基于多维度数据仲裁机制的情绪管理与交互系统及方法与流程
1.本发明属于汽车技术领域,具体的说是一种基于多维度数据仲裁机制的情绪管理与交互系统及方法。
背景技术:
2.随着智能座舱概念的逐渐普及,人们赋予了座舱更多的属性和能力。在感知维度上,图像、声音为主要的感知手段,也同样得到了升级和运用。专利文献1公开了一种情绪管理方法,该情绪管理方法包括:获取用户的语音特征数据和身体特征数据;对所述语音特征数据和所述身体特征数据进行处理,确定用户情绪结果;根据所述用户情绪结果和预设规则对所述用户进行情绪管理。本发明还公开了一种情绪管理设备和一种计算机可读存储介质。本发明能够实现发现用户情绪变化的功能,实现管理和调节用户情绪的功能。
3.专利文献2公开了一种基于机器人的情绪管理调节系统和方法,包括机器人本体和智能终端,所述机器人本体包括开关模块、信息模块、性格选择模块、情绪表达模块和综合模块,所述智能终端包括情绪储存数据库和情绪表达数据库,所述情绪储存数据库用于储存不同个人的信息和不同的情绪模式,所述情绪表达数据库用于收集不同的个人信息和情绪模式的混合表达方式,所述机器人本体和智能终端通过网络利用无线网络和有线网络中的一种进行数据的传输,所述开关模块包括开关机单元、密码验证单元、待机单元和声控唤醒单元。该基于机器人的情绪管理调节系统和方法,不仅能够调节的方面很广,而且情绪表达的更加立体,使得情绪管理更加灵活。
4.通过对现有技术的分析,如果提供一种交互系统,能通过感知脸部表情、语音的语气等的感知,构建出当前的用户情绪状态,必将使智能座舱更加能满足用户的实时需求。
技术实现要素:
5.本发明的目的是提供一种基于多维度数据仲裁机制的情绪管理与交互系统及方法,驾驶员与实车在交互的过程中,实车对驾驶员的面部表情、音色、语气语调、语义等多渠道状态进行识别,并将识别结果综合加权判断,最终得到用户当前情绪;之后,将识别出的用户当前情绪作为一种影响因子融入到后续的人车交互中,实现基于情绪的人车交互。
6.本发明的技术方案结合附图说明如下:
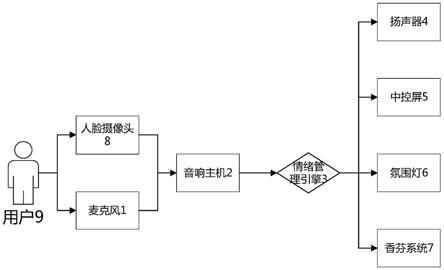
7.作为本发明的一方面,提供一种基于多维度数据仲裁机制的情绪管理与交互系统,包括麦克风1、音响主机2、情绪管理引擎3、扬声器4、中控屏5、环境氛围系统、人脸摄像头8;所述麦克风和音响主机2通过线束连接;所述音响主机2和情绪管理引擎3由软件接口连接;所述情绪管理引擎3分别与扬声器4、中控屏5、环境氛围系统通过线束连接;所述人脸摄像头8和音响主机2通过线束连接。
8.进一步地,所述音响主机2用于对接收到的声音进行降噪及回声消除处理,形成纯净的人声;以及对人声进行语义解析和语气判断,形成意图和语音情绪状态;对接收到的人脸表情数据进行算法拟合,推断人脸情绪状态;
9.所述情绪管理引擎3用于对接收到的语音情绪状态、人脸情绪状态及语义意图进行仲裁,并根据预先制定的情绪调节逻辑,分别分配给相应的控制单元。
10.进一步地,所述扬声器4用于播放相应的音乐、声音;
11.所述中控屏5用于动态展示情绪调节的文字及图像信息;
12.所述人脸摄像头8用于人脸状态的采集。
13.进一步地,所述环境氛围系统包括氛围灯6、香芬系统7,氛围灯6和香芬系统7与所述情绪管理引擎3通过线束连接。
14.更进一步地,所述香芬系统7用于针对不同的指令执行多种香型喷发;
15.所述人脸摄像头8用于人脸状态的采集。
16.作为本发明的另一方面,提供一种基于多维度数据仲裁机制的情绪管理与交互系统的交互方法,该交互方法包括以下步骤:
17.步骤一、人脸摄像头8采集用户9的人脸状态,并将用户9的人脸照片文件传给音响主机2;麦克风接收用户9的语音,并将用户9的声音文件传给音响主机2;
18.步骤二、音响主机2对接收到的声音进行降噪及回声消除处理,形成纯净的人声;对人声进行语义解析和语气判断,形成意图和语音情绪状态;对接收到的人脸表情数据进行算法拟合,推断人脸情绪状态;
19.步骤三、情绪管理引擎3对接收到的语音情绪状态、人脸情绪状态及语义意图进行仲裁,并根据预先制定的情绪调节逻辑,分别分配给相应的控制单元;
20.步骤四、扬声器4对响应声音进行听觉响应;
21.步骤五、中控屏5执行主结果及ui动效的视觉显示;
22.步骤六、氛围灯6通过固定频率的闪烁及变色进行视觉显示;
23.步骤七、香芬系统7执行多种香型的喷发达到嗅觉响应。
24.本发明的有益效果为:
25.本发明在驾驶员与实车的交互过程中,实车可以实时检测驾驶员的情绪状态,并进行情绪仲裁,根据仲裁的结果,对驾驶员的视觉、听觉、嗅觉方面进行反馈,动态调节驾驶员情绪,以达到提高驾驶安全的目的。
附图说明
26.图1为本发明的结构示意图。
27.图中:1、麦克风;
28.2、音响主机;
29.3、情绪管理引擎;
30.4、扬声器;
31.5、中控屏;
32.6、氛围灯;
33.7、香芬系统;
34.8、人脸摄像头;
35.9、用户。
具体实施方式
36.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。
37.基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
38.一种基于多维度数据仲裁机制的情绪管理与交互系统,包括麦克风、音响主机2、情绪管理引擎3、扬声器4、中控屏5、环境氛围系统、人脸摄像头8;所述麦克风和音响主机2通过线束连接;所述音响主机2和情绪管理引擎3由软件接口连接;所述情绪管理引擎3分别与扬声器4、中控屏5、环境氛围系统通过线束连接;所述人脸摄像头8和音响主机2通过线束连接。
39.进一步地,所述音响主机2用于对接收到的声音进行降噪及回声消除处理,形成纯净的人声;以及对人声进行语义解析和语气判断,形成意图和语音情绪状态;对接收到的人脸表情数据进行算法拟合,推断人脸情绪状态;
40.所述情绪管理引擎3用于对接收到的语音情绪状态、人脸情绪状态及语义意图进行仲裁,并根据预先制定的情绪调节逻辑,分别分配给相应的控制单元。
41.进一步地,所述扬声器4用于播放相应的音乐、声音;
42.所述中控屏5用于动态展示情绪调节的文字及图像信息;
43.所述人脸摄像头8用于人脸状态的采集。
44.进一步地,所述环境氛围系统包括氛围灯6、香芬系统7,氛围灯6和香芬系统7与所述情绪管理引擎3通过线束连接。
45.更进一步地,所述香芬系统7用于针对不同的指令执行多种香型喷发;
46.所述人脸摄像头8用于人脸状态的采集。
47.实施例1
48.参阅图1,一种基于多维度数据仲裁机制的情绪管理与交互系统,包括麦克风、音响主机2、语音引擎3、扬声器4、中控屏5、氛围灯6、香芬系统7、人脸摄像头8。
49.所述麦克风用于接收用户9的语音,并且将语音文件传给音响主机2;
50.所述音响主机2用于对接收到的声音进行降噪及回声消除处理,形成纯净的人声;对人声进行语义解析和语气判断,形成意图和语音情绪状态;对接收到的人脸表情数据进行算法拟合,推断人脸情绪状态。
51.所述情绪管理引擎3用于对接收到的语音情绪状态、人脸情绪状态及语义意图进行仲裁,并根据预先制定的情绪调节逻辑,分别分配给相应的控制单元。
52.所述扬声器4用于播放相应的音乐、声音。
53.所述中控屏5用于动态展示情绪调节的文字及图像信息。
54.所述氛围灯6用于通过固定频率的闪烁及变色,对用户9进行提醒。
55.所述香芬系统7用于针对不同的指令执行多种香型喷发。
56.所述人脸摄像头8用于人脸状态的采集。
57.实施例2
58.一种基于多维度数据仲裁机制的情绪管理与交互系统的方法,该交互方法包括以下步骤:
59.步骤一、当用户9在汽车座舱内发起语音交互时,通过麦克风接收用户9的语音,麦克风把用户9的声音文件传给音响主机2;
60.步骤二、音响主机2的语音助手引擎会对声音进行判定,并且主机根据预先制定的逻辑对判定结果进行执行相应分配,分别分配给相应的控制单元;
61.步骤三、扬声器4对响应声音进行听觉响应;
62.步骤四、中控屏5执行主结果及ui动效的视觉显示;
63.步骤五、氛围灯6通过固定频率的闪烁及变色进行视觉显示;
64.步骤六、香芬系统7执行多种香型的喷发达到嗅觉响应。
65.本发明多渠道情绪仲裁,最终为用户提供一个情绪管理和疏导的交互方式。
66.以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
67.另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
68.此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1