检测稀有突变和拷贝数变异的系统和方法与流程
检测稀有突变和拷贝数变异的系统和方法
本技术是申请日为2014年03月15日、申请号为201480024935.1、发明名称为“检测稀有突变和拷贝数变异的系统和方法”的中国专利申请(其对应pct申请的申请日为2014年03月15日、申请号为pct/us2014/000048)的分案申请。交叉引用
1.本技术涉及2013年9月4日提交的pct专利申请号pct/us2013/058061和2013年12月28日提交的美国临时专利申请号61/921,456,上述各个专利申请均为所有目的通过引用而整体并入本文。
背景技术:
2.多核苷酸的检测和定量对于分子生物学和医学应用如诊断学是重要的。遗传检测特别可用于许多诊断方法。例如,由稀有遗传改变(例如,序列变异体)或外遗传标记物的改变引起的病症,如癌症和部分或完全的非整倍性,可以用dna序列信息进行检测或更准确地表征。
3.遗传性疾病如癌症的早期检测和监测在疾病的成功治疗或管理中通常是有用的或需要的。一种方法可以包括监测来源于无细胞的核酸的样品,其为可在不同类型的体液中发现的多核苷酸群体。在一些情况下,可以基于检测遗传异常,如一个或多个核酸序列的拷贝数变异和/或序列变异的变化,或其它某些稀有遗传改变的发展,来表征或检测疾病。无细胞的dna(“cfdna”)几十年来已为本领域所知,并且可以包含与特定疾病相关的遗传异常。随着测序和操纵核酸的技术的改进,本领域中存在对使用无细胞的dna来检测和监测疾病的改进方法和系统的需求。
技术实现要素:
4.本公开内容提供了一种用于检测拷贝数变异的方法,该方法包括:a)对来自受试者的身体样品的细胞外多核苷酸进行测序,其中该细胞外多核苷酸中的每一个任选地附接至独特条形码;b)过滤掉未能满足所设定的阈值的阅读值;c)将由步骤(a)获得的序列阅读值定位(mapping)至参考序列;d)对在所述参考序列的两个或更多个预定义区域中定位的阅读值进行定量/计数;e)通过下列步骤确定在一个或多个预定义区域中的拷贝数变异:(i)将预定义区域中的阅读值的数目相对于彼此进行归一化,和/或将预定义区域中的独特条形码的数目相对于彼此进行归一化;和(ii)将从步骤(i)中获得的归一化的数目与从对照样品获得的归一化的数目进行比较。
5.本公开内容还提供了一种用于检测从受试者获得的无细胞的或基本无细胞的样品中的稀有突变的方法,该方法包括:a)对来自受试者的身体样品的细胞外多核苷酸进行测序,其中所述细胞外多核苷酸中的每一个生成多个测序阅读值;b)对来自受试者的身体样品的细胞外多核苷酸进行测序,其中所述细胞外多核苷酸中的每一个生成多个测序阅读值;对来自受试者的身体样品的细胞外多核苷酸进行测序,其中所述细胞外多核苷酸中的每一个生成多个测序阅读值;c)过滤掉未能满足所设定的阈值的阅读值;d)将从测序得到
的序列阅读值定位至参考序列上;e)鉴别在各个可定位的碱基位置处与参考序列的变异体对准的被定位序列阅读值的亚组;f)对各个可定位的碱基位置,计算出(a)与参考序列相比包含变异体的被定位序列阅读值的数目与(b)各个可定位碱基位置的序列阅读值总数的比值;g)将各个可定位碱基位置的变异的比值或频率进行归一化并确定潜在的稀有变异体或突变;h)以及将具有潜在的稀有变异体或突变的各个区域的所得数目与从参考样品类似地得到的数目进行比较。
6.另外,本公开内容还提供了一种用于表征受试者中的异常状况的异质性的方法,该方法包括生成受试者的细胞外多核苷酸的遗传谱(genetic profile),其中所述遗传谱包含由拷贝数变异和/或其它稀有突变(例如,遗传改变)分析得到的多个数据。
7.在一些实施方案中,同时报告和定量在受试者中鉴别的各个稀有变异体的出现率(prevalence)/浓度。在其它实施方案中,报告关于受试者中稀有变异体的出现率/浓度的置信得分(confidence score)。
8.在一些实施方案中,细胞外多核苷酸包含dna。在其它实施方案中,细胞外多核苷酸包含rna。多核苷酸可以是片段或在分离后被片段化。此外,本公开内容提供了用于循环核酸分离和提取的方法。
9.在一些实施方案中,从身体样品分离细胞外多核苷酸,该身体样品可选自血液、血浆、血清、尿液、唾液、粘膜分泌物、痰、粪便和泪。
10.在一些实施方案中,本公开内容的方法还包括确定在所述身体样品中具有拷贝数变异或其它稀有遗传改变(例如,序列变异体)的序列的百分比的步骤。
11.在一些实施方案中,通过计算所具有的多核苷酸的量高于或低于预定阈值的预定义区域的百分比,来确定在所述身体样品中具有拷贝数变异的序列的百分比。
12.在一些实施方案中,体液从疑似具有异常状况的受试者抽取,该异常状况可选自突变、稀有突变、单核苷酸变异体、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染和癌症。
13.在一些实施方案中,受试者可以是妊娠的女性,其中异常状况可以是选自单核苷酸变异体、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染和癌症的胎儿异常。
14.在一些实施方案中,该方法可以包括在测序前将一个或多个条形码附接至细胞外多核苷酸或其片段,其中包含的条形码是独特的。在其它实施方案中,在测序前附接至细胞外多核苷酸或其片段的条形码不是独特的。
15.在一些实施方案中,本公开内容的方法可以包括在测序前从受试者的基因组或转录组选择性地富集区域。在其它实施方案中,本公开内容的方法包括在测序前从受试者的基因组或转录组选择性地富集区域。在其它实施方案中,本公开内容的方法包括在测序前从受试者的基因组或转录组非选择性地富集区域。
16.此外,本公开内容的方法包括在任何扩增或富集步骤前,将一个或多个条形码附
接至细胞外多核苷酸或其片段。
17.在一些实施方案中,所述条形码是多核苷酸,其可以进一步包含随机序列或固定的或半随机的一组寡核苷酸,该寡核苷酸与从选定区域测序的分子的多样性组合能够鉴别独特的分子并且为至少3、5、10、15、20、25、30、35、40、45或50聚物碱基对的长度。
18.在一些实施方案中,可以扩增细胞外多核苷酸或其片段。在一些实施方案中,扩增包括全局扩增或全基因组扩增。
19.在一些实施方案中,可以基于在序列阅读值的开始(启动)或结束(终止)区域处的序列信息和序列阅读值的长度来检测独特身份的序列阅读值。在其它实施方案中,可以基于在序列阅读值的开始(启动)或结束(终止)区域处的序列信息、序列阅读值的长度和条形码的附接来检测独特身份的序列分子。
20.在一些实施方案中,扩增包括选择性扩增、非选择性扩增、抑制扩增或消减富集。
21.在一些实施方案中,本公开内容的方法包括在对阅读值进行定量或计数前从进一步的分析中除去所述阅读值的亚组。
22.在一些实施方案中,该方法可包括过滤掉准确度或质量得分小于阈值例如90%、99%、99.9%或99.99%和/或定位得分小于阈值例如90%、99%、99.9%或99.99%的阅读值。在其它实施方案中,本公开内容的方法包括过滤质量得分小于所设定的阈值的阅读值。
23.在一些实施方案中,预定义区域在大小上是均一的或基本均一的,大小为约10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb或100kb。在一些实施方案中,分析至少50、100、200、500、1000、2000、5000、10,000、20,000或50,000个区域。
24.在一些实施方案中,遗传变异体、稀有突变或拷贝数变异发生在选自基因融合、基因复制、基因缺失、基因易位、微卫星区域、基因片段或其组合的基因组区域中。在其它实施方案中,遗传变异体、稀有突变或拷贝数变异发生在选自基因、癌基因、肿瘤抑制基因、启动子、调节序列元件或其组合的基因组区域中。在一些实施方案中,该变异体是1、2、3、4、5、6、7、8、9、10、15或20个核苷酸长度的核苷酸变异体、单碱基置换、或小插入缺失、颠换、易位、倒位、缺失、截短或基因截短。
25.在一些实施方案中,该方法包括使用条形码或单个阅读值的独特性质来校正/归一化/调整所定位的阅读值的量。
26.在一些实施方案中,通过对各个预定义区域中的独特条形码进行计数并将这些数目在所测序的预定义区域的至少一个亚组中进行归一化来对阅读值进行计数。在一些实施方案中,分析以连续的时间间隔来自相同受试者的样品并将其与以前的样品结果进行比较。本公开内容的方法可以进一步包括在扩增附接有条形码的细胞外多核苷酸后确定部分拷贝数变异频率、杂合性的丢失、基因表达分析、外遗传分析和过度甲基化分析。
27.在一些实施方案中,使用多重测序在从受试者获得的无细胞或基本无细胞的样品中确定拷贝数变异和稀有突变分析,该多重测序包括进行超过10,000个测序反应;同时对至少10,000个不同的阅读值进行测序;或者在整个基因组中对至少10,000个不同的阅读值进行数据分析。该方法可以包括多重测序,该多重测序包括在整个基因组中对至少10,000个不同的阅读值进行数据分析。该方法可进一步包括对可独特鉴别的测序阅读值进行计数。
28.在一些实施方案中,本公开内容的方法包括使用隐马尔可夫(hidden markov)、动
态编程、支持向量机、贝叶斯网络、网格解码、维特比译码、期望最大化、卡尔曼过滤或者神经网络方法中的一个或多个进行归一化和检测。
29.在一些实施方案中,本公开内容的方法包括基于所发现的变异体监测疾病进展、监测残留疾病、监测疗法、诊断状况、状况预后或者选择疗法。
30.在一些实施方案中,基于最近的样品分析来修改疗法。此外,本公开内容的方法包括推断肿瘤、感染或其它组织异常的遗传谱。在一些实施方案中,监测肿瘤、感染或其它组织异常的生长、缓解或演变。在一些实施方案中,在单一情况下或随时间推移分析和监测受试者的免疫系统。
31.在一些实施方案中,本公开内容的方法包括通过成像测试(例如,ct、pet-ct、mri、x射线、超声波)追踪的变异体的鉴别,以便定位疑似引起所鉴别的变异体的组织异常。
32.在一些实施方案中,本公开内容的方法包括使用从来自相同患者的组织或肿瘤活检获得的遗传数据。在一些实施方案中,由此推断肿瘤、感染或其它组织异常的系统发生学。
33.在一些实施方案中,本公开内容的方法包括对低置信区域进行基于群体的非判定(no-calling)和鉴别。在一些实施方案中,获得序列覆盖度的测量数据包括测量基因组的每个位置处的序列覆盖深度。在一些实施方案中,针对序列覆盖偏倚校正测量数据包括计算窗口平均的覆盖度。在一些实施方案中,针对序列覆盖偏倚校正测量数据包括进行调整以应对在文库构建和测序过程中的gc偏倚。在一些实施方案中,针对序列覆盖偏倚校正测量数据包括基于与个体定位相关联的附加加权因子进行调整,以补偿偏倚。
34.在一些实施方案中,本公开内容的方法包含源自病变细胞来源的细胞外多核苷酸。在一些实施方案中,细胞外多核苷酸源自健康细胞来源。
35.本公开内容还提供了一种包含计算机可读介质的系统,该计算机可读介质用于执行以下步骤:选择基因组中的预定义区域;对所述预定义区域中的序列阅读值的数目进行计数;对所述预定义区域上的序列阅读值的数目进行归一化;以及确定所述预定义区域中的拷贝数变异的百分比。在一些实施方案中,分析整个基因组或基因组的至少10%、20%、30%、40%、50%、60%、70%、80%或90%。在一些实施方案中,计算机可读介质将关于血浆或血清中的癌症dna或rna百分比的数据提供给终端用户。
36.在一些实施方案中,分析遗传变异如多态性或因果变异体(causal variant)的量。在一些实施方案中,检测遗传改变的存在与否。
37.本公开内容还提供了一种用于在从受试者获得的无细胞或基本无细胞的样品中检测稀有突变的方法,该方法包括:a)对来自受试者的身体样品的细胞外多核苷酸进行测序,其中所述细胞外多核苷酸中的每一个产生多个测序阅读值;b)过滤掉未能满足所设定的质量阈值的阅读值;c)将从测序得到的序列阅读值定位至参考序列上;d)鉴别在各个可定位的碱基位置处与该参考序列的变异体对准的被定位序列阅读值的亚组;e)对于各个可定位的碱基位置,计算出(a)与该参考序列相比包含变异体的被定位序列阅读值的数目与(b)各个可定位碱基位置的序列阅读值总数的比值;f)将各个可定位碱基位置的变异的比值或频率进行归一化,并确定潜在的稀有变异体或其它遗传改变;以及g)比较各个区域的所得数目。
38.本公开内容还提供了一种方法,该方法包括:a.提供至少一组标记的亲本多核苷
酸,并且对于各组标记的亲本多核苷酸;b.扩增该组中的标记的亲本多核苷酸,以产生相应的一组扩增的子代多核苷酸;c.对该组扩增的子代多核苷酸的亚组(包括真亚组(proper subset))进行测序,以产生一组测序阅读值;以及d.使该组测序阅读值分解(collapsing),以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸。在某些实施方案中,该方法还包括:e.针对每组标记的亲本分子对该组共有序列进行分析。
39.在一些实施方案中,一组中的各个多核苷酸可定位至参考序列。
40.在一些实施方案中,该方法包括提供多组标记的亲本多核苷酸,其中各组可定位至不同的参考序列。
41.在一些实施方案中,该方法还包括将初始起始遗传材料转换成标记的亲本多核苷酸。
42.在一些实施方案中,初始起始遗传材料包含不超过100ng的多核苷酸。
43.在一些实施方案中,该方法包括在转换前瓶颈化(bottlenecking)初始起始遗传材料。
44.在一些实施方案中,该方法包括以至少10%、至少20%、至少30%、至少40%、至少50%、至少60%、至少80%或至少90%的转换效率将初始起始遗传材料转换成标记的亲本多核苷酸。
45.在一些实施方案中,转换包括平端连接、粘端连接、分子倒位探针、pcr、基于连接的pcr、单链连接和单链环化中的任何方法。
46.在一些实施方案中,初始起始遗传材料是无细胞的核酸。
47.在一些实施方案中,多个参考序列来自相同的基因组。
48.在一些实施方案中,该组中的各个标记的亲本多核苷酸是独特地标记的。
49.在一些实施方案中,标签是非独特的。
50.在一些实施方案中,共有序列的生成基于来自标签的信息和/或在序列阅读值的开始(启动)区域、序列阅读值的结束(终止)区域的序列信息和序列阅读值的长度中的至少一个。
51.在一些实施方案中,该方法包括对该组扩增的子代多核苷酸的亚组进行测序,该测序足以对至少一个子代产生序列阅读值,所述序列阅读值来自该组标记的亲本多核苷酸中的独特多核苷酸的至少20%、至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、至少98%、至少99%、至少99.9%或至少99.99%中的每一个。
52.在一些实施方案中,所述至少一个子代是多个子代,例如,至少2个、至少5个或至少10个子代。
53.在一些实施方案中,该组序列阅读值中的序列阅读值的数目大于该组标记的亲本多核苷酸中的独特标记的亲本多核苷酸的数目。
54.在一些实施方案中,被测序的该组扩增的子代多核苷酸的亚组具有足够的大小,以使得以与所用测序平台的每碱基测序错误率百分比相同的百分比在该组标记的亲本多核苷酸中呈现的任何核苷酸序列有至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、至少98%、至少99%、至少99.9%或至少99.99%的机会在该组共有序列中呈现。
55.在一些实施方案中,该方法包括通过以下步骤,针对定位至一个或多个选定参考序列的多核苷酸,富集该组扩增的子代多核苷酸:(i)来自已转换成标记的亲本多核苷酸的
初始起始遗传材料的序列的选择性扩增;(ii)标记的亲本多核苷酸的选择性扩增;(iii)扩增的子代多核苷酸的选择性序列捕获;或(iv)初始起始遗传材料的选择性序列捕获。
56.在一些实施方案中,分析包括将从一组共有序列获得的度量(measure)(例如,数目)相对于从来自对照样品的一组共有序列获得的度量进行归一化。
57.在一些实施方案中,分析包括检测突变、稀有突变、单核苷酸变异体、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染或癌症。
58.在一些实施方案中,所述多核苷酸包含dna、rna、这两者的组合或dna加rna衍生的cdna。
59.在一些实施方案中,针对或基于碱基对的多核苷酸长度从多核苷酸的初始组或从扩增的多核苷酸中选择或富集多核苷酸的某个亚组。
60.在一些实施方案中,分析进一步包括检测和监测个体内的异常或疾病,例如,感染和/或癌症。
61.在一些实施方案中,该方法与免疫组库谱分析(immune repertoire profiling)组合进行。
62.在一些实施方案中,从由血液、血浆、血清、尿液、唾液、粘膜分泌物、痰、粪便和泪组成的组中提取多核苷酸。
63.在一些实施方案中,分解包括检测和/或校正在标记的亲本多核苷酸或扩增的子代多核苷酸的有义或反义链中存在的错误、切口或损伤。
64.本公开内容还提供了一种方法,该方法包括以至少5%、至少1%、至少0.5%、至少0.1%或至少0.05%的灵敏度检测在初始起始遗传材料中的遗传变异。在一些实施方案中,初始起始遗传材料以小于100ng的核酸的量来提供,该遗传变异是拷贝数/杂合性变异,并且检测在亚染色体分辨率下进行;例如,至少100兆碱基分辨率、至少10兆碱基分辨率、至少1兆碱基分辨率、至少100千碱基分辨率、至少10千碱基分辨率或至少1千碱基分辨率。在另一个实施方案中,该方法包括提供多组标记的亲本多核苷酸,其中各组可定位至不同参考序列。在另一个实施方案中,参考序列是肿瘤标志物的基因座,并且分析包括检测该组共有序列中的肿瘤标志物。在另一个实施方案中,肿瘤标志物以小于在扩增步骤中引入的错误率的频率存在于该组共有序列中。在另一个实施方案中,所述至少一组是多组,并且参考序列包含多个参考序列,其中各个参考序列是肿瘤标志物的基因座。在另一个实施方案中,分析包括检测在至少两组亲本多核苷酸间的共有序列的拷贝数变异。在另一个实施方案中,分析包括检测与参考序列相比序列变异的存在。在另一个实施方案中,分析包括检测与参考序列相比序列变异的存在并检测在至少两组亲本多核苷酸间的共有序列的拷贝数变异。在另一个实施方案中,分解包括:i.将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记的亲本多核苷酸扩增;以及ii.基于家族中的序列阅读值确定共有序列。
65.本公开内容还提供了一种包含计算机可读介质的系统,该计算机可读介质用于执行以下步骤:a.提供至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b.扩增该组中的标记的亲本多核苷酸,以产生相应的一组扩增的子代多核苷酸;c.对该组扩
增的子代多核苷酸的亚组(包括真亚组)进行测序,以产生一组测序阅读值;以及d.分解该组测序阅读值,以生成一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸间的独特多核苷酸,以及任选地e.针对各组标记的亲本分子对该组共有序列进行分析。
66.本公开内容还提供了一种方法,该方法包括:a.提供至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b.扩增该组中的标记的亲本多核苷酸,以产生相应的一组扩增的子代多核苷酸;c.对该组扩增的子代多核苷酸的亚组(包括真亚组)进行测序,以产生一组测序阅读值;d.分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸间的独特多核苷酸,以及e.从共有序列中过滤掉那些未满足质量阈值的共有序列。在一个实施方案中,该质量阈值考虑分解成共有序列的来自扩增的子代多核苷酸的序列阅读值的数目。在另一个实施方案中,该质量阈值考虑分解成共有序列的来自扩增的子代多核苷酸的序列阅读值的数目。本公开内容还提供了一种包含用于执行上述方法的计算机可读介质的系统。
67.本公开内容还提供了一种方法,该方法包括:a.提供至少一组标记的亲本多核苷酸,其中各组定位至一个或多个基因组中的不同参考序列,并且对于各组标记的亲本多核苷酸;i.扩增第一多核苷酸,以产生一组扩增的多核苷酸;ii.对该组扩增的多核苷酸的亚组进行测序,以产生一组测序阅读值;以及iii.通过以下步骤分解该序列阅读值:1.将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记的亲本多核苷酸扩增。在一个实施方案中,分解进一步包括:2.确定各个家族中序列阅读值的定量度量。在另一个实施方案中,该方法还包括(包括a):b.确定独特家族的定量度量;以及c.基于(1)独特家族的定量度量,和(2)各组中的序列阅读值的定量度量,推断在该组中的独特标记亲本多核苷酸的度量。在另一个实施方案中,使用统计或概率模型进行推断。在另一个实施方案中,其中所述至少一个组是多个组。在另一个实施方案中,该方法进一步包括校正两组之间的扩增或呈现偏倚。在另一个实施方案中,该方法进一步包括使用对照或一组对照样品来校正两组之间的扩增或呈现偏倚。在另一个实施方案中,该方法进一步包括确定组间的拷贝数变异。在另一个实施方案中,该方法进一步包括(包括a、b、c):d.确定家族之间的多态性形式的定量度量;以及e.基于所确定的多态性形式的定量度量,来推断在推断的独特标记亲本多核苷酸的数目上的多态性形式的定量度量。在另一个实施方案中,其中多态性形式包括但不限于:置换、插入、缺失、倒位、微卫星改变、颠换、易位、融合、甲基化、过度甲基化、羟甲基化、乙酰化、外遗传变异体、与调节相关的变异体或蛋白质结合位点。在其中所述组源自共同的样品的另一个实施方案中,所述方法进一步包括:a.基于定位至多个参考序列中每一个的各组中标记亲本多核苷酸的推断数目的比较,来推断所述多个组的拷贝数变异。在另一个实施方案中,进一步推断在各组中的多核苷酸的原始数目。本公开内容还提供了一种包含用于执行上述方法的计算机可读介质的系统。
68.本公开内容还提供了一种确定在包含多核苷酸的样品中的拷贝数变异的方法,该方法包括:a.提供至少两组第一多核苷酸,其中各组定位至基因组中的不同参考序列,以及对于各组第一多核苷酸;i.扩增该多核苷酸,以产生一组扩增的多核苷酸;ii.对该组扩增的多核苷酸的亚组进行测序,以产生一组测序阅读值;iii.将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族从所述组中的相同的第一多核苷酸扩增;iv.推断该组中的家族的定量度量;b.通过比较各组中的家族的定量度量来确定拷贝数变异。本公开内容还
提供了一种包含用于执行上述方法的计算机可读介质的系统。
69.本公开内容还提供了一种推断多核苷酸样品中的序列判定频率的方法,该方法包括:a.提供至少一组第一多核苷酸,其中各组定位至一个或多个基因组中的不同参考序列,并且对于各组第一多核苷酸;i.扩增第一多核苷酸,以产生一组扩增的多核苷酸;ii.对该组扩增的多核苷酸的亚组进行测序,以产生一组测序阅读值;iii.将该序列阅读值分组成家族,各个家族包含从相同的第一多核苷酸扩增的扩增多核苷酸的序列阅读值;b.对于各组第一多核苷酸,推断对在该组第一多核苷酸中的一个或多个碱基的判定频率,其中推断包括:i.针对各个家族,对多个判定中的每一个判定分配置信得分,该置信得分考虑家族成员之间的判定频率;以及ii.考虑分配给每个家族的一个或多个判定的置信得分,来估算一个或多个判定的频率。本公开内容还提供了一种包含用于执行上述方法的计算机可读介质的系统。
70.本公开内容还提供了一种将关于至少一个单个多核苷酸分子的序列信息进行通信的方法,该方法包括:a.提供至少一个单个多核苷酸分子;b.编码所述至少一个单个多核苷酸分子中的序列信息,以产生信号;c.使该信号的至少一部分通过通道,以产生包含关于所述至少一个单个多核苷酸分子的核苷酸序列信息的接收信号,其中所述接收信号包含噪声和/或畸变;d.解码该接收信号,以产生包含关于所述至少一个单个多核苷酸分子的序列信息的消息,其中解码减少了该消息中的噪声和/或畸变;以及e.将该消息提供给接收者。在一个实施方案中,所述噪声包含不正确的核苷酸判定。在另一个实施方案中,畸变包含单个多核苷酸分子与其它单个多核苷酸分子相比的不均匀扩增。在另一个实施方案中,畸变是由扩增或测序偏倚导致的。在另一个实施方案中,所述至少一个单个多核苷酸分子是多个单个多核苷酸分子,并且解码产生关于所述多个分子中的每一个分子的消息。在另一个实施方案中,编码包括扩增已经任选地标记的至少单个多核苷酸分子,其中所述信号包含扩增的分子的集合。在另一个实施方案中,所述通道包括多核苷酸测序仪且所述接收信号包括从所述至少一个单个多核苷酸分子扩增的多个多核苷酸的序列阅读值。在另一个实施方案中,解码包括将从所述至少一个单个多核苷酸分子中的每一个扩增的扩增分子的序列阅读值进行分组。在另一个实施方案中,解码由过滤所生成的序列信号的概率或统计方法组成。本公开内容还提供了一种包含用于执行上述方法的计算机可读介质的系统。
71.在另一个实施方案中,多核苷酸源自肿瘤基因组dna或rna。在另一个实施方案中,多核苷酸源自无细胞多核苷酸、核外(exosomal)多核苷酸、细菌多核苷酸或病毒多核苷酸。在另一个实施方案中,进一步包括受影响的分子通路的检测和/或关联。在另一个实施方案中,进一步包括连续监测个体的健康或疾病状态。在另一个实施方案中,由此推断个体内与疾病相关的基因组的种系发生。在另一个实施方案中,进一步包括疾病的诊断、监测或治疗。在另一个实施方案中,基于所检测到的多态性形式或cnv或相关的通路来选择或修改治疗方案。在另一个实施方案中,治疗包括联合疗法。
72.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成执行以下步骤的可执行代码:选择在基因组中的预定义区域;访问序列阅读值并对预定义区域中的序列阅读值数目进行计数;将预定义区域上的序列阅读值的数目进行归一化;以及确定在预定义区域中的拷贝数变异的百分比。
73.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成
执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件;b.过滤掉未能满足所设定的阈值的阅读值;c.将从测序得到的序列阅读值定位至参考序列;d.鉴别在各个可定位碱基位置处与参考序列的变异体对准的被定位序列阅读值的亚组;e.对于各个可定位碱基位置,计算出(a)与参考序列相比包含变异体的被定位序列阅读值的数目与(b)各个可定位碱基位置的序列阅读值总数的比值;f.将各个可定位碱基位置的变异的比值或频率进行归一化并确定潜在的稀有变异体或其它遗传改变;以及g.将具有潜在的稀有变异体或突变的各个区域的所得数目与从参考样品类似地得到的数目进行比较。
74.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b.分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸。
75.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b.分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸;c.从共有序列中过滤掉那些未满足质量阈值的共有序列。
76.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;以及i.通过以下步骤分解该序列阅读值:1.将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记亲本多核苷酸扩增,以及任选地2.确定各个家族中序列阅读值的定量度量。在某些实施方案中,所述可执行代码进一步执行以下步骤:b.确定独特家族的定量度量;c.基于(1)独特家族的定量度量和(2)各组中的序列阅读值的定量度量,来推断在该组中的独特标记亲本多核苷酸的度量。在某些实施方案中,所述可执行代码进一步执行以下步骤:d.确定家族之间的多态性形式的定量度量;以及e.基于所确定的多态性形式的定量度量,来推断在推断的独特标记亲本多核苷酸的数目上的多态性形式的定量度量。
77.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族从所述组中的相同的第一多核苷酸扩增;b.推断该组中的家族的定量度量;c.通过比较各组中的家族的定量度量来确定拷贝数变异。
78.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含被配置成执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;将序列阅读值分组成家族,各个家族包含从相同的第一多核苷酸扩增的扩增多核苷酸的序列阅读值;b.对于各组第一多核苷酸,推断对在该组第一多核苷酸中的一个或多个碱基的判定频率,其中推断包括:c.针对各个家族,对多个判定中的每一个判定分配置信得分,该置信得分考虑家族成员之间的判定频率;以及d.考虑分配给每个家族的一个或多个判定的置信得分,来估算一
个或多个判定的频率。
79.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成执行以下步骤的可执行代码:a.访问包含接收信号的数据文件,该接收信号包含来自至少一个单个多核苷酸分子的编码的(endoded)序列信息,其中所述接收信号包含噪声和/或畸变;b.解码所述接收信号,以产生包含关于所述至少一个单个多核苷酸分子的序列信息的消息,其中解码减少了该消息中关于各个单个多核苷酸的噪声和/或畸变;以及c.将包含关于所述至少一个单个多核苷酸分子的序列信息的消息写入计算机文件。
80.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b.分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸;c.从共有序列中过滤掉那些未满足质量阈值的共有序列。
81.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;以及b.通过以下步骤分解该序列阅读值:i.将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记亲本多核苷酸扩增;以及ii.任选地,确定各个家族中序列阅读值的定量度量。在某些实施方案中,所述可执行代码进一步执行以下步骤:c.确定独特家族的定量度量;d.基于(1)独特家族的定量度量和(2)各组中的序列阅读值的定量度量,来推断在该组中的独特标记亲本多核苷酸的度量。在某些实施方案中,所述可执行代码进一步执行以下步骤:e.确定家族之间的多态性形式的定量度量;以及f.基于所确定的多态性形式的定量度量,来推断在推断的独特标记亲本多核苷酸的数目上的多态性形式的定量度量。在某些实施方案中,所述可执行代码进一步执行以下步骤:e.基于与定位至多个参考序列中每一个的各组中标记亲本多核苷酸的推断数目的比较,来推断所述多个组的拷贝数变异。
82.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配置成执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b.将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族从所述组中的相同的第一多核苷酸扩增;c.推断该组中的家族的定量度量;d.通过比较各组中的家族的定量度量来确定拷贝数变异。
83.本公开内容还提供了一种非暂时性、有形形式的计算机可读介质,其包含配制成执行以下步骤的可执行代码:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;将序列阅读值分组成家族,各个家族包含从相同的第一多核苷酸扩增的扩增多核苷酸的序列阅读值;以及b.对于各组第一多核苷酸,推断对在该组第一多核苷酸中的一个或多个碱基的判定频率,其中推断包括:i.针对各个家族,对多个判定中的每一个判定分配置信得分,该置信得分考虑家族成员之间的判定频率;以及ii.考虑分配给每个家族的一个或多个判定的置信得分,来估算一个或多个判定的频率。
84.本公开内容还提供了一种方法,该方法包括:a.提供包含100至100,000个单倍体人基因组当量(haploid human genome equivalent)的无细胞dna(“cfdna”)多核苷酸的样
品;以及b.用2至1,000,000个独特标识符标记所述多核苷酸。在某些实施方案中,独特标识符的数目为至少3个、至少5个、至少10个、至少15个或至少25个和至多100个、至多1000个或至多10,000个。在某些实施方案中,独特标识符的数目为至多100个、至多1000个、至多10,000个、至多100,000个。
85.本公开内容还提供了一种方法,该方法包括:a.提供包含多个人单倍体基因组当量的片段化多核苷酸的样品;b.确定z,其中z是在基因组中任何位置开始的重复多核苷酸的预期数目的居中趋势度量(例如,平均值、中位数或众数),其中重复多核苷酸具有相同的启动和终止位置;以及c.用n个独特标识符标记样品中的多核苷酸,其中n是2至100,000*z、2至10,000*z、2至1,000*z或2至100*z。
86.本公开内容还提供了一种方法,该方法包括:a.提供至少一组标记的亲本多核苷酸,以及对于各组标记的亲本多核苷酸;b.对该组中的各个标记的亲本多核苷酸产生多个序列阅读值,以产生一组测序阅读值;以及c.分解该组测序阅读值,以生成一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸。
87.本公开内容提供了一种用于检测拷贝数变异的方法,该方法包括:a)对来自受试者的身体样品的细胞外多核苷酸进行测序,其中细胞外多核苷中的每一个生成多个测序阅读值;b)过滤掉未能满足所设定的阈值的阅读值;c)在过滤掉阅读值后,将由步骤(a)获得的序列阅读值定位至参考序列;d)对在所述参考序列的两个或更多个预定义区域中定位的阅读值进行定量或计数;以及e)通过下列步骤确定在一个或多个预定义区域中的拷贝数变异:(i)将预定义区域中的阅读值的数目相对于彼此进行归一化,和/或将预定义区域中的独特序列阅读值的数目相对于彼此进行归一化;(ii)将从步骤(i)中获得的归一化的数目与从对照样品获得的归一化的数目进行比较。
88.本公开内容还提供了一种用于检测从受试者获得的无细胞或基本无细胞的样品中的稀有突变的方法,该方法包括:a)对来自受试者的身体样品的细胞外多核苷酸进行测序,其中细胞外多核苷酸的每一个生成多个测序阅读值;b)如果未进行富集,则进行区域上的多重测序或全基因组测序;c)过滤掉未能满足所设定的阈值的阅读值;d)将由测序得到的序列阅读值定位至参考序列上;e)鉴别在各个可定位的碱基位置处与参考序列的变异体对准的被定位序列阅读值的亚组;f)对各个可定位的碱基位置,计算出(a)与参考序列相比包含变异体的被定位序列阅读值的数目与(b)各个可定位的碱基位置的序列阅读值总数的比值;g)将各个可定位碱基位置的变异的比值或频率进行归一化并确定潜在的稀有变异体或突变;以及h)将具有潜在的稀有变异体或突变的各个区域的所得数目与从参考样品类似地得到的数目进行比较。
89.本公开内容还提供了一种用于表征受试者中的异常状况的异质性的方法,该方法包括产生受试者的细胞外多核苷酸的遗传谱,其中所述遗传谱包含由拷贝数变异和稀有突变分析得到的多个数据。
90.在一些实施方案中,同时报告和定量在受试者中鉴别的各个稀有变异体的出现率/浓度。在一些实施方案中,报告关于受试者中稀有变异体的出现率/浓度的置信得分。
91.在一些实施方案中,细胞外多核苷酸包含dna。在一些实施方案中,细胞外多核苷酸包含rna。
92.在一些实施方案中,该方法进一步包括从身体样品分离细胞外多核苷酸。在一些
实施方案中,该分离包括用于循环核酸分离和提取的方法。在一些实施方案中,该方法进一步包括对所述分离的细胞外多核苷酸进行片段化。在一些实施方案中,所述身体样品选自血液、血浆、血清、尿液、唾液、粘膜分泌物、痰、粪便和泪。
93.在一些实施方案中,该方法进一步包括确定在所述身体样品中具有拷贝数变异或稀有突变或变异体的序列的百分比。在一些实施方案中,所述确定包括计算具有高于或低于预定阈值的多核苷酸量的预定义区域的百分比。
94.在一些实施方案中,所述受试者疑似具有异常状况。在一些实施方案中,该异常状况选自突变、稀有突变、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染和癌症。
95.在一些实施方案中,所述受试者是妊娠的女性。在一些实施方案中,拷贝数变异或稀有突变或遗传变异体指示胎儿异常。在一些实施方案中,该胎儿异常选自突变、稀有突变、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染和癌症。
96.在一些实施方案中,该方法进一步包括在测序前将一个或多个条形码附接至细胞外多核苷酸或其片段。在一些实施方案中,在测序前附接至细胞外多核苷酸或其片段的各个条形码是独特的。在一些实施方案中,在测序前附接至细胞外多核苷酸或其片段的各个条形码不是独特的。
97.在一些实施方案中,该方法进一步包括在测序前从受试者的基因组或转录组选择性地富集区域。在一些实施方案中,该方法进一步包括在测序前从受试者的基因组或转录组非选择性地富集区域。
98.在一些实施方案中,该方法进一步包括在任何扩增或富集步骤前,将一个或多个条形码附接至细胞外多核苷酸或其片段。在一些实施方案中,该条形码是多核苷酸。在一些实施方案中,该条形码包含随机序列。在一些实施方案中,该条形码包含固定的或半随机的一组寡核苷酸,该寡核苷酸与从选定区域测序的分子的多样性相组合能够鉴别独特的分子。在一些实施方案中,该条形码包含长度至少为3、5、10、15、20、25、30、35、40、45或50聚物碱基对的寡核苷酸。
99.在一些实施方案中,该方法进一步包括扩增细胞外多核苷酸或其片段。在一实施方案中,该扩增包括全局扩增或全基因组扩增。在一些实施方案中,该扩增包括选择性扩增。在一些实施方案中,该扩增包括非选择性扩增。在一些实施方案中,进行抑制扩增或消减富集。
100.在一些实施方案中,基于在序列阅读值的开始(启动)和结束(终止)区域的序列信息和序列阅读值的长度来检测独特身份的序列阅读值。在一些实施方案中,基于在序列阅读值的开始(启动)和结束(终止)区域的序列信息、序列阅读值的长度和条形码的附接来检测独特身份的序列阅读值。
101.在一些实施方案中,该方法进一步包括在对阅读值进行定量或计数前从进一步的
分析中除去阅读值的亚组。在一些实施方案中,除去包括过滤掉准确度或质量得分小于阈值例如90%、99%、99.9%或99.99%和/或定位得分小于阈值例如90%、99%、99.9%或99.99%的阅读值。在一些实施方案中,该方法进一步包括过滤质量得分小于所设定的阈值的阅读值。
102.在一些实施方案中,预定义区域在大小上是均一或基本均一的。在一些实施方案中,预定义区域的大小是至少约10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb或100kb。
103.在一些实施方案中,分析至少50、100、200、500、1000、2000、5000、10,000、20,000或50,000个区域。
104.在一些实施方案中,变异体发生在选自基因融合、基因复制、基因缺失、基因易位、微卫星区域、基因片段或其组合的基因组区域中。在一些实施方案中,变异体发生在选自基因、癌基因、肿瘤抑制基因、启动子、调节序列元件或其组合的基因组区域中。在一些实施方案中,变异体是1、2、3、4、5、6、7、8、9、10、15或20个核苷酸长度的核苷酸变异体、单碱基置换、小插入缺失、颠换、易位、倒位、缺失、截短或基因截短。
105.在一些实施方案中,该方法进一步包括使用条形码或单个阅读值的独特性质来校正/归一化/调整被定位的阅读值的量。在一些实施方案中,通过在各个预定义区域中的独特条形码的计数和对在所测序的预定义区域的至少一个亚组中的这些数目进行归一化来对阅读值进行计数。
106.在一些实施方案中,分析以连续的时间间隔来自相同受试者的样品并将其与以前的样品结果进行比较。在一些实施方案中,该方法进一步包括扩增附接有条形码的细胞外多核苷酸。在一些实施方案中,该方法进一步包括确定部分拷贝数变异频率、确定杂合性的丢失、进行基因表达分析、进行外遗传分析和/或进行过度甲基化分析。
107.本公开内容还提供了一种方法,该方法包括使用多重测序在从受试者获得的无细胞或基本无细胞的样品中确定拷贝数变异或进行稀有突变分析。
108.在一些实施方案中,所述多重测序包括进行超过10,000个测序反应。在一些实施方案中,所述多重测序包括同时对至少10,000个不同的阅读值进行测序。在一些实施方案中,所述多重测序包括在整个基因组中对至少10,000个不同的阅读值进行数据分析。在一些实施方案中,使用隐马尔可夫、动态编程、支持向量机、贝叶斯或概率建模、网格解码、维特比解码、期望最大化、卡尔曼过滤或者神经网络方法中的一个或多个进行归一化和检测。在一些实施方案中,该方法进一步包括基于所发现的变异体对受试者监测疾病进展、监测残留疾病、监测疗法、诊断状况、状况预后或者选择疗法。在一些实施方案中,基于最近的样品分析来修改疗法。在一些实施方案中,推断肿瘤、感染或其它组织异常的遗传谱。
109.在一些实施方案中,监测肿瘤、感染或其它组织异常的生长、缓解或演变。在一些实施方案中,在单一情况下或随时间推移分析和监测与受试者的免疫系统相关的序列。在一些实施方案中,通过成像测试(例如,ct、pet-ct、mri、x射线、超声)追踪变异体的鉴别,以便定位疑似引起所鉴别的变异体的组织异常。在一些实施方案中,该分析进一步包括使用从来自同一患者的组织或肿瘤活检获得的遗传数据。在一些实施方案中,推断肿瘤、感染或其它组织异常的系统发生学。在一些实施方案中,该方法进一步包括对低置信区域进行基于群体的非判定和鉴别。在一些实施方案中,获得序列覆盖度的测量数据包括测量基因组
的每个位置处的序列覆盖深度。在一些实施方案中,针对序列覆盖偏倚校正测量数据包括计算窗口平均的覆盖度。在一些实施方案中,针对序列覆盖偏倚校正测量数据包括进行调整以应对在文库构建和测序过程中的gc偏倚。在一些实施方案中,针对序列覆盖偏倚校正测量数据包括基于与个体定位相关联的附加加权因子进行调整,以补偿偏倚。
110.在一些实施方案中,细胞外多核苷酸源自病变细胞来源。在一些实施方案中,细胞外多核苷酸源自健康细胞来源。
111.本公开内容还提供了一种包含计算机可读介质的系统,该计算机可读介质用于执行以下步骤:选择在基因组中的预定义区域;对预定义区域中的序列阅读值的数目进行计数;对预定义区域上的序列阅读值的数目进行归一化并且确定在预定义区域中的拷贝数变异的百分比。
112.在一些实施方案中,分析整个基因组或基因组的至少85%。在一些实施方案中,计算机可读介质向终端用户提供关于血浆或血清中的癌症dna或rna百分比的数据。在一些实施方案中,由于样品中的异质性,因此鉴别的拷贝数变异是分数(即非整数水平)。在一些实施方案中,对选定的区域进行富集。在一些实施方案中,根据本文所述的方法同时提取拷贝数变异信息。在一些实施方案中,该方法包括瓶颈化多核苷酸以限制样品中的多核苷酸的起始初始拷贝或多样性的数目的初始步骤。
113.本公开内容还提供了一种用于检测在从受试者获得的无细胞或基本无细胞的样品中的稀有突变的方法,该方法包括:a)对来自受试者的身体样品的细胞外多核苷酸进行测序,其中细胞外多核苷酸中的每一个产生多个测序阅读值;b)过滤掉未能满足所设定的质量阈值的阅读值;c)将从测序得到的序列阅读值定位至参考序列上;d)鉴别在各个可定位的碱基位置处与参考序列的变异体对准的被定位的序列阅读值的亚组;e)对于各个可定位的碱基位置,计算出(a)与参考序列相比包含变异体的被定位序列阅读值的数目与(b)各个可定位碱基位置的序列阅读值总数的比值;f)将各个可定位碱基位置的变异的比值或频率进行归一化并确定潜在的稀有变异体或其它遗传改变;以及g)将具有潜在的稀有变异体或突变的各个区域的所得数目与从参考样品类似地得到的数目进行比较。
114.本公开内容还提供了一种方法,该方法包括:a)提供至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b)扩增该组中的标记的亲本多核苷酸,以产生相应的一组扩增的子代多核苷酸;c)对该组扩增的子代多核苷酸的亚组(包括真亚组)进行测序,以产生一组测序阅读值;以及d)使该组测序阅读值分解,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸。
115.在一些实施方案中,一组中的各个多核苷酸可定位至参考序列。在一些实施方案中,该方法包括提供多组标记的亲本多核苷酸,其中各组可定位至参考序列中的不同的可定位位置。在一些实施方案中,该方法还包括:e)分开地或组合地针对每组标记的亲本分子对该组共有序列进行分析。在一些实施方案中,该方法进一步包括将初始起始遗传材料转换成标记的亲本多核苷酸。在一些实施方案中,初始起始遗传材料包含不超过100ng的多核苷酸。在一些实施方案中,该方法包括在转换之前瓶颈化初始起始遗传材料。在一些实施方案中,该方法包括以至少10%、至少20%、至少30%、至少40%、至少50%、至少60%、至少80%或至少90%的转换效率将初始起始遗传材料转换成标记的亲本多核苷酸。在一些实施方案中,该转换包括平端连接、粘端连接、分子倒位探针、pcr、基于连接的pcr、单链连接和
单链环化中任何方法。在一些实施方案中,初始起始遗传材料是无细胞的核酸。在一些实施方案中,多个组定位至在来自相同基因组的参考序列中的不同可定位位置。
116.在一些实施方案中,所述组中的各个标记的亲本多核苷酸是独特地标记的。在一些实施方案中,各组亲本多核苷酸可定位至参考序列中的位置,并且各组中的多核苷酸不是独特地标记的。在一些实施方案中,共有序列的生成基于来自标签的信息和/或(i)序列阅读值的开始(启动)区域的序列信息、(ii)序列阅读值的结束(终止)区域的序列信息和(iii)序列阅读值的长度中的至少一种。
117.在一些实施方案中,该方法包括对该组扩增的子代多核苷酸的亚组进行测序,该测序足以对至少一个子代产生序列阅读值,所述序列阅读值来自该组标记的亲本多核苷酸中的独特多核苷酸的至少20%、至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、至少98%、至少99%、至少99.9%或至少99.99%中的每一个。在一些实施方案中,所述至少一个子代是多个子代,例如,至少2个、至少5个或至少10个子代。在一些实施方案中,该组序列阅读值中的序列阅读值的数目大于该组标记的亲本多核苷酸中的独特标记的亲本多核苷酸的数目。在一些实施方案中,被测序的该组扩增的子代多核苷酸的亚组具有足够的大小,以使得以与所用测序平台的每碱基测序错误率百分比相同的百分比在该组标记的亲本多核苷酸中呈现的任何核苷酸序列有至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、至少98%、至少99%、至少99.9%或至少99.99%的机会在该组共有序列中呈现。
118.在一些实施方案中,该方法包括通过以下步骤,针对定位至参考序列中的一个或多个选定可定位位置的多核苷酸,富集该组扩增的子代多核苷酸:(i)来自已转换成标记的亲本多核苷酸的初始起始遗传材料的序列的选择性扩增;(ii)标记的亲本多核苷酸的选择性扩增;(iii)扩增的子代多核苷酸的选择性序列捕获;或(iv)初始起始遗传材料的选择性序列捕获。
119.在一些实施方案中,分析包括将从一组共有序列获得的度量(例如,数目)相对于从来自对照样品的一组共有序列获得的度量进行归一化。在一些实施方案中,分析包括检测突变、稀有突变、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染或癌症。
120.在一些实施方案中,多核苷酸包含dna、rna、这两者的组合或dna加rna衍生的cdna。在一些实施方案中,针对或基于碱基对的多核苷酸长度从多核苷酸的初始组或从扩增的多核苷酸中选择或富集多核苷酸的某个亚组。在一些实施方案中,分析进一步包括检测和监测个体内的异常或疾病,例如,感染和/或癌症。在一些实施方案中,该方法与免疫组库谱分析组合进行。在一些实施方案中,从选自血液、血浆、血清、尿液、唾液、粘膜分泌物、痰、粪便和泪的样品中提取多核苷酸。在一些实施方案中,分解包括检测和/或校正在标记的亲本多核苷酸或扩增的子代多核苷酸的有义或反义链中存在的错误、切口或损伤。
121.本公开内容还提供了一种方法,该方法包括以至少5%、至少1%、至少0.5%、至少0.1%或至少0.05%的灵敏度检测在未独特标记的初始起始遗传材料中的遗传变异。
122.在一些实施方案中,初始起始遗传材料以小于100ng的核酸的量来提供,该遗传变
异是拷贝数/杂合性变异,并且检测在亚染色体分辨率下进行;例如,至少100兆碱基分辨率、至少10兆碱基分辨率、至少1兆碱基分辨率、至少100千碱基分辨率、至少10千碱基分辨率或至少1千碱基分辨率。在一些实施方案中,该方法包括提供多组标记的亲本多核苷酸,其中各组可定位至参考序列中的不同的可定位位置。在一些实施方案中,参考序列中的可定位位置是肿瘤标志物的基因座,并且分析包括检测该组共有序列中的肿瘤标志物。
123.在一些实施方案中,肿瘤标志物以小于在扩增步骤中引入的错误率的频率存在于该组共有序列中。在一些实施方案中,所述至少一组是多个组,并且参考序列的可定位位置包含参考序列中的多个可定位位置,其中各个可定位位置是肿瘤标志物的基因座。在一些实施方案中,分析包括检测在至少两组亲本多核苷酸间的共有序列的拷贝数变异。在一些实施方案中,分析包括检测与参考序列相比序列变异的存在。
124.在一些实施方案中,分析包括检测与参考序列相比序列变异的存在并且检测在至少两组亲本多核苷酸间的共有序列的拷贝数变异。在一些实施方案中,分解包括:(i)将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记亲本多核苷酸扩增;以及(ii)基于家族中的序列阅读值确定共有序列。
125.本公开内容还提供了一种包含计算机可读介质的系统,该计算机可读介质用于执行以下步骤:a)接受至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b)扩增该组中的标记的亲本多核苷酸,以产生相应的一组扩增的子代多核苷酸;c)对该组扩增的子代多核苷酸的亚组(包括真亚组)进行测序,以产生一组测序阅读值;d)分解该组测序阅读值,以生成一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸间的独特多核苷酸;以及任选地e)针对各组标记的亲本分子对该组共有序列进行分析。
126.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少10%进行测序。
127.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少20%进行测序。
128.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少30%进行测序。
129.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少40%进行测序。
130.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少50%进行测序。
131.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少60%进行测序。
132.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否或
遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少70%进行测序。
133.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少80%进行测序。
134.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少90%进行测序。
135.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少10%进行测序。
136.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少20%进行测序。
137.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少30%进行测序。
138.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少40%进行测序。
139.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少50%进行测序。
140.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少60%进行测序。
141.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少70%进行测序。
142.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少80%进行测序。
143.本公开内容还提供了一种方法,该方法包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少90%进行测序。
144.在一些实施方案中,所述遗传改变是拷贝数变异或一种或多种稀有突变。在一些实施方案中,所述遗传变异包含一种或多种因果变异体和一种或多种多态性。在一些实施方案中,个体中的遗传改变和/或遗传变异的量可以与一个或多个患有已知疾病的个体中的遗传改变和/或遗传变异的量相比较。在一些实施方案中,个体中的遗传改变和/或遗传
变异的量可以与一个或多个未患有疾病的个体中的遗传改变和/或遗传变异的量相比较。在一些实施方案中,所述无细胞核酸是dna。在一些实施方案中,所述无细胞核酸是rna。在一些实施方案中,所述无细胞核酸是dna和rna。在一些实施方案中,所述疾病是癌症或癌前期。在一些实施方案中,该方法进一步包括疾病的诊断或治疗。
145.本公开内容还提供了一种方法,该方法包括:a)提供至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b)扩增该组中的标记的亲本多核苷酸,以产生相应的一组扩增的子代多核苷酸;c)对该组扩增的子代多核苷酸的亚组(包括真亚组)进行测序,以产生一组测序阅读值;d)分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸;以及e)从共有序列中过滤掉那些未满足质量阈值的共有序列。
146.在一些实施方案中,所述质量阈值考虑分解成共有序列的来自扩增的子代多核苷酸的序列阅读值的数目。在一些实施方案中,所述质量阈值考虑分解成共有序列的来自扩增的子代多核苷酸的序列阅读值的数目。
147.本公开内容还提供了一种包含用于执行本文所述方法的计算机可读介质的系统。
148.本公开内容还提供了一种方法,该方法包括:a)提供至少一组标记的亲本多核苷酸,其中各组定位至一个或多个基因组中的参考序列的不同可定位位置,并且对于各组标记的亲本多核苷酸;i)扩增第一多核苷酸,以产生一组扩增的多核苷酸;ii)对该组扩增的多核苷酸的亚组进行测序,以产生一组测序阅读值;以及iii)通过以下步骤分解该测序阅读值:(1)将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记亲本多核苷酸扩增。
149.在一些实施方案中,分解进一步包括确定在各个家族中的序列阅读值的定量度量。在一些实施方案中,该方法进一步包括:a)确定独特家族的定量度量;以及b)基于(1)独特家族的定量度量和(2)各组中的序列阅读值的定量度量,推断在该组中的独特标记的亲本多核苷酸的度量。在一些实施方案中,使用统计或概率模型进行推断。在一些实施方案中,所述至少一组是多个组。在一些实施方案中,该方法进一步包括校正两组之间的扩增或呈现偏倚。在一些实施方案中,该方法进一步包括使用对照或一组对照样品校正两组之间的扩增或呈现偏倚。在一些实施方案中,该方法进一步包括确定组间的拷贝数变异。
150.在一些实施方案中,该方法还包括:d)确定所述家族之间的多态性形式的定量度量;以及e)基于所确定的多态性形式的定量度量,推断在推断的独特标记亲本多核苷酸的数目上的多态性形式的定量度量。在一些实施方案中,多态性形式包括但不限于:置换、插入、缺失、倒位、微卫星改变、颠换、易位、融合、甲基化、过度甲基化、羟甲基化、乙酰化、外遗传变异体、与调节相关的变异体或蛋白质结合位点。
151.在一些实施方案中,所述组源自共同的样品,并且该方法进一步包括:d)基于定位至参考序列中的多个可定位位置中每一个的各组中标记亲本多核苷酸的推断数目的比较,推断所述多个组的拷贝数变异。在一些实施方案中,进一步推断各组中的多核苷酸的原始数目。在一些实施方案中,各组中的标记亲本多核苷酸中的至少一个亚组为非独特地标记的。
152.本公开内容还提供了一种确定包含多核苷酸的样品中的拷贝数变异的方法,该方法包括:a)提供至少两组第一多核苷酸,其中各组定位至基因组中的参考序列的不同可定
位位置,并且对于各组第一多核苷酸;(i)扩增所述多核苷酸,以产生一组扩增的多核苷酸;(ii)对该组扩增的多核苷酸的亚组进行测序,以产生一组测序阅读值;(iii)将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族从所述组中的相同的第一多核苷酸扩增;(iv)推断该组中的家族的定量度量;以及b)通过比较各组中的家族的定量度量来确定拷贝数变异。
153.本公开内容还提供了一种推断多核苷酸样品中的序列判定频率的方法,该方法包括:a)提供至少一组第一多核苷酸,其中各组定位至一个或多个基因组中的参考序列的不同可定位位置,并且对于各组第一多核苷酸;(i)扩增第一多核苷酸,以产生一组扩增的多核苷酸;(ii)对该组扩增的多核苷酸的亚组进行测序,以产生一组测序阅读值;(iii)将该序列阅读值分组成家族,各个家族包含从相同的第一多核苷酸扩增的扩增多核苷酸的序列阅读值;b)对于各组第一多核苷酸,推断对在该组第一多核苷酸中的一个或多个碱基的判定频率,其中推断包括:(i)针对各个家族,对多个判定中的每一个判定分配置信得分,该置信得分考虑家族成员之间的判定频率;以及(ii)考虑分配给每个家族的一个或多个判定的置信得分,来估算一个或多个判定的频率。
154.本公开内容还提供了一种对关于至少一个单个多核苷酸分子的序列信息进行通信的方法,该方法包括:a)提供至少一个单个多核苷酸分子;b)编码至少一个单个多核苷酸分子中的序列信息,以产生信号;c)使该信号的至少一部分通过通道,以产生包含关于所述至少一个单个多核苷酸分子的核苷酸序列信息的接收信号,其中该接收信号包含噪声和/或畸变;d)解码该接收信号,以产生包含关于所述至少一个单个多核苷酸分子的序列信息的消息,其中解码减少了该消息中关于各个单个多核苷酸的噪声和/或畸变;以及e)将包含关于所述至少一个单个多核苷酸分子的序列信息的消息提供至接收者。
155.在一些实施方案中,所述噪声包含不正确的核苷酸判定。在一些实施方案中,畸变包含单个多核苷酸分子与其它单个多核苷酸分子相比的不均匀扩增。在一些实施方案中,畸变是由扩增或测序偏倚导致的。在一些实施方案中,所述至少一个单个多核苷酸分子是多个单个多核苷酸分子,并且解码产生关于所述多个分子中的每一个分子的消息。在一些实施方案中,编码包括扩增已经任选地标记的所述至少一个单个多核苷酸分子,其中所述信号包括扩增的分子的集合。在一些实施方案中,所述通道包括多核苷酸测序仪且所述接收信号包括从至少一个单个多核苷酸扩增的多个多核苷酸的序列阅读值。在一些实施方案中,解码包括将从所述至少一个单个多核苷酸分子中的每一个扩增的扩增分子的序列阅读值进行分组。在一些实施方案中,解码由过滤所生成的序列信号的概率或统计方法组成。
156.在一些实施方案中,多核苷酸源自肿瘤基因组dna或rna。在一些实施方案中,多核苷酸源自无细胞的多核苷酸、核外多核苷酸、细菌多核苷酸或病毒多核苷酸。在任何本文所述方法的一些实施方案中,该方法进一步包括受影响的分子通路的检测和/或关联。在任何本文所述方法的一些实施方案中,该方法进一步包括连续监测个体的健康或疾病状态。在一些实施方案中,推断个体内与疾病相关的基因组的种系发生。在一些实施方案中,任何本文所述方法进一步包括疾病的诊断、监测或治疗。在一些实施方案中,基于检测到的多态性形式或cnv或相关的通路来选择或修改治疗方案。在一些实施方案中,治疗包括联合疗法。在一些实施方案中,诊断进一步包括使用诸如ct-扫描、pet-ct、mri、超声、微泡超声等放射线照相技术定位疾病。
157.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:选择在基因组中的预定义区域;访问序列阅读值并对预定义区域中的序列阅读值的数目进行计数;对预定义区域上的序列阅读值的数目进行归一化;以及确定在预定义区域中的拷贝数变异的百分比。
158.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:访问包含多个测序阅读值的数据文件;过滤掉未能满足所设定的阈值的阅读值;将从测序得到的序列阅读值定位至参考序列上;鉴别在各个可定位的碱基位置处与参考序列的变异体对准的被定位序列阅读值的亚组;对于各个可定位的碱基位置,计算出(a)与参考序列相比包含变异体的被定位序列阅读值的数目与(b)各个可定位碱基位置的序列阅读值总数的比值;将各个可定位碱基位置的变异的比值或频率进行归一化并确定潜在的稀有变异体或其它遗传改变;以及将具有潜在的稀有变异体或突变的各个区域的所得数目与从参考样品类似地得到的数目进行比较。
159.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a)访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;以及b)分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸。
160.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a)访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b)分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸;c)从共有序列中过滤掉那些未满足质量阈值的共有序列。
161.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a)访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;以及i)通过以下步骤分解该序列阅读值:(1)将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记亲本多核苷酸扩增,以及任选地(2)确定各个家族中序列阅读值的定量度量。
162.在一些实施方案中,可执行代码在被计算机处理器执行时进一步执行以下步骤:b)确定独特家族的定量度量;以及c)基于(1)独特家族的定量度量和(2)各组中的序列阅读值的定量度量,推断在该组中的独特标记的亲本多核苷酸的度量。
163.在一些实施方案中,可执行代码在被计算机处理器执行时进一步执行以下步骤:d)确定家族之间的多态性形式的定量度量;以及e)基于所确定的多态性形式的定量度量,推断在推断的独特标记亲本多核苷酸的数目上的多态性形式的定量度量。
164.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a)访问包含
多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族从所述组中的相同的第一多核苷酸扩增;b)推断该组中的家族的定量度量;以及c)通过比较各组中的家族的定量度量来确定拷贝数变异。
165.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a)访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;将该序列阅读值分组成家族,各个家族包含从相同的第一多核苷酸扩增的扩增多核苷酸的序列阅读值;b)对于各组第一多核苷酸,推断对在该组第一多核苷酸中的一个或多个碱基的判定频率,其中推断包括:c)针对各个家族,对多个判定中的每一个判定分配置信得分,该置信得分考虑家族成员之间的判定频率;以及d)考虑分配给每个家族的一个或多个判定的置信得分,来估算一个或多个判定的频率。
166.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a)访问包含接收信号的数据文件,该接收信号包含来自至少一个单个多核苷酸分子的编码的序列信息,其中所述接收信号包含噪声和/或畸变;b)解码所述接收信号,以产生包含关于所述至少一个单个多核苷酸分子的序列信息的消息,其中解码减少了该消息中关于各个单个多核苷酸的噪声和/或畸变;以及c)将包含关于所述至少一个单个多核苷酸分子的序列信息的消息写入计算机文件。
167.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a)访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b)分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸;以及c)从共有序列中过滤掉那些未满足质量阈值的共有序列。
168.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a)访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;以及b)通过以下步骤分解该序列阅读值:(i)将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记亲本多核苷酸扩增;以及(ii)任选地确定各个家族中序列阅读值的定量度量。
169.在一些实施方案中,可执行代码在被计算机处理器执行时进一步执行以下步骤:d)确定独特家族的定量度量;e)基于(1)独特家族的定量度量和(2)各组中的序列阅读值的定量度量,推断在该组中的独特标记亲本多核苷酸的度量。
170.在一些实施方案中,可执行代码在被计算机处理器执行时进一步执行以下步骤:e)确定家族之间的多态性形式的定量度量;以及f)基于所确定的多态性形式的定量度量,推断在推断的独特标记亲本多核苷酸的数目上的多态性形式的定量度量。
171.在一些实施方案中,可执行代码在被计算机处理器执行时进一步执行以下步骤:e)基于定位至多个参考序列中的每一个的各组中的标记亲本多核苷酸的推断数目的比较,
来推断所述多个组的拷贝数变异。
172.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a)访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b)将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族从所述组中的相同的第一多核苷酸扩增;c)推断该组中的家族的定量度量;d)通过比较各组中的家族的定量度量来确定拷贝数变异。
173.本公开内容还提供了一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族包含从相同的第一多核苷酸扩增的扩增多核苷酸的序列阅读值;以及对于各组第一多核苷酸,推断对在该组第一多核苷酸中的一个或多个碱基的判定频率,其中推断包括:(i)针对各个家族,对多个判定中的每一个判定分配置信得分,该置信得分考虑家族成员之间的判定频率;以及(ii)考虑分配给每个家族的一个或多个判定的置信得分,来估算一个或多个判定的频率。
174.本公开内容还提供了一种组合物,其包含100至100,000个人单倍体基因组当量的cfdna多核苷酸,其中所述多核苷酸用2至1,000,000个独特标识符标记。
175.在一些实施方案中,所述组合物包含1000至50,000个单倍体人基因组当量的cfdna多核苷酸,其中所述多核苷酸用2至1,000个独特标识符标记。在一些实施方案中,该独特标识符包含核苷酸条形码。本公开内容还提供了一种方法,该方法包括:a)提供包含100至100,000个单倍体人基因组当量的cfdna多核苷酸的样品;以及b)用2至1,000,000个独特标识符标记所述多核苷酸。
176.本公开内容还提供了一种方法,该方法包括:a)提供包含多个人单倍体基因组当量的片段化多核苷酸的样品;b)确定z,其中z是在基因组中任何位置开始的重复多核苷酸的预期数目的居中趋势度量(例如,平均值、中位数或众数),其中重复多核苷酸具有相同的启动和终止位置;以及c)用n个独特标识符标记样品中的多核苷酸,其中n是2至100,000*z、2至10,000*z、2至1,000*z或2至100*z。本公开内容还提供了一种方法,该方法包括:a)提供至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b)对该组中的各个标记的亲本多核苷酸产生多个序列阅读值,以产生一组测序阅读值;以及c)分解该组测序阅读值,以生成一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸。
177.本公开内容还提供了一种包含计算机可读介质的系统,该计算机可读介质包含本文所述的机器可执行代码。本公开内容还提供了一种包含计算机可读介质的系统,该计算机可读介质包含机器可执行代码,该机器可执行代码在被计算机处理器执行时实现本文所述的方法。
178.通过下列详细描述,本公开内容的其它方面和优点对本领域技术人员而言将会变得显而易见,详细描述中仅示出和描述了本发明的说明性实施方案。如将会意识到的,本公开内容能够具有其它和不同的实施方案,并且其若干细节能够在各种明显的方面进行修
改,所有这些都不脱离本公开内容。因此,附图和说明书本质上将被视为说明性的而不是限制性的。援引并入
179.本说明书中提及的所有出版物、专利和专利申请均通过引用以相同的程度并入本文,犹如特别地和单独地指出每个单独的出版物、专利或专利申请均通过引用而并入。
附图说明
180.本发明的系统和方法的新颖特征特别地在所附权利要求中阐述。通过参考以下对其中利用了本发明系统和方法的原理的说明性实施方案加以阐述的发明详述及其附图,将会获得对本公开内容的特征和优势的更好的理解,在附图中:
181.图1是使用单一样品检测拷贝数变异的方法的流程图图示。
182.图2是使用成对样品检测拷贝数变异的方法的流程图图示。
183.图3是检测稀有突变(例如,单核苷酸变异体)的方法的流程图图示。
184.图4a是由正常的、非癌变受试者生成的图形化拷贝数变异检测报告。
185.图4b是由患有前列腺癌的受试者生成的图形化拷贝数变异检测报告。
186.图4c是经因特网访问由患有前列腺癌的受试者的拷贝数变异分析生成的报告的示意图。
187.图5a是由具有前列腺癌缓解的受试者生成的图形化拷贝数变异检测报告。
188.图5b是由具有前列腺癌复发的受试者生成的图形化拷贝数变异检测报告。
189.图6a是使用含有met和tp53的野生型及突变型拷贝的dna样品从多种混合实验生成的图形化检测报告(例如,针对单核苷酸变异体)。
190.图6b是(例如,单核苷酸变异体)检测结果的对数图示。对于使用含有met、hras和tp53的野生型及突变型拷贝的dna样品的多种混合实验,显示了观察的对比预期的%癌症测量。
191.图7a是患有前列腺癌的受试者与参考(对照)相比,在两种基因pik3ca和tp53中的两种(例如,单核苷酸变异体)的百分比的图形报告。
192.图7b是经因特网访问由患有前列腺癌的受试者的(例如,单核苷酸变异体)分析生成的报告的示意图。
193.图8是一种分析遗传材料的方法的流程图图示。
194.图9是一种方法的流程图图示,该方法用于解码一组序列阅读值中的信息以在降低的噪声和/或畸变下产生一组标记的亲本多核苷酸中的信息的呈现。
195.图10是一种在从一组序列阅读值确定cnv中减少畸变的方法的流程图图示。
196.图11是一种方法的流程图图示,该方法用于从一组序列阅读值估算在标记的亲本多核苷酸群体中的基因座处的碱基或碱基序列的频率。
197.图12示出了一种对序列信息进行通信的方法。
198.图13示出了使用标准测序和数字测序工作流程在0.3%lncap cfdna滴定中在整个70kb组中检测到的次要等位基因频率。标准“模拟”测序(图13a)尽管经过q30过滤,仍因pcr和测序错误而在巨大噪声中掩盖了全部真阳性稀有变异。数字测序(图13b)消除了所有pcr和测序噪声,揭示出真正的突变而没有假阳性:绿色圆圈是在正常cfdna中的snp点,而
红色圆圈是检测到的lncap突变。
199.图14:显示了lncap cfdna的滴定。
200.图15示出了一种被编程为或以其它方式配置成实现本发明的各种方法的计算机系统。发明详述i.一般概述
201.本公开内容提供了一种用于检测无细胞多核苷酸中的稀有突变(例如,单或多核苷酸变异)和拷贝数变异的系统和方法。通常,该系统和方法包括样品制备或者从体液中提取和分离无细胞多核苷酸序列;随后通过本领域已知的技术对无细胞多核苷酸进行测序;以及使用生物信息学工具来与参考相比检测稀有突变和拷贝数变异。该系统和方法还可以包含不同疾病的不同稀有突变或拷贝数变异谱的数据库或集合,以便用作附加的参考来辅助疾病的稀有突变检测(例如,单核苷酸变异谱分析)、拷贝数变异谱分析或普通遗传谱分析。
202.该系统和方法可特别适用于无细胞dna的分析。在一些情况下,无细胞dna从容易获得的体液如血液中提取和分离。例如,无细胞dna可以使用本领域中已知的多种方法进行提取,包括但不限于异丙醇沉淀和/或基于二氧化硅的纯化。无细胞dna可以从任何数目的受试者中提取,诸如未患有癌症的受试者、具有患癌风险的受试者或已知患有癌症的受试者(例如,通过其它手段)。
203.在分离/提取步骤后,可对无细胞多核苷酸样品进行许多不同测序操作中任何操作。样品在测序前可用一种或多种试剂(例如,酶、独特标识符(例如,条形码)、探针等)进行处理。在一些情况下,如果用独特标识符诸如条形码处理样品,则可用独特标识符单独地或成亚组地(in subsets)标记该样品或该样品的片段。标记的样品随后可用于下游应用,如测序反应,通过该下游应用可将单个分子追踪至亲本分子。
204.在收集无细胞多核苷酸序列的测序数据后,可对该序列数据应用一个或多个生物信息学过程,以检测遗传特征或异常,诸如拷贝数变异、稀有突变(例如,单或多核苷酸变异)或外遗传标记物的改变,包括但不限于甲基化谱。在其中需要拷贝数变异分析的一些情况下,序列数据可以:1)与参考基因组进行比对;2)过滤和定位;3)分割成序列窗口或箱元(bin);4)对各个窗口的覆盖阅读值进行计数;5)然后可以使用随机或统计建模算法对覆盖阅读值进行归一化;6)以及可以生成输出文件,其反映在基因组中的各位置处的离散的拷贝数状态。在其中需要稀有突变分析的其它情况下,序列数据可以1)与参考基因组进行比对;2)过滤和定位;3)基于该特定碱基的覆盖阅读值而计算变异碱基的频率;4)使用随机、统计或概率建模算法来对变异碱基频率进行归一化;5)以及可以生成输出文件,其反映在基因组中的各位置处的突变状态。
205.多种不同的反应和/操作可在本文公开的系统和方法中发生,包括但不限于:核酸测序、核酸定量、测序优化、检测基因表达、基因表达定量、基因组谱分析、癌症谱分析或表达的标记物的分析。此外,该系统和方法具有许多医学应用。例如,它可用于各种遗传性和非遗传性疾病和病症(包括癌症)的鉴定、检测、诊断、治疗、分期或风险预测。它可以用于评估受试者对所述遗传性和非遗传性疾病的不同治疗的响应,或提供关于疾病进展和预后的信息。
206.多核苷酸测序可以与通信理论中的问题进行比较。最初的单个多核苷酸或成组多核苷酸被认为是原始消息。标记和/或扩增可被认为是将原始消息编码成信号。测序可以被认为是通信通道。测序仪的输出,例如序列阅读值,可以被认为是接收的信号。生物信息学处理可以被认为是解码接收信号以产生发送的消息(例如,一个或多个核苷酸序列)的接收器。接收的信号可以包括伪像,诸如噪声和畸变。噪声可以被认为是信号的不希望的随机增加。畸变可以被认为是信号或信号一部分的幅值变化。
207.噪声可通过在拷贝和/或读取多核苷酸中的错误而引入。例如,在测序过程中,单个多核苷酸可以首先经历扩增。扩增可引入错误,从而使扩增的多核苷酸的亚组可以在特定的基因座处包含与在该基因座处的原始碱基不同的碱基。此外,在读取过程中,在任何特定基因座处的碱基可能被不正确地读取。因此,序列阅读值的集合可包含一定百分比的在基因座处与原始碱基不同的碱基判定。在典型的测序技术中,这种错误率可以是个位数,例如,2%-3%。当对全部假定为具有相同序列的分子集合进行测序时,这样的噪声是足够小,使得人们可以高可靠性地鉴别原始碱基。
208.然而,如果亲本多核苷酸的集合包括在特定基因座处具有序列变异体的多核苷酸亚组,则噪声可能是一个显著的问题。例如,当无细胞dna不仅包括种系dna还包括来自另一来源的dna诸如胎儿dna或来自癌细胞的dna时,情况可能是这样。在这种情况下,如果具有序列变异体的分子的频率与通过测序过程引入的错误的频率在相同的范围内,则真序列变异体可能无法与噪声区别。这可能会干扰例如样品中的序列变异体的检测。
209.畸变可以在测序过程表现为由在相同频率下的亲本群体中的分子产生的信号强度的差异,例如序列阅读值的总数。例如,可以通过扩增偏倚、gc偏倚或测序偏倚引入畸变。这可能会干扰样品中的拷贝数变异的检测。gc偏倚导致了在序列读取中gc含量丰富或贫乏区域的不均匀呈现。
210.本发明提供了减少多核苷酸测序过程中的测序伪像如噪声和/或畸变的方法。将序列阅读值分组成源自原始单个分子的家族可减少来自单个个体分子或来自成组分子的噪声和/或畸变。关于单个分子,将阅读值分组成家族通过例如指出许多序列阅读值实际上代表单个分子而非许多不同的分子而减少了畸变。将序列阅读值分解成共有序列是一种减少从一个分子接收到的消息中的噪声的方式。使用转换接收到的频率的概率函数是另一种方式。关于成组分子,将阅读值分组成家族并确定家族的定量度量减少了例如在多个不同基因座中的每一个基因座处的分子的量的畸变。再者,将不同家族的序列阅读值分解成共有序列消除了由扩增和/或测序错误引入的错误。此外,基于由家族信息得出的概率来确定碱基判定的频率也减少了从成组分子接收到的消息中的噪声。
211.减少来自测序过程的噪声和/或畸变的方法是已知的。这些方法包括,例如过滤序列,例如,要求它们满足质量阈值或降低gc偏倚。这样的方法通常在作为测序仪的输出的序列阅读值集合上进行,并可以以逐个序列阅读值的方式进行,而无需考虑家族结构(来源于一个原始亲本分子的序列的子集)。本发明的某些方法通过减少序列阅读值的家族内的噪声和/或畸变来减少噪声和畸变,即在分组成来源于单个亲本多核苷酸分子的家族的序列阅读值上运行。家族水平上的信号伪像的减少可以在提供的最终消息中产生比在逐个序列阅读值水平上或在作为整体的测序仪输出上进行的伪像减少显著较少的噪声和畸变。
212.本公开内容进一步提供了用于高灵敏度地检测在初始遗传材料的样品中的遗传
变异的方法和系统。该方法包括使用下列工具中的一个或两个:第一,将初始遗传材料的样品中的单个多核苷酸有效转换成测序就绪的标记的亲本多核苷酸,以便增加初始遗传材料的样品中的单个多核苷酸将在测序就绪的样品中呈现的概率。这可以产生关于初始样品中的更多多核苷酸的序列信息。第二,通过从标记的亲本多核苷酸扩增的子代多核苷酸的高速率采样,以及将生成的序列阅读值分解成呈现亲本标记的多核苷酸的序列的共有序列,来高产量地生成标记的亲本多核苷酸的共有序列。这可以减少由扩增偏倚和/或测序错误引入的噪声并且可以提高检测的灵敏度。分解在由扩增的分子的阅读值生成或由单个分子的多个阅读值生成的多个序列阅读值上进行。
213.测序方法通常包括样品制备,对所制成样品中的多核苷酸进行测序以产生序列阅读值,以及对序列阅读值进行生物信息学操作以产生关于样品的定量和/或定性的遗传信息。样品制备一般包括将样品中的多核苷酸转换成与所用测序平台兼容的形式。这种转换可以涉及标记多核苷酸。在本发明的某些实施方案中,标签包括多核苷酸序列标签。在测序中使用的转换方法可能不是100%有效的。例如,以约1-5%的转换效率来转换样品中的多核苷酸并不少见,也就是说,样品中的约1-5%的多核苷酸被转换成标记的多核苷酸。未转换成标记的分子的多核苷酸没有在用于测序的标记的文库中呈现。因此,具有在初始遗传材料中以低频率呈现的遗传变异体的多核苷酸可能未在标记的文库中呈现,因此可能不被测序或检测。通过提高转换效率,在初始遗传材料中的稀有多核苷酸将在标记的文库中呈现且因此通过测序检测出来的概率得到增加。此外,并非直接解决文库制备的转换效率低的问题,迄今为止的大多数方案要求大于1微克的dna作为输入材料。然而,当输入样品材料受到限制或需要检测低呈现度的多核苷酸时,高转换效率可以有效地对样品进行测序和/或充分地检测此类多核苷酸。
214.本公开内容提供了以至少10%、至少20%、至少30%、至少40%、至少50%、至少60%、至少80%或至少90%的转换效率将初始多核苷酸转换成标记的多核苷酸的方法。该方法涉及,例如,使用平端连接、粘端连接、分子倒位探针、pcr、基于连接的pcr、多重pcr、单链连接和单链环化中的任何方式。该方法还可以涉及限定初始遗传材料的量。例如,初始遗传材料的量可以小于1μg、小于100ng或小于10ng。这些方法在本文中更详细地描述。
215.获得关于标记文库中的多核苷酸的准确定量和定性信息可导致对初始遗传材料的更灵敏的表征。通常,扩增在标记的文库中的多核苷酸并对所得扩增分子进行测序。根据所用测序平台的通量,在扩增的文库中仅有分子的亚组产生序列阅读值。因此,例如,为测序而采样的扩增分子的数目可以仅为标记的文库中的独特多核苷酸的约50%。此外,扩增可被偏置为有利于或不利于标记的文库的某些序列或某些成员。这可能会使标记文库中的序列的定量测量发生畸变。此外,测序平台可以在测序中引入错误。例如,序列可以具有0.5-1%的每碱基错误率。扩增偏倚和测序错误将噪声引入至最终测序产物中。这种噪声可以降低检测的灵敏度。例如,在标记的群体中的频率比测序错误率低的序列变异体可以被误认为是噪声。此外,通过以比它们在群体中的实际数目更大或更小的量提供序列阅读值,扩增偏倚可以使拷贝数变异的测量发生畸变。或者,可以不经扩增而产生来自单一多核苷酸的多个序列阅读值。例如,这可以用纳米孔方法实现。
216.本公开内容提供了准确地检测和读取标记的集合体中的独特多核苷酸的方法。在某些实施方案中,本公开内容提供了序列标记的多核苷酸,该序列标记的多核苷酸当被扩
增和测序时或者当被多次测序以产生多个序列阅读值时,提供了允许将子代多核苷酸追溯至或分解成独特标记的亲本多核苷酸分子的信息。分解扩增的子代多核苷酸的家族通过提供关于原始独特亲本分子的信息而降低扩增偏倚。分解也通过从测序数据中消除子代分子的突变序列而减少测序错误。
217.检测和读取标记的文库中的独特多核苷酸可以涉及两种策略。在一种策略中,对扩增的子代多核苷酸集合体的足够大的亚组进行测序,使得对于该组标记的亲本多核苷酸中的高百分比的独特标记的亲本多核苷酸,存在针对在由独特标记的亲本多核苷酸产生的家族中的至少一个扩增的子代多核苷酸而产生的序列阅读值。在第二个策略中,以一定的水平对扩增的子代多核苷酸组进行采样测序,以便由来源于独特亲本多核苷酸的家族的多个子代成员产生序列阅读值。由家族的多个子代成员生成序列阅读值允许将序列分解成共有亲本序列。
218.因此,例如,从该组扩增的子代多核苷酸中采样与该组标记的亲本多核苷酸中的独特标记的亲本多核苷酸的数目(特别是当该数目为至少10,000时)相等数目的扩增的子代多核苷酸,将在统计学上产生针对该组中约68%的标记的亲本多核苷酸的子代中的至少一个的序列阅读值,且在原始组中的约40%的独特标记的亲本多核苷酸将由至少2个子代序列阅读值呈现。在某些实施方案中,充分地对扩增的子代多核苷酸组进行采样,以便针对每个家族产生平均五到十个序列阅读值。从扩增的子代组采样多达独特标记的亲本多核苷酸的数目的10倍的分子,将在统计学上产生关于99.995%的家族的序列信息,其中,总家族的99.95%将被多个序列阅读值覆盖。共有序列可以由每个家族中的子代多核苷酸构建,从而将错误率从标称的每碱基测序错误率显著地减低至可能低几个数量级的错误率。例如,如果测序仪具有1%的随机每碱基错误率且所选择的家族有10个阅读值,则由这10个阅读值建立的共有序列将具有低于0.0001%的错误率。因此,可以选择待测序的扩增子代的采样大小,以确保样品中具有一定频率(即不大于标称的每碱基测序错误率到所用测序平台的错误率)的序列有至少99%的机会被至少一个阅读值呈现。
219.在另一个实施方案中,该组扩增的子代多核苷酸以一定的水平采样,以产生在该组标记的亲本多核苷酸中以约等于所用测序平台的每碱基测序错误率的频率呈现的序列被至少一个序列阅读值覆盖且优选地被多个序列阅读值所覆盖的高概率,例如至少90%。因此,例如,如果测序平台具有0.2%的每碱基错误率,序列或一组序列在该组标记的亲本多核苷酸中以约0.2%的频率呈现,则在所测序的扩增子代集合体中多核苷酸的数目可以为在该组标记的亲本多核苷酸中的独特分子的数目的约x倍。
220.这些方法可以与任何所述的噪声减少方法相组合。包括,例如,使序列阅读值有资格包含在用于产生共有序列的序列集合体中。
221.该信息现在可用于定性和定量分析。例如,对于定量分析,确定定位至参考序列的标记亲本分子的量的度量,例如计数。这种度量可以与定位至不同基因组区域的标记亲本分子的度量进行比较。也就是说,定位至参考序列(如人类基因组)中的第一位置或可定位位置的标记亲本分子的量可以与定位至参考序列中的第二位置或可定位位置的标记亲本分子的度量相比较。这种比较可以揭示,例如,定位至各个区域的亲本分子的相对量。进而,这提供了定位至特定区域的分子的拷贝数变异的指示。例如,如果定位至第一参考序列的多核苷酸的度量大于定位至第二参考序列的多核苷酸的度量,则这可能表明亲本群体和
(引申开来)原始样品包括来自表现出非整倍性的细胞的多核苷酸。这种度量可相对于对照样品进行归一化,从而消除各种偏倚。定量度量可以包括,例如数字、计数、频率(无论是相对的、推断的还是绝对的)。
222.参考基因组可以包括任何感兴趣的物种的基因组。可用作参考的人类基因组序列可以包括hgl9组装体或任何以前的或可用的hg组装体。这样的序列可以使用在genome.ucsc.edu/index.html上可得的基因组浏览器进行查询。其它物种基因组包括,例如pantro2(黑猩猩)和mm9(小鼠)。
223.对于定性分析,可以针对变异体序列分析来自定位至参照序列的一组标记的多核苷酸的序列,并且可以测量它们在标记的亲本多核苷酸的群体中的频率。ii.样品制备a.多核苷酸分离和提取
224.本发明的系统和方法在无细胞多核苷酸的操作、制备、鉴别和/或定量中可以具有广泛用途。多核苷酸的实例包括但不限于:dna、rna、扩增子、cdna、dsdna、ssdna、质粒dna、粘粒dna、高分子量(mw)dna、染色体dna、基因组dna、病毒dna、细菌dna、mtdna(线粒体dna)、mrna、rrna、trna、nrna、sirna、snrna、snorna、scarna、微rna、dsrna、核酶、核糖开关和病毒rna(例如,逆转录病毒rna)。
225.无细胞多核苷酸可以来源于多种来源,包括人、哺乳动物、非人哺乳动物、猿、猴、黑猩猩、爬行类动物、两栖动物或禽类来源。此外,样品可以提取自多种包含无细胞序列的动物流体,包括但不限于血液、血清、血浆、玻璃质、痰、尿液、泪、汗液、唾液、精液、粘膜分泌物、粘液、脊髓液、羊水、淋巴液等。无细胞多核苷酸可以是胎儿来源的(通过取自妊娠受试者的流体),或可以得自受试者自身的组织。
226.无细胞多核苷酸的分离和提取可以通过使用多种技术采集体液进行。在一些情况中,采集可以包括使用注射器从受试者抽吸体液。在其它情况中,采集可以包括移液或直接采集流体到采集容器中。
227.在采集体液后,可以使用本领域已知的多种技术分离和提取无细胞多核苷酸。在一些情况中,可以使用商业可得试剂盒例如qiagencirculating nucleic acid kit规程分离、提取和制备无细胞dna。在其它实例中,可以使用qiagen qubit
tm
dsdna hs assay试剂盒规程、agilent
tm
dna 1000试剂盒或truseq
tm
sequencing library preparation;low-throughput(lt)规程。
228.一般地,通过分割步骤(partitioning step)从体液中提取和分离无细胞多核苷酸,在该分割步骤中,如在溶液中发现的无细胞dna与细胞和体液的其它不可溶组分分离。分割可以包括但不限于诸如离心或过滤的技术。在其它情况中,细胞并非首先与无细胞dna分割,而是经裂解。在该实例中,完整细胞的基因组dna通过选择性沉淀来分割。包括dna在内的无细胞多核苷酸可以保持可溶性并可以与不可溶性基因组dna分离并提取。通常,在添加不同试剂盒特定的缓冲液和其它洗涤步骤后,可以使用异丙醇沉淀来沉淀dna。可以使用进一步的清洁步骤例如基于二氧化硅的柱以去除污染物或盐。可以针对特定应用优化一般步骤。例如,可以贯穿反应添加非特异性批量(bulk)载体多核苷酸以优化该程序的特定方面例如收率。
229.无细胞dna的分离和纯化可以使用任意手段实现,所述手段包括但不限于使用由
例如sigma aldrich、life technologies、promega、affymetrix、ibi等公司提供的商业试剂盒和规程。试剂盒和规程还可以是非商业可得的。
230.在分离后,在一些情况中,无细胞多核苷酸在测序前与一种或多种附加材料例如一种或多种试剂(例如,连接酶、蛋白酶、聚合酶)预混合。
231.一种提高转换效率的方法涉及使用针对在单链dna上的最佳反应性而工程构建的连接酶,例如thermophage ssdna连接酶衍生物。此类连接酶绕过文库制备中末端修复和a加尾的传统步骤——该步骤由于中间清洁步骤而可能具有较差的效率和/或累积的损失,并使得有义或反义起始多核苷酸转换为适当地标记的多核苷酸的概率加倍。其还可以转换可具有突出端的双链多核苷酸,该突出端可能无法通过典型的末端修复反应充分地平端化。此ssdna反应的最佳反应条件是:1x反应缓冲液(50mm mops(ph 7.5),1mm dtt,5mm mgcl2,10mm kcl)。50mm atp、25mg/ml bsa、2.5mm mncl2、200pmol 85nt ssdna寡聚物和5u ssdna连接酶在65℃下温育1小时。使用pcr的后续扩增可进一步将标记的单链文库转换为双链文库并产生远高于20%的总转换效率。将转换率提高至例如大于10%的其它方法包括例如单独的或组合的下列中的任意方法:退火优化的分子倒位探针、具有良好控制的多核苷酸大小范围的平端连接、粘端连接或者使用或不使用融合引物的预先(upfront)多重扩增步骤。b.无细胞多核苷酸的分子条形码编码
232.本发明的系统和方法还可以使无细胞多核苷酸能够被标记或追踪以允许随后对特定多核苷酸的鉴别和起源确定。这一特征与使用合并的或多重的反应且仅提供作为多个样品的平均值的测量或分析的其它方法不同。在此,将标识符分配至多核苷酸的个体或亚组可以允许将独特的身份(identity)分配给单个序列或序列的片段。这可以允许从单个样品获取数据而不限于样品的平均值。
233.在一些实例中,来源于同一链的核酸或其它分子可以共享共同的标签或标识符并因此可以随后被鉴别为来源于该链。类似地,来自核酸的单链的所有片段可以用相同的标识符或标签来标记,由此允许随后鉴别来自该亲本链的片段。在其它情况中,可以标记基因表达产物(例如,mrna)以对表达进行定量,借此可以对条形码或对条形码与其所附接的序列的组合进行计数。在又另一些情况中,可以使用该系统和方法作为pcr扩增控制。在此类情况中,得自pcr反应的多个扩增产物可以用相同的标签或标识符进行标记。如果该产物随后被测序并证明有序列差异,则在具有相同标识符的产物之间的差异可归因于pcr错误。
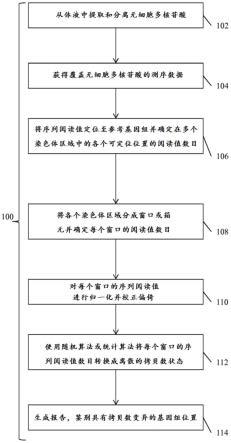
234.另外,可以基于阅读值的序列数据自身的特征鉴别单个序列。例如,在单个测序阅读值的开始(起始)和结束(终止)部分的独特序列数据的检测可以单独地使用,或与各个序列阅读值独特序列的长度或碱基对数目相组合地使用,以将独特的身份分配给单个分子。来自已经分配了独特身份的核酸同一链的片段可以由此允许随后鉴别来自该亲本链的片段。这可以与瓶颈化初始起始遗传材料一起使用以限制多样性。
235.此外,使用在单个测序阅读值的开始(起始)和结束(终止)部分的独特序列数据和测序阅读值长度可以单独地使用或与条形码的使用相组合地使用。在一些情况中,条形码可以如本文所述是独特的。在另一些情况中,条形码自身可以不是独特的。在此情况中,非独特条形码与在单个测序阅读值的开始(起始)和结束(终止)部分的序列数据以及测序阅读值长度相组合的使用,可以允许将独特的身份分配给单个序列。类似地,来自已经分配了
独特身份的核酸同一链的片段可以由此允许随后鉴别来自亲本链的片段。
236.通常,本文提供的方法和系统对于准备无细胞多核苷酸序列以用于下游应用测序反应是有用的。通常,测序方法是经典的sanger测序。测序方法可以包括但不限于:高通量测序、焦磷酸测序、合成测序、单分子测序、纳米孔测序、半导体测序、连接测序、杂交测序、rna-seq(illumina)、数字基因表达(digital gene expression)(helicos)、新一代测序、单分子合成测序(single molecule sequencing by synthesis)(smss)(helicos)、大规模并行测序、克隆单分子阵列(clonal single molecule array)(solexa)、鸟枪法测序、maxim-gilbert测序、引物步移法和本领域中已知的任何其它测序方法。c.向无细胞多核苷酸序列分配条形码
237.本文公开的系统和方法可用于涉及将独特或非独特标识符或分子条形码分配至无细胞多核苷酸的应用。通常,标识符是用于标记多核苷酸的条形码寡核苷酸;但在一些情况中,使用不同的独特标识符。例如,在一些情况中,独特标识符是杂交探针。在其它情况中,独特标识符是染料,在此情况中,附接可以包括染料嵌入到分析物分子中(例如嵌入到dna或rna中)或结合至用染料标记的探针。在又一些其它情况中,该独特标识符可以是核酸寡核苷酸,在此情况中,与多核苷酸序列的附接可以包括在寡核苷酸和序列之间的连接反应或通过pcr的并入。在其它情况中,该反应可以包括金属同位素直接向分析物的添加或通过用同位素标记的探针的添加。通常,在本发明的反应中独特或非独特标识符或分子条形码的分配可以依循由例如美国专利申请20010053519、20030152490、20110160078和美国专利us 6,582,908所述的方法和系统。
238.通常,该方法包括通过包括但不限于连接反应的酶反应将寡核苷酸条形码附接至核酸分析物。例如,连接酶可以将dna条形码共价附接到片段化的dna(例如,高分子量dna)。在条形码附接后,分子可以进行测序反应。
239.但是,也可以使用其它反应。例如,可以在dna模板分析物的扩增反应(例如,pcr、qpcr、逆转录酶pcr、数字pcr等)中使用包含条形码序列的寡核苷酸引物,由此产生标记的分析物。在将条形码分配给单个无细胞多核苷酸序列后,可以对分子的集合体进行测序。
240.在一些情况中,pcr可以用于无细胞多核苷酸序列的全局扩增。这可以包括使用衔接子序列,该衔接子序列可以首先连接至不同的分子,然后使用通用引物进行pcr扩增。用于测序的pcr可以使用任何手段进行,该手段包括但不限于使用由nugen(wga试剂盒)、life technologies、affymetrix、promega、qiagen等提供的商业试剂盒。在其它情况中,可以仅扩增在无细胞多核苷酸分子群体中的特定靶分子。特定的引物,可以与衔接子连接一起,可以用于选择性扩增用于下游测序的特定靶标。
241.可以将独特标识符(例如,寡核苷酸条形码、抗体、探针等)随机地或非随机地引入至无细胞多核苷酸序列。在一些情况中,它们以独特标识符比微孔的预期比值引入。例如,可以加载独特标识符以使每个基因组样品加载超过约1、2、3、4、5、6、7、8、9、10、20、50、100、500、1000、5000、10000、50,000、100,000、500,000、1,000,000、10,000,000、50,000,000或1,000,000,000个独特标识符。在一些情况中,可以加载独特标识符以使每个基因组样品加载少于约2、3、4、5、6、7、8、9、10、20、50、100、500、1000、5000、10000、50,000、100,000、500,000、1,000,000、10,000,000、50,000,000或1,000,000,000个独特标识符。在一些情况中,每个样品基因组加载的独特标识符的平均数为每个基因组样品小于或大于约1、2、3、4、5、
6、7、8、9、10、20、50、100、500、1000、5000、10000、50,000、100,000、500,000、1,000,000、10,000,000、50,000,000或1,000,000,000个独特标识符。
242.在一些情况中,独特标识符可以是多种长度,使得各个条形码是至少约1、2、3、4、5、6、7、8、9、10、20、50、100、500、1000个碱基对。在其它情况中,条形码可以包含少于1、2、3、4、5、6、7、8、9、10、20、50、100、500、1000个碱基对。
243.在一些情况中,独特标识符可以是预确定的或随机的或半随机的序列寡核苷酸。在其它情况中,可以使用多个条形码以使条形码在所述多个条形码中相对于彼此不一定是独特的。在此实例中,条形码可以连接至单个分子,使得条形码和其可以连接的序列的组合产生可以单独追踪的独特序列。如本文所述,非独特条形码的检测与测序阅读值的开始(起始)和结束(终止)部分的序列数据相组合可以允许将独特身份分配给特定分子。单个序列阅读值的长度或碱基对数目还可以用于将独特身份分配给这样的分子。如本文所述,来自已经分配了独特身份的核酸的同一链的片段可以由此允许随后鉴别来自亲本链的片段。以此方法,样品中的多核苷酸可以独特地或基本独特地得到标记。
244.独特标识符可以用于标记宽范围的分析物,包括但不限于rna或dna分子。例如,独特标识符(例如,条形码寡核苷酸)可以附接至核酸的整条链或附接至核酸的片段(例如,片段化的基因组dna、片段化的rna)。独特标识符(例如,寡核苷酸)还可以结合至基因表达产物、基因组dna、线粒体dna、rna、mrna等。
245.在许多应用中,确定单个无细胞多核苷酸序列是否各自接受不同的独特标识符(例如,寡核苷酸条形码)可能是重要的。如果引入系统和方法的独特标识符群体不是显著不同的,则可以用相同的标识符标记不同的分析物。在本文中公开的系统和方法可以使得能够检测用相同标识符标记的无细胞多核苷酸序列。在一些情况中,参考序列可以与待分析的无细胞多核苷酸序列群体一同包含在内。参考序列可以是例如具有已知序列和已知量的核酸。如果独特标识符是寡核苷酸条形码且分析物是核酸,则可以随后对标记的分析物进行测序和定量。这些方法可以指示是否一个或多个片段和/或分析物可能已经分配有相同的条形码。
246.在本文中公开的方法可以包括使用对于将条形码分配给分析物来说所必需的试剂。在连接反应的情况中,可以将包括但不限于连接酶、缓冲液、衔接子寡核苷酸、多个独特标识符dna条形码等的试剂加载到系统和方法中。在富集的情况中,包括但不限于多个pcr引物、包含独特的标识序列的寡核苷酸、或条形码序列、dna聚合酶、dntp和缓冲液等的试剂可以在测序准备中使用。
247.通常,本发明的方法和系统可在使用分子条形码对分子或分析物进行计数时采用美国专利us 7,537,897的方法,该专利通过引用整体并入本文。
248.在包含来自多个基因组的片段化基因组dna例如无细胞dna(cfdna)的样品中,存在一定的如下可能性:来自不同的基因组的多于一个多核苷酸具有相同的起始和终止位置(“复制物”或“同源物”)。在任意位置开始的复制物的可能数目是样品中单倍体基因组当量的数目和片段大小的分布的函数。例如,cfdna具有在约160个核苷酸处的片段峰,且在此峰中的大部分片段为约140个核苷酸至180个核苷酸。因此,来自具有约30亿个碱基的基因组(例如,人类基因组)的cfdna可以包含几乎2千万(2x107)个多核苷酸片段。具有约30ng dna的样品可以包含约10,000个单倍体人基因组当量。(类似地,具有约100ng的dna的样品可以
包含约30,000个单倍体人基因组当量。)包含约10,000(104)个单倍体基因组当量的此dna的样品可以具有约2000亿(2x10
11
)个单个多核苷酸分子。已经根据经验确定,在具有约10,000个单倍体基因组当量的人dna的样品中,在任意给定位置开始存在约3个复制多核苷酸。因此,这样的收集可包含约6x10
10
至8x10
10
(约600亿至800亿,例如,约700亿(7x10
10
))个序列不同的多核苷酸分子的多样性。
249.正确鉴别分子的可能性取决于基因组当量的初始数目、所测序的分子的长度分布、序列均一性和标签的数目。当标签计数等于1时,即等同于不具有独特的标签或未标记。下表列出了假定有如上的典型无细胞大小分布,正确地将分子鉴别为独特的概率。标签计数正确地独特鉴别的标签%1000个人单倍体基因组当量 196.9643499.2290999.65391699.80642599.874110099.9685
ꢀꢀ
3000个人单倍体基因组当量 191.7233497.8178999.01981699.44242599.641210099.9107
250.在此情况中,经对基因组dna进行测序,也许不能确定哪些序列阅读值来自哪些亲本分子。这个问题可以通过以下方式来消除:用足够数目的独特标识符标记亲本分子(例如,标签计数),使得存在两个复制分子(即,具有相同起始和终止位置的分子)带有不同的独特标识符的可能性,以使序列阅读值可追溯至特定的亲本分子。此问题的一个解决方法就是独特地标记样品中的每一个或几乎每一个不同的亲本分子。但是,取决于单倍体基因当量的数目和样品中的片段大小的分布,这可能需要数十亿不同的独特标识符。
251.上述方法可能是繁琐和昂贵的。本发明的发明人已经意外地意识到,基因组核酸样品(例如基因组dna样品)中的单个多核苷酸片段能够通过用非独特标识符标记,例如非独特地标记该单个多核苷酸片段而独特地鉴别。如本文所用的,如果分子的集合中至少95%的分子携带不被该集合中的任何其他分子所共有的标识标签(“标识符”)(“独特标签”或“独特标识符”),则可以认为该集合是“独特标记的”。如果分子的集合中至少1%、至少5%、至少10%、至少15%、至少20%、至少25%、至少30%、至少35%、至少40%、至少45%或至少或约50%的分子携带被该集合中的至少一个其他分子所共有的标识标签(“非独特标签”或“非独特标识符”),则可以认为该集合是“非独特标记的”。在一些实施方案中,对于非独特标记的群体,不超过1%、5%、10%、15%、20%、25%、30%、35%、40%、45%或50%的
分子是独特标记的。在一些实施方案中,对于独特标记,相比样品中的分子的估计数目,使用至少两倍的不同标签。用来标记集合中的分子的不同标识标签的数目可以在以下范围内,例如,以2、4、8、16或32中的任一个作为该范围的下限,以50、100、500、1000、5000和10,000中的任一个作为该范围的上限。因此,例如,1千亿至1万亿个分子的集合可以用4至100个不同的标识标签来标记。
252.本发明提供了其中用n个不同的独特标识符标记在片段化基因组dna的样品中的多核苷酸群体的方法和组合物。在一些实施方案中,n至少为2且不大于100,000*z,其中z是具有相同起始和终止位置的复制分子的预期数目的居中趋势度量(例如,平均值、中值、众数)。在一些实施方案中,z为1、2、3、4、5、6、7、8、9、10或大于10。在一些实施方案中,z小于10、小于9、小于8、小于7、小于6、小于5、小于4、小于3。在某些实施方案中,n至少是2*z、3*z、4*z、5*z、6*z、7*z、8*z、9*z、10*z、11*z、12*z、13*z、14*z、15*z、16*z、17*z、18*z、19*z或20*z中的任一个(例如,下限)。在另一些实施方案中,n不大于100,000*z、10,000*z、1000*z或100*z(例如,上限)。因此,n的范围可以在这些下限和上限的任意组合之间。在特定的实施方案中,n在5*z和15*z之间、8*z和12*z之间或为约10*z。例如,单倍体人基因组当量具有约3皮克的dna。具有约1微克的dna的样品包含约300,000个单倍体人基因组当量。在一些实施方案中,数字n可以为5至95、6至80、8至75、10至70、15至45、24至36或约30。在一些实施方案中,数字n小于96。例如,数字n可以大于或等于2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94或95。在一些情况下,数字n可以大于0但小于100、99、98、97、96、95、94、93、92、91或90。在一些实例中,数字n为64。数字n可以小于75、小于50、小于40、小于30、小于20、小于10或小于5。只要至少部分的复制或同源多核苷酸带有独特标识符,即带有不同的标签,就可以实现测序的改进。然而,在某些实施方案中,选择所用的标签的数目,以使所有包含相同的起始和终止序列的复制分子带有独特标识符的机会至少为95%。
253.一些实施方案提供了进行连接反应的方法,在该连接反应中,样品中的亲本多核苷酸与包含y个不同条形码寡核苷酸的反应混合物混合,其中y=n的平方根。该连接可导致条形码寡核苷酸向样品中的亲本多核苷酸上的随机附接。该反应混合物然后可以在足以实现条形码寡核苷酸与样品的亲本多核苷酸连接的连接条件下温育。在一些实施方案中,选自y个不同条形码寡核苷酸的随机条形码连接至亲本多核苷酸的两个末端。y个条形码与亲本多核苷酸的一个或两个末端的随机连接可导致产生y2个独特标识符。例如,包含约10,000个单倍体人基因组当量的cfdna的样品可以用约36个独特标识符标记。该独特标识符可以包含6个独特dna条形码。6个独特条形码与多核苷酸的两端的连接可以导致产生36个可能的独特标识符。
254.在一些实施方案中,包含约10,000个人单倍体基因组当量的dna的样品用64个独特标识符标记,其中这64个独特标识符通过8个独特条形码连接至亲本多核苷酸的两端而产生。该反应的连接效率可以超过10%、超过20%、超过30%、超过40%、超过50%、超过60%、超过70%、超过80%或超过90%。连接条件可以包括使用能够结合片段的任一末端并且仍可扩增的双向衔接子。连接条件可以包括平端连接,这不同于用叉形衔接子加尾。连接
条件可以包括仔细滴定衔接子和/或条形码寡核苷酸的量。连接条件可以包括使用与反应混合物中的亲本多核苷酸片段的量相比超过2x、超过5x、超过10x、超过20x、超过40x、超过60x、超过80x(例如约100x)摩尔过量的衔接子和/或条形码寡核苷酸。连接条件可以包括使用t4 dna连接酶(例如,nebnext ultra ligation module)。在一个实例中,18微升连接酶主混合物用于90微升连接(90份中的18份)和连接增强子。因此,用n个独特标识符标记亲本多核苷酸可以包括使用数目为y的不同条形码,其中y=n的平方根。以此方式标记的样品可以是这样的样品:其具有范围为约10ng至约100ng、约1μg、约10μg中的任一个的片段化多核苷酸,例如基因组dna,例如cfdna。用来鉴别样品中的亲本多核苷酸的条形码的数目y可以取决于样品中的核酸量。
255.本发明还提供了标记的多核苷酸的组合物。该多核苷酸可以包含片段化的dna,例如cfdna。定位至基因组中的可定位碱基位置的组合物中的一组多核苷酸可以被非独特地标记,即不同标识符的数目可以是至少2且小于定位至可定位碱基位置的多核苷酸的数目。约10ng至约10μg(例如,约10ng-1μg、约10ng-100ng、约100ng-10μg、约100ng-1μg、约1μg-10μg中的任一个)的组合物可以带有2、5、10、50或100中的任一个至100、1000、10,000或100,000中的任一个的不同标识符。例如,5至100个不同的标识符可以用于标记此组合物中的多核苷酸。iii.核酸测序平台
256.在从体液提取和分离无细胞多核苷酸后,可以对无细胞序列进行测序。通常,测序方法是经典的sanger测序。测序方法可以包括但不限于:高通量测序、焦磷酸测序、合成测序、单分子测序、纳米孔测序、半导体测序、连接测序、杂交测序、rna-seq(illumina)、数字基因表达(digital gene expression)(helicos)、新一代测序、单分子合成测序(smss)(helicos)、大规模并行测序、克隆单分子阵列(solexa)、鸟枪法测序、maxim-gilbert测序、引物步移法、使用pacbio、solid、ion torrent或纳米孔(nanopore)平台的测序和本领域中已知的任何其它测序方法。
257.在一些情况下,本文所述的各种类型的测序反应可包含多种样品处理单元。样品处理单元可包括但不限于多个泳道、多个通道、多个孔或基本上同时处理多个样品组的其它装置。另外,样品处理单元可以包含多个样品腔室,以能够同时处理多个运行。
258.在一些实例中,可以使用多重测序进行同时测序反应。在一些情况下,无细胞多核苷酸可以用至少1000、2000、3000、4000、5000、6000、7000、8000、9000、10000、50000、100,000个测序反应进行测序。在其它情况下,无细胞多聚核苷酸可以用少于1000、2000、3000、4000、5000、6000、7000、8000、9000、10000、50000、100,000个测序反应进行测序。测序反应可以顺序或同时进行。随后的数据分析可以对所有或部分测序反应进行。在一些情况下,数据分析可以对至少1000、2000、3000、4000、5000、6000、7000、8000、9000、10000、50000、100,000个测序反应进行。在其它情况下,数据分析可以对少于1000、2000、3000、4000、5000、6000、7000、8000、9000、10000、50000、100,000个测序反应进行。
259.在其它实例中,测序反应数可提供不同量的基因组的覆盖度。在一些情况下,基因组的序列覆盖度可以为至少5%、10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%、95%、99%、99.9%或100%。在其它情况下,基因组的序列覆盖度可以为小于5%、10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%、95%、99%、99.9%或
100%。
260.在一些实例中,可对可能包含多种不同类型的核酸的无细胞多核苷酸进行测序。核酸可以是多核苷酸或寡核苷酸。核酸包括但不限于单链或双链的dna或rna,或rna/cdna对。iv.多核苷酸分析策略
261.]图8是框图,800,示出了用于分析初始遗传材料样品中的多核苷酸的策略。在步骤802中,提供了含有初始遗传材料的样品。该样品可以包含低丰度的靶核酸。例如,来自正常或野生型基因组(例如,种系基因组)的核酸可以在样品中占绝大多数,该样品还包括不超过20%、不超过10%、不超过5%、不超过1%、不超过0.5%或不超过0.1%的来自含有遗传变异的至少一个其它基因组(例如,癌症基因组或胎儿基因组或来自另一个物种的基因组)的核酸。该样品可以包含,例如无细胞核酸或含有核酸的细胞。初始遗传材料可构成不大于100ng的核酸。这可以促进测序或遗传分析过程对原始多核苷酸的适当的过采样。可替代地,可以对样品进行人工加帽或瓶颈化以使核酸的量降低至不大于100ng,或进行选择性富集以仅分析感兴趣的序列。可以修改该样品,以选择性地产生定位至参考序列中一个或多个选定位置中的每一个的分子的序列阅读值。100ng核酸的样品可以含有约30,000个人单倍体基因组当量,即,一起提供人类基因组的30,000倍覆盖度的分子。
262.在步骤804中,将初始遗传材料转换成一组标记的亲本多核苷酸。标记可包括:将测序标签附接至初始遗传材料中的分子。可以选择测序标签,以使定位至参考序列中的相同位置的所有独特多核苷酸具有独特的标识标签。转换可以在高效率,例如至少50%下进行。
263.在步骤806中,扩增该组标记的亲本多核苷酸,以产生一组扩增的子代多核苷酸。扩增可以是,例如1000倍扩增。
264.在步骤808中,对该组扩增的子代多核苷酸进行采样以用于测序。选择采样率,使得产生的序列阅读值既(1)覆盖该组标记的亲本多核苷酸中的目标数目的独特分子,又(2)以目标覆盖倍数(例如,亲本多核苷酸的5至10倍覆盖度)覆盖该组标记的亲本多核苷酸中的独特分子。
265.在步骤810中,分解该组序列阅读值,以产生对应于独特标记的亲本多核苷酸的一组共有序列。可审查序列阅读值包含在分析中的资格。例如,未能满足质量控制得分的序列阅读值可以从集合体中移除。序列阅读值可被分类成代表由特定独特亲本分子衍生的子代分子的阅读值的家族。例如,扩增的子代多核苷酸的家族可以构成由单个亲本多核苷酸衍生的那些扩增的分子。通过比较家族中的子代的序列,可以推断原始亲本多核苷酸的共有序列。这产生代表标记的集合体中的独特亲本多核苷酸的一组共有序列。
266.在步骤812中,使用本文所述的任何分析方法对该组共有序列进行分析。例如,可以分析定位至特定参考序列位置的共有序列,以检测遗传变异的情况。可以测量定位至特定参考序列的共有序列并且相对于对照样品进行归一化。定位至参考序列的分子的度量可以在整个基因组上进行比较,以鉴别基因组中拷贝数变化或杂合性丢失的区域。
267.图9是一个框图,其示出了从由序列阅读值集合呈现的信号中提取信息的更通用的方法。在该方法中,对扩增的子代多核苷酸进行测序之后,将该序列阅读值分组成从独特身份的分子扩增的分子的家族(910)。这种分组可以是用于解读该序列中的信息的方法的
起点,以具有较高保真度(例如,较少噪声和/或畸变)地确定标记亲本多核苷酸的含量。
268.对序列阅读值集合的分析允许人们作出关于产生序列阅读值的亲本多核苷酸群体的推论。此类推论可以是有用的,因为测序一般涉及仅读取整个总扩增的多核苷酸的部分亚组。因此,人们不能确定每一个亲本多核苷酸都将由序列阅读值集合中的至少一个序列阅读值来呈现。
269.一种这样的推论是在原始集合体中的独特亲本多核苷酸的数目。可以基于序列阅读值可分组成的独特家族的数目和各个家族中的序列阅读值的数目而作出这样的推论。在这种情况下,家族是指可追溯至原始亲本多核苷酸的序列阅读值的集合。该推论可以使用公知的统计方法来作出。例如,如果分组产生多个家族且每个家族由一个或几个子代呈现,那么人们可以推断:原始群体包括更多未测序的独特亲本多核苷酸。另一方面,如果分组仅产生很少的家族且每个家族由许多子代呈现,那么人们可以推断:亲本群体中的大多数独特多核苷酸由分组成该家族的至少一个序列阅读值呈现。
270.另一种这样的推论是在多核苷酸的原始集合体中的特定基因座处碱基或碱基序列的频率。可以基于序列阅读值可分组成的独特家族的数目和各个家族中的序列阅读值的数目来作出这样的推论。通过分析在序列阅读值家族中的基因座处的碱基判定,将置信得分分配给各个特定碱基判定或序列。继而,考虑在多个家族中的各个碱基判定的置信得分,确定在基因座处的各个碱基或序列的频率。v.拷贝数变异检测a.使用单一样品的拷贝数变异检测
271.图1是框图,100,示出了用于检测单个受试者中的拷贝数变异的策略。如本文所示,拷贝数变异检测方法可以如下实现。在步骤102中的无细胞多核苷酸的提取和分离后,在步骤104中可以通过本领域中已知的核酸测序平台对单个独特的样品进行测序。这一步骤产生多个基因组片段的序列阅读值。在一些情况下,这些序列阅读值可能包含条形码信息。在其它实例中,不采用条形码。测序后,对阅读值分配质量得分。质量得分可以是阅读值的表示,其基于阈值表明这些阅读值是否可用于随后的分析。在一些情况下,一些阅读值不具有足够的质量或长度来执行后续的定位步骤。具有至少90%、95%、99%、99.9%、99.99%或99.999%的质量得分的测序阅读值可以从数据中过滤掉。在其它情况下,分配有小于90%、95%、99%、99.9%、99.99%或99.999%的质量得分的测序阅读值可以从数据集中过滤掉。在步骤106中,将满足规定的质量得分阈值的基因组片段阅读值定位至参考基因组或者已知不包含拷贝数变异的模板序列。定位对准后,对序列阅读值分配定位得分。定位得分可以是定位回参考序列的表示或阅读值,表明各个位置是或者不是独特地可定位的。在一些情况中,阅读值可能是与拷贝数变异分析无关的序列。例如,一些序列阅读值可以来源于污染物多核苷酸。具有至少90%、95%、99%、99.9%、99.99%或99.999%的定位得分的测序阅读值可以从数据集中过滤掉。在其它情况下,分配有小于90%、95%、99%、99.9%、99.99%或99.999%的定位得分的测序阅读值可以从数据集中过滤掉。
272.数据过滤和定位后,多个序列阅读值产生覆盖的染色体区域。在步骤108中,可以将这些染色体区域分成可变长度的窗口或箱元。窗口或箱元可以是至少5kb、10、kb、25kb、30kb、35kb、40kb、50kb、60kb、75kb、100kb、150kb、200kb、500kb或1000kb。窗口或箱元也可以具有多达5kb、10kb、25kb、30kb、35kb、40kb、50kb、60kb、75kb、100kb、150kb、200kb、500kb
或1000kb的碱基。窗口或箱元也可以是约5kb、10kb、25kb、30kb、35kb、40kb、50kb、60kb、75kb、100kb、150kb、200kb、500kb或1000kb。
273.对于在步骤110中的覆盖度归一化,选择各个窗口或箱元,以包含大约相同数目的可定位碱基。在一些情况下,在染色体区域中的各个窗口或箱元可以含有确切数目的可定位碱基。在其它情况下,各个窗口或箱元可以含有不同数目的可定位碱基。此外,各个窗口或箱元可以与相邻的窗口或箱元不重叠。在其它情况下,窗口或箱元可以与另一相邻的窗口或箱元重叠。在一些情况下,窗口或箱元可重叠至少1bp、2bp、3bp、4bp、5bp、10bp、20bp、25bp、50bp、100bp、200bp、250bp、500bp或1000bp。在其它情况下,窗口或箱元可重叠多达1bp、2bp、3bp、4bp、5bp、10bp、20bp、25bp、50bp、100bp、200bp、250bp、500bp或1000bp。在一些情况下,窗口或箱元可重叠约1bp、2、bp、3bp、4bp、5bp、10bp、20bp、25bp、50bp、100bp、200bp、250bp、500bp或1000bp。
274.在一些情况下,可设置各个窗口区域的大小,使得它们含有大约相同数目的独特可定位碱基。确定构成窗口区域的各个碱基的可定位性(mappability),并且将其用于产生可定位性文件,该文件包含来自参考的阅读值的呈现,该阅读值被定位回每个文件的参考。该可定位性文件包含一行/每个位置,表明各个位置是否是或者不是独特地可定位的。
275.此外,在整个基因组中已知难以测序或含有相当高gc偏倚的预定窗口可从数据集中过滤掉。例如,已知落入邻近染色体的着丝粒(即,着丝粒dna)的区域已知包含可产生假阳性结果的高度重复序列。可过滤掉这些区域。基因组的其它区域,例如含有异常高浓度的其它高度重复序列如微卫星dna的区域,可以从数据集中过滤掉。
276.所分析的窗口数也可以不同。在一些情况下,分析至少10、20、30、40、50、100、200、500、1000、2000、5,000、10,000、20,000、50,000或100,000个窗口。在其它情况下,所分析的窗口数为多达10、20、30、40、50、100、200、500、1000、2000、5,000、10,000、20,000、50,000或100,000个窗口。
277.对于来自无细胞多核苷酸序列的示例性基因组,下一个步骤包括确定各个窗口区域的阅读值覆盖度。这可以使用具有条形码的阅读值或不使用条形码来进行。在不使用条形码的情况下,先前的定位步骤将提供不同碱基位置的覆盖度。可以对具有足够的定位和质量得分并落入未过滤掉的染色体窗口内的序列阅读值进行计数。可按照各个可定位位置给覆盖阅读值的数目分配得分。在涉及条形码的情况下,具有相同条形码、物理性质或二者组合的所有序列可分解成一个阅读值,因为它们都源自样品亲本分子。这个步骤降低了可能在任何前面的步骤中,例如涉及扩增的步骤期间已引入的偏倚。例如,如果一个分子被扩增10倍但另一个被扩增1000倍,则每个分子在分解后仅被呈现一次,从而消除了不均匀扩增的效果。对各个可定位位置可以仅对具有独特条形码的阅读值进行计数并且这些阅读值影响所分配的得分。
278.可以通过本领域中已知的任何方法从序列阅读值的家族产生共有序列。这样的方法包括,例如,由数字通信理论、信息论或生物信息学衍生的构建共有序列的线性或非线性方法(例如,选举、平均、统计、最大后验概率或最大似然检测、动态编程、贝叶斯、隐马尔可夫或支持向量机方法等)。
279.在已经确定序列阅读值覆盖度之后,使用随机建模算法将各个窗口区域的归一化的核酸序列阅读值覆盖度转换成离散的拷贝数状态。在一些情况下,这种算法可包括下列
中的一个或多个:隐马尔可夫模型、动态编程、支持向量机、贝叶斯网络、网格解码、维特比解码、期望最大化、卡尔曼过滤方法和神经网络。
280.在步骤112中,各个窗口区域的离散拷贝数状态可以用于鉴别在染色体区域中的拷贝数变异。在一些情况下,具有相同拷贝数的所有相邻窗口区域可以合并成一个区段,以报告拷贝数变异状态的存在与否。在一些情况下,各个窗口可以在它们与其它区段合并前被过滤。
281.在步骤114中,拷贝数变异可以报告为图表,指示基因组中的各个位置以及在各个相应位置处拷贝数变异的相应增加或减少或维持。另外,拷贝数变异可用于报告百分比得分,表明在无细胞多核苷酸样品中存在多少疾病材料(或具有拷贝数变异的核酸)。
282.一种确定拷贝数变异的方法示于图10中。在该方法中,将序列阅读值分组成由单一亲本多核苷酸产生的家族(1010)后,例如通过确定定位至多个不同参考序列位置中的每一个的家族的数目来对家族进行定量。可直接通过比较在多个不同基因座中的每一个处的家族的定量度量来确定cnv(1016b)。可替代地,人们可以使用家族的定量度量和各个家族中的家族成员的定量度量,例如如上所讨论的,来推断在标记的亲本多核苷酸群体中的家族的定量度量。然后,可以通过比较在多个基因座处的量的推断度量来确定cnv。在其它实施方案中,可以采取混合方法,借此可以在测序过程中的呈现偏倚如gc偏倚等的归一化后进行原始量的类似推断。b.使用成对样品的拷贝数变异检测
283.成对样品拷贝数变异检测与本文所述的单样品方法共有多个步骤和参数。然而,如图2的200中所示,使用成对样品的拷贝数变异检测需要将序列覆盖度与对照样品进行比较,而非将其与基因组的预期的可定位性相比较。这种方法可有助于在整个窗口上的归一化。
284.图2是框图,200,示出了一种用于检测成对受试者中的拷贝数变异的策略。如本文所示,拷贝数变异检测方法可以如下实现。在步骤204中,在步骤202中的样品的提取和分离后,单个独特样品可通过本领域中已知的核酸测序平台进行测序。这一步骤生成多个基因组片段序列阅读值。此外,从另一个受试者中采集样品或对照样品。在一些情况下,对照受试者可以是已知未患有疾病的受试者,而其他受试者可以患有特定疾病或处于患该疾病的风险中。在一些情况下,这些序列阅读值可包含条形码信息。在其它实例中,不采用条形码。测序后,对阅读值分配质量得分。在一些情况下,一些阅读值不具有足够的质量或长度来执行后续的定位步骤。具有至少90%、95%、99%、99.9%、99.99%或99.999%的质量得分的测序阅读值可以从数据集中过滤掉。在其它情况下,分配有小于90%、95%、99%、99.9%、99.99%或99.999%的质量得分的测序阅读值可以从数据集中过滤掉。在步骤206中,将满足规定的质量得分阈值的基因组片段阅读值定位至参考基因组或者已知不包含拷贝数变异的模板序列。定位对准后,对序列阅读值分配定位得分。在一些实例中,阅读值可以是与拷贝数变异分析无关的序列。例如,一些序列阅读值可以来源于污染物多核苷酸。具有至少90%、95%、99%、99.9%、99.99%或99.999%的定位得分的测序阅读值可以从数据集中过滤掉。在其它情况下,分配有小于90%、95%、99%、99.9%、99.99%或99.999%的定位得分的测序阅读值可以从数据集中过滤掉。
285.数据过滤和定位后,多个序列阅读值产生针对各个测试和对照受试者的覆盖的染
色体区域。在步骤208中,这些染色体区域可以分成可变长度的窗口或箱元。窗口或箱元可以是至少5kb、10kb、25kb、30kb、35kb、40kb、50kb、60kb、75kb、100kb、150kb、200kb、500kb或1000kb。窗口或箱元也可以小于5kb、10kb、25kb、30kb、35kb、40kb、50kb、60kb、75kb、100kb、150kb、200kb、500kb或1000kb。
286.对于在步骤210中的覆盖度归一化,针对各个测试或对照受试者,选择各个窗口或箱元,以包含大约相同数目的可定位碱基。在一些情况下,在染色体区域中的各个窗口或箱元可以含有确切数目的可定位碱基。在其它情况下,各个窗口或箱元可以含有不同数目的可定位碱基。此外,各个窗口或箱元可以与相邻窗口或箱元不重叠。在其它情况下,窗口或箱元可与另一相邻窗口或箱元重叠。在一些情况下,窗口或箱元可重叠至少1bp、2、bp、3bp、4bp、5bp、10bp、20bp、25bp、50bp、100bp、200bp、250bp、500bp或1000bp。在其它情况下,窗口或箱元可重叠小于1bp、2、bp、3bp、4bp、5bp、10bp、20bp、25bp、50bp、100bp、200bp、250bp、500bp或1000bp。
287.在一些情况下,针对各个测试和对照受试者,设置各个窗口区域的大小,使得它们包含大约相同数目的独特地可定位的碱基。确定构成窗口区域的各个碱基的可定位性,并且将其用于产生可定位性文件,该文件包含来自参考的阅读值的呈现,该阅读值被定位回每个文件的参考。该可定位性文件包含一行/每个位置,表明各个位置是否是或者不是独特地可定位的。
288.此外,在整个基因组中已知难以测序或含有相当高gc偏倚的预定义窗口可从数据集中过滤掉。例如,已知落入邻近染色体的着丝粒(即,着丝粒dna)的区域已知包含可产生假阳性结果的高度重复序列。可过滤掉这些区域。基因组的其它区域,例如含有异常高浓度的其它高度重复序列如微卫星dna的区域,可以从数据集中过滤掉。
289.所分析的窗口数目也可以变化。在一些情况下,分析至少10、20、30、40、50、100、200、500、1000、2000、5,000、10,000、20,000、50,000或100,000个窗口。在另一些情况下,分析少于10、20、30、40、50、100、200、500、1000、2000、5,000、10,000、20,000、50,000或100,000个窗口。
290.对于源自无细胞多核苷酸序列的示例性基因组,下一个步骤包括针对各个测试和对照受试者确定各个窗口区域的阅读值覆盖度。这可以使用具有条形码的阅读值或不使用条形码来进行。在不使用条形码的情况下,先前的定位步骤将提供不同碱基位置的覆盖度。可以对具有足够的定位和质量得分并落入未过滤掉的染色体窗口内的序列阅读值进行计数。可按照各个可定位位置对覆盖阅读值的数目分配得分。在涉及条形码的情况下,具有相同条形码的所有序列可分解成一个阅读值,因为它们都源自样品亲本分子。这个步骤降低了可能在任何前面的步骤,例如涉及扩增的步骤期间已引入的偏倚。对各个可定位位置可以仅对具有独特条形码的阅读值进行计数并且其影响所分配的得分。出于这个原因,条形码连接步骤以为了产生最低量的偏倚而优化的方式来进行是重要的。
291.在确定各个窗口的核酸阅读值覆盖度时,各个窗口的覆盖度可以用该样品的平均覆盖度进行归一化。使用这样的方法,可能期望在类似条件下对测试受试者和对照进行测序。各个窗口的阅读值覆盖度于是可以表示为类似窗口中的比值。
292.可以通过将测试样品的各个窗口区域的阅读值覆盖度除以对照样品的相应窗口区域的阅读值覆盖度,来确定测试受试者的各个窗口的核酸阅读值覆盖度比值。
293.在已经确定序列阅读值覆盖度比值之后,使用随机建模算法将各个窗口区域的归一化比值转换成离散的拷贝数状态。在一些情况下,这种算法可包括隐马尔可夫模型。在其它情况下,该随机模型可包括动态编程、支持向量机、贝叶斯建模、概率建模、网格解码、维特比解码、期望最大化、卡尔曼过滤方法和神经网络。
294.在步骤212中,可以采用各个窗口区域的离散拷贝数状态来鉴别在染色体区域中的拷贝数变异。在一些情况下,具有相同拷贝数的所有相邻窗口区域可以合并成一个区段,以报告拷贝数变异状态的存在与否。在一些情况下,各个窗口可以在它们与其它区段合并前被过滤。
295.在步骤214中,拷贝数变异可以报告为图表,指示基因组中的各个位置以及在各个相应位置处拷贝数变异的相应增加或减少或维持。另外,拷贝数变异可用于报告百分比得分,表明在无细胞多核苷酸样品中存在多少疾病材料。vi.稀有突变的检测
296.稀有突变检测与两种拷贝数变异方法共有类似的特征。然而,如图3中的300所示,稀有突变检测采用序列覆盖度与对照样品或参考序列的比较,而非将其与基因组的相对可定位性相比较。这种方法可有助于在整个窗口上的归一化。
297.通常,稀有突变检测可以在步骤302中纯化和分离的基因组或转录组的选择性富集区域上进行。如本文所述,可从无细胞多核苷酸的总群体中选择性地扩增特定区域,该特定区域可以包括但不限于:基因、癌基因、肿瘤抑制基因、启动子、调节序列元件、非编码区、mirna、snrna等。这可如本文所述来进行。在一个实例中,在使用或不使用针对单个多核苷酸序列的条形码标记物下,可以使用多重测序。在其它实例中,可以使用本领域中已知的任何核酸测序平台进行测序。这一步骤生成多个基因组片段序列阅读值,如在步骤304中所示。另外,从取自另一个受试者的对照样品获得参考序列。在一些情况下,对照受试者可以是已知不具有已知遗传异常或疾病的受试者。在一些情况下,这些序列阅读值可包含条形码信息。在其它实例中,不采用条形码。测序后,对阅读值分配质量得分。质量得分可以是阅读值的表示,其表明这些阅读值是否可基于阈值而用于随后的分析。在一些情况下,一些阅读值不具有足够的质量或长度来执行后续的定位步骤。具有至少90%、95%、99%、99.9%、99.99%或99.999%的质量得分的测序阅读值可以从数据集中过滤掉。在其它情况下,分配有至少90%、95%、99%、99.9%、99.99%或99.999%的质量得分的测序阅读值可以从数据集中过滤掉。在步骤306中,将满足规定的质量得分阈值的基因组片段阅读值定位至已知不包含稀有突变的参考基因组或者参考序列。定位对准后,对序列阅读值分配定位得分。定位得分可以是定位回参考序列的表示或阅读值,表明各个位置是否是或不是独特地可定位的。在一些实例中,阅读值可以是与稀有突变分析无关的序列。例如,一些序列阅读值可以来源于污染物多核苷酸。具有至少90%、95%、99%、99.9%、99.99%或99.999%的定位得分的测序阅读值可以从数据集中过滤掉。在其它情况下,分配有小于90%、95%、99%、99.9%、99.99%或99.999%的定位得分的测序阅读值可以从数据集中过滤掉。
298.对于各个可定位的碱基,未满足可定位性的最小阈值的碱基或低质量碱基可以被替换为如在参考序列中发现的相应碱基。
299.数据过滤和定位之后,分析了在从受试者获得的序列阅读值与参考序列中发现的变异碱基。
300.对于由无细胞多核苷酸序列得到的示例性基因组,下一个步骤包括针对各个可定位碱基位置确定阅读值覆盖度。这可以使用具有条形码的阅读值或者不使用条形码来执行。在不使用条形码的情况下,先前的定位步骤将提供不同碱基位置的覆盖度。可以对具有足够的定位和质量得分的序列阅读值进行计数。可按照各个可定位位置对覆盖阅读值的数目分配得分。在涉及条形码的情况下,具有相同条形码的所有序列可分解成一个共有阅读值,因为它们都源自样品亲本分子。将针对各个碱基的序列对准为该特定位置的最主要的核苷酸阅读值。而且,可以在各个位置对独特分子的数目进行计数,以获得在各个位置的同时定量。这个步骤降低了可能在任何前面的步骤,例如涉及扩增的步骤期间已引入的偏倚。对各个可定位位置可以仅对具有独特条形码的阅读值进行计数并且这些阅读值影响所分配的得分。
301.一旦可以确定阅读值覆盖度并鉴别了在各个阅读值中相对于对照序列的变异碱基,就可以通过将含有变异体的阅读值的数目除以阅读值的总数来计算变异碱基的频率。这可以表示为在基因组中的各个可定位位置的比值。
302.对于各个碱基位置,所有四种核苷酸即胞嘧啶、鸟嘌呤、胸腺嘧啶、腺嘌呤的频率在与参考序列的比较下进行分析。使用随机或统计建模算法转换各个可定位位置的归一化比值,以反映各个碱基变异体的频率状态。在一些情况下,该算法可包括下列中的一个或多个:隐马尔可夫模型、动态编程、支持向量机、贝叶斯或概率建模、网格解码、维特比解码、期望最大化、卡尔曼过滤方法和神经网络。
303.在步骤312中,可以采用各个碱基位置的离散稀有突变状态来鉴别与参考序列的基线相比具有高变异频率的碱基变异体。在一些情况下,基线可能表示至少0.0001%、0.001%、0.01%、0.1%、1.0%、2.0%、3.0%、4.0%、5.0%、10%或25%的频率。在其它情况下,基线可能表示至少0.0001%、0.001%、0.01%、0.1%、1.0%、2.0%、3.0%、4.0%、5.0%、10%或25%的频率。在一些情况下,具有碱基变异体或突变的所有相邻碱基位置可合并成一个区段,以报告稀有突变的存在与否。在一些情况下,各个位置可以在它们与其它区段合并前被过滤。
304.在计算各个碱基位置的变异频率后,来自受试者的序列中的特定位置与参考序列相比具有最大偏倚的变异体被鉴别为稀有突变。在一些情况下,稀有突变可以是癌症突变。在另一些情况下,稀有突变可能与疾病状态相关。
305.稀有突变或变异体可包含遗传异常,该遗传异常包括但不限于:单碱基置换或小插入缺失、颠换、易位、倒位、缺失、截短或基因截短。在一些情况下,稀有突变可以是至多1、2、3、4、5、6、7、8、9、10、15或20个核苷酸的长度。在其它情况下,稀有突变可以是至少1、2、3、4、5、6、7、8、9、10、15或20个核苷酸的长度。
306.在步骤314中,突变的存在与否可以以图形形式反映,指示基因组中的多个位置和在各个相应位置上的突变频率的相应增加或降低或维持。此外,稀有突变可用于报告百分比得分,表明在无细胞多核苷酸样品中存在多少疾病材料。鉴于在非疾病参考序列中报告的位置处的典型变异的统计数据已知,置信得分可以伴随各个检测到的突变。突变还可以按照在受试者中的丰度的顺序排序或按照临床可发挥作用的(actionable)重要性排序。
307.图11示出了一种推断多核苷酸群体中在特定基因座处的碱基或碱基序列的频率的方法。将序列阅读值分组成由原始标记的多核苷酸生成的家族(1110)。对于各个家族,给
基因座处的一个或多个碱基各自分配置信得分。置信得分可通过多种已知统计方法中的任何方法来分配,并且可以至少部分地基于在属于该家族的序列阅读值中出现碱基的频率(1112)。例如,该置信得分可以是在序列阅读值中出现碱基的频率。作为另一个实例,对于各个家族,可建立隐马尔可夫模型,使得可以基于单个家族中的特定碱基的频率或发生率来作出最大似然或最大后验概率决定。作为该模型的一部分,也可以输出特定决定的误差概率和所得的置信得分。碱基在原始群体中的频率继而可以基于家族之间的置信得分来分配(1114)。vii.应用a.癌症的早期检测
308.使用本文所述的方法和系统可检测多种癌症。癌细胞,如大部分细胞一样,其特征可以是更新率,其中旧细胞死亡并被较新的细胞所取代。通常,与给定受试者中的脉管系统相接触的死细胞可将dna或dna片段释放至血流中。在疾病不同阶段中的癌细胞也是如此。根据疾病的阶段,癌细胞的特征还可以是各种遗传异常,如拷贝数变异以及稀有突变。这种现象可以用于使用本文所述的方法和系统检测癌症个体的存在与否。
309.例如,可以从具有患癌风险的受试者抽取血液并如本文所述制备以产生无细胞多核苷酸群体。在一个实例中,这可以是无细胞的dna。本发明的系统和方法可用于检测可存在于某些现有癌症中的稀有突变或拷贝数变异。该方法可以帮助检测体内癌细胞的存在,即使不存在疾病的症状或其它标志。
310.可检测到的癌症的类型和数目可包括但不限于:血癌、脑癌、肺癌、皮肤癌、鼻癌、喉癌、肝癌、骨癌、淋巴瘤、胰腺癌、皮肤癌、肠癌、直肠癌、甲状腺癌、膀胱癌、肾癌、口腔癌、胃癌、实体肿瘤、异质肿瘤、均质肿瘤等。
311.在癌症的早期检测中,可使用本文所述的任何系统或方法(包括稀有突变检测或拷贝数变异检测)来检测癌症。这些系统和方法可用于检测任何数目的可能导致或起因于癌症的遗传异常。这些可包括但不限于:突变、稀有突变、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染和癌症。
312.此外,本文所述的系统和方法还可以用于帮助表征某些癌症。从本发明的系统和方法产生的遗传数据可以帮助执业医生更好地表征癌症的具体形式。很多时候,癌症在组成和分期上是异质的。遗传谱数据可以允许表征癌症的具体亚型,该表征在该具体亚型的诊断或治疗中可能是重要的。此信息还可以向受试者或执业医生提供关于癌症具体类型的预后的线索。b.癌症的监测和预后
313.本文提供的系统和方法可用于监测特定受试者中已知的癌症或其它疾病。这可以允许受试者或执业医生根据疾病的进展调整治疗选项。在该实例中,本文所述的系统和方法可用于构建疾病进程中特定受试者的遗传谱。在一些情况下,癌症可以进展,成为更具侵袭性和遗传学上不稳定性。在其它实例中,癌症可以保持为良性的、非活动的、休眠的或缓解的。本发明的系统和方法可用于确定疾病进展、缓解或复发。
314.此外,本文所述的系统和方法可用于确定特定治疗选项的功效。在一个实例中,如
果治疗成功,则成功的治疗选项可实际上增加在受试者血液中检测到的拷贝数变异或稀有突变的量,因为癌可能死亡并释放dna。在其它实例中,这可能不会发生。在另一个实例中,也许某些治疗选项可能与癌症随时间推移的遗传谱相关联。这种相关性可用于选择疗法。此外,如果观察到癌症在治疗后缓解,则本文所述的系统和方法可用于监测残留疾病或疾病的复发。
315.例如,在以阈值水平开始的频率范围内发生的突变可从来自受试者例如患者的样品中的dna来确定。该突变可以是,例如癌症相关的突变。该频率的范围可以是从例如至少0.1%、至少1%或至少5%至100%。所述样品可以是,例如无细胞的dna或肿瘤样品。可以基于在该频率范围内发生的任何或全部突变,包括例如它们的频率,开出疗程。可在任何后续时间从受试者采集样品。可以确定在原始频率范围内或不同频率范围内发生的突变。疗程可基于后续测量来调整。c.其它疾病或疾病状态的早期检测和监测
316.本文所述的方法和系统可以不限于仅与癌症相关的稀有突变和拷贝数变异的检测。各种其它疾病和感染可导致其它类型的可适合早期检测和监测的状况。例如,在某些情况下,遗传性病症或传染性疾病可在受试者中导致某些遗传镶嵌(genetic mosaicism)。这种遗传镶嵌可导致可观察到的拷贝数变异和稀有突变。在另一实例中,本发明的系统和方法也可用于监测体内免疫细胞的基因组。免疫细胞,如b细胞,当存在某些疾病时可经历快速克隆扩增。使用拷贝数变异检测可监测克隆扩增并可监测某些免疫状态。在本实例中,拷贝数变异分析可随时间推移而进行,以产生特定疾病可能如何进展的谱。
317.此外,本发明的系统和方法还可以用于监测自身的系统性感染,其可以由病原体诸如细菌或病毒引起。拷贝数变异乃至稀有突变的检测可用于确定病原体群体在感染过程中是如何变化的。这在慢性感染如hiv/aids或肝炎感染中可能特别重要,由此病毒可在感染过程中改变生命周期状态和/或突变成毒力更强的形式。
318.可以使用本发明的系统和方法的又一个实例是移植受试者的监测。通常,移植组织在移植后经历一定程度的身体排斥。当免疫细胞试图破坏移植组织时,本发明的方法可以用于确定或概况分析宿主体的排斥活动。这可用于监测移植组织的状态以及改变排斥的治疗或预防过程。
319.此外,本发明的方法可用于表征受试者的异常状况的异质性,所述方法包括产生受试者中的细胞外多核苷酸的遗传谱,其中该遗传谱包含由拷贝数变异和稀有突变分析得到的多个数据。在一些情况下,包括但不限于癌症,疾病可以是异质的。疾病细胞可能不相同。在癌症的实例中,一些肿瘤已知包含不同类型的肿瘤细胞、在癌症不同阶段的一些细胞。在其它实例中,异质性可以包括疾病的多个病灶。再次,在癌症的实例中,可存在多个肿瘤病灶,或许其中一个或多个病灶是已从原发部位扩散的转移的结果。
320.本发明的方法可用于生成或概况分析数据指纹或数据集,该数据指纹或数据集是由异质性疾病中的不同细胞得到的遗传信息的总和。这种数据集可包含单独的或组合的拷贝数变异和稀有突变分析。d.胎儿来源的其它疾病或疾病状态的早期检测和监测
321.此外,本发明的系统和方法可用于诊断、预后、监测或观察胎儿来源的癌症或其它疾病。也就是说,这些方法可用于妊娠的受试者,以诊断、预后、监测或观察未出生受试者的
癌症或其它疾病,未出生受试者的dna和其它多核苷酸可与母体分子共循环。viii.术语
322.本文所用的术语仅用于描述特定实施方案的目的而非旨在限制本发明的系统和方法。如本文所用,单数形式“一种”、“一个”和“该”也意图包括复数形式,除非上下文另外明确指出。此外,在术语“包含”、“包括”、“具有”、“有”、“带有”或其变化形式在发明详述和/或权利要求书中使用的情况下,这样的术语旨在以类似于术语“包含”的方式为包含性的。
323.上文参考用于说明的示例应用描述了本发明的系统和方法的多个方面。应当理解,阐述许多具体细节、关系和方法是为了提供对系统和方法的全面了解。然而,相关领域的普通技术人员将会容易地认识到:可在没有一个或多个所述具体细节或在具有其它方法的情况下实施系统和方法。本公开内容不受动作或事件的所示顺序的限制,因为一些动作可以按不同顺序发生和/或与其它动作或事件同时发生。此外,并不是所有示出的动作或事件都是根据本发明内容来实施方法所需要的。
324.范围在本文中可表示为从“约”一个特定值和/或至“约”另一个特定值。当表示这样的范围时,另一个实施方案包括从一个特定值和/或到另一个特定值。类似地,当数值表示为近似值时,通过使用先行词“约”,将会理解该特定值形成另一个实施方案。应当进一步理解,每个范围的端点在与另一端点相关以及独立于另一端点时都是有意义的。如本文所用的术语“约”是指从特定使用的上下文中的规定数值加或减15%的范围。例如,约10将包括从8.5到11.5的范围。计算机系统
325.本发明的方法可使用计算机系统或在其帮助下来实现。图15示出了被编程或以其它方式配置成实现本发明的方法的计算机系统1501。该计算机系统1501可以调节样品制备、测序和/或分析等各个方面。在一些实例中,计算机系统1501配置成执行样品制备和样品分析,包括核酸测序。
326.计算机系统1501包括中央处理单元(cpu,本文也称为“处理器”和“计算机处理器”)1505,其可以是单核或多核处理器,或用于并行处理的多个处理器。计算机系统1501还包括存储器或存储器位置1510(例如,随机存取存储器、只读存储器、闪速存储器)、电子存储单元1515(例如,硬盘)、用于与一个或多个其它系统通信的通信接口1520(例如,网络适配器)和外围装置1525,如高速缓冲存储器、其它存储器、数据存储和/或电子显示适配器。存储器1510、存储单元1515、接口1520和外围装置1525通过通信总线(实线)如主板来与cpu 1505通信。存储单元1515可以是用于存储数据的数据存储单元(或数据储存库)。计算机系统1501可以在通信接口1520的辅助下可操作地耦合至计算机网络(“网络”)1530。网络1530可以是因特网、互联网和/或外联网、或与因特网通信的内联网和/或外联网。在一些情况下,网络1530是电信和/或数据网络。网络1530可以包括一个或多个计算机服务器,这可以支持分布式计算,例如云计算。在一些情况下,在计算机系统1501的辅助下,网络1530可以实现对等网络,其可以使耦合至计算机系统1501的装置能够作为客户端或服务器运行。
327.cpu 1505可以执行一系列的机器可读指令,该机器可读指令可以体现在程序或软件中。指令可存储于存储器位置,如存储器1510中。由cpu 1505执行的操作的实例可包括读取、解码、执行和写回。
328.存储单元1515可存储文件,如驱动程序、库和保存的程序。存储单元1515可存储由
用户和记录的会话所生成的程序以及与程序相关的输出。存储单元1515可存储用户数据,例如用户偏好和用户程序。在一些情况下,计算机系统1501可以包括一个或多个附加的数据存储单元,该数据存储单元在计算机系统1501的外部,诸如位于通过内联网或因特网而与计算机系统1501通信的远程服务器上。
329.计算机系统1501可通过网络1530与一个或多个远程计算机系统进行通信。例如,计算机系统1501可以与用户(例如,操作者)的远程计算机系统进行通信。远程计算机系统的实例包括个人计算机(如便携式pc)、板型或平板pc(例如ipad、galaxy tab)、电话、智能电话(例如iphone、android支持的装置、)或个人数字助理。用户可以通过网络1530访问计算机系统1501。
330.如本文所述的方法可通过机器(例如,计算机处理器)可执行代码来实现,该机器可执行代码存储于计算机系统1501的电子存储位置,诸如存储器1510或电子存储单元1515上。该机器可执行代码或机器可读代码可以以软件的形式提供。在使用过程中,该代码可以由处理器1505执行。在一些情况下,代码可以从存储单元1515检索并存储到存储器1510中,以备由处理器1505访问。在一些情况下,可排除电子存储单元1515,而将机器可执行指令存储于存储器1510中。
331.代码可以被预编译并配置成用于与具有适用于执行该代码的处理器的机器一起使用,或者可以在运行时间过程中编译。代码可提供于编程语言中,可选择该编程语言以使代码能够以预编译或按编译原样的方式来执行。
332.本文所提供的系统和方法的各方面,如计算机系统1501,可以在编程中体现。该技术的各个方面可以被认为是“产品”或“制造物品”,通常为在机器可读介质类型中执行或体现的机器(或处理器)可执行代码和/或相关数据的形式。机器可执行代码可存储于电子存储单元,例如存储器(例如,只读存储器、随机存取存储器、闪速存储器)或硬盘上。“存储”型介质可以包括计算机、处理器等的任何或所有有形存储器,或其相关模块,如各种半导体存储器、磁带驱动器、磁盘驱动器等,其可以在任何时间为软件编程提供非暂时性存储。该软件的全部或部分有时可以通过因特网或各种其它电信网络进行通信。例如,此类通信可使软件能够从一台计算机或处理器加载到另一台中,例如,从管理服务器或主计算机加载至应用程序服务器的计算机平台。因此,能够承载软件元件的另一种类型的介质包括光波、电波和电磁波,如跨本地设备之间的物理接口、通过有线和光纤陆线网络以及在各种空中链路上使用的光波、电波和电磁波。携载此类波的物理元件,诸如有线或无线链路、光链路等,也可以被认为是承载软件的介质。如本文所用,除非限制于非暂时性的、有形“存储”介质,诸如计算机或机器“可读介质”等术语是指参与将指令提供给处理器以供执行的任何介质。
333.因此,机器可读介质,诸如计算机可执行代码,可以采取多种形式,包括但不限于有形存储介质、载波介质或物理传输介质。非易失性存储介质包括,例如光盘或磁盘,诸如在任何计算机等中的任何存储设备,例如可用于实现如附图所示的数据库等。易失性存储介质包括动态存储器,诸如这样的计算机平台的主存储器。有形传输介质包括同轴电缆、铜线和光纤,包括构成计算机系统内的总线的导线。载波传输介质可以采取电信号或电磁信号或者声波或光波的形式,如在射频(rf)和红外(ir)数据通信期间生成的那些。因此,计算机可读介质的常见形式包括,例如:软盘、柔性盘、硬盘、磁带、任何其它磁介质、cd-rom、dvd
或dvd-rom、任何其它光学介质、穿孔卡片纸带、其它任何具有孔洞图案的物理存储介质、ram、rom、prom和eprom、flash-eprom、任何其它存储器芯片或盒、载波传输数据或指令、传送此类载波的缆线或链路,或者任何可让计算机从中读取编程代码和/或数据的其它介质。这些计算机可读介质的形式中的许多形式可参与向处理器传送一个或多个序列的一个或多个指令以供执行。
334.计算机系统1501可包括电子显示器或与电子显示器进行通信,该电子显示器包括用于提供例如样品分析的一个或多个结果的用户界面(ui)。ui的实例包括但不限于:图形用户界面(gui)和基于网络的用户界面。本发明提供了包括但不限于以下实施方式:1.一种用于检测拷贝数变异的方法,所述方法包括:a.对来自受试者的身体样品的细胞外多核苷酸进行测序,其中所述细胞外多核苷酸中的每一个产生多个测序阅读值;b.过滤掉未满足所设定的阈值的阅读值;c.在过滤掉阅读值后,将由步骤(a)获得的所述序列阅读值定位至参考序列;d.对在所述参考序列的两个或更多个预定义区域中定位的阅读值进行定量或计数;以及e.通过下述确定在一个或多个所述预定义区域中的拷贝数变异:i.将所述预定义区域中的阅读值的数目相对于彼此进行归一化,和/或将所述预定义区域中的独特序列阅读值的数目相对于彼此进行归一化;ii.将从步骤(i)中获得的归一化的数目与从对照样品获得的归一化的数目进行比较。2.一种用于检测从受试者获得的无细胞的或基本无细胞的样品中的稀有突变的方法,所述方法包括:a.对来自受试者的身体样品的细胞外多核苷酸进行测序,其中所述细胞外多核苷酸中的每一个生成多个测序阅读值;b.如果未进行富集,则进行区域上的多重测序或全基因组测序;c.过滤掉未满足所设定的阈值的阅读值;d.将从所述测序得到的序列阅读值定位至参考序列上;e.鉴别在各个可定位的碱基位置处与所述参考序列的变异体对准的被定位序列阅读值的亚组;f.对各个可定位的碱基位置,计算出(a)与所述参考序列相比包含变异体的被定位序列阅读值的数目与(b)各个可定位碱基位置的序列阅读值总数的比值;g.将各个可定位碱基位置的变异的所述比值或频率进行归一化并确定潜在的稀有变异体或突变;以及h.将具有潜在的稀有变异体或突变的各个区域的所得数目与从参考样品类似地得到的数目进行比较。3.一种表征受试者中的异常状况的异质性的方法,所述方法包括生成所述受试者的细胞外多核苷酸的遗传谱,其中所述遗传谱包含由拷贝数变异和稀有突变分析得到的多个数据。
4.根据实施方式1、2或3所述的方法,其中同时报告和定量在所述受试者中鉴别的各个稀有变异体的出现率/浓度。5.根据实施方式1、2或3所述的方法,其中报告关于所述受试者中稀有变异体的出现率/浓度的置信得分。6.根据实施方式1、2或3所述的方法,其中所述细胞外多核苷酸包含dna。7.根据实施方式1、2或3所述的方法,其中所述细胞外多核苷酸包含rna。8.根据实施方式1、2或3所述的方法,其进一步包括从所述身体样品中分离细胞外多核苷酸。9.根据实施方式1、2或3所述的方法,其中所述分离包括用于循环核酸分离和提取的方法。10.根据实施方式1、2或3所述的方法,其进一步包括对所述分离的细胞外多核苷酸进行片段化。11.根据实施方式8所述的方法,其中所述身体样品选自血液、血浆、血清、尿液、唾液、粘膜分泌物、痰、粪便和泪。12.根据实施方式1、2或3所述的方法,其进一步包括确定在所述身体样品中具有拷贝数变异或稀有突变或变异体的序列的百分比的步骤。13.根据实施方式12所述的方法,其中所述确定包括计算所具有的多核苷酸的量高于或低于预定阈值的预定义区域的百分比。14.根据实施方式1、2或3所述的方法,其中所述受试者疑似具有异常状况。15.根据实施方式14所述的方法,其中所述异常状况选自突变、稀有突变、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染和癌症。16.根据实施方式1、2或3所述的方法,其中所述受试者是妊娠的女性。17.根据实施方式1或2所述的方法,其中所述拷贝数变异或稀有突变或遗传变异体指示胎儿异常。18.根据实施方式17所述的方法,其中所述胎儿异常选自突变、稀有突变、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染和癌症。19.根据实施方式1、2或3所述的方法,其进一步包括在测序前将一个或多个条形码附接至所述细胞外多核苷酸或其片段。20.根据实施方式19所述的方法,其中在测序前附接至细胞外多核苷酸或其片段的各个条形码是独特的。21.根据实施方式19所述的方法,其中在测序前附接至细胞外多核苷酸或其片段的各个条形码不是独特的。22.根据实施方式1、2或3所述的方法,其进一步包括在测序前从所述受试者的基
因组或转录组选择性地富集区域。23.根据实施方式1、2或3所述的方法,其进一步包括在测序前从所述受试者的基因组或转录组非选择性地富集区域。24.根据实施方式1、2或3所述的方法,其进一步包括在任何扩增或富集步骤前,将一个或多个条形码附接至所述细胞外多核苷酸或其片段。25.根据实施方式19所述的方法,其中所述条形码是多核苷酸。26.根据实施方式19所述的方法,其中所述条形码包含随机序列。27.根据实施方式19所述的方法,其中所述条形码包含固定的或半随机的一组寡核苷酸,该寡核苷酸与从选定区域测序的分子的多样性组合能够鉴别独特的分子。28.根据实施方式19所述的方法,其中所述条形码包含长度至少为3、5、10、15、20、25、30、35、40、45或50聚物碱基对的寡核苷酸。29.根据实施方式1、2或3所述的方法,其进一步包括扩增所述细胞外多核苷酸或其片段。30.根据实施方式29所述的方法,其中所述扩增包括全局扩增或全基因组扩增。31.根据实施方式1、2或3所述的方法,其中基于在所述序列阅读值的开始(启动)和结束(终止)区域处的序列信息和所述序列阅读值的长度来检测独特身份的序列阅读值。32.根据实施方式31所述的方法,其中基于在所述序列阅读值的开始(启动)和结束(终止)区域处的序列信息、所述序列阅读值的长度和条形码的附接来检测独特身份的序列分子。33.根据实施方式30所述的方法,其中所述扩增包括选择性扩增。34.根据实施方式33所述的方法,其中所述扩增包括非选择性扩增。35.根据实施方式1、2或3所述的方法,其中进行抑制扩增或消减富集。36.根据实施方式1、2或3所述的方法,其进一步包括在对阅读值进行定量或计数前从进一步的分析中除去所述阅读值的亚组。37.根据实施方式36所述的方法,其中所述除去包括过滤掉准确度或质量得分小于阈值例如90%、99%、99.9%或99.99%和/或定位得分小于阈值例如90%、99%、99.9%或99.99%的阅读值。38.根据实施方式1、2或3所述的方法,其进一步包括过滤质量得分小于所设定的阈值的阅读值。39.根据实施方式1所述的方法,其中所述预定义区域在大小上是均一的或基本均一的。40.根据实施方式39所述的方法,其中所述预定义区域的大小是至少约10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb或100kb。41.根据实施方式1、2或3所述的方法,其中分析至少50、100、200、500、1000、2000、5000、10,000、20,000或50,000个区域。42.根据实施方式1、2或3所述的方法,其中所述变异体发生在选自基因融合、基因复制、基因缺失、基因易位、微卫星区域、基因片段或其组合的基因组区域中。43.根据实施方式1、2或3所述的方法,其中所述变异体发生在选自基因、癌基因、肿瘤抑制基因、启动子、调节序列元件或其组合的基因组区域中。
44.根据实施方式2所述的方法,其中所述变异体是1、2、3、4、5、6、7、8、9、10、15或20个核苷酸长度的核苷酸变异体、单碱基置换、小插入缺失、颠换、易位、倒位、缺失、截短或基因截短。45.根据实施方式1、2或3所述的方法,其进一步包括使用所述条形码或单个阅读值的独特性质来校正/归一化/调整所定位的阅读值的量。46.根据实施方式1或2所述的方法,其中通过对各个所述预定义区域中的独特条形码进行计数并将这些数目在所测序的预定义区域的至少一个亚组中进行归一化,来对所述阅读值进行计数。47.根据实施方式1、2或3所述的方法,其中分析以连续的时间间隔来自相同受试者的样品并将其与以前的样品结果进行比较。48.根据实施方式45所述的方法,其中所述方法进一步包括扩增所述附接有条形码的细胞外多核苷酸。49.根据实施方式1、2或3所述的方法,其进一步包括确定部分拷贝数变异频率、确定杂合性的丢失、进行基因表达分析、进行外遗传分析和/或进行过度甲基化分析。50.一种方法,该方法包括:使用多重测序在从受试者获得的无细胞或基本无细胞的样品中确定拷贝数变异或进行稀有突变分析。51.根据实施方式50所述的方法,其中所述多重测序包括进行超过10,000个测序反应。52.根据实施方式50所述的方法,其中所述多重测序包括同时对至少10,000个不同的阅读值进行测序。53.根据实施方式50所述的方法,其中所述多重测序包括在整个基因组上对至少10,000个不同的阅读值进行数据分析。54.根据实施方式1或2所述的方法,其中使用隐马尔可夫、动态编程、支持向量机、贝叶斯或概率建模、网格解码、维特比解码、期望最大化、卡尔曼过滤或神经网络方法中的一个或多个进行所述归一化和检测。55.根据实施方式1、2或3所述的方法,其进一步包括基于所发现的变异体对所述受试者监测疾病进展、监测残留疾病、监测疗法、诊断状况、状况预后或者选择疗法。56.根据实施方式55所述的方法,其中基于最近的样品分析来修改疗法。57.根据实施方式1、2或3所述的方法,其中推断肿瘤、感染或其它组织异常的遗传谱。58.根据实施方式1、2或3所述的方法,其中监测肿瘤、感染或其它组织异常的生长、缓解或演变。59.根据实施方式1、2或3所述的方法,其中在单一情况下或随时间推移分析和监测与所述受试者的免疫系统相关的序列。60.根据实施方式1、2或3所述的方法,其中通过成像测试(例如,ct、pet-ct、mri、x射线、超声波)追踪变异体的鉴别,以便定位疑似引起所鉴别的变异体的组织异常。61.根据实施方式1、2或3所述的方法,其中所述分析进一步包括使用从来自相同患者的组织或肿瘤活检获得的遗传数据。62.根据实施方式1、2或3所述的方法,其中推断肿瘤、感染或其它组织异常的系统
发生学。63.根据实施方式1或2所述的方法,其中所述方法进一步包括对低置信区域进行基于群体的非判定和鉴别。64.根据实施方式1或2所述的方法,其中获得序列覆盖度的测量数据包括测量基因组的每个位置处的序列覆盖深度。65.根据实施方式64所述的方法,其中针对序列覆盖偏倚校正测量数据包括计算窗口平均的覆盖度。66.根据实施方式64所述的方法,其中针对序列覆盖偏倚校正测量数据包括进行调整以应对在文库构建和测序过程中的gc偏倚。67.根据实施方式64所述的方法,其中针对序列覆盖偏倚校正测量数据包括基于与个体定位相关联的附加加权因子进行调整,以补偿偏倚。68.根据实施方式1、2或3所述的方法,其中细胞外多核苷酸源自病变细胞来源。69.根据实施方式1、2或3所述的方法,其中细胞外多核苷酸源自健康细胞来源。70.一种包含计算机可读介质的系统,该计算机可读介质用于执行以下步骤:选择基因组中的预定义区域;对所述预定义区域中的序列阅读值的数目进行计数;对所述预定义区域上的序列阅读值的数目进行归一化;以及确定所述预定义区域中的拷贝数变异的百分比。71.根据实施方式70所述的系统,其中分析整个基因组或基因组的至少85%。72.根据实施方式70所述的系统,其中所述计算机可读介质将关于血浆或血清中的癌症dna或rna百分比的数据提供给终端用户。73.根据实施方式1所述的方法,其中由于样品的异质性,所鉴别的拷贝数变异体是分数(即,非整数水平)。74.根据实施方式1所述的方法,由此进行选定的区域的富集。75.根据实施方式1所述的方法,由此基于实施方式1、64、65、66和67所述的方法同时提取拷贝数变异信息。76.根据实施方式1或2所述的方法,其与多核苷酸瓶颈化的初始步骤一起使用以限制样品中的多核苷酸的起始初始拷贝数或多样性。77.一种用于在从受试者获得的无细胞或基本无细胞的样品中检测稀有突变的方法,该方法包括:a.对来自受试者的身体样品的细胞外多核苷酸进行测序,其中所述细胞外多核苷酸中的每一个产生多个测序阅读值;b.过滤掉未满足所设定的质量阈值的阅读值;c.将从所述测序得到的序列阅读值定位至参考序列上;d.鉴别在各个可定位的碱基位置处与所述参考序列的变异体对准的被定位序列阅读值的亚组;e.对于各个可定位的碱基位置,计算出(a)与所述参考序列相比包含变异体的被定位序列阅读值的数目与(b)各个可定位碱基位置的序列阅读值总数的比值;f.将各个可定位碱基位置的变异的比值或频率进行归一化,并确定潜在的稀有变异体或其它遗传改变;以及
g.将具有潜在的稀有变异体或突变的各个区域的所得数目与从参考样品类似地得到的数目进行比较。78.一种方法,该方法包括:a.提供至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b.扩增该组中的标记的亲本多核苷酸,以产生相应的一组扩增的子代多核苷酸;c.对该组扩增的子代多核苷酸的亚组(包括真亚组)进行测序,以产生一组测序阅读值;以及d.使该组测序阅读值分解,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸。79.根据实施方式78所述的方法,其中一组中的各个多核苷酸可定位至参考序列。80.根据实施方式78所述的方法,其包括提供多组标记的亲本多核苷酸,其中各组可定位至所述参考序列中不同的可定位位置。81.根据实施方式78所述的方法,其进一步包括:e.分开地或组合地针对每组标记的亲本分子对该组共有序列进行分析。82.根据实施方式78所述的方法,其进一步包括将初始起始遗传材料转换成标记的亲本多核苷酸。83.根据实施方式82所述的方法,其中所述初始起始遗传材料包含不超过100ng的多核苷酸。84.根据实施方式82所述的方法,其包括在转换前瓶颈化所述初始起始遗传材料。85.根据实施方式82所述的方法,其包括以至少10%、至少20%、至少30%、至少40%、至少50%、至少60%、至少80%或至少90%的转换效率将所述初始起始遗传材料转换成标记的亲本多核苷酸。86.根据实施方式82所述的方法,其中转换包括平端连接、粘端连接、分子倒位探针、pcr、基于连接的pcr、单链连接和单链环化中的任何方法。87.根据实施方式82所述的方法,其中所述初始起始遗传材料是无细胞的核酸。88.根据实施方式79所述的方法,其中多个所述组定位至来自相同基因组的参考序列中的不同可定位位置。89.根据实施方式78所述的方法,其中所述组中的各个标记的亲本多核苷酸是独特地标记的。90.根据实施方式78所述的方法,其中各组亲本多核苷酸可定位至参考序列中的位置,并且各组中的多核苷酸不是独特地标记的。91.根据实施方式78所述的方法,其中共有序列的生成基于来自标签的信息和/或以下至少一个:(i)在所述序列阅读值的开始(启动)区域的序列信息、(ii)在所述序列阅读值的结束(终止)区域的序列信息和(iii)所述序列阅读值的长度。92.根据实施方式78所述的方法,其包括对该组扩增的子代多核苷酸的亚组进行测序,该测序足以对至少一个子代产生序列阅读值,所述序列阅读值来自该组标记的亲本多核苷酸中的独特多核苷酸的至少20%、至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、至少98%、至少99%、至少99.9%或至少99.99%中的每一个。
93.根据实施方式92所述的方法,其中所述至少一个子代是多个子代,例如,至少2个、至少5个或至少10个子代。94.根据实施方式78所述的方法,其中该组序列阅读值中的序列阅读值的数目大于该组标记的亲本多核苷酸中的独特标记的亲本多核苷酸的数目。95.根据实施方式78所述的方法,其中被测序的该组扩增的子代多核苷酸的亚组具有足够的大小,以使得以与所用测序平台的每碱基测序错误率百分比相同的百分比在该组标记的亲本多核苷酸中呈现的任何核苷酸序列有至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、至少98%、至少99%、至少99.9%或至少99.99%的机会在该组共有序列中呈现。96.根据实施方式78所述的方法,其包括通过以下步骤,针对定位至参考序列中一个或多个选定的可定位位置的多核苷酸,富集该组扩增的子代多核苷酸:(i)对来自已转换成标记的亲本多核苷酸的初始起始遗传材料的序列的选择性扩增;(ii)对标记的亲本多核苷酸的选择性扩增;(iii)对扩增的子代多核苷酸的选择性序列捕获;或(iv)对初始起始遗传材料的选择性序列捕获。97.根据实施方式81所述的方法,其中分析包括将从一组共有序列获得的度量(例如,数目)相对于从来自对照样品的一组共有序列获得的度量进行归一化。98.根据实施方式81所述的方法,其中分析包括检测突变、稀有突变、插入缺失、拷贝数变异、颠换、易位、倒位、缺失、非整倍性、部分非整倍性、多倍性、染色体不稳定性、染色体结构改变、基因融合、染色体融合、基因截短、基因扩增、基因复制、染色体损伤、dna损伤、核酸化学修饰的异常变化、外遗传模式的异常变化、核酸甲基化的异常变化、感染或癌症。99.根据实施方式78所述的方法,其中所述多核苷酸包含dna、rna、这两者的组合或dna加rna衍生的cdna。100.根据实施方式82所述的方法,其中针对或基于碱基对的多核苷酸长度从多核苷酸的初始组或从扩增的多核苷酸中选择或富集多核苷酸的某个亚组。101.根据实施方式82所述的方法,其中分析进一步包括检测和监测个体内的异常或疾病,例如,感染和/或癌症。102.根据实施方式101所述的方法,其与免疫组库谱分析组合进行。103.根据实施方式78所述的方法,其中所述多核苷酸从选自血液、血浆、血清、尿液、唾液、粘膜分泌物、痰、粪便和泪的样品中提取。104.根据实施方式78所述的方法,其中分解包括检测和/或校正在标记的亲本多核苷酸或扩增的子代多核苷酸的有义或反义链中存在的错误、切口或损伤。105.一种方法,其包括以至少5%、至少1%、至少0.5%、至少0.1%或至少0.05%的灵敏度检测非独特标记的初始起始遗传材料中的遗传变异。106.根据实施方式105所述的方法,其中所述初始起始遗传材料以小于100ng的核酸的量来提供,该遗传变异是拷贝数/杂合性变异,并且检测在亚染色体分辨率下进行;例如,至少100兆碱基分辨率、至少10兆碱基分辨率、至少1兆碱基分辨率、至少100千碱基分辨率、至少10千碱基分辨率或至少1千碱基分辨率。107.根据实施方式81所述的方法,其包括提供多组标记的亲本多核苷酸,其中各组可定位至参考序列中不同的可定位位置。
108.根据实施方式107所述的方法,其中所述参考序列中的可定位位置是肿瘤标志物的基因座,并且分析包括检测该组共有序列中的肿瘤标志物。109.根据实施方式108所述的方法,其中所述肿瘤标志物以小于在扩增步骤中引入的错误率的频率存在于该组共有序列中。110.根据实施方式107所述的方法,其中所述至少一组是多个组,并且所述参考序列的可定位位置包含该参考序列中的多个可定位位置,其中各个可定位位置是肿瘤标志物的基因座。111.根据实施方式107所述的方法,其中分析包括检测至少两组亲本多核苷酸之间的共有序列的拷贝数变异。112.根据实施方式107所述的方法,其中分析包括检测与参考序列相比序列变异的存在。113.根据实施方式107所述的方法,其中分析包括检测与参考序列相比序列变异的存在及检测在至少两组亲本多核苷酸间的共有序列的拷贝数变异。114.根据实施方式78所述的方法,其中分解包括:i.将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记的亲本多核苷酸扩增;以及ii.基于家族中的序列阅读值确定共有序列。115.一种包含计算机可读介质的系统,该计算机可读介质用于执行以下步骤:a.接受至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b.扩增该组中的标记的亲本多核苷酸,以产生相应的一组扩增的子代多核苷酸;c.对该组扩增的子代多核苷酸的亚组(包括真亚组)进行测序,以产生一组测序阅读值;以及d.分解该组测序阅读值,以生成一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸,以及任选地e.针对各组标记的亲本分子对该组共有序列进行分析。116.一种方法,其包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少10%进行测序。117.一种方法,其包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少20%进行测序。118.一种方法,其包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少30%进行测序。119.一种方法,其包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少40%进行测序。120.一种方法,其包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少50%进行测
序。121.一种方法,其包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少60%进行测序。122.一种方法,其包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少70%进行测序。123.一种方法,其包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少80%进行测序。124.一种方法,其包括检测个体中的遗传改变的存在与否或遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少90%进行测序。125.一种方法,其包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少10%进行测序。126.一种方法,其包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少20%进行测序。127.一种方法,其包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少30%进行测序。128.一种方法,其包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少40%进行测序。129.一种方法,其包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少50%进行测序。130.一种方法,其包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少60%进行测序。131.一种方法,其包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少70%进行测序。132.一种方法,其包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少80%进行测序。133.一种方法,其包括检测个体中的遗传改变的存在与否和遗传变异的量,其中所述检测在对无细胞核酸的测序的辅助下进行,其中对个体的基因组的至少90%进行测序。
134.根据实施方式116-133所述的方法,其中所述遗传改变是拷贝数变异或一种或多种稀有突变。135.根据实施方式116-133所述的方法,其中所述遗传变异包含一种或多种因果变异体和一种或多种多态性。136.根据实施方式116-133所述的方法,其中所述个体中的遗传改变和/或遗传变异的量可以与一个或多个患有已知疾病的个体中的遗传改变和/或遗传变异的量相比较。137.根据实施方式116-133所述的方法,其中所述个体中的遗传改变和/或遗传变异的量可以与一个或多个未患有疾病的个体中的遗传改变和/或遗传变异的量相比较。138.根据实施方式116-133所述的方法,其中所述无细胞核酸是dna。139.根据实施方式116-133所述的方法,其中所述无细胞核酸是rna。140.根据实施方式116-133所述的方法,其中所述无细胞核酸是dna和rna。141.根据实施方式136所述的方法,其中所述疾病是癌症或癌前期。142.根据实施方式116-133所述的方法,该方法进一步包括疾病的诊断或治疗。143.一种方法,其包括:a.提供至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b.扩增该组中的标记的亲本多核苷酸,以产生相应的一组扩增的子代多核苷酸;c.对该组扩增的子代多核苷酸的亚组(包括真亚组)进行测序,以产生一组测序阅读值;d.分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸;以及e.从所述共有序列中过滤掉未满足质量阈值的那些。144.根据实施方式143所述的方法,其中所述质量阈值考虑来自分解成共有序列的扩增子代多核苷酸的序列阅读值的数目。145.根据实施方式143所述的方法,其中所述质量阈值考虑分解成共有序列的来自扩增的子代多核苷酸的序列阅读值的数目。146.一种包含计算机可读介质的系统,该计算机可读介质用于执行实施方式143-145中任一项的方法。147.一种方法,其包括:a.提供至少一组标记的亲本多核苷酸,其中各组定位至一个或多个基因组中的参考序列的不同可定位位置,并且对于各组标记的亲本多核苷酸;i.扩增第一多核苷酸,以产生一组扩增的多核苷酸;ii.对该组扩增的多核苷酸的亚组进行测序,以产生一组测序阅读值;以及iii.通过以下步骤分解所述测序阅读值:1.将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记亲本多核苷酸扩增。148.根据实施方式147所述的方法,其中分解进一步包括:2.确定在各个家族中的序列阅读值的定量度量。149.根据实施方式148所述的方法,其进一步包括:b.确定独特家族的定量度量;以及
c.基于(1)独特家族的定量度量和(2)各组中的序列阅读值的定量度量,推断在该组中的独特标记亲本多核苷酸的度量。150.根据实施方式149所述的方法,其中使用统计或概率模型进行推断。151.根据实施方式149所述的方法,其中所述至少一组是多个组。152.根据实施方式151所述的方法,其进一步包括校正两组之间的扩增或呈现偏倚。153.根据实施方式152所述的方法,其进一步包括使用对照或一组对照样品来校正两组之间的扩增或呈现偏倚。154.根据实施方式151所述的方法,其进一步包括确定所述组之间的拷贝数变异。155.根据实施方式149所述的方法,其进一步包括:d.确定所述家族之间的多态性形式的定量度量;以及e.基于所确定的多态性形式的定量度量,推断在推断的独特标记亲本多核苷酸的数目中的多态性形式的定量度量。156.根据实施方式155所述的方法,其中多态性形式包括但不限于:置换、插入、缺失、倒位、微卫星改变、颠换、易位、融合、甲基化、过度甲基化、羟甲基化、乙酰化、外遗传变异体、与调节相关的变异体或蛋白质结合位点。157.根据实施方式149所述的方法,其中所述组源自共同的样品,并且该方法进一步包括:d.基于定位至参考序列中的多个可定位位置中每一个的各组中标记亲本多核苷酸的推断数目的比较,推断所述多个组的拷贝数变异。158.根据实施方式157所述的方法,其中进一步推断各组中的多核苷酸的原始数目。159.根据实施方式147所述的方法,其中各组中的标记亲本多核苷酸中的至少一个亚组为非独特地标记的。160.一种包含计算机可读介质的系统,该计算机可读介质包含机器可执行代码,该机器可执行代码在被计算机处理器执行时实现实施方式147-158中任一项的方法。161.一种确定包含多核苷酸的样品中的拷贝数变异的方法,该方法包括:a.提供至少两组第一多核苷酸,其中各组定位至基因组中的参考序列的不同可定位位置,并且对于各组第一多核苷酸;i.扩增所述多核苷酸,以产生一组扩增的多核苷酸;ii.对该组扩增的多核苷酸的亚组进行测序,以产生一组测序阅读值;iii.将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族从所述组中的相同的第一多核苷酸扩增;iv.推断所述组中的家族的定量度量;以及b.通过比较各组中的家族的定量度量来确定拷贝数变异。162.一种包含计算机可读介质的系统,该计算机可读介质包含机器可执行代码,该机器可执行代码在被计算机处理器执行时实现实施方式161的方法。163.一种推断多核苷酸样品中的序列判定频率的方法,该方法包括:a.提供至少一组第一多核苷酸,其中各组定位至一个或多个基因组中的参考序列
的不同可定位位置,并且对于各组第一多核苷酸;i.扩增第一多核苷酸,以产生一组扩增的多核苷酸;ii.对该组扩增的多核苷酸的亚组进行测序,以产生一组测序阅读值;iii.将所述序列阅读值分组成家族,各个家族包含从相同的第一多核苷酸扩增的扩增多核苷酸的序列阅读值;b.对于各组第一多核苷酸,推断对在该组第一多核苷酸中的一个或多个碱基的判定频率,其中推断包括:i.针对各个家族,对多个判定中的每一个判定分配置信得分,该置信得分考虑该家族的成员之间的判定频率;以及ii.考虑分配给每个家族的一个或多个判定的置信得分,来估算一个或多个判定的频率。164.一种包含计算机可读介质的系统,该计算机可读介质包含机器可执行代码,该机器可执行代码在被计算机处理器执行时实现实施方式163的方法。165.一种对关于至少一个单个多核苷酸分子的序列信息进行通信的方法,该方法包括:a.提供至少一个单个多核苷酸分子;b.编码所述至少一个单个多核苷酸分子中的序列信息,以产生信号;c.使该信号的至少一部分通过通道,以产生包含关于所述至少一个单个多核苷酸分子的核苷酸序列信息的接收信号,其中该接收信号包含噪声和/或畸变;d.解码该接收信号,以产生包含关于所述至少一个单个多核苷酸分子的序列信息的消息,其中解码减少了该消息中关于各个单个多核苷酸的噪声和/或畸变;以及e.将包含关于所述至少一个单个多核苷酸分子的序列信息的消息提供至接收者。166.根据实施方式165所述的方法,其中所述噪声包含不正确的核苷酸判定。167.根据实施方式165所述的方法,其中畸变包含所述单个多核苷酸分子与其它单个多核苷酸分子相比的不均匀扩增。168.根据实施方式167所述的方法,其中畸变是由扩增或测序偏倚导致的。169.根据实施方式165所述的方法,其中所述至少一个单个多核苷酸分子是多个单个多核苷酸分子,并且解码产生关于所述多个分子中的每一个分子的消息。170.根据实施方式165所述的方法,其中编码包括扩增已经任选地标记的所述至少一个单个多核苷酸分子,其中所述信号包括扩增的分子的集合。171.根据实施方式165所述的方法,其中所述通道包括多核苷酸测序仪且所述接收信号包括从所述至少一个单个多核苷酸分子扩增的多个多核苷酸的序列阅读值。172.根据实施方式165所述的方法,其中解码包括将从至少一个单个多核苷酸分子中的每一个扩增的扩增分子的序列阅读值进行分组。173.根据实施方式169所述的方法,其中解码由过滤所生成的序列信号的概率或统计方法组成。174.一种包含计算机可读介质的系统,该计算机可读介质包含机器可执行代码,该机器可执行代码在被计算机处理器执行时实现实施方式165-173中任一项的方法。175.根据实施方式143-145、147-159和161中任一项所述的方法,其中所述多核苷
酸源自肿瘤基因组dna或rna。176.根据实施方式143-175中任一项所述的方法,其中所述多核苷酸源自无细胞的多核苷酸、核外多核苷酸、细菌多核苷酸或病毒多核苷酸。177.根据实施方式1-3或143-175中任一项所述的方法,其进一步包括受影响的分子通路的检测和/或关联。178.根据实施方式1-3或143-175中任一项所述的方法,其进一步包括连续监测个体的健康或疾病状态。179.根据实施方式1-3或143-175中任一项所述的方法,由此推断个体内与疾病相关的基因组的种系发生。180.根据实施方式1-3或143-175中任一项所述的方法,其进一步包括疾病的诊断、监测或治疗。181.根据实施方式180所述的方法,其中基于检测到的多态性形式或cnv或相关的通路来选择或修改治疗方案。182.根据实施方式180或181所述的方法,其中所述治疗包括联合疗法。183.根据实施方式179所述的方法,其中所述诊断进一步包括使用诸如ct-扫描、pet-ct、mri、超声、微泡超声等放射线照相技术定位疾病。184.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:选择在基因组中的预定义区域;访问序列阅读值并对该预定义区域中的序列阅读值数目进行计数;对在该预定义区域上的序列阅读值的数目进行归一化;以及确定在该预定义区域中的拷贝数变异的百分比。185.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件;b.过滤掉未满足所设定的阈值的阅读值;c.将从测序得到的序列阅读值定位至参考序列上;d.鉴别在各个可定位的碱基位置处与参考序列的变异体对准的被定位序列阅读值的亚组;e.对于各个可定位的碱基位置,计算出(a)与参考序列相比包含变异体的被定位序列阅读值的数目与(b)各个可定位碱基位置的序列阅读值总数的比值;f.将各个可定位碱基位置的变异的比值或频率进行归一化并确定潜在的稀有变异体或其它遗传改变;以及g.将具有潜在的稀有变异体或突变的各个区域的所得数目与从参考样品类似地得到的数目进行比较。186.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;以及
b.分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸。187.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b.分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸;c.从所述共有序列中过滤掉未满足质量阈值的那些。188.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;以及i.通过以下步骤分解所述序列阅读值:1.将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记亲本多核苷酸扩增,以及任选地,2.确定各个家族中序列阅读值的定量度量。189.根据实施方式188所述的计算机可读介质,其中所述可执行代码在被计算机处理器执行时进一步执行以下步骤:b.确定独特家族的定量度量;c.基于(1)独特家族的定量度量和(2)各组中的序列阅读值的定量度量,推断在该组中的独特标记的亲本多核苷酸的度量。190.根据实施方式189所述的计算机可读介质,其中所述可执行代码在被计算机处理器执行时进一步执行以下步骤:d.确定所述家族之间的多态性形式的定量度量;以及e.基于所确定的多态性形式的定量度量,推断在推断的独特标记亲本多核苷酸的数目中的多态性形式的定量度量。191.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族从所述组中的相同的第一多核苷酸扩增;b.推断该组中的家族的定量度量;c.通过比较各组中的家族的定量度量来确定拷贝数变异。192.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;将所述序列阅读值分组成家族,各个家族包含从相同的第一多核苷酸扩增的扩增多核苷酸的序列阅读值;
b.对于各组第一多核苷酸,推断对在该组第一多核苷酸中的一个或多个碱基的判定频率,其中推断包括:c.针对各个家族,对多个判定中的每一个判定分配置信得分,该置信得分考虑该家族的成员之间的判定频率;以及d.考虑分配给每个家族的一个或多个判定的置信得分,来估算一个或多个判定的频率。193.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含接收信号的数据文件,该接收信号包含来自至少一个单个多核苷酸分子的编码的序列信息,其中所述接收信号包含噪声和/或畸变;b.解码所述接收信号,以产生包含关于所述至少一个单个多核苷酸分子的序列信息的消息,其中解码减少了该消息中关于各个单个多核苷酸的噪声和/或畸变;以及c.将包含关于所述至少一个单个多核苷酸分子的序列信息的消息写入计算机文件。194.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b.分解该组测序阅读值,以产生一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸;以及c.从所述共有序列中过滤掉未满足质量阈值的那些。195.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;以及b.通过以下步骤分解该序列阅读值:i.将从扩增的子代多核苷酸测序的序列阅读值分组成家族,各个家族从相同的标记亲本多核苷酸扩增;以及ii.任选地确定各个家族中序列阅读值的定量度量。196.根据实施方式195所述的计算机可读介质,其中所述可执行代码在被计算机处理器执行时进一步执行以下步骤:c.确定独特家族的定量度量;d.基于(1)独特家族的定量度量和(2)各组中的序列阅读值的定量度量,推断在该组中的独特标记亲本多核苷酸的度量。197.根据实施方式196所述的计算机可读介质,其中所述可执行代码在被计算机处理器执行时进一步执行以下步骤:e.确定所述家族之间的多态性形式的定量度量;以及f.基于所确定的多态性形式的定量度量,推断在推断的独特标记亲本多核苷酸的数目中的多态性形式的定量度量。
198.根据实施方式196所述的计算机可读介质,其中所述可执行代码在被计算机处理器执行时进一步执行以下步骤:e.基于定位至多个参考序列中的每一个的各组中的标记亲本多核苷酸的推断数目的比较,来推断所述多个组的拷贝数变异。199.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;b.将从扩增的多核苷酸测序的序列阅读值分组成家族,各个家族从所述组中的相同的第一多核苷酸扩增;c.推断该组中的家族的定量度量;以及d.通过比较各组中的家族的定量度量来确定拷贝数变异。200.一种包含非暂时性机器可执行代码的计算机可读介质,该非暂时性机器可执行代码在被计算机处理器执行时实现一种方法,该方法包括:a.访问包含多个测序阅读值的数据文件,其中所述序列阅读值源自从至少一组标记的亲本多核苷酸扩增的一组子代多核苷酸;将所述序列阅读值分组成家族,各个家族包含从相同的第一多核苷酸扩增的扩增多核苷酸的序列阅读值;以及b.对于各组第一多核苷酸,推断对在该组第一多核苷酸中的一个或多个碱基的判定频率,其中推断包括:i.针对各个家族,对多个判定中的每一个判定分配置信得分,该置信得分考虑家族成员之间的判定频率;以及ii.考虑分配给每个家族的一个或多个判定的置信得分,来估算一个或多个判定的频率。201.一种组合物,其包含100至100,000个人单倍体基因组当量的cfdna多核苷酸,其中所述多核苷酸用2至1,000,000个独特标识符标记。202.根据实施方式201所述的组合物,其包含1000至50,000个单倍体人基因组当量的cfdna多核苷酸,其中所述多核苷酸用2至1,000个独特标识符标记。203.根据实施方式201所述的组合物,其中所述独特标识符包含核苷酸条形码。204.一种方法,其包括:a.提供包含100至100,000个单倍体人基因组当量的cfdna多核苷酸的样品;以及b.用2至1,000,000个独特标识符标记所述多核苷酸。205.一种方法,其包括:a.提供包含多个人单倍体基因组当量的片段化多核苷酸的样品;b.确定z,其中z是在基因组中任何位置开始的重复多核苷酸的预期数目的居中趋势度量(例如,平均值、中位数或众数),其中重复多核苷酸具有相同的启动和终止位置;以及c.用n个独特标识符标记样品中的多核苷酸,其中n是2至100,000*z、2至10,000*z、2至1,000*z或2至100*z。206.一种方法,其包括:
a.提供至少一组标记的亲本多核苷酸,并且对于各组标记的亲本多核苷酸;b.对该组中的各个标记的亲本多核苷酸产生多个序列阅读值,以产生一组测序阅读值;以及c.分解该组测序阅读值,以生成一组共有序列,各个共有序列对应于该组标记的亲本多核苷酸中的独特多核苷酸。
实施例
实施例1-前列腺癌的预后和治疗
335.从一名前列腺癌受试者中获取血液样品。先前,肿瘤科医生确定了该受试者具有ii期前列腺癌并建议治疗。在初步诊断后,每6个月提取、分离、测序并分析无细胞的dna。
336.使用qiagen qubit试剂盒规程从血液中提取并分离无细胞的dna。加入载体dna,以提高收率。使用pcr和通用引物扩增dna。采用illumina miseq个人测序仪,使用大规模并行测序方法对10ng的dna进行测序。通过对无细胞dna的测序而覆盖该受试者的基因组的90%。
337.将序列数据组装起来并分析其拷贝数变异。定位序列阅读值并将其与健康个体(对照)进行比较。基于序列阅读值的数目,将染色体区域分成50kb的非重叠区域。将序列阅读值彼此进行比较,并且为各个可定位位置确定一个比值。
338.使用隐马尔可夫模型将拷贝数转换成各个窗口的离散状态。
339.生成报告,定位基因组位置和拷贝数变异示于图4a(健康个体)和图4b(患有癌症的受试者)中。
340.与具有已知结果的受试者的其它谱相比较,这些报告表明这种特定的癌症是侵袭性的并且对治疗具有抗性。无细胞肿瘤负荷为21%。对受试者监测18个月。在第18月,拷贝数变异谱开始急剧增加,无细胞肿瘤负荷从21%升至30%。与其它前列腺受试者的遗传谱进行比较。确定拷贝数变异的这种增加指示前列腺癌从ii期进展到iii期。所开出的原治疗方案不再能够治疗该癌症。开出新的治疗。
341.此外,这些报告经由因特网以电子方式进行提交和访问。在除受试者的位置外的地点进行序列数据的分析。生成报告并发送到受试者的位置。通过支持因特网的计算机,受试者访问反映其肿瘤负荷的报告(图4c)。实施例2-前列腺癌的缓解和复发
342.从一名前列腺癌幸存者获取血液样品。该受试者先前曾接受了多轮化疗和放疗。在测试时该受试者没有出现与癌症相关的症状或健康问题。标准扫描和分析显示该受试者没有癌症。
343.使用qiagen truseq试剂盒规程从血液中提取并分离无细胞的dna。加入载体dna,以提高收率。使用pcr和通用引物扩增dna。采用illumina miseq个人测序仪,使用大规模并行测序方法对10ng的dna进行测序。使用连接方法将12聚物条形码加至单个分子上。
344.将序列数据组装起来并分析其拷贝数变异。定位序列阅读值并将其与健康个体(对照)进行比较。基于序列阅读值的数目,将染色体区域分成40kb的非重叠区域。将序列阅读值彼此进行比较,并且为各个可定位位置确定一个比值。
345.将非独特条形码编码的序列分解成单个阅读值,以帮助对来自扩增的偏倚进行归
一化。
346.使用隐马尔可夫模型将拷贝数转换成各个窗口的离散状态。
347.生成报告,定位基因组位置和拷贝数变异示于图5a(处于缓解期的癌症受试者)和图5b(处于复发期的癌症受试者)中。
348.与具有已知结果的受试者的其它谱相比较,该报告表明,在第18个月,在5%的无细胞肿瘤负荷下检测到对拷贝数变异的稀有突变分析。肿瘤科医生再次开出治疗。实施例3-甲状腺癌和治疗
349.一名受试者已知患有iv期甲状腺癌并经受标准治疗,包括使用i-131的放射疗法。ct扫描对该放射疗法是否正在破坏癌性团块没有结论。在最近的放射期之前和之后抽取血液。
350.使用qiagen qubit试剂盒规程从血液中提取并分离无细胞的dna。将非特异性批量dna的样品加入到样品制备反应中,以提高收率。
351.众所周知,在这种甲状腺癌中,braf基因可以在氨基酸位置600处突变。使用对该基因具有特异性的引物从无细胞dna群体选择性地扩增braf dna。将20聚物条形码加到亲本分子上作为用于阅读值计数的对照。
352.采用illumina miseq个人测序仪,使用大规模并行测序方法对10ng的dna进行测序。
353.将序列数据组装起来并分析其拷贝数变异检测。定位序列阅读值并将其与健康个体(对照)进行比较。基于序列阅读值的数目,如通过条形码序列计数所确定的,将染色体区域分成50kb的非重叠区域。将序列阅读值彼此进行比较,并且为各个可定位位置确定一个比值。
354.使用隐马尔可夫模型将拷贝数转换成各个窗口的离散状态。
355.生成报告,定位基因组位置和拷贝数变异。
356.对治疗之前和之后生成的报告进行比较。在放射期之后,肿瘤细胞负荷百分比从30%猛增至60%。肿瘤负荷的猛增被确定为由治疗引起的癌组织相比于正常组织的坏死的增加。肿瘤科医生建议受试者继续遵医嘱治疗。实施例4-稀有突变检测的灵敏度
357.为了确定存在于dna群体中的稀有突变的检测范围,进行混合实验。dna的序列以不同的比例混合在一起,其中一些包含基因tp53、hras和met的野生型拷贝,而另一些包含在相同基因中具有稀有突变的拷贝。制备dna混合物,使得突变dna与野生型dna的比例或百分比的范围是从100%到0.01%。
358.对于各个混合实验,采用illumina miseq个人测序仪,使用大规模并行测序方法对10ng的dna进行测序。
359.将序列数据组装起来并分析其稀有突变检测。定位序列阅读值并将其与参考序列(对照)进行比较。基于序列阅读值的数目,确定各个可定位位置的变异频率。
360.使用隐马尔可夫模型将各个可定位位置的变异频率转换成碱基位置的离散状态。
361.生成报告,定位基因组碱基位置和在由参考序列确定的基线以上的稀有突变的检测百分比(图6a)。
362.范围从0.1%到100%的各种混合实验的结果示于对数标度图中,其中具有稀有突
变的dna的所测得的百分比作为具有稀有突变的dna的实际百分比的函数来作图(图6b)。示出了tp53、hras和met这三种基因。在测量的和期望的稀有突变群体之间发现了很强的线性相关性。此外,经这些实验发现了在非突变dna群体中约0.1%的具有稀有突变的dna的较低灵敏度阈值(图6b)。实施例5-在前列腺癌受试者中的稀有突变检测
363.一名受试者被认为患有早期前列腺癌。其它临床试验没有提供确定的结果。从该受试者抽取血液并提取、分离、制备和测序无细胞的dna。
364.选择一组不同的癌基因和肿瘤抑制基因,以供使用pcr试剂盒(invitrogen)、使用基因特异性引物进行选择性扩增。被扩增的dna区域包括含有pik3ca和tp53基因的dna。
365.采用illumina miseq个人测序仪,使用大规模并行测序方法对10ng的dna进行测序。
366.将序列数据组装起来并分析其稀有突变检测。定位序列阅读值并将其与参考序列(对照)进行比较。基于序列阅读值的数目,确定各个可定位位置的变异频率。
367.使用隐马尔可夫模型将各个可定位位置的变异频率转换成各个碱基位置的离散状态。
368.生成报告,定位基因组碱基位置和在由参考序列确定的基线以上的稀有突变的检测百分比(图7a)。稀有突变以5%的发生率分别出现在两种基因pik3ca和tp53中,表明该受试者具有早期癌症。开始治疗。
369.此外,这些报告经由因特网以电子方式进行提交和访问。在除受试者的位置外的地点进行序列数据的分析。生成报告并发送到受试者的位置。通过支持因特网的计算机,受试者访问反映其肿瘤负荷的报告(图7b)。实施例6-在结肠直肠癌受试者中的稀有突变检测
370.一名受试者被认为患有中期结直肠癌。其它临床试验没有提供确定的结果。从受试者抽取血液并提取无细胞的dna。
371.使用10ng从一管血浆中提取的无细胞遗传材料。将初始遗传材料转换成一组标记的亲本多核苷酸。该标记包括:将测序所需的标签以及用于追踪子代分子的非独特标识符附接到亲本核酸上。通过如上文所述的优化的连接反应进行该转换并且通过观察连接后分子的大小谱来确定转换率。转换率被测量为在两端连接有标签的起始初始分子的百分比。使用这种方法的转换以高效率例如至少50%进行。
372.对标记的文库进行pcr扩增并针对与结直肠癌最相关的基因(例如,kras、apc、tp53等)进行富集,并且采用illumina miseq个人测序仪使用大规模并行测序方法对所得dna进行测序。
373.将序列数据组装起来并分析其稀有突变检测。将序列阅读值分解成属于亲本分子的家族组(以及在分解时错误校正)并使用参考序列(对照)进行定位。基于序列阅读值的数目,确定各个可定位位置的拷贝数和杂合性(适当的时候)的稀有变异(置换、插入、缺失等)和变异的频率。
374.生成报告,定位基因组碱基位置和在由参考序列确定的基线以上的稀有突变的检测百分比。稀有突变以0.3-0.4%的发生率分别出现在两种基因kras和fbxw7中,表明该受
试者具有残留的癌症。开始治疗。
375.此外,这些报告经由因特网以电子方式进行提交和访问。在除受试者的位置外的地点进行序列数据的分析。生成报告并发送到受试者的位置。通过支持因特网的计算机,受试者访问反映其肿瘤负荷的报告。
376.实施例7-数字测序技术
377.肿瘤释放的核酸的浓度通常非常低,使得当前的新一代测序技术只能偶然地或在具有终末高肿瘤负荷的患者中检测到这类信号。主要原因是,这些技术受到错误率和偏倚的困扰,其错误率和偏倚可能比在循环dna中可靠地检测出与癌症相关的从头(de novo)遗传改变所需要的高几个数量级。本文显示了一种新的测序方法,即数字测序技术(dst),其使得在种系片段之间检测和定量罕见肿瘤来源的核酸的灵敏度和特异性提高了至少1-2个数量级。
378.dst架构受到最先进的数字通信系统的启发,该数字通信系统克服由现代通信信道引起的高噪声和畸变并能够以非常高的数据速率完美无缺地传输数字信息。同样,当前的新一代工作流程受到非常高的噪声和畸变(由于样品准备、基于pcr的扩增和测序)的困扰。数字测序能够消除由这些过程产生的错误和畸变并产生所有稀有变异体(包括cnv)的近乎完美的呈现。
379.高多样性文库的准备
380.传统的测序文库制备规程使大多数提取的循环dna片段由于低效文库转换而丢失,与之不同,我们的数字测序技术工作流程使绝大多数起始分子能够得到转换和测序。这对于稀有变异体的检测极为重要,因为在10ml管的一整管血液中可能仅存在少量体细胞突变的分子。所开发的高效分子生物学转换过程使得稀有变异体的检测能够具有最高的可能的灵敏度。
381.全面的可发挥作用的癌基因组(panel)
382.围绕dst平台设计的工作流程是灵活和高度可调的,因为所针对的区域可以与单一外显子一样小或与整个外显子组(或甚至整个基因组)一样宽。标准组由15种可发挥作用的癌症相关基因的所有外显子碱基和另外36种癌基因/肿瘤抑制基因的“热点”外显子(例如,含有cosmic中的至少一个或多个所报告的体细胞突变的外显子)的覆盖范围组成。
383.实施例8:分析性研究
384.为了研究我们的技术的性能,评估了其对分析性样品的灵敏度。我们将不同量的lncap癌细胞系dna掺入至正常cfdna的背景中并能够以低至0.1%的灵敏度成功地检测到体细胞突变(参见图13)。
385.临床前研究
386.在小鼠中的人异种移植模型中研究了循环dna与肿瘤gdna的一致性。在分别荷有两种不同人乳腺癌肿瘤之一的7只ctc阴性小鼠中,使用dst,在肿瘤gdna中检测到的所有体细胞突变也在小鼠血液cfdna中检测到,进一步验证了cfdna对于非侵入性肿瘤遗传谱分析的效用。
387.先期临床研究
388.肿瘤活检与循环dna体细胞突变的相关性
389.用不同肿瘤类型的人类样品开始先期研究。研究了由循环无细胞dna得到的肿瘤
突变谱与由匹配的肿瘤活检样品得到的肿瘤突变谱的一致性。在14名患者中,在结直肠癌和黑素瘤癌症中均发现了肿瘤与cfdna体细胞突变谱之间有高于93%的一致性(表1)。表1表1
390.根据以上所述应当理解,虽然已示出和描述了特定实施方案,但可对其作出各种修改并且这些修改是本发明所预期的。并不打算以本说明书中所提供的具体实施例限制本发明。虽然已经参考上述说明书描述了本发明,但本文优选实施方案的描述和例示并不意味着以限制性的意义来解释。此外,应当理解,本发明的所有方面不限于本文阐述的取决于各种条件和变量的具体描述、配置或相对比例。本发明实施方案的形式和细节的各种修改对本领域技术人员而言将是显而易见的。因此,可以预期,本发明也应涵盖任何此类修改、变化和等同物。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1