条形码序列和有关系统与方法与流程
条形码序列和有关系统与方法
1.本技术是申请日为2016年5月13日,申请号为201680027931.8,发明名称为“条形码序列和有关系统与方法”的发明专利申请的分案申请。
2.本技术书主张 62/161,309 号美国临时专利申请中的权益,该临时专利申请于 2015 年 5 月 14 日提交,并通过整体引用而成为本文的一部分。
3.序列表本技术含有序列表,所述序列表已经以 ascii 格式以电子方式提交并且以全文引用的方式并入本文中。创建于 2016 年 5 月 12 日的所述 ascii 拷贝的名称为 lt01016_sl.txt 且大小为 18,815 个字节。
技术领域
4.本公开一般涉及样本鉴定的方法、系统和套件,具体涉及样本区分码或样本区分条形码的设计和/或制作和/或使用的方法、系统和套件,所述样本区分码或样本区分条形码被用于鉴定样本核酸或其它生物分子或聚合物。
背景技术:
5.各仪器、装置和/或系统采用边合成边测序的方式进行核酸测序,例如包括基因组分析仪 / hiseq / miseq 平台(illumina 公司;例如参见美国专利6,833,246 号和 5,750,341 号);gs flx、gs flx titanium 和 gs junior 平台(罗氏 / 454 生命科学公司;例如参见 ronaghi et al., science, 281:363-365 (1998) 和 margulies et al., nature, 437:376-380 (2005));以及 ion pgm
™ꢀ
测序仪和 ion proton
™ꢀ
测序仪(生命科学公司 / ion torrent;例如参见美国专利 7,948,015 号和美国专利申请公开说明书2010/0137143 号、2009/0026082 号和 2010/0282617 号,这些专利均通过整体引用的方式并入本文作为参考)。为增加测序通量和/或降低边合成边测序(和其它测序方法,诸如边杂交边测序、边连接边测序等)的成本,需要新的方法、系统、可机读介质和套件需允许高效制备和/或鉴定可能高度复杂的样本。
技术实现要素:
6.本公开一般涉及样本鉴定的方法、系统和套件,具体涉及样本区分码或样本区分条形码的设计和/或制作和/或使用的方法、系统和套件,所述样本区分码或样本区分条形码被用于鉴定样本核酸或其它生物分子或聚合物。一个实施例提供了一种方法,用于设计与流空间码字对应的条形码序列。可生成多个由一串字符组成的流空间码字。可确定所述流空间码字内至少一个填充字符的位置。可将所述填充字符插入所述流空间码字的确定位置。插入后,在满足预定最小距离准则的基础上,可选定多个流空间码字,其中,所选码字按预定流序对应于有效的碱基空间序列。并可制备对应于所选码字的条形码序列。
7.若干实施例中,在插入填充字符后,按预定流序至少可过滤一个码字,包括一个无效碱基空间平移。若干实施例中,所选码字全体包括一个符合预定最小距离准则的容错码。
8.若干实施例中,流空间码字内的填充字符的位置确定还可包括在码字内该填充字符的多个位置迭代。此外,每次迭代时,可计算按预定流序对应于某一有效碱基空间序列的码字的数量。然后可在所述多个位置中选定对应于某一有效碱基空间序列的码字的计算数量最高的位置。
9.若干实施例中,流空间码字内的填充字符的位置确定还可包括,每次迭代时确定对应于流空间码字的碱基空间序列,当把该填充字符插入到所述码字的迭代位置处后,所述碱基空间序列对应于有效碱基空间序列。每次迭代时,根据所定序列的至少一个长度准则,可过滤所定的碱基空间序列。并可计算过滤后迭代位置的有效碱基空间序列的数量。若干实施例中,每次迭代时的过滤还包括,根据核苷酸百分含量准则,过滤所定的碱基空间序列。
10.若干实施例中,插入至少一个填充字符后,容错码的码字在流空间内同步。
11.若干实施例中,生成的流空间码字包括码字间的一个初始距离,如此使得所选码字间的最小距离大于所生成的码字间的最小距离。插入填充字符后,可保持码字间的该初始距离。
12.若干实施例中,多个码字的选择还包括码字分组,如此使得各组内的码字间的组内最小距离由一个第一值构成,且不同组间的码字组外最小距离由一个第二值构成,第一值大于第二值。
13.若干实施例中,可确定所选码字的一个子集,包含一个不表示合并的终止流。可制得对应于所选码字子集的条形码序列子集,如此使得根据不表示合并的码字子集所对应的终止流,选定所述条形码序列子集的一个接头。
14.若干实施例中,条形码序列的制备还包括给该条形码序列附加一系列关键碱基,其中,对于此条形码序列的首段,所附加的关键碱基以一个重复碱基终止。例如,首段可包含一半的条形码序列。若干实施例中,对于条形码序列的第二段,所附加的关键碱基可由一个非重复碱基终止。若干实施例中,所选码字全体包含一个容错码,由码字间的最小距离构成,如此使得对应于所选码字的所制条形码所附加的终止关键碱基的变化增大码字间的最小距离。
15.一个实施例提供了一种方法,用于对包含条形码序列的多核苷酸样本进行测序。多个条形码中至少有若干可并入多个目标核酸中,形成多核苷酸,其中,多个条形码的设计使得这些条形码按某一预定流序对应于某一流空间码字,该流空间码字由一个或多个容错码组成,且所述多个条形码至少包括1000个条形码。按照预定流序,在多核苷酸中,可引入一系列核苷酸。由于往目标核酸中引入核苷酸,可获得一系列信号。该系列信号可在条形码范围内解析,呈递流空间字符串,使得所呈递的流空间字符串匹配码字,其中,在存在一个或多个错误的情况下,至少一个呈递的流空间字符串匹配至少一个码字。若干实施例中,在存在一个或多个错误的情况下,至少匹配一个流空间码字的至少一个呈递的流空间字符串被用于鉴定从多个目标核酸序列之一所获得的信号,关联于对应所匹配流空间码字的码字。
16.若干实施例中,提供了一个与核酸测序仪器配套的使用套件。该套件可由多个符合以下准则的条形码序列组成:按某一预定流序,条形码序列对应于流空间码字,如此使得所对应的码字包括最小距离至少为三的一个容错码;该条形码序列的长度位于某一预定长
度范围内;该条形码序列在流空间里同步;且所述多个条形码序列至少是 500 个不同的条形码序列。若干实施例中,所述多个条形码序列至少是 1000 个不同的条形码序列。
附图说明
17.并入到说明书中并且形成说明书的一部分的随附图式说明一个或多个示例性实施例并且用以解释各个示例性实施例的原理。附图仅是示例性和解释性的,并且不应解释为以任何方式限制或约束。
18.图1 为说明某一示例性核酸测序系统的组件的框图。
19.图2a 说明了某一示例性核酸测序流通池的横截面视图和详细视图。
20.图2b 说明了 流过一个示例性反应室阵列一部分的连续试剂之间的一个示例性均匀流锋。
21.图3 说明了一个示例性无标记、 基于 ph 的测序过程。
22.图4 为说明一个用于获取、处理和/或分析多重核酸测序数据的示例性系统的框图。
23.图5 显示一个表示可实现碱基响应的信号的示例性电离图。
24.图 6a 和 6b 演示了一个碱基空间序列与一个流空间矢量之间的关系。
25.图7 说明了一个用于设计对应于流空间码字的条形码序列的示例性方法。
26.图8 说明了一个用于测序含有一个条形码序列的多核苷酸样本的示例性方法。
27.图9 说明了一组各不相同的多核苷酸链,各链均有一个唯一的条形码序列。
28.图10a-10c 说明了一个用于制备一个多重样本的示例性工作流程。
29.图11 说明了一个包含一个条形码序列的示例性微珠模板。
30.图12 说明了另一个包含一个条形码序列的示例性微珠模板。
具体实施方式
31.以下说明和本文件所述的各种实施例仅是示例性和解释性的,并且不应理解为以任何方式限制或约束。通过说明书、附图和权利要求,本资料的其它实施例、功能、对象及优点显而易见。
32.根据所述各种实施例,提供了允许有效制备和/或鉴定样本的方法、系统和套件。若干实例中,所述方法、系统和套件可通过允许多个样本同时测序和/或分析(如多重测序),用样本区分码或编码分子构想促进所述测序分析,从而有助于增加通量。多重测序可允许在单次测序运行中(如某一普通玻片、芯片、底物或其它样本夹持装置上)或在基本上同时测序运行中(如多个玻片、芯片、底物或样本夹持器上)基本同时分析多个编码样本(例如不同样本或来源不同的样本)。
33.若干实施例中,所公开的方法、系统和套件可用于鉴定多重测序中所用样本的一个来源。所述鉴定可涉及对样本测序数据的分析。测序数据源可以是唯一被标记、编码或鉴定(如,为了分辨与某一特定样本总体相关联的某种特定核酸种类)。通过使用独特的可内嵌于样本或跟样本相关的样本区分码或序列(也叫条形码,如合成核酸条形码),促进所述鉴定。样本区分码的使用仍受限于测序过程中可发生的错误或误读。例如,一次错误的条码解读可能改变条形码信息的解释,使该条形码不可识别并妨碍样本的正确鉴定。一次错误
的条码解读还可导致某一样本关联至一个错误的样本源或源总体。
34.不过,公开的各实施例可缓解检出和/或纠正含条形码样本的测序过程中可出现的错误的问题。例如,提供了样本区分码或序列或条形码和开发稳健样本区分码或序列或条形码的方法,所述样本区分码或序列或条形码均结合了一个容错码(如,一个纠错码或一个检错码)。
35.公开的各实施例还可生成大量潜在条形码,如可用于互相区分样本的条形码,这些条形码还可对应于包含一个容错码的码字(如,一个纠错码或一个检错码)。比如,对所生成的条形码进行测序时,一个测序仪器可接收信号,而所接收的最终信号可代表某一容错码的一个码字。若干实施例中,结合了条形码容错设计的大量潜在条形码可改进多重分析的效率(如,可测序的同步目标的数量)、准确度(如,容错)和灵活性及定制化。
36.除非本文中另外具体指定,本文所用的生物化学、细胞生物学、细胞和组织培养、遗传学、分子生物学、核酸化学和有机化学方面(包括聚合物颗粒的化学物理分析、酶反应和纯化、核酸纯化和制备、核酸测序和分析、聚合技术、合成多核苷酸的制备、重组技术等)的术语、技术和符号均遵循有关领域的标准协议和文本。参见 kornberg and baker, dna replication, 2nd ed. (w.h.freeman, new york, 1992)(kornberg 和 baker,《dna 复制》,第 2 版,w. h. freeman 出版社,纽约,1992 年); lehninger, biochemistry, 2nd ed. (worth publishers, new york, 1975)(lehninger,《生物化学》,第 2 版,worth publishers 出版社,纽约,1975 年);strachan and read, human molecular genetics, 2nd ed. (wiley-liss, new york, 1999)(strachan 和 read,《人类分子遗传学》,第 2 版,wiley-liss 出版社,纽约,1999 年);birren et al.(eds.), genome analysis:a laboratory manual series (vols. i-iv), dieffenbach and dveksler (eds.), pcr primer:a laboratory manual, and green and sambrook (eds.), molecular cloning:a laboratory manual (all from cold spring harbor laboratory press)(birren 等编,《基因组分析:实验室手册系列》(i-iv 卷),dieffenbach 和 dveksler 编,《pcr 引物:实验室手册》,和 green 和 sambrook 编,《分子克隆:实验室手册》(均由冷泉港实验室出版社出版);及 hermanson, bioconjugate techniques, 2nd ed. (academic press, 2008)(hermanson,《生物共轭技术》,第 2 版,美国学术出版社,2008 年)。
37.本文所用的“扩增”一般指进行一次扩增反应。本文所用的“扩增子”一般指一个多核苷酸扩增反应的产物,包括多核苷酸的一个克隆群体,扩增子可以是单链也可以是双链,且可从一个或多个起始序列复制而成。一个实例中,所述一个或多个起始序列可以是同一序列的一个或多个拷贝,也可以是含有一个扩增的共同区的不同序列的混合物,例如在从某一样本提取的 dna 片段的混合物中所存在的一个特异性外显子序列。也可通过单个起始序列的扩增而形成扩增子。通过多个扩增反应可产生扩增子,反应产物包括一个或多个起始核酸或目标核酸的复制物。产生扩增子的扩增反应可能是“模板驱动”,依据是反应物(核苷酸或寡核苷酸)的碱基配对在一个模板多核苷酸上有补体,这是形成反应产物的必要条件。模板驱动型反应可以是用一个核酸聚合酶延伸引物,也可以是用一个核酸连接酶连接寡核苷酸。这种反应的实例有聚合酶链式反应 (pcr)、线性聚合酶反应、基于核酸序列的扩增 (nasba)、滚环扩增或利用滚环扩增形成一个单体,可专门占据一个微孔,如在 drmanac 等人的美国专利中公开的。申请公开说明书2009/0137404 号所公开,该说明书通
过整体引用而成为本文的一部分。本文所用的“固相扩增子”一般指一种固相载体,如一个颗粒或微珠,核酸序列的一个克隆群体被附接至此载体上,该群体可通过乳液 pcr 之类的方法产生。
38.本文所用的“分析物”一般指一个分子或生物学样本,可直接影响某一区的一个电子传感器(例如,一个限定空间或反应限制区或微孔)或通过涉及位于此区的所述分子或生物细胞的一个反应的某一副产物,可间接影响这样一个电子传感器。一个实施例中,分析物可以是一种样本核酸或模板核酸,可经历一个测序反应,反过来,又可生成一种反应副产物,如一个或多个氢离子,可影响一个电子传感器。术语“分析物”还可以涵盖蛋白质、肽、核酸等分析物的多个拷贝,所述分析物被附接到固体载体,如微珠或颗粒。一个实施例中,一个分析物可以是一种核酸扩增子,也可以是一个固相扩增子。样本核酸模板可通过共价键合或某一特异性结合或偶联反应与某一表面缔合,且可衍生于一个霰弹法片段化 dna 扩增子文库(本文后续探讨的文库片段实例)或一个样本乳液 pcr 过程,在 ionsphere
™ꢀ
之类的微粒上形成克隆扩增的样本核酸模板。分析物可包括已附接到 dna 片段的克隆群体上的微粒,所述 dna 片段比如有基因组 dna 片段、cdna 片段。
39.本文所用的“引物”一般指一种天然或合成的寡核苷酸,当与某一多核苷酸模板形成一个双链体后,即能作为核酸合成的一个起始点并延伸,如从其 3’端沿着模板延伸,使之形成一个延伸双链体。可用一种核酸聚合酶进行引物延伸,如 dna 或 rna 聚合酶。所述延伸过程中所添加的核苷酸序列可取决于所述模板多核苷酸的序列。引物体长可介于 14 至 40 个核苷酸,比如介于 18 至 36 个核苷酸,或介于 n 至 m 个核苷酸,其中,n 是大于 18 的一个整数,而 m 是大于 n 且小于 36 的一个整数。各实施例可应用其它合适的引物长度。在多个扩增反应中可应用引物,例如,线性扩增反应采用单一引物,聚合酶链式反应采用两种或两种以上的引物。引物长度和序列的选择指南可见于 dieffenbach and dveksler (eds.), pcr primer:a laboratory manual, 2nd ed. (cold spring harbor laboratory press, new york, 2003)(dieffenbach 和 dveksler 编,《pcr 引物:实验室手册》,第 2 版,冷泉港实验室出版社,纽约,2003 年)。
40.本文所用的“多核苷酸”或“寡核苷酸”一般指核苷酸单体的一种线性聚合物,可以是 dna 也可以是 rna。通过单体-单体相互作用的一种规律,组成多核苷酸的单体能特异性结合一个天然多核苷酸,这种相互作用有 watson-crick 型碱基配对、碱基堆积、hoogsteen 或反 hoogsteen 型碱基配对。这样的单体及其核苷间键可以是天然存在的,也可以是其类似物(如,天然存在或非天然存在的类似物)。非天然类似物的实例有 pna、硫代磷酸核苷间键、含有键合基团允许附接荧光团之类的标记或半抗原的碱基。一个实施例中,寡核苷酸指(相对)较小的多核苷酸,如有 5
ꢀ–ꢀ
40 个单体单元的多核苷酸。若干实例中,多核苷酸包括由磷酸二酯键键合的天然脱氧核苷(如,dna 的脱氧腺苷、脱氧胞苷、脱氧鸟苷和脱氧胸苷,或 rna 的核糖对应物)。不过,它们也可包括非天然核苷酸类似物(如改性碱基、糖或核苷间键)。一个实施例中,可用一系列字母(大写或小写)表示一种多核苷酸,如“atgcctg”,该核苷酸被理解为 5
’ꢀ→ꢀ3’
从左至右顺序,且“a”表示脱氧腺苷,“c
”ꢀ
表示脱氧胞苷,“g”表示脱氧鸟苷,“t”表示脱氧胸苷,“i”表示脱氧肌苷,“u”表示脱氧尿苷,除非另外注明或上下文暗示。每当寡核苷酸或多核苷酸的使用跟酶处理有关时,如通过聚合酶延伸或通过连接酶连接,则所述实例中的寡核苷酸或多核苷酸不可含有核苷间键的一些类似
物、糖单元或任何或若干位置的碱基。除非另外注解,术语和原子编号惯例遵循以下文献的公开信息:strachan and read, human molecular genetics, 2nd ed. (wiley-liss, new york, 1999)(strachan 和 read,《人类分子遗传学》,第 2 版,wiley-liss 出版社,纽约,1999 年)。多核苷酸的大小可介于几个单体单元(如 5
ꢀ–ꢀ
40)至几千个单体单元之间。
41.例如,本文所用的“限定空间”(或“反应空间”,与“限定空间”可互用)一般指某一分子、液体和/或固体的至少若干部分可在其中受限、保留和/或定位的任何空间或区域(可为一维、二维或三维)。各实施例中,所述空间可以是一个预定面积(平坦区域)或容积,且可限定于一块微孔板、微量滴定板、酶标仪或芯片中或与之相关的一个凹陷或一个微加工孔。根据液体或固体的一个量,还可确定所述面积或容积,例如,沉积于一块面积或容积上的液体或固体,该液体或固体另外限定一个空间。例如,大体上憎水性表面上的孤立憎水区可提供限定空间。一个实施例中,限定空间可以是一个反应腔,如一个孔或微孔,该反应腔可在芯片里。一个实施例中,限定空间可以是无孔基材上的一块基本平坦的区域。限定空间可包含或暴露于核苷酸结合中所用的酶和试剂。
42.本文所用的“反应局限区”或“反应腔”一般指某一反应受限的任何区域,且包括一个“反应腔”、一个“孔”或一个“微孔”(均可互用)。反应局限区可包括这样一个区域,其中一种固体基材的某一物理或化学属性可允许某一目标反应的定位。若干实施例中,反应局限区可包括某一基材表面的一块不连续区域,可特异性地结合一种目标分析物(如具有跟该表面共价键合的寡核苷酸或抗体的一块不连续区)。反应局限区可以是中空的,也可以有边界分明的形状和容积,可制成基材。若干实施例中,上述后几类反应局限区在本文中可指微孔或反应腔,可采用任何合适的显微制作技术制作,且可具有容积、形状、宽深比(如底面宽度与孔深之比)及其它可根据特定应用而选择的尺寸特征,包括所发生的反应的性质以及所用的试剂、副产物和标记技术(如有)。例如,反应局限区还可以是无孔基材上的基本平坦的区域。各实施例中,可采用任何合适的业内已知的制作技术制作微孔。以下专利公开了微孔或反应腔的示例性构型(如间距、外形和容积):rothberg 等人,美国专利公开说明书2009/0127589 号和 2009/0026082 号;rothberg 等人,英国专利申请公开说明书gb 2461127 号;和 kim 等人,美国专利7,785,862 号,这些专利均通过整体引用而成为本文的一部分。
43.可将限定空间或反应局限区排列为一个阵列,所述阵列基本上是一个传感器或孔之类的单元的一维或二维平面排列。二维阵列的列(或行)数可以相同也可以不同。若干实施例中,所述阵列至少由 100000 个腔组成。例如,反应腔可有一个横向宽度和一个竖向深度,其宽深比约为 1:1 或更小。若干实施例中,反应腔的间距不大于约 10 微米,且每一反应腔的容积不大于 10 立方微米(即 1 皮升)) ,或不大于 0.34 皮升,或不大于 0.096 皮升,或在若干实例中,不大于 0.012 皮升。例如,一个反应腔顶部的横截面面积可以是 22、32、42、52、62、72、82、9
2 或 10
2 平方微米。若干实施例中,所述阵列可以至少有 102、103、104、105、106、107、108、10
9 或更多个反应腔。所述反应腔可与 chemfet 偶联。
44.限定空间或反应局限区,无论是排成一个阵列还是排成其它构型,均可与至少一个传感器有电气接触,以便检测或测量一个或多个可检出或可测量的参数或特征。所述传感器可将反应副产物的有无、浓度或含量的变化(或反应物的离子特性的变化)转化为一个
输出信号,该信号可被电子记录为电压或电流的变化,反过来,所述电压或电流变化又可经过处理,提取某一化学反应或理想缔合事件的有关信息,所述事件的一个例子就是核苷酸结合事件。所述传感器至少包括一个化学敏感场效应晶体管 (“chemfet”),所述晶体管经配置可生成至少一个跟某一化学反应的特性或邻近的目标分析物有关的输出信号。所述特性可包括某一反应物、产物或副产物的浓度(或浓度变化),或某一物理特性如离子浓度的值(或该值的一个变化)。例如,某一限定空间或反应局限区的酸碱度的一次初始测量或检测可以表示为可数字化的一个电信号或一个电压(如,转化为该电信号或电压的一个数字表达形式)。各实施例中,可认为这些测量和表达形式是原始数据或一个原始信号。
45.本文所用的“核酸模板”(或“测序模板”,可与“核酸模板”互用)一般指一个核酸序列,所述序列是一个或多个核酸测序反应的靶物。一个核酸模板序列可包括一个天然或合成的核酸序列。一个核酸模板序列还可包括来自某一目标样本的一个已知或未知的核酸序列。各实施例中,核酸模板可以附接至一个固体载体,如微珠、微粒、流通池或其它任何表面、支架或对象。
46.本文所用的“片段文库”一般指一系列核酸片段,其中的一个或多个片段被用作一个测序模板。有很多方式可生成一个片段文库(如通过切割、剪切、限制或将一个较大的核酸分解成较小的片段)。片段文库都可以由天然核酸生成或获取,比如来自细菌、癌细胞、正常细胞、固体组织等等。还可生成由合成核酸序列构成的文库,以形成一个合成片段文库。
47.本文所用的一个“分子样本区分码”(或“分子条形码”,可与“分子样本区分码”互用)一般指一个可识别或可分辨的分子标志物,可被唯一分辨并可附接至某一样本核酸、生物分子或聚合物。所述分子样本区分码可用于跟踪、整理、分离和/或识别样本核酸、生物分子或聚合物,且可设计成具有对操作核酸、生物分子、聚合物或其它分子有用的特性。分子样本区分码可由与其旨在识别的核酸、生物分子或聚合物同一种/类的物质或亚基构成,也可以由一个或多个不同的物质或亚基构成。一个分子样本区分码可由一个短链核酸构成,该核酸包括一个已知的、预定的或设计的序列。一个分子样本区分码可以是一个核酸样本区分码(或核酸条形码),该区分码可以是一个可识别或可分辨的核苷酸序列(如,一个寡核苷酸或多核苷酸序列)。若干分子样本区分码可包括一个或多个限制性核酸内切酶识别序列或切割位点、突出端、接头序列、引物序列等等(包括特征或特性的组合)。分子样本区分码可以是一个生物聚合物样本区分码,所述区分码可包括一个或多个抗体识别位点、限制位点、分子内或分子间结合位点等等(包括特征或特性的组合)。多个不同的分子样本区分码可用于鉴别或表征同属一个公共组的样本,且可附接至、偶联或关联到核酸、生物分子、聚合物或其它分子的文库(如片段文库)。各实施例中,一个样本区分码或序列或条形码可代表一个分子样本区分码或分子条形码,可包括一组符号、组件或字符,用于代表或定义一个分子样本区分码或条形码。例如,一个样本区分码或条形码可由一个字母序列组成,所述系列定义了一个已知或预定的核酸碱基或其它生物分子或聚合物组分的序列。其它实施例可采用其它任何合适的符号和/或非字母的字母数字混排的字符。样本区分码或条形码可用于多个集合、子集和分组,例如作为一个测序循环的一部分或为了完成多重测序。样本区分码或条形码可被解读、识别、鉴别或诠释为一个序列或其它排列或共同形成单码的亚基的关系的一个函数。若干实施例中,所述样本区分码可由一系列信号组成,这些信号是由一台测序仪器按预定流序(如一个条形码对应的一个流空间)进行条形码测序时输出的,详见
下文。若干实施例中,样本区分码或条形码也可包含一个或多个附加功能要素,包括质控和样本检测的关键序列、引物位点、连接接头、底物附接连接体、插入体及其它任何合适的要素。
48.图1 说明了一个可用各实施例实现的示例性核酸测序系统的组件。所述组件包括由一个传感器阵列 100 组成的流通池、一个参比电极 108、多种试剂 114、一个阀组 116、一种清洗液 110、一个阀 112、一个射流控制器 118、管线 120/122/126、通道 104/109/111、一个废液容器 106、一个阵列控制器 124 和一个用户界面 128。所述流通池和传感器阵列 100 包括一个进口 102、一个出口 103、一个反应腔阵列 107 和一个流动腔 105,限定试剂在反应腔阵列 107 上的一个流路。参比电极 108 可能是任何适当的类型或形状,包括具有流体通道的同心圆柱体或插入通道 111 内腔的导线。试剂 114 可在泵、气体压力或其它适当方法的驱动下通过流体通道、阀和流通池,并可在流出流通池和传感器阵列 100 之后弃置于废液容器 106 内。
49.例如,若干实施例中,试剂 114 可含有 dntp,将流经通道 130 和阀组 116,该阀组可控制试剂 114 经由通道 109 向流动腔 105 的流动。例如,该系统可包括一个含有一种清洗液的储液器 110,所述清洗液可用于洗去事先已流出的 dntp。反应腔阵列 107 可包括诸如孔或微孔等限定空间或反应局限区的一个阵列,通过操作,该阵列可与一个传感器阵列关联,使得各反应腔均有一个适合探测分析物或目标反应特性的传感器。反应腔 107 可作为单个器件或芯片与所述传感器阵列集成。该流通池可有多种设计,用于控制试剂在反应腔阵列 107 内的路径和流速,且可为一个微流控器件。阵列控制器 124 可向传感器提供偏压和定时及控制信号,并收集和/或处理输出信号。用户界面 128 可显示来自流通池和传感器阵列 100 的信息以及仪器设置和控制,并允许用户输入或设定仪器设置和控制。
50.若干实施例中,可配置该系统,让单一流体或试剂在某一多步反应期间接触参比电极 108。可关闭阀 112 以防在试剂流动时清洗液 110 流入通道 109。尽管可以停止清洗液的流动,但参比电极 108、通道 109 和微孔阵列 107 之间仍然可能存在不间断的流体和电连通。可能选择参比电极 108 以及通道 109 与 111 间接合点之间的距离,以使通道 109 中流动的可能扩散至通道 111 内的试剂几乎或者完全不会到达参比电极 108。一个实施例中,可选择清洗液 110 连续接触参比电极 108。一个实例中,这样一个构型可用于含频繁清洗步骤的多步反应。各实施例中,利用任一合适的仪器控制软件,如 labview(美国德克萨斯州奥斯汀市美国国家仪器有限公司),射流控制器 118 可程控试剂 114 流动的驱动力和阀 112 与阀组 116 的操作,按某一预定的试剂流序将试剂输送至流通池和传感器阵列 100。在预定持续时间内,以预定流速可输送试剂,并可测量物理和/或化学参数,提供有关限定空间或反应局限区如孔或微孔内发生的一个或多个反应的状态的信息。
51.图2a 说明各实施例中某一示例性核酸测序流通池 200 的横截面视图和详细视图。流通池 200 可包括一个反应腔阵列 202、一个传感器阵列 205、一个流动腔 206,试剂流 208 可在此流动腔中通过反应腔阵列 202 的一个表面,穿越某一反应腔的开口端。试剂流(如核苷酸种类)可有任一合适方式,包括吸移管输送、或通过跟某一反应腔相连的管道或通道输送。各试剂流的持续时间、浓度和/或其它流动参数可以相同,也可以不同。类似地,各清洗流的持续时间、成分和/或浓度可以相同,也可以不同。
al., a system for multiplexed direct electrical detection of dna synthesis, sensors and actuators b:chem., 129:79-86 (2008)(anderson 等,一种用于 dna 合成的多重直接电导检测系统,《传感器和执行器 b:化学》,129 期,79-86 页,2008 年);rothberg 等,美国专利申请公开说明书2009/0026082 号;和 pourmand et al., direct electrical detection of dna synthesis, proc.natl.acad.sci., 103:6466-6470 (2006)(pourmand 等,dna 合成的直接电导检测,《美国科学院学报》,103 期,6466-6470 页,2006 年),这些文献通过整体引用而成为本文的一部分。 一个实施例中,每次添加 dntp 后,可以增加一个步骤,用一种 dntp 破坏剂(如三磷酸腺苷双磷酸酶)处理反应腔,以消除任何残留在腔室中的 dntp,而 dntp 残留可能导致后续循环中的假延伸。
57.一个实施例中,按预定或已知的序列或排序,引物-模板-聚合酶复合体可接触一系列不同的核苷酸。当掺入一个或多个核苷酸时,可检出掺合反应产生的信号,而且经过添加核苷酸、延伸引物和采集信号等几次循环后,可确定模板链的核苷酸序列。一个实例中,这一过程全程测量的输出信号取决于核苷酸掺入的次数。尤其在每个附加测序步骤中,当模板中的下一个碱基与所添加的 dntp 互补时,聚合酶通过掺入所添加的 dntp 而延伸引物。有一个互补碱基,就有一次掺入;有两个互补碱基,则有两次掺入;有三个互补碱基,则有三次掺入,以此类推。随着每次掺入,氢离子被释放,且所释放的氢离子群体共同地改变反应腔的局部 ph。
58.一个实施例中,氢离子的产生与模板中的连续互补碱基的数目(以及具有参与延伸反应的引物和聚合酶的模板分子的总数)单调相关。因而,当模板中有一系列连续一样的互补碱基(可代表一个均聚物区)时,所生成的氢离子的数目和局部 ph 变化幅度正比于连续等同的互补碱基的数目(而对应的输出信号有时被称为“单聚体”、“二聚体”、“三聚体”输出信号等)。若模板中的下一个碱基不是所添加的 dntp 的互补物,则不发生掺入,也不释放氢离子(且此时的输出信号有时被称为“零聚体”输出信号)。若干实例中,所述循环的每一清洗步骤里,可用预定 ph 的未缓冲清洗液除去上一步的 dntp,以防后续循环中发生误掺入。核苷酸至某一反应容器或反应腔的输送可被称为核苷酸三磷酸酯(即 dntp)的“流动”。为方便起见,有时将 datp 流称为“a 的流动”或“a 流”,而一系列流动可表示为一个字母序列,如“atgt”表示“datp 流,随后依次为 dttp 流、dgtp 流和 dttp 流”。
59.一个实施例中,将四种不同的 dntp 依次添加到反应腔中,使得每个反应暴露于这四种不同的 dntp 中,一次一种。一个实施例中,按以下顺序添加这四种不同的 dntp:datp、dctp、dgtp、dttp、datp、dctp、dgtp、dttp 等,而暴露、掺入和检测步骤之后是一次清洗步骤。暴露于核苷酸,随即一步清洗,此过程可视为一次“核苷酸流”。若干实例中,连续四次核苷酸流可视为一个“循环”。例如,两循环的核苷酸流序可如下表示:datp、dctp、dgtp、dttp、datp、dctp、dgtp、dttp,而每次暴露的后续步骤是清洗。可实施不同流序,详见下文。各实施例中,预定序列或排序可依据预定试剂流序的连续重复的循环反复规律(如四种核苷酸试剂的预定序列的连续反复,如
ꢀ“
tacg tacg .。.”),也可依据随机试剂流序,或者依据全部或部分由以下文献所述的一种保相试剂流序构成的排序:hubbell 等,美国专利申请号 13/440,849,2012 年 10 月 28 日作为美国专利公开号 2012/0264621 发布,题为 phase-protecting reagent flow orderings for use in sequencing-by-synthesis(《用于边合成边测序的保相试剂流序》),通过整体引用或其若干组合的引用而成为本文的
一部分。其它实施例中,可用类似方式实施有标记的、基于 ph 的测序。
60.图4 说明了各示例性实施例中用于获得、处理和/或分析多重核酸测序数据的一个示例性系统。该系统包括一台测序仪器 601、一台服务器 402 和一台或多台终端用户计算机 405。经配置,测序仪器 401 可处理含条形码的样本或按本文详述的预定顺序输送试剂。所述预定顺序可依据预定试剂流序的连续重复的循环反复规律(如四种核苷酸试剂的预定序列的连续反复,如
ꢀ“
tacg tacg .。.”),也可依据随机试剂流序,或者依据全部或部分一种保相试剂流序构成的排序,或依据其若干组合。一个实施例中,条形码至少可部分地确定为所述排序的一个函数。例如,条形码可由流空间设计的条形码组成,按预定流序设计,详见下文。可连同本公开说明书的条形码一起使用的示例性测序仪器包括但不限于 ion pgm
tm
、ion proton
tm
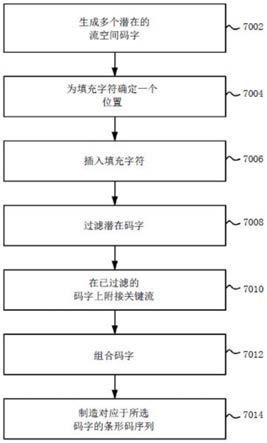
、ion s5
tm 和 ion s5 xl next generation
tm 测序系统。具备业内普通技术的人士会对以下事实感到欣慰:其它测序仪器和平台,如各种荧光团标记的核苷酸测序平台,也可同本公开说明书的条形码一起使用。
61.服务器 402 可包括一个处理器 403 和一个存储器和/或数据库 404。测序仪器 401 和服务器 402 可包括一种或多种可机读的介质,用于获取、处理和/或分析多重核酸测序数据。一个实施例中,所述仪器和服务器或其它计算手段或资源可经配置,作为单一组件。这些组件中的一个或多个可用于执行本文所述的全部或部分实施例。
62.若干实施例中,按本公开说明书,条形码由某一容错码的码字组成,其中的码字表现于流空间(如包括数字、字符或对应于核苷酸掺入次数的若干其它符号,该掺入是预定核苷酸流的响应)而非碱基空间。
63.各示例性实施例中,采用边合成边测序的方法可确定一个序列且/或鉴定一个或多个核酸样本。边合成边测序过程中,通过在某一目标核酸(其序列和/或一致度待定)上逐步合成互补性核酸链,可确定该目标核酸的序列,所述核酸链被用作合成反应的一个模板,例如,借助一个聚合酶延伸反应,该反应一般包括形成含有一个模板(或目标多核苷酸)、一种退火引物和一种聚合酶的一种复合体,通过操作,该聚合酶与引物-模板混合体偶联或缔合,以便能够往引物掺入一种核苷酸(如,核苷三磷酸酯、核苷酸三磷酸酯、前体核苷或核苷酸)。边合成边测序过程中,跟模板多核苷酸分子或链互补的位置处,可依次添加核苷酸至在那里生长中的多核苷酸分子或链。可用多种方法(如,焦磷酸测序、荧光检测、无标记电子探测等等)检测生长中的互补链,向其中添加核苷酸,可用于鉴定所述模板核酸的序列组成。可迭代这一过程,直至已合成一种全长或选定长度的模板互补序列。
64.如上所提,各实施例中,对于可生成、处理和/或分析的数据和信号,可用电子或电荷型核酸测序获得。在基于电子或电荷的测序(例如基于 ph 的测序)中,可通过检测作为聚合酶催化的核苷酸延伸反应的天然副产物而产生的离子(例如氢离子)来确定核苷酸掺入事件。这可用于对样本或模板核酸进行测序,所述样本或模板核酸可以是目标核酸序列的一个片段,并且可作为克隆群体直接或间接地附接到一种固相载体,如颗粒、微粒、微珠等等。通过操作,所述样本或模板核酸可跟某一引物和聚合酶缔合,并可经历脱氧核苷三磷酸酯(“dntp”)的添加和清洗的反复循环或“流动”。引物可退火到样本或模板,以便只要加入与模板中下一个碱基互补的 dntp,该引物的 3' 末端即可通过某一聚合酶得到延伸。根据核苷酸流的已知序列以及每个核苷酸流中的离子浓度的实测指示信号,可确定与反应腔中的样本核酸缔合的核苷酸的类型、序列和数量的一致度。
65.图5 显示一个表示可实现碱基响应的信号的示例性电离图。本例中,x 轴显示的是流出的核苷酸,而通过将 y 轴示值四舍五入取整,可估计对应的核苷酸掺入次数。在建立碱基响应和确定测序数据(如流空间矢量)中所用的信号可来自对测序操作所接收的数据信号进行采集或处理的过程中的任何合适时间点。例如,所述信号可以是原始采集数据或已被处理过的数据(如,通过背景过滤、归一化、信号衰减修正、以及/或者相差或相效修正等等)。通过分析任何合适的信号特征(如信号幅度、强度等等)可建立碱基响应。
66.各实施例中,若知道流出的预定核苷酸和获取这些信号的顺序,则可进一步处理因核苷酸掺入而产生的输出信号,以建立针对流动的碱基响应,并将跟某一样本核酸模板相关联的连续碱基响应编译为读数。碱基响应指特定的核苷酸鉴定,如,datp (“a”)、dctp (“c”)、dgtp (“g”) 或 dttp (“t”)。碱基响应可包括执行一次或多次信号归一化、估计信号相位和信号软化(如,酶失效)及修正信号,且可鉴定或估计每一限定空间的每个流动的碱基响应。碱基响应可包括执行或实施以下文献所公开的资料的一项或多项:davey 等,美国专利申请号 13/283,320,2012 年 5 月 3 日作为美国专利公开号 2012/0109598 发布,题为 predictive model for use in sequencing-by-synthesis(《用于边合成边测序的预测模型》),通过整体引用而成为本文的一部分。信号处理和碱基响应的其它方面可包括执行或实施以下文献所公开的资料的一项或多项:davey 等,美国专利申请号 13/340,490,2012 年 7 月 5 日作为美国专利公开号 2012/0173159 发布,题为 method, system, and computer readable media for nucleic acid sequencing(《用于核酸测序的方法、系统和可机读介质》);sikora 等,美国专利申请号 13/588,408,2013 年 3 月 7 日作为美国专利公开号 2013/0060482 发布,题为 method, system, and computer readable media for making base calls in nucleic acid sequencing (《核酸测序中用于建立碱基响应的方法、系统和可机读介质》),上述文献均通过整体引用而成为本文的一部分。
67.图6a 和 6b 演示了一个碱基空间序列与一个流空间矢量之间的关系。代表掺入次数(如,流出 dntp 至多聚核苷酸的掺入)或缺少掺入(如,零聚体、单聚体、二聚体等)的一系列信号(如,有多核苷酸时,流动 dntp 产生)可被称为一个流空间矢量、序列或字符串。一个实施例中,流空间矢量、序列或字符串可包括一系列代表掺入的符号(如,0、1、2、3 等等)。当预定流序连同一个流空间矢量为已知时,可产生至碱基空间的翻译。例如,给定掺入数(如,0、1、2 或 3)和特定的流出 dntp(如 a、g、t、c),则所翻译的碱基空间可包括一个跟流出并掺入的 dntp 互补的碱基,其中连续重复碱基的个数可跟流空间矢量指示的掺入数(如 2 或更多)一致。
68.一个实施例中,采用任一合适的核苷酸流序可产生流空间矢量,该流序包括基于预定试剂流序的连续重复的循环反复规律、基于一个随机试剂流序、或基于全部或部分包括一个保相试剂流序的一个排序的一个预定排序,或其若干组合。图6a 和 6b 中,示例性碱基空间 agtcca 经历采用 tacg 循环流序的测序操作。流动产生一系列信号,信号振幅(如信号强度)与核苷酸掺入数(如,零聚体、单聚体、二聚体等)有关。该系列信号生成流空间矢量 101001021。如图6a 所示,在 tacg
‑‑
循环排序下,碱基空间序列 agtcca 可翻译成流空间矢量 101001021。如图6b 和本文详述,流空间矢量可映射回碱基空间序列,预定流序下,该序列跟样本有关联。
69.条形码各实施例中,样本区分码或条形码可包括或对应于(无论直接还是间接)核苷酸序列、生物分子成分和/或亚基的序列、或聚合物成分和/或亚基的序列。一个实施例中,样本区分码或条形码可对应于核酸中的单一核苷酸的一个序列,或生物分子或聚合物的亚基,或对应于这些核苷酸或亚基的集合、组或连续或不连续序列。一个实施例中,样本区分码或条形码也可对应于(无论直接还是间接)核苷酸、生物分子亚基或聚合物亚基之间的转换,或用于形成样本区分码或条形码的亚基(如接头、关键碱基等等)之间的其它关系。
70.各实施例中,样本区分码或条形码可具有这样的特性,使其被测序、识别、鉴定或解读,对给定的码型、长度或复杂度有更高准确度和/或更小出错率。一个实施例中,可将样本区分码或条形码设计为单一样本区分码或条形码的一个集合(可包括子集)。若干实施例中,某一集合(或该集合的一个子集)中的一个或多个样本区分码或条形码的选择可基于一个或多个准则,以便在这些码的读序、识别、鉴定、区分或解读方面提高准确度和/或减小出错率。
71.各实施例中,可设计样本区分码或条形码,呈现高逼真度读序,根据经验测序量值可评估此读序。逼真度可基于对具有特定核苷酸序列的样本区分码或条形码的读序准确度的预测。可避免一些已知会引起读序不清、错误或测序偏差的核苷酸序列。设计可基于对样本区分码或条形码(和相关样本或核酸群体)的准确响应,即使有一个或多个错误。各实施例中,逼真度可基于对样本区分码或条形码正确测序的概率,此概率至少为 82%、85%、90%、95%、99% 或更大。
72.各实施例中,可设计样本区分码或条形码,对采用边合成边测序平台的测序(如前探讨)呈现较高的读序准确度,此类平台可包括荧光团标记的核苷酸测序平台或无标记的测序平台,诸如 ion pgm
tm 和 ion proton
tm 测序仪、ion s5
tm 和 ion s5 xl next generation
tm 测序系统。不过,样本区分码或条形码和特异性序列的设计不限于任何特定的仪器平台或测序技术。就非核酸码而言,可用业内已知的方法对样本区分码或条形码进行测序、鉴定、解读或识别,此类方法包括蛋白样本区分码的氨基酸测序。
73.各实施例中,设计手段可包括运用一系列样本区分码或条形码约束或准则,实现理想特性或性能。这样的约束或准则可包括一个或多个核酸条形码序列的唯一性,和其与其它核酸条形码序列的分离度。一个条形码集合可以是条形码的一个嵌套集合,可基于一个或多个设计准则。一个实施例中,嵌套条形码集合的设计可类似于 matryoshka 嵌套,使得某一子集的特性完全包含于一个种属集合的特性。例如,符合一定特性(如较高的测序逼真度)的首个条形码子集可从符合同样特性的某一较大的条形码集合中选择。例如,若一个条形码集合由 96 个可唯一鉴别的条形码组成,则对于仅含 16 个多重测序样本的一个测序试验,可从 96 个可用条形码中选择一个含 16 个条形码的子集。从而可将这一含 16 个条形码的子集优化至类似于从 96 个条形码组成的全集中选出的一个含 32 或 48 个条形码的较大子集。一个实施例中,可将条形码设计为一列有序的嵌套条形码。一个实施例中,可将条形码(如一个 96 码集合)如下排序:具有一个首码,一个在合适距离度量下离首码最远的次码(剩余 95 码中的一码),一个在合适距离度量下离首码和次码最远的第三码(剩余 94 码中的一码),依此类推,直至所述条形码都已排好序。
74.各实施例中,样本区分码或条形码可与某一目标序列结合,这种情况下有助于唯
一鉴定或区分不同的目标序列。例如,目标序列可为来自任何目标源的任一类序列,包括扩增子、候选基因、突变热点、单核苷酸多态性、基因组文库片段等。例如,在样本制备过程中的任一时间点,采用 pcr 扩增、dna 连接、细菌克隆等技术,通过操作,可将样本区分码或条形码序列偶联至目标序列。样本区分码或条形码序列可包含于寡核苷酸,并采用任一合适的 dna 连接技术与基因组文库片段连接。
75.各实施例中,样本区分码或条形码的长度可各异。例如,基于待鉴定的样本数量,可选择样本条形码的长度。各实施例中,对于样本数为 16 的多重测序试验,16 个可唯一鉴定的条形码可足以唯一鉴定各样本。类似地,对于样本数为 64 或 96 的多重测序试验,64 或 96 个条形码可分别足够。
76.若干组态可利用较长的码或较大的条形码,以便得到较大的多重测序数。虽然较长的条形码会允许鉴定较多的样本,但若干情形下,这些较长的条形码可能有不足。例如,边合成边测序中,较长条形码需要额外的核苷酸流,若较早的流动中的测序趋于最准,则这可降低准确度。此外,若某一测序系统有一个长度准则(如 200 个碱基对),则较长的条形码可占据较多的测序空间。因此,可要求附加于条形码的目标片段符合较小长度准则(如,较长的条形码更适用于对较短的靶标进行测序)。
77.各实施例中,可基于上述一个或多个准则(可单选或组合),设计样本区分码或条形码。基于测序试验,可选取不同的准则组合。例如,若较少的样本需用到条形码,则不一定要将此条形码设计为具有嵌套子集。基于样本数、目标准确度、测序仪器的单样本检测灵敏度、测序仪器的准确度等等,可选择设计准则。
78.各实施例中,本文所述样本区分码或条形码可以任何适当方式用于帮助鉴定或分辨样本。例如,可单用条形码,也可组合使用两个或两个以上的条形码。一个实施例中,单个条形码可鉴定一个或多个目标序列。例如,单个条形码可鉴定一组目标序列。一个条形码的读序可与目标序列分开,或作为涵盖条形码和目标序列的较大的读序操作的一部分。条形码可定位于样本内的任一适当位置,包括某一目标序列的前后。
79.条形码设计和流空间各实施例中,可基于一个流空间,设计样本区分码或条形码。换言之,可至少部分基于流空间矢量(如作为一个流序函数),设计条形码。例如,样本区分码或条形码的设计可基于对流空间内的投射,作为选定或预定核苷酸流序下的一个流空间矢量。另一实例中,可生成一系列流空间矢量,然后可将这些矢量翻译成碱基空间(如按预定流序),以便产生条形码序列。
80.一个实施例中,一个条形码流空间矢量可由一串符号组成(如一串数字或字符,如 0、1、2 等等,分别代表无掺入、单聚体掺入、二聚体掺入等等),是对按预定排序流出或引入的核苷酸流的响应。各实施例中,流空间串或矢量可代表或对应于某一容错码(如一个纠错码)的一个码字。一个纠错码中,一串字符可使得被引入该串(如测序期间)的错误可基于该串中的剩余字符被检出和/或纠正。一个纠错码可由给定的字符单元的有限字母表 σ 上可被称为码字的不同字符串的一个集合组成。一个码字可被视为包括一个报文加上若干冗余数据或奇偶校验数据,让解码器正确解码某一含有一个或多个错误的码字。码字可设计为足够相互区分,允许在一个码字的传输中检测到容许数量的错误,而且在若干情形下,通过计算哪个实际码字离接收的码字最近而纠正这些错误。
81.各实施例中,可采用任一合适类型的纠错码设计样本区分码或条形码。纠错码可为一个采用字符单元字母表 σ 的线性块码,其每一码字均有 n 个编码字符单元。可将冗余和/或奇偶校验数据添加至某一报文(如该码字的子集)中,让接收器检测和/或纠正所传输的一个码字中的错误,并采用某一合适的解码算法恢复原有报文。例如,在边合成边测序中,当某一条形码已被测序且作为一个流空间串被投射进流空间内时,可认为一个报文串被“传输过”。
82.各实施例中,可采用码字母表中的不同数量的字符单元,设计样本区分码或条形码,该字母表可因特定应用而异。纠错码可为一个二进制码,采用两字符单元的一个字母表。纠错码可为一个三进制码,采用三字符单元的一个字母表。一个实施例中,字符单元数可取决于条形码序列中所允许的最长均聚物序列的长度。例如,若一个条形码仅有单聚体(无重复碱基),则纠错码可为一个二进制码,含一个代表无掺入的字符和另一个代表单碱基掺入的字符(如,这样一个二进制码的字母表 σ 可为{0, 1})。另一例中,若所述条形码仅有单聚体和二聚体,则纠错码可为一个三进制码,含同样的代表无掺入的字符和代表单碱基掺入的字符以及第三个代表双碱基掺入的字符(如,这样一个三进制码的字母表 σ 可为{0,1,2})。若条形码序列有三聚体、四聚体等等,则对其它码字母表所用字符的大小和集合,可适当修改。
83.各实施例中,可采用一个至少部分基于汉明码、格雷码和或 tetracode 码的纠错码设计样本区分码或条形码。一个实施例中,纠错码可为一个二进制汉明码、一个二进制格雷码、三进制汉明码、一个三进制格雷码及/或其它任何合适的码。参见 hoffman et al., coding theory:the essentials, marcel dekker, inc. (1991)(hoffman 等,《基础编码原理》,marcel dekker 出版社,1991 年;和 lin et al., error control coding:fundamentals and applications, prentice hall, inc. (1983)(lin 等,《控错编码:基本原理和应用》,prentice hall 出版社,1983 年)。
84.各实施例中,可将样本区分码或条形码设计成具有流空间内表达的容错特性。换言之,测序错误可与条形码按预定流序进行的流空间表现形式中的错误数字或字符有关(如,本该位于流空间表现形式中的“1”或“单聚体”却出现了错误的“0”或“零聚体”)。例如,可这样设计一个单碱基(流空间内)容错条形码集合,使得如果在该集合的一个或多个条形码的流空间表现形式中的任一位置遇到一个测序错误,则每个条形码仍可与该集合中的其它条形码分辨开来,因为它们的流空间表现形式至少在两个数字位均不同于该错误条形码的流空间表现形式;这样一来,若这两个数字位中有一处出错,则其它数字位仍然可用,允许区别条形码。也可这样设计该集合,使得即使在流空间内有多个错误(如 2、3 等),也能够区分其中的条形码。在有潜在的测序错误的情况下分辨复杂的多重测序样本的时候,这样的容错特性有助于提供较高的置信度(如准确度)。可比较一个集合中的候选条形码,以确证流空间内的容错性。例如,可比较这样的条形码(如通过计算机分析或模拟),以确定若流空间内发生任一错误(或 2、3 等,因准则而异)是否仍可分辨这些码。另一例中,可比较候选的流空间码字(如按某一预定流序翻译为候选条形码序列的码字),以确证容错性。
85.可用各种算法和/或软件工具帮助生成纠错码。编码策略开发中可纳入一系列不同的设计思路。如本文解释,对给定流序,条形码序列与流空间码字有相互映射关系。因而,跟条形码序列有关的设计或选择准则可被翻译成对应的流空间编码设计/选择准则。同样,
跟流空间编码有关的设计/选择准则可被翻译成对应的条形码序列设计/选择准则。
86.各实施例中,可采用能评价码字间距的一个或多个距离度量,设计样本区分码或条形码。一个实施例中,距离度量可为汉明距离,对应于两码字相异的位置的数量。从数学角度看,若一个码字集中的每一个码字跟该集的其它所有码字之间的汉明距离至少为d,那么该码可纠正至多(d-1)/2个错误,反之,至多可解码x个错误的汉明距离d为2x+1。可将量d称为最小码距。记号[n,k,d]可用于表征长为n位的纠错码,该码对k个信息位进行编码且有最小距离d。例如,可用其它距离度量,包括欧几里得距离度量、两码字的对应输入项之差的绝对值之和、两码字的对应输入项的平方差之和。各实施例中,采用这样的距离度量,可让码字间距得以在流空间内评价。
[0087]
各实施例中,可设计样本区分码或条形码,使之有一个最小距离为五的纠错码,最多能纠正码字内的两位错误。另一个实施例中,纠错码可有的最小距离为三且能纠正码字内的个位错误。若干实例中,某一软件算法或方法将某一候选组内的每个码字与该组内其它所有码字进行比较,以构建一个维持理想的最小距离且有理想的纠错能力的最大码字集,可用这样的算法或方法选择或组合包括纠错码的码字。可将码字(或对应条形码)进一步分成子集,单独使用时,这些子集可纠正多个流空间错误(如,两个或两个以上的错误)。这使得一个条码集至少可纠正两个流空间错误。采用三进制编码方案可在流空间内生成条码集(如在流空间内的给定流中,可视条形码有0、1或2个掺入)。
[0088]
各实施例中,可设计样本区分码或条形码,使之鉴别流空间而非碱基空间内的读序,这对边合成边测序有效,且有助于避免过多的流,从而减少错误积累和测序能力的损耗。若干情形下,汉明距离在碱基空间内的效果不差。例如,序列起始端的单碱基插入(如acgt至aacgt)将得到汉明距离3(尽管插入/缺失距离仅为1)。而且,当配对位元把一个二进制码翻译为4个字母时,错误自动地同时影响两个位元,且不保证1位的一次纠错可纠正碱基读序中的1个错误。而且,常规的条形码设计未必适当地对测序错误模体寻址。一个实施例中,可为了有用的生物学特性而选择码字。
[0089]
若干实施例中,可围绕一个被映射到特定的预定流序中的三进制汉明码,设计样本区分码或条形码。例如,此码可为一个[n=13,k=10,d=3]三进制汉明码;此映射可取头10个“三进位”(如三进制码符号0、1和2)并将它们分配给预定流序(如,流9-18)的若干流,再取三个“奇偶校验”三进位并将它们分配给其它流(如19-21)。若干实施例中,最终同步流就是一个单聚体(如流22处的一个
‘
c’),结果,若被指定为零,则码字的终止流为零。汉明码下生成的若干码字可以不是可容许的流空间表示形式(如,它们可以是流空间内有效的数学码字,按一定的预定流序,不对应碱基空间内的一个可能的核酸序列)。可将这些码字过滤。若干实施例中,可进一步过滤码字,使之仅包括理想长度(如9-15个碱基)的码字。
[0090]
若干构型中,一个多重测序应用利用一个可纠正流空间串中的两个错误的含96个条形码的集合,有若干空间容许因有问题的条形码而造成的潜在损失,并有一个预定流序tacg,然后依次为tacg、tctg、agca、tcga、tcga、tgta、cagc;对于这样的应用,可采用一个13位长的三进制汉明码生成一个条形码序列集,该码的十个位被当成数据,该码的三个位被当成码字奇偶校验。此特定编码方案得到可纠正最多两个错误的大约140个码字。
[0091]
一个实例中,可这样选择条形码,使之长9-11个碱基,并设计用于ionpgm
tm
测
序仪多重测序所用的寡核苷酸。本例寡核苷酸含有如下顺序的成分:一个引物位点、一个用于质控和样本检测的 tcag 关键序列(如关键碱基)、一个唯一的条形码序列、条形码序列的 3’端的一个同步共用 c 碱基(以确保,若被指定为零时,码字终止流为零)、条形码与插入体之间的一个 gat 缓冲区(以最大限度减小可变条码区对接头连接的影响)。同用于 ion pgm
tm 测序仪的 p1 接头一样,该 gat 缓冲区是后三个碱基。下面表 1 的信息是按所生成的条形码的序列号整理的。第二列显示关键序列、条形码序列和共用 c 碱基。第三列显示条形码序列和共用 c 碱基。第四列显示组合序列单元对流空间内的投射。表中,碱基和对应于条形码的流空间矢量单元均用粗体显示。流空间映射中,流 1-8 被分配给关键序列(即,流 1 = t、流 2 = a、流 3 = c、流 4 = g、流 5-8 重复流 1-4),流 9-18 被分配给条形码的数据位(即,流 9 = t、流 10 = c、流 11 = t、流 12 = g、流 13 = a、流 14 = g、流 15 = c、流 16 = a、流 17 = t、流 18 = c),而流 19-21 被分配给奇偶校验位(即,流 19 = g、流 20 = a、流 21 = t)。因为在本例中,所有条形码的后面都紧接着一个共用 c 碱基,流 22(即,流 22 = c)用作同步。一个实施例中,预定流序可包括这些 22 个流和附加的流,使得流序由 32 个流的一个重复系列组成(即,流 23 = g、流 24 = a、流 25 = t、流 26 = g、流 27 = t、流 28 = a、流 29 = c、流 30 = a、流 31 = g、流 32 = c)。也可实行本文所述的其它合适的流序。其它实施例中,密钥、同步碱基和/或缓冲区可不同。
[0092]
表 1
ꢀ–ꢀ
示例性条形码和空间内的投射
[0093]
各实施例中,可围绕采用值 0、1、2 的一个 [n=11, k=6, d=5] 三进制格雷码,设计样本区分码或条形码。该码有 729(即 36)个不同的码字,长度为 11,码字间距为 5,纠正 2 个错误。可线性、循环或采用任一合适方法,如通过一个生成器矩阵或一个生成器多项式,生成所述码字。其它实施例中,用于条形码(或流空间码字)的关键碱基(或流)的变化和终止碱基(如终止“c”碱基和/或对应的终止“1”流)的变化可生成用于多重反应的额外条形码。例如,若共用关键碱基(或流)和一个终止静态碱基的使用限制了用于多重测序的合格条形码序列的个数(如,至多为 96 或 384 个条形码序列),则这些特性的变化可生成较
多的用于多重测序的条形码序列(如,至少 1000 个条形码序列)。
[0094]
图7 说明了一个用于设计对应于流空间码字的条形码序列的示例性方法。步骤 7002 中,可生成多个潜在的流空间码字。例如,一个生成器函数可生成一个潜在的流空间码字集,采用一个长度为 13 位的三进制 [n=13,k=10,d=3] 汉明码,其中十位被当成数据,而其中的三位被当成码字奇偶校验。所生成的潜在码字数可包括 n^k,本例中为 3^10。所生成的流空间码字可包括一个有序的字符系列,如字母数字混排的字符或其它符号。对汉明码或格雷码的其它组态,可类似实施。可线性、循环或采用任一合适方法,如通过一个生成器矩阵或一个生成器多项式,生成所述码字。
[0095]
步骤 7004 中,可确定一个位置,用于潜在流空间码字内的一个填充字符。例如,若干构型中,可将一个碱基,如一个填充碱基,附接到条形码末端,以辅助测序。流空间内,按预定流序,填充碱基可对应于一个填充流。例如,填充碱基可包括一个“c”碱基,按预定流序,对应的填充流(或字符)可包括一个“1”。这些构型中,流空间码字末尾可附接一个终止“1”,类似地,对应的条形码序列的末端可附接一个终止 c 碱基。例如,若所生成的流空间码字由 13 个字符组成,那么在加入填充字符后,该码字可包括 14 个字符。一个实施例中,预定流序可包括基于一个流序循环反复规律、基于一个随机流序、或基于全部或部分包括一个保相流序的一个排序的一个顺序,或其若干组合。
[0096]
若干实施例中,可移动填充字符,使其不在某一码字的终止流(且对应的填充碱基不是某一条形码序列的终止碱基)。重新定位填充字符/碱基这一灵活性将产生一系列潜在的位置选择,使之可获得设计效益。例如,将填充字符插入选定位置的一个 13-字符的流空间码字,可增加按预定流序映射到一个有效碱基空间序列的码字的个数。根据流出的已知 dntp 试剂和试剂掺入状态(如,0、1、2 等),按预定流序可确定对应的用于流空间码字的碱基空间序列。虽然所翻译的序列可有不同的碱基长度,但基于对应的同步流空间码字,它们仍可在流空间内同步。
[0097]
一个实施例中,按预定流序,若干码字未能翻译成一个有效的碱基空间序列。一个实例中,给定流序“a”“g”“a,”,一个流空间串(或矢量)101 不会翻译成一个有效的碱基空间。这里,第二次掺入(如 101 中的 1 的第二次出现)不会翻译成有效的碱基序列。例如,若条形码中出现两个“a”而无一个间隔碱基,则“a”的首流将展现一个二聚体(如,会呈递一个流空间值 2),因而不可能呈递第二次掺入。可实施其它方法,以确定无效的碱基空间翻译。
[0098]
一个实施例中,在码字的不同位置插入填充字符,可提供一个调整,使得先前未能映射到一个有效的碱基空间序列的多个码字在插入后成功映射至一个有效的碱基空间序列。若干实例中,可选择导致最多码字的位置,该码字对应于有效的碱基空间序列。这里,对于所生成的码字,所选的填充碱基插入位置可一致,以便保留码字的距离性(如,保留用于生成码字的距离性)。
[0099]
一个实施例中,确定填充字符在流空间码字内的位置,可包括在填充字符在码字内的多个位置处的迭代,使得在迭代位置将填充字符插入到码字的基础上,可计算每一位置的码字数量,按预定流序,该码字对应于有效的碱基空间序列。例如,给定一个长度为 13 的码字,存在 14 个可能的填充字符位置(即,第一个字符前,第一和第二个字符之间,依此类推)。这里,可设计一个算法,使得填充字符被迭代插入这 14 个可能位置,而且对每次迭
代,可计算在迭代位置插入填充流后的码字的数目,所述码字映射至有效的碱基空间序列。例如,此算法可确定在迭代位置插入后,码字是否按预定流序映射到一个有效的碱基空间序列。接着针对每个迭代位置,可计算映射至有效的碱基空间序列的这些码字的个数。
[0100]
一个实施例中,对给定迭代位置的流空间码字(按预定流序映射至一个有效的碱基空间序列)数量的计算,还包括确定对应于流空间码字(在迭代位置插入填充字符后,映射至有效的碱基空间序列)的碱基空间序列。若干实施例中,所计算的码字数量可包括所确定的碱基空间序列的数量。其它实施例中,可进一步过滤所确定的碱基空间序列。例如,按照一个或多个序列长度准则和核苷酸百分含量(如gc含量)及其它合适准则,可过滤所确定的碱基空间序列。例如,一个序列长度准则可包括9-11或9-14个碱基,且可过滤所确定的大于准则要求的碱基空间序列。也可实施其它合适的长度范围。
[0101] 另一个实例中,可设计或选择条形码序列,避免一些已知会引起测序错读或测序偏差的核苷酸序列。这可增强pcr和/或测序性能。若干实施例中,因为一个序列的gc(鸟嘌呤/胞嘧啶)含量可影响测序质量,所以过滤准则可包括一个gc含量40-60%范围。也可类似处理at含量。一个实例中,所确定的碱基空间序列如不符合gc和/或at含量准则,则可过滤。
[0102]
一个实施例中,所计算的一定迭代位置的流空间码字(按预定流序映射至一个有效的碱基空间序列)数量可包括过滤后确定的碱基空间序列数量。
[0103]
一个实例中,在填充字符的可能位置迭代后,如对一个13-字符的流空间迭代,可选择对应于最高计算数量的位置。该选定位置会生成一个较大的流空间码字数量,该码字映射至一个有效的碱基空间序列,因而对应的条形码序列数也较大(如,可用于多重测序)。
[0104]
介绍下例,以说明以上原理。本例中,所选位置可包括流空间码字的流5(如,根据对应于最高计算数量的这一位置而选择)。本例将说明如何利用填充字符重定位(从终止流至某一选定位置)的灵活性调整一个码字(未曾翻译至一个有效的碱基空间),使得在所选位置插入填充字符后,该码字成功映射到一个有效的碱基空间序列。采用一个样本生成的流空间码字“20012220010121”和一个样本流序“tctgagcatcgatc”(seqi.d.no.19),流空间码字可包括一个填充终止符“1”。按照样本流序,虽然填充字符位于终止流,但样本流空间码字不映射到一个有效碱基空间序列,至少是因为发生连续的两次掺入而中间没有碱基掺入。例如,当考虑一个假设性同步流时,码字20012220010121中有下划线的流空间符号会对应于样本流序tctgagcatcgatc中有下划线的流(seqi.d.no.19).这里,起始的“2”代表起始“c”流出时的一次二聚体掺入。随后的“00”代表后续的“a”和“t”流出时的两个零聚体。不过,流空间码字中的后续“1”代表一个单聚体,不能在样本流序的对应“c”流的基础上生成。这至少是因为,若存在这样一个互补碱基,则因起始“c”流而掺入的起始“2”本当作为一个“3”或三聚体而掺入。本例中,填充字符从第14流重新定位至第5流,将按样本流序产生一个有效的碱基空间序列。这一重定位得到码字“20011222001012”。然后,已调整的流空间码字会按相同的样本流序映射到一个有效的碱基空间翻译。基于本公开说明书的资料,业内普通技术人员会对以下事实感到欣慰:可类似地实施其它可能的重定位位置,也会导致一个有效的碱基空间翻译。
[0105]
另一例也说明了如何利用填充字符从终止流重新定位至某一选定位置(如上文,也是第5流)的灵活性调整一个码字(未曾翻译至一个有效的碱基空间),使得在所选位置
pcr 和/或测序性能。若干实施例中,因为一个序列的 gc(鸟嘌呤/胞嘧啶)含量可影响测序质量,所以过滤准则可包括一个 gc 含量 40-60% 的范围 。也可类似处理 at 含量。一个实例中,翻译成碱基空间序列的潜在码字如不符合 gc 和/或 at 含量准则,则可予以过滤。
[0112]
若干实施例中,可按试验中的次级结构或性能,过滤潜在码字。例如,自补或与某一引物序列(偶联至该条形码)互补的条形码序列的试验性能可能不佳。相应地,对翻译成碱基空间序列(自补或与偶联至该条形码的某一引物序列互补)的潜在码字,可予以过滤。
[0113]
步骤 7010 中,已过滤的码字后面可附接关键流。例如,在跟踪条形码或对应核酸片段(如目标核酸)时,可用关键流。关键流可按预定流序对应于关键碱基。若干实施例中,可用静态关键碱基(如“t”、“c”、“a”、“g”)附接于条形码序列。本例中,按预定流序对应的流空间串可类似地包括可附接于流空间码字的静态关键流(如 10100101)。
[0114]
若干实施例中,可实施可变关键流(或碱基),以进一步相互隔开流空间码字。例如,可用两个不同的关键碱基的可能集合,它们基于一个重复终止碱基而异(如“t”、“c”、“a”、“g”和“t”、“c”、“a”、“g”、“g”)。本例中,按预定流序对应的流空间的变化可包括在最末的关键流中,要么是“1”要么是“2”(如 10100101 和 10100102)。一个实施例中,流空间码字末尾可附接两个不同的关键流,进一步相互隔开码字。
[0115]
若干实施例中,可复制已过滤的码字的集合,其中第一个码字集被附接上第一个关键流,而复制的码字集被附接上第二个关键流。这里,同一码字的两个版本可因码字末尾附接的关键流而异(如因为针对终止关键流的“1”或“2”)。关键流的变化可有效地增大码字间的最小距离,至少增加一个单位。
[0116]
其它实施例中,可类似地实施其它可变关键流(或碱基)。例如,终止流可包括一个“1”、“2”或“3”,使得可生成三个不同的关键流并附接至码字末尾。其它实施例中,可类似地实施关键流的其它差异,以增大码字间距。
[0117]
步骤 7012 中,可选择和组合已过滤的码字。例如,可按最小距离组合码字。一个实施例中,可实施分类算法,该算法选择一个有预定最小距离的码字子集。一个实例中,可选择码字组,使得它们实现一个相互之间的最小距离和与其它组的其它码字之间的第二最小距离。若干实施例中,分类算法所用的最小距离可包括,因向码字末尾附接可变关键流而有效增大最小距离。一个实施例中,第一最小距离可大于第二最小距离。例如,第一最小距离可包括 6,而第二最小距离可包括 4。若干实施例中,一个或多个码字组可包括一个通用组,使得该通用组中的码字包括相对于所有其它码字的第一最小距离(如组内和组间)。可实施其它合适的最小距离值。
[0118]
一个实施例中,单一码字组可包括第一容错码,而选定的条形码可共同(如各组联合)包括一个第二容错码。例如,同一组内的码字间的最小距离可定义第一容错码,而不同组的码字间的最小距离可定义第二容错码。基于不同的最小距离,比起第二容错码,第一容错码能够分辨和/或纠正较多测序错误。
[0119]
一个实施例中,过滤和分类后,分组流空间码字至少可包括 500、1000、3000、5000、7000 或 9000 个码字。按照本公开说明书,采用参考图 7 的上述技术对应于这些分组码字的一个代表性条形码列表可见于下面的表 2 和以下美国专利的附录 a:申请号 62/161,309,2016 年 5 月 14 日提交,本应用对其主张优先权,且其通过整体引用而成为
本文的一部分。
[0120]
步骤 7014 中,可制造或得以制造对应于分组流空间码字的条形码。例如,按预定流序对应于分组流空间码字的条形码可按本文提供的详情制造。若干实例中,制造可包括使所述条形码得以制造。一个实施例中,分组并制造的条形码至少可包括 500、1000、3000、5000、7000 或 9000 个条形码。
[0121]
一个实施例中,对应于分组码字的条形码可由平板组织。例如,如本文所述,为某组选定的码字可对应于一组条形码。该组条形码可由平板组织(如贮存分组条形码的结构)。因此,某一特定平板的条形码可包括对应于那些条形码的分组码字的容错性(如最小距离特性),且平板间条形码可包括对应于那些条形码的非分组码字的容错性(如最小距离特性)。
[0122]
各示例性实施例中,当制造条形码时,条形码序列后可附接多个条形码接头。不过,当正按预定流序测序时,对应于已调整过(如,一个终止静态或填充流的情况下,对应碱基已被重定位)的码字的条形码不再包括一个静态终止输出信号(如,流空间内)。这里,可基于预定流序和流空间码字,预测终止输出信号(如,流空间内)。一个实施例中,条形码可分为两个类别,比如,第一类别包括按预定流序以一个正掺入信号结尾的条形码(如流空间内的一个“1”或“2”),而第二类别包括不一个正掺入信号结尾的条形码(如流空间内的一个“0”)。若干实施例中,第一类别的条形码可使用任一合适的接头(如一个通用接头)。不过,第二类别的条形码可使用以一个特定碱基(如 g)起头的接头,因缺少一个掺入信号而这样做,以便缓解潜在的测序错误。按预定流序,特定碱基可包括一个预定碱基。例如,可这样预定特定碱基,使得基于预定流序的一个预期 dntp 流产生一次掺入(如,生成一个掺入信号)。
[0123]
一个实施例中,条形码制造可包括正向条形码、正向引物(p1a)、反向条形码和反向引物(p1b)的制造。一个实施例中,一个初始步骤可纯化这些寡核苷酸,其中的全部核苷酸都被归一至 100-400 μm 的 te 或低 te 缓冲液。一个实施例中,非连接型寡核苷酸(如反向条形码和 p1b)可用高效液相色谱法 (hplc) 纯化,而连接型寡核苷酸(如正向条形码和 p1a)可用一种脱盐技术纯化。具备业内普通技能的人士熟悉可用于条形码制造的各种脱盐技术。
[0124]
例如,对反向条形码和 p1b 采用 hplc,有助于减轻测序错误。寡核苷酸是从 3'至 5'合成的,因而源于反向条形码和 p1b 的合成失败可能是在 5' 端截断的。对这些链缺乏 hplc 处理,可增加接头二聚体(如从大体 0% 至大体 5-15%)。此外,正向条形码和 p1a 直接连接扩增子,任何交叉污染都可导致碱基误响应。此外,由于序列数较大,hplc 既成本高昂(或成本效益低)又易受交叉污染。将这些链脱盐而不进行 hplc,成本低些,而且不要求在普通实验室设备(即 hplc 仪)上使用这些链,从而消除了一个交叉污染源。而且在缺口平移期间,以正向条形码和 p1a 为一模板,dna 聚合酶重写反向条形码和 p1b,从而除去任何源于 p1b 和反向条形码序列的 hplc 污染的污染。这进一步降低了进行 hplc 分析的链的污染风险。
[0125]
一个实施例中,纯化后,等量的正向和反向条形码寡核苷酸与 p1a 和 p1b 寡核苷酸可组合在一起并用一定的退火条件在不同的试管中退火。例如,退火条件可包括:95
ꢀº
c 变性 5 分钟;开始在 89
ꢀº
c 保温 2 分钟,随后每 2 分钟降低 1
º
c,这样进行 64 个循
环;4
º
c保温1小时,至多过夜(如,介于6至12小时)。
[0126]
退火后,可组合等量的退火条形码接头和p1接头。可用一种低te缓冲液将样本稀释5倍。可增加2μl的稀释混合物/ampliseq反应。可类似地实施条形码制造的其它变通方法。
[0127]
一个实施例中,条形码制造步骤可包括合成多核苷酸。采用业内已知的常规多核苷酸合成技术,可制造一个含有条形码序列的多核苷酸。
[0128]
按照各示例性实施例,可组合所制造的条形码,形成一个测序用的条形码套件。例如,可将分组条形码划拨至一个或多个平板或其它用于核酸测序(包括多重测序)的平台。例如,与某一特定平板内的条形码对应的码字可离该特定平板内的条形码的对应码字有一个第一最小距离,而离其它平板的条形码的对应码字有一个第二最小距离。若干实施例中,一个条形码平板可由一个柔性平板构成,使得该柔性平板内的条形码的对应码字包括相对于该包的其它所有条形码的对应码字的第一最小距离。这里,考虑到条形码的对应流空间码字的最小距离特性,柔性平板的条形码可用作其它所有平板的替代条形码。通过选择若干有效的条形码,可基于目标应用而定制条形码套件,该条形码套件也可包括条形码的一个全集。
[0129]
测序套件还可包括一个聚合酶。测序套件还可包括容纳不同多核苷酸的多个容器,各个不同的多核苷酸可存放在各个不同的容器内。所述多核苷酸可为长度为5
–
40个碱基的寡核苷酸。测序套件还可包括多个不同种的核苷酸单聚体。测序套件还可包括一个连接酶。
[0130]
若干实施例中,测序套件可包括多个不同的多核苷酸(如,可存放在西林瓶中),各个不同的多核苷酸包括本文所述的不同的一个条形码序列。所述多核苷酸可为有5
–
40个碱基的寡核苷酸。所述多核苷酸本身可为条形码序列,它们还可包括其它单元,如引物位点、接头、连接位点、连接体等。测序套件也可包括前体核苷酸单聚体的一个集合(以执行边合成边测序操作)和/或用于样本制备和/或测序的某一工作流程涉及的其它各种试剂。
[0131]
一个实施例中,条形码或条形码组可用于进行多重测序。例如,多个目标核酸后面可附接独特的条形码,使得该独特条形码序列(或流空间表现形式)测序后可鉴定此目标核酸。
[0132]
图8说明了一个按本公开说明书的示例性实施例用条形码序列对多核苷酸样本进行测序的方法。例如,根据本文所述的示例性实施例,按预定流序与流空间码字对应的多个条形码。
[0133]
步骤8002中,可将多个条形码掺入多个目标核酸,以创建多核苷酸。例如,用任何常规手段可将条形码附接至目标核酸,使得测序期间从该条形码获得的信号可鉴别附接于该条形码的特定目标核苷酸。
[0134]
一个实施例中,提供了多个不同的目标核酸,用于通过预定的核苷酸流进行多重测序,各个不同的目标核酸都被附接到各个不同的所供条形码序列,该条形码序列对应于不同的流空间串,而各个不同的流空间串是容错码或纠错码的不同码字。一个实施例中,所利用的条形码至少可包括500、1000、3000、5000、7000或9000个条形码。类似地,一个实施例中,不同的目标核酸至少可为500、1000、3000、5000、7000或9000个。
[0135]
步骤8004中,可按预定流序,往多核苷酸中引入一系列核苷酸。例如,dntp试剂
流可按预定流序流出,使得多核苷酸暴露于试剂流中,且可发生掺入事件。步骤 8006 中,因引入所述系列核苷酸,可获得一系列信号。例如,可检出因核苷酸掺入到多聚核苷酸而释放的氢离子,其中,信号振幅可跟所检出的氢离子的量有关。另一例中,可检出因核苷酸掺入到多核苷酸而释放的无机焦磷酸盐,其中,信号振幅跟所检出的无机焦磷酸盐的量有关。
[0136]
步骤 8008 中,可分辨条形码序列的一系列信号,以呈递流空间串,使得所呈递的流空间串匹配所述码字,其中,在存在一个或多个错误的情况下,至少一个呈递的流空间串至少匹配一个码字。一个实施例中,所述系列信号可包括一个流空间矢量或由符号组成的串(如 0、1、2 等),代表了一定流的掺入数(如,零聚体、单聚体、二聚体等等)。
[0137]
一个实施例中,任何合适的解码算法和/或软件工具可用于条形码序列的流空间串的解码,以纠正和/或检出错误。例如,可采用一个穷举算法进行解码,该算法将一个有一错误的码字与该码的所有其它成员对比,并解码为最近匹配的码字。若有错码字与两个码字等距或离任何码字远于一半的最小距离,则该算法提示检出一个错误,而不做纠正。另一例中,解码可涉及反向执行编码操作。另一例中,解码算法可运用线性代数技术将码字解码。
[0138]
一个实施例中,一旦至少一个有错码字匹配容错码或纠错码的一个码字,就可鉴定从目标核酸序列之一(与所匹配的流空间码字的对应条形码相关)获得的信号。例如,对基于所匹配的码字的目标核酸,可鉴定一个呈递的流空间串和对应的碱基空间序列。
[0139]
若干实施例中,因所供条形码的数目较大而促成的多重测序的规模可方便一些测序应用。例如,利用促成高度多重测序的大量条形码,可更有效地进行边测序边基因分型、克隆验证和其它检测合成验证(如验证某一合成序列正确)。若干实施例中,还提供了一种包括指令的非暂态可机读的存储介质,当处理器执行该指令时,该指令促使该处理器执行本文详述的方法及其变通方式。还提供了一个系统,包括:一个可机读的内存;一个经配置可执行可机读的指令的处理器,当处理器执行该指令时,该指令促使该系统执行本文详述的方法及其变通方式。
[0140]
按照一个示例性实施例,提供了一组不同的多核苷酸链,多核苷酸链的条形码序列各异;其中,各条形码序列按预定流序的流空间投射给出不同的流空间串,这些串是本文详述的某一容错码的码字。图9 说明了一组各自与一个唯一的条形码序列相关的七个不同的多核苷酸链。各实施例包括较大量的条形码序列和多核苷酸链,所述七个多核苷酸就是代表性实例。每个多核苷酸链可有一个引物位点、一个标准关键序列和一个唯一的条形码序列。每个多核苷酸链还可有一个不同的目标序列。对这样一组多核苷酸链,可进行多重测序,而条形码有助于鉴定某一多重样本所衍生的序列数据源。
[0141]
按照一个示例性实施例,提供了一个样本鉴定套件,包括:多个样本区分码,其中:a) 每个样本区分码由单个亚基的一个序列组成;b) 每个样本区分码的亚基序列可与多个样本区分码当中的其它每一成员的单一亚基的序列相区分;c) 每个样本区分码容忍一个或多个错误,以便可独立地分辨其它样本区分码。
[0142]
按照一个示例性实施例,提供了一个样本鉴定套件,包括:多个样本区分码,其中:a) 每个样本区分码由单个亚基的一个序列组成;b) 一个可检出的信号与每个亚基或亚基对或亚基集相关,使得每个样本区分码与可检出信号的一个序列相关;c) 每个可检出信号
序列可与多个样本区分码当中的其它每一成员的可检出信号的序列相区分;及 d) 每个样本区分码的可检出信号序列至少容忍一个错误,以便可独立地分辨其它样本区分码。
[0143]
图10a-10c 说明了一个用于制备一个多重样本的示例性工作流程。图10a 显示了一个某一基因组 dna 片段文库的构建实例。采用任何合适技术,如超声、机械剪切或酶切,可将一个细菌基因组 dna 10 破碎成许多 dna 片段 12。然后可将平台专用接头 14 连接到片段 12 上面。参考图10b,接着可分离出每个片段样本 18,并与一个微珠 16 组合。考虑到片段 18 的鉴定,可将一个条形码序列(图中未显示)连接至片段 18。然后可将片段 18 通过克隆扩增到微珠 16 上,在微珠 16 上得到片段 18 的许多克隆拷贝。对文库中的不同片段 12,可重复这一过程,得到许多微珠,每个微珠均有单个文库片段 12 多次扩增的产物。参考图10c,接着可将微珠 16 加载到一个反应腔阵列上(如,微孔阵列)。图10c 显示了某一反应腔内正经历测序反应的一个 dna 片段的部分视图。一个模板链 20 可与一个生长中的互补链 22 配对。左屏里,一个 a 核苷酸被添加至反应腔,产生一个单碱基掺入事件,生成一个氢离子。右屏里,一个 t 核苷酸被添加至反应腔,产生一个双碱基掺入事件,生成两个氢离子。氢离子产生的信号在电离图中显示为峰 26。各实施例中,一个测序包可含有上述样本制备和测序流程所需的物质当中的一种或多种,包括 dna 破碎试剂、接头、引物、连接酶、微珠或其它固相载体、聚合酶或用于掺入反应的前体核苷酸单聚体。
[0144]
按照一个示例性实施例,提供了一个系统,由多个可鉴定的核酸条形码组成。核酸条形码可附接或缔合目标核酸片段,形成加有条形码的目标片段(如多核苷酸)。一个加有条形码的目标片段文库可包括多个第一条形码,附接于来自第一源的目标片段。一个加有条形码的目标片段文库也可包括不同的可鉴定条形码,附接于不同源的目标片段,以建立一个多重文库。例如,一个多重文库可包括多个第一条形码和多个第二条形码的一种混合体,第一条形码附接于第一源的目标片段,而第二条形码附接于第二源的目标片段。该多重文库中,第一和第二条形码可分别用于鉴定第一和第二目标片段的来源。任意数量的不同条形码可附接于任意数量的不同来源的目标片段。一个加有条形码的目标片段文库中,条形码部分可用于鉴定:单个目标片段;目标片段的单个来源;一组目标片段;来自单个来源的目标片段;来自不同源的目标片段;来自一个用户自定义组的目标片段;或要求或受益于鉴定的其它任何组。一个加有条形码的目标片段的条码标记部分序列可与目标片段分开读序,或作为涵盖所述条形码和所述目标片段的较大读序的一部分进行读序。一个测序试验中,可用目标片段对核酸条形码测序,然后在测序数据的处理过程中用算法进行句法分析。各实施例中,一个核酸条形码可包括一个合成或天然的核酸序列、dna、rna 或其它核酸和/或衍生物。例如,一个核酸条形码可包括核苷酸碱基腺嘌呤、鸟嘌呤、胞嘧啶、胸腺嘧啶、尿嘧啶、肌苷或其类似物。这些条形码可用于鉴定一个多核苷酸链和/或将其与其它多核苷酸链(如含有一个不同的感兴趣的目标序列的多核苷酸链)相区分,且可用于各种目的,如跟踪、分类和/或鉴定样本。由于不同条形码序列可以与不同多核苷酸链相关,这些条码序列可以适用于不同样品的多重测序。
[0145]
多重文库各实施例中,提供了样本区分码或条形码(如核酸条形码),它们可附接或缔合靶标(如核酸片段),生成带条形码的文库(如加有条形码的核酸文库)。可采用一个或多个合适的核酸或生物分子操作程序制备这样的文库,所述程序包括:破碎;尺寸选择;末端修复;
拖尾;接头拼合;缺口平移;纯化。各实施例中,采用一个或多个合适程序,包括连接、粘性末端混杂、缺口平移、引物延伸或扩增,核酸条形码可附接或缔合某一目标核酸样本的片段。若干实施例中,采用具有一个特定条形码序列的扩增引物,核酸条形码可附接于一个目标核酸。
[0146]
各实施例中,一个目标核酸或生物分子(如蛋白质、多糖和核酸及其聚合物亚基等)样本可从任一合适来源中分离出来,该源的例子有固体组织、组织、细胞、酵母菌、细菌或类似来源。可用任何合适方法,从这些源中分离样本。例如,可将固体组织或组织称重、切割、捣碎、匀化,再从匀化的样本中分离出样本。分离出的核酸样本可为染色质,在 chip(染色质免疫沉淀)程序中,该染色质可与 dna 结合蛋白交联。若干实施例中,可用任一合适程序破碎样本,包括酶法或化学法切割,或剪切。酶促切割可包括限制性核酸内切酶、核酸内切酶或转座酶介导的切割。
[0147]
片段文库各实施例中,提供了片段文库,可包括:一个第一引发位点 (p1)、一个第二引发位点 (p2)、一个插入体、一个内部接头 (ia)和一个条形码 (bc)。若干实施例中,一个片段文库可包括具有一定排列的框架,如:一个 p1 引发位点、一个插入体、一个内部接头 (ia)、一个条形码 (bc) 和一个 p2 引发位点。若干实施例中,片段文库可附接于一个固相载体,如微珠。
[0148]
图11 说明了根据一个片段文库实施例的一个示例性微珠模板。它显示了一个附接于一个固相载体(如微珠)的示例性核酸。一个微珠模板 700 包括一个有接头序列 720 的微珠 710,该接头序列将模板 730 附接到固相载体。模板 730 可包括第一或 p1 引发位点 740、一个插入体 750 和第二或 p2 引发位点 760。模板 730 可为合成模板。模板 730 可代表一个片段文库。模板 730 可包括一个核酸条形码 bc,该条形码可定位于 p1 引发位点 740 和插入体 750 之间。一个内部接头可置于 p1 引发位点 740 和条形码 bc 之间,或条形码 bc 和插入体 750 之间,或插入体 750 和 p2 引发位点 760 之间。
[0149]
图12 说明了根据一个片段文库实施例的另一个示例性微珠模板。核酸条形码 bc 可定位于插入体 750 和 p2 引发位点 760 之间。一个内部接头可置于 p1 引发位点 740 和插入体 750 之间,或插入体 750 和条形码 bc 之间,或条形码 bc 和 p2 引发位点 760 之间。
[0150]
各实施例中,接头序列 720 和模板 730 的长度可各异。例如,接头序列 720 的长度可介于 10 至 100 个碱基,或 15 至 45 个碱基,且可为 18 个碱基 (18b)。模板 730 由 p1 引发位点 740、插入体 750 和 p2 引发位点 760 组成,其长度也可不同。例如,p1 引发位点 740 和 p2 引发位点 760 的各自长度可介于 10 至 100 个碱基,或 15 至 45 个碱基,且可为 23 个碱基 (23b)。插入体 750 的长度可介于 2 个碱基 (2b) 至 20,000 个碱基 (20kb),且可为 60 个碱基 (60b)。一个实施例中,插入体 750 可包括 100 多个碱基,如 1,000 个或更多的碱基。各实施例中,插入体可为连接体形式,这种情况下,插入体 750 可由多达 100,000 个碱基 (100 kb) 或更多碱基组成。
[0151]
各实施例中,可基于不同思路,如插入体长度、信噪比问题和/或测序偏差问题,选择条形码 bc 的位置。例如,若信噪比有问题时(如,边连接边测序过程中进行额外的连接循环时,信噪比可下降),条形码 bc 可定位于 p1 引发位点 740 附近,以减轻因信噪比下
降造成的潜在错误。若信噪比不是一个显著问题,则可将条形码 bc 置于 p1 引发位点 740 或 p2 引发位点 760 附近。若干情况下,模板序列与测序试验期间所用的探针序列的相互作用可不同。将条形码 bc 放在插入体 750 前面,可影响插入体 750 的测序结果。将条形码 bc 放在插入体 750 后面,可减少因偏差导致的测序错误。总之,条形码位置可受到测序的影响或者影响测序,可选择基于测序过程的条件所获得的结果最好的位置。
[0152]
各实施例中,可利用一个正向序列读序(如,沿着模板的 5
’ꢀ–ꢀ3’
方向)进行某一核酸条形码的测序和解码,如,一次读序中,读取条形码 bc 和插入体 750。一个实施例中,通过算法,可将正向读序解析为条形码部分和插入体部分。
[0153]
除了片段文库和对应的本文所述的微珠模板,也可利用公开的条形码构建额外的文库和/或微珠模板。例如,美国专利申请号 13/599,876,2015 年 2 月 28 日作为美国专利公开号 2013/0053256 发布,专利权人 hubbell,专利名为 methods, systems, and kits for sample identification (用于样本鉴定的方法、系统和套件),通过整体引用而成为本文的一部分,该专利还公开了 mate pair 文库、paired end 文库、sage
tm 文库、酵母菌测序文库和 chip-seq 文库,可用各种公开的实施例进行构建。
[0154]
按照各实施例,对以上讨论的资料和/或实施例之中的一项或多项的一个或多个功能,均可采用适当配置且/或编程的硬件和/或软件单元执行或实施。确定是否采用硬件和/或软件单元实施了某一实施例,这可基于任意多的因素,如理想的运算速率、功率电平、耐热性、处理循环预算、输入数据率、输出数据率、内存资源、数据总线速度等,以及其它设计约束或性能约束。
[0155]
硬件单元的实例有处理器、微处理器、通过一个本地接口电路相互偶联的输入和/或输出 (i/o) 器件(或外设)、电路单元(如晶体管、电阻器、电容器、电感器等等)、集成电路、专用集成电路 (asic)、可编程逻辑器件 (pld)、数字信号处理器 (dsp)、现场可编程门阵列 (fpga)、逻辑门、寄存器、半导体器件、芯片、微芯片、芯片组等。本地接口可包括一条或多条总线或其它有线或无线连接、控制器、缓冲器(缓存)、驱动器、中继器和接收器等,以允许在硬件元件之间进行适当通信。处理器是一个硬件设备,用于执行软件特别是内存中存储的软件。处理器可以是任何定制的也可以是可市售的处理器、中央处理单元 (cpu)、计算机相关的几个处理器之中的辅助处理器、半导体型微处理器(如微芯片或芯片组)、宏处理器、或通常用于执行软件指令的任何器件。处理器也可代表一个分布式处理架构。i/o 器件可包括输入器件,例如键盘、鼠标、扫描仪、麦克风、触摸屏、医疗器械和/或实验室仪器的使用接口、条形码读码器、手写笔、激光读码器、射频器件读码器等。而且,i/o 器件还可包括输出器件,例如打印机、条码打印机、显示屏等。最后,i/o 器件还可包括输入输出通信器件,例如调制器/解调器(调制解调器;以便访问其它器件、系统或网络)、射频 (rf) 收发器或其它收发器、电话接口、桥接器、路由器等。
[0156]
软件实例可包括软件组件、程序、应用、计算机程序、应用程序、系统程序、机器程序、操作系统软件、中间件、固件、软件模块、例程、子例程、函数、方法、段程序、软件接口、应用程序接口 (api)、指令集、运算代码、代码段、计算机代码段、字、值、符号或它们的任意组合。内存软件可包括一个或多个独立程序,此程序可包括可执行指令的有序列表,用于实施逻辑功能。内存软件可包括一个用于按现有资料鉴定数据流的系统和任何合适的定制或可市售的操作系统 (o/s),此操作系统可控制其它计算机程序如系统的执行,并提供排程、输
入输出控制、文件和数据管理、内存管理、通信控制等。
[0157]
按照各实施例,对以上讨论的资料和/或实施例当中的任何一项或多项的一个或多个功能,均可采用适当配置且/或编程的非暂态可机读介质或物品来执行或实施,该介质或物品可储存一个指令或指令集,此指令或指令集若被机器执行,则可促使该机器执行实施例中的某一方法和/或操作。此机器可包括任何合适的处理平台、运算平台、运算器件、处理器件、运算系统、处理系统、计算机、处理器、科学仪器或实验室仪器等,且可采用任何合适的硬件和/或软件的组合来实施。可机读的介质或物品可包括任何合适类型的记忆单元、记忆器件、记忆品、记忆介质、存储器件、存储品、存储介质和/或存储单元,如内存、可移动或不可移动介质、可擦或不可擦介质、可写或可重写介质、数字或模拟介质、硬盘、软盘、压缩式光盘只读存储器 (cd-rom)、可记录压缩光盘 (cd-r)、可写压缩光盘 (cd-rw)、光盘、磁性介质、光磁介质、可移除内存卡或盘、各类数字光盘 (dvd)、磁带、磁盒等,包括任何适用于计算机的介质。内存可包括任一个易失性记忆单元或其任一组合(如随机存取内存 ram, 诸如 dram、sram、sdram 等)和非易失性记忆单元(如 rom、eprom、eerom、闪存、硬盘驱动器、磁带、cdrom 等)。而且,内存可结合电子、磁性、光学和/或其它类型的存储介质。内存可有一个分布式架构,其中的各个组件相距较远,但仍可由处理器存取。指令可包括任何合适类型的代码,如源代码、汇编码、解释码、可执行码、静态码、动态码、加密码等,采用任何合适的高级、低级、面向对象的、直观、汇编和/或解释的编程语言实施。
[0158]
按照各实施例,对以上讨论的资料和/或实施例之中的任一项或多项的一个或多个功能,均可至少部分采用一个分布式、集群式、远程或云计算资源。
[0159]
按照各实施例,对以上讨论的资料和/或实施例之中的任一项或多项的一个或多个功能,均可采用一个源程序、可执行程序(对象代码)、脚本或其它任何由一个指令集组成的实体执行或实施。通过一个编译器、汇编器、解释器等(内存里可含或可不含)翻译源程序,以便连同 o/s 一起正确操作。可用以下工具写指令:a) 一种面向对象的编程语言,有多类数据和方法,或 (b) 一种程序性编程语言,有例程、子例程和/或函数,可包括 c、c++、pascal、basic、fortran、cobol、perl、java 和 ada。
[0160]
按各实施例,以上讨论的实施例当中的一例或多例可包括向用户接口器件、计算机可读的存储介质、本地计算机系统或远程计算机系统传输、显示、存储、打印或输出与所述实施例生成、存取或使用的任何信息、信号、数据和/或中间结果或最终结果有关的信息。这样传输、显示、存储、打印或输出的信息可采取可搜索和或可过滤的运行列表形式,和报告、图片、表格、数据图、曲线图、电子表格、相互关系、序列及其组合。
[0161]
通过重复、添加或替代任何笼统或具体描述的功能和/或上述实施例当中的一个或多个里所阐述的组件和/或物质和/或步骤和/或操作条件,可派生出其它各实施例。而且宜理解,只要步骤或动作的目标仍可实现,则用于执行一定动作的某一步骤顺序或命令是无关紧要的,除非另外具体说明。而且,只要步骤或动作的目标仍可实现,则可同时进行两个或多个步骤或动作,除非另外具体说明。而且,只要上文讨论的实施例中的其它任何一例的目标仍可实现,则上文讨论的实施例之一里提及的任何一个或多个功能、组件、方面、步骤或其它特点可视为上文讨论的实施例中的其它任何一例的一个潜在的可选功能、组件、方面、步骤或其它特点,除非另外具体说明。
[0162]
虽然利用边合成边测序的方式可有效使用本资料的各实施例,如本文和以下文献
所述:rothberg 等,美国专利公开说明书号 2009/0026082;anderson 等,sensors and actuators b chem.(传感器和执行器 b:化学), 129 期,79-86 页,2008 年;pourmand 等,proc.nat1acad.sci.(美国科学院院报),103 期,6466-6470 页,2006 年,均通过整体引用而成为本文的一部分,但是,还可用其它方式使用本资料,如边合成边测序的变通方法,包括将核苷酸前体或核苷酸三磷酸酯前体改性为可逆终止子的方法【有时叫循环可逆终止 (crt) 法)】和对核苷酸前体或核苷酸三磷酸酯前体不改性的方法【有时叫循环单碱基传递 (csd)】,或更通用的方法,包括传递核苷酸(至聚合酶-引物-模板复合体)并采集信号(或直接或间接检测掺入)的重复步骤(或响应传递的延伸)。
[0163]
虽然可连同基于 ph 的序列检测一起有效使用本资料的各实施例,如本文和以下文献所述:rothberg 等,美国专利申请公开说明书号 2009/0127589 和 2009/0026082,以及 rothberg 等,英国专利申请公开说明书号 gb2461127,均通过整体引用而成为本文的一部分,但是,用其它检测方式也可使用本资料,包括对掺入反应所释放的焦磷酸根离子 (ppi) 的检测(参见美国专利号 6,210,891、6,258,568 和 6,828,100)、各种荧光测序仪器法(参见美国专利号 7,211,390、7,244,559 和 7,264,929)、若干边合成边测序技术【可检测与核苷酸相关的标记,如质量标签、荧光和/或化学发光标签,这种情况下,一个钝化步骤可纳入下一个合成检测循环之前的工作流程(如,通过化学切割或光漂白)】、以及更通用的方法,其中,一个掺入反应生成或导致一个具有某一特性的产物或组分,该特性就是能被监测和用于检测掺入事件,包括幅度(如热量)或浓度(如焦磷酸根离子和/或氢离子)和信号(如荧光、化学发光、光发生)的变化,这些情况下,所检出的产物或组分的量可与掺入事件的数目单调相关。
[0164]
虽然本说明书详述了一些实施例,但是其它实施例也是可能的,且属于本发明的范围内。例如,本领域的技术人员可能对本说明感到欣慰:本资料可用多种形式实施,如采用各种测序仪器,而且各实施例均可单独或组合实施。对于本领域的技术人员而言,考虑到说明书和附图以及权利要求书中所述的说明、图和专利实践,变化和修改都会是显而易见的。
[0165]
表2 显示了按照本文所述的各实施例的代表性条形码序列seq.i.d.条形码序列组别(seq.id.no.20)ttccggaggatgcc平板_xx(seq.id.no.21)ttgaggccaagtcc平板_xx(seq.id.no.22)gaccaccggttc平板_xx(seq.id.no.23)gtggacctccgttc平板_xx(seq.id.no.24)tggaccacgaattc平板_xx(seq.id.no.25)ttctggacatccgc平板_xx(seq.id.no.26)ttaggcctccattc平板_xx(seq.id.no.27)gttgaggaaccacc平板_xx(seq.id.no.28)ccggacaagaattc平板_xx(seq.id.no.29)cggagttccggttc平板_xx(seq.id.no.30)gtccaccaaccacc平板_xx(seq.id.no.31)gttccagccatctc平板_xx
(seq.id.no.32)gttagcggattc平板_xx(seq.id.no.33)gccacaacttcc平板_xx(seq.id.no.34)gttccttagaagac平板_xx(seq.id.no.35)gccagcaccaattc平板_xx(seq.id.no.36)gcttggagccgttc平板_01(seq.id.no.37)tccaggcaccttcc平板_01(seq.id.no.38)gttcctacgttc平板_01(seq.id.no.39)ccagaacggaatcc平板_01(seq.id.no.40)gtcaggaccaac平板_02(seq.id.no.41)cttaccatccttcc平板_02(seq.id.no.42)gctgacaccacc平板_02(seq.id.no.43)tcaccaacggac平板_02(seq.id.no.44)ctgagaatccaacc平板_02(seq.id.no.45)ttcctacaatctcc平板_02(seq.id.no.46)gtcttgacaagaac平板_02(seq.id.no.47)gttcttagagaacc平板_02(seq.id.no.48)gtccaggaggtc平板_02(seq.id.no.49)tcggaccaattgcc平板_02(seq.id.no.50)ccttaccaataacc平板_03(seq.id.no.51)tcgaggccatcgac平板_03(seq.id.no.52)ttccttaccttatc平板_03(seq.id.no.53)ttctgagccgac平板_03(seq.id.no.54)gtcctaccaatgac平板_03(seq.id.no.55)tagccaattgaacc平板_03(seq.id.no.56)gccttagcaacacc平板_03(seq.id.no.57)gtcctgagcagaac平板_03(seq.id.no.58)gtctacctcggc平板_03(seq.id.no.59)gtctgaccggatcc平板_03(seq.id.no.60)ccagaattcggacc平板_04(seq.id.no.61)ttccggagttcatc平板_04(seq.id.no.62)ccttagatccttcc平板_04(seq.id.no.63)gccttaggatcgcc平板_04(seq.id.no.64)gccaggattggtcc平板_04(seq.id.no.65)gtccggagatgaac平板_04(seq.id.no.66)gccttattccaacc平板_04(seq.id.no.67)gttctaggattcac平板_04(seq.id.no.68)tcctagtccggtcc平板_04(seq.id.no.69)gtcttggagttaac平板_04(seq.id.no.70)gttctatcgttc平板_05
(seq.id.no.71)ttcgagtgttcc平板_05(seq.id.no.72)tcttgattggtc平板_05(seq.id.no.73)gcttactccggtcc平板_05(seq.id.no.74)gattcggattcc平板_05(seq.id.no.75)gttcctgagttctc平板_05(seq.id.no.76)gtcggaccatgaac平板_05(seq.id.no.77)cagatccgttcc平板_05(seq.id.no.78)gttctgacgtcc平板_05(seq.id.no.79)tccgaggatgaatc平板_05
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1