lncRNA的高通量测序文库的构建方法及应用与流程
lncrna的高通量测序文库的构建方法及应用
技术领域
1.本发明涉及生命科学技术领域,具体而言,涉及一种lncrna的高通量测序文库的构建方法及应用。
背景技术:
2.外泌体是由细胞质中产生,经细胞膜释放,直径在30~100nm之间,携带有母细胞的多种蛋白质、脂类和核酸等物质的一种外囊泡结构。其来源多样,广泛分布于血液、唾液、尿液、脑脊液、乳汁等体液中。近年来,外泌体凭借其有别于普通样本的独特组分和构造,以及含有丰富标志物,几乎可以与任何疾病相关联的特点,逐渐成为医学领域研究趋势之一。随着外泌体研究的挖掘和深入,它在人类生命活动中的重要性也日益凸显。
3.外泌体中携带的ncrna(非编码rna)包括small rna(小rna)、lncrna(长链非编码rna)、circrna(环状rna),这些ncrna在细胞间信息传递、调控基因表达等方面有着重要作用。对外泌体中的mirna(micro rna,微小rna)、lncrna、circrna进行研究能够深入了解疾病或不同发育阶段的内在机制和功能调控机制,而筛选外泌体特异biomarker(生物标志物)也有着非常高的临床应用价值。目前在科研上一般是采用芯片的方式进行高通量测序,但是只能检测已知lncrna,有明显的数据缺陷。
4.ffpe(formalin fixation and paraffin embedding)是福尔马林固定、石蜡包埋的样本,是医学领域常见的生物材料。但低质量ffpe样本(rin值低于4.0)一般存在严重的rna降解,常阻碍科学研究。最早ffpe样本主要是用于病理形态学观察,近些年,随着精准医疗的渗透发展,ffpe样本在临床病理检验、肿瘤基因检测中也得到广泛使用。研究人员将ffpe样本中的核酸提取出来进行建库,然后利用高通量测序技术对ffpe样本的核酸进行测序和分析,就能得到病理和肿瘤相关的很多重要信息。
5.但是因为低质量ffpe样本中有多种因素会影响其中核酸的质量:例如,福尔马林固定使核酸与蛋白发生交联,影响核酸提取质量;石蜡高温渗入过程加速磷酸二脂键的水解,导致核酸降解;福尔马林固定以及不理想的保存条件使胞嘧啶脱氨基引入c
→
t,g
→
a等突变;固定和包埋增加核酸分子脆性,造成核酸高度片段化等。取样部位导致的微生物污染等,使得低质量ffpe样本中的核酸质量往往很差,用低质量ffpe样本使用普通lncrna建库方式搭建的文库进行测序就面临诸多挑战:文物产量低,文库质量差,外显子比例低,突变检出率低等等,针对以上问题一般建议使用目的区域捕获的方法进行建库和数据分析。但是该方法存在一定缺陷,比如无法获悉非已知基因表达情况,与其他方法的基因检出量趋势不一致等问题。在二代测序技术中的建库及测序环节,通常需要进行一定次数的pcr扩增,以满足测序所需的文库量。然而,由于扩增的偏好性以及扩增倍数的不确定性(在pcr扩增时,所有的文库片段并非以同等速率等量的扩增,扩增速率受到片段长度、gc含量、片段浓度等多方面的影响,容易扩增的片段极大的被富集,一些含量较低的片段或碱基偏好严重的片段甚至完全丢失,最终影响测序结果的准确性),导致各个片段被扩增的倍数是不一定相同的,这种因pcr扩增产生的重复reads即为duplication。duplication存在会导致后
续分析中各个基因表达量和真实情况不一致,降低了结果的可信度。而umi标记技术是一种可以准确识别并去除pcr产生的duplication的技术手段,在文库扩增之前为每一条逆转录的cdna片段加上唯一的身份标签(uniqueidentifier,umi或uid),也称为数字标签。数字标签会伴随片段扩增、测序、分析的全过程。同一个片段经过pcr扩增出来的产物均带有相同的数字标签,测序完成后利用umi追溯每一个片段的来源,将相同来源的片段(具有相同的序列和umi)进行合并,就能准确去除pcr扩增重复,一比一准确还原样本扩增前的原始状态。在此过程中,pcr扩增和测序错误同样可以被纠正:扩增和测序的错误会使得相同umi标签对应多个不同的序列,那么只需比较这些序列的相似性,即可纠正这些错误。
技术实现要素:
6.本发明的主要目的在于提供一种lncrna的高通量测序文库的构建方法及应用,以解决现有技术中难以对未知lncrna进行高通量测序的问题。
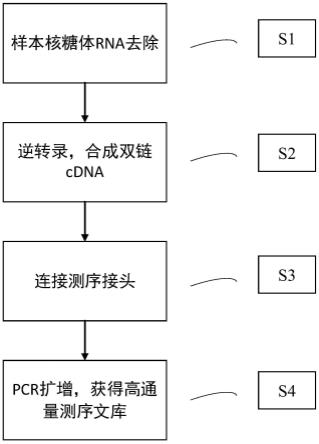
7.为了实现上述目的,根据本发明的第一个方法,提供了一种lncrna的高通量测序文库的构建方法,该构建方法包括:s1,去除待检样本总rna中的核糖体rna,获得不含核糖体rna的总rna;s2,将不含核糖体rna的总rna逆转录,形成双链cdna;s3,在双链cdna的5’和3’端连接测序接头,得到接头连接产物;s4,pcr扩增富集接头连接产物,回收获得待检样本的lncrna的高通量测序文库;待检样本包括外泌体样本或低质量ffpe样本。
8.进一步地,核糖体rna包括真核核糖体rna和/或原核核糖体rna;优选地,在s1,中利用核糖体去除试剂或磁珠,去除待检样本总rna中的核糖体rna,获得不含核糖体rna的总rna;优选地,核糖体去除试剂包括真核核糖体去除试剂和/或原核核糖体去除试剂;优选地,真核核糖体去除试剂包括qiaseq fastselect-rrna hmr;优选地,原核核糖体去除试剂包括fastselect 5s/16s/23s;优选地,核糖体去除的反应体系包括:fastselect 5s/16s/23s 1μl和/或fastselect rrna hmr 1μl,样本总rna 12.5μl和fastselect fh buffer 1.5μl;优选地,反应体系的反应程序包括:75℃反应2min,70℃反应2min,65℃反应2min,60℃反应2min,55℃反应2min,37℃反应2min;25℃反应2min,4℃保持。
9.进一步地,在s2中,逆转录包括第一链合成反应和第二链合成反应,得到双链cdna;优选地,在得到双链cdna后,不对双链cdna进行打断操作;优选地,s3包括:依次分别对双链cdna进行第一纯化、末端修复及加a,得到修复dna;在修复dna的5’端和3’端添加测序接头,得到接头连接产物;优选地,第一纯化包括第一磁珠纯化。
10.进一步地,第一链合成反应的反应体系包括:不含核糖体rna的总rna 10μl,反转录试剂8μl和一链合成酶复合物2μl;优选地,第一链合成反应的反应程序包括:25℃反应10min,42℃反应15min,70℃反应15min,4℃保持。
11.进一步地,第二链合成反应的反应体系包括:第一链合成反应的反应体系20μl,第二链合成反应缓冲液8μl,第二链合成酶混合物4μl,无核酸酶水48μl;优选地,第二链合成反应的反应程序包括:16℃反应1h。
12.进一步地,末端修复的反应溶液包括:第一纯化后的溶液,42μl;末端体系修复液1,6.8μl;末端修复酶,1.2μl;优选地,末端修复的反应程序包括:37℃反应30min,72℃反应30min,4℃保持。
13.进一步地,在s3,中,测序接头为含有umi的测序接头;优选地,连接测序接头后,进
行第二纯化;优选地,第二纯化包括第二磁珠纯化;优选地,连接测序接头的反应溶液包括:含有双链cdna的反应溶液,50μl;酶反应缓冲液2-1 8.4μl;酶反应缓冲液2-2 15μl;快速连接酶1.6μl;含有umi的测序接头1μl;无核酸酶水3μl;enzyme 2 1μl;优选地,连接测序接头的反应程序包括:20℃反应30min,4℃保持。
14.进一步地,s4中,在pcr扩增前消化含u碱基的接头连接产物;优选地,利用udg酶消化含u碱基的接头连接产物;优选地,在pcr扩增后进行第三纯化,获得样本lncrna的高通量测序文库;优选地,第三纯化包括第三磁珠纯化;优选地,不含核糖体rna的总rna包括mrna、lncrna或circrna中的一种或多种;优选地,消化和pcr扩增的反应溶液包括:含有接头连接产物的反应溶液,22μl;user酶1μl;pcr缓冲液(2x)25μl;index(x)引物/i7引物25μm 1μl;p5 pcr引物25μm 1μl;优选地,消化和pcr扩增的反应程序包括:37℃反应10min,98℃预变性30s;98℃变性10s,65℃退火30s,72℃延伸30s,10-15个循环;72℃延伸5min;4℃保持。
15.为了实现上述目的,根据本发明的第二个方法,提供了一种lncrna的高通量测序文库,该lncrna的高通量测序文库,利用上述构建方法构建得到。
16.为了实现上述目的,根据本发明的第三个方法,提供了上述构建方法在构建lncrna的高通量测序文库中的应用。
17.为了实现上述目的,根据本发明的第四个方法,提供了一种lncrna测序方法,该测序方法包括:对上述lncrna的高通量测序文库进行测序。
18.为了实现上述目的,根据本发明的第五个方法,提供了上述构建方法、或lncrna的高通量测序文库,在制备疾病早期筛查、预后评估、科学基础研究和/或临床疗效监测的产品中的应用。
19.应用本发明的技术方案,以不同来源的样本总rna为起始样本,去除核糖体后,反转录合成cdna并连接测序接头,富集回收获得高通量测序文库。能够将文库构建过程及上机测序过程中产生的pcr重复(duplication)进行精准去除。与常规的样本lncrna文库相比,具有定量更准,序列测序更准,低拷贝序列定量更准的优势,确保了内含的ncrna及mrna的定量结果无偏差,能够对未知lncrna进行高通量测序,为样本rna的研究提供可靠的数据结果。
附图说明
20.构成本技术的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
21.图1示出了根据本发明实施例1的样本lncrna的高通量测序文库的构建方法流程图。
22.图2示出了根据本发明实施例1的外泌体lncrna的高通量测序文库利用安捷伦2100生物分析仪获得的质检图。
23.图3示出了根据本发明实施例2的外泌体lncrna的高通量测序文库利用安捷伦2100生物分析仪获得的质检图。
24.图4示出了根据本发明对比例2的外泌体lncrna的高通量测序文库利用安捷伦2100生物分析仪获得的质检图。
25.图5示出了根据本发明对比例1的外泌体lncrna的高通量测序文库利用安捷伦
2100生物分析仪获得的质检图。
26.图6示出了根据本发明对比例3的低质量ffpe样本lncrna的高通量测序文库利用安捷伦2100生物分析仪获得的质检图。
27.图7示出了根据本发明对比例4的低质量ffpe样本lncrna的高通量测序文库利用安捷伦2100生物分析仪获得的质检图。
28.图8示出了根据本发明实施例2的低质量ffpe样本的rna电泳图。
29.图9示出了根据本发明实施例1的外泌体总样本的检测图。
具体实施方式
30.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将结合实施例来详细说明本发明。
31.术语解释:
32.lncrna:长链非编码rna,是长度大于200个核苷酸的非编码rna,在生物体内不编码蛋白质。
33.如背景技术所提到的,现有技术中,对于外泌体lncrna、低质量ffpe等样本的高通量测序由于利用常规建库方法,难以获得高质量的文库,因此多利用芯片的方式对外泌体lncrna进行高通量测序。但是只能利用芯片只能检测已知lncrna,在获得的测序数据中有明显的数据缺陷,对于未知lncrna无法进行高通量测序。
34.因为外泌体样本本身的特性,单个体环境中所有细胞均有可能分泌外泌体,在外泌体提取后,尤其是人源的细菌、真菌感染导致外源污染,以及真核细胞在培养过程中的支原体、细菌等污染,会直接导致使用二代测序建库后的数据mapping较低,严重污染低于1%的mapping。芯片技术是对已知的lncrna进行高通量的qpcr,因为技术的原理限制,不能进行未知lncrna的挖掘和研究。发明人根据实际的操作和分析,发现用于外泌体lncrna建库的样品来源多是临床或者细胞培养,因此在样品中易存在部分外源微生物干扰,可能是影响lncrna建库质量的原因。又因其内含rna片段偏小,主要分布在25~200nt范围内,使用常规ncrna或者微量扩增的方式建库,常会导致数据质量差的问题。
35.对于低质量ffpe样本也存在严重的rna降解,且有低质量ffpe中存在多重因素影响核酸质量。因此低质量ffpe样本中的核酸质量往往很差,用低质量ffpe样本建库测序就面临诸多挑战:文物产量低,文库质量差,突变检出率低等。普通建库方式获取的高通量数据质量差,无法进行有效精准的数据分析和数据结果的应用。因而,在本技术中发明人尝试对样本lncrna的高通量测序文库的构建方法进行探究,通过优化逆转录前的核糖体rna去除试验等操作,获得了一种行之有效的样本lncrna的高通量测序文库的构建方法,因而提出了本技术的一系列保护方案。
36.在本技术第一种典型的实施方式中,提供了一种lncrna的高通量测序文库的构建方法,该构建方法包括:s1,去除待测样本总rna中的核糖体rna,获得不含核糖体rna的总rna;s2,将不含核糖体rna的总rna逆转录,形成双链cdna;s3,在双链cdna的5’和3’端连接测序接头,得到接头连接产物;s4,pcr扩增富集接头连接产物,回收获得待测样本的lncrna的高通量测序文库;上述待测样本包括外泌体样本或低质量ffpe样本。构建方法流程图如图1所示。
37.含有外泌体lncrna的样本,可来源于动物的血液、体液、组织或者细胞培养的细胞上清液中的外泌体,以及植物组织分泌的外泌体提取的总rna。申请人发现,在上述样本和实际操作中,易存在原核或真核生物的污染,因此在上述构建方法,去除外泌体总rna中的核糖体rna,以获得不含核糖体rna的总rna。
38.低质量ffpe中的rna,受到样本制作、保存等多种因素的影响,多为存在微生物污染且核酸高度降解的状态,因此利用上述构建方法,能够减少低质量ffpe中的外源核酸、杂质等影响,从而获得高质量的低质量ffpe的lncrna的高通量测序文库。
39.在现有技术中二代测序技术中的建库及测序环节,通常需要进行一定次数的pcr扩增,以满足测序所需的文库量。然而,由于扩增的偏好性以及扩增倍数的不确定性,导致各个片段被扩增的倍数是不一定相同的,会导致后续分析中各个基因表达量和真实情况不一致,降低了结果的可信度。而在本技术中,通过将不含核糖体rna的总rna逆转录形成双链cdna后连接测序接头,从而实现精准定量起始lncrna的分子数并削减测序及文库制备产生的错误以及pcr扩增所造成的不均一性,有效分辨文库构建过程中引入的假阳突变,从而可更加有效检测超低丰度突变。能够克服外源核酸的干扰,解决了样本外源污染导致的有效数据少以及文库pcr duplication导致的定量偏差的问题。
40.对于样本中的小rna,如小ncrna(包括mirna),是在建库接头连接及文库出库片选环节中去除。对于环状rna,不做去除,故在上述高通量测序文库的构建方法中,也能够对circrna进行的分析。因此利用上述构建方法构建的文库,一个文库能够进行三类rna(mrna,lncrna,circrna)的分析,解决了现有技术中利用芯片测序难以实现的问题。
41.在一种优选的实施例中,核糖体rna包括真核核糖体rna和/或原核核糖体rna;优选地,在s1,中利用核糖体去除试剂或磁珠,去除待检样本总rna中的核糖体rna,获得不含核糖体rna的总rna;优选地,核糖体去除试剂包括真核核糖体去除试剂和/或原核核糖体去除试剂;优选地,真核核糖体去除试剂包括qiaseq fastselect-rrna hmr;优选地,原核核糖体去除试剂包括fastselect 5s/16s/23s;优选地,核糖体去除的反应体系包括:fastselect 5s/16s/23s 1μl和/或fastselect rrna hmr 1μl,样本总rna 12.5μl和fastselect fh buffer 1.5μl;优选地,反应体系的反应程序包括:75℃反应2min,70℃反应2min,65℃反应2min,60℃反应2min,55℃反应2min,37℃反应2min;25℃反应2min,4℃保持。
42.由于含有lncrna的样本易收到原核、真核生物或其他杂质的污染和干扰,因此利用核糖体去除试剂或磁珠,对真核核糖体rna和原核核糖体rna同时去除,能够获得最佳的去除效果,防止残留的核糖体rna干扰建库后的测序结果和数据质量。在本技术中,创造性的同时利用市售的真核核糖体去除试剂qiaseq fastselect-rrna hmr和原核核糖体去除试剂fastselect 5s/16s/23s,2种试剂同时发挥作用,在核糖体去除的反应体系能够取得较好的核糖体rna去除效果。也可以灵活选用现有技术中其他的核糖体去除方法,以实现对原核和真核核糖体rna的高效去除。对于真核核糖体去除试剂qiaseq fastselect-rrna hmr和原核核糖体去除试剂fastselect 5s/16s/23s,利用上述核糖体去除的反应体系和反应程序,能够获得最佳的去除效果,核糖体rna去除率高,反应简便,且不影响lncrna的含量、活性以及后续的试验。
43.本技术中对于核糖体去除试剂的使用,一方面是对于核糖体的去除效率的提高,
数据质量会获得明显提升;另一方面是此种去除方法,对样本质量及建库起始量的要求低。可以实现低于100ng,rin值低于4的样本。且在建库中使用测序接头,能够提高对于降解样本的精准定量,对于测序质量的提升和数据的分析有明显应用价值。而现有方法是使用核糖体探针将样本中的核糖体进行杂交,再使用磁珠吸附或者rna酶消化,去除样本中的核糖体污染。该方法在操作上较为复杂,对于样本提取量普遍较低的ffpe rna来讲,无法满足现有核糖体去除试剂盒的起始量的要求。本技术的构建方法,可以极大的忽略样本起始量的要求,且能满足对核糖体去除效率的要求。在一种优选的实施例中,在s2中,逆转录包括第一链合成反应和第二链合成反应,得到双链cdna;优选地,在得到双链cdna后,不对双链cdna进行打断操作;优选地,s3包括:依次分别对双链cdna进行第一纯化、末端修复及加a,得到修复dna;在修复dna的5’端和3’端添加测序接头,得到接头连接产物;优选地,第一纯化包括第一磁珠纯化。
44.上述第一链合成反应,即为利用逆转录酶,将lncrna逆转录为相应的单链逆序cdna。再进行第二链合成反应,以获得的单链逆序cdna为模板进行dna合成,获得与lncrna方向相同的单链正序cdna,单链正序cdna和单链逆序cdna能够互补配对,形成双链cdna。由于以lncrna为模板获得的双链cdna长度较短,因此不同于现有的高通量测序建库中的方法,在获得双链cdna后,不进行打断操作,防止双链cdna被破坏,生成过短的dna片段,影响后续测序质量。
45.在s3步骤中,对上述获得的双链cdna进行纯化,末端修复和加a后,在双链cdna末端生成突出的a碱基,便于与测序接头利用t-a克隆等方法进行连接,获得接头连接产物。在末段修复前对双链cdna进行纯化,能够去除lncrna和其他如小rna、环状rna等杂质
46.在一种优选的实施例中,第一链合成反应的反应体系包括:不含核糖体rna的总rna 10μl,反转录试剂(rt reagent)8μl和一链合成酶复合物(first strand synthesis enzyme mix,含有dutp)2μl;优选地,第一链合成反应的反应程序包括:25℃反应10min,42℃反应15min,70℃反应15min,4℃保持。
47.在第一链合成反应中,所用试剂均为市售试剂,也可根据实际需要选择其他品牌或功能的试剂。为了构建链特异性lncrna文库,在第一链合成反应中,将dntp原料替换为dutp原料,使得反转录获得的单链逆序cdna中不存在t碱基,理应存在t碱基的位置实际均为u碱基。从而实现在后续处理中区分与lncrna顺序或逆序的cdna单链,仅对于顺序的链进行测序,保证了测序结果能直接反应rna的方向。
48.在一种优选的实施例中,第二链合成反应的反应体系包括:第一链合成反应的反应体系20μl,第二链合成反应缓冲液(second strand synthesisi reaction buffer)8μl,第二链合成酶混合物(second strand synthesis enzyme mix)4μl,无核酸酶水48μl;优选地,第二链合成反应的反应程序包括:16℃反应1h。
49.在第二链合成反应中,本技术中所用的试剂均为市售试剂,也可根据实际需要选择其他品牌或功能的试剂。第二链合成反应以上述获得的单链逆序cdna为模板,通过碱基互补配对的原理,获得一条与单链逆序cdna互补配对的单链顺序cdna,2条cdna单链互补配对,构成双链cdna。单链顺序cdna,即5’到3’端的碱基排列顺序,与lncrna的5’到3’端的碱基排列顺序相同,因此对于单链顺序cdna的测序,能够直观的体现lncrna的正确方向。
50.在一种优选的实施例中,末端修复的反应溶液包括:第一纯化后的溶液,42μl;末
端体系修复液(buffer 1),6.8μl;末端修复酶(enzyme 1),1.2μl;优选地,末端修复的反应程序包括:37℃反应30min,72℃反应30min,4℃保持。
51.利用上述试剂和反应程序,能够对纯化后的双链cdna进行末端修复,从而进行后续的末端加a。
52.在一种优选的实施例中,在s3,中,测序接头为含有umi的测序接头;优选地,连接测序接头后,进行第二纯化;优选地,第二纯化包括第二磁珠纯化;优选地,连接测序接头的反应溶液包括:含有双链cdna的反应溶液,50μl;酶反应缓冲液2-1(buffer 2-1)8.4μl;酶反应缓冲液2-2(buffer 2-2)15μl;快速连接酶(enhancer)1.6μl;含有umi的测序接头1μl;无核酸酶水3μl;enzyme 2 1μl;优选地,连接测序接头的反应程序包括:20℃反应30min,4℃保持。
53.利用含有umi(特异性分子标签,unique molecular identifiers)的测序接头,在修复dna上增加特有的序列标签,能够区分同一样本中不同的片段,或区分不同样品中的片段。umi会伴随片段扩增、测序、分析的全过程。同一个片段经过pcr扩增出来的产物均带有相同的umi,测序完成后利用umi追溯每一个片段的来源,将相同来源的片段(具有相同的序列和umi)进行合并,就能准确去除pcr扩增重复,一比一准确还原样本扩增前的原始状态。在此过程中,pcr扩增和测序错误同样可以被纠正:扩增和测序的错误会使得相同umi标签对应多个不同的序列,那么只需比较这些序列的相似性,即可纠正这些错误。从而实现对于lncrna、尤其是低拷贝序列的定量更加准确。
54.在一种优选的实施例中,s4中,在pcr扩增前消化含u碱基的接头连接产物;优选地,利用udg酶消化含u碱基的接头连接产物;优选地,在pcr扩增后进行第三纯化,获得样本lncrna的高通量测序文库;优选地,第三纯化包括第三磁珠纯化;优选地,不含核糖体rna的总rna包括mrna、lncrna或circrna中的一种或多种;优选地,消化和pcr扩增的反应溶液包括:含有接头连接产物的反应溶液,22μl;user酶(udg enzyme)1μl;pcr缓冲液(pcr mix,2x)25μl;index(x)引物/i7引物25μm 1μl;p5 pcr引物25μm 1μl;优选地,消化和pcr扩增的反应程序包括:37℃反应10min,98℃预变性30s;98℃变性10s,65℃退火30s,72℃延伸30s,10-15个循环;72℃延伸5min;4℃保持。
55.在第一链和第二链合成反应中,使用含有dutp而非dntp的原料,构建的含有u碱基的双链cdna,在连接测序接头形成接头连接产物后,对含有u碱基的单链进行消化处理,能够清除与lncrna顺序相反的单链cdna(单链逆序cdna),仅保留与lncrna顺序相同的cdna单链,从而在后续测序中,获得最真实、与lncrna方向相同的转录信息。在消化后进行pcr,将方向正确的单链cdna扩增为双链dna,继续pcr从而富集该双链dna,得到能够满足后续高通量测序样本量的双链dna。pcr后进行第三纯化,能够去除消化产生的dna片段、pcr所用试剂等杂质,提高测序样品纯度,即获得外泌体lncrna的高通量测序文库。本技术中将消化和pcr体系混合,利用市售试剂,在同一反应内完成消化和pcr过程。也可以使用其他现有技术或试剂,对反应体系和程序进行灵活调整,以实现相同的技术效果。
56.在本技术第二种典型的实施方式中,提供了一种构建lncrna的高通量测序文库的装置,该装置利用上述构建方法,构建lncrna的高通量测序文库;装置包括:核糖体去除模块,用于去除样本总rna中的核糖体rna,获得不含核糖体rna的总rna;逆转录模块,用于将不含核糖体rna的总rna逆转录,形成双链cdna;接头连接模块,用于在双链cdna的5’和/或
3’端连接测序接头,得到接头连接产物;富集回收模块,用于pcr扩增富集接头连接产物,回收获得样本lncrna的高通量测序文库。
57.利用上述装置,能够在该装置中实现从初始的样品处理到最终的样本lncrna的高通量测序文库获得的一系列工艺步骤,能够方便快捷的获得批量高通量测序问题。该装置也能够与后续所需的高通量测序设备进行连接组合,将获得的样本lncrna的高通量测序文库送入高通量测序设备,能够完成从原始样品输入到测序结果输出的一系列自动化的处理流程,适用于大批量的高通量测序项目的实施,利用装置处理也能保证样品处理的均一性,利于不同样品之间的比较分析。
58.在本技术第三种典型的实施方式中,提供了一种lncrna的高通量测序文库,该lncrna的高通量测序文库,利用上述构建方法或装置构建得到。
59.在本技术第四种典型的实施方式中,提供了一种上述构建方法或装置,在构建样本lncrna的高通量测序文库中的应用。
60.在本技术第五种典型的实施方式中,提供了一种lncrna测序方法,该测序方法包括:对上述lncrna的高通量测序文库进行测序。
61.在本技术第六种典型的实施方式中,提供了上述构建方法、或装置、或lncrna的高通量测序文库,在制备疾病早期筛查、预后评估、科学基础研究和/或临床疗效监测的产品中的应用。
62.利用上述用于构建方法或装置的产品,能够获得对应样本的lncrna的高通量测序文库,样本来源包括但不限于人或动物的样本,来源于血浆、组织或已有的组织切片等。利用该产品完成对于这些样品中lncrna的检测和分析,从而反应样本中lncrna的状态,从而上述多种应用场景中发挥重要作用。
63.下面将结合具体的实施例来进一步详细解释本技术的有益效果。
64.实施例1
65.步骤s1,以血浆来源的外泌体总rna为例,该外泌体rna样本的检测图如图9所示。rna浓度为71ng/μl,rin值(rna integrity number)为2.6。本举例以图9所示质量的外泌体总rna为例,并不以此为限。
66.使用人/鼠去核糖体试剂去除核糖体rna。具体的,步骤s1进一步包括:
67.s1.1,核糖体去除体系配置:
68.取2
×
frag/elute buffer 5μl,总rna 4μl,1μl qiaseq fastselect-rrna hmr 1μl,fastselect 5s/16s/23s 1μl,充分吹打混匀,瞬离。
69.s1.2,pcr仪上执行表1所示程序:
70.表1
71.[0072][0073]
s1.3程序执行完后,立即将反应体系置于冰上;
[0074]
具体地,步骤s2进一步包括:
[0075]
因提取后的外泌体lncrna的片段较短,为避免因正常ngs建库的打断环节对该文库mapping及dup的影响,不进行打断环节。
[0076]
s2.1,first strand cdna合成:
[0077]
s2.1.1,取上述反应体系,加入rt reagent 8μl,first strand synthesis enzyme mix 2μl,移液器吹打混匀,瞬离;
[0078]
s2.1.2,pcr仪上执行表2所示程序:
[0079]
表2
[0080]
步骤温度(℃)时间12510min24215min37015min84∞
[0081]
s2.1.3,程序执行完后,立即将反应体系置于冰上;
[0082]
s2.2,second strand cdna合成:
[0083]
s2.2.1,取上述反应体系,加入second strand synthesis reaction buffer 8μl,second strand synthesis enzyme mix 4μl,nuclease-free水48μl,移液器吹打混匀,瞬离;
[0084]
s2.2.2,pcr仪上执行表3所示程序:
[0085]
表3
[0086][0087][0088]
s2.2.3,程序执行完后,立即将反应体系置于冰上;
[0089]
s2.3,cdna纯化:
[0090]
s2.3.1,取144μl xp beads于1.5ml ep管中,向其中加入上述反应体系,充分混
匀。室温静置5min,磁力架上静置5min,弃上清。;
[0091]
s2.3.2,保持ep管在磁力架上,将新鲜配制的80%乙醇加入ep管中,静置30s,弃上清。;
[0092]
s2.3.3,重复步骤s2.2.2,室温晾干磁珠3-5mi;
[0093]
s2.3.4,将ep管从磁力架上取下来,向260样本中其中加入43μl nuclease-free水,充分混匀,室温放置5min,磁力架上放置5min,取42μl上清液于0.2ml ep管中,进行下一步。
[0094]
s2.4端修复、加a:
[0095]
s2.4.1上述上清进行末端修复、加a:取上述上清液42μl,buffer 1 6.8μl,enzyme 1 1.2μl,吹打混匀,瞬离;
[0096]
s2.4.2pcr仪上执行表4所示程序:
[0097]
表4
[0098]
步骤温度(℃)时间13730min27230min34∞
[0099]
s2.4.3程序执行完后立刻放置冰上,立即进入下一步接头连接反应。
[0100]
具体地,步骤s3进一步包括:
[0101]
s3.1 cdna的5’端和3’端连接含有umi的测序接头:
[0102]
s3.1.1向上述反应体系中加入buffer 2-1 8.4μl,buffer 2-2 15μl,enhancer 1.6μl
[0103]
umi adaptor 1μl,nuclease-free水3μl,enzyme 2 1μl,吹打混匀,瞬离(该系列试剂使用novogene ngs dna library prep,试剂盒(novogene/pt004));
[0104]
s3.1.2pcr仪上执行表5所示程序:
[0105]
表5
[0106]
步骤温度(℃)时间12030min34∞
[0107]
s3.1.3程序执行完毕,立即取出置于室温;
[0108]
s3.2接头连接产物回收:
[0109]
s3.2.1向样品中加入23μl nuclease-free水,补体系至100μl;
[0110]
s3.2.2加入30μl xp beads(0.3x),充分混匀后,室温静置5min,磁力架上放置5min,取上清,弃磁珠;
[0111]
s3.2.3小心将全部上清取出,向其中加入20μl xp beads,充分混匀后,室温静置5min,磁力架上放置5min,留磁珠,弃上清;
[0112]
s3.2.4将200μl新鲜配制的80%的乙醇加入到磁珠中,静置放置30s,弃上清;
[0113]
s3.2.5重复步骤s2.4.10一次,弃上清后,瞬时离心,用10μl移液器吸走所有液体,室温下晾干磁珠,约3min;
[0114]
s3.2.6向磁珠中加入24μl的nf-w,充分混匀,室温静置5min,磁力架上放置5min,
取22μl上清进行pcr文库扩增。
[0115]
具体地,步骤s4过程如下:
[0116]
s4.1,消化含有u碱基的dna链,并进行文库扩增:
[0117]
s4.1.1将pcr管置于冰上,顺序加入如下试剂:udg enzyme 1μl,pcr mix(2
×
),p5 pcr引物(25μm)1μl,index引物(25μm)1μl,充分吹打混匀,瞬离;
[0118]
s4.1.2pcr仪上执行表6所示程序:
[0119]
表6
[0120][0121][0122]
s4.2,文库纯化:
[0123]
s4.2.1向上述反应体系中加入53μl nf-w,补足至100μl体系;
[0124]
s4.2.2取60μl(0.6
×
)磁珠,加入上述体系中,充分混匀后,室温静置5min,磁力架上放置5min,取上清,弃磁珠;
[0125]
s4.2.3将全部上清取出至新的ep管中,向其中加入15μl(0.15
×
)的磁珠,充分混匀后,室温静置5min,磁力架上放置5min,留磁珠,弃上清;
[0126]
s4.2.4重复步骤s4.2.3一次,吸走所有液体后瞬时离心,再用10μl移液器彻底吸干液体,室温下晾干磁珠,约3min;
[0127]
s4.2.6向磁珠中加入15μl的eb(常温),充分混匀,室温静置5min,磁力架上放置5min,取14μl上清,即为umi外泌体lnc文库原液;
[0128]
文库构建,质检:dna片段和浓度检测均合格,即目的片段大小为300-600bp,
[0129]
浓度≥1ng,体积≥10μl,无接头污染后即可上机检测。共进行2次平行试验,试验结果参见表7中实施例1-1、实施例1-2。实施例1-1的质检图如图2所示。在本技术的质检图中,lm和um为检测使用的marker,为agilent dna12000 kit(货号:5067-1508)中成分。rfu为相对荧光强度(relative fluorescence units)。
[0130]
构建方法流程图参见图1。
[0131]
实施例2
[0132]
步骤s1,以提取后的低质量ffpe样本rna为例,使用的rna总量为100ng,具体核酸质量见图8;本举例以图8所示质量的总rna为例,并不以此为限。对于低质量ffpe样本,一般均为该类胶图,量少且高度弥散。
[0133]
步骤s1包括:
[0134]
s1.1,核糖体去除体系配置:
[0135]
取2
×
frag/elute buffer 5μl,总rna(提取核酸样本的取样体系)4μl,1μl qiaseq fastselect-rrna hmr 1μl,qiaseq fastselect 5s/16s/24s hmr 1μl充分吹打混匀,瞬离;
[0136]
s1.2,pcr仪上执行表1所示程序。
[0137]
s1.3程序执行完后,立即将反应体系置于冰上;
[0138]
具体地,步骤s2进一步包括:
[0139]
s2.1,first strand cdna合成:
[0140]
s2.1.1,取上述反应体系,加入rt reagent 8μl,first strand synthesis enzyme mix 2μl,移液器吹打混匀,瞬离;
[0141]
s2.1.2,pcr仪上执行表2所示程序。
[0142]
s2.1.3,程序执行完后,立即将反应体系置于冰上;
[0143]
s2.2,second strand cdna合成:
[0144]
s2.2.1,取上述反应体系,加入second strand synthesis reaction buffer 8μl,second strand synthesis enzyme mix 4μl,nuclease-free水48μl,移液器吹打混匀,瞬离;
[0145]
s2.2.2,pcr仪上执行表3所示程序。
[0146]
s2.2.3,程序执行完后,立即将反应体系置于冰上;
[0147]
s2.3,cdna纯化:
[0148]
s2.3.1,取144μl xp beads于1.5ml ep管中,向其中加入上述反应体系,充分混匀。室温静置5min,磁力架上静置5min,弃上清。;
[0149]
s2.3.2,保持ep管在磁力架上,将新鲜配制的80%乙醇加入ep管中,静置30s,弃上清。;
[0150]
s2.3.3,重复步骤s2.2.2,室温晾干磁珠3-5mi;
[0151]
s2.3.4,将ep管从磁力架上取下来,向260样本中其中加入43μl nuclease-free水,充分混匀,室温放置5min,磁力架上放置5min,取42μl上清液于0.2ml ep管中,进行下一步。
[0152]
s2.4端修复、加a:
[0153]
s2.4.1上述上清进行末端修复、加a:取上述上清液42μl,buffer 1 6.8μl,enzyme 1 1.2μl,吹打混匀,瞬离;
[0154]
s2.4.2pcr仪上执行表4所示程序。
[0155]
s2.4.3程序执行完后立刻放置冰上,立即进入下一步接头连接反应。
[0156]
具体地,步骤s3进一步包括:
[0157]
s3.1 cdna的5’端和3’端连接含有umi的测序接头:
[0158]
s3.1.1向上述反应体系中加入buffer 2-1 8.4μl,buffer 2-2 15μl,enhancer 1.6μl
[0159]
umi adaptor 1μl,nuclease-free水3μl,酶反应缓冲液2 1μl,吹打混匀,瞬离;
[0160]
s3.1.2pcr仪上执行表5所示程序。
[0161]
s3.1.3程序执行完毕,立即取出置于室温;
[0162]
s3.2接头连接产物回收:
[0163]
s3.2.1向样品中加入23μl nuclease-free水,补体系至100μl;
[0164]
s3.2.2加入30μl xp beads(0.3x),充分混匀后,室温静置5min,磁力架上放置5min,取上清,弃磁珠;
[0165]
s3.2.3小心将全部上清取出,向其中加入20μl xp beads,充分混匀后,室温静置5min,磁力架上放置5min,留磁珠,弃上清;
[0166]
s3.2.4将200μl新鲜配制的80%的乙醇加入到磁珠中,静置放置30s,弃上清;
[0167]
s3.2.5重复步骤s2.4.10一次,弃上清后,瞬时离心,用10μl移液器吸走所有液体,室温下晾干磁珠,约3min;
[0168]
s3.2.6向磁珠中加入24μl的nf-w,充分混匀,室温静置5min,磁力架上放置5min,取22μl上清进行pcr文库扩增。
[0169]
具体地,步骤s4过程如下:
[0170]
s4.1,消化含有u碱基的dna链,并进行文库扩增:
[0171]
s4.1.1将pcr管置于冰上,顺序加入如下试剂:udg enzyme 1μl,pcr mix(2
×
),
[0172]
p5 pcr引物(25μm)1μl,index引物(25μm)1μl,充分吹打混匀,瞬离;
[0173]
s4.1.2pcr仪上执行表6所示程序。
[0174]
s4.2,文库纯化:
[0175]
s4.2.1向上述反应体系中加入53μl nf-w,补足至100μl体系;
[0176]
s4.2.2取60μl(0.6
×
)磁珠,加入上述体系中,充分混匀后,室温静置5min,磁力架上放置5min,取上清,弃磁珠;
[0177]
s4.2.3将全部上清取出至新的ep管中,向其中加入15μl(0.15
×
)的磁珠,充分混匀后,室温静置5min,磁力架上放置5min,留磁珠,弃上清;
[0178]
s4.2.4重复步骤s4.2.3一次,吸走所有液体后瞬时离心,再用10μl移液器彻底吸干液体,室温下晾干磁珠,约3min;
[0179]
s4.2.6向磁珠中加入15μl的eb(常温),充分混匀,室温静置5min,磁力架上放置5min,取14μl上清,即为低质量ffpe样本的绝对定量lncrna文库原液;
[0180]
文库构建,质检:dna片段和浓度检测均合格,即目的片段大小为300-600bp,
[0181]
浓度≥1ng,体积≥10μl,无接头污染后即可上机检测,如图3所示。
[0182]
对比例1
[0183]
建库方法与实施例1相同,仅在s1.1核糖体去除体系配置有差异:取2
×
frag/elute buffer 5μl,总rna 4μl,1μl qiaseq fastselect-rrna hmr 1μl,充分吹打混匀,瞬离。对比例1文库检测结果如图5和表7所示。
[0184]
对比例2
[0185]
使用现有的试剂盒ovation solo rna-seq system,从血浆来源的外泌体总rna反转录合成cdna,进行第一轮扩增,然后末端修复,加接头,纯化后进行第二轮扩增,随后扩增产物进行人/鼠(仅支持这两个物种)去核糖体,再进行第三轮扩增,纯化出库。现有技术中,外泌体目前主要的来源动物血液或细胞上清,该试剂盒去核糖体仅针对人/鼠的核糖体序列进行了设计。对比例2文库检测结果如图4和表7所示。
[0186]
表7
[0187][0188]
对比例3
[0189]
在对比例实施中,仅与实施例2的区别在于。在步骤s1,只使用qiaseq fastselect-rrna hmr进行真核核糖体的去除,其他操作完全保持一致。检测结果如图6和表8所示
[0190]
对比例4
[0191]
对于ffpe样本的普通建库方式。
[0192]
rna检测合格后,通过epicentre ribo-zerotm试剂盒去除rrna。随后加入片段化试剂,将rna打断成250-300bp的短片段,以短片段rna为模板,用六碱基随机引物(randomhexamers)合成一链cdna,然后加入缓冲液、dntps(dutp、datp、dgtp和dctp)和dna polymerasei合成二链cdna,随后利用ampurexpbeads纯化双链cdna。纯化的双链cdna再进行末端修复、加a尾并连接测序接头,然后用ampurexpbeads进行片段大小选择。之后用user酶降解含有u的cdna第二链,最后进行pcr富集得到链特异性cdna文库。
[0193]
检测结果如图7和表8所示。rfu为相对荧光强度(relative fluorescence units)。
[0194]
表8
[0195][0196]
从以上的描述中,可以看出,本发明上述的实施例实现了如下技术效果:本技术通过去核糖体后的总rna直接反转录合成cdna,然后连接含有umi序列的接头,进一步扩增获得低质量ffpe样本的绝对定量lncrna文库,从而到达在低起始量低质量ffpe样本的lncrna文库实现精准定量起始的分子数并削减测序及文库制备产生的错误以及pcr扩增所造成的
不均一性的目的,有效的分辨文库构建过程中引入的假阳突变,从而可更加有效检测超低丰度突变,避免出现因为样本质量差异而导致的建库数据偏好性。
[0197]
从以上的描述中,可以看出,本发明上述的实施例实现了如下技术效果:通过去核糖体后的总rna直接反转录合成cdna,然后连接含有umi序列的接头,进一步扩增获得umi样本lncrna文库,从而到达在低起始量样本lncrna文库实现精准定量起始的分子数并削减测序及文库制备产生的错误以及pcr扩增所造成的不均一性的目的,有效的分辨文库构建过程中引入的假阳突变,从而可更加有效检测超低丰度突变。
[0198]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1