用于求得车辆的重心的位置的方法与流程
本发明涉及一种方法,在该方法中求得行驶的机动车的重心的位置,其中,考虑相关的/相互关联的输入参数的至少一个组。输入参数组至少包括机动车的纵向加速度、机动车的横向加速度、机动车的横摆率和至少一个车轮转速。本发明也涉及一种电子控制器。
背景技术:
在已知的用于估算重心位置的方法中,大多忽略横向的重心坐标y,并且前提是纵向的坐标x是部分已知的或者假设其为零。重心高度z的估算质量常常不能令人满意。
从专利文献de102014200987a1中已知一种方法,在该方法中求得行驶的机动车的重心的位置,其中,考虑相关的输入参数中的至少两个数据点,所述相关的输入参数至少包括机动车的加速度、至少两个车轮的、尤其是四个车轮的车轮速度以及车轮上的驱动或制动力矩。共同求得在相对于车辆固定的坐标系中的至少一个重心坐标和摩擦值特性曲线的至少一个匹配参数。
已知的方法具有的缺点是,必须事先已知多个车辆参数,并且常常仅仅对一个或两个坐标进行估算,而不是对所有三个空间坐标进行估算。常常得到对竖向的重心坐标的低的估算质量,并且重心坐标相互耦合。现有的基于学习的方案需要非常大量的分类器。部分地以高的计算功率/算力为前提,这成本高并且在行驶的车辆中常常不能实现。
技术实现要素:
因此本发明的目的是,给出一种用于获得重心位置的方法,该方法是稳定的、准确的且自主的,并且在此需要较小的计算功率。
根据本发明,在稳态的行驶操纵期间求得输入参数组,将可能的重心位置的集合判定成类别并根据该输入参数组借助基于学习的分类算法选择一给出估算的重心位置的类别。
相关的输入参数组在此理解成同时测得或求得的并且描述机动车在同一时刻的行驶状态的不同行驶动力参数的数据组。不同的行驶动力参数包括至少机动车的纵向加速度、机动车的横向加速度、机动车的横摆率和至少一个车轮转速。优选地,输入参数组包括四个车轮转速。
根据本发明的方法具有的优点是,在估算算法中不需要车辆参数。显著减少了分类器和模型参数的数量。改善了竖向的重心坐标的估算质量。与测量噪声、尤其是无平均值的测量噪声相比该方法实现了更高的稳定性。此外,与质量估算和道路摩擦值的偏差相比实现了高的稳定性。
优选地,检测多个车轮转速,尤其优选地检测车辆的每个车轮的车轮转速。如果检测多个车轮转速,则有利地计算车轮转速的平均值或加权平均值。车轮转速的平均值或加权平均值用作输入参数(平均车轮转速)。与单个车轮转速相比,平均值或加权平均值在避免测量误差方面更稳定。
优选地,在使用机动车的模型的模拟数据的情况下,学习在输入参数组与重心位置的类别之间的非线性的对应关系。在此,非线性的对应关系理解成,在所述对应关系中在输入参数与重心位置的坐标之间不必是成比例的关系。
基于学习的分类算法用于,形成在行驶动力数据(标准-esp传感器数据)与所属的重心位置之间的非线性对应关系。优选地,通过在其期间生成模拟数据的训练过程进行该对应关系。紧接着,例如可将随机森林分类器用于估算x和y坐标。
在训练过程期间,优选地,定义可能的重心位置的空间,并且将待学习的重心位置的集合判定为类别。优选地,在使用目标车辆的模型的模拟数据的情况下学习在传感器数据与所属的重心位置之间的非线性对应关系。在此,优选地使用为每个单个类别给出概率的分类算法。有利地,该方法推荐随机森林算法。备选地,可使用输入向量机。
在训练过程结束之后,该方法可用于求得机动车的重心位置。优选地,分类算法在分类器中实现,该分类器根据在训练过程中学习的对应关系进行分类。
优选地,输入参数组包括转向角。
优选地,输入参数组包括机动车总质量的估计值。
代替机动车的总质量,也可将装载质量的估计值作为输入参数进入计算中。在清楚机动车的空载质量的情况下,总质量和装载质量可相互换算。
优选地,输入参数可以是连续的传感器信号:纵向和横向加速度、横摆率、转向角和至少一个、但最好是所有四个车轮转速以及车辆当前总质量的估计值。
优选地,通过行驶稳定系统的传感装置检测机动车的纵向加速度、机动车的横向加速度、机动车的横摆率和车轮转速。使用已由行驶稳定系统及其esp标准传感装置检测的测量参数具有的优点是,为了估算纵向和横向的重心坐标所需的代价低。
优选地,可通过计算单元进行该方法,该计算单元在eps控制器的一个/多个接口上读取所述参数。
优选地,当在预设的时间段上车辆速度、横向加速度和/或横摆率和/或转向角恒定时,识别到稳态的行驶操纵。
有利地,当在预设的时间段上车辆速度是恒定的并且附加地在该预设的时间段上横向加速度、横摆率或转向角这些参数中的至少一个是恒定的时,识别到稳态的行驶操纵。
尤其优选地,根据一个车轮转速或根据平均的车轮转速确定车辆速度。
优选地,当在预设的时间段上出现如下情况时,识别到稳态的行驶操纵:
-车辆速度的变化低于第一阈值,以及
-横向加速度的变化低于第二阈值,和/或
-横摆率的变化低于第四阈值,和/或
-转向角的变化低于第三阈值。
有利地,当在某一时间段上行驶动力参数的变化低于相应的阈值时,行驶动力参数(横向加速度、横摆率、转向角)被视为在该时间段上恒定。
优选地,为了确定重心位置,考虑至少两个输入参数组,其中,在第一稳态行驶操纵期间求得第一输入参数组,并且在第二稳态行驶操纵期间求得第二输入参数组。使用多组输入参数导致方法的更好的精度。
尤其优选地,为了确定重心位置,考虑至少三个输入参数组,其中,在第三稳态行驶操纵期间求得第三输入参数组。这实现了进一步的精度改善。
优选地,借助于分类算法根据不同的输入参数组求得至少两个中间结果。
尤其优选地,分别根据第一输入参数组和根据第二输入参数组求得各一个中间结果。
尤其优选地,根据所述至少两个中间结果计算估算的重心位置。有利地,借助于最小均方误差(mmse)算法从中间结果计算出估算的重心位置。
类别代表着空间的离散化,而mmse估算值是在三维空间中的预期值并且也可占据在类别的位置之间的任意位置。通过该方法求得的重心位置优选地相应于借助于mmse计算出的估算的重心位置。这实现了从中间结果到提供尤其准确的结果的得出的重心位置的计算。
优选地,考虑数量为n(n>2)的输入参数组并且为每一个组求得中间结果。根据n个中间结果,优选地借助于最小均方误差算法,计算出估算的重心位置。
尤其优选地,第一行驶操纵与第二行驶操纵不同。使用不同的行驶操纵证实为尤其准确。
优选地,每个稳态的行驶操纵根据其类型被归类为稳态的左转弯、稳态的右转弯或者稳态的直行。
优选地,借助于加速度和横摆率的变化计算检查行驶状态是否为稳态状态,并且确定其类型“稳态的直行”、“稳态的左转弯”或“稳态的右转弯”。
优选地,所述方法包括自动地识别有效的稳态行驶操纵。该识别的输入参数是车辆的纵向和横向加速度以及横摆率和可选地转向角。在每个探测时刻,借助于计算所述识别的每个输入参数在可移动的时间窗的范围中的变化并且在预设阈值的情况下检查是否为稳态状态。如果存在稳态状态,则根据横摆率和/或横向加速度确定操纵的类型。
这给出的优点是,自动地识别稳态状态及其类型(直行、左转弯、右转弯),并且作为特征矢量将重心估算提供给进一步的方法。
具体地,操纵优选包括稳态的左转弯、稳态的右转弯和稳态的直行。这些操纵中的每一个通过恒定的转向角、衡定的速度和恒定的横向加速度以及横摆率来表征。
尤其优选地,第一稳态行驶操纵在其类型方面与第二稳态行驶操纵不同。例如,第一稳态行驶操纵为稳态的左转弯,而第二稳态行驶操纵为稳态的直行,等。
根据本发明的一种优选的改进方案,借助于分类算法确定类别的至少一个概率分布,该概率分布为重心位置的每个类别分配一个概率值。
通过类别的空间分布,利用分类器的输出实现空间的概率分布,其最小均方误差(mmse)是重心位置的估算值。
尤其优选地,存在概率分布的形式的每个中间结果。
优选地,分别为所使用的稳态行驶操纵中的每一个使用所描述的分类器。
尤其优选地,为三个不同的稳态行驶操纵中的每一个分别使用一个分类器。三个分类器提供三个概率分布(每个操纵一个分布),从中通过组合以及计算最小均方误差(mmse)得到重心位置(x,y,z)的估算值。
优选地,借助于贝叶斯干涉将空间的概率分布与另一行驶操纵的概率分布组合成共同的概率分布并且通过紧接着计算预期值导致用于车辆的重心位置的估算值。
优选地,分类算法是随机森林算法或输入向量机方法。
优选地,确定估算的重心位置的横向坐标和纵向坐标。
优选地,借助于分类算法首先确定估算的重心位置的横向坐标和纵向坐标。尤其优选地,借助于第一部分分类器、例如随机森林分类器确定横向坐标和纵向坐标。第一部分分类器仅仅确定空间坐标的一部分,即横向坐标和纵向坐标,而不确定竖向坐标。
优选地,根据首先计算出的横向坐标和纵向坐标确定估算的重心位置的竖向坐标。
尤其优选地,借助于另外的部分分类器、即线性的部分分类器确定竖向坐标,已经确定的横向坐标和纵向坐标的值进入该另外的部分分类器中。这种做法简化了计算并且因此需要较少的计算功率。线性的部分分类器执行线性分类并且在此根据线性公式计算竖向坐标。横向坐标和纵向坐标作为变量进入线性公式中和/或方法的输入参数、例如侧倾角作为变量进入。进行线性插值。
有利地,第一部分分类器确定横向坐标和纵向坐标的概率分布,并且借助于用于确定竖向坐标的所述另外的部分分类器、即线性的部分分类器使用该概率分布的预期值。
有利地,所述第一部分分类器和所述另外的部分分类器是分类器的组成部分。因此,该分类器确定所有三个空间坐标。
优选地,输入参数组包括测得的或估算的机动车的侧倾角。有利地,从侧倾率传感器的测量值的积分获得侧倾角。
优选地,为了确定估算的重心位置的竖向坐标,使用包括侧倾角的输入参数组。侧倾角的使用实现了尤其准确地确定竖向坐标。
有利地,借助于线性的部分分类器,从横向坐标和纵向坐标的概率分布的预期值结合侧倾角确定竖向坐标。
为了确定空间的重心位置,有利地,将随机森林分类器与以线性插值为基础的分类器相组合。在稳态的转弯行驶中,由随机森林部分分类器提供在纵向和横向方向上的概率分布,在此基础上,线性的部分分类器估算重心高度,并且将二维的概率分布补充成三维的概率分布。
根据本发明,电子控制器包括执行根据本发明的方法的计算单元。
附图说明
以下根据附图详细解释本发明的有利的设计方案。其中:
图1示出了方法的示例的示意性流程图,
图2示出了示例的分类器的内部结构,
图3示出了示例性的稳态行驶操纵的信息内容的三维图,
图4示出了重心估算示例的评估。
具体实施方式
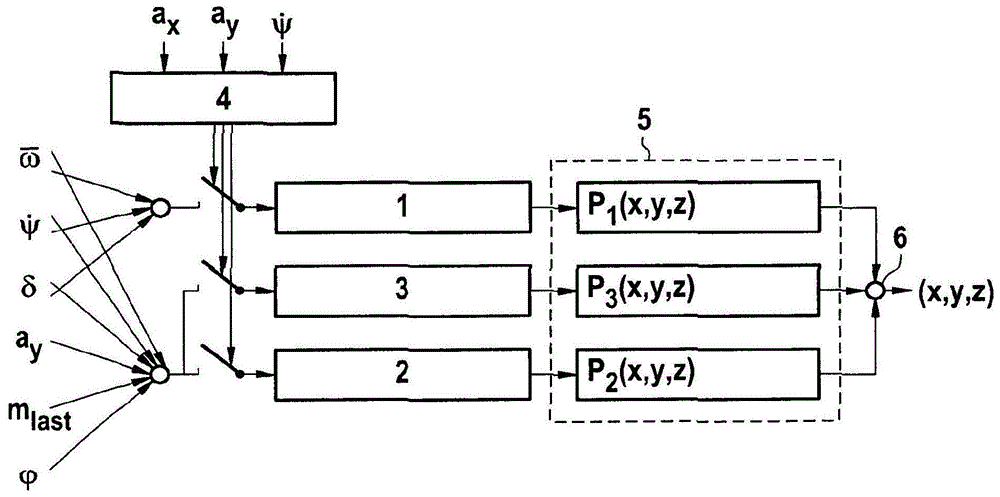
在图1中示意性地示出了方法的流程图,其具有输入参数
输入参数例如是如下信号:车轮转速的平均值
进行对有效的行驶操纵的自动识别4。根据输入参数横摆率
附加地,也可监控转向角δ,并且仅当转向角δ也恒定时,将行驶操纵识别为稳态的。另选地,对转向角δ的监控可替代对横摆率
在此,当在预设的时间跨度上值的变化保持低于阈值时,将该值视为恒定。
根据横摆率
例如,平均车轮转速
例如,除了平均车轮转速
通过所选择的分类器1、2或3,计算出概率分布pi(x,y,z)作为中间结果,并且储存在缓存器5中。下标i相应于所选择的分类器1、2或3。
一旦第一稳态行驶操纵结束,继续监控机动车的行驶状态并且识别下一个稳态行驶操纵。对于每个识别出的稳态行驶操纵,计算新的概率分布pi(x,y,z)并储存在缓存器5中。
优选地,在缓存器5中为每种类型的稳态行驶操纵最多储存数量为k的概率分布pi(x,y,z)。例如,在缓存器5中,尤其是为每种类型的稳态行驶操纵储存刚好一个概率分布pi(x,y,z)。
如果为新的稳态行驶操纵(在缓存器5中已经为该类型的行驶操纵储存了最大数量的概率分布)计算了概率分布,则通过新的概率分布替代已经储存的概率分布。即,例如最多使用三种不同的稳态行驶操纵,每种类型的行驶操纵一个概率分布。
从在缓存器5中储存的概率分布p1(x,y,z)、p2(x,y,z)、p3(x,y,z)中,借助于最小均方误差计算6计算出估算的重心位置(x,y,z)。
缓存器5中的概率分布p1(x,y,z)、p2(x,y,z)、p3(x,y,z)根据贝叶斯滤波公式相互组合。从得到的共同的概率分布p(x,y,z)中计算最小均方误差估计值。
优选地,在每次新识别出稳态行驶操纵之后,重新计算估算的重心位置(x,y,z)。
有利地,当满足中断标准时,结束该方法并且不再重新计算估算的重心位置(x,y,z)。
在图2中示出了在图1中阐述的分类器1、2、3的内部结构。分类器1、2、3中的每一个例如都具有这种结构。
例如,在识别的稳态行驶操纵期间,分别对车轮转速
例如,也分别对侧倾角φ的检测值和/或车辆质量mload的估计值求平均。
在对稳态状态中的信号求平均之后,将所得到的特征矢量提供给随机森林部分分类器20,该特征矢量包括车轮转速
在计算步骤23中,确定概率分布p(x,y)的预期值μx、μy。μx是所述分布在纵向方向上的预期值,μy是所述分布在横向方向上的预期值。
根据概率分布p(x,y)的预期值μx、μy并且在考虑横向加速度ay、估计的车辆质量mload和侧倾角φ的情况下,借助于线性的部分分类器21确定竖直方向上的概率分布p(z)。通过将这两个结果组合起来,得到用于一个行驶操纵的概率分布p(x,y,z)。在缓存器5中储存获得的概率分布。
图3以图形示出了示例的稳态行驶操纵的信息内容。在可能的重心位置的三维空间中,作为最强的特征的转向角δ描述了在用于右转弯(31、32、33)的可能的重心位置的面与用于左转弯的(30)的可能的重心位置的面之间的相交线,该相交线刚好通过重心。紧接着,借助于侧倾角φ确定重心高度。
在图4中,示出了利用示例的方法对示例性的重心估算的评估。借助于已知的模拟程序模拟蜿蜒的道路。例如以信噪比snr=20db为测量信号叠加了高斯噪声。横向加速度ay和侧倾角φ以具有测量噪声和没有测量噪声的方式示出。在所有曲线图i-vii的横坐标上示出了时间t。
在第一曲线图(i)中,示出了模拟的横向加速度曲线41以及具有叠加的噪声42的相同曲线。在第二曲线图(ii)中,示出了模拟的侧倾角曲线43以及具有叠加的噪声44的相同曲线。根据受噪声污染的信号进行状态识别和重心估算。
状态识别4识别了稳态的行驶操纵并且根据其类型a将其归类。在第三曲线图(iii)中,该识别的结果作为曲线45被示出。在此,在纵坐标上以值(1:直行,2:右转弯和3:左转弯)示出了所识别的类型a。在该示例中,正确地识别了五个稳态操纵:左转弯,右转弯,直行,右转弯,右转弯。
在出现稳态操纵期间,分别对信号求平均并在操纵结束时作为输入参数的单个特征矢量传递给相应的分类器1、2、3。在该示例中,总共进行五次分类,相应于五个顺序识别的稳态行驶操纵。为重心估算使用mmse估算值(x,y,z)。
在曲线图iv-vi中示出了mmse估算值的分量x、y和z。这些分量在每个时间步骤中从缓存器5中的各概率分布pi(x,y,z)的联合/结合中得到。在曲线图iv-vi中,示出了相应坐标的真实值(为该示例假设的值)x46、y49、z52以及通过该方法估算的值x47、y50、z53的曲线。为纵坐标x和横坐标y还分别示出了概率分布的方差x48、y51的曲线。
在方法开始时,缓存器5中的用于所有坐标的概率分布相应于均匀分布,在均匀分布中,重心位置的所有类别假设为相同的概率。由此,在可能的重心位置的区域的中心得到mmse估算值(x,y,z)。
在该示例中的第一次左转弯之后,在缓存器5中储存用于该左转弯的概率分布p3(x,y,z),并且x分量47和y分量50接近真实值46、49。随后的稳态操纵的分类结果同样进入缓存器5中。估计误差f(其曲线在图vii中示出)随着每次新的稳态行驶操纵以及与之相关的分类而减小。
优选地,当估计误差f下降到误差阈值之下时,认为满足了用于方法的中断标准。
- 还没有人留言评论。精彩留言会获得点赞!