用于将D-果糖生物转化为D-阿洛酮糖的D-阿洛酮糖3-差向异构酶的制作方法
用于将d-果糖生物转化为d-阿洛酮糖的d-阿洛酮糖3-差向异构酶
1.相关申请
2.本技术根据35u.s.c.
§
119(e)要求2020年5月11日提交的标题为“d-allulose 3-epimerases for bioconversion of d-fructose to d-allulose”的美国临时申请号63/022,617的权益,其内容特此通过引用整体并入。
发明领域
3.本发明涉及一种使用d-阿洛酮糖3-差向异构酶酶由果糖生产d-阿洛酮糖的方法。本发明提供了具有d-阿洛酮糖3-差向异构酶活性的多肽,以及编码所述多肽的核酸分子。本发明还涉及包含载体的重组核酸构建体和包含重组核酸构建体的重组宿主细胞。
背景技术:
4.d-阿洛酮糖(d-allulose),也称为d-阿洛酮糖(d-psicose),是一类结构类似于果糖的糖,果糖是水果中天然存在的糖。d-阿洛酮糖可以颗粒形式获得并且看起来像蔗糖晶体。阿洛酮糖是一种低热量甜味剂,具有蔗糖甜度的70%。根据美国食品和药品管理局(fda),阿洛酮糖提供约0.4卡路里/克,显著低于蔗糖所提供的4卡路里/克。虽然人体有吸收阿洛酮糖的能力,但却缺乏代谢阿洛酮糖的能力。因此,阿洛酮糖对血糖或胰岛素水平几乎没有影响。由于这个原因,阿洛酮糖被认为是一种低热量甜味剂。
5.阿洛酮糖以极少的量天然存在于一些食物,诸如干果、红糖和枫糖浆中。阿洛酮糖难以化学合成,并且在本领域中存在对使用重组微生物由容易获得的糖诸如果糖生产阿洛酮糖的需要。
技术实现要素:
6.来自酮糖3-差向异构酶家族的酶,包括d-阿洛酮糖3-差向异构酶(d-allulose 3-epimerase,dae;也称为d-阿洛酮糖3-差向异构酶(d-psicose 3-epimerase,dpe)),可以催化d-果糖可逆地转化为d-阿洛酮糖。d-阿洛酮糖3-差向异构酶对于d-果糖向d-阿洛酮糖的生物转化可以具有高活性。本发明尤其提供了一种用于使用具有d-阿洛酮糖3-差向异构酶活性的重组多肽由d-果糖生产d-阿洛酮糖的方法。
7.在一个实施方案中,本发明方法涉及使果糖底物与包含酶系统的反应混合物在使得d-果糖底物转化为d-阿洛酮糖的条件下接触,所述酶系统包含具有d-阿洛酮糖3-差向异构酶酶活性的重组多肽。在本发明的一个方面,酶系统提供了具有d-阿洛酮糖3-差向异构酶酶活性的重组多肽和作为底物的d-果糖以生产作为产物的d-阿洛酮糖。在本发明的另一方面,本发明方法可以包括使果糖底物与反应混合物接触,所述反应混合物包含能够表达外源性d-阿洛酮糖3-差向异构酶的宿主细胞或所述宿主细胞的裂解物作为d-阿洛酮糖3-差向异构酶酶的来源。在该实施方案的某些方面,酶系统中存在的d-阿洛酮糖3-差向异构酶酶是纯化的酶,并且它可以使用本领域已知的一种或多种生化技术衍生自表达d-阿洛酮
糖3-差向异构酶酶的宿主细胞的裂解物。在本发明的另一方面,d-阿洛酮糖3-差向异构酶的纯化形式固定化在固体支持物上。在各种实施方案中,本发明方法还可以包括向反应系统中添加至少一种类型的金属离子。例如,金属离子可以选自由以下组成的组:镁离子、锰离子、铜离子、锌离子、镍离子、钴离子、铁离子、铝离子和钙离子。在一些优选实施方案中,向反应系统中添加锰离子和/或镁离子。金属离子可以以约0.01mm至约5mm(例如,0.01mm、0.05mm、0.1mm、0.2mm、0.3mm、0.4mm、0.5mm、0.6mm、0.7mm、0.8mm、0.9mm、1mm、2mm、3mm、4mm或5mm)的浓度添加。在各个方面,本发明方法可以包括移除反应系统中包含不含剩余果糖的阿洛酮糖的产物流。
8.在另一个实施方案中,本发明提供了编码具有d-阿洛酮糖3-差向异构酶活性的多肽的多核苷酸序列。在该实施方案的一个方面,将编码具有d-阿洛酮糖3-差向异构酶活性的多肽的多核苷酸克隆到具有所需调控元件诸如启动子和终止子的适当的质粒表达载体中。在一个方面,质粒表达载体具有诱导型启动子,从而可以通过使用某些化学品来诱导d-阿洛酮糖3-差向异构酶酶活性的表达。
9.在另一个实施方案中,使用包含编码具有d-阿洛酮糖3-差向异构酶活性的多肽的多核苷酸序列的表达质粒载体转化宿主细胞,包括原核微生物细胞或真核微生物细胞或真核动物细胞或真核植物细胞。在一个方面,转化的宿主细胞内的表达质粒载体作为自我复制的核酸实体存在。在该实施方案的另一方面,表达质粒载体被整合到宿主染色体dna中。
10.在另一个实施方案中,本发明提供了一种用于在涉及d-阿洛酮糖3-差向异构酶的反应中回收不含作为底物的d-果糖的d-阿洛酮糖的方法。
11.在一些实施方案中,本文所述的生产阿洛酮糖的方法包括使果糖底物与反应混合物在使得果糖底物转化为阿洛酮糖的条件下接触,所述反应混合物包含:
12.(a)包含d-阿洛酮糖3-差向异构酶酶的酶系统;
13.(b)用包含编码d-阿洛酮糖3-差向异构酶酶的核酸分子的重组载体转化的宿主细胞;和/或
14.(c)(b)的宿主细胞的裂解物,其中d-阿洛酮糖3-差向异构酶酶包含与选自由seq id no:1、seq id no:3、seq id no:5、seq id no:7、seq id no:9、seq id no:11、seq id no:13、seq id no:15、seq id no:17、seq id no:19、seq id no:21、seq id no:23、seq id no:25、seq id no:27、seq id no:29、seq id no:31、seq id no:33、seq id no:35、seq id no:37、seq id no:39、seq id no:41和seq id no:43组成的组的多肽具有至少80%(例如,至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%)序列同一性的氨基酸序列。在一些实施方案中,反应混合物包含d-阿洛酮糖3-差向异构酶酶,所述酶包含与选自由seq id no:1、seq id no:5、seq id no:7、seq id no:9、seq id no:13、seq id no:15、seq id no:17、seq id no:19、seq id no:21、seq id no:23和seq id no:25组成的组的多肽具有至少80%(例如,至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%)序列同一性的氨基酸序列。
15.在一些实施方案中,d-阿洛酮糖3-差向异构酶酶包含与选自由seq id no:1、seq id no:5、seq id no:7、seq id no:9、seq id no:13、seq id no:15、seq id no:17、seq id no:19、seq id no:21、seq id no:23和seq id no:25组成的组的多肽具有至少90%(例如,90%、91%、92%、93%、94%、95%、96%、97%、98%、00%或100%)序列同一性的氨基酸序
列。
16.在一些实施方案中,d-阿洛酮糖3-差向异构酶酶包含与选自由seq id no:1、seq id no:5、seq id no:7、seq id no:9、seq id no:13、seq id no:15、seq id no:17、seq id no:19、seq id no:21、seq id no:23和seq id no:25组成的组的多肽具有至少95%(例如,95%、96%、97%、98%、00%或100%)序列同一性的氨基酸序列。
17.在一些实施方案中,d-阿洛酮糖3-差向异构酶酶包含seq id no:1、seq id no:5、seq id no:7、seq id no:9、seq id no:13、seq id no:15、seq id no:17、seq id no:19、seq id no:21、seq id no:23或seq id no:25的氨基酸序列。在一些实施方案中,d-阿洛酮糖3-差向异构酶酶包含seq id no:5的氨基酸序列。
18.在一些实施方案中,反应混合物包含d-阿洛酮糖3-差向异构酶酶,所述酶包含与选自由seq id no:3、seq id no:11、seq id no:27、seq id no:29、seq id no:31、seq id no:33、seq id no:35、seq id no:37、seq id no:39、seq id no:41和seq id no:43组成的组的多肽具有至少80%(例如,至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%)序列同一性的氨基酸序列。
19.在一些实施方案中,d-阿洛酮糖3-差向异构酶酶包含与选自由seq id no:3、seq id no:11、seq id no:27、seq id no:29、seq id no:31、seq id no:33、seq id no:35、seq id no:37、seq id no:39、seq id no:41和seq id no:43组成的组的多肽具有至少90%(例如,90%、91%、92%、93%、94%、95%、96%、97%、98%、00%或100%)序列同一性的氨基酸序列。
20.在一些实施方案中,d-阿洛酮糖3-差向异构酶酶包含与选自由seq id no:3、seq id no:11、seq id no:27、seq id no:29、seq id no:31、seq id no:33、seq id no:35、seq id no:37、seq id no:39、seq id no:41和seq id no:43组成的组的多肽具有至少95%(例如,95%、96%、97%、98%、00%或100%)序列同一性的氨基酸序列。
21.在一些实施方案中,d-阿洛酮糖3-差向异构酶酶包含seq id no:3、seq id no:11、seq id no:27、seq id no:29、seq id no:31、seq id no:33、seq id no:35、seq id no:37、seq id no:39、seq id no:41和seq id no:43的氨基酸序列。
22.在一些实施方案中,条件包括将酶系统和果糖底物维持在25℃与75℃之间的温度下(例如,25℃、30℃、35℃、40℃、45℃、50℃、55℃、60℃、65℃、70℃或75℃)。
23.在一些实施方案中,条件包括将酶系统和果糖底物维持在4与10之间的ph下(例如,4、4.5、5、5.5、6、6.5、7、7.5、8、8.5、9、9.5或10)。
24.在一些实施方案中,d-阿洛酮糖3-差向异构酶酶为分离形式。在一些实施方案中,d-阿洛酮糖3-差向异构酶酶固定化在固体基质上。
25.在一些实施方案中,反应混合物包含用包含编码d-阿洛酮糖3-差向异构酶酶的核酸分子的重组载体转化的宿主细胞或所述宿主细胞的裂解物,其中编码d-阿洛酮糖3-差向异构酶酶的核酸分子包含与选自由seq id no:2、seq id no:4、seq id no:6、seq id no:8、seq id no:10、seq id no:12、seq id no:14、seq id no:16、seq id no:18、seq id no:20、seq id no:22、seq id no:24、seq id no:26、seq id no:28、seq id no:30、seq id no:32、seq id no:34、seq id no:36、seq id no:38、seq id no:40、seq id no:42和seq id no:44组成的组的多核苷酸序列具有至少80%(例如,至少80%、至少85%、至少90%、至
少95%、至少98%、至少99%或100%)序列同一性的多核苷酸序列。在一些实施方案中,编码d-阿洛酮糖3-差向异构酶酶的核酸分子包含seq id no:44的多核苷酸序列。
26.在一些实施方案中,宿主细胞选自由以下组成的组:酵母细胞、丝状真菌细胞、细菌细胞、哺乳动物细胞、植物细胞以及网粘菌纲(labryinthulomycetes)细胞。在一些实施方案中,宿主细胞是大肠杆菌(e.coli)或巴斯德毕赤酵母(p.pastoris)。在一些实施方案中,重组载体在宿主细胞内作为自我复制的核酸分子存在。在一些实施方案中,重组载体被整合到宿主细胞染色体中。
27.在一些实施方案中,所述方法还包括向反应系统中添加至少一种类型的金属离子,所述至少一种类型的金属离子选自由以下组成的组:镁离子、锰离子、铜离子、锌离子、镍离子、钴离子、铁离子、铝离子和钙离子。在一些实施方案中,金属离子以约0.01mm至约5mm(例如,0.01mm、0.05mm、0.1mm、0.2mm、0.3mm、0.4mm、0.5mm、0.6mm、0.7mm、0.8mm、0.9mm、1mm、2mm、3mm、4mm或5mm)的浓度添加。在一些实施方案中,所述方法还包括在果糖底物转化为阿洛酮糖时从反应系统中移除包含阿洛酮糖的产物流。
附图说明
28.以下附图构成本说明书的一部分并且被包括在内以进一步展示本公开的某些方面,通过参考这些附图中的一个或多个并结合本文呈现的具体实施方案的详细描述可以更好地理解这些方面。
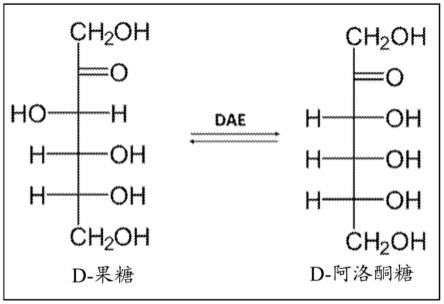
29.图1.通过d-阿洛酮糖3-差向异构酶(dae)将d-果糖生物转化为d-阿洛酮糖。
30.图2a-2b.d-阿洛酮糖3-差向异构酶候选物的酶促筛选。将具有d-阿洛酮糖3-差向异构酶活性的纯化的候选重组多肽针对50mm磷酸盐缓冲液(ph 7.2)透析,并使用d-果糖作为底物测定d-阿洛酮糖合成。通常,重组多肽(5-10μg)在200μl体外反应系统中进行测试。反应系统含有20mm tris-hcl缓冲液ph 8.0、3mm mgcl2或mnso4、20g/l d-果糖。反应在60℃进行并且在2小时(图2a)和16小时(图2b)时通过加热10min终止反应。通过hplc分析样品以确定d-果糖和d-阿洛酮糖的量。
31.图3.phka-al39质粒构建体的图谱。
32.图4a-4b.由工程化的巴斯德毕赤酵母菌株产生的al酶的鉴定和表征。图4a示出来自工程化的巴斯德毕赤酵母菌株的培养基的分泌性al39酶的sds-page(16%)分析。al39酶由箭头指示。m:蛋白质阶梯(protein ladder);s:工程化的巴斯德毕赤酵母菌株的培养基样品(12μl)。图4b示出dae活性。在反应1小时后分析培养基中果糖和阿洛酮糖的存在。
33.图5.固定化的al39酶在重复使用循环(1-5)中的dae活性比较。
具体实施方式
34.根据本发明的用于生产阿洛酮糖的方法包括使果糖底物与包含具有d-阿洛酮糖3-差向异构酶活性的多肽的反应混合物接触。d-果糖是优选底物并且d-阿洛酮糖3-差向异构酶是优选酶。根据本发明的反应混合物还可以包含一种或多种辅因子。在根据本发明的反应混合物中,二价阳离子是优选的辅因子。锰和镁是优选的二价阳离子并且它们可以分别以mgcl2和mnso4的形式提供。其他合适的二价阳离子可以包括铜离子、锌离子、镍离子、钴离子、铁离子、铝离子和钙离子。在本发明的一个实施方案中,根据本发明使用的d-阿洛酮
糖3-差向异构酶作为在合适缓冲液中的高度纯化的同源重组蛋白提供。在本发明的另一个实施方案中,根据本发明使用的d-阿洛酮糖3-差向异构酶作为固定化在固体支持物上的高度纯化的重组蛋白提供。在本发明的另一个实施方案中,反应混合物包含表达重组d-阿洛酮糖3-差向异构酶的重组原核细胞或重组真核细胞并且所述重组原核细胞或重组真核细胞用作d-阿洛酮糖3-差向异构酶的来源。
35.根据本发明的宿主细胞是适用于表达具有d-阿洛酮糖3-差向异构酶活性的异源蛋白质的任何细胞。这样的表达具有3-差向异构酶活性的异源蛋白质的宿主细胞是用包含编码具有d-阿洛酮糖3-差向异构酶活性的多肽的多核苷酸序列的重组质粒转化宿主细胞得到的,并且这样的宿主细胞在本发明中称为重组宿主细胞。适用于本发明的宿主细胞的列表包括但不限于细菌细胞、酵母细胞、植物细胞、动物细胞以及网粘菌纲细胞。在一些实施方案中,细胞系统包括细菌细胞、酵母细胞或其组合。适用于本发明的细菌细胞包括但不限于埃希氏菌属物种(escherichia spp.)、链霉菌属物种(streptomyces spp.)、发酵单胞菌属物种(zymomonas spp.)、醋杆菌属物种(acetobacter spp.)、柠檬酸杆菌属物种(citrobacter spp.)、集胞藻属物种(synechocystis spp.)、根瘤菌属物种(rhizobium spp.)、梭菌属物种(clostridium spp.)、棒状杆菌属物种(corynebacterium spp.)、链球菌属物种(streptococcus spp.)、黄单胞菌属物种(xanthomonas spp.)、乳杆菌属物种(lactobacillus spp.)、乳球菌属物种(lactococcus spp.)、芽孢杆菌属物种(bacillus spp.)、产碱杆菌属物种(alcaligenes spp.)、假单胞菌属物种(pseudomonas spp.)、气单胞菌属物种(aeromonas spp.)、固氮菌属物种(azotobacter spp.)、丛毛单胞菌属物种(comamonas spp.)、分枝杆菌属物种(mycobacterium spp.)、红球菌属物种(rhodococcus spp.)、葡糖杆菌属物种(gluconobacter spp.)、罗尔斯通氏菌属物种(ralstonia spp.)、硫杆菌属物种(acidithiobacillus spp.)、小月菌属物种(microlunatus spp.)、地杆菌属物种(geobacter spp.)、地芽胞杆菌属物种(geobacillus spp.)、节杆菌属物种(arthrobacter spp.)、黄杆菌属物种(flavobacterium spp.)、沙雷氏菌属物种(serratia spp.)、糖多孢菌属物种(saccharopolyspora spp.)、栖热菌属物种(thermus spp.)、寡养单胞菌属物种(stenotrophomonas spp.)、色杆菌属物种(chromobacterium spp.)、中华根瘤菌属物种(sinorhizobium spp.)、糖多孢菌属物种(saccharopolyspora spp.)、土壤杆菌属物种(agrobacterium spp.)、泛菌属物种(pantoea spp.)以及需钠弧菌(vibrio natriegens)。适用于本发明的酵母细胞包括但不限于工程化的酵母属物种(saccharomyces spp.)、裂殖酵母属(schizosaccharomyces)、汉逊酵母属(hansenula)、假丝酵母属(candida)、克鲁维酵母属(kluyveromyces)、耶氏酵母属(yarrowia)、博伊丁假丝酵母(candida boidinii)以及毕赤酵母属(pichia)。
36.术语细胞培养物是指处于培养物中的任何一个或多个细胞,包括重组宿主细胞。培养是使细胞在受控条件下(通常在其自然环境之外)生长的过程。例如,细胞,诸如酵母细胞,可作为在液体营养肉汤中的细胞悬液生长。细胞培养物包括但不限于细菌细胞培养物、酵母细胞培养物、植物细胞培养物和动物细胞培养物。
37.在一些实施方案中,在16℃至40℃的温度下培养细胞。例如,可在16℃、17℃、18℃、19℃、20℃、21℃、22℃、23℃、24℃、25℃、26℃、27℃、28℃、29℃、30℃、31℃、32℃、33℃、34℃、35℃、36℃、37℃、38℃、39℃或40℃的温度下培养细胞。
38.在一些实施方案中,将细胞培养12小时至72小时或更长的时间段。例如,可将细胞培养12、18、24、30、36、42、48、54、60、66或72小时的时间段。通常,将细胞,诸如细菌细胞,培养12至24小时的时间段。在一些实施方案中,将细胞在37℃的温度下培养12至24小时。在一些实施方案中,将细胞在16℃的温度下培养12至24小时。
39.在一些实施方案中,将细胞培养至每毫升细胞培养基1x108(od
600
《1)至2x10
11
(od
ˉ
200)个活细胞的密度。在一些实施方案中,将细胞培养至1x108、2x108、3x108、4x108、5x108、6x108、7x108、8x108、9x108、1x109、2x109、3x109、4x109、5x109、6x109、7x109、8x109、9x109、1x10
10
、2x10
10
、3x10
10
、4x10
10
、5x10
10
、6x10
10
、7x10
10
、8x10
10
、9x10
10
、1x10
11
或2x10
11
个活细胞/毫升的密度。(转化因子:od 1=8x108个细胞/毫升)。
40.为了诱导宿主细胞表达蛋白质,添加0.5mm的异丙基β-d-1-硫代半乳糖苷(iptg),并使培养物在16℃下进一步生长22hr。通过离心(3,000x g;10min;4℃)收获细胞。收集细胞沉淀并立即使用或储存于-80℃。
41.在一些实施方案中,从表达具有d-阿洛酮糖3-差向异构酶活性的多肽的宿主细胞收获细胞沉淀。在一些实施方案中,可以各种浓度重悬宿主细胞沉淀。在一些实施方案中,以1g/l至250g/l的浓度重悬宿主细胞沉淀。在一些实施方案中,将从细胞系统收获的宿主细胞沉淀以1g/l、10g/l、25g/l、50g/l、75g/l、100g/l、125g/l、150g/l、175g/l、200g/l、225g/l或250g/l的浓度重悬。
42.如本文所用,术语“孵育(incubating)”和“孵育(incubation)”是指将两种或更多种化学或生物实体或至少一种化学实体和至少一种生物实体(诸如化合物和酶)混合并允许它们在有利于产生如本文所述的产物诸如d-阿洛酮糖的条件下相互作用的过程。
43.术语“下游分离过程”是指从原始底物d-果糖中回收最终产物d-阿洛酮糖。当果糖在酶促反应中用作底物以产生d-阿洛酮糖时,果糖在反应中并未完全消耗,并且在酶促反应结束时,反应介质中仍存在大量果糖。d-果糖和d-阿洛酮糖具有相似的物理和化学性质,并且在包括d-阿洛酮糖3-差向异构酶和作为底物的果糖的酶促反应结束时很难将它们分开。回收不含d-果糖的d-阿洛酮糖的一种可能的方式是将剩余的果糖转化为甘露糖醇并将d-阿洛酮糖与甘露糖醇分开。nadph或nadh依赖性甘露糖醇脱氢酶可以用于将d-果糖转化为甘露糖醇。甘露糖醇脱氢酶可以连同甲酸脱氢酶一起在双酶系统中使用,以再生甘露糖醇脱氢酶的作用所需要的还原辅因子nadh。甲酸脱氢酶将甲酸盐转化为二氧化碳并将nad还原为nadh。甘露糖醇可以通过冷结晶从水溶液中结晶出来,并且可以以不含d-果糖的形式回收d-阿洛酮糖。(saha,b.c.和racine,f.m.(2011)biotechnological production of mannitol and its applications.appl microbiol biotechnol.89:879
–
891;美国专利号10266862b2)。
44.术语固定化是指使用本领域众所周知的一种或其他方法将表达d-阿洛酮糖3-差向异构酶的宿主细胞或具有d-阿洛酮糖3-差向异构酶活性的纯化多肽结合至固体支持物。源自海藻的海藻酸钠可以用作固体支持物以固定化表达d-阿洛酮糖3-差向异构酶的宿主细胞或具有d-阿洛酮糖3-差向异构酶活性的纯化多肽,如专利文件us2019169591a1中所详细描述的。
45.术语“核酸”和“核苷酸”根据本领域普通技术人员所理解的它们各自的普通和习惯含义使用,并且不受限制地用于指代单链或双链形式的脱氧核糖核苷酸或核糖核苷酸及
其聚合物。除非特别限定,否则该术语涵盖含有天然核苷酸的已知类似物的核酸,其具有与参考核酸相似的结合特性并且以与天然存在的核苷酸相似的方式代谢。除非另外指明,否则具体核酸序列还隐含地涵盖其保守修饰或简并变体(例如,简并密码子取代)和互补序列,以及明确指明的序列。
46.术语“多肽”、“蛋白质”和“肽”根据本领域普通技术人员所理解的它们各自的普通和习惯含义使用;这三个术语有时可互换使用,并且不受限制地用于指代氨基酸聚合物或氨基酸类似物,无论其大小或功能如何。尽管“蛋白质”通常关于相对较大的多肽使用,而“肽”通常关于小多肽使用,但这些术语在本领域中的用法是重叠和变化的。如本文所用,术语“多肽”是指肽、多肽和蛋白质,除非另外指明。当提及多肽产物时,术语“蛋白质”、“多肽”和“肽”在本文中可互换使用。因此,示例性多肽包括多肽产物、天然存在的蛋白质、同源物、直系同源物、旁系同源物、片段以及前述各项的其他等效物、变体和类似物。
47.多肽或蛋白质的术语“功能片段”是指作为全长多肽或蛋白质的一部分的肽片段,并且其具有与全长多肽或蛋白质基本上相同的生物学活性,或执行基本上相同的功能(例如,进行相同的酶促反应)。
48.术语“功能变体”还包括保守取代变体。术语“保守取代变体”是指所具有的氨基酸序列与参考肽相差一个或多个保守氨基酸取代并保持参考肽的一些或全部活性的肽。“保守氨基酸取代”是用功能相似的残基取代氨基酸残基。保守取代的实例包括用一个非极性(疏水性)残基(诸如异亮氨酸、缬氨酸、亮氨酸或甲硫氨酸)取代另一个残基;用一个带电或极性(亲水性)残基取代另一个残基,诸如在精氨酸与赖氨酸之间、在谷氨酰胺与天冬酰胺之间、在苏氨酸与丝氨酸之间;用一个碱性残基(诸如赖氨酸或精氨酸)取代另一个残基;或用一个酸性残基(诸如天冬氨酸或谷氨酸)取代另一个残基;或用一个芳香族残基(诸如苯丙氨酸、酪氨酸或色氨酸)取代另一个残基。预期此类取代对蛋白质或多肽的表观分子量或等电点几乎没有影响。短语“保守取代变体”还包括其中残基被化学衍生的残基替换的肽,条件是所得的肽保持如本文所述的参考肽的一些或全部活性。
49.与主题技术的多肽有关的术语“变体”还包括所具有的氨基酸序列与参考多肽的氨基酸序列具有至少75%、至少76%、至少77%、至少78%、至少79%、至少80%、至少81%、至少82%、至少83%、至少84%、至少85%、至少86%、至少87%、至少88%、至少89%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%以及甚至100%同一性的功能活性多肽。
50.术语“同源”在其所有语法形式和拼写变型中是指具有“共同进化起源”的多核苷酸或多肽之间的关系,包括来自超家族的多核苷酸或多肽以及来自不同物种的同源多核苷酸或蛋白质(reeck等人,cell 50:667,1987)。此类多核苷酸或多肽具有序列同源性,正如它们的序列相似性所反映的,无论是就同一性百分比还是特定氨基酸或基序在保守位置的存在而言。例如,两个同源多肽可以具有至少75%、至少76%、至少77%、至少78%、至少79%、至少80%、至少81%、至少82%、至少83%、至少84%、至少85%、至少86%、至少87%、至少88%、至少89%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%以及甚至100%相同的氨基酸序列。
51.关于主题技术的变体多肽序列的“氨基酸序列同一性百分比(%)”是指在比对序列并引入空位(如果需要的话)以实现最大的序列同一性百分比之后,并在不将任何保守取
代视为序列同一性的一部分的情况下,候选序列中与参考多肽的氨基酸残基相同的氨基酸残基的百分比。
52.用于确定氨基酸序列同一性百分比的比对可以通过本领域技术范围内的多种方式实现,例如,使用可公开获得的计算机软件诸如blast、blast-2、align、align-2或megalign(dnastar)软件。本领域技术人员可以确定用于测量比对的适当参数,包括在所比较序列的全长上实现最大比对所需要的任何算法。例如,可使用序列比较程序ncbi-blast2确定%氨基酸序列同一性。ncbi-blast2序列比较程序可从ncbi.nlm.nih.gov.下载。ncbi blast2使用若干检索参数,其中所有那些检索参数都设置为默认值,包括例如无屏蔽是(unmask yes)、链=全部(strand=all)、期望发生(expected occurrences)10、最小低复杂度长度(minimum low complexity length)=15/5、多遍e值(multi-pass e-value)=0.01、多遍常数(constant for multi-pass)=25、最终空位化比对的下降值(drop off for final gapped alignment)=25以及评分矩阵=blosum62。在使用ncbi-blast2进行氨基酸序列比较的情况下,给定氨基酸序列a与、和,或对给定氨基酸序列b的%氨基酸序列同一性(可以替代地表述为给定氨基酸序列a与、和,或对给定氨基酸序列b具有或包括一定的%氨基酸序列同一性)计算如下:100乘以分数x/y,其中x是在ncbi-blast2程序的a和b比对时通过该序列比对程序评为相同配对的氨基酸残基的数目;并且其中y是b中的氨基酸残基的总数。应当理解,当氨基酸序列a的长度不等于氨基酸序列b的长度时,a与b的%氨基酸序列同一性将不等于b与a的%氨基酸序列同一性。
53.用于确定氨基酸序列“相似性”的技术是本领域众所周知的。一般而言,“相似性”是指两个或更多个多肽在适当位置的精确氨基酸与氨基酸比较,其中氨基酸是相同的或具有相似的化学和/或物理性质,诸如电荷或疏水性。然后可确定所比较的多肽序列之间的“相似性百分比”。用于确定核酸和氨基酸序列同一性的技术也是本领域众所周知的,并且包括确定所述基因的mrna的核苷酸序列(通常通过cdna中间体)和确定其中编码的氨基酸序列,并将其与第二氨基酸序列相比较。一般而言,“同一性”是指两个多核苷酸或多肽序列相应的精确的核苷酸与核苷酸或氨基酸与氨基酸对应。可以通过确定它们的“同一性百分比”来比较两个或更多个多核苷酸序列,两个或更多个氨基酸序列也可以这样。wisconsin序列分析软件包版本8(可从genetics computer group,madison,wis.获得)中可获得的程序,例如gap程序,能够分别计算两个多核苷酸之间的同一性以及两个多肽序列之间的同一性和相似性。用于计算序列之间的同一性或相似性的其他程序是本领域技术人员已知的。
[0054]“对应于”参考位置的氨基酸位置是指与参考序列对齐的位置,如通过比对氨基酸序列所鉴定的。此类比对可以手动完成,或可以使用众所周知的序列比对程序(诸如clustalw2、blast 2等)完成。
[0055]
除非另外指明,否则两个多肽或多核苷酸序列的同一性百分比是指在两个序列中的较短序列的整个长度上相同氨基酸残基或核苷酸的百分比。
[0056]
如本文所用,术语“表达”根据本领域普通技术人员所理解的其普通和习惯含义使用,并且不受限制地用于指代衍生自主题技术的核酸片段的有义(mrna)或反义rna的转录和稳定积聚。“过表达”是指在转基因或重组生物体中产生的基因产物超过正常或非转化生物体中的产生水平。
[0057]“转化”根据本领域普通技术人员所理解的其普通和习惯含义使用,并且不受限制
地用于指代将多核苷酸转移到靶细胞中。转移的多核苷酸可以掺入靶细胞的基因组或染色体dna中,从而导致基因稳定遗传,或者它可以独立于宿主染色体dna进行复制。含有转化的核酸片段的宿主生物体被称为“转基因的”或“重组的”或“转化的”生物体。
[0058]
术语“转化的”、“转基因的”和“重组的”当在本文中与宿主细胞结合使用时,根据本领域普通技术人员所理解的它们的普通和习惯含义使用,并且不受限制地用于指代其中已引入异源核酸分子的宿主生物体的细胞,诸如植物或微生物细胞。核酸分子可以稳定地整合到宿主细胞的基因组中,或者核酸分子可以作为染色体外分子存在。这样的染色体外分子可以自我复制。转化的细胞、组织或受试者被理解为不仅包括转化过程的最终产物,而且还包括其转基因后代。
[0059]
术语“重组的”、“异源的”和“外源的”,当在本文中与多核苷酸结合使用时,根据本领域普通技术人员所理解的它们的普通和习惯含义使用,并且不受限制地用于指代源自对于特定宿主细胞而言为外来的来源或者如果源自相同的来源,则由其原始形式修饰得到的多核苷酸(例如,dna序列或基因)。因此,宿主细胞中的异源基因包括对于特定宿主细胞而言为内源的但已通过例如使用定点诱变或其他重组技术进行修饰的基因。该术语还包括天然存在的dna序列的非天然存在的多个拷贝。因此,所述术语是指对于细胞而言是外来的或异源的,或与细胞同源但在宿主细胞内处于通常不存在该元件的位置或形式的dna链段。
[0060]
类似地,术语“重组的”、“异源的”和“外源的”,当在本文中与多肽或氨基酸序列结合使用时,是指源自对于特定宿主细胞而言为外来的来源,或者如果源自相同来源,则由其原始形式修饰得到的多肽或氨基酸序列。因此,重组dna链段可以在宿主细胞中表达以产生重组多肽。
[0061]
术语“质粒”、“载体”和“盒”根据本领域普通技术人员所理解的它们的普通和习惯含义使用,并且不受限制地用于指代常常携带不是细胞中心代谢的一部分的基因并且通常为环状双链dna分子形式的染色体外元件。此类元件可以是源自任何来源的自主复制序列、基因组整合序列、噬菌体或单链或双链dna或rna的核苷酸序列(线性或环状),其中多个核苷酸序列已连接或重组为独特构造,所述独特构造能够将所选基因产物的启动子片段和dna序列连同适当的3’非翻译序列一起引入细胞中。“转化盒”是指含有外来基因并且除了外来基因之外还具有有利于转化特定宿主细胞的元件的特定载体。“表达盒”是指含有外来基因并且除了外来基因之外还具有使得所述基因在外来宿主中的表达增强的元件的特定载体。
[0062]
本文使用的标准重组dna和分子克隆技术是本领域众所周知的,并且描述于,例如,sambrook,j.、fritsch,e.f.和maniatis,t.molecular cloning:a laboratory manual,第2版;cold spring harbor laboratory:cold spring harbor,n.y.,1989(下文为“maniatis”);和silhavy,t.j.、bennan,m.l.和enquist,l.w.experiments with gene fusions;cold spring harbor laboratory:cold spring harbor,n.y.,1984;以及ausubel,f.m.等人,在current protocols in molecular biology中,由greene publishing and wiley-interscience出版,1987;在与本文一致的范围内,它们中的每一个的全部内容特此通过引用并入本文。
[0063]
除非另外定义,本文所用的所有技术和科学术语均具有与本公开所属领域中的普通技术人员通常所理解的相同含义。虽然在本公开的实践或测试中可使用类似于或等效于
本文所描述的那些方法和材料的任何方法和材料,但下文描述优选的方法和材料。
[0064]
实施例
[0065]
实施例1:构建用于表达d-阿洛酮糖3-差向异构酶的质粒载体
[0066]
d-阿洛酮糖3-差向异构酶(dae)具有将d-果糖转化为d-阿洛酮糖的能力(图1)。为了鉴定使用d-果糖作为底物产生d-阿洛酮糖的特定d-阿洛酮糖3-差向异构酶酶,使用多基因(polygenetic)和blast分析鉴定了编码具有d-阿洛酮糖3-差向异构酶活性的多肽的多核苷酸序列。所有候选的d-阿洛酮糖3-差向异构酶基因的全长dna片段都是商业合成的。将几乎所有的cdna密码子都变成大肠杆菌(e.coli)偏好的那些(twist bioscience,ca)。将合成dna克隆到细菌表达载体中以生成表达构建体。
[0067]
实施例2:重组大肠杆菌细胞中d-阿洛酮糖3-差向异构酶酶活性的测量
[0068]
将如实施例1中那样制备的具有编码具有d-阿洛酮糖3-差向异构酶活性的多肽的多核苷酸的各表达载体构建体转化到大肠杆菌t7表达细胞(biolabs,ma)中,随后使所述细胞在含有50μg/ml氨苄青霉素的terrific broth培养基中在37℃下生长,直到达到0.8-1.0的od600。通过添加0.5mm异丙基β-d-1-硫代半乳糖苷(iptg)诱导蛋白质表达,并使培养物在16℃下进一步生长22hr。通过离心(3,000x g;10min;4℃)收获细胞。收集细胞沉淀并立即使用或储存于-80℃。
[0069]
通过提取缓冲液(bugbuster master mix,emd millipore,us)提取细胞沉淀。离心后,将上清液添加到反应混合物中用于活性测定。通常,上清液(5μl)在200μl体外反应系统中进行测试。反应系统含有20mm tris-hcl缓冲液ph 8.0、1mm mgcl2或mnso4、10g/l d-果糖。反应在60℃下进行并且通过加热10min终止反应。通过hplc分析样品。
[0070]
d-果糖和d-阿洛酮糖的浓度通过配备有refractormax521检测器(idex health&science kk,japan)的hplc系统(vanquish,thermo scientific,usa)确定。使用rezex rcm-单糖ca
2+
柱(100x7.8mm,phenomenex,ca)进行色谱分离。柱在80℃下用水以0.5ml/min的流速洗脱。通过对d-阿洛酮糖3-差向异构酶酶活性的分析,共鉴定了21种具有将d-果糖生物转化为d-阿洛酮糖的适当酶活性的候选d-阿洛酮糖3-差向异构酶酶(表1)。
[0071]
实施例3:重组d-阿洛酮糖3-差向异构酶的纯化
[0072]
为了纯化重组蛋白,通常将细胞沉淀重悬于裂解缓冲液(50mm磷酸钾缓冲液ph 7.2、25mg/ml溶菌酶、5mg/ml dna酶i、20mm咪唑、500mm nacl、10%甘油和0.4%triton x-100)中。在4℃下通过超声破碎细胞,并通过离心(18,000xg;30min)澄清细胞碎片。将上清液加载到用含有50mm磷酸钾缓冲液ph 7.2、20mm咪唑、500mm nacl和10%甘油的平衡缓冲液平衡的亲和柱ni-nta(qiagen)中。加载蛋白质样品后,用平衡缓冲液洗涤柱以去除未结合的污染蛋白。具有d-阿洛酮糖3-差向异构酶活性的带his标签的重组多肽用含有250mm咪唑的平衡缓冲液洗脱。
[0073]
将具有d-阿洛酮糖3-差向异构酶活性的纯化的候选重组多肽针对50mm磷酸盐缓冲液(ph 7.2)透析,并使用d-果糖作为底物测定d-阿洛酮糖合成。通常,重组多肽(5-10μg)在200μl体外反应系统中进行测试。反应系统含有20mm tris-hcl缓冲液ph 8.0、3mm mgcl2或mnso4、20g/l d-果糖。反应在60℃进行并且在2小时和16小时时通过加热10min终止反应。通过hplc分析样品。
[0074]
这些具有d-阿洛酮糖3-差向异构酶活性的候选重组多肽具有产生阿洛酮糖的不
同酶活性,并且对二价金属因子的偏好不同。如图2a-2b所示,所有选定的候选物在2hr时具有d-阿洛酮糖3-差向异构酶活性(图2a)并且当反应延长至16hr时可以产生更多的d-阿洛酮糖(图2b)。与添加mg
2+
相比,添加mn
2+
可以增加大多数酶(al28、35、39、42、50和51)的活性,表明这些酶偏好mn
2+
辅因子。
[0075]
实施例4:生成工程化的巴斯德毕赤酵母菌株以产生dae酶
[0076]
合成了al39基因的全长dna片段(seq id no:43)以用于转化巴斯德毕赤酵母细胞。具体而言,针对巴斯德毕赤酵母表达对cdna进行密码子优化以产生al39酶(seq id no:5)。将al39基因插入具有α交配因子信号肽的框中。使用ecori和noti限制性消化,将合成的融合基因克隆到phka载体(修饰的巴斯德毕赤酵母表达载体)中。在表达质粒(phka-al39,图3)中,表达盒含有aox1启动子、α-交配因子信号肽、al39基因以及aox1转录终止子。
[0077]
使用本领域已知的方法(lin-cereghino等人,biotechniques,38(1):44-48,2005)将线性化的phka-al39质粒转化到巴斯德毕赤酵母(gs115)细胞中,并将表达盒整合到巴斯德毕赤酵母基因组中的his4基因座处。
[0078]
为了证明分泌性al39酶的产生,将巴斯德毕赤酵母菌株phka-al39的单个菌落接种在带挡板烧瓶中的bmgy培养基中,并使其在振荡培养箱(250-300rpm)中在28-30℃下生长,直到培养物达到2-6的od600(对数期生长)。通过离心收获phka-al39细胞并在bmmy培养基中重悬至od600为1.0以诱导表达。每24小时向bmmy培养基中添加100%甲醇至最终浓度为1%甲醇,以维持表达的诱导。通过离心收获来自phka-al39培养物的培养基并如下所述对其进行dae活性分析和sds-page分析。
[0079]
离心后,将上清液添加到反应混合物中用于活性测定。通常,上清液(65μl)在200μl体外反应系统中进行测试。反应系统含有20mm tris-hcl缓冲液ph 8.0、1mm mnso4、30g/l d-果糖。反应在55-60℃下进行并且通过加热10min终止反应。通过hplc分析样品。
[0080]
d-果糖和d-阿洛酮糖的浓度通过配备有refractormax521检测器(idex health&science kk,japan)的hplc系统(vanquish,thermo scientific,usa)确定。使用rezex rcm-单糖ca
2+
柱(100x7.8mm,phenomenex,ca)进行色谱分离。柱在80℃下用水以0.5ml/min的流速洗脱。
[0081]
通过sds-page分析确定al39蛋白的存在(图4a)。使用本领域已知的方法通过sds-page分离培养基样品(laemmli,nature,227(5259):680-685,1970)。所产生的al39蛋白在用染色溶液染色后可见。基于sds-page分析,所产生的al39是培养基样品中的主要蛋白质(图4a)。
[0082]
在sds-page和dae活性筛选后,最佳菌株被鉴定为具有高分泌性al39酶产量。所产生的al39酶具有将d-果糖生物转化为d-阿洛酮糖的活性。如图4a所示,通过sds-page分析可以在发酵培养基中检测到所产生的al39蛋白,表明所产生的al39酶可以分泌到工程化的巴斯德毕赤酵母菌株的细胞外空间。通过离心去除细胞沉淀后,可以很容易地从发酵培养基中收集和浓缩所产生的酶。可以在培养基样品中检测到dae活性。如图4b所示,反应1hr后,大约25%的果糖可以转化为阿洛酮糖。
[0083]
实施例5:使用固定化的dae酶的生物转化
[0084]
酶固定化为增加酶对其底物的可获得性提供了优异的基础,并且在相当长的时间段内具有更大的周转率。下文描述一种用于有效产生固定化的d-阿洛酮糖差向异构酶的方
法,所述酶对于果糖向阿洛酮糖的生物转化具有高活性和优异的持久性。
[0085]
通过过滤浓缩al39蛋白。将所提取的al39溶解到20mm磷酸盐缓冲液(ph 8.0)中以用于固定化。一个单位的dae活性定义为在ph8.0和55℃下每分钟催化形成1μmol d-阿洛酮糖的酶量。固定化的dae酶的比活性定义为每毫克酶的单位。
[0086]
将所制备的al39蛋白与水预处理的离子交换树脂(lxp-505,sunresin)在20mm磷酸盐缓冲液(ph 8.0)中混合并在反应器中在25℃下缓慢搅拌24小时。随后,去除上清液,并将所得混合物用20mm磷酸盐缓冲液(ph 8.0)洗涤以获得固定化的dae酶。
[0087]
将固定化的dae酶添加到反应混合物中用于活性测定。固定化的酶在1ml体外反应系统中进行测试。反应系统含有20mm磷酸盐缓冲液ph 8.0、1mm mnso4、500g/l d-果糖。反应在55℃进行并且通过加热10min终止反应。通过hplc分析样品。3小时后,固定化的酶将多于23%的果糖转化为阿洛酮糖。
[0088]
为了确定al39在使用后是否能够保持活性,测试了固定化的al39的重复使用循环。在含有20mm磷酸盐缓冲液(ph 8.0)、1mm mnso4、500g/l d-果糖的1l反应液中添加180mg固定化的al39。反应在55℃进行。反应5小时后,通过过滤收集固定化的酶。通过hplc分析上清液以测量阿洛酮糖的产生,并用20mm磷酸盐缓冲液(ph 8.0)洗涤固定化的酶5次以用于下一循环反应。5个循环后,比较每个循环的活性。如图5所示,与第一循环相比,固定化的al39的活性在第五循环仅损失10.76%,表明固定化的al39对于阿洛酮糖的生物转化是稳定的。
[0089]
参考文献:
[0090]
1.lin-cereghino j,wong ww,xiong s,et al.condensed protocol for competent cell preparation and transformation of the methylotrophic yeast pichia pastoris.biotechniques.2005;38(1):44-48.
[0091]
2.laemmli,u.k.(1970).
″
cleavage of structural proteins during the assembly of the head of bacteriophage t4
″
.nature.227(5259):680-685.
[0092]
[0093][0094]
序列信息
[0095]
seq id no:1;蛋白质;西尔瓦诺斯亚栖热菌
[0096]
mprfgahafiwaaewnpeaaekviqgatrvgldfveipllhpesfdveltrrllngygvgctcslglpreaslpehpeaatrfliqalnvahqigsevltgvtyatlgtlsgrapreadyqavvkalkpaarhaaalgmrlgiepvnryetylinlaaqglelirrldepnvflhldtyhmnieekgfrgpiveagahlgyihlsesdrgtpgtgnvhwdavf
aglreigfsgdlvmesfvalnpdiaratcmwrdvvgdpqalvqeglaflrgkaseygllg
[0097]
seq id no:2;dna;西尔瓦诺斯亚栖热菌
[0098]
atgccacgcttcggagctcatgcgttcatttgggccgctgagtggaacccggaagcggcagagaaagtgattcagggtgcaacccgtgttggcctcgacttcgttgaaattccgctcttgcacccggaatccttcgatgtcgagctcacacgtcgtttactaaacgggtacggcgtcggttgtacgtgttctctgggcttgccgcgtgaagcgtccctgccggagcaccccgaagccgcgactcgttttctgattcaggccctgaatgttgcacatcagattggctcagaggtgctgaccggggtaacctacgcgactttaggcactttatctggccgggcgccgcgcgaagctgattatcaagcagtcgtaaaagcactgaaaccggcggctagacatgcagcagcactgggtatgcgcctcggcattgaacccgttaatcgttatgaaacttatttaattaacctggccgctcagggcctggagttaatccgtcgtctggacgaaccgaatgtgttcctgcacctggatacgtaccacatgaatattgaagagaaaggtttccggggcccgatcgtggaagcgggcgcccacctggggtatattcatctgagcgagagtgatcgcggcacccctggaacgggcaacgtccattgggacgcggtgttcgcggggctgcgtgaaattggcttctcaggcgatttggtcatggaaagcttcgtcgcactgaaccctgatattgcgcgcgctacatgcatgtggcgggacgtcgttggcgatccccaggcgctggtccaggaaggcttagcatttctccgtggcaaggctagcgagtatggcctactcggttaa
[0099]
seq id no:3;蛋白质;深海热泉宏基因组
[0100]
megfgvhtsmwtmswdkkgaeyavsqavryqmdfleiallspldvdaqhsrrlleknhmraicslglpegawlsnnpqagveylkialektaemgcealsgviyggigertgfpptekeldnvvralgeaasyakslglllgiepvnryeshlintgrqsvemiekvgasnmfvhldtyhmnieekgvaqgildarehikyihlsesdrgtpgagtcdwdeifavlaainfkgglamesfvnmppeiayglsiwrpvaksadevmenglpflrnkarqyqll
[0101]
seq id no:4;dna;深海热泉宏基因组
[0102]
atggaaggttttggagtgcacacgagcatgtggactatgagttgggataagaagggtgcggagtatgctgtaagccaggcggtgcgctatcagatggattttcttgaaatcgctctgctgagtccactggatgtcgatgcccagcatagtcgccgtctgctagagaagaaccacatgcgcgcgatttgcagccttgggttaccggaaggtgcgtggctcagtaataaccctcaggccggagtggaatacctgaagatcgccctggaaaagactgcggagatgggttgcgaagcgctgtccggcgtaatctacggcggcattggcgaaagaacaggttttccgccgacggagaaagagctggacaatgtcgtgcgcgcgctgggtgaagcggcatcttacgcaaaatcgttaggccttctgctcggtattgaaccggtgaaccggtatgagtctcatctgattaatacgggacgtcagagtgtggaaatgattgaaaaggtcggtgcctctaacatgtttgttcaccttgacacataccacatgaatattgaagaaaagggtgtggcacaagggattctggacgcgcgcgaacacataaaatatatccacctgtcagagtctgaccgagggactccgggcgcaggcacgtgtgactgggatgagattttcgcagtcctggccgcaattaactttaaaggcggcttagcgatggaatcgttcgtgaacatgccgccggaaattgcctatggtctgtccatttggcgtccggtggctaaatcggctgatgaagtcatggaaaacggcctgccgtttctacgcaacaaagcgcgccagtatcagctgctgtaa
[0103]
seq id no:5;protein;污泥嗜热梭菌
[0104]
mkygifyaywekewkgdfityiekvkklgfdilevgcgdfhkqpdsyfhtlrdaareydiiltggygpraehnlcspdtavvenalafysdifrkmeiagirsiggglyaywpvdysrepdkagdlersiknmrrladiaerhgitlnmevlnrfegylindtneglayiravdkpnvklmldtfhmnieedsftepilqagkylghvhvgepnrkppregripwgeigkalrqigydgpvvmepfvtmggqvgkdicvwrdlsqgateedldrdaekslaflkgmfea
[0105]
seq id no:6;dna;污泥嗜热梭菌
[0106]
atgaaatatggtatattttacgcatattgggagaaagaatggaaaggcgactttatcacatacattga
gaaagttaagaaattaggctttgacattttggaagtcggctgcggtgattttcataaacagccggattcatacttccacaccctgcgtgatgccgctcgcgaatacgacattattctgaccggcggctatgggccgcgcgccgaacacaacttgtgtagcccggatacagcggtcgttgaaaatgccctggcattttactccgatatatttcgcaaaatggaaattgccggcatccgttcgatcggcggcggtctatatgcgtattggccagttgattacagccgtgaacccgacaaagccggcgatttagaacgttccattaagaacatgcgtcgcttagccgatattgcggaacggcatggtatcacgctgaatatggaagtgctcaatcgcttcgaaggttaccttattaatgataccaatgaaggtctggcctacattcgtgccgtcgataaacccaacgtaaagttgatgctggatacatttcacatgaacattgaggaagatagctttaccgaacccattctccaggctggtaagtacctgggccatgtacatgtcggcgaaccaaatcgtaaaccaccacgggaaggtcgtattccgtggggcgagattggcaaagcgctgcgccagattgggtacgacggtcccgtggtgatggaaccgtttgttaccatgggcggccaagtggggaaagacatttgtgtgtggcgggaccttagccaaggtgcgaccgaagaagatctggatcgcgatgctgagaaaagcctggcctttctgaaaggaatgtttgaagcctaa
[0107]
seq id no:7;蛋白质;深海热泉宏基因组
[0108]
mnlpakkmvlgvhtfavapfwdlevmrhearrlkshgvglleipllrpeeinikatrafarefgfelvtslglpsnidavedpqsalaflepafkvaaeigsnmlsgvtyapigkisgqpvtqrekdgicrflqqaaalaanhglklgvepcnryethlmntaaqaveyveavaaenlfihldtyhmnieeesfaagfakaapylgyvhlsesnrgvpgraminwdavmgaladigyhgaltlesmnyvdpdiatalavwrpvaknpddvidfglafllkaaadagltfg
[0109]
seq id no:8;dna;深海热泉宏基因组
[0110]
atgaacctgccggctaagaagatggtcctgggagtccatacgttcgcagtcgccccgttttgggatcttgaagtaatgcgccacgaggcccgccgtttaaagagccatggcgtagggttattggaaatcccacttctccggccagaagaaattaatattaaagcgacccgcgcatttgctcgtgaatttgggtttgaattagtgaccagtttaggcctgccttcgaatatcgacgctgtagaagatccgcagtctgctttagcctttctggaaccggcgttcaaagtggctgctgaaattggtagcaatatgctttcaggcgttacctatgctccgattggaaagataagtggtcagccggtgacccagcgtgagaaggatggtatttgtcggttcctacaacaagcggctgcgttggccgcgaaccatgggttgaaactgggcgtagagccttgtaatcgctatgaaacgcatctgatgaacacagcagcccaagcagttgaatacgttgaggctgtggcagcggaaaaccttttcatccacttagatacctaccacatgaacatcgaagaagaaagttttgcagcagggtttgcgaaagcggcgccttatctggggtacgtgcatctgagcgagagcaatcgcggcgtaccgggccgcgccatgatcaattgggatgcagtgatgggtgcccttgccgacatcgggtatcatggggcactgactctggagtctatgaattatgtggatccggatattgcgactgcccttgcggtctggcgtccggttgccaagaacccggacgatgtgatagactttggcctggcgtttctgctgaaggccgcagcggatgcgggtttgacattcggttaa
[0111]
seq id no:9;蛋白质;谷粒亚栖热菌
[0112]
marfgahafiwsadwtpqaaekvaagaaaagldfveipllrpeafdstltrrllehhglgctcslglpteaalpdhpqaaarfliqaldvahqmgspvlsgvtyatlgalsgrppteadyetlaktlkpvaqhaarlgmrlglepvnryetylinlgsqaldliqrigepnvfvhldtyhmnieekgfknpivtvgkhlgyihlsesdrgtpgsgnvhwdevfsglqaigfqgdlvmesfvalnpdiaratcmwrdvvgdpktlvhdglaflrgkareygll
[0113]
seq id no:10;dna;谷粒亚栖热菌
[0114]
atggcgcgctttggtgcgcatgcttttatttggagtgctgattggacccctcaagccgccgaaaaggtcgcagcgggagcagcggcggcgggactggattttgtcgaaataccgcttcttcgtccagaggcgttcgattcgacacttacccgtaggttattagagcatcatggactgggatgcacctgctctctgggtctgcctaccgaggcagcactcccggaccatcctcaagcagcagcccgttttctcatccaggccttggatgtagcccatcaaatgggcagcccggtcct
gagtggggtcacctacgcaaccctgggcgcactgtcaggccgcccgccgaccgaggccgattatgaaaccctggcgaaaacactgaagccagtagcgcagcacgccgcccgcctgggtatgcgactcgggcttgaaccggttaaccgctatgaaacatacctgataaacttagggtcacaggcgctggatctcatccaacgtatcggcgaaccgaacgtgttcgtacacctggatacttatcacatgaacatcgaagagaaaggttttaagaacccgattgttaccgtcggtaaacatcttggttatattcacctgtctgaaagcgaccgtggtaccccaggtagcggtaatgtgcattgggatgaagtgttctccggcctgcaagcaatcggttttcagggtgaccttgtgatggagtcgtttgtggcactgaatccggatattgcccgcgccacgtgcatgtggcgggatgttgtgggagatccgaaaacactggtgcatgatggcctagctttcctgcgcggtaaagctcgcgaatacggactgctgtaa
[0115]
seq id no:11;蛋白质;嗜热微红微菌
[0116]
mqgfgvhtsmwtmhwdragaertipaaaaykmdfieialldtaivdaahtrallekhglravcslglpepvwasvnpegaiahlkraldktaemgaealsgvtyggigqrtgvpptpqeydniaraleaaakhakalglafgiepvnryenhlintgrqavemiekvgadnifihldtyhmnieekgvangildarehlryihlsesdrgtpgegtcdwdeifaalaaigfkgglamesfinmppqvayglavwrpvaesfeevmdrglpflrnkarqyrlia
[0117]
seq id no:12;dna;嗜热微红微菌
[0118]
atgcaaggtttcggcgtacacactagcatgtggacgatgcattgggatcgcgcgggcgccgagcgcaccattccggccgccgccgcctacaaaatggactttatcgaaattgcgctgctggatacagctatagtcgatgcagcgcacacccgtgcgctgctggagaagcacggcctgcgtgcagtttgttcactcggattaccggagccggtctgggcctctgtgaacccggaaggggccattgctcacctgaaacgcgcgctggacaagaccgcagagatgggagctgaagctctgtctggtgtgacttacggcggtatcggccagcgcacaggcgtaccaccaacgccccaagaatacgataacattgcccgtgcccttgaagcagctgcgaaacatgccaaagccttaggcctggcctttggtatcgaaccggttaacaggtatgaaaaccatttgataaacaccggacgtcaagctgtagaaatgatcgaaaaggtcggggcagataacattttcatacacctggatacgtatcacatgaatatcgaagagaaaggtgtggcaaacggtatcctggatgcccgagaacaccttcgttatattcacctgtcagaaagcgatcgcggcactcctggcgaagggacgtgtgattgggacgaaatcttcgctgcgttggccgccatcggttttaaaggcggccttgctatggaatcctttattaacatgccgcctcaagtcgcttacggcctggcggtgtggcgtcctgttgccgaatcttttgaagaagtcatggaccgtggcctgccgtttctacgtaacaaggctcgtcagtatagattgatcgcttaa
[0119]
seq id no:13;蛋白质;暂定纲thermofons ia分支1细菌
[0120]
mptfgahafvwigdwttesgnyaiaqagalgfdfieipllapqrfdaashrqalaqagiqatcslvlpkgahmpryperarqflyealekveavgsqylggciayelgyltgqpptpeerqvvvevlrdvaaearrrgiqlaleacnryetylyntladvretvlavgapnlklhadtyhmnieeegfaqpliacadvldyihmseshrglvgsgnvnwaqvwqalaairfngklvlesfaainpdlqaatclwrppnqppevlareglrflregaaqaqlp
[0121]
seq id no:14;dna;暂定纲thermofons ia分支1细菌
[0122]
atgccaaccttcggcgcccatgcatttgtgtggattggagattggacgacagaatcgggaaactatgcgatcgcgcaagccggcgcactgggcttcgacttcattgagattccgcttttggcaccgcagcgttttgatgccgcttcccaccgtcaagccctggcgcaggccggcattcaggcgacgtgcagcctggtattgccaaaaggcgctcacatgcccaggtatccagaacgtgcgcgtcagttcttgtatgaagcgttagaaaaggtagaggcggttggaagtcaatacttgggcggttgcatcgcgtacgaacttgggtatcttaccggtcagccaccgaccccggaagagcgtcaggttgttgtggaagtgctgcgcgatgtagccgcagaagcacgccgtcgcggcattcagttggcactggaagcatgcaatcgctatgagacttacctgtacaacacgctggcggacgtgcgcgaaacggttttagcggtgggcgcgccaaacttgaagctgca
tgcggatacctaccacatgaacatcgaagaagaaggctttgcccagccgcttattgcctgtgccgacgtgctggattatatccacatgtcggaatcccatcgcggcctggtcggaagcggcaacgttaattgggcgcaggtctggcaagcgctcgccgcaattcgcttcaatggcaaactggtgctggaatcgtttgccgcgattaacccggaccttcaggccgctacttgtctgtggcgcccgcccaaccagccgccggaagtgctggcccgcgaaggactgcgatttctccgagaaggtgcggcacaggcccaactaccgtaa
[0123]
seq id no:15;蛋白质;韩国异常球菌
[0124]
mlkfgahafcwegdwtdeigdrvieqaaragldfieipllhpetfdarrhrrhleavglacvsslglprdahmphepekavtfltgvldrmeelgardltgctgysigvltgqgptsqeldrmvdglarvtedarsrgigvgleainryetymvntlddalavvnrvgsdnlrvhadtyhmnieetnlrealgrvkgklnfihmseshrglvgtgtvpwedvwqgladiefsgyltlesfaapnaelaaatciwkpprhsgqelaqgglaflregatrhglm
[0125]
seq id no:16;dna;韩国异常球菌
[0126]
atgttgaagttcggcgcgcacgccttttgctgggaaggcgattggaccgatgaaattggcgatcgcgtcatcgagcaagcggcgcgggccggattggatttcattgaaatcccgctcttgcaccctgaaaccttcgatgcgcgccgtcatcgtcgccatcttgaggctgtgggcctggcgtgcgtttccagcctgggccttccgcgtgacgcccacatgccacatgaaccggagaaagcggtaacattccttaccggcgtactggatcgcatggaagaactgggcgctcgcgaccttaccggttgtaccggttatagcattggcgtactgaccggccagggtccgacctctcaagagctcgatcgtatggtggatggtctggctcgtgtgactgaagatgcacggtcgcgcgggattggcgtaggccttgaagccatcaatcgttatgaaacttatatggtaaacacgctggacgatgcgttagcggtcgtgaatcgtgtcgggagtgacaatcttcgcgttcatgccgatacataccacatgaacatagaagaaaccaacctgcgtgaggcgcttgggcgagttaagggtaagctgaacttcattcacatgagtgaaagtcatcgtggtctggttggtaccgggacagttccatgggaagatgtttggcagggtctggcggatattgagttcagcgggtatcttactcttgaatcgtttgcagctccgaatgccgagttggcggcagctacctgtatctggaaaccaccacggcatagcggccaggaactggcgcagggtggcctagcttttctgcgcgagggcgcgactcgccacggcttaatgtaa
[0127]
seq id no:17;蛋白质;阿氏厄尔巴线虫螺旋体内共生体
[0128]
mkfgahafvwepewndttsrrviseaarigldfveipllrperfdgaatkvlldehavgatyslglpsdkslperpylaepflrsaidaiesaggdtltgvlygtlgelpgrppnekdykviaqvlrsvadyakdrgiklgiepvnryetflvntaeqaitlldriesdnvfihldtyhvnieedsfgaairlagdrlgyihlseshrgtpgkgtvdwddvfgalsdigfagplvmesfvklnadiaratcmwrdivkdpealirdgiaflegkakgyglf
[0129]
seq id no:18;dna;阿氏厄尔巴线虫螺旋体内共生体
[0130]
atgaaatttggtgcgcatgctttcgtctgggaaccagaatggaatgataccacctcgcgccgtgtgatttcagaggccgcgcgcatcggcctggattttgtggaaataccgctccttcgcccagaacgctttgacggcgccgctaccaaagtcttgctggatgaacatgccgtgggcgccacttattcattgggcctgcccagtgacaaaagcctgccagaacgcccgtatctggctgaacccttcttacggtctgcaatcgacgccattgaatccgcaggcggtgatacactgacaggcgtgctgtatggcactctgggtgagctgccgggccgcccgccgaacgaaaaggactacaaagtgattgcgcaggtattacgtagtgttgctgattacgcgaaagaccgtggcatcaaactgggcattgagccggtaaaccgttatgaaacctttctggtgaataccgcagagcaggcgatcacattgttagaccgtatcgaaagcgacaatgtctttattcatctggatacctatcacgtgaacatcgaagaagatagttttggcgcggctatccgcctggctggggatcgtttaggctacatccacctgtccgaaagccaccgtggcacgccaggcaagggtactgtggattgggacgacgttttcggagcgctttccgatattggtttcgcaggccctcttgtgatggaaagctttgtcaagctgaatgcagacattgcacgtgcgacctg
catgtggcgtgatattgtgaaagacccagaagccctgattcgcgatggtattgcgtttctcgaggggaaagcgaaaggctatggtctgttttaa
[0131]
seq id no:19;蛋白质;嗜酸菌属(acidiphilium)
[0132]
mkgfgihtslwahdwteqaarlaipeaakhglafveialiepdraetevtrglleqhglaaccslglpeearpttnpdkalefvtlalektaaigaslftgvtygsigertgqpptaaeldavarfldkaaavargfgiifgievvnryeshlfntteqavaliervgapnivlhldtyhmnieatgqanairaagahlayihlseshrgvpgtgtiawdevfaglaglgftggmalesfihmpprlaaalsvwrpvapsraaiideglpflrnkarqygli
[0133]
seq id no:20;dna;嗜酸菌属
[0134]
atgaaaggctttggcattcatacaagtctgtgggcccatgactggaccgagcaagcggctcgtttagcaattccggaagcggcaaaacatggcctggcgtttgtcgaaattgctttaattgaaccagatcgcgcggaaactgaagttacccgcgggctgctggaacagcacggcttggctgcctgctgctctctgggcttacctgaggaagcgcggccaacgacgaacccggataaagcgttggagttcgtcactttagctctggaaaagaccgcggcgataggggctagcctgtttaccggtgtgacctacgggagcattggcgaacgtacgggccagccacctactgccgccgaacttgatgcagtagcaaggttcttggataaggctgccgcagtagcgcgcggtttcggtatcattttcggtatcgaagtagtgaatcggtacgagtctcatctgtttaacaccaccgaacaggccgttgcactgatcgaacgtgtcggcgcaccgaacatagtgctgcacttagacacgtatcacatgaacatcgaagccacgggccaggccaacgcaatacgcgcggcgggtgcacatctggcctatattcacctgagtgaatcgcacaggggtgttccgggcacagggaccatcgcctgggacgaggtgtttgcaggtcttgccggcctgggctttaccggcgggatggccctcgaatcatttattcacatgccgccccgcctggccgccgcgctgagcgtctggcgtccagttgcaccgagtcgcgcggccatcatcgatgaaggccttccatttctgcgaaataaagcccgtcaatacggcctcatttaa
[0135]
seq id no:21;蛋白质;红杆菌目细菌
[0136]
mlslglhalaaapewrpdlwaailprmaahgvsvieipllrpaeldiagtralaakhdvelvcslglpatlnvaerpdeafdfirvalevtasagatalsgvtfgvigqttgaapttreidamtrhvsrsaalakklglrfgiepcnryethllntgaaaraviersgadnafihldtyhmnieevshaqgfadagdllgyvhlsesnrgvpgrgtvdwanvfqglkaagfdgcaalesfvfvdadlasglaiwrpvaenpddvidvgfpflrtageaaglrwar
[0137]
seq id no:22;dna;红杆菌目细菌
[0138]
atgctttctctgggactgcatgcgcttgcagccgcccctgaatggcgcccggatctgtgggcggcgatcctgccgcgtatggcggcccacggtgttagcgttatcgaaattccgctgctccgtcctgctgaactggatattgcgggcacgcgggctttagcggctaaacatgatgttgaactcgtttgttcattggggctgccagccaccctcaatgttgcggaacgccctgatgaggcgtttgattttatccgcgtggcgttagaagtgaccgcgagcgcgggtgcgaccgcgctgtcaggagtgacatttggcgtgattgggcagacgacgggcgccgccccaaccacgcgcgaaatcgatgctatgacccggcatgtgagccgtagcgcagccctcgccaagaaactgggcttgcgctttggcattgagccgtgcaaccgctacgaaacccacttactgaatactggcgcagccgctcgggccgtgatagaacgctcaggcgctgataacgccttcatccatttggatacatatcacatgaatatcgaagaagtgtctcatgctcagggttttgcagatgcgggcgacctgctgggatatgtgcacttgtcagaaagcaatcgaggcgtcccggggcgtggtaccgtcgattgggcgaatgtatttcagggtctgaaagccgccggattcgatggttgcgccgcactcgaaagtttcgtgttcgttgacgcggacttagcatccggacttgccatctggcgtcctgttgctgaaaacccagatgacgtgattgacgtaggtttcccgttcttgcggacagccggagaggcggcgggcttgcgctgggcgcgttaa
[0139]
seq id no:23;蛋白质;绿弯菌门细菌
[0140]
mvlfgahtfiwsaewnpetaehvidgaaragldfveipllhpdqmdaggtrrllenyglqctcslglpreahlpfapdkatgfleqavdvtsdlgspvltgclythlgtltgkpptdeeidlvvrvlkriaryaqdrgislgiepvnryetyllnlaeqasalldrideanvfvhldtyhmnieekgfytpivdtgprlqyihlsesdrgipgtgnvhwdevfrglkavkyegrlvmesfaavnedlmgatamwrdvvgdpdrlvteglaflrgkaieygll
[0141]
seq id no:24;dna;绿弯菌门细菌
[0142]
atggtactgtttggggcgcatacctttatttggagcgccgaatggaacccagaaacggcggaacatgtaattgatggcgcagctcgcgccggcctggatttcgttgagattccgttgctgcatcccgatcagatggacgcaggcggcacgcgccggcttttggaaaactatggtctgcaatgcacatgtagcttgggcctgccgcgcgaagcgcatctgccattcgcccctgacaaggcaacaggctttctggaacaggccgtcgatgtgacaagtgacctgggtagccctgttttgaccggctgtttatatacccacttaggaacgctgacaggaaagccgcctaccgacgaagagattgatttggtcgttcgtgtcctgaagcgaattgcgcgctacgcccaggaccgagggattagtctgggcatcgaaccggtcaaccgctatgaaacctatcttctgaatctggcggagcaagcgtctgcactgctcgatcgtattgacgaagccaatgtatttgtgcatctggatacctatcacatgaacattgaagaaaagggcttttatactccgatcgttgataccgggccgcgtttacagtacattcacctgtccgaatcggaccgcggtatcccgggtactggcaacgttcattgggacgaggtgtttcgaggcctcaaggccgttaaatacgaaggccgtcttgtgatggaatctttcgccgcagtcaacgaagatctgatgggtgcaacggcgatgtggcgggatgtggtgggtgatccggatcgattagtcacggaaggcctggcgttcttacgtggaaaggcgattgagtacggcctgctgtaa
[0143]
seq id no:25;蛋白质;螺旋杆菌属物种e85
[0144]
maefgahafiwesdwnpasarrviagaaaagldfveipllrpesmdtagtrrllaehrlgvrcslglppaaslpahpqaaeaflcraldvtralggpvltgviygtlgqlpghpprpgdldivaqtlrrvaayaadqglalgiepvnryethlvnltdqalelldaigadnvflhldtyhmnveekgfrgpveaagkrlryihlsesdrgtpgtgnvhwdevfdglaaigyrgdlvmesfaavnediaratciwrqvapdpdtlvreglaflrgkatarglip
[0145]
seq id no:26;dna;螺旋杆菌属物种e85
[0146]
atggcggagttcggtgcacatgctttcatttgggagtctgactggaatccggcgtcagctcgccgtgtcattgccggcgccgctgccgccggcctagatttcgtcgagatcccactgctccgcccggaatccatggacaccgcgggaacccgcagattacttgctgaacatcgcctcggcgtgcgctgttcactgggcctgccgccggcagcgagtctacccgctcatccgcaggccgcagaagcattcctttgccgcgccctagacgttacgcgtgcgttgggcggacccgtactcactggtgtcatctatggcactctgggccagttaccgggtcacccgccacgccctggcgatcttgacattgtcgcacagaccttacggcgcgtggcagcgtacgccgcagatcagggtctggccctgggcattgaaccagtgaaccgttatgaaacacatttagtgaatctcacggatcaagccctagaactgttagatgcgattggcgccgacaatgtattcctgcatctggatacctatcacatgaacgtggaagagaaaggttttcgtggtccagttgaagcagctggtaaacgtttgagatacattcatctttcggagtcagatcgtggtaccccggggacaggcaacgttcactgggatgaagtattcgacggtctggctgcaatcggataccgtggggatctggtgatggaaagttttgcggccgtgaatgaggacattgcgcgtgcgacctgcatctggcgtcaagttgccccagacccggacactctggttagagaaggcttggcgtttcttcgcggcaaagcgaccgcccgcggccttatcccttaa
[0147]
seq id no:27;蛋白质;大不里士杆菌属物种th137
[0148]
megfgvhtsmwtmhwdragaertipaaaayrmdfieiallntaivdaahtrallerhgmravcslglpernwasvnpegaiahlcdcidtaaamgaealsgvtyggigqrtglpptmaeydniaralaavakhakargiafgiepvnryenhlintaaqakwmiekvgadnifihldtyhmnieekgagngildardhlryihlsesdrgtpgegtcdwdevy
atlaaigfkgglamesfinmppevayglavwrpvaenfeevmdkglpflrnkarqyrli
[0149]
seq id no:28;dna;大不里士杆菌属物种th137
[0150]
atggaaggatttggtgtacatacttccatgtggacaatgcactgggatcgcgcgggcgctgaacgtaccattcctgccgcagctgcgtaccgcatggatttcatagagattgctttattaaacacagccattgttgacgcggcacacacgagggctctccttgaacggcatggcatgcgcgcagtgtgttcattgggcttacctgaacgcaattgggcgagcgtgaacccggaaggcgccatcgcacatctgtgcgattgtattgacacagcagcagccatgggcgccgaagccctatccggcgtcacgtatggcggcatcgggcaacgtacggggctcccgcctacgatggccgaatacgataacattgcccgcgctctggcagctgtggcgaaacatgctaaagcacgcggcattgcgtttggtatcgaacccgtgaatcgctacgaaaatcacttgattaataccgccgcacaagctaaatggatgatcgaaaaggttggggctgataatatatttattcatctggacacctatcacatgaacatagaggaaaagggagccggcaatgggatcctcgatgcgcgtgatcatttgagatatatccacttatcggaatcggatcgcggcactccgggcgaaggcacgtgtgactgggatgaggtatatgctaccctggccgccattggttttaaaggcggtttggctatggaatcgtttattaatatgccaccggaagtggcctatggtcttgccgtctggcgtccggtggcggaaaattttgaggaagtgatggataaaggactcccgttcttgcgtaataaagcgcgccaatatcgcctgatataa
[0151]
seq id no:29;蛋白质;异食烷烃热带单胞菌
[0152]
mkgfgvhtsmwtmhwdrdgaertipataaygmdfveialldtsivdaahtrallekhelravcslglpegswpsvapeaavahlkdvfetaaamgaeavsgvtyggigqrsgvppteeeydnvaralqqaaayakrlglafgiepvnryenhlintawqardmiekvgsdnifihldtyhmnieekgvangildardhlryihlsesdrgtpgegccdwnevfgtlsaigfeggmamesfinmppqiayglavwrpvadsfedvmdrglpflrnkarqyrla
[0153]
seq id no:30;dna;异食烷烃热带单胞菌
[0154]
atgaagggtttcggggtgcacacgagtatgtggacgatgcattgggaccgggatggcgcggaacgtacaattccagcgacggccgcgtatggcatggattttgtcgagatcgctctgttggatacctctatcgttgatgctgcgcacacccgggcgctcctggagaaacacgagctgcgcgccgtttgctcgttgggcctgccggaaggctcgtggccttcggttgccccagaggcggcggtagcgcatctgaaagacgtatttgaaaccgcagccgcgatgggcgccgaagcggtttcgggcgtcacatacggcggtattggccaacgttccggtgtgccgcccaccgaggaagaatatgacaacgtagctcgtgccctgcaacaggcagcggcttacgccaaacgcttaggcttagcctttggcattgaacctgtgaaccgctacgaaaaccatttgatcaacactgcatggcaggcccgtgacatgattgaaaaggtaggctcggacaatattttcatccatttagatacttaccacatgaatatagaagagaaaggtgtggcgaacggtatcttagacgcacgtgatcaccttcgttatattcatctttcagagagcgaccgtggcactccgggtgaaggttgctgcgattggaacgaagttttcgggaccttgagcgctattgggtttgaaggtggtatggcgatggaatcgtttattaacatgccgccgcagatagcttacggcctggccgtttggcgaccagttgcggactccttcgaagatgtgatggatcgcgggctgccgtttctgcgtaacaaagcgcgtcagtaccgtctggcttaa
[0155]
seq id no:31;蛋白质;红杆菌科细菌
[0156]
mqgfgvhtsmwtmhwdrlgaertipaaaaykmdfieialldtsvvdahhtrdllakhemravcslglpreswasvnpdgaiahlidamdytkemggealsgvtyggigersgvppteaeydniaralevaakyaktlgiafgiepvnryeshlintswqakemidkigadnifihldtyhmnieekgagngilaarehlryihlsesdrgtpgegtcdwdeifatlaavefkgglamesfinmppqvgyglgiwrpvansfeevmdkglpflrnkaaqyrli
[0157]
seq id no:32;dna;红杆菌科细菌
[0158]
atgcaaggttttggtgtccataccagtatgtggacaatgcactgggatcgcctgggcgcggaacgaac
cattccggccgcggctgcgtacaaaatggactttattgaaattgctcttctggacaccagcgtcgtggatgcgcatcacactcgtgatcttctggcgaaacatgaaatgcgtgcggtttgctcgctgggcttgcctcgcgaatcttgggccagtgttaacccggatggtgccatagctcaccttatagatgcaatggactatactaaagagatgggcggcgaggcactgtctggcgtcacctatggcggtatcggtgaacgtagcggtgttccgccgacggaagctgaatatgataatatcgcacgtgccctagaagttgccgccaaatacgccaaaacgctgggcattgcctttggcattgaacccgtgaaccgctatgaaagccacctgattaataccagttggcaggctaaagaaatgattgataaaatcggtgcagataacatcttcattcacttagatacctaccacatgaacattgaagagaaaggcgccggtaatggaatcctggcagctcgggaacaccttcgctacattcatttgagcgaaagcgaccggggtacacccggcgaaggcacctgtgattgggacgaaatatttgcgacccttgctgccgttgagttcaaaggtggcttggccatggagagtttcattaatatgccgccgcaagtgggatatggcttgggtatctggcgcccggtcgccaattcattcgaggaagtgatggataaaggcctgccgttcctgcgtaacaaagcggcccagtatcgtcttatttaa
[0159]
seq id no:33;蛋白质;红细菌属物种sw2
[0160]
megfgvhtsmwtmqwdragaertipaaaaykmdfieiallntaivdaphtrallqkhglravaslglpqqnwasvnpegaieqlcrsldtaaamgcealsgvtyggigersglpptmaeydnvaralaaaakhakklglafgiepvnryeshlintgwqakwmiekvgadnifihldtyhmnieekgagngildarehlryvhlsesdrgtpgegtvdwdeifatlaavgfkgglamesfinmppelgyglavwrpvaesfqavmdkglpflrnkarqyrli
[0161]
seq id no:34;dna;红细菌属物种sw2
[0162]
atggaaggtttcggtgtccatacttccatgtggaccatgcaatgggaccgtgctggtgccgaacggacgataccagccgctgcggcatataagatggatttcatcgaaatcgcgctgctgaatacggccattgtggatgccccgcatacccgcgcactgttacagaaacatggtctgcgcgccgttgcgagtctgggcctgccacaacagaactgggcgagtgtcaatcctgagggtgccattgagcagttatgccgctcactggacaccgctgccgcgatgggttgcgaagccctgtcaggggttacctacggcggcatcggagagcgcagcggtctgccgccaacaatggcagaatatgacaacgtggcccgtgcgttggcggcggcagcaaaacacgctaagaaactgggcctggcgtttggaatcgaacctgtgaacagatatgagtctcacttgatcaacaccggatggcaagcaaaatggatgattgaaaaggtgggtgcggataacatctttatccacctggatacttatcacatgaatattgaggaaaagggtgcaggcaacggcattctcgatgcgcgcgaacacctgcgttacgtgcatcttagcgaaagcgaccgtgggacccctggagaaggtactgttgactgggatgaaatattcgcgacactcgccgcagttggatttaaaggcggattagcaatggaaagctttatcaacatgccaccggaactgggatatggcctggcagtatggcgcccggtggcggaatcctttcaagcagtaatggataaaggtttaccttttctgcggaacaaagcgcgtcagtatcgtctgatctaa
[0163]
seq id no:35;蛋白质;甲型变形菌纲细菌hgw-甲型变形菌-8
[0164]
mrgfgvhtsmwtmkwdragaeravaaaahykmdfieiallnapgvdaphsrallekhglravcslglpeaawpsrnpeaavahlkvaldktaemgcealtgvtyggigertglppsateldnvaralreaaahakklgllfgiepvnryethlintgrqavemiekvgaenmfihldtyhmnieekgaangildarehikyihlsesdrgtpgwgtcdwdeifavlsaigfkgglamesfinmppevayglsvwrpvardeaevmdnglpflrgkarqyrli
[0165]
seq id no:36;dna;甲型变形菌纲细菌hgw-甲型变形菌-8
[0166]
atgcgtggttttggcgtccatacatctatgtggactatgaaatgggaccgtgcaggtgccgagcgtgccgtggcggcggcagcccactataagatggacttcatcgaaattgcgctgctgaacgcgccgggtgtcgatgcaccgcatagtcgggcactcctggagaaacatggactgcgcgcggtctgttcattggggcttccggaagccgcttggccgagccgcaacccggaagccgccgttgctcatctgaaagtggcgctcgataaaaccgctgaaatgggttgtgaagcgct
gaccggagtcacctacggcggcatcggggaacggaccggcctgccaccgtctgccaccgaactggataacgtggcacgcgctttacgcgaagccgcagcacacgctaagaagctggggctcctcttcggcatcgaaccggttaaccgctacgaaacccatctgattaacactggtcggcaagccgttgaaatgattgagaaagtcggcgcagagaatatgtttattcacctggacacctatcacatgaacatcgaggaaaagggcgcagcgaatggtattctggatgcacgcgaacacattaaatatatccatctttcagaatctgatcgcggtaccccgggctggggtacctgcgattgggatgaaattttcgcagtgctgagcgcaattggatttaaaggtggtttggcgatggaaagttttattaacatgccgccggaagttgcgtatggcctgtcagtatggcgaccagtcgcacgggatgaagcggaagttatggataacggccttccgtttcttcgtggtaaagcccgccagtaccgcttaatttaa
[0167]
seq id no:37;蛋白质;中温微红微菌
[0168]
mqgfgvhtsmwtmnwdragaertipaasaygmdfieiallnapavdaphtrallekhgmravcslglpernwasvnpegaiehlrqalevtaalgaealsgvtyggigqrtgvpptageydniaraleaaaryarelgiafgiepvnryenhlvntaaqakwmiekvgadnifihldtyhmnieekgvgngildarehlryihlsesdrgtpgegtcdwdevfatlaaigfkgglamesfinmppeigyglavwrpvaesfeevmdrglpflrnkakqyrlv
[0169]
seq id no:38;dna;中温微红微菌
[0170]
atgcaagggtttggcgtccacacttcgatgtggaccatgaactgggatcgtgccggcgccgaacgtacaatcccggccgcgagcgcatacggtatggattttattgaaattgcgctgctgaatgccccggcggtggacgctccacatacgcgcgcccttcttgaaaagcacgggatgcgtgcagtttgcagtttgggtttgcctgagcgtaattgggcaagcgtcaaccctgaaggcgcgatcgagcaccttcgacaagccctcgaagtgaccgccgcccttggggcagaagcgttaagcggtgtcacatacggcggtataggtcagcgcacaggggtgccacccaccgctggcgagtatgataacatcgcccgtgcactggaagccgctgcacgctatgcacgagaactgggtatcgcctttggtatcgaaccggttaaccggtacgagaaccatctggtgaacaccgcggcccaagctaaatggatgatagaaaaggttggcgcggataatattttcatccatttggatacatatcacatgaacattgaggagaaaggtgtcggcaacggtatcctggatgcgcgtgagcacctgcgctatattcatctgtctgagagcgatcgcggcacaccaggcgagggtacttgcgattgggacgaagtattcgcaaccctggcagcaattggtttcaaaggcggacttgctatggaatcgtttatcaacatgccgccagaaattggatacggcttggccgtttggcgacctgtggcagagagttttgaagaagtcatggaccgcggcctgccgttcctgcggaacaaggcgaaacagtaccgtcttgtgtaa
[0171]
seq id no:39;蛋白质;红杆菌目细菌
[0172]
megfgvhtsmwtmhwdragaertipaaaaykmdfieiallnaamidpphtrallekhnmravaslglpqrnwasvnpdgaaahlieamdvaaamgaealsgvtyggigertglpptmaeydniaralgqaakhakklgiafgiepvnryenhlintgwqakwmiekvgadnifihldtyhmnieekgagngildarehlryihlsesdrgtpgegtcdwdevyatlaaigfkgglamesfinmppevgyglavwrpvansfeevmdkglpflrnkarqyrli
[0173]
seq id no:40;dna;红杆菌目细菌
[0174]
atggaaggcttcggtgtgcacacgagtatgtggacgatgcactgggatcgtgctggtgctgaacgtacgattccggccgccgccgcgtacaagatggacttcattgaaattgcgctgctgaacgcagcgatgatcgatccgccacatactcgcgcgcttctggagaaacataacatgcgggctgttgcgagtctcggacttccacaacgcaattgggcctcggttaatccagatggtgccgcggcccatcttatcgaggcgatggacgtggcggcagcaatgggtgccgaagcgctttccggagtgacatacggcggaatcggtgaacgcactggcctgccgccaactatggcagagtacgataacattgcacgagcactcgggcaggccgccaaacatgccaagaagcttgggatcgctttcggcatagagccggtgaatcgctatgagaatcatctgatcaacactggctggcaggccaaatggatgattgagaaagtgggtgctgataacatctttatcca
tctggatacatatcacatgaatatcgaggaaaagggcgctggtaatggtattttagatgcacgtgaacacctgcgttatattcatttgtctgagtccgatcgcggcacgccgggtgaaggcacgtgtgactgggatgaagtttacgcgacactggcagccattggctttaaaggtggactcgcgatggaatcattcatcaacatgccgccggaagtgggttatggtctggcagtttggcgcccggtggcgaacagctttgaagaagttatggacaaaggtctgccgtttctccgcaataaagcgcggcagtaccgcctgatctaa
[0175]
seq id no:41;蛋白质;红杆菌目细菌rifcsphigho2_02_full_62_130》
[0176]
megfgvhtsmwtmkwdregteravqaavdykmdfleialldapsvdaahtrklledndmravcslglpeavwpsrdpesaiafmkgvfdkanemgaeavsgvtyggigertdmppteaelsnvaraleacasyakslglrfgiepvnryethllntgwqardmierigsdnifihldtyhmnieekgaasgildarehlkyihlsesdrgtpgegccdwdeifatlaainftgglamesfinmppelahglsvwrpvapdfqavmdkglpflrnkaaqyrlv
[0177]
seq id no:42;dna;红杆菌目细菌rifcsphigho2_02_full_62_130
[0178]
atggaaggttttggggtacacaccagcatgtggacgatgaaatgggatcgtgagggcaccgagcgggctgtacaggcggcagttgattacaaaatggattttctggaaattgctctgcttgacgctccgagcgtggacgcggcacacacgcgcaaactcctggaagataacgatatgcgtgcggtgtgcagtttagggttaccagaagcggtgtggccgagtcgcgacccagagagcgcaattgcttttatgaaaggagtattcgataaggccaacgaaatgggcgccgaggcagtgagtggggtcacgtatggcggcataggcgaacgcacagacatgccaccgacagaagcggagctgagcaacgtagcccgcgcactggaagcgtgcgcgagttatgcaaaatcattaggtctgcgatttggcattgagcctgtgaatcgttatgaaacccatctgctgaataccggttggcaagcacgcgatatgatcgaacgtatcggttcagataacattttcattcatttggatacgtaccacatgaatatcgaagagaaaggcgcggcctctggtattttagatgcccgtgaacacttgaaatacatccatttatctgaaagtgacagaggcacgccaggcgaaggttgttgcgactgggatgaaattttcgccaccctcgccgccattaattttaccggcggtcttgccatggaaagtttcattaacatgccgccagagctggcgcatggtctgagcgtgtggcgccccgtggccccggacttccaagcggtgatggataaaggcctgccgttcctgcgaaacaaagccgcgcagtaccgcctggtctaa
[0179]
seq id no:43;蛋白质;污泥嗜热梭菌,由经密码子优化的dna序列seq id no:44编码
[0180]
kygifyaywekewkgdfityiekvkklgfdilevgcgdfhkqpdsyfhtlrdaareydi iltggygpraehnlcspdtavvenalafysdifrkmeiagirsiggglyaywpvdysrepdkagdlersiknmrrladiaerhgitlnmevlnrfegylindtneglayiravdkpnvklmldtfhmnieedsftepilqagkylghvhvgepnrkppregripwgeigkalrqigydgpvvmepfvtmggqvgkdicvwrdlsqgateedldrdaekslaflkgmfea
[0181]
seq id no:44;dna;污泥嗜热梭菌,经密码子优化
[0182]
aagtacggtatcttctatgcttattgggaaaaggaatggaagggtgacttcattacttacattgaaaaggttaagaagctgggattcgatattcttgaagttggttgtggtgacttccataaacaacctgattcttacttccatactcttagagatgctgctagagaatatgatattattcttactggtggttacggtcctagagctgaacataacttgtgttctccagatactgctgttgttgaaaacgctcttgccttctattctgatatcttcagaaaaatggagatcgctggtattagatccattggtggtggtctgtatgcttactggcctgttgattattctagagaacctgataaggctggtgatcttgaaagatccattaagaacatgagaagattggctgatattgctgaaagacatggtattactcttaatatggaagttcttaacagattcgaaggttatcttattaacgatactaacgaaggtcttgcttatattagagctgttgataaaccaaacgttaaattgatgttggataccttccacatgaacattgaagaagattccttcactgaacctattcttcaagctggtaagtatcttggtcatgttcatgttggtgaacctaatagaaagccacctagagaaggtagaatcccttggggtgaaattggta
aagctcttagacaaattggttacgatggtcctgttgttatggaaccattcgttactatgggtggtcaagttggtaaggatatctgtgtctggagagacttatctcaaggtgctactgaagaggatcttgatagagatgctgaaaagtctcttgccttcttgaaaggtatgttcgaagct
[0183]
其他实施方案
[0184]
本说明书中公开的所有特征可以任何组合进行组合。本说明书中公开的每个特征可被用于相同、等效或类似目的的替代特征替换。因此,除非另外明确说明,否则所公开的每个特征仅是一系列等效或相似特征的实例。从以上描述,本领域的技术人员可以容易地确定本公开的必需特征,并且在不脱离本公开的精神和范围的情况下,可以对本公开进行各种变化和修改以使其适于各种用法和条件。因此,其他实施方案也在权利要求的范围内。
[0185]
等效物和范围
[0186]
本领域技术人员仅使用常规实验将认识到或能够确定本文所述的本公开的具体实施方案的许多等效方案。本公开的范围并不旨在局限于以上描述,而是如随附权利要求中所阐述。
[0187]
如本文在说明书和权利要求中所使用的不定冠词“一个”和“一种”,除非有相反的明确说明,应理解为意指“至少一个/种”。
[0188]
如本文在说明书和权利要求中所使用的短语“和/或”应理解为是指这样结合的元素中的“一者或两者”,即,在一些情况下结合存在并且在其他情况下分离存在的元素。用“和/或”列出的多个元素应以相同的方式解释,即“一个或多个/一种或多种”这样结合的元素。除了通过“和/或”子句具体标识的元素之外,可任选地存在其他元素,无论与那些具体标识的元素相关还是不相关。因此,作为一个非限制性实例,当与诸如“包括”之类的开放式语言结合使用时,对“a和/或b”的引用在一个实施方案中可以仅指a(任选地包括除b之外的元素);在另一个实施方案中,仅指b(任选地包括除a之外的元素);在另一个实施方案中,指a和b两者(任选地包括其他元素);等等。
[0189]
如本文在说明书和权利要求中所使用的,“或”应理解为具有与如上定义的“和/或”相同的含义。例如,当分隔列表中的项目时,“或”或“和/或”应解释为是包含性的,即包括多个元素或元素列表中的至少一个,但也包括其中的多于一个,以及(任选地)其他未列出的项目。只有明确指出相反的术语,诸如“仅一个”或“恰好一个”,或当在权利要求中使用时,“由...组成”将指包括多个元素或元素列表中的恰好一个元素。一般而言,在后面有排他性术语,诸如“任一个”、“中的一个”、“中的仅一个”或“中的恰好一个”时,如本文所用的术语“或”应仅解释为表示排他性替代方案(即“一个或另一个但不是两者”)。当在权利要求中使用时,“基本上由
……
组成”应具有专利法领域中所使用的其普通含义。
[0190]
如本文在说明书和权利要求中所使用的,短语“至少一个”在提及一个或多个元素的列表时,应理解为是指选自元素列表中的任何一个或多个元素的至少一个元素,但不必须包括元素列表中具体列出的每一个元素中的至少一个,并且不排除元素列表中的元素的任何组合。该定义还允许除了在短语“至少一个”所指的元素列表中具体标识的元素之外的元素可任选存在,无论与那些具体标识的元素相关还是不相关。因此,作为一个非限制性实例,“a和b中的至少一个”(或等效地,“a或b中的至少一个”,或等效地“a和/或b中的至少一个”)可以指,在一个实施方案中,至少一个,任选地包括多于一个a,不存在b(并且任选地包括除b之外的元素);在另一个实施方案中,至少一个,任选地包括多于一个b,不存在a(并且
任选地包括除a之外的元素);在另一个实施方案中,至少一个,任选地包括多于一个a,以及至少一个,任选地包括多于一个b(并且任选地包括其他元素);等等。
[0191]
还应该理解的是,除非有相反的明确说明,否则在本文要求保护的任何包括多于一个步骤或动作的方法中,所述方法的步骤或动作的顺序不必须局限于所列举的方法的步骤或动作的顺序。
[0192]
在权利要求以及以上说明书中,所有连接词诸如“包含”、“包括”、“携带”、“具有”、“含有”、“涉及”、“持有”、“由
……
构成”等应被理解为是开放式的,即意味着包括但不限于。如美国专利局专利审查程序手册第2111.03节中所阐述,只有连接词“由
……
组成”和“基本上由
……
组成”应分别为封闭或半封闭的连接词。应当理解的是,在本文件中使用开放式连接词(例如,“包含”)描述的实施方案在替代实施方案中也被设想为“由通过开放式连接词描述的特征组成”和“基本上由其组成”。例如,如果本公开描述了“一种包含a和b的组合物”,则本公开还设想了替代实施方案“一种由a和b组成的组合物”和“一种基本上由a和b组成的组合物”。
[0193]
此外,本公开涵盖所有变型、组合和排列,其中将来自一个或多个所列权利要求的一个或多个限制、元素、条款和描述性术语引入另一权利要求中。例如,可以修改从属于另一权利要求的任何权利要求以包括在从属于同一基本权利要求的任何其他权利要求中存在的一个或多个限制。在元素被呈现为列表的情况下,例如,以马库什(markush)组的格式,元素的每个子组也被公开,并且任何一个或多个元素可以从组中去除。应当理解,一般而言,在本公开或本公开的方面被称为包括特定元素和/或特征的情况下,本公开或本公开的方面的某些实施方案由此类元素和/或特征组成,或基本上由其组成。为简单起见,那些实施方案并未在本文中用同样的话具体阐述。还应注意,术语“包含”和“含有”旨在为开放的并允许包括另外的元素或步骤。在给出范围的情况下,端点被包括在内。此外,除非另外指出或从上下文和本领域普通技术人员的理解以其他方式显而易见,表示为范围的值可以在本公开的不同实施方案中假设所述范围内的任何特定值或子范围,至范围下限单位的十分之一,除非上下文另外明确指出。
[0194]
本技术参考了各种授权专利、公布的专利申请、杂志文章以及其他出版物,所有这些均通过引用并入本文。本文公开的所有参考文献、专利和专利申请均相对于引用每一个所针对的主题通过引用并入,在一些情况下,可涵盖整个文件。如果任何并入的参考文献与本说明书之间存在冲突,应以本说明书为准。此外,本公开落入现有技术的任何特定实施方案可明确地排除在任何一项或多项权利要求之外。因为此类实施方案被认为是本领域普通技术人员已知的,所以即使在本文没有明确阐述排除,它们也可被排除在外。本公开的任何特定实施方案可以出于任何原因从任何权利要求中排除,无论是否与现有技术的存在有关。
[0195]
本领域技术人员仅使用常规实验就将认识到或将能够确定本文所述的具体实施方案的许多等效方案。本文所述的本发明实施方案的范围不旨在局限于以上具体实施方式,而是如所附权利要求中所阐述。然而,本领域普通技术人员将了解,可在不脱离如以下权利要求所定义的本公开的精神或范围的情况下对本说明书做出各种改变和修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1