预测前列腺癌对象对治疗的反应或者对前列腺癌对象的治疗进行个性化的制作方法
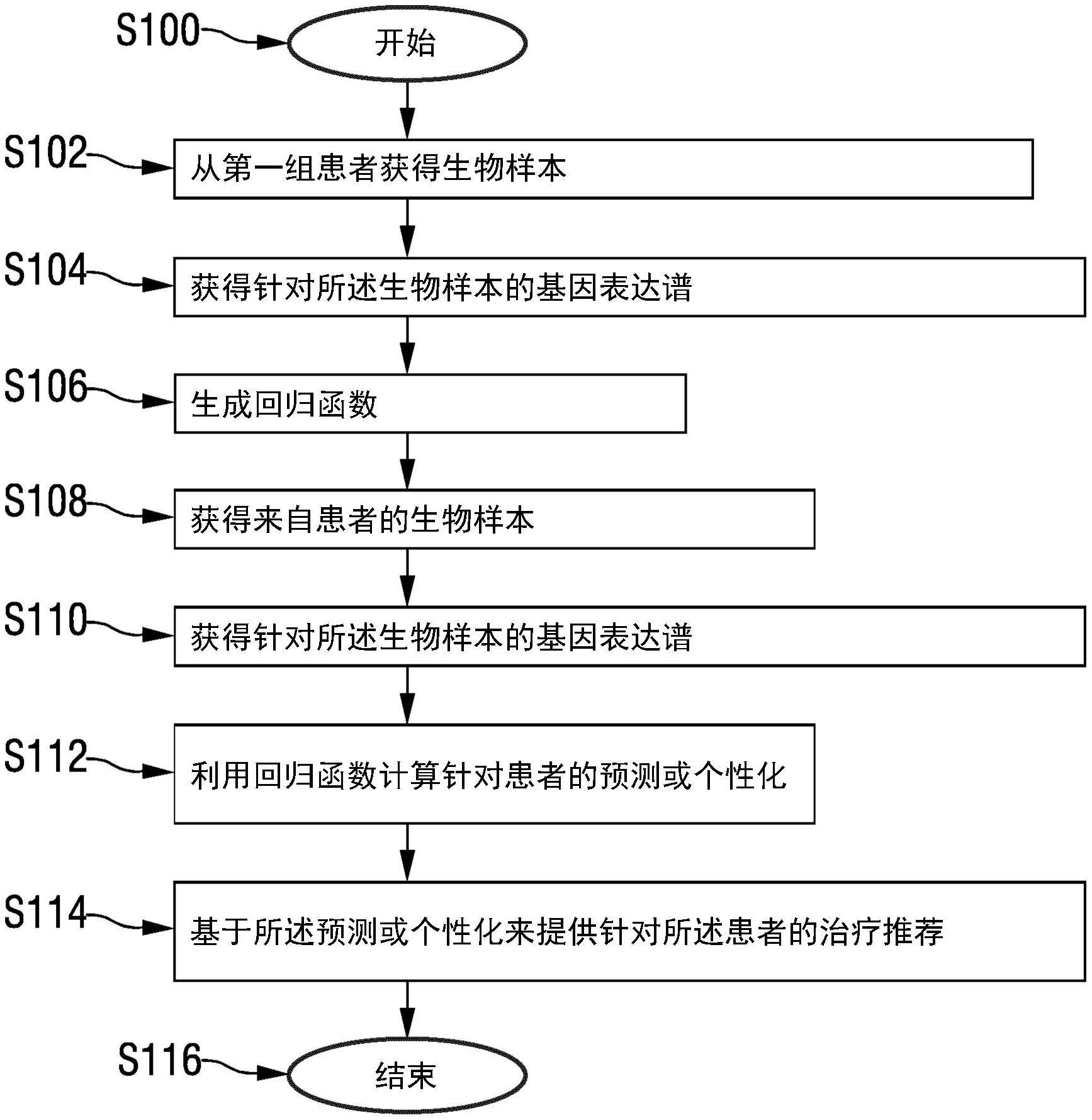
本发明涉及一种预测前列腺癌对象对治疗的反应或者对前列腺癌对象的治疗进行个性化的方法,以及一种用于前列腺癌对象对治疗的反应或者对前列腺癌对象的治疗进行个性化的装置。此外,本发明涉及一种诊断套件、该套件的使用、该套件在预测前列腺癌对象对治疗的反应或者对前列腺癌对象的治疗进行个性化的方法中的中的使用,以及在预测前列腺癌对象对治疗的反应或者对前列腺癌对象的治疗进行个性化的方法中使用第一、第二和第三(一个或多个)基因表达谱,以及对应的计算机程序产品。
背景技术:
1、癌症是一类疾病,其中,一组细胞表现出不受控制的生长、侵袭以及有时候转移。癌症的这三种恶性特性将它们与良性肿瘤区分开来,良性肿瘤是自限性的,不会侵袭或转移。前列腺癌(pca)是男性第二大最常见的非皮肤恶性肿瘤,2018年全球估计有130万例新确诊病例和360000例死亡(参见brayf.等人的“global cancer statistics 2018:globocan estimates of incidence and mortality worldwide for 36cancers in185countries”,ca cancer j clin,vol.68,第6期,第394-424页,2018年)。在美国,大约90%的新病例涉及局部癌症,这意味着尚未形成转移(参见acs(美国癌症协会),“cancerfacts&figures 2010”,2010年)。
2、对于原发性局限性前列腺癌的治疗,有几种根治性疗法可用,其中,最常用的是手术(根治性前列腺切除术,rp)和放疗(rt)。rt是通过外部射束或通过将放射性粒子植入前列腺(近距离放疗)或两者结合进行的。其对于不符合手术条件或已被诊断患有晚期局部或区域阶段肿瘤的患者尤其优选。在美国,高达50%的诊断为局限性前列腺癌的患者接受了根治性rt(见acs,2010,出处同上)。
3、在处置之后,测量血液中的前列腺癌抗原(psa)水平以进行疾病监测。血液psa水平的升高为癌症复发或进展提供了生化替代量度。然而,报告的生化无进展生存期(bpfs)的差异很大(参见grimm p.等人的“comparative analysis of prostate-specificantigen free survival outcomes for patients with low,intermediate and highrisk prostate cancer treatment by radical therapy.results from the prostatecancer results study group”,bju int,suppl.1,第22-29页,2012年)。对于许多患者而言,根治性放疗后5年甚至10年的bpfs可能超过90%。遗憾的是,对于处于中度和特别是较高复发风险的患者组,bpfs可能降到5年时40%左右,具体取决于所使用的rt类型(参见grimm p.等人,2012年,出处同上)。
4、大量未利用rt进行处置的原发性局限性前列腺癌患者将接受rp(参见acs,2010,出处同上)。在rp后,最高风险组中平均有60%的患者在5年和10年后经历生化复发(参见grimm p.等人,2012,出处同上)。在rp后生化进展的情况下,主要挑战之一是不确定这是否是由于复发的局部疾病、一个或多个转移或者甚至不会导致临床疾病进展的惰性疾病(见dal pra a.等人的“contemporary role of postoperative radiotherapy for prostatecancer”,transl androl urol,vo.7,no.3,第399-413页,2018年,以及herrera f.g.和berthold d.r.的“radiation therapy after radical prostatectomy:implicationsfor clinicians”,front oncol,vol.6,no.117,2016年)。rt根除前列腺床中的剩余的癌细胞是在rp后psa增大之后挽救生存率的主要处置选项之一。挽救性放疗(srt)的有效性使18%至90%的患者达到了5年的bpfs,具体取决于多种因素(参见herrera f.g.和bertholdd.r.,2016年,出处同上,以及pisansky t.m.等人的“salvage radiation therapy doseresponse for biochemical failure of prostate cancer after prostatectomy–amulti-institutional observational study”,int j radiat oncol biol phys,vol.96,no.5,第1046-1053页,2016年)。
5、清楚的是,对于特定患者组,根治性rt或挽救性rt是无效的。rt能够导致的严重副作用(例如,肠道炎症和功能障碍、尿失禁和勃起功能障碍)甚至使他们的情况更加恶化(参见resnick m.j.等人的“long-term functional outcomes after treatment forlocalized prostate cancer”,n engl j med,vol.368,no.5,第436-445页,2013年和hegarty s.e.等人的“radiation therapy after radical prostatectomy for prostatecancer:evaluation of complications and influence of radiation timing onoutcomes in a large,population-based cohort”,plos one,vol.10,no.2,2015年)。另外,基于医疗保险报销,一个rt疗程的成本的中位值为18000美元,该成本的差异很大,最高达到约40000美元(参见paravati a.j.等人的“variation in the cost of radiationtherapy among medicare patients with cancer”,j oncol pract,vol.11,no.5,第403-409页,2015年)。这些数字不包括在根治性rt和挽救性rt后的后续护理的可观的纵向成本。
6、对每个患者的rt有效性的改进预测(无论是在根治性背景中还是在挽救性背景中)都将改进治疗选择和提高潜在生存率。这能够通过以下操作来实现:1)为那些预测rt有效的患者优化rt(例如通过剂量递增或不同的开始时间),以及2)将预测rt无效的患者引导到可能更有效的处置形式的替代方案。另外,这将减少那些免于无效治疗的患者的痛苦并减少在无效治疗上花费的成本。
7、已经对根治性rt(参见hall w.a.等人的“biomarkers of outcome in patientswith localized prostate cancer treated with radiotherapy”,semin radiat oncol,vol.27,第11-20页,2016年和raymond e.等人的“an appraisal of analytical toolsused in predicting clinical outcomes following radiation therapy treatment ofmen with prostate cancer:a systematic review”,radiat oncol,vol.12,no.1,第56页,2017年)和srt(参见herrera f.g.和berthold d.r.,2016年,出处同上)的反应预测指标进行了大量的研究。这些指标中的许多指标取决于基于血液的生物标志物psa的浓度。为在rt(根治性以及挽救性)开始前预测反应而研究的度量包括psa浓度的绝对值、psa相对于前列腺体积的绝对值、一定时间内的绝对增大量和倍增时间。其他经常考虑的因素是格里森评分和临床肿瘤分期。对于srt场景,其他因素是相关的,例如,手术切缘状态、rp后复发时间、手术前/围手术期psa值和临床病理参数。
8、虽然这些临床变量在各个风险组中的患者分层方面提供了有限的改进,但是仍然需要更好的预测工具。
9、已经研究了在组织和体液中种类众多的候选生物标志物,但是验证通常很有限并且通常证明预后信息并且不是预测(治疗特异性)值(参见hall w.a.等人,2016年,出处同上)。当前,商业组织正在验证少数基因表达板。这些基因表达板中的一个或多个基因表达板可以示出对未来的rt的预测值(参见dal pra a.等人,2018年,出处同上)。
10、总之,对于原发性前列腺癌以及术后环境,仍然强烈需要对rt的反应更好预测以及更好的治疗的个性化。这同样适用于预测对挽救雄激素剥夺疗法(sadt)和细胞毒性化疗(ctx)的反应。
技术实现思路
1、本发明的一个目的是提供一种预测前列腺癌对象对治疗的反应或者对前列腺癌对象的治疗进行个性化的方法,以及一种用于预测前列腺癌对象对治疗的反应或者对前列腺癌对象的治疗进行个性化的装置,其允许做出更好的处置决策。本发明的另一个方面是提供一种诊断套件、该套件的使用、该套件在预测前列腺癌对象对治疗的反应或者对前列腺癌对象的治疗进行个性化的方法中的中的使用,以及在预测前列腺癌对象对治疗的反应或者对前列腺癌对象的治疗进行个性化的方法中使用第一、第二和第三(一个或多个)基因表达谱,以及对应的计算机程序产品。
2、在本发明的第一方面中,提出了一种预测前列腺癌对象对治疗的反应或对前列腺癌对象的治疗进行个性化的方法,包括:
3、确定或接收针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,免疫防御反应基因中的每个的第一基因表达谱的确定的结果:aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8和zbp1,所述第一(一个或多个)基因表达谱是在从所述对象获得的生物样本中确定的,
4、确定或接收针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,t细胞受体信号传导基因中的中的每个的第二(一个或多个)基因表达谱的确定的结果:cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、lat、lck、pag1、pde4d、prkaca、prkacb、ptprc和zap70,所述第二(一个或多个)基因表达谱是在从所述对象获得的生物样本中确定的,
5、确定或接收针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个或者所有,pde4d7相关基因中的每个的第三(一个或多个)基因表达谱的确定的结果:abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2,所述第三(一个或多个)基因表达谱是在从所述对象获得的生物样本中确定的,
6、基于所述第一、第二和第三(一个或多个)基因表达谱来确定对治疗反应的预测或治疗的个性化,以及
7、任选地,基于所述预测或所述个性化向医疗护理人员或对象提供所述预测或所述个性化或治疗推荐。
8、因此,在一个实施例中,本发明涉及一种预测前列腺癌对象对治疗的反应或前列腺癌对象的个性化治疗的方法,包括:
9、确定针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,免疫防御反应基因中的每个的第一基因表达谱:aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8和zbp1,所述第一(一个或多个)基因表达谱是在从所述对象获得的生物样本中确定的,
10、确定对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,t细胞受体信号传导基因中的中的每个的第二(一个或多个)基因表达谱:cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、lat、lck、pag1、pde4d、prkaca、prkacb、ptprc和zap70,所述第二(一个或多个)基因表达谱是在从所述对象获得的生物样本中确定的,
11、确定针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个或者所有,pde4d7相关基因中的每个的第三(一个或多个)基因表达谱:abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2,所述第三(一个或多个)基因表达谱是在从所述对象获得的生物样本中确定的,
12、基于所述第一、第二和第三(一个或多个)基因表达谱来确定对治疗反应的预测或治疗的个性化,以及
13、任选地,基于所述预测或所述个性化向医疗护理人员或对象提供所述预测或所述个性化或治疗推荐。例如,可以使用报告基因、northern印迹、蛋白质印迹(westernblotting)、荧光原位杂交(fish)、逆转录聚合酶链反应(rt-pct)、定量聚合酶链反应(qpcr)、基因表达的序列分析(sage)、dna微阵列、rna测序或拼贴阵列(tiling array)来确定所述表达水平。
14、在替代实施例中,本发明涉及一种计算机实现的方法,所述方法预测预测前列腺癌对象对治疗的反应或前列腺癌对象的个性化治疗,包括:
15、接收针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,免疫防御反应基因中的每个的第一基因表达谱的确定的结果:aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8和zbp1,所述第一(一个或多个)基因表达谱是在从所述对象获得的生物样本中确定的,
16、接收针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,t细胞受体信号传导基因中的中的每个的第二(一个或多个)基因表达谱的确定的结果:cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、lat、lck、pag1、pde4d、prkaca、prkacb、ptprc和zap70,所述第二(一个或多个)基因表达谱是在从所述对象获得的生物样本中确定的,
17、接收针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个或者所有,pde4d7相关基因中的每个的第三(一个或多个)基因表达谱的确定的结果:abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2,所述第三(一个或多个)基因表达谱是在从所述对象获得的生物样本中确定的,
18、基于所述第一、第二和第三(一个或多个)基因表达谱来确定对治疗反应的预测或治疗的个性化,以及
19、任选地,基于所述预测或所述个性化向医疗护理人员或对象提供所述预测或所述个性化或治疗推荐。
20、近年来,免疫系统在癌症抑制以及癌症起始、促进和转移中的重要性变得非常明显(参见mantovania.等人r“cancer-related inflammation”,cancer-relatedinflammation”,nature,vol.454,no.7203,第436-444页,2008年,以及giraldona等人的““the clinical role of the tme in solid cancer”,br j cancer,vol.120,no.1,第45-53页,2019年)。免疫细胞及其分泌的分子构成了肿瘤微环境的重要组成部分,并且大多数免疫细胞可以浸润肿瘤组织。免疫系统和肿瘤相互影响和塑造。因此,抗肿瘤免疫可以防止肿瘤形成,而炎性肿瘤环境可以促进癌症的发生和增殖。与此同时,可能起源于免疫系统非依赖性方式的肿瘤细胞会通过募集免疫细胞来塑造免疫微环境,并且具有促炎作用同时也抑制抗癌免疫。
21、肿瘤微环境中的一些免疫细胞将具有一般的肿瘤促进或一般的肿瘤抑制作用,而其他免疫细胞表现出可塑性并显示出肿瘤促进和肿瘤抑制两者的潜力。因此,肿瘤的整体免疫微环境是存在的各种免疫细胞、它们产生的细胞因子以及它们与肿瘤细胞和肿瘤微环境中其他细胞的相互作用的混合物(参见giraldo n.a等人,2019,出处同上)。
22、上述关于免疫系统在癌症中的作用的原则通常也适用于前列腺癌。慢性炎症与良性和恶性前列腺组织的形成有关(参见hall w.a等人,2016年,出处同上),并且大多数前列腺癌组织样本显示免疫细胞浸润。具有促肿瘤作用的特定免疫细胞的存在与较差的预后相关,而自然杀伤细胞被更多激活的肿瘤表现出对治疗有更好的反应和更长的无复发期(参见shiao s.l.等人的“regulation of prostate cancer progression by tumormicroenvironment”,cancer lett,vol.380,no.1,第340-348页,2016年)。
23、虽然治疗会受到肿瘤微环境的免疫成分的影响,但rt本身会广泛影响这些成分的构成(参见barker h.e.等人,“the tumor microenvironment after radiotherapy:mechanisms of resistance or recurrence”,nat rev cancer,vol.15,no.7,第409-425页,2015年)。由于抑制性细胞类型对辐射相对不敏感,因此它们的相对数量会增加。相反,造成的辐射损伤激活细胞存活途径并刺激免疫系统,引发炎症反应和免疫细胞募集。净效应是促进肿瘤还是抑制肿瘤尚不确定,但正在研究其增强癌症免疫疗法的潜力。
24、本发明基于这样的想法,即由于免疫系统和免疫微环境的状态对治疗效果有影响,识别预测这种效果的标志物的能力可能有助于更好地预测对手术前放疗以及手术后治疗(如srt、sadt或ctx)的反应。
25、本发明还基于这样的想法,即由于已知的pde4d7生物标志物已被证明是放疗反应的良好预测因子,识别与pde47生物标志物高度相关的标志物的能力也可能有助于能够更好地预测对术前rt以及术后疗法(如srt、sadt或ctx)的反应。
26、免疫反应防御基因
27、基因组dna的完整性和稳定性永久处于由各种细胞内部和外部因素引起的压力下,例如暴露于辐射、病毒或细菌感染,以及氧化和复制压力(参见gasser s.等人的“sensing of dangerous dna”,mechanisms of aging and development,第165卷,第33-46页,2017年)。为了维持dna结构和稳定性,细胞必须能够识别由各种因素引起的所有类型的dna损伤,如单链或双链断裂等。这个过程涉及大量特异性蛋白质的参与,具体取决于作为dna识别途径的部分的损伤类型。
28、最近的证据表明,错误定位的dna(例如,与细胞核相反,dna非自然地出现在细胞的胞质部分)和受损的dna(例如,通过癌症发展中发生的突变)被免疫系统用于识别感染或者患病细胞,而健康细胞中存在的基因组和线粒体dna会被dna识别途径忽略。在患病细胞中,细胞溶质dna传感器蛋白已被证明参与检测细胞胞质溶胶中非自然发生的dna。通过不同的核酸传感器检测此类dna会转化为类似的反应,导致核因子kappa-b(nf-kb)和i型干扰素(ifni型)信号传导,然后激活先天免疫系统成分。虽然已知病毒dna的识别会诱导ifni型反应,但最近才积累了检测dna损伤可以启动免疫反应的证据。
29、位于核内体中的tlr9(toll样受体9)是首批被确定参与dna免疫识别的dna传感器分子之一,经由衔接蛋白骨髓分化初级反应蛋白88(myd88)而向下游发出信号。这种相互作用反过来激活丝裂原活化蛋白激酶(mapk)和nf-kb。tlr9还通过经由浆细胞样树突状细胞(pdc)中的ikb激酶alpha(ikkalpha)来激活irf7而诱导i型干扰素的产生。各种其他dna免疫受体,包括ifi16(ifn-gamma诱导蛋白16)、cgas(环状dmp-amp合酶、ddx41(dead-box解旋酶41)以及zbp1(z-dna结合蛋白1)与sting相互作用(ifn基因的刺激剂),其通过tbk1(tank结合激酶1)而激活ikk复合物和irf3。zbp1还经由募集rip1和rip3(分别为受体相互作用蛋白1和3)而激活nf-kb。虽然解旋酶dhx36(deah-box解旋酶36)在复合物中与trid相互作用以诱导nf-kb和irf-3/7,但dhx9解旋酶刺激浆细胞样树突状细胞中的myd88依赖性信号传导。dna传感器lrrfip1(富含亮氨酸的重复不能飞行的相互作用蛋白)与β-连环蛋白复合以激活irf3的转录,而aim2(黑色素瘤2中不存在)募集衔接蛋白asc(凋亡斑点样蛋白)以诱导激活caspase-1的感染性复合物导致白介素-1β(il-1beta)和il-18的分泌(参见gasser s.等人2017年文章的图1,出处同上,共提供了dna损伤和dna传感器导致炎性细胞因子产生和激活先天免疫受体的配体表达的途径的示意性概览。示出了非同源末端连接通路(橙色)、同源重组(红色)、炎性体(深绿色)、nf-kb和干扰素反应(浅绿色)的成员)。
30、负责激活癌症中dna传感器通路的因素和机制目前尚未得到很好的阐明。重要的是要识别在疾病各个阶段的不同癌症类型中的与ifn的表达有关的肿瘤内dna种类、传感器和通路。除了癌症的治疗目标外,这些因素还可能具有预后和预测价值。目前正在临床前试验中开发和测试新型dna传感器通路激动剂和拮抗剂。这些化合物将有助于表征dna传感器通路在癌症、自身免疫和其他潜在疾病的发病机制中的作用。
31、识别出的免疫防御反应基因zbp1和aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8、zbp1分别如下地被识别:一组538例前列腺癌症患者接受rp治疗,并且前列腺癌组织与临床(例如,病理格里森分级组(pggg)、病理状态(pt分期))以及相关结果参数(例如,生化复发(bcr)、转移性复发、前列腺癌特异性死亡(pca死亡)、挽救性放疗(srt)、挽救性雄激素剥夺治疗(sadt)、化疗(ctx))一起被存储。对于这些患者中的每个,计算pde4d7评分并将其分为四个pde4d7评分类别,如alves deinda m.等人的“validation of cyclic adenosine monophosphate phosphodiesterase-4d7 for its independent contribution to risk stratification in a prostatecancer patient cohort with longitudinal biological outcomes”,eur urol focus,vol.4,no.3,第376-384页(2018年)中所描述。pde4d7评分等级1代表具有最低pde4d7表达水平的患者样本,而pde4d7评分等级4代表具有最高pde4d7表达水平的患者样本。然后研究了538名前列腺癌对象的rnaseq表达数据(tpm-每百万转录本),以了解pde4d7评分等级1与4之间的差异基因表达。特别是,针对大约20000个蛋白质编码转录本确定了pde4d7评分1级患者的平均表达水平是否是pde4d7评分4级患者平均表达水平的两倍以上。该分析得到具有pde4d7得分类别1/pde4d7得分类别4的比率>2的637个基因,在四个pde4d7得分类别中的每个中,最小平均表达为1tpm。然后对这637个基因进一步进行分子通路分析(www.david.ncifcrf.gov),从而产生一系列富集注释簇。注释簇#2显示了具有对病毒的防御反应、病毒基因组复制的负调节以及i型干扰素信号传导的功能的30个基因中的富集(富集分数:10.8)。进一步的热图分析证实,这些免疫防御反应基因在pde4d7评分1级患者样本中的表达普遍高于pde4d7评分4级患者样本。具有对病毒的防御反应、病毒基因组复制的负调节以及i型干扰素信号传导功能的基因类别通过文献检索进一步富集到61个基因,以识别具有相同分子功能的其他基因。根据将死于前列腺癌的患者与未死于前列腺癌的患者区分开来的组合能力,从61个基因中进行了进一步选择,从而产生了优选的一组14个基因。结果发现,与总患者群组(#538)和在术后疾病复发后接受挽救性放疗(srt)的151名患者的子群组相比,具有这些基因低表达的子群组中事件的数量(转移、前列腺癌特异性死亡)有所增加。
32、t细胞受体信号传导基因
33、可以在不同层面引发针对病原体的免疫反应:物理屏障(例如皮肤)可以将入侵者拒之门外。如果被破坏,先天免疫就会发挥作用;第一个并且快速的非特异性反应。如果这还不够,则会引发适应性免疫反应。这更加特异性,并且在第一次遇到病原体时需要时间来发展。淋巴细胞通过与来自先天免疫系统的活化抗原呈递细胞相互作用而被激活,并且还负责维持记忆以在下次遇到相同病原体时更快地做出反应。
34、由于淋巴细胞在激活时具有高度特异性和有效性,因此它们会因其识别自身的能力而受到负面选择,这一过程称为中心耐受。由于并非所有自身抗原都在选择位点表达,外周耐受机制也在进化,例如在没有共同刺激的情况下tcr的连接、抑制性共同受体的表达和tregs的抑制。激活和抑制之间的平衡失调可能分别导致自身免疫性疾病,或免疫缺陷和癌症。
35、t细胞激活可以产生不同的功能结果,这取决于所涉及的t细胞类型的位置。cd8+t细胞分化为细胞毒性效应细胞,而cd4+t细胞可分化为th1(ifnγ分泌和促进细胞介导的免疫)或th2(il4/5/13分泌和促进b细胞和体液免疫)。分化为其他最近发现的t细胞亚群也是可能的,例如tregs,它对免疫激活具有抑制作用(参见mosenden r.和tasken k.的“cyclicamp-mediated immune regulation–overview of mechanisms of action in t-cells”,cell signal,vol.23,no.6,第1009-1016页,2011年,特别是图4,其中,t细胞激活及其通过pka的调节,以及tasken k.和ruppelt a.的“negative regulation of t-cell receptoractivation by the camp-pka-csk signaling pathway in t-cell lipid rafts”,frontbiosci,vol.11,第2929-2939页,2006年)。
36、pka和pde4调节的信号与tcr诱导的t细胞激活相交以微调其调节,具有相反的效果(参见abrahamsen h.等人的“tcr-and cd28-mediated recruitment ofphosphodiesterase 4to lipid rafts potentiates tcr signaling”,j immunol,vol.173,第4847-4848页,2004年,特别是图6,其显示了pka和pde4对tcr激活的相反作用)。连接这些效应子的分子是环腺苷酸(camp),它是细胞外配体作用的细胞内第二信使。在t细胞中,它介导前列腺素、腺苷、组胺、β-肾上腺素能激动剂、神经肽激素和β-内啡肽的作用。这些细胞外分子与gpcr的结合导致它们的构象变化、刺激亚基的释放和随后的腺苷酸环化酶(ac)的激活,其将atp水解为camp(参见abrahamsen h.等人2004年文章的图6,出处同上)。虽然不是唯一的,但pka是camp信号的主要效应器(参见mosenden r.和tasken k.,2011,出处同上,以及tasken k.和ruppelt a.,2006,出处同上)。在功能水平上,增加的camp水平导致t细胞中ifnγ和il-2的产生减少(参见abrahamsen h.等人,2004,出处同上)。除了干扰tcr激活外,pka还有更多的效应器(参见torheim e.a.的“immunityleashed–mechanisms of regulation in the human immune system”,thesis for thedegree of philosophiae doctor(phd),the biotechnology centre of ola,挪威奥斯陆大学(2009年)中的图15)。
37、在幼稚t细胞中,过度磷酸化的pag将csk靶向脂筏。经由ezrin-ebp50-pag支架复合体,pka靶向csk。经由pka的特异性磷酸化,csk可以负向调节lck和fyn以抑制它们的活性并下调t细胞活化(参见abrahamsen h.等人2004年文章中的图6,出处同上)。在tcr激活后,pag被去磷酸化,并且csk从筏中释放出来。t细胞激活需要csk的解离才能继续进行。在相同的时间过程中,csk-g3bp复合物形成,并且似乎将csk隔离在脂筏外(参见mosenden r.和tasken k.2011年的文章,出处同上,以及taskenk.和ruppelta.2006年的文章,出处同上)。
38、相反,组合的tcr和cd28刺激介导环核苷酸磷酸二酯酶pde4向脂筏的募集,这增强了camp降解(参见abrahamsen h.等人2004年的文章中的图6,出处同上)。因此,tcr诱导的camp产生被抵消,t细胞免疫反应增强。在仅有tcr刺激时,pde4募集可能太低而无法完全降低camp水平,因并且此无法发生最大t细胞激活(参见abrahamsen h.等人2004年的文章,出处同上)。
39、因此,通过主动抑制近端tcr信号,通过camp-pka-csk的信号被认为设置了t细胞激活的阈值(截止)。pde的募集可以对抗这种抑制。组织或细胞类型的特异性调节是通过表达ac、pka和pde的多种亚型来实现的。如上所述,需要严格调节激活和抑制之间的平衡,以防止自身免疫性疾病、免疫缺陷和癌症的发展。
40、所识别的t细胞受体信号传导基因cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、lat、lck、pag1、pde4d、prkaca、prkacb、ptprc和zap70如下地被识别:一组538名前列腺癌患者接受了rp处置,并且前列腺癌组织与临床(例如,病理格里森分级组(pggg)、病理状态(pt分期))以及相关结果参数(例如,生化复发(bcr))、转移性复发、前列腺癌特异性死亡(pca死亡)、挽救性放疗(srt)、挽救性雄激素剥夺治疗(sadt)、化疗(ctx))一起被存储。对于这些患者中的每个,计算pde4d7评分并将其分为四个pde4d7评分类别,如alves de indam.等人的“validation of cyclic adenosine monophosphate phosphodiesterase-4d7for its independent contribution to risk stratification in a prostate cancerpatient cohort with longitudinal biological outcomes”,eur urol focus,vol.4,no.3,第376-384页(2018年)中所描述。pde4d7评分等级1代表具有最低pde4d7表达水平的患者样本,而pde4d7评分等级4代表具有最高pde4d7表达水平的患者样本。然后研究了538名前列腺癌对象的rnaseq表达数据(tpm-每百万转录本),以了解pde4d7评分等级1与4之间的差异基因表达。特别是,针对大约20000个蛋白质编码转录本确定了pde4d7评分1级患者的平均表达水平是否是pde4d7评分4级患者平均表达水平的两倍以上。该分析得到具有pde4d7得分类别1/pde4d7得分类别4的比率>2的637个基因,在四个pde4d7得分类别中的每个中,最小平均表达为1tpm。然后对这637个基因进一步进行分子通路分析(www.david.ncifcrf.gov),从而产生一系列富集注释簇。注释簇#6显示了17个基因的富集(富集分数:5.9),这些基因在原发性免疫缺陷和t细胞受体信号传导激活中发挥作用。进一步的热图分析证实,这些t细胞受体信号传导基因在来自pde4d7评分1级患者样本中的表达普遍高于来自pde4d7评分4级的患者。
41、pde4d7相关基因
42、识别的pde4d7相关基因abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2如下地被识别:我们在571名前列腺癌患者生成的rnaseq数据中近60000个转录本上识别了一系列与该数据中已知生物标志物pde4d7的表达有关的基因。571个样本中的这些基因中的任何基因的表达与pde4d7之间的相关性通过皮尔森相关性完成,并且在正相关的情况下表示为0到1之间的值,或者在负相关的情况下表示为-1到0之间的值。
43、针对相关系数的公式为:
44、
45、其中,和分别是所有样本的样本均值average(pde4d7)和average(gene)。作为用于计算相关系数的输入数据,我们使用pde4d7评分(参见alves de inda m.等人2018年的文章,出处同上)和rnaseq确定的每个感兴趣基因的tpm基因表达值(见下文)。
46、在大约60000个转录本中的任何一个的表达与pde4d7的表达之间确定的最大负相关系数为-0.38,而在大约60000个转录本的任何一个的表达与pde4d7的表达之间确定的最大正相关系数为+0.56。我们选择了相关性范围为-0.31至-0.38以及+0.41至+0.56的基因。我们总共确定了77个符合这些特征的转录本。我们通过在由于术后生化复发接受补救性放疗(srt)的186名患者的子群组中迭代测试cox回归组合模型而从这77个转录本中选择了八个pde4d7相关基因abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2。测试的临床终点是srt开始后前列腺癌特异性死亡。选择八个基因的边界条件是由多变量cox回归中的p值对于模型中保留的所有基因<0.1的限制给出的。
47、术语“abcc5”是指人类atp结合盒亚家族c成员5基因(ensembl:ensg00000114770),例如,是指ncbi参考序列nm_001023587.2或ncbi参考序列nm_005688.3中定义的序列,特别地,seq id no:1或seq id no:2中所示的核苷酸序列,其对应于上述abcc5转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如在seq id no:3或seq id no:4中所示的,其对应于ncbi蛋白质登录参考序列np_001018881.1和ncbi蛋白质登录参考序列np_005679中定义的编码abcc5多肽的蛋白质序列。
48、术语“abcc5”还包括显示与abcc5高度同源性的核苷酸序列,例如,与seq id no:1或seq id no:2中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:3或seq id no:4所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:3或seq id no:4所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq idno:1或seq id no:2中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
49、术语“aim2”是指黑色素瘤2基因缺失(ensembl:ensg00000163568),例如,是指ncbi参考序列nm_004833中所定义的序列,特别地,是指seq id no:5中所示的核苷酸序列,其对应于上述aim2转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:6中所示的,其对应于ncbi蛋白质登录参考序列np_004824中定义的编码cd28多肽aim2多肽的蛋白质序列。
50、术语“aim2”还包括显示与aim2高度同源性的核苷酸序列,例如,与seq id no:5中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:6所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:6所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:5中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
51、术语“apobec3a”是指载脂蛋白bmrna编辑酶催化亚基3a基因(ensembl:ensg00000128383),例如,是指ncbi参考序列nm_145699中所定义的序列,特别地,是指seqid no:7中所示的核苷酸序列,其对应于上述apobec3a转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:8中所示的,其对应于ncbi蛋白质登录参考序列np_663745中定义的编码apobec3a多肽的蛋白质序列。
52、术语“apobec3a”还包括显示与apobec3a高度同源性的核苷酸序列,例如,与seqid no:7中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:8所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq idno:8所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:7中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
53、术语“cd2”是指分化簇2基因(ensembl:ensg00000116824),例如,是指ncbi参考序列nm_001767中所定义的序列,特别地,是指seq id no:9中所示的核苷酸序列,其对应于上述cd2转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:10中所示的,其对应于ncbi蛋白质登录参考序列np_001758中定义的编码cd2多肽的蛋白质序列。
54、术语“cd2”还包括显示与cd2高度同源性的核苷酸序列,例如,与seq id no:9中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:10所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:10所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:9中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
55、术语“cd247”是指分化簇247基因(ensembl:ensg00000198821),例如,是指ncbi参考序列nm_000734或ncbi参考序列nm_198053中定义的序列,特别地,seq id no:11或seqid no:12中说明的核苷酸序列,其对应于上述cd247转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如在seq id no:13或seq id no:14中所示的,其对应于ncbi蛋白质登录参考序列np_000725和ncbi蛋白质登录参考序列np_932170中定义的编码cd247多肽的蛋白质序列。
56、术语“cd247”还包括显示与cd247高度同源性的核苷酸序列,例如,与seq id no:11或seq id no:12中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:13或seq id no:14所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:13或seq id no:14所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seqid no:11或seq id no:12中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
57、术语“cd28”是指分化簇28基因(ensembl:ensg00000178562),例如,是指ncbi参考序列nm_006139或ncbi参考序列nm_001243078中定义的序列,特别地,seq id no:15或seqid no:16中说明的核苷酸序列,其对应于上述cd28转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如在seq id no:17或seq id no:18中所示的,其对应于ncbi蛋白质登录参考序列np_006130和ncbi蛋白质登录参考序列np_001230007中定义的编码cd28多肽的蛋白质序列。
58、术语“cd28”还包括显示与cd28高度同源性的核苷酸序列,例如,与seq id no:15或seq id no:16中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:17或seq id no:18所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:17或seq id no:18所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seqid no:15或seq id no:16中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
59、术语“cd3e”是指分化簇3e基因(ensembl:ensg00000198851),例如,是指ncbi参考序列nm_000733中所定义的序列,特别地,是指seq id no:19中所示的核苷酸序列,其对应于上述cd3e转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq idno:20中所示的,其对应于ncbi蛋白质登录参考序列np_000724中定义的编码cd3e多肽的蛋白质序列。
60、术语“cd2”还包括显示与cd2高度同源性的核苷酸序列,例如,与seq id no:19中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:20所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:20所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:19中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
61、术语“cd3g”是指分化簇3g基因(ensembl:ensg00000160654),例如,是指ncbi参考序列nm_000073中所定义的序列,特别地,是指seq id no:21中所示的核苷酸序列,其对应于上述cd3g转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq idno:22中所示的,其对应于ncbi蛋白质登录参考序列np_000064中定义的编码cd3g多肽的蛋白质序列。
62、术语“cd3g”还包括显示与cd3g高度同源性的核苷酸序列,例如,与seq id no:21中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:22所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:22所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:21中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
63、术语“cd4”是指分化簇4基因(ensembl:ensg00000010610),例如,是指ncbi参考序列nm_000616中所定义的序列,特别地,是指seq id no:23中所示的核苷酸序列,其对应于上述cd4转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq idno:24中所示的,其对应于ncbi蛋白质登录参考序列np_000607中定义的编码cd4多肽的蛋白质序列。
64、术语“cd4”还包括显示与cd4高度同源性的核苷酸序列,例如,与seq id no:23中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:24所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:24所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:23中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
65、术语“ciao1”指胞浆铁硫组件1基因(ensembl:ensg00000144021),例如,是指ncbi参考序列nm_004804中所定义的序列,特别地,是指seq id no:25中所示的核苷酸序列,其对应于上述cd2转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seqid no:26中所示的,其对应于ncbi蛋白质登录参考序列np_663745中定义的编码ciao1多肽的蛋白质序列。
66、术语“ciao1”还包括显示与ciao1高度同源性的核苷酸序列,例如,与seq id no:25中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:26所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:26所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:25中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
67、术语“csk”是指c-末端src激酶基因(ensembl:ensg00000103653),例如,是指ncbi参考序列nm_004383中所定义的序列,特别地,是指seq id no:27中所示的核苷酸序列,其对应于上述csk转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seqid no:28中所示的,其对应于ncbi蛋白质登录参考序列np_004374中定义的编码csk多肽的蛋白质序列。
68、术语“csk”还包括显示与csk高度同源性的核苷酸序列,例如,与seq id no:27中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:28所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:28所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:27中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
69、术语“cux2”是指人类同cut like源盒2基因(ensembl:ensg00000111249),例如,是指ncbi参考序列nm_015267.3中所定义的序列,特别地,是指seq id no:29中所示的核苷酸序列,其对应于上述cux2转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:30中所示的,其对应于ncbi蛋白质登录参考序列np_056082.2中定义的编码cux2多肽的蛋白质序列。
70、术语“cux2”还包括显示与cux2高度同源性的核苷酸序列,例如,与seq id no:29中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:30所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:30所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:29中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
71、术语“ddx58”是指dexd/h-box解旋酶58基因(ensembl:ensg00000107201),例如,是指ncbi参考序列nm_014314中所定义的序列,特别地,是指seq id no:31中所示的核苷酸序列,其对应于上述ddx58转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:32中所示的,其对应于ncbi蛋白质登录参考序列np_055129中定义的编码ddx58多肽的蛋白质序列。
72、术语“ddx58”还包括显示与ddx58高度同源性的核苷酸序列,例如,与seq id no:31中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:32所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:32所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:31中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
73、术语“dhx9”是指dexd/h-box解旋酶9基因(ensembl:ensg00000135829),例如,是指ncbi参考序列nm_001357中所定义的序列,特别地,是指seq id no:33中所示的核苷酸序列,其对应于上述dhx9转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:34中所示的,其对应于ncbi蛋白质登录参考序列np_001348中定义的编码dhx9多肽的蛋白质序列。
74、术语“dhx9”还包括显示与dhx9高度同源性的核苷酸序列,例如,与seq id no:33中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:34所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:34所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:33中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
75、术语“ezr”是指ezrin基因(ensembl:ensg00000092820),例如,是指ncbi参考序列nm_003379中所定义的序列,特别地,是指seq id no:35中所示的核苷酸序列,其对应于上述csk转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:36中所示的,其对应于ncbi蛋白质登录参考序列np_003370中定义的编码ezr多肽的蛋白质序列。
76、术语“ezr”还包括显示与ezr高度同源性的核苷酸序列,例如,与seq id no:35中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:36所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:36所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:35中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
77、术语“fyn”是指fyn原癌基因(ensembl:ensg00000010810),例如,是指ncbi参考序列nm_002037或ncbi参考序列nm_153047或ncbi参考序列nm_153048中定义的序列,特别地,是指如在seq id no:37或seq id no:38或seq id no:39所示的核苷酸序列,其对应于上述fyn转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如在seq id no:40或seq id no:41或seq id no:42中所示的序列,其对应于ncbi蛋白质登录参考序列np_002028和ncbi蛋白质登录参考序列np_694592中以及在ncbi蛋白质登录参考序列xp_005266949中定义的编码fyn多肽的蛋白质序列。
78、术语“fyn”还包括显示与fyn高度同源性的核苷酸序列,例如,与seq id no:37或seq id no:38或seq id no:39中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:42或seq id no:41或seq id no:42所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:40或seq id no:41或seq id no:42所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:37或seq id no:38或seq id no:39中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
79、术语“ifi16”是指干扰素gamma可诱导蛋白质16基因(ensembl:ensg00000163565),例如,是指ncbi参考序列nm_005531中所定义的序列,特别地,是指seqid no:43中所示的核苷酸序列,其对应于上述ifi16转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:44中所示的,其对应于ncbi蛋白质登录参考序列np_005522中定义的编码ifi16多肽的蛋白质序列。
80、术语“ifi16”还包括显示与ifi16高度同源性的核苷酸序列,例如,与seq id no:43中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:44所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:44所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:43中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
81、术语“ifih1”是指个解旋酶c结构域1基因的干扰素诱导的(ensembl:ensg00000115267),例如,是指ncbi参考序列nm_022168中所定义的序列,特别地,是指seqid no:45中所示的核苷酸序列,其对应于上述ifih1转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:46中所示的,其对应于ncbi蛋白质登录参考序列np_071451中定义的编码ifih1多肽的蛋白质序列。
82、术语“ifih1”还包括显示与ifih1高度同源性的核苷酸序列,例如,与seq id no:45中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:46所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:46所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:45中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
83、术语“ifit1”是指具有四肽重复序列1基因的干扰素诱导蛋白(ensembl:ensg00000185745),例如ncbi参考序列nm_001270929或ncbi参考序列nm_001548.5中定义的序列,特别地,核苷酸序列如seq id no:47或seq id no:48所示,其对应于上述ifit1转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如seq id no:48idno:49或seq id no:50,其对应于ncbi蛋白质登录参考序列np_001257858和ncbi蛋白质登录参考序列np_001539中定义的编码ifit1多肽的蛋白质序列。
84、术语“ifit1”还包括显示与ifit1高度同源性的核苷酸序列,例如,与seq id no:47或seq id no:48中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:49或seq id no:50所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:49或seq id no:50所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seqid no:47或seq id no:48中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
85、术语“ifit3”是指具有四肽重复序列3基因的干扰素诱导蛋白(ensembl:ensg00000119917),例如,是指ncbi参考序列nm_001031683中所定义的序列,特别地,是指seq id no:51中所示的核苷酸序列,其对应于上述ifit3转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:52中所示的,其对应于ncbi蛋白质登录参考序列np_001026853中定义的编码ifit3多肽的蛋白质序列。
86、术语“ifit3”还包括显示与ifit3高度同源性的核苷酸序列,例如,与seq id no:51中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:52所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:52所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:51中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
87、术语“kiaa1549”是指人类kiaa1549基因(ensembl:ensg00000122778),例如,是指ncbi参考序列nm_020910或ncbi参考序列nm_001164665中定义的序列,特别地,seq id no:53或seq id no:54中说明的核苷酸序列,其对应于上述kiaa1549转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如在seq id no:55或seq id no:56中所示的,其对应于ncbi蛋白质登录参考序列np_065961和ncbi蛋白质登录参考序列np_001158137中定义的编码kiaa1549多肽的蛋白质序列。
88、术语“kiaa1549”还包括显示与kiaa1549高度同源性的核苷酸序列,例如,与seqid no:53或seq id no:54中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:55或seq id no:56所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:55或seq id no:56所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:53或seq id no:54中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
89、术语“lat”是指用于激活t细胞基因的接头(ensembl:ensg00000213658),例如,是指ncbi参考序列nm_001014987或ncbi参考序列nm_014387中定义的序列,特别地,seq idno:57或seq id no:58中说明的核苷酸序列,其对应于上述lat转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如在seq id no:59或seq id no:60中所示的,其对应于ncbi蛋白质登录参考序列np_001014987和ncbi蛋白质登录参考序列np_055202中定义的编码lat多肽的蛋白质序列。
90、术语“lat”还包括显示与lat高度同源性的核苷酸序列,例如,与seq id no:57或seq id no:58中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:59或seq id no:60所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:59或seq id no:60所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seqid no:57或seq id no:58中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
91、术语“lck”是指lck原癌基因(ensembl:ensg00000182866),例如,是指ncbi参考序列nm_005356中所定义的序列,特别地,是指seq id no:61中所示的核苷酸序列,其对应于上述lck转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq idno:62中所示的,其对应于ncbi蛋白质登录参考序列np_005347中定义的编码lck多肽的蛋白质序列。
92、术语“lck”还包括显示与lck高度同源性的核苷酸序列,例如,与seq id no:61中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:62所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:62所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:61中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
93、术语“lrrfip1”指lrr结合flii相互作用蛋白质1基因(ensembl:ensg00000124831),例如,是指ncbi参考序列nm_004735或ncbi参考序列nm_001137550或ncbi参考序列nm_001137553或ncbi参考序列nm_001137552中定义的序列,特别地,是指如在seq id no:63或seq id no:64或seq id no:65或seq id no:66所示的核苷酸序列,其对应于上述lrrfip1转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如在seq id no:67或seq id no:68或seq id no:69或seq id no:70中所示的序列,其对应于ncbi蛋白质登录参考序列np_004726和ncbi蛋白质登录参考序列np_001131022和ncbi蛋白质登录参考序列np_001131025中以及在ncbi蛋白质登录参考序列xp_001131024中定义的编码lrrfip1多肽的蛋白质序列。
94、术语“lrrfip1”还包括显示与lrrfip1高度同源性的核苷酸序列,例如,与seq idno:63或seq id no:64或seq id no:65或seq id no:66中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seqid no:67或seq id no:68或seq id no:69或seq id no:70所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:67或seq id no:68或seq id no:69或seq id no:70所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:63或seq id no:64或seq id no:65或seq id no:66中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
95、术语“myd88”是指myd88先天免疫信号传导衔接子基因(ensembl:ensg00000172936),例如,是指ncbi参考序列nm_001172567或ncbi参考序列nm_001172568或ncbi参考序列nm_001172569或ncbi参考序列nm_001172566或ncbi参考序列nm_0002468中定义的序列,特别地,是指如在seq id no:71或seq id no:72或seq id no:73或seq idno:74或seq id no:75所示的核苷酸序列,其对应于上述myd88转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如在seq id no:76或seq id no:77或seq id no:78或seq id no:79或seq id no:80中所示的序列,其对应于ncbi蛋白质登录参考序列np_001166040和ncbi蛋白质登录参考序列np_001166037中以及在ncbi蛋白质登录参考序列np_002459中定义的编码myd88多肽的蛋白质序列。
96、术语“myd88”还包括显示与myd88高度同源性的核苷酸序列,例如,与seq id no:71或seq id no:72或seq id no:73或seq id no:74或seq id no:75中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:76或seq id no:77或seq id no:78或seq id no:79或seq id no:80所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:76或seq id no:77或seq id no:78或seq id no:79或seq id no:80所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:71或seq id no:72或seq id no:73或seq id no:74或seq id no:75中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
97、术语“oas1”是指2'-5'-寡聚腺苷酸合成酶1基因(合集:ensg00000089127),例如,是指ncbi参考序列nm_001320151或ncbi参考序列nm_002534或ncbi参考序列nm_001032409或ncbi参考序列nm_016816中定义的序列,特别地,是指如在seq id no:81或seq id no:82或seq id no:83或seq id no:84所示的核苷酸序列,其对应于上述oas1转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如在seq id no:85或seq id no:86或seq id no:87或seq id no:88中所示的序列,其对应于ncbi蛋白质登录参考序列np_001307080和ncbi蛋白质登录参考序列np_002525中以及在ncbi蛋白质登录参考序列np_001027581以及在ncbi蛋白质登录参考序列np058132中定义的编码oas1多肽的蛋白质序列。
98、术语“oas1”还包括显示与oas1高度同源性的核苷酸序列,例如,与seq id no:81或seq id no:82或seq id no:83或seq id no:84中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq idno:85或seq id no:86或seq id no:87或seq id no:88所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq idno:85或seq id no:86或seq id no:87或seq id no:88所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:81或seq id no:82或seq id no:83或seq id no:84中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
99、术语“pag1”是指具有糖鞘脂微结构域的磷蛋白膜锚1基因(ensembl:ensg00000076641),例如,是指ncbi参考序列nm_018440中所定义的序列,特别地,是指seqid no:89中所示的核苷酸序列,其对应于上述pag1转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如,如seq id no:90中所示的,其对应于ncbi蛋白质登录参考序列np_060910中定义的编码pag1多肽的蛋白质序列。
100、术语“pag1”还包括显示与pag1高度同源性的核苷酸序列,例如,与seq id no:89中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:90所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:90所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:89中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
101、术语“pde4d”是指人磷酸二酯酶4d基因(合集:ensg00000113448),例如,是指如ncbi参考序列nm_001104631或ncbi参考序列nm_001349242或ncbi参考序列nm_001197218或ncbi参考序列nm_006203或在ncbi参考序列nm_001197221或ncbi参考序列nm_001197220或ncbi参考序列nm_001197223或ncbi参考序列nm_001165899或ncbi参考序列nm_001165899中所定义的序列,特别地,是指如seq id no:91或seq id no:92或seq id no:93或seq id no:94或seq id no:95或seq id no:96或seq id no:97或seq id no:98或seqid no:99中所示的核苷酸序列,其对应于上述pde4d转录本的ncbi参考序列的序列,并且还涉及例如,如在seq id no:100或seq id no:101或seq id no:102或在seq id no:103或seq id no:104或seq id no:105或seq id no:106或seq id no:107或seq id no:108中所示的对应的氨基酸序列,其对应于ncbi蛋白质登录参考序列np_001098101和ncbi蛋白质登录参考序列np_001336171和ncbi蛋白质登录参考序列np_001184147和ncbi蛋白质登录参考序列np_006194和ncbi蛋白质登录参考序列np_001184150和ncbi蛋白质登录参考序列np_001184149和ncbi蛋白质登录参考序列np_001184152和在ncbi蛋白质登录参考序列np_001159371和ncbi蛋白质登录参考序列np_001184148中定义的编码pde4d多肽的蛋白质序列。
102、术语“pde4d”还包括显示与pde4d高度同源性的核苷酸序列,例如,与seq id no:91或seq id no:92或seq id no:93或seq id no:94或seq id no:95或seq id no:96或seqid no:97或seq id no:98或seq id no:99中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列或者与seq id no:100或seq id no:101或seq id no:102或seq id no:103或seq id no:104或seq id no:105或seq id no:106或seq id no:107或seq id no:108中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列或与seq idno:100或seq id no:101或seq id no:102或seq id no:103或seq id no:104或seq idno:105或seq id no:106或seq id no:107或seq id no:108中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或者与seq id no:91或seq id no:92或seq id no:93或seq id no:94或seq idno:95或seq id no:96或seq id no:97或seq id no:98或seq id no:99中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
103、术语“prkaca”是指蛋白激酶camp激活的催化亚基α基因(ensembl:ensg00000072062),例如,是指ncbi参考序列nm_002730或ncbi参考序列nm_207518中所定义的序列,特别地,如在核苷酸序列如seq id no:109或seq id no:110中所示,其对应于上述prkaca转录本的ncbi参考序列的序列,并且还涉及例如在seqid中no:111或seq id no:112所示的相应氨基酸序列,其对应于ncbi蛋白质登录参考序列np_002721和ncbi蛋白质登录参考序列np_997401中定义的编码prkaca多肽的蛋白质序列。
104、术语“prkaca”还包括显示与prkaca高度同源性的核苷酸序列,例如,与seq idno:109或seq id no:110中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:111或seq id no:112所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:111或seq id no:112所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:109或seq id no:110中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
105、术语“prkacb”是指蛋白激酶camp激活的催化亚基β基因(ensembl:ensg00000142875),例如,是指如ncbi参考序列nm_002731或ncbi参考序列nm_182948或ncbi参考序列nm_001242860或ncbi参考序列nm_001242859或ncbi参考序列nm_001242858或ncbi参考序列nm_001242862或ncbi参考序列nm_001242861或ncbi参考序列nm_001300915或ncbi参考序列nm_207578或ncbi参考序列nm_001242857或ncbi参考序列nm_001300917中所定义的序列,特别地,是指seq id no:113或seq id no:114或seq id no:115或seq id no:116或seq id no:117或seq id no:118或seq id no:119或seq id no:120或seq id no:121或seq id no:122或seq id no:123中所示的核苷酸序列,其对应于上述prkacb转录本的ncbi参考序列的序列,并且还涉及,例如,如在seq id no:124或seq idno:125或seq id no:126或seq id no:127或seq id no:128或seq id no:129或seq idno:130或seq id no:131或seq id no:132或seq id no:133或seq id no:134中所示的相应的氨基酸序列,其对应于ncbi登录参考序列np_002722和ncbi蛋白质登录参考序列np_891993和ncbi蛋白质登录参考序列np_001229789和ncbi蛋白质登录参考序列np_001229788和ncbi蛋白质登录参考序列np_001229787和ncbi蛋白质登录参考序列np_001229791和ncbi蛋白质登录参考序列np_001229790和ncbi蛋白质登录参考序列np_001287844和ncbi蛋白质登录参考序列np_997461和ncbi蛋白质登录参考序列np_001229786和ncbi蛋白质登录参考序列np_001287846中定义的编码prkacb多肽的蛋白质序列。
106、术语“prkacb”还包括示出与prkacb高度同源性的核苷酸序列,例如与seq id no:113或seq id no:114或seq id no:115或seq id no:116或seq id no:117或seq id no:118或seq id no:119或seq id no:120或seq id no:121或seq id no:122或seq id no:123中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同核酸序列或者与如在seq id no:124或seq id no:125或seq id no:126或seq id no:127或seq id no:128或seq id no:129或seq id no:130或seq id no:131或seq id no:132或seq id no:133或seq id no:134中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列或者与在seqid no:124或seq id no:125或seq id no:126或seq id no:127或seq id no:128或seq idno:129或seq id no:130或seq id no:131或seq id no:132或seq id no:133或seq idno:134中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或者与在seq idno:113或seq id no:114或seq id no:115或seq id no:116或seq id no:117或seq id no:118或seq id no:119或seq id no:120或seq id no:121或seq id no:122或在seq id no:123中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
107、术语“ptprc”是指c型蛋白酪氨酸磷酸酶受体基因(ensembl:ensg00000081237),例如,是指ncbi参考序列nm_002838或ncbi参考序列nm_080921中定义的序列,特别地,seqid no:135或seq id no:136中说明的核苷酸序列,其对应于上述ptprc转录本的ncbi参考序列的序列,并且还涉及相应的氨基酸序列,例如在seq id no:137或seq id no:138中所示的,其对应于ncbi蛋白质登录参考序列np_002829和ncbi蛋白质登录参考序列np_563578中定义的编码ptprc多肽的蛋白质序列。
108、术语“ptprc”还包括显示与ptprc高度同源性的核苷酸序列,例如,与seq id no:135或seq id no:136中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:137或seq id no:138所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:137或seq id no:138所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:135或seq id no:136中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
109、术语“rap1gap2”指人类rap1 gtp酶激活蛋白2基因(ensg00000132359),例如,是指如在ncbi参考序列nm_015085或ncbi参考序列nm_001100398或ncbi参考序列nm_001330058中所定义的序列,特别地,如在seq id no:139或seq id no:140或seq id no:141所示的核苷酸序列,其对应于上述rap1gap2转录本的ncbi参考序列的序列,并且还涉及例如如在seq id no:142或seq id no:143或seq id no:144中所示的相应的氨基酸序列,其对应于ncbi蛋白质登录参考序列np_055900和ncbi蛋白质登录参考序列np_001093868和在的ncbi蛋白质登录参考序列np_001316987中所定义的编码rap1gap2多肽的蛋白质序列。
110、术语“rap1gap2”还包括显示与rap1gap2高度同源性的核苷酸序列,例如,与seqid no:139或seq id no:140或seq id no:141所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:142或seq id no:143或seq id no:144所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:142或seq idno:143或seq id no:144所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:139或seqid no:140或seq id no:141中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
111、术语“slc39a11”是指人类溶质载体家族39成员11基因(ensembl:ensg00000133195),例如,是指如在ncbi参考序列nm_139177或ncbi参考序列nm_001352692中所定义的序列,特别地,如在seq id no:145或seq id no:146中所示的核苷酸序列,其对应于上述slc39a11转录本的ncbi参考序列的序列,并且还涉及例如seq id no:147或seqid no:148中所示的相应氨基酸序列,其对应于ncbi蛋白质登录参考序列np_631916和ncbi蛋白质登录参考序列np_001339621中定义的编码slc39a11多肽的蛋白质序列。
112、术语“slc39a11”还包括显示与slc39a11高度同源性的核苷酸序列,例如,与seqid no:145或seq id no:146中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:147或seq id no:148所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:147或seq id no:148所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:145或seq id no:146中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
113、术语“tdrd1”是指人类都铎域包含1基因(ensembl:ensg00000095627),例如,是指ncbi参考序列nm_198795中定义的序列,特别地,是指seq id no:149中所示的核苷酸序列,其对应于上述tdrd1转录本的ncbi参考序列的序列,并且还涉及例如seq id no:150中所示的相应氨基酸序列,其对应于ncbi蛋白质登录参考np_942090中定义的编码tdrd1多肽的蛋白质序列。
114、术语“tdrd1”还包括显示与tdrd1高度同源性的核苷酸序列,例如,与seq id no:149中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:150所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:150所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:149中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
115、术语“tlr8”是指类铎受体8基因(ensembl:ensg00000101916),例如,是指ncbi参考序列nm_138636或ncbi参考序列nm_016610中所定义的序列,特别地,是指seq id no:151或seq idno:152中所示的核苷酸序列,其对应于上述tlr8转录本的ncbi参考序列的序列,并且还涉及例如seq id no:153或在seq id no:154中所示的相应的氨基酸序列,其对应于ncbi蛋白质登录参考序列np_619542和ncbi蛋白质登录参考序列np_057694中定义的编码tlr8多肽的蛋白质序列。
116、术语“tlr8”还包括显示与tlr8高度同源性的核苷酸序列,例如,与seq id no:151或seq idno:152中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:153或seq id no:154所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:153或seq id no:154所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:151或seq id no:152中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
117、术语“vwa2”是指人von willebrand因子a域包含2基因(ensembl:ensg00000165816),例如,是指ncbi参考序列nm_001320804中定义的序列,特别地,是指seqid no:155中所示的核苷酸序列,其对应于上述vwa2转录本的ncbi参考序列的序列,并且还涉及例如seq id no:156中所示的相应氨基酸序列,其对应于ncbi蛋白质登录参考np_001307733中定义的编码vwa2多肽的蛋白质序列。
118、术语“vwa2”还包括显示与vwa2高度同源性的核苷酸序列,例如,与seq id no:155中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:156所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:156所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:155中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
119、术语“zap70”指t细胞受体相关蛋白激酶70基因的zeta链(ensembl:ensg00000115085),例如,是指ncbi参考序列nm_001079或ncbi参考序列nm_207519中定义的序列,特别地,是指seq id no:157或seq id no:158中所示的核苷酸序列,其对应于上述zap70转录本的ncbi参考序列的序列,并且还涉及例如在seq id no:159或seq id no:160中所示的相应氨基酸序列,其对应于ncbi蛋白质登录参考序列np_001070和ncbi蛋白质登录参考序列np_997402中定义的编码zap70多肽的蛋白质序列。
120、术语“zap70”还包括显示与zap70高度同源性的核苷酸序列,例如,与seq id no:157或seq id no:158中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:159或seq id no:160所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:159或seq id no:160所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:157或seq id no:158中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
121、术语“zbp1”是指z-dna结合蛋白1基因(ensembl:ensg00000124256),例如,如ncbi参考序列nm_030776或ncbi参考序列nm_001160418或ncbi参考序列nm_001160419中定义的序列,特别地,是指seq id no:161或seq id no:162或seq id no:163中所示的核苷酸序列,其对应于上述zbp1转录本的ncbi参考序列的序列,并且还涉及例如在seq id no:164或seq idno:165或seq id no:166中所示的相应的氨基酸序列,其对应于ncbi蛋白质登录参考序列np_110403和ncbi蛋白质登录参考序列np_001153890和ncbi蛋白质登录参考序列np_001153891中定义的编码zbp1多肽的蛋白质序列。
122、术语“zbp1”还包括显示与zbp1高度同源性的核苷酸序列,例如,与seq id no:161或seq idno:162或seq id no:163中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的核酸序列,或与seq id no:164或seq idno:165或seq id no:166所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的氨基酸序列,或与seq id no:164或seq id no:165或seq id no:166所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的编码氨基酸序列的核酸序列或与seq id no:161或seq id no:162或seq id no:163中所示的序列至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的由核酸序列编码的氨基酸序列。
123、术语“生物样本”或“从对象获得的样本”是指通过本领域技术人员已知的合适方法从对象例如前列腺癌患者获得的任何生物材料。术语“前列腺癌对象”是指患有或疑似患有前列腺癌的人。
124、进一步证明,使用完整模型(即使用所有8个pde4d7相关基因、所有14个免疫防御反应基因和所有17个t细胞受体信号传导基因)不是获得显著预测效果所必需的,并且已经可以通过随机选择一个pde4d7相关基因与一种随机选择的免疫防御反应基因和一种随机选择的t细胞受体信号传导基因的组合来获得显著结果。实施例和图15-32表明选自基因的完整集合的随机选择pde4d7相关基因中的与一个随机选择的免疫防御反应基因和一个随机选择的t细胞受体信号传导基因相组合足以做出显著预测。这些随机选择使我们有理由相信,从每组中选择一个基因都可以显著预测前列腺癌对放疗的反应。
125、可以以临床上可接受的方式收集所使用的生物样本,例如以保存核酸(特别是rna)或蛋白质的方式。
126、所述(一个或多个)生物样本可包括身体组织和/或体液,例如但不限于血液、汗液、唾液和尿液。此外,生物样本可包含源自上皮细胞的细胞提取物或细胞群,所述上皮细胞例如癌性上皮细胞或源自疑似癌性组织的上皮细胞。生物样本可包含源自腺体组织的细胞群,例如,样本可源自男性对象的前列腺。此外,如果需要,可以从获得的身体组织和体液中纯化细胞,然后用作生物样本。在一些实现中,样本可以是组织样本、尿液样本、尿液沉渣样本、血液样本、唾液样本、精液样本、包括循环肿瘤细胞的样本、细胞外囊泡、含有前列腺分泌的外来体的样本,或细胞系或癌细胞系。
127、在一个特定的实现中,可以获得和/或使用活组织检查或切除样本。这样的样本可以包括细胞或细胞裂解物。
128、还可以设想将生物样本的内容物提交给富集步骤。例如,样本可以与特定细胞类型(例如前列腺细胞)的细胞膜或细胞器特异性的配体接触,例如用磁性颗粒功能化。由磁性颗粒浓缩的材料可随后用于如上文或下文所述的检测和分析步骤。
129、此外,细胞,例如肿瘤细胞,可以通过流体或液体样本例如血液、尿液等的过滤过程来富集。这样的过滤过程也可以与基于如上文所述的配体特异性相互作用的富集步骤组合。
130、术语“前列腺癌”是指男性生殖系统中的前列腺癌,当前列腺细胞发生突变并开始失控增殖时就会发生这种癌症。通常,前列腺癌与前列腺特异性抗原(psa)水平升高有关。在本发明的一个实施方案中,术语“前列腺癌”涉及显示psa水平高于3.0的癌症。在另一个实施例中,该术语涉及显示psa水平高于2.0的癌症。术语“psa水平”是指血液中psa的浓度,单位为ng/ml。
131、术语“非进行性前列腺癌状态”是指个体样本未示出指示“生化复发”和/或“临床复发”和/或“转移”和/或“去势抵抗性疾病”和/或“前列腺癌或疾病特异性死亡”的参数值。
132、术语“进行性前列腺癌状态”是指个体样本示出指示“生化复发”和/或“临床复发”和/或“转移”和/或“去势抵抗性疾病”和/或“前列腺癌或疾病特异性死亡”的参数值。
133、术语“生化复发”通常是指指示样本中存在前列腺癌细胞的psa升高的复发生物学值。然而,也可以使用可用于检测存在或引起对此类存在的怀疑的其他标记。
134、术语“临床复发”是指临床体征的存在指示所测量的肿瘤细胞的存在,例如使用体内成像。
135、术语“转移”是指在前列腺以外的器官中存在转移性疾病。
136、术语“去势抵抗性疾病”是指存在激素不敏感的前列腺癌;即,不再对雄激素剥夺疗法(adt)产生反应的前列腺癌。
137、术语“前列腺癌特异性死亡或疾病特异性死亡”是指患者死于前列腺癌。
138、优选的是:
139、所述一个或多个免疫防御反应基因包含所述免疫防御基因中的三个或更多,优选地,六个或更多,更优选地,九个或更多,最优选地,所有,和/或
140、所述一个或多个t细胞受体信号传导基因包含所述t-细胞受体信号传导基因中的三个或更多个,优选地六个或更多个,更优选地,九个或更多个,最优选地,所有,和/或
141、所述一个或多个pde4d7相关基因包含所述pde4d7相关基因中的三个或更多个,优选地,六个或更多个,最优选地,所有。
142、优选地,确定治疗反应的预测或治疗的个性化包括:
143、利用已经从前列腺癌对象的群体导出的回归函数将针对两个或更多个,例如,2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个或者所有,免疫防御反应基因的第一基因表达谱进行组合,和/或
144、利用已经从前列腺癌对象的群体导出的回归函数将针对两个或更多个,例如,2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,t细胞受体信号传导基因的第二基因表达谱进行组合,和/或
145、利用已经从前列腺癌对象的群体导出的回归函数将针对两个或更多个,例如,2个、3个、4个、5个、6个、7个或者所有,pde4d7相关基因的第三基因表达谱进行组合。
146、cox比例风险回归允许分析几个风险因素对时间对测试事件(如生存)的影响。因此,风险因素可能是二分变量或离散变量,如风险评分或临床阶段,但也可能是连续变量,如生物标志物测量结果或基因表达值。终点(例如,死亡或疾病复发)的概率称为风险。除了关于例如患者群组中的对象是否达到测试终点的信息(例如,患者是否死亡),在回归分析中也考虑了到达终点的时间。危害建模为:h(t)=h0(t)·exp(w1·v1+w2·v2+w3·v3+…),其中,v1、v2、v3…是预测变量,并且h0(t)是基线危害,而h(t)是任何时间t时的危害。危害比(或到达事件的风险)由ln[h(t)/h0(t)]=w1·v1+w2·v2+w3·v3+…表示,其中,系数或权重w1、w2、w3…通过cox回归分析估计,并且可以用与逻辑回归分析类似的方式进行解读。
147、在一个特定的实现中,针对两个或更多个,例如2、3、4、5、6、7、8、9、10、11、12、13或者所有,免疫防御反应基因的第一基因表达谱与回归函数的组合如下地确定:
148、idr_模型:
149、(w1·aim2)+(w2·apobec3a)+(w3·ciao1)+(w4·ddx58)+
150、(w5·dhx9)+(w6·ifi16)+(w7·ifih1)+(w8·ifit1)+(w9·ifit3)+ (2)
151、(w10·lrrfip1)+(w11·myd88)+(w12·oas1)+(w13·tlr8)+
152、(w14·zbp1)
153、其中,w1到w14是权重,并且aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8和zbp1是免疫防御反应基因的表达水平。
154、在一个示例中,w1可以是大约-0.8到0.2,例如,-0.313,w2可以是大约-0.7到0.3,例如,-0.1417,w3可以是大约-0.4到0.6,例如,0.1008,w4可以是大约-0.5到0.5,例如,-0.07478,w5可以是大约-0.2到0.8,例如,0.277,w6可以是大约-0.6到0.4,例如,-0.07944,w7可以是大约-0.2到0.80.8,例如,0.3036,w8可以是大约-0.6至0.4,例如,-0.09188,w9可以是大约-0.3至0.7,例如,0.1661,w10可以是大约-1.2至0.2,例如,-0.7105,w11可以是大约-0.3至0.7,例如,0.1615,w12可以是大约-0.6至0.4,例如,-0.07468,w13可以是大约-0.6至0.4,例如,-0.06677,并且w14可以是大约-0.7至0.3,例如,-0.155。
155、在一个特定的实现中,针对两个或多个,例如,2、3、4、5、6、7、8、9、10、11、12、13、14、15、16个或者所有,t细胞受体信号传导基因的第二基因表达谱与回归函数的组合如下地确定:
156、tcr_signaling_模型:
157、(w15·c2)+(w16·cd247)+(w17·cd28)+(w18·cd3e)+(w19·cd3g)
158、+(w20·cd4)+(w21·csk)+(w22·ezr)+(w23·fyn)+(w24·lat)+ (3)
159、(w25·lck)+(w26·pag1)+(w27·pde4d)+(w28·prkaca)+
160、(w29·prkacb)+(w30·ptprc)+(w31·zap70)
161、其中,w15到w31是权重,并且cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、
162、lat、lck、pag1、pde4d、prkaca、prkacb、ptprc和zap70是t-细胞受体信号传导基因的表达水平。
163、在一个示例中,w15可以是大约-0.1到0.9,例如,0.4137,w16可以是大约-0.6到0.4,例如,-0.1323,w17可以是大约-0.1到0.9,例如,0.3695,w18大约-0.8至0.2,例如,-0.267,w19可以是约-0.7至0.3,例如,-0.1984,w20可以是约-0.2至0.8,例如,0.3018,w21可以是约0.1至1.1,例如,0.6169,w22可以是大约-0.8至0.2,例如,-0.2789,w23可以是大约-0.7至0.3,例如,-0.1842,w24可以是大约0.5至1.5,例如,0.4672,w25可以是大约-0.5至0.5,例如,-0.07028,w26可以是大约-0.2至0.8,例如,0.3278,w27可以是大约-1.3至-0.3,例如,-0.8253,w28可以是大约0.1至1.1,例如,0.6212,w29可以是大约-0.9至0.1,例如,-0.4462,w30可以是大约–0.9至0.1,例如,-0.4622,且w31可以是大约-0.1至0.9,例如,-0.3702。
164、在一个具体实现方式中,针对两个或更多个,例如,2个、3个、4个、5个、6个、7个或者所有,pde4d7相关基因的第三基因表达谱与回归函数的组合如下地确定:
165、pde4d7_corr_模型:
166、(w32·abcc5)+(w33·cux2)+(w34·kiaa1549)+(w35·pde4d)+ (4)
167、(w36·rap1gap2)+(w37·slc39a11)+(w38·tdrd1)+(w39·vwa2)
168、其中,w32到w39是权重,并且abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2是pde4d7相关基因的表达水平。
169、在一个示例中,w32可以是大约-0.1到0.9,例如,0.368,w33可以是大约-0.3到-1.3,例如,-0.7675,w34可以是大约-0.1到0.9,例如,0.4108,w35可以是大约-0.1到0.9,比如0.4007,w36可以是大约-1.2至-0.2,例如,-0.679,w37可以是大约0.0至0.1,例如,0.5433,w38可以是大约0.1至1.1,例如,0.6366,且w39可以是大约-1.0到0.0,例如,-0.4749。
170、进一步优选地,确定治疗反应的预测或治疗的个性化还包括利用已经从前列腺癌对象的群体导出的回归函数将所述第一基因表达谱的所述组合、所述第二基因表达谱的所述组合以及所述第三基因表达谱回归函数的所述组合进行组合。
171、在一个特定的实现中,治疗反应的预测或治疗的个性化确定如下:
172、pcai_模型:
173、(w40·idr_模型)+(w41·tcr_signaling模型)+ (5)
174、(w42·pde4d7_corr_模型)
175、其中,w40到w42是权重,idr_模型是基于针对两个或多个,例如2、3、4、6、7、8、9、10、11、12、13或者所有,免疫防御响应基因的表达谱的上述回归模型,tcr_signaling模型是基于针对两个或多个,例如2、3、4、6、7、8、9、10、11、12、13、14、15、16或者所有,t细胞受体信号传导基因表达谱的上述回归模型,pde4d7_corr_模型是基于针对两个或多个,例如,2、3、4、6、7或者所有,pde4d7相关基因的表达谱的上述回归模型。
176、在一个示例中,w40可以是大约0.2到1.2,例如,0.674,w41可以是大约0.0到1.0,例如,0.5474,并且w42可以是大约0.1到1.1,例如,0.6372。
177、基于治疗反应的预测值,也可以将治疗反应的预测分类或归类为至少两个风险组中的一个。例如,可能有两个风险组,或三个风险组,或四个风险组,或四个以上的预定义风险组。每个风险组涵盖治疗反应预测值的相应范围(非交叠)。例如,风险组可以指示特定临床事件发生的概率从0到<0.1或从0.1到<0.25或从0.25到<0.5或从0.5到1.0等。
178、进一步优选地,治疗反应的预测或治疗的个性化的确定进一步基于从对象获得的一个或多个临床参数。
179、如上所述,已经研究了基于临床参数的各种指标。通过进一步将对治疗反应的预测或治疗的个性化基于这样的(一个或多个)临床参数,可以进一步改进预测。
180、优选临床参数包括以下一项或多项:(i)前列腺特异性抗原(psa)水平;(ii)病理性格里森评分(pgs);(iii)临床肿瘤分期;(iv)病理学格里森分级组(pggg);(v)病理阶段;(vi)一个或多个病理变量,例如,手术切缘和/或淋巴结浸润和/或前列腺外生长和/或精囊浸润的状态;(vii)capra;(viii)capra-s;(ix)eau-bcr风险组,以及;(x)另一个临床风险评分。
181、进一步优选地,确定对治疗反应的预测或治疗的个性化包括利用已经从前列腺癌对象的群体导出的回归函数将以下中的一项或多项进行组合:(i)针对所述一个或多个免疫防御反应基因的第一(一个或多个)基因表达谱;(ii)针对所述一个或多个t细胞受体信号传导基因的第二(一个或多个)基因表达谱;(iii)针对所述一个或多个pde4d7相关基因的第三(一个或多个)基因表达谱,以及;(iv)所述第一基因表达谱的组合、所述第二基因表达谱的组合以及所述第三基因表达谱的组合以及从所述对象获得的一个或多个临床参数。
182、在一个特定的实现方式中,对治疗反应的预测如下地确定:
183、
184、其中,w43和w44是权重,pcai_模型是上述回归模型,其基于两个或多个,例如2、3、4、6、7、8、9、10、11、12、13个或者所有,免疫防御反应基因的表达谱,针对两个或多个,例如,2、3、4、6、7、8、9、10、11、12、13、14、15,16个或者所有的t细胞受体信号传导基因的表达谱,以及针对两个或更多个,例如,2、3、4、6、7个或者所有,pde4d7相关基因的表达谱,并且eau_bcr是eau-bcr风险组(参见tilki d.等人的“external validation of the europeanassociation of urology biochemical recurrence risk groups to predictmetastasis and mortality after radical prostatectomy in a european cohort”,eur urol,vol.75,no.6,第896-900页,2019年)。
185、在一个示例中,w43可以是大约0.4到1.4,例如,0.8887,并且w44可以是大约1.1到2.1,例如,1.6085。
186、优选地,生物样本在治疗开始之前从对象获得。可以以前列腺癌组织中的mrna或蛋白质的形式确定所述(一个或多个)基因表达谱。替代地,如果基因以可溶形式存在,则可以在血液中测定基因表达谱。
187、进一步优选的是,该治疗是根治性放疗、挽救性放疗(srt)、挽救性雄激素剥夺疗法(sadt)或细胞毒性化疗(ctx)。
188、优选地,所述治疗是放疗,其中,对治疗反应的预测对于治疗的有效性是负面的或正面的,其中,基于预测推荐治疗,并且如果预测是负面的,则推荐的治疗包括以下中的一项或多项:(i)早于标准提供的放疗;(ii)辐射剂量增加的放疗;(iii)辅助治疗,例如雄激素剥夺疗法;以及iv)不是放疗的替代治疗。
189、在本发明的另一方面中,提出了一种用于预测前列腺癌对象对治疗或对前列腺癌对象的治疗进行个性化的反应的装置,包括:
190、输入部,其适于接收第一基因表达谱、第二基因表达谱和第三基因表达谱的数据,所述第一基因表达谱针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,免疫防御反应基因中的每个:aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8和zbp1,所述第一(一个或多个)基因表达谱是在从对象获得生物样本中确定的,所述第二基因表达谱指示针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,t细胞受体信号传导基因中的每个:cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、lat、lck、pag1、pde4d,prkaca、prkacb、ptprc和zap70,所述第二(一个或多个)基因表达谱是在从对象获得的生物样本中确定的,所述第三基因表达谱指示针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个或者所有,pde4d7相关基因中的每个:abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2,所述第三(一个或多个)基因表达谱是在从对象获得的生物样本中确定的,
191、处理器,其适于基于所述第一、第二和第三(一个或多个)基因表达谱来确定对治疗反应的预测或治疗的个性化,以及
192、任选地,提供单元,其适于向医疗护理人员或所述对象提供所述预测或基于所述预测或所述个性化的所述个性化或治疗推荐。
193、在本发明的另一方面中,提供了一种包括指令的计算机程序产品,当所程序由计算机运行时,所述指令使计算机执行包括以下操作的方法:
194、接收指示第一基因表达谱、第二基因表达谱和第三基因表达谱的数据,所述第一基因表达谱针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,免疫防御反应基因中的每个:aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8和zbp1,所述第一(一个或多个)基因表达谱是在从对象获得生物样本中确定的,所述第二基因表达谱指示针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,t细胞受体信号传导基因中的每个:cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、lat、lck、pag1、pde4d,prkaca、prkacb、ptprc和zap70,所述第二(一个或多个)基因表达谱是在从对象获得的生物样本中确定的,所述第三基因表达谱指示针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个或者所有,pde4d7相关基因中的每个:abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2,所述第三(一个或多个)基因表达谱是在从对象获得的生物样本中确定的,
195、基于所述第一、第二和第三(一个或多个)基因表达谱来确定前列腺癌对象对治疗的反应或对前列腺癌对象的治疗进行个性化的反应的预测,以及
196、任选地,基于所述预测或所述个性化向医疗护理人员或对象提供所述预测或所述个性化或治疗推荐。
197、在本发明的另一方面中,提出了一种诊断套件,其包括:
198、至少一个引物和/或探针,其用于在从对象获得的生物样本中确定针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,免疫防御反应基因中的每个的第一基因表达谱:aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8和zbp1,
199、至少一个引物和/或探针,其用于在从所述对象获得的生物样本中确定针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,t细胞受体信号传导基因中的中的每个的第二(一个或多个)基因表达谱:cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、lat、lck、pag1、pde4d、prkaca、prkacb、ptprc和zap70,
200、至少一个引物和/或探针,其用于在从所述对象获得的生物样本中确定针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个种或者所有,pde4d7相关基因中的每个的基因表达谱:abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2,以及
201、任选地,根据权利要求11所述的装置或根据权利要求12所述的计算机程序产品。
202、在本发明的另一方面中,提出了根据权利要求13所述的套件的使用。
203、优选地,根据权利要求14所述的使用是在用于预测前列腺癌对象对治疗的反应或前列腺癌对象的个性化治疗的方法中使用。
204、在本发明的另一方面中,提出了一种方法,其包括:
205、接受从前列腺癌对象获得的一个或多个生物样本,
206、使用根据权利要求13所述的套件来在从对象获得的生物样本中确定针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,免疫防御反应基因中的每个的第一基因表达谱:aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8和zbp1,
207、使用根据权利要求13所述的套件来在从对象获得的生物样本中确定针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,t细胞受体信号传导基因中的中的每个的第二(一个或多个)基因表达谱:cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、lat、lck、pag1、pde4d、prkaca、prkacb、ptprc和zap70,
208、使用根据权利要求13所述的套件来在从对象获得的生物样本中确定针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个种或者所有,pde4d7相关基因中的每个的基因表达谱:abcc5、cux2、kiaa1549、pde4d、rap1gap2、slc39a11、tdrd1和vwa2。
209、在本发明的另一方面,提出了在预测前列腺癌对象对治疗的反应或对前列腺癌对象的治疗进行个性化的方法中使用针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,免疫防御反应基因中的每个的第一基因表达谱:aim2、apobec3a、ciao1、ddx58、dhx9、ifi16、ifih1、ifit1、ifit3、lrrfip1、myd88、oas1、tlr8和zbp1,针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个或者所有,t细胞受体信号传导基因中的每个的第二基因表达谱:cd2、cd247、cd28、cd3e、cd3g、cd4、csk、ezr、fyn、lat、lck、pag1、pde4d、prkaca、prkacb、ptprc和zap70,以及针对从包括以下项的组中选择的一个或多个,例如,1个、2个、3个、4个、5个、6个、7个或者所有,pde4d7相关基因中的每个的第三基因表达谱:pde4d、rap1gap2、slc39a11、tdrd1,和vwa2,包括:
210、基于所述第一、第二和第三(一个或多个)基因表达谱来确定对治疗反应的预测或治疗的个性化,以及
211、任选地,基于所述预测或所述个性化向医疗护理人员或对象提供所述预测或所述个性化或治疗推荐。
212、应当理解,根据权利要求1所述的方法、根据权利要求11所述的装置、根据权利要求12的所述计算机程序产品、根据权利要求13所述的诊断套件、根据权利要求14所述的诊断套件的用途、根据权利要求16所述的方法,以及根据权利要求17所述的第一、第二和第三基因表达谱的使用具有相似和/或相同的优选实施例,特别是如从属权利要求中所定义的。
213、应该理解,本发明的优选实施例也可以是从属权利要求或以上实施例与各自的独立权利要求的任何组合。
214、参考本文下文中所描述的实施例,本发明的这些和其他方面将显而易见并将得以阐述。
- 还没有人留言评论。精彩留言会获得点赞!