用于修饰靶核酸的组合物和方法
用于修饰靶核酸的组合物和方法
相关申请的交叉引用
1.本技术要求2020年3月13日递交的美国临时申请第62/989,501号的优先权,其公开内容在此通过引用整体并入本文中,以用于所有目的。关于在联邦政府赞助的研究和开发下进行的发明权利的声明
2.本发明是根据国立卫生研究院(the national institutes of health)授予的第p50 gm082250号基金在政府支持下进行的。政府享有本发明的某些权利。本公开的背景
3.成簇的规律间隔短回文重复序列(crispr)和crispr相关(cas)蛋白的应用通过使基因组编辑成为可能,从而彻底改变了分子生物学。crispr介导的基因编辑是一种强大而实用的工具,其具有创造新的科学工具、纠正临床相关突变并使新的基于细胞的免疫疗法工程化的潜力。本公开的概述
4.在一方面,本公开的特征在于供体构建体,其包含含有单链同源定向修复模板(hdrt)以及一条或多条dna结合蛋白靶序列的至少一个供体模板,其中至少一条dna结合蛋白靶序列与互补多核苷酸序列形成双链双链体。
5.在一些实施方案中,所述供体构建体包含(a)含有单一供体模板的第一多核苷酸,和(b)含有互补的多核苷酸序列的至少一个第二多核苷酸,其中所述供体模板是单链线性模板。在一些实施方案中,所述供体模板仅包含一条dna结合蛋白靶序列,并且其中所述dna结合蛋白靶序列与所述互补的多核苷酸序列杂交。在某些实施方案中,所述dna结合蛋白靶序列位于所述供体模板的5’端处或所述供体模板5’端的近端。在其他实施方案中,所述dna结合蛋白靶序列位于所述供体模板的3’端处或所述供体模板3’端的近端。
6.在本方面的一些实施方案中,所述供体模板包含:位于所述供体模板的5’端处或所述供体模板5’端近端的第一dna结合蛋白靶序列;位于所述供体模板的3’端处或所述供体模板3’端近端的第二dna结合蛋白靶序列;第一互补的多核苷酸序列;和第二互补的多核苷酸序列,其中所述第一dna结合蛋白靶序列与所述第一互补的多核苷酸序列杂交,并且所述第二dna结合蛋白靶序列与所述第二互补的多核苷酸序列杂交。
7.在本方面的一些实施方案中,所述供体构建体包含(a)第一供体模板,其含有位于所述第一供体模板的3’端处或所述第一供体模板3’端近端的第一dna结合蛋白靶序列,和(b)第二供体模板,其含有位于所述第二供体模板的3’端处或所述第二供体模板3’端近端的第二dna结合蛋白靶序列,其中所述第一dna结合蛋白靶序列与所述第二dna结合蛋白靶序列杂交。在一些实施方案中,所述第二供体模板还包含位于所述第二供体模板的5’端处或所述第二供体模板5’端近端的第三dna结合蛋白靶序列,并且所述供体构建体还包含(c)第三供体模板,其含有位于所述第三模板的5’端处或所述第三模板5’端近端的第四dna结合蛋白靶序列,其中所述第三dna结合蛋白靶序列与所述第四dna结合蛋白靶序列杂交。
8.在本方面的一些实施方案中,所述dna结合蛋白靶序列和所述互补的多核苷酸序列形成发夹。在某些实施方案中,所述供体构建体包含单一供体模板,并且所述供体模板包
含由第一dna结合蛋白靶序列和作为互补的多核苷酸序列的第二dna结合蛋白靶序列形成的单一发夹。在一些实施方案中,所述供体构建体包含单一供体模板,并且所述供体模板包含两个发夹以及:(a)第一dna结合蛋白靶序列;(b)作为第一互补的多核苷酸序列的第二dna结合蛋白靶序列;(c)第三dna结合蛋白靶序列;和(d)作为第二互补的多核苷酸序列的第四dna结合蛋白靶序列,其中所述第一dna结合蛋白靶序列与所述第二dna结合蛋白靶序列杂交以在所述供体模板的5’端处或所述供体模板5’端的近端形成第一发夹,并且所述第三dna结合蛋白靶序列与所述第四dna结合蛋白靶序列杂交以在所述供体模板的3’端处所述供体模板3’端的近端形成第二发夹。
9.在某些实施方案中,所述供体模板还包含第三dna结合蛋白靶序列,并且所述供体构建体还包含含有第二互补的多核苷酸序列的多核苷酸,其中所述第三dna结合蛋白靶序列与所述第二互补的多核苷酸序列杂交。
10.在一些实施方案中,所述供体构建体包含第一供体模板和第二供体模板,所述第一供体模板和所述第二供体模板各自包含第一dna结合蛋白靶序列和作为互补的多核苷酸序列的第二dna结合蛋白靶序列,并且其中所述第一供体模板的一部分和所述第二供体模板的一部分彼此杂交。
11.在一些实施方案中,所述供体构建体包含单一供体模板,并且所述供体模板包含:(a)第一片段,其包含由第一dna结合蛋白靶序列和作为互补的多核苷酸序列的第二dna结合蛋白靶序列形成的第一发夹;(b)第二片段,其包含由第三dna结合蛋白靶序列和作为互补的多核苷酸序列的第四dna结合蛋白靶序列形成的第二发夹;和(c)第三片段,其包含hdrt,其中所述第一片段的一部分与所述第三片段的5’部分杂交,并且所述第二片段的一部分与所述第三片段的3’部分杂交。
12.在本方面的一些实施方案中,所述dna结合蛋白靶序列被供体向导rna(grna)结合,所述供体向导rna被rna引导的核酸酶结合。在具体实施方案中,所述rna引导的核酸酶是cas蛋白。cas蛋白的实例包括但不限于:cas1、cas1b、cas2、cas3、cas4、cas5、cas6、cas7、cas8、cas9(也被称为csn1和csx12)、cas10、csy1、csy2、csy3、cse1、cse2、csc1、csc2、csa5、csn2、csm2、csm3、csm4、csm5、csm6、cmr1、cmr3、cmr4、cmr5、cmr6、csb1、csb2、csb3、csx17、csx14、csx10、csx16、csax、csx3、csx1、csx15、csf1、csf2、csf3、csf4、cpf1和以上的变体。
13.在一些实施方案中,所述dna结合蛋白靶序列包含seq id nos:30-35中任一个的序列。在一些实施方案中,所述供体模板包含一个或多个原间隔序列邻近基序(pam)。在具体实施方案中,所述pam位于所述dna结合蛋白靶序列的5’端处。在具体实施方案中,所述pam位于所述dna结合蛋白靶序列的3’端处。
14.在另一方面,本公开提供了用于修饰靶核酸的组合物,其包含:(a)可靶向的核酸酶;(b)dna结合蛋白;(c)本文所描述的供体构建体。在一些实施方案中,所述可靶向的核酸酶和dna结合蛋白相同并且包含rna引导的核酸酶(例如,cas蛋白)。cas蛋白的实例包括但不限于:cas1、cas1b、cas2、cas3、cas4、cas5、cas6、cas7、cas8、cas9(也被称为csn1和csx12)、cas10、csy1、csy2、csy3、cse1、cse2、csc1、csc2、csa5、csn2、csm2、csm3、csm4、csm5、csm6、cmr1、cmr3、cmr4、cmr5、cmr6、csb1、csb2、csb3、csx17、csx14、csx10、csx16、csax、csx3、csx1、csx15、csf1、csf2、csf3、csf4、cpf1和以上的变体。
15.在该方面的一些实施方案中,所述组合物包含靶向导rna(grna)和供体grna。在某
些实施方案中,所述靶grna与所述靶核酸互补。在某些实施方案中,所述dna结合蛋白靶序列与所述供体grna序列的等长部分互补。此外,所述组合物可以包含阴离子聚合物,例如聚谷氨酸(pga)、聚天冬氨酸或聚羧基谷氨酸。
16.在另一方面,本公开提供了用于修饰细胞中靶核酸的方法,其包括向所述细胞中引入上述组合物,其中所述hdrt被整合到所述靶核酸中。在所述方法的一些实施方案中,所述引入包括电穿孔。在具体实施方案中,所述细胞是原代细胞(如原代t细胞)。在一些实施方案中,将外源核苷酸序列引入所述细胞中,并且所述修饰包括将所述外源核苷酸序列插入所述靶核酸中。在其他实施方案中,所述修饰包括切除所述靶核酸。在一些实施方案中,所述修饰包括将外源蛋白靶向所述靶核酸。例如,所述外源蛋白可以是转录激活物或阻遏物。在一些实施方案中,所述方法在体内、在体外或离体进行。在一些实施方案中,所述方法使得能够相对于相应hdrt的浓度或量使用较低浓度或量的本文所述的供体构建体,以实现相同或更高的基因编辑(例如敲入)效率。在一些实施方案中,所使用的hdrt的量少于1pmol(例如,少于0.8pmol、少于0.6pmol、少于0.4pmol、少于0.2pmol、少于0.1pmol、少于0.08pmol、少于0.06pmol、少于0.04pmol、少于0.02pmol或少于0.01pmol)。定义
17.如本说明书和所附权利要求书中所用的,除非上下文另有明确规定,否则单数形式“一个/种(a/an)”和“所述(the)”包括复数参考物。
18.如本文所用的,“crispr-cas”系统是指用于防御外源核酸的一类细菌系统。crispr-cas系统广泛存在于真细菌和古细菌生物体中。crispr-cas系统包括i型、ii型和iii型子类型。野生型ii型crispr-cas系统利用rna介导的核酸酶(例如cas9蛋白)与向导和激活rna(例如,单向导rna或sgrna)复合,以识别和切割外源核酸,即包括天然或修饰的核苷酸的外源核酸。
19.如本文所用的,术语“可靶向的核酸酶”是指能够识别靶核酸序列(例如,基因组内的靶基因)并结合到靶核酸的蛋白质。在一些实施方案中,可靶向的核酸酶可以修饰靶核酸。在一些实施方案中,可靶向的核酸酶可以是rna引导的核酸酶(例如cas蛋白)。在其他实施方案中,可靶向的核酸酶可以是融合蛋白,其包括可结合到靶核酸的蛋白质(例如,转录激活因子样(tal)效应dna结合蛋白或锌指dna结合蛋白)和可修饰靶核酸的蛋白(例如,核酸酶、转录激活物或阻遏物)。在一些实施方案中,可靶向的核酸酶具有核酸酶活性。在其他实施方案中,可靶向的核酸酶不具有核酸酶活性。在一些实施方案中,可靶向的核酸酶可以通过切割靶核酸来修饰靶核酸。然后,切割的靶核酸可以与附近的同源定向修复(hdr)模板进行同源重组。在其他实施方案中,可靶向的核酸酶(例如,无任何核酸酶活性的可靶向的核酸酶)可以调节靶核酸的表达。例如,可靶向的核酸酶可以是包含tal效应dna结合蛋白和转录激活物的融合蛋白。
20.如本文所用的,术语“dna结合蛋白”是指能够直接或间接结合供体模板(其包括hdr模板)内的dna结合蛋白靶序列的蛋白质。不受任何理论的束缚,dna结合蛋白用于将供体模板转运或穿梭到靠近靶核酸的细胞位置。因此,dna结合蛋白可以改善hdr模板递送进入靶细胞,特别是细胞核,并提高敲入效率。在一些实施方案中,dna结合蛋白可以是转录激活因子样(tal)效应dna结合蛋白或锌指dna结合蛋白。转录激活因子样(tal)效应dna结合蛋白和锌指dna结合蛋白中的每一种都可以直接与供体模板内的dna结合蛋白靶序列结合。
在一些实施方案中,dna结合蛋白可以是rna引导的核酸酶(例如cas蛋白),其可以经由供体grna间接结合供体模板内的dna结合蛋白靶序列。
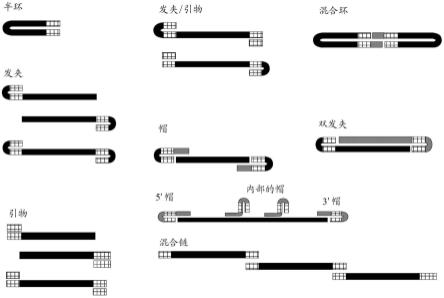
21.如本文所用的,术语“供体模板”是指一起形成同源定向修复模板(hdrt)和一条或多条dna结合蛋白靶序列的一条或多条链的多核苷酸。hdrt可以包括5’同源臂、核苷酸插入(例如,外源序列和/或编码异源蛋白或其片段的序列)和3’同源臂。在一些实施方案中,供体模板还可以在供体模板的一端或两端处包括一个或多个边缘序列。在一些实施方案中,供体模板可以由单个多核苷酸分子形成(例如,如图1中所示的“半环”和“发夹”)。在其他实施方案中,供体模板可以由两个或更多个多核苷酸分子形成(例如,如图1中所示的“帽”)。在某些实施方案中,供体模板是线性模板(例如,如图1中所示的“引物”中的供体模板),这意味着供体模板没有任何发夹区域。在其他实施方案中,供体模板可以包含发夹区域(例如,如图1中所示的“半环”中的供体模板)。
22.如本文所用的,术语“供体构建体”是指包含一个或多个供体模板的分子。在一些实施方案中,当供体构建体包含两个或更多个供体模板时,每个供体模板中的hdrt可以具有相同序列或不同序列。
23.如本文所用的,术语“单链”是指其中超过80%(例如,超过85%、90%或95%)的其核苷酸不与其他核苷酸(例如,其他互补的核苷酸)杂交的多核苷酸。在一些情况下,单链多核苷酸中的一些核苷酸可以与其他核苷酸(例如,其他互补的核苷酸)杂交,但单链多肽中的大多数(例如,超过80%)核苷酸不与其他核苷酸(例如,其他互补的核苷酸)杂交。
24.如本文所用的,术语“双链双链体”是指多核苷酸的两个区域,它们相互互补并经由氢键彼此杂交以形成双链区域。在一些实施方案中,互补多核苷酸的两个区域可以位于同一链多核苷酸分子内。在其他实施方案中,互补多核苷酸的两个区域可以来自单独的多核苷酸分子链。
25.如本文所用的,术语“发夹”是指当同一多核苷酸链内的两个多核苷酸区域杂交形成以未成对环结束的双螺旋或双链双链体区域时形成的核苷酸结构。在一些实施方案中,发夹中的未成对环具有4至200(例如,4至180、4至160、4至140、4至120、4至100、4至80、4至60、4至40、4至20、4至10、4至8、8至200、10至200、20至200、40至200、60至200、80至200、100至200、120至200、140至200、160至200或180至200)个核苷酸。在一些实施方案中,在发夹中杂交的两个多核苷酸区域中的每一个都是10-50(例如,10至45、10至40、10至35、10至30、10至25、10至20、10至15、15至50、20至50、25至50、30至50、35至50、40至50或45至50)个核苷酸。
26.如本文所用的,术语“dna结合蛋白靶序列”是指由dna结合蛋白识别和结合的核苷酸序列。在一些实施方案中,dna结合蛋白(例如转录激活因子样(tal)效应dna结合蛋白或锌指dna结合蛋白)可以直接识别和结合dna结合蛋白靶序列。在其他实施方案中,dna结合蛋白(例如rna引导的核酸酶)可以经由供体grna间接识别和结合dna结合蛋白靶序列。dna结合蛋白(例如rna引导的核酸酶)与供体grna结合,所述供体grna与dna结合蛋白靶序列杂交。在一些实施方案中,dna结合蛋白靶序列是靶核酸的一部分。在一些实施方案中,dna结合蛋白靶序列具有15至40(例如,15至35、15至30、15至25、15至20、20至35、25至35或30至35)个核苷酸。
27.如本文所用的,“rna引导的核酸酶”是指结合到向导rna(grna)并利用grna搜索其
可靶向的dna多核苷酸内的区域的核酸酶。通常,rna引导的核酸酶可以靶向与grna互补的dna多核苷酸内的几乎任何序列。在一些实施方案中,rna引导的核酸酶具有核酸酶活性,并且可以切割dna多核苷酸中核苷酸之间的键连(例如,磷酸二酯键)。在其他实施方案中,rna引导的核酸酶不具有核酸酶活性,并且可以被用于靶向或定位融合到rna引导的核酸酶的dna多核苷酸内的靶区域的其他蛋白质(例如,转录激活物或阻遏物)。
28.如本文所用的,术语“向导rna”或“grna”是指可通过与靶核酸杂交将rna引导的核酸酶(例如,cas蛋白)引导至靶核酸的dna靶向rna。在一些实施方案中,向导rna可以是单向导rna(sgrna),它包含将rna引导的核酸酶靶向靶核酸的向导序列(即,单向导rna的crrna等效部分)和与rna引导的核酸酶相互作用的支架序列(即单向导rna的tracrrna等效部分)。在其他实施方案中,向导rna可以包含两个组分,即将rna引导的核酸酶靶向靶核酸的向导序列(即单向导rna的crrna等效部分)和与rna引导的核酸酶相互作用的支架序列(即单向导rna的tracrrna等效部分)。向导序列的一部分可以与支架序列的一部分杂交,以形成双组分向导rna。
29.如本文所用的,术语“靶向导rna”或“靶grna”是指能够与靶核酸杂交的grna,例如,在靶核酸中hdr模板发生整合的位置处。
30.如本文所用的,术语“供体向导rna”或“供体grna”是指能够在供体模板内杂交dna结合蛋白靶序列的grna。在一些实施方案中,dna结合蛋白靶序列可以与供体grna序列的等长部分互补(例如,部分互补或完全互补)。
31.如本文所用的,术语“单向导rna”或“sgrna”是指dna靶向rna,其包含将cas蛋白靶向靶dna的向导序列(即,单向导rna的crrna等效部分)和与cas蛋白相互作用的支架序列(即单向导rna中的tracrrna等效部分)。
32.如本文所用的,术语“近端”是指来自某一特定位置的20(例如,20、19、18、17、16、15、14、13、12、11、10、9、8、7、6、5、4、3、2或1)个内的核苷酸。例如,多核苷酸5’端的近端的序列意指该序列位于来自多核苷酸5’端的20个核苷酸范围内。
33.如本文所用的,术语“杂交(hybridize/hybridization)”是指通过互补核酸碱基、核苷或核苷酸之间发生的氢键相互作用对互补核酸进行退火。氢键相互作用可以是watson-crick氢键或hoogsteen氢键或反向hoogstene氢键。互补碱基对的实例包括但不限于腺嘌呤和胸腺嘧啶、胞嘧啶和鸟嘌呤以及腺嘌呤和尿嘧啶,它们都通过氢键的形成配对。
34.如本文所用的,术语“互补(complementary)”或“互补性(complementarity)”是指核酸碱基、核苷或核苷酸之间的碱基配对能力,以及一个多核苷酸与另一个多肽之间的碱基配对能力。在一些实施方案中,一个核苷酸可以与另一个核苷酸具有“完全互补性”或是“完全互补的”,这意味着当两个多核苷酸任选地对齐时,一个多核苷酸中的每个核苷酸可以与其他多核苷酸中对应的核苷酸以watson-crick碱基配对接合。在其他实施方案中,一个多核苷酸可以与另一个多肽具有“部分互补性”或是“部分互补的”,这意味着当两个多核苷酸任选地对齐时,一个多核苷酸中至少60%(例如65%、70%、75%、80%、85%、90%、95%或97%)但少于100%的核苷酸可以与其他多核苷酸中的它们的对应核苷酸以watson-crick碱基配对接合。换句话说,当两个多核苷酸杂交时,至少有一个(例如,一个、两个、三个、四个、五个、六个、七个、八个、九个或十个)错配的核苷酸碱基对。参与watson-crick碱基配对的核苷酸对包括,例如,腺嘌呤和胸腺嘧啶、胞嘧啶和鸟嘌呤,以及腺苷酸和尿嘧啶,
它们都通过氢键的形成配对。错配碱基的实例包括鸟嘌呤和尿嘧啶、鸟嘌呤和胸腺嘧啶以及腺嘌呤与胞嘧啶配对。
35.如本文所用的,术语“cas蛋白”是指成簇的规律间隔短回文重复序列相关蛋白或核酸酶。cas蛋白可以是野生型cas蛋白或cas蛋白变体。cas9蛋白是属于ii型crispr-cas系统的cas蛋白的实例(例如,rath等人,biochimie 117:119,2015)。本文进一步详细描述cas蛋白的其他实例。天然存在的cas蛋白需要crrna和tracrrna进行位点特异性dna识别和切割。crrna通过部分互补区域与tracrrna缔合,以将cas蛋白引导至被称为“原间隔序列”的靶dna中与crrna同源的区域。天然存在的cas蛋白在包含在crrna转录物中的向导序列所指定的位点处切割dna,以在双链断裂处生成平端。在本文所述组合物和方法的一些实施方案中,cas蛋白与靶grna或供体grna缔合以形成核糖核蛋白(rnp)复合体。在本文所述组合物和方法的一些实施方案中,cas蛋白具有核酸酶活性。在其他实施方案中,cas蛋白不具有核酸酶活性。
36.如本文所用的,术语“cas蛋白变体”是指相对于野生型cas蛋白序列具有至少一个氨基酸取代(例如,一个、二个、三个、四个、五个、六个、七个、八个、九个、十个或更多个氨基酸取代)的cas蛋白,和/或是野生型cas蛋白的截短形式或片段。在一些实施方案中,cas蛋白变体与野生型cas蛋白序列具有至少75%的序列同一性(例如,至少75%、80%、85%、90%、91%、92%、93%、94%95%、96%、97%、98%、99%或100%序列同一性)。在一些实施方案中,cas蛋白变体是野生型cas蛋白的片段,并且相对于野生型cas蛋白序列具有至少一个氨基酸取代。cas蛋白变体可以是cas9蛋白变体。在一些实施方案中,cas蛋白变体具有核酸酶活性。在其他实施方案中,cas蛋白变体不具有核酸酶活性。
37.如本文所用的,术语“核糖核蛋白复合体”或“rnp复合体”是指包含cas蛋白或变体(例如,cas9蛋白或变体)以及grna的复合体。
38.如本文所用的,在修饰细胞基因组中的靶核酸的上下文中,术语“修饰”是指在靶核酸中引起变化(例如,切割)。在一些实施方案中,变化可以是靶核酸序列的结构变化。例如,修饰可以采取将核苷酸序列插入靶核酸中的形式。例如,可以将外源核苷酸序列插入靶核酸中。靶核酸也可以被切除并替换为外源核苷酸序列。在另一实例中,修饰可以采取切割靶核酸的形式,而无需将核苷酸序列插入靶核酸中。例如,靶核酸可以被切割和切除。例如,可以通过引起靶核酸内的双链断裂,或在相反的链上引起一对单链缺口并侧接靶核酸来进行此类修饰。用于在靶核酸处或靶核酸内引起单链或双链断裂的方法包括使用本文所述的针对靶核酸的可靶向的核酸酶(例如,cas蛋白)。在其他实施方案中,修饰靶核酸包括将另一蛋白质靶向靶核酸,并且不包括切割靶核酸。
39.如本文所用的,术语“阴离子聚合物”是指由具有总体负电荷的多个亚单元或单体组成的分子。聚合物中的每个亚单元或单体可以独立地是氨基酸、小有机分子(例如有机酸)、糖分子(例如单糖或二糖)或核苷酸。阴离子聚合物可以包含多个氨基酸、有机小分子(例如有机酸)、核苷酸(例如,天然或非天然核苷酸或其类似物)、或以上的组合。阴离子聚合物可以是阴离子均聚物,其中聚合物中的所有亚单元或单体都是相同的。阴离子聚合物可以是聚合物中的亚单元和单体不同的阴离子杂聚合物。阴离子聚合物不是指完全由核苷酸组成的核酸,如脱氧核糖核酸(dna)、核糖核酸(rna)。然而,阴离子聚合物可以包括一个或多个核酸碱基(例如鸟苷、胞苷、腺苷、胸苷和尿苷)以及其他亚单元或单体,如氨基酸和/
或有机小分子(例如,有机酸)。在一些实施方案中,聚合物中的亚单元或单体的至少50%(例如,55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)不是核苷酸或不包含核酸碱基。阴离子聚合物可以是阴离子多肽或阴离子多糖。阴离子聚合物可以包含至少两个亚单元或单体(例如,至少5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190、200、210、220、230、240、250、260、270、280、290、300、310、320、330、340、350、360、370、380、390或400个亚单元或单体;100至400、120至400、140至400、160至400、180至400、200至400、220至400、240至400、260至400、280至400、300至400、320至400、340至400、360至400、380至400、100至380、100至360、100至340、100至320、100至300、100至280、100至260、100至240、100至220、100至200、100至180、100至160、100至140或100至120个亚单元或单体)。
40.如本文所用的,术语“阴离子多肽”是指其亚单元或单体中至少50%(例如55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)为氨基酸(如酸性氨基酸(例如谷氨酸和天冬氨酸))或其衍生物的阴离子聚合物。除氨基酸外,阴离子多肽还可以包含有机小分子(例如有机酸)、糖分子(例如单糖或二糖)、或核苷酸。在一些实施方案中,阴离子多肽可以是其所有亚单元都相同的均聚物。在其他实施方案中,阴离子多肽可以是包含两个或更多个不同亚单元的杂聚合物。例如,阴离子多肽可以是聚谷氨酸(pga)(例如,聚γ-谷氨酸)、聚天冬氨酸和聚羧基谷氨酸。在另一实例中,阴离子多肽可以包含谷氨酸和天冬氨酸的混合物。在一些实施方案中,阴离子多肽中的亚单元或单体的至少50%(例如,55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)可以是谷氨酸和/或天冬氨酸。阴离子多肽可以含有至少两个亚单元或单体(例如,至少5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190、200、210、220、230、240、250、260、270、280、290、300、310、320、330、340、350、360、370、380、390或400个亚单元或单体;100至400、120至400、140至400、160至400、180至400、200至400、220至400、240至400、260至400、280至400、300至400、320至400、340至400、360至400、380至400、100至380、100至360、100至340、100至320、100至300、100至280、100至260、100至240、100至220、100至200、100至180、100至160、100至140、或者100至120个亚单元或单体)。
41.如本文所用的,术语“阴离子多糖”是指其亚单元或单体中至少50%(例如55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)为糖分子(如单糖(例如果糖、半乳糖和葡萄糖)和二糖(例如透明质酸、乳糖、麦芽糖和蔗糖))、或其衍生物的阴离子聚合物。除了糖分子外,阴离子多糖还可以包含有机小分子(例如有机酸)、氨基酸(例如谷氨酸或天冬氨酸)、或核苷酸。在一些实施方案中,阴离子多糖可以是其所有单元都相同的均聚物。在其他实施方案中,阴离子多糖可以是包含两个或更多个不同亚单元的杂聚合物。例如,阴离子多糖可以是透明质酸(ha)、肝素、硫酸肝素或糖胺聚糖。在一些实施方案中,阴离子多糖中的亚单元或单体的至少50%(例如,55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)可以是ha。阴离子多糖可以包含至少两个亚单元或单体(例如,至少5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190、200、210、220、230、240、250、260、270、280、290、300、310、320、330、340、350、360、370、380、390或400个亚单元或单体;100至400、120至400、140至400、160至400、180至400、200至400、220至400、240至400、260至400、280至400、300至400、320至400、340至400、360至
400、380至400、100至380、100至360、100至340、100至320、100至300、100至280、100至260、100至240、100至220、100至200、100至180、100至160、100至140、或100至120个亚单元或单体)。附图简述
42.本技术包括以下附图。附图旨在说明组合物和方法的某些实施方案和/或特征,并补充组合物和方法的任何描述。除非书面描述明确指出情况如此,否则附图并不限制组合物和方法的范围。
43.图1显示了各种形式的供体构建体的示意图。格子区域表示dna结合蛋白靶序列。两个格子区域重叠的区域表明来自两个互补的dna结合蛋白靶序列的杂交的双链双链体形式。黑色和灰色区域是单链的。黑色区域与灰色区域重叠的区域表明这两个区域杂交。混合环是包含两个灰色区域重叠区域的唯一情况——这两个灰色区彼此杂交。d一条或多条dna结合蛋白靶序列,其中至少一条dna结合蛋白靶序列与互补的多核苷酸序列形成双链双链体。
44.图2a显示了通过对dsdna的一条链进行生物素化,然后将其变性以释放非生物素化链来生成长ssdna的方法。
45.图2b显示了四种不同构建体的ssdna的产率百分比,其作为最大理论产率的百分比。
46.图3显示了少于40bps的不同量的构建体的敲入效率。
47.图4a-4c显示了当将ha标签靶向cd5基因座时,与dsdna、具有穿梭体端的dsdna、和ssdna相比,不同量的引物供体构建体(“ssdna+穿梭体”)的敲入百分比、总细胞计数和敲入细胞计数。
48.图5a-5c显示了当将cd25-gfp cdna敲入靶向il2ra基因座时,与dsdna、具有穿梭体端的dsdna、和ssdna相比,不同量的引物供体构建体(“ssdna+穿梭体”)的敲入百分比、总细胞计数和敲入细胞计数。
49.图6a-6c显示了当将ny-eso-1特异性t细胞受体靶向内源性trac基因座时,与dsdna、具有穿梭体端的dsdna、和ssdna相比,不同量引物供体构建体(“ssdna+穿梭体”)的敲入百分比、总细胞计数和敲入细胞计数。
50.图7a-7f显示了代表性的流式图,其展示了构建体cd5-ha、il2ra tngfr和il2ra-cd25-gfp的敲入群体。
51.图8a-8i显示了随着hdrt浓度的增加,构建体cd5-ha、il2ra-tngfr和il2ra-cd25-gfp的敲入效率、活细胞计数和敲入细胞的绝对数量。
52.图9a和9b显示了与ssdna对照相比,具有与对应grna互补序列的ssdna穿梭体增加了敲入效率。
53.图9c和9d显示了ssdna穿梭hdrt的敲入效率,每个都包含不同数量的错配碱基,以改变grna结合亲和力。具有2-8bp错配的hdrt表现出最高的敲入效率增加。
54.图9e和9f显示了具有dsdna末端的ssdna的敲入效率,其中所述dsdna末端覆盖穿梭序列的不同区段并侧接同源臂。
55.图9g和9h显示了具有dsdna穿梭端的ssdna的敲入效率,其中所述dsdna穿梭端包括grna序列、pam序列以及不同量的具有侧接5’同源臂的重叠。
56.图9i和9j显示包括核定位序列(nls)的cas9变体提供了敲入效率的额外的提高。
57.图9k和9l显示阴离子聚合物与ssdna穿梭序列组合提供了毒性的额外的降低。
58.图10a-10c显示使用ssdna穿梭技术对22个靶点进行了表面标志物敲入测试。
59.图11a-11m显示ssdna穿梭技术可以被用于许多不同的原代人细胞类型。
60.图12a-12c显示了流式图,其表明car和tcr构建体的敲入群体进入了原代人t细胞的trac基因组位点中。
61.图12d和12e显示了具有两种不同grna靶序列的ssdna穿梭构建体的敲入效率和存活率。
62.图12f-12h显示了流式图,其展示了使用g526 grna序列,利用三种不同tcr敲入ssdna穿梭构建体的敲入率。发明详述
63.以下描述叙述了本发明组合物和方法的各个方面和实施方案。没有特定实施方案旨在限定组合物和方法的范围。相反,实施方案仅提供至少包括在所公开的组合物和方法范围内的各种组合物和方法的非限制性实例。从本领域普通技术人员的角度阅读描述;因此,本领域技术人员熟知的信息不必包括在内。i.引言
64.病毒修饰的t细胞被批准用于癌症免疫疗法,但更广泛的过继细胞疗法需要更通用和更精确的基因组修饰(yin等人,nat rev clin oncol,16(5):281-295,2019;dunbar等人,science 359:6372,2018;cornu等人,nat med 23:415-423,2017;以及david和doherty,toxicol sci 155:315-325,2017)。crispr(成簇的规律间隔短回文重复序列)-cas(crispr相关蛋白)核酸酶系统是一种基于细菌系统的经工程化的核酸酶系统,其可以被用于基因组工程。它是基于许多细菌和古生菌的部分适应性免疫应答。当病毒或质粒侵入细菌时,侵略者的dna区段通过“免疫”应答转化为crispr rna(crrna)。然后,crrna通过部分互补区域与另一种被称为tracrrna的rna缔合,以将cas(例如,cas9)核酸酶引导至靶dna中与crrna同源的区域,该区域称为“原间隔序列”。cas(例如,cas9)核酸酶在crrna转录物中包含的20个核苷酸向导序列指定的位点处,在双链断裂处切割dna以生成平端。cas(例如,cas9)核酸酶可能需要crrna和tracrrna两者来进行位点特异性dna识别和切割。该系统现在已经被工程化使得可以将crrna和tracrrna组合成一个分子(“单向导rna”或“sgrna”),并且可以工程化sgrna的crrna等效部分,以引导cas(例如cas9)核酸酶靶向任何所期望的序列(参见例如,jinek等人(2012)science 337:816-821;jinek等人,(2013)elife 2:e00471;segal(2013)elife2:e00563)。因此,可以对crispr-cas系统进行工程化,以在细胞基因组中所期望的靶点创建双链断裂,并利用细胞的内源性机制修复引起的断裂,例如通过同源定向修复(hdr)。
65.hdrt可以由双链dna(dsdna)或单链dna(ssdna)组成。在一些实施方案中,与dsdna hdrt相比,ssdna hdrt(sshdrt)可以具有降低的毒性和降低的脱靶整合。然而,dsdna可能更容易产生,并且有时可以提供更高的敲入效率。如本文所述的,当在hdrt末端添加时,一条或多条dna结合蛋白靶序列可与dna结合蛋白相互作用,以在电穿孔后改善运输hdrt进入细胞中,并将hdrt“穿梭”到所期望的细胞位置(例如,靶核酸近端的细胞位置(例如细胞核)),并提高靶核酸的修饰效率。更高的hdrt细胞浓度可产生更高的敲入效率。本公开提供
了具有位于hdrt末端的一条或多条dna结合蛋白靶序列的sshdrt,其中一条或多条的dna结合蛋白靶序列与互补多核苷酸序列形成双链双链体。如图1中所示和本文进一步描述的,dna结合蛋白靶序列可以与hdrt融合或分离。不受任何理论的束缚,包含本文所述的sshdrt和dna结合蛋白靶序列的序列既提供了ssdna hdrt的优点(如降低的毒性和减少的脱靶整合),也提供了dsdna hdrt优点(如易于产生和更高的敲入效率)。
66.本文所述组合物和方法可以被用于基因修饰,其提高细胞存活率,实现治疗相关的大转基因插入水平,并最小化对外源dna的依赖,从而降低脱靶遗传毒性的可能性。本公开提供了改进cas蛋白和sgrna rnp复合体编辑结果的策略,其结合改进了细胞基因编辑,例如原代人t细胞编辑和细胞存活,并在ips来源和原代人造血干细胞中实现高效大转基因敲入。ii.供体构建体
67.本公开提供了用于修饰靶核酸的供体构建体,其包括至少一个供体模板,所述供体模板包含单链同源定向修复模板(sshdrt)和一条或多条dna结合蛋白靶序列,其中至少一条dna结合蛋白靶序列与互补的多核苷酸序列形成双链双链体。在一些实施方案中,供体构建体可由单个多核苷酸分子形成。在其他实施方案中,供体构建体可由两个或更多个多核苷酸分子形成。本文详细描述了供体构建体的各种形式。引物供体构建体
68.供体构建体的一种形式是如图1中所示的“引物”供体构建体。通常,引物供体构建体具有是线性模板的供体模板和由两个互补的dna结合蛋白靶序列形成的一个或两个双链双链体区域。引物供体构建体可以包含含有单一供体模板的第一多核苷酸和含有互补的多核苷酸序列的至少一个第二多核苷酸,其中供体模板是线性模板。在一些实施方案中,供体模板包含一个sshdrt和一个dna结合蛋白靶序列(例如,如图1中所示的前两种类型的引物供体构建体)。在其他实施方案中,供体模板包含一个sshdrt和两个dna结合蛋白靶序列(例如,如图1中所示的第三种类型的引物供体构建体)。每个dna结合蛋白靶序列形成一个双链双链体,其具有不延伸到sshdrt序列中的互补多核苷酸序列。在一些实施方案中,供体模板可以包含两个多核苷酸分子,其中一个多核苷酸包含具有一个sshdrt和一个dna结合蛋白靶序列的供体模板,并且第二多核苷酸分子包含互补的多核苷酸序列。在其他实施方案中,供体模板可以包含三个多核苷酸分子,其中第一多核苷酸分子包含具有一个sshdrt和一个dna结合蛋白靶序列的供体模板,并且第二和第三多核苷酸分子中的每一个都包含互补的多核苷酸序列。
69.dna结合蛋白靶序列可以位于供体模板的5’和/或3’端处或供体模板5’和/或3’端的近端。
70.引物供体构建体中供体模板的一些示例性序列(例如,如图1中所示的第三种类型的引物供体构建体)显示在seq id no:1-4中。在seq id no:1-4的序列的每一个中,第一dna结合蛋白靶序列以粗体显示,并且第二dna结合蛋白靶序列加了下划线显示。例如,如seq idno:1的序列中所示的,一个dna结合蛋白靶序列可以位于sshdrt的5’同源臂的5’端处(在seq id no:1中以粗体显示),而另一个作为第一dna结合蛋白靶序列的反向互补序列的dna结合蛋白靶序列可以位于sshdrt的3’同源臂的3’端处(在序列id no:1中加了下划线显示)。核苷酸区域(例如,3至10(例如,3、4、5、6、7、8、9或10)个核苷酸的区域)可以是随机
的或以其他方式可以放置在第一dna结合蛋白靶序列的5’处,以及第二dna结合蛋白靶序列的3’处,以便促进dna结合蛋白的结合。混合链供体构建体
71.如图1中所示的,供体构建体的另一种形式是“混合链”供体构建体。混合链供体构建体可以包含多个供体模板(例如,两个、三个、四个或五个供体模板),其中每个供体模板包含至少一个dna dna结合蛋白靶序列。在该混合链供体构建体的实例中,一个供体模板的dna结合蛋白靶序列可以与另一供体模板的dna结合蛋白靶序列杂交(即一个dna结合蛋白靶序列可以作为另一个dna结合蛋白靶序列的互补多核苷酸序列),以便通过不同供体模板中dna结合蛋白靶序列之间的氢键的方式将混合链供体构建体中的多个供体模板结合在一起。此外,多个供体模板可以具有相同的sshdrt序列或不同的sshdrt序列。
72.例如,混合链供体构建体可以包含(a)第一供体模板,其包含位于第一供体模板的3’端处或第一供体模板3’端的近端的第一dna结合蛋白靶序列,以及(b)第二供体模板,其包含位于第二供体模板的3’端处或第二供体模板3’端的近端的第二dna结合蛋白靶序列,其中第一dna结合蛋白靶序列与第二dna结合蛋白靶序列杂交。此外,为了将第三供体模板引入混合链供体构建体中,第二供体模板还可以包含第三dna结合蛋白靶序列,其位于第二供体模板的5’端处或第二供体模板5’端的近端,并且第三供体模板可以包含位于第三模板的5’端处或第三模板5’端的近端的第四dna结合蛋白靶序列。以这种方式,第二供体模板中的第三dna结合蛋白靶序列可以与第三供体模板中的第四dna结合蛋白靶序列杂交,从而通过dna结合蛋白靶序列之间的氢键方式将所有三个供体模板结合在一起。例如,参见图1中的“混合链”。
73.按照相同的方法,只要另外的供体模板包含互补的dna结合蛋白靶序列,并且可以与邻近供体模板中的dna结合蛋白靶序列杂交,就可以将另外的供体模板添加到混合链供体构建体中。
74.混合链供体构建体中供体模板的一些示例性序列显示在seq id no:5和6中。该示例性供体构建体包含具有seq id no:5的序列第的一供体模板和具有seq id no:6的序列的第二供体模板,其中第一供体模板包含第一dna结合蛋白靶序列(在seq id no:5中以粗体显示)和第二dna结合蛋白靶序列(在seq id no:5中加了下划线显示),并且第二供体模板包含第三dna结合蛋白靶序列(在seq id no:6中以粗体显示)以及第四dna结合蛋白靶序列(在seq id no:6中加了下划线显示)。第四dna结合蛋白靶序列与第二dna结合蛋白靶序列杂交,以将两个dna模板结合在一起,从而形成混合链供体构建体。随机核苷酸区域可以放置在第一或第三dna结合蛋白靶序列的5’处,以及第二或第四dna结合蛋白靶序列的3’处,以便促进dna结合蛋白的结合。半环供体构建体
75.如图1中所示的,供体构建体的另一种形式是“半环”供体构建体。半环供体构建体可以包含一个供体模板,其具有两个dna结合蛋白靶序列,其中的每一个位于供体模板的末端处或供体模板末端的近端。两个dna结合蛋白靶序列可以彼此杂交,并将发夹引入半环供体构建体中。当同一多核苷酸链中的两个多核苷酸区域杂交形成以未配对环结束的双螺旋或双链双链体时,形成发夹。在一些实施方案中,发夹中的未配对环具有4至200(例如,4至180、4至160、4至140、4至120、4至100、4至80、4至60、4至40、4至20、4至10、4至8、8至200、10
至200、20至200、40至200、60至200、80至200、100至200、120至200、140至200、160至200或180至200)个核苷酸。在一些实施方案中,在发夹中杂交的两个多核苷酸区域中的每个为10至50(例如,10至45、10至40、10至35、10至30、10至25、10至20、10至15、15至50、20至50、25至50、30至50、35至50、40至50或45至50)个核苷酸。如图1中所示的,半环供体构建体中的两个dna结合蛋白靶序列彼此杂交以形成双螺旋,而sshdrt形成未配对环。
76.半环供体构建体中供体模板的序列如seq id no:7所示。如seq id no:7的序列中可见的,第一dna结合蛋白靶序列位于sshdrt的5’同源臂的5’端处(在seq id no:7中以粗体显示),并且第二dna结合蛋白靶序列位于sshdrt的3’同源臂的3’端处(在seq id no:7中加了下划线显示)。随机核苷酸区域可以被放置在第一dna结合蛋白靶序列的5’处和第二dna结合蛋白靶序列的3’处,以促进dna结合蛋白的结合。发夹供体构建体
77.如图1中所示的,供体构建体的另一种形式是“发夹”供体构建体。在发夹供体构建体中,发夹位于构建体的一端或两端处,其中发夹的双链区域由两个互补的dna结合蛋白靶序列形成。在一些实施方案中,发夹供体构建体可以包含一个发夹。例如,发夹供体构建体可以包含具有两个dna结合蛋白靶序列的一个供体模板,其中一个dna结合蛋白靶序列位于供体模板的5’或3’端处或供体模板5’或3’端的近端,而另一个dna结合蛋白靶序列位于供体模板内(例如,如图1中所示的前两种类型的发夹供体构建体)。在某些实施方案中,第一dna结合蛋白靶序列位于供体模板的5’端处或供体模板5’端的近端,而第二dna结合蛋白靶序列位于第一dna结合蛋白靶序列的下游(例如,3至10、3至9、3至8、3至7、3至6或3至5个核苷酸),并且位于供体模板内(例如,如图1中所示的第一种类型的发夹供体构建体)。在某些实施方案中,第一dna结合蛋白靶序列位于供体模板的3’端处或供体模板3’端的近端,而第二dna结合蛋白靶序列位于第一dna结合蛋白靶序列的上游(例如,3至10、3至9、3至8、3至7、3至6或3至5个核苷酸),并且位于供体模板内(例如,如图1中所示的第二种类型的发夹供体构建体)。
78.当同一多核苷酸链中的两个多核苷酸区域杂交形成以未配对环结束的双螺旋或双链双链体时,形成发夹。在一些实施方案中,发夹中的未配对环具有4至200(例如,4至180、4至160、4至140、4至120、4至100、4至80、4至60、4至40、4至20、4至10、4至8、8至200、10至200、20至200、40至200、60至200、80至200、100至200、120至200、140至200、160至200或180至200)个核苷酸。在一些实施方案中,在发夹中杂交的两个多核苷酸区域中的每一个为10至50(例如,10至45、10至40、10至35、10至30、10至25、10至20、10至15、15至50、20至50、25至50、30至50、35至50、40至50或45至50)个核苷酸。
79.在一些实施方案中,发夹供体构建体可以包含两个发夹(例如,如图1中所示的第三种类型的发夹供体构建体)。例如,发夹供体构建体可以包含具有四个dna结合蛋白靶序列的一个供体模板,其中两个dna结合蛋白靶序列分别位于供体模板的5’或3’端或供体模板5’或3’端的近端,而两个dna结合蛋白靶序列位于供体模板内(例如,如图1中所示的第三种类型的发夹供体构建体)。在某些实施方案中,供体构建体可以包含单一供体模板,并且供体模板可以包含两个发夹,即位于供体模板5’端处或供体模板5’端的近端的第一dna结合蛋白靶序列、位于第一dna结合蛋白下游(例如,3至10、3至9、3至8、3至7、3至6或3至5个核苷酸)并可作为第一dna结合蛋白靶序列的互补多核苷酸序列的第二dna结合蛋白靶序列、
位于供体模板3’端处或供体模板3’端的近端的第三dna结合蛋白靶序列,以及位于第三dna结合蛋白上游(例如,3至10、3至9、3至8、3至7、3至6或3至5个核苷酸)并可作为第三dna结合蛋白靶序列的互补多核苷酸序列的第四dna结合蛋白靶序列。因此,第一dna结合蛋白靶序列与第二dna结合蛋白靶序列杂交,以在供体模板的5’端处或供体模板5’端的近端形成第一发夹,并且第三dna结合蛋白靶序列与第四dna结合蛋白靶序列杂交,以在供体模板的3’端处或供体模板3’端的近端形成第二发夹。(例如,如图1中所示的第三种类型的发夹供体构建体)。
80.如图1中所示的,第一种类型的发夹供体构建体中供体模板的示例性序列显示在seq id no:8中。如seq id no:8的序列中可见的,第一dna结合蛋白靶序列位于供体模板5’端的近端(在seq id no:8中以粗体显示),并且第二dna结合蛋白靶序列位于第一dna结合蛋白靶序列的下游(在seq id no:8中加了下划线显示)。如图1中所示的,第二种类型的发夹供体构建体中供体模板的示例性序列显示在序列seq id no:9中。如seq id no:9的序列中可见的,第一dna结合蛋白靶序列位于供体模板3’端的近端(在seq id no:9中以粗体显示),并且第二dna结合蛋白靶序列位于第一dna结合蛋白靶序列的上游(在seq id no:9中加了下划线显示)。发夹/引物供体构建体
81.如图1中所示的,供体构建体的另一种形式是“发夹/引物”供体构建体。发夹/引物供体构建体可以包含两个多核苷酸分子。第一多核苷酸可以包含具有sshdrt、第一dna结合蛋白靶序列、第二dna结合蛋白靶序列和第三dna结合蛋白靶序列的供体模板。第一dna结合蛋白靶序列可以位于供体模板的5’端处或供体模板5’端的近端;第二dna结合蛋白靶序列可以位于第一dna结合蛋白靶序列的下游(例如,3至10、3至9、3至8、3至7、3至6或3至5个核苷酸),以与第一dna结合蛋白靶序列形成发夹;并且第三dna结合蛋白靶序列可以位于供体模板的3’端处或供体模板3’端的近端(例如,如图1中所示的第一种类型的发夹/引物供体构建体)。第一和第二dna结合蛋白靶序列可以彼此杂交,以在供体模板中形成发夹。发夹/引物供体构建体可包含具有第四dna结合蛋白靶序列的第二多核苷酸,其中第四dna结合蛋白靶序列可与供体构建体中第一多核苷酸中的第三dna结合蛋白靶序列杂交。在发夹/引物供体构建体的其他实施方案中,供体构建体中的第一多核苷酸可以包含位于供体模板3’端处或供体模板3’端的近端的第一dna结合蛋白靶序列、位于第一dna结合蛋白靶序列上游(例如,3至10、3至9、3至8、3至7、3至6或3至5个核苷酸)的第二dna结合蛋白靶序列,以及位于供体模板5’端处或供体模板5’端的近端的第三dna结合蛋白靶序列(例如,如图1中所示的第二种类型的发夹/引物供体构建体)。
82.当同一多核苷酸链中的两个多核苷酸区域杂交形成以未配对环结束的双螺旋或双链双链体时,形成发夹。在一些实施方案中,发夹中的未配对环具有4至200(例如,4至180、4至160、4至140、4至120、4至100、4至80、4至60、4至40、4至20、4至10、4至8、8至200、10至200、20至200、40至200、60至200、80至200、100至200、120至200、140至200、160至200或180至200)个核苷酸。在一些实施方案中,在发夹中杂交的两个多核苷酸区域中的每一个都是10至50(例如,10至45、10至40、10至35、10至30、10至25、10至20、10至15、15至50、20至50、25至50、30至50、35至50、40至50或45至50)个核苷酸。
83.发夹/引物供体构建体中供体模板的一些示例性序列显示在seq id no:10和11
中。如seq id no:10的序列中可见的,第一dna结合蛋白靶序列位于供体模板5’端的近端(在seq id no:10中以粗体显示),第二dna结合蛋白靶序列位于第一dna结合蛋白靶序列的下游(在seq id no:10中加了下划线显示),且第三dna结合蛋白靶序列位于供体模板的3’端的近端(在seq id no:10中以粗体和下划线显示)。随机核苷酸区域可以被放置在第一dna结合蛋白靶序列的5’处,以及第三dna结合蛋白靶序列的3’处,以便促进dna结合蛋白的结合。
84.在另一实例中,如seq id no:11的序列中可见的,第一dna结合蛋白靶序列位于供体模板5’端的近端(在seq id no:11中以粗体显示),第二dna结合蛋白靶序列位于供体模板3’端的近端(在seq id:11中加了下划线显示),且第三dna结合蛋白靶序列位于第二dna结合蛋白靶序列的上游(在序列seq id no:11中以粗体和下划线显示)。随机核苷酸区域可以被放置在第一dna结合蛋白靶序列的5’处,以及第二dna结合蛋白靶序列的3’处,以促进dna结合蛋白的结合。混合环供体构建体
85.如图1中所示的,供体构建体的另一种形式是“混合环”供体构建体。混合环供体构建体包含两个供体模板,它们经由每个供体模板末端处的序列彼此杂交。在一些实施方案中,混合环供体构建体中的两个供体模板中的每一个都有发夹。混合环供体构建体可以包含具有第一sshdrt、第一dna结合蛋白靶序列和第二dna结合蛋白靶序列的第一供体模板,以及具有第二sshdrt、第三dna结合蛋白靶序列以及第四dna结合蛋白靶序列的第二供体模板。第一和第二dna结合蛋白靶序列可以彼此杂交,从而使第一供体模板形成发夹。第三和第四dna结合蛋白靶序列可以彼此杂交,从而使第二供体模板形成发夹。在一些实施方案中,第一供体模板在其5’端处包含杂交序列,且第二供体模板在其5’端处包含互补的杂交序列,使得两个杂交序列可以彼此杂交,以将第一和第二供体模板结合在一起,从而形成混合环供体构建体。在其他实施方案中,第一供体模板在其3’端处包含杂交序列,且第二供体模板在其3’端处包含互补的杂交序列,使得两个杂交序列可以彼此杂交,以将第一和第二供体模板结合在一起,从而形成混合环供体构建体。此外,它们各自的供体模板中的第一sshdrt和第二sshdrt可以具有相同的序列或不同的序列。每个供体模板中的末端序列可以具有4至30(例如,4至28、4至26、4至24、4至22、4至20、4至18、4至16、4至14、4至12、4至10、4至8、4至6、6至30、8至30、10至30、12至30、14至30、16至30、18至30、20至30、22至30、24至30、26至30或28至30)个核苷酸。
86.当同一多核苷酸链中的两个多核苷酸区域杂交形成以未配对环结束的双螺旋或双链双链体时,形成发夹。在一些实施方案中,发夹中的未配对环具有4至200(例如,4至180、4至160、4至140、4至120、4至100、4至80、4至60、4至40、4至20、4至10、4至8、8至200、10至200、20至200、40至200、60至200、80至200、100至200、120至200、140至200、160至200或180至200)个核苷酸。在一些实施方案中,在发夹中杂交的两个多核苷酸区域中的每个为10至50(例如,10至45、10至40、10至35、10至30、10至25、10至20、10至15、15至50、20至50、25至50、30至50、35至50、40至50或45至50)个核苷酸。
87.混合环供体构建体中供体模板的一些示例性序列显示在seq id no:12和13中。seq id no:12的序列中的双下划线部分可以与seq id no:13的序列中的双下划线部分杂交,以将两个供体模板结合在一起,从而形成混合环供体构建体。此外,第一供体模板包含
第一dna结合蛋白靶序列(在seq id no:12中以粗体显示)和第二dna结合蛋白靶序列(在seq id no:12中加了下划线显示),其中第一和第二dna结合蛋白靶序列彼此杂交,以在第一供体模板中形成发夹。第二供体模板包含第三dna结合蛋白靶序列(在seq id no:13中以粗体显示)和第四dna结合蛋白靶序列(在seq id no:13中加了下划线显示),其中第三和第四dna结合蛋白靶序列彼此杂交,以在第二供体模板中形成发夹。
88.在另一实例中,混合环供体构建体包含序列seq id no:14和15。第一供体模板(seq id no:14)具有dna结合蛋白靶序列(在seq idno:14中以粗体显示),并且第二供体模板(seq id no:15)具有dna结合蛋白靶序列(在seq id no:15中以粗体显示)。seq id no:14中的双下划线部分与seq id no:15中的双下划线部分杂交,以将两个供体模板结合在一起,从而形成混合环供体构建体。帽供体构建体
89.如图1中所示的,供体构建体的另一种形式是“帽”供体构建体。帽供体构建体包含由两个或更多个多核苷酸分子形成的一个供体模板。在一些实施方案中,帽供体构建体包含由两个多核苷酸分子形成的一个供体模板。例如,帽供体构建体可以包含具有sshdrt的第一多核苷酸,以及具有第一dna结合蛋白靶序列、第二dna结合蛋白靶序列和5’端序列的第二多核苷酸。第一和第二dna结合蛋白靶序列可以彼此杂交,以在供体构建体的第二多核苷酸中形成发夹。此外,第二多核苷酸中的5’端序列可以与第一多核苷酸5’端处的序列杂交。
90.在另一实例中,帽供体构建体可以包含具有sshdrt的第一多核苷酸,具有第一dna结合蛋白靶序列、第二dna结合蛋白靶序列和5’端序列的第二多核苷酸,具有第三dna结合蛋白靶序列、第四dna结合蛋白靶序列和3’端序列的第三多核苷酸。第一和第二dna结合蛋白靶序列可以彼此杂交,以在供体构建体的第二多核苷酸中形成发夹。第三和第四个dna结合蛋白靶序列可以彼此杂交,以在供体构建体的第三多核苷酸中形成发夹。此外,第二多核苷酸中的5’端序列可以与第一多核苷酸5’端处的序列杂交,并且第三多核苷酸中的3’端序列可以与第一多核苷酸3’端处的序列杂交,以形成帽供体构建体(例如,参见图1)。此外,帽供体构建体可以包含与sshdrt的内部序列杂交的多核苷酸分子(例如,参见图1中的内部帽)。内部帽供体构建体可以包含具有sshdrt的第一多核苷酸,具有第一dna结合蛋白靶序列、第二dna结合蛋白靶序列和第一内部序列的第二多核苷酸,具有第三dna结合蛋白靶序列、第四dna结合蛋白靶序列和第二内部序列的第三多核苷酸。第二多核苷酸中的第一内部序列可以与第一多核苷酸的sshdrt中的序列杂交,并且第三多核苷酸中的第二内部序列可以与第一多核苷酸的sshdrt中的序列杂交,以形成内部帽供体构建体(例如,参见图1)。
91.当同一多核苷酸链中的两个多核苷酸区域杂交形成以未配对环结束的双螺旋或双链双链体时,形成发夹。在一些实施方案中,发夹中的未配对环具有4至200(例如,4至180、4至160、4至140、4至120、4至100、4至80、4至60、4至40、4至20、4至10、4至8、8至200、10至200、20至200、40至200、60至200、80至200、100至200、120至200、140至200、160至200或180至200)个核苷酸。在一些实施方案中,在发夹中杂交的两个多核苷酸区域中的每个为10至50(例如,10至45、10至40、10至35、10至30、10至25、10至20、10至15、15至50、20至50、25至50、30至50、35至50、40至50或45至50)个核苷酸。
92.在帽供体构建体的其他实施方案中,构建体可以由两个多核苷酸形成。例如,具有
sshdrt的第一多核苷酸和具有第一dna结合蛋白靶序列、第二dna结合蛋白靶序列和5’端序列的第二多核苷酸,其中第一和第二dna结合蛋白靶序列可以彼此杂交以在第二多核苷酸中形成发夹,并且5’端序列可以与第一多核苷酸5’端处的序列杂交。在其他实施方案中,第二多核苷酸可以在3’端处具有序列,而不是5’端序列,该序列可以与第一多核苷酸3’端处的序列杂交。
93.帽供体构建体中供体模板的一些示例性序列显示在seq idno:18-20中,它们分别形成帽供体构建体中的第一、第二和第三多核苷酸。帽供体构建体包含具有sshdrt的第一多核苷酸(seq id no:18),具有第一dna结合蛋白靶序列(在seq id no:19中以粗体显示)、第二dna结合蛋白靶序列(在seq id no:19中加了下划线显示)和5’端序列(在seq id no:19中以双下划线显示)的第二多核苷酸,具有第三dna结合蛋白靶序列(在seq id no:20中以粗体显示)、第四dna结合蛋白靶序列(在seq id no:20中加了下划线显示)和3’端序列(在seq id no:20中以双下划线显示)的第三多核苷酸。此外,第二多核苷酸的5’端序列(在seq id no:19中以双下划线显示)可以与第一多核苷酸5’端处的序列(在seq id no:18中以双下划线显示)杂交,并且第三多核苷酸中的3’端序列(在seq id no:20中以双下划线显示)可以与第一多核苷酸的3’端处序列(在seq id no:18中以双下划线显示)杂交,以形成帽供体构建体(参见,例如,图1)。
94.在另一实例中,内部帽供体构建体中供体模板的一些示例性序列显示在seq id no:21-24中,它们分别形成内部帽供体结构中的第一、第二、第三和第四多核苷酸。内部帽供体构建体包含具有sshdrt的第一多核苷酸(seq id no:21),具有第一dna结合蛋白靶序列(在seq id no:22中以粗体显示)、第二dna结合蛋白靶序列(在seq id no:22中以加了下划线显示)和第一内部序列(在seq id no:22中加了下划线显示)的第二多核苷酸,具有第三dna结合蛋白靶序列(在seq id no:23中以粗体显示)、第四dna结合蛋白靶序列(在seq id no:23中加了下划线显示)和第二内部序列(在seq id no:23中以双下划线显示)的第三多核苷酸,以及具有第五dna结合蛋白靶序列(在seq id no:24中以粗体显示)、第六dna结合蛋白靶序列(在seq id no:24中加了下划线显示)和第三内部序列(在seq id no:24中以双下划线显示)的第四多核苷酸。此外,第二多核苷酸中的第一内部序列(在seq id no:22中以双下划线显示)可以与第一多核苷酸内的序列(在seq id no:21中以粗体显示)杂交,第三多核苷酸中的第二内部序列(在seq id no:23中以双下划线显示)可以与第一多核苷酸内的序列(在seq id no:21中加了下划线显示)杂交,并且第四多核苷酸中的第三内部序列(在seq id no:24中以双下划线显示)可以与第一多核苷酸内的序列(在seq id no:21中以双下划线显示)杂交,以形成内部帽供体构建体(参见,例如,图1)。双发夹供体构建体
95.如图1中所示的,供体构建体的另一种形式是“双发夹”供体构建体。双发夹供体构建体包含经由供体模板中的sshdrt区域彼此杂交的两个供体模板。例如,第一供体模板可以具有sshdrt、位于第一供体模板的5’端处或第一供体模板5’端的近端的第一dna结合蛋白靶序列,以及位于第一dna结合蛋白靶序列下游(例如,3至10、3至9、3至8、3至7、3至6或3至5个核苷酸)的第二dna结合蛋白靶序列,其中第一和第二dna结合蛋白靶序列可以彼此杂交,以在第一供体模板中形成发夹。第二供体模板可以具有sshdrt、位于第二供体模板的5’端处或第二供体模板5’端的近端的第三dna结合蛋白靶序列,以及位于第三dna结合蛋白靶
序列下游(例如,3至10、3至9、3至8、3至7、3至6或3至5个核苷酸)的第四dna结合蛋白靶序列,其中第三和第四dna结合蛋白靶序列可以彼此杂交,以在第二供体模板中形成发夹。此外,两个供体模板中的两个sshdrt区域可以彼此杂交,以将两个供体模板结合在一起,从而形成双发夹供体构建体。
96.双发夹供体构建体中供体模板的一些示例性序列显示在seq id no:16和17中。如seq id no:16中的序列可见的,第一供体模板包含第一dna结合蛋白靶序列(在seq id no:16中以粗体显示)和位于第一dna结合蛋白靶序列下游的第二dna结合蛋白靶序列(在seq idno:16中加了下划线显示),其中第一和第二dna结合蛋白靶序列可以彼此杂交,以在第一供体模板中形成发夹。第二供体模板包含第三dna结合蛋白靶序列(在seq id no:17中以粗体显示)和位于第三dna结合蛋白靶序列下游的第四dna结合蛋白靶序列(在seq id no:17中加了下划线显示),其中第三和第四dna结合蛋白靶序列可以彼此杂交,以在第二供体模板中形成发夹。此外,seq id no:16的序列中的双下划线部分和seq id no:17的序列中的双下线部分可以彼此杂交,以将两个供体模板结合在一起,从而形成双发夹供体构建体。
97.当同一多核苷酸链中的两个多核苷酸区域杂交形成以未配对环结束的双螺旋或双链双链体时,形成发夹。在一些实施方案中,发夹中的未配对环具有4至200(例如,4至180、4至160、4至140、4至120、4至100、4至80、4至60、4至40、4至20、4至10、4至8、8至200、10至200、20至200、40至200、60至200、80至200、100至200、120至200、140至200、160至200或180至200)个核苷酸。在一些实施方案中,在发夹中杂交的两个多核苷酸区域中的每个为10至50(例如,10至45、10至40、10至35、10至30、10至25、10至20、10至15、15至50、20至50、25至50、30至50、35至50、40至50或45至50)个核苷酸。供体模板的表征
98.此外,在本文所述的供体模板中,供体模板还可以包括原间隔序列邻近基序(pam)序列。cas9蛋白通过首先识别位于靶核酸3’处的3碱基对pam来识别靶核酸。一旦pam被识别,rnp复合体中的靶grna与pam上游的靶核酸杂交。供体构建体中的供体模板还可以在供体模板的5’和3’端的一处或两处包含一个或多个边缘序列。供体模板中的边缘序列可以促进供体模板和dna结合蛋白(例如rna引导的核酸酶)之间的结合。在一些实施方案中,边缘序列可以具有至少2个核苷酸,例如2至24个核苷酸(例如,2至22、2至20、2至18、2至16、2至14、2至12、2至10、2至8、2至6、2至4、4至24、6至24、8至24、10至24、12至24、14至24、16至24、18至24、20至24或22至24个核苷酸;2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23或24个核苷酸)。
99.在一些实施方案中,供体构建体中供体模板的大小或长度大于约200bp、250bp、300bp、350bp、400bp、450bp、500bp、550bp、600bp、650bp、700bp、750bp、800bp、850bp、900bp、1kb、1.1kb、1.2kb、1.3kb、1.4kb、1.5kb、1.6kb、1.7kb、1.8kb、1.9kb、2.0kb、2.1kb、2.2kb、2.3kb、2.4kb、2.5kb、2.6kb、2.7kb、2.8kb、2.9kb、3kb、3.1kb、3.2kb、3.3kb、3.4kb、3.5kb、3.6kb、3.7kb、3.8kb、3.9kb、4.0kb、4.1kb、4.2kb、4.3kb、4.4kb、4.5kb、4.6kb、4.7kb、4.8kb、4.9kb、5.0kb、5.1kb、5.2kb、5.3kb、5.4kb、5.5kb、5.6kb、5.7kb、5.8kb、5.9kb、6.0kb、6.1kb、6.2kb、6.3kb、6.4kb、6.5kb、6.6kb、6.7kb、6.8kb、6.9kb、7.0kb、7.1kb、7.2kb、7.3kb、7.4kb、7.5kb、7.6kb、7.7kb、7.8kb、7.9kb、8.0kb、8.1kb、8.2kb、8.3kb、8.4kb、8.5kb、8.6kb、8.7kb、8.8kb、8.9kb、9.0kb、9.1kb、9.2kb、9.3kb、9.4kb、
9.5kb、9.6kb、9.7kb、9.8kb、9.9kb、10.0kb,这些尺寸中的任何大小的模板,或大于10kb。例如,模板的大小可以为约200bp至约500bp、约200bp至约750bp、约200bp至约1kb、约200bp至约1.5kb、约200bp至约2.0kb、约200bp至约2.5kb、约200bp至约3.0kb、约200bp至约3.5kb、约200bp至约4.0kb、约200bp至约4.5kb、约200bp至约5.0kb。iii.组合物
100.本公开提供了用于修饰靶核酸的组合物和方法,其包括:(a)可靶向的核酸酶;(b)dna结合蛋白;和(c)本文所描述的供体构建体。可靶向的核酸酶和dna结合蛋白可以相同,例如,rna引导的核酸酶(例如,cas蛋白,在本文中进一步详细描述的)。组合物可以包含靶向导rna(grna)和供体grna。在某些实施方案中,靶grna与靶核酸互补。在一些实施方案中,dna结合蛋白靶序列与供体grna序列的等长部分互补。
101.dna结合蛋白可以直接或间接结合供体构建体内的dna结合蛋白靶序列。如本文进一步详细描述的,在一些实施方案中,当dna结合蛋白是转录激活因子样(tal)效应dna结合蛋白时,tal效应dna结合蛋白可以直接识别并结合到dna结合靶序列。在一些实施方案中,当dna结合蛋白是锌指dna结合蛋白时,锌指dna结合蛋白可以直接识别并结合到dna结合靶序列。在其他实施方案中,当dna结合蛋白是rna引导的核酸酶(例如,cas蛋白)时,rna引导的核酸酶可以经由供体grna间接结合到dna结合蛋白靶序列,供体grna可与dna结合蛋白靶序列杂交。不受任何理论的束缚,dna结合蛋白用于将供体构建体转运或穿梭到靠近靶核酸的细胞位置。因此,dna结合蛋白可以改善hdrt向靶细胞内的递送,尤其是向细胞核的递送,并提高敲入效率。
102.在一些实施方案中,将可靶向的核酸酶与核定位信号(nls)序列融合。在一些实施方案中,dna结合蛋白与nls序列融合。本领域已知nls序列的实例,例如,如描述于lange等人,j biol chem.282(8):5101-5,2007,并且还包括但不限于:avkrpaatkkagqakkkkld(seq idno:25)、msrrrkanptklsenakklakeven(seq id no:26)、paakrvkld(seq id no:27)、klkikrpvk(seq id no:28)和pkkkrkv(seq id no:29)。可以与rna引导的核酸酶融合的其他肽或蛋白质的实例(如细胞穿透肽和细胞靶向肽)在本领域中是可用的,并被描述于,例如,viv
è
s等人,biochim biophys acta.1786(2):126-38,2008。在某些实施方案中,可靶向的核酸酶具有核酸酶活性。在其他实施方案中,可靶向的核酸酶不具有核酸酶活性。
103.此外,可以向组合物中添加阴离子聚合物。不受任何理论的束缚,向组合物中添加阴离子聚合物可以稳定cas蛋白和sgrna核糖核蛋白(rnp)复合体并防止聚集。本文进一步描述了阴离子聚合物的实例。
104.在该组合物的一些实施方案中,靶grna和供体grna可以具有相同的序列。在其他实施方案中,靶grna和供体grna具有不同的序列。
105.在本文所述组合物的一些实施方案中,可靶向的核酸酶是第一rna引导的核酸酶,dna结合蛋白是第二rna引导的核酸蛋白酶,并且供体构建体中的供体模板还包含一个或多个原间隔序列邻近基序(pam)。在一些实施方案中,组合物还进一步包含与靶核酸互补的靶grna以及与dna结合蛋白靶序列杂交的供体grna。靶grna可以与第一rna引导的核酸酶形成第一rnp复合体,并将第一rna引导的核酸酶(例如,cas蛋白)引导至靶核酸。在一些实施方案中,靶grna的一部分(例如,作为至少15个核苷酸(例如,15、16、17、18、19、20、21、22、23、24或25个核苷酸)的靶grna的一部分)与靶核酸互补。供体grna可以与第二rna引导的核酸
酶形成第二rnp。供体模板中的dna结合蛋白靶序列可以与供体grna或其一部分杂交。因此,含有第二rna引导的核酸酶、供体grna和供体构建体的复合体可以将供体结构引入所期望的细胞内位置(例如细胞核),以用于在靶核酸的整合位点处发生同源重组。在一些实施方案中,第一和第二rna引导的核酸酶是相同的。在其他实施方案中,第一和第二rna引导的核酸酶不同。在其他实施方案中,本文所述组合物还可以被用于通过非同源定向修复介导的方法(如不依赖同源性的靶向整合(hiti))来整合供体构建体。iv.单向导rna
106.cas蛋白可以由单向导rna(sgrna)引导至其靶dna。sgrna是天然存在的两段式向导rna(crrna和tracrrna)的一种形式,其被工程化为单连续的序列。sgrna可以包含将cas蛋白靶向靶dna的向导序列(例如,sgrna的crrna等效部分),以及与cas蛋白相互作用的支架序列(例如,sgrna的tracrrna等效部分)。可以使用软件选择sgrna。作为一个非限制性实例,选择sgrna的考虑因素可以包括,例如,待使用的cas9蛋白的pam序列,以及最小化脱靶修饰的策略。诸如和crispr设计工具的工具可以提供用于制备sgrna的序列,以用于评估靶修饰效率、和/或评估脱靶位点的切割。在一些实施方案中,代替sgrna,grna也可以被作为包含crrna和tracrrna的两段氏组分来递送。向导序列
107.sgrna中的向导序列可能与靶dna中的特定序列互补。靶dna序列的3’端后可以是pam序列。pam序列上游大约20个核苷酸是靶dna。通常,cas9蛋白或其变体在pam序列上游切割约三个核苷酸。sgrna中的向导序列可以与靶dna的任一条链互补。
108.在一些实施方案中,sgrna的向导序列在可以使用rna-dna互补碱基配对将cas蛋白导向至靶dna位点的sgrna的5’端处,可以包含约10至约2000个核酸,例如,约10至约100个核酸、约10至约500个核酸、约10至约1000个核酸、约10至约1500个核酸、约10至约2000个核酸、约50至约100个核酸、约50至约500个核酸、约50至约1000个核酸、约50至约1500个核酸、约50至约2000个核酸、约100至约500个核酸、约100至约1000个核酸、约100至约1500个核酸、约100至约2000个核酸、约500至约1000个核酸、约500至约1500个核酸、约500至约2000个核酸、约1000至约1500个核酸、约1000至约2000个核酸或约1500至约2000个核酸。在一些实施方案中,sgrna的向导序列在可以使用rna-dna互补碱基配对将cas蛋白导向至靶dna位点的sgrna的5’端处包含约100个核酸。在一些实施方案中,向导序列在可以使用rna-dna互补碱基配对将cas蛋白导向至靶dna位点的sgrna的5’端处包含20个核酸。在其他实施方案中,向导序列包含少于20个(例如19、18、17、16、15个或更少)与靶dna位点互补的核酸。在一些情况下,sgrna中的向导序列在靶dna位点的互补区域中包含至少一个核酸错配。在一些情况下,向导序列在靶dna位点的互补区域中包含约1至约10个核酸错配(例如,1、2、3、4、5、6、7、8、9或10个核酸错配)。支架序列
109.sgrna中的支架序列可以作为与cas蛋白或其变体相互作用的蛋白结合序列。在一些实施方案中,sgrna中的支架序列可以包含两个互补的核苷酸片段,其彼此杂交以形成双链rna双链体(dsrna双链体)。支架序列可以具有诸如下茎、凸起、上茎、连结(nexus)和/或发夹的结构。在一些实施方案中,sgrna中的支架序列可以为约90个核酸至约120个核酸,例如,约90个核酸至约115个核酸、约90个核酸至约110个核酸、约90个核酸至约105个核酸、约
90个核酸至约100个核酸、约90个核酸至约95个核酸、约95个核酸至约120个核酸、约100个核酸至约120个核酸、约105个核酸至约120个核酸、约110个核酸至约120个核酸或约115个核酸至约120个核酸。v.靶grna和供体grna
110.向导rna(grna)通常指dna靶向rna,其包含(1)向导序列,其与靶核酸互补,并将rna引导的核酸酶引导至靶核酸,和(2)支架序列,其与rna引导的核酸酶相互作用和结合。在本公开的一些实施方案中,靶grna和供体grna具有相同的序列。在本公开的其他实施方案中,靶grna和供体grna具有不同的序列。在本文所述的组合物和方法中,靶grna包含与靶核酸互补的部分。一旦靶grna与可靶向的核酸酶(例如,第一rna引导的核酸酶)形成rnp复合体,rnp复合体就可以通过靶grna和靶核酸之间的互补性被引导至靶核酸。在一些实施方案中,可靶向的核酸酶是cas蛋白(如cas9蛋白)。cas9蛋白通过首先识别位于靶核酸3’处的3碱基对原间隔序列邻近基序(pam)来识别靶核酸。一旦pam被识别,rnp复合体中的靶grna就与pam上游的靶核酸杂交。在一些实施方案中,靶grna包括与靶核酸中为pam序列上游大约20个核苷酸的部分互补的核苷酸的一部分。通常,cas9蛋白或其变体切割pam序列上游的约三个核苷酸。可以使用软件选择grna。作为一个非限制性实例,选择grna的考虑因素可以包括,例如,待使用的rna引导的核酸酶的pam序列,以及最小化脱靶修饰的策略。诸如和crispr设计工具的工具可以提供用于制备grna的序列,以用于评估靶修饰效率和/或评估脱靶位点处的切割。
111.在一些实施方案中,靶grna包含与靶核酸互补的至少15个核苷酸(例如,15、16、17、18、19、20、21、22、23、24或25个核苷酸)的一部分。在一些实施方案中,靶grna可以与靶核酸完全互补或部分互补。在一些实施方案中,靶核酸中至少60%(例如,65%、70%、75%、80%、85%、90%、95%或97%)的核苷酸可以与其靶grna中的它们对应的核苷酸进行watson-crick碱基配对。
112.与靶grna类似,供体grna与dna结合蛋白形成复合体(例如,rna引导的核酸酶)。在本文所述的组合物和方法中,供体grna包含与dna结合蛋白靶序列互补的部分。一旦供体grna与dna结合蛋白(例如rna引导的核酸酶)形成rnp复合体,rnp复合体就可以通过供体grna与dna结合蛋白靶序列之间的互补性被引导至供体构建体。在一些实施方案中,dna结合蛋白靶序列与供体grna序列的等长部分互补。在一些实施方案中,供体grna包含可以与dna结合蛋白靶序列杂交的至少15个核苷酸(例如,15、16、17、18、19、20、21、22、23、24或25个核苷酸)的一部分。供体grna可以与dna结合蛋白靶序列完全互补或部分互补。在一些实施方案中,dna结合蛋白靶序列中的核苷酸的至少60%(例如,65%、70%、75%、80%、85%、90%、95%或97%)可以与供体grna中的它们的对应核苷酸进行watson-crick碱基配对。在一些实施方案中,当dna结合蛋白靶序列和供体grna杂交时,dna结合蛋白靶序列可以具有与供体grna中的其对应的核苷酸错配的至少一个(例如,一个、两个、三个、四个、五个、六个、七个、八个、九个或十个)核苷酸。错配碱基的实例包括鸟嘌呤和尿嘧啶、鸟嘌呤和胸腺嘧啶以及腺嘌呤与胞嘧啶配对。
113.在本公开的一些实施方案中,靶grna和供体grna具有相同的序列,并且可靶向的核酸酶和dna结合蛋白中的每一种都是rna引导的核酸酶(例如,cas蛋白)。在这种情况下,grna可以与rna引导的核酸酶形成第一rnp复合体。第一rnp复合体可以经由grna和靶核酸
albus)、嗜黏蛋白阿克曼菌(akkermansia muciniphila)、嗜酸纤维素分解菌(acidothermus cellulolyticus)、长双歧杆菌(bifidobacterium longum)、齿双歧杆菌(bifidobacterium dentium)、白喉棒状杆菌(corynebacterium diphtheria)、细小迷踪菌(elusimicrobium minutum)、硝化裂化器菌(nitratifractor salsuginis)、螺旋体球菌(sphaerochaeta globus)、产琥珀酸丝状杆菌产琥珀酸亚种(fibrobacter succinogenes subsp.succinogenes)、脆弱拟杆菌(bacteroides fragilis)、黄褐二氧化碳嗜纤维菌(capnocytophaga ochracea)、沼泽红假单胞菌(rhodopseudomonas palustris)、彩虹普雷沃菌(prevotella micans)、栖瘤胃普雷沃氏菌(prevotella ruminicola)、柱状黄杆菌(flavobacterium columnare)、少食氨基单胞菌(aminomonas paucivorans)、深红红螺菌(rhodospirillum rubrum)、海水螺菌暂定种(candidatus puniceispirillum marinum)、艾森氏蠕形杆菌(verminephrobacter eiseniae)、蒲桃雷尔氏菌(ralstonia syzygii)、恒雄芝氏沟鞭藻玫瑰杆菌(dinoroseobacter shibae)、固氮螺菌属(azospirillum)、汉氏硝化细菌(nitrobacter hamburgensis)、慢生根瘤菌(bradyrhizobium)、产琥珀酸沃廉菌(wolinella succinogenes)、空肠弯曲杆菌空肠亚种(campylobacter jejuni subsp.jejuni)、幽门螺杆菌(helicobacter mustelae)、蜡状芽孢杆菌(bacillus cereus)、食酸铁氧化菌(acidovorax ebreus)、产气荚膜梭菌(clostridium perfringens)、食清洁剂细小棒菌(parvibaculum lavamentivorans)、肠道罗斯拜瑞氏菌(roseburia intestinalis)、脑膜炎奈瑟菌(neisseria meningitidis)、多杀巴斯德杆菌病多杀亚种(pasteurella multocida subsp.multocida)、华德萨特菌(sutterella wadsworthensis)、变形菌门(proteobacterium)、嗜肺军团菌(legionella pneumophila)、parasutterella excrementihominis、产琥珀酸沃廉菌(wolinella succinogenes)和新凶手弗朗西斯菌(francisella novicida)。
117.cas9蛋白是指rna引导的双链dna结合核酸酶蛋白或切口酶蛋白。野生型cas9核酸酶有两个功能结构域(例如ruvc和hnh),其切割不同的dna链。当两个功能结构域都有活性时,cas9可以诱导基因组dna(靶dna)的双链断裂。cas9酶可包含一个或多个cas9蛋白的催化结构域,该cas9蛋白来源于以下的细菌:棒状杆菌属(corynebacter)、萨特氏菌属(sutterella)、军团菌属(legionella)、密螺旋体属(treponema)、产线菌(属filfactor)、真杆菌属(eubacterium)、链球菌属(streptococcus)、乳酸杆菌属(lactobacillus)、支原体属(mycoplasma)、拟杆菌属(bacteroides)、弗维菌属(flavivola)、黄杆菌属(flavobacterium)、鳞球菌属(sphaerochaeta)、固氮螺旋菌属(azospirillum)、葡糖醋杆菌属(gluconacetobacter)、奈瑟氏菌属(neisseria)、罗氏菌属(roseburia)、细小棒状菌属(parvibaculum)、葡萄球菌属(staphylococcus)、nitratifractor和弯曲杆菌属(campylobacter)。在一些实施方案中,cas9可以是融合蛋白,例如,两个催化结构域来源于不同的细菌物种。
118.在一些实施方案中,cas蛋白可以是cas蛋白变体。例如,cas9核酸酶的有用变体可以包括单非活性催化结构域,如ruvc酶或hnh-酶或切口酶。cas9切口酶只有一个活性功能结构域,并且只能切割靶dna的一条链,从而产生单链断裂或切口。在一些实施方案中,cas9核酸酶可以是具有一个或多个氨基酸突变的突变cas9核酸酶。例如,至少具有d10a突变的突变cas9是cas9切口酶。在其他实施方案中,具有至少h840a突变的突变cas9核酸酶是cas9
切口酶。cas9切口酶中存在的突变的其他实例包括但不限于n854a和n863a。如果使用靶向相反dna链的至少两种dna靶向rna,则可以使用cas9切口酶引入双链断裂。通过nhej或hdr可修复双切口引起的双链断裂(ran等人,2013,cell,154:1380-1389)。cas9核酸酶或切口酶的非限制性实例描述于例如,在美国专利第8,895,308号;第8,889,418号和第8,865,406号以及美国申请公开第2014/0356959号、第2014/0273226号和第2014/0186919号中。可以针对靶细胞或靶生物体对cas9核酸酶或切口酶进行密码子优化。
119.在一些实施方案中,缺乏切割(例如,切口酶)活性的cas蛋白变体。cas蛋白变体可以包含一个或多个点突变,其消除蛋白的切口酶活性。在一些实施方案中,此类cas蛋白变体可与其他蛋白质融合并用作靶向结构域以将其他蛋白质导向至靶核酸。例如,无切口酶活性的cas蛋白变体可以与转录激活或抑制结构域融合,以控制基因表达(ma等人,protein and cell,2(11):879-888,2011;maeder等人,nature methods,10:977-979,2013;和konermann等人,nature,517:583-588,2014)。缺乏切口酶活性的cas蛋白变体可以被用于靶向基因组区域,产生rna定向转录对照。在一些实施方案中,无任何切割(例如,切口酶)活性的cas蛋白变体可以被用于将外源蛋白靶向至靶核酸。外源蛋白可以与cas蛋白变体融合,并且可以通过添加阴离子聚合物增强融合蛋白。外源蛋白可以是效应蛋白结构域。外源蛋白可以是转录激活物或阻遏物。外源蛋白的其他实例包括但不限于vp64-p65-rta(vpr)、vp64、p65、krab、十-十一易位甲基胞嘧啶双加氧酶(tet)和dna甲基转移酶(dnmt)。下面还描述了缺乏切割(例如切口酶)活性的特定cas蛋白变体。
120.在一些实施方案中,cas核酸酶可以是高保真或增强特异性的cas9多肽变体,其具有减少的脱靶效应和强的靶上切割。具有改善的靶上特异性的cas9多肽变体的非限制性实例包括slaymaker等人,science,351(6268):84-8(2016)中描述的spcas9(k855a)、spcas9(k810a/k1003a/r1060a)(也被称为espcas9(1.0))和spcas9(k848a/k1003a/r1060a)(也被称为espcas9(1.1))变体,以及kleinstiver等人,nature,529(7587):490-5(2016)中描述的spcas9变体,其包含以下突变中的一个、两个、三个或四个:n497a、r661a、q695a和q926a(例如,spcas9-hf1包含所有四个突变)。
121.在一些实施方案中,可靶向的核酸酶也可以是包含可结合至靶核酸的蛋白质和可切割靶核酸的蛋白质的融合蛋白。例如,能够识别并结合至靶核酸的蛋白质可以是没有任何切割活性的cas蛋白变体。没有任何切割活性的cas蛋白变体可以是包含ruvc1和hnh核酸酶结构域的两个沉默突变(d10a和h840a)的cas9多肽,其被称为dcas9(jinek等人,science,2012,337:816-821;qi等人,cell,152(5):1173-1183)。在一实施方案中,来自化脓性链球菌的dcas9多肽在位置d10、g12、g17、e762、h840、n854、n863、h982、h983、a984、d986、a987或以上的任何组合处包含至少一个突变。例如,国际专利公开第wo 2013/176772号中提供了此类dcas9多肽及其变体的描述。dcas9酶可以包含d10、e762、h983或d986处的突变,以及h840或n863处的突变。在一些情况下,dcas9酶可以包含d10a或d10n突变。而且,dcas9酶可以包含h840a、h840y或h840n。在一些实施方案中,dcas9酶可包含d10a和h840a;d10a和h840y;d10a和h840n;d10n和h840a;d10n和h840y;或d10n和h840n的取代。取代可以是保守性或非保守性取代,以使cas9多肽催化失活,并能够与靶dna结合。
122.在其他实施方案中,能够识别并结合至靶核酸的蛋白质可以是转录激活因子样(tal)效应dna结合蛋白或锌指dna结合蛋白。tal效应dna结合蛋白具有dna结合串联重复序
列的中心结构域,其通常含有长度为33-35个的氨基酸,以及在位置12和13处的可以识别一个或多个特定的dna碱基对的两个高变氨基酸残基。锌指dna结合蛋白具有dna结合基序,其特征在于通常是缺少或存在一个或多个锌离子,以协调和稳定基序折叠。锌指dna结合蛋白包含多个手指样突起,这使得与它们的靶分子串联接触。一些锌指dna结合蛋白也会形成盐桥来稳定手指样折叠。它们最初被鉴定为来自非洲爪蟾(xenopus laevis)(非洲爪蛙)的转录因子tfiiia中的dna结合基序,但现在它们被认为可以结合dna、rna、蛋白质和/或脂质底物。
123.在一些实施方案中,本文所述组合物和方法中的可靶向核酸酶可以是包含tal效应dna结合蛋白和可切割靶核酸的蛋白(也被称为“转录激活因子样效应核酸酶(talen)”)的融合蛋白。在其他实施方案中,本文所述组合物和方法中的可靶向的核酸酶可以是包含锌指dna结合蛋白和可切割靶核酸的蛋白的融合蛋白。例如,能够切割靶核酸的蛋白质可以是野生型或突变的foki核酸内切酶或foki的催化结构域。talen及其用于基因编辑的详细描述可见于例如美国专利第8,440,431号;第8,440,432号;第8,450,471号;第8,586,363号和第8,697,853号;scharenberg等人,curr gene ther,2013,13(4):291-303;gaj等人,nat methods,2012,9(8):805-7;beurdeley等人,nat commun,2013,4:1762;以及joung和sander,nat rev mol cell biol,2013,14(1):49-55。本领域描述了与可切割靶核酸的蛋白质融合的锌指dna结合蛋白的实例,并且包括但不限于以下中描述的那些:urnov等人,nature reviews genetics,2010,11:636-646;gaj等人,nat methods,2012,9(8):805-7;美国专利第6,534,261号;第6,607,882号;第6,746,838号;第6,794,136号;第6,824,978号;第6,866,997号;第6,933,113号;第6,979,539号;第7,013,219号;第7,030,215号;第7,220,719号;第7,241,573号;第7,241,574号;第7,585,849号;第7,595,376号;第6,903,185号;第6,479,626号;和美国申请公开第2003/0232410号和第2009/0203140号。
124.在一些实施方案中,可靶向的核酸酶不具有核酸酶活性。例如,可靶向的核酸酶(例如,无任何核酸酶活性的可靶向的核酸酶)可以调节靶核酸的表达。在一些实施方案中,可靶向的核酸酶可以是融合蛋白,其包括可结合至靶核酸的蛋白质,如无任何切割活性的cas蛋白变体(例如dcas9)、tal效应dna结合蛋白和如上所述的锌指dna结合蛋白,以及可修饰靶核酸的蛋白(如转录激活物或阻遏物)。在一些实施方案中,没有任何切割活性的cas蛋白变体(例如,dcas9)可以结合至由供体构建体中的dna结合蛋白靶序列形成的双链双链体,而具有切割活性的cas蛋白可以切割靶核酸,使其与供体构建体中的hdrt进行同源重组。vii.dna结合蛋白
125.dna结合蛋白是可以直接或间接与供体模板(其包括hdrt)内的dna结合蛋白靶序列结合的蛋白质。在一些实施方案中,dna结合蛋白可以是rna引导的核酸酶(例如,cas蛋白),其可以识别并结合dna结合蛋白靶序列,但不能切割dna结合蛋白靶序列。如上所述,rna引导的核酸酶可以经由供体grna与dna结合蛋白靶序列结合。在一些实施方案中,供体grna和dna结合蛋白靶序列可以具有部分互补性,这允许rna引导的核酸酶经由供体grna与dna结合蛋白靶序列结合,但不切割dna结合蛋白靶序列。在其他实施方案中,dna结合蛋白可以是如上所述的没有任何切割活性的cas蛋白变体(例如,dcas9)、tal效应dna结合蛋白或锌指dna结合蛋白。tal效应dna结合蛋白和锌指dna结合蛋白中的每一个都可以直接与
dna结合蛋白靶序列结合。不受任何理论的束缚,dna结合蛋白用于将供体构建体转运或穿梭到靠近靶核酸的细胞位置(例如细胞核)。viii.dna结合蛋白靶序列
126.dna结合蛋白靶序列是由dna结合蛋白识别并结合的核苷酸序列。在本文所述的组合物和方法中,一个或多个dna结合蛋白靶序列与hdrt一起存在于供体模板中,使得hdrt可以被带到或“穿梭”至所期望的细胞内位置(例如,细胞核)中,以靠近靶核酸。因此,dna结合蛋白靶序列可以帮助提高同源定向修复效率和靶核酸修饰效率。在一些实施方案中,dna结合蛋白靶序列可以与seq id no:30-35中任一个的序列具有至少90%(例如91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)的序列同一性。
127.在一些实施方案中,dna结合蛋白靶序列可被dna结合蛋白,例如,tal效应器dna结合蛋白或锌指dna结合蛋白直接识别和结合。在其他实施方案中,dna结合蛋白靶序列可经由供体grna被dna结合蛋白(例如rna引导的核酸酶)间接识别和结合。在一些实施方案中,dna结合蛋白靶序列中的核苷酸的至少60%(例如,65%、70%、75%、80%、85%、90%、95%或97%)可以与供体grna中的它们的对应核苷酸以watson-crick碱基配对接合。在一些实施方案中,当dna结合蛋白靶序列和供体grna杂交时,dna结合蛋白靶序列可以具有至少一个(例如,一个、两个、三个、四个、五个、六个、七个、八个、九个或十个)与供体grna中的其对应的核苷酸错配的核苷酸。错配碱基的实例包括鸟嘌呤和尿嘧啶、鸟嘌呤和胸腺嘧啶以及腺嘌呤与胞嘧啶配对。在一些实施方案中,dna结合蛋白靶序列是靶核酸的一部分。
128.dna结合蛋白靶序列仅被dna结合蛋白(例如,rna引导的核酸酶)识别和结合,但不被切割。在一些实施方案中,dna结合蛋白靶序列与供体grna序列的等长部分互补。在一些实施方案中,dna结合蛋白靶序列具有至少14个核苷酸,例如14至20个核苷酸(例如14至19、14至18、14至17、14至16或14至15个核苷酸;14、15、16、17、18、19或20个核苷酸)。dna结合蛋白靶序列可以包括12-20、14-20、14-19、16-18、15-17、12、13、14、15、16、17、18、19或20个核苷酸。在一些实施方案中,与供体grna序列的等长部分相比,dna结合蛋白靶序列是部分互补的,即包含核苷酸错配。例如,与供体grna序列的20个核苷酸部分相比,具有20个核苷酸的dna结合蛋白靶序列可能具有1至6个核苷酸错配(例如,1至5、1至4、1至3、1至2个核苷酸错配;1、2、3、4、5或6个核苷酸错配)。ix.阴离子聚合物
129.在本文所述组合物的一些实施方案中,可以将阴离子聚合物添加到组合物中,例如,以提高cas9蛋白和sgrna核糖核蛋白复合体(rnp)的稳定性和编辑效率。在一些实施方案中,将阴离子聚合物添加到含有cas蛋白(例如,cas9蛋白)的组合物或含有cas蛋白(例如,cas9蛋白)和sgrna-rnp复合体的组合物中,可以稳定cas蛋白或rnp复合体并防止聚集,从而产生高核酸酶活性和编辑效率。不受任何理论的束缚,阴离子聚合物(例如pga)可与cas蛋白有利地相互作用,即阴离子聚合物(如pga)可以与带正电荷(在生理ph下)的cas9蛋白有利地相互作用,将rnp复合体稳定成分散的颗粒,防止聚集,并提高核酸酶编辑活性和效率。阴离子聚合物可以是水溶性的。阴离子聚合物具有生物学上惰性的。在一些方面,阴离子聚合物不是dna序列。阴离子聚合物可能能够进行冷冻/解冻循环,同时保留全部或实质性功能。阴离子聚合物可以被冻干,同时保留全部或实质性功能。阴离子聚合物可以具有15,000至50,000kda(例如,15,000至45,000kda、15,000至40,000kda、15,000至35,000kda、
15,000至30,000kda、15,000至25,000kda、15,000至20,000kda、20,000至50,000kda、25,000至50,000kda、30,000至50,000kda、35,000至50,000kda、40,000至50,000kda或45,000至50,000kda)的分子量。阴离子聚合物可以是聚谷氨酸(pga)。在一些实施方案中,可以使用单链供体寡核苷酸(ssodn)来代替或添加至阴离子聚合物。ssodn的实例描述于例如okamoto等人,scientific report 9:4811,2019;和hu等人,nucleic acids,17:p198,2019中。
130.本文所述的阴离子聚合物可以被添加到组合物中,以稳定组合物、改善编辑、降低毒性、并使组合物能够冻干而不丧失活性。在一些实施方案中,含有cas蛋白和阴离子聚合物的组合物是水性组合物,其呈现均质,具有清晰的视觉外观,并且不含混浊沉淀物或聚集物。在一些实施方案中,含有cas蛋白和sgrna rnp复合体和阴离子聚合物的组合物是水性组合物,其呈现均质,具有清晰的视觉外观,并且不含混浊沉淀物或聚集物。在一些实施方案中,包含可靶向的核酸酶、dna结合蛋白、供体构建体和阴离子聚合物的组合物是水性组合物,其呈现均质,具有清晰的视觉外观,并且不含混浊沉淀物或聚集物。具有稳定的组成允许以高细胞存活率高效敲出基因和大规模转基因敲入。此外,组合物还可以被冻干燥以长期储存,并重构用于后续使用。包含阴离子聚合物的组合物也可以被用于修饰靶核酸的方法中,其中靶核酸可以被移除、替换为外源核酸序列,或外源核酸序列可以被插入到靶核酸中。
131.可添加至本文所述组合物中的阴离子聚合物是由具有总负电荷的亚单元或单体组成的分子。阴离子聚合物可以是阴离子多肽或阴离子多糖。阴离子多肽是一种阴离子聚合物,其至少50%(例如55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)的亚单元或单体是氨基酸(如酸性氨基酸(例如谷氨酸和天冬氨酸))、或其衍生物。阴离子多肽的实例包括但不限于聚谷氨酸(pga)(例如聚γ-谷氨酸)、聚天冬氨酸和聚羧基谷氨酸。在一些实施方案中,阴离子多肽是pga(例如,聚γ-谷氨酸),如聚(l-谷氨)酸或聚(d-谷氨)酸。阴离子多肽可以包含谷氨酸和天冬氨酸的混合物。在一些实施方案中,阴离子多肽中的亚单元或单体的至少50%(例如,55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)可以是谷氨酸和/或天冬氨酸。阴离子多糖是一种阴离子聚合物,其至少50%(例如55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)的亚单元或单体是糖分子(如单糖(例如果糖、半乳糖和葡萄糖)和二糖(例如透明质酸、乳糖、麦芽糖和蔗糖))、或其衍生物。阴离子多糖的实例包括但不限于透明质酸(ha)、肝素、硫酸肝素和糖胺聚糖。在一些实施方案中,阴离子多糖中的亚单元或单体的至少50%(例如,55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)可以是ha。阴离子聚合物的其他实例包括但不限于聚(丙烯酸)(paa)、聚(甲基丙烯酸)(pmaa)、聚(苯乙烯磺酸)和聚磷酸酯。
132.本文中的阴离子聚合物不是指完全由核苷酸组成的核酸(如脱氧核糖核酸(dna)、核糖核酸)。在一些实施方案中,阴离子聚合物可以包括一个或多个核酸碱基(例如鸟苷、胞苷、腺苷、胸苷和尿苷)以及其他亚单元或单体(如氨基酸和/或有机小分子(例如有机酸))。在一些实施方案中,阴离子聚合物中的亚单元或单体的至少50%(例如,55%、60%、65%、70%、75%、80%、85%、90%、95%或100%)不是核苷酸或不包含核酸碱基。阴离子聚合物可以包含至少两个亚单元或单体(例如,至少5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190、200、210、220、230、
240、250、260、270、280、290、300、310、320、330、340、350、360、370、380、390或400个亚单元或单体;100至400、120至400、140至400、160至400、180至400、200至400、220至400、240至400、260至400、280至400、300至400、320至400、340至400、360至400、380至400、100至380、100至360、100至340、100至320、100至300、100至280、100至260、100至240、100至220、100至200、100至180、100至160、100至140或100至120个亚单元或单体)。在一些实施方案中,阴离子聚合物具有至少3kda(例如,5、10、15、20、25、30、35、40、45或50kda)的分子量。在一些实施方案中,阴离子聚合物具有3kda至50kda(例如,3kda至45kda、3kda至40kda、3kda至35kda、3kda至30kda、3kda至25kda、3kda至20kda、3kda至15kda、3kda至10kda、3kda至5kda、5kda至50kda、10kda至50kda、15kda至50kda、20kda至50kda、25kda至50kda、30kda至50kda、35kda至50kda、40kda至50kda或45kda至50kda)的分子量。在一些实施方案中,阴离子聚合物具有50kda至150kda(例如,50kda至140kda、50kda至130kda、50kda至120kda、50kda至110kda、50kda至100kda、50kda至90kda、50kda至80kda、50kda至70kda、50kda至60kda、60kda至150kda、70kda至150kda、80kda至150kda、90kda至150kda、100kda至150kda、110kda至150kda、120kda至150kda、130kda至150kda或140kda至150kda)的分子量。在一些实施方案中,阴离子聚合物具有15kda至50kda(例如,15kda至45kda、15kda至40kda、15kda至35kda、15kda至30kda、15kda至25kda、15kda至20kda、20kda至50kda、25kda至50kda、30kda至50kda、35kda至50kda、40kda至50kda或45kda至50kda)的分子量。在一些实施方案中,本文所述的组合物具有的阴离子聚合物:可靶向的核酸酶摩尔比为10:1至120:1,例如,10:1、20:1、30:1、40:1、50:1、60:1、70:1、80:1、90:1、100:1、110:1、or、120:1;10:1至110:1、10:1至100:1、10:1至90:1、10:1至80:1、10:1至70:1、10:1至60:1、10:1至50:1、10:1至40:1、10:1至30:1、10:1至20:1、20:1至120:1、30:1至120:1、40:1至120:1、50:1至120:1、60:1至120:1、70:1至120:1、80:1至120:1、90:1至120:1、100:1至120:1或110:1至120:1。x.细胞中的基因靶向核酸
133.本文所述组合物可以被用于修饰细胞(例如真核细胞、原核细胞、动物细胞、植物细胞、真菌细胞等)中的靶核酸的方法中。任选地,细胞是哺乳动物细胞,例如人类细胞。细胞可以为体外的、离体的或体内的。细胞也可以是原代细胞、生殖细胞、干细胞或前体细胞。例如,前体细胞可以是多能干细胞或造血干细胞。在一些实施方案中,细胞是原代造血细胞、原代造血干细胞或原代t细胞。在一些实施方案中,原代造血细胞是免疫细胞。在一些实施方案中,免疫细胞是t细胞。在一些实施方案中,t细胞是调节性t细胞、效应t细胞或幼稚t细胞。在一些实施方案中,t细胞是cd4
+
t细胞。在一些实施方案中,t细胞是cd8
+
t细胞。在一些实施方案中,t细胞是cd4
+
cd8
+
t细胞。在一些实施方案中,t细胞是cd4-cd8-t细胞。在一些实施方案中,t细胞是αβt细胞。在一些实施方案中,t细胞是γδt细胞。还提供了通过本文所描述的任何方法修饰的任何细胞群体。在一些实施方案中,该方法还包括扩增修饰的细胞群。
134.本文所述的供体构建体可以被用于识别细胞基因组中靶向插入的方法(例如,如roth等人,(2019).rapid discovery of synthetic dna sequences to rewrite endogenous t cell circuits.biorxiv 10.1101/604561中所述的)中。例如,可以建立具有相同类型供体构建体(例如,如图1中所示的供体构建体)的文库,其中每个供体构建体具有不同的hdrt。任选地,文库中的每一个供体构建体可以包括唯一的条形码核苷酸序列,该
序列表明供体构建体中特定hdrt的身份。该方法提供了切割细胞基因组中的靶区域以创建靶插入位点的靶向核酸酶(例如cas9);各自具有不同的hdrt的供体构建体的文库;与供体构建体内的dna结合蛋白靶序列杂交的供体grna;以及识别供体构建体并将其带到靶插入位点的dna结合靶蛋白。供体构建体的文库包括两种或更多种因其hdrt序列而不同的供体构建体。在某些实施方案中,供体构建体的文库包括至少10、20、30、40、50、60、70、80、90或100种因其hdrt序列而不同的供体构建体。重组发生并产生一批经修饰的细胞后,可以使用引物从经修饰的细胞中扩增dna。随后,可以对dna进行测序,以鉴定插入细胞靶插入位点中的模板。在一些实施方案中,该方法可以包括确定群体中具有插入在靶插入位点中的不同模板的细胞的相对数量。
135.在具体方面,提供了细胞群(例如,t细胞群)。细胞群可以包含本文所述的任何经修饰的细胞。经修饰的细胞可以在异源细胞群和/或不同细胞类型的异源细胞群中。就基因组编辑的细胞百分比而言,细胞群体可能是异源的。细胞群体可以有大于10%、大于20%、大于30%、大于40%、大于50%、大于60%、大于70%、大于80%或大于90%的群体包含整合的核苷酸序列。在某一方面,细胞群包含整合的核苷酸序列,其中整合的核苷酸序列包含基因的至少一部分,整合的核苷酸序列被整合在内源性基因组靶基因座处,并且整合的核苷酸序列被定向使得基因的至少一部分能够被表达,其中细胞群基本上不含病毒介导的递送组分,并且其中细胞群中超过10%、超过20%、超过30%、超过40%、超过50%、超过60%、超过70%、超过80%或超过90%的细胞包含整合的核苷酸序列。
136.本文所述的用于修饰细胞中靶核酸的方法包括向细胞中引入本文所述的组合物,其中hdrt被整合到靶核酸中。在一些实施方案中,本文所述的组合物经由电穿孔被引入细胞中。在一些情况下,从对象移除细胞,使用本文所述的任何方法进行修饰细胞并施用于对象。在其他情况下,本文所述的组合物可以在体内被递送至对象。例如,参见美国专利第9737604号和zhang等人,“lipid nanoparticle-mediated efficient delivery of crispr/cas9 for tumor therapy,”npg asia materials第9卷,第e441页(2017)。
137.在一些实施方案中,细胞是选自以下的原代细胞:免疫细胞(例如,原代t细胞)、血细胞、其祖细胞或干细胞、间充质细胞及以上的组合。在一些情况下,免疫细胞选自:t细胞、b细胞、树突状细胞、自然杀伤细胞、巨噬细胞、嗜中性粒细胞、嗜酸性粒细胞、嗜碱性粒细胞、肥大细胞、以上的前体及以上的组合。祖细胞或干细胞可以选自:造血祖细胞、造血干细胞及以上的组合。在一些情况下,血细胞是血液干细胞。在一些情况下,间充质细胞选自:间充质干细胞、间充质祖细胞、间充质前体细胞、分化的间充质细胞及以上的组合。分化的间充质细胞可以选自:骨细胞、软骨细胞、肌细胞、脂肪细胞、基质细胞、成纤维细胞、真皮细胞及以上的组合。在一些实施方案中,原代细胞可以包括原代细胞群。在一些情况下,原代细胞的群体包括异源的原代细胞群。在其他情况下,原代细胞群包括同源的原代细胞群。
138.本文所述组合物可以使用本领域的可用方法和技术引入细胞(例如原代细胞)中。合适方法的非限制性实例包括电穿孔、粒子枪技术和直接显微注射。在一些实施方案中,将本文所述组合物引入细胞中的步骤包括将组合物电穿孔到细胞中。
139.本文引用的出版物及其引用的材料在此通过引用整体具体地并入本文中。
2,以使最终浓度达到500u/ml,并且必要时将细胞转移到更大的培养容器中,以保持100万个细胞/ml的密度。rnp的产生
147.rnp是通过将双组分grna与cas9复合而产生的。简而言之,化学合成crrna和tracrrna(dharmacon,idt),并重组产生和纯化重组cas9-nls、d10a-nls或dcas9-nls(qb3 macrolab)。将冻干的rna重新以160μm的浓度悬浮在具有150mm kcl的10mm tris-hcl(7.4ph)中,并在-80℃下以等分试样保存。解冻crrna和tracrrna等分试样,按体积1:1混合,并在37℃下通过孵育退火30min,以形成80μmgrna溶液。将重组cas9或d10a cas9变体以40μm存储在20mm hepes-koh、ph 7.5、150mm kcl、10%甘油、1mm dtt中,然后在37℃下以体积比1:1与80μm grna(2:1的grna与cas9的摩尔比)混合15min,从而以20μm形成rnp。rnp在复合后立即电穿孔。双链dna hdrt的产生
148.使用gibson assemblies构建新的hdr序列,以将由同源臂(通常合成为来自idt的gblocks)和所期望的插入物(如gfp)组成的hdr模板序列插入到克隆载体中,以用于序列确认和未来扩增。这些质粒被用作高输出pcr扩增(kapa hotstart聚合酶)的模板。pcr扩增子(dsdna hdrt)经spri纯化(1.0
×
),并洗脱至终体积为每100μl pcr反应输入3μl h2o。hdrt的浓度通过使用1:20稀释的纳米液滴测定。在1.0%琼脂糖凝胶中通过凝胶电泳确认扩增的hdrt的大小。单链dna(ssdna)hdrt和ssdna穿梭hdrt的产生
149.如dsdna hdrt所述的,通过pcr制备ssdna hdrt,但在反向引物上包含5’生物素修饰。然后将pcr产物与链霉亲和素偶联的磁珠(dynabeads strepatavidin myone c1#65001)一起孵育,以结合生物素化的链。然后,dsdna在125mm naoh存在下被变性。如上所述的,使用spri珠清洁法收集、纯化并浓缩含有非生物素化链的上清液。
150.为了产生ssdna穿梭hdrt,然后将ssdna hdrt与6倍摩尔过量的与5’和3’端互补的寡聚物一起孵育。将混合物加热至95℃,并在~1小时时程内缓慢冷却至室温,以允许有效退火。原代t细胞电穿孔
151.将rnp和hdr模板在初始t细胞刺激后2天电穿孔。从其培养容器中收集t细胞,并通过将细胞放置在easysep细胞分离磁体上2min,去除磁性抗cd3/抗cd28 dynabeads。在电穿孔之前不久,以90g将脱珠细胞离心10min,抽吸,并使用每100万个细胞20μl缓冲液将其重新悬浮在lonza电穿孔缓冲液p3中。为了优化编辑,使用具有脉冲编码eh115的lonza 4d 96孔电穿孔系统,每孔电穿孔100万个t细胞。流式细胞术和细胞分选
152.在attune nxt声学聚焦细胞仪(thermofisher)或lsrii流式细胞仪(bd)上进行流式细胞分析。在facsaria平台(bd)上进行facs。用于流式细胞术和细胞分选的表面染色是通过使细胞沉淀和在25μlfacs缓冲液(于pbs中的2% fbs)中,于黑暗下用不同浓度的抗体在4℃下再悬浮20min来进行的。在再悬浮前将细胞在facs缓冲液中洗涤一次。实施例5
–
用大引物供体构建体的原代人t细胞敲入
153.本实施例展示并比较了不同大小的大引物供体构建体(“ssdna+穿梭体”)与
dsdna、具有穿梭末端的dsdna和未修饰的ssdna的敲入效率。这里使用的构建体是cd5-ha hdrt、il2ra tngfr hdrt和il2ra-cd25-gfp hdrt。未处理对照和敲入群体的代表性流式图如图7a-图7f中所示。具有增加浓度的hdrt的敲入效率、活细胞计数和敲入细胞的绝对数量如图8a-图8i中所示。与所有其他变体相比,ssdna穿梭版本显示了增加的敲入效率、更低的毒性和增加的敲入细胞数量。本实施例中使用的序列如seq id no:36-43中所示。实施例6
–
穿梭体设计和机械论研究
154.本实验检查了cd5-ha和cd25-gfp引物供体构建体(“ssdna+穿梭体”),以确定设计原理和受益机制。
155.改变ssdna穿梭末端以确定序列要求。与ssdna对照相比,具有与对应grna互补序列的ssdna穿梭体增加了敲入效率。所有其他变异均未显示出益处,其包括保护同源臂末端(“末端保护”)的等效长度的dsdna、来自其他hdrt的错配的穿梭序列,以及等效长度的加扰dsdna(图9a和图9b)。本实验中使用的序列如下表1中所示。表1
156.显示了与ssdna对照相比,在20bp grna互补序列上具有变异的ssdna穿梭hdrt。每个变体都包含不同数量的错配碱基,以改变grna结合亲和力,从而使cas9 rnp可以在不切断穿梭序列的情况下结合。具有2-8bp错配的变体表现出最高的敲入效率增加。两种不同的cas9物种(wt和spyfi)表现出相似的反应(图9c和9d)。本实验中使用的序列如下表2中所示。表2
157.比较了具有dsdna末端覆盖穿梭序列不同区段和两侧同源臂的ssdna。敲入效率的增加需要dsdna覆盖grna序列、pam序列和一段同源臂。dsdna没有覆盖这3种组分的变体没有显示益处。穿梭序列仅在5’端有利,在3’端(红色)没有影响,且对5’和3’端的组合没有额外的益处(图9e和图9f)。本实验中使用的序列如下表3中所示。表3
*1:是;0:否。
158.对具有dsdna穿梭末端的ssdna进行了测试和比较,所述dsdna穿梭末端包括grna序列、pam序列和与侧接5’同源臂不同量的重叠。随着同源臂重叠的增加,敲入效率增加,最大可达~20bp(图9g和图9h)。
159.具有核定位序列(nls)的cas9变体提供了敲入效率的额外提高,表明蛋白质修饰可以进一步增强ssdna穿梭效应(图9i和图9j)。
160.阴离子聚合物(如聚谷氨酸(pga))与ssdna穿梭序列组合,显示毒性的额外降低(图9k和图9l)。实施例7
–
ssdna穿梭技术可用于各种靶位点
161.产生了人类基因组中22个靶位点的hdrt和对应的rnp,并被用于敲入来自2名供体的原代人t细胞中的可检测表面标志物。引物供体构建体(“ssdna+穿梭体”)显示敲入效率和敲入细胞绝对计数的增加(图10a和图10c)。实施例8
–
ssdna穿梭技术可用于各种原代人类细胞类型
162.生成了引物供体构建体(“ssdna+穿梭体”)和dsdna穿梭体,以敲入clathrin基因内的荧光mcherry标志物。如图11a中的流式图所示的,mcherry+细胞被门控。在一系列hdrt浓度范围内,比较了原代人大量(bulk)t细胞(图11b-图11d)和各种其他原代人类细胞类型中的绝对敲入计数、敲入效率和总细胞计数,这些原代人类细胞类型包括cd4+t细胞(图11e)、cd8+t细胞(图11f)、调节性t细胞(treg)(图11g)、cd34+造血干细胞(hsc)(图11h)、b细胞(图11i)、nk细胞(图11j)和γδt细胞(γδ)(图11k)。所有细胞类型的绝对敲入计数(图11l)、敲入效率(图11m)和毒性均得到改善。实施例9
–
针对car-t细胞和tcr敲入细胞生成的应用
163.嵌合抗原受体(car)和t细胞受体(tcr)构建体被敲入至原代人t细胞中的内源性
tcrα链(trac)基因组基因座。bcma抗原特异性car敲入的代表性门控策略如图12a-图12c所示。显示了使用2种不同的grna靶序列(g526(tcagggttctggatatctgt(seq idno:121))和g527(ctggatatctgtgggacaag(seq id no:120))的2种不同引物供体构建体(“ssdna+穿梭体”)的敲入效率(图12d)和存活率(图12e)。两种引物供体构建体都优于对应的dsdna穿梭体、dsdna和ssdna hdrt,在无毒剂量下达到30%-40%的敲入效率。图12f-图12h显示了使用相同g526 ssdna穿梭系统的各种不同tcr敲入构建体的相似的敲入率。
164.应当理解,本文所描述的实施例和实施方案仅用于说明目的,并且将向本领域技术人员建议根据其进行的各种修改或更改,并且将包括在本技术的精神和范围以及所附权利要求的范围内。本文引用的所有出版物、专利和专利申请均在此通过引用整体并入本文中,以用于所有目的。非正式序列表
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1