-150μe/m2/s)存在的情况下在旋转振荡器上,在tap(tris乙酸盐磷酸盐)培养基中生长至对数生长中期(mid-logarithmic phase)(约1-2x106细胞/ml的密度)。
[0175]
根据转化载体中存在的可选择标志物基因,转化株在相同条件和含有100μg/ml壮观霉素或100μg/ml卡那霉素的相同培养基中生长。
[0176]
生长动力学也接着通过使用分光光度计测量750nm处的光密度。
[0177]
藻类转化
[0178]
如文章boynton等,1988中描述的,使用与转化dna复合的金微弹射的氦枪轰击技术转化莱茵衣藻细胞。简而言之,莱茵衣藻细胞在tap培养基中培养至对数生长中期,通过温和离心收获,并且然后重悬浮于tap培养基中至1.108个细胞/ml的终浓度。根据转化载体中存在的可选择标志物基因,将300μl的这种细胞悬浮液铺平板于补充有100μg/ml壮观霉素或100μg/ml卡那霉素的tap琼脂培养基上。如制造商描述的,用转化载体涂布的金颗粒(s550d;seashell technology)轰击板。然后在标准光照条件下在25℃放置板以允许选择和形成转化的菌落。
[0179]
阳性转化株的总dna提取和pcr筛选
[0180]
使用螯合树脂chelex 100(biorad)从野生型和/或抗生素抗性转化株衣藻菌株的单个菌落(直径大约1mm的尺寸)中进行总dna提取。
[0181]
从分离的菌落中,用尖头(pick)挑出对应于直径约0.5mm的一些细胞并且重悬浮于20μl的h2o中。添加200μl的乙醇并且在室温孵育1min。并入200μl的5%chelex且涡旋。在100℃孵育8min后,将混合物冷却并且以13,000rpm离心5min。最后,收集上清液。
[0182]
转化后,生长在限制性固体培养基平板上的藻类菌落预计具有抗生素抗性基因,并且其他转基因将转基因并入它们的基因组中。
[0183]
为了鉴定重组基因到藻类基因组中的稳定整合,使用1μl先前提取的总dna作为模板、两种合成的和特异性的寡核苷酸(引物)和taq聚合酶(gotaq,promega),在热循环仪中通过聚合酶链式反应(pcr或pcr扩增)筛选抗生素抗性转化株。pcr扩增循环遵循制造商推荐的指南。对pcr反应进行凝胶电泳以检查感兴趣的pcr片段。
[0184]
蛋白质提取,蛋白质印迹分析
[0185]
通过离心收集衣藻细胞(50ml,1-2.106个细胞/ml)。将细胞小球(pellet)重悬浮于裂解缓冲液(50mm tris-hcl ph 6.8、2%sds、10mm edta)中。如以下进一步详述,在实施例的一些实施方式中,裂解缓冲液不含有10mm edta。在室温30min后,通过以13000rpm离心去除细胞碎片,并且收集含有总可溶性蛋白质的上清液。
[0186]
根据进一步的分析步骤,在不同缓冲液中在非变性条件下提取总可溶性蛋白质。将细胞小球重悬浮于含有50mm tris-hcl(ph 6.8或8)或20mm tris-hcl(ph 6.8或8)的缓冲液中。将藻类细胞悬浮液保持在冰上进行超声处理步骤,使用细胞破碎仪、超声仪fb505 500w(sonic/fisherbrand)并且将微尖探针设置为20%功率,连续超声处理5min。超声处理后,通过以13000rpm离心30min来去除细胞碎片。
[0187]
按照供应商(thermofisher)的说明,使用pierce bca蛋白质测定试剂盒对上清液中存在的总可溶性蛋白质进行定量。
[0188]
在根据laemmli(1970)制备的12或15%tris-甘氨酸sds-page中分离总可溶性蛋白质样品(在根据实验的实施例中进一步提到的50或100μg或另一个量)。
[0189]
对于在还原条件下进行的实验,样品在具有50mm dtt(或更多,根据融合蛋白)或5%β-巯基乙醇的laemmli样品加载缓冲液中制备,并且在加载前在95℃进一步变性5min。sds page实验使用来自biorad的蛋白质凝胶罐(protein gel tank)进行。
[0190]
分离后,使用标准转移缓冲液和来自biorad的turbo
tm
转移系统将样品印迹到硝化纤维素膜(ge healthcare)上。为了可视化转移的蛋白质,由丽春红s染料染色硝化纤维素膜。用含有5%牛血清白蛋白(bsa)的tris缓冲盐水tween缓冲液(tbs-t)(50mm tris-hcl ph 7.5、150mm nacl、0.1%tween-20)进一步封闭膜。在室温轻轻摇动饱和一小时后,用含有小鼠一级抗体的ttbs缓冲液在4℃孵育膜一晚(参见表1)。
[0191]
表1:一级抗体
[0192][0193]
[0194]
用tbs-t-bsa缓冲液洗涤三次后,用含有二级抗体(抗小鼠igg(h+l)、hrp缀合物;promega)的tbs-t-bsa缓冲液在室温孵育膜一小时。在用ttbs缓冲液洗涤四次且用tbs缓冲液洗涤一次后,在增强的化学发光(ecl)底物(clarity max ecl底物;biorad)中孵育膜。使用chemidoc
tm
xrs+系统(biorad)可视化ecl信号。
[0195]
蛋白质纯化
[0196]
离心后,将藻类细胞小球重悬浮于不同的缓冲液中,根据蛋白质和蛋白质所进行的进一步步骤。如果下一个步骤是抗flag m2亲和色谱,则缓冲液含有50mm tris-hcl ph8、500mm nacl和0.1%tween 20。如果下一个步骤是抗ha亲和色谱,则缓冲液含有20mm tris-hcl ph8。大概地,每g湿藻类细胞使用10ml的缓冲液,这根据转化株。在与先前描述的相同条件下超声处理重悬浮的细胞。
[0197]
亲和色谱
[0198]
所有重组蛋白质在它们的n-末端用将特异性结合到抗flag m2亲和凝胶(sigma/merck)上的flag标签表位标记。该树脂含有共价连接至琼脂糖的小鼠单克隆抗m2抗体。
[0199]
该实验的所有步骤都按照制造商所述进行。简而言之,使用乙酸纤维素0.45μm过滤器过滤总可溶性蛋白质样品,并且与由制造商推荐制备的抗m2亲和凝胶混合,且在结合缓冲液(50mm tris-hcl ph8、500mm nacl、0.1%tween 20)中平衡。大概地,每4至8g湿藻类细胞使用1ml的树脂,这根据转化株。重组融合蛋白的结合在4℃进行4小时或过夜,轻轻且连续的上下颠倒(end-over-end)混合。孵育后,将用树脂孵育的可溶性蛋白质混合物通过重力加载到空的bio-rad econo-pac柱上或通过离心收集,并且用40柱体积的tbs和20柱体积的tbs洗涤数次。使用100mm甘氨酸ph 3.5、500mm nacl从树脂中洗脱感兴趣的蛋白质,并且用tris-hcl ph 8中和至50mm的终浓度。
[0200]
一些重组蛋白质用将特异性结合到抗ha琼脂糖树脂(pierce/thermo scientific)上的ha表位标签标记。该实验的所有步骤都按照制造商所述进行。简而言之,将总可溶性蛋白质的过滤样品与由制造商推荐制备的抗ha琼脂糖树脂混合,并且在tbs中平衡,并且在4℃以轻轻连续上下颠倒混合或震荡平台孵育过夜。孵育后,树脂以12,000g沉淀5至10秒(重复3次)。保留上清液用于进一步分析。用10个床体积的tbst洗涤沉淀的树脂数次。在30℃将树脂与10个床体积的1mg/ml pierce ha肽一起孵育15min后,从树脂中洗脱感兴趣的蛋白质。通过离心(以12,000g,5至10秒)沉淀树脂。收集含有融合蛋白的上清液。该洗脱步骤再重复另外3次。
[0201]
通过sds-page和蛋白质印迹进一步分析亲和色谱的每个洗脱级分。
[0202]
根据进一步的步骤,如制造商描述的,在slide-a-lyzer透析盒(3.5kda mwco,thermo scientific)中针对进一步的步骤,例如,用于蛋白酶消化中使用的缓冲液对含有感兴趣的蛋白质的洗脱级分进行透析。使用vivaspin 6(3kda mwco,ge healthcare)浓缩透析样品。
[0203]
感兴趣的蛋白质与载体的分离
[0204]
通过蛋白酶消化,特别地在本发明中,通过来自new england biolabs(neb)的肠激酶(轻链)或烟草蚀刻病毒(tev)蛋白酶进行感兴趣的蛋白质与载体的分离。
[0205]
按照制造商的推荐进行酶消化。
[0206]
例如,对于肠激酶轻链消化,反应将20μl的缓冲液(20mm tris-hcl ph 8.0、50mm nacl、2mm cacl2)中25μg的感兴趣的蛋白质与1μl的肠激酶轻链组合。在25℃进行孵育16h。
[0207]
例如,对于tev消化,制造商推荐的典型反应将15μg的蛋白质底物与5μl的tev蛋白酶反应缓冲液(10x)组合,以制造50μl的总反应体积。添加1μl的tev蛋白酶后,将反应在30℃孵育1小时或在4℃过夜。
[0208]
例如,对于因子xa消化,制造商推荐的在23℃,在50μl体积中用1μg的fxa消化50μg的融合蛋白6小时。反应缓冲液包括20mm tris-hcl ph 8.0、100mm nacl和2mm cacl2。
[0209]
胞内蛋白酶对多肽的切割
[0210]
用于切割感兴趣的多肽的胞内蛋白酶的选择根据该多肽的氨基酸序列。胞内蛋白酶可以是例如,胞内蛋白酶glu-c、胞内蛋白酶arg-c、胞内蛋白酶asp-c、胞内蛋白酶asp-n或胞内蛋白酶lys-c。
[0211]
按照制造商的推荐进行酶消化。例如,对于胞内蛋白酶glu-c消化(来自neb),制造商推荐在37℃用50ng的胞内蛋白酶glu-c消化1μg底物蛋白质16h。反应缓冲液包括50mm tris-hcl ph 8.0和0.5mm gluc-gluc。
[0212]
尺寸排阻色谱(sec)
[0213]
使用akta pure系统(ge healthcare)对纯化和消化的融合蛋白进行尺寸排阻色谱,以便从载体中分离感兴趣的蛋白质。
[0214]
首先,使用用2x pbs缓冲液(或用于进一步步骤的适当缓冲液)稀释的两种标准物:抑肽酶(牛肺;6.5kda)和甘氨酸(75da),校准superdex s30增加g10/300gl色谱柱(ge healthcare)和hiload 26/600superdex30制备级色谱柱。
[0215]
在水中洗涤步骤后,将superdex s30增加g10/300gl色谱柱在运行缓冲液(2x pbs,ph 7.4;或1x pbs,ph 7.4;或用于进一步步骤的适当缓冲液)中平衡,并且将200至500μl样品以0.5ml/min的速度流过色谱柱。通过测量280、224和214nm处的光学吸光度来检测蛋白质的洗脱。收集0.5ml级分并且通过sds-page分析,随后进行蛋白质印迹或由考马斯蓝色染料染色。
[0216]
在水中洗涤步骤后,hiload 26/600superdex 30制备级色谱柱在运行缓冲液(2x pbs,ph 7.4;或1x pbs,ph 7.4;或用于进一步步骤的适当缓冲液)中平衡,并且将样品(4至30ml)以2.6ml/min的速度流过色谱柱。通过测量280、224和214nm处的光学吸光度来检测蛋白质的洗脱。收集4ml级分并且通过sds-page分析,随后进行蛋白质印迹。
[0217]
在一些实施方式中,使用speedvac(eppendorf)汇集和蒸发感兴趣的洗脱级分。对这些蒸发样品中存在的肽或多肽或蛋白质进行edman降解,以确认感兴趣的蛋白质的n-末端的氨基酸序列。
[0218]
实施例2
[0219]
叶绿体基因组转化的莱茵衣藻叶绿体中胶原蛋白样蛋白质、胶原蛋白样结构域和胶原蛋白样多肽的产生
[0220]
用于胶原蛋白样蛋白质表达的转化载体的构建
[0221]
为了产生创新的胶原蛋白样蛋白质(clp)和/或胶原蛋白样结构域,我们筛选了数据库以寻找来自不同来源的编码胶原蛋白样结构域的胶原蛋白样基因。发现的序列之一是
来自微藻类蓝隐藻(g.theta)的ccmp2712蛋白。来自蓝隐藻的ccmp2712蛋白的氨基酸序列(称为gtclp seq id n
°
51)含有胶原蛋白样结构域,并且从genbank登录号xm_005827950中提取。
[0222]
没有描述关于由已鉴定的基因编码的蛋白质形成胶原蛋白样三螺旋结构的能力。
[0223]
在莱茵衣藻中,密码子的使用已被证明在蛋白质积累中起显著作用(franklin等,2002;mayfield and schultz,2004)。
[0224]
设计和优化编码ccmp2712蛋白的核酸序列以改善其在莱茵衣藻宿主细胞中的表达。
[0225]
改变核酸序列用于宿主细胞中的改善表达的方法是本领域已知的,特别地在藻类细胞中,特别地在莱茵衣藻中。
[0226]
在http://www.kazusa.or.jp/codon/中找到了密码子使用数据库(参见莱茵衣藻叶绿体基因组的密码子使用;图1)。
[0227]
为了改善感兴趣的基因在莱茵衣藻叶绿体中的表达,将不是常用的来自它们的天然序列中的密码子用编码莱茵衣藻叶绿体密码子偏倚中更常用的相同或相似氨基酸残基的密码子替换。此外,其他密码子被替换以避免多个或扩展密码子重复序列,或一些限制性酶切位点,或具有可降低或干扰表达效率的二级结构的更高概率。
[0228]
为了检查且满足以上提到的所有标准,还通过eurofins的软件geneius使用莱茵衣藻叶绿体的适当密码子使用来优化感兴趣的蛋白质的氨基酸序列。
[0229]
在其密码子优化后,编码来自蓝隐藻的天然ccmp2712蛋白的基因gtclp(称为“重组gtclp”或3f-tv-gtclp-tv-ha)被设计为在其5'端可操作地融合到编码含有3xflag表位标签(seq.dykddddkdykddddkdykddddk;seq id n
°
25),随后tev蛋白酶的识别位点(seq enlyfqg;seq id n
°
52)的氨基酸序列的密码子优化的核酸序列。在其3'端,优化的基因gtclp可操作地融合到编码tev蛋白酶识别位点,随后ha表位标签(seq id n
°
26)的优化的核酸序列。在莱茵衣藻叶绿体中体内产生的重组gtclp也称为3f-tv-gtclp-tv-ha。tev蛋白酶的两个识别位点允许通过体外蛋白酶消化消除3xflag和ha标签。
[0230]
合成编码称为3f-tv-gtclp-tv-ha(seq id n
°
55)的重组gtclp的该所得融合基因3f-tv-gtclp-tv-ha(seq id n
°
10)并且通过eurofins genomics克隆到载体pex-a258,产生载体pal70。
[0231]
在使用引物o5'scl70(seq id n
°
56)和o3'scl70(seq id n
°
57)从载体pal70进行pcr扩增后,使用new england biolabs的gibson组装(按照制造商的推荐)将1317bp的pcr片段fpcr-scl70(seq id n
°
58)克隆到由ncoi和sali线性化的叶绿体转化载体ple56中存在的感兴趣的基因(goi)的表达盒以形成载体pco86(图2)。
[0232]
叶绿体表达载体ple56含有两个表达盒,用于表达编码可选择标志物(gos)和感兴趣的重组蛋白质(goi)的基因。选择盒含有编码氨基糖苷3
″‑
腺苷酸转移酶且赋予壮观霉素和链霉素抗性的可选择标志物aada基因。该基因在其5'端可操作地连接至融合至atpa 5'utr的莱茵衣藻16s rrna启动子(prrn),并且在其3'端可操作地连接至莱茵衣藻rbcl基因的3'utr。在第二盒中,重组goi的稳定表达由启动子和来自莱茵衣藻psbd的5'utr和来自莱茵衣藻atpa的3'utr控制。
[0233]
这两个表达盒两侧是左(lhrr)和右(rhrr)内源同源重组序列,所述序列与围绕莱
茵衣藻叶绿体基因组的靶向整合位点的序列相同。叶绿体基因组内插入位点的选择通常是比如为了不破坏必需基因或不干扰多顺反子单元的表达进行。在优选的实施方式中,本发明中的叶绿体转化载体允许将转基因靶向整合到莱茵衣藻的叶绿体基因组5s rdna和psba基因之间(并且源自例如序列genbank登录号nc005352的例子)。
[0234]
用于蓝隐藻ccmp2712 clp的嵌合胶原蛋白样结构域表达的叶绿体转化载体的构建。
[0235]
来自蓝隐藻ccmp2712蛋白(seq id n
°
59;命名为gtcld)的胶原蛋白样结构域被设计为以便在其n-末端与含有cys结和cr4重复序列的氨基酸序列(seq.gpccgppgppgppgpp,seq id n
°
60)融合。cys结(knot)和cr4重复序列在本领域中已知为增加序列的构象刚性。在其c-末端,gtcld与cr4重复序列融合,随后是cys结序列和t4噬菌体的折叠纤维蛋白(seq.gyipeaprdgqayvrkdgewvllstfl,seq id n
°
61)。所得重组蛋白质被命名为来自蓝隐藻的嵌合胶原蛋白样结构域或gtccld(seq id n
°
62)。gtccld蛋白还设计为在其c-末端融合3xha表位标签(称为3ha;seq id n
°
63:ypydvpdyaypydvpdyaypydvpdya)。
[0236]
合成密码子优化的基因gtccld-3ha(seq id n
°
84)由eurofins genomics合成并且克隆到载体pex-a258中以形成pal81。将基因gtccld-3ha亚克隆到之前由bamhi和pmei消化线性化的叶绿体转化载体ple63的goi表达盒中,以得到pco96。更准确地,gtccld-3ha被亚克隆到编码连接至信号肽(sp)然后是3xflag表位标签的ha表位标签(ha)的核酸序列ha-sp-3f(ha-sp-3f)的下游(图2)。
[0237]
然后,在莱茵衣藻叶绿体中,产生了重组gtccld-3ha(seq id n
°
64),在其n-末端与氨基酸序列ha-sp-3f融合,并且被称为ha-sp-3f-gtccld-3ha(seq id n
°
83)。该重组蛋白质由称为ha-sp-3f-gtccld-3ha的核酸序列(seq id n
°
19)编码。叶绿体表达载体ple63含有与ple56相同的可选择标志物表达盒(图2)。goi的稳定表达由启动子和来自莱茵衣藻psbd的5'utr和来自莱茵衣藻atpa的3'utr控制。在该表达盒中,goi在其5'端与核酸序列ha-sp-3f融合。ple63允许重组基因与ple56和pco86相同的靶向整合到莱茵衣藻叶绿体基因组中。
[0238]
为了去除编码3xha标签的核酸序列,通过pcr从pal81扩增含有编码来自蓝隐藻gtccld的重组嵌合胶原蛋白样结构域的核序列的pcr片段gtccld-2(seq id n
°
65),并且通过gibson组装方法在psbd启动子/5'utr和atpa 3'utr之间克隆到通过bamhi和pmei线性化的ple63中以形成pco26(图2)。与pco96一样,基因ccld-2被亚克隆到编码氨基酸序列ha-sp-3f的核酸序列ha-sp-3f的下游(图2)。
[0239]
然后,在莱茵衣藻叶绿体中,产生了来自蓝隐藻gtccld的重组嵌合胶原蛋白样结构域,在其n-末端与氨基酸序列ha-sp-3f融合,并且被称为由核酸序列ha-sp-3f-gtccld(seq id n
°
20)编码的ha-sp-3f-gtccld(seq id n
°
85)。
[0240]
为了仅从蓝隐藻产生胶原蛋白样结构域而没有cys结和cr4重复序列,含有基因的核序列的pcr片段gtcld(seq id n
°
66)通过pcr从pal81扩增并且由gibson组装方法在psbd启动子/5'utr和atpa 3'utr之间克隆到由bamhi和pmei线性化的ple63以形成pco28(图2)。如pco96和pco26中的,基因gtcld被亚克隆到编码氨基酸序列ha-sp-3f的核酸序列ha-sp-3f的下游(图2)。
[0241]
然后,在莱茵衣藻叶绿体中,产生了来自蓝隐藻gtcld的重组胶原蛋白样结构域,
在其n-末端与氨基酸序列ha-sp-3f融合,并且被称为由核酸序列ha-sp-3f-gtcld(seq id n
°
21)编码的ha-sp-3f-gtcld(seq id n
°
86)。
[0242]
在它们产生在藻类叶绿体中后,信号肽(sp)将在体内从重组蛋白质ha-sp-3f-gtccld-3ha、ha-sp-3f-gtccld和ha-sp-3f-gtcld在易位期间切割进入类囊体。因此,可以产生其他3种蛋白质3f-gtccld-3ha、3f-gtccld和3f-gtcld。
[0243]
3xflag标签将通过这些重组蛋白的体外肠激酶消化来切割。
[0244]
藻类的转化
[0245]
如实施例1中描述的,在莱茵衣藻细胞(137c和cw15)中轰击转化载体pco86、pco96、pco26和pco28。
[0246]
为了鉴定编码融合蛋白的重组基因到叶绿体藻类基因组中的稳定整合,通过pcr分析筛选壮观霉素抗性菌落。对于co96、co26和co28转化株中融合蛋白基因的阳性pcr筛选,引物o5'astatpa2(seq id n
°
67)和o3'sutrpsbd(seq id n
°
68)退火分别在atpa 3'utr和psbd 5'utr中被使用。对于co86转化株,使用两种其他引物在感兴趣的基因和psbd启动子中分别退火o5'scl70(seq id n
°
69)和o5'ppsbdcla2(seq id n
°
70)。
[0247]
分析和结果
[0248]
在还原条件下,对从用pco86、pco96、pco26和pco28(来自137c和cw15菌株)转化后获得的几种转化株中提取的总可溶性蛋白样品进行蛋白质印迹分析。
[0249]
结果显示产生了四种重组蛋白质,被抗flag抗体和/或抗ha抗体探测。
[0250]
图2显示了对产生重组蛋白质3f-tv-gtclp-tv-ha和ha-sp-3f-gtccld-3ha的cw-co86和cw-co96转化株的总可溶性蛋白提取物进行蛋白质印迹的结果。
[0251]
为了从与信号肽sp融合或不融合的n-末端表位标签中释放感兴趣的重组蛋白质,从co96、co26和co28转化株的一种克隆中提取的总可溶性蛋白样品在体外通过肠激酶消化来进行消化,如实施例1中描述的。图4显示了对从137c-co96-4转化株中提取的总可溶性蛋白样品进行肠激酶消化的蛋白质印迹。将体内产生的重组蛋白ha-sp-3f-gtccld-3ha切割以形成gtccld-3ha。
[0252]
在产生重组蛋白质3f-tv-gtclp-tv-ha的co86转化株的情况下,总可溶性蛋白样品在体外通过肠激酶消化以产生蛋白质tv-gtclp-tv-ha或通过tev蛋白酶消化以产生蛋白质gtclp。
[0253]
137c-co96-4细胞由大约900ml培养物产生。如实施例1中描述的重悬浮藻类细胞(大约3g)并且进行超声处理。获得14.6ml的总可溶性蛋白质提取物。
[0254]
使用抗ha树脂(150μl)通过亲和色谱纯化来自137c-co96-4的6.5ml蛋白提取物的重组蛋白。通过蛋白质印迹分析分析洗脱级分。作为示例,图5中显示的结果揭示了嵌合胶原蛋白样结构域的亲和色谱纯化的有效性。
[0255]
在非还原条件下进行的蛋白质印迹分析(在加载到聚丙烯酰胺凝胶上之前没有ddt和煮沸或没有蛋白质样品)显示,在co96转化株中产生的嵌合胶原蛋白样结构域在体内形成了高表观分子量的多聚体结构,与还原条件下蛋白质的表观分子量形成对照。
[0256]
实施例3
[0257]
通过叶绿体基因组转化在莱茵衣藻叶绿体中使用抑肽酶作为载体在融合蛋白中产生弹性蛋白样肽或多肽或衍生物
[0258]
转化载体(pla01、pla02、pal03和pal04)的构建
[0259]
在叶绿体转化载体elp4中,由重复的vgvapg六肽(seq id n
°
5),更特别地4倍重复的该六肽(seq id n
°
81:vgvapgvgvapgvgvapgvgvapg)组成的弹性蛋白样多肽被表达在其中在嵌合抑肽酶ha-sp-3f-fx-apro(seq id n
°
41和42)的c-末端融合它的融合蛋白中。该融合配偶体含有在其n-末端与由ha表位标签(ha)随后信号肽(sp)、3xflag表位标签(3f)和因子xa(fx;seq id n
°
71:iegr)的切割位点制成的氨基酸序列融合的抑肽酶。将是肠激酶的切割位点的flag表位标签序列(seq id n
°
24:dykddddk)插入嵌合抑肽酶和elp4之间,以便允许以肠激酶通过融合蛋白的体外位点特异性蛋白水解从抑肽酶释放elp4。
[0260]
藻类叶绿体中产生融合蛋白ha-sp-3f-fx-apro-f-elp4(seq id n
°
87)后,n-末端片段ha-sp将在蛋白质易位到类囊体的期间被切割,并且将在体内产生以下重组蛋白质3f-fx-apro-f-elp4。
[0261]
如实施例2中解释的,在莱茵衣藻中,编码感兴趣的蛋白质的核酸序列中的密码子使用已显示在蛋白质积累中起显著作用。
[0262]
如实施例2中描述的设计和优化编码抑肽酶的核酸序列,以提高莱茵衣藻宿主细胞中它们的表达。优化后,编码抑肽酶(apro)的基因在其5'端可操作地融合到编码ha表位标签(ha),随后信号肽、3xflag表位标签(3f)和被因子xa蛋白酶(fx)识别的切割位点的密码子优化的核酸序列,以形成嵌合抑肽酶基因ha-sp-3f-fx-apro(seq id n
°
42)。
[0263]
使用实施例1中描述的相同方法和莱茵衣藻叶绿体基因组的密码子使用,首先密码子优化编码elp4的核酸序列。所得序列用于设计两个重叠寡聚体o5'gibs-elp4(seq id n
°
72)和o3'gibs-elp4(seq id n
°
73),它们用作引物和模板以通过pcr扩增194bp的片段fgibs-elp4。使用来自new england biolabs的gibson assembly master mix(按照制造商的推荐)将该扩增的dna克隆到叶绿体转化载体pau76中,并且通过pmei线性化以形成载体pla00。
[0264]
用于叶绿体基因组转化的表达载体pau76含有两个表达盒,用于表达编码可选择标志物(与之前的转化载体相同)和嵌合抑肽酶ha-sp-3f-fx-apro的基因。pau76允许重组基因与ple63相同的靶向整合到莱茵衣藻叶绿体基因组中。
[0265]
使用引物o5'gibs01be(seq id n
°
74)和o3'gibs01be(seq id n
°
75)通过pcr从pla00扩增编码elp4的核酸序列。使用gibson assembly master mix将359pb的pcr片段fpcr-ap-felp4(seq id n
°
76)克隆到由bamhi和pmei线性化的ple63中以形成载体pla01。转化载体pla01允许产生融合蛋白ha-sp-3f-fx-apro-f-elp4,其含有在其n-末端与嵌合抑肽酶ha-sp-3f-fx-apro,随后1x flag标签连接的elp4(图6)。
[0266]
叶绿体转化载体pla02是通过gibson组装方法克隆到ple63(由bamhi和pmei线性化)中获得的,pcr片段fpcr-felp4-ha(seq id n
°
77)(359pb)用引物o5'gibs02be(seq id n
°
78)和o3'gibs02be(seq id n
°
79)从pla00扩增。转化载体pla02允许产生融合蛋白质ha-sp-3f-1f-elp4,其含有在其n-末端与嵌合序列ha-sp-3f,随后1x flag标签连接的elp4(图6)。
[0267]
在由pla01或pla02转化的藻类叶绿体的情况下,如果信号肽sp在融合蛋白易位到类囊体腔后被切割,则可以在体内产生两种其他不同的蛋白质,3f-fx-apro-1f-elp4或3f-1f-elp4(seq id n
°
88)。
[0268]
在两种类型的转化载体中,elp4从融合蛋白中的释放可以通过肠激酶消化在体外进行,肠激酶消化正好在elp4上游的1x flag标签中存在的基序序列dykddddk(seq id n
°
24)中的第二个赖氨酸氨基酸之后切割蛋白质序列。
[0269]
称为elpe4的弹性蛋白样多肽由重复的gvapge(seq id n
°
9)、肽vgvapg的衍生物,更特别地4倍重复的该肽(seq id n
°
80,vgvapgevgvapgevgvapgevgvapge)组成。在叶绿体转化载体中,elpe4也在融合蛋白中表达,其中它在嵌合抑肽酶ha-sp-3f-fx-apro的c-末端融合。
[0270]
为了通过elpe4在体外从载体分离,添加柔性连接体lgm(seq id n
°
50:rsggggssggggggssrs)随后tev蛋白酶(tv;seq id n
°
52:enlyfqg)或肠激酶(ek;seq id n
°
38:ddddk)。
[0271]
两种类型的融合蛋白已经从两种不同的叶绿体表达载体产生:ha-sp-3f-fx-apro-lgm-tv-elpe4(seq id n
°
89)或ha-sp-3f-fx-apro-lgm-ek-elpe4(seq id n
°
90)。
[0272]
还使用实施例1中描述的相同方法和莱茵衣藻叶绿体基因组的密码子使用对编码lgm-tv-elpe4或lgm-ek-elpe4的核酸序列进行密码子优化。在密码子优化后,通过eurofins合成了不同的合成基因lgm-tv-elpe4(seq id n
°
40)和lgm-ek-elpe4(seq id n
°
48)。这些优化的基因通过gibson组装方法在编码载体的基因下游克隆到存在于通过pmei线性化的叶绿体转化载体pau76中的表达盒(seq n
°
82)中,分别产生pla03和pla04。
[0273]
藻类的转化
[0274]
如实施例1中描述的,在莱茵衣藻细胞(137c和cw15)中轰击转化载体pal01、pla02、pla03和pla04。
[0275]
为了鉴定编码融合蛋白的重组基因稳定整合到叶绿体藻类基因组中,分别在atpa 3'utr和psbd 5'utr中使用引物o5'astatpa2(seq id n
°
67)和o3'sutrpsbd(seq id n
°
54)退火通过pcr分析筛选壮观霉素抗性菌落。
[0276]
分析和结果
[0277]
使用抗flag抗体对从la01、la03或la04转化株的不同独立株中提取的总可溶性蛋白进行的蛋白质印迹分析揭示了在莱茵衣藻叶绿体中产生融合蛋白ha-sp-3f-fx-apro-f-elp4(seq id n
°
87)、ha-sp-3f-fx-apro-lgm-tv-elpe4(seq id n
°
89)和ha-sp-3f-fx-apro-lgm-ek-elpe4(seq id n
°
91)。
[0278]
如图7中显示的,蛋白质印迹分析显示,使用抗flag抗体在la01转化株中非常好地产生了与3f-fx-apr融合的elp4多肽。此外,在所有la01转化株中,ha表位标签和信号肽似乎都被切割了,因为对相同的总可溶性蛋白提取物进行的蛋白质印迹显示一级抗ha抗体不识别任何融合蛋白(图7)。
[0279]
在la02转化株中,没有检测到重组蛋白质(图7),表明elp4与3f-fx-apro(或抑肽酶作为一般方式)的融合允许elp4的积累。
[0280]
产生了一种转化株cw-la01的生物质。细胞小球重悬浮于超声缓冲液中。
[0281]
通过抗flag m2亲和色谱纯化融合蛋白。通过蛋白质印迹分析鉴定、透析和浓缩含有融合蛋白的洗脱级分。进行肠激酶蛋白酶消化,随后进行尺寸排阻色谱(hiload 26/00superdex 30),以允许纯化多肽elp4。
[0282]
相同的方法用于elpe4的纯化。通过亲和色谱纯化融合蛋白。通过蛋白质印迹分析
鉴定、透析和浓缩含有融合蛋白的洗脱级分。根据转化株进行肠激酶或tev蛋白酶消化,随后进行尺寸排阻色谱(hiload 26/00superdex 30),以允许纯化多肽elpe4。
[0283]
在la03转化株的情况下,并且在tev蛋白酶消化后,释放的多肽是gvgvapgevgvapgevgvapgevgvapge(seq id n
°
53)。
[0284]
为了通过胞内蛋白酶将多肽elpe4切割成肽vgvapge,使用具有1kda截止值(cutoff)的透析管蒸发和透析sec洗脱级分以除去盐和更换缓冲液。
[0285]
如实施例1中描述的,在被透析样品的glu-c_胞内蛋白酶消化后,释放的肽通过尺寸排阻色谱纯化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1