用于对车辆的乘员提供保护的方法与流程
本发明总体上涉及车辆辅助系统,并且具体地涉及用于帮助保护车辆乘员的视觉系统。
背景技术:
当前的驾驶员辅助系统(adas——高级驾驶员辅助系统)在车辆中提供了一系列监测功能。特别地,adas可以监测车辆内的环境,并将该环境中的状况通知给车辆的驾驶员。为此,adas可以捕获车辆内部的图像,并对这些图像进行数字处理以提取信息。响应于所提取的信息,车辆可以执行一个或多个功能。
技术实现要素:
在一个示例中,一种用于对车辆的乘员提供保护的方法包括获取车辆内部的至少一个实时图像。在该至少一个实时图像内检测乘员。基于该至少一个实时图像对被检测乘员进行分类。向该车辆的操作者通知该检测分类。基于该分类设置与该被检测乘员相关联的安全气囊的至少一个展开特性。
在另一个示例中,一种用于对车辆的乘员提供保护的方法包括获取车辆内部的至少一个实时图像。在该至少一个实时图像内检测乘员。估计该被检测乘员的年龄和重量。基于该估计的年龄和重量对该被检测乘员进行分类。向该车辆的操作者通知该检测分类。响应于该通知接收来自该操作者的反馈。基于该分类和该反馈设置与该被检测乘员相关联的安全气囊的至少一个展开特性。
通过以下的详细描述和附图,将掌握本发明的其他目的和优点以及对本发明的更全面的理解。
附图说明
图1a是根据本发明包括示例视觉系统的车辆的俯视图。
图1b是沿图1a的车辆的线1b-1b截取的截面视图。
图2a是车辆内部的理想对准图像的示意性展示。
图2b是另一个示例理想对准图像的示意性展示。
图3是车辆内部的实时图像的示意性展示。
图4是使用生成的关键点在理想对准图像与实时图像之间进行的比较。
图5是具有理想对准感兴趣区域的经校准的实时图像的示意性展示。
图6是具有经校准的感兴趣区域的实时图像的示意性展示。
图7是由视觉系统获取的连续实时图像的示意性展示。
图8是用于评估实时图像的置信水平的示意性展示。
图9是图8的置信水平的一部分的放大视图。
图10是车辆的前排座椅上的儿童和成人的示意性展示。
图11是车辆的前排座椅上的老年人和青少年的示意性展示。
图12是连接到车辆部件的控制器的示意性展示。
图13是包括乘员保护设备的车辆内部的示意性展示。
具体实施方式
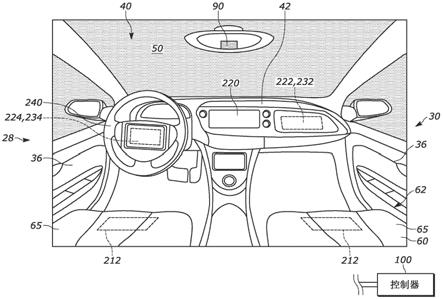
本发明总体上涉及车辆辅助系统,并且具体地涉及用于帮助保护车辆乘员的视觉系统。图1a和图1b展示了具有呈视觉系统10的形式的示例车辆辅助系统的车辆20,该视觉系统用于获取和处理车辆内的图像。车辆20沿中心线22从第一端或前端24延伸到第二端或后端26。车辆20在中心线22的相反两侧延伸到左侧28和右侧30。前门36和后门38设置在两侧28、30上。车辆20包括车顶32,该车顶与每侧28、30的前门36和后门38配合以限定客厢或内部40。以41指示车辆20的外部。
车辆20的前端24包括面向内部40的仪表板42。方向盘44从仪表板42延伸。可替代地,如果车辆20是自主车辆,则可以省略方向盘44(未示出)。无论哪种方式,挡风玻璃或风挡50可以位于仪表板42与车顶32之间。后视镜52连接到挡风玻璃50的内部。车辆20的后端26处的后窗56帮助封闭内部40。
座椅60被定位在内部40中,用于接纳一个或多个乘员70。在一个示例中,座椅60可以被分别布置在前排62和后排64,以面向前方的方式定向。在自主车辆配置(未示出)中,前排62可以面向后方。安全带59与每个座椅60相关联,以帮助将乘员70约束在相关联的座椅中。中控台66被定位在前排62中的座椅60之间。
视觉系统10包括被定位在车辆20内用于获取内部40的图像的至少一个相机90。如所示出的,相机90连接到后视镜52,但可以设想其他位置,例如车顶32、后窗56等。在任何情况下,相机90具有在内部40的较大百分比(例如,门36、38之间以及从挡风玻璃50到后窗56的空间)上向后延伸穿过该内部的视野92。相机90产生指示所拍摄的图像的信号,并将这些信号发送到控制器100。应理解的是,相机90可以可替代地安装在车辆20上,使得视野92在车辆外部41上延伸或包括该车辆外部。控制器100进而处理信号以供将来使用。
如图2a所示,当制造车辆20时,创建内部40的模板或理想对准图像108用于帮助在安装好相机时或此后周期性地校准相机90。理想对准图像108反映了相机90以规定方式与内部40对准以产生期望的视野92的理想位置。为此,针对车辆20的每个品牌和型号,相机90被定位成使得其实时图像(即,在车辆使用期间拍摄的图像)最接近地匹配内部40中的理想对准的期望取向,包括期望的位置、深度和边界。理想对准图像108捕获在车辆20的操作期间期望在其中监测/检测对象的内部40的部分,这些对象例如是座椅60、乘员70、宠物或个人财物。
理想对准图像108由边界110限定。边界110具有顶部边界110t、底部边界110b和一对侧边界110l、110r。即,所示的边界110是矩形的,但可以设想边界的其他形状,例如,三角形、圆形等。由于相机90在车辆20中面向后方,侧边界110l在图像108的左侧但在车辆20的右侧30上。类似地,侧边界110r在图像108的右侧但在车辆20的左侧28上。理想对准图像108上覆加有具有x轴、y轴和z轴的全局坐标系112。
控制器100可以将理想对准图像108划分成一个或多个感兴趣区域114(在图中缩写为“roi”)和/或一个或多个无兴趣区域116(在图中以“roi之外”指示)。在所示的示例中,边界线115从其两侧的无兴趣区域116划定中间的感兴趣区域114。边界线115在边界点111之间延伸,这些边界点在该示例中与边界110相交。感兴趣区域114位于边界110t、110b、115之间。左边的无兴趣区域116(如在图2中观察到的)位于边界110t、110b、110l、115之间。右边的无兴趣区域116位于边界110t、110b、110r、115之间。
在图2a所示的示例中,感兴趣区域114可以是包括两排(62、64)座椅60的区域。感兴趣区域114可以与一个或多个特定对象将合理地驻留的内部40的区域重合。例如,乘员70位于任一排62、64中的座椅60中是合理的,因此,所示出的感兴趣区域114总体上延伸到各排的横向范围。换言之,所示出的感兴趣区域114具体地针对乘员70确定尺寸和形状——可以说是特定于乘员的感兴趣区域。
应理解的是,不同的感兴趣对象(例如,宠物、笔记本电脑等)可以具有特定尺寸和形状的感兴趣区域,该感兴趣区域预定义了该特定对象在车辆20中的合理位置。这些不同的感兴趣区域在理想对准图像108内具有预定且已知的位置。取决于与每个感兴趣区域向相关联的感兴趣对象,这些不同的感兴趣区域可以彼此重叠。
考虑到这一点,图2b展示了理想对准图像108中针对不同的感兴趣对象的不同的感兴趣区域,即感兴趣区域114a是针对后排64中的宠物,感兴趣区域114b是针对驾驶员座椅60中的乘员,并且感兴趣区域114c是针对笔记本电脑。每个感兴趣区域114a至114c被界定在相关联的边界点111之间。在各自情况下,感兴趣区域114a至114c是(多个)无兴趣区域116的逆区域,使得这些区域共同形成整个理想对准图像108。换言之,理想对准图像108中未被感兴趣区域114a至114c界定的任何地方均被认为是(多个)无兴趣区域116。
返回图2a所示的示例,无兴趣区域116是在排62、64的横向外侧并且与门36、38相邻的区域。无兴趣区域116与对象(这里是乘员70)不合理地驻留的内部40的区域重合。例如,乘员70位于车顶32的内部是不合理的。
在车辆20操作期间,相机90获取内部40的图像并且向控制器100发送指示这些图像的信号。响应于所接收到的信号,控制器100对该图像执行一个或多个操作,并且然后检测内部40中的感兴趣对象。在车辆20操作期间拍摄的图像在本文中被称为“实时图像”。拍摄的示例实时图像118在图3中示出。
所示出的实时图像118由边界120限定。边界120包括顶部边界120t、底部边界120b和一对侧边界120l、120r。由于相机90在车辆20中面向后方,侧边界120l在实时图像118的左侧但在车辆20的右侧30上。类似地,侧边界120r在实时图像118的右侧但在车辆20的左侧28上。
从相机90的角度来看,实时图像118上覆加有具有x轴、y轴和z轴的局部坐标系122,或者与该局部坐标系相关联。即,实时图像118可以指示相机90的位置/取向出于若干原因与生成理想对准图像108的相机的位置/取向相比具有偏差。首先,相机90可能被不恰当地或以其他方式安装在捕获视野92的取向上,该视野与拍摄理想对准图像108的相机所生成的视野偏离。其次,在安装之后,相机90的位置可能会受到来自例如道路状况的振动和/或对后视镜52的冲击的影响。在任何情况下,坐标系112、122可能不相同,因此,期望校准相机90以解决捕获实时图像118的相机的位置与捕获理想对准图像108的相机的理想位置之间的任何取向差异。
在一个示例中,控制器100使用一种或多种图像匹配技术(诸如定向fast和旋转brief(orientedfastandrotatedbrief,orb)特征检测)来生成每个图像108、118中的关键点。控制器100然后从匹配的关键点对生成单应性矩阵,并使用该单应性矩阵以及已知的相机90的固有属性来在八个自由度上识别相机位置/取向偏差,以帮助控制器100校准相机。这允许视觉系统最终更好地在实时图像118内检测对象,并且响应于此而作出决策。
图4展示了该过程的一个示例实施方式。为了说明目的,理想对准图像108和实时图像118彼此相邻放置。控制器100识别每个图像108、118内的关键点——所展示的关键点被指示为①、②、③、④。关键点是图像108、118中企图在各图像中彼此相匹配并与同一精确点/位置/斑点相对应的不同位置。特征可能是例如拐角、缝线等。尽管仅具体地识别了四个关键点,但是应理解的是,视觉系统10可以依赖于数百个或数千个关键点。
在任何情况下,识别关键点并在图像108、118之间映射它们的位置。控制器100基于实时图像118中与理想对准图像108的关键点匹配来计算单应性矩阵。利用相机的固有属性的附加信息,然后对单应性矩阵进行分解以识别捕获实时图像118的相机90相对于捕获理想对准图像108的理想相机的任何平移(x轴、y轴和z轴)、旋转(偏航、俯仰和滚转)以及转向(sheer)和缩放。因此,单应性矩阵的分解量化了捕获实时图像118的相机90与捕获理想对准图像108的理想相机之间八个自由度上的未对准。
未对准阈值范围可以与每个自由度相关联。在一个实例中,阈值范围可以用于识别哪些实时图像118的自由度偏差是可忽略的以及哪些自由度偏差被认为足够大,以保证对相机90的位置和/或取向进行物理校正。换言之,图像108与图像118之间的一个或多个特定自由度的偏差可能小到足以保证被忽略——不会对这种自由度进行校正。每个自由度的阈值范围可以是对称的或不对称的。
例如,如果围绕x轴旋转的阈值范围是+/-0.05°,则在对相机90进行物理调整时不会考虑所计算的实时图像118与理想对准图像108处于阈值范围内的x轴旋转偏差。另一方面,关于x轴的在对应阈值范围外的旋转偏差将造成严重的未对准,并且需要对相机90进行重新校准或物理重定位。因此,阈值范围充当每个自由度的偏差的合格与否过滤器。
单应性矩阵信息可以存储在控制器100中,并且用于校准由相机90拍摄的任何实时图像118,从而使视觉系统10可以更好地对所述实时图像做出反应,例如更好地确定内部40中的变化。为此,视觉系统10可以使用单应性矩阵来变换整个实时图像118,并产生如图5所示的经校准或经调整的实时图像119。当这种情况发生时,经校准的实时图像119可以相对于实时图像118的边界120旋转或偏斜。然后,经由边界点111将感兴趣区域114投影到经校准的实时图像119上。换言之,未经校准的感兴趣区域114被投影到经校准的实时图像119上。然而,实时图像118的这种变换可能涉及控制器100的大量计算。
即,控制器100可以可替代地仅变换或校准感兴趣区域114,并将经校准的感兴趣区域134投影到未经校准的实时图像118上以形成如图6所示的经校准的图像128。换言之,感兴趣区域114可以经由平移、旋转和/或存储在单应性矩阵中的转向/缩放数据进行变换,并且被投影或映射到未经变换的实时图像118上以形成经校准的图像128。
更具体地,使用所生成的单应性矩阵通过变换对感兴趣区域114的边界点111进行校准,以产生经校准的图像128中的对应边界点131。然而,应理解的是,当感兴趣区域投影到实时图像118上时,一个或多个边界点131可能位于边界120之外,在这种情况下,将边界点连接的线与边界120的交点帮助限定经校准的感兴趣区域134(未示出)。无论哪种方式,当原始感兴趣区域114在理想对准图像108上对准时,新的经校准的感兴趣区域134在实时图像118上(在经校准的图像128中)对准。该校准实际上固定了感兴趣区域114,使得不需要将图像变换应用于整个实时图像118,从而减少了所需的处理时间和处理能力。
为此,使用单应性矩阵来校准限定感兴趣区域114的少数边界点111远比在图5中执行的对整个实时图像118进行变换或校准更加容易、快捷和高效。感兴趣区域114的校准确保了相机90与理想位置的任何未对准将对视觉系统10检测内部40中的对象的准确性具有最小的不利影响(如果有的话)。视觉系统10可以以预定的时间间隔或事件发生(例如,车辆20的启动或以五秒的间隔)执行对感兴趣区域114的校准——每次都基于新的实时图像生成新的单应性矩阵。
经校准的感兴趣区域134可以用于检测内部40中的对象。控制器100分析经校准的图像128或经校准的感兴趣区域134,并确定哪些对象(如果有的话)位于其中。在所示出的示例中,控制器100检测经校准的感兴趣区域134内的乘员70。然而,将理解的是控制器100可以校准任何替代的或附加的感兴趣区域114a至114c,以形成相关联的经校准的感兴趣区域并检测其中的特定感兴趣对象(未示出)。
在分析经校准的图像128时,控制器100可以检测在经校准的感兴趣区域134之外相交或交叉、并且因此在经校准的感兴趣区域的内部和外部均存在的对象。当这种情况发生时,控制器100可以依赖于确定被检测对象是否被忽略的阈值百分比。更具体地,控制器100可以确认与经校准的感兴趣区域134具有至少例如75%重叠的被检测对象或将其“认定为合格”。因此,与经校准的感兴趣区域134重叠的百分比小于阈值百分比的被检测对象将被忽略或“认定为不合格”。仅满足该标准的被检测对象将被考虑进行进一步处理或动作。
视觉系统10可以响应于在经校准的实时图像128内检测和/或识别到对象而执行一个或多个操作。这可以包括但限于基于(多个)乘员在内部40中的位置展开一个或多个安全气囊。
参照图7至图9,视觉系统10包括附加安全措施(包括呈计数器形式的置信水平),以帮助确保在实时图像118内准确地检测到对象。置信水平可以与前述校准结合使用,也可以与其分开使用。在车辆20的操作期间,相机90快速连续地拍摄多个实时图像118(见图7),例如每秒拍摄多个图像。为了清晰起见,给连续的每个实时图像118赋予索引,例如第一、第二、第三…直到第n个图像以及对应的后缀“a”、“b”、“c”…“n”。因此,第一实时图像在图7中以118a指示。第二实时图像以118b指示。第三实时图像以118c指示。第四实时图像以118d指示。尽管仅示出了四个实时图像118a至118d,但是应理解的是,相机90可以拍摄更多或更少的实时图像。无论哪种方式,控制器100都在每个实时图像118中执行对象检测。
考虑到这一点,控制器100评估第一实时图像118a并使用图像推理来确定哪个(哪些)对象(在该示例中为后排64中的乘员70)位于第一实时图像内。图像推理软件被配置为使得在没有至少预定置信水平(例如,对象在图像中的置信度至少为70%)的情况下不会将对象指示为被检测到。
应理解的是,该检测可以在如上所述校准第一实时图像118a(和后续实时图像)之后发生,或者不进行校准而发生。换言之,对象检测可以在每个实时图像118中都发生,或者具体地在投影到实时图像118上的经校准的感兴趣区域134中发生。随后的讨论集中于在实时图像118中检测对象/乘员70,而没有首先校准实时图像并且未使用感兴趣区域。
当控制器100在实时图像118中检测一个或多个对象时,将唯一的识别号和置信水平150(见图8)与每个被检测对象相关联或分配至每个被检测对象。尽管可以检测多个对象,但在图7至图9所示出的示例中,仅检测单个对象(在这种情况下为乘员70),并且因此为了简洁起见,仅示出和描述了与其相关联的单个置信水平150。置信水平150帮助评定对象检测的可靠性。
置信水平150具有在第一值152到第二值154之间的范围,例如,从-20到20的范围。第一值152可以用作计数器150的最小值。第二值154可以用作计数器150的最大值。置信水平150的值为0指示尚未评估任何实时图像118,或者无法确定实时图像118中是实际存在还是不存在被检测对象。置信水平150的正值指示被检测对象更可能实际存在于实时图像118中。置信水平150的负值指示被检测对象更可能实际不存在于实时图像118中。
此外,当置信水平150从值0朝向第一值152减小时,被检测对象实际不存在于实时图像118中的置信度(“错误”指示)增大。另一方面,当置信水平150从值0朝向第二值154增大时,被检测对象实际存在于实时图像118中的置信度(“正确”指示)增大。
在评估第一实时图像118a之前,置信水平150的值为0(也见图9)。如果控制器100在第一实时图像118a内检测到乘员70,则置信水平150的值增大至1。该增大在图9中由箭头a示意性地示出。可替代地,在第一实时图像118a中检测到对象可以将置信水平150保持在值0,但是触发或启动多图像评估过程。
针对每个后续实时图像118b至118d,控制器100检测乘员70是否存在。当控制器100在实时图像118b至118d中的每个实时图像中检测到乘员70时,置信水平150的值将增大(移近第二值154)。每当控制器100在实时图像118b至118d中的每个实时图像中未检测到乘员70时,置信水平150的值将减小(移近第一值152)。
针对每个连续的实时图像,置信水平150增大或减小的量可以相同。例如,如果在五个连续的实时图像118中检测到乘员70,则置信水平150可以如下增大:0、1、2、3、4、5。可替代地,当检测到乘员70的实时图像的连续数量增大时,置信水平150可以以非线性方式增大。在该实例中,在每个实时图像118检测到乘员70之后,置信水平150可以如下增大:0、1、3、6、10、15。换言之,当在更多连续的图像中检测到对象时,对象检测评定的可靠性或置信度可以快速地增大。
类似地,如果在五个连续的实时图像118中未检测到乘员70,则置信水平150可以如下减小:0、-1、-2、-3、-4、-5。可替代地,如果在五个连续的实时图像118中未检测到乘员70,则置信水平150可以以非线性方式如下减小:0、-1、-3、-6、-10、-15。换言之,当在更多连续的图像中未检测到对象时,对象检测评定的可靠性或置信度可以快速地减小。在所有情况下,当对每个连续的实时图像118进行对象检测评估时,对置信水平150进行调整,即增大或减小。应理解的是,针对与每个被检测对象相关联的每个置信水平150重复此过程,并且因此,每个被检测对象将经历相同的对象检测评估。
还将理解的是,一旦计数器150达到最小值152,则任何后续的未检测到都不会将计数器的值从最小值改变。类似地,一旦计数器150达到最大值154,则任何后续的检测到都不会将计数器的值从最大值改变。
利用所示出的示例,在第一实时图像118a中检测到乘员70之后,控制器然后在第二实时图像118b中检测到乘员,在第三实时图像118c中未检测到乘员,并且在第四实时图像118d中检测到乘员。第三实时图像118c中未检测到可能归因于照明变化、乘员70的快速运动等。如所示出的,第三实时图像118c由于车辆20中/周围的照明状况而变暗,从而使得控制器100未能检测到乘员70。即,响应于在第二实时图像118b中检测到乘员70,置信水平150的值以箭头b所指示的方式增大2。
然后,响应于在第三实时图像118c中未检测到乘员70,置信水平150的值以箭头c所指示的方式减小1。然后,响应于在第四实时图像118d中检测到乘员70,置信水平150的值以箭头d所指示的方式增大1。在对所有实时图像118a至118d进行对象检测评估之后,最终置信水平150的值为3。
在第一值152与第二值154之间的置信水平150的最终值可以指示控制器100确定被检测乘员70实际上存在的情况以及在该确定中的置信度。置信水平150的最终值还可以指示控制器100确定被检测乘员70实际上不存在的情况以及在该确定中的置信度。控制器100可以被配置成在评估预定数量的连续实时图像118(在这种情况下为四个实时图像)之后或在获取实时图像的预定时间帧(例如,秒或分钟)之后最终确定被检测乘员70实际上是否存在。
在检查了四个实时图像118a至118d之后,置信水平150的正值指示乘员70更可能实际存在于车辆20中。最终置信水平150的值指示该评定相比于更接近第二值154的最终值具有较低的置信度,但是相比于接近0的最终值具有更高的置信度。控制器100可以被配置成将特定百分比或值与每个最终置信水平150值或介于值152与154之间并包括这些值的值范围相关联。
控制器100可以被配置成响应于最终置信水平150的值来启用、禁用、致动和/或停用一个或多个车辆功能。这可以包括例如控制车辆安全气囊、安全带预紧器、门锁、紧急制动、hvac等。应理解的是,不同的车辆功能可以与不同的最终置信水平150值相关联。例如,相比与乘员安全无关的车辆功能而言,与乘员安全相关联的车辆功能可能需要相对更高的最终置信水平150值来启动致动。为此,在一些情形下,最终置信水平150值为0或以下的对象检测评估可以被完全丢弃或忽略。
在车辆20的操作期间,可以多次或周期性地对实时图像118进行评估。当相机90的视野92面向内部时,可以在车辆内部40中进行评估,或者当视野面向外部时,可以在车辆外部41周围进行评估。在各自情况下,控制器100单独地检查多个实时图像118以进行对象检测,并且利用相关联的置信度值最终确定被检测对象是否实际存在于实时图像中。
本文中示出和描述的视觉系统的优点在于,该视觉系统在车辆内和周围的对象检测中提供了提高的可靠性。在短时间帧内拍摄同一视野的多个图像时,一个或多个图像的质量可能会受到例如照明状况、阴影、在相机前面通过并遮挡相机的对象、和/或运动模糊的影响。因此,当前相机可能会对视野中的对象产生误报检测和/或漏报检测。该错误信息可能对依赖于对象检测的下游应用产生不利影响。
通过单独地分析一系列连续的实时图像以确定累积的置信度分数,本发明的视觉系统有助于减轻可能存在于单个帧中的前述缺陷。因此,本文中示出和描述的视觉系统有助于减少对象检测中的误报和漏报。
即,控制器100不仅可以检测车辆20内的对象,而且可以对被检测对象进行分类。在分类的第一阶段,控制器100确定被检测对象是人/乘员还是动物/宠物。在前一种情况下,可以基于年龄、身高、重量或其任意组合对被检测乘员进行第二次分类。
在图10所示的示例中,控制器100检测并识别车辆内部40(例如,前排62座椅60)中的儿童190和成人192。在图11所示的示例中,控制器100检测并识别前排62座椅60中的老年人194和青少年196。应理解的是,儿童190、成人192、老年人194或青少年196中的任一个也可以位于后排64(未示出)。
在每个实例中,可以在校准或不校准实时图像118或与理想对准图像108相关联的感兴趣区域114的情况下进行乘员检测。也可以在利用或不利用置信水平/计数器150的情况下执行检测。在任何情况下,在控制器100确定乘员在车辆20中之后发生上述过程。
无论哪种方式,响应于从相机90接收信号,控制器110使用人工智能(ai)模型、图像推理软件和/或模式识别软件来估计每个被检测乘员的年龄。可以针对该应用在监督学习下准备和训练ai模型。还可以利用ai模型、图像推理软件和/或模式识别软件来估计被检测乘员的其他特征(例如,坐姿高度和重量)。
参考图12和图13,控制器100连接到或包括一体式安全气囊控制器200。一个或多个重量传感器212位于车辆20中的每个座椅60的座椅底座65中,并且连接到安全气囊控制器200。重量传感器212检测座椅底座65上任何对象的重量,并将指示检测到的重量的信号发送至控制器200。结果,视觉系统10可以依赖于相机90和重量传感器212两者来帮助估计每个被检测乘员的重量。
控制器100可以包括将坐姿高度和重量(或其范围)与特定年龄分类关联的查找表等。即,控制器100可以将估计年龄与估计坐姿高度和重量结合使用,以高可靠性针对每个被检测乘员做出基于年龄的分类确定。
基于年龄的分类可以基于以下估计:被检测乘员具有在规定范围内的年龄,例如,12岁以下为儿童190,12岁到19岁为青少年196,20岁到60岁为成人192,并且60岁以上为老年人194。然而可以针对每个识别设想其他年龄范围。
控制器100还连接到车辆内部40中的显示器220,并且对乘员70可见。在一个示例中,显示器220位于仪表板42上(见图13)。
安全气囊控制器200连接到一个或多个充气机,该一个或多个充气机流体地连接到相关联的安全气囊。在所示的示例中,第一充气机222流体地连接到安装在仪表板42中的乘客侧正面安全气囊232。另一个充气机224流体地连接到安装在方向盘240中的驾驶员侧正面安全气囊234。
充气机222、224可以是能够以一种或多种速率和/或压力将充气流体传递到相关联的安全气囊232、234的单级或多级充气机。安全气囊232、234可以包括被动或主动自适应特征,诸如系绳、通气口、撕裂线、斜坡等。因此,每个安全气囊232、234的展开特性(例如,尺寸、形状、轮廓、刚度、速度、压力和/或方向)可以由充气机222、224和/或通过操作自适应特征来控制。通过安全气囊控制器200连接到充气机222、224和安全气囊232、234(更具体地为自适应特征)的控制器100可以影响每个安全气囊的展开特性。
考虑到这一点,每个乘员分类可以具有与其相关联的特定的一组安全气囊展开特性,这些安全气囊展开特性取决于安全气囊的类型和该安全气囊在车辆20中的位置。换言之,安全气囊控制器200可以配备有表格等,该表格将每种类型的乘员分类与特定的安全气囊展开特性关联。这些关联性还可以考虑安全气囊的类型(例如,正面安全气囊、侧帘、护膝垫等),以及该安全气囊在车辆中的位置(例如,前排或后排)。展开特性的每个组合可以具有与其相关联的对应的一组充气机222、224和/或安全气囊232、234命令或控制。安全气囊控制器200可以将每个独特的一组命令/控制与独特“模式”相关联。
安全气囊控制器200可以连接到与被定位在整个车辆20中的附加安全气囊(未示出)(例如,沿左侧28或右侧30的侧帘式安全气囊、安装在底座上的安全气囊、安装在车顶上的安全气囊和/或安装在座椅上的安全气囊)相关联的附加充气机。因此,安全气囊控制器200和控制器100可以影响或控制这些附加安全气囊的展开特性。
考虑到这一点,一旦控制器100识别(多个)乘员并对其进行分类,便将信号发送到显示器220,以通知车辆20的操作者在车辆中已经检测到乘员的位置(例如前排62或后排64)以及每个被检测乘员的分类。这包括与操作者本身的分类相关的信息。
例如,当控制器检测到右/乘客侧30的前排62中的儿童190(图10)以及左/驾驶员侧28的成人192时,控制器100可以向显示器220发送通知。车辆20的操作者(在这种情况下是成人192)可以提供反馈,例如,触摸显示器220或语音命令,从而确认乘员分类是否准确。如果操作者指示儿童190的分类是准确的,则控制器100指示安全气囊控制器200将乘客安全气囊232的展开特性设置为“婴儿”或“儿童”模式,该模式与发生车辆撞击时提供相对减小的冲击力的安全气囊展开相对应。这些减小的冲击力可以是与儿童安全气囊安全标准相当的力。
另一方面,如果操作者指示儿童190的分类是不准确的(例如,被分类为儿童的乘员实际上是成人),则控制器100指示安全气囊控制器200将乘客安全气囊232的展开特性设置为“成人”模式,该模式与发生车辆撞击时提供标准冲击力的安全气囊展开相对应。这些冲击力可以是与成人安全气囊安全标准相当的力。
其余与年龄相关的分类可以具有相关联的安全气囊展开特性,这些展开特性与“成人模式”或“儿童模式”相同或不同。特别地,响应于将被检测乘员分类为图11所示的老年人194或青少年196,控制器100可以指示安全气囊控制器200将展开特性设置为“中间模式”。该“中间模式”可以与提供的反作用力值介于“儿童模式”反作用力与“成人模式”反作用力之间的安全气囊展开特性相对应。
应理解的是,尽管使用被检测乘员的身高、重量和年龄来共同确定乘员的基于年龄的分类,但是控制器可替代地以不同方式(例如基于重量)对乘员进行分类,并且使用其余的收集数据来调整安全气囊的展开特性。换言之,控制器可以初始地确定基于重量的展开特性,并且随后基于其余的身高和年龄信息调整这些展开特性。
在每个场景中,控制器从相机和(多个)重量传感器接收信号,基于这些信号对车辆中的被检测乘员进行分类,并向车辆操作者通知这些分类。作为响应,操作者通过确认或校正每个分类来提供反馈。然后控制器相应地设置每个安全气囊的展开特性或“模式”。
本发明的视觉系统的优点在于,在对车辆的乘员进行分类并且此后响应于这些分类调整乘员保护措施(例如,安全气囊的展开)中提供了提高的可靠性。此外,通过允许车辆操作者在设置特定保护措施之前向这些分类提供反馈,操作者可以对所作出的分类确定进行检查,从而有助于确保实施适当的保护措施。
上面已经描述的是本发明的示例。当然,不可能为了描述本发明的目的而描述部件或方法的每种可想到的组合,但是本领域的普通技术人员将认识到,本发明的许多其他组合和置换是可能的。因此,本发明旨在涵盖落入所附权利要求的精神和范围内的所有这样的更改、修改和变型。
- 还没有人留言评论。精彩留言会获得点赞!