用于准确的平行定量核酸的高灵敏度方法与流程
1.本发明公开内容涉及改进的下一代dna测序方法,用于一种或多种核酸靶的准确且大规模的平行定量。更具体地,本公开内容涉及包含用于检测且定量复杂dna池中的遗传靶的探针的方法和试剂盒,所述复杂dna池主要用于遗传靶和变体检测。本发明使用桥寡核苷酸或桥寡核苷酸复合物和每种遗传靶的一种或多种靶特异性核酸探针(左探针和右探针)。
背景技术:
2.随着研究遗传变异的技术的进步,在植物和动物中对其检测并不复杂。然而,尽管测序成本降低,但特别是在具有弱信号的样品中检测且准确定量遗传变异如突变目前仍是复杂、费力且昂贵的。可以更准确地表述各种问题,例如为了针对一致背景检测遗传信号的特异性、为了检测微弱遗传信号的灵敏度、用于准确定量检测信号的准确度、靶向遗传靶/测定的通量数目、成本/测定,确定当平行测定多重样品时的测定成本规模的缩放,以及确定从取样到结果的时间多长的周转。
3.目前,用于液体活组织检查和概念上相似的测定(如抗生素抗性基因检测)的典型定量方法包括定量pcr(qpcr)、阵列qpcr、数字pcr、多重连接依赖性探针扩增(mlpa)或来自下一代dna测序数据的定量。虽然定量方法是稳固且充分确定的方法,但每种方法都与下文更详细地讨论的具体问题相关:
4.定量pcr:定量pcr(qpcr)是包括在pcr期间(即实时)扩增靶向dna分子的技术。实时pcr可以定量(定量实时pcr)和半定量,即高于/低于一定量的dna分子(半定量实时pcr)使用。定量pcr(qpcr)是遗传靶定量的黄金标准。目前,qpcr反应的实验室成本为大约$2。然而,将用于建立反应的大量动手时间(劳动力成本)、关于标准曲线的需要连同关于每个定量靶的重复计算在内,实际成本事实上要高得多。由于对于每种遗传靶都需要分开的定量实验,因此随着样品数目增加,动手时间的量急剧增加。
5.阵列pcr:pcr阵列是用于分析专注于相关通路或疾病的基因实验对象组表达的最可靠工具。每个96孔板、384孔板或100孔盘pcr阵列都包括sybr green优化的引物测定,用于充分研究集中的基因实验对象组的实验对象组。qpcr技术的较新迭代是使各个qpcr反应小型化的阵列qpcr。阵列pcr降低了各个qpcr反应的成本,并且改善了该方法对多重靶和样品的可缩放性。然而,该方法目前限于对来自12个样品的384种靶(或相反地来自384个样品的12种靶)进行概况分析,以数千美元/芯片的成本加上读出基础设施的大量资本成本。因此,使用前述设置对数千个样品进行概况分析仍然是非常昂贵的。
6.数字pcr:数字聚合酶链反应(数字pcr、digitalpcr、dpcr或depcr)是通过液滴-微流体和荧光检测提供靶的绝对定量的方法。该方法是相对成本效益的(一种靶/样品花费$3左右),但是对于每个样品中的每种靶制备、设置和运行各个实验的动手时间很难扩展到数千个样品。
7.多重连接依赖性探针扩增(mlpa)提供了简化各个样品中的多重遗传靶检测的方
法。然而,mlpa仅提供靶的相对定量,并且需要对于每个样品分开的检测实验。最近以来,mlpa的变体引入来自dna条形码的概念。与传统的mlpa工作流相比,该概念允许更好的定量分辨率和样品多重化。
8.基于下一代测序的方法:下一代测序(ngs),也称为高通量测序,其使得基于序列的基因表达分析成为模拟技术的“数字”替代方案。随着dna测序的成本不断下降,来自下一代dna测序数据的靶计数变得越来越有吸引力,并且目前用于例如nipt筛查中。然而,目前的方法具有高测序文库制备成本和浪费在测序无关遗传靶上的测序工作的缺点。例如,在癌症相关的液体活组织检查中,非靶向方法导致对肿瘤学无关基因座的测序努力的浪费。在胎儿诊断中,基因座的非靶向取样相当大地限制了用于解释数据的统计选项。guardant health inc提供了更靶向的测序方法,其中rna捕获探针的阵列富集了用于下一代dna测序的靶。
9.akhras等人(2007)plos one 2(2):e223公开了多重病原体检测测定,其涉及加上条形码的靶特异性探针、靶环化和测序。还公开了使用桥接寡核苷酸来连接靶特异性探针。
10.wo2018109206描述了使用锁式探针和滚环扩增,用于检测样品中的分析物的方法。没有描述桥接寡核苷酸的使用。
11.wo2019038372描述了下一代测序方法,其中通过体外转录从含有关于t7聚合酶的启动子的连接复合物中选择性地扩增目的靶序列,随后为cdna合成和测序。虽然这种方法允许样品中的许多靶序列的准确和平行的检测和定量,但更复杂、大体积、稀释和/或不纯的样品仍然是挑战性的。
12.因此,鉴于前文讨论,需要通过核酸靶的准确和大规模平行定量来克服上述缺点,例如但不限于特异性、灵敏度、准确度、通量、成本、缩放和周转。
技术实现要素:
13.本发明提供了使用下一代测序,用于来自大体积样品(高达数十毫升)和/或稀释和/或未纯化的样品材料的高灵敏度、可缩放和准确靶定量的方法。此外,避免了如wo2019038372中描述的rna扩增步骤,致使该方法更加简单。
14.在第一个主要方面,本发明涉及用于高通量检测多个样品中的一种或多种靶核苷酸序列的方法,所述方法包括以下步骤:
15.(i)对于每个样品中的每种靶核苷酸序列提供:
16.第一探针、第二探针和桥寡核苷酸或能够彼此退火以形成桥寡核苷酸复合物的多个寡核苷酸,
17.其中所述第一探针从分子的5'端开始包含第一桥寡核苷酸特异性序列、任选的第一序列条形码,以及在第一探针的3'端处的第一靶特异性部分;
18.并且其中所述第二探针从分子的5’端开始包含第二靶特异性部分、任选的第二序列条形码,以及在第二探针的3'端处的第二桥寡核苷酸特异性序列;
19.并且其中所述桥寡核苷酸或桥寡核苷酸复合物含有分别与第一探针和第二探针中的第一桥寡核苷酸特异性序列和第二桥寡核苷酸特异性序列互补的序列,以及任选的第三条形码;
20.并且其中所述第一序列条形码或第二序列条形码或第三条形码中的至少一种分
别存在于第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中;
21.并且其中所述第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中的至少一种包含关于核酸内切酶的识别序列;
22.并且其中任选地,所述第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中的至少一种包含第一捕获部分,
23.(ii)对于一种或多种靶核苷酸序列中的每种,优选地对于分开管中的每个样品,使第一探针和第二探针与桥寡核苷酸或能够形成桥寡核苷酸复合物的多个寡核苷酸接触,并且允许自退火成多个连接复合物;
24.(iii)使待测试靶核苷酸序列的每个样品中存在的核酸与连接复合物接触;
25.(iv)允许第一探针和第二探针分别的第一靶特异性部分和第二靶特异性部分与靶序列上的基本上相邻的区段杂交,从而形成杂交复合物;
26.(v)任选地,使杂交复合物与包含第二捕获部分的固体支持物接触,允许第一捕获部分和第二捕获部分相互作用,使得杂交复合物变得与固体支持物连接,并且将连接有固体支持物的杂交复合物与未连接到固体支持物的样品组分分开;
27.(vi)连接杂交复合物中的探针,以提供经连接的连接复合物;
28.(vii)合并来自多个样品的经连接的连接复合物;
29.(viii)使用链置换聚合酶通过滚环扩增,由一种或多种经连接的连接复合物扩增核酸;
30.(ix)任选地使步骤(viii)中获得的经扩增的一种或多种单链多联体序列经受与含有关于核酸内切酶的识别序列的特异性寡核苷酸的退火,其中所述寡核苷酸与步骤(i)中指定的识别序列退火,使得获得关于核酸内切酶的识别位点;
31.(x)任选地用所述核酸内切酶切割步骤(viii)中获得的单链多联体序列或步骤(ix)中获得的经退火复合物;
32.(xi)使步骤(x)中获得的核酸片段或步骤(viii)中获得的多联体序列经受高通量测序技术,以确定条形码序列;和
33.(xii)通过确定第一靶特异性部分和/或第二靶特异性部分的至少一部分,和/或第一条形码和/或第二条形码的至少一部分,和/或第三条形码的至少一部分,来鉴定多个样品中的靶核苷酸序列的存在和/或数目,
34.其中步骤(vi)和(vii)可以以任何次序执行。
附图说明
35.图1示出了根据本文的一个实施例的多重连接测定(mla)的流程图;
36.图2a示出了根据本文的一个实施例,具有多个探针实体的探针三联体的原理结构;
37.图2b示出了根据本文的一个实施例,填充于第一探针和第二探针之间的间隙。
38.图2c示出了根据本文的一个实施例,填充于第一探针和第二探针与桥复合物之间的间隙。
39.图3示出了在通过限制性核酸内切酶消化之前(泳道2)和之后(泳道1),来自工作流的rca产物。
40.图4示出了通过计数分子条形码从下一代dna测序数据推断的,实验工作流对四个重复反应中对数递减的遗传靶数目的线性应答。每行代表靶序列的三个浓度。应答跨越三个数量级呈线性。
具体实施方式
41.定义:
42.靶核苷酸序列:术语靶核苷酸序列可以是需要检测其的任何目的核苷酸序列。应理解,所给出的术语指邻接核苷酸的序列以及具有互补序列的核酸分子。在一些实施例中,靶序列是代表多态性或与多态性相关的核苷酸序列。
43.多态性:术语多态性指在群体中出现两个或更多个遗传上确定的替代序列或等位基因。多态性标记物或位点是在其处出现序列分歧的基因座。多态性基因座可以小至一个碱基对。
44.样品:术语样品在本文中用于含有两种或更多种靶序列的两个或更多个样品。可以制备如根据本发明的方法中提供的样品,以便至少提取靶核酸并且使得这些靶核酸可由如本发明中使用的探针接近。特别地,在一些实施例中,样品各自包含至少两种不同的靶序列,优选至少100种,更优选至少250种,更优选至少500种,最优选至少2000种或更多种。术语样品可以指但不限于从人体/动物体中获得的两个或更多个样品,包括尿、活组织检查、唾液和其它分泌物、呼出的水分提取物、组织、血浆(液体活组织检查),或者从环境中获得的两个或更多个样品,包括水、废水、土壤、植物,或者含有病毒或细菌的两个或更多个样品等等。在一个实施例中,多个样品包括血液样品、唾液样品、尿样品或粪便样品、另一种体液样品或来自身体材料的提取物例如毛发或皮肤薄片。
45.探针:术语探针是可变长度(通常为50-1000个碱基长,优选50-200个碱基长)的dna或rna片段,其可以用于dna或rna样品中,以检测与探针中的序列互补的核苷酸序列(dna或rna靶)的存在。这样设计与靶序列互补的寡核苷酸探针的区段,使得对于样品中的每种靶序列,提供一对左探针和右探针,其中所述探针各自含有在其末端处的与靶序列的一部分互补的区段。此外,本公开内容描述了桥寡核苷酸或桥寡核苷酸复合物,其用于连接左探针和右探针。
46.通用:当用于描述扩增程序时,术语通用指使得能够将单个引物或引物组用于多个扩增反应的序列。此类引物的使用极大地简化了多重化,因为只需要两个引物来扩增多个选定的核酸序列。当用于描述引发位点时,术语通用是通用引物将与之杂交的位点。还应注意,可以使用通用引发序列/引物“组”。
47.杂交:术语杂交(hybridization)(或杂交(hybridisation))描述了脱氧核糖核酸(dna)或核糖核酸(rna)分子对互补dna或rna退火的过程。dna或rna复制和dna转录成rna两者均依赖核苷酸杂交。
48.连接:术语连接是通过酶的作用连接两个核酸片段。dna连接酶是能够催化在互补链上的相邻位点处结合的两条多核苷酸链(的端部)之间形成磷酸二酯键的酶。在一个实施例中,连接也可以用化学方法执行,特别是如果多核苷酸的两个相邻端部进行修饰以允许化学连接。
49.扩增:如本文使用的术语扩增表示使用dna聚合酶,来增加核苷酸序列的混合物内
的特定核苷酸序列的浓度。“pcr”或“聚合酶链反应”是用于特异性dna/rna区段的体外酶促扩增的快速程序。待扩增的dna/rna可以通过加热样品来变性。术语引物是rna或dna的短链(一般约18-22个碱基),其充当dna合成的起点。它是dna复制所必需的,因为催化这一过程的酶,dna聚合酶,只能将新的核苷酸加入现有的dna链中。
50.聚合酶:聚合酶是合成核酸长链或聚合物的酶。dna聚合酶和rna聚合酶分别通过使用碱基配对相互作用来拷贝dna或rna模板链,用于组装dna和rna分子。
51.高通量:术语高通量表示同时加工且筛选大量dna样品的能力;以及同时筛选单个dna样品内的大量不同遗传基因座的能力。高通量测序或筛选,经常缩写为hts,是用于尤其与同时有效筛选大量样品有关的科学实验的方法。
52.核酸内切酶:核酸内切酶是在随机或指定位置处切割dna双链或单链的酶。
53.如上所述,本公开内容涉及通过利用连接依赖性测定,在非常大量的样品中高通量检测靶核苷酸序列检测的方法。本公开内容提供了使用由下一代测序所允许的技术,用于确定复杂核酸池中的遗传靶序列的方法。本公开内容还提供了通过利用连接依赖性测定,对大量样品,优选非常大量的样品中的多重遗传靶进行概况分析的方法。本公开内容提供了用于多重连接依赖性探针扩增的方法,使得能够查询多个样品中的不同靶核酸。本发明的方法对于不同的靶核酸提供多个不同的探针组,允许多个样品中的一种或多种靶核苷酸序列的测序。在处理测序数据时,独特的序列标识符用于遗传靶的鉴定和来自样品池的各个样品的绝对定量。
54.在第一个主要方面,本发明涉及用于高通量检测多个样品中的一种或多种靶核苷酸序列的方法,所述方法包括以下步骤:
55.(i)对于每个样品中的每种靶核苷酸序列提供:
56.第一探针、第二探针和桥寡核苷酸或能够彼此退火以形成桥寡核苷酸复合物的多个寡核苷酸,
57.其中所述第一探针从分子的5'端开始包含第一桥寡核苷酸特异性序列、任选的第一序列条形码,以及在第一探针的3'端处的第一靶特异性部分;
58.并且其中所述第二探针从分子的5’端开始包含第二靶特异性部分、任选的第二序列条形码,以及在第二探针的3'端处的第二桥寡核苷酸特异性序列;
59.并且其中所述桥寡核苷酸或桥寡核苷酸复合物含有分别与第一探针和第二探针中的第一桥寡核苷酸特异性序列和第二桥寡核苷酸特异性序列互补的序列,以及任选的第三条形码;
60.并且其中所述第一序列条形码或第二序列条形码或第三条形码中的至少一种分别存在于第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中;
61.并且其中所述第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中的至少一种包含关于核酸内切酶的识别序列;
62.并且其中任选地,所述第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中的至少一种包含第一捕获部分,
63.(ii)对于一种或多种靶核苷酸序列中的每种,优选地对于分开管中的每个样品,使第一探针和第二探针与桥寡核苷酸或能够形成桥寡核苷酸复合物的多个寡核苷酸接触,并且允许自退火成多个连接复合物;
64.(iii)使待测试靶核苷酸序列的每个样品中存在的核酸与连接复合物接触;
65.(iv)允许第一探针和第二探针分别的第一靶特异性部分和第二靶特异性部分与靶序列上的基本上相邻的区段杂交,从而形成杂交复合物;
66.(v)任选地,使杂交复合物与包含第二捕获部分的固体支持物接触,允许第一捕获部分和第二捕获部分相互作用,使得杂交复合物变得与固体支持物连接,并且将连接有固体支持物的杂交复合物与未连接到固体支持物的样品组分分开;
67.(vi)连接杂交复合物中的探针,以提供经连接的连接复合物;
68.(vii)合并来自多个样品的经连接的连接复合物;
69.(viii)使用链置换聚合酶通过滚环扩增由一种或多种经连接的连接复合物扩增核酸;
70.(ix)任选地使步骤(viii)中获得的经扩增的一种或多种单链多联体序列经受与含有关于核酸内切酶的识别序列的特异性寡核苷酸的退火,其中所述寡核苷酸与步骤(i)中指定的识别序列退火,使得获得关于核酸内切酶的识别位点;
71.(x)任选地用所述核酸内切酶切割步骤(viii)中获得的单链多联体序列或步骤(ix)中获得的经退火复合物;
72.(xi)使步骤(x)中获得的核酸片段或步骤(viii)中获得的多联体序列经受高通量测序技术,以确定条形码序列;和
73.(xii)通过确定第一靶特异性部分和/或第二靶特异性部分的至少一部分,和/或第一条形码和/或第二条形码的至少一部分,和/或第三条形码的至少一部分,来鉴定多个样品中的靶核苷酸序列的存在和/或数目,
74.其中步骤(vi)和(vii)可以以任何次序执行。
75.图1提供了本发明的方法的一个实施例的非限制性图示。
76.本发明的方法利用三种核酸探针,其中两种靶特异性核酸探针(左探针和右探针)对于遗传靶是特异性的,并且一种核酸探针通常是通用的(桥寡核苷酸或桥寡核苷酸复合物)。左探针和右探针与桥探针或桥寡核苷酸复合物杂交,形成连接复合物。在样品dna或rna上具有靶鉴定位点的连接复合物(含有一个或多个条形码序列)被允许针对查询样品的互补靶序列杂交。在杂交后,左探针和右探针用化学方法进行连接或通过dna连接酶进行酶促连接,以形成连接的连接复合物。在本发明中,在待分析的多个样品中的样品分析期间,将形成多个此类经连接的连接复合物。
77.在一个实施例中,“多个样品”可以指但不限于从人体或动物体中获得的两个或更多个样品,包括活组织检查、唾液和其它分泌物、呼出的水分提取物、组织、血浆(液体活组织检查),从环境中获得的两个或更多个样品,包括水、废水、土壤、植物,或者含有病毒或细菌的两个或更多个样品等等。在一个实施例中,样品无需任何事先纯化或核酸浓缩而使用。在另一个实施例中,样品可以进行预处理,例如使细胞裂解以暴露核酸。
78.靶序列可以包括需要针对其检测的任何感兴趣的核苷酸序列。本公开内容的靶核苷酸序列可以得自(但不限于)患者的血液中的dna级分或母体血液中的dna级分。患者的血液中的dna级分可能得自凋亡/坏死的癌细胞,或者来自胎儿和/或母体起源的母体血液中的dna级分。进一步地,分析结果用于例如评价个体患给定类型癌症的风险,确定给定治疗针对给定癌症的功效,在肿瘤中的药物抗性有关突变的发展,或胎儿携带遗传病症例如常
见的三体综合征唐氏综合征、帕陶综合征(patau)和爱德华综合征的风险。在某些实施例中,该方法包括对于每种靶核苷酸序列提供多个不同的探针组。
79.如本文使用的,术语探针组包括第一探针、第二探针和桥寡核苷酸或桥寡核苷酸复合物。
80.在某些实施例中,第一探针从分子的5'端开始包括任选的5'磷酸盐、第一桥寡核苷酸特异性序列、任选的第一通用序列、任选的第一序列条形码,以及在其3'端处的第一靶特异性部分。在某些实施例中,第二探针从分子的5’端开始包括任选的5'磷酸盐、第二靶特异性部分、任选的第二序列条形码、任选的第二通用序列,以及在其3'端处的第二桥寡核苷酸特异性序列。
81.在一个优选的实施例中,第一探针或第二探针含有第一序列条形码或第二序列条形码中的至少一种。第一序列条形码或第二序列条形码或两者,可以是随机序列或者可以含有靶核苷酸序列标识符序列、样品标识符序列和/或用于靶计数的分子条形码。
82.在优选的实施例中,桥寡核苷酸或桥寡核苷酸复合物含有分别与第一探针和第二探针中的第一桥寡核苷酸特异性序列和第二桥寡核苷酸特异性序列互补的序列,任选的通用序列,和/或可以含有第三条形码,其可以是随机序列或者可以含有样品或序列标识符序列。在这方面,第三条形码并不一定意味着已经存在第一条形码和第二条形码。如较早描述的,经连接的连接复合物中应该存在至少一种条形码,其使得能够独特地定义在测试的所有样品中的所有连接复合物内的该复合物。
83.此外,第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中的至少一种包含关于核酸内切酶的识别序列。识别序列是步骤(x)中的多联体序列切割所必需的。在一个实施例中,识别序列是关于限制性核酸内切酶如ecori的识别序列。在另一个实施例中,识别序列是关于归巢核酸内切酶如i-ceui的识别序列。在另一个实施例中,识别序列是关于引导dnaasei或crispr-cas样切割系统的识别序列。
84.任选地,第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中的至少一种包含第一捕获部分。当在本文中使用时,第一捕获部分指允许探针、连接复合物或杂交复合物由连接到固体支持物的第二捕获部分捕获,即与之结合的部分,例如化学基团。本领域已知的任何合适的捕获部分都可以用于此目的。众所周知的合适例子是使用链霉亲和素包被的磁珠捕获生物素化的分子。因此,在一个实施例中,第一捕获部分是生物素部分,其可以与连接到固体支持物如磁珠的链霉亲和素或亲和素部分(第二捕获部分)相互作用。其它选项包括可以用于与链霉亲和素/亲和素缀合的生物素衍生物,例如双生物素、脱硫生物素或光可切割生物素。进一步的选项包括使用硫醇和丙烯酸酯基团用于丙烯酸酯/丙烯酰胺缀合,使用炔烃和叠氮基用于点击化学,以及使用地高辛配基用于抗地高辛配基抗体缀合。缀合配偶体可以在任何固体表面例如珠(磁性或其它方式)或固体支持物上提供。
85.第一靶特异性部分、第二靶特异性部分、第一桥寡核苷酸特异性序列和/或第二桥寡核苷酸特异性序列,优选彼此独立地含有至少一种化学修饰的核苷酸以增加探针结合。增加探针结合的化学修饰包括但不限于核糖核酸、肽核酸和锁核酸(例如,如通过引用并入本文的wo2019038372的图3中所示)。在一个实施例中,第一探针或第二探针或两者的桥接部分包含化学修饰的碱基,以改善与桥寡核苷酸或桥寡核苷酸复合物的结合。在另一个实施例中,第一靶特异性部分、第二靶特异性部分、第一桥寡核苷酸特异性序列和/或第二桥
寡核苷酸特异性序列,彼此独立地含有一种或多种化学修饰的核苷酸。在某些实施例中,化学修饰允许相邻探针的化学连接。在一些实施例中,前述探针结合完全相邻的遗传基因座或相隔至多500个碱基对,例如相隔至多200个碱基对,例如相隔至多50个碱基对,优选相隔至多40个碱基对,更优选相隔至多30个碱基对,更优选相隔至多20个碱基对,更优选相隔至多10个碱基对,最优选相隔至多5个碱基对。
86.在一些实施例中,第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物可以包括用于dna测序平台例如(但不限于)illumina的接头序列。这些接头序列允许所得到的测序文库与测序装置的检测部分(例如illumina流动槽)结合。
87.此外,在一些实施例中,桥寡核苷酸或桥寡核苷酸复合物包含:
88.(i)一至五个3'突出碱基(即不与第二探针形成双螺旋的另外碱基),和/或
89.(ii)3'磷酸盐,和/或
90.(iii)在自3'端的三个位置内的一个或多个硫代磷酸酯修饰。
91.在使探针与包含靶序列的样品接触之前,优选地对于分开管中的每个样品,使第一探针和第二探针与桥寡核苷酸或能够形成桥寡核苷酸复合物的多个寡核苷酸接触,并且允许自退火成连接复合物(步骤(ii))。在其中桥不是一个寡核苷酸,而是能够彼此退火以形成桥寡核苷酸复合物的多个寡核苷酸,例如三个或五个寡核苷酸(本文在图2c中示出)的一个实施例中,多个寡核苷酸可以在与第一探针和第二探针退火之前进行预退火,或所有退火步骤可以一次完成。
92.优选地,每种连接复合物对于第一靶特异性序列、第二靶特异性序列和一种或多种条形码序列的组合是独特的。这使得能够在扩增和分析结果后计数靶序列。
93.此后,使多个样品中的一种或多种靶核苷酸序列与多个连接复合物接触(步骤(iii))。第一探针和第二探针分别的第一靶特异性部分和第二靶特异性部分与靶序列上的基本上相邻的区段杂交,从而形成杂交复合物(步骤(iv))。在一些实施例中,样品具有多于100微升,例如多于1ml的体积。在一个进一步的实施例中,样品具有低于5pmol,例如低于1pmol,例如低于200fmol的核酸浓度。在一个实施例中,多个样品包括一个或多个血液样品、一个或多个唾液样品、一个或多个尿样品或者一个或多个粪便样品。
94.随后,在一些实施例中,如果第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中的至少一种包含第一捕获部分,则使杂交复合物与包含第二捕获部分的固体支持物接触,并且允许第一捕获部分和第二捕获部分相互作用,使得杂交复合物变得与固体支持物连接(任选的步骤(v))。此后,将连接有固体支持物的杂交复合物与未连接到固体支持物的样品组分分开。如果固体支持物是磁珠,则可以使用磁体来固定珠,并且可以去除剩余的液体样品。任选地,在进行之前执行洗涤步骤。
95.步骤(v)引起核酸的纯化和富集,改善特别是对于高度不纯的样品的结果。在一个实施例中,本发明的方法并不包括在步骤(v)之前富集核酸的步骤。因此,在一个实施例中,该方法在步骤(vi)之前并不含有其中原始样品中的核酸被浓缩超过2倍、超过10倍或超过100倍的步骤。在另一个实施例中,本发明的方法并不包括在步骤(vi)中的连接之后的纯化步骤。
96.随后,用酶促或化学方法进行所形成的杂交复合物中的探针连接,以提供经连接的连接复合物(步骤(vi))。任选地,作为步骤(vi)的一部分,在第一探针和第二探针之间的
间隙(如果存在的话)可以通过引入聚合酶和一种或多种核苷酸进行填充。聚合酶添加(a)与通用桥寡核苷酸序列互补的核苷酸和/或(b)与条形码序列互补的核苷酸,从而填充第一探针和第二探针之间的两个间隙,引起连接的左探针和右探针以及通用序列和/或第三条形码序列包括到桥互补链内。桥寡核苷酸或桥寡核苷酸复合物从与连接探针互补的5'位点或3'位点延伸,使得存在于第一探针或第二探针中的靶序列标识符序列整合到桥寡核苷酸或桥寡核苷酸复合物内。优选地,使用不破坏双链dna的聚合酶,例如taq聚合酶,以便在第一探针和第二探针两者对靶序列退火时,不干扰第一探针与第二探针的连接。
97.然后合并来自一个或多个靶样品的所连接的连接复合物(步骤(vii))。步骤(vi)和(vii)可以以指定的次序执行,或可替代地以相反的次序执行。
98.接下来,由一种或多种经连接的连接复合物扩增核酸(步骤(viii))。使用链置换聚合酶通过滚环扩增来执行扩增,所述链置换聚合酶例如phi29聚合酶(uniprotkb-p03680;dpol_bpph2)或bst聚合酶(p52026;dpo1_geose)。在随后的步骤(ix)中,任选地使步骤(viii)中获得的经扩增的一种或多种单链多联体序列经受与含有关于核酸内切酶的识别序列的特异性寡核苷酸的退火,其中所述寡核苷酸与步骤(i)中指定的所述识别序列退火,使得获得关于核酸内切酶的识别位点。含有识别序列的特异性寡核苷酸通常含有在识别序列周围的一些另外的特异性序列,以便允许形成稳定的双螺旋用于切割。
99.随后,任选地用所述核酸内切酶切割步骤(viii)中获得的单链多联体序列或步骤(ix)中获得的退火复合物(步骤(x)),产生ngs文库。
100.任选地,在扩增后,去除固体支持物(如果存在的话)并且将上清液用于后续加工。例如,如果固体支持物是磁性颗粒,则这些磁性颗粒可以使用磁体去除。在本发明的方法的一些其它实施例中,第一捕获部分和第二捕获部分之间的相互作用在步骤(vi)之后、在步骤(vii)之后或在步骤(viii)之后立即被破坏。例如,如果第一捕获部分是生物素,而第二捕获部分是链霉亲和素,则可以通过添加过量的可溶性生物素来破坏相互作用。如果链霉亲和素与磁性颗粒结合,则它随后可以使用磁体去除。
101.此外,任选地,使用与第一探针和第二探针的通用部分结合的引物,在步骤(x)和步骤(xi)之间执行pcr扩增,其中所述引物任选地包括用于步骤(xi)中的后续测序的接头序列。
102.例如使用包括但不限于illumina iseq、miseq、hiseq、nextseq或novaseq的下一代测序平台,通过高通量测序技术,通过确定第一靶特异性部分和/或第二靶特异性部分的至少一部分、第一条形码和/或第二条形码的至少一部分,和/或第三条形码的至少一部分,可以执行多个样品中的靶核苷酸序列的存在和/或数目的鉴定(步骤(xi)和(xii))。优选地,通过计数每种靶和每个样品的分子条形码数目来允许遗传靶计数。样品从序列数据中分离(解卷积),并且在dna测序后在计算机芯片上(in silico)定量序列靶。
103.在一个优选的实施例中,分子用第一引物和第二引物进行进一步扩增,以提供扩增产物。优选地,使用通用第一引物和通用第二引物,它们与连接复合物中存在的第一通用序列或第二通用序列反向互补。
104.本发明的优点包括但不限于与传统核酸测序技术相比,具有低成本、高简单性、高特异性、高灵敏度、高准确度、高通量、高可缩放性和高周转的定量测定。本发明的另一个方面是本发明的方法允许多重样品包括人和动物群体,并且包括大体积的未纯化的样品材料
中的多个核酸靶的准确和大规模平行定量。如提到的,在一个优选的实施例中,样品例如尿样品无需任何事先纯化或核酸浓缩而使用。在另一个实施例中,样品可以进行预处理,例如使细胞裂解以暴露核酸。本发明的一个特别优点在于使得能够使用独特的探针设计,即探针三联体来检测和扩增感兴趣的靶序列。探针被设计为具有特别放置的经修饰核苷酸,其改善了退火和结合效率。结合性质的改善带来更高的测定特异性、灵敏度和准确度。本发明的方法同样适用于研究遗传变体且可应用于诊断和预后,包括但不限于关于一种或多种序列和/或多态性例如snp和/或插入缺失、癌症诊断或来自母体血液的胎儿染色体病症,对样品进行基因分型。在一个优选的实施例中,对于两个或更多个样品或者两个或更多个基因座/等位基因组合,条形码序列用于关于一种或多种序列和/或多态性例如snp和/或插入缺失,对样品进行基因分型。
105.在另一个方面,本发明提供了包括多个容器的多部分试剂盒(kit of parts),其中至少一个容器包含一组或多组的第一探针和第二探针,并且至少一个容器包含一种或多种桥寡核苷酸或能够彼此退火以形成桥寡核苷酸复合物的多个寡核苷酸,
106.其中所述第一探针从分子的5'端开始包含第一桥寡核苷酸特异性序列、任选的第一序列条形码,以及在第一探针的3'端处的第一靶特异性部分;
107.其中所述第二探针从分子的5’端开始包含第二靶特异性部分、任选的第二序列条形码,以及在第二探针的3'端处的第二桥寡核苷酸特异性序列;
108.其中所述桥寡核苷酸或桥寡核苷酸复合物包含分别与第一探针和第二探针中的第一桥寡核苷酸特异性序列和第二桥寡核苷酸特异性序列互补的序列,以及任选的第三条形码;
109.其中所述第一序列条形码或第二序列条形码或第三条形码中的至少一种分别存在于第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中;
110.其中所述第一探针或者第二探针或者桥寡核苷酸或桥寡核苷酸复合物中的至少一种包含关于核酸内切酶的识别序列;
111.并且其中所述多部分试剂盒进一步包含能够与所述识别序列退火的寡核苷酸,使得获得关于所述核酸内切酶的识别位点。
112.优选地,第一探针的3'端或第二探针的5'端或两者进行了修饰,以允许第一探针与第二探针的化学连接。
113.优选地,桥寡核苷酸或桥寡核苷酸复合物在与第一探针的序列互补的序列中或在与第二探针的序列互补的序列中或两者中包含一种或多种化学修饰的核苷酸。
114.优选地,第一探针的3'端或第二探针的5'端或两者进行了修饰,以允许第一探针与第二探针的化学连接。
115.优选地,第一探针或第二探针或两者的桥接部分包含化学修饰的碱基,以改善与桥寡核苷酸或桥寡核苷酸复合物的结合。
116.在一个具体实施例中,包含第一探针和第二探针组的至少一个容器,以及包含桥寡核苷酸或能够彼此退火以形成桥寡核苷酸复合物的多个寡核苷酸的至少一个容器是同一个容器。在此类情况下,三种探针可以预先退火并且已形成连接复合物。
117.本发明的一个特别优点在于使得能够使用独特的探针设计,即探针三联体来检测和扩增感兴趣的靶序列。探针被设计为具有改善的结合性质,带来更高的测定特异性、灵敏
度和准确度。本发明可应用于分子生物学、进化生物学、宏基因组学、基因分型领域,并且更具体而言(但不限于)癌症诊断或胎儿染色体病症,包括但不限于关于一种或多种序列和/或多态性例如snp和/或插入缺失,对样品进行基因分型。
118.在一个特别优选的实施例中,桥寡核苷酸或桥寡核苷酸复合物包含鉴定样品的信息并且包括独特条形码。在此类情况下,第一探针和第二探针通用地适用于所有样品(并且仅包含鉴定靶的信息)。因此,在一个优选的实施例中,提供了根据本发明的方法或试剂盒,其中所述桥寡核苷酸或桥寡核苷酸复合物包含条形码,其包含使得能够计数每个样品的靶序列的独特序列。
119.此外,本发明涉及:
120.实施例1:一种用于高通量检测多个样品中的一种或多种靶核苷酸序列的方法,所述方法包括以下步骤:
121.(i)对于每个样品中的每种靶核苷酸序列提供:
122.第一探针、第二探针和桥寡核苷酸,
123.其中所述第一探针从分子的5'端开始包含第一桥寡核苷酸特异性序列、任选的第一序列条形码,以及在第一探针的3'端处的第一靶特异性部分;
124.并且其中所述第二探针从分子的5’端开始包含第二靶特异性部分、任选的第二序列条形码,以及在第二探针的3'端处的第二桥寡核苷酸特异性序列;
125.并且其中所述桥寡核苷酸含有分别与第一探针和第二探针中的第一桥寡核苷酸特异性序列和第二桥寡核苷酸特异性序列互补的序列,以及任选的第三条形码;
126.并且其中所述第一序列条形码或第二序列条形码或第三条形码中的至少一种分别存在于第一探针或第二探针或桥寡核苷酸中;
127.并且其中所述第一探针或第二探针或桥寡核苷酸中的至少一种包含关于核酸内切酶的识别序列;
128.并且其中任选地,所述第一探针或第二探针或桥寡核苷酸中的至少一种包含第一捕获部分,
129.(ii)对于一种或多种靶核苷酸序列中的每种,优选地对于分开管中的每个样品,使第一探针和第二探针与桥寡核苷酸接触,并且允许自退火成多个连接复合物;
130.(iii)使待测试靶核苷酸序列的每个样品中存在的核酸与连接复合物接触;
131.(iv)允许第一探针和第二探针分别的第一靶特异性部分和第二靶特异性部分与靶序列上的基本上相邻的区段杂交,从而形成杂交复合物;
132.(v)任选地,使杂交复合物与包含第二捕获部分的固体支持物接触,允许第一捕获部分和第二捕获部分相互作用,使得杂交复合物变得与固体支持物连接,并且将连接有固体支持物的杂交复合物与未连接到固体支持物的样品组分分开;
133.(vi)连接杂交复合物中的探针,以提供经连接的连接复合物;
134.(vii)合并来自多个样品的经连接的连接复合物;
135.(viii)使用链置换聚合酶通过滚环扩增由一种或多种经连接的连接复合物扩增核酸;
136.(ix)任选地使步骤(viii)中获得的经扩增的一种或多种单链多联体序列经受与含有关于核酸内切酶的识别序列的特异性寡核苷酸的退火,其中所述寡核苷酸与步骤(i)
中指定的识别序列退火,使得获得关于所述核酸内切酶的识别位点;
137.(x)用所述核酸内切酶切割步骤(viii)中获得的单链多联体序列或步骤(ix)中获得的经退火复合物;
138.(xi)使步骤(x)中获得的核酸片段经受高通量测序技术,以确定条形码序列;和
139.(xii)通过确定第一靶特异性部分和/或第二靶特异性部分的至少一部分,和/或第一条形码和/或第二条形码的至少一部分,和/或第三条形码的至少一部分,来鉴定多个样品中的靶核苷酸序列的存在和/或数目,
140.其中步骤(vi)和(vii)可以以任何次序执行。
141.实施例2:根据实施例1的方法,其中所述多个样品包括血液样品、唾液样品、尿样品或粪便样品。
142.实施例3:根据实施例1或2的方法,其中所述第一探针或第二探针或桥寡核苷酸中的至少一种包含第一捕获部分,其中所述方法包括步骤(v),并且其中所述方法在步骤(v)之前并不包括富集核酸的步骤。
143.实施例4:根据实施例1-3中任一项的方法,其中所述第一探针或第二探针或桥寡核苷酸中的至少一种包含第一捕获部分,其中所述方法包括步骤(v),并且其中所述第一捕获部分是生物素部分,并且所述第二捕获部分是链霉亲和素部分或亲和素部分。
144.实施例5:根据实施例1-4中任一项的方法,其中所述第一探针或第二探针或桥寡核苷酸中的至少一种包含第一捕获部分,其中所述方法包括步骤(v),并且其中在步骤(v)和(vi)之间执行洗涤步骤。
145.实施例6:根据实施例1-5中任一项的方法,其中所述桥寡核苷酸包含:
146.(i)一至五个3'突出碱基,和/或
147.(ii)3'磷酸盐,和/或
148.(iii)在自3'端的三个位置内的一个或多个硫代磷酸酯修饰。
149.实施例7:根据实施例1-6中任一项的方法,其中所述第一探针的3'端或第二探针的5'端或两者进行了修饰,以允许第一探针与第二探针的化学连接。
150.实施例8:根据实施例1-7中任一项的方法,其中所述第一探针或第二探针或两者的桥接部分包含化学修饰的碱基,以改善与桥寡核苷酸的结合。
151.实施例9:根据实施例1-8中任一项的方法,其中所述第一靶特异性部分、第二靶特异性部分、第一桥寡核苷酸特异性序列和/或第二桥寡核苷酸特异性序列,彼此独立地含有一种或多种化学修饰的核苷酸。
152.实施例10:根据实施例1-9中任一项的方法,其中步骤(viii)使用phi29聚合酶或bst聚合酶来执行。
153.实施例11:根据权利要求1-9中任一项的方法,其中使用与第一探针和第二探针的通用部分结合的引物,在步骤(x)和步骤(xi)之间执行pcr扩增,其中所述引物任选地包括用于步骤(xi)中的后续测序的接头。
154.实施例12:根据实施例1-11中任一项的方法,其中通过计算每种靶和每个样品的分子条形码数目来允许遗传靶计数。
155.实施例13:根据实施例1-12中任一项的方法,其中对于两个或更多个样品或者两个或更多个基因座/等位基因组合,条形码序列用于关于一种或多种序列和/或多态性例如
snp和/或插入缺失,对样品进行基因分型。
156.实施例14:包括多个容器的多部分试剂盒,其中至少一个容器包含一组或多组的第一探针和第二探针,并且至少一个容器包含一种或多种桥寡核苷酸,
157.其中所述第一探针从分子的5'端开始包含第一桥寡核苷酸特异性序列、任选的第一序列条形码,以及在第一探针的3'端处的第一靶特异性部分;
158.其中所述第二探针从分子的5’端开始包含第二靶特异性部分、任选的第二序列条形码,以及在第二探针的3'端处的第二桥寡核苷酸特异性序列;
159.其中所述桥寡核苷酸包含分别与第一探针和第二探针中的第一桥寡核苷酸特异性序列和第二桥寡核苷酸特异性序列互补的序列,以及任选的第三条形码;
160.其中所述第一序列条形码或第二序列条形码或第三条形码中的至少一种分别存在于第一探针或第二探针或桥寡核苷酸中;
161.并且其中所述第一探针或第二探针或桥寡核苷酸中的至少一种包含关于核酸内切酶的识别序列;
162.并且其中所述多部分试剂盒进一步包含能够与所述识别序列退火的寡核苷酸,使得获得关于所述核酸内切酶的识别位点。
163.实例
164.方法
165.1.探针复合物的形成
166.探针复合物含有基因组靶向、样品索引和构建illumina测序文库所需的序列。
167.允许形成三部分探针复合物(如图2中所示),其包含:
168.(a)第一探针,其从分子的5'端开始具有第一桥寡核苷酸特异性序列以及在第一探针的3'端处的第一靶特异性部分;
169.(b)第二探针,其从分子的5'端开始具有第二靶特异性部分、第二序列条形码,以及在第二探针的3'端处的第二桥寡核苷酸特异性序列;
170.以及(c)桥寡核苷酸,其具有分别与所述第一探针和第二探针中的第一桥寡核苷酸特异性序列和第二桥寡核苷酸特异性序列互补的序列,
171.通过在退火反应中以等摩尔量组合所有三个部分(桥、右臂和左臂)来构建探针复合物。反应在热循环仪中进行(表1中的退火程序)。
172.表1.
[0173][0174]
2.靶捕获
[0175]
靶向含有感兴趣的突变的特异性基因组区域。纯化的dna(例如来自组织、血浆、尿或唾液)可以用作样品,或者样品可以是未纯化的,而是仅例如通过煮沸和/或离心进行预处理。
[0176]
探针复合物经由碱基序列互补相互作用与靶区域杂交。为了开始靶捕获,将反应探针和靶dna混合并在热循环仪中温育(表2中的靶捕获和gapfill程序)。
[0177]
表2.
[0178][0179]
3.gapfill反应
[0180]
在靶捕获后,通过添加phusion dna聚合酶、核苷酸和ampligase dna连接酶的组合,并且在+45℃下温育45分钟,使探针复合物延伸并连接。
[0181]
4.滚环扩增
[0182]
在延伸和连接后,使环状探针分子经受滚环扩增(rca)。对于rca反应,使靶捕获反应与含有equipphi29(thermo scientific)聚合酶的rca反应混合物混合。使反应在+42℃下温育30分钟-2小时。在rca反应后,通过用qubit荧光计测量单链dna(ssdna)的浓度来分析反应效率。
[0183]
5.酶促消化
[0184]
rca反应产生具有靶文库的多重拷贝的长多联体ssdna分子。每个完整的靶文库由ecori限制性酶识别序列分开。该序列允许经由与含有ecori限制性酶识别序列的特异性寡核苷酸退火来序列特异性切割长多联体,并释放准备好的靶文库。这些文库在简单的纯化步骤后准备好用于进一步分析。rca产物在+37℃下用ecori消化1小时。
[0185]
6.文库纯化
[0186]
在ecori消化后,文库分子通过在电泳后从琼脂糖凝胶中提取或用大小选择珠(例如macherey nagel nucleomag)进行纯化。
[0187]
7.测序
[0188]
使纯化的miseq或iseq100相容文库经受使用最先进的测序仪器的序列分析。重要的是,可以通过简单的寡核苷酸修饰,将文库转换为适合任何可用的测序平台。使用unix命令行工具以及python和r编程语言的组合来处理测序数据。简言之,关于序列处理的基本原理是鉴定每个读数内的探针序列,对它们之间的基因组区域进行测序,并且计数与每种遗传靶相关的分子条形码数目。
[0189]
实验1.
[0190]
在第一个实验中,探针混合物是四种不同索引探针的集合,带来四个重复反应。它们靶向eml-alk融合物。靶寡核苷酸具有允许鉴定每种靶的独特识别序列。
[0191]
作为样品,三种合成靶寡核苷酸以对数渐增的浓度混合。如上所述进行靶捕获、延伸和连接反应、滚环扩增和后续用ecori的消化。典型结果的例子显示于图3中。
[0192]
用miseq和iseq100仪器对准备好的文库进行测序,并且通过匹配每个读数内的探针序列,鉴定探针序列之间的基因组序列区域并计数分子条形码,在序列数据内检测靶区域。计数数据准确地反映了掺料模板分子的数目,并且检测到的信号对于靶分子的存在是高度特异性的(图4)。
[0193]
图1和图2的详细描述
[0194]
图1示出了本发明的一个实施例的工作流。在步骤1中,使样品(102)内的核酸(dna或rna)与一组连接复合物(104)接触。连接复合物在靶核酸(106)上退火。在步骤2中,任选地从样品材料中捕获靶结合的连接复合物,留下样品杂质(103)。在步骤3中,将退火的连接复合物连接,得到经连接的连接复合物。在步骤4中,将来自多重样品(110)的经连接的连接复合物合并在一起(112)。在步骤5中,使用phi29聚合酶或其它链置换聚合酶,通过滚环扩增来扩增探针序列,得到探针的长多联体拷贝(116)。在步骤6中,多联体探针拷贝任选地使用限制性核酸内切酶如ecori或归巢核酸酶如i-ceui切割成单体单元,并且任选地使用pcr或乳液pcr进行进一步扩增(117)。在步骤7中,使用下一代dna测序对扩增的dna进行测序。在步骤8中,使用生物信息学管道,将dna测序结果转换成靶计数。
[0195]
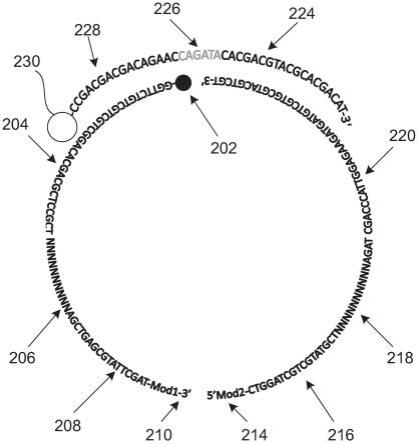
图2a示出了根据本文的一个实施例,具有多个探针实体的探针三联体的原理结构。多个探针实体包括在样品退火之前组装的左探针、右探针和桥寡核苷酸。左探针的第一个碱基任选地包括用于酶促连接的磷酸盐部分或允许化学连接到相邻探针的5'端的修饰,称为修饰1(202)。左探针的15-25个碱基包括桥结合序列1(204),其可以进一步包括用于有效桥寡核苷酸结合的化学修饰碱基,称为桥位点1。左探针进一步任选地包括自5'端的随后10-20个碱基,其包括形成分子特异性条形码或样品特异性条形码的随机核苷酸区段,称为条形码1(206)。左探针进一步包括自5'端的与遗传靶结合的随后15-30个碱基(208)。204或
208的一些或全部核苷酸可以包括增加探针对靶或桥寡核苷酸(228)的亲和力的化学修饰。左探针的最后一个碱基任选地包括用于酶促连接的磷酸盐部分或允许化学连接到相邻探针的5'端的修饰,称为修饰1(210)。
[0196]
右探针的第一个碱基任选地包括用于酶促连接的磷酸盐部分或允许化学连接到相邻探针的5’端的修饰,称为修饰2(214)。自右探针的5’端的15-30个碱基包括与遗传靶结合的右探针的一部分(216)。自右探针的5'端的随后10-20个碱基任选地包括随机核苷酸区段,其形成分子特异性条形码或样品特异性条形码,称为条形码2(218)。右探针的最后15-25个碱基包括用于有效桥寡核苷酸结合的序列,称为桥序列2(220)。204、208、216或220的一些或全部核苷酸可以包括增加探针对靶或桥寡核苷酸的亲和力的化学修饰。
[0197]
自桥寡核苷酸的5’端的前15-25个碱基,称为桥序列3(228),与左探针的桥序列1(204)反向互补,并且任选地包括化学修饰的核苷酸用于增加结合。桥的最后15-25个碱基,称为桥序列2(224),与右探针的桥序列2(220)序列反向互补,并且任选地包括化学修饰的核苷酸用于增加结合。此处的桥接序列包括关于限制性核酸内切酶如ecori或归巢核酸内切酶如i-ceui的识别位点(226)。桥寡核苷酸的5'端任选地包括用于捕获连接复合物的捕获部分(230)。
[0198]
图2b示出了根据本文的一个实施例,填充于第一探针和第二探针之间的间隙。此处,桥寡核苷酸含有在桥序列1(228)和桥序列2(224)之间的间隙1。探针1和2的靶结合部分(208和216)之间形成间隙2。通过引入聚合酶和一种或多种核苷酸来填充这些间隙。对于这个过程,可以使用stoffel片段、taq聚合酶或phusion聚合酶以及dna连接酶(例如ampligase)的混合物。聚合酶添加(a)与通用桥寡核苷酸序列互补的核苷酸和(b)与靶序列互补的核苷酸,从而填充两个间隙,即第一探针和第二探针之间的间隙1和间隙2,并且dna连接酶的后续作用使得与桥寡核苷酸和靶序列互补的左探针和右探针连接成环状复合物。
[0199]
图2c示出了根据本文的一个实施例,具有多个探针实体的探针五联体(quintet)的原理结构。多个探针实体包括左探针、右探针以及由三个寡核苷酸组成的桥。此处,探针复合物含有在左探针和第二桥(228和236)之间、在第二桥和右探针(240和222)之间、在第一桥寡核苷酸和第三桥寡核苷酸(238和242)之间,以及在左探针和右探针(208和216)之间的间隙。通过引入聚合酶和一种或多种核苷酸来填充这些间隙。对于这个过程,可以使用stoffel片段、taq聚合酶或phusion聚合酶以及dna连接酶(例如ampligase)的混合物。聚合酶填充这些间隙,并且dna连接酶的后续作用使得探针和桥寡核苷酸连接成环状复合物。
[0200]
左探针的15-25个碱基包括桥结合序列1(228),其任选地包括用于有效桥寡核苷酸结合的化学修饰碱基,称为桥序列1。左探针进一步任选地包括自5'端的随后10-20个碱基,其包括用于文库索引的通用序列(204)。左探针进一步任选地包括自5'端的随后10-20个碱基,其包括形成分子特异性条形码或样品特异性条形码的随机核苷酸区段,称为条形码1(206)。左探针进一步包括自5'端的遗传靶结合的随后15-30个碱基(208)。228的一些或全部核苷酸可以包括增加探针对靶或桥(226)的亲和力的化学修饰。左探针的最后一个碱基任选地包括用于酶促连接的磷酸盐部分或允许化学连接到相邻探针的5'端的修饰,称为修饰1(210)。
[0201]
右探针的第一个碱基任选地包括用于酶促连接的磷酸盐部分或允许化学连接到相邻探针的5’端的修饰,称为修饰2(214)。自右探针的5’端的15-30个碱基包括与遗传靶结
合的右探针的一部分(216)。自右探针的5'端的随后10-20个碱基任选地包括随机核苷酸区段,其形成分子特异性条形码或样品特异性条形码,称为条形码2(218)。自右探针的5'端的随后10-20个碱基任选地包括通用序列(220)。右探针的最后15-25个碱基,称为桥序列8(222),与第三桥寡核苷酸的桥序列7(224)反向互补。208、216、222或228的一些或全部核苷酸可以包括增加探针对靶或桥寡核苷酸的亲和力的化学修饰。
[0202]
自第一桥寡核苷酸的5’端的前15-25个碱基,称为桥序列3(226),与左探针的桥序列1(228)反向互补,并且任选地包括化学修饰的核苷酸用于增加结合。第一桥寡核苷酸的最后15-25个碱基,称为桥序列2(238),与第二桥寡核苷酸的桥序列4(236)序列反向互补,并且任选地包括化学修饰的核苷酸用于增加结合。第一桥寡核苷酸的5'端任选地包括用于捕获连接复合物的捕获部分(230)。
[0203]
自第二桥寡核苷酸的5'端的前15-25个碱基,称为桥序列5(240),与第三桥寡核苷酸的桥序列6(242)反向互补,并且任选地包括化学修饰的核苷酸用于增加结合。第二桥寡核苷酸的最后15-25个碱基,称为桥序列4(236),与第一桥寡核苷酸的桥序列2(238)序列反向互补,并且任选地包括化学修饰的核苷酸用于增加结合。
[0204]
自5'端的第三桥寡核苷酸的前15-25个碱基,称为桥序列6(242),与第二桥寡核苷酸的桥序列5(240)序列反向互补,并且任选地包括化学修饰的核苷酸用于增加结合。第三桥寡核苷酸的最后15-25个碱基,称为桥序列7(224),与右探针的桥序列8(222)序列反向互补,并且任选地包括化学修饰的核苷酸用于增加结合。第三桥寡核苷酸的3'端任选地包括磷酸盐(或其它可切割的)部分(234),以防止在间隙填充期间的延伸。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1