一种基于可编程核酸酶的超灵敏目标核酸富集检测方法
本发明涉及生物,具体涉及一种基于可编程核酸酶的超灵敏目标核酸富集检测方法。
背景技术:
1、体细胞突变与肿瘤发生密切相关,突变检测对疾病早期筛查、精准治疗决策、复发监测具有重要意义。近年来,以液体活检为代表的非侵入性诊断成为一种趋势。液体活检通过检测体液中来源于肿瘤的游离核酸片段,分析肿瘤的基因型,具有无创性、易于实现动态监测等优势。然而,液体活检面临如下问题:1)突变核酸与野生型核酸具有较高的序列同源性,通常只有单个或几个核苷酸的差别,对于在大量游离的野生型等位基因中鉴定出低丰度的突变等位基因提出了挑战;2)对于体液中低丰度甲基化基因的检测也面临同样问题,甲基化基因与非甲基化基因序列相同,只存在碱基修饰的差异,对于在大量游离的非甲基化基因中鉴定出低丰度的甲基化基因提出了挑战。
2、目前突变等位基因的高灵敏检测通常使用下一代测序(ngs)或依赖数字pcr的蛮力计数来检测微弱的信号。尤其在微小残留病灶(mrd)检测中,针对极低丰度的突变基因,主要基于超深度(50000x)ngs测序,存在费用高,耗时长,难以普及到临床的问题。因此,亟需开发一种低成本的超灵敏极低丰度突变等位基因检测方法,以促进临床应用。
3、近年来,基于crispr-cas可编程核酸酶的诊断技术成为研究热点。crispr-cas系统是古细菌和大多数细菌在生物进化过程中抵御病毒入侵而形成的一种适应性免疫防御系统,由cas效应蛋白和向导rna组成,在向导rna的引导下,cas蛋白识别并切割含有5’端pam位点的靶序列。基于crispr-cas的低丰度突变等位基因检测方法,旨在通过特殊的向导rna设计,使cas蛋白特异性切割野生型等位基因,去除大量的野生型核酸,保留突变等位基因,以提高下游分析的灵敏度。同时,也有研究者基于argonaute蛋白(ago),通过和guidedna形成复合物,建立了类似的低丰度突变等位基因检测方法。
4、cas蛋白的切割受pam位点的限制,当突变导致pam位点的破坏时,在同一样品中,cas蛋白靶向切割大量的野生型核酸,而保留突变核酸。已有研究者针对位于pam位点的突变,分别开发了dash(depletion of abundant sequences by hybridization)和cut-pcr等低丰度突变等位基因检测方法。argonaute蛋白不受pam位点的限制,已有研究者开发了navigater(nucleicacid enrichmentvia dnaguidedargonaute fromthermusthermophilus)低丰度突变等位基因检测方法。
5、dash法和cut-pcr虽然在一定程度上提高了下游分析的灵敏度,但现有的基于可编程核酸内切酶检测方法的有效性因酶和靶标之间的无效结合事件受到影响,由于cas9的解离效率非常缓慢,使得部分野生型等位基因靶标受到保护而不被切割,同时非特异的脱靶切割会耗尽极稀少的突变型等位基因。navigater也存在类似问题。为了克服这些缺点,研究人员采用了多轮选择性切割野生型等位基因,然后进行聚合酶链反应,使突变型等位基因的片段富集10倍。尽管有了这些改进,突变等位基因检测的高灵敏度仍然需要使用下一代测序技术(next generation sequencing,ngs)或依赖于数字pcr,使得这些方法费力、耗时和昂贵。
6、对于液体活检中的低丰度甲基化基因检测,以上技术存在类似问题,也难以满足要求。
技术实现思路
1、本发明的目的在于提供一种基于可编程核酸酶的超灵敏肿瘤相关基因富集方法,使用本发明方法能够高效对低丰度突变基因以及甲基化基因进行富集,同时利用微流控芯片技术使本发明方法能够自动化。
2、为达到上述发明目的,采用如下技术方案:
3、一种核糖核蛋白复合物,包括:
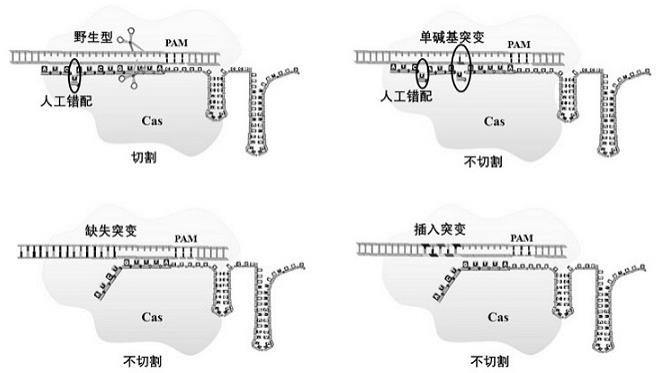
4、组分(a),包含能够与靶核酸互补配对的核酸区域和0-4bp错配片段;或能够与靶核酸互补配对的核酸区域且相邻pam包括易突变位点;
5、组分(b),能够与靶核酸结合并使靶核酸链断裂;
6、其中,组分(a)选自选自tracrrna和/或crrna和/或sgrna和/或tracrrna衍生物和/或crrna衍生物和/或sgrna衍生物和/或guide dna和/或guide rna ;组分(b)包括cas蛋白和/或cas蛋白衍生物和/或ago蛋白和/或ago蛋白衍生物;组分(a)和(b)能够结合。优选地,组分(a)可携带标记,标记包括链霉亲和素或生物素。
7、优选地,错配的核苷酸片段长度为0bp 或1bp或2bp或3bp或4bp。
8、优选地,组分(a)携带化学修饰,化学修饰包括硫取代氧或甲氧基修饰。
9、优选地,组分(a)中sgrna、guide dna或guide rna包括错配核苷酸片段。本发明所设计的错配核苷酸片段有利于扩大sgrna、guide dna或guide rna的使用范围,能够使sgrna、guide dna或guide rna识别更多突变。
10、优选地,组分(a)中sgrna相邻的pam含有肿瘤热点突变位点。
11、优选地,组分(a)中sgrna的spacer序列长度为16-22nt。
12、更优选地,sgrna序列如下所示:
13、ucuuaauuccuugauagcga(seq id no.1);
14、uagcuacagugaacucucga(seq id no.2);
15、uagcuacagugaaaucacga(seq id no.3);
16、gcuacagugaacucucga(seq id no.4);
17、gucuagcuacagugaaa(seq id no.5);
18、gucuagcugcagugaaa(seq id no.6);
19、ggcagccgaagggcaugagc(seq id no.27);
20、ggcagccgaagagcaugagc(seq id no.28);
21、aauuuuuguuugagugguug (seq id no.37);
22、uccagcuguauccaguaugu(seq id no.42)。
23、更优选地,guide dna序列如下所示:
24、正向guide:p-tagatttcactgtagc-3’(seq id no.43);
25、反向guide:p-ttctagctacagtgaa -3’(seq id no.44)。
26、优选地,组分(b)包括以下至少一种:cas12a,saccas9,cjcas9,spcas9,nmcas9,sp-cas9 hf1,evocas9,hypacas9,hifi cas9,sniper-cas9,xcas9,espcas9 1.1,superficas9,sacas9,sacas9-hf,efsacas9,sccas9,cas9—sc++,cas9 hifi-sc++,spacas9,spacas9-hf,fncas9,anacas9,spycas9,fncas12a,lbcas12a,ascas12a,cbago,ttago,pfago,kmago或kpago。
27、更优选地,cas12a来自以下至少一个菌种: francisella novicida; acidaminococcus; lachnospiraceae。
28、更优选地,saccas9来自菌种 staphylococcus aureus。
29、更优选地,cjcas9来自菌种 campylobacter jejuni。
30、更优选地,spcas9来自菌种 streptococcus pyogenes。
31、更优选地,nmcas9来自菌种 neisseria meningitidis。
32、更优选地,sacas9来自菌种 staphylococcus aureus。
33、更优选地,sccas9来自菌种 streptococcus canis。
34、更优选地,spacas9来自菌种 streptococcus pasteurianus。
35、优选地,核糖核蛋白复合物中,组分(a)的终浓度为0.1-2μm。
36、优选地,核糖核蛋白复合物中,组分(b)的终浓度为0.1-3μm。
37、优选地,核糖核蛋白复合物中,还包括氢离子缓冲剂。
38、更优选地,核糖核蛋白复合物中,氢离子缓冲剂终浓度为1mm-2 m。
39、本发明还公开了上述核糖核蛋白在富集和/或检测突变基因中的用途。
40、本发明还公开了上述核糖核蛋白在富集和/或检测甲基化dna中的用途。
41、优选地,基因包括以下至少一种:egfr,braf,pik3ca,tp53,lrp1b,apc,cyp1a1,np01,ephx1,kras,brca1,brca2,met,mlh1,msh2,msh3,msh6,palb2,bmpr1a,smad4,stk11,pten,axin2,blm,bub1b,cdh1,cep57,chek2,eng,epcam,flcn,galnti2,grem1,fat4,kmt2d,kmt2c,arid1a,fat1,pten,atm,zfhx3,crebbp,grin2a,nras或nf1。
42、本发明还公开了一种核糖核蛋白复合物的制备方法,包括:将cas9、sgrna和氢离子缓冲剂混合孵育,将ago、guide dna或rna和氢离子缓冲剂混合孵育。
43、优选地,氢离子缓冲剂包括hepes。
44、优选地,核糖核蛋白复合物的制备中,所使用的cas9的终浓度为0.1-3μm。
45、更优选地,核糖核蛋白复合物的制备中,所使用的cas9的终浓度为2.5μm。
46、优选地,核糖核蛋白复合物的制备中,所使用的sgrna的终浓度为0.1-2μm。
47、更优选地,核糖核蛋白复合物的制备中,所使用的sgrna的终浓度为2.5μm。
48、优选地,核糖核蛋白复合物的制备中,所使用的hepes的终浓度为1mm-2m。
49、优选地,核糖核蛋白复合物的制备中,所使用的hepes的终浓度为1m。
50、优选地,核糖核蛋白复合物的制备中,反应温度为34-39℃,反应时间为3-18min。
51、更优选地,核糖核蛋白复合物的制备中,反应温度为37℃,反应时间为10min。
52、本发明还公开了一种用于可编程酶的突变基因的富集和/或甲基化dna的富集的反应体系,该反应体系包括上述核糖核蛋白复合物。
53、优选地,核糖核蛋白复合物包括:
54、组分(a),包含能够与靶核酸互补配对的核酸区域和0-4bp错配片段;
55、组分(b),能够与靶核酸结合并使靶核酸链断裂;
56、其中,组分(a)选自tracrrna和/或crrna和/或sgrna和/或tracrrna衍生物和/或crrna衍生物和/或sgrna衍生物和/或guide dna和/或guide rna;组分(b)包括cas蛋白和/或cas蛋白衍生物和/或ago蛋白和/或ago蛋白衍生物;组分(a)和(b)能够结合。优选地,组分(a)携带标记,标记包括链霉亲和素或生物素。
57、优选地,错配的核苷酸片段长度为0bp 或1bp或2bp或3bp或4bp。
58、更优选地,组分(a)携带化学修饰,化学修饰包括硫取代氧或甲氧基修饰。
59、更优选地,组分(a)中sgrna、guide dna或guide rna包括错配核苷酸片段。
60、更优选地,组分(a)中sgrna、guide dna或guide rna的spacer序列长度为16-22nt。
61、更进一步优选地,sgrna序列下所示:
62、ucuuaauuccuugauagcga(seq id no.1);
63、uagcuacagugaacucucga(seq id no.2);
64、uagcuacagugaaaucacga(seq id no.3);
65、gcuacagugaacucucga(seq id no.4);
66、gucuagcuacagugaaa(seq id no.5);
67、gucuagcugcagugaaa(seq id no.6);
68、ggcagccgaagggcaugagc(seq id no.27);
69、ggcagccgaagagcaugagc(seq id no.28);
70、aauuuuuguuugagugguug (seq id no.37);
71、uccagcuguauccaguaugu(seq id no.42)。
72、更优选地,guide dna序列如下所示:
73、正向guide:p-tagatttcactgtagc-3’(seq id no.43);
74、反向guide:p-ttctagctacagtgaa -3’(seq id no.44)。
75、更优选地,组分(b)包括以下至少一种:cas12a,saccas9,cjcas9,spcas9,nmcas9,sp-cas9 hf1,evocas9,hypacas9,hifi cas9,sniper-cas9,xcas9,espcas9 1.1,superficas9,sacas9,sacas9-hf,efsacas9,sccas9,cas9—sc++,cas9 hifi-sc++,spacas9,spacas9-hf,fncas9,anacas9,spycas9,fncas12a,lbcas12a,ascas12a,cbago,ttago,pfago,kmago或kpago。
76、更进一步优选地,cas12a来自以下至少一个菌种: francisella novicida; acidaminococcus; lachnospiraceae。
77、更进一步优选地,saccas9来自菌种 staphylococcus aureus。
78、更进一步优选地,cjcas9来自菌种 campylobacter jejuni。
79、更进一步优选地,spcas9来自菌种 streptococcus pyogenes。
80、更进一步优选地,nmcas9来自菌种 neisseria meningitidis。
81、更优选地,sacas9来自菌种 staphylococcus aureus。
82、更优选地,sccas9来自菌种 streptococcus canis。
83、更优选地,spacas9来自菌种 streptococcus pasteurianus。
84、更优选地,核糖核蛋白复合物中,组分(a)的终浓度为0.1-2μm。
85、更优选地,核糖核蛋白复合物中,组分(b)的终浓度为0.1-3μm。
86、更优选地,核糖核蛋白复合物中,还包括氢离子缓冲剂。
87、更进一步优选地,核糖核蛋白复合物中,氢离子缓冲剂终浓度为1mm-2 m。
88、优选地,反应体系中,核糖核蛋白复合物的终浓度0.1-2μm。
89、优选地,反应体系还包括:引物、目的基因、酶和助色基团。
90、优选地,反应体系还包括:dntp、单链结合蛋白。
91、更优选地,目的基因包括:基因组dna或cell-free dna。
92、更进一步优选地,目的基因包括从以下至少一种细胞株中提取的基因组dna:
93、egfr 19del野生型细胞株;egfr 19 e746_a750 del(2235-2249del)细胞株;egfr19 e746_a750 del(2236-2250del);braf v600e突变型;brafv600e野生型细胞株;b-cpap细胞株。
94、更优选地,引物包括能够与目的基因结合并且引导合成的核苷酸序列。
95、更进一步优选地,引物包括以下至少一条序列:
96、gcatgtggcaccatctcaca(seq id no.15);
97、agagcagctgccagacatga(seq id no.16);
98、ctacacctcagatatatttc(seq id no.19);
99、tggatccagacaactgt(seq id no.20);
100、tacgtgatggccagcgtgga(seq id no.23);
101、actgggagccaatattgt(seq id no.24);
102、tcgttaaatagatacgttacgc(seq id no.33);
103、taaaaactaaaaactttccgcg(seq id no.34);
104、tcgttaaatagatacgttacgc(seq id no.35);
105、caacgcctcgaaacctacg(seq id no.36)。
106、cccccaggattcttacagaaaacaagtggt(seq id no.38);
107、gcaaatacacagaggaagccttcgcctgtcctc(seq id no.39);
108、caagtggttatagatggtga(seq id no.40);
109、cgcctgtcctcatgtattgg(seq id no.41)。
110、更优选地,酶包括:dna聚合酶和/或重组酶。
111、更优选地,助色基团包括mgoac。
112、优选地,上述反应体系可用于富集maf≥0.01%的突变型等位基因。
113、本发明还公开了上述反应体系的用途,包括以下至少一种:
114、(1)靶向结合靶核酸片段;
115、(2)靶向切割靶核酸片段;
116、(3)富集突变基因;
117、(4)检测突变基因;
118、(5)富集甲基化dna;或,
119、(6)检测甲基化dna。
120、优选地,上述富集包括自动化富集;上述检测包括自动化检测。
121、更优选地,上述自动化富集包括使用微流控芯片进行富集;上述自动化检测包括使用微流控芯片进行检测。
122、更进一步优选地,微流控芯片分为三部分,由顶层封装片、底层封装片以及中间的反应层构成。
123、更进一步优选地,顶层封装片结构包括:微流控芯片安装孔;微流控芯片封装定位孔;微流控芯片进样孔。
124、更进一步优选地,中间反应层结构包括:微流控芯片封装定位孔;微流控芯片安装孔;预扩增反应腔;虹吸阀;消化反应腔;预分配腔;pcr反应腔;废液腔;毛细阀;10:气体通路。
125、更进一步优选地,底层封装片结构包括:微流控芯片安装孔;微流控芯片封装定位孔;rnasea加样腔;proteinasek加样腔。
126、优选地,突变基因包括癌症相关基因。
127、优选地,癌症相关基因包括以下至少一种:
128、egfr,braf,pik3ca,tp53,lrp1b,apc,cyp1a1,np01,ephx1,kras,brca1,brca2,met,mlh1,msh2,msh3,msh6,palb2,bmpr1a,smad4,stk11,pten,axin2,blm,bub1b,cdh1,cep57,chek2,eng,epcam,flcn,galnti2,grem1,fat4,kmt2d,kmt2c,arid1a,fat1,pten,atm,zfhx3,crebbp,grin2a,nras或nf1。
129、优选地,甲基化dna包括癌症相关甲基化基因和/或其启动子。
130、优选地,癌症相关甲基化基因包括以下至少一种:
131、pcdh-10,brca1,rassf1a,esr1,apc,p14arf,p16ink4a,dapk,cdh1,runx3,tfpi2,sfrp5,hic1,pax5,pgr,thbs1,esr,col23a1,c2cd4d,wnt6,opcml,znf154,rarb2,atm,mgmt,gstp1,mir129-2,linc01158,ccdc181,prkcb,tbr1,znf781,march11,vwc2,slc9a3,hoxa7,septin9,ikzf1,bcat1,hmlh1,wif1,cdkn2a,shox2,3ost2,assf1a,rarb,pitx2,nid2,neurog2或hoxa1;
132、启动子包括以下基因的启动子中的至少一种:
133、pcdh-10,brca1,rassf1a,esr1,apc,p14arf,p16ink4a,dapk,cdh1,runx3,tfpi2,sfrp5,hic1,pax5,pgr,thbs1,esr,col23a1,c2cd4d,wnt6,opcml,znf154,rarb2,atm,mgmt,gstp1,mir129-2,linc01158,ccdc181,prkcb,tbr1,znf781,march11,vwc2,slc9a3,hoxa7,septin9,ikzf1,bcat1,hmlh1,wif1,cdkn2a,shox2,3ost2,assf1a,rarb,pitx2,nid2,neurog2或hoxa1。
134、本发明还公开了上述核糖核蛋白复合物的用途,包括以下至少一种:
135、(1)富集基因突变;
136、(2)检测基因突变;
137、(3)富集甲基化dna;或,
138、(4)检测甲基化dna。
139、优选地,基因包括:egfr,braf,pik3ca,tp53,lrp1b,apc,cyp1a1,np01,ephx1,kras,brca1,brca2,met,mlh1,msh2,msh3,msh6,palb2,bmpr1a,smad4,stk11,pten,axin2,blm,bub1b,cdh1,cep57,chek2,eng,epcam,flcn,galnti2,grem1,fat4,kmt2d,kmt2c,arid1a,fat1,pten,atm,zfhx3,crebbp,grin2a,nras或nf1。
140、本发明还公开了cas蛋白的用途,包括以下至少一种:
141、(1)富集基因突变;
142、(2)检测基因突变;
143、(3)富集甲基化dna;或,
144、(4)检测甲基化dna。
145、本发明还公开了ago蛋白的用途,包括以下至少一种:
146、(1)富集基因突变;
147、(2)检测基因突变;
148、(3)富集甲基化dna;或,
149、(4)检测甲基化dna。
150、优选地,基因包括以下至少一种:egfr,braf,pik3ca,tp53,lrp1b,apc,cyp1a1,np01,ephx1,kras,brca1,brca2,met,mlh1,msh2,msh3,msh6,palb2,bmpr1a,smad4,stk11,pten,axin2,blm,bub1b,cdh1,cep57,chek2,eng,epcam,flcn,galnti2,grem1,fat4,kmt2d,kmt2c,arid1a,fat1,pten,atm,zfhx3,crebbp,grin2a,nras或nf1。
151、优选地,cas蛋白包括以下至少一种:cas12a,saccas9,cjcas9,spcas9,nmcas9,sp-cas9 hf1,evocas9,hypacas9,hifi cas9,sniper-cas9,xcas9,espcas9 1.1,superficas9,sacas9,sacas9-hf,efsacas9,sccas9,cas9—sc++,cas9 hifi-sc++,spacas9,spacas9-hf,fncas9,anacas9,spycas9,fncas12a,lbcas12a或ascas12a。
152、优选地,ago蛋白包括以下至少一种:cbago,ttago,pfago,kmago或kpago。
153、本发明还公开了一种用于可编程酶的突变基因的富集的试剂盒,试剂盒包括上述核糖核蛋白复合物。
154、优选地,核糖核蛋白复合物包括:
155、组分(a),包含能够与靶核酸互补配对的核酸区域和0-4bp错配片段;
156、组分(b),能够与靶核酸结合并使靶核酸链断裂;
157、其中,组分(a)选自tracrrna和/或crrna和/或sgrna和/或tracrrna衍生物和/或crrna衍生物和/或sgrna衍生物和/或guide dna和/或guide rna;组分(b)包括cas蛋白和/或cas蛋白衍生物和/或ago蛋白和/或ago蛋白衍生物;组分(a)和(b)能够结合。
158、优选地,错配的核苷酸片段长度为0bp 或1bp或2bp或3bp或4bp。
159、优选地,组分(a)携带标记,标记包括链霉亲和素或生物素。
160、更优选地,组分(a)携带化学修饰,化学修饰包括硫取代氧或甲氧基修饰。
161、更优选地,组分(a)中sgrna包括错配核苷酸片段。
162、更优选地,组分(a)中sgrna的spacer序列长度为16-22nt。
163、更进一步优选地,sgrna序列如下所示:
164、ucuuaauuccuugauagcga(seq id no.1);
165、uagcuacagugaacucucga(seq id no.2);
166、uagcuacagugaaaucacga(seq id no.3);
167、gcuacagugaacucucga(seq id no.4);
168、gucuagcuacagugaaa(seq id no.5);
169、gucuagcugcagugaaa(seq id no.6);
170、ggcagccgaagggcaugagc(seq id no.27);
171、ggcagccgaagagcaugagc(seq id no.28);
172、aauuuuuguuugagugguug (seq id no.37);
173、uccagcuguauccaguaugu(seq id no.42)。
174、更优选地,guide dna序列如下所示:
175、正向guide:p-tagatttcactgtagc-3’(seq id no.43);
176、反向guide:p-ttctagctacagtgaa-3’(seq id no.44)。
177、更优选地,组分(b)包括以下至少一种:cas12a,saccas9,cjcas9,spcas9,nmcas9,sp-cas9 hf1,evocas9,hypacas9,hifi cas9,sniper-cas9,xcas9,espcas9 1.1,superficas9,sacas9,sacas9-hf,efsacas9,sccas9,cas9—sc++,cas9 hifi-sc++,spacas9,spacas9-hf,fncas9,anacas9,spycas9,fncas12a,lbcas12a,ascas12a,cbago,ttago,pfago,kmago或kpago。
178、更进一步优选地,cas12a来自以下至少一个菌种: francisella novicida; acidaminococcus; lachnospiraceae。
179、更进一步优选地,saccas9来自菌种 staphylococcus aureus。
180、更进一步优选地,cjcas9来自菌种 campylobacter jejuni。
181、更进一步优选地,spcas9来自菌种 streptococcus pyogenes。
182、更进一步优选地,nmcas9来自菌种 neisseria meningitidis。
183、更优选地,sacas9来自菌种 staphylococcus aureus。
184、更优选地,sccas9来自菌种 streptococcus canis。
185、更优选地,spacas9来自菌种 streptococcus pasteurianus。
186、更优选地,核糖核蛋白复合物中,组分(a)的终浓度为0.1-2μm。
187、更优选地,核糖核蛋白复合物中,组分(b)的终浓度为0.1-3μm。
188、更优选地,核糖核蛋白复合物中,还包括氢离子缓冲剂。
189、更进一步优选地,核糖核蛋白复合物中,氢离子缓冲剂终浓度为1mm-2 m。
190、优选地,试剂盒还包括恒温切割-扩增反应体系。
191、优选地,反应体系中,核糖核蛋白复合物的终浓度0.1-2μm。
192、优选地,反应体系还包括:引物、目的基因、酶和助色基团。
193、优选地,反应体系还包括:dntp、单链结合蛋白。
194、更优选地,目的基因包括:基因组dna或cell-free dna。
195、更进一步优选地,目的基因包括从以下至少一种细胞株中提取的基因组dna:
196、egfr 19del野生型细胞株;egfr 19 e746_a750 del(2235-2249del)细胞株;egfr19 e746_a750 del(2236-2250del);braf v600e突变型;brafv600e野生型细胞株;b-cpap细胞株。
197、更优选地,引物包括能够与目的基因结合并且引导合成的核苷酸序列。
198、更进一步优选地,引物包括以下至少一条序列:
199、gcatgtggcaccatctcaca(seq id no.15);
200、agagcagctgccagacatga(seq id no.16);
201、ctacacctcagatatatttc(seq id no.19);
202、tggatccagacaactgt(seq id no.20);
203、tacgtgatggccagcgtgga(seq id no.23);
204、actgggagccaatattgt(seq id no.24);
205、tcgttaaatagatacgttacgc(seq id no.33);
206、taaaaactaaaaactttccgcg(seq id no.34);
207、tcgttaaatagatacgttacgc(seq id no.35);
208、caacgcctcgaaacctacg(seq id no.36)。
209、cccccaggattcttacagaaaacaagtggt(seq id no.38);
210、gcaaatacacagaggaagccttcgcctgtcctc(seq id no.39);
211、caagtggttatagatggtga(seq id no.40);或,
212、cgcctgtcctcatgtattgg(seq id no.41)。
213、更优选地,酶包括:dna聚合酶和/或重组酶。
214、更优选地,助色基团包括mgoac。
215、优选地,上述反应体系可用于富集maf≥0.01%的突变型等位基因。
216、本发明还公开了一种使用上述试剂盒进行检测和/或富集低丰度突变基因的方法,操作步骤包括:
217、收集样品;
218、制备核糖核蛋白复合物;
219、配制反应体系;
220、富集分析。
221、优选地,收集样品步骤包括使用核酸提取试剂盒对样品中的dna和/或rna进行提取。
222、更优选地,样品包括以下至少一种:血液、血浆/血清、脑脊液、尿液、唾液。
223、更进一步优选地,样品包括以下至少一种从癌症患者体内获得的:血液、血浆/血清、脑脊液、尿液、唾液。
224、优选地,制备核糖核蛋白复合物步骤包括:
225、将cas9、sgrna和氢离子缓冲剂混合孵育。
226、优选地,氢离子缓冲剂包括hepes。
227、优选地,核糖核蛋白复合物的制备中,所使用的cas9的终浓度为0.1-3μm。
228、更优选地,核糖核蛋白复合物的制备中,所使用的cas9的终浓度为2.5μm。
229、优选地,核糖核蛋白复合物的制备中,所使用的sgrna的终浓度为0.1-2μm。
230、更优选地,核糖核蛋白复合物的制备中,所使用的sgrna的终浓度为2.5μm。
231、优选地,核糖核蛋白复合物的制备中,所使用的hepes的终浓度为1mm-2m。
232、更优选地,核糖核蛋白复合物的制备中,所使用的hepes的终浓度为1m。
233、优选地,核糖核蛋白复合物的制备中,反应温度为34-39℃,反应时间为3-18min。
234、更优选地,核糖核蛋白复合物的制备中,反应温度为37℃,反应时间为10min。
235、优选地,配制反应体系步骤包括配制恒温切割-扩增反应体系。
236、更优选地,反应体系中,核糖核蛋白复合物的终浓度0.1-2μm。
237、更优选地,反应体系还包括:引物、目的基因、酶和助色基团。
238、更优选地,反应体系还包括:dntp、单链结合蛋白。
239、更进一步优选地,目的基因包括:基因组dna。
240、更进一步优选地,目的基因包括从以下至少一种细胞株中提取的基因组dna:
241、egfr 19del野生型细胞株;egfr 19 e746_a750 del(2235-2249del)细胞株;egfr19 e746_a750 del(2236-2250del);braf v600e突变型;brafv600e野生型细胞株;b-cpap细胞株。
242、更进一步优选地,引物包括能够与目的基因结合并且引导合成的核苷酸序列。
243、更进一步优选地,引物包括以下至少一条序列:
244、gcatgtggcaccatctcaca(seq id no.15);
245、agagcagctgccagacatga(seq id no.16);
246、ctacacctcagatatatttc(seq id no.19);
247、tggatccagacaactgt(seq id no.20);
248、tacgtgatggccagcgtgga(seq id no.23);
249、actgggagccaatattgt(seq id no.24);
250、tcgttaaatagatacgttacgc(seq id no.33);
251、taaaaactaaaaactttccgcg(seq id no.34);
252、tcgttaaatagatacgttacgc(seq id no.35);
253、caacgcctcgaaacctacg(seq id no.36)。
254、cccccaggattcttacagaaaacaagtggt(seq id no.38);
255、gcaaatacacagaggaagccttcgcctgtcctc(seq id no.39);
256、caagtggttatagatggtga(seq id no.40);或,
257、cgcctgtcctcatgtattgg(seq id no.41)。
258、更进一步优选地,酶包括:dna聚合酶和/或重组酶。
259、更进一步优选地,助色基团包括mgoac。
260、优选地,富集分析步骤包括qpcr分析、测序、及时检测(poct)以及上述基于可编程核酸酶的低丰度突变基因的检测方法。
261、更优选地,qpcr分析步骤包括配制qpcr反应体系。
262、更进一步优选地,qpcr反应体系包括:
263、引物、助色基团、dntp、酶。
264、更进一步优选地,引物包括以下至少一条:
265、tgtcatagggactctggatcccaga(seq id no.17);
266、gcagaaactcacatcgaggatttccttgt(seq id no.18);
267、cctcagatatatttcttcatga(seq id no.21);
268、tgttcaaactgatgggac(seq id no.22);
269、tgatggccagcgtggacaa(seq id no.25);或,
270、ttgtgttcccggacatagtc(seq id no.26)。
271、更进一步优选地,助色基团包括mgoac。
272、更进一步优选地,酶包括dna聚合酶。
273、本发明还公开了一种基于crispr系统的sgrna的设计方法,sgrna包括特异性识别核苷酸片段、错配核苷酸片段;其中,错配的核苷酸片段长度为0-4bp。
274、优选地,特异性识别核苷酸片段为spacer序列。
275、更优选地,spacer序列长度为18-22nt。
276、优选地,错配的核苷酸片段长度为0bp 或1bp或2bp或3bp或4bp。
277、使用本发明sgrna设计方法设计的sgrna能够有效区分野生型等位基因和突变型等位基因.,并且使用本发明sgrna设计方法设计的sgrna的spacer序列识别和切割效率高。本发明所设计的错配核苷酸片段有利于扩大sgrna的使用范围,能够使sgrna识别更多突变。
278、本发明还公开了一种sgrna,该sgrna包括特异性识别核苷酸片段、错配核苷酸片段;其中,错配核苷酸片段长度为0-4bp。
279、优选地,错配的核苷酸片段长度为0bp 或1bp或2bp或3bp或4bp。
280、优选地,上述sgrna使用上述方法设计得到。
281、优选地,错配核苷酸的位点在突变基因的前5bp和/或突变基因的后5bp。
282、优选地,特异性识别核苷酸片段为spacer序列。
283、更优选地,spacer序列长度为18-22nt。
284、更优选地,sgrna序列如下所示:
285、ucuuaauuccuugauagcga(seq id no.1);
286、uagcuacagugaacucucga(seq id no.2);
287、uagcuacagugaaaucacga(seq id no.3);
288、gcuacagugaacucucga(seq id no.4);
289、gucuagcuacagugaaa(seq id no.5);
290、gucuagcugcagugaaa(seq id no.6);
291、ggcagccgaagggcaugagc(seq id no.27);
292、ggcagccgaagagcaugagc(seq id no.28);
293、aauuuuuguuugagugguug (seq id no.37);
294、uccagcuguauccaguaugu(seq id no.42)。
295、本发明还公开了上述sgrna的用途,包括以下至少一种:
296、(1)富集基因突变;
297、(2)检测基因突变;
298、(3)富集甲基化dna;或,
299、(4)检测甲基化dna。
300、本发明还公开了一种guide dna或guide rna,其特征在于,所述guide dna或guiderna包括特异性识别核苷酸片段、错配核苷酸片段;其中,错配的核苷酸片段长度为0-4bp。
301、优选地,错配的核苷酸片段长度为0bp 或1bp或2bp或3bp或4bp。
302、优选地,上述的guide dna包括如下序列:
303、seq id no.43:正向guide:p-tagatttcactgtagc-3’;
304、seq id no.44:反向guide:p-ttctagctacagtgaa-3’。
305、本发明还公开了上述guide dna或guide rna的用途,包括以下至少一种:
306、(1)富集基因突变;
307、(2)检测基因突变;
308、(3)富集甲基化dna;或,
309、(4)检测甲基化dna。
310、本发明还公开了一种基于可编程酶的突变基因和/或甲基化dna的富集方法,使用crispr系统对野生型等位基因进行特异性切割,同时扩增突变型等位基因;其中,crispr系统包括:
311、组分(a),包含能够与靶核酸互补配对的核酸区域和0-4bp错配片段;
312、组分(b),能够与靶核酸结合并使靶核酸链断裂;
313、其中,组分(a)选自tracrrna和/或crrna和/或sgrna和/或tracrrna衍生物和/或crrna衍生物和/或sgrna衍生物和/或guide dna和/或guide rna;组分(b)包括cas蛋白和/或cas蛋白衍生物和/或ago蛋白和/或ago蛋白衍生物;组分(a)和(b)能够结合。优选地,组分(a)携带标记,标记包括链霉亲和素或生物素。
314、优选地,错配的核苷酸片段长度为0bp 或1bp或2bp或3bp或4bp。
315、优选地,组分(a)携带化学修饰,化学修饰包括硫取代氧或甲氧基修饰。
316、优选地,组分(a)中sgrna包括错配核苷酸片段。本发明所设计的错配核苷酸片段有利于扩大sgrna的使用范围,能够使sgrna识别更多突变。
317、优选地,组分(a)中sgrna的spacer序列长度为16-22nt。
318、优选地,组分(b)包括以下至少一种:cas12a,saccas9,cjcas9,spcas9,nmcas9,sp-cas9 hf1,evocas9,hypacas9,hifi cas9,sniper-cas9,xcas9,espcas9 1.1,superficas9,sacas9,sacas9-hf,efsacas9,sccas9,cas9-sc++,cas9 hifi-sc++,spacas9,spacas9-hf,fncas9,anacas9,spycas9,fncas12a,lbcas12a,ascas12a,cbago,ttago,pfago,kmago或kpago。
319、更优选地,cas12a来自以下至少一个菌种: francisella novicida; acidaminococcus; lachnospiraceae。
320、更优选地,saccas9来自菌种 staphylococcus aureus。
321、更优选地,cjcas9来自菌种 campylobacter jejuni。
322、更优选地,spcas9来自菌种 streptococcus pyogenes。
323、更优选地,nmcas9来自菌种 neisseria meningitidis。
324、更优选地,sacas9来自菌种 staphylococcus aureus。
325、更优选地,sccas9来自菌种 streptococcus canis。
326、更优选地,spacas9来自菌种 streptococcus pasteurianus。
327、优选地,crispr系统中,组分(a)的终浓度为0.1-2μm。
328、优选地,crispr系统中,组分(b)的终浓度为0.1-3μm。
329、优选地,crispr系统中,还包括氢离子缓冲剂。
330、更优选地,crispr系统中,氢离子缓冲剂包括:hepes。
331、更优选地,crispr系统中,氢离子缓冲剂终浓度为1mm-2 m。
332、优选地,扩增突变型等位基因的方法包括pcr、lamp、rpa。
333、更优选地,扩增突变型等位基因的反应体系包括核糖核蛋白复合物。
334、优选地,反应体系中,核糖核蛋白复合物的终浓度0.1-2μm。
335、优选地,反应体系还包括:引物、目的基因、酶和助色基团。
336、优选地,反应体系还包括:dntp、单链结合蛋白。
337、更优选地,目的基因包括:基因组dna。
338、更进一步优选地,目的基因包括从以下至少一种细胞株中提取的基因组dna:
339、egfr 19del野生型细胞株;egfr 19 e746_a750 del(2235-2249del)细胞株;egfr19 e746_a750 del(2236-2250del);braf v600e突变型;brafv600e野生型细胞株;b-cpap细胞株。
340、更优选地,引物包括能够与目的基因结合并且引导合成的核苷酸序列。
341、更进一步优选地,引物包括以下至少一条序列:
342、gcatgtggcaccatctcaca(seq id no.15);
343、agagcagctgccagacatga(seq id no.16);
344、ctacacctcagatatatttc(seq id no.19);
345、tggatccagacaactgt(seq id no.20);
346、tacgtgatggccagcgtgga(seq id no.23);
347、actgggagccaatattgt(seq id no.24);
348、tcgttaaatagatacgttacgc(seq id no.33);
349、taaaaactaaaaactttccgcg(seq id no.34);
350、tcgttaaatagatacgttacgc(seq id no.35);
351、caacgcctcgaaacctacg(seq id no.36)。
352、cccccaggattcttacagaaaacaagtggt(seq id no.38);
353、gcaaatacacagaggaagccttcgcctgtcctc(seq id no.39);
354、caagtggttatagatggtga(seq id no.40);或,
355、cgcctgtcctcatgtattgg(seq id no.41)。
356、更优选地,guide dna序列如下所示:
357、正向guide:p-tagatttcactgtagc-3’(seq id no.43);
358、反向guide:p-ttctagctacagtgaa-3’(seq id no.44)。
359、更优选地,酶包括:dna聚合酶和/或重组酶。
360、更优选地,助色基团包括mgoac。
361、更进一步优选地,核糖核蛋白复合物包括cas9、sgrna和氢离子缓冲剂。
362、更进一步优选地,核糖核蛋白复合物的制备方法包括:将cas9、sgrna和氢离子缓冲剂混合孵育。
363、更进一步优选地,氢离子缓冲剂包括hepes。
364、更进一步优选地,核糖核蛋白复合物的制备中,所使用的cas9的终浓度为0.1-3μm。
365、更进一步优选地,核糖核蛋白复合物的制备中,所使用的sgrna的终浓度为0.1-2μm。
366、更进一步优选地,核糖核蛋白复合物的制备中,所使用的hepes的终浓度为1mm-2m。
367、更进一步优选地,核糖核蛋白复合物的制备中,反应温度为34-39℃,反应时间为3-18min。
368、本发明还公开了一种基于可编程核酸酶的低丰度突变基因和/或甲基化dna的检测方法,使用上述crispr系统或ago系统对野生型等位基因进行特异性切割,同时扩增突变型等位基因;包括如下步骤:
369、设计sgrna;
370、目的基因的获取;
371、扩增与切割;
372、突变基因检测。
373、优选地,sgrna包括错配核苷酸片段。
374、优选地,sgrna的spacer序列长度为16-22nt。
375、优选地,目的基因包括egfr,braf,pik3ca,tp53,lrp1b,apc,cyp1a1,np01,ephx1,kras,brca1,brca2,met,mlh1,msh2,msh3,msh6,palb2,bmpr1a,smad4,stk11,pten,axin2,blm,bub1b,cdh1,cep57,chek2,eng,epcam,flcn,galnti2,grem1,fat4,kmt2d,kmt2c,arid1a,fat1,pten,atm,zfhx3,crebbp,grin2a,nras或nf1。
376、优选地,扩增方法包括:pcr、lamp和rpa。
377、优选地,突变基因检测方法包括sanger测序。
378、优选地,扩增使用的反应体系包括:目的基因、核糖核蛋白复合物、mgoac、引物、dna聚合酶、重组酶和单链结合蛋白。
379、优选地,切割使用的反应体系包括:目的基因、核糖核蛋白复合物、mgoac。
380、本发明还公开了一种自动化富集和/或检测突变基因和/或甲基化dna的微流控芯片。
381、优选地,微流控芯片分为三部分,由顶层封装片、底层封装片以及中间的反应层构成。
382、更优选地,顶层封装片结构包括:微流控芯片安装孔;微流控芯片封装定位孔;微流控芯片进样孔。
383、更优选地,中间反应层结构包括:微流控芯片封装定位孔;微流控芯片安装孔;预扩增反应腔;虹吸阀;消化反应腔;预分配腔;pcr反应腔;废液腔;毛细阀;10:气体通路。
384、更优选地,底层封装片结构包括:微流控芯片安装孔;微流控芯片封装定位孔;rnasea加样腔;proteinasek加样腔。
385、本发明还公开了一种自动化富集和/或检测突变基因和/或甲基化dna的方法,包括如下步骤:
386、1)加样:预扩增体系加入预扩增反应腔;将rnasea加入rnasea加样腔;将proteinasek加入proteinasek加样腔;将qpcr体系加入pcr反应腔;
387、2)密封;
388、3)装载并完成实验:将密封后的微流控芯片装载在离心微流控平台上。
389、与现有技术相比,本发明的有益效果为:
390、本发明基于crispr系统、可编程核酸酶以及核酸扩增技术,在核酸扩增的同时,利用可编程核酸酶特异性切割野生型核酸,让样品中突变等位基因的数量连续不断地呈指数增加,达到廉价的sanger测序可检出的水平。不仅达到了可与超深度ngs测序相媲美的检测灵敏度,还有检测周期短、无需依赖大型仪器设备等特点,大大降低了检测成本,极大推动了低丰度突变等位基因检测在临床上的应用。本发明富集方法能够用于富集maf≥0.01%的突变型等位基因,能够使突变型等位基因的频率明显增加。
- 还没有人留言评论。精彩留言会获得点赞!